 |
Обновление сертификатов oVirt |
Автор: casm
[комментарии]
|
| | oVirt - свободная, кроссплатформенная система управления виртуализацией.
Была разработана компанией Red Hat как проект сообщества, на котором основан
продукт Red Hat Virtualization.
oVirt состоит из двух основных компонентов - oVirt engine и oVirt node.
oVirt engine управляет всеми хостами виртуализации, общими дисковыми ресурсами
и виртуальными сетями. Может быть размещён как на отдельном сервере
(standalone), так и на виртуальной машине внутри гипервизоров, которыми
управляет (self-hosted engine).
oVirt node - физический сервер с RHEL, Centos, Scientific Linux с KVM
гипервизором и службой VDSM (Virtual Desktop and Server Manager), которая
управляет всеми ресурсами, доступными серверу (вычисления, ОЗУ, хранилище,
сеть), а также управляет запуском виртуальных машин. Несколько узлов могут быть
объединены в кластер.
В примерах ниже будут один oVirt engine и три oVirt node:
oVirt engine - virt-he.example.test
oVirt node - virt-host1.example.test, virt-host2.example.test, virt-host3.example.test
Обмен данными между oVirt engine и oVirt node осуществляется с использованием SSL-сертификатов.
Автоматическое обновление сертификатов не производится, поэтому очень
важно обновлять сертификаты вручную до истечения сроков их действия.
Стандартными средствами обновить сертификаты можно, если до окончания срока
действия осталось менее 60 дней (для версии 4.5).
В oVirt необходимо обновлять вручную два типа сертификатов:
сертификаты oVirt Engine - службы, которая предоставляет графический
интерфейс и REST API для управления ресурсами виртуальных машин
сертификаты для обмена данным между гипервизорами oVirt node и центром
управления виртуальными машинами oVirt Engine
Определить дату окончания действия сертификатов oVirt Engine можно в свойствах сертификата сайта.
Определить дату окончания действия сертификатов oVirt node можно с помощью openssl:
Подключаемся через SSH на физический сервер oVirt node
Определяем дату:
[root@virt-host1 ~]# openssl x509 -noout -enddate -in /etc/pki/vdsm/certs/vdsmcert.pem
В версиях oVirt до 4.5, у всех сертификатов время жизни составляет 398 дней.
Начиная с версии 4.5, у самоподписанных сертификатов для обмена данным между
гипервизорами oVirt node и центром управления виртуальными машинами oVirt
engine установлено время действия 5 лет.
У сертификатов, которые видят браузеры, срок действия установлен в 398 дней, их
необходимо обновлять раз в год.
Процедура обновления действующих сертификатов описана в официальной документации.
Если вы допустите истечение срока действия сертификатов, то гипервизоры и
центр управления Engine перестанут взаимодействовать.
В Web-консоль невозможно будет войти, виртуальные машины продолжать работать,
но с ними ничего нельзя будет сделать: нельзя изменить параметры виртуального
железа, нельзя мигрировать на другой узел, после выключения ВМ её будет
невозможно включить снова.
Восстановление займёт много времени.
Процедура восстановления просроченных сертификатов описана в руководстве.
Для доступа к нему необходима действующая платная подписка Red Hat
Virtualization (RHV) 4.x.
Решение для восстановления без подписки я обнаружил на GitHub.
Автор подготовил решения для Ansible в соответствии с рекомендациями от Red
Hat. Если вы знакомы с Ansible и у вас много гипервизоров с просроченными
сертификатами, то можно использовать решение от natman.
Решение ниже подходит для небольшого числа гипервизоров, но при условии, что
центр управления Engine у вас запущен, и вы можете получить к нему доступ через
ssh. Предполагается, что в качестве центра управления используется HostedEngine
- центр управления гипервизорами запускается внутри самого гипервизора.
Если центр управления Engine выключен и не запускается, а в журнале journalctl
на гипервизоре появляются записи
libvirtd[2101]: The server certificate /etc/pki/vdsm/certs/vdsmcert.pem has expired
...
systemd[1]: Failed to start Virtualization daemon
то единственным вариантом восстановления будет изменение времени на гипервизоре
на более ранее (в пределах срока действия сертификатов) и обновление
сертификатов стандартным образом.
Обновление сертификатов до истечения сроков действия
Обновление сертификатов oVirt node
Переводим узел (гипервизор) в режим обслуживания (Managеment -> Maintenance) -
все машины на узле будут мигрированы, привязанные (pinned) машины будут выключены.
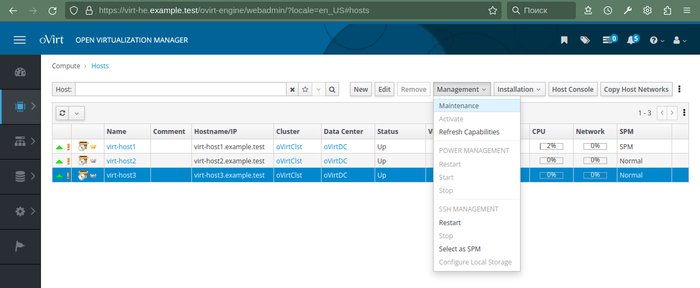 Выбираем Installation -> Enroll Certificate
Выбираем Installation -> Enroll Certificate
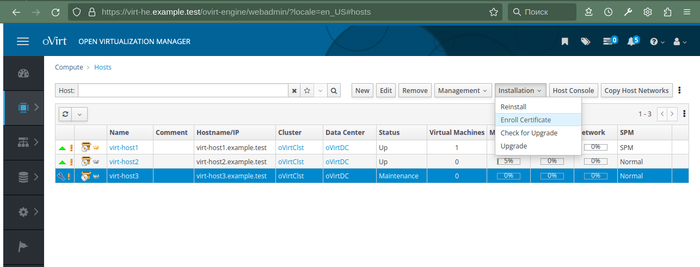 Выводим узел из режима обслуживания
Выводим узел из режима обслуживания
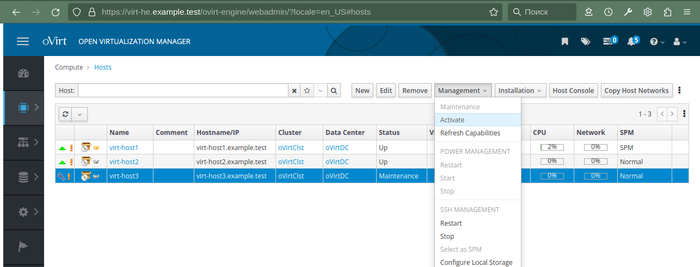 Повторяем операции для всех оставшихся узлов в кластере
Обновление сертификатов oVirt Engine
Подключаемся к физическому серверу гипервизору oVirt node через SSH
С узла Ovirt host переводим центр управления ВМ в режим обслуживания (для
Self-hosted типа развёртывания)
[root@virt-host1 ~]# hosted-engine --set-maintenance --mode=global
Подключаемся к виртуальной машине с центром управления oVirt engine через SSH,
запускаем настройку engine (web-консоль будет остановлена)
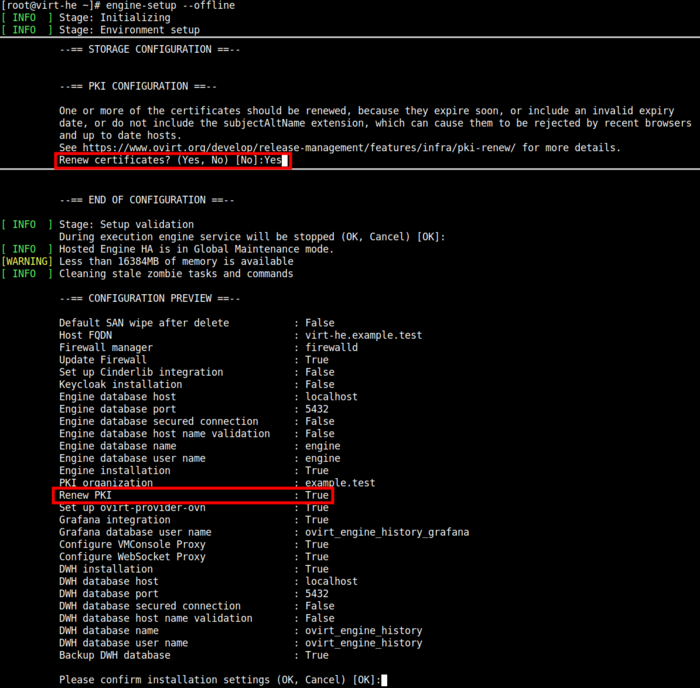
[root@virt-he ~]# engine-setup --offline
Отвечаем на вопросы
Если до истечения срока действия сертификата осталось менее 60 дней,
то скрипт предложит обновить сертификаты:
Renew certificates? (Yes, No) [No]: Yes
Повторяем операции для всех оставшихся узлов в кластере
Обновление сертификатов oVirt Engine
Подключаемся к физическому серверу гипервизору oVirt node через SSH
С узла Ovirt host переводим центр управления ВМ в режим обслуживания (для
Self-hosted типа развёртывания)
[root@virt-host1 ~]# hosted-engine --set-maintenance --mode=global
Подключаемся к виртуальной машине с центром управления oVirt engine через SSH,
запускаем настройку engine (web-консоль будет остановлена)
[root@virt-he ~]# engine-setup --offline
Отвечаем на вопросы
Если до истечения срока действия сертификата осталось менее 60 дней,
то скрипт предложит обновить сертификаты:
Renew certificates? (Yes, No) [No]: Yes
 Дожидаемся окончания работы скрипта.
С узла Ovirt host выводим центр управления ВМ из режима обслуживания:
[root@virt-host1 ~]# hosted-engine --set-maintenance --mode=none
Подключаемся к web-консоли и проверяем дату окончания действия сертификата.
Обновление сертификатов после истечения сроков действия
Если вы допустите истечение срока действия сертификатов, то в web-консоль невозможно будет войти.
Дожидаемся окончания работы скрипта.
С узла Ovirt host выводим центр управления ВМ из режима обслуживания:
[root@virt-host1 ~]# hosted-engine --set-maintenance --mode=none
Подключаемся к web-консоли и проверяем дату окончания действия сертификата.
Обновление сертификатов после истечения сроков действия
Если вы допустите истечение срока действия сертификатов, то в web-консоль невозможно будет войти.
 Гипервизоры и центр управления Engine перестанут взаимодействовать.
Гипервизоры и центр управления Engine перестанут взаимодействовать.
 Чтобы восстановить сертификаты выполняем следующие шаги.
Подключаемся через SSH на узел гипервизора oVirt node с истёкшим сертификатом
(в примере имя узла virt-host1).
Создаем запрос сертификата на основании ключа службы VDSM /etc/pki/vdsm/keys/vdsmkey.pem
[root@virt-host1 ~]# openssl req -new \
-key /etc/pki/vdsm/keys/vdsmkey.pem \
-out /tmp/test_virt-host1_vdsm.csr \
-batch \
-subj "/"
Подписываем запрос с помощью корневого сертификата oVirt engine, для этого
подключаемся через SSH на ВМ с oVirt engine, копируем запрос с oVirt node
(virt-host1) на oVirt engine в /tmp и выполняем команды
[root@virt-he ~]# cd /etc/pki/ovirt-engine/
[root@virt-he ~]# openssl ca -batch \
-policy policy_match \
-config openssl.conf \
-cert ca.pem \
-keyfile private/ca.pem \
-days +"365" \
-in /tmp/test_virt-host1_vdsm.csr \
-out /tmp/test_virt-host1_vdsm.cer \
-startdate `(date --utc --date "now -1 days" +"%y%m%d%H%M%SZ")` \
-subj "/O=example.test/CN=virt-host1.example.test\
-utf8
Имя субъекта в сертификате должно быть в формате
"/O=example.test/CN=virt-host1.example.test", укажите ваши значения.
Копируем новый сертификат с oVirt engine на oVirt node (virt-host1) в /tmp.
Копируем новый сертификат в каталоги служб предварительно создав копию существующих сертификатов
[root@virt-host1 ~]# cp /etc/pki/vdsm/certs/vdsmcert.pem /etc/pki/vdsm/certs/vdsmcert.pem.bak
[root@virt-host1 ~]# cp /tmp/test_virt-host1_vdsm.cer /etc/pki/vdsm/certs/vdsmcert.pem
[root@virt-host1 ~]# cp /etc/pki/vdsm/libvirt-spice/server-cert.pem /etc/pki/vdsm/libvirt-spice/server-cert.pem.bak
[root@virt-host1 ~]# cp /etc/pki/vdsm/certs/vdsmcert.pem /etc/pki/vdsm/libvirt-spice/server-cert.pem
[root@virt-host1 ~]# cp /etc/pki/libvirt/clientcert.pem /etc/pki/libvirt/clientcert.pem.bak
[root@virt-host1 ~]# cp /etc/pki/vdsm/certs/vdsmcert.pem /etc/pki/libvirt/clientcert.pem
Перезапускаем службы:
[root@virt-host1 ~]# systemctl restart libvirtd
[root@virt-host1 ~]# systemctl restart vdsmd
Проверяем срок действия сертификата
[root@virt-host1 ~]# openssl x509 -noout -enddate -in /etc/pki/vdsm/certs/vdsmcert.pem
Повторяем процедуру на остальных узлах с истёкшим сроком действия сертификатов.
Выполняем обновления сертификатов центра управления, как описано в "Обновление
сертификатов oVirt Engine"
Заходим на web-консоль и проверяем работу кластера.
У созданных таким образом сертификатов будет отсутствовать subject alternative
name, о чём будет выдано предупреждение (через несколько часов):
Certificate of host virt-host1.example.test is invalid. The
certificate doesn't contain valid subject alternative name, please
enroll new certificate for the host.
Поэтому после восстановления доступа к web-консоли необходимо выполнить
обновление сертификатов согласно официальной документации.
Обновление сертификатов после истечения сроков действия при недоступном HostedEngine
На практике данное решение не проверялось, но теоретически оно должно сработать.
Если центр управления Engine выключен и не запускается, а в журнале journalctl
на гипервизоре появляются записи
libvirtd[2101]: The server certificate /etc/pki/vdsm/certs/vdsmcert.pem has expired
...
systemd[1]: Failed to start Virtualization daemon
Оставляем включенным один гипервизор oVirt node.
Определяем время окончания действия сертификата гипервизора:
[root@virt-host1 ~]# openssl x509 -noout -enddate -in /etc/pki/vdsm/certs/vdsmcert.pem
Устанавливаем дату и время до окончания действия сертификата
[root@virt-host1 ~]# systemctl stop chronyd
[root@virt-host1 ~]# timedatectl set-time "2023-01-01 12:00:00"
Перезапускаем службы
[root@virt-host1 ~]# systemctl restart libvirtd
[root@virt-host1 ~]# systemctl restart vdsmd
Подключаемся к libvirtd через virsh и ждём, когда запустится HostedEngine
[root@virt-host1 ~]# virsh -c qemu:///system?authfile=/etc/ovirt-hosted-engine/virsh_auth.conf
virsh # list --all
Id Name State
------------------------------
1 HostedEngine running
Выполняем обновление сертификатов по процедуре "Обновление сертификатов до
истечения сроков действия"
Использованные материалы
Документация oVirt
Проект natman
Wikipedia
Блог IT-KB
Чтобы восстановить сертификаты выполняем следующие шаги.
Подключаемся через SSH на узел гипервизора oVirt node с истёкшим сертификатом
(в примере имя узла virt-host1).
Создаем запрос сертификата на основании ключа службы VDSM /etc/pki/vdsm/keys/vdsmkey.pem
[root@virt-host1 ~]# openssl req -new \
-key /etc/pki/vdsm/keys/vdsmkey.pem \
-out /tmp/test_virt-host1_vdsm.csr \
-batch \
-subj "/"
Подписываем запрос с помощью корневого сертификата oVirt engine, для этого
подключаемся через SSH на ВМ с oVirt engine, копируем запрос с oVirt node
(virt-host1) на oVirt engine в /tmp и выполняем команды
[root@virt-he ~]# cd /etc/pki/ovirt-engine/
[root@virt-he ~]# openssl ca -batch \
-policy policy_match \
-config openssl.conf \
-cert ca.pem \
-keyfile private/ca.pem \
-days +"365" \
-in /tmp/test_virt-host1_vdsm.csr \
-out /tmp/test_virt-host1_vdsm.cer \
-startdate `(date --utc --date "now -1 days" +"%y%m%d%H%M%SZ")` \
-subj "/O=example.test/CN=virt-host1.example.test\
-utf8
Имя субъекта в сертификате должно быть в формате
"/O=example.test/CN=virt-host1.example.test", укажите ваши значения.
Копируем новый сертификат с oVirt engine на oVirt node (virt-host1) в /tmp.
Копируем новый сертификат в каталоги служб предварительно создав копию существующих сертификатов
[root@virt-host1 ~]# cp /etc/pki/vdsm/certs/vdsmcert.pem /etc/pki/vdsm/certs/vdsmcert.pem.bak
[root@virt-host1 ~]# cp /tmp/test_virt-host1_vdsm.cer /etc/pki/vdsm/certs/vdsmcert.pem
[root@virt-host1 ~]# cp /etc/pki/vdsm/libvirt-spice/server-cert.pem /etc/pki/vdsm/libvirt-spice/server-cert.pem.bak
[root@virt-host1 ~]# cp /etc/pki/vdsm/certs/vdsmcert.pem /etc/pki/vdsm/libvirt-spice/server-cert.pem
[root@virt-host1 ~]# cp /etc/pki/libvirt/clientcert.pem /etc/pki/libvirt/clientcert.pem.bak
[root@virt-host1 ~]# cp /etc/pki/vdsm/certs/vdsmcert.pem /etc/pki/libvirt/clientcert.pem
Перезапускаем службы:
[root@virt-host1 ~]# systemctl restart libvirtd
[root@virt-host1 ~]# systemctl restart vdsmd
Проверяем срок действия сертификата
[root@virt-host1 ~]# openssl x509 -noout -enddate -in /etc/pki/vdsm/certs/vdsmcert.pem
Повторяем процедуру на остальных узлах с истёкшим сроком действия сертификатов.
Выполняем обновления сертификатов центра управления, как описано в "Обновление
сертификатов oVirt Engine"
Заходим на web-консоль и проверяем работу кластера.
У созданных таким образом сертификатов будет отсутствовать subject alternative
name, о чём будет выдано предупреждение (через несколько часов):
Certificate of host virt-host1.example.test is invalid. The
certificate doesn't contain valid subject alternative name, please
enroll new certificate for the host.
Поэтому после восстановления доступа к web-консоли необходимо выполнить
обновление сертификатов согласно официальной документации.
Обновление сертификатов после истечения сроков действия при недоступном HostedEngine
На практике данное решение не проверялось, но теоретически оно должно сработать.
Если центр управления Engine выключен и не запускается, а в журнале journalctl
на гипервизоре появляются записи
libvirtd[2101]: The server certificate /etc/pki/vdsm/certs/vdsmcert.pem has expired
...
systemd[1]: Failed to start Virtualization daemon
Оставляем включенным один гипервизор oVirt node.
Определяем время окончания действия сертификата гипервизора:
[root@virt-host1 ~]# openssl x509 -noout -enddate -in /etc/pki/vdsm/certs/vdsmcert.pem
Устанавливаем дату и время до окончания действия сертификата
[root@virt-host1 ~]# systemctl stop chronyd
[root@virt-host1 ~]# timedatectl set-time "2023-01-01 12:00:00"
Перезапускаем службы
[root@virt-host1 ~]# systemctl restart libvirtd
[root@virt-host1 ~]# systemctl restart vdsmd
Подключаемся к libvirtd через virsh и ждём, когда запустится HostedEngine
[root@virt-host1 ~]# virsh -c qemu:///system?authfile=/etc/ovirt-hosted-engine/virsh_auth.conf
virsh # list --all
Id Name State
------------------------------
1 HostedEngine running
Выполняем обновление сертификатов по процедуре "Обновление сертификатов до
истечения сроков действия"
Использованные материалы
Документация oVirt
Проект natman
Wikipedia
Блог IT-KB
|
| |
 |
|
|
Создание виртуальных машин с помощью Qemu KVM (доп. ссылка 1) |
Автор: Slonik
[комментарии]
|
| | В статье опишу мой опыт про подготовку и запуск виртуальных машин (ВМ) с
помощью открытых и бесплатных средств виртуализации в Linux - Qemu KVM.
В качестве среды для выполнения виртуальных машин будет использоваться Fedora
Linux 36, аналогично ВМ можно запускать в Centos 8 и выше.
Для запуска ВМ понадобятся пакеты:
qemu-kvm (qemu-system-x86) - эмулятор
qemu-img - средство создания и управления виртуальными дисками
edk2-ovmf - образы прошивки UEFI
Будет рассмотрено три типа виртуальных машин:
Виртуальная машина с BIOS
Виртуальная машина с UEFI
Кластер виртуальных машин с общим диском
Подготовка виртуальной сети
В Qemu я использую два режима подключения сети в гостевую ВМ - user networking
и с использованием устройств tap.
Первый режим проще, не требует root прав, но у него меньше производительность,
в таком режиме не работает протокол ICMP и он не позволяет обратится к ВМ из
физической сети.
Второй режим предоставляет большее быстродействие при работе с сетью, его можно
гибко настраивать, но он требует root права.
Пользовательская виртуальная сеть
Простейшую ВМ с пользовательской сетью можно запустить так:
qemu-kvm \
-m 1G \
-device virtio-net-pci,netdev=lan \
-netdev user,id=lan \
-drive file=/tmp/livecd.iso,media=cdrom
Ключевым параметром, который включает пользовательский режим сети это -netdev user.
Такая команда запустит LiveCD внутри ВМ c 1024 МБ ОЗУ, в качестве сетевой карты
будет использовано устройство Virtio.
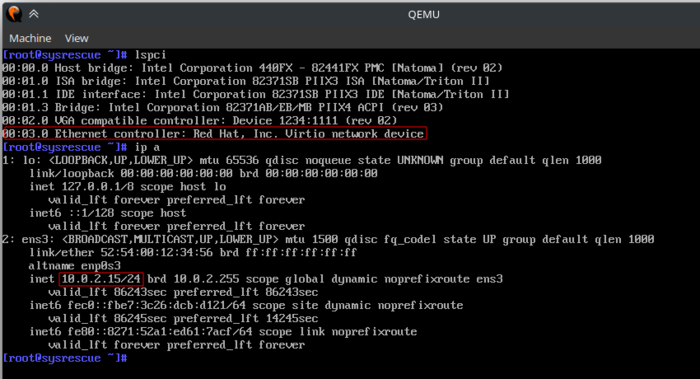 Виртуальная машина автоматически получит ip-адрес из подсети 10.0.2.0/24, шлюз
- 10.0.2.2, dns-сервер - 10.0.2.3.
К физическому хосту можно обратиться по адресу 10.0.2.2.
ICMP пакеты через такой тип сети не проходят.
Виртуальная сеть с использованием tap-устройств
В данном режиме при запуске ВМ в физической системе будет создано виртуальное
сетевое tap-устройство, что потребует root прав
sudo qemu-kvm \
-m 1G \
-device virtio-net-pci,netdev=lan \
-netdev tap,id=lan,ifname=tap0 \
-drive file=/tmp/livecd.iso,media=cdrom
При таких настройках машина запустится, но не будет иметь доступа к физической
сети. Для предоставления доступа необходимо создать сетевой мост, добавить в
него физический сетевой адаптер хоста и настроить скрипты добавления
виртуального сетевого tap-устройства в сетевой мост.
Предположим, что физический хост подключен к сети через адаптер enp3s0 и имеет
адрес 192.168.1.50/24, шлюз 192.168.1.1.
Удалим все сетевые настройки у адаптера enp3s0 и создадим сетевой мост с помощью Network Manager:
root# nmcli connection show
root# nmcli connection delete <имя подключения enp3s0>
root# nmcli connection add type bridge ifname br0 con-name bridge bridge.stp false ipv4.method manual ipv4.addresses "192.168.1.50/24" ipv4.gateway 192.168.1.1 ipv6.method disabled
Добавляем физический адаптер хоста в сетевой мост:
nmcli con add type bridge-slave ifname enp3s0 con-name nicHost master br0
Настраиваем скрипт добавления виртуального сетевого tap-устройства к мосту - /etc/qemu-ifup:
#!/bin/sh
/usr/sbin/brctl addif br0 $1
/usr/sbin/ip link set dev $1 up
Скрипт удаления tap-устройства из моста /etc/qemu-ifdown:
#!/bin/sh
/usr/sbin/ip link set dev $1 down
/usr/sbin/brctl delif br0 $1
В скриптах $1 указывает на имя виртуального сетевого адаптера (tap0, tap1 и т.п.).
Если потребуется разместить скрипты по другому пути, то их месторасположение
можно указать в свойствах виртуального сетевого устройства с помощью директив
script и downscript:
sudo qemu-kvm \
-m 1G \
-device virtio-net-pci,netdev=lan \
-netdev tap,id=lan,ifname=tap0,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-drive file=/tmp/livecd.iso,media=cdrom
Запускаем виртуальную машину и проверяем сеть.
Виртуальная машина автоматически получит ip-адрес из подсети 10.0.2.0/24, шлюз
- 10.0.2.2, dns-сервер - 10.0.2.3.
К физическому хосту можно обратиться по адресу 10.0.2.2.
ICMP пакеты через такой тип сети не проходят.
Виртуальная сеть с использованием tap-устройств
В данном режиме при запуске ВМ в физической системе будет создано виртуальное
сетевое tap-устройство, что потребует root прав
sudo qemu-kvm \
-m 1G \
-device virtio-net-pci,netdev=lan \
-netdev tap,id=lan,ifname=tap0 \
-drive file=/tmp/livecd.iso,media=cdrom
При таких настройках машина запустится, но не будет иметь доступа к физической
сети. Для предоставления доступа необходимо создать сетевой мост, добавить в
него физический сетевой адаптер хоста и настроить скрипты добавления
виртуального сетевого tap-устройства в сетевой мост.
Предположим, что физический хост подключен к сети через адаптер enp3s0 и имеет
адрес 192.168.1.50/24, шлюз 192.168.1.1.
Удалим все сетевые настройки у адаптера enp3s0 и создадим сетевой мост с помощью Network Manager:
root# nmcli connection show
root# nmcli connection delete <имя подключения enp3s0>
root# nmcli connection add type bridge ifname br0 con-name bridge bridge.stp false ipv4.method manual ipv4.addresses "192.168.1.50/24" ipv4.gateway 192.168.1.1 ipv6.method disabled
Добавляем физический адаптер хоста в сетевой мост:
nmcli con add type bridge-slave ifname enp3s0 con-name nicHost master br0
Настраиваем скрипт добавления виртуального сетевого tap-устройства к мосту - /etc/qemu-ifup:
#!/bin/sh
/usr/sbin/brctl addif br0 $1
/usr/sbin/ip link set dev $1 up
Скрипт удаления tap-устройства из моста /etc/qemu-ifdown:
#!/bin/sh
/usr/sbin/ip link set dev $1 down
/usr/sbin/brctl delif br0 $1
В скриптах $1 указывает на имя виртуального сетевого адаптера (tap0, tap1 и т.п.).
Если потребуется разместить скрипты по другому пути, то их месторасположение
можно указать в свойствах виртуального сетевого устройства с помощью директив
script и downscript:
sudo qemu-kvm \
-m 1G \
-device virtio-net-pci,netdev=lan \
-netdev tap,id=lan,ifname=tap0,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-drive file=/tmp/livecd.iso,media=cdrom
Запускаем виртуальную машину и проверяем сеть.
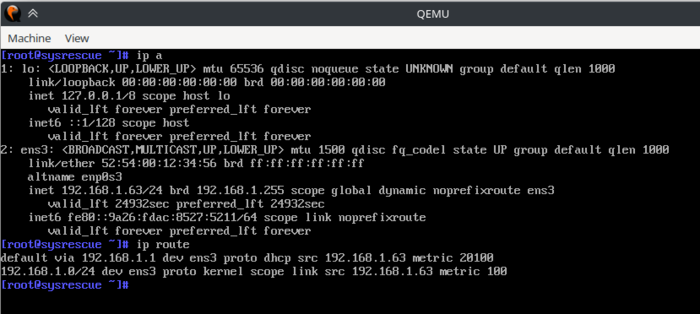 ВМ получила адрес от DHCP сервера локальной сети.
Проверяем состав сетевого моста на физическом хосте с помощью команды brctl show:
ВМ получила адрес от DHCP сервера локальной сети.
