Статус: Окончательная версия (18.01.2005)
Описание протокола Label Distribution Protocol (LDP)
Протокол LDP регламентируется стандартом IETF "LDP Specification" RFC 3036. Протокол LDP функционирует в рамках архитектуры MPLS. Для полного понимания работы LDP рекомендуется сначала ознакомиться с данной архитектурой.- Назначение протокола LDP
- Установка соседских отношений
- Сообщения KeepAlive
- Обмен информацией о метках
- Параметры функционирования LDP
- Типы сообщений LDP
- Документация
Назначение протокола LDP
Протокол LDP предназначен для построения целостных маршрутов коммутации по меткам LSP.Установка соседских отношений
Установление соседских отношений между маршрутизаторами осуществляется в две фазы:- обмен сообщениями Hello;
- установление сессии LDP.
Обмен сообщениями Hello
Сообщения Hello посылаются маршрутизатором через все интерфейсы, на которых включен LDP, каждые 15 секунд на адрес 224.0.0.2 (all-routers), порт 646, транспортный протокол UDP. Возможен обмен сообщений Hello и между LSR-ами не соединенными непосредственно. В этом случае сообщение посылается на уникастовый адрес.Сообщения Hello содержат следующую информацию:
Holddown timer - промежуток времени, в течении которого, соседи должны послать хотя бы одно сообщение Hello. Если соседи предлагают разное значение, то принять они должны минимальное. Так как протокол UDP не обеспечивают гарантии доставки, то рекомендуется посылать сообщения Hello с периодом в три раза меньшим, чем Holddown timer. Если Holddown timer равен 0, то принимаются следующие значения по умолчанию:
- 15с - для обыкновенных hello сообщений на адрес all-routers;
- 45c - для сообщений посылаемых на конкретный адрес (Targeted Hello).
T bit - (Targeted Hello) если данный бит 1, то это означает, что сообщение послано на конкретный (unicast) адрес, иначе сообщение послано на 224.0.0.2.
R bit - (Request Send Targeted Hellos) если данный бит 1, то это означает, что получатель должен ответить на это сообщение (Hello), иначе не должен. Данный бит может быть установлен в 1, только в случае если T-bit=1.
Примечание: Targeted Hello используются при реализации дополнительного функционала на базе MPLS.
Transport Address - данное поле в Hello пакете не обязательно. Если оно присутствует, то адрес, указанный в нем, используется в дальнейшем для установления LDP сессии между устройствами. Если данное поле отсутствует, то для установления сессии должен использоваться адрес источника Hello пакета. Адрес, используемый для установки LDP сессии, мы будем называть "транспортный адрес".
Configuration Sequence Number - Поле содержит номер конфигурации. При изменении настроек на LSR, соответственно меняется этот номер. Изменение номера может вызывать переустановление LDP сессии (а может и не вызывать - RFC тут не однозначно).
Сообщения hello могут отбрасываться, и соответственно, фаза N1 установления соседских отношений может быть не выполнена, в силу следующих причин:
- LSR-у административно запрещено принимать сообщения hello определенного типа (например, TargetHello) или с определенного адреса;
- Не совпадения типов транспортных адресов (например, IPv4 и IPv6).
Установление LDP сессии
LDP сессия функционирует по верх TCP/IP (порт 646).LSR1 и LSR2 при обмене сообщениями hello узнают транспортные адреса друг друга. Если транспортный адрес LSR1 больше чем транспортный адрес LSR2, то LSR1 становиться "активным" соседом, а LSR2 "пассивным", иначе, наоборот. Далее, LDP сессия устанавливается по следующему сценарию.
- "Активный" сосед устанавливает TCP/IP сессию на порт 646.
- "Активный" сосед посылает сообщение Init, включающее в себя свои параметры LDP сессии (формат см.далее).
- "Пассивный" сосед проверяет параметры LDP сессии в сообщении Init
на предмет совместимости с локальными
настройками LDP.
- "Пассивный" сосед отвечает сообщением Init , включающее в себя свои параметры LDP сессии.
- "Активный сосед проверяет параметры LDP сессии в сообщении Init на предмет совместимости с локальными настройками LDP
- Сессия установлена.
Сообщение Init
Сообщение Init содержит следующую информацию:Protocol Version - версия протокола.
KeepAlive Time - максимальное время между служебными сообщениями KeepAlive. Обе стороны могут предлагать различные значения - использоваться должно минимальное.
A-bit, Label Advertisement Discipline - режим обмена информацией о метках. Возможно использование двух режимов обмена информацией о метках:
- 1 - Downstream On Demand;
- 0 - Downstream Unsolicited.
PVLim, Path Vector Limit - Переменная используется для работы механизма предотвращения циклов.
Max PDU Length - LDP сообщения группируются в PDU (Protocol Data Units) и передаются в одном пакете TCP/IP. Max PDU Length - означает максимально возможную длину совмещенных сообщений LDP в байтах. Соседи могут предлагать различные значения, но оба должны выбрать минимальное. Заметим, что даже одно сообщение упаковывается внутрь PDU.
Receiver LDP Identifier - Идентификатор пространства меток (или Label Space Identifier). Формат поля следующий: LSR_ID:Label_Space_ID. LSR_ID это идентификатор LSR. Данный идентификатор должен быть уникален в рамках домена MPLS и един для каждого LSR-а. Label_Space_ID - это идентификатор множества меток. Label Space Identifier указывается в заголовке PDU, идентифицируя тем самым соседа и интерфейс по которому установлено соседство. Например, два LSR-а могут быть соединены двумя каналами, и для каждого канала должен быть выделен разные Label Space Identifier, отличаться которые будут только значением Label_Space_ID.
Примечание: Сообщение Init так же содержит несколько дополнительных, необязательных полей, описание которых опущено. Толку от этих полей в сетях IP все равно нет.
LDP сессия устанавливается при выполнении следующих условий:
- совпадение версий протокола (в прямую RFC этого не требует, но если в этом поле будет что-то неожиданное, уважающий себя LSR не установит LDP сессию);
- совпадение значений А-бит, в сети на разных соединениях возможно использование различных режимов распространения иформации о метках, но на одном соединение режим должен совпадать.
Сообщения KeepAlive
За каждой сессией LDP LSR должен закреплять таймер. После получения любого сообщения LDP, LSR устанавливает таймер в 00:00 и снова запускает его. До достижения таймером значения "KeepAlive Time" соседний LSR должен прислать любое LDP сообщение. Если у соседа нет информативных сообщений для пересылки, то он должен послать сообщение KeepAlive.Примечание: При конкретной реализации таймер может работать как от 00:00 до "KeepAlive Time", так и в обратную сторону.
Если в назначенный срок сообщения не приходят, то сосед считается отключенным и сессия с ним должна установливаться заново.
Обмен информацией о метках
Рассмортим схему представленную на рис. N1.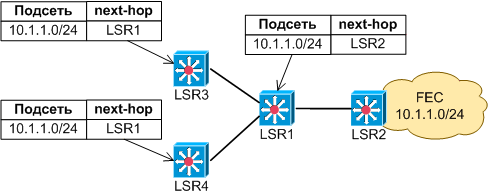
Рис N1. Схема типичного LSR.
- Upstream LSR-ы - это LSR3, LSR4.
- Downstream LSR - это LSR2. Иначе Downstream LSR можно назвать next-hop-LSR (NH-LSR).
Параметры функционирования LDP
Существует несколько параметров функционирования LDP:- режим обмена информацией о метках (Label Distribution Mode)
- режим контроля над распространением меток (Label Distribution Control)
- механизм сохранения меток (Label Retention Mode)
Режим обмена информацией о метках
Между соседями возможно использования двух режимов обмена информацией о метках:- Downstream On Demand - с запросом;
- Downstream Unsolicited - без запроса.
Механизм контроля над распространением меток
Также существует несколько механизмов контроля над распространением меток (Label Distribution Control Mode):- Independent Label Distribution Control - независимый контроль;
- Ordered Label Distribution Control - упорядоченный контроль.
Режим сохранения меток
Режим сохранения меток (Label Retention Mode)- Conservative Label Retention Mode (сдержанный режим сохранения
меток);
- Liberal Label Retention Mode (свободный режим сохранения меток).
уничтожении маршрута на FEC метка не удаляется, а лишь помечается как неактивная. И в случае, если маршрут на FEC восстанавливается через тот же NH-LSR, то метка не запрашивается, а используется старая, статус которой меняется на активный.
Примечание: Режим сохранения меток, механизм контроля над распространением меток и режим удержания меток могут быть не согласованы между соседями по LDP.
Протокол LDP должен реагировать на следующие события:
- появления новой записи FEC в таблице маршрутизации;
- исчезновение записи FEC из таблицы маршрутизации;
- смена next-hop для записи FEC.
Возможные комбинации режимов работы протокола LDP, а так же примеры функционирования приведены в табл. N1.
Табл. N1. Режимы функционирования протокола LDP.
| Режим обмена информацией о метках | Downstream Unsolicited |
Downstream Unsolicited | Downstream Unsolicited | Downstream On Demand | Downstream On Demand |
| Механиз контроля над
распростра- нением меток |
Independed Control | Ordered Control | Ordered Control | Ordered Control | Independed Control |
| Режим удержания меток | liberal | liberal | conservative | conservative | conservative |
| появления новой записи FEC | 1) Отсылаем всем соседям
метки
на все известные FEC. 2) Ожидаем метку от NH-LSR. 3) Используем полученную метку для коммутации ПримерN1 |
1)
Ждем,
пока придет метка от NH-LSR. 2) Отсылаем всем соседям метку на FEC 3) Используем полученную метку для коммутации PS. Первый отсылает метку маршрутизатор присоединенный к FEC ПримерN2 |
1)
Посылаем запрос NH-LSR о
выделении метки 2) Ждем ответа 3) Используем полученную метку для коммутации. ПримерN3 (Ordered Control) ПримерN4 (Independed Control) |
||
| смена next-hop для записи FEC | 1)
Ищем
метку в списке "отложенных". 2) Если не находится то посылаем запрос NH-LSR о выделении метки, иначе п.4. 3) ждем ответа. 4) Используем полученную метку для коммутации. |
1)
Посылаем запрос NH-LSR о
выделении метки 2) Ждем ответа 3) Используем полученную метку для коммутации |
|||
| Получение запроса на выделение
метки |
метку выделяем, не дожидаясь ответа от своего NH-LSR. | метку
выделяем только после
ответа от своего NH-LSR. |
метку выделяем, не дожидаясь ответа от своего NH-LSR. | ||
При исчезновении записи FEC из таблиц маршрутизации все LSR должны в обязательном порядке отозвать назначенные метки для коммутации FEC у своих соседей. Делается это посредством посылки сообщения Label Withdraw.
Механизм предотвращения циклов
Протокол LDP имеет в своем составе механизм предотвращения циклов.
Назначение этого механизма не допускать зацикливания запросов и
маршрутов. Данный эффект достигается включением во все сообщения Label
Mapping и Label Mapping Request информации об LSR через которые данные
запросы прошли. В случае если LSR-ы функционируют в режиме Ordered
Control данный эффект достигается легко. Если LSR-ы используют
Independed Control, то в этом случае LSR-ы должны заново отсылать
запросы и ответы на них, так как информация о LSR-ах, через которые
прошли запросы, будет обновляться.Механизм предотвращения циклов может и не использоваться, так как по идее отсутствие циклов должен гарантировать протокол IP-маршрутизации, информацию от которого использует LDP.
Зацикливания могут возникать на не продолжительный период, только в случае если протокол IP-маршрутизации медленно сходиться и LDP работает быстрее, чем протокол IP-маршрутизации.
Типы сообщений LDP
В табл. N2 приведены типы LDP сообщений:Табл. N2. Сообщения протокола LDP.
| Сообщение |
Описание |
|---|---|
| Hello |
Сообщение используется для
идентификации соседей, установления фазы N1 соседских отношений. |
| Init |
Сообщение используется для
установления соседских отношений (фаза N2), обмена и согласования
параметров LDP сессии. |
| KeepAlive |
Сообщение используется для
поддержания активного статуса LDP сессии. |
| Address Message | Сообщение используется для
оповещения соседей о появлении новых, непосредственно присоединенных к
LSR, IP сетей. |
| Address Withdraw | Сообщение используется для оповещения соседей об исчезновении, непосредственно присоединенных к LSR, IP сетей. |
| Label Mapping | Сообщение содержит описание FEC
и метку, назначенную посылающим LSR-ом. |
| Label Request | Данным сообщением LSR запрашивает у соседей метку для коммутации для конкретного FEC. Описание FEC включается в запрос. |
| Label Release | Поддтверждение получения метки в сообщении Label Mapping. Посылается в случае, если метка запрашивалась Label Request-ом. |
| Label Abort Request | Отмена запроса на выделение метки предворительно посланного в сообщении Label Request |
| Label Withdraw | Отзыв назначенной метки у
соседа. Сосед должне прекратить использовать отозванную метку для
коммутации. |
Документация
Список терминов
На данной страничке приведены русские аналоги англоязычных терминов использующихся при описании MPLS и смежных с ней технологий.Отзывы об удачности переводов, а так же свои предложения предлагается оставлять в форуме.
Страничка будет динамично изменяться.
| Английское название |
Русский аналог |
|---|---|
| Incoming Interface |
Входной интерфейс (интерфейс,
через который пакет попадает в маршрутизатор) |
| Incoming Label |
Входная метка (метка с которой
пакет попадает в маршрутизатор) |
| Incoming Packet |
Входящий в маршрутизатор пакет |
| Label Assignment | Выделение метки |
| Label Imposing | Назначение метки |
| Label Popping | Снятие метки |
| Label Stack | Стек меток |
| Label Swapping | Переназначение метки |
| Label Switching |
Коммутация по меткам |
| LSP (Label Switch Path) |
Маршрут коммутации по меткам |
| MPLS | Мултипротокольная коммутация по меткам |
| MPLS Architecure |
Архитектура MPLS |
| MPLS Domain |
MPLS-домен |
| MPLS Label | Метка MPLS |
| MPLS Shim Header | MPLS заголовок |
| Outgoing Interface |
Выходной интерфейс (интерфейс, через который пакет покидает маршрутизатор после коммутации или маршрутизации) |
| Outgoing Label |
Выходная метка (метка с которой пакет покидает маршрутизатор после коммутации) |
| Outgoing Packet |
Исходящий пакет (пакет,
покидающий маршрутизатор) |
Применение MPLS
Автор: Юшков Тарас (taras at mpls-exp.ru)
Данная статья рассматривает преимущества применения MPLS в IP сети.
- Высокоскоростная коммутация внутри MPLS домена
- Разделение функций между устройствами
- Создание базы для внедрения нового функционала на сети
- Документация
Высокоскоростная коммутация внутри MPLS домена
Рассмотрим схему сети представленную на рисунке.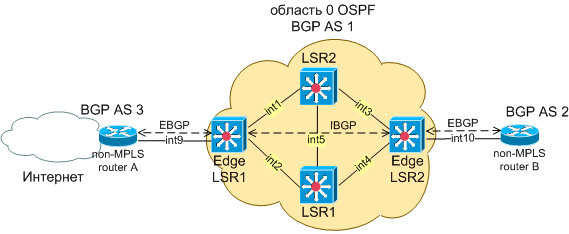
Рис. N1. Схема организации маршрутизации.
Примечание: BGP на маршрутизаторах E-LSR1 и E-LSR2 настроен таким образом, что атрибут next-hop у сетей передаваемых по IBGP устанавливается адресом передающего E-LSR-а, не внешнего соседа по EBGP (маршрутизатор А или В). Так же на маршрутизаторах E-LSR отключена синхронизация таблицы BGP и OSPF.
При такой конфигурации маршрутизатору В не будет доступна сеть Интернет, так как LSR1 и LSR2 не имеют таблицы маршрутизации Интернет и не смогут маршрутизировать пакеты предназначенные для сети Интернет. Рассмотрим таблицу маршрутизации E-LSR2 (пока без MPLS).
| N |
Протокол |
Подсеть |
Next-hop |
Выходной
интерфейс |
Комментарий |
|---|---|---|---|---|---|
| 1 |
BGP |
60.50.0.0/16 |
E-LSR1 |
нет |
Маршруты
на сети Интернет. В примере представлены две. На самом далее объем
маршрутной информации более 100 тысяч записей |
|
|
... |
... |
... |
... |
|
| 2 |
BGP |
160.40.0.0/16 | E-LSR1 |
нет |
|
| 3 |
OSPF |
E-LSR1 |
LSR2 |
int3 |
Маршрут на E-LSR1.
Предполагается, что сеть построена так, что маршрут от E-LSR2 до E-LSR1
через LSR2 более приоритетен. |
| 4 |
BGP |
192.10.10.0/24 |
routerB |
int10 |
Данный маршрут получен по EBGP
от маршрутизатора В. |
При попытке E-LSR маршрутизировать пакет пришедший от маршрутизатора В и предназначенный для сети 60.50.0.0/16 произойдёт следующее:
- В таблице маршрутизации будет найдена запись N1, которая соответствует подсети 60.50.0.0/16.
- Так как запись N1 не содержит выходящего интерфейса, но содержит адрес next-hop, то E-LSR будет искать адрес E-LSR1 в таблице маршрутизации (рекурсивный поиск).
- В результате будет найдена запись N3 и пакет будет переслан через int3 в сторону LSR2.
- Так как LSR2 не обладает маршрутной информацией о сети 60.50.0.0/16 (на LSR2 нет BGP), то данный пакет будет уничтожен.
|
N
|
Протокол
|
Подсеть |
Next-hop |
Выходной интерфейс | Выходная метка |
Комментарий |
|---|---|---|---|---|---|---|
| 1 |
BGP |
60.50.0.0/16 |
E-LSR1 |
int3 | 100 |
Маршруты
на сети Интернет. В примере представлены две. На самом деле объем
маршрутной информации более 100 тысяч записей |
|
|
|
... |
|
|
|
|
| 2 |
BGP |
160.40.0.0/16 | E-LSR1 |
int3 |
100 |
|
| 3 |
OSPF |
E-LSR1 |
LSR2 |
int3 | 100 |
Маршрут на E-LSR1.
