| Архив документации на OpenNet.ru / Раздел "Программирование в Linux" | (Для печати) |
Оригинал: skif.bas-net.by
Садыхов Р.Х., Поденок Л.П., Отвагин А.В., Глецевич И.И., Пынькин Д.А.
Средства параллельного программирования в ОС Linux: Учеб. пособие / Под ред. Р.Х. Садыхова.
- Мн.: ЕГУ, 2004. - 475 с.
ISBN 000-0000-00-0.
Пособие посвящено средствам программирования, позволяющим организовать различные уровни параллельного взаимодействия между процессами в операционной системе Linux. В нем последовательно рассмотрены основные понятия (процессы, потоки, сигналы и т.д.), встроенные средства межпроцессного взаимодействия Linux, высокоуровневые средства построения параллельных приложений, основанные на применении библиотек поддержки параллельных вычислений, таких, как DIPC, MPI, PVM. Отдельный раздел посвящен использованию специализированной библиотеки научных вычислений PETSc на базе MPI.
Пособие предназначено для программистов, желающих освоить принципы и средства разработки параллельных программ в ОС Linux. Оно может также служить начальным руководством для обучения разработке параллельного программного обеспечения, ориентированного на применение в высокопроизводительных кластерах семейства СКИФ.
DIPC обеспечивает строгую совместимость, т. е. при чтении будет возвращаться последнее записанное значение. Это явление хорошо знакомо программистам. В одно и то же время может быть большое количество читателей разделяемой памяти, но только один писатель. Менеджер разделяемой памяти, выполняющийся на владельце разделяемой памяти, будет получать запросы о чтении или записи целыми сегментами или индивидуальными страницами. Он будет решать, кто получит право на чтение или запись и при необходимости предоставлять запрашивающей машине адекватное содержимое разделяемой памяти.
Поэтому следует всегда помнить, что процессы будут только претендовать на разделяемую память. Они никого не ставят в известность о завершении своего доступа. Значит, нет возможности ожидать завершения использования ими разделяемой памяти для того, чтобы разрешить доступ другим процессам.
Чтобы защитить страницы разделяемой памяти от записи, нужно подвергнуть изменениям таблицы MMU. Аналогично делается и защита страниц от записи (в версиях DIPC до 2.0 желательно подгрузить страницу свопа для того, чтобы защитить ее от записи). Любой процесс, при попытке прочитать или записать защищенные от чтения страницы, столкнется со страничной ошибкой и будет приостановлен ядром. Для того чтобы страницы снова стали доступными для чтения или записи, новое содержимое передается по сети и замещает старое. С этого момента пользовательские процессы могут обращаться к нему.
DIPC может воспринимать в связке множество страниц виртуальной памяти, одновременно управляя ими всеми и передавая требующиеся. Это значит, что для любого целого n >= 1:
n * <размер_страницы_виртуальной_памяти>.
Установка большего размера страницы DIPC будет означать меньшие затраты при пересылках, а также создаст возможность для компьютеров с различными исходными размерами страниц совместно работать, используя DIPC. Значение должно устанавливаться исходя из максимального размера страниц виртуальной памяти компьютеров кластера.
Писатели имеют более высокий приоритет, чем читатели. Ситуация могла бы быть обратной, но философия реализации требует обновления информации писателями в то время, когда ей пользуются только читатели. Так что, писатель будет получать доступ к разделяемой информации даже тогда, когда с ней работают другие, ``желающие быть читателями'', процессы.
Для информирования процессов о том, что они становятся писателями или читателями используются два сигнала - процессы могут выполнять любые необходимые преобразования данных в гетерогенной среде. В настоящее время при записи используется сигнал SIGURG, а при чтении - SIGPWR. В дальнейшем возможны изменения, если этим сигналам будет найдено иное применение. Они приемлемы для программ с именами DIPC_SIG_READER и DIPC_SIG_WRITER.
Все процессы на одной машине имеют одинаковый статус в отношении разделяемой памяти. Либо они все могут читать ее или записывать в нее, либо никто из них не может этого делать. Когда тип доступа машины к разделяемой памяти меняется, это затрагивает все процессы на данной машине.
Система DIPC может быть сконфигурирована для управления разделяемой памятью и ее постраничной передачей. Это так называемый режим страничной передачи. Он позволяет различным компьютерам в кластере одновременно читать или записывать различные страницы разделяемой памяти. DIPC также может воспринимать целый сегмент как неделимый блок. В этом случае можно сказать, что она оперирует в режиме посегментной передачи. Каждый участник кластера DIPC, сконфигурированный для использования собственных режимов передачи, может работать с любым другим, хотя он не всегда может получить то, что просит. Ниже показано, как два компьютера с различными режимами передачи управляют работой друг друга:
Следствия разрешения пересылок целыми сегментами при DIPC:
Компьютер-владелец разделяемой памяти - это ее первостепенный писатель, которого всегда ``окружают'' читатели (если имеется хотя бы один читатель). Последовательность действий компьютера-владельца, всегда присутствующего среди читателей разделяемой памяти, примерно такая. Владелец всегда запускается как писатель, а когда возникает запрос о чтении, он конвертируется в читателя. Если процесс на другом компьютере "желает" записать данные в разделяемую память, то владелец не сможет иметь никаких прав доступа. Как только возникает запрос о чтении, менеджер разделяемой памяти размещает его перед изначальным запросом о чтении - от имени машины-владельца. В этом случае, владелец сначала становится читателем, забирающим содержимое разделяемой памяти от текущего писателя (см. ниже). Затем он предоставляет содержимое изначальному читателю (и, возможно другим ``просителям'').
Описанное поведение упрощает алгоритмы: поскольку всегда известно, как забрать содержимое разделяемой памяти, то выбирают дополнительно к существующим читателям нового. Но если надо использовать одного читателя из группы, то следует обеспечить и способы разрешения сетевых трудностей, чтобы этот пользователь не потерпел неудачи.
Короче говоря, в текущей версии DIPC лишь одна машина всегда ответственна за предоставление другим компьютерам содержимого разделяемой памяти: если это писатели, то и машина является писателем. Если присутствуют один или более читателей, то машина является владельцем. В обоих случаях, если встретилась ошибка, по большому счету ничего нельзя сделать. Если писатель не может передать содержимое, то места с обновленными данными не может быть. И если владелец терпит неудачу при выдаче запрашивающей машине данных - либо из-за ошибок сети, либо ошибок запрашивающей машины - то опять можно сделать очень немного, потому что использование отдельного читателя, возможно, завершится с тем же результатом.
Как при запросе о чтении, так и при запросе о записи, запрашивающий компьютер (если находится на связи) в конечном счете будет искать причину ошибки посредством тайм-аута и передавать SIGSEGV (сбой сегментации) всем процессам, которые имеют распределенную память, присоединенную к их адресному пространству.
Возможны следующие четыре варианта запроса машинами доступа к разделяемой памяти:
На схеме показано, как это происходит:
Сеть
(Запрашивающий компьютер) | (Компьютер-владелец)
|
|-1->back_end >-2-+ | <----------5----+ |
| | | | | |
ядро| employer--3--|->front_end --4-->shm_man |ядро
| | | |
| | +--6-->worker |
Когда процесс "желает" прочесть разделяемую память, уместное содержимое которой отсутствует, возникает исключение, о чем уведомляется часть DIPC в ядре. Внутри ядра подготавливается запрос, который для ``пробуждения'' порождает back_end (1) и раздваивает employer (2); employer подключается к компьютеру-владельцу (3) и доставляет запрос о чтении соответствующего содержимого разделяемой памяти процессу shm_man (4); shm_man посылает сообщение front_end (используя ``разворачивающий'' Internet-сокет) (5); front_end раздваивает worker (6) для действительного выполнения пересылки.