Проверяем состав сетевого моста на физическом хосте с помощью команды brctl show:
 В хост-системе появилось устройство tap0, и оно автоматически добавилось в сетевой мост.
По-умолчанию, все виртуальные сетевые адаптеры получают MAC адрес
52:54:00:12:34:56, если потребуется запустить несколько виртуальных машин на
хосте, то необходимо указать разные адреса с помощью параметра mac:
sudo qemu-kvm \
-m 1G \
-device virtio-net-pci,mac=52:54:00:00:00:01,netdev=lan \
-netdev tap,id=lan,ifname=tap0,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-drive file=/tmp/livecd.iso,media=cdrom
Подготовка виртуальных дисков
Ранее мы запускали ВМ с LiveCD. Для того чтобы установить операционную систему
в виртуальную машину нам понадобится создать виртуальные диски для хранения данных.
Создание виртуальных дисков
qemu-img create -f qcow2 vmpath/disk.qcow2 20G
Данная команда создаст "тонкий" диск в формате qcow2, объёмом 20 Гб.
Если потребуется создать кластерный диск, то необходимо для него всё место
выделить заранее и использовать тип диска raw:
qemu-img create -f raw -o preallocation=falloc shared/shared.raw 10G
Использование снимков состояния дисков
Формат дисков qcow2 позволяет создавать и удалять внутри диска снимки состояний (снапшоты):
создание снимка:
qemu-img snapshot -c snapshotName vmpath/disk.qcow2
список снимков:
qemu-img snapshot -l vmpath/disk.qcow2
применить снимок (вернуть диск в состояние на момент снимка):
qemu-img snapshot -a snapshotName vmpath/disk.qcow2
удалить снимок:
qemu-img snapshot -d snapshotName vmpath/disk.qcow2
Вся работа со снимками будет производится внутри одного образа, что может потребовать времени.
Другим способом создания снимков состояний является создание промежуточного
файла (backing file) - при создании такого файла вся запись будет вестись в
него вместо базового образа:
qemu-img create -f qcow2 -F qcow2 -b vmpath/disk.qcow2 vmpath/backingDisk.qcow2
При запуске ВМ указываем в качестве диска промежуточный файл:
qemu-kvm -m 1G -drive file=vmpath/backingDisk.qcow2,media=disk
Чтобы откатить снапшот, достаточно перенастроить запуск на изначальный образ
диска и удалить снапшот.
qemu-kvm -m 1G -drive file=vmpath/disk.qcow2 ,media=disk
rm vmpath/backingDisk.qcow2
Изменение первоначального образа приведёт к повреждению снапшота, поэтому после
запуска ВМ с оригинальным диском все снапшоты станут бесполезными.
Подключение разделов виртуального диска к хост-системе
Если возникнет необходимость обратиться к файлам на виртуальном диске напрямую
с хост-системы, то необходимо сначала смонтировать образ. Для того, чтобы
смонтировать разделы виртуального диска к хост-системе необходимо
воспользоваться утилитой qemu-nbd.
1. Загружаем модуль ядра nbd
root# modprobe nbd max_part=8
2. Подключаем образ виртуального диска как сетевое блочное устройство:
root# qemu-nbd --connect=/dev/nbd0 vmpath/disk.qcow2
3. Выполняем нужные нам операции с устройством:
root# fdisk /dev/nbd0 -l
root# mount /dev/nbd0p1 /mnt/volume/
root# umount /dev/nbd0p1
4. Отключаем устройство
root# qemu-nbd --disconnect /dev/nbd0
root# rmmod nbd
Запуск виртуальной машины с BIOS в Qemu KVM
По-умолчанию Qemu KVM запускает виртуальные машины с BIOS, поэтому особых настроек не требуется.
Готовим диск для гостевой системы:
qemu-img create -f qcow2 /mnt/virtual/bios/bios.qcow2 20G
Запускаем ВМ:
sudo qemu-kvm \
-machine pc \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=2,sockets=1,cores=2 \
-m 1G \
-k en-us \
-vga qxl \
-rtc base=localtime \
-netdev tap,id=lan,ifname=tap0,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-device virtio-net-pci,mac=52:54:00:00:00:01,netdev=lan \
-drive file=/mnt/virtual/bios/bios.qcow2,if=virtio,media=disk,index=0 \
-drive file=/mnt/shared/linuxos.iso,media=cdrom,index=1
Параметры:
machine - свойства чипсета, основные это pc (совместимый со многими и ОС) и
q35 (поддерживает новые устройства)
smbios - описание BIOS
cpu - тип эмулируемого ЦП, host указывает использовать как в физической системе
accel - тип ускорение виртуализации
smp - описываем кол-во виртуальных ядер ЦП и их распределение по сокетам
m - объём ОЗУ
k - раскладка клавиатуры консоли
vga - тип виртуального видеоадаптера
rtc base - настройки часов RTC
netdev/device и drive - описание сетевой карты и виртуальных дисков
Загружаемся с CD-ROM и устанавливаем ОС.
Запуск виртуальной машины с UEFI в Qemu KVM
Для запуска виртуальной машины с UEFI нам потребуются прошивки из пакета edk2-ovmf.
Готовим виртуальный диск для гостевой системы:
qemu-img create -f qcow2 /mnt/virtual/uefi/uefi.qcow2 20G
Из пакета edk2-ovmf копируем образы UEFI и NVRAM:
cp /usr/share/edk2/ovmf/OVMF_CODE.fd /mnt/virtual/uefi
cp /usr/share/edk2/ovmf/OVMF_VARS.fd /mnt/virtual/uefi
Запускаем ВМ:
sudo qemu-kvm \
-machine q35 \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=4,sockets=1,cores=4 \
-m 4G \
-k en-us \
-vga qxl \
-device virtio-net-pci,mac=52:54:00:00:00:02,netdev=lan \
-netdev tap,id=lan,ifname=tap1,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-drive if=pflash,format=raw,readonly=on,file=/mnt/virtual/uefi/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=/mnt/virtual/uefi/OVMF_VARS.fd \
-drive file=/mnt/virtual/uefi/uefi.qcow2,if=virtio,media=disk \
-drive file=/mnt/shared/linuxos.iso,media=cdrom
Подключаем прошивку UEFI для чтения с помощью drive if=pflash с указанием
readonly=on, а также файл для хранения NVRAM, но уже в режиме записи.
Загружаемся с CD-ROM и устанавливаем ОС.
Запуск виртуальных машин с UEFI с общим кластерным диском в Qemu KVM
Рассмотрим пример запуска двух машин, где у каждой будет свой индивидуальный
диск для ОС и один общий диск для кластера.
Подключать диски будем с помощью устройства -device virtio-blk-pci, оно
позволяет включить совместную запись на диск с нескольких виртуальных машин c
помощью параметра share-rw=on.
Готовим диски для гостевых систем:
qemu-img create -f qcow2 /mnt/virtual/cluster/vm1-system.qcow2 20G
qemu-img create -f qcow2 /mnt/virtual/cluster/vm2-system.qcow2 20G
Для кластерного диска используем формат raw и заранее резервируем место.
qemu-img create -f raw -o preallocation=falloc /mnt/virtual/cluster/shared.raw 10G
Копируем образы прошивки UEFI и NVRAM:
cp /usr/share/edk2/ovmf/OVMF_CODE.fd /mnt/virtual/cluster
cp /usr/share/edk2/ovmf/OVMF_VARS.fd /mnt/virtual/cluster/OVMF_VARS_VM1.fd
cp /usr/share/edk2/ovmf/OVMF_VARS.fd /mnt/virtual/cluster/OVMF_VARS_VM2.fd
Запускаем ВМ 1:
sudo qemu-kvm \
-machine q35 \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=2,sockets=1,cores=2 \
-m 2G \
-k en-us \
-vga qxl \
-device virtio-net-pci,netdev=lan,mac=52:54:00:00:00:11 \
-netdev tap,id=lan,ifname=tap11 \
-drive if=pflash,format=raw,readonly=on,file=/mnt/virtual/cluster/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=/mnt/virtual/cluster/OVMF_VARS_VM1.fd \
-device virtio-blk-pci,drive=drive0,share-rw=off \
-drive file=/mnt/virtual/cluster/vm1-system.qcow2,id=drive0,format=qcow2,if=none \
-device virtio-blk-pci,drive=drive1,share-rw=on \
-drive file=/mnt/virtual/cluster/shared.raw,id=drive1,format=raw,if=none \
-drive file=/mnt/shared/linuxos.iso,media=cdrom
Запускаем ВМ 2:
sudo qemu-kvm \
-machine q35 \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=2,sockets=1,cores=2 \
-m 2G \
-k en-us \
-vga qxl \
-device virtio-net-pci,netdev=lan,mac=52:54:00:00:00:12 \
-netdev tap,id=lan,ifname=tap12 \
-drive if=pflash,format=raw,readonly=on,file=/mnt/virtual/cluster/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=/mnt/virtual/cluster/OVMF_VARS_VM2.fd \
-device virtio-blk-pci,drive=drive0,share-rw=off \
-drive file=/mnt/virtual/cluster/vm2-system.qcow2,id=drive0,format=qcow2,if=none \
-device virtio-blk-pci,drive=drive1,share-rw=on \
-drive file=/mnt/virtual/cluster/shared.raw,id=drive1,format=raw,if=none \
-drive file=/mnt/shared/linuxos.iso,media=cdrom
Далее нужно установить ОС внутри ВМ и настроить работу с кластерным диском.
В хост-системе появилось устройство tap0, и оно автоматически добавилось в сетевой мост.
По-умолчанию, все виртуальные сетевые адаптеры получают MAC адрес
52:54:00:12:34:56, если потребуется запустить несколько виртуальных машин на
хосте, то необходимо указать разные адреса с помощью параметра mac:
sudo qemu-kvm \
-m 1G \
-device virtio-net-pci,mac=52:54:00:00:00:01,netdev=lan \
-netdev tap,id=lan,ifname=tap0,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-drive file=/tmp/livecd.iso,media=cdrom
Подготовка виртуальных дисков
Ранее мы запускали ВМ с LiveCD. Для того чтобы установить операционную систему
в виртуальную машину нам понадобится создать виртуальные диски для хранения данных.
Создание виртуальных дисков
qemu-img create -f qcow2 vmpath/disk.qcow2 20G
Данная команда создаст "тонкий" диск в формате qcow2, объёмом 20 Гб.
Если потребуется создать кластерный диск, то необходимо для него всё место
выделить заранее и использовать тип диска raw:
qemu-img create -f raw -o preallocation=falloc shared/shared.raw 10G
Использование снимков состояния дисков
Формат дисков qcow2 позволяет создавать и удалять внутри диска снимки состояний (снапшоты):
создание снимка:
qemu-img snapshot -c snapshotName vmpath/disk.qcow2
список снимков:
qemu-img snapshot -l vmpath/disk.qcow2
применить снимок (вернуть диск в состояние на момент снимка):
qemu-img snapshot -a snapshotName vmpath/disk.qcow2
удалить снимок:
qemu-img snapshot -d snapshotName vmpath/disk.qcow2
Вся работа со снимками будет производится внутри одного образа, что может потребовать времени.
Другим способом создания снимков состояний является создание промежуточного
файла (backing file) - при создании такого файла вся запись будет вестись в
него вместо базового образа:
qemu-img create -f qcow2 -F qcow2 -b vmpath/disk.qcow2 vmpath/backingDisk.qcow2
При запуске ВМ указываем в качестве диска промежуточный файл:
qemu-kvm -m 1G -drive file=vmpath/backingDisk.qcow2,media=disk
Чтобы откатить снапшот, достаточно перенастроить запуск на изначальный образ
диска и удалить снапшот.
qemu-kvm -m 1G -drive file=vmpath/disk.qcow2 ,media=disk
rm vmpath/backingDisk.qcow2
Изменение первоначального образа приведёт к повреждению снапшота, поэтому после
запуска ВМ с оригинальным диском все снапшоты станут бесполезными.
Подключение разделов виртуального диска к хост-системе
Если возникнет необходимость обратиться к файлам на виртуальном диске напрямую
с хост-системы, то необходимо сначала смонтировать образ. Для того, чтобы
смонтировать разделы виртуального диска к хост-системе необходимо
воспользоваться утилитой qemu-nbd.
1. Загружаем модуль ядра nbd
root# modprobe nbd max_part=8
2. Подключаем образ виртуального диска как сетевое блочное устройство:
root# qemu-nbd --connect=/dev/nbd0 vmpath/disk.qcow2
3. Выполняем нужные нам операции с устройством:
root# fdisk /dev/nbd0 -l
root# mount /dev/nbd0p1 /mnt/volume/
root# umount /dev/nbd0p1
4. Отключаем устройство
root# qemu-nbd --disconnect /dev/nbd0
root# rmmod nbd
Запуск виртуальной машины с BIOS в Qemu KVM
По-умолчанию Qemu KVM запускает виртуальные машины с BIOS, поэтому особых настроек не требуется.
Готовим диск для гостевой системы:
qemu-img create -f qcow2 /mnt/virtual/bios/bios.qcow2 20G
Запускаем ВМ:
sudo qemu-kvm \
-machine pc \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=2,sockets=1,cores=2 \
-m 1G \
-k en-us \
-vga qxl \
-rtc base=localtime \
-netdev tap,id=lan,ifname=tap0,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-device virtio-net-pci,mac=52:54:00:00:00:01,netdev=lan \
-drive file=/mnt/virtual/bios/bios.qcow2,if=virtio,media=disk,index=0 \
-drive file=/mnt/shared/linuxos.iso,media=cdrom,index=1
Параметры:
machine - свойства чипсета, основные это pc (совместимый со многими и ОС) и
q35 (поддерживает новые устройства)
smbios - описание BIOS
cpu - тип эмулируемого ЦП, host указывает использовать как в физической системе
accel - тип ускорение виртуализации
smp - описываем кол-во виртуальных ядер ЦП и их распределение по сокетам
m - объём ОЗУ
k - раскладка клавиатуры консоли
vga - тип виртуального видеоадаптера
rtc base - настройки часов RTC
netdev/device и drive - описание сетевой карты и виртуальных дисков
Загружаемся с CD-ROM и устанавливаем ОС.
Запуск виртуальной машины с UEFI в Qemu KVM
Для запуска виртуальной машины с UEFI нам потребуются прошивки из пакета edk2-ovmf.
Готовим виртуальный диск для гостевой системы:
qemu-img create -f qcow2 /mnt/virtual/uefi/uefi.qcow2 20G
Из пакета edk2-ovmf копируем образы UEFI и NVRAM:
cp /usr/share/edk2/ovmf/OVMF_CODE.fd /mnt/virtual/uefi
cp /usr/share/edk2/ovmf/OVMF_VARS.fd /mnt/virtual/uefi
Запускаем ВМ:
sudo qemu-kvm \
-machine q35 \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=4,sockets=1,cores=4 \
-m 4G \
-k en-us \
-vga qxl \
-device virtio-net-pci,mac=52:54:00:00:00:02,netdev=lan \
-netdev tap,id=lan,ifname=tap1,script=/etc/qemu-ifup,downscript=/etc/qemu-ifdown \
-drive if=pflash,format=raw,readonly=on,file=/mnt/virtual/uefi/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=/mnt/virtual/uefi/OVMF_VARS.fd \
-drive file=/mnt/virtual/uefi/uefi.qcow2,if=virtio,media=disk \
-drive file=/mnt/shared/linuxos.iso,media=cdrom
Подключаем прошивку UEFI для чтения с помощью drive if=pflash с указанием
readonly=on, а также файл для хранения NVRAM, но уже в режиме записи.
Загружаемся с CD-ROM и устанавливаем ОС.
Запуск виртуальных машин с UEFI с общим кластерным диском в Qemu KVM
Рассмотрим пример запуска двух машин, где у каждой будет свой индивидуальный
диск для ОС и один общий диск для кластера.
Подключать диски будем с помощью устройства -device virtio-blk-pci, оно
позволяет включить совместную запись на диск с нескольких виртуальных машин c
помощью параметра share-rw=on.
Готовим диски для гостевых систем:
qemu-img create -f qcow2 /mnt/virtual/cluster/vm1-system.qcow2 20G
qemu-img create -f qcow2 /mnt/virtual/cluster/vm2-system.qcow2 20G
Для кластерного диска используем формат raw и заранее резервируем место.
qemu-img create -f raw -o preallocation=falloc /mnt/virtual/cluster/shared.raw 10G
Копируем образы прошивки UEFI и NVRAM:
cp /usr/share/edk2/ovmf/OVMF_CODE.fd /mnt/virtual/cluster
cp /usr/share/edk2/ovmf/OVMF_VARS.fd /mnt/virtual/cluster/OVMF_VARS_VM1.fd
cp /usr/share/edk2/ovmf/OVMF_VARS.fd /mnt/virtual/cluster/OVMF_VARS_VM2.fd
Запускаем ВМ 1:
sudo qemu-kvm \
-machine q35 \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=2,sockets=1,cores=2 \
-m 2G \
-k en-us \
-vga qxl \
-device virtio-net-pci,netdev=lan,mac=52:54:00:00:00:11 \
-netdev tap,id=lan,ifname=tap11 \
-drive if=pflash,format=raw,readonly=on,file=/mnt/virtual/cluster/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=/mnt/virtual/cluster/OVMF_VARS_VM1.fd \
-device virtio-blk-pci,drive=drive0,share-rw=off \
-drive file=/mnt/virtual/cluster/vm1-system.qcow2,id=drive0,format=qcow2,if=none \
-device virtio-blk-pci,drive=drive1,share-rw=on \
-drive file=/mnt/virtual/cluster/shared.raw,id=drive1,format=raw,if=none \
-drive file=/mnt/shared/linuxos.iso,media=cdrom
Запускаем ВМ 2:
sudo qemu-kvm \
-machine q35 \
-smbios type=1,manufacturer=oVirt,product=RHEL,version=1 \
-cpu host \
-accel kvm \
-smp cpus=2,sockets=1,cores=2 \
-m 2G \
-k en-us \
-vga qxl \
-device virtio-net-pci,netdev=lan,mac=52:54:00:00:00:12 \
-netdev tap,id=lan,ifname=tap12 \
-drive if=pflash,format=raw,readonly=on,file=/mnt/virtual/cluster/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=/mnt/virtual/cluster/OVMF_VARS_VM2.fd \
-device virtio-blk-pci,drive=drive0,share-rw=off \
-drive file=/mnt/virtual/cluster/vm2-system.qcow2,id=drive0,format=qcow2,if=none \
-device virtio-blk-pci,drive=drive1,share-rw=on \
-drive file=/mnt/virtual/cluster/shared.raw,id=drive1,format=raw,if=none \
-drive file=/mnt/shared/linuxos.iso,media=cdrom
Далее нужно установить ОС внутри ВМ и настроить работу с кластерным диском.
|
| |
|
|
|
Использование инструментария Podman для запуска контейнеров во FreeBSD (доп. ссылка 1) |
[комментарии]
|
| | Начиная с выпуска FreeBSD 14.2 стали формироваться образы контейнеров в
формате OCI (Open Container Initiative). Для запуска контейнеров на основе
этих образов можно применять инструментарий Podman, который портирован для
FreeBSD и доступен для установки из пакетов.
Для загрузки предложены три варианта образов FreeBSD:
static - урезанное окружение для выполнения только статически собранных исполняемых файлов
dynamic - расширенный вариант окружения static с компонентами для
использования разделяемых библиотек и запуска динамически скомпонованных
исполняемых файлов.
minimal - дополняет вариант dynamic утилитами для формирования привычного
консольного окружения с UNIX shell и пакетным менеджером.
Установка Podman во FreeBSD.
pkg install -r FreeBSD -y podman-suite emulators/qemu-user-static
Настройка ZFS-раздела для контейнеров:
zfs create -o mountpoint=/var/db/containers zroot/containers
zfs snapshot zroot/containers@empty
При желании использовать UFS вместо ZFS в
/usr/local/etc/containers/storage.conf заменяем "zfs"/driver на "vfs":
sed -I .bak -e 's/driver = "zfs"/driver = "vfs"/' \
/usr/local/etc/containers/storage.conf
Создаём конфигурацию межсетевого экрана PF - /etc/pf.conf, используя пример
/usr/local/etc/containers/pf.conf.sample. Перезапускаем PF
sysctl net.pf.filter_local=1
service pf restart
Монтируем /dev/fd:
mount -t fdescfs fdesc /dev/fd
Создаём необходимые для Podman файлы конфигурации, используя примеры:
/usr/local/etc/containers/containers.conf.sample
/usr/local/etc/containers/policy.json.sample
/usr/local/etc/containers/registries.conf.sample
/usr/local/etc/containers/storage.conf.sample
Устанавливаем образы контейнеров minimal, dynamic и static с FreeBSD 4.2:
export OCIBASE=https://download.freebsd.org/releases/OCI-IMAGES/14.2-RELEASE/amd64/Latest
podman load -i=$OCIBASE/FreeBSD-14.2-RELEASE-amd64-container-image-minimal.txz
podman load -i=$OCIBASE/FreeBSD-14.2-RELEASE-amd64-container-image-dynamic.txz
podman load -i=$OCIBASE/FreeBSD-14.2-RELEASE-amd64-container-image-static.txz
Проверяем список установленных образов контейнеров командами "podman images" и "buildah images":
podman images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/freebsd14-minimal 14.2-RELEASE-amd64 c5f3e77557a9 4 days ago 35.1 MB
localhost/freebsd14-dynamic 14.2-RELEASE-amd64 ebf7538b22f4 4 days ago 15.9 MB
localhost/freebsd14-static 14.2-RELEASE-amd64 7876fe59dbb3 4 days ago 5.45 MB
buildah images
REPOSITORY TAG IMAGE ID CREATED SIZE
localhost/freebsd14-minimal 14.2-RELEASE-amd64 c5f3e77557a9 4 days ago 35.1 MB
localhost/freebsd14-dynamic 14.2-RELEASE-amd64 ebf7538b22f4 4 days ago 15.9 MB
localhost/freebsd14-static 14.2-RELEASE-amd64 7876fe59dbb3 4 days ago 5.45 MB
Анализируем слои, образующие образ minimal, который является надстройкой над
образами static и dynamic:
podman image tree localhost/freebsd14-minimal:14.2-RELEASE-amd64
Image ID: c5f3e77557a9
Tags: [localhost/freebsd14-minimal:14.2-RELEASE-amd64]
Size: 35.07MB
Image Layers
├── ID: cd53fb07fb66 Size: 5.449MB Top Layer of: [localhost/freebsd14-static:14.2-RELEASE-amd64]
├── ID: a01d37f7777b Size: 10.4MB Top Layer of: [localhost/freebsd14-dynamic:14.2-RELEASE-amd64]
└── ID: 36b0c80ca1f7 Size: 19.21MB Top Layer of: [localhost/freebsd14-minimal:14.2-RELEASE-amd64]
Сверяем контрольные суммы образов:
podman inspect localhost/freebsd14-minimal:14.2-RELEASE-amd64
Запускаем /bin/sh в контейнере:
podman run -it localhost/freebsd14-minimal:14.2-RELEASE-amd64 /bin/sh
|
| |
|
|
|
Проброс графического адаптера в виртуальную машину KVM |
Автор: anon1233456
[комментарии]
|
| | Для проброса графического адаптера в виртуальную машину KVM следует указать
при загрузке параметры ядра
rd.driver.pre=vfio_pci rd.driver.pre=vfio-pciwq iommu=pt intel_iommu=on kvm.ignore_msrs=1
и добавить vfio-pci в initramfs:
# as Root
gpu="0000:06:00.0"
aud="0000:06:00.1"
gpu_vd="$(cat /sys/bus/pci/devices/$gpu/vendor) $(cat /sys/bus/pci/devices/$gpu/device)"
aud_vd="$(cat /sys/bus/pci/devices/$aud/vendor) $(cat /sys/bus/pci/devices/$aud/device)"
function bind_vfio {
echo "$gpu" > "/sys/bus/pci/devices/$gpu/driver/unbind"
echo "$aud" > "/sys/bus/pci/devices/$aud/driver/unbind"
# https://www.kernel.org/doc/Documentation/ABI/testing/sysfs-bus-pci
echo "$gpu_vd" > /sys/bus/pci/drivers/vfio-pci/new_id
echo "$aud_vd" > /sys/bus/pci/drivers/vfio-pci/new_id
}
function unbind_vfio {
echo "$gpu_vd" > "/sys/bus/pci/drivers/vfio-pci/remove_id"
echo "$aud_vd" > "/sys/bus/pci/drivers/vfio-pci/remove_id"
echo 1 > "/sys/bus/pci/devices/$gpu/remove"
echo 1 > "/sys/bus/pci/devices/$aud/remove"
echo 1 > "/sys/bus/pci/rescan"
}
bind_vfio
#QEMU emulator version 8.2.2 (qemu-8.2.2-1.fc40)
NETWORK_DEVICE="virtio-net"
MAC_ADDRESS="00:16:cb:00:21:19"
# 0x28 - Raptor Lake fix. https://github.com/tianocore/edk2/discussions/4662
CPU="host,host-phys-bits-limit=0x28"
args=(
-display gtk,grab-on-hover=on,full-screen=on
-machine q35
-accel kvm
-cpu $CPU
-m size=17338368k
-overcommit mem-lock=off
-smp 32,sockets=1,dies=1,clusters=1,cores=32,threads=1
-no-user-config
-nodefaults
-rtc base=localtime,driftfix=slew
-global kvm-pit.lost_tick_policy=delay
-global ICH9-LPC.disable_s3=1
-global ICH9-LPC.disable_s4=1
-boot menu=off,strict=on
-device qemu-xhci,id=xhci
# VFIO
# VERY IMPORTANT PART. PLEASE NOTE THE FORMAT OF COMMAND
# id":"pci.5","bus":"pcie.0","addr":"0x2.0x4" and "id":"pci.6","bus":"pcie.0","addr":"0x2.0x5"
-device pcie-root-port,bus=pcie.0,id=pci_root,multifunction=true,addr=0x2
-device '{"driver":"pcie-root-port","port":20,"chassis":5,"id":"pci.5","bus":"pcie.0","addr":"0x2.0x4"}'
-device '{"driver":"pcie-root-port","port":21,"chassis":6,"id":"pci.6","bus":"pcie.0","addr":"0x2.0x5"}'
-device '{"driver":"vfio-pci","host":"0000:06:00.0","id":"gpu","bus":"pci.5","addr":"0x0"}'
-device '{"driver":"vfio-pci","host":"0000:06:00.1","id":"hdmiaudio","bus":"pci.6","addr":"0x0"}'
#
-drive id=HDD,if=virtio,file="$HDD",format=qcow2
# Network
-netdev user,id=net0
-device "$NETWORK_DEVICE",netdev=net0,id=net0,mac="$MAC_ADDRESS"
#
-device virtio-serial-pci
-usb
-device usb-kbd
-device usb-tablet
-monitor stdio
# Audio
-audiodev pa,id=aud1,server="/run/user/1000/pulse/native"
-device ich9-intel-hda
-device hda-duplex,audiodev=aud1
#
-device qxl-vga,vgamem_mb=128,vram_size_mb=128
-device virtio-balloon-pci
)
qemu-system-x86_64 "${args[@]}"
unbind_vfio
|
| |
|
|
|
Подключение в BHyVe zvol-диска с другой машины |
Автор: КриоМух
[комментарии]
|
| | Ситуация такова: Когда-то давно в 2019 году, обратилась знакомая бухгалтер, с
проблемой, что вирусы зашифровали все её базы 1С, хранящиеся на личном сервере,
который ей поднял и оформил для работы по RDP - её айтишник. Когда вирус всё
пожрал, внезапно обнаружилось, что отсутствуют резервные копии, так как они
хранились на том же WIN-сервере, и оказались также пожранными. Более того, в
процессе разбирательств с этой машиной, выяснилось, что там 4 диска, 2 - HDD и
2 SSD - и при этом все они отдельными устройствами, без намёка на хоть какую-то
реализацию зеркалирования. Айтишника этого она с позором выгнала (отказавшись с
ним иметь дело) и обратилась ко мне.
Понятно что не за восстановлением пожранного, а за организацией сервера, в
работе и надёжности которого она бы могла быть уверена.
Я как старый пользователь FreeBSD, конечно сразу ей сформировал предложение -
эту её машину превратить в сервер на FreeBSD, а уже на нём развернуть виртуалку
с виндой, 1С и всей этой нужной для её работы кухней.
На предложение докупить ещё один ПК, чтобы был отдельной машиной для резервных
копий - отказалась, так как женщина она во-первых бухгалтер, а во-вторых
прижимистый бухгалтер :)
Всё ей в итоге оформил в виде хоста на FreeBSD, c её ZFS-ным зеркалом на 2 HDD
и 2 SSD, и самбой, на которую складировались ежедневные бэкапы, которые затем
скриптом самого хоста перекладывались в samba-ресурс, доступный только на чтение.
Виртуалку оформил на BHyVe'е, так как виртуалбокс медленнен, а BHyVe и
православный и производительней. Sparse - файлом оформил диск на HDD-пуле под
систему в виртуалке, и SSD-пул - подключил zvol'ом как диск под базы 1С.
Разворачивал BHyVe не голый, а с управлением с помощью vm-bhyve. Всё
завелось и работало, как часы. Но через год-полтора, женщина-бухгалтер и со
мной "рассталась", так как всё работало, а я за поддержку желал ежемесячную,
оговорённую сумму.
Никаких козней я понятное дело не строил, да и не собирался, так как честь
IT-шную беречь должно всегда. И все актуальные копии хранилища со всеми
доступами и чего там наворочено в её "инфраструктуре" я ей при внесении правок
сразу высылал и при завершении сотрудничества также актуальную выдал, с
пояснениями, что там всё что есть, все доступы и прочая-прочая, что может
понадобиться знать любому, кто будет заниматься её сервером. Ответы на все
вопросы так сказать. Всё.
Собственно прошло 3-4 года, и вот недавно звонит она мне и говорит, что всё
пропало. Сервак не грузится, её текущий админ не знает что со всем этим делать,
так как с его слов "там сложная распределённая система и диски эти не может
посмотреть". Короче сервак подох, ничего не работает, и ей главное выцарапать
оттуда 1С базы.
Получил, включил, смотрю: Действительно ничего не грузится, что-то там с uefi
разделом, и загрузка дохнет на начальных этапах. Думаю - ничего страшного, там
же бэкапы были, сейчас быстренько смонтирую пул, да последний достану и дело с
концом. Загрузился с флешки, подмонтировал пул, который был HDD, под самбу -
смотрю а бэкап последний лежит прошлогодний. Место на пуле закончилось, так как
самбу они ещё и как файловую шару использовали и накидали туда всякого, что
подъело весь ресурс и баз видимо 1С ещё добавилось, и бэкапы делаться просто не
смогли, а текущий специалист, то ли не следил, то ли не знал как следить,
короче перефразируя (надеюсь) из тех, кто: "Не следил и не проверял бэкапы, но
теперь уже будет всегда это делать (ещё раз надеюсь)".
Тогда остался один путь - получить данные непосредственно с диска в виртуалке,
который реализован был как отдельный датасет на SSD пуле. Отцепил я значит один
из SSD'шников и подключил к своему домашнему ПК, на котором у меня также
FreeBSD и виртуалка BHyVe, с виндой, на случай если что-то виндовое
потребуется. В общем вся соль этого была в подключении к BHyVe'овой машине
диска оформленного как сырой ZFS-датасет. То есть в нём ни файлов нет, просто
особого типа ZFS датасет.
В итоге, чтобы его подключить на посторонней системе с FreeBSD, надо конечно
первым делом ZFS-пул импортировать:
zpool import -f
-f нужен, так как он ругнётся что этот пул использовался на другой машине и
вроде как может не надо его тут подключать.
А после этого в
zfs list
ищем где наш датасет и объявляем его в конфигурации нашей рабочей виртуалки:
disk1_type="virtio-blk"
disk1_dev="custom"
disk1_name="/dev/zvol/oldSSD/BHYVE/1C-BASES"
И это тут так всё просто и безоблачно описано, а на деле я часа два наверное
бодался с тем, как именно объявить zvol-овый диск в BHyVe. И в итоге
disk_type - должен быть virtio-blk
disk_dev - должен быть custom
disk_name - абсолютный путь к zvol'у в /dev, сперва это можно просто проверить ls'ом.
Ну а дальше - ещё в самой загруженной ОСи диск не увиделся, но появился SCSI
контроллер какой-то, который потребовал драйвера с диска
virtio-win-0.1.229 и всё.
Женщина - оплатила услуги непростого восстановления файлов, получила инструктаж
на тему того, что её админ должен ей подтверждать что бэкап есть и он надёжен.
Ну а она со своей стороны должна за этим бдить :)
|
| |
|
|
|
Запуск macOS в виртуальной машине на базе QEMU/KVM (доп. ссылка 1) (доп. ссылка 2) (доп. ссылка 3) |
[комментарии]
|
| | Скрипт для запуска macOS в виртуальной машине (файлы с прошивками можно
скопировать из snap sosum, proxmox или пакета ovmf из Fedora, Ubuntu или Debian).
#!/bin/bash
OSK="ourhardworkbythesewordsguardedpleasedontsteal(c)AppleComputerInc"
/usr/bin/qemu-system-x86_64 \
-enable-kvm \
-m 2G \
-machine q35,accel=kvm \
-smp 4,cores=2 \
-cpu Penryn,vendor=GenuineIntel,kvm=on,+sse3,+sse4.2,+aes,+xsave,+avx,+xsaveopt,+xsavec,+xgetbv1,+avx2,+bmi2,+smep,+bmi1,+fma,+movbe,+invtsc \
-device isa-applesmc,osk="$OSK" \
-smbios type=2 \
-object rng-random,id=rng0,filename=/dev/urandom -device virtio-rng-pci,rng=rng0 \
-serial mon:stdio \
-drive if=pflash,format=raw,readonly,file=./firmware/OVMF_CODE.fd \
-drive if=pflash,format=raw,file=./firmware/OVMF_VARS-1024x768.fd \
-device virtio-vga,virgl=on \
-display sdl,gl=on \
-L "$SNAP"/usr/share/seabios/ \
-L "$SNAP"/usr/lib/ipxe/qemu/ \
-audiodev pa,id=pa,server="/run/user/$(id -u)/pulse/native" \
-device ich9-intel-hda -device hda-output,audiodev=pa \
-usb -device usb-kbd -device usb-mouse \
-netdev user,id=net0 \
-device vmxnet3,netdev=net0,id=net0 \
-drive id=ESP,if=virtio,format=qcow2,file=./ESP.qcow2 \
-drive id=SystemDisk,if=virtio,file=./macos.qcow2
Для установки macOS в виртуальной машине c использованием образа BaseSystem.img
дополнительно нужно добавить строку:
-drive id=InstallMedia,format=raw,if=virtio,file=./BaseSystem.img
Для загрузки установочного образа macOS можно использовать скрипт fetch-macos.py.
|
| |
|
|
|
vmhgfs в старых CentOS и RHEL |
Автор: пох
[комментарии]
|
| | Если понадобилось достучаться из CentOS 6 до хостового shared folder в VMware
Workstation или чем-то совместимом, а стандартные способы приводят только к
появлению загадочных мусорных сообщений в логах, что что-то где-то кого-то не
нашло, можно поступить так:
Поставить vmware-tools от VMware (да, понадобится перл и может даже gcc).
Ключевой момент - _целиком_. Понадобится версия 8.любая (я свою стащил из
vsphere5.0, но вообще-то они доступны с родного сайта даже без регистрации и sms).
Если в системе подключен EPEL, из которого установлен open-vm-tools - его
потребуется удалить через yum erase, так как это устаревший и неработающий
бэкпорт. Также понадобиться удалить уже установленные модули (как минимум сам
модуль vmhgfs), полученные из других источников.
В чем суть? В том, что как обычно - эру немого кино объявили deprecated, а со
звуковым что-то пошло не так. В десятой версии VMware перешла на новый-модный
метод доступа к hgfs через fuse - в чем не было бы ничего плохого (дергать
гипервизор все равно, из ядра или userspace), если бы, разумеется, всё было
реализовано корректно. Прибить гвоздем непрошенное кэширование, игнорируя
существующие API - норм. Исправить нельзя - "я в отпуске!" (по возвращении
исправлено не то и не до конца, потом переисправлено, но с уровнем
единственного штатного разработчика и качеством его кода, надеюсь, уже все ясно).
Поэтому нет смысла пол-системы апгрейдить ради "поддерживаемой" таким способом мусорной версии.
Ключевой момент при этом - что устанавливать старые vmware-tools надо целиком -
чтобы mount.vmhgfs был той же самой (старой!) версии, что и vmhgfs.ko -
поскольку там, внезапно, тоже stable api is nonsense - поэтому и необходимо
удалить "опен"-vm-tools - ничего хорошего они не содержат. API самого
гипервизора при этом не меняется (или там хорошо сохраняют обратную
совместимость) поэтому модуль работает с любой версией.
P.S. Если у вас именно штатный CentOS/RHEL, все пройдет гладко, а если что-то
несколько отличающееся и придётся модуль пересобирать из исходников - в
vmhgfs-only/fsutil.c в 65й строке исправьте "if" так, чтобы он всегда был
"false" - там проверка минимальной версии, которая неправильна из-за сделанного
rh бэкпортирования патчей, вам этот блок не нужен.
|
| |
|
|
|
Сборка ChromiumOS из исходных текстов для запуска в QEMU (доп. ссылка 1) |
[комментарии]
|
| | Доступный в исходных текстах ChromiumOS главным образом отличается отсутствием
элементов брендинга ChromeOS и компонентов DRM для просмотра защищённого контента.
Для сборки вначале нужно клонировать репозиторий с инструментарием:
git clone https://chromium.googlesource.com/chromium/tools/depot_tools.git
export PATH=$PATH:$PWD/depot_tools
После чего можно приступить к загрузке и сборки исходных текстов ChromiumOS
(сборку осуществляем для целевой платформы amd64-generic, при низкой скорости
сети или недосаточном свободном дисковом пространстве в "repo init" также можно
указать опцию "-g minilayout" для загрузки минимально необходимого набора кода):
mkdir chromiumos
cd chromiumos
repo init -u https://chromium.googlesource.com/chromiumos/manifest.git --repo-url https://chromium.googlesource.com/external/repo.git -g minilayout
repo sync -j75
cros_sdk
export BOARD=amd64-generic
./setup_board --board=${BOARD}
./build_packages --board=${BOARD}
./build_image --board=${BOARD} --boot_args "earlyprintk=serial,keep console=tty0" --noenable_rootfs_verification test
./image_to_vm.sh --board=${BOARD} --test_image
Для запуска окружения ChromiumOS можно воспользоваться командной cros_start_vm:
cros_sdk
./bin/cros_start_vm --image_path=../build/images/${BOARD}/latest/chromiumos_qemu_image.bin --board=${BOARD}
но при использовании cros_start_vm наблюдаются мешающие полноценной работе
ограничения, такие как невозможность перенаправить графический вывод через VNC.
Поэтому будем запускать ChromiumOS при помощи QEMU и виртуального GPU Virglrenderer.
Установим сборочные зависимости (список для Ubuntu 17.10):
sudo apt install autoconf libaio-dev libbluetooth-dev libbrlapi-dev \
libbz2-dev libcap-dev libcap-ng-dev libcurl4-gnutls-dev libepoxy-dev \
libfdt-dev \
libgbm-dev libgles2-mesa-dev libglib2.0-dev libgtk-3-dev libibverbs-dev \
libjpeg8-dev liblzo2-dev libncurses5-dev libnuma-dev librbd-dev librdmacm-dev \
libsasl2-dev libsdl1.2-dev libsdl2-dev libseccomp-dev libsnappy-dev l\
ibssh2-1-dev libspice-server-dev libspice-server1 libtool libusb-1.0-0 \
libusb-1.0-0-dev libvde-dev libvdeplug-dev libvte-dev libxen-dev valgrind \
xfslibs-dev xutils-dev zlib1g-dev libusbredirhost-dev usbredirserver
Соберём Virglrenderer, который позволяет задействовать виртуальный GPU и
использовать из гостевой системы графические возможности хост-системы, в том
числе аппаратное ускорение для OpenGL. Virglrenderer является не обязательным,
если не нужно ускорение вывода графики можно обойтись без сборки Virglrenderer
и убрать из строки запуска QEMU "virgl".
git clone git://git.freedesktop.org/git/virglrenderer
cd virglrenderer
./autogen.sh
make -j7
sudo make install
Собираем QEMU для целевой платформы x86_64:
git clone git://git.qemu-project.org/qemu.git
mkdir -p qemu/build
cd qemu/build
../configure --target-list=x86_64-softmmu --enable-gtk --with-gtkabi=3.0 \
--enable-kvm --enable-spice --enable-usb-redir --enable-libusb --enable-virglrenderer --enable-opengl
make -j7
sudo make install
Запускаем ChromiumOS в QEMU с использованием драйверов virtio (Linux-ядро
хост-системы должно быть собрано с опциями CONFIG_DRM_VIRTIO,
CONFIG_VIRT_DRIVERS и CONFIG_VIRTIO_XXXX):
cd chromiumos
/usr/local/bin/qemu-system-x86_64 \
-enable-kvm \
-m 2G \
-smp 4 \
-hda src/build/images/amd64-generic/latest/chromiumos_qemu_image.bin \
-vga virtio \
-net nic,model=virtio \
-net user,hostfwd=tcp:127.0.0.1:9222-:22 \
-usb -usbdevice keyboard \
-usbdevice mouse \
-device virtio-gpu-pci,virgl \
-display gtk,gl=on
|
| |
|
|
|
Сборка системы виртуализации crosvm из Chrome OS в обычном дистрибутиве Linux (доп. ссылка 1) |
[комментарии]
|
| | В Chrome/Chromium OS для изоляции приложений развивается система crosvm,
основанная на использовании гипервизора KVM. Код crosvm написан на языке Rust
и примечателен наличием дополнительного уровня защиты на основе пространств
имён, применяемого для защиты от атак на инструментарий виртуализации.
Из других особенностей crosvm отмечаются встроенные средства для запуска
Wayland-клиентов внутри изолированных окружений с выполнением композитного
сервера на стороне основного хоста и возможность эффективного использования GPU
из гостевых систем. Подобные возможности делают crosvm интересным решением для
изолированного запуска графических приложений.
Crosvm не привязан к Chromium OS и может быть собран и запущен в любом
дистрибутиве Linux (протестировано в Fedora 26).
Собираем ядро Linux для гостевой системы:
cd ~/src
git clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git
cd linux
git checkout v4.12
make x86_64_defconfig
make bzImage
cd ..
Собираем инструментарий minijail для запуска программ в изолированных окружениях:
git clone https://android.googlesource.com/platform/external/minijail
cd minijail
make
cd ..
Собираем crosvm:
git clone https://chromium.googlesource.com/a/chromiumos/platform/crosvm
cd crosvm
LIBRARY_PATH=~/src/minijail cargo build
Генерируем образ корневой ФС (rootfs) для изолированного окружения:
cd ~/src/crosvm
dd if=/dev/zero of=rootfs.ext4 bs=1K count=1M
mkfs.ext4 rootfs.ext4
mkdir rootfs/
sudo mount rootfs.ext4 rootfs/
debootstrap testing rootfs/
sudo umount rootfs/
Запускаем crosvm:
LD_LIBRARY_PATH=~/src/minijail ./target/debug/crosvm run -r rootfs.ext4 --seccomp-policy-dir=./seccomp/x86_64/ ~/src/linux/arch/x86/boot/compressed/vmlinux.bin
|
| |
|
|
|
Создание чистого openvz-контейнера на основе CentOS 6 (доп. ссылка 1) |
Автор: umask
[комментарии]
|
| | Разработчики OpenVZ предлагают загрузить заранее созданные шаблоны
контейнеров, но у этих шаблонов есть недостаток - в них присутствует довольно
много лишних пакетов, которые не хотелось бы вычищать руками. Помимо этого, в
этих шаблонах присутствуют неподписаные пакеты, а так же репозиторий с
пакетами-заглушками, цифровая подпись пакетов из которого не проверяется. В
общем всё это и заставило сделать свой собственный чистый контейнер с нуля.
Далее предлагается скрипт, который в хост-системе на основе centos6 создаёт
чистый контейнер с это же самой ОС.
Сам скрипт:
#!/bin/bash
### exit on errors (in pipes too) and verbose execution
set -o pipefail -e -x
TMPDIR=$(mktemp -d)
VEID=777
DESTDIR=/vz/private/${VEID}
### veid config
cat << _EOF_ > /etc/vz/conf/${VEID}.conf
# This config is only valid for decent VSwap-enabled kernel
# (version 042stab042 or later).
ONBOOT="yes"
# RAM
PHYSPAGES="0:2G"
# Swap
SWAPPAGES="0:0G"
# Disk quota parameters (in form of softlimit:hardlimit)
DISKSPACE="20G:22G"
DISKINODES="200000:220000"
QUOTATIME="0"
# CPU fair scheduler parameter
CPUUNITS="1000"
VE_ROOT="/vz/root/\\$VEID"
VE_PRIVATE="/vz/private/\\$VEID"
OSTEMPLATE="centos-6-secured-x86_64"
ORIGIN_SAMPLE="basic"
HOSTNAME="localhost"
SEARCHDOMAIN=""
NAMESERVER="8.8.8.8 8.8.4.4"
IP_ADDRESS="10.20.30.40"
CPULIMIT="100"
CPUS="1"
_EOF_
### stop / destroy if exists / recreate
vzctl stop ${VEID}
[[ -d ${DESTDIR} ]] && rm -rf ${DESTDIR}
mkdir -p ${DESTDIR}
mkdir -p /vz/root/${VEID}
### init rpm db
rpm --root ${DESTDIR} --initdb
### download packages for create base directory
yum install -q -y yum-utils
yumdownloader --destdir ${TMPDIR} centos-release centos-release-cr
### install base directory rpms
TO_INSTALL=""
for i in ${TMPDIR}/*.rpm; do
TO_INSTALL="${TO_INSTALL} ${i}"
done
rpm --root ${DESTDIR} -i ${TO_INSTALL}
### Save random seed
touch ${DESTDIR}/var/lib/random-seed
chmod 600 ${DESTDIR}/var/lib/random-seed
dd if=/dev/urandom of=/var/lib/random-seed count=1 bs=512 2>/dev/null
### import centos pubkey
rpm --root ${DESTDIR} --import /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6
### install required rpms
yum --installroot=${DESTDIR} install -q -y postfix filesystem tzdata glibc procps \\
coreutils rpm yum yum-utils udev openssh basesystem bash grep MAKEDEV \\
openssl gnupg2 logrotate rsyslog screen openssh-server openssh-clients \\
info ca-certificates libuuid sed vim-enhanced findutils iproute tmpwatch \\
wget curl patch vixie-cron sysstat htop telnet which diffutils rsync \\
sudo yum-cron psacct lftp tcpdump numactl git vconfig nc xz bzip2 \\
nscd passwd tar
### pts only in fstab
cat << _EOF_ > ${DESTDIR}/etc/fstab
none /dev/pts devpts gid=5,mode=620 0 0
_EOF_
chmod 0644 ${DESTDIR}/etc/fstab
mkdir -p ${DESTDIR}/dev/pts
### create devices
for INPATH in dev etc/udev/devices; do
/sbin/MAKEDEV -x -d ${DESTDIR}/${INPATH} console core fd full kmem kmsg mem null port \\
ptmx {p,t}ty{a,p}{0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f} random \\
urandom zero ram{,0,1,disk} std{in,out,err}
done
### do not run agetty's
sed -i 's/^ACTIVE_CONSOLES=\\(.*\\)/#ACTIVE_CONSOLES=\\1\\nACTIVE_CONSOLES=""/g' ${DESTDIR}/etc/sysconfig/init
### run minimum services
SERVICES="(network|crond|sshd|sysstat|snmpd|syslog|psacct|udev-post|nscd)"
chroot ${DESTDIR} "/sbin/chkconfig" "--list" | grep -oP '^\\S+' | \\
sort | uniq | egrep -vE "${SERVICES}" | xargs -I{} chroot ${DESTDIR} "/sbin/chkconfig" "{}" "off"
chroot ${DESTDIR} "/sbin/chkconfig" "--list" | grep -oP '^\\S+' | \\
sort | uniq | egrep -E "${SERVICES}" | xargs -I{} chroot ${DESTDIR} "/sbin/chkconfig" "{}" "--level" "2345" "on"
### clock/timezone
cat << _EOF_ > ${DESTDIR}/etc/sysconfig/clock
ZONE="Europe/Moscow"
_EOF_
chroot ${DESTDIR} "/usr/sbin/tzdata-update"
### make mtab actual every time
chroot ${DESTDIR} 'rm' '-fv' '/etc/mtab'
chroot ${DESTDIR} 'ln' '-s' '/proc/mounts' '/etc/mtab'
### cleanup
rm -rf ${TMPDIR}
### set locale to UTF
cat << _EOF_ > ${DESTDIR}/etc/sysconfig/i18n
LANG="en_US.UTF-8"
SYSFONT="latarcyrheb-sun16"
_EOF_
chroot ${DESTDIR} 'localedef' '-c' '-f' 'UTF-8' '-i' 'en_US' '/usr/lib/locale/en_US.utf8'
### TODO:
### 1. check ssh keys and delete them
### 2. make template.tar.gz
После создания контейнера я удаляю ssh host keys и делаю дамп контейнера
утилитой vzdump, а затем клонирую контейнеры через vzrestore. При желании можно
сделать шаблон самостоятельно, например как написано здесь или здесь.
|
| |
|
|
|
Сборка ядра FreeBSD для выполнения в роли паравиртуализированной гостевой системы под управлением Xen (доп. ссылка 1) |
[комментарии]
|
| | В репозитории http://svn.freebsd.org/base/projects/amd64_xen_pv/ доступны
свежие версии драйверов для обеспечения работы гостевых систем FreeBSD в режиме
паравиртуализации под управлением Xen.
Для сборки паравиртуализированного ядра FreeBSD для Xen можно использовать следующую инструкцию:
mkdir /dirprefix/
mkdir /amd64_xen_pv/
svn checkout svn://svn.freebsd.org/base/projects/amd64_xen_pv/ /amd64_xen_pv/
cd /amd64_xen_pv/
setenv MAKEOBJDIRPREFIX ../dirprefix/
make -j10 -s buildkernel KERNCONF=XEN
В результате ядро и необходимые модули будут размещены в директории ../dirprefix/amd64_xen_pv/sys/XEN/kernel
|
| |
|
|
|
Настройка сетевого доступа в окружениях QEMU |
Автор: Аноним
[комментарии]
|
| | Заметка о том, как настроить сеть между гостевой и хостовой ОС при
использовании QEMU. В качестве хостовой ОС Ubuntu 10.04.
На стороне хоста устанавливаем uml-utilities:
sudo apt-get install uml-utilities
Это нужно делать только один раз. Создаем сетевой интерфейс:
sudo tunctl -t qemu
Вешаем на него адрес и включаем:
sudo ip address add 192.168.0.1/24 dev qemu
sudo ip link set up dev qemu
Запускаем qemu (например):
sudo qemu-system-x86_64 -hda HDD.img -cdrom FreeBSD-9.0-RC1-amd64-dvd1.iso \\
-net nic -net tap,ifname=qemu,script=no,downscript=no -boot d
Делаем простой NAT на хостовой ОС:
sudo bash -c 'echo 1 > /proc/sys/net/ipv4/ip_forward'
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
На гостевой cистеме прописываем конфигурацию маршрута по-умолчанию и конфигурацию DNS-клиента.
Еще небольшая рекомендация: запускайте qemu на десктопе под управлением утилиты
screen. Это спасет вас, если вы вдруг решите закрыть окно терминала, в котором
запустили qemu.
screen -S qemu sudo qemu-system-x86_64 ...
Потом делаем detach (^D) и закрываем окно терминала.
|
| |
|
|
|
Установка XCP XenAPI в Ubuntu 11.10 или Debian GNU/Linux (доп. ссылка 1) |
[комментарии]
|
| | Благодаря портированию XCP XenAPI для Debian и Ubuntu Linux у пользователей
данных дистрибутивов появилась возможность создания сервера виртуализации,
функционально эквивалентного стандартному дистрибутиву XCP на базе CentOS.
В процессе развертывания Xen хоста следует не поддастся искушению установки
пакета с ядром Linux, оканчивающегося на "-virtual". Такие ядра в Ubuntu/Debian
оптимизированы для использования внутри гостевых систем и не сконфигурированы
для использования в роли Dom0.
После установки XAPI будут запущены сервисы, использующие сетевые порты 80 и
443. Поэтому важно проследить, чтобы на текущем сервере до этого не был запущен
http-сервер или настроить раздельный запуск XAPI на другом IP. При
использовании VPN и сетевого интерфейса tun0, наблюдается ряд проблем, которые
могут привести к невозможности запуска XAPI.
Установка XAPI
Устанавливаем компоненты XAPI из специального PPA-репозитория ubuntu-xen-org.
Добавляем в /etc/apt/sources.list
deb http://ppa.launchpad.net/ubuntu-xen-org/xcp-unstable/ubuntu oneiric main
deb-src http://ppa.launchpad.net/ubuntu-xen-org/xcp-unstable/ubuntu oneiric main
или подключаем репозиторий для Debian:
apt-get install curl
echo "deb http://downloads.xen.org/XCP/debian/repo/debian unstable main" > /etc/apt/sources.list.d/kronos.list
echo "deb-src http://downloads.xen.org/XCP/debian/repo/debian unstable main" >> /etc/apt/sources.list.d/kronos.list
wget --quiet -O - http://downloads.xen.org/XCP/debian/xcp.gpg.key | apt-key add -
Устанавливаем xapi:
apt-get update
apt-get install xcp-xapi
Вариант сборки свежей версии инструментария XCP из исходных текстов с
использованием xapi-autobuilder.
Устанавливаем необходимые для сборки компоненты:
apt-get install pbuilder debhelper dh-ocaml dh-autoreconf cdebootstrap python-debian mercurial git
wget http://downloads.xen.org/XCP/debian/blktap-dkms_0.1_all.deb
dpkg -i blktap-dkms_0.1_all.deb
Клонируем Git-репозиторий xapi-autobuilder и выполняем сборку:
git clone https://github.com/jonludlam/xapi-autobuilder.git
cd xapi-autobuilder
make clean ; make
в итоге будут подготовлены необходимые для установки в Debian пакеты, свежие
версии которых также можно загрузить командой:
wget -r -l1 --no-parent -nd http://downloads.xen.org/XCP/debian/latest/
rm index.html*
Настройка XAPI
Активируем по умолчанию опцию загрузки Xen в Grub:
sed -i 's/GRUB_DEFAULT=""/GRUB_DEFAULT="Xen 4.1-amd64"/' /etc/default/grub
update-grub
Настраиваем параметры сети
В /etc/network/interfaces добавляем запуск интерфейсе xenbr0:
auto lo xenbr0
iface xenbr0 inet dhcp
bridge_ports eth0
Вместо "dhcp" при необходимости можно прописать статический IP.
Настраиваем содержимое файла xensource-inventory (в скрипте ниже
подразумевается, что корневой раздел /dev/sda1, а управляющий сетевой интерфейс
xenbr0). Для генерации xensource-inventory запускаем простой shell-скрипт:
control_domain=`uuidgen`
installation=`uuidgen`
cat > /etc/xensource-inventory << EOF
CURRENT_INTERFACES='xenbr0'
BUILD_NUMBER='0'
CONTROL_DOMAIN_UUID='${control_domain}'
INSTALLATION_UUID='${installation}'
MANAGEMENT_INTERFACE='xenbr0'
PRIMARY_DISK='/dev/sda1'
EOF
Перезагружаем систему
reboot
Использование XCP
Убедимся, что xapi запущен
service xapi status
если нет, то запустим его командой
service xapi start
Добавим к переменноё окружения PATH путь к исполняемым файлам xapi:
export PATH=$PATH:/usr/lib/xen-common/xapi/bin
Создадим репозиторий хранения. Рекомендуется использовать NFS или EXT, если в
системе есть свободное блочное устройство.
Для NFS (в переменную SR будет записан идентификатор хранилища):
SR=`xe sr-create type=nfs name-label=nfs device-config:server=<nfs server> device-config:serverpath=<path on server>`
Для незанятого блочного устройства /dev/sda3 (внимание, указанный раздел будет отформатирован !)
SR=`xe sr-create type=ext device-config:device=/dev/sda3 name-label=ext`
Свяжем созданное хранилище с пулом:
POOL=`xe pool-list --minimal`
xe pool-param-set uuid=$POOL default-SR=$SR
Решение проблемы с памятью для Dom0
В штатном ядре Ubuntu 11.10 наблюдается проблема с выделением недостаточного
объема памяти для Dom0. Данная проблема решена в ядре 3.2. В качестве обходного
пути решения, можно вручную увеличить размер выделенной для нужд Dom0 памяти
(посмотреть текущее значением можно через "cat /proc/meminfo" ).