Предполагается, что сеть построена так, что маршрут от E-LSR2 до E-LSR1
через LSR2 более приоритетен. |
| 4 |
BGP |
192.10.10.0/24 |
routerB |
int10 |
|
Данный маршрут получен по EBGP
от маршрутизатора В. |
При включении MPLS, внутри MPLS домена будет осуществляться построение LSP с использованием внутреннего протокола маршрутизации - OSPF и протокола распространения меток - LDP. Для E-LSR2 маршрутизатор E-LSR1 будет доступен через LSP начинающийся меткой 100 и интерфейсом int3 (запись N3). В записях N1 и 2 будет назначена метка 100 и выходной интерфейс int3, так как данные подсети так же доступны через E-LSR1. То есть, если пакет будет переслан от E-LSR2 с меткой 100 через интерфейс int3, то пакет будет доставлен до E-LSR1 без использования IP-маршрутизации. LSR2 будет использовать процесс и таблицу коммутации по меткам. Таким образом, LSR2 передаст пакет для сети 60.50.0.0/16, не осуществляя IP-маршрутизацию. Заметим, что все подсети Интернет, доступные через E-LSR1 будут образовывать на E-LSR2 единый FEC, так как при прохождении через MPLS домен от E-LSR2 до E-LSR1 они будут использовать один LSP.
Использование MPLS позволяет освободить LSR-ы от необходимости обладать всей маршрутной информацией. Им достаточно только владеть маршрутной информацией о сетях внутри домена, что бы обеспечить корректное построение LSP. В нашем случае объем маршрутных таблиц на E-LSR будет составлять более 100 тысяч записей, объем же таблиц MPLS-коммутации на LSR будет на несколько порядков меньше, и зависит только от количества устройств и соединений в MPLS домене.
Разделение функций между устройствами
Вернёмся к схеме, описанной в предыдущем разделе. Для устройств E-LSR, LSR можно выделить следующие основные функции:| Функция |
Устройство |
Комментарий |
|---|---|---|
| Построение LSP |
LSR/E-LSR | Устройства LSR/E-LSR должны использовать внутренний протокол маршрутизации и протокол LDP для построения LSP. |
| Обработка отказов внутри MPLS
домена |
LSR/E-LSR | При изменении внутренней
топологии сети происходит изменение LSP, таблиц внутренней
IP-маршрутизации и MPLS-коммутации. Устройства, присоединённые к MPLS
домену не "видят" изменений внутри домена, так как таблицы
маршрутизации внешних сетей не изменяются (за редким исключением) |
| Обмен маршрутной информацией c
устройствами вне MPLS домена |
E-LSR |
При изменении топологии сети за пределами MPLS домена, обновления передаются только через E-LSR-ы. Никаких изменений LSP, таблиц внутренней IP-маршрутизации и MPLS-коммутации не происходит. LSR-ы не "видят" изменений за пределами домена. |
Резюмируя информацию, представленную в таблице можно сказать следующее:
- Устройства за пределами MPLS домена не "видят" изменений внутри
домена, так как изменения внутри домена не влияют на распространение
маршрутной информации за пределы MPLS домена (за редким исключением).
- Никакие изменения в маршрутной информации за пределами MPLS домена остаются незамеченными для LSR-ов.
Создание базы для
внедрения нового функционала на сети
На базе MPLS возможна организация следующих сервисов:- MPLS/VPN - возможность создания распределённых VPN на крупных сетях без участия туннелей и шифрования;
- MPLS/TrafficEnginering - возможность гибко управлять потоками трафика внутри MPLS домена, и соответственно более полно использовать канальную инфраструктуру сети;
- AnyTransportOverMPLS - достаточно загадочный функционал, суть которого в том, что через MPLS домен становиться возможным, прозрачно передавать кадры ATM, Frame Relay, Ethernet и т.п.
Документация
Примеры функционирования протокола LDP
В статье рассмотрены несколько примеров функционирования протокола LDP в различных режимахПример N1
Данный пример описывает функционирование протокола LDP при появлении новой FEC в MPLS домене. Режим функционирования: Downstream Unsolicited, Independed Control, liberal retention.Исходные данные:
- Все LSR-ы получили по протоколу внутренней маршрутизации (например, OSPF) маршрут на FEC 10.1.1.0/24.
- Протокол маршрутизации для всех LSR для данного FEC установил
следующие NH-LSR.
| LSR |
NH-LSR |
|---|---|
| LSR1 |
LSR2 |
| LSR2 | LSR3 |
| LSR3 | LSR5 |
| LSR4 | LSR5 |
- Схема MPLS домена приведена на рисунке.
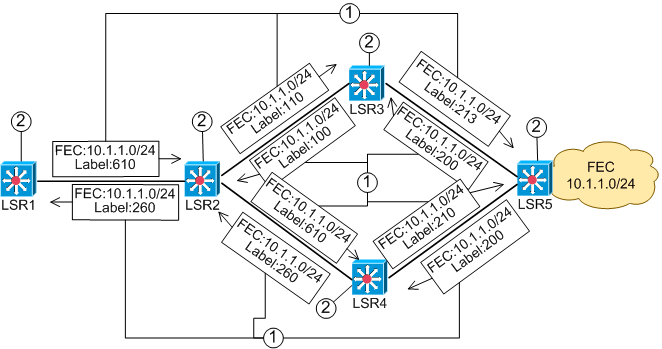
- Все LSR-ы назначают метки для нового FEC и посылают сообщение Label Mapping всем своим соседям.
- LSR- получает метки от всех соседей, запоминают их и устанавливают метку, полученную от NH-LSR для данного FEC в таблицу коммутации.
| FEC |
Входной интерфейс |
Входная метка |
Выходной интерфейс |
Выходная метка |
|---|---|---|---|---|
| 10.1.1.0/24 |
от LSR1 |
260 |
к LSR3 |
100 |
| 10.1.1.0/24 | от LSR4 |
610 |
к LSR3 | 100 |
Пример N2
Данный пример описывает функционирование протокола LDP при появлении новой FEC в MPLS домене. Режим функционирования: Downstream Unsolicited, Ordered Control, liberal/concervative retention.Исходные данные:
- Все LSR-ы получили по протоколу внутренней маршрутизации (например, OSPF) маршрут на FEC 10.1.1.0/24.
- Протокол маршрутизации для всех LSR для данного FEC установил
следующие NH-LSR.
| LSR |
NH-LSR |
|---|---|
| LSR1 |
LSR2 |
| LSR2 | LSR3 |
| LSR3 | LSR5 |
| LSR4 | LSR5 |
- Схема MPLS домена приведена на рисунке.
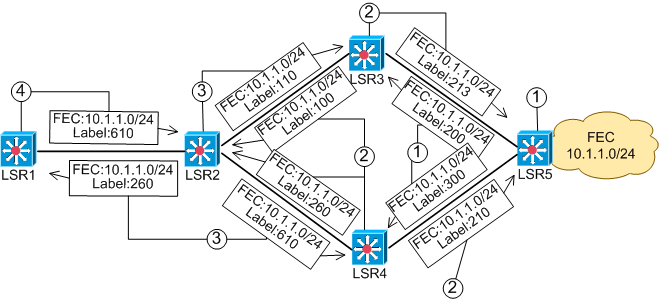
- LSR5 опознает что FEC (подсеть) 10.1.1.0/24 является присоединенной к нему. LSR5 назначает метки для коммутации для данного FEC и рассылает их своим соседям LSR3 и LSR4 (сообщение Label Mapping).
- LSR3 и LSR4 получают метки от LSR5, устанавливают метку в таблицу коммутации, так как LSR5 является NH-LSR для FEC 10.1.1.0/24. После этого LSR3 и LSR4 назначают свои метки для FEС 10.1.1.0/24 и отсылают их всем своим соседям, включая LSR5 (сообщение Label Mapping).
- LSR2 получает две метки от LSR3 и LSR4 на FEC 10.1.1.0/24. Метка полученная от LSR3, устанавливается в таблицу коммутации, так как LSR3 является NH-LSR для FEC 10.1.1.0/24. Метка полученная LSR2 от LSR4 в случае использования liberal label retention запоминается, а в случае concervative label retantion отбрасывается. LSR5 так же получает метки от LSR3 и LSR4, но так как ни LSR3, ни LSR4 не являются NH-LSR для FEC 10.1.1.0/24 (с точки зрения LSR5), то метка или запоминается (в случае liberal label retention), или отбрасывается (в случае concervative label retantion). LSR2 так же назначает метки для всех соседей, для FEC 10.1.1.0/24 и рассылает их всем своим соседям (сообщение Label Mapping).
- LSR3 и LSR4 получив метку от LSR2, поступают с ней так же как
LSR5
на шаге 3. LSR1 получив метку от LSR2, который для него является
NH-LSR, устанавливает ее в таблицу коммутации. LSR4 назначает метку для
FEC 10.1.1.0/24 и отсылает ее LSR2 (сообщение LabelMapping). LSR2
поступает с ней по уже не раз указанной схеме.
| FEC |
Входной интерфейс |
Входная метка |
Выходной интерфейс |
Выходная метка |
|---|---|---|---|---|
| 10.1.1.0/24 |
от LSR1 |
260 |
к LSR3 |
100 |
| 10.1.1.0/24 | от LSR4 |
610 |
к LSR3 | 100 |
Пример N3
Данный пример описывает функционирование протокола LDP при появлении новой FEC в MPLS домене. Режим функционирования: Downstream On Demand, Ordered Control, conservative retention.Исходные данные:
- Все LSR-ы получили по протоколу внутренней маршрутизации (например OSPF) маршрут на FEC 10.1.1.0/24.
- Протокол маршрутизации для всех LSR для данного FEC установил
следующие NH-LSR.
| LSR |
NH-LSR |
|---|---|
| LSR1 |
LSR2 |
| LSR2 | LSR3 |
| LSR3 | LSR5 |
| LSR4 | LSR5 |
- Схема MPLS домена приведена на рисунке.

- Все LSR-ы посылают своим NH-LSR-ам для нового FEC сообщение Label Mapping Reqest.
- LSR5 получает Label Mapping Reqest от своих соседей. Так как FEC непосредственно присоединен к LSR5, то LSR5 первым отвечает на Label Mapping Reqest от своих соседей. LSR5 назначает метки для FEC и рассылает их в сообщении LabelMapping.
- LSR3 и LSR4 получают назначенные метки от своего NH-LSR. Так как LSR4 не получал никаких запросов, то он просто устанавливает полученную метку в таблицу коммутации. LSR3 получал запрос от LSR2, поэтому он назначает метку для FEC и пересылает ее к LSR2 (сообщение Label Mapping).
- LSR2 получает назначенную метку от своего NH-LSR (LSR3) и устанавливает ее в таблицу коммутации. Так как LSR2 получал запрос от LSR1, то он назначает метку для FEC и пересылает ее к LSR1 (сообщение Label Mapping).
- LSR1 устанавливает полученную от LSR2 метку в таблицу коммутации.
Так как LSR1 не получал никаких запросов на выделение метки, то он
никому ничего и не пересылает.
| FEC |
Входной интерфейс |
Входная метка |
Выходной интерфейс |
Выходная метка |
| 10.1.1.0/24 |
от LSR1 |
260 |
к LSR3 |
100 |
Пример N4
Данный пример описывает функционирование протокола LDP при появлении новой FEC в MPLS домене. Режим функционирования: Downstream On Demand, Independend Control, conservative retention.Исходные данные:
- Все LSR-ы получили по протоколу внутренней маршрутизации (например OSPF) маршрут на FEC 10.1.1.0/24.
- Протокол маршрутизации для всех LSR для данного FEC установил
следующие NH-LSR.
| LSR |
NH-LSR |
|---|---|
| LSR1 |
LSR2 |
| LSR2 | LSR3 |
| LSR3 | LSR5 |
| LSR4 | LSR5 |
- Схема MPLS домена приведена на рисунке.

- Все LSR-ы посылают своим NH-LSR-ам для нового FEC сообщение Label Mapping Reqest.
- Все LSR-ы в ответ на полученные ими от соседей запросы выделяют метки для FEC и пересылают их соседям, приславшим запрос. Полученные метки устанавливаются LSR-ами в свои таблицы коммутации для данного FEC.
| FEC |
Входной интерфейс |
Входная метка |
Выходной интерфейс |
Выходная метка |
| 10.1.1.0/24 |
от LSR1 |
260 |
к LSR3 |
100 |
Документация
Архитектура MPLS
Данная статья описывает архитектуру мультипротокольной коммутации по меткам (MPLS - Multi-Protocol Label Switching). Архитектура MPLS регламентируется в документе IETF "Multiprotocol Label Switching Architecture" (RFC3031).- Основные понятия
- Процесс коммутации по меткам (label switching)
- Отличия MPLS от Frame Relay и ATM
- Документация
Основные понятия
В традиционных сетях IP, в общем случае, маршрутизация пакетов
осуществляется на основе
IP адреса назначения (destination IP address). Каждый маршрутизатор в
сети обладает информацией о том, через какой интерфейс и какому соседу
необходимо перенаправить пришедший IP-пакет.Мультипротокольная коммутация по меткам предлагает несколько другой подход. Каждому IP-пакету назначается некая метка. Маршрутизаторы принимают решение о передаче пакета следующему устройству на основании значения метки. Метка добавляется в составе MPLS заголовка, который добавляется между заголовком кадра (второй уровень OSI) и заголовком пакета (третий уровень модели OSI). Пример на рис. N1.

Рис. N1. Место MPLS заголовка в кадре.

Рис. N2. Формат MPLS-метки.
- Метка - собственно метка по которой и осуществляется коммутация;
- CoS - поле описывающее класс обслуживания пакета (аналог IP precedence);
- TTL - time-to-live - аналог IP TTL;
-
S - Одному пакету может
быть
назначено несколько меток ("стек" меток). S - поле-флаг
обозначающий то что метка последняя в "стеке".
Пример изображён на рис N3.
У последней метки в стеке значение поля "S" равно 1 (на рисунке это метка MPLS N1). У остальных меток (метка MPLS N2 и N3) значение поля "S" равно 0. Стек меток используется для реализации дополнительных возможностей сети на базе MPLS, например MPLS/VPN или MPLS/TrafficEnenirring.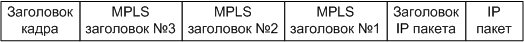
Рис N3. Пример назначения стека меток.
- LSR - Label-Switch Router - маршрутизатор, поддерживающий коммутацию по меткам и традиционную IP-маршрутизацию.
- Edge LSR - маршрутизатор, подключённый к устройствам, не осуществляющим коммутацию по меткам (устройства могут используют другую политику маршрутизации или вообще не поддерживают MPLS).
- MPLS domain - MPLS-домен - группа соединённых устройств осуществляющих коммутацию по меткам, находящихся под единым административным подчинением и функционирующих в соответствии с единой политикой маршрутизации. MPLS домен образуется LSR-ами, а на границе домена размещаются устройства E-LSR.
Процесс коммутации по
меткам (label switching)
Рассмотрим схему, приведённую на рис N4. MPLS-домен образован двумя
LSR-ами и двумя E-LSR-ами. К домену подключены два маршрутизатора
использующие традиционную IP-маршрутизацию.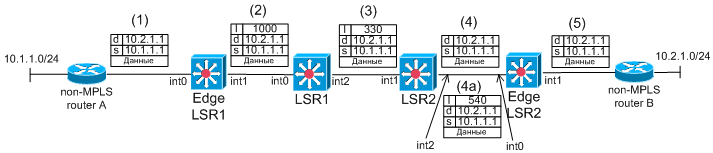
Рис. N4. Пример прохождения пакета через MPLS-домен.
| Табл. N1. Edge LSR1
(IP
маршрутизация) |
|
Табл. N2. LSR1
(коммутация по меткам) |
||||||||||||||||
|
|
|
||||||||||||||||
| Табл. N3. LSR2
(коммутация по меткам) |
|
Табл. N4. Edge LSR2 (коммутация по меткам) | ||||||||||||||||
|
|
|
||||||||||||||||
|
|
|
Табл. N5. Edge LSR2
(IP
маршрутизация) |
||||||||||||||||
|
|
|
|
||||||||||||||||
Этап N1 - маршрутизатор А пересылает обыкновенный IP-пакет в сторону E-LSR.
Этап N2 - E-LSR получает IP-пакет и на основе таблиц IP-маршрутизации (табл. N1) определяет, что данному пакету должна быть назначена метка 1000 (на рисунке обозначено "l") и пакет должен быть переслан в сторону LSR1. Данный процесс называется "назначение метки" (label imposing).
Примечание: Образование таблиц MPLS-коммутации рассмотрено далее.
Этап N3 - LSR1 получает IP-пакет с меткой 1000 и на основе таблицы MPLS-коммутации (табл. N2) определяет, что метка пакета должна быть сменена на 330 и пакет должен быть переслан в сторону LSR2. Данный процесс называется переписывание метки (label swapping).
Этап N4 - LSR2 получает IP-пакет с меткой 330 и на основе таблицы MPLS-коммутации (табл. N3) определяет, что пакет должен быть переслан в сторону LSR2 без меток (значение pop). Возможен так же вариант, когда LSR2 пересылает пакет в сторону E-LSR с меткой (в нашем случае 540). Если пакет следует по этапу N4 то такое поведение называется Penultimate Hop Popping. Поведение LSR в соответствии с этапом N4а является классическим для MPLS.
Этап N5 - E-LSR получает IP-пакте (как с меткой, так и без) и на основании таблиц IP-маршрутизации (табл. N5) или MPLS-коммутации (табл. N6) определяет, что данный пакет должен быть переслан, как обыкновенный IP-пакет (без метки) в сторону маршрутизатора В. Если пакет был получен без метки (Penultimate Hop Popping), то E-LSR должен выполнять только анализ таблицы IP-маршрутизации. Если пакет получен с меткой, то маршрутизатор должен сначала проанализировать таблицу MPLS-коммутации, на основании её определить, что для данного пакета необходимо выполнить анализ таблицы IP-маршрутизации. И только после анализа таблицы IP-маршрутизации определяется тот сосед, которому должен быть переслан пакет. Именно для исключения промежуточного анализа таблицы MPLS-коммутации на E-LSR-е применяется Penultimate Hop Popping.
Label Switch Path
В примере, приведённом выше, IP-пакет проследовал через "маршрут коммутации по меткам" - Label Switch Path (LSP). LSP - это последовательность устройств в MPLS домене, через которые проследовал пакет с меткой при фиксированном размере стека меток. Принципиально важно в определении LSP, то что, на всем пути размер стека не меняется. То есть, если где-то на пути следования пакета к одной метке добавляется другая (в стеке получается две метки), то LSR-ы коммутирующие по второй (внешней метке) из LSP исключаются. Подробно такие случаи будут рассмотрены далее. Для нашего примера LSP это последовательность: E-LSR, LSR1, LSR2, E-LSR. При использовании PHP, строго говоря, второй E-LSR не должен быть включён в LSP, так как при пересылке ему стек меток был пуст. Но для PHP допускается исключение.Примечание: Иногда LSP описывают последовательностью меток и выходных интерфейсов, в этом случае LSP из примера: 1000(int1), 330(int2), 540(int2) или LSP: 1000(int1), 330(int2), null(int2) - в случае использования PHP.
На LSR для каждой "входящей" метки на основе таблицы MPLS-коммутации однозначно определяется "выходящая" метка и интерфейс, через который пакет должен быть переслан. Поэтому, первая метка, устанавливаемая E-LSR-ом, однозначно определяет весь маршрут следования пакета через MPLS домен. Этот маршрут и называется LSP.
Forwarding Equivalence Classes
E-LSR каждому LSP в соответствие устанавливает некоторое множество подсетей. Пакеты, предназначенные этим подсетям, передаются E-LSR-ом по одному LSP. В примере, описанном выше, подсети 10.2.1.0/24 соответствует LSP: E-LSR, LSR1, LSR2, E-LSR. Таким образом, уже на E-LSR становиться однозначно понятно по какому маршруту будет коммутироваться пакет. Множество подсетей, поставленное в соответствии конкретному LSP, называется Forwarding Equivalence Classes (FEC).Архитектура E-LSR/LSR
LSR выполняет два процесса: маршрутизации и коммутации по меткам. Процесс маршрутизации функционирует на базе внутреннего протокола маршрутизации (например, OSPF). Процесс маршрутизации получает маршрутную информацию от соседей и формирует таблицу маршрутизации. Таблица маршрутизации используется для маршрутизации обыкновенных IP-пакетов.Процесс коммутации функционирует на базе протокола обмена метками между соседями (Label Distribution Protocol). Протокол обмена метками согласует конкретные значения меток для создания целостных маршрутов коммутации по меткам (LSP). Подробно функционирование данного протокола рассмотрено в отдельной статье. Процесс коммутации по меткам при составлении таблиц коммутации использует так же таблицу IP-маршрутизации. Взаимосвязь процессов коммутации по меткам и IP-маршрутизации приведена на рис. N5. Описание основных функций выполняемых E-LSR/LSR-ами приведено в табл. N5.
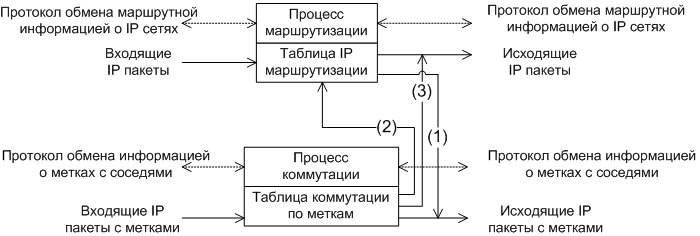
Рис. 5. Взаимосвязь процессов MPLS-коммутации и IP-маршрутизации на LSR/E-LSR.
| Функция |
Англоязычное название |
Описание |
|---|---|---|
| Традиционная маршрутизация IP-пакетов | IP routing |
Входящие IP-пакеты маршрутизируются на основе таблицы маршрутизации. |
| Назначение метки | label imposing | Если устройство функционирует в
качестве E-LSR, то для входящего IP-пакета на
базе таблицы IP-маршрутизации определяется метка, которая должна быть
назначена, и выходной интерфейс, через который должен быть
переслан пакет (1) |
| Коммутация по метке | label swapping | Входящие
IP-пакеты с метками
обрабатываются процессом коммутации по меткам, который на основании
таблицы коммутации по меткам определяет, какое из следующих действий
будет выполнено:
Примечание: выходной интерфейс определяется на основе таблицы коммутации по меткам. |
| Снятие метки | label poping | |
| Снятие метки (PHP) |
label poping with PHP |
Примеры таблиц маршрутизации и коммутации.
Примеры таблиц IP-маршрутизации и MPLS-коммутации приведены в табл. N6-7.Табл. N6. Пример таблицы IP-маршрутизации на E-LSR.
| Адрес подсети |
Адрес next-hop |
Исходящий
интерфейс |
Метка |
Комментарий |
|---|---|---|---|---|
| 10.1.2.0/24 |
10.1.3.1 |
Serial1 |
нет |
Запись для традиционной
IP-маршрутизации |
| 10.1.4.0/24 | 10.1.5.1 | Serial2 |
100 |
Записи, в соответствии с которыми, пакету предназначенному для сети 10.1.4.0/24 или 10.3.0.0/16 будет назначена метка 100. Пакет с меткой будет переслан через интерфейс Serial1 (label imposing). Заметим, что подсети 10.1.4.0/24 и 10.3.0.0/16 образуют единый FEC. |
| 10.3.0.0/16 | 10.1.5.1 | Serial2 | 100 | |
| 10.1.6.0/24 | 10.1.7.1 | Serial3 |
300/200 |
Запись, в соответствии с которой, пакету предназначенному для сети 10.1.6.0/24 будут назначены две метки 300, 200 в стеке, и пакет с метками будет переслан через интерфейс Serial1 (label imposing) |
Табл. N7. Пример таблицы MPLS-коммутации на E-LSR/LSR.
| Входящий
интерфейс |
Входящая метка |
Исходящий
интерфейс |
Исходящая
метка |
Комментарий |
|---|---|---|---|---|
| Serial1 |
100 |
Serial3 |
200 |
Обыкновенная коммутация (label
swapping) |
| Ethernet2 |
100 |
Serial2 |
305/200 |
Коммутация с добавлением меток в
стек (label swapping) |
| Serial2 |
300 |
Serial3 |
pop |
Снятие метки и пересылка пакета
через интерфейс Serial3. Данный вариант возможен в двух случаях:
|
| Serial3 |
245 |
|
pop |
Снятие метки и передача IP-пакета процессу маршрутизации |
Необходимо отметить, что уникальность меток обеспечиваться только на уровне интерфейса. То есть для двух разных входных интерфейсов могут встречаться одинаковые значения меток (в таблице коммутации первая и вторая запись). Таким образом, пакет, пришедший с меткой 100 с интерфейса Serial1 и пакет, пришедший с меткой 100 с интерфейса Ethernet2, проследуют по разным LSP. Уникальной комбинацией является входящий интерфейс и метка. И для этой уникальной комбинации однозначно определяется выходной интерфейс и операция, которая должна быть произведена над меткой. Такой подход позволяет образовывать целостные LSP между E-LSR-ам.
Примечание: различные производители могут по-разному реализовывать архитектуру LSR/E-LSR. Например, возможно использовать объединённую таблицу IP-маршрутизации и MPLS-коммутации. Или использовать три таблицы: одна только для традиционной IP-маршрутизации, другая для назначения меток, третья для MPLS-коммутации. Приведённая в данном документе архитектура LSR/E-LSR лишь абстрактная модель.
Отличия MPLS от Frame Relay и ATM
Как можно понять из описания архитектуры MPLS, все это отдаленно напоминает Frame Relay или ATM. Действительно, MPLS в некотором смысле, базируется на этих идеях. Архитектура MPLS допускает использование в качестве LSR коммутаторов Frame Relay или ATM, при условии поддержки последними протокола назначения меток (LDP). Но коммутаторы ATM и Frame Relay имеют ключевое отличие от классических LSR. Суть его в следующем. LSR-ы могут две разные входные метки отображать в одну выходную при процедуре замены метки (label swapping). Даллее приведены примеры таблицы коммутации классического LSR (табл. N8) и Frame Relay коммутатора (табл. N9).Табл. N8. Таблица MPLS-коммутации классического LSR
| Входной
интерфейс |
Входящая метка |
Выходной интерфейс |
Выходная метка |
|---|---|---|---|
| Serial1 |
1000 |
Serial3 |
4000 |
| Serial2 |
2000 |
Serial3 |
4000 |
Табл. N9. Таблица MPLS-коммутации для Frame Ralay коммутатора
| Входной
интерфейс |
Входная метка (DLCI) |
Выходной интерфейс |
Выходная метка (DLCI) |
|---|---|---|---|
| Serial1 |
1000 |
Serial3 |
3000 |
| Serial2 |
2000 |
Serial3 |
4000 |
Как видно из примера классический LSR объединяет два LSP в один, а Frame Relay коммутатор оставляет оба LSP следовать параллельно. Данный подход Frame Relay/ATM коммутаторов несколько сужает возможность их применения врамках архитектуры MPLS, хотя и не запрещает это делать. Классические LSR (производящие коммутацию по меткам) называют merge capatible LSR, а LSR на базе Frame Relay или ATM коммутации называют non-merge capatible LSR.
Еще в литературе встречаются понятия: frame-based LSR - это про обыкновенные LSR и cell-based LSR - это про non-merge capatible LSR (то есть ATM/FrameRelay).
Дальнейшее изложение будет сфокусировано на merge capatible LSR, так как всяко за ними будущее. Все реверансы в сторону non-merge capatible LSR, на мой взгляд, делаются для достижения совместимости с существующими сетями ATM и Frame Relay.
Документация
(taras at mpls-exp.ru)
Организация VPN на базе MPLS
Данная статья описывает принципы организации и функционирования VPN на базе MPLS- Общие понятия
- Функционирование PE
- Механизм коммутации пакетов
- Обмен маршрутной информацией между PE
- Организация VPN
- Преимущества организации VPN на базе MPLS
- Сравнение механизмов организации VPN на базе MPLS и туннелей (IPSec и GRE)
- Документация
Общие понятия
VPN - это принцип объединения узлов клиента, находящихся под единым административным подчинением, через публичную сеть оператора(ов).Определим следующие понятия:
- CE - маршрутизатор со стороны узла клиента, который
непосредственно подключается к маршрутизатору оператора.
- PE - граничный маршрутизатор со стороны оператора (MPLS домена),
к которому подключаются устройства CE.
PE устройства выполняют функции E-LSR-ов.
- P - маршрутизатор внутри сети Оператора (MPLS домена). P
устройства выполняют функции LSR.
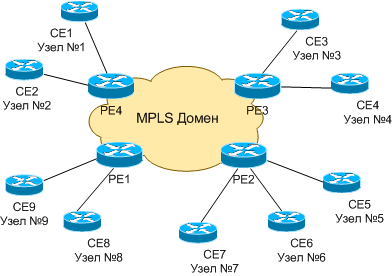
Рис. N1. Схема MPLS домена и подключенных узлов клиентов
Табл. N1. Пример схемы
объединения
узлов в VPN
| Клиент |
VPNs |
Узлы |
|---|---|---|
| КлиентN1 |
A |
1, 6 |
| КлиентN2 |
B |
3, 4, 5 |
| КлиентN3 |
C |
2, 8 |
| КлиентN4 |
D |
7, 9 |
В рамках MPLS/VPN допускается организация взаимодействия нескольких разных узлов в соответствии со следующими схемами:
- закрытая абонентская группа (Closed User Group - CUG). данная схема предусматривает взаимодействия узлов только друг с другом. Например, в CUG может входить узлы 1, 3, 4, 5, 6. Это означает, что данные узлы будут свободно обмениваться IP трафиком. В рамках CUG не допускается пересечения адресного пространства узлов.
-
центр-периферия (hub-and-spoke).
Схема подразумевает объединение нескольких узлов, один или несколько из
которых объявляется центральным, а остальные периферийными. Центральные
узлы могут обмениваться IP трафиком друг с другом. Периферийные узлы
могут обмениваться трафиком с центральными. Но периферийные узлы не
могут
обмениваться трафиком друг с другом.
Примечание: Узел может быть как членом закрытой абонентской группы, так и членом группы центр-периферия (как в качестве центрального узла, так и в качестве периферийного).
В примере, приведенном на рисунке, VPN могут объединяться в группы так:
- Узлы 3, 4, 5, 7, 9 - образуют закрытую абонентскую группу (Closed User Group - CUG).
- VPN 1, 2, 6, 7, 8, 9 - hub-and-spoke, где узлы 1 и 6 - центральные, 2, 7, 8 и 9 - периферийные VPN (spokes).
Функционирование PE
Для обслуживания клиентов разных VPN на устройстве PE (к которому эти клиенты присоединены) создается несколько виртуальных объектов (по одной на каждый VPN). Называются такие объекты - VPN Routing and Forwarding (VRF). VRF образовываются:- отдельной таблицей IP-маршрутизации, использующейся для
маршрутизации пакетов VPN (далее VRF-таблица);
- множеством интерфейсов устройства PE, по которым подключены
устройства CE, принадлежащие одной VPN. То есть, интерфейс на
устройстве PE, к которому
подключен узел, входящий в VPN Х, принадлежит VRF Х.

Рис. N2. Пример подключения узлов маршрутизаторов CE к PE.
Табл. N2. Разбиение интерфейсов
по VRF.
| Интерфейс |
Сосед |
VPN |
VRF |
|---|---|---|---|
| int0 |
CE3 |
B |
B |
| int1 |
CE2 |
A |
A |
| int2 |
CE1 |
A |
A |
Таблица маршрутизации на устройстве PE1 представлена в табл N3.
Табл. N4. Таблица маршрутизации
на устройстве PE1
| N |
Протокол |
VRF |
Подсеть |
Next-Hop |
|---|---|---|---|---|
| 1 |
OSPF |
A |
10.1.1.0/24 |
CE1 |
| 2 |
OSPF |
А |
10.3.1.0/24 |
CE2 |
| 3 |
RIP |
B |
10.1.1.0/24 | CE3 |
Примечание: Для удобства я объединил все таблицы маршрутизации в одну. Принадлежность маршрута той или иной VRF таблице определяется значением в колонке "VRF".
Описание полей таблицы:
Протокол - название протокола маршрутизации, по которому была получена маршрутная информация о префиксе.
VRF - название VRF-таблицы, которой принадлежит префикс.
Подсеть, Next-hop - уже знакомые нам поля.
Запись N1 и N2 в таблице маршрутизации PE1 были созданы на основании маршрутной информации полученной от CE1 и CE2 по протоколу OSPF. Так как данные маршруты были получены от устройств CE1 и CE2, принадлежащих VPN A, то записи принадлежат VRF-таблице A (колонка VRF).
Запись N3 была создана на основании маршрутной информации полученной от устройства CE3 по протоколу RIP. Так как данный маршрут был получен от устройства CE3, принадлежащего VPN B, то запись принадлежит VRF-таблице B.
Заметим, что устройства CE1 и CE2 могут обмениваться трафиком друг с другом через PE1. Для маршрутизации пакетов между устройствами CE1 и CE2 на PE1 используется VRF-таблица А (записи N1 и N2). Устройство CE3 не может обмениваться трафиком ни c CE1, ни с CE2, так как для маршрутизации пакетов пришедших от CE3 используется VRF-таблица B. В этой таблице нет маршрутной информации от CE1 и CE2.
Таким образом, PE1 может осуществлять маршрутизацию трафика для разных VPN на основании разных таблиц маршрутизации. Для того, что бы различные CE, принадлежащие одной VPN и подключенные к разным PE могли обмениваться трафиком необходимо наличие механизмов:
- коммутации пакетов разных VPN внутри MPLS домена (устройствами LSR);
- обмена маршрутной информацией между устройствами PE, включая информацию о VPN.
Отличие понятий VPN и VRF
VPN - это принцип объединения узлов клиента, находящихся под единым административным подчинением, через публичную сеть оператора(ов). Описывается VPN множеством узлов, которые он объединяет и технологией использующейся для организации VPN. Например: MPLS/VPN, IPSec/VPN и т.д.VRF - это объект в состав которого входят:
- множество интерфейсов PE, к которым подключаются CE из одного VPN;
- VRF-таблица;
- атрибуты и правила распространения маршрутной информации (об этом будет рассказано далее).
Механизм коммутации пакетов
Определим следующие понятия:- входной PE - первое устройство PE на пути следования IP пакета от одного устройства CE до другого через MPLS домен;
- выходной PE - последнее устройство PE на пути следования IP пакета от одного устройства CE до другого через MPLS домен.
Для коммутации пакетов VPN между устройствами PE используется две метки, образующие стек. Это означает, что IP пакету, полученному от CE, входной PE назначает стек из двух меток. Одна ("внешняя") используется непосредственно для коммутации пакета устройствами LSR (или P). "Внешняя" метка определяет LSP от одного PE до другого. Вторая метка - "внутренняя" идентифицирует VRF на выходном PE, которому принадлежит пакет.
Примечание: "Внутренняя" метка может идентифицировать даже не VRF на выходном PE, а конкретный интерфейс на устройстве выходном PE, через который должен быть переслан пакет. Подробнее об этом случае будет сказано далее.
Рассмотрим MPLS домен, к которому подключены два VPN A и B (рис. N3). VPN A образован узлами CE1 и CE2, VPN B - узлами CE3 и CE4. Как видно из рисунка IP адресация внутри VPN A и B пересекается. Таблица маршрутизации (включая VRF-таблицы) представлена в табл. N4.
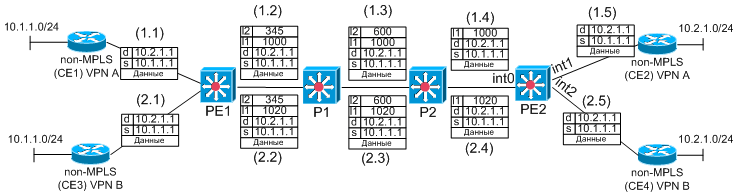
Рис N3. Схема прохождения
пакета VPN через MPLS домен.
Табл. N4. Таблица маршрутизации
на PE1.
| N |
Протокол |
VRF |
Подсеть |
Next-Hop |
Метка |
Комментарий |
|---|---|---|---|---|---|---|
| 1 |
OSPF |
A |
10.1.1.0/24 |
CE1 |
--- |
|
| 2 |
iBGP | A |
10.2.1.0/24 | PE2 |
1000/345 | О назначении меток будет сказано
далее |
| 3 |
RIP |
B |
10.1.1.0/24 | CE3 |
--- |
|
| 4 |
iBGP | B |
10.2.1.0/24 | PE2 |
1020/345 | О назначении меток будет сказано далее |
| 5 |
OSPF/LDP |
--- |
PE2 |
P1 |
345 |
О назначении меток будет сказано далее |
Запись N1 была создана на основании маршрутной информации полученной от CE1 по протоколу OSPF. Так как данный маршрут был получен от устройства CE1, принадлежащего VPN A, то запись отнесена в VRF-таблицу A (колонка VRF).
Запись N3 была создана на основании маршрутной информации полученной от CE3 по протоколу RIP. Так как данный маршрут был получен от устройства CE3, принадлежащего VPN B, то запись отнесена в VRF-таблицу B.
Запись N5 была создана на основании протокола маршрутизации, функционирующего внутри MPLS домена, и протокола LDP. Метка 345 будет назначаться пакетам, предназначенным для PE2. То есть данная метка определяет LSP от PE1 до PE2.
Записи N2 и N4 были созданы на основании маршрутной информации полученной от PE2 (выходного PE) по протоколу iBGP. Данная информация содержала префиксы подсетей с указанием "внутренней" метки, которая для выходного PE определяет VRF-таблицу, к которой данные префиксы относятся. То есть, для каждого VPN маршрута (префикса) PE2 назначил метку, определяющую его локальный VRF к которому данный префикс относиться. Для VPN A это метка 1000, для В это 1020. Метки 1000 и 1020 - "внутренние" метки.
Так как next-hop-ом для маршрутов VRF является устройство не присоединенное к PE1 непосредственно, то для обеспечения коммутации сквозь MPLS домен назначается дополнительная "внешняя" метка 345, определяющая LSP до PE2. Таким образом, пакетам VPN назначается две метки. Рассмотрим таблицу коммутации на выходном PE (PE2).
Табл N5. Таблица коммутации на
PE2.
| Входной интерфейс |
Входная метка |
Выходной интерфейс |
Выходная метка |
| int0 |
1000 |
int1/VRF A |
нет |
| int0 |
1020 |
int2/VRF B |
нет |
Возможно два режима назначения "внутренней" метки устройством PE:
- "внутренняя" метка определяет выходной интерфейс на выходном PE. В этом случае выходной интерфейс (и соответственно CE которому предназначен пакет) определяется значением этой метки;
- "внутренняя" метка определяет VRF на выходном PE. В этом случае
выходной
интерфейс (и соответственно CE которому предназначен пакет)
определяется после анализа соответствующей VRF-таблицы.
Примечание: В примере таблицы коммутации PE2 в колонке "Выходной интерфейс" указано два значения через "/". Первое для режима "внутренняя метка определяет интерфейс", второе для режима "внутренняя метка определяет VRF".
Рис N3. Схема прохождения пакета VPN через MPLS домен (повторение).
Рассмотрим прохождения пакета из VPN A от CE1 до CE2 через MPLS-домен.
1.1 PE1 получает пакет от CE1. По интерфейсу от которого пришел пакет PE1 определяет, что пришедший пакет принадлежит VRF А.
1.2 По VRF-таблице PE1 определяет, что подсеть 10.2.1.0/24 (которой предназначен пакет) доступна через MPLS-домен и пакету необходимо назначить две метки 1000/345. Метки назначаются, и пакет пересылается устройству P1
1.3, 1.4 Устройства P1 и P2 на основании своих таблиц коммутации переправляют пакет устройству PE2. Отметим то, что "внешняя" метка 345 назначенная пакету устройством PE1 определяет LSP от PE1 до PE2.
1.5 PE2 получает пакет только со "внутренней" меткой 1000 и на основании таблицы коммутации определяет выходной интерфейс, через который должен быть переслан пакет (уже без метки).
Примечание: Прохождения пакета из VPN B от CE3 до CE4 через MPLS-домен происходит аналогично предыдущему примеру. Отличие, лишь, в значении "внутренней" метки, которая определяет, или другой исходящий интерфейс на PE2, или другой VRF.
Примечание: Прохождение пакета в обратную сторону, например от CE2 до CE1 происходит, так же аналогично приведенному примеру, за исключением значений меток. "внешняя" метка в этом случае будет определять LSP от PE2 до PE1, а "внутренняя" метка будет назначаться устройством PE1 и обозначать VRF или интерфейсы на устройства PE1.
Обмен маршрутной информацией между PE
В данном разделе рассмотрим механизм распространения маршрутной информации о сетях VPN и "внутренних" метках. Для распространения данной информации используется протокол BGP.Традиционно маршрутная информация передаваемая по BGPv4 состояла из двух компонент:
- NLRI - Network Layer Reachability Information - данная компонента описывала только префикс маршрута (например: 10.1.1.0/24).
- Path attributes - атрибуты маршрута, включая адрес next-hop.
Компонента NLRI была переведена в класс атрибутов маршрута, поменяла свою структуру и стала называться MP_REACH_NLRI (attribute type code = 14). Состав атрибута:
- Address Family Identifier (AFI) (2 байта) = 1 (маршрут класса
IPv4);
- Subsequent Address Family Identifier (AFI) (1 байт) = 4 (описание маршрута включает "внутренние" метки VPN);
- Next-hop;
- SNPA - Subnetwork Points of Attachment - параметр мутный, для MPLS/VPN не используется;
- Структура MP_NLRI - Multi Protocol Network Layer Reachability
Information (определена в RFC
3107 "Carrying Label Information in
BGP-4"):
- метка;
- префикс подсети VPN маршрута.
Примечание: Некоторые реализации MPLS/VPN используют значение SAFI=128, это устаревший подход. В соответствии с RFC3107 и распределением IANA значение SAFI должно равняться 4.
Заметим, что информация о next-hop и NLRI (описание подсети) мигрировала из отдельных атрибутов в состав структуры MP_REACH_NLRI. Изменения так же коснулись и структуры представления next-hop и адреса подсети.
Так как подсети различных VPN могут пересекаться, то для обеспечения их уникальности префиксы подсетей VPN состоят из двух частей:
- Route Distinguisher (RD) - дискриминатор маршрутной информации. RD обеспечивает уникальность префикса VPN (8 байт);
- IPv4 network address - традиционный префикс IPv4 (4 байта).
RD состоит из трех полей:
- тип (2 байта) - данное поле определяет структуру и размер следующих полей;
- глобальная (административная) компонента;
- локальная компонента (индекс).
Табл. N6. Форма представления
поля RD.
| Значение поля "тип" |
Размер глобальной
компоненты (байт) |
Значение глобальной
компоненты |
Размер локальной компоненты
(байт) |
Значение локальной компоненты |
| 0 |
2 |
Номер автономной системы в
соответствии с RFC1930
|
4 |
Номер
уникально идентифицирующий RD. |
| 1 |
4 |
IPv4 адрес |
2 |
|
| 2 |
4 |
Номер автономной системы в соответствии с (draft-ietf-idr-as4bytes) | 2 |
Особого смысла значение административной компоненты и "номера" не имеют. Основная их цель формировать RD по правилам, обеспечивающим глобальную уникальность префиксов VPN. Именно поэтому, RD должен образовываться или IP адресом или номером Автономной системы. Данные номера (адреса) распределяются централизовано (например: RIPE NNC), тем самым обеспечена их глобальная уникальность в рамках всех сетей.
Так же "BGP Extended Communities Attribute" (draft-ietf-idr-bgp-ext-communities) вводит понятие расширенные атрибуты маршрута включающее в себя следующие атрибуты:
- Site of Origin - атрибут, идентифицирующий точку подключения клиента (site).
- Route Target - набор идентификаторов, описывающих правила импорта/экспорта.
Форма представления расширенных атрибутов следующая:
- тип атрибута атрибута (1 байт);
- идентификатор атрибута (1 байт) Site of Origin = 3, Route Target
= 2;
- глобальная компонента (длинна перемена);
- локальная компонента (длинна перемена);
Route Target является обязательным атрибутом, в то время как Site of Origin нет.
Оба атрибута являются транзитивными, то есть сохраняются при передаче маршрутов по EBGP сессиям между разными Автономными системами.
В состав атрибутов одного VPN маршрута может входит несколько атрибутов RT. Далее мы будем говорить о множестве атрибутов RT, ассоциированных с данным VPN маршрутом.
Организация VPN
К каждому объекту VRF на каждом PE привязывается два множества атрибутов RT:- import;
- export.
- Все маршруты, полученные от CE, принадлежащие VRF X, передаются другим PE с добавлением множества атрибутов RT "export" VRF-а X.
- Маршрут, полученный от другого PE, будет установлен в VRF-таблицу Y, только если множество атрибутов RT полученное с маршрутом и множество "import" VRF-а Y имеют хотя бы один общий атрибут.
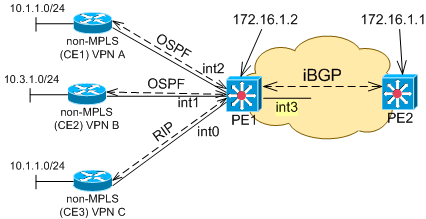
Рис. N4. Схема подключения
маршрутизаторов CE к PE
Табл. N7. Конфигурация VRF на
PE1
| VRF |
import |
export |
значение RD |
| A |
1:1, 2:1 | 2:1 |
6:1 |
| B |
1:1, 3:2 |
3:2 |
7:2 |
| C |
2:2, 3:1, 4:5 |
6:2, 6:4 |
7:1 |
Маршрутизатор PE1 получает по iBGP от
маршрутизатора PE2 информацию о маршрутах VPN. Содержание информации
представлено в табл. N8.
Табл. N8. Маршрутная информация, получаемая по BGP устройством
PE1 от
PE2.
| Префикс |
Атрибуты RT |
Next-hop |
VPN-label |
| 8:1:10.2.1.0/24 |
4:2, 2:1 |
172.16.1.1 |
100 |
| 8:2:10.2.1.0/24 | 3:1 |
172.16.1.1 |
200 |
| 8:3:172.16.1.0/24 | 1:1, 7:1 |
172.16.1.1 |
300 |
В соответствии с правилами использования атрибутов RT префиксы распределяются по таблицам маршрутизации следующим образом:
-
8:1:10.2.1.0/24
устанавливается в таблицу VRF A, так как атрибут RT 2:1 входит только
во множество import VRF-а A. Атрибут 4:2 не входит ни в какое множество
import ни какого VRF в рамках данного PE;
- 8:2:10.2.1.0/24 устанавливается в таблицу VRF C, так как атрибут RT 3:1 входит только во множество import VRF-а C;
- 8:3:172.16.1.0/24 устанавливается в таблицы VRF A и B, так как атрибут RT 1:1 входит во множество import VRF-ов A и B. Атрибут 7:1 не входит ни в какое множество import ни какого VRF в рамках данного PE.
Табл. N10. Таблицы
маршрутизации VRF на PE1.
| VRF-таблица |
Протокол |
Префикс |
Выходной интерфейс |
Next-hop |
Метки для коммутации |
| A |
iBGP | 10.2.1.0/24 |
int3 |
172.16.1.1 |
100/1001 |
| A |
iBGP |
172.16.1.0/24 |
int3 | 172.16.1.1 | 300/1001 |
| A |
OSPF |
10.1.1.0/24 |
int2 | CE1 |
нет |
| B |
iBGP |
172.16.1.0/24 |
int3 |
172.16.1.1 | 300/1001 |
| B |
OSPF |
10.3.1.0/24 |
int1 |
CE2 |
нет |
| C |
iBGP |
10.2.1.0/24 | int3 |
172.16.1.1 | 200/1001 |
| C |
RIP |
10.1.1.0/24 |
int0 |
CE3 |
нет |
- "внешняя" - определяет LSP от одного PE до другого (в нашем случае 1001);
- "внутренняя" - определяет VRF или интерфейс на PE, к которому присоединен абонент (данная метка распространяется по BGP, значения для нашего случая представлены в табл. N8, колонка "VPN-label").
Отметим, что префиксам 10.2.1.0/24 в разных VRF-таблицах (A и C) устанавливается разная "внутренняя" метка. Это означает, что IP пакет, предназначенный для подсети 10.2.1.0/24 и пришедший от CE1 будет переправлен с "внутренней" меткой 100, а пришедший от CE3 с "внутренней" меткой 200. Таким образом, эти пакеты попадут в разные VRF на PE2 и соответственно, будут перенаправлены разным CE. Таким образом, MPLS/VPN позволяет объединять узлы с пересекающимися адресными пространствами в различные VPN.
Рассмотрим пример маршрутной информации передаваемой от PE1 до PE2 по протоколу BGP. PE1 получает, от подключенных к нему CE, три префикса. Каждый префикс принадлежит определенному VRF (см табл N10). В соответствии с настройками VRF-ов (см. табл. N7), каждому префиксу назначается RD и множество атрибутов RT. Например, префикс 10.1.1.0/24, полученный от CE1 принадлежит к VRF А, так как CE1 принадлежит к VPN A. В соответствии с конфигурацией VRF A данному префиксу назначается RD 6:1 и множество RT, которое полностью копируется из множества "export" VRF-а A. Так же PE1 назначает "внутреннюю" метку для префикса 6:1:10.1.1.0/24. Метка назначается автоматически в зависимости от режима назначения меток: или VRF-а, или интерфейса, через которые получен маршрут. Так как, VPN маршруты образовываются на PE1, то значение атрибута next-hop устанавливается равным 172.16.1.2 - виртуальный интерфейс, от которого PE1 устанавливает iBGP сессию.
Табл. N10. Маршрутная
информация,
отправляемая по BGP устройством PE1 устройству PE2.
| Источник маршрута |
VRF |
Префикс |
Префикс+RD |
Назначенный RT |
назначенная VPN метка |
Next-Hop |
| CE1 |
A |
10.1.1.0/24 |
6:1:10.1.1.0/24 | 2:1 | 200 |
172.16.1.2 |
| CE2 |
B |
10.3.1.0/24 | 7:2:10.3.1.0/24 | 3:2 | 400 |
172.16.1.2 |
| CE3 |
C |
10.1.1.0/24 | 7:1:10.1.1.0/24 | 6:2, 6:4 | 100 |
172.16.1.2 |
Примечание: Непосредственно по iBGP передаются только поля: префикс+RD, RT, VPN метка и next-hop.
Примечание: Назначение "внутренних" меток личное дело каждого PE, то есть одинаковая метка от разных PE вовсе не означает один и тот же VPN.
Отметим, что PE1 получает маршрут 10.1.1.0/24 от двух разных CE (CE1 и CE3), но так как эти CE принадлежат разным VRF, то этим префиксам назначаются разные RD, множество RT и VPN метка.
Итак, подводя итоги долгому и нудному повествованию:
- VPN пакеты передаются через MPLS домен с двумя метками ("внешней" и "внутренней").
- "Внешняя" метка определяет LSP от одного PE до другого.
- "Внутренняя" метка определяет или VRF или выходной интерфейс на
устройстве PE.
- Правила импорта маршрутной информации задаются значением множеств VRF import и export (подробно о том как использовать эти возможности будет сказано в отдельной статье).
Преимущества организации VPN на базе MPLS
Основными преимуществами организации VPN на базе MPLS можно назвать:- масштабируемость;
- возможность пересечения адресных пространств, узлов подключенных в различные VPN;
- изолирование трафика VPN друг от друга на втором уровне модели OSI.
В различных VPN адресные пространства могут пересекаться, что может быть чрезвычайно полезным, в случае если оператору необходимо предоставить VPN нескольким клиентам, использующим одинаковое приватное адресное пространство, например адреса 10.0.0.0/8.
Устройства P (LSR) при коммутации анализируют только внешнюю метку, определяющую LSP между PE, и не анализируют заголовок IP пакета, то справедливо говорить о том, что P устройства выполняют функции коммутации на втором уровне модели OSI. Устройства PE так же разделяют маршрутную информацию, таблицы маршрутизации, интерфейсы, направленные в сторону устройств CE, между VRF. Тем самым процессы маршрутизации разных VPN полностью разделяются, и обеспечивается разделение трафика от разных VPN на втором уровне модели OSI. На этот предмет компания Miercom провела исследование, и показала, что технология MPLS/VPN в реализации компании Cisco Systems обеспечивает такой же уровень безопасности как сети Frame Relay и ATM. С отчетом можно ознакомиться здесь или скачать его с сайта компании.
Сравнение механизмов
организации VPN на базе MPLS и туннелей (IPSec и GRE)
Сравнение основных технологий по организации VPN приведено в табл. N 11.
Табл. N 11. Сравнение основных
технологий по организации VPN.
| Критерии |
MPLS/VPN |
ATM/Frame Relay |
IPSec |
GRE |
|---|---|---|---|---|
| Масштабируемость |
высокая |
низкая |
низкая |
низкая |
| Требования к оператору |
поддержка технологии MPLS/VPN |
поддержка ATM/Frame Relay |
нет |
нет |
| Требования к клиенту |
нет |
поддержка ATM/Frame Relay | наличие средств шифрования |
поддержка туннелирования трафика |
| Обеспечение целостности и
конфиденциальности |
нет |
нет |
да |
нет |
| Пересечение адресных пространств
узлов подключенных в разные VPN |
допускается |
допускается |
необходимо использовать NAT со
стороны клиента |
необходимо использовать NAT со стороны клиента |
Особо необходимо отметить, что технология MPLS/VPN не обеспечивает целостности и конфиденциальности передаваемых данных.
Документация
- "Multiprotocol Extensions for BGP-4" (RFC2858)
- "BGP/MPLS VPNs" (draft-ietf-l3vpn-rfc2547bis)
- "Carrying Label Information in BGP-4" (RFC3107)
- "BGP Extended Communities Attribute" (draft-ietf-idr-bgp-ext-communities)
-
"Applicability
Statement for BGP/MPLS IP VPNs" (draft-ietf-l3vpn-as2547)
Организация VPN на базе MPLS
Автор: Максимович Вадим (vmaksv at gmail.com)В данной статье разобраны типовые решения для реализации VPN на базе MPLS сети использующей в качестве внутреннего протокола маршрутизации (IGP) EIGRP. Я надеюсь, что это статья будет полезна при внедрении технологии MPLS/VPN в вашей сети. Используя этот документ, Вы как минимум получите сеть, изображенную на Рис.1, использующую технологию MPLS/VPN. Любые замечания, пожелания, найденные ошибки и опечатки приветствуются.
- Введение
- Этапы настройки
- Настройка EIGRP и CEF
- Настройка TDP
- Настройка VRF
- Настройка MP-BGP
- Настройка маршрутизации между PE-CE по протоколу EIGRP
- PE-CE соединение с использованием OPSF.
- PE-CE соединение с использованием RIP.
Введение
В данной статье разобраны типовые решения для реализации L3 VPN на базе сети MPLS использующей в качестве внутреннего протокола маршрутизации (IGP) EIGRP. На полигоне использовалось оборудование Cisco Systems 26xxXM, 36xx c программным обеспечением IOS 12.3.10. Соответственно, в статье будет разобрана работа MPLS/VPN только для пакетных сетей. В статье не будут обсуждаться вопросы и команды связанные с TE и QoS.В рамках технологии MPLS/VPN принято использование следующих терминов:
- CE (Customer Edge) - маршрутизатор со стороны узла клиента, который непосредственно подключается к маршрутизатору оператора.
- PE (Provider Edge) - граничный маршрутизатор со стороны оператора (MPLS домена), к которому подключаются устройства CE. PE устройства выполняют функции E-LSR-ов. На нашем полигоне эту роль выполняют маршрутизаторы Router_A, Router_B, Router_C, Router_I, Router_F.
- P (Provider) - маршрутизатор внутри сети Оператора (MPLS домена). P устройства выполняют функции LSR. На нашем полигоне роль маршрутизатора P возложена на маршрутизатор Router_G.
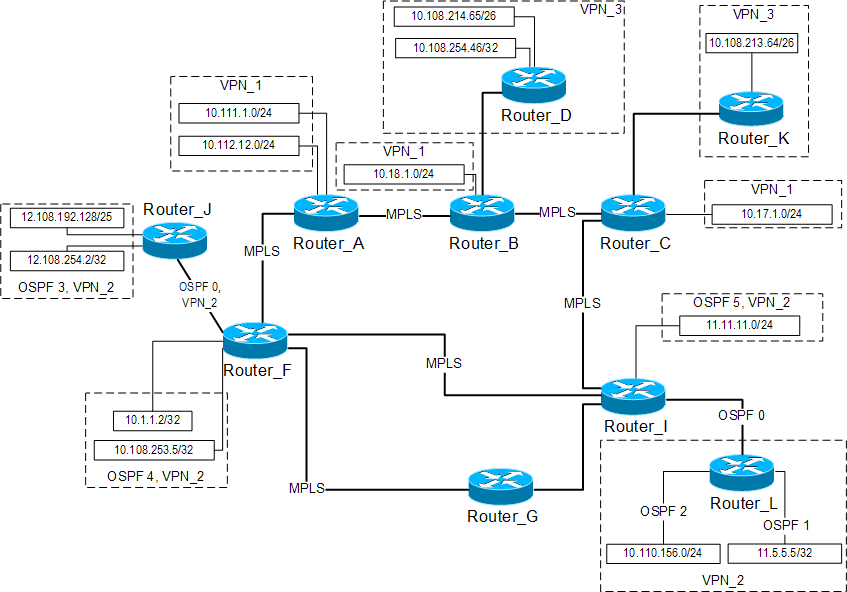
Рис. 1. Схема полигона.
Этапы настройки
- Настройка EIGRP и CEF
- Настройка TDP
- Настройка VRF
- Настройка MP-BGP
- Настройка маршрутизации между устройствами PE-CE с использованием протоколов:
- EIGRP;
- OSPF;
- RIP.
Настройка EIGRP и CEF
Для начала необходимо запустить на всех маршрутизаторах входящих в MPLS домен протокол маршрутизации (в нашем случае EIGRP) и включить на этих маршрутизаторах коммутации Cisco Express Forwarding (CEF).router eigrp 1#запущен процесс маршрутизации EIGRP 1
network 10.0.0.0#Маршрутизировать все сети, подключенные к этому маршрутизаторы с адресами, попадающими в диапазон 10.0.0.0/8.
no auto-summary#отключить автоматическую суммаризацию.
#включена коммутация Cisco Express Forwarding
ip cef
Проверить функционирование протокола EIGRP можно командой show ip protocols (команда также покажет основные параметры протокола EIGRP на маршрутизаторе) и командой show ip eigrp neighbors убедится в создание соседских отношений между маршрутизаторами. Проверить работу CEF можно выполнив команду show ip cef summary:
Подробно на этом этапе мы останавливаться не будем, так как рассмотрение настройки и отладки EIGRP и CEF выходит за рамки статьи.
Настройка TDP
По умолчанию IOS использует протокол TDP, но можно выбрать LDP командой mpls label protocol ldp. Можно также этой командой включить или выключить на отдельном интерфейсе любой из протоколов. При выполнении команды mpls label protocol both на интерфейсах соседей маршрутизаторов маршрутизаторы будут использовать протокол LDP.Так как настройка протокола LDP является типовым процессом, то мы рассмотрим настройку только маршрутизатора Router_B, предполагая, что на остальных маршрутизаторах MPLS домена протокол LDP уже функционирует. Изначально маршрутизатор Router_B имеет следующую конфигурацию:
Current configuration : 1122 bytes
!
version 12.3
!
hostname Router_B
!
ip cef
no tag-switching ip
!
interface Loopback0
ip address 10.108.254.45 255.255.255.255
!
interface FastEthernet0/0
ip address 10.18.1.1 255.255.255.0
!
interface Serial0/0:0
description Router_C
ip address 10.108.253.190 255.255.255.252
!
interface Serial0/1:0
description Router_A
ip address 10.108.253.201 255.255.255.252
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
end
На маршрутизаторе Router_A поднят Loopback0 с сетью 10.108.254.39/32, на маршрутизаторе Router_C поднят Loopback0 с сетью 10.108.254.40/32.
Запускаем поддержку MPLS используя команду mpls ip
Router_B(config)# mpls ip
Создание Label Information Base и запуск TDP/LDP произойдет только после запуска MPLS на одном из интерфейсов. Предварительно запустим на маршрутизаторе debug для наглядности.
Router_B#show debug
MPLS:
MPLS events debugging is on
LFIB data structure changes debugging is on
LFIB enable/disable state debugging is on
MPLS adjacency debugging is on
MPLS ldp:
LDP Label Information Base (LIB) changes debugging is on
LDP received messages, excluding periodic Keep Alives debugging is on
LDP sent PDUs, excluding periodic Keep Alives debugging is on
LDP transport events debugging is on
LDP transport connection events debugging is on
LDP session state machine (low level) debugging is on
Запускаем MPLS на интерфейсе
Router_B(config)#interface Serial0/0:0
Router_B(config-if)#tag-switching ip
01:32:07: mpls: Add mpls app; Serial0/0:0
01:32:07: mpls: Add mpls app; Serial0/0:0
01:32:07: mpls: Add mpls app; i/f status change; Serial0/0:0
01:32:07: ldp: enabling ldp on Serial0/0:0#Подготовка к запуску MPLS
01:32:07: LFIB: enable entered, table does not exist,enabler type=0x1
01:32:07: LFIB: enable, TFIB allocated, size 6032 bytes, maxtag = 500#База LFIB создана
01:32:07: tib: find route tags: 10.18.1.0/24, Fa0/0, nh 0.0.0.0, res nh 0.0.0.0
01:32:07: tagcon: tibent(10.18.1.0/24): created; find route tags request
01:32:07: tagcon: tibent(10.18.1.0/24): label 1 (#2) assigned
01:32:07: tagcon: announce labels for: 10.18.1.0/24; nh 0.0.0.0, Fa0/0,inlabel imp-null,
outlabel unknown (from 0.0.0.0:0), find route tags
01:32:07: tib: find route tags: 10.108.253.188/30, Se0/0:0, nh 0.0.0.0, res nh 0.0.0.0
01:32:07: tagcon: tibent(10.108.253.188/30): created; find route tags request
01:32:07: tagcon: tibent(10.108.253.188/30): label 1 (#4) assigned
01:32:07: tagcon: announce labels for: 10.108.253.188/30; nh 0.0.0.0, Se0/0:0, inlabel imp-null
outlabel unknown (from 0.0.0.0:0), find route tags
01:32:07: tib: find route tags: 10.108.253.200/30, Se0/1:0, nh 0.0.0.0, res nh 0.0.0.0
01:32:07: tagcon: tibent(10.108.253.200/30): created; find route tags request
01:32:07: tagcon: tibent(10.108.253.200/30): label 1 (#6) assigned
01:32:07: tagcon: announce labels for: 10.108.253.200/30; nh 0.0.0.0, Se0/1:0, inlabel imp-null,
outlabel unknown (from 0.0.0.0:0), find route tags
01:32:07: tib: find route tags: 10.108.254.40/32, Se0/0:0, nh 10.108.253.189, res nh 10.108.253.189
01:32:07: tagcon: tibent(10.108.254.40/32): created; find route tags request
01:32:07: tagcon: tibent(10.108.254.40/32): label 16 (#8) assigned#Маршрутизатор начинает расставлять локальные метки на маршруты находящиеся в таблице маршрутизации
01:32:07: mpls: Enable MPLS forwarding on Serial0/0:0
01:32:07: ldp: enabling ldp on Serial0/0:0#После привязки меток маршрутизатор готов к работе по MPLS на интерфейсе Serial0/0:0. Стартует LDP/TDP.
01:32:07: ldp: Got LDP Id, ctx 0
01:32:07: ldp: LDP Hello process inited
01:32:07: ldp: Start MPLS discovery Hellos for Serial0/0:0
01:32:07: ldp: Got TDP UDP socket for port 711
01:32:07: ldp: Got LDP UDP socket for port 646#Как видно из сообщений IOS открывает порты для обоих протоколов распространения меток, внезависимости от значения команды mpls label protocol. И разумеется первыми исходят сообщения Hello.
01:32:07: ldp: Send tdp hello; Serial0/0:0, src/dst 10.108.253.190/255.255.255.255, inst_id 0
01:32:08: ldp: Ignore Hello from 10.108.253.202, Serial0/1:0; no intf#Хотя на интерфейсе Serial0/1:0 у нас находится маршрутизатор, готовый работать по MPLS, на этом интерфейсе у нас не разрешен MPLS, поэтому пакеты LDP/TDP игнорируются
01:32:09: ldp: Rcvd tdp hello; Serial0/0:0, from 10.108.253.189 (10.108.254.40:0), intf_id 0, opt 0x4#Ура сосед ответил
01:32:09: ldp: tdp Hello from 10.108.253.189 (10.108.254.40:0) to 255.255.255.255, opt 0x4
01:32:09: ldp: New adj 0x82EA0510 for 10.108.254.40:0, Serial0/0:0#Обнаружен новый сосед с ID 10.108.254.40 на Serial 0/0:0
01:32:09: ldp: adj_addr/xport_addr 10.108.253.189/10.108.254.40
01:32:09: ldp: local idb = Serial0/0:0, holdtime = 15000, peer 10.108.253.189 holdtime = 15000
01:32:09: ldp: Link intvl min cnt = 2, intvl = 5000, idb = Serial0/0:0
01:32:09: ldp: Opening tdp conn; adj 0x82EA0510, 10.108.254.45 <-> 10.108.254.40; with normal priority#Оба маршрутизатора обменялись своими ID и устанавливают соединение по TDP
01:32:09: ldp: ptcl_adj:10.108.253.189(0x82EA0A60): Non-existent -> Opening Xport
01:32:09: ldp: create ptcl_adj: tp = 0x82EA0A60, ipaddr = 10.108.253.189
01:32:09: ldp: ptcl_adj:10.108.253.189(0x82EA0A60): Event: Xport opened;
Opening Xport -> Init sent
01:32:09: ldp: tdp conn is up; adj 0x82EA0510, 10.108.254.45:11000 <-> 10.108.254.40:711
01:32:09: ldp: Sent open PIE to 10.108.254.40 (pp 0x0)
01:32:09: ldp: Rcvd open PIE from 10.108.254.40 (pp 0x0)
01:32:09: ldp: ptcl_adj:10.108.253.189(0x82EA0A60): Event: Rcv Init;
Init sent -> Init rcvd actv
01:32:09: ldp: Rcvd keep_alive PIE from 10.108.254.40:0 (pp 0x0)
01:32:09: ldp: ptcl_adj:10.108.253.189(0x82EA0A60): Event: Rcv KA;
Init rcvd actv -> Oper
01:32:09: tagcon: Assign peer id; 10.108.254.40:0: id 0
01:32:09: %LDP-5-NBRCHG: TDP Neighbor 10.108.254.40:0 is UP#Маршрутизаторы договорились между собой, установили соседские отношения и теперь информацию о соседе можно получить, выполнив команду show mpls ldp neighbor
01:32:09: ldp: Sent address PIE to 10.108.254.40:0 (pp 0x82EA0C10)
01:32:09: ldp: Sent bind PIE to 10.108.254.40:0 (pp 0x82EA0C10)#PIE это protocol information element, если я правильно понял это у нас теперь так пакет с данным называется
01:32:09: ldp: Rcvd address PIE from 10.108.254.40:0 (pp 0x82EA0C10)
01:32:09: tagcon: 10.108.254.40:0: 10.108.254.40 added to addr<->ldp ident map
01:32:09: tagcon: 10.108.254.40:0: 10.108.253.189 added to addr<->ldp ident map
01:32:09: ldp: Rcvd bind PIE from 10.108.254.40:0 (pp 0x82EA0C10)
01:32:09: tagcon: tibent(10.108.253.188/30): label imp-null from 10.108.254.40:0 added#Получаем метки от соседа и передаем их в LFIB
01:32:09: tib: Not OK to announce label; nh 0.0.0.0 not bound to 10.108.254.40:0
01:32:09: tagcon: omit announce labels for: 10.108.253.188/30; nh 0.0.0.0, Se0/0:0,
from 10.108.254.40:0: add rem binding: connected route
01:32:09: tagcon: tibent(10.108.254.40/32): label imp-null from 10.108.254.40:0 added
01:32:09: tagcon: announce labels for: 10.108.254.40/32; nh 10.108.253.189, Se0/0:0,
inlabel 16, outlabel imp-null (from 10.108.254.40:0), add rem binding
01:32:09: LFIB: set loadinfo,tag=16,no old loadinfo,no new loadinfo
01:32:09: LFIB: delete tag rew, incoming tag 16
01:32:09: LFIB: create tag rewrite: inc 16,outg Imp_null
-------------------------------------------------
01:32:09: tagcon: tibent(10.108.254.39/32): label 19 from 10.108.254.40:0 added
01:32:09: tib: Not OK to announce label; nh 10.108.253.202 not bound to 10.108.254.40:0
01:32:09: tagcon: omit announce labels for: 10.108.254.39/32; nh 10.108.253.202, Se0/1:0,
from 10.108.254.40:0: add rem binding: next hop = 10.108.253.202
01:32:11: ldp: Send tdp hello; Serial0/0:0, src/dst 10.108.253.190/255.255.255.255, inst_id 0
01:32:13: ldp: Rcvd tdp hello; Serial0/0:0, from 10.108.253.189 (10.108.254.40:0), intf_id 0, opt 0x4
01:32:15: ldp: Send tdp hello; Serial0/0:0, src/dst 10.108.253.190/255.255.255.255, inst_id 0
01:32:17: ldp: Rcvd tdp hello; Serial0/0:0, from 10.108.253.189 (10.108.254.40:0), intf_id 0, opt 0x4g#Процесс установления соседских отношений завершен, обмен необходимой информацией закончен и маршрутизаторы обмениваются пакетами Hello
В качестве идентификатора выбирается наибольший IP адрес из интерфейсов Loopback. Если интерфейсы Loopback отсутствуют, то в качестве идентификатора выбирается наибольший IP адрес с любого интерфейса. Можно установить идентификатор вручную, используя команду mpls ldp router-id interface с необязательным параметром force. Только с параметром force ID будет изменен для существующих сессий и повлечет за собой переустановление соседских отношений.
Многие не задумываются о сходимости пакетной MPLS сети, хотя для многих приложений MPLS этот параметр очень важен (например для MPLS/VPN) так как он может повлечь увеличение задержки распространения меток. В пакетных сетях при использовании режима обмена информацией о метках без запроса (Downstream Unsolicited), независимого контроля над распространением меток (Independent Label Distribution Control) и свободного режима сохранения меток (Liberal Label Retention Mode) время сходимости сведено до минимума, позволяя находить метки после завершения процесса сходимости IGP без опрашивания соседа. Но это быстро и хорошо работает при падении канала, но не при более глубоких изменениях сети. Надо иметь ввиду, что сначала должен завершить свою работу по поиску маршрутов IGP, и только после завершения его работы начнется работа по поиску меток MPLS. Из вышесказанного следует, что при проблемах с MPLS не забудьте проверить работу IGP.
Настроим MPLS на втором интерфейсе.
Router_B(config)#interface Serial0/1:0
Router_B(config-if)# tag-switching ip
Выполним еще раз команду show mpls forwarding-table на маршрутизаторе Router_B.
Router_B#show mpls forwarding-table
Local Outgoing Prefix Bytes tag Outgoing Next Hop
tag tag or VC or Tunnel Id switched interface
16 Pop tag 10.108.254.40/32 214 Se0/0:0 point2point
17 Pop tag 10.108.254.39/32 170 Se0/1:0 point2point
Router_B#
Из всех маршрутизируемых сетей в LFIB маршрутизатора Router_B присутствует только две сети. Такой результат связан с работой механизма PHP (Penultimate Hop Popping). При использовании механизма PHP последний маршрутизатор сообщает предыдущему о том, что он может удалять метку у себя для определенного FEC. Сделано это для снижения нагрузки на PE маршрутизатор за счет перекладывание части работы на предыдущий P маршрутизатор. Информация об использовании PHP передается с помощью TDP или LDP, использующими для этого специальные метки (3 для LDP, 1 для TDP), которые принято называть implicit-null метками. В выводе команд show mpls ip bindings и show mpls ldp bindings такие метки показываются как imp-null. Команда show mpls ip bindings показывает информацию о привязке меток полученных через протокол LDP/TDP. Команда show mpls ldp bindings показывает содержимое Label Information Base.
Router_B#show mpls ip binding
10.108.254.39/32
in label: 17
out label: imp-null lsr: 10.108.254.39:0 inuse
10.108.254.40/32
in label: 16
out label: imp-null lsr: 10.108.254.40:0 inuse
10.108.254.254/32 (no route)
in label: 20
out label: 17 lsr: 10.108.254.39:0
out label: 17 lsr: 10.108.254.40:0
Router_B#
Поле in label - содержит входящую метку, параметр inuse указывает на то, что метка сейчас используется для работы, out label содержит исходящую метку, то есть метку, полученную от маршрутизатора, ID которого выведен в поле lsr.
Router_B#show mpls ldp bindings
tib entry: 10.108.254.39/32, rev 12
local binding: tag: 17
remote binding: tsr: 10.108.254.40:0, tag: 19
remote binding: tsr: 10.108.254.39:0, tag: imp-null
tib entry: 10.108.254.40/32, rev 8
local binding: tag: 16
remote binding: tsr: 10.108.254.40:0, tag: imp-null
remote binding: tsr: 10.108.254.39:0, tag: 19
Router_B#
Поле rev есть так называемый revision number - используется для внутреннего управления метками, remote binding - тоже самое, что out label.
Присутствие записи с пометкой (no route) вызвано работой механизма Liberal Label Retention Mode. В данном случае маршрут 10.108.254.254/32 был удален по каким то причинам из таблицы маршрутизации, но маршрутизатор сохранил метку для уменьшения времени сходимости при восстановлении данного маршрута.
Механизм PHP используется только для сетей, непосредственно подключенных к маршрутизатору или для суммарных маршрутов.
Можно использовать вместо implicit-null метки так называемую explicit null метки. В случае использования explicit null метки, предпоследний маршрутизатор устанавливает в пакет метку 0 (для IPv4) или 2 (для IPv6). Это необходимо для передачи на последний маршрутизатор поля MPLS-exp. Включается такой режим работы командой mpls ldp explicit-null. Используя параметры этой команды можно ограничить работу этого механизма только для определенных соседей. По умолчанию включается для всех соседей. Далее показан пример вывода команды show mpls ldp bindings с использованием explicit null меток.
Router_B#show mpls ldp bindings
tib entry: 10.108.254.39/32, rev 12
local binding: tag: 17
remote binding: tsr: 10.108.254.40:0, tag: 19
remote binding: tsr: 10.108.254.39:0, tag: exp-null
tib entry: 10.108.254.40/32, rev 8
local binding: tag: 16
remote binding: tsr: 10.108.254.40:0, tag: exp-null
remote binding: tsr: 10.108.254.39:0, tag: 19
Router_B#
Вывод команды show mpls forwarding-table на остальных маршрутизаторах.
Router_C#show mpls forwarding-table
Local Outgoing Prefix Bytes tag Outgoing Next Hop
tag tag or VC or Tunnel Id switched interface
16 Pop tag 10.108.253.200/30 0 Se0/1:0 point2point
17 Pop tag 10.108.254.45/32 0 Se0/1:0 point2point
18 Pop tag 10.18.1.0/24 0 Se0/1:0 point2point
19 17 10.108.254.39/32 0 Se0/1:0 point2point
Router_C#
Router_A#show mpls forwarding-table
Local Outgoing Prefix Bytes tag Outgoing Next Hop
tag tag or VC or Tunnel Id switched interface
16 Pop tag 10.108.253.188/30 0 Se0/0:0 point2point
17 Pop tag 10.108.254.45/32 0 Se0/0:0 point2point
18 Pop tag 10.18.1.0/24 0 Se0/0:0 point2point
19 16 10.108.254.40/32 0 Se0/0:0 point2point
Router_A#
Разберем подробно вывод команды show mpls forwarding-table.
- Поле Local tag показывает локальное значение метки для префикса, указанного в поле Prefix or Tunnel Id.
- Поле Outgoing tag or VC указывает исходящую метку или действие производимое с меткой. Pop tag означает удаление метки из пакета (в данном случае удаляется метка 16). Untagged означает, что IP префикс доступен через неMPLS интрефейс. Aggregate означает использование метки для нескольких префиксов.
- Поле Bytes tag switched показывает количество переданных байтов с этой меткой.
- В поле Outgoing interface указывается исходящий интерфейс.
- Поле Next hop показывает IP адрес следующего маршрутизатора или, как в этом случае, тип интерфейса.
Router_B#show mpls ldp neighbor
Peer TDP Ident: 10.108.254.40:0; Local TDP Ident 10.108.254.45:0
TCP connection: 10.108.254.40.711 - 10.108.254.45.11004
State: Oper; PIEs sent/rcvd: 8/8; Downstream
Up time: 00:03:25
TDP discovery sources:
Serial0/0:0, Src IP addr: 10.108.253.189
Addresses bound to peer TDP Ident:
10.108.254.40 10.108.253.189Описание полей выводе данной команды приведено в таблице.
|
Поле |
Описание
|
|---|---|
| Peer TDP Ident |
идентификатор соседа |
| Local TDP Ident |
идентификатор маршрутизатора |
| TCP connection |
содержит информацию о соединении
TCP между локальным маршрутизатором и соседом |
| State |
состояние соединения,
кратковременно может менять свое значение на отличные от Oper
(Operational) |
| Downstream |
тип обмена метками, может быть
Downstream, как сейчас и Downstream on demand |
| Uptime |
время существования сессии |
| PIEs sent/rcvd |
количество переданных пакетов. В
случае протокола LDP название этого поля будет изменено на Msgs
sent/rcvd |
| TDP discovery sources |
информацию через какой интерфейс
доступен сосед и какой у него IP адрес. Addresses bound to peer TDP
Ident: известные адреса для этой TDP/LDP сессии. Информация об этих
адресах берется из LFIB |
Есть возможность указать маршрутизатору соседа вручную командой mpls ldp neighbor. Однажды пришлось использовать эту команду при нежелании двух маршрутизаторов друг друга находить по LDP/TDP. Команда использовалась как временная мера, так как последующая замена IOSa на одном из них решила эту проблему. Команда mpls ldp neighbor используется также в целях повышении безопасности, так как позволяет установить пароль на сессию для соседа (рекомендовано использовать MD5) mpls ldp neighbor ip-address password [0-7] password-string.
Узнать параметры протокола распространения меток вы можете, выполнив команду show mpls ldp parameters
Router_B#show mpls ldp parameters
Protocol version: 1
Downstream label generic region: min label: 16; max label: 100000
Session hold time: 180 sec; keep alive interval: 60 sec
Discovery hello: holdtime: 15 sec; interval: 5 sec
Discovery targeted hello: holdtime: 90 sec; interval: 10 sec
Downstream on Demand max hop count: 255
TDP for targeted sessions
LDP initial/maximum backoff: 15/120 sec
LDP loop detection: off
Router_B#
В выводе команды show mpls ldp parameters выводится информация о версии протокола, диапазоне используемых меток, временных параметрах протоколов TDP/LDP. Поле TDP for targeted sessions зависит от команды mpls ldp targeted-sessions. Эта команда используется для установление сессии между маршрутизаторами не соединенными прямым каналом. В результате маршрутизатор опрашивает соседей перечисленных в этой команде не многоадресной рассылкой, а одноадресными пакетами. Параметры LDP backoff командой mpls ldp backoff. Параметр Session hold time можно изменить командой mpls ldp hold-time.
Замечу, что механизм предотвращения колец (LDP loop detection) выключен потому, что этим по идее должен протокол маршрутизации заниматься. Этот механизм можно включить командой mpls ldp loop-detection и используется он, как правило, в сетях ATM совместно с механизмом Downstream on demand.
Временные параметры можно изменить командой mpls ldp discovery. При этом возможно указание разных параметров для разных соседей.
Настройка VRF
Вернемся к полигону. Настроим маршрутизатор Router_A для работы в MPLS сети с VPN vpn_1.Для определения VPN комплекса маршрутизации на маршрутизаторе Router_A для VPN vpn_1 выполним следующие действия:
Назначим имя vrf :
Router_A(config)# ip vrf vpn_1Назначим Route Distinguisher:
Router_A(config-vrf)# rd 1:1Можно RD конфигурировать одним из двух форматов:
- 16-bit номер AS: 32-bit номер. Пример, 101:3.
- 32-bit IP адрес: 16-bit номер. Пример, 192.168.122.15:1.
Router_A(config-vrf)# route-target export 1:1
Router_A(config-vrf)# route-target import 1:1Подход к формированию значения RT такой же, как и к RD.
Возможно использование различных правил обработки для импортируемых маршрутов с помощью команды import map route-map. Необходимо помнить, что параметры VRF локальны и распространяются только на конфигурируемый маршрутизатор.
Указать интерфейсы, входящие в vrf комплекс, используя команду ip vrf forwarding vrf-name:
Router_A(config)# interface FastEthernet0/1
Router_A(config-interface)# ip vrf forwarding vpn_1Так как при связывание интерфейса с vrf удаляется адрес интерфейса (о чем IOS радостно сообщает) назначаем интерфейсу адрес:
Router_A(config-interface)# ip address 10.112.12.1 255.255.255.0Теперь можно посмотреть таблицу маршрутизации vrf vpn_1, используя команду show ip route vrf vpn_1:
Router_A# show ip route vrf vpn_1
Routing Table: vpn_1
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 9 subnets, 4 masks
C 10.112.12.0/24 is directly connected, FastEthernet0/1
Router_A#Таким же образом настраиваем остальные интерфейсы.
Настройка MP-BGP
Теперь необходимо сконфигурировать обмен маршрутной информацией vrf между PE маршрутизаторами. Для этого надо настроить протокол маршрутизации MP-BGP.Назначаем номер автономной системы:
Router_A(config)#router bgp 1Назначаем идентификатор для BGP. Обычно это, как в примере, адрес интерфейса Loopback0:
Router_A(config-router)# bgp router-id 10.108.254.39Отключаем одноадресатные аносы префиксов протокола IPv4. Теперь BGP будет переносить только информацию о VRF:
Router_A(config-router)# no bgp default ipv4-unicastОписываем соседа по протоколу BGP. IP адрес 10.108.254.40 принадлежит маршрутизатору Router_C на котором будет настроен рефлектор маршрутной информации. Настройка рефлектора маршрутной информации будет рассмотрена ниже, а на этом этапе рассмотрим вариант точка-точка:
Router_A(config-router)# neighbor 10.108.254.40 remote-as 1Посылать пакеты будем от имени Loopback0:
Router_A(config-router)# neighbor 10.108.254.40 update-source Loopback0Поднимаемся в режим конфигурирования VPN:
Router_A(config-router)# address-family vpnv4Разрешаем обмен информацией с соседом 10.108.254.40:
Router_A(config-router-af)# neighbor 10.108.254.40 activateРазрешаем рассылку только расширенных атрибутов BGP:
Router_A(config-router-af)# neighbor 10.108.254.40 send-community extendedПри настройке маршрутизатора Router_C мы получим следующую конфигурацию:
Router_C#show running-config
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
!
ip cef
!
interface Loopback0
ip address 10.108.254.40 255.255.255.255
!
interface FastEthernet0/0
ip vrf forwarding vpn_1
ip address 10.17.1.1 255.255.255.0
!
interface Serial0/0:0
description Router_G
ip address 10.108.253.185 255.255.255.252
tag-switching ip
!
!
interface Serial0/1:0
description Router_B
ip address 10.108.253.189 255.255.255.252
tag-switching ip
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
address-family ipv4 vrf vpn_1
redistribute bgp 1 metric 1000 1000 1 255 1500
network 10.0.0.0
no auto-summary
autonomous-system 3
exit-address-family
!
!
router bgp 1
bgp router-id 10.108.254.40
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.39 remote-as 1
neighbor 10.108.254.39 update-source Loopback0
!
address-family vpnv4
neighbor 10.108.254.39 activate
neighbor 10.108.254.39 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_1
redistribute eigrp 3
no auto-summary
no synchronization
exit-address-family
!
!
endПосле ввода команды neighbor 10.108.254.39 send-community extended не стоит удивляться отсутствию каких либо изменений в таблице маршрутизации vrf vpn_1. Протокол BGP торопливостью не отличается и на данном полигоне время, затрачиваемое на обмен маршрутной информацией, доходило до 15 секунд.
Обмен маршрутной информацией между PE осуществляется через протокол MP-BGP. Самый простой вариант настроить соединения точка-точка между маршрутизаторами PE. За простоту приходится платить сложностью администрирования. Второй вариант заключается в настройке двух(редко более) маршрутизаторов как рефлекторов маршрутной информации. Режим рефлектора включается для каждого соседа BGP командой neighbor x.x.x.x|peer-group route-reflector-client. Так как настройки для большинства соседей BGP однотипны, рекомендовано объединять соседей в группы, а уже группам присваивать необходимые настройки. На полигоне в качестве рефлектора настроен маршрутизатор Router_C. Рассмотрим настройку протокола BGP на маршрутизаторе Router_C
router bgp 1#запускаем процесс маршрутизации BGP для автономной системы 1.
bgp router-id 10.108.254.40#назначаем идентификатор маршрутизатора для протокола BGP
no bgp default ipv4-unicast#Отключаем передачу одноадресатных анонсов протокола IPv4. Сейчас BGP будет переносить информацию только о VPNах.
bgp log-neighbor-changes
neighbor clients peer-group#Объявляем группу соседей clients
neighbor clients remote-as 1#Объявляем, что члены группы clients принадлежат автономной системе 1.
neighbor clients update-source Loopback0#Весь обмен с членами группы clients будет происходить от адреса интерфейса Loopback0
neighbor 10.108.253.252 peer-group clients#10.108.253.252 объявляется членом группы clients
neighbor 10.108.254.39 peer-group clients
neighbor 10.108.254.45 peer-group clients
neighbor 10.108.254.254 peer-group clients
!
address-family vpnv4
neighbor clients activate#Объявляется группа clients
neighbor clients route-reflector-client#Для всех членов группы clients маршрутизатор Rooter_C является отражателем маршрутной информации
neighbor clients send-community extended#Разрешить посылать расширенные атрибуты членам группы clients
neighbor 10.108.253.252 peer-group clients
neighbor 10.108.254.39 peer-group clients
neighbor 10.108.254.45 peer-group clients
neighbor 10.108.254.254 peer-group clients
exit-address-family
!
address-family ipv4 vrf vpn_1#Настройка BGP для vpn_1
#передавать информацию о маршрутах vpn_1 в процесс EIGRP 3
redistribute eigrp 3
no auto-summary
no synchronization
exit-address-family
!
address-family ipv4 vrf vpn_3
redistribute eigrp 2
no auto-summary
no synchronization
exit-address-family
!
Кстати, очень много интересной информации можно получить из вывода команды show ip bgp vpnv4 all:
Команда выводит содержимое таблицы BGP на маршрутизаторе.
Вывод команды show ip bgp vpnv4 all на маршрутизаторе Router_A:
Router_A#show ip bgp vpnv4 all
BGP table version is 346, local router ID is 10.108.254.39
Status codes: s suppressed, d damped, h history, * valid, > best, i - internal,
r RIB-failure, S Stale
Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path
Route Distinguisher: 1:1 (default for vrf vpn_1)
*>i10.1.1.2/32 10.108.254.254 0 100 0 ?
*>i10.17.1.0/24 10.108.254.40 0 100 0 ?
*>i10.18.1.0/24 10.108.254.45 0 100 0 ?
r>i10.108.213.64/26 10.108.254.40 2172416 100 0 ?
r>i10.108.214.64/26 10.108.254.45 2172416 100 0 ?
r>i10.108.253.5/32 10.108.254.254 0 100 0 ?
r>i10.108.253.192/30 10.108.254.40 0 100 0 ?
r>i10.108.253.204/30 10.108.254.45 0 100 0 ?
r>i10.108.254.46/32 10.108.254.45 2297856 100 0 ?
*> 10.111.1.0/24 0.0.0.0 0 32768 ?
*> 10.112.12.0/24 0.0.0.0 0 32768 ?
r>i11.5.5.5/32 10.108.253.252 65 100 0 ?
r>i11.110.254.36/30 10.108.253.252 0 100 0 ?
r>i12.108.253.4/30 10.108.254.254 0 100 0 ?Присутствие в Status Code значение r указывает на наличие маршрута в таблице BGP при отсутствии его в таблице маршрутизации VRF. Рассмотрение причин этого явления выходит за рамки этой статьи.
Настройка маршрутизации между PE-CE по протоколу EIGRP
Настраиваем маршрутизации между PE и CE:Router_A(config)#router eigrp 1Объявляем семейств адресов vrf vpn_1:
Router_A(config-router)#address-family ipv4 vrf vpn_1Разрешаем перераспределять маршруты из BGP в EIGRP, без указания метрики EIGRP будем назначать полученным маршрутам метрику infinity, то есть бесконечность:
Router_A(config-router-af)# redistribute bgp 1 metric 1000 1000 1 255 1500
Router_A(config-router-af)# network 10.0.0.0
Router_A(config-router-af)# no auto-summaryУказываем номер автономной системы для процесса маршрутизации для vrf vpn_1:
Router_A(config-router-af)# autonomous-system 3
Настроим bgp для vrf vpn_1:
Router_A(config)#router bgp 1Объявлем семейство адресов vpn_1 для bgp:
Router_A(config-router)#address-family ipv4 vrf vpn_1Настраиваем обмен маршрутов в MP-BGP:
Router_A(config-router-af)#redistribute eigrp 3
Router_A(config-router-af)#no auto-summaryОтключаем синхронизацию:
Router_A(config-router-af)#no synchronization
Конфигурация маршрутизатора CE Router_M
hostname Router_M
!
ip cef
!
interface fastethernet0/2
ip address 10.111.1.3 255.255.255.0
!
router eigrp 3
network 10.111.0.0 0.0.255.255
auto-summary
!
end
На данном этапе маршрутизаторы Router_M и Router_A установили соседские отношения между собой по протоколу EIGRP, используя номер процесс 3. Выполнив команду show ip eigrp neighbors на маршрутизаторе Router_M и команду show ip eigrp vrf vpn_1 neighbors на маршрутизаторе Router_A, мы удостоверимся в этом. Команда show ip route vrf vpn_1 выполняемая на маршрутизаторе Router_A покажет таблицу маршрутизации для vrf vpn_1. Команды show ip cef vrf vpn_1 и show ip vrf vpn_1 выведут, соответственно, таблицу CEF для vrf vpn_1 и общую информацию о vrf vpn_1.
Также маршрутизаторы Router_C и Router_A установили соседские отношения по протоколу BGP и обменялись необходимой информацией.
Настройка vpn_3 аналогична настройке vpn_1, конфигурация маршрутизаторов Router_B, Router_C приведена ниже:
!
hostname Router_B
!
ip vrf vpn_3
rd 1003:1003
route-target export 1003:1003
route-target import 1003:1003
!