Процесс shm_man никогда не передает данные сам, а использует для этого worker на одной из отдельных машин. Для того, чтобы соблюдать общность, он делает то же самое даже на машине, на которой запущен. Дальнейшая последовательность операций показана на следующей схеме:
Сеть
(Запрашивающий компьютер)|(Компьютер-владелец)
|
| | |
| | |
ядро | +-8-<front_end<---|-------7---worker | ядро
| | | | | |
|<-11-worker<-------------|--10--------+ +-9--<|
Итак, worker на машине-владельце ``отдает'' разделяемую память (с помощью системного вызова shmget()) и подключается к front_end на запрашивающей машине (7), который раздваивает еще один worker (8). Затем worker на машине-владельце читает соответствующее содержимое разделяемой памяти (9) и сразу передает его (без вмешательства front_end) вновь раздвоенному worker (10), который помещает его в разделяемую память запрашивающего компьютера (11). После этого, запрашивающая машина наконец получает информацию, которую хотела.
Ниже представлены оставшиеся действия:
Сеть
(Запрашивающий компьютер) | (Компьютер-владелец)
|
| worker--------12-----|------------->front_end
| | |
| | |
ядро| front_end <----|--14--shm_man <-13-+
| | |
|<-16-employer<-15-+
После того, как worker поместил содержимое в разделяемую память, он посылает подтверждение shm_man (12 и 13). Затем shm_man посылает сигнальное сообщение оригинальному employer, который передает запрос о чтении (14 и 15); employer сообщает ядру об этом (16) и ядро перезапускает процессы, "желающие" читать разделяемую память. На этом вся операция завершается.
Сеть
(Запрашивающий компьютер) | (Компьютер-владелец)
|
|-1->back_end>-2-+ | |
| | | |
ядро| employer--3----|->front_end--4-->shm_man|ядро
| | |
Запрос о записи попадает внутрь ядра, и back_end активируется для его обработки (1). В дальнейшем об этом информируется shm_man на машине-владельце (2, 3 и 4). Заметьте, что все сказанное может происходить на одном компьютере (если владелец хочет записывать в разделяемую память). Иногда все показанные процессы, действительно, выполняются на одной машине:
Сеть
(Компьютер-читатель) | (Компьютер-владелец)
| |
ядро |<-7-worker<-6-front_end<--|------------5-----shm_man
| |
Менеджер разделяемой памяти посылает защищенное от чтения сообщение всем компьютерам-читателям (среди которых может быть и машина-владелец - в этом случае используется разворачивающий адрес) (5); front_end на каждой машине раздваивает worker (6) и запрос исполняется (7). С этого момента все попытки чтения или записи соответствующего содержимого разделяемой памяти любым из этих компьютеров приведут к остановке ответственных процессов. Указанные выше действия повторяются для каждого читателя.
Если компьютер, запрашивающий возможность записи, был одним из читателей, ему содержимое не посылается: владелец ответственен за предоставление новому ``просителю'' содержимого разделяемой памяти.
Далее shm_man ожидает подтверждение, и когда оно прибывает, посылает сигнал employer, который изначально инициировал все процессы.
Если shm_man ``включает'' владельца, как ``желающую читать'' машину, происходит следующее:
Сеть
(Компьютер-писатель) | (Компьютер-владелец)
| |
ядро | worker <-6- front_end <--|------------5-----shm_man
| |
Владелец будет запрашивать у действующего компьютера - писателя о передаче ему соответствующего содержимого разделяемой памяти. Это реализуется посылкой запроса процессу front_end писателя (5), который в свою очередь разветвит worker для выполнения пересылки (6).
Соответствующее содержимое разделяемой памяти передается компьютеру - владельцу (компьютер - владелец заменяется компьютером - писателем, а запрашивающий компьютер - владельцем).
Когда владелец становится читателем разделяемой памяти, он обслуживает оригинальный запрос о чтении. Данная ситуация похожа на ситуацию, описанную в первом пункте.
Сначала shm_man уведомляется о запросе. Затем он пошлет сообщение текущему писателю защитить от записи соответствующие части разделяемой памяти и передаст содержимое новому писателю.
Садыхов Р.Х., Поденок Л.П., Отвагин А.В., Глецевич И.И., Пынькин Д.А.
Средства параллельного программирования в ОС Linux: Учеб. пособие / Под ред. Р.Х. Садыхова.
- Мн.: ЕГУ, 2004. - 475 с.
ISBN 000-0000-00-0.
Пособие посвящено средствам программирования, позволяющим организовать различные уровни параллельного взаимодействия между процессами в операционной системе Linux. В нем последовательно рассмотрены основные понятия (процессы, потоки, сигналы и т.д.), встроенные средства межпроцессного взаимодействия Linux, высокоуровневые средства построения параллельных приложений, основанные на применении библиотек поддержки параллельных вычислений, таких, как DIPC, MPI, PVM. Отдельный раздел посвящен использованию специализированной библиотеки научных вычислений PETSc на базе MPI.
Пособие предназначено для программистов, желающих освоить принципы и средства разработки параллельных программ в ОС Linux. Оно может также служить начальным руководством для обучения разработке параллельного программного обеспечения, ориентированного на применение в высокопроизводительных кластерах семейства СКИФ.
Сигналы являются программными прерываниями, которые посылаются процессу, когда случается некоторое событие. Сигналы могут возникать синхронно с ошибкой в приложении, например SIGFPE (ошибка вычислений с плавающей запятой) и SIGSEGV (ошибка адресации), но большинство сигналов является асинхронными. Сигналы могут посылаться процессу, если система обнаруживает программное событие, например, когда пользователь дает команду прервать или остановить выполнение, или получен сигнал на завершение от другого процесса. Сигналы могут прийти непосредственно от ядра ОС, когда возникает сбой аппаратных средств ЭВМ. Система определяет набор сигналов, которые могут быть отправлены процессу. В Linux применяется около 30 различных сигналов. При этом каждый сигнал имеет целочисленное значение и приводит к строго определенным действиям.
Механизм передачи сигналов состоит из следующих частей:
Известно три варианта реакции на сигналы:
void(*signal(int signr, void(*sighandler)(int)))(int);
signalfunction *sighandler);
| Номер | Значение | Реакция программы по умолчанию |
| SIGABRT | Ненормальное завершение (abort()) | Завершение |
| SIGALRM | Окончание кванта времени | Завершение |
| SIGBUS | Аппаратная ошибка | Завершение |
| SIGCHLD | Изменение состояния потомка | Игнорирование |
| SIGCONT | Продолжение прерванной программы | Продолжение / игнорирование |
| SIGEMT | Аппаратная ошибка | Завершение |
| SIGFPE | Ошибка вычислений с плавающей запятой | Завершение |
| SIGILL | Неразрешенная аппаратная команда | Завершение |
| SIGINT | Прерывание с терминала | Завершение |
| SIGIO | Асинхронный ввод/вывод | Игнорирование |
| SIGKILL | Завершение программы | Завершение |
| SIGPIPE | Запись в канал без чтения | Завершение |
| SIGPWR | Сбой питания | Игнорирование |
| SIGQUIT | Прерывание с клавиатуры | Завершение |
| SIGSEGV | Ошибка адресации | Завершение |
| SIGSTOP | Остановка процесса | Остановка |
| SIGTTIN | Попытка чтения из фонового процесса | Остановка |
| SIGTTOU | Попытка записи в фоновый процесс | Остановка |
| SIGUSR1 | Пользовательский сигнал | Завершение |
| SIGUSR2 | Пользовательский сигнал | Завершение |
| SIGXCPU | Превышение лимита времени CPU | Завершение |
| SIGXFSZ | Превышение пространства памяти (4GB) | Завершение |
| SIGURG | Срочное событие | Игнорирование |
| SIGWINCH | Изменение размера окна | Игнорирование |
Переменная sighandler определяет функцию обработки сигнала.
В заголовочном файле <signal.h> определены две константы
SIG_DFL и SIG_IGN. SIG_DFL означает
выполнение действий по умолчанию - в большинстве случаев - окончание
процесса. Например, определение signal(SIGINT, SIG_DFL);
приведет к тому, что при нажатии на комбинацию клавиш CTRL+C
во время выполнения сработает реакция по умолчанию на сигнал SIGINT
и программа завершится. С другой стороны, можно определить
signal(SIGINT, SIG_IGN);
Если теперь нажать на комбинацию клавиш CTRL+C, ничего не
произойдет, так как сигнал SIGINT игнорируется. Третьим способом
является перехват сигнала SIGINT и передача управления на
адрес собственной функции, которая должна выполнять действия, если
была нажата комбинация клавиш CTRL+C, например
signal(SIGINT, function);
Пример использования обработчика сигнала приведен ниже:
#include <stdlib.h>
#include <signal.h>
void sigfunc(int sig) {
char c;
if(sig != SIGINT)
return;
else {
printf("\nХотите завершить программу (y/n) : ");
while((c=getchar()) != 'n')
return;
exit (0);
}
}
int main() {
int i;
signal(SIGINT,sigfunc);
while(1)
{
printf(" Вы можете завершить программу с помощью
CTRL+C ");
for(i=0;i<=48;i++)
printf("\b");
}
return 0;
}
rpcgen можно использовать для создания процедур XDR, которые будут преобразовывать локальные структуры данных в формат XDR и наоборот.
Пусть dir.x содержит сервис удаленного чтения каталога, созданный с помощью rpcgen, процедуры сервера и процедуры XDR.
Файл описания протокола RPC dir.x имеет следующий вид:
* dir.x: Протокол вывода удаленного каталога
*/
/*максимальная длина элемента каталога */
const MAXNAMELEN = 255;
/* элемент каталога */
typedef string nametype<MAXNAMELEN>;
/* ссылка в списке */
typedef struct namenode *namelist;
/* Узел в списке каталога */
struct namenode {
nametype name; /* имя элемента каталога */
namelist next; /* следующий элемент */
};
union readdir_res switch (int errno) {
case 0:
namelist list; /* нет ошибок:
возвращает оглавление каталога */
default:
void; /*возникла ошибка: возвращать нечего*/
};
/* Определение программы каталога */
program DIRPROG {
version DIRVERS {
readdir_res
READDIR(nametype) = 1;
} = 1;
} = 0x20000076;
При запуске rpcgen для dir.x создаются четыре файла:
Серверная часть процедуры READDIR, в файле dir_proc.c:
* dir_proc.c: удаленная реализация readdir
*/
#include <dirent.h>
#include "dir.h" /* Создается rpcgen */
extern int errno;
extern char *malloc();
extern char *strdup();
readdir_res *
readdir_1(nametype *dirname, struct svc_req *req)
{
DIR *dirp;
struct dirent *d;
namelist nl;
namelist *nlp;
static readdir_res res; /* должен быть static! */
/* Открыть каталог */
dirp = opendir(*dirname);
if (dirp == (DIR *)NULL) {
res.errno = errno;
return (&res);
}
/* Очистить предыдущий результат */
xdr_free(xdr_readdir_res, &res);
/*
* Собрать элементы каталога.
*/
nlp = &res.readdir_res_u.list;
while (d = readdir(dirp)) {
nl = *nlp = (namenode *)
malloc(sizeof(namenode));
if (nl == (namenode *) NULL) {
res.errno = EAGAIN;
closedir(dirp);
return(&res);
}
nl->name = strdup(d->d_name);
nlp = &nl->next;
}
*nlp = (namelist)NULL;
/* Вывести результат */
res.errno = 0;
closedir(dirp);
return (&res);
}
Клиентская часть процедуры READDIR, файл rls.c:
* rls.c: Клиент для удаленного чтения каталогов
*/
#include <stdio.h>
#include "dir.h" /* создается rpcgen */
extern int errno;
main(int argc, char *argv[])
{
CLIENT *clnt;
char *server;
char *dir;
readdir_res *result;
namelist nl;
if (argc != 3) {
fprintf(stderr, "usage: %s host
directory\n",argv[0]);
exit(1);
}
server = argv[1];
dir = argv[2];
/*
* Создает обработчик клиента,
* вызывающий MESSAGEPROG на сервере
*/
cl = clnt_create(server, DIRPROG, DIRVERS, "tcp");
if (clnt == (CLIENT *)NULL) {
clnt_pcreateerror(server);
exit(1);
}
result = readdir_1(&dir, clnt);
if (result == (readdir_res *)NULL) {
clnt_perror(clnt, server);
exit(1);
}
/* Успешный вызов удаленной процедуры. */
if (result->errno != 0) {
/* Ошибка на удаленной системе.
*/
errno = result->errno;
perror(dir);
exit(1);
}
/* Оглавление каталога получено.
* Вывод на экран.
*/
for (nl = result->readdir_res_u.list;
nl != NULL;
nl = nl->next) {
printf("%s\n", nl->name);
}
xdr_free(xdr_readdir_res, result);
clnt_destroy(cl);
exit(0);
}
Код клиента, создаваемый rpcgen, не освобождает память, выделенную для результатов запроса RPC. Поэтому следует вызывать xdr_free(), чтобы освободить память после завершения работы. Это похоже на вызов free(), за исключением того, что здесь для получения результата передается процедура XDR.
Программа rpcgen поддерживает препроцессор C. При этом препроцессор C применяется ко входным файлам rpcgen перед компиляцией. В исходных файлах .x поддерживаются все стандартные директивы препроцессора C. В зависимости от типа генерируемого выходного файла, пять символов определяются самой rpcgen, обеспечивающей поддержку дополнительных возможностей препроцессинга: любая строка, которая начинается с символа процента (%), передается непосредственно в выходной файл, независимо от содержания.
Чтобы создать файл определенного вида, можно использовать следующие символы:
* time.x: Удаленный протокол времени
*/
program TIMEPROG {
version TIMEVERS {
unsigned int TIMEGET() = 1;
} = 1;
} = 0x20000044;
#ifdef RPC_SVC
%int *
%timeget_1()
%{
% static int thetime;
%
% thetime = time(0);
% return (&thetime);
%}
#endif
DIPC состоит из двух частей: основная часть выполняется в пространстве пользователя как обыкновенный процесс с правами суперпользователя и применяется для управления. Она называется dipcd. Этот демон может привести к снижению производительности, но увеличивает гибкость системы: изменения установок dipcd могут вступить в силу без необходимости замены ядра. Он также упрощает разработку и предохраняет ядро от еще большего усложнения; dipcd создает большое количество дочерних процессов для выполнения различных задач во время своей активности. Другая часть DIPC находится внутри ядра и предоставляет первой части необходимую функциональность и информацию для выполнения ее заданий. Не предоставляется возможным работа dipcd на базе ядра без поддержки DIPC.
Часть DIPC, относящаяся к ядру, ``заглушена'', когда dipcd не выполняется. При отсутствии dipcd, вызовы DIPC в программе должны происходить так же, как если бы они были нормальными вызовами IPC System V. Сам dipcd использует обычные средства для получения доступа к механизмам IPC System V. Эти механизмы изменчивы - так, они предполагают отличие dipcd от других пользовательских процессов. Например, dipcd может получить доступ к сегменту разделяемой памяти с помощью smget(), даже в том случае, если он был удален (shmctl() - вследствие команды IPC_RMID), - но не окончательно из ядра. Все манипуляции dipcd со структурами IPC делаются локально, без проявления вне данной машины. Это противоречит подходам к нормальным пользовательским процессам, когда действия с распределенными структурами IPC могут затронуть другие компьютеры в сети.
DIPC затрагиваются только при передаче данных в распределенной среде. Запуск соответствующих программ на различных компьютерах - это дело пользователя/программиста DIPC. Это значит, что программы для исполнения могут нуждаться в размещении на компьютере, который предназначен для их исполнения. Программы могут быть перенесены на различные компьютеры один раз и использованы множество раз после этого. Это не вызывает перегрузок при передаче кода по сети во всех случаях, когда программа запускается. Считается, что код программы остается без изменений в течение относительно долгого периода, в то время как используемые им данные изменяются часто (может быть, от одного запуска к другому), что в большинстве случаев должно считаться плюсом.
Важно учитывать, что DIPC - это набор механизмов. Речь идет не о выборе стратегии: как распараллеливается программа, где должны запускаться процессы и т.д. - решает пользователь/программист. Известно несколько иных доступных средств для решения данного класса задач, хотя в полной мере удовлетворительного решения пока не известно.
Выделяют два вида активности DIPC:
Сигналы позволяют осуществить самый примитивный способ коммуникации между двумя процессами. С помощью функции kill() процесс может послать сигнал другому процессу, а затем процесс-приемник может реагировать на принятый сигнал. Разумеется, в качестве IPC сигналы используются крайне редко. Для примера приведена программа, которая создает с помощью fork() второй процесс. Затем оба процесса (родитель и потомок) обмениваются данными и выводят сообщения на экран. При этом потомок переводится в состояние ожидания, пока родительский процесс выводит сообщение. Родитель посылает сигнал потомку посредством kill(), а затем сам переводится в состояние ожидания. Потомок выводит сообщение, пробуждает родительский процесс и переводится в состояние ожидания и все повторяется. Программа приведена ниже:
#include <stdio.h>
#include <signal.h>
#include <sys/types.h>
enum { FALSE, TRUE };
sigset_t sig_m1, sig_m2, sig_null;
int signal_flag=FALSE;
void sig_func(int signr) {
start_signalset();
signal_flag = TRUE;
}
void start_signalset() {
if(signal(SIGUSR1, sig_func) == SIG_ERR)
exit(0);
if(signal(SIGUSR2, sig_func) == SIG_ERR)
exit(0);
sigemptyset(&sig_m1);
sigemptyset(&sig_null);
sigaddset(&sig_m1,SIGUSR1);
sigaddset(&sig_m1,SIGUSR2);
if(sigprocmask(SIG_BLOCK, &sig_m1, &sig_m2) < 0)
exit(0);
}
void message_for_parents(pid_t pid) {
kill(pid,SIGUSR2);
}
void wait_for_parents() {
while(signal_flag == FALSE)
sigsuspend(&sig_null);
signal_flag = FALSE;
if(sigprocmask(SIG_SETMASK, &sig_m2, NULL) < 0)
exit(0);
}
void message_for_child(pid_t pid) {
kill(pid, SIGUSR1);
}
void wait_for_child(void) {
while(signal_flag == FALSE)
sigsuspend(&sig_null);
signal_flag = FALSE;
if(sigprocmask(SIG_SETMASK, &sig_m2, NULL) < 0)
exit(0);
}
int main()
{
pid_t pid;
char x,y;
start_signalset();
switch( pid = fork())
{
case -1 : fprintf(stderr, "Ошибка fork()\n");
exit(0);
case 0 : /*...в потомке...*/
for(x=2;x<=10;x+=2) {
wait_for_parents();
write(STDOUT_FILENO, "ping-",
strlen("ping-"));
message_for_parents(getppid());
}
exit(0);
default : /*...в родителе....*/
for(y=1;y<=9;y+=2) {
write(STDOUT_FILENO, "pong-",
strlen("pong-"));
message_for_child(pid);
wait_for_child();
}
}
printf("\n\n");
return 0; }
Система состоит из определенного количества компьютеров, соединенных посредством TCP/IP или UDP/IP сети. Некоторые (или все) машины могут быть в одном ``кластере''. В сети может быть более одного кластера, но каждая машина будет принадлежать только одному из них. Кластеры являются логическими объектами: они могут быть созданы или удалены, членство в них подвергается изменениям без необходимости изменения любого физического свойства сети.
Компьютеры одного кластера могут использовать DIPC для передачи данных и их синхронизации - без вмешательства в работу других кластеров в любом виде, даже в том случае, если они также используют DIPC при выполнении приложений. Другими словами, в течение всего того времени, когда DIPC задействована, компьютеры никогда не взаимодействуют с другими машинами вне пределов своего кластера в любой форме.
Можно осуществить обмен данными между программами, выполняющимися на различных машинах в кластере, который делает DIPC распределенной системой, или выполнять всю гамму процессов разрешающего работу DIPC приложения на единственной машине. Процессы должны вести себя так, будто они используют нормальную IPC System V, поскольку явной ссылки на любой частный компьютер в DIPC нет. Некоторая программа может использовать различные компьютеры в процессе обращения с целью ее успешного завершения, тем самым, освобождая находящуюся в зависимости программу на других машинах с определенными адресами. Отсюда также следует, что программисты могут использовать одиночные машины для разработки своих приложений, а позже выполнять их на многомашинном кластере. Другими словами, пользователь может по своему усмотрению осуществить конечное отображение ресурсов, требующихся программе, на доступных физических ресурсах (cм. в качестве примера программу в каталоге /examples/pi).
В программах, использующих DIPC, могут возникать два вида ошибок:
Процесс попытки вывода системы из ошибочной ситуации (такой, как ошибка сети) сложен, а иногда и невозможен, что добавляет сложности DIPC. Таким образом, когда DIPC обнаруживают ошибку, они не пытаются осуществить повторное выполнение, а делают в точности то, что и IPC: пытаются информировать приложение об ошибке через код возврата, или, в случае, когда процесс пытается получить доступ к разделяемому сегменту памяти через сигнал (SIGSEGV). Остальное возлагается на приложение. Следует помнить, что только ``ответственные'' процессы будут проинформированы об ошибке - для того, чтобы они предприняли что-нибудь, - а не все процессы распределенной программы.
DIPC пытаются что-либо предпринять не более одного раза. Это либо получается, либо не получается, однако повторных попыток не делается (в смысле: ``не более одного раза''). Это означает, что один и тот же запрос не имеет возможности быть обработанным более одного раза.
Следует отметить, что ошибки могут порождаться невнимательным отношением к системе. Например, структура IPC может быть окончательно удалена на одном компьютере, а другие могут не знать об этом. Они могут считать, что структура продолжает существовать - это может вызвать затруднения в дальнейшем (см. программы в каталоге tools, частично разрешающие эту проблематику).
Процессы в кластере могут использовать один и тот же ключ для получения доступа к структуре DIPC. Эта структура должна быть создана первой. Это делается одним из системных вызовов xxxget (shmget(), semget() или msgget()). После создания и инициализации другие процессы, возможно, на других машинах, могут получить доступ к этой структуре. В данном случае ключ имеет одинаковый смысл для всех компьютеров в пределах кластера. Другими словами, компьютеры в кластере имеют общее ключевое пространство DIPC.
Много наработанного программного обеспечения с закрытыми исходными текстами может использовать IPC System V в процессе функционирования, а некоторое - использовать ключи. Поскольку эти программы могут нуждаться в наличии ряда машин в составе кластера, важно обеспечить их работу без конфликтов - с помощью DIPC. Поэтому необходимо ввести в кластер два типа отличающихся друг от друга ключей IPC:
Таким образом, для предоставления возможности запуска старых программ, соответствующие структуры IPC с набором локальных ключей должны находиться в группе компьютеров. И наконец, локальные ключи имеют тип по умолчанию, поэтому создание распределенного ключа требует от программиста явного добавления IPC_DIPC к другим пользовательским флагам в процессе создания структуры IPC или получения доступа к ней с помощью системного вызова xxxget().
Если не обращать внимания на приведенное выше требование, то структура DIPC
может использоваться полностью прозрачно. Даже при написании современных
программ, единственная вещь, которую программист должен сделать -
это указать флаг
DIPC_IPC.
В этом разделе описывается, как используется TCP. Для получения дополнительной информации о UDP, пожалуйста, обратитесь к разделу о UDP/IP.
Обычно пользовательские программы DIPC взаимодействуют только с локальным ядром компьютера, на котором выполняются. Запросы пользовательских программ на действия DIPC, либо синхронного типа - подобно системным вызовам, которые предназначены для удаленного исполнения, - либо асинхронного типа - подобно попыткам чтения разделяемой памяти, чьи страницы не доступны на локальном компьютере, - направляются ядру. Все такие запросы помещаются в один связанный список. Идентификатор процесса запрашивающей пользовательской задачи запоминается и используется для поиска данного начального запроса при возвращении результатов. Этим путем результаты могут быть корректно доставлены в пользовательскую программу.
Ядро в свою очередь будет обращаться к части DIPC, образующей пользовательское пространство (dipcd) для действительной реализации таких запросов. Это значит, что присутствие dipcd не заметно для пользовательской программы и в течение всего периода, когда он затрагивается, ядро обслуживает его запросы.
Часть dipcd внутри ядра находится в постоянном ожидании таких запросов. В момент, когда она отыскивает новый запрос, другие части dipcd активизируются и обрабатывают ситуацию. Эти части получают все необходимые данные (например, параметры системного вызова) для генерации запроса изнутри ядра и возвращении каждого результата в ядро, после чего они будут возвращены исходному пользовательскому процессу.
Именно dipcd реально исполняет удаленные функции, передает любые данные по сети или решает, какой компьютер может читать распределенную разделяемую память или писать в нее. Он также содержит необходимую информацию о структурах IPC в системе и выполняет арбитраж процессов для различных машин, желающих получить доступ к определенным структурам в определенное время.
Необходимо создавать условия, чтобы dipcd смог получить доступ к требующейся информации в структурах ядра. Новый системный вызов, перекликающийся с прочими вызовами IPC System V, добавлен в Linux только с этой целью; dipcd и другие ``инструменты'' DIPC (такие как dipcker) используют его для передачи данных в ядро и из него. Этот новый системный вызов (известный в программах DIPC как dipc()) предназначен для использования dipcd и другими связанными с ним программами. Пользовательские программы непосредственно применять его не должны.
Важно помнить, что системные вызовы IPC, инициированные dipcd, всегда исполняются локальным ядром, даже, когда работа происходит с распределенными структурами IPC. Это подпадает в зону действия ``специального соглашения'' о процессах dipcd в ядре с поддержкой DIPC.
Демон dipcd ``раздваивает'' нужные процессы для выполнения
своей задачи. Вы можете видеть, что все процессы имеют свои собственные
исходные тексты. Ниже приводится список процессов
dipcd
(их осложняют перекрестные ссылки, поэтому для понимания написанного
может понадобится ``многопроходное'' чтение):
Здесь находится функция main() программы dipcd. Только один back_end может присутствовать на каждом компьютере в кластере. back_end и front_end (см. ниже) - это единственные процессы dipcd, которые используют fork() для создания других процессов: back_end запускает систему - он регистрирует себя в ядре, как процесс, ответственный за обработку запросов DIPC, - читает конфигурационный файл, инициализирует переменные и раздваивает задачу front_end. Если машина, на которой он запущен, является арбитражной, то он также раздваивает и арбитражный процесс.
После этого back_end зацикливается на сборе запросов из ядра и связанных с ними данных - в те моменты, когда это возможно. Эти запросы (наряду с другими) могут быть предназначены для чтения распределенной разделяемой памяти и записи в нее, а также могут запрашивать сведения о некоторых структурах IPC. При этом, back_end будет раздваивать процесс employer (см. ниже) для обработки каждого из этих запросов.
Процесс ответственный за обработку входящих запросов и передачу данных для компьютера по сети. На каждой машине в кластере DIPC может быть только один процесс front_end. Его предназначение объясняется тем, что в сетях TCP/IP для подсоединения к компьютеру вам нужно знать не только IP-адрес соответствующей машины, но и номер порта TCP; dipcd при работе создает неизвестное заранее число процессов и многие из них требуют получения информации по сети. Таким образом, для избавления от проблемы, возникающей, когда каждый процесс использует собственный номер порта TCP, было решено обрабатывать все входящие запросы единственной общей задачей. В результате, каждый процесс ``знает'' номер порта TCP, который должен использоваться для подключения к другому компьютеру с поддержкой DIPC.
Каждый процесс для взаимодействия с другими машинами может подключаться прямо к front_end любого компьютера. (Это не приводит к взаимодействию с referee. См. ниже.) Если входящее соединение предназначено для выполнения полезной нагрузки, то front_end раздваивает рабочий процесс для обработки. В противном случае он только переправляет входящие данные процессу, для которого они предназначены и который может быть employer, ожидающим результатов, или менеджером разделяемой памяти (см. shm_man).
Играет важную роль в налаживании порядка в системе. Во всем кластере может быть только один referee, следовательно, он может выполняться только на одном из компьютеров. Для того, чтобы DIPC работала, каждый компьютер должен знать адрес машины, на которой выполняется referee. Подобно случаю с front_end, referee имеет свой собственный номер порта TCP, и прочие процессы могут взаимодействовать непосредственно с ним; referee хранит всю информацию о действующих структурах IPC в нескольких связанных списках (в документации DIPC на них ссылаются, как на арбитражные таблицы). Наличие одних списков связано со структурами IPC, которые уже созданы, а других - со структурами, которые удаленный процесс пытается создать. Такой подход приводит к возложению на referee функции сервера имен DIPC.
В этом случае referee предоставляет механизм ``черного хода'' (используемый в доменных сокетах UNIX), посредством которого процессы могут посылать свои команды и принимать определенную информацию ( См. документацию на программу dipcref (в каталоге tools) для получения дополнительной информации. См. также раздел ``Арбитраж'', находящийся ниже).
Создается на машинах, которые владеют сегментами разделяемой памяти (машины, которые сначала создали соответствующие структуры) как менеджер разделяемой памяти. Имеется по одному процессу shm_man для каждой распределенной разделяемой памяти в системе. Он исполняется задачей employer, которая успешно обработала shmget(); shm_man определяет, кто может читать разделяемую память или записывать в нее и имеет соответствующий счетчик. Он также управляет передачей содержимого разделяемой памяти на нуждающиеся в нем компьютеры. shm_man будет присоединять разделяемую память к себе. Это предохраняет разделяемую память от разрушения, если она удаляется (shmctl() вследствие команды IPC_RMID), а все процессы в машине-создателе отсоединяют ее от себя. Это может привести к осложнениям, если иные процессы на других компьютерах продолжают нуждаться в разделяемой памяти.
Нет необходимости в процессах, раздваиваемых для обработки набора семафоров и очередей сообщений на компьютере, который создал их (т. е. нет sem_man и msg_man). Только в случае с разделяемой памятью вводится управляющий процесс. Это происходит по следующим причинам:
Запускается для обработки при удаленном исполнении системного вызова (такого, как shmctl()) или для обработки других видов запросов (таких, как запросы на чтение/запись разделяемой памяти). Он соединяется с соответствующим компьютером (например, с тем, на котором структура IPC создана первой) и затем перенаправляет необходимые данные ответственному процессу (например, front_end) - с ожиданиями подтверждений. Он использует механизм тайм-аута для обнаружения возможных сетевых или машинных проблем.
Запускается процессом front_end для исполнения запрашиваемых действий. Запросы могут приходить от employer, referee или shm_man и включать исполнение удаленного системного вызова или пересылку содержимого разделяемой памяти из компьютера в компьютер. Для успешного завершения работы worker может подключаться к оригинальной запрашивающей машине и предоставлять соответствующие результаты; worker может обратиться к прокси и оставаться на связи с ним после реализации такого соответствия (См. раздел о прокси для получения более подробной информации).
Функция raise() имеет следующий вид:
int raise(int sig);
int main()
{
int a,b;
printf("Число : ");
scanf("%d",&a);
printf("делится на : ");
scanf("%d",&b);
if(b==0)
raise(SIGFPE);
else
printf("Результат = %d\n",a/b);
return 0;
}
Для передачи сигнала некоторому процессу применяется функция kill(), синтаксис которой приведен ниже.
#include <signal.h>
int kill(pid_t pid, int signalnumber);
Потоки позволяют ``разветвить'' задачи для их параллельного выполнения и предоставить совместный доступ к общему адресному пространству. К сожалению, иногда потоки могут не поддерживаться. Это означает, что если в программе желательно выполнять множество действий в одно и то же время, то в ней нужно использовать системный вызов fork(), предполагая, что общего адресного пространства нет, и заботиться о средствах связи между процессами.
Другим способом разрешения данной проблемы является реализация процессом его предназначения настолько быстро, насколько это возможно - при этом способе процессы отрабатывают один за другим; dipcd использует оба метода: некоторые из процессов раздваиваются, когда ожидается их активность в течение длительного времени (например, referee раздваивается), а некоторые процессы выполняются последовательно, с надеждой, что запросы на обслуживание не будут подавлять их (shm_man работает таким образом).
На рис. 1 показаны взаимоотношения между процессами dipcd и последбвательность их создания.
Различные части dipcd используют структуру, называемую ``сообщением'' (не путайте с сообщениями IPC) для передачи любой информации между собой. В эти сообщения включаются: IP-адреса отправителя и получателя, локальный pid отправителя, функция для реализации, необходимые аргументы и т.д. В некоторых случаях может потребоваться больше данных, чем вмещает структура message - такая информация может ``сопровождать'' сообщение. Содержимое сообщения IPC или структуры msgid_ds, использующееся в msgctl() вследствие команды IPC_SET, - это два примера данных, которые посылаются после сообщения dipcd.
Каждое сообщение имеет поле запроса, которое определяет процесс ``назначения''.
Оно может принимать значения REQ_DOWORK - для рабочих, REQ_SHMMAN
- для менеджера разделяемой памяти и
REQ_REFEREE - для арбитра.
Ответные сообщения содержат в своих полях запроса REQS_DOWORK,
RES_SHMMAN либо RES_REFEREE - в зависимости от того, какой из процессов
отвечает данным сообщением.
TCP/IP или UDP/IP сокеты являются главным средством передачи информации от машины к машине; dipcd должен быть проинформирован о том, какой из этих протоколов в первую очередь использовать с помощью опций командной строки при запуске.
Доменные сокеты UNIX используются для коммуникаций между задачами dipcd, которые всегда выполняются на одном компьютере. Применение сокетов в каждом из случаев унифицирует процесс обмена данными между этими процессами. Сокеты UNIX создаются в домашнем каталоге dipcd.
Процессы, которые устанавливают сокеты TCP/IP - это referee и front_end. Все внутримашинные коммуникации должны вызывать один из них. Процессы, которые устанавливают доменные сокеты UNIX - это employer (для приема каждого результата от front_end на локальной машине), referee (для реализации механизма ``черного хода''), менеджер разделяемой памяти (для приема запросов, связанных с распределенной разделяемой памятью, которой он управляет, а также для реализации механизма ``черного хода'') и worker, когда он переходит к исполнению системного вызова semop(). В случаях с shm_man и employer все данные от других компьютеров первоначально посылаются в TCP/IP сокет front_end, а он копирует их в доменные сокеты UNIX. Доменный сокет UNIX referee доступен локально с помощью средства dipcref. Процесс worker принимает файловый дескриптор, соответствующий межсетевому сокету, когда раздваивается процессом front_end; таким образом, он может непосредственно взаимодействовать с удаленными процессами. Прокси принимают данные от front_end посредством сокетов UNIX.
Имя доменного сокета UNIX для employer назначается примерно так: сначала следует строка DIPC, затем идет тип структуры IPC (SEM - для семафоров, MSG - для очередей сообщений и SHM - для разделяемой памяти) плюс соответствующий структуре IPC ключ и, наконец, идентификатор процесса employer. Это делает имя сокета уникальным, поэтому результаты могут быть отосланы назад ``правильному'' employer. Например, DIPC_SEM.45.89 - дается employer с идентификатором процесса 89, который обрабатывает запрос семафора. Набор семафоров имеет ключевой номер 45. Имя сокета менеджера разделяемой памяти также назначается аналогичным способом, за исключением того, что оно не включает число, соответствующее его идентификатору процесса, так как некоторые процессы могут потребовать связать их без указания таких номеров. Фактически процессы, запрашивающие доступ к разделяемой памяти, не осведомлены о процессе, который управляет этой памятью (См. в разделе о прокси, как эти процессы устанавливают доменные сокеты UNIX).
Некоторые процессы должны использовать сокеты TCP/IP в большинстве случаев информационного обмена (например, между shm_man и front_end, который выполняется на компьютере-читателе разделяемой памяти или писателе), поскольку они обычно находятся на различных компьютерах. Однако бывает, что оба процесса располагаются на одной машине. Для поддержки общих алгоритмов при этом также применяются сокеты TCP/IP, но на сей раз адреса заменяются на так называемые разворачивающие адреса.
Может возникнуть ситуация, когда более одного процесса в кластере стремятся создать структуру IPC с одним и тем же ключом. Эти процессы могут протекать на одной или на нескольких машинах. Поэтому, для предотвращения нежелательных взаимодействий вследствие попыток разных процессов делать одно и то же и предотвращения возможного введения целой системы в противоречивое состояние, создание структуры IPC должно выполняться автоматически: пока один процесс пытается создать структуру IPC, ни один прочий процесс не должен пытаться сделать это с идентичным ключом.
Части ядра, относящиеся к DIPC, препятствуют тому, чтобы более одного процесса на одной машине могли создать структуру IPC в одно и то же время. Они последовательно упорядочиваются внутри ядра. Достижение этого эффекта в пространстве всего кластера возможно введением специального процесса, ответственного за такую работу: он будет играть роль арбитра для запросов от различных машин и регистрировать необходимую информацию о всех структурах IPC в системе. Дополнительно он будет контролировать попытки удалять структуры IPC или, напротив, манипулировать ими. Этот процесс и называется referee.
Может быть только один арбитр в пределах кластера. Все машины в данном кластере должны знать, на каком из компьютеров в текущий момент выполняется арбитр, и обращаться к нему при необходимости. Фактически единственный арбитр помещает две или более машины в кластер. Другими словами, кластер создается машинами с одним арбитром. Адрес арбитра может быть задан системным администратором с помощью конфигурационного файла dipc.conf. Изменение адреса арбитра на компьютере перемещает этот компьютер в другой кластер. Машина, на которой выполняется процесс арбитра, может работать в кластере, как и всякая другая машина.
При обычной IPC системные вызовы исполняются локально. Данные, предоставленные процессом как параметры системного вызова, копируются в ядро и удерживаются там. Каждый вызов IPC должен возвратить некий результат в адресное пространство вызывающего процесса. Вызывающий процесс не сможет продолжиться до тех пор, пока к нему не вернутся результаты. В течение этого времени он находится в ядре в состоянии ожидания. Период времени между генерацией вызова и получением ответа может сильно варьироваться для различных системных вызовов и зависеть от состояния структуры IPC.
Некоторые
вызовы (например, xxxctl() вследствие команды
IPC_STAT)
отрабатывают быстро, другие (например, вызов semop()) - могут
отнимать очень длительное, если не бесконечное время:
Сначала параметры копируются в ядро (1), а затем возвращаются результаты (2).
Таким образом, системный вызов IPC требует осуществления двух операций копирования между адресными пространствами пользователя и ядра. Обратите внимание на то, что порция копируемых данных (параметры или результаты) может быть очень маленькой (одно целое число, совпадающее с кодом ошибки) или весьма большой (содержимое сообщения IPC).
В дальнейшем помните, что программа dipcd выполняется в пользовательском адресном пространстве и применяет обычные средства взаимодействия с ядром. Не подразумевается также, что пользовательский процесс обязательно выполняется на машине владельца. Под ``данными'' понимаются либо входные параметры, либо результаты.
Удаленный вызов процедур (Remote Procedure Call - RPC) применяется для исполнения системного вызова на удаленном компьютере. Для обеспечения ``прозрачности'' ни один из процессов, использующих DIPC, не должен ``видеть'' какие-либо изменения в сравнении с нормальной (локальной) активностью IPC. К тому же, данные процесса копируются в память ядра. Затем dipcd переносит эти данные в свое адресное пространство и передает их по сети компьютеру, ответственному за обработку запроса. Это должен быть компьютер, на котором структура IPC создана в первую очередь, - в этом случае он называется владельцем данной структуры (см. раздел о владельцах для получения более подробной информации). Удаленный dipcd будет копировать вновь прибывшие данные в пространство ядра машины-владельца. В результате, при такой симуляции системного вызова на целевом компьютере получается три копирования и одно ``задействование'' в сети - для процесса.
После этого системный вызов может исполняться dipcd на удаленном ядре, а результаты будут отсылаться назад тем же самым способом, который описан выше: удаленное ядро будет копировать данные в пользовательское пространство, после чего dipcd сможет передать их по сети; dipcd на стороне оригинального процесса принимает эти данные и передает их своему локальному ядру. Наконец, данные копируются в адресное пространство оригинального процесса:
{Генерация вызова через сеть:
(Запрашивающий компьютер) | (Запрашиваемый компьютер)
процесс-1-> локальное ядро |
| |
+-2-> локальный dipcd --|-3->dipcd владельца-4->удаленное
| ядро
|
Получение результатов: |
локальный~dipcd~<--|-6-dipcd владельца<-5-удаленное
| | ядро
процесс <-8-локальное ядро<-7-+|
Процесс приостанавливается до тех пор, пока результаты не возвратятся.
Как видно, пользовательский процесс взаимодействует лишь с локальным ядром и не отмечает изменений при вызовах подпрограмм IPC System V.
Помните, что передача данных по сети требует дополнительного копирования в ядро и из него. Это происходит вследствие ``дизайна'' сетевой поддержки внутри ядра и поэтому неизбежно.
Следующий алгоритм отображает, как производится решение проблемы удаленного исполнения операций.
ЕСЛИ присутствует dipcd и вызывающий процесс - не dipcd ТО
ЕСЛИ операция поддерживается DIPC ТО
ЕСЛИ операция - в достоверной распределенной структуре и
это - не компьютер владельца ТО исполнить вызов удаленно
КОНЕЦ
Очевидно, что доступ к сети обеспечить весьма непросто. В некоторых операционных системах используется переотображение адресов (с помощью блока управления памятью (Memory Management Unit - MMU) - для предоставления доступа к части памяти процесса другому процессу), следовательно, пересылки данных между адресными пространствами ядра и пользователя должны быть очень ``дешевыми''. К сожалению, Linux не поддерживает этого метода при реализации механизмов IPC System V.
Одним из возможных путей уменьшения числа копирований между адресными пространствами пользователя и ядра является воздержание от копирования данных из адресного пространства процесса в память ядра в тех случаях, когда нужный процесс на вызываемой машине еще не выполняется, а данные снова будут скопированы в адресное пространство dipcd для посылки по сети. Этот подход также помогает избегать копирований данных, поступающих из сети, в ядро, когда известно, что они будут скопированы повторно в адресное пространство пользовательского процесса.
Можно использовать и ``заглушки'' в пользовательском пространстве для перемещения обычного кода IPC System V в ядро. Код "заглушки" должен протестировать данные и цель и решить, нужно ли послать данные по сети, не беспокоясь о локальном ядре. Другой процесс на вызываемой машине должен принять эти данные, выполнить операцию и передать результаты назад, после чего они доставляются оригинальному процессу-заглушке. Для этого необходимо предоставить возможность этому процессу заменить обычные заглушки IPC. Следует также обеспечить наличие объектных файлов, которые должны прикомпоновываться к программе или, что еще лучше, изменить стандартные библиотеки C.
Эти две проблемы можно сформулировать так:
Первая причина состоит в том, что решение рассматриваемых проблем указанными методами в простой и удовлетворительной форме не представляется возможным.
Вторая причина состоит в том, что необходимость прикомпоновки специального объектного файла к программе может столкнуться с помехами и вызвать ошибки. К тому же часто нет доступа к исходным текстам стандартных библиотек C. В любом случае обновление DIPC может потребовать перекомпиляции использующих его программ. Еще одним сдерживающим фактором является то, что более старые программы, которые не скомпонованы с измененными заглушками, не смогут информировать DIPC о своем ``присутствии'' и не будут предоставлять ему необходимую информацию. DIPC должна "знать" обо всех ключах IPC в кластере, даже если они представляют собой обычные структуры IPC. Программы, скомпилированные без новых заглушек, могут привести DIPC к недееспособности.
Необходимо также иметь в виду, что некоторые пользователи могут пожелать использовать DIPC посредством языков, отличных от C, - при этом могут воникнуть неразрешимые проблемы предоставления альтернативных объектных файлов поддержки всех этих языков.
Использование среды ядра для информационной пересылки и приостановления выполнения задачи дает ряд преимуществ:
Нормальное поведение программ, желающих воспользоваться механизмами System V IPC для обмена данными, заключается в следующем. Процесс сначала создает структуру IPC посредством доступного системного вызова xxxget(), используя заранее оговоренный ключ. Другие процессы после этого могут использовать xxxget() для получения доступа к этой же ранее созданной структуре. При ``нормальной'' IPC первый процесс инициирует ``установку'' адекватных структур внутри ядра. При последующих вызовах xxxget() просто возвращается значение числового идентификатора, которое может использоваться для обращения к структуре. Таким образом, все перечисленные процессы будут использовать одну структуру и манипулировать ею.
DIPC пытаются ``скрыть'' эту ситуацию настолько, насколько возможно. Процессам на разных машинах нужно использовать один и тот же ключ, чтобы обращаться к одной структуре IPC. При DIPC, когда процесс желает организовать или получить доступ к структуре IPC с определенным ключом, локальное ядро в первую очередь отслеживает, используется ли уже данный ключ. При ``нормальной'' IPC эти процессы очень похожи. Если структура найдена, запрос обрабатывается локально, без обращения к арбитру. Но если структура IPC с указанным ключом не найдена, то арбитру нужно осуществить поиск и выяснить, используется ли уже такой ключ в кластере. Арбитр ищет ключ в своих таблицах и сообщает запрашивающему процессу, найден ключ или нет и, если найден, является ли он распределенным ключом или нет. Арбитр может ответить незамедлительно, если ключ присутствует или отсутствует, но ни одна из машин не запрашивает его. После посылки информации в запрашивающий компьютер арбитр ожидает подтверждения, создала ли данная машина локально структуру IPC с этим ключом или нет, чтобы при необходимости смочь обновить свою информацию. Но если ключ не найден, а арбитр уже послал соответствующее сообщение машине, то он не отвечает на все последующие запросы такого ключа, пока машина не ответит, создала ли она структуру IPC. Когда информация поступит, арбитр сможет обслужить прочие поступающие запросы.
Такой централизованный (последовательный) алгоритм прост и легок в реализации. Распределенный алгоритм может быть комплексным, требующим большого числа обменов сообщениями. Также считается, что на создание структуры IPC затрачивается относительно малая доля времени, затраченного на выполнение программы.
В двух приведенных ниже таблицах (табл. 6 и 7),
тип_удаленного_ключа
- это тип, зарегистрированный арбитром, и возвращенный запрашивающему
компьютеру.
тип_запрашиваемого_ключа -
желательный для локального запрашивающего компьютера. Во всех
случаях, сам ключ не найден в структурах IPC локального ядра.