Находим uuid идентификатор Dom0:
xe vm-list
uuid ( RO) : f5d0039b-1138-4635-c153-6203bfdc330f
name-label ( RW): Control domain on host: piggy
power-state ( RO): running
Вручную назначаем нижний и верхний лимит памяти:
xe vm-param-set uuid=f5d0039b-1138-4635-c153-6203bfdc330f memory-dynamic-max=2GiB
xe vm-param-set uuid=f5d0039b-1138-4635-c153-6203bfdc330f memory-dynamic-min=2GiB
Установка гостевой системы с Linux
Находим шаблон для установки интересующего дистрибутива:
xe template-list
Ниже представленный скрипт позволяет автоматизировать выполнение установки.
Скрипт следует запускать из локальной системы (Dom0), но его можно легко
модифицировать для организации удалённой установки с другого хоста. На
завершающем этапе работы скрипта будет произведён запуск виртуальной машины для
выполнения финального этапа установки.
В скрипте может понадобиться поменять следующие переменные:
"vm-label" - метка для ссылки на VM из Dom0;
"hostname" - имя хоста;
"domain" - локальный домен
В качестве шаблона для установки выбран Ubuntu Lucid Lynx 10.04 (64-bit)
#!/bin/bash
set -e
set -x
template=`xe template-list name-label="Ubuntu Lucid Lynx 10.04 (64-bit)" --minimal`
vm=`xe vm-install template=$template new-name-label=vm-label`
network=`xe network-list bridge=xenbr0 --minimal`
vif=`xe vif-create vm-uuid=$vm network-uuid=$network device=0`
xe vm-param-set uuid=$vm other-config:install- repository=http://archive.ubuntu.com/ubuntu
xe vm-param-set uuid=$vm PV-args="auto-install/enable=true interface=auto netcfg/dhcp_timeout=600 hostname=vm-host-name domain=mydomain.is.best"
xe vm-start uuid=$vm
Для завершения установки следует подключиться к виртуальной машине, например, через "xe console"
Перед этим следует запустить демон xapissl:
service start xapissl
Список активных консолей VM можно посмотреть командой:
xe console-list
Выбрав нужный vm-uuid выполняем:
xe console uuid=593c6788-1ddc-e7d7-c6b1-0de0778c78b7
Если что-то пошло не так удалить установленную виртуальную машину можно командой:
xe vm-uninstall name-label=vm-label --multiple
Установка гостевой системы с Windows
Для установки Windows необходимо наличие установочного iso-образа, который
может быть импортирован с другой машины по NFS:
xe-mount-iso-sr nfs-server:/path/to/isos
Создаём виртуальную машину с Windows:
xe vm-install template=Windows\ 7\ \(32-bit\) new-name-label=windows
xe vm-cd-add vm=windows cd-name=win7.iso device=3
xe vm-start vm=windows
Для обеспечения работы сети выполняем создание сетевого моста:
brctl addbr xenbr0
brctl addif xenbr0 eth0
Поднимаем IP на интерфейсе сетевого бриджа вместо физического интерфейса. После чего запускаем:
xe pif-scan
Устанавливаем в Window паравиртуальные драйверы, которые можно загрузить следующим образом:
wget http://downloads.xen.org/XCP/debian/xs-tools-5.9.960.iso
mv xs-tools-5.9.960.iso /usr/lib/xen-common/xapi/packages/iso
|
| |
|
|
|
Тестирование во FreeBSD системы виртуализации BSD Hypervisor (BHyVe) (доп. ссылка 1) (доп. ссылка 2) |
[комментарии]
|
| | Разработчики FreeBSD приглашают принять участие в тестировании гипервизора
BSD Hypervisor (BHyVe), открытого в этом году компанией NetApp. Гипервизор
BHyVe обладает прекрасной производительностью, но пока не входит в состав
основной кодовой базы FreeBSD и нуждается в дополнительном тестировании.
Для работы BHyVe требуется наличие новых CPU Intel Core i3, i5 и i7,
поддерживающих механизм виртуализации VT-x и работу со вложенными страницами
памяти (EPT - Extended Page Tables). Опционально для проброса PCI-устройств в
госетвые окружения может быть задействована технология VT-d (Direct Device
Attach). Проверить наличие VY-x можно просмотрев флаги в секции "Features" в
выводе dmesg, в списке должен присутствовать флаг VMX.
В качестве гостевой системы пока может работать только FreeBSD. Созданные в
рамках проекта паравиртуальные драйверы для ускорения работы с устройствами
хранения и сетевого доступа (virtio, if_vtnet, virtio_pci, virtio_blk) в
дальнейшем могут быть адаптированы для работы гостевых систем совместно с
другими системами виртуализации.
Подготовка хост-окружения
Пользователи FreeBSD-CURRENT могут загрузить необходимые патчи из специального репозитория:
svn co http://svn.freebsd.org/base/projects/bhyve /usr/src/
Для FreeBSD 9.0BETA3 можно использовать ревизию 225769 из этого же SVN-репозитория BHyVe.
Устанавливаем необходимые порты:
pkg_add -r subversion
pkg_add -r binutils
pkg_add -r curl
rehash
Загружаем исходные тексты из SVN (грузим ревизию 225769):
svn co http://svn.freebsd.org/base/projects/bhyve@225769 /usr/src/
Пересобираем ядро и перезагружаем систему:
cd /usr/src
make buildkernel KERNCONF=GENERIC
make installkernel KERNCONF=GENERIC
reboot
После перезагрузки необходимо загрузить модуль ядра vmm.ko:
kldload vmm
Для управления BHyVe необходимо установить несколько вспомогательных утилит:
/usr/sbin/bhyve, /usr/sbin/bhyveload и /usr/sbin/vmmctl, а также библиотеку
/usr/lib/libvmmapi.*. Уже собранные данные компоненты можно загрузить здесь,
для установки следует запустить скрипт cpinstall.sh.
Для сборки из исходных текстов можно использовать примерно такие команды:
cd /usr/src/
make buildworld
mkdir /usr/jail/
make installworld DESTDIR=/usr/jail/
cp /usr/jail/usr/sbin/bhyve* /usr/sbin/
cp /usr/jail/usr/sbin/vmm* /usr/sbin/
cp /usr/jail/usr/lib/libvmmapi* /usr/lib/
rehash
Правим /boot/loader.conf. Отключаем вывод отладочных предупреждений и изменяем
лимит памяти до 4 Гб для системы с 8 Гб ОЗУ (остальные 4 Гб будут отданы
гостевым системам):
debug.witness.watch="0"
hw.physmem="0x100000000"
После перезагрузки вывод dmesg для системы с 8 Гб ОЗУ выглядит примерно так:
real memory = 8589934592 (8192 MB)
avail memory = 3021811712 (2881 MB)
Подготовка гостевой системы:
Для упрощения тестирования подготовлен уже сконфигурированный образ гостевой
системы, который можно загрузить и установить выполнив:
cd /usr/share/
curl -O http://people.freebsd.org/~neel/bhyve/vm1.tar.gz
gunzip vm1.tar.gz
tar -xf vm1.tar
Данный образ содержит скрипт запуска и образ коревой ФС, размером 300 Мб
(/usr/share/vm1/boot/kernel/mdroot). При загрузке создаётся два virtio-устройства:
vtnet0: виртуальный сетевой интерфейс, привязанный к интерфейсу tap0 на стороне хост-системы
vtbd0: виртуальной блочное устройство, использующее 32 Гб дисковый образ /usr/share/vm1/diskdev
Скрипт /usr/share/vm1/vmprep.sh предназначен для подготовки хост-системы для
использования BHyVe, включая загрузку модуля ядра vmm.ko и настройку сети
(вместо em0 следует указать текущий сетевой адаптер).
#!/bin/sh
kldload vmm
kldload if_tap
ifconfig tap0 create
kldload bridgestp
kldload if_bridge
ifconfig bridge0 create
ifconfig bridge0 addm em0
ifconfig bridge0 addm tap0
ifconfig bridge0 up
ifconfig tap0 up
Запуск гостевой системы в среде виртуализации:
Выполняем скрипт конфигурации хост-системы и запускаем гостевое окружение vm1:
cd /usr/share/vm1/
sh vmprep.sh
sh vmrun.sh vm1
Если не удаётся загрузить модуль vmm.ko на экран будет выведена примерно такая ошибка:
Launching virtual machine "vm1" with 768MB memory below 4GB and 2048MB memory above 4GB ...
vm_create: No such file or directory
В случае успеха будет отображён процесс загрузки FreeBSD:
Launching virtual machine "vm1" with 768MB memory below 4GB and 2048MB memory above 4GB ...
Consoles: userboot
FreeBSD/amd64 User boot, Revision 1.1
(neel@freebsd.org, Sun Sep 25 22:19:14 PDT 2011)
Loading /boot/defaults/loader.conf
/boot//kernel/kernel text=0x41e94f data=0x57ac0+0x273590 syms=[0x8+0x737b8+0x8+0x6abe3]
/boot//kernel/virtio.ko size 0x4ad8 at 0xbc8000
/boot//kernel/if_vtnet.ko size 0xac80 at 0xbcd000
/boot//kernel/virtio_pci.ko size 0x56c0 at 0xbd8000
/boot//kernel/virtio_blk.ko size 0x4f60 at 0xbde000
....
Если используемый в системе процессор не содержит возможностей, необходимых
для работы BHyVe, будет выведен примерно такой текст ошибки:
...
AMD Features=0x20100800<SYSCALL,NX,LM>
AMD Features2=0x1<LAHF>
kldload vmm.ko
vmx_init: processor does not support desired primary processor-based controls
module_register_init: MOD_LOAD (vmm, 0xffffffff816127a0, 0) error 22
Тестовая гостевая система сконфигурирована с пустым паролем для пользователя
root. После входа следует настроить параметры сети указав IP в ручную через
команду ifconfig или получив адрес по DHCP, запустив "dhclient vtnet0".
Для остановки виртуальной машины нужно перезагрузить гостевое окружение, нажать
ESC при появлении экрана загрузки и набрать "quit" в приглашении загрузчика.
|
| |
|
|
|
Опыт восстановления работы zones в Solaris 11 Express/OpenSolaris (доп. ссылка 1) |
Автор: sergm
[комментарии]
|
| | После скоропостижной гибели жесткого диска с лежащими на нем зонами, наступило
время восстановить их из бекапа и запустить. Казалось, тривиальная процедура,
отрепетированная на тестовых системах (но не тех, где лежали зоны - это
важно) отняла много времени и поставила несколько вопросов, ответы на которые
еще придется поискать.
Восстанавливаем зону из бекапа:
# zfs send -R backup/zone/develop@rep201108250419 | zfs receive -F vol01/ zone/develop@rep201108250419
Стартуем зону и наблюдаем странное:
# zoneadm -z develop boot
zone 'develop': ERROR: no active dataset.
zone 'develop':
zoneadm: zone 'develop': call to zoneadmd failed
Ошибка явно говорит о том, что у нас что-то не в порядке со свойствами датасета.
Начинаем осмотр датасета
Чтобы было с чем сравнивать, я создал и запустил тестовую зону, свойства ее
файловых систем и брал за эталон.
Тестовая зона создается примерно так:
# zonecfg -z testzone
testzone: No such zone configured
Use’create’ to begin configuring a new zone.
zonecfg:testzone>create
zonecfg:testzone>set zonepath=/vol01/zone/testzone
zonecfg:testzone>set autoboot=false
zonecfg:testzone>add net
zonecfg:testzone:net>set physical=e1000g4
zonecfg:testzone:net>set address=192.168.0.24/24
zonecfg:testzone:net>end
zonecfg:testzone>verify
zonecfg:testzone>commit
zonecfg:testzone>exit
# zoneadm -z testzone install
...
# zoneadm -z testzone boot
При инсталляции в OpenSolaris/Solaris 11 создаются три датасета (по адресу zonepath):
# zfs list | grep vol01/zone/testzone
NAME
vol01/zone/testzone
vol01/zone/testzone/ROOT
vol01/zone/testzone/ROOT/zbe
Лечение
Смотрим полный список свойств датасетов исправной и сломанной зон и сравниваем их:
# zfs get all vol01/zone/testzone
(сдесь должен быть очень большой вывод, который я пропустил и самое интересное из которого можно увидеть ниже)
# zfs get all vol01/zone/testzone/ROOT
...
# zfs get all vol01/zone/testzone/ROOT/zbe
...
# zfs get all vol01/zone/develop
...
# zfs get all vol01/zone/develop/ROOT
...
# zfs get all vol01/zone/develop/ROOT/zbe
...
Наблюдаем основную разницу в данных свойствах датасета:
# zfs get zoned,canmount,mountpoint,org.opensolaris.libbe:parentbe,org.opensolaris.libbe:active vol01/zone/testzone/ROOT/zbe
NAME PROPERTY VALUE SOURCE
vol01/zone/testzone/ROOT/zbe zoned on inherited from vol01/zone/testzone/ROOT
vol01/zone/testzone/ROOT/zbe canmount noauto local
vol01/zone/testzone/ROOT/zbe mountpoint legacy inherited from vol01/zone/testzone/ROOT
vol01/zone/testzone/ROOT/zbe org.opensolaris.libbe:parentbe 2aadf62d-9560-e14b-c36a-f9136fbce6e9 local
vol01/zone/testzone/ROOT/zbe org.opensolaris.libbe:active on local
# zfs get zoned,canmount,mountpoint,org.opensolaris.libbe:parentbe,org.opensolaris.libbe:active vol01/zone/develop/ROOT/zbe
NAME PROPERTY VALUE SOURCE
vol01/zone/develop/ROOT/zbe zoned off default
vol01/zone/develop/ROOT/zbe canmount on default
vol01/zone/develop/ROOT/zbe mountpoint /vol01/zone/develop/ROOT/zbe default
vol01/zone/develop/ROOT/zbe org.opensolaris.libbe:parentbe - -
vol01/zone/develop/ROOT/zbe org.opensolaris.libbe:active - -
Исправляем, чтобы было нормально:
# zfs set zoned=on vol01/zone/develop/ROOT/zbe
# zfs set canmount=noauto vol01/zone/develop/ROOT/zbe
# zfs set mountpoint=legacy vol01/zone/develop/ROOT/zbe
# zfs set org.opensolaris.libbe:parentbe=2aadf62d-9860-e14b-c36a-f9106fbce6e9 vol01/zone/develop/ROOT/zbe
# zfs set org.opensolaris.libbe:active=on vol01/zone/develop/ROOT/zbe
Аналогично, правим vol01/zone/develop/ROOT после сравнения с работающей зоной:
# zfs get zoned,canmount,mountpoint,org.opensolaris.libbe:parentbe,org.opensolaris.libbe:active vol01/zone/testzone/ROOT
NAME PROPERTY VALUE SOURCE
vol01/zone/testzone/ROOT zoned on local
vol01/zone/testzone/ROOT canmount on default
vol01/zone/testzone/ROOT mountpoint legacy local
vol01/zone/testzone/ROOT org.opensolaris.libbe:parentbe - -
vol01/zone/testzone/ROOT org.opensolaris.libbe:active - -
# zfs get zoned,canmount,mountpoint,org.opensolaris.libbe:parentbe,org.opensolaris.libbe:active vol01/zone/develop/ROOT
NAME PROPERTY VALUE SOURCE
vol01/zone/develop/ROOT zoned off default
vol01/zone/develop/ROOT canmount on default
vol01/zone/develop/ROOT mountpoint /vol01/zone/develop/ROOT default
vol01/zone/develop/ROOT org.opensolaris.libbe:parentbe - -
vol01/zone/develop/ROOT org.opensolaris.libbe:active - -
# zfs set zoned=on vol01/zone/develop/ROOT
# zfs set canmount=on vol01/zone/develop/ROOT
После этого у нас все хорошо: свойства датасетов практически идентичны.
# zlogin -C develop
[Connected to zone 'develop' console]
[NOTICE: Zone booting up]
SunOS Release 5.11 Version snv_134 64-bit
Copyright 1983-2010 Sun Microsystems, Inc. All rights reserved.
Use is subject to license terms.
Hostname: develop
Reading ZFS config: done.
Mounting ZFS filesystems: (5/5)
develop console login: mike
Password:
Last login: Mon Aug 2 06:41:54 from nostalgia
Sun Microsystems Inc. SunOS 5.11 snv_134 February 2010
(mike@develop)$ su
Password:
Aug 27 15:04:13 develop su: ‘su root’ succeeded for mike on /dev/console
(root@develop)# svcs -xv
(root@develop)#
Вместо послесловия
Если у зоны были смонтированы из глобальной зоны файловые системы через lofs,
будет такой казус - зона загрузиться, но локальные файловые системы не будут
смонтированы, сервис filesystem/local:default перейдет в состояние maintenance
с ошибкой 262 в логах:
/usr/bin/zfs mount -a failed: cannot mount local filesystem.
Проблему можно решить экспортировав и затем импортировав зону
# zoneadm -z webapp detach
# zoneadm -z webapp attach
После этого все будет работать нормально.
|
| |
|
|
|
Использование PaaS-платформы CloudFoundry в Ubuntu 11.10 (доп. ссылка 1) (доп. ссылка 2) |
[обсудить]
|
| | В universe-репозиторий Ubuntu 11.10 будут входить пакеты с реализацией
поддержки серверной и клиентской части PaaS-платформы (Platform as a Service) [[https://www.opennet.ru/opennews/art.shtml?num=30241
CloudFoundry]], развиваемой компанией VMware и доступной в исходных текстах под
лицензией Apache.
Платформа позволяет сформировать инфраструктуру для выполнения в облачных
окружениях конечных приложений на Java (Spring), Grails, Ruby (Rails, Sinatra),
JavaScript (Node.js), Scala и других языках, работающих поверх JVM. Из СУБД
поддерживаются СУБД MySQL, Redis и MongoDB. PaaS-платформа, в отличие от IaaS,
работает на более высоком уровне, чем выполнение готовых образов операционных
систем, избавляя потребителя от необходимости обслуживания ОС и системных
компонентов, таких как СУБД, языки программирования, программные фреймворки и
т.п. В PaaS от пользователя требуется только загрузка приложения, которое будет
запущено в готовом окружении, предоставляемом платформой.
Устанавливаем необходимые серверные пакеты из отдельного PPA-репозитория:
sudo apt-add-repository ppa:cloudfoundry/ppa
sudo apt-get update
sudo apt-get install cloudfoundry-server
В процессе установки потребуется ответить на несколько вопросов debconf, таких как пароль к MySQL.
Устанавливаем клиентские пакеты для тестирования сервера:
sudo apt-get install cloudfoundry-client
В итоге имеем сервер "vcap" и клиент "vmc".
Настройка
По умолчанию vmc-клиент настроен для работы с внешним сервисом
CloudFoundry.com. Для того, чтобы обеспечить его работу с локальным сервером
потребуется настроить сопутствующие локальных службы.
Во первых требуется обеспечить автоматическое сопоставление для выполняемых
приложений IP-адреса cloud-окружения с доменным именем. Самым типичным способом
является использование готовых DNS-сервисов, таких как DynDNS.com, настроить
автоматическую отправку обновлений на сервис SynDNS.com можно запустив:
dpkg-reconfigure cloudfoundry-server
В более простом случае, для проведения экспериментов можно обойтись правкой
/etc/hosts на стороне клиента и сервера.
Смотрим внешний IP-адрес сервера. Если сервер запущен не на локальной машине, а
в сервисе Amazon EC2 адрес можно посмотреть через обращение к API Amazon командой:
wget -q -O- http://169.254.169.254/latest/meta-data/public-ipv4
174.129.119.101
Соответственно, в /etc/hosts на сервере и клиентских машинах добавляем
управляющий хост api.vcap.me, а также хост для тестового приложения (в нашем
случае приложение будет называться testing123):
echo "174.129.119.101 api.vcap.me testing123.vcap.me" | sudo tee -a /etc/hosts
Привязываем vmc-клиент к серверу vcap (CloudFoundry):
vmc target api.vcap.me
Succesfully targeted to [http://api.vcap.me]
Добавляем на сервер нового пользователя:
vmc add-user
Email: test@example.com
Password: ********
Verify Password: ********
Creating New User: OK
Successfully logged into [http://api.vcap.me]
Заходим на сервер:
vmc login
Email: test@example.com
Password: ********
Successfully logged into [http://api.vcap.me]
Размещаем своё приложение на сервере. В качестве примера, загрузим простую
программу на языке Ruby, использующую фреймворк Sinatra. Примеры можно найти в
директории /usr/share/doc/ruby-vmc/examples.
Переходим в директорию с приложением:
cd /usr/share/doc/ruby-vmc/examples/ruby/hello_env
Копируем его на сервер:
vmc push
Would you like to deploy from the current directory? [Yn]: y
Application Name: testing123
Application Deployed URL: 'testing123.vcap.me'?
Detected a Sinatra Application, is this correct? [Yn]: y
Memory Reservation [Default:128M] (64M, 128M, 256M, 512M, 1G or 2G)
Creating Application: OK
Would you like to bind any services to 'testing123'? [yN]: n
Uploading Application:
Checking for available resources: OK
Packing application: OK
Uploading (0K): OK
Push Status: OK
Staging Application: OK
Starting Application: OK
Все готово! Теперь можно открыть в браузере http://testing123.vcap.me/ и
насладиться результатом работы загруженной программы.
Пример развертывания приложения в сервисе CloudFoundry.com
Подкоючаем vmc-клиент к сервису CloudFoundry.com:
vmc target https://api.cloudfoundry.com
Succesfully targeted to [https://api.cloudfoundry.com]
Входим, предварительно зарегистрировавшись на сайте CloudFoundry.com:
vmc login
Email: test@example.com
Password: **********
Successfully logged into [https://api.cloudfoundry.com]
Размещаем NodeJS-приложение:
cd /usr/share/doc/ruby-vmc/examples/nodejs/hello_env
vmc push
Would you like to deploy from the current directory? [Yn]: y
Application Name: example102
Application Deployed URL: 'example102.cloudfoundry.com'?
Detected a Node.js Application, is this correct? [Yn]: y
Memory Reservation [Default:64M] (64M, 128M, 256M, 512M or 1G) 64M
Creating Application: OK
Would you like to bind any services to 'example102'? [yN]: n
Uploading Application:
Checking for available resources: OK
Packing application: OK
Uploading (0K): OK
Push Status: OK
Staging Application: OK
Starting Application: OK
Открываем в браузере http://example102.cloudfoundry.com/ и видим результат работы
Размещаем программу на Java:
Переходим в директорию с примером:
cd /usr/share/doc/ruby-vmc/examples/springjava/hello_env
Собираем JAR-архив:
sudo apt-get install openjdk-6-jdk maven2
...
cd $HOME
cp -r /usr/share/doc/ruby-vmc/examples/springjava .
cd springjava/hello_env/
mvn clean package
...
cd target
Загружаем на сервер:
vmc push
Would you like to deploy from the current directory? [Yn]: y
Application Name: example103
Application Deployed URL: 'example103.cloudfoundry.com'?
Detected a Java Web Application, is this correct? [Yn]: y
Memory Reservation [Default:512M] (64M, 128M, 256M, 512M or 1G) 512M
Creating Application: OK
Would you like to bind any services to 'example103'? [yN]: n
Uploading Application:
Checking for available resources: OK
Packing application: OK
Uploading (4K): OK
Push Status: OK
Staging Application: OK
Starting Application: OK
Открываем в браузере http://example103.cloudfoundry.com/.
Размещаем более сложное готовое web-приложение Drawbridge, требующее для
своей работы СУБД MySQL (параметры подключаемого сервиса mysql-4a958 задаются
отдельно, в web-интерфейсе cloudfoundry.com):
cd $HOME
bzr branch lp:~kirkland/+junk/drawbridge
cd drawbridge
vmc push
Would you like to deploy from the current directory? [Yn]: y
Application Name: example104
Application Deployed URL: 'example104.cloudfoundry.com'?
Detected a Node.js Application, is this correct? [Yn]: y
Memory Reservation [Default:64M] (64M, 128M, 256M or 512M) 128M
Creating Application: OK
Would you like to bind any services to 'example104'? [yN]: y
Would you like to use an existing provisioned service [yN]? n
The following system services are available:
1. mongodb
2. mysql
3. redis
Please select one you wish to provision: 2
Specify the name of the service [mysql-4a958]:
Creating Service: OK
Binding Service: OK
Uploading Application:
Checking for available resources: OK
Processing resources: OK
Packing application: OK
Uploading (77K): OK
Push Status: OK
Staging Application: OK
Starting Application: OK
Открываем http://example104.cloudfoundry.com
Просмотр размещенных приложений и доступных сервисов.
Выводим список приложений:
vmc apps
| Application | # | Health | URLS | Services |
| example102 | 1 | RUNNING | example102.cloudfoundry.com | |
| example103 | 1 | RUNNING | example103.cloudfoundry.com | |
| example101 | 1 | RUNNING | example101.cloudfoundry.com | |
| example104 | 1 | RUNNING | example104.cloudfoundry.com | mysql-4a958 |
Выводим список доступных сервисов:
vmc services
| Service | Version | Description |
| redis | 2.2 | Redis key-value store service |
| mongodb | 1.8 | MongoDB NoSQL store |
| mysql | 5.1 | MySQL database service |
== Provisioned Services ==
| Name | Service |
| mysql-4a958 | mysql |
| mysql-5894b | mysql |
Выводим список доступных фреймворков:
vmc frameworks
| Name |
| rails3 |
| sinatra |
| lift |
| node |
| grails |
| spring |
Изменение выделенных для приложения ресурсов
Увеличение доступной памяти:
vmc mem example101
Update Memory Reservation? [Current:128M] (64M, 128M, 256M or 512M) 512M
Updating Memory Reservation to 512M: OK
Stopping Application: OK
Staging Application: OK
Starting Application: OK
Проверяем, какие ресурсы доступны:
vmc stats example101
| Instance | CPU (Cores) | Memory (limit) | Disk (limit) | Uptime |
| 0 | 0.1% (4) | 16.9M (512M) | 40.0K (2G) | 0d:0h:1m:22s |
Увеличение числа одновременно выполняемых окружений для приложения example104 до 4:
vmc instances example104 4
Scaling Application instances up to 4: OK
Проверяем, какие ресурсы доступны:
vmc stats example104
| Instance | CPU (Cores) | Memory (limit) | Disk (limit) | Uptime |
| 0 | 0.0% (4) | 21.0M (128M) | 28.0M (2G) | 0d:0h:19m:33s |
| 1 | 0.0% (4) | 15.8M (128M) | 27.9M (2G) | 0d:0h:2m:38s |
| 2 | 0.0% (4) | 16.3M (128M) | 27.9M (2G) | 0d:0h:2m:36s |
| 3 | 0.0% (4) | 15.8M (128M) | 27.9M (2G) | 0d:0h:2m:37s |
|
| |
|
|
|
Использование системы виртуализации KVM в OpenIndiana (доп. ссылка 1) |
[комментарии]
|
| | В бета-версии 151 сборки проекта OpenIndiana, в рамках которого независимым
сообществом развивается построенное на кодовой базе Illumos ответвление от
OpenSolaris, появилась поддержка системы виртуализации KVM. Поддержка KVM была ранее
портирована компанией
Joyent для своей ОС SmartOS и на днях перенесена в Illumos (за исключением
поддержки KVM branded zone, которая пока не добавлена).
<p>Для использования KVM пользователям последней доступной сборки oi_148
необходимо выполнить обновление до oi_151_beta:
sudo pkg set-publisher -g http://pkg.openindiana.org/dev-il -G http://pkg.openindiana.org/dev openindiana.org
sudo pkg image-update --be-name oi_151_beta
После чего можно подключить репозиторий с пакетами для работы с KVM и
установить требуемые инструменты:
sudo pkg set-publisher -p http://pkg.openindiana.org/kvm-test
sudo pkg install driver/i86pc/kvm system/qemu system/qemu/kvm
Управление окружениями производится при помощи стандартных утилит из состава
QEMU. Использование libvirt пока не поддерживается.
Пример использования.
Создаем образ гостевой системы:
qemu-img create -f qcow2 virt.img 15G
Устанавливаем операционную систему в гостевое окружение:
qemu-kvm -hda virt.img -cdrom install_cd.iso -boot d -m 512
Запускаем гостевое окружение (вместо qemu-kvm можно использовать qemu-system-x86_64):
qemu-kvm -hda virt.img -net nic -net user
|
| |
|
|
|
Изменение размера виртуального диска KVM/QEMU/VirtualBox |
[комментарии]
|
| | При необходимости расширения размера виртуального диска в формате qcow2,
используемом в системах виртуализации KVM и QEMU, можно обойтись без
клонирования и создания нового образа.