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
!
ip cef
!
interface Loopback0
ip address 10.108.254.45 255.255.255.255
!
interface FastEthernet0/0
ip vrf forwarding vpn_1
ip address 10.18.1.1 255.255.255.0
!
interface Serial0/0:0
ip address 10.108.253.190 255.255.255.252
tag-switching ip
!
interface Serial0/1:0
ip address 10.108.253.201 255.255.255.252
tag-switching ip
!
interface Serial0/2
description Router_D
ip vrf forwarding vpn_3
ip address 10.108.253.205 255.255.255.252
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
address-family ipv4 vrf vpn_1
redistribute bgp 1 metric 1000 1000 1 255 1500
network 10.0.0.0
no auto-summary
autonomous-system 3
exit-address-family
!
address-family ipv4 vrf vpn_3
redistribute bgp 1 metric 1000 1000 1 255 1500
network 10.0.0.0
no auto-summary
autonomous-system 2
exit-address-family
!
router bgp 1
bgp router-id 10.108.254.45
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.40 remote-as 1
neighbor 10.108.254.40 update-source Loopback0
!
address-family vpnv4
neighbor 10.108.254.40 activate
neighbor 10.108.254.40 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_1
redistribute eigrp 3
no auto-summary
no synchronization
exit-address-family
!
address-family ipv4 vrf vpn_3
redistribute eigrp 2
no auto-summary
no synchronization
exit-address-family
!
end
Конфигурация Router_C
Router_C#show running-config
!
ip vrf vpn_3
rd 1003:1003
route-target export 1003:1003
route-target import 1003:1003
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
!
ip cef
!
interface Loopback0
ip address 10.108.254.40 255.255.255.255
!
interface FastEthernet0/0
ip vrf forwarding vpn_1
ip address 10.17.1.1 255.255.255.0
!
interface Serial0/0:0
description Router_G
ip address 10.108.253.185 255.255.255.252
tag-switching ip
!
!
interface Serial0/1:0
description Router_B
ip address 10.108.253.189 255.255.255.252
tag-switching ip
!
interface Serial0/2
description Router_K
ip vrf forwarding vpn_3
ip address 10.108.253.193 255.255.255.252
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
address-family ipv4 vrf vpn_1
redistribute bgp 1 metric 1000 1000 1 255 1500
network 10.0.0.0
no auto-summary
autonomous-system 3
exit-address-family
!
address-family ipv4 vrf vpn_3
redistribute bgp 1 metric 1000 1000 1 255 1500
network 10.0.0.0
no auto-summary
autonomous-system 2
exit-address-family
!
router bgp 1
bgp router-id 10.108.254.40
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.39 remote-as 1
neighbor 10.108.254.39 update-source Loopback0
!
address-family vpnv4
neighbor 10.108.254.39 activate
neighbor 10.108.254.39 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_1
redistribute eigrp 3
no auto-summary
no synchronization
exit-address-family
!
!
address-family ipv4 vrf vpn_3
redistribute eigrp 2
no auto-summary
no synchronization
exit-address-family
!
end
Приводить конфигурацию маршрутизаторов Router_K, Router_D не вижу смысла, так как она принципиально не отличается от конфигурации маршрутизатора Router_M. Как видно из конфигураций vrf vpn_3 использует номер процесса 2 для работы с CE по EIGRP.
Можно объединить два VPN разрешив взаимный импорт маршрутной информации.
!
hostname Router_B
!
ip vrf vpn_3
rd 1003:1003
route-target export 1003:1003
route-target import 1003:1003
route-target import 1:1
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
route-target import 1003:1003
!
end
Необходимо помнить, что настройки vrf локальны, то есть если взаимный импорт настроен только на одном маршрутизаторе Router_C, то между собой будут работать пользователи VPNов, подключенные к маршрутизатору Router_C.
Конфигурация Router_C
!
hostname Router_C
!
ip vrf vpn_3
rd 1003:1003
route-target export 1003:1003
route-target import 1003:1003
route-target import 1:1
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
route-target import 1003:1003
!
end
Разумеется, такое объединение разных VPNов возможно при отсутствии перекрывающихся адресных пространств в обоих VPNах. Иначе необходимо использовать NAT.
PE-CE соединение с использованием OPSF.
Соединение PE-CE с использованием OSPF можно реализовать двумя вариантами:- С использованием Зоны 0.
- Без использования Зоны 0.
Рис. 1 Схема полигона
В отличии от EIGRP, OSPF на каждый vrf запускает отдельные копии своих процессов, что требует больших, по сравнению с EIGRP, ресурсов маршрутизатора.
Конфигурация Router_F.
Router_F#show running-config
!
hostname Router_F
!
ip vrf vpn_2
rd 100:100
route-target export 100:100
route-target import 100:100
!
interface Loopback0
ip address 10.108.254.254 255.255.255.255
!
interface Loopback1
ip vrf forwarding vpn_2
ip address 10.1.1.2 255.255.255.255
!
interface Loopback3
ip vrf forwarding vpn_2
ip address 10.108.253.5 255.255.255.255
!
interface Serial0/0:0
description Router_G
ip address 10.111.3.13 255.255.255.252
tag-switching ip
!
interface Serial0/1:0
description Router_I
ip address 10.108.253.1 255.255.255.252
tag-switching ip
!
interface Serial0/2:0
description Router_A
ip address 10.108.253.170 255.255.255.252
tag-switching ip
!
interface Serial1/0
description Router_J
ip vrf forwarding vpn_2
ip address 12.108.253.5 255.255.255.252
!
router eigrp 1
redistribute static
network 10.0.0.0
no auto-summary
!
router ospf 2 vrf vpn_2#Настраиваем перераспределение маршрутов. Рекомендуется жестко устанавливать ID OSPF командой router-id a.b.c.d.
redistribute bgp 1 metric 20 subnets
network 10.0.0.0 0.255.255.255 area 4
network 12.108.253.4 0.0.0.3 area 0
!#Для BGP настройка отличается только в настройке перераспределения маршрутов.
router bgp 1
bgp router-id 10.108.254.254
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.40 remote-as 1
neighbor 10.108.254.40 update-source Loopback0
!
address-family vpnv4
neighbor 10.108.254.40 activate
neighbor 10.108.254.40 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_2
redistribute ospf 2 match internal external 1 external 2
no auto-summary
no synchronization
exit-address-family
!
end
Конфигурация Router_I.
Router_I#show running-config
!
hostname Router_I
!
ip vrf vpn_2
rd 100:100
route-target export 100:100
route-target import 100:100
!
interface Loopback0
ip address 10.108.253.252 255.255.255.255
no clns route-cache
!
interface FastEthernet0/0
ip vrf forwarding vpn_2
ip address 11.11.11.1 255.255.255.0
!
interface Serial0/0:0
description Router_C
ip address 10.108.253.186 255.255.255.252
tag-switching ip
!
interface Serial0/1:0
description Router_G
ip address 10.111.3.18 255.255.255.252
tag-switching ip
!
interface Serial0/2:0
description Router_F
ip address 10.108.253.2 255.255.255.252
tag-switching ip
!
interface Serial2/0
description Router_L
ip vrf forwarding vpn_2
ip address 11.110.254.37 255.255.255.252
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
router ospf 2 vrf vpn_2
log-adjacency-changes
redistribute bgp 1 metric 20 subnets
network 11.11.11.0 0.0.0.255 area 5
network 11.110.254.36 0.0.0.3 area 0
!
router bgp 1
bgp router-id 10.108.253.252
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.40 remote-as 1
neighbor 10.108.254.40 update-source Loopback0
neighbor 10.108.254.254 remote-as 1
!
address-family vpnv4
neighbor 10.108.254.40 activate
neighbor 10.108.254.40 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_2
redistribute ospf 2 match internal external 1 external 2
no auto-summary
no synchronization
exit-address-family
!
!
end
Вывод команды show ip ospf на маршрутизаторе Router_F.
Router_F#show ip ospf
Routing Process "ospf 2" with ID 10.108.253.5
Domain ID type 0x0005, value 0.0.0.2
Supports only single TOS(TOS0) routes
Supports opaque LSA
Supports Link-local Signaling (LLS)
Connected to MPLS VPN Superbackbone
It is an area border and autonomous system boundary router
Redistributing External Routes from,
bgp 1 with metric mapped to 20, includes subnets in redistribution
Initial SPF schedule delay 5000 msecs
Minimum hold time between two consecutive SPFs 10000 msecs
Maximum wait time between two consecutive SPFs 10000 msecs
Minimum LSA interval 5 secs. Minimum LSA arrival 1 secs
LSA group pacing timer 240 secs
Interface flood pacing timer 33 msecs
Retransmission pacing timer 66 msecs
Number of external LSA 4. Checksum Sum 0x01C550
Number of opaque AS LSA 0. Checksum Sum 0x000000
Number of DCbitless external and opaque AS LSA 0
Number of DoNotAge external and opaque AS LSA 0
Number of areas in this router is 2. 2 normal 0 stub 0 nssa
External flood list length 0
Area BACKBONE(0)
Number of interfaces in this area is 1
Area has no authentication
SPF algorithm last executed 9w6d ago
SPF algorithm executed 3 times
Area ranges are
Number of LSA 9. Checksum Sum 0x05B20B
Number of opaque link LSA 0. Checksum Sum 0x000000
Number of DCbitless LSA 0
Number of indication LSA 0
Number of DoNotAge LSA 0
Flood list length 0
Area 4
Number of interfaces in this area is 2 (2 loopback)
Area has no authentication
SPF algorithm last executed 9w6d ago
SPF algorithm executed 2 times
Area ranges are
Number of LSA 7. Checksum Sum 0x045B47
Number of opaque link LSA 0. Checksum Sum 0x000000
Number of DCbitless LSA 0
Number of indication LSA 0
Number of DoNotAge LSA 0
Flood list length 0
Router_F#
В этом примере важна строка Connected to MPLS VPN Superbackbone, показывающая, что OSPF корректно увидел MPLS/VPN. При этом команда show ip protocols показывает информацию по протоколам маршрутизации, работающим во вне VPN.
Вывод команды show ip protocols на маршрутизаторе Router_F.
Router_F#show ip protocols
Routing Protocol is "eigrp 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: static, eigrp 1
EIGRP NSF-aware route hold timer is 240s
Automatic network summarization is not in effect
Maximum path: 4
Routing for Networks:
10.0.0.0
Routing Information Sources:
Gateway Distance Last Update
10.108.253.169 90 2w0d
10.111.3.14 90 2w0d
10.108.253.2 90 2w0d
Distance: internal 90 external 170
Routing Protocol is "bgp 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
IGP synchronization is disabled
Automatic route summarization is disabled
Maximum path: 1
Routing Information Sources:
Gateway Distance Last Update
Distance: external 20 internal 200 local 200
Также как мы объединяли VPNы с EIGRP, можно объединить VPNы с разными протоколами IGP, например, vpn_1 и vpn_2.
Конфигурация Router_I.
Router_I#show running-config
!
hostname Router_I
!
ip vrf vpn_2
rd 100:100
route-target export 100:100
route-target import 100:100
route-target import 1:1
Конфигурация Router_A.
Router_A# show running-config
!
hostname Router_A
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
route-target import 100:100
Для импорта маршрутной информации не имеет значения, каким образом маршруты попали в MP-BGP.
Вывод команды show ip route vrf vpn_2
Router_F# show ip route vrf vpn_2
Routing Table: vpn_2
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/8 is variably subnetted, 7 subnets, 2 masks
B 10.1.1.2/32 [200/0] via 10.108.254.254, 00:02:09
B 10.18.1.0/24 [200/0] via 10.108.254.45, 00:08:00
B 10.17.1.0/24 [200/0] via 10.108.254.40, 00:08:00
B 10.111.1.0/24 [200/0] via 10.108.254.39, 00:08:00
B 10.112.12.0/24 [200/0] via 10.108.254.39, 00:08:00
B 10.108.253.5/32 [200/0] via 10.108.254.254, 00:02:09
O IA 10.110.156.0/24 [110/74] via 11.110.254.38, 00:01:59, Serial2/0
11.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
O IA 11.5.5.5/32 [110/65] via 11.110.254.38, 00:02:00, Serial2/0
C 11.110.254.36/30 is directly connected, Serial2/0
12.0.0.0/8 is variably subnetted, 3 subnets, 3 masks
B 12.108.192.128/25 [200/74] via 10.108.254.254, 00:02:11
B 12.108.253.4/30 [200/0] via 10.108.254.254, 00:02:11
B 12.108.254.2/32 [200/65] via 10.108.254.254, 00:02:11
Router_I#
В выводе команды видно присутствие в таблице маршрутизации маршрутов из vpn_1 (10.111.1.0/24, 10.112.12.0/24 и тд).
Теперь рассмотрим вариант использования протокола OSPF без Зоны 0. У нас немного изменится логическая топология полигона на маршрутизаторах, работающих с OSPF (см рис. 2). Остальные маршрутизаторы изменения не затронут, поэтому они скрыты облаком MPLS backbone.
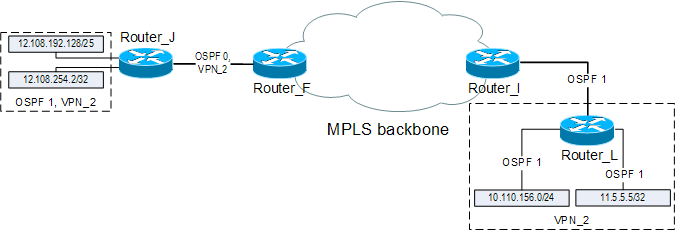
Рис. 2. Логическая топология полигона.
Конфигурация маршрутизатора Router_F
!
ip vrf vpn_2
rd 100:100
route-target export 100:100
route-target import 100:100
route-target import 1:1
!
!
router eigrp 1
redistribute static
network 10.0.0.0
no auto-summary
!
router ospf 2 vrf vpn_2
log-adjacency-changes
redistribute bgp 1 metric 20 subnets
network 12.0.0.0 0.255.255.255 area 1
!
router bgp 1
bgp router-id 10.108.254.254
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.253.252 remote-as 1
neighbor 10.108.254.40 remote-as 1
neighbor 10.108.254.40 update-source Loopback0
!
address-family vpnv4
neighbor 10.108.254.40 activate
neighbor 10.108.254.40 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_2
redistribute ospf 2 match internal external 1 external 2
no auto-summary
no synchronization
exit-address-family
!Конфигурация маршрутизатора Router_I
!
ip vrf vpn_2
rd 100:100
route-target export 100:100
route-target import 100:100
route-target import 1:1
!
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
router ospf 2 vrf vpn_2
log-adjacency-changes
redistribute bgp 1 metric 20 subnets
network 11.0.0.0 0.255.255.255 area 1
!
router bgp 1
bgp router-id 10.108.253.252
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.40 remote-as 1
neighbor 10.108.254.40 update-source Loopback0
neighbor 10.108.254.254 remote-as 1
!
address-family vpnv4
neighbor 10.108.254.40 activate
neighbor 10.108.254.40 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_2
redistribute ospf 2 match internal external 1 external 2
no auto-summary
no synchronization
exit-address-family
!
Вывод команды show ip route vrf vpn_2
Routing Table: vpn_2
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is not set
10.0.0.0/24 is subnetted, 5 subnets
B 10.18.1.0 [200/0] via 10.108.254.45, 00:04:54
B 10.17.1.0 [200/0] via 10.108.254.40, 00:04:54
B 10.111.1.0 [200/0] via 10.108.254.39, 00:04:54
B 10.112.12.0 [200/0] via 10.108.254.39, 00:04:54
B 10.110.156.0 [200/74] via 10.108.253.252, 00:04:38
11.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
B 11.5.5.5/32 [200/65] via 10.108.253.252, 00:04:38
B 11.110.254.36/30 [200/0] via 10.108.253.252, 00:04:40
12.0.0.0/8 is variably subnetted, 3 subnets, 3 masks
O 12.108.192.128/25 [110/74] via 12.108.253.6, 00:06:25, Serial1/0
C 12.108.253.4/30 is directly connected, Serial1/0
O 12.108.254.2/32 [110/65] via 12.108.253.6, 00:06:26, Serial1/0
Как видно, мало что изменилось.
PE-CE соединение с использованием RIP.
В этом случае все очень похоже на EIGRP, только отсутствует необходимость указывать номер процесса и другие значения метрик. Так как никаких сложностей здесь, на мой взгляд нет, подробных комментариев не будет.
Конфигурация соединения PE-CE на маршрутизаторе Router_B
Router_B#sh run
!
hostname Router_B
!
ip vrf vpn_3
rd 1003:1003
route-target export 1003:1003
route-target import 1003:1003
route-target import 1:1
!
ip vrf vpn_1
rd 1:1
route-target export 1:1
route-target import 1:1
route-target import 1003:1003
!
interface Loopback0
ip address 10.108.254.45 255.255.255.255
no clns route-cache
!
interface FastEthernet0/0
ip vrf forwarding vpn_1
ip address 10.18.1.1 255.255.255.0
!
interface Serial0/2
description Router_D
ip vrf forwarding vpn_3
ip address 10.108.253.205 255.255.255.252
clockrate 64000
no clns route-cache
!
router eigrp 1
network 10.0.0.0
no auto-summary
!
router rip
version 2
!
address-family ipv4 vrf vpn_1
version 2
redistribute bgp 1 metric 1
network 10.0.0.0
no auto-summary
exit-address-family
!
address-family ipv4 vrf vpn3
version 2
redistribute bgp 1 metric 1
network 10.0.0.0
no auto-summary
exit-address-family
!
router bgp 1
bgp router-id 10.108.254.45
no bgp default ipv4-unicast
bgp log-neighbor-changes
neighbor 10.108.254.40 remote-as 1
neighbor 10.108.254.40 update-source Loopback0
!
address-family vpnv4
neighbor 10.108.254.40 activate
neighbor 10.108.254.40 send-community extended
exit-address-family
!
address-family ipv4 vrf vpn_1
redistribute rip metric 1
no auto-summary
no synchronization
exit-address-family
!
address-family ipv4 vrf vpn3
redistribute rip metric 1
no auto-summary
no synchronization
exit-address-family
Вишняков vishnya@gmail.com
Сигнализация VPLS: LDP или BGP?