В табл. 6 показано, как процесс решает, может ли он при необходимости создать ранее не существовавшую структуру IPC (xxxget() с флагом IPC_CREAT).
| Тип запрашиваемого ключа | Тип удаленного ключа | Действие |
| локальный | не_существующий | создание |
| локальный | локальный | создание |
| локальный | распределенный | ошибка |
| распределенный | не_существующий | создание |
| распределенный | локальный | ошибка |
| распределенный | распределенный | ошибка |
В табл. 7 показано, как процесс решает, может ли он создать
структуру при необходимости получения доступа к предварительно созданной
структуре IPC (xxxget() без флага IPC_CREAT).
| Тип запрашиваемого ключа | Тип удаленного ключа | Действие |
| локальный | не_существующий | ошибка |
| локальный | локальный | ошибка |
| локальный | распределенный | ошибка |
| распределенный | не_существующий | ошибка |
| распределенный | локальный | ошибка |
| распределенный | распределенный | проверка |
Проверка подразумевает выполнение действий с целью получения гарантии того, что указанные флаги для xxxget() и права доступа к распределенной структуре IPC позволяют процессу получить доступ к структуре. В успешном случае, ``действие'' становится ``созданием''.
В данном случае, правила проверки флагов близки к правилам для обычной IPC. Например, указание IPC_EXCL и IPC_DIPC при одном системном вызове приводит к ошибке, если структура IPC с указанным распределенным ключом уже присутствует на другой машине. Метод, применяющийся для проверки прав доступа: имя эффективного пользовательского логина, наряду со всеми параметрами xxxget() передается машине, которая имеет структуру с распределенным ключом. Затем dipcd исполняет системный вызов xxxget() на этом компьютере. Если он завершается успешно, то осуществляется попытка выполнения тех же действий на оригинальной запрашивающей машине. Если любое из приведенных действий завершается ненормально, то и оригинальный xxxget() также потерпит неудачу. Для получения более подробной информации о том, как DIPC обрабатывает имена пользователей, обратитесь к разделу о безопасности.
Если ``действие'' - это ``создание'', локальная структура будет создана даже в том случае, если иная структура с тем же самым ключом присутствует где-либо еще в кластере. Короче говоря, на любой машине, где определенные процессы используют ключ для коммуникаций, есть структура с этим ключом.
Ниже показано, как DIPC обрабатывает запрос о новом создании IPC.
Первая фаза: поиск
Сеть
(Запрашивающий компьютер) | (Арбитрирующий компьютер)
|-1->back_end >-2-+ |
| |
ядро|<--------6--employer --3-------|-> referee
| | |
+-5-< front_end <-|<-----4-+
Предполагается, что структура IPC с указанным ключом на вызывающей машине не заменяется. В этом случае back_end находит запрос о поиске ключа (1) и раздваивает employer для его обработки (2); employer вызывает referee и ``спрашивает'' его (3); referee посылает ответ (нашел или нет ...) процессу front_end запрашивающего компьютера (4) и затем ответ доставляется оригинальному employer (5), который отдает результаты назад в ядро (6). Ядро должно однозначно определить, может быть создана структура IPC или нет. По ходу дела referee запускает таймер - для того, чтобы гарантировать своевременное предоставление информации. После этого может начинаться вторая фаза (непосредственная передача).
Вы можете обратиться к предыдущей схеме для понимания второй фазы.
Во время фазы непосредственной передачи referee информируется
о результате работы системного вызова xxxget(). Все действия
аналогичны действиям во время предыдущей фазы:
back_end
находит сведения о результате работы xxxget() (1) и информирует
referee (2 и 3), но на сей раз целью действий (4), (5) и
(6) является обеспечение гарантии того, что исходный запрашивающий
процесс будет продолжен только после того, как информация referee
будет обновлена.
Рассмотрите следующий алгоритм, показывающий, насколько часть ядра DIPC зависит от того, как создается новая структура или происходит доступ к ней. Символ (*) нужен для индикации возможного привлечения сети.
НАЧАЛО
ЕСЛИ указанный ключ используется в локальной структуре ТО
~КОНЕЦ~алгоритма
ЕСЛИ dipcd присутствует и вызывающий процесс - это не dipcd ТО
искать с помощью referee ключ (*)
ЕСЛИ ключ найден ТО
протестировать совместимость запрашиваемой структуры с
удаленной структурой. В СЛУЧАЕ если обе структуры
являются распределенными
ВЫПОЛНИТЬ проверку прав доступа (*).
ЕСЛИ все условия обеспечены ТО попытаться
создать структуру
информировать referee о результатах (непосредственная передача)(*)
КОНЕЦ
Проблемы с back_end и employer мгновенно передаются
ядру. Прочие ошибки обнаруживаются с помощью механизмов тайм-аута
для employer и referee.
Если в системе отсутствует возможность получения необходимой информации от referee, то принимается, что данный ключ не используется, и она ведет себя так, как будто referee сказал ``да''. Это значит, что система будет проявлять себя ``владельцем'' (см. следующий раздел). Хотя такой подход и заставляет процесс продолжаться, он может создать проблемы тогда, когда структуры IPC с тем же самым ключом будут на других машинах. Аналогичные проблемы могут возникнуть, если во время непосредственного обмена не окажется с referee. В таком случае будет наступать тайм-аут, а referee будет предполагать, что запрашивающий процесс при попытке создания структуры завершился ненормально. Таким образом, referee может владеть ошибочной информацией.
Данная концепция применима только к структурам IPC с распределенными ключами. Когда процесс впервые создает структуру IPC в пределах кластера при помощи xxxget(), компьютер, на котором он выполняется, становится ее ``владельцем''. Все операции манипулирования с данной структурой проводятся на машине-владельце. Фактически это означает, что может существовать только один активный экземпляр структуры IPC. Это свойство сильно влияет на простоту и семантику при обеспечении сохранности DIPC.
При DIPC процесс-производитель и процесс-потребитель данных могут состоять в следующих отношениях:
Все запросы об удалении структуры IPC (xxxctl() вследствие команды IPC_RMID) посылаются машине-владельцу. Если структура действительно удалена, то об этом информируется referee, который, в свою очередь, информирует другие машины со структурами с таким же ключом - с целью удаления и этих структур. Удаление делается при наличии прав суперпользователя.
Схема ниже показывает, как обрабатывается ключевое удаление:
Сеть
(Компьютер-владелец) | (Арбитрирующий компьютер)
|
|-1->back_end >-2-+ |
| | |
ядро | employer-3--|-> referee
| |
Здесь структура IPC удаляется на компьютере-владельце;
back_end
находит запрос об этом (1) и раздваивает employer для его
обработки (2), employer информирует referee об удалении
(3).
На следующей схеме показано, что происходит после того, как referee получает эту информацию:
Сеть
(Арбитрирующий компьютер) | (Компьютер с ключом)
|
| |
referee~--4------|-> front_end -->worker -6->| ядро
| | |
| +-7--<---|
То, что показано выше, происходит на всех компьютерах, которые имеют созданные структуры IPC с данным ключом: referee посылает запрос об удалении ключа front_end (4), который раздваивает worker для реализации xxxctl() и непосредственного удаления с привилегиями суперпользователя; worker получает результаты этого процесса, но referee не беспокоится (не ожидает) об этом.
Дополнительно referee проверяет, находится ли структура IPC в разделяемой памяти и только ли один компьютер имеет такую структуру. Если это так, то посылается запрос менеджеру разделяемой памяти (shm_man) этой машины об отсоединении от разделяемой памяти. Это можно сделать по следующей причине: известно, что нет такого процесса на любом из компьютеров, имеющих разделяемую память, который будет обращаться к ней, так как при изначальном присоединении (предотвращение разрушения разделяемой памяти, когда все процессы на машине-владельце завершились) не ставилась цель захватывать что-либо еще. На следующей схеме показаны соответствующие действия для случая, когда сказанное выше справедливо:
Сеть
(Арбитрирующий компьютер | (Владелец