Завершаем работу виртуальной машины, связанной с изменяемым дисковым образом.
Увеличиваем размер образа. В случае использования KVM/QEMU:
qemu-img resize vm.qcow2 +5GB
В случае использования VirtualBox, потребуется дополнительный шаг с
промежуточным преобразованием VDI в qcow2 или raw-формат:
qemu-img convert -f vdi -O qcow2 vm.vdi vm.qcow2
qemu-img resize vm.qcow2 +5G
qemu-img convert -f qcow2 -O vdi vm.qcow2 vm.vdi
Другой вариант с использованием штатной утилиты VBoxManage:
VBoxManage internalcommands converttoraw vm.vdi vm.raw
qemu-img resize vm.raw +5G
VBoxManage convertfromraw --format VDI --variant Standard vm.raw vm.vdi
Также можно создать новый большой VDI-раздел и клонировать в него старое содержимое:
VBoxManage clonehd --existing old.vdi new.vdi
Для задействования появившегося свободного пространства, необходимо расширить
размер связанной с дисковым образом файловой системы. Для расширения ФС проще
всего воспользоваться приложением gparted.
Скачиваем из сети Live-дистрибутив Parted Magic или SystemRescueCd.
Загружаем Live-дистрибутив в новой виртуальной машине, не забыв присоединить к
ней изменяемый дисковый образ.
После загрузки запускаем gparted, выбираем виртуальный диск и видим в хвосте
нераспределенную область. Кликаем правой кнопкой мыши на имеющейся ФС и
выбираем "Resize/Move", следуя дальнейшим подсказкам в интерфейсе.
После завершения расширения размера, загружаем изначальную виртуальную машину и
запускаем утилиту fsck для проверки раздела, размер которого был изменен:
sudo fsck /dev/sda1
|
| |
|
|
|
Использование cloud-init для запуска cloud-редакции Ubuntu в локальном KVM-окружении (доп. ссылка 1) (доп. ссылка 2) |
[комментарии]
|
| | В состав адаптированных для установки в cloud-окружениях сборок Ubuntu 10.10
(UEC) был интегрирован cloud-init, конфигурируемый процесс инициализации,
позволяющий унифицировать процесс задания конфигурации во время загрузки,
например, указать локаль, имя хоста, SSH-ключи и точки монтирования.
Ниже представлен скрипт по установке и преднастройке UEC-сборки в виде гостевой
системы, работающей под управлением локального гипервизора KVM.
# Загружаем свежую сборку UEC с http://uec-images.ubuntu.com,
# например, стабильный выпуск Ubuntu 10.10 (http://uec-images.ubuntu.com/maverick/current/)
# или тестовую версию Ubuntu 11.04 (http://uec-images.ubuntu.com/natty/current/).
uecnattyservercurrent=http://uec-images.ubuntu.com/server/natty/current/natty-server-uec-i386.tar.gz
# Распаковываем img-образ и устанавливаем несколько переменных, указываем
# на ядро и базовые директории:
tarball=$(basename $uecnattyservercurrent)
[ -f ${tarball} ] || wget ${uecnattyservercurrent}
contents=${tarball}.contents
tar -Sxvzf ${tarball} | tee "${contents}"
cat natty-server-uec-i386.tar.gz.contents
base=$(sed -n 's/.img$//p' "${contents}")
kernel=$(echo ${base}-vmlinuz-*)
floppy=${base}-floppy
img=${base}.img
# Преобразуем образ UEC в формат qcow2, для запуска под управлением KVM:
qemu-img create -f qcow2 -b ${img} disk.img
# Подготавливаем набор мета-данных (файлы meta-data и user-data) для
# автоматизации настройки гостевой системы, примеры можно посмотреть здесь
# Запускаем простейший HTTP-сервер для отдачи файлов с мета-данными
# Сервер будет запущен на 8000 порту и будет отдавать файлы meta-data
# и user-data из текущей директории, которые следует модифицировать в зависимости
# от текущих предпочтений (можно прописать команды по установке дополнительных пакетов,
# запустить любые команды, подключить точки монтирования и т.п.)
python -m SimpleHTTPServer &
websrvpid=$!
# Запускаем гостевую систему под управлением KVM, базовый URL для загрузки
# мета-данных передаем через опцию "s=":
kvm -drive file=disk.img,if=virtio,boot=on -kernel "${kernel}" \
-append "ro init=/usr/lib/cloud-init/uncloud-init root=/dev/vda ds=nocloud-net;s=http://192.168.122.1:8000/ ubuntu-pass=ubuntu"
# Завершаем выполнение http-сервера, используемого для отдачи мета-данных.
kill $websrvpid
Пример файла user-data:
#cloud-config
#apt_update: false
#apt_upgrade: true
#packages: [ bzr, pastebinit, ubuntu-dev-tools, ccache, bzr-builddeb, vim-nox, git-core, lftp ]
apt_sources:
- source: ppa:smoser/ppa
disable_root: True
mounts:
- [ ephemeral0, None ]
- [ swap, None ]
ssh_import_id: [smoser ]
sm_misc:
- &user_setup |
set -x; exec > ~/user_setup.log 2>&1
echo "starting at $(date -R)"
echo "set -o vi" >> ~/.bashrc
cat >> ~/.profile <<EOF
export EDITOR=vi
EOF
runcmd:
- [ sudo, -Hu, ubuntu, sh, -c, 'grep "cloud-init.*running" /var/log/cloud-init.log > ~/runcmd.log' ]
- [ sudo, -Hu, ubuntu, sh, -c, 'read up sleep < /proc/uptime; echo $(date): runcmd up at $up | tee -a ~/runcmd.log' ]
- [ sudo, -Hu, ubuntu, sh, -c, *user_setup ]
Пример файла meta-data
#ami-id: ami-fd4aa494
#ami-launch-index: '0'
#ami-manifest-path: ubuntu-images-us/ubuntu-lucid-10.04-amd64-server-20100427.1.manifest.xml
#block-device-mapping: {ami: sda1, ephemeral0: sdb, ephemeral1: sdc, root: /dev/sda1}
hostname: smoser-sys
#instance-action: none
instance-id: i-87018aed
instance-type: m1.large
#kernel-id: aki-c8b258a1
local-hostname: smoser-sys.mosers.us
#local-ipv4: 10.223.26.178
#placement: {availability-zone: us-east-1d}
#public-hostname: ec2-184-72-174-120.compute-1.amazonaws.com
#public-ipv4: 184.72.174.120
#public-keys:
# ec2-keypair.us-east-1: [ssh-rsa AAAA.....
# ec2-keypair.us-east-1, '']
#reservation-id: r-e2225889
#security-groups: default
|
| |
|
|
|
Подготовка DomU FreeBSD-окружения для выполнения в Linux Dom0 Xen с LVM (доп. ссылка 1) |
[комментарии]
|
| | В качестве хост-системы будет использован сервер на базе Debian GNU/Linux 5, на
котором дисковые разделы разбиты с использованием LVM.
Для сборки работающего в режиме паравиртуализации ядра FreeBSD и формирования
образа системы понадобится уже установленная FreeBSD. В простейшем случае можно
воспользоваться VirtualBox для временной установки FreeBSD.
Заходим в существующую FreeBSD систему и подготавливаем дисковый образ /tmp/freebsd.img для Xen.
cd /usr/src
truncate -s 1G /tmp/freebsd.img
Привязываем файл с дисковым образом к устройству /dev/md0
mdconfig -f freebsd.img
Разбиваем разделы, форматируем и монтируем в /mnt:
fdisk -BI /dev/md0
bsdlabel -wB md0s1
newfs -U md0s1a
mount /dev/md0s1a /mnt
Собираем мир и ядро с паравиртуальными драйверами Xen и устанавливаем в директорию /mnt:
make buildworld
make buildkernel KERNCONF=XEN
make DESTDIR=/mnt installworld
make DESTDIR=/mnt installkernel KERNCONF=XEN
make DESTDIR=/mnt distribution
В /mnt/etc/ttys добавляем строку с описанием терминала xc0
xc0 "/usr/libexec/getty Pc" vt100 on secure
В /mnt/etc/fstab прописываем параметры монтирования корня:
/dev/ad0s1a / ufs rw 0 0
Отмонтируем сформированный образ и скопируем его на хост-систему, на которой будет работать DomU:
umount /mnt
mdconfig -d -u 0
bzip2 -v9 /tmp/freebsd.img
scp /tmp/freebsd.img.bz2 user@dom0-host.example.com:/tmp/freebsd.img.bz2
Отдельно копируем ядро с паравиртуальными драйверами:
scp /usr/obj/usr/srcsys/XEN/kernel user@dom0-host.example.com:/tmp/freebsd_8.2-RC1_kernel
Настраиваем Dom0
Подготавливаем LVM-разделы, которые будут использоваться для работы FreeBSD.
Создадим два раздела - один для изменения размера рабочего раздела и второй -
рабочий раздел, на котором будет работать гостевая система.
Создаем LVM-разделы в уже присутствующей физической группе xen-vol:
lvcreate -L1000 -n freebsdmaint.example.com xen-vol
lvcreate -L110000 -n freebsd-dom0.example.com xen-vol
копируем ранее созданный образ в данные разделы:
dd if=freebsd.img of=/dev/xen-vol/freebsdmaint.example.com bs=1M
dd if=freebsd.img of=/dev/xen-vol/freebsd-dom0.example.com bs=1M
Конфигурируем Xen:
Создаем два файла конфигурации: первый для обслуживания изменения размера
раздела и второй для рабочего виртуального окружения (отдельный раздел нужен
так как мы не можем переконфигурировать текущий раздел без его отмонтирования,
смонтировать файл через "mount -o loop" мы не можем так как в Linux отсутствует
полноценная поддержка UFS).
Ранее подготовленное ядро копируем в /xen/kernels/freebsd_8.2-RC1_kernel
Окружение для изменения размера дискового раздела freebsdmaint.example.conf.cfg:
kernel = "/xen/kernels/freebsd_8.2-RC1_kernel"
vcpus = '1' # 1 CPU
memory = '64' # 64 Мб ОЗУ
disk = [ 'phy:/dev/xen-vol/freebsdmaint.example.com,hda,w', 'phy:/dev/xen-vol/freebsd-dom0.example.com,hdb,w' ]
name = 'freebsdmaint.example.com'
vif = [ 'bridge=eth0,mac=00:16:3E:62:DB:03' ]
extra = 'xencons=tty1'
extra = "boot_verbose"
extra += ",boot_single"
extra += ",kern.hz=100"
extra += ",vfs.root.mountfrom=ufs:/dev/ad0s1a"
Рабочее окружение freebsd-dom0.example.conf.cfg (отличается от предыдущей
конфигурации указанием только одного раздела freebsd-dom0.example.com):
kernel = "/xen/kernels/freebsd_8.2-RC1_kernel"
vcpus = '1'
memory = '64'
disk = [ 'phy:/dev/xen-vol/freebsd-dom0.example.com,hda,w' ]
name = 'freebsd-dom0.example.com'
vif = [ 'bridge=eth0,mac=00:16:3E:62:DB:03' ]
extra = 'xencons=tty1'
extra = "boot_verbose"
extra += ",boot_single"
extra += ",kern.hz=100"
extra += ",vfs.root.mountfrom=ufs:/dev/ad0s1a"
Запускаем обслуживающее окружение:
xm create -c freebsdmaint.example.conf.cfg
Изменяем размер рабочего раздела, который виден как /dev/ad1s1a (после запуска
fdisk на первые два вопроса отвечаем 'y', после запроса размера указываем
размер основного раздела как "число Мб * 2048"):
fdisk -u /dev/ad1
******* Working on device /dev/ad1 *******
parameters extracted from in-core disklabel are:
cylinders=14023 heads=255 sectors/track=63 (16065 blks/cyl)
Figures below won't work with BIOS for partitions not in cyl 1
parameters to be used for BIOS calculations are:
cylinders=14023 heads=255 sectors/track=63 (16065 blks/cyl)
Do you want to change our idea of what BIOS thinks ? [n] n
Media sector size is 512
Warning: BIOS sector numbering starts with sector 1
Information from DOS bootblock is:
The data for partition 1 is:
sysid 165 (0xa5),(FreeBSD/NetBSD/386BSD)
start 63, size 2088387 (1019 Meg), flag 80 (active)
beg: cyl 0/ head 1/ sector 1;
end: cyl 129/ head 254/ sector 63
Do you want to change it? [n] y
...
Supply a decimal value for "size" [2088387]
fdisk: WARNING: partition does not end on a cylinder boundary
fdisk: WARNING: this may confuse the BIOS or some operating systems
Correct this automatically? [n] y
Should we write new partition table? [n] y
Изменяем размер слайса:
bsdlabel -e /dev/ad1s1
# size offset fstype [fsize bsize bps/cpg]
a: 2088351 16 unused 0 0
c: 2088387 0 unused 0 0 # "raw" part, don't edit
Не трогаем значение "raw" и правим размер слайса "a", приписав туда вычисленное
на прошлом шаге значение дискового раздела минус 16 байт. Т.е. получаем после
правки (raw-значение рассчитается автоматически):
# size offset fstype [fsize bsize bps/cpg]
a: 225279416 16 unused 0 0
c: 225279432 0 unused 0 0 # "raw" part, don't edit
Запускаем growfs для расширения существующей файловой системы:
growfs /dev/ad1s1a
Выключаем обслуживающую VM и запускаем основную. Внимание, одновременно
основной и обслуживающий VM запускать нельзя, так как они работают с одинаковым
дисковым разделом freebsd-dom0.example.com.
|
| |
|
|
|
Как подключить физический диск в VirtualBox |
[комментарии]
|
| | Иногда требуется использовать в VirtualBox не образ виртуального диска, а
настоящее блочное устройство, такое как диск или USB Flash. В нашем случае,
была поставлена задача загрузки в VirtualBox для проведения эксперимента копии
одного из серверов, содержимое дисков которого было скопировано на
USB-накопитель. При этом система должна была поддерживать загрузку не только в
VirtualBox, но и без виртуализации - при соединении USB-накопителя к любому компьютеру.
Для подключения блочного устройства /dev/sdc необходимо выполнить (тем же
методом можно подключать отдельные разделы, например, /dev/sdc2):
sudo VBoxManage internalcommands createrawvmdk -filename ~/.VirtualBox/HardDisks/sdc.vmdk -rawdisk /dev/sdc
В дальнейшем, в настройках виртуальной машины выбираем образ sdc.vmdk, который
ссылается на /dev/sdc. При подключении необходимо обратить внимание на права
доступа к заданному блочному устройству, например, в нашем случае текущий
пользователь должен входить в группу, для которой разрешена запись /dev/sdc.
|
| |
|
|
|
Установка и запуск гостевой ОС на FreeBSD под VirtualBox без X11 |
Автор: Михаил Григорьев
[комментарии]
|
| | Исходные данные: Сервер FreeBSD 8.1-RELEASE
Задача: Запустить на VirtualBox гостевую ОС Windows или Ubuntu.
Решение:
1. Устанавливаем VirtualBox из портов (не забываем вначале обновить порты)
cd /usr/ports/emulators/virtualbox-ose
make config
/------------------------------------------------------\
| Options for virtualbox-ose 3.2.10 |
| |
| [ ] QT4 Build with QT4 Frontend |
| [ ] DEBUG Build with debugging symbols |
| [X] GUESTADDITIONS Build with Guest Additions |
| [X] DBUS Build with D-Bus and HAL support|
| [ ] PULSEAUDIO Build with PulseAudio |
| [ ] X11 Build with X11 support |
| [ ] VDE Build with VDE support |
| [X] VNC Build with VNC support |
| [ ] WEBSERVICE Build Webservice |
| [ ] NLS Native language support |
\------------------------------------------------------/
make install
2. Добавляем запуск модулей при старте сервера:
echo vboxdrv_load="YES" >> /boot/loader.conf
Загружаем нужный модуль:
kldload vboxdrv
3. Создаем пользователя vbox под которым будем запускать VirtualBox
pw useradd vbox -c 'VirtualBox Daemon' -d /home/vbox -g vboxusers -w none -s /bin/sh
4. Создаем домашний каталог пользователя vbox где будем хранить виртуалки
mkdir /home/vbox
5. Даем права:
chown -R vbox:vboxusers /home/vbox/
chmod -R 770 /home/vbox/
6. Входим под пользователем и создаем виртуальную машину:
Под рукой был только диск с Ubuntu, для Windows нужно лишь
изменить опцию --ostype, имя виртуалки, имя hdd и путь до iso-образа.
Список возможных значений --ostype смотрим командой: VBoxManage list ostypes
su -l vbox
VBoxManage createvm --name Ubuntu --ostype Ubuntu --register --basefolder /home/vbox
VBoxManage modifyvm "Ubuntu" --memory 256 --acpi on --boot1 dvd --nic1 nat
VBoxManage createhd --filename "Ubuntu.vdi" --size 10000 --remember
VBoxManage storagectl "Ubuntu" --name "IDE Controller" --add ide --controller PIIX4
VBoxManage storageattach "Ubuntu" --storagectl "IDE Controller" --port 0 --device 0 --type hdd --medium "Ubuntu.vdi"
VBoxManage openmedium dvd /mnt/ubuntu-9.10-dvd-i386.iso
VBoxManage storageattach "Ubuntu" --storagectl "IDE Controller" --port 0 --device 1 --type dvddrive --medium /mnt/ubuntu-9.10-dvd-i386.iso
7. Смотрим конфигурацию созданной машины:
VBoxManage showvminfo Ubuntu
8. Создаем скрипт /usr/local/etc/rc.d/vbox.sh для запуска VirtualBox:
#!/bin/sh
echo "Starting VirtualBox..."
su -l vbox -c '/usr/bin/nohup /usr/local/bin/VBoxHeadless --startvm Ubuntu --vnc --vncport 2222 --vncpass 1234567890 &'
9. Подключаемся к VirtualBox с помощью любого VNC клиента. (порт 2222, пароль 1234567890)
10. Устанавливаем и настраиваем ОС, ставим на неё VirtualBox GuestAdditions.
На этом все, если есть вопросы, пишите, буду рад ответить.
(с) Михаил Григорьев (sleuthhound@gmail.com)
|
| |
|
|
|
Преобразование дисковых разделов для VirtualBox и обратно |
[комментарии]
|
| | Преобразование существующего дискового раздела в формат виртуальной машины VirtualBox.
Создаем слепок дискового раздела /dev/sda1
dd if=/dev/sda1 bs=512k of=os_image.img
Преобразуем созданный образ в формат VDI:
VBoxManage convertdd os_image.img os_image.vdi --format VDI
Преобразование образа виртуальной машины для записи на диск/Flash.
Если внутри виртуального диска один раздел, конвертируем VDI в сырой дамп:
VBoxManage internalcommands converttoraw os_image.vdi os_image.img
или
VBoxManage clonehd os_image.vdi /путь/os_image.img --format RAW
Вычисляем смещение до нужного раздела:
fdisk os_image.img
Команда (m для справки): p
Диск os_image.img: 0 МБ, 0 байт
16 heads, 63 sectors/track, 0 cylinders
Units = цилиндры of 1008 * 512 = 516096 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
Устр-во Загр Начало Конец Блоки Id Система
os_image.img1 1 213 107320+ 83 Linux
Раздел начинается с первого трека, значит смещение будет 63 * 512 = 32256
Монтируем:
sudo mount -o loop,offset=32256 os_image.img /mnt
Записываем на диск /dev/sda8 (skip=63 - пропускаем 63 блока по 512 байт (bs=512)):
dd if=os_image.img bs=512 skip=63 of=/dev/sda8
если в образе больше одного раздела необходимо также указать размер копируемых
данных через опцию count=N, где N - размер в 512 байтных блоках.
Локальное монтирование статического VDI-образа.
К ранее рассчитанному смещению для дискового раздела, нужно учесть размер
заголовка (512 байт) и системного индекса VDI (4 байт на каждый мегабайт
размера VDI).
ls -al os_image.vdi
-rw------- 1 test test 110101504 2010-12-20 21:47 os_image.vdi
Для диска размером 105 Мб получаем смещение: 32256 + 512 + 4*(110101504/(1024*1024)) = 33188
Значение 33188 дополняем до границы в 512 байт:
echo "33188 - 33188 % 512 + 512" | bc
33280
Монтируем:
mount -o loop,offset=33280 os_image.vdi /mnt/vdi
Внимание ! Монтирование динамически расширяемых VDI невозможно, так как они
имеют неоднородную структуру.
Изменение размера VDI-образа:
Самый простой способ создать пустой VDI нужного размера, из виртуального
окружения разметить на нем ФС и скопировать данные. Любители графических
интерфейсов могут загрузить в виртуальном окружении LiveCD c gparted (http://gparted.sourceforge.net/).
Дополнение от pavlinux:
Еще один метод локального монтирования статического VDI-образа.
# modprobe nbd max_part=8 nbds_max=1
# qemu-nbd --connect=/dev/nbd0 WindowsXPSP3.vdi
# fdisk -l /dev/nbd0
Устр-во Загр Начало Конец Блоки Id Система
/dev/nbd0p1 * 1 2813 22595391 7 HPFS/NTFS
# mount -t ntfs-3g /dev/nbd0p1 /media/foofeel
# ls /media/foofeel
AUTOEXEC.BAT boot.ini Documents and Settings MSDOS.SYS
|
| |
|
|
|
VirtualBox на отдельной виртуальной консоли (доп. ссылка 1) |
Автор: Wizard
[комментарии]
|
| | При локальном использовании VitrualBox'а можно запускать виртуальные машины на
отдельных виртуальных консолях с переключением по Ctrl+Alt+Fn с помощью xinit(1).
Пример для 8-й консоли (Гость - Ctrl+Alt+F8, хост - Ctrl+Alt+F7):
xinit /usr/bin/VirtualBox --startvm "My beloved VM" --fullscreen -- /usr/bin/Xorg :1
Соответственно, при желании запуска таким образом более одной виртуальной
машины, необходимо увеличивать номер виртуального терминала для X-сервера (:2,
:3 и т.д.) и, конечно, указывать соответствующие имена виртуальных машин в
параметре "--startvm".
|
| |
|
|
|
Использование контейнеров LXC в Debian/Ubuntu |
Автор: Heretic
[комментарии]
|
| | Контейнеры LXC позволяют изолировать процессы и ресурсы, работающие в рамках
одной операционной системы, не прибегая к использованию виртуализации.
Положительным аспектом LXC является использование единого пространства
системных буферов, например, единый для базовой системы и всех контейнеров
дисковый кэш. Наиболее близкими аналогами LXC являются Solaris Zones и FreeBSD jail.
В качестве серверной операционной системы была использована Ubuntu 10.04 LTS, в
качестве виртуальных машин использован Debian Lenny.
Организация сетевого соединения для контейнера.
Воспользуемся сетевым мостом для создания общего сегмента сети.
Устанавливаем пакеты для создания моста:
sudo aptitude install bridge-utils
Настроим мост, для этого приведем файл /etc/network/interfaces к следующему виду:
# The loopback network interface
auto lo
iface lo inet loopback
# Комментируем активные до настройки сетевого моста опции
#allow-hotplug eth0
#iface eth0 inet dhcp
# Setup bridge
auto br0
iface br0 inet dhcp
bridge_ports eth0
bridge_fd 0
Как можно увидеть из файла /etc/network/interfaces, eth0 закомментирован и
добавлен новый интерфейс br0.
Далее перезапускаем сеть:
sudo /etc/init.d/networking restart
Если использует ручная настройка сети, то нужно сделать так:
auto br0
iface br0 inet static
bridge_ports eth0
bridge_fd 0
address 192.168.82.25
netmask 255.255.255.0
gateway 192.168.82.1
dns-nameservers 192.168.82.1
Установка LXC, установка cgroups
Установим lxc:
sudo aptitude install lxc
Создадим директорию /cgroup и примонтируем cgroup (может быть где угодно):
sudo mkdir /cgroup
Добавляем следующие строки в /etc/fstab:
cgroup /cgroup cgroup defaults 0 0
И монтируем cgroups:
sudo mount cgroup
До того как начать собирать контейнер, проверим окружение через lxc-checkconfig:
lxc-checkconfig
Kernel config /proc/config.gz not found, looking in other places...
Found kernel config file /boot/config-2.6.32-3-686
--- Namespaces ---
Namespaces: enabled
Utsname namespace: enabled
...
Все параметры должны быть включены (для ubuntu 10.04, в Debian squeeze Cgroup
memory controller: disabled ).
Создание первого контейнера
Мы будем использовать оригинальную версию скрипта lxc-debian, он находится в
файле /usr/share/doc/lxc/examples/lxc-debian.gz.
Скопируем файл /usr/share/doc/lxc/examples/lxc-debian.gz в /usr/local/sbin/
распакуем его и поставим бит запуска:
sudo cp /usr/share/doc/lxc/examples/lxc-debian.gz /usr/local/sbin/
sudo gunzip /usr/local/sbin/lxc-debian.gz
sudo chmod +x /usr/local/sbin/lxc-debian
Перед запуском этого скрипта требуется установить debootstrap.
sudo aptitude install debootstrap
Теперь сделаем первую вирутальную машину. По умолчанию директория развертывания
контейнеров находится в /var/lib/lxc/ , параметром -p можно указать
произвольное расположение вируальной машины.
sudo mkdir -p /lxc/vm0
sudo lxc-debian -p /lxc/vm0
Это может занять некоторое время. Скрипт так же настроит локаль. После
окончания установки нужно настроить виртуальную машину.
Идем в /lxc/vm0 и правим файл конфигурации (config):
lxc.tty = 4
lxc.pts = 1024
lxc.rootfs = /srv/lxc/vm0/rootfs
lxc.cgroup.devices.deny = a
# /dev/null and zero
lxc.cgroup.devices.allow = c 1:3 rwm
lxc.cgroup.devices.allow = c 1:5 rwm
# consoles
lxc.cgroup.devices.allow = c 5:1 rwm
lxc.cgroup.devices.allow = c 5:0 rwm
lxc.cgroup.devices.allow = c 4:0 rwm
lxc.cgroup.devices.allow = c 4:1 rwm
# /dev/{,u}random
lxc.cgroup.devices.allow = c 1:9 rwm
lxc.cgroup.devices.allow = c 1:8 rwm
lxc.cgroup.devices.allow = c 136:* rwm
lxc.cgroup.devices.allow = c 5:2 rwm
# rtc
lxc.cgroup.devices.allow = c 254:0 rwm
# <<<< Добавляем эти строки
lxc.utsname = vm0
lxc.network.type = veth
lxc.network.flags = up
lxc.network.link = br0
# lxc.network.name = eth0
# lxc.network.hwaddr = 00:FF:12:34:56:78
lxc.network.ipv4 = 192.168.82.28/24
Рассмотрим параметры поподробнее:
lxc.utsname = vm0 Имя хоста виртуальной машины
lxc.network.type = veth Тип сети с которой работаем (man lxc.conf), используем
veth если работаем с мостом.
lxc.network.flags = up Сообщаем что нужно поднимать сетевой интерфейс при запуске системы.
lxc.network.link = br0 Мост через который будет работать вируальный интерфейс.
lxc.network.name = eth0 Имя сетевого интерфейса в контейнере. Если не
устанавливать будет eth0, по умолчанию.
lxc.network.hwaddr = 00:FF:12:34:56:78 Мак адрес устройства которое используется.
lxc.network.ipv4 = 192.168.82.28/24 Сетевой адрес который будет присвоен виртуальному интерфейсу.
Так же требуется отредактировать /etc/network/interfaces в контейнере (/lxc/vm0/rootfs/etc/network/interfaces)
Создаем контейнер который связывает имя конрейнера с файлом настроек. Имя будет
использовано для управления единичным контейнером.
sudo lxc-create -n vm0 -f /lxc/vm0/config
Запустим вируальную машину.
sudo lxc-start -n vm0 -d
Проверяем запущена ли она:
sudo lxc-info -n vm0
'vm0' is RUNNING
Теперь можно подключиться к консоли контейнера используя lxc-console:
sudo lxc-console -n vm0
Вводим имя пользователя root и получаем вход в систему (без пароля).
Устанавливаем пароль пользователю root:
sudo passwd
Добавляем не привилегированного пользователя.
sudo adduser admin
Хорошо наш контейнер работает, теперь остановим его делается это следующим образом:
sudo lxc-stop -n vm0
И проверяем его статус через lxc-info
sudo lxc-info -n vm0
'vm0' is STOPPED
Еще один контейнер
У нас есть контейнер vm0 с минимальной системой и установленными паролями рута
и не привилегированного пользователя, из этого контейнера клонируем еще один.
Для этого первая виртуальная машина должна быть остановлена. Создаем папку vm1
в /lxc и копируем туда содержимое vm0
cd /lxc
sudo mkdir vm1
sudo cp -Rv ./vm0/* ./vm1/
cd ./vm1/
Теперь нужно подправить файл конфигурации для vm1 (сеть, имя и т.д.)
Ограничения
При настройке Xen или KVM можно настроить количество памяти, количество
виртуальных процессов, а так же настроить планировщик. Это же можно сделать с
помощью cgroups в LXC. Прежде нужно запомнить что все настройки cgroup
полностью динамические, т.е. вы можете их изменять в любое время, так что
будьте осторожны.
Все значения cgroup можно задать следующими способами:
lxc-cgroup -n vm0 <cgroup-name> <value>
echo <value> > /cgroup/vm0/<cgroup-name>
в конфигурационном файле: "lxc.cgroup.<cgroup-name> = <value>"
В примерах будем использовать настройку через конфигурационный файл.
Для обозначения размера, например памяти, можно использовать K, M или G, например:
echo "400M" > /cgroup/vm0/memory.limit_in_bytes
Допустимые параметры. Для начала, мы можем посмотреть в каталог /cgroup/vm0
(если vm0 не запущен - запустите сейчас). Мы можем увидеть следующее:
ls -1 /cgroup/vm0/
cgroup.procs
cpuacct.stat
cpuacct.usage
cpuacct.usage_percpu
cpuset.cpu_exclusive
cpuset.cpus
cpuset.mem_exclusive
cpuset.mem_hardwall
cpuset.memory_migrate
cpuset.memory_pressure
cpuset.memory_spread_page
cpuset.memory_spread_slab
cpuset.mems
cpuset.sched_load_balance
cpuset.sched_relax_domain_level
cpu.shares
devices.allow
devices.deny
devices.list
freezer.state
memory.failcnt
memory.force_empty
memory.limit_in_bytes
memory.max_usage_in_bytes
memory.memsw.failcnt
memory.memsw.limit_in_bytes
memory.memsw.max_usage_in_bytes
memory.memsw.usage_in_bytes
memory.soft_limit_in_bytes
memory.stat
memory.swappiness
memory.usage_in_bytes
memory.use_hierarchy
net_cls.classid
notify_on_release
tasks
Не будем вдаваться в описание каждого параметра, подробно можно посмотреть здесь.
Ограничение памяти и файла подкачки
Не снижайте количество памяти для запущенного контейнера, если вы не уверены что делаете.
Максимальное количество памяти для виртуальной машины:
lxc.cgroup.memory.limit_in_bytes = 256M
Максимальное количество swap для виртуальной машины:
lxc.cgroup.memory.memsw.limit_in_bytes = 1G
Больше информации по работе с памятью можно найти здесь.
Ограничение CPU
Есть два варианта ограничения CPU. Первый, можно ограничить через планировщик и
второй - можно ограничить через cgroup.
Планировщик
Планировщик работает следующим образом: Можно присвоить vm0 значение 10 и vm1
значение 20. Это означает что каждую секунду процессорного времени vm1 получит
двойное количество циклов процессора. По умолчанию значение установлено в 1024.
lxc.cgroup.cpu.shares = 512
Больше о планировщике CPU читаем здесь.
Так же можно установить количество используемых процессоров в контейнере.
Допустим у вас 4 CPU, то по умолчанию для всех является значение 0-3
(использовать все процессоры).
Использовать первый cpu:
lxc.cgroup.cpuset.cpus = 0
использовать первый, второй и последний cpu.
lxc.cgroup.cpuset.cpus = 0-1,3
использовать первый и последний cpu.
lxc.cgroup.cpuset.cpus = 0,3
Подробнее здесь.
Ограничение жесткого диска
Пока это нельзя сделать через cgroups, но можно сделать через LVM.
Как безопасно остановить виртуальную машину
lxc-stop просто убивает родительский процесс lxc-start, если требуется
безопасно выключить, то в настоящие время не существует другого решения, как
остановить виртуальную машину через SSH или lxc-console:
sudo lxc-console -n vm0
#vm0> init 0
Нужно подождать пока остановятся все процессы (за этим можно понаблюдать через
pstree или htop) и затем останавливаем виртуальную машину.
sudo lxc-stop -n vm0
Как навсегда удалить виртуальную машину
Останавливаем виртуальную машину и используем команду lxc-destroy
sudo lxc-destroy -n vm0
Она удалит все файлы из /lxc/vm0, так сказано в документации, но она не удалила
файлы из каталога поэтому пришлось удалять самому.
Как заморозить и "разморозить" контейнер
LXC может заморозить все процессы в запущенном контейнере, тем самым LXC просто
блокирует все процессы.
sudo lxc-freeze -n vm0
После запуска все будет записано в память (и swap).
Использованные источники
* http://www.ibm.com/developerworks/ru/library/l-lxc-containers/
* https://help.ubuntu.com/community/LXC
* http://blog.bodhizazen.net/linux/lxc-configure-ubuntu-lucid-containers/
* http://blog.bodhizazen.net/linux/lxc-linux-containers/
* http://lxc.teegra.net/#_setup_of_the_controlling_host
* http://blog.foaa.de/2010/05/lxc-on-debian-squeeze/#pni-top0
|
| |
|
|
|
Запуск виртуальных машин Qemu и KVM в распределенном хранилище Sheepdog (доп. ссылка 1) |
[комментарии]
|
| | Пример настройки Sheepdog в Fedora Linux для организации выполнения в Qemu или
KVM виртуального окружения поверх распределенного на несколько машин
высоконадежного хранилища Sheepdog (подробнее см. https://www.opennet.ru/27251/ )
Устанавливаем и запускаем кластерный движок Corosync (http://www.corosync.org/)
на всех узлах кластера хранения:
yum install corosync
service corosync start
После интеграции sheepdog-драйвера в состав пакета qemu и qemu-kvm, достаточно будет выполнить:
yum install qemu-kvm
(сейчас еще нужно собирать драйвер из исходных текстов)
Запускаем на каждом узле кластера хранения управляющий процесс Sheepdog,
передав в качестве аргумента директориею для хранения объектов в локальной ФС каждого узла:
sheep /store
Форматируем и настраиваем параметры кластера хранения, указываем дублирование
каждого блока данных на три разных узла:
collie cluster format --copies=3
Создаем в распределенном хранилище дисковый образ, размером 256Гб, для
виртуальной машины с именем Alice:
qemu-img create sheepdog:Alice 256G
Импортируем существующий образ виртуальной машины в распределенное хранилище с именем Bob:
qemu-img convert ~/amd64.raw sheepdog:Bob
Смотрим список активных хранилищ:
collie vdi list
Bob 0 2.0 GB 1.6 GB 0.0 MB 2010-03-23 16:16 80000
Alice 0 256 GB 0.0 MB 0.0 MB 2010-03-23 16:16 40000
Запускаем виртуальную машину:
qemu-system-x86_64 sheepdog:Alice
Создаем снапшот виртуальной машины Alice:
qemu-img snapshot -c name sheepdog:Alice
Параллельно запускаем созданный снапшот:
qemu-system-x86_64 sheepdog:Alice:1
Клонируем снапшот Alice:1 в новую виртуальную машину Charlie
qemu-img create -b sheepdog:Alice:1 sheepdog:Charlie
Просматриваем состояние узлов кластера:
collie node list
|
| |
|
|
|
Запуск Firefox в контейнере OpenVZ (доп. ссылка 1) |
[комментарии]
|
| | Для повышении безопасности при просмотре в Firefox небезопасных сайтов, браузер
можно дополнительно изолировать от системы, запустив его в контейнере OpenVZ.
Создаем контейнер на базе шаблона Fedora 12:
vzctl create 777 --ostemplate fedora-12-x86
vzctl start 777
Настраиваем внутри контейнера доступ к сети, используя NAT ( см. инструкцию
http://wiki.openvz.org/NAT). Не забываем прописать ДНС-сервер в /etc/resolv.conf.
Проверяем:
vzctl exec 777 ping -c 1 openvz.org
Устанавливаем в контейнер Firefox:
vzctl exec 777 yum install firefox xauth liberation\*fonts
Разрешаем перенаправление X11-соединений в ssh:
vzctl exec 777 sed 's/^.*X11Forwarding .*$/X11Forwarding yes/'
vzctl exec 777 /etc/init.d/sshd restart
Создаем аккаунт пользователя для запуска Firefox:
vzctl set 777 --userpasswd ffox:mysecpass
Запускаем Firefox из контейнера:
ssh -Y x.x.x.x dbus-launch firefox -no-remote
|
| |
|
|
|
Подготовка паравиртуализированного гостевого окружения с FreeBSD 8 для Xen (доп. ссылка 1) (доп. ссылка 2) (доп. ссылка 3) |
[комментарии]
|
| | В заметке рассказано о подготовке образа гостевой системы с FreeBSD 8,
предназначенного для работы под управлением Xen в режиме паравиртуализации,
позволяющем добиться более высокой производительности по сравнению с
HVM-режимом (полная аппаратная виртуализация).
В настоящее время нет готовых бинарных образов ядра и системы, предназначенных
для установки в роли гостевой ОС. Придется создавать их вручную. Для начала
поставим FreeBSD обычным образом на диск или под управлением VirtualBox, после
чего займемся созданием образа, пригодного для использования в Xen DomU.
Создадим каркас будущего образа гостевой ОС (размер можно сразу изменить исходя из решаемых задач):
# truncate -s 256M freebsd.img
Привяжем к этому файлу виртуальный диск:
# mdconfig -f freebsd.img
Установим загрузчик, создадим дисковые разделы и отформатируем под UFS2 с включенными softupdates:
# fdisk -BI md0
# bsdlabel -wB md0s1
# newfs -U md0s1a
Монтируем локально созданную внутри файла ФС:
# mount /dev/md0s1a /mnt
В /usr/src текущей системы должен быть полный набор исходных текстов, обновим их:
# csup -h cvsup2.ru.FreeBSD.org -L 2 /usr/share/examples/cvsup/standard-supfile
Примечание: C 2012 года проект FreeBSD перешёл на использование Subversion.
Вместо cvsup следует использовать svnup (или freebsd-update для системы,
portsnap/pkg для портов):
cd /usr/ports/net/svnup && make install
svnup stable -h svn0.us-west.freebsd.org
svnup ports -h svn0.us-west.freebsd.org
Соберем ядро и мир
# make buildworld && make buildkernel KERNCONF=XEN
Установим итоговые собранные файлы на ранее подготовленный дисковый образ в
файле, примонтированный в /mnt:
# export DESTDIR=/mnt && make installworld && make installkernel KERNCONF=XEN && cd etc && make distribution
Адаптируем настройки для работы в качестве гостевой системы Xen.
В /mnt/etc/fstab добавим:
/dev/xbd0 / ufs rw 1 1
В /mnt/etc/ttys:
xc0 "/usr/libexec/getty Pc" vt100 on secure
Сохраним отдельно ядро гостевой системы, так как его потребуется скопировать для загрузки из dom0:
# cp /mnt/boot/kernel/kernel /some/place/freebsd-kernel
Отмонтируем виртуальный диск:
# umount /mnt
# mdconfig -d -u md0
В результате получены файл с гостевой системой freebsd.img и файл с ядром freebsd-kernel.
Конфигурируем управляющее окружение Xen (dom0):
Проверяем работает ли xen:
# xm list
Создаем файл конфигурации /etc/xen/freebsd:
kernel = "/virt/freebsd-8.0p2-i386-xen-domu-kernel"
memory = 512
name = "freebsd"
vif = [ '' ]
disk = [ 'file:/virt/freebsd-8.0p2-i386-xen-domu.img,hda,w' ]
extra = "boot_verbose=1"
extra += ",vfs.root.mountfrom=ufs:/dev/ad0s1a"
extra += ",kern.hz=100"
где, /virt/freebsd-8.0p2-i386-xen-domu-kernel путь к предварительно
скопированному в файловую систему dom0 подготовленного ранее ядра FreeBSD.
В /etc/xen/xend-config.sxp активируем сетевой мост для работы сети внутри FreeBSD:
#(network-script network-dummy)
(network-script network-bridge)
Запускаем гостевое окружение и сразу входим в консоль:
# xm create freebsd
# xm console freebsd
Из проблем, отмечена неработа настройки ifconfig_xn0="DHCP", для получения
адреса dhclient нужно запускать вручную.
|
| |
|
|
|
Настройка кластера для запуска Cloud-окружений с использованием Ubuntu Enterprise Cloud (доп. ссылка 1) |
[комментарии]
|
| | Для настройки сервера для запуска Cloud-окружений будем использовать
дистрибутив Ubuntu Enterprise Cloud (http://www.ubuntu.com/cloud/private) в
который интегрирована поддержка платформы Eucalyptus
(http://www.eucalyptus.com/). Будет создан один управляющий
cloud-инфраструктурой фронтэнд-сервер и несколько работающих под его началом
вспомогательных узлов.
Установленный на машинах процессор должен поддерживать средства аппаратной
виртуализации Intel VTx (vmx) или AMD-V (svm). Проверить поддержку можно
убедившись наличие соответствующих флагов в файле /proc/cpuinfo:
egrep '(vmx|svm)' /proc/cpuinfo
Устанавливаем на сервер и вспомогательные узлы Linux дистрибутив Ubuntu Server
9.10, выбрав в меню загрузчика "Install Ubuntu Enterprise Cloud". Далее
проводим инсталляцию с соответствие с личными предпочтениями, а в блоке "Cloud
Installation Mode" выбираем для управляющего сервера значение по умолчанию
"Cluster", а при установке дополнительных узлов - "Node".
Настройка вспомогательных узлов Cloud-инфраструктуры.
Устанавливаем на узлах публичный SSH-ключ управляющего сервера:
1. Задаем пользователю eucalyptus на конечных узлах пароль:
sudo passwd eucalyptus
2. На стороне управляющего сервера запускаем команду копирования ssh-ключа на узлы:
sudo -u eucalyptus ssh-copy-id -i ~eucalyptus/.ssh/id_rsa.pub eucalyptus@IP_адрес_узла
3. Очищаем ранее установленный пароль для пользователя eucalyptus, чтобы
заходить можно было только по ключам шифрования:
sudo passwd -d eucalyptus
После того как аутентификация по ssh-ключам настроена на всех узлах запускаем
на стороне управляющего сервера процесс регистрации узлов:
sudo euca_conf --no-rsync --discover-nodes
Получаем и устанавливаем мандат для пользователей cloud-инфраструктуры.
На управляющем пользователе создаем директорию ~/.euca и генерируем
идентификационные параметры cloud-инфраструктуры:
mkdir -p ~/.euca
chmod 700 ~/.euca
cd ~/.euca
sudo euca_conf --get-credentials mycreds.zip
unzip mycreds.zip
cd -
Настройка EC2 API и AMI утилит.
На управляющем сервере запускаем скрипт для создания параметров окружения Eucalyptus:
~/.euca/eucarc
Для автоматизации запуска добавляем его вызов в ~/.bashrc:
echo "[ -r ~/.euca/eucarc ] && . ~/.euca/eucarc" >> ~/.bashrc
Устанавливаем вспомогательный набор AMI утилит:
sudo apt-get install ec2-ami-tools ec2-api-tools
Для проверки, что все работает, запускаем:
. ~/.euca/eucarc
в ответ должно появиться:
euca-describe-availability-zones verbose
Настройка через управляющий web-интерфейс
В браузере открываем страницу https://IP_управляющего_сервера:8443
В качестве имени пользователя и пароля указываем "admin". После первого входа
будет сразу предложено поменять пароль и указать контактный email.
Установка образов пользовательских cloud-окружений.
В панели управления web-интерфейса выбираем вкладку "Store" и жмем кнопку
"Install" рядом с выбранным в списке образом системы. Сразу после нажатия
начнется загрузка из сети выбранного образа и затем его установка.
Запуск образов пользовательских cloud-окружений.
Перед первым стартом окружения на узле создаем для него SSH-ключ на управляющем узле:
touch ~/.euca/mykey.priv
chmod 0600 ~/.euca/mykey.priv
euca-add-keypair mykey > ~/.euca/mykey.priv
На узле открываем 22 порт, запустив следующие команды:
euca-describe-groups
euca-authorize default -P tcp -p 22 -s 0.0.0.0/0
После этого можно запустить зарегистрированный образ окружения через
web-интерфейс: во вкладке "Store" выбираем ссылку "How to Run", в появившемся
окне будет отражена полная команда для запуска. Первый запуск может занять
довольно долго, так как потребуется время на его копирование в кеш.
За статусом запуска окружения можно наблюдать выполнив команду:
watch -n5 euca-describe-instances
Когда состояние "pending" заменится на "running", к окружению можно подключаться.
Для сохранения IP созданного окружения в переменной IPADDR и входа в него по ssh выполним команду:
IPADDR=$(euca-describe-instances | grep $EMI | grep running | tail -n1 | awk '{print $4}')
ssh -i ~/.euca/mykey.priv ubuntu@$IPADDR
Для принудительного завершения работы окружения:
INSTANCEID=$(euca-describe-instances | grep $EMI | grep running | tail -n1 | awk '{print $2}')
euca-terminate-instances $INSTANCEID
Полезная информация
Перезапуск управляющего сервера eucalyptus:
sudo service eucalyptus restart
Для перезапуска ПО на стороне узла:
sudo service eucalyptus-nc restart
Лог сохраняется в /var/log/eucalyptus
Файлы конфигурации находятся в директории /etc/eucalyptus
БД: /var/lib/eucalyptus/db
Ключи шифрования: /var/lib/eucalyptus и /var/lib/eucalyptus/.ssh
Подробнее см. официальное руководство пользователя http://help.ubuntu.com/community/UEC
|
| |
|
|
|
Доступ к файлам виртуальных машин VMware ESX из Fedora Linux (доп. ссылка 1) |
Автор: Andrey Markelov
[обсудить]
|
| | Richard W.M. Jones в своем блоге опубликовал интересный пост
(http://rwmj.wordpress.com/2010/01/06/examine-vmware-esx-with-libguestfs/) о
работе при помощи утилит libguestfs с образами VMware ESX4. Немного дополнив,
напишу, в чем суть.
Во-первых нам понадобятся пакеты fuse-sshfs и guestfish. Первый позволяет
монтировать при помощи FUSE удаленную файловую систему по SSH FTP, а второй
установит в систему интерактивную командную оболочку, из которой можно получать
доступ к образам дисков виртуальных машин, в том числе и vmdk. Естественно, в
системе должны присутствовать стандартные компоненты виртуализации Fedora, в
частности, работающий демон libvirtd.
Для начала проверяем, какие присутствуют на хосте ESX виртуальные машины:
$ virsh -c esx://192.168.1.12?no_verify=1 list --all
Enter username for 192.168.1.12 [root]:
Enter root password for 192.168.1.12:
ID Имя Статус
----------------------------------
208 www выполнение
224 mail выполнение
- 2RHEL5_DS отключить
- 2W2003_DC отключить
- RHEL5_IPA отключить
- RHEL5_Satellite53 отключить
- RHEL5_Server1 отключить
- RHEL5_Station отключить
- RHEL5_Station2 отключить
- RHEL5_Zimbra отключить
Далее смонтируем через FUSE соответствующую директорию файловой системы vmfs:
$ mkdir esx
$ sshfs root@192.168.1.12:/vmfs/volumes esx
root@192.168.1.12's password:
$ cd esx/
$ ls
4ac343f6-500e2828-d805-0022640793d2 LocalStorage1
Естественно, мы ничего нового по сравнению с тем, что нам покажет vCenter
client, не увидели. Далее переходим в директорию с нужной нам виртуальной машиной:
$ cd LocalStorage1/RHEL5_IPA/
$ ls
RHEL5_IPA-flat.vmdk RHEL5_IPA.vmdk RHEL5_IPA.vmx vmware.log
RHEL5_IPA.nvram RHEL5_IPA.vmsd RHEL5_IPA.vmxf
При помощи новой утилиты virt-list-filesystems (в версии libguestfs репозитория
Fedora 12 пока ее нет, зато есть в Rawhide) смотрим какие разделы доступны
внутри образа:
$ virt-list-filesystems -al RHEL5_IPA-flat.vmdk
/dev/sda1 ext3
/dev/vol0/home ext3
/dev/vol0/root ext3
/dev/sda3 swap
И, наконец, запускаем интерактивную командную оболочку:
$ guestfish --ro -a RHEL5_IPA-flat.vmdk -m /dev/vol0/root
Welcome to guestfish, the libguestfs filesystem interactive shell for
editing virtual machine filesystems.
Type: 'help' for help with commands
'quit' to quit the shell
> ll /
total 192
drwxr-xr-x. 22 root root 4096 Oct 24 07:47 .
dr-xr-xr-x 29 root root 0 Jan 8 12:59 ..
drwxr-xr-x. 2 root root 4096 Oct 7 15:07 bin
drwxr-xr-x. 2 root root 4096 Oct 7 13:45 boot
drwxr-xr-x. 4 root root 4096 Oct 7 13:45 dev
drwxr-xr-x. 93 root root 12288 Oct 24 07:47 etc
drwxr-xr-x. 2 root root 4096 Oct 7 13:45 home
....
Ну, а дальше man guestfish и help для списка команд оболочки. Для виртуальных
машин с включенным SELinux крайне желательно использовать ключ --selinux, иначе
при попытке записи файлов вы можете создать при монтировании образа r/w файлы
без меток SELinux.
|
| |
|
|
|
Как установить FreeBSD 8.0 DomU в окружении Xen Dom0 (доп. ссылка 1) |
Автор: Василий Лозовой
[комментарии]
|
| | Во FreeBSD 8.0 была объявлена экспериментальная поддержка DomU для Xen, что
позволяет установить FreeBSD в паравиртуальном режиме и использовать все
возможности Xen с FreeBSD.
В качестве хост-окружения будем использовать Xen 3 в Debian GNU/Linux.
Не забудьте скомпилировать hvmloader для поддержки HMV режима (режим полной
виртуализации нужен для установки FreeBSD) и включить в BIOS поддержку
аппаратной акселерации виртуализации.
На данном этапе имеем гипервизор Xen hypervisor (Dom0) в Linux:
# xm list
Name ID Mem VCPUs State Time
Domain-0 0 3692 8 r----- 1799656.1
Подготавливаем виртуальную машину для запуска на ней FreeBSD, выделяем место на диске.
Создаем конфигурационный файл Xen (/etc/xen/freebsd_vps):
kernel = "/usr/lib/xen/boot/hvmloader"
builder='hvm'
memory = 1024
name = "FreeBSD VPS"
vif = [ '' ]
disk = [ 'phy:/dev/mylvm0/lvol9,hda,w', 'file:/.1/8.0-RELEASE-i386-dvd1.iso,hdc:cdrom,r' ]
boot="cda"
vnc=1
vncpasswd=''
Запускаем виртуальную машину:
# xm create freebsd_vps
Подключаемся к запущенному окружению при помощи vncviewer. Видим процесс
загрузки FreeBSD и запуск инсталлятра sysinstall. Устанавливаем FreeBSD по
своему усмотрению, не забыв установить полные исходные тексты FreeBSD для
последующей пересборки.
После того как система установлена, пересобираем ядро FreeBSD включив поддержку
Xen. Собранное ядро копируем во внешнее управляющее Dom0 окружение.
# cd /boot/kernel/
scp /boot/kernel/kernel user@dom0-host:/usr/lib/xen/boot/kernel
На FreeBSD в /etc/ttys добавляем консоль xc0:
xc0 "/usr/libexec/getty Pc" vt100 on secure
В управляющем Dom0 прописываем в параметры гостевой системы (файл
/etc/xen/freebsd_vps) вызов ядра FreeBSD, собранного с поддержкой
паравиртуализации, также отключаем HVM и убираем ссылку на загрузочный iso:
kernel = "/usr/lib/xen/boot/kernel"
memory = 1024
name = "FreeBSD VPS"
vif = [ 'bridge=outeth0', 'bridge=mir111', 'bridge=mir113', 'bridge=mir114', 'bridge=mir115' ]
disk = [ 'phy:/dev/mylvm0/lvol9,hda1,w' ]
extra = "boot_verbose=1"
extra += ",vfs.root.mountfrom=ufs:/dev/ad0s1a"
extra += ",kern.hz=100"
pae=1
В вышеприведенном примере подсоединено 5 сетевых интерфейсов.
Перезагружаем FreeBSD в DomU паравиртуальном (PVM) режиме:
# xm destroy freebsd_vps
# xm create -c freebsd_vps
# xm list
Name ID Mem VCPUs State Time(s)
Domain-0 0 3692 8 r----- 1800450.2
FreeBSD 117 1024 1 r----- 137712.0
|
| |
|
|
|
Установка и запуск OpenVZ на Debian Lenny (доп. ссылка 1) |
Автор: DennisK
[комментарии]
|
| | Имеем сервер с установленным Debian Lenny. Задача: настроить на серверe несколько VPS-ов.
1. Устанавливаем ядро с поддержкой OpenVZ
aptitude install linux-image-openvz-amd64
2. Для нормальной работы OpenVZ-контейнеров необходимо чтобы /etc/sysctl.conf
содержал следующие строки:
net.ipv4.conf.all.rp_filter=1
net.ipv4.icmp_echo_ignore_broadcasts=1
net.ipv4.conf.default.forwarding=1
net.ipv4.conf.default.proxy_arp = 0
net.ipv4.ip_forward=1
kernel.sysrq = 1
net.ipv4.conf.default.send_redirects = 1
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.eth0.proxy_arp=1
3. Перезагружаем сервер
4. Проверяем, что сервер загрузился с новым ядром
uname -r
если система выдаст 2.6.26-2-openvz-amd64, то всё установилось корректно
5. Ядро, которое было установлено по-умолчанию мне не нужно и я его удаляю
(если хотите оставить предыдущее ядро - шаг пропускаем)
apt-get remove --purge linux-image-2.6.26-2-amd64
6. Для контейнеров OpenVZ у меня выделен отдельный раздел подмонтированный в
/vz. По-умолчанию OpenVZ в Debian всё складывает в /var/lib/vz. Переношу всё с
/var/lib/vz в /vz и создаю симлинк
/etc/init.d/vz stop
mv /var/lib/vz/* /vz/
rmdir /var/lib/vz
ln -s /vz /var/lib/vz
/etc/init.d/vz start
7. В контейнере у меня будет работать Debian Lenny х86. Загружаем шаблон контейнера с сайта OpenVZ
cd /var/lib/vz/template/cache
wget -c http://download.openvz.org/template/precreated/debian-5.0-x86.tar.gz
8. Создаём контейнер (101 - это уникальный идентификатор контейнера)
vzctl create 101 --ostemplate debian-5.0-x86 --config vps.basic
9. Указываем чтобы контейнер запускался в вместе с OpenVZ
vzctl set 101 --onboot yes --save
10. Конфигурируем имя хоста, IP и dns-сервер для контейнера
vzctl set 101 --hostname vps1.local --save
vzctl set 101 --ipadd 10.1.1.101 --save
vzctl set 101 --nameserver 10.1.1.2 --save
11. Запускаем контейнер и устанавливаем пароль для root-a
vzctl start 101
vzctl exec 101 passwd
12. Переключаемся в контейнер
vzctl enter 101
Для выхода из контейнера необходимо дать команду exit. Зайти можно и по ssh.
13. Устанавливаем необходимое ПО в контейнере.
14. Успешно эксплуатируем.
P.S. Несколько необходимых команд для работы с контейнерами:
vzlist -a - список запущенных контейнеров и их состояние
vzctl stop <UID> - остановить контейнер
vzctl restart <UID> - перезагрузить контейнер
vzctl destroy <UID> - удалить контейнер
где <UID> - уникальный идентификатор OpenVZ-контейнера
|
| |
|
|
|
Создание бекапа OpenVZ контейнера (доп. ссылка 1) |
[обсудить]
|
| | Для создания инкрементального бэкапа по сети можно использовать готовый скрипт ezvzdump,
суть работы которого в создании копии через rsync, заморозке окружения с
сохранением дампа состояния (vzctl chkpnt $VEID --suspend
), копированию сохраненного дампа и изменившихся с момента последнего rsync
файлов, продолжению работы остановленного OpenVZ контейнера (vzctl chkpnt $VEID --resume).