Данный документ рассматривает два подхода к орагнизации сигнализации при построению виртуальных частных сетей второго уровня: на базе протокола LDP и протокола BGP.- Введение
- Сигнализации VPLS на основе L2VPN-LDP
-
Сигнализация VPLS на основе L2VPN-BGP
- Эффективность распространения сигнальной информации
- Эффективность распределением меток, сигнализирующих виртуальные каналы
- Поиск взаимодействующих в рамках VPLS PE устройств
- Масштабируемость
- Использование компонент, проверенных на практике
- Организации VPLS на сетях нескольких взаимодействующих операторов
- Инструментарий администрирования и отладки
- Вместо заключения
- Документация
Введение
Работы по стандартизации подобных решений ведутся в рамках IETF рабочей группы Layer 2 Virtual Private Networks (l2vpn), которая в частности ставит своей задачей разработку L2 сервисов (Virtual Private LAN Service), имитирующих LAN сеть по IP и MPLS/IP сети оператора. Такая виртуальная LAN сеть позволяет стандартным Ethernet устройствам взаимодействовать "каждый с каждым", как будто они подключены к одному широковещательному Ethernet сегменту.В соответствии с определением рабочей группы l2vpn, выделяют следующие направления работ:
- Разработка механизмов автоматического обнаружения PE устройств, организующих VPLS сервис.
- Сигнализация, установление и управление l2vpn каналами передачи данных, по возможности должна использоваться сигнализация, определенная PWE3 рабочей группой (PWE3-CONTROL). Отметим, что вопрос инкапсуляции данных не рассматривается в рамках l2vpn рабочей группы, должны использоваться механизмы определенные группой PWE3.
- Архитектура, документ, определяющий основные понятия, механизмы без указания конкретных реализации протоколов обнаружения PE устройств, сигнализации и инкапсуляции данных, их взаимосвязь. Вопросы безопасности рассматриваются отдельной группой.
- Определение MIB.
- Инструментарий отладки L2VPN сервисов.
Сравнение двух подходов будет проводиться по следующим критериям:
- Эффективность распространения сигнальной информации.
- Эффективность распределением меток.
- Поиск взаимодействующих в рамках VPLS PE устройств.
- Масштабируемость.
- Использование компонент, проверенных на практике.
- Возможность организации VPLS на сетях нескольких взаимодействующих операторов.
- Наличие инструментария администрирования и отладки.
Сигнализации VPLS на основе L2VPN-LDP
Драфт описывает использование MPLS или IP туннелей для передачи трафика VPLS сервисов. Документ определяют дополнительный набор меток (так называемые метки виртуальных каналов - vc-labels), служащих для разделения, демультиплексирования виртуальных каналов (pseudowires), передаваемых внутри одного туннеля. Отметим (это верно при использовании MPLS как транспортной инфраструктуры), что один или несколько виртуальных каналов могут передаваться по одному MPLS туннелю, несколько путей Label Switch Pass (LSP) могут использоваться для организации одного MPLS туннеля, к примеру, основной и запасной (standby) пути.Для сигнализации vc-labels предлагается использовать расширение протокола LDP. PE маршрутизаторы договариваются об использовании vc-labels меток в рамках данной VPLS для определения соответствия полученного пакета какому-либо VPLS сервису, то есть задается соответствие между виртуальным каналом и VPLS.
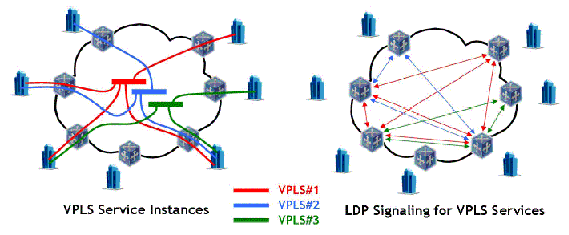
Рис. N1. Организация LDP сессий (target LDP) между взаимодействующими в рамках организации VPLS устройствами.
Эффективность распространения сигнальной информации
LDP - сигнальный протокол "точка-точка", с возможностью расширения на основе определения новых TLV соответствий, может использоваться для сигнализации, установления виртуальных каналов между устройствами, взаимодействующих при построении VPLS сети. Если учесть, что для построения некоторой VPLS может быть задействована лишь небольшая часть всех PE маршутизаторов оператора, то намного эффективнее позволить PE устройствам напрямую взаимодействовать друг с другом, чем рассылать сигнальную информацию всем устройствам сети с возможностью дальнейшей фильтрации ими полученных данных.Достигается эффективность распространения сигнальной информации в смысле минимизации нагрузки на маршрутизаторы, отстутствия "лишнего" трафика в сети за счет увеличения административных накладных.
Эффективность распределением меток
MPLS метки представляют собой довольно ценный ресурс, так как PE маршрутизаторы обычно поддерживают единое пространство меток на устройство (к примеру, это верно для frame-mode интерфейсов согласно RFC 3036). Если учесть, что MPLS метки используются следующими протоколами:- RSVP-TE для установления Traffic-Engineered (TE) транспортных LSP.
- LDP для установления основанных на информации IGP протоколов маршрутизации транспортных LSP.
- LDP для установления виртуальных каналов передачи данных в Virtual Leased Line сервисах.
- LDP для установления виртуальных каналов передачи данных в VPLS.
- BGP для установления L3 VPN сервисов согласно RFC 2547.
Использование LDP полностью устраняет необходимость административного контроля за распределением меток, используемых для сигнализации VPLS, что крайне немаловажно в больших сетях.
Поиск взаимодействующих в рамках VPLS PE устройств
Драфт L2VPN-LDP не определяет механизмов автоматического поиска PE устройств (auto-discovery), взаимодействующих в рамках построения какой-либо VPLS сети. В современных реализаций VPLS сервиса необходимо явно указать - к каким PE маршрутизаторам подключены клиентские устройства. В большинстве случаев на практике для этого используется система управления. В последнем случае механизм auto-discovery будет лишним, привнесет дополнительную сложность в протокол сигнализации и затруднит отладку.Отметим, что драфт не отрицает возможности использования механизмов автоматического поиска взаимодействующих устройств на основе, к примеру, BGP или RADIUS.
На данный момент все производители оборудования, реализующие VPLS на базе LDP, разработали системы управления автоматизирующие поиск, настройку PE устройств для организации L2 сервисов.
Масштабируемость
Архитектура VPLS предполагает "плоскую" или иерархическую топологию. В случае "плоской" топологии необходима организация IP или IP/MPLS туннелей и установление LDP сессий между всеми PE устройствами (target-LDP сессии) для согласования VC меток виртуальных каналов (pseudo-wires). В данном случае вопрос масштабируемости следует рассматривать с позиции числа target-LDP сессий, которые могут поддерживать PE устройства. Если число подобных сессий ограничено производительностью маршрутизаторов, то единственным выходом наращивания сети является иерархическая архитектура, ограничивающая число устройств в полносвязном ядре. Как видно на рисунке, полносвязный граф LDP сессий и IP/MPLS туннелей между PE устройствами заменен на 'hub' ядро и 'spoke' ответвления в сети оператора. Иерархический VPLS использует протокол LDP для установления hub и spoke соединений. Подобный подход за счет единого сигнального протокола и использования IP/MPLS во всей сети предоставляет унифицированный механизм установления соединений, резервирования туннелей, обеспечения качества сервиса и администрирования.
Рис. N2. Минимизация числа target-LDP сессий при переходе от полносвязной топологии к иерархической.
Использование компонент, проверенных на практике
В то время как сам по себе сервис VPLS является относительно новым, использование протокола LDP для сигнализации в VPLS идентично подходу, применяемому для сигнализации Virtual Leased Line сервисов (сервисов передачи Ethernet фреймов "точка-точка"), которые в настоящее время реализованы большинством производителей и довольно успешно применяются на практике. Более того, протокол LDP широко используется для сигнализации транспортных LSP при построении L3 VPN (RFC2547).В качестве референса приведем таблицу, отражающую применение расширений стандартных протоколов к построению новых VPN сервисов.
| Сервис |
Сигнализация |
LSP-сигнализация |
Механизмы автоматического
определения устройств PE |
| Virtual Leased Line |
LDP |
RSVP-TE/LDP |
нет |
| VPLS-LDP |
LDP |
RSVP-TE/LDP |
любой |
| VPLS-BGP |
BGP |
RSVP-TE/LDP | BGP |
| RFC2547bis |
BGP |
RSVP-TE/LDP | BGP |
Организация VPLS сервиса поверх сетей нескольких операторов
Требования к построению VPLS поверх сетей нескольких операторов:- Архитектура: Архитектура должна быть эффективна в смысле
сигнализации и репликации пакетов, то есть эффективность напрямую
зависит от необходимости установления туннелей между всеми PE
устройствами через границу сетей операторов. Действительно, если все PE
устройства соединены MPLS туннелями, то в случае передачи
широковещательного пакета, он будет передан по каналу связи между
операторами несколько раз. Использование LDP spoke сигнализации при
иерархическом построение VPLS, очень кстати оказывается при построении
межоператорского VPLS сервиса. Как показано на рисунке,
межоператорская VPLS может быть построена на основе определения нового
уровня иерархии между пограничными PE устройствами операторов.

Рис. N3. Организация межоператорской сети как следствие развития концепции иерархической VPLS.
- Уникальный глобальный идентификатор: для организации любого междоменного или межоператорского сервиса необходим глобальный уникальный идентификатор. В случае VPLS-LDP используется 32 битный параметр VC-id, его значения должны совпадать в сетях двух операторов для одной и той же VPLS.
- Разрешение петель: драфт VPLS-LDP устраняет необходимость в Spanning Tree протоколе за счет реализации split-horizon коммутации пакетов на full-mesh соединениях. Например, если пакет получен на одном full-mesh виртуальном канале (виртуальный канал образует hub сети), то PE устройство не пересылает пакет никому другому в ядре, так как считает, что все устройства получили данный пакет благодаря полносвязной схеме туннелей, но в тоже время пересылает пакет в 'spoke' ответвление.
- Безопасность: так же как и в BGP, MD5 аутентификация может использоваться в LDP для аутентификации сессий между PE маршрутизаторами на границе доменов операторов.
Инструментарий управления и отладки
Для администрирования VPLS сервиса необходимы средства отладки сигнализации, передачи Ethernet фреймов и заучивания MAC адресов. Драфт stokes-vkompella определяет механизмы VPLS Ping и VPLS Traceroute, позволяющие проверить:- Соединение между PE маршрутизаторами.
- Корректность передачи данных и сигнализацию между PE узлами сети.
- Определить, кто анонсировал MAC адрес в VPLS.
Сигнализация VPLS на основе L2VPN-BGP
Драфт L2VPN-BGP описывает механизм автоматического определения PE устройств, взаимодействующих при построении VPLS сервисов, и сигнализации меток виртуальных каналов на основе расширения протокола BGP. Данное расширение, а именно MP-BGP, уже используется при построении L3 VPN (RFC 2547). Рассмотрим, насколько протокол BGP применим для сигнализации VPLS.Эффективность распространения сигнальной информации
При использовании протокола BGP для распространения сигнальной информации необходима full-mesh связь между всеми PE маршрутизаторами, этого можно избежать при использовании Route Reflectors (RR). В последнем случае каждый маршрутизатор должен поддерживать только одно TCP соединение с RR или несколько, в случае кластера RR для целей обеспечения отказоустойчивости. На первый взгляд проблема масштабирования сети устранена, однако объем информации ранее передаваемой по множеству full-mesh соединений теперь передается по одному, то есть достигнута только эффективность конфигурации, но не объема передаваемых данных.Рисунок отражает объем реплицируемых данных в случае всего лишь трех VPLS сервисов, в среднем образуемых 3 PE маршрутизаторами.

Рис. N4. Объем реплицируемых данных растет как (число PE)*(среднее число VPN на устройство)
Эффективность распределением меток, сигнализирующих виртуальные каналы
Принцип работы протокола BGP определяет режим передачи сигнальной информации point-to-multipoint, что означает принципиальную невозможность распределять метки, сигнализирующие виртуальные каналы на основе механизма "запрос-ответ" (в принципе, конечно, можно, но с учетом того, что подобная информация будет рассылаться всем PE устройствам сети это неэффективно). Решением данной проблемы является анонсирование PE маршрутизаторами диапазона меток, что могут использоваться взаимодействующими устройствами при организации виртуальных каналов, составляющих VPLS. Столкновений при выборе меток не происходит, так как все маршрутизаторы знают число устройств, организующих VPLS сервис.Подобный подход априорного задания множества меток виртуальных каналов VPLS и соответственно максимального числа PE устройств, организующих VPLS сервис, приводит к нерациональному использованию пространства меток, его фрагментации, что негативно сказывается на масштабируемости сети и сложности конфигурации.
Поиск взаимодействующих в рамках VPLS PE устройств
При использовании протокола BGP сигнальная информация распространяется всем PE маршрутизаторам в пределах автономной системы. Для фильтрации, получения только необходимой в рамках организации определенной VPLS информации, применяются routing policies. Применение подобных механизмов на границе автономной системы является обычным дело, но внутри может привести к трудно отлавливаемым ошибкам. Например, число VPLS сервисов в сети может быть несколько сотен, и для каждой должен быть настроен разрешающий фильтр в routing policies. По логике работы протокола BGP база данных RIB-IN может содержать NLRI для всех VPLS, даже тех, в образовании которых маршрутизатор не участвует. Этого можно избежать двумя способами:- Удалением всех неактуальных NLRI записей, это возможно, если маршрутизаторы поддерживают Route Refresh функциональность.
- Использованием Outbound Route Filtering (ORF), что позволяет PE маршрутизаторам динамически установить, к примеру, на RR фильтр, препятствующий передаче ненужной информации. Однако это приведет к снижению предсказуемости работы сети.
Масштабируемость
VPLS может строиться на основе "плоской" или иерархичекой топологии виртуальных каналов. В случае LDP сигнализации иерархическая топология предлагает большие возможности масштабирования за счет ограничения числа устройств, образующих полносвязную сеть виртуальных каналов. Вариант построения VPLS с использованием BGP сигнализации не страдает проблемой ограниченного числа target-LDP сессий между PE устройствами. На первый взгляд иерархическая топология здесь кажется лишней, однако нужно учесть, что в случае "плоской" топологии все PE устройства должны быть дорогостоящими маршрутизаторами с полноценным BGP. Драфт L2VPN-BGP определяет иерархическую топологию на основе использования устройств Layer 2 агрегации, то есть организацию уровня доступа на базе L2 коммутаторов, что в итоге негативно сказывается на устойчивости сети за счет использования Spanning-Tree протокола.
Рис. N5. Организация иерархической топологии на базе Layer 2 устройств агрегации трафика.
Использование компонент, проверенных на практике
BGP как протокол междоменной маршрутизации доказал свою состоятельность, немного позже был удачно применен для распространения сигнальной информации L3 VPN (RFC25457). Действительно, имело смысл применить проверенный, масштабируемый мезанизм для сигнализации VPLS сервисов. Однако не было учтено, что сигнализация L2 VPN имеет мало общего с IP маршрутизацией - по сути, пришлось разрабатывать новый протокол, а также то, что для построения VLL все равно придется использовать LDP, так что подход не бесспорен.Организации VPLS на сетях нескольких взаимодействующих операторов
Для передачи информации внутри автономной системы (AS) используется iBGP, при организации VPLS сервиса на сетях нескольких операторов возникает вопрос о сигнализации между AS и организации MPLS туннелей между PE маршрутизаторами в разных автономных системах. Драфт L2VPN-BGP предлагает следующие решения:- На границе автономных систем VPLS терминируется в определенный VLAN, то есть для PE маршрутизаторов межоператорский канал связи выглядит обычным абонентским подключением. Для резервирования подобных подключений требуется применение протокола Spanning Tree, что сказывается на масштабировании.
- Организация eBGP сессий между PE ASBR маршрутизаторами операторов.
- eBGP сессия между RR операторов. ASBR маршрутизаторы на границах сетей в данном случае не взаимодействуют по eBGP, а только коммутируют MPLS пакеты, выполняют функциональность P маршрутизаторов. RR передают NLRI информацию о VPLS сервисах с применением опции next-hop-unchanged, что позволяют сигнализировать MPLS туннели между PE маршрутизаторами операторов. Решение аналогично описываемому в драфте draft-ietf-l3vpn-rfc2547bis раздел 10(c).
В случаях b) и c) так или иначе устанавливаются туннели между всеми PE устройствами (full-mesh), что означает многократную передачу широковещательных (broadcast, multicast, unknown) данных по каналу связи между операторами.
Рис. N6. Многократная пересылка широковещательных данных по каналу связи между операторами.
Инструментарий администрирования и отладки
Никаких специализированных механизмов отладки L2VPN-BGP в настоящее время не разрабатывается, остается надеяться только на собственные навыки работы с протоколом BGP.Вместо заключения
В настоящее время VPLS сервис на основе LDP поддерживается такими производителями как Alcatel, Cisco, Riverstone. Иерархический VPLS с поддержкой PWE3-CONTROL (то есть используется не Q-in-Q, а LDP) пока реализует только Alcatel. Драфт на основе BGP был разработан и реализован Juniper.В IETF ведутся работы по обоим предложениям к стандартизации, однако следует учитывать, что драфт может стать RFC только в случае его реализации тремя производителями, так что положение Juniper выглядит не столь безоблачным.
Подводя итог, хотелось бы представить таблицу, в которую можно было бы свести все "за и против" предложенных решений. Уточню, таблица отражает мнение автора, основанное на понимании драфтов и особенностей их реализации в устройствах, все возражения и дополнения можно обсудить на форуме.
| Критерий |
L2VPN-LDP | L2VPN-BGP |
|---|---|---|
| Эффективность распространения
сигнальной информации |
Высокая |
Низкая |
| Эффективность распределением
меток, использования их как ресурса |
Высокая, полностью
автоматизировано |
Низкая, требует настройки |
| Поиск взаимодействующих в рамках
VPLS PE устройств |
Опционален |
Встроенный механизм |
| Масштабируемость |
Высокая |
Высокая - средняя |
| Использование компонент,
проверенных на практике. |
Да |
Да |
| Возможность организации VPLS на
сетях нескольких взаимодействующих операторов |
Легкость конфигурации |
Сложность конфигурации,
неоптимальное распространение широковещательных данных |
| Наличие специализированного
инструментария администрирования и отладки |
Да |
Использование средств BGP |
Документация
- TiMetra Networks, "VPLS SIGNALING: LDP OR BGP?"
- "Framework for Layer 2 Virtual Private Networks (L2VPNs)" (draft-ietf-l2vpn-l2-framework)
- "Virtual Private LAN Service" (draft-ietf-l2vpn-vpls-bgp)
- " Virtual Private LAN Services over MPLS " (draft-ietf-l2vpn-vpls-ldp)
- "BGP/MPLS IP VPNs" (draft-ietf-l3vpn-rfc2547bis)