| Каталог документации / Раздел "Программирование, языки" / Оглавление документа |
| |
| Разработка графического интерфейса с помощью библиотеки Qt3 | ||
|---|---|---|
| Пред. | Глава 4. Реализация функциональности приложения. | След. |
Класс Cell порожден от класса QTableItem. Он предназначен для совместной работы с Spreadsheet, но никак не зависит от этого класса и теоретически может работать с любым экземпляром QTable.
Заголовочный файл:
#ifndef CELL_H
#define CELL_H
#include <qtable.h>
#include <qvariant.h>
class Cell : public QTableItem
{
public:
Cell(QTable *table, const QString &formula);
void setFormula(const QString &formula);
QString formula() const;
void setDirty();
QString text() const;
int alignment() const;
private:
QVariant value() const;
QVariant evalExpression(const QString &str, int &pos) const;
QVariant evalTerm(const QString &str, int &pos) const;
QVariant evalFactor(const QString &str, int &pos) const;
QString formulaStr;
mutable QVariant cachedValue;
mutable bool cacheIsDirty;
};
#endif
Класс Cell расширяет функциональные
возможности своего предка за счет добавления трех приватных переменных:
formulaStr -- формула ячейки, QString.
cachedValue -- кэш ячейки, QVariant.
cacheIsDirty -- true, если значение в кэше необходимо обновить.
Переменные cachedValue и cacheIsDirty объявлены со спецификатором mutable. Это позволяет модифицировать их из const-функций. В противном случае нам пришлось бы пересчитывать значение ячейки всякий раз, при вызове функции text(), но это было бы неэффективной тратой времени.
Примечательно, что в определении класса отсутствует макрос Q_OBJECT. Дело в том, что Cell -- это обычный класс, который не имеет ни сигналов, ни слотов. Фактически, QTableItem не является наследником класса QObject, поэтому Cell не может иметь своих собственных сигналов и слотов. Вообще, классы элементов в Qt не являются потомками QObject, чтобы свести накладные расходы к минимуму. Если вам потребуются сигналы и слоты в классах-элементах, то вы можете реализовать свой виджет, который будет содержать элемент или, в исключительных случаях, воспользоваться возможностью множественного наследования, указав в качестве одного из предков класс QObject.
Перейдем к файлу cell.cpp:
#include <qlineedit.h>
#include <qregexp.h>
#include "cell.h"
Cell::Cell(QTable *table, const QString &formula)
: QTableItem(table, OnTyping)
{
setFormula(formula);
}
Конструктор принимает указатель на QTable и формулу. Указатель на таблицу передается в
унаследованный конструктор QTableItem и
позднее может быть получен вызовом QTableItem::table(). Второй аргумент, передаваемый
конструктору базового класса -- OnTyping,
указывает, что компонент-редактор должен появляться сразу же, как
только пользователь начнет вводить символы в текущую ячейку.
void Cell::setFormula(const QString &formula)
{
formulaStr = formula;
cacheIsDirty = true;
}
Функция setFormula() записывает
формулу в ячейку. Она так же устанавливает флаг
cacheIsDirty, который сигнализирует о том, что cachedValue должно быть пересчитано. Она вызывается
из конструктора Cell и из Spreadsheet::setFormula().
QString Cell::formula() const
{
return formulaStr;
}
Функция formula() вызывается из
Spreadsheet::formula().
void Cell::setDirty()
{
cacheIsDirty = true;
}
Функция setDirty() вызывается в
случае, когда необходимо заставить ячейку пересчитать свое значение.
Она просто устанавливает флаг cacheIsDirty.
Пересчет выполняется только тогда, когда это действительно необходимо.
QString Cell::text() const
{
if (value().isValid())
return value().toString();
else
return "####";
}
Функция text() перекрывает метод
QTableItem. Она возвращает текст, который
должен быть отображен в таблице. Значение ячейки вычисляется функцией
value(). Если оно не является допустимым
(скорее всего из-за ошибки в формуле), то возвращается строка
"####".Функция value() возвращает значение типа QVariant. Этот тип может хранить значения самых разных типов, таких как double или QString и предоставляет в распоряжение программиста ряд методов преобразования вариантного типа в другие типы. Например, вызов toString, для варианта типа double, вернет его строковое представление.
int Cell::alignment() const
{
if (value().type() == QVariant::String)
return AlignLeft | AlignVCenter;
else
return AlignRight | AlignVCenter;
}
Функция alignment() перекрывает метод
QTableItem. Она возвращает значение,
характеризующее выравнивание текста в ячейке. В нашем случае для строк
используется выравнивание по левому краю, для чисел -- по правому. Все
значения, независимо от своего типа, центрируются по вертикали.