Для создания целостных дампов можно воспользоваться утилитой vzdump:
vzdump 777
После этого образ текущего состояния OpenVZ контейнера будет сохранен в /vz/dump/
Утилита vzdump также поддерживает схему suspend/rsync/resume:
vzdump --suspend 777
А также можно сохранить дамп почти мгновенно методом suspend/LVM2 snapshot/resume:
vzdump --dumpdir /space/backup --snapshot 777
В итоге будет сформирован архив /space/backup/vzdump-777.tar, который можно восстановить командой:
vzdump --restore /space/backup/vzdump-777.tar 600
|
| |
|
|
|
Запуск win2k3 на freebsd под virtualbox без x11 (доп. ссылка 1) |
Автор: shurik
[комментарии]
|
| | Задача: запустить виртуальную машину с win2k3 на хосте с freebsd без установленого Х-сервера.
Имеем:
FreeBSD 7.2-RELEASE-p3,
virtualbox-3.0.51.r22226 (WITHOUT_QT4=true WITHOUT_DEBUG=true WITH_GUESTADDITIONS=true
WITHOUT_DBUS=true WITHOUT_PULSEAUDIO=true WITH_NLS=true)
Сразу хочу заметить, что поскольку протокол VRDP в virtualbox под freebsd пока не реализован,
то для первоначальной инсталяции виртуальной машины нам все же понадобится другой хост
с установленным окружением X11. Установка win2k3 в виртуальное окружение -
задача весьма тривиальная,
поэтому её описание я опущу...
Итак, мы имеем установленную виртуальную систему, которую нам необходимо пренести на
другой хост и попытаться там запустить. Для этого экспортируем виртуальную машину на хосте,
где мы ее устанавливали:
VBoxManage export WIN2003STD -o ~/WIN2003STD.ovf
где WIN2003STD - имя виртуальной машины,
~/WIN2003STD.ovf - файл, в котором будут храниться экспортируемые параметры виртуальной машины.
В итоге имеем 3 файла, которые нам необходимо перенести на удаленный хост:
WIN2003STD.mf - файл, содержащий контрольные суммы двух последующих файлов
WIN2003STD.ovf - файл параметров экспортируемой машины
WIN2003STD.vmdk - упакованный файл-образ жесткого диска виртуальной машины.
Повторюсь, что поскольку реализации протокола VRDP в virtualbox для freebsd нет,
то изначально перед экспортом виртуальной машины нам необходимо будет дать удаленный доступ
внутрь гостевого окружения с помощью RDP или VNC. В моем случае я сделал доступ через
удаленный рабочий стол win2k3.
На удаленном хосте я создал для запуска виртуального окружения отдельного пользователя
vbox с группой vboxusers, которому запретил вход через ssh. Файлы WIN2003STD.mf, WIN2003STD.ovf
и WIN2003STD.vmdk я положил в его домашнюю директорию и сделал их владельцем пользователя vbox.
Далее от пользователя vbox делаем импорт виртуальной машины:
VBoxManage import ~/WIN2003STD.ovf
Далее нам необходимо пробросить внутрь виртуальной машины tcp-порт 3389 для
доступа к удаленному рабочему столу win2k3:
VBoxManage setextradata WIN2003STD "VBoxInternal/Devices/pcnet/0/LUN#0/Config/RDP/HostPort" 3389
VBoxManage setextradata WIN2003STD "VBoxInternal/Devices/pcnet/0/LUN#0/Config/RDP/GuestPort" 3389
VBoxManage setextradata WIN2003STD "VBoxInternal/Devices/pcnet/0/LUN#0/Config/RDP/Protocol" tcp
Если в виртуальной машине при конфигурирации был выбран сетевой адаптер Intel,
то следует заменить в выше указанных строках pcnet на e1000.
Все, виртуальную машину можно запускать:
VBoxManage startvm WIN2003STD --type headless
"--type headless" позволяет запутить виртуальную машину в фоновом режиме.
О том, что проброс tcp-порта выполнен свидетельствуют строки в логе вмртуальной машины и sockstat:
$ grep -i nat ~/.VirtualBox/Machines/WIN2003STD/Logs/VBox.log
00:00:00.535 Driver = "NAT" (cch=4)
00:00:00.538 AIS - Alternate Instruction Set = 0 (1)
00:00:00.942 NAT: ICMP/ping not available (could open ICMP socket, error VERR_ACCESS_DENIED)
00:00:00.942 NAT: value of BindIP has been ignored
00:00:35.141 NAT: set redirect TCP hp:3389 gp:3389
00:01:05.062 NAT: old socket rcv size: 64KB
00:01:05.062 NAT: old socket snd size: 64KB
$ sockstat -4 -l | grep 3389
vbox VBoxHeadle 982 32 tcp4 :3389 :*
Следует заметить, что icmp во внешний мир из виртуальной машины работать не
будет, это требует прав суперпользователя,
о чем нам сказано в логе - "00:00:00.942 NAT: ICMP/ping not available (could
open ICMP socket, error VERR_ACCESS_DENIED)",
поэтому проверять работоспособность сети внутри виртуального хоста с помощью
ping не стоит. Все, задачу можно считать выполненной.
P.S. После выключения удаленной виртуальной машины через сеанс RDP, система выпадает в BSOD и
дальше возможен вход только в безопасном режиме, что в нашем случае уже не возможно. Беглый поиск
в google дает нам такое решение - необходимо предварительно в ветке реестра
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\intelppm\Start
выставить значение 4.
P.P.S. Для автоматического старта виртуальной машины при старте системы я в
/usr/local/etc/rc.d/ создал скрипт вида:
#!/bin/sh
echo "Starting VirtualBox..."
su vbox -c '/usr/local/bin/VBoxManage startvm WIN2003STD --type headless'
|
| |
|
|
|
Настройка аутентификации для управления окружениями в libvirt (доп. ссылка 1) |
[обсудить]
|
| | Настройка SASL DIGEST-MD5 аутентификации в libvirt для управления удаленными
виртуальными окружениями
в недоверительной сети. Для шифрования передаваемого трафика можно использовать TLS.
Добавляем пользователя virt в SASL базу:
saslpasswd2 -a libvirt virt
Password:
Again (for verification):
Через опцию "-a" передаем имя приложения для привязки пользователя к нему.
Утилита saslpasswd2 входит в состав пакета cyrus-admin.
Для просмотра списка пользователей из SASL базы libvirt выполняем:
sasldblistusers2 -f /etc/libvirt/passwd.db
Включаем механизм digest-md5 в /etc/sasl2/libvirt.conf:
# Default to a simple username+password mechanism
mech_list: digest-md5
В настойках /etc/libvirt/libvirtd.conf разрешаем только SASL аутентификацию, при использовании TCP
для соединения необходимо поменять схему через директиву аутентификации auth_tcp:
auth_tcp = "sasl"
Но более правильно, чтобы не передавать пароли и другую важную информацию
открытым текстом, использовать в качестве транспорта TLS, через определение
директивы auth_tls:
auth_tls = "sasl"
Далее для TLS нужно сгенерирвать серверные и клиентские сертификаты, о создании
которых рассказано здесь http://libvirt.org/remote.html
После активации SASL, для каждой операции libvirt будет запрошен логин и пароль.
$ virsh
virsh # migrate --live kvmnode2 qemu+tls://disarm/system
Please enter your authentication name:virt
Please enter your password:
|
| |
|
|
|
Управление гостевым окружением с CentOS/Fedora через последовательный порт (доп. ссылка 1) |
[комментарии]
|
| | Настройка управления виртуальным окружением через консоль virsh
(http://www.libvirt.org/), без использования vnc-клиента.
Перенаправляем вывод Grub для виртуального окружения в последовательный порт.
В /boot/grub/menu.lst добавляем:
serial --speed=115200 --unit=0 --word=8 --parity=no --stop=1
terminal --timeout=10 serial
Отключаем показ заставки splash и перенаправляем вывод ядра в последовательный порт (в menu.lst):
title CentOS (2.6.18-128.1.10.el5)
root (hd0,0)
kernel /boot/vmlinuz-2.6.18-128.1.10.el5 ro root=LABEL=/ console=ttyS0
initrd /boot/initrd-2.6.18-128.1.10.el5.img
Настраиваем запуск getty процесса для логина через ttyS0. В /etc/inittab прописываем:
S0:12345:respawn:/sbin/agetty ttyS0 115200
Разрешаем вход суперпользователем через ttyS0:
echo "ttyS0" >> /etc/securetty
Подключаемся к гостевому окружению kvmnode1 через команду virsh:
$ virsh
virsh # console kvmnode1
Connected to domain kvmnode1
Escape character is ^]
CentOS release 5.3 (Final)
Kernel 2.6.18-128.1.10.el5 on an x86_64
kvmnode1 login:
|
| |
|
|
|
Быстрая настройка qemu/kvm окружений при помощи virt-manager (доп. ссылка 1) |
[комментарии]
|
| | Для упрощения и унификации работы с различными системами виртуализации можно использовать
удобный фронтэнд virt-manager (http://virt-manager.et.redhat.com/).
В Ubuntu ставим необходимые пакеты:
sudo apt-get install kvm qemu libvirt-bin bridge-utils ubuntu-virt-mgmt ubuntu-virt-server
Отдельно GUI интерфейс можно поставить из пакетов virt-manager и virt-viewer.
Пакет для формирования гостевых окружений: python-vm-builder
Пакет для создание гостевых VM с другими ОС внутри: python-virtinst
Добавляем себя в группу администраторов виртуальных серверов:
sudo usermod -aG libvirtd `id -un`
Далее, управление виртуальными машинами производится командой virsh.
Создаем файл конфигурации test.xml и определяем новую виртуальную машину test c Ubuntu внутри:
sudo python-vm-builder kvm jaunty \
--domain test \
--dest описание \
--arch i386 \
--hostname имя_хоста \
--mem объем_памяти_в_мегабайтах \
--user имя_пользователя \
--pass пароль \
--ip 192.168.0.12 \
--mask 255.255.255.0 \
--net 192.168.0.0 \
--bcast 192.168.0.255 \
--gw 192.168.0.1 \
--dns 192.168.0.1 \
--components main,universe \
--addpkg vim openssh-server \
--libvirt qemu:///system ;
virsh dumpxml test > ~/test.xml
редактируем test.xml
virsh define ~/test.xml
При необходимости создания гостевой VM с другой операционной системой, можно
использовать python-virtinst:
sudo virt-install --connect qemu:///system -n test -r 512 -f test.qcow2 -s 12 \
-c test_inst.iso --vnc --noautoconsole --os-type linux --os-variant ubuntuJaunty --accelerate --network=network:default
Для контроля процесса установки, соединяемся GUI интрфейсом:
virt-viewer -c qemu:///system test # локально
virt-viewer -c qemu+ssh://ip_адрес_хоста/system test # с внешнего IP
Если необходимо, чтобы гостевая ОС работала в отдельном разделе диска, то
файловый образ нужно сконвертировать:
sudo qemu-img convert root.qcow2 -O raw /dev/sdb
Клонирование ранее созданного гостевой системы:
virt-clone --connect=qemu:///system -o srchost -n newhost -f /path/to/newhost.qcow2
А затем поправить в XML файле "<source file='/dev/sdb'/>"
Управление окружением.
Заходим в shell virsh:
virsh --connect qemu:///system
Стартуем виртуалную машину:
virsh # start test
Замораживаем состояние виртуальной машины:
virsh # suspend test
Продолжаем выполнение с момента остановки:
virsh # resume test
Список активных виртуальных машин:
virsh # list
Список всех определенных в системе виртуальных машин:
virsh # list --all
Останавливаем виртуальную машину test (эквивалент выполнения shutdown -h now):
virsh # shutdown test
Мгновенно останавливаем виртуальную машину, как при выключении питания:
virsh # destroy test
Удаляем виртуальную машину test из списка (удалем файл конфишурации virsh):
virsh # undefine test
Для управления виртуальными машинами с удаленного ПК 10.0.0.1 через GUI
интерфейс можно использовать:
virt-manager -c qemu+ssh://10.0.0.1/system
на локальной машине:
virt-manager -c qemu:///system
Настройка сети.
Настройка эмуляции локальной сети и создания полноценного сетевого соединения
внутри виртуального окружения.
В хост-окружении создаем интерфейс для бриждинга, в /etc/network/interfaces добавляем:
auto br0
iface br0 inet static
address 192.168.0.10
network 192.168.0.0
netmask 255.255.255.0
broadcast 192.168.0.255
gateway 192.168.0.1
bridge_ports eth0
bridge_fd 9
bridge_hello 2
bridge_maxage 12
bridge_stp off
Рестартуем сеть:
sudo /etc/init.d/networking restart
В XML конфигурации гостевой системы правим настройки сети на:
<interface type='bridge'>
<mac address='00:11:22:33:44:55'/>
<source bridge='br0'/>
<model type='virtio'/>
</interface>
|
| |
|
|
|
Установка ARM-сборки Debian GNU/Linux в qemu (доп. ссылка 1) (доп. ссылка 2) (доп. ссылка 3) |
[комментарии]
|
| | Перед экспериментами по установке Linux на устройства на базе архитектуры ARM
(например, Sharp Zaurus,
Openmoko FreeRunner, планшетные ПК NOKIA, NAS на базе SoC Marvell) вначале
стоит потренироваться в эмуляторе.
Кроме того, окружение созданное в эмуляторе удобно использовать
для создания и сборки пакетов программ или модулей ядра.
Ставим на рабочую машину qemu. Для debian/ubuntu:
sudo apt-get install qemu
Создаем дисковый образ размером 10Гб для виртуальной машины:
qemu-img create -f qcow hda.img 10G
Загружаем ядро, initrd и инсталлятор Debian для архитектуры ARM:
wget http://people.debian.org/~aurel32/arm-versatile/vmlinuz-2.6.18-6-versatile
wget http://people.debian.org/~aurel32/arm-versatile/initrd.img-2.6.18-6-versatile
wget http://ftp.de.debian.org/debian/dists/etch/main/installer-arm/current/images/rpc/netboot/initrd.gz
Загружаем инсталлятор и устанавливаем Debian по сети, следуя инструкциям программы установки:
qemu-system-arm -M versatilepb -kernel vmlinuz-2.6.18-6-versatile -initrd initrd.gz -hda hda.img -append "root=/dev/ram"
Запускаем установленную систему:
qemu-system-arm -M versatilepb -kernel vmlinuz-2.6.18-6-versatile -initrd initrd.img-2.6.18-6-versatile \
-hda hda.img -append "root=/dev/sda1"
Устанавливаем дополнительные программы, например, gcc:
apt-get install gcc
Проверяем:
gcc -dumpmachine
"arm-linux-gnu"
|
| |
|
|
|
Установка Xen 3.3.1 в Ubuntu, используя модифицированное ядро от Novell (доп. ссылка 1) |
[обсудить]
|
| | Основная причина использования релиза Xen 3.3.1 в возможность запуска немодифицированного
64-разрядного Solaris 10U6 в HVM режиме на SMP машине с несколькими vcpu.
Для установки Xen необходимо установить пакеты с openssl, x11, gettext,
python-devel, bcc, libc6-dev-i386.
Собираем Xen из исходных текстов:
cd /usr/src
tar zxvf xen-3.3.1.tar.gz
cd xen-3.3.1
make xen
make install-xen
make tools
make install-tools
Собираем hvmloader:
cd tools/firmware
make
make install
Устанавливаем из mercurial репозитория модифицированное Linux ядро:
apt-get install build-essential libncurses5-dev gawk mercurial
mkdir -p ~/build/linux-2.6.27-xen
cd /usr/src/
hg clone http://xenbits.xensource.com/ext/linux-2.6.27-xen.hg
cd linux-2.6.27-xen.hg
make O=~/build/linux-2.6.27-xen/ menuconfig
make O=~/build/linux-2.6.27-xen/ -j12
make O=~/build/linux-2.6.27-xen/ modules_install install
depmod 2.6.27.5
mkinitramfs -o /boot/initrd-2.6.27.5.img 2.6.27.5
Настраиваем /etc/init.d/xend и xendomains для автоматической загрузки.
В настройки grub (/boot/grub/menu.lst) помещаем:
title Xen 3.3 / Ubuntu 8.10, kernel 2.6.27-xen
kernel /boot/xen-3.3.1.gz
module /boot/vmlinuz-2.6.27.5 root=/dev/sdb1 ro console=tty0
module /boot/initrd-2.6.27.5.img
Загружаем систему с новым ядром и проверяем работу Xen:
xm info
host : ServerUbuntu
release : 2.6.27.5
...
brctl show
bridge name bridge id STP enabled interfaces
eth1 8000.001e8c25cca5 no peth1
pan0 8000.000000000000 no
Xen профайл для установки Solaris 10U6 в режиме аппаратной виртуализации (HVM):
name = "S10U6"
builder = "hvm"
memory = "2048"
disk = ['phy:/dev/loop0,hdc:cdrom,r','phy:/dev/sdb3,hda,w']
# disk = ['phy:/dev/sdb3,hda,w']
vif = [ 'bridge=eth1' ]
device_model = "/usr/lib64/xen/bin/qemu-dm"
kernel = "/usr/lib/xen/boot/hvmloader"
cpuid=[ '1:edx=xxxxxxxxxxxxxx1xxxxxxxxxxxxxxxxx' ]
vnc=1
boot="cd"
usb=1
usbdevice="tablet"
vcpus=2
# serial = "pty" # enable serial console
on_reboot = 'restart'
on_crash = 'restart'
|
| |
|
|
|
Настройка сетевого доступа для VirtualBox окружения в Ubuntu/Debian Linux (доп. ссылка 1) |
[комментарии]
|
| | В простейшем случае работу сети внутри гостевой системы в VirtualBox можно обеспечить через NAT.
Достаточно выбрать тип эмуляции сетевого интерфейса - NAT, а в гостевой ОС получить IP по DHCP или
установить вручную из диапазона 10.0.2.0/24, шлюз 10.0.2.2, DNS 10.0.2.3.
Для проброса портов из вне можно использовать:
VBoxManage setextradata "freebsd" "VBoxInternal/Devices/e1000/0/LUN#0/Config/guestssh/Protocol" TCP
VBoxManage setextradata "freebsd" "VBoxInternal/Devices/e1000/0/LUN#0/Config/guestssh/GuestPort" 22
VBoxManage setextradata "freebsd" "VBoxInternal/Devices/e1000/0/LUN#0/Config/guestssh/HostPort" 2222
где, "freebsd" - это имя виртуальной машины, а e1000 тип эмулируемой карты
(можно посмотреть в VBox.log).
Заходя на 2222 порт хостовой машины мы будем переброшены на 22 порт виртуального окружения.
Для обеспечения полноценного сетевого окружения для виртуального сервера
необходимо поднять виртуальный сетевой интерфейс.
Устанавливаем пакеты:
sudo apt-get install uml-utilities bridge-utils
Настраиваем бриждинг, редактируем /etc/network/interfaces в случае если IP
хост-система получает динамически (DHCP):
auto eth0
iface eth0 inet manual
auto br0
iface br0 inet dhcp
bridge_ports eth0 vbox0
# The loopback network interface
auto lo
iface lo inet loopback
eth0 - сетевой интерфейс, br0 - создаваемый бридж, vbox0 - имя устройства,
используемого в VirtualBox
Если виртуальных окружений несколько, можно написать:
bridge_ports eth0 vbox0 vbox1 vbox2 vbox3 vbox4
В случае со статическим IP настройки примут вид:
auto eth0
iface eth0 inet manual
auto br0
iface br0 inet static
address 192.168.0.100
netmask 255.255.255.0
gateway 192.168.0.1
bridge_ports eth0 vbox0 vbox1
# The loopback network interface
auto lo
iface lo inet loopback
При использовании статического IP в eth0, его настройки должны совпадать с br0
Перезапускаем сетевую подсистему:
sudo /etc/init.d/networking restart
В сетевых настройках VirtualBox определяем виртуальные интерфейсы.
Для этого редактируем файл /etc/vbox/interfaces:
# Each line should be of the format :
# <interface name> <user name> [<bridge>]
vbox0 <your user name> br0
vbox1 <your user name> br0
Перезапускаем virtualbox для принятия изменений:
Для OpenSource версии:
sudo /etc/init.d/virtualbox-ose restart
Для проприетарной сборки:
sudo /etc/init.d/vboxnet restart
Не забываем убедиться в наличии прав доступа на чтение и запись для
пользователей группы vboxusers для устройства /dev/net/tun
sudo chown root:vboxusers /dev/net/tun
sudo chmod g+rw /dev/net/tun
Чтобы права автоматически установились после перезагрузки в
/etc/udev/rules.d/20-names.rules меняем
KERNEL=="tun", NAME="net/%k"
на
KERNEL=="tun", NAME="net/%k", GROUP="vboxusers", MODE="0660"
В настройках VirtualBox для гостевого окружения выбираем "host networking" указав имя
созданного виртуального интерфейса, а внутри оргужения ставим IP из
представленного на интерфейсе диапазона адресов (192.168.0.x).
Вручную отдельный TUN интерфейс без бриджинга можно поднять используя tunctl из
пакета uml-utilities:
tunctl -t vbox0 -u имя_текущего_пользователя
ifconfig vbox0 192.168.0.254 up
route add -host 192.168.0.253 dev vbox0
echo 1 > /proc/sys/net/ipv4/conf/vbox0/proxy_arp
arp -Ds 192.168.0.253 eth0 pub
С бриджем:
brctl addbr br0
ifconfig eth0 0.0.0.0 promisc up
ifconfig vbox0 0.0.0.0 promisc up
ifconfig br0 192.168.0.1 netmask 255.255.255.0 up
brctl stp br0 off
brctl setfd br0 1
brctl sethello br0 1
brctl addif br0 eth0
brctl addif br0 vbox0
|
| |
|
|
|
Как преобразовать образ виртуальной машины Qemu в VirtualBox и VmWare |
[комментарии]
|
| | Для преобразования образа виртуальной машины Qemu в вид пригодный для запуска в VirtualBox,
можно использовать следующие команды:
qemu-img convert qemu.img tmp.bin
VBoxManage convertdd tmp.bin virtualbox.vdi
VBoxManage modifyvdi virtualbox.vdi compact
Для старых версий VirtualBox, нужно было использовать вместо VBoxManage - vditool:
vditool DD virtualbox.vdi tmp.bin
vditool SHRINK virtualbox.vdi
Преобразование qemu образа в формат пригодный для использования в VmWare:
qemu-img convert -6 qemu.img -O vmdk vmware.vmdk
Для преобразования формата VmWare в qemu:
qemu-img convert vmware.vmdk -O qcow2 qemu.img
Для преобразования образа диска или livecd в вид пригодный для использования в qemu:
qemu-img convert -f raw disk.img -O qcow2 qemu.img
qemu-img convert -f cloop cloop.img -O qcow2 qemu.img
|
| |
|
|
|
OpenVZ в ALT Linux Lite 4.0 (доп. ссылка 1) |
Автор: Евгений Прокопьев
[комментарии]
|
| | Для запуска OpenVZ необходимо и достаточно сказать:
# apt-get install kernel-image-ovz-smp vzctl
После перезагрузки с новым ядром можно создавать виртуальные машины (VE)
следующим простым скриптом-оберткой:
#!/bin/sh
# проверяем параметры
if [ -z "$4" ]; then
echo "Usage : $0 \$VEID \$NAME \$BRANCH \$ARCH"
exit 1
fi
# определяем переменные
VE_NAMESERVER="192.168.1.1"
VE_DOMAIN="local"
VE_NET="192.168.0."
VE_REPO="/repo"
HN_REPO="/lvm/distrib/free/linux/alt"
# создаем VE
vzctl create $1 --ostemplate altlinux-$3-$4
# задаем дефолтные значения для VE
vzctl set $1 --name $2 --ipadd $VE_NET$1 --hostname $2.$VE_DOMAIN \
--nameserver $VE_NAMESERVER --searchdomain $VE_DOMAIN --onboot yes --save
# создаем каталог с репозитарием внутри VE
mkdir /var/lib/vz/private/$1/repo
# создаем скрипт, который будет монтировать репозитарий из HN
cat > /etc/vz/conf/$1.mount <<END
#!/bin/sh
. /etc/vz/vz.conf
mount -n -o bind $HN_REPO/$3 \$VE_ROOT/repo
END
# делаем скрипт исполняемым
chmod 700 /etc/vz/conf/$1.mount
# настроиваем apt
cat > /var/lib/vz/private/$1/etc/apt/sources.list <<END
rpm file:///repo/branch/ $4 classic
rpm file:///repo/branch/ noarch classic
END
Многое здесь прибито гвоздями: например, предполагается, что в /lvm/distrib/free/linux/alt
находятся копии branch/4.0 и branch/4.1, а в /var/lib/vz/template/cache/ -
собранные из бранчей с помощью Hasher шаблоны VE:
altlinux-4.0-i586.tar.gz
altlinux-4.0-x86_64.tar.gz
altlinux-4.1-i586.tar.gz
altlinux-4.1-x86_64.tar.gz
В шаблонах находятся basesystem, apt, sysklogd, etcnet, glibc-nss, glibc-locales,
netlist, passwd, su, openssh-server, vim-console, mc, less, man и все, что было
вытянуто по зависимостям.
Предполагается, что свежесозданные VE будут запущены с помощью vzctl start и
первоначально настроены
с помощью vzctl enter (т.е. будут созданы необходимые пользователи и пароли/ключи) -
далее с ними можно будет работать обычным образом по ssh, сверяясь по мере
надобности с полезными советами.
|
| |
|
|
|
Настройка сети для виртуального окружения на основе KVM (доп. ссылка 1) |
[комментарии]
|
| | Имеется машина с Ubuntu Linux, имеющая один сетевой интерфейс. При помощи гипервизора KVM создано
два гостевых окружения - debian01 и debian02. Задача организовать сетевую связь
(виртуальная LAN) между
гостевыми системами и корневой системой и обеспечить выход в интернет, через
сетевой интерфейс корневой системы.
Настройка корневой системы.
Первым делом нужно создать виртуальный Ethernet коммутатор на базе пакета VDE,
при помощи которого будет создан виртуальный интерфейс tap0, через который будет организована связь
между гостевыми окружениями.
Создаем интерфейс:
sudo vde_switch -tap tap0 -daemon
Проверяем:
ifconfig tap0
tap0 Link encap:Ethernet direcciónHW 00:ff:1b:e7:76:46
DIFUSIÓN MULTICAST MTU:1500 Métrica:1
RX packets:1 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
colisiones:0 txqueuelen:500
RX bytes:53 (53.0 B) TX bytes:0 (0.0 B)
Привязываем адреса виртуальной сети (192.168.254.0/255):
ifconfig tap0 192.168.254.254 netmask 255.255.255.0
для гостевых окружений, адрес 192.168.254.254 будет использоваться в роли шлюза.
Настройка гостевых систем.
Настраиваем в гостевом окружении сетевой интерфейс eth0 (выделяем первому - IP 192.168.254.1,
второму - 192.168.254.2 и т.д.)
Содержимое /etc/network/interfaces
# loopback
auto lo
iface lo inet loopback
allow-hotplug eth0
#iface eth0 inet dhcp
iface eth0 inet static
address 192.168.254.1
netmask 255.255.255.0
network 192.168.254.0
broadcast 192.168.254.255
gateway 192.168.254.254
Для предотвращения виртуальных окружений под одним MAC адресом, меняем MAC виртуальных карт:
sudo aptitude install macchanger
Создаем скрипт /etc/network/if-pre-up.d/macchange, меняющий MAC
#!/bin/sh
if [ ! -x /usr/bin/macchanger ]; then
exit 0
fi
/usr/bin/macchanger -a eth0
Перезапускаем гостевые окружения (вместо $IMAGE подставляем путь к окружению):
sudo /usr/bin/vdeq /usr/bin/kvm $IMAGE -m 512 -localtime -k es
Настройка выхода гостевых систем в интернет.
Проверяем на корневой системе, включен ли форвардинг пакетов между интерфейсами:
sysctl net.ipv4.ip_forward
Если выдало 0, то форвардинг отключен, включаем:
sudo -w sysctl net.ipv4.ip_forward=1
и сохраняем в /etc/sysctl.conf строку
net.ipv4.ip_forward = 1
В скрипте инициализации, после поднятия tap0 интерфейса, включаем трансляцию адресов:
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
|
| |
|
|
|
Запуск NetBSD в qemu под FreeBSD (доп. ссылка 1) |
Автор: Anton Yuzhaninov
[комментарии]
|
| | Недавно понадобилось посмотреть на NetBSD. Сходу в сети не нашлось описания как это можно сделать,
поэтому может кому то пригодится описание того, как это получилось у меня.
1. Создаем образ, на который будет установлена система:
qemu-img create -f qcow2 netbsd.img 4G
2. Подгружаем модуль aio
sudo kldload aio
3. Скачиваем iso-шку с дистрибутивом и загружаем с неё виртуальную машинку:
qemu -m 256 -curses -hda netbsd.img -cdrom i386cd-4.0.iso -boot d
Далее netbsd устанавливается так же как на обычный PC.
