|
Подготовлен первый экспериментальный выпуск СУБД EuclidesDB, предоставляющей средства для использования моделей машинного обучения при индексировании и выборке данных. СУБД позволяет привязывать к различным классам информации отдельные модели машинного обучения, например, можно подключить модель для классификации изображений и применять СУБД для поиска похожих фотографий или выборки изображений, на которых присутствует определённый объект. Проект написан на языке С++ и распространяется под лицензией Apache 2.0. Модели машинного обучения обрабатываются при помощи библиотеки PyTorch (используется C++-интерфейс libtorch).
СУБД EuclidesDB предоставляет универсальное решение для создания систем обработки данных с использованием моделей машинного обучения, образующее готовый каркас для подключения необходимых моделей и их применения для поиска похожих данных. Для каждой категории данных могут подключаться отдельные модели, например, для поиска туфель может использоваться одна модель, натренированная на изображениях обуви, а для поиска футболок - другая. На практике, данные модели могут применяться для рекомендации клиенту интернет-магазина туфель и футболок, наиболее похожих на те, что уже выбрал покупатель.
При добавлении новых данных в БД, например, изображения, вместе с данными указывается модель машинного обучения, которую следует применить для индексации. Результаты обработки сохраняются в локальное хранилище в формате ключ/значение, и используются при построении индекса запросов. При обработке запроса похожих элементов, переданный в запросе эталонный элемент обрабатывается с использованием одного из выбранных алгоритмов поиска похожих объектов. В запросе определяется допустимый диапазон моделей, которые следует использовать при поиске. На выходе для каждой из выбранных моделей возвращается список наиболее близких элементов с указанием уровня релевантности.
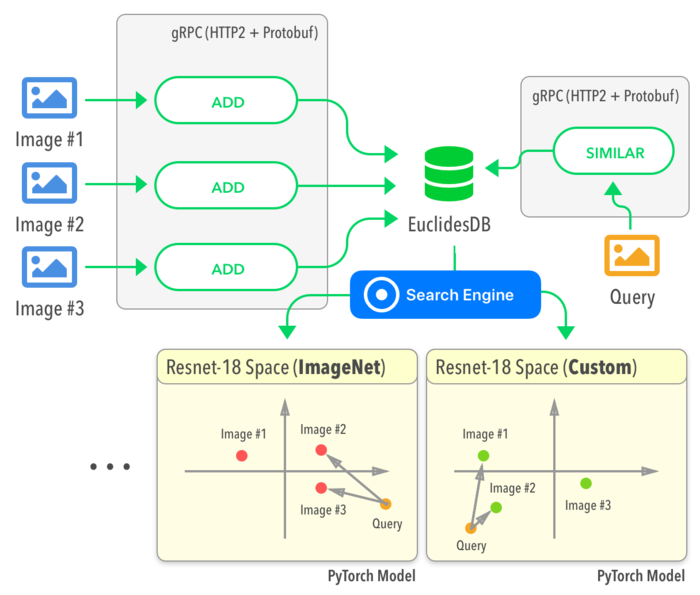
Взаимодействие с СУБД осуществляется с использованием протокола gRPC c применением HTTP/2 для сетевого взаимодействия и Protocol Buffers для сериализации данных. Низкоуровневое хранение данных реализовано с использованием LevelDB. Логика обработки моделей задаётся на языке Python (TorchScript ) и оформляется в виде модулей к PyTorch. В комплекте поставляются три готовые модели (resnet101, resnet18 и vgg16), обеспечивающие распознавание и классификацию изображений. В дальнейшем планируется включить в состав модели для обработки других видов информации.
Поддерживается несколько методов индексации и поиска данных:
- annoy - движок нечёткого поиска на базе библиотеки Annoy (Approximate Nearest Neighbors Oh Yeah), которая применяется для формирования рекомендаций в музыкальном сервисе Spotify. Библиотека реализует алгоритм решения
задачи поиска ближайшего соседа, оптимизированный для снижения потребления оперативной памяти и использования подкачки данных с диска;
- faiss - движок на основе библиотеки поиска похожих элементов Faiss, развиваемой компанией Facebook. Faiss предлагает большой набор настроек, позволяющих добиться необходимого компромисса в отношении времени поиска, качества поиска, потребления оперативной памяти и длительности обучения;
- exact_disk - простейший движок, в котором применяется линейный поиск точных совпадений. Индекс сразу сохраняется на диск, что позволяет добиться минимального расхода оперативной памяти.
| 