const QVariant Invalid;
QVariant Cell::value() const {
if (cacheIsDirty) {
cacheIsDirty = false;
if (formulaStr.startsWith("'")) {
cachedValue = formulaStr.mid(1);
} else if (formulaStr.startsWith("=")) {
cachedValue = Invalid;
QString expr = formulaStr.mid(1);
expr.replace(" ", "");
int pos = 0;
cachedValue = evalExpression(expr, pos);
if (pos < (int)expr.length())
cachedValue = Invalid;
} else {
bool ok;
double d = formulaStr.toDouble(&ok);
if (ok)
cachedValue = d;
else
cachedValue = formulaStr;
}
}
return cachedValue;
}
Приватная функция value() возвращает
значение ячейки. Если установлен флаг cacheIsDirty, то значение ячейки пересчитывается.Если формула начинается с одиночной кавычки (например, "'12345"), то в качестве значения возвращается часть строки, начиная с позиции 1 и до конца. (Одиночная кавычка занимает позицию 0.)
Если формула начинается с символа "=", то берется часть строки, начиная с позиции 1 и до конца, Из нее удаляются все пробелы. Затем производится вычисление по формуле, с помощью функции evalExpression(). Аргумент pos, передаваемый по ссылке, указывает -- с какого символа в строке необходимо начинать разбор выражения. По окончании работы функции он содержит позицию символа, на котором завершился разбор. Если pos не соответствует позиции последнего символа в строке, то это означает ошибку в выражении и в этом случае cachedValue будет содержать значение Invalid.
Если формула начинается не с символа "=" и не с одиночной кавычки, то делается попытка преобразовать строку в число с плавающей точкой. Если преобразование завершилось успешно, то в cachedValue записывается число типа double, в противном случае -- строка с формулой. Например, формула "1.50" будет благополучно преобразована в число 1.5, а формула "World Population" не может быть преобразована в число и в этом случае в cachedValue будет записана сама строка "World Population".
Функция value() -- это const-функция. Но благодаря тому, что переменные-члены cachedValue и cacheIsValid объявлены как mutable, компилятор позволит нам модифицировать их внутри функции. Вам может показаться, что достаточно убрать спецификатор const функции value() и можно будет отказаться от спецификатора mutable, для переменных cachedValue и cacheIsValid, но такой вариант все равно породит ошибку времени компиляции, поскольку value() вызывается из const-функции text(). Вообще, в мире C++, кэширование и mutable идут рядом, рука об руку.
Мы практически закончили рассмотрение приложения Spreadsheet. Осталось только разобраться с синтаксическим анализом формул. Далее, до конца этого раздела, мы сконцентрируемся на evalExpression() и двух вспомогательных функциях evalTerm() и evalFactor(). Реализация функций достаточно сложна, но они совершенно необходимы для нашего приложения. С другой стороны, поскольку эти функции напрямую не связаны с разработкой графического интерфейса, вы смело можете пропустить оставшуюся часть раздела и сразу перейти к Главе 5.
Функция evalExpression() возвращает результат вычисления выражения. Выражение -- это один или более термов (term), отделяемых друг от друга операторами '+' или '-', например, "2*C5+D6" -- это выражение, состоящее из термов "2*C5" и "D6". Термы, в свою очередь, могут состоять из одного или более факторов (factor), отделяемых друг от друга операторами '*' или '/', например, терм "2*C5" состоит из двух факторов -- "2" и "C5". И наконец, фактор может быть числом ("2"), адресом ячейки ("C5") или выражением в скобках с необязательным предшествующим знаком '-' (признак отрицательного числа). Разложив выражение на термы, а термы на факторы, мы получим правильную обработку приоритетов операций.
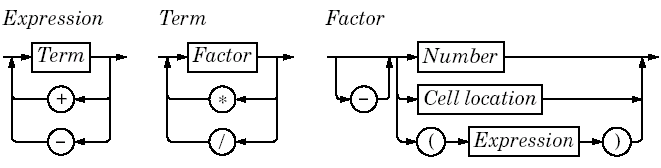
Рисунок 4.12. Синтаксическая диаграмма выражений в электронной таблице.
Начнем с функции evalExpression(), которая отвечает за разбор элемента Expression:
QVariant Cell::evalExpression(const QString &str, int &pos) const
{
QVariant result = evalTerm(str, pos);
while (pos < (int)str.length()) {
QChar op = str[pos];
if (op != '+' && op != '-')
return result;
++pos;
QVariant term = evalTerm(str, pos);
if (result.type() == QVariant::Double
&& term.type() == QVariant::Double) {
if (op == '+')
result = result.toDouble() + term.toDouble();
else
result = result.toDouble() - term.toDouble();
} else {
result = Invalid;
}
}
return result;
}
В первой строке, вызовом evalTerm(),
предпринимается попытка получить значение первого терма. Если за ним
стоит оператор '+' или '-', то
evalTerm() вызывается второй раз, в противном случае,
выражение состоит из единственного терма и мы возвращаем его
значение как результат выражения. После того, как будут получены
значения обоих термов -- вычисляется результат операции. Если оба
терма имеют тип double, вычисляется
результат этого же типа, в противном случае, возвращается результат
Invalid.Так продолжается до тех пор, пока не будут исчерпаны все термы. В данной ситуации все работает корректно, благодаря тому, что операции сложения и вычитания лево-ассоциативны, т.е. выражению "1-2-3" соответствует "(1-2)-3", а не "1-(2-3)".