4. Для работы сети внутри виртуальной машины можно сделать бридж между
физическим интерфейсом и tap:
sudo ifconfig tap create
sudo ifconfig bridge create
sudo ifconfig bridge0 addm tap0 addm re0 up
sudo sysctl net.link.tap.up_on_open=1
sudo sysctl net.link.tap.user_open=1
Чтобы запускать qemu из под пользователя надо дать ему права на /dev/tap0
4. Без отключения ACPI NetBSD не захотела видеть ни одну из сетевух, которые эмулирует qemu,
поэтому ACPI пришлось отключить:
qemu -m 256 -curses -hda netbsd.img -no-acpi -net nic -net tap
|
| |
|
|
|
Решение проблемы с ошибкой при загрузке снапшота VirtualBox (доп. ссылка 1) |
Автор: Heckfy
[комментарии]
|
| | Бывает, виртуальная машина отказывается загружаться со следующей ошибкой:
Unable to restore the virtual machine's saved state from
'M:\VM\Machines\Windows Xp Sviluppo\Snapshots\{ce28664d-45f3-46dd8468-9ba91a689e7b}.sav'.
It may be damaged or from an older version of VirtualBox. Please discard the
saved state before starting the virtual machine. VBox status code: -1829 (VERR_SSM_UNEXPECTED_DATA).
Для решения проблемы требуется восстановить условия, в которых находилась виртуальная машина:
сетевые папки (в моем случае, это каталог /media/ в линуксе и всё дерево каталогов,
доступных виртуальной машине на тот момент), компакт-диски, Flash и прочее съемное.
|
| |
|
|
|
Установка FreeBSD в окружении Virtualbox |
[комментарии]
|
| | FreeBSD 6.3 в Virtualbox 1.6 и 2.0 (сборка для Ubuntu Linux 7.10) запустить не удалось
(были испробованы всевозможные комбинации конфигурации VirtualBox),
наблюдается крах в процессе загрузки ядра.
FreeBSD 7.0 был удачно установлен и использован в Virtualbox 1.6.x, но в VirtualBox 2.0
перестал работать режим аппаратной виртуализации VT-x/AMD-V, при включении данной
опции bootloader вываливается в бесконечную демонстрацию регистровых дампов.
Пришлось откатиться обратно до Virtualbox 1.6.6.
Далее, привожу особенности установки FreeBSD 7.0 в Virtualbox.
Во время установки FreeBSD в виртуальном окружении Virtualbox, процесс зависает
во время отображения меню bootloader'а.
Чтобы зависания не произошло нужно в параметрах VirtualBox запретить использование VT-x/AMD-V.
В форумах также можно найти жалобы на зависание в процессе загрузки ядра,
решаемые выключением ACPI в VirtualBox.
После завершения установки, загрузившись в новую гостевую систему, меняем /boot/loader.conf:
kern.hz="50"
beastie_disable="YES"
Т.е. уменьшаем частоту генерации прерываний от таймера, чтобы виртуальная машина
не грузила CPU хост-системы и запрещаем отображение меню загрузчика, на котором
система повисает при включении VT-x/AMD-V.
Включаем в настройках VT-x/AMD-V. Тип эмулируемого сетевого адаптера нужно
выбрать PCNet-PCI II или Intel Pro,
тот что ставится по умолчанию (PCNet-Fast III) не работает во FreeBSD.
Тип эмуляции сетевого интерфейса выбираем NAT, а в FreeBSD получаем адрес по DHCP или
устанавливаем IP из диапазона 10.0.2.0/24, шлюз 10.0.2.2, DNS 10.0.2.3.
Внимание, ping в NAT режиме не работает, проверять приходится через telnet.
Для того чтобы в гостевую систему можно было зайти по SSH, нужно перебросить 22 порт из вне.
Запускаем в консоли хост-системы:
VBoxManage setextradata "freebsd" "VBoxInternal/Devices/pcnet/0/LUN#0/Config/guestssh/Protocol" TCP
VBoxManage setextradata "freebsd" "VBoxInternal/Devices/pcnet/0/LUN#0/Config/guestssh/GuestPort" 22
VBoxManage setextradata "freebsd" "VBoxInternal/Devices/pcnet/0/LUN#0/Config/guestssh/HostPort" 2222
где, "freebsd" - это имя виртуальной машины, а pcnet тип эмулируемой карты.
После перезапуска гостевого окружения, заходя на 2222 порт хостовой машины мы будем
переброшены на 22 порт виртуального окружения.
ssh -p2222 localhost
В форумах советуют создать для FreeBSD образ диска фиксированного размера,
но я использую динамически расширяемый образ и проблем не наблюдаю.
|
| |
|
|
|
Создание initrd образа для гостевого Xen окружения в CentOS |
[комментарии]
|
| | В CentOS 5, при установке пакета kernel-xen с ядром, по умолчанию создается initrd образ для Dom0.
Для использования данного ядра в гостевом окружении необходимо создать initrd
с поддержкой сетевого и блочного xen модулей, иначе ядро в гостевой ФС не сможет
смонтировать корневую ФС на дисковом разделе.
Имеем ядро kernel-xen-2.6.18-53.1.13.el5
Создаем initrd:
/sbin/mkinitrd --with=xennet --preload=xenblk /boot/initrd-centos5-xen.img 2.6.18-53.1.13.el5xen
Пример xen профайла vps3:
kernel = "/boot/vmlinuz-2.6.18-53.1.21.el5xen"
ramdisk = "/boot/initrd-centos5-xen.img"
memory = 1024
name = "vps3"
cpus = "0" # all vcpus run on CPU0
vcpus = 1
vif = [ '', 'mac=00:16:3E:00:00:02, bridge=virbr1, vifname=eth2, ip=192.168.122.2' ]
disk = [ 'phy:/dev/mapper/sil_ahajbjcdabeip7,sda1,w' ]
root = "/dev/sda1 ro"
extra = "4"
|
| |
|
|
|
Установка OpenSolaris2008/05 DomU в Xen 3.2.1 CentOS 5.1 Dom0 (64-bit) (доп. ссылка 1) |
Автор: Boris Derzhavets
[комментарии]
|
| | Вариант 1.
Установка OpenSolaris2008/05 HVM DomU в Xen 3.2.1 CentOS 5.1 Dom0 (64-bit)
на машине с процессором поддерживающим технологии Intel VT или AMD-V
Определяем, поддерживаем ли процессор аппаратную виртуализацию:
Intel:
grep -i vmx /proc/cpuinfo
AMD:
grep -i svm /proc/cpuinfo
Активирован ли HVM в BIOS (также можно поискать по ключам VT, VMX, SVM):
grep -i hvm /sys/hypervisor/properties/capabilities
Создаем слепок установочного DVD диска с OpenSolaris 2008/05:
# dd if=/dev/hda of=/usr/lib/xen-solaris/os200805.iso
Создаем Xen профайл для установки OpenSolaris2008/05:
[root@dhcppc3 vm]# cat OS0805.hvm
name = "OS200805HVM"
builder = "hvm"
memory = "1024"
disk = ['phy:/dev/sdb11,ioemu:hda,w','file:/usr/lib/xen-solaris/os200805.iso,hdc:cdrom,r']
vif = [ 'type=ioemu,bridge=eth0' ]
device_model = "/usr/lib64/xen/bin/qemu-dm"
kernel = "/usr/lib/xen/boot/hvmloader"
vnc=1
boot="d"
vcpus=1
serial = "pty" # enable serial console
on_reboot = 'restart'
on_crash = 'restart'
Запускаем установку в гостевом окружении Xen:
# xm create OS200805.hvm
Подключаем VNC клиент для управления установкой:
# vncviewer localhost:0
После установки меняем Xen профайл на рабочий и запускаем его:
[root@dhcppc3 vm]# cat OS0805RT.hvm
name = "OS200805HVM"
builder = "hvm"
memory = "1024"
disk = ['phy:/dev/sdb11,ioemu:hda,w']
vif = [ 'type=ioemu,bridge=eth0' ]
device_model = "/usr/lib64/xen/bin/qemu-dm"
kernel = "/usr/lib/xen/boot/hvmloader"
vnc=1
boot="c"
vcpus=1
serial = "pty" # enable serial console
on_reboot = 'restart'
on_crash = 'restart'
Редактируем конфигурацию Grub (/rpool/boot/grub/menu.lst) в Solaris, для загрузки 64-битного ядра.
Вариант 2.
Установка OpenSolaris2008/05 DomU в Xen 3.2.1 CentOS 5.1 Dom0 (64-bit) в режиме
паравиртуализации, используя модифицированное ядро Solaris
Создаем слепок установочного DVD диска с OpenSolaris 2008/05:
# dd if=/dev/hda of=/usr/lib/xen-solaris/os200805.iso
Копируем 64-битное ядро xen-solaris и x86.microroot в хостовое окружение (Dom0):
mkdir -p /mnt01/tmp
mount -o loop,ro os200805.iso /mnt01/tmp
cp /mnt01/tmp/boot/x86.microroot /usr/lib/xen-solaris/x86.microroot
cp /mnt01/tmp/boot/platform/i86xpv/kernel/amd64/unix /usr/lib/xen-solaris/unix-0805
umount /mnt01/tmp
Для установки используем Xen профайл:
name = "OpenSolaris"
vcpus = 1
memory = "1024"
kernel = "/usr/lib/xen-solaris/unix-0805"
ramdisk = "/usr/lib/xen-solaris/x86.microroot"
extra = "/platform/i86xpv/kernel/amd64/unix -kd - nowin -B install_media=cdrom"
disk = ['file:/usr/lib/xen-solaris/os200805.iso,6:cdrom,r','phy:/dev/sdb8,0,w']
vif = ['bridge=eth0']
on_shutdown = "destroy"
on_reboot = "destroy"
on_crash = "destroy"
Во время загрузки виртуальной машины набираем:
Welcome to kmdb
Loaded modules: [ unix krtld genunix ]
[0]> gnttab_init+0xce/W 403
gnttab_init+0xce: 0x3 = 0x403
[0]> :c
Входим в систему как jack/jack и выполняем установку LiveCD на виртуальный жесткий диск.
Когда установка будет завершена не производите перезагрузку, а откройте root-терминал и выполните:
# mdb -w /a/platform/i86xpv/kernel/amd64/unix
> gnttab_init+0xce?W 403
unix`gnttab_init+0xce: 0x403 = 0x403
> $q
# /usr/bin/scp -S /usr/bin/ssh /a/platform/i86xpv/kernel/amd64/unix \
> IP-ADDRESS-Dom0:/usr/lib/xen-solaris/unix-0805
# /usr/bin/scp -S /usr/bin/ssh /a/platform/i86pc/amd64/boot_archive \
> IP-ADDRESS-Dom0:/usr/lib/xen-solaris/boot_archive
bash-3.2# shutdown -y -i0 -g0
После установки меняем Xen профайл на рабочий:
name = "OpenSolaris"
vcpus = 1
memory = "1024"
kernel = "/usr/lib/xen-solaris/unix-0805"
ramdisk = "/usr/lib/xen-solaris/boot_archive"
extra = "/platform/i86xpv/kernel/amd64/unix -B zfs-bootfs=rpool/27"
disk = ['file:/usr/lib/xen-solaris/os200805.iso,6:cdrom,r','phy:/dev/sdb8,0,w']
vif = ['bridge=eth0']
on_shutdown = "destroy"
on_reboot = "destroy"
on_crash = "destroy"
|
| |
|
|
|
Установка и использование OpenVZ в Debian GNU/Linux (доп. ссылка 1) |
Автор: Falko Timme
[комментарии]
|
| | Добавляем в /etc/apt/sources.list репозиторий с OpenVZ:
deb http://download.openvz.org/debian-systs etch openvz
Далее:
wget -q http://download.openvz.org/debian-systs/dso_archiv_signing_key.asc -O- | apt-key add -
apt-get update
Устанавливаем ядро с OpenVZ.
В репозитории доступны ядра версий 2.6.18 и 2.6.24 в сборках 486, 686,
686-bigmem (до 63 Гб ОЗУ) и amd64.
apt-get install fzakernel-2.6.18-686-bigmem
update-grub
Устанавливаем утилиты и минимальный образ гостевой системы:
apt-get install vzctl vzquota vzprocps vzdump
apt-get install vzctl-ostmpl-debian
Для работы сети в VPS проверяем настройки /etc/sysctl.conf:
net.ipv4.conf.all.rp_filter=1
net.ipv4.conf.default.forwarding=1
net.ipv4.conf.default.proxy_arp = 0
net.ipv4.ip_forward=1
Перечитываем настойки: sysctl -p
Если IP виртуальной машины находится вне подсети, используемой на хост-машине:
В /etc/vz/vz.conf ставим:
NEIGHBOUR_DEVS=all
Перезагружаем машину с новым OpenVZ ядром и приступаем к поднятию виртуального окружения.
Создаем виртуальную машину с ID 101 на основе ранее загруженного шаблона (vzctl-ostmpl-debian):
vzctl create 101 --ostemplate debian-4.0-i386-minimal --config vps.basic
Включаем автоматиеческий запуск созданного VPS на стадии загрузки системы:
vzctl set 101 --onboot yes --save
Назначаем VPS имя хоста и IP:
vzctl set 101 --hostname test.example.com --save
vzctl set 101 --ipadd 1.2.3.101 --save
Ограничиваем число открытых сокетов, число процессов и объем памяти:
vzctl set 101 --numothersock 100 --save
vzctl set 101 --numtcpsock 100 --save
vzctl set 101 --numproc 150 --save
vzctl set 101 --vmguarpages 65536 --save # гарантированный объем 256Мб, в блоках по 4Кб
vzctl set 101 --privvmpages 131072 --save # максимальный объем 512Мб, в блоках по 4Кб
Список возможных ограничений - http://wiki.openvz.org/UBC_parameters_table
Прописываем DNS серверы для VPS:
vzctl set 101 --nameserver 213.133.98.98 --nameserver 213.133.99.99 \
--nameserver 213.133.100.100 --nameserver 145.253.2.75 --save
Можно вместо вызова vzctl напрямую отредактировать файл конфигурации /etc/vz/conf/101.conf
Запускаем созданную VPS:
vzctl start 101
Устанавливаем пароль суперпользователя VPS, запустив внутри команду passwd:
vzctl exec 101 passwd
Входим в shell VPS (можно сразу зайти по SSH):
vzctl enter 101
Останавливаем VPS:
vzctl stop 101
Удаляем VPS с жесткого диска:
vzctl destroy 101
Просматриваем список VPS и их статус:
vzlist -a
Просмотр ресурсов доступных внутри VPS:
vzctl exec 101 cat /proc/user_beancounters
Подробнее см. http://wiki.openvz.org/
|
| |
|
|
|
Как в Linux примонтировать образ QEMU диска |
[комментарии]
|
| | mount -o loop,offset=32256 qemu_image.img /mnt/qemu_image
|
| |
|
|
|
Запуск ChromeOS Flex в виртуальной машине Proxmox (доп. ссылка 1) |
[комментарии]
|
| | Chrome OS Flex представляет собой отдельный вариант Chrome OS,
предназначенный для использования на обычных компьютерах, а не только на
изначально поставляемых с Chrome OS устройствах, таких как Chromebook,
Chromebase и Chromebox. Изначально сборки Chrome OS Flex рассчитаны на загрузку
с USB-накопителя или установку на диск для работы поверх оборудования. Ниже
показано как можно запустить recovery-образ Chrome OS Flex в виртуальных
машинах на базе QEMU или Proxmox.
Загружаем с сайта Google и распаковываем bin-файл c ChromeOS Flex,
рассчитанный на загрузку c USB накопителя (файл также можно получить
при помощи утилиты Chromebook Recovery).
wget https://dl.google.com/chromeos-flex/images/latest.bin.zip
unzip latest.bin.zip
Устанавливаем пакеты, необходимые для виртуализации GPU (VirGL). Для Proxmox/Debian/Ubuntu:
apt-get install libgl1 libegl1
Создаём виртуальную машину, например, в интерфейсе Proxmox VM выбрав режим
загрузки Linux, тип системы - q35, тип CPU - host и тип BIOS - OVMF (UEFI).
Отключаем для EFI опцию "Pre-Enroll keys".
После создания виртуальной машины в свойствах графической карты в секции
Hardware выбираем VirGL GPU (в качестве альтернативы можно выбрать и VirtIO-GPU).
Создаём блочное устройство для доступа к системному образу ChromeOS Flex в loop-режиме:
losetup --partscan /dev/loop1 chromeos_15393.58.0_reven_recovery_stable-channel_mp-v2.bin
Пробрасываем созданное блочное устройство в виртуальную машину:
qm set vm_id -scsi2 /dev/loopN
где vm_id - идентификактор виртуальной машины, а /dev/loopN - созданное на
предыдущем этапе блочное устройство, например, /dev/loop1.
В Proxmox в настройках виртуальной машины в секции Options меняем порядок
загрузки, выставив загрузку с устройства scsi2 на первое место.
Запускаем виртуальную машину.
|
| |
|
|
|
Откуда берется steal внутри виртуальных машин и что с этим делать (доп. ссылка 1) |
Автор: Mail.Ru Cloud Solutions
[комментарии]
|
| | CPU steal time - это время, в течение которого виртуальная машина не получает
ресурсы процессора для своего выполнения. Это время считается только в гостевых
операционных системах в средах виртуализации.
Что такое steal
Steal - это метрика, указывающая на нехватку процессорного времени для
процессов внутри виртуальной машины. Как описано в патче ядра KVM, steal -
это время, в течение которого гипервизор выполняет другие процессы на хостовой
операционной системе, хотя он поставил процесс виртуальной машины в очередь на
выполнение. То есть steal считается как разница между временем, когда процесс
готов выполниться, и временем, когда процессу выделено процессорное время.
Метрику steal ядро виртуальной машины получает от гипервизора. При этом
гипервизор не уточняет, какие именно другие процессы он выполняет, просто
"пока занят, тебе времени уделить не могу". На KVM поддержка подсчёта
steal добавлена в патчах. Ключевых моментов здесь два:
1. Виртуальная машина узнает о steal от гипервизора. То есть, с точки зрения
потерь, для процессов на самой виртуалке это непрямое измерение, которое может
быть подвержено различным искажениям.
2. Гипервизор не делится с виртуалкой информацией о том, чем он занят -
главное, что он не уделяет время ей. Из-за этого сама виртуалка не может
выявить искажения в показателе steal, которые можно было бы оценить по
характеру конкурирующих процессов.
Как вычислить steal
По сути, steal считается как обычное время утилизации процессора. В ядре
добавляется ещё один счетчик непосредственно для процесса KVM (процесса
виртуальной машины), который считает длительность пребывания процесса KVM в
состоянии ожидания процессорного времени. Счетчик берет информацию о процессоре
из его спецификации и смотрит, все ли его тики утилизированы процессом
виртуалки. Если все, то считаем, что процессор занимался только процессом
виртуальной машины. В ином случае информируем, что процессор занимался чем-то
еще, появился steal.
Подробнее читайте в статье Brendann Gregg.
Как мониторить steal
Мониторить steal внутри виртуальной машины можно как любую другую процессорную
метрику. Главное, чтобы виртуалка была на Linux. Windows такую информацию не предоставляет.
Сложность возникает при попытке получить эту информацию с гипервизора. Можно
попробовать спрогнозировать steal на хостовой машине, например, по параметру
Load Average (LA) - усредненного значения количества процессов, ожидающих в
очереди на выполнение. Методика подсчета этого параметра непростая, но в целом
пронормированный по количеству потоков процессора LA > 1 указывает на
перегрузку Linux-сервера.
Чего же ждут все эти процессы? Очевидный ответ - процессора. Но иногда
процессор свободен, а LA зашкаливает. На самом деле, процессы могут ожидать
окончания любой блокировки, как физической, связанной с устройством
ввода/вывода, так и логической, например мьютекса. Туда же относятся блокировки
на уровне железа (того же ответа от диска) или логики (так называемых
блокировочных примитивов).
Ещё одна особенность LA в том, что оно считается как среднее значение по ОС,
причём не меньше, чем за минуту. Например, 100 процессов конкурируют за один
файл, тогда LA=50. Такое большое значение, казалось бы, говорит, что ОС плохо.
Но для криво написанного кода это может быть нормой - плохо только ему, а
другие процессы не страдают. Из-за этого усреднения (причём не меньше, чем за
минуту), определение чего-либо по LA может закончиться весьма неопределенными
результатами в конкретных случаях.
Почему появляется steal и что делать
Остановимся на основных причинах появления steal, с которыми мы столкнулись при
работе с облачной платформой MCS, и способах борьбы с ними.
Переутилизация. Самое простое и частое - много запущенных виртуальных машин,
большое потребление процессора внутри них, большая конкуренция, утилизация по
LA больше 1 (в нормировке по процессорным тредам). Внутри всех виртуалок всё
тормозит. Steal, передаваемый с гипервизора, также растёт, надо
перераспределять нагрузку или кого-то выключать.
При этом нужно учитывать, что соотношение нагрузки на гипервизоре и steal
внутри виртуальной машины не всегда однозначно взаимосвязаны. Обе оценки steal
могут быть ошибочными в конкретных ситуациях при разных нагрузках.
Паравиртуализация против одиноких инстансов. На гипервизоре одна единственная
виртуалка, она потребляет небольшую его часть, но дает большую нагрузку по
вводу/выводу, например по диску. И откуда-то в ней появляется небольшой steal,
до 10%.
Тут дело как раз в блокировках на уровне паравиртуализированных драйверов.
Внутри виртуалки создается прерывание, оно обрабатывается драйвером и уходит в
гипервизор. Из-за обработки прерывания на гипервизоре для виртуалки это
выглядит как отправленный запрос, она готова к исполнению и ждёт процессора, но
процессорного времени ей не дают. Виртуалка думает, что это время украдено.
Это происходит в момент отправки буфера, он уходит в kernel space гипервизора,
и мы начинаем его ждать. Хотя, с точки зрения виртуалки, он должен сразу
вернуться. Следовательно, по алгоритму расчета steal это время считается
украденным. Скорее всего, в этой ситуации могут быть и другие механизмы
(например, обработка ещё каких-нибудь sys calls), но они не должны сильно отличаться.
Небольшой steal можно считать нормой (даже и без паравиртуализации, с учётом
нагрузки внутри виртуалки, особенностей нагрузки соседей, распределения
нагрузки по тредам и прочего). Однако важно обращать внимание на то, как себя
чувствуют приложения внутри виртуалок.
Шедулер против высоконагруженных виртуалок. Когда одна виртуалка страдает от
steal больше других, это связано с шедулером (распределением ресурсов между
процессами) - чем сильнее процесс нагружает процессор, тем скорее шедулер
его выгонит, чтобы остальные тоже могли поработать. Если виртуалка потребляет
немного, она почти не увидит steal: её процесс честно сидел и ждал, ему дадут
время. Если виртуалка дает максимальную нагрузку по всем своим ядрам, её чаще
выгоняют с процессора и не дают много времени. Шедулер плохо относится к
процессам, которые много просят. Большие виртуалки - зло.
Низкий LA, но есть steal. LA примерно 0,7 (то есть, гипервизор, кажется
недозагружен), но внутри отдельных виртуалок наблюдается steal:
1. Уже описанный выше вариант с паравиртуализацией. Виртуалка может получать
метрики, указывающие на steal, хотя у гипервизора всё хорошо. По результатам
наших экспериментов, такой вариант steal не превышает 10 % и не должен
оказывать существенного влияния на производительность приложений внутри виртуалки.
2. Неверно считается LA. Точнее, в каждый конкретный момент он считается
верно, но при усреднении получается заниженным. Например, если одна виртуалка
на треть гипервизора потребляет все свои процессоры ровно полминуты, LA за
минуту на гипервизоре будет 0,15; четыре такие виртуалки, работающие
одновременно, дадут 0,6. А то, что полминуты на каждой из них был steal под 25
% по LA, уже не вытащить.
3. Из-за шедулера, решившего, что кто-то слишком много ест, и пусть он
подождет, пока я займусь другими важными системными вещами. В итоге одни
виртуалки не видят никаких проблем, а другие испытывают серьезную деградацию производительности.
Другие искажения
Есть другие причины для искажений честной отдачи процессорного времени на
виртуалке. Например, сложности в расчёты вносят гипертрединг и NUMA. Они
запутывают выбор ядра для исполнения процесса, потому что шедулер использует
коэффициенты - веса, которые при переключении контекста выполняют
усложнённый подсчёт.
Бывают искажения из-за технологий типа турбобуста или, наоборот, режима
энергосбережения, которые при подсчёте утилизации могут искусственно повышать
или понижать частоту или даже квант времени на сервере. Включение турбобуста
уменьшает производительность одного процессорного треда из-за увеличения
производительности другого. В этот момент информация об актуальной частоте
процессора виртуальной машине не передается, и она считает, что её время кто-то
тырит (например, она запрашивала 2 ГГц, а получила вдвое меньше).
В общем, причин искажений может быть много. Чтобы выяснить steal в конкретной
системе, исследуйте различные варианты, собирайте метрики, тщательно их
анализируйте и продумывайте, как равномерно распределять нагрузку. От любых
кейсов возможны отклонения, которые надо подтверждать экспериментально или
смотреть в отладчике ядра. Начать лучше с книг, на которые я дал линки выше, и
съёма статистики с гипервизора утилитами типа perf, sysdig, systemtap, коих десятки.
|
| |
|
|
|
Установка Xen 4.0.0 в Ubuntu Linux 10.04 (доп. ссылка 1) |
[комментарии]
|
| | В заметке показано как запустить Xen 4.0.0 (dom0) с Linux ядром 2.6.32.10
поверх 64-разрядной сборки Ubuntu 10.04-beta.
Устанавливаем необходимые для сборки пакеты:
sudo aptitude install build-essential libncurses5-dev dpkg-dev debhelper fakeroot
Загружаем Linux ядро с dom0-патчами:
sudo -s
cd /usr/src
git clone git://git.kernel.org/pub/scm/linux/kernel/git/jeremy/xen.git linux-2.6-xen
cd linux-2.6-xen
git checkout -b xen/stable origin/xen/stable
Копируем файл с параметрами конфигурации ядра:
curl http://opennet.ru/soft/xen40_config.txt > /usr/src/linux-2.6-xen/.config
Анализируем различия с базовым файлом конфигурации Ubuntu и при необходимости вносим изменения:
diff /boot/config-2.6.32-17-generic /usr/src/linux-2.6-xen/.config | vim -
Собираем ядро:
make menuconfig # включаем поддержку dom0 и Xen
make
chmod g-s /usr/src -R # для того чтобы избежать ошибки "dpkg-deb: control directory has bad permissions..."
make deb-pkg
Собираем и устанавливаем пакет с ядром, настраиваем initramfs и grub:
dpkg -i ../linux-image*2.6.32.10*.deb
depmod 2.6.32.10
update-initramfs -c -k 2.6.32.10
update-grub
echo "xen-evtchn" >> /etc/modules
Готовим окружение для сборки
apt-get build-dep xen-3.3
aptitude install uuid-dev iasl texinfo
Загружаем Xen
cd /usr/src
hg clone -r 4.0.0 http://xenbits.xensource.com/xen-unstable.hg
cd xen-unstable.hg
Собираем
make xen
make tools
make stubdom
make install-xen
make install-tools PYTHON_PREFIX_ARG=
make install-stubdom
update-rc.d xend defaults 20 21
update-rc.d xendomains defaults 21 20
Настраиваем Grub2 через создание файла /etc/grub.d/40_custom:
#!/bin/sh
exec tail -n +3 $0
menuentry "Xen 4.0.0-rc8 / Ubuntu 10.4 kernel 2.6.32.10 pvops" {
insmod ext2
set root=(hd0,1)
multiboot (hd0,1)/xen-4.0.0.gz dummy=dummy
module (hd0,1)/vmlinuz-2.6.32.10 dummy=dummy root=/dev/mapper/HyperDeskVG01-tcmc-dell-lucid ro
module (hd0,1)/initrd.img-2.6.32.10
}
Не забудьте изменить значение параметра "root=" на корневой раздел текущей системы.
Обновляем параметры Grub:
update-grub
Перезагружаем систему с dom0-ядром:
reboot
Проверяем работает ли Xen:
xm list
xm info
Если нет, пытаемся выполнить:
/etc/init.d/xendomains stop
/etc/init.d/xend stop
/etc/init.d/xend start
/etc/init.d/xendomains start
|
| |
|
|
|



 Как вариант предложено дополнительно использовать
Как вариант предложено дополнительно использовать