QVariant Cell::evalTerm(const QString &str, int &pos) const
{
QVariant result = evalFactor(str, pos);
while (pos < (int)str.length()) {
QChar op = str[pos];
if (op != '*' && op != '/')
return result;
++pos;
QVariant factor = evalFactor(str, pos);
if (result.type() == QVariant::Double
&& factor.type() == QVariant::Double) {
if (op == '*') {
result = result.toDouble() * factor.toDouble();
} else {
if (factor.toDouble() == 0.0)
result = Invalid;
else
result = result.toDouble() / factor.toDouble();
}
} else {
result = Invalid;
}
}
return result;
}
evalTerm() очень похожа на
evalExpression(), за исключением того,
что она обслуживает операции умножения и деления. Единственный
тонкий момент -- необходимо избежать выполнения деления на ноль.
Вообще нецелесообразно проверять на равенство значения с плавающей
точкой, поскольку могут возникнуть ошибки, связанные с погрешностью
округления, хотя в данном случае, выполнять такую проверку вполне
допустимо.
QVariant Cell::evalFactor(const QString &фьзжstr, int &фьзжpos) const
{
QVariant result;
bool negative = false;
if (str[pos] == '-') {
negative = true;
++pos;
}
if (str[pos] == '(') {
++pos;
result = evalExpression(str, pos);
if (str[pos] != ')')
result = Invalid;
++pos;
} else {
QRegExp regExp("[A-Za-z][1-9][0-9]{0,2}");
QString token;
while (str[pos].isLetterOrNumber() || str[pos] == '.') {
token += str[pos];
++pos;
}
if (regExp.exactMatch(token)) {
int col = token[0].upper().unicode() - 'A';
int row = token.mid(1).toInt() - 1;
Cell *c = (Cell *)table()->item(row, col);
if (c)
result = c->value();
else
result = 0.0;
} else {
bool ok;
result = token.toDouble(&ok);
if (!ok)
result = Invalid;
}
}
if (negative) {
if (result.type() == QVariant::Double)
result = -result.toDouble();
else
result = Invalid;
}
return result;
}
Функция evalFactor() гораздо сложнее,
чем evalExpression() и evalTerm(). Начинается она с проверки -- не
инвертирован ли фактор (наличие унарного минуса). Затем проверяется --
не начинается ли он с открывающей скобки. Если да, то содержимое скобок
вычисляется как выражение, вызовом evalExpression(). Это то самое место, где возникает
рекурсия -- evalExpression() вызывает
evalTerm(), которая вызывает evalFactor(), которая опять вызывает evalExpression().Если фактор не является выражением в скобках, то извлекается лексема, которая может оказаться адресом ячейки или числом. Если лексема соответствует регулярному выражению QRegExp, то она воспринимается как адрес ячейки и вызывается value() для данной ячейки. Ячейка может находиться в любом месте электронной таблицы, а ее значение может так же вычисляться на основе других ячеек. Подобные зависимости не являются проблемой для нас, просто это может потребовать некоторого дополнительного времени для рассчета значений тех ячеек, у которых установлен флаг cacheIsDirty. Если лексема не является адресом ячейки, то она считается числом.
Что произойдет, если значение ячейки A1 вычисляется по формуле "=A1"? Или если ячейка A1 вычисляется по формуле "=A2", а ячейка A2 -- по формуле "=A1"? Хотя мы и не предусмотрели проверки циклических зависимостей, тем не менее наш анализатор довольно изящно решает эту проблему, возвращая ошибочный QVariant. Это происходит потому, что в функции value() сбрасывается флаг cacheIsDirty, а в cachedValue записывается Invalid до того, как будет вызвана функция evalExpression(). Если evalExpression() рекурсивно вызывает value() своей собственной ячейки, то ей сразу же возвращается значение Invalid, которое становится результатом всего выражения.
На этом мы завершаем обсуждение синтаксического анализатора формул. Он может быть расширен за счет введения обработки предопределенных функций электронной таблицы, таких как "sum()" и "avg()", в синтаксическом элементе фактор. Довольно просто в него можно добавить операцию конкатенации ("+") строк.
| Пред. | В начало | След. |
| Реализация других меню. | На уровень выше | Создание собственных виджетов. |



|
Закладки на сайте Проследить за страницей |
Created 1996-2025 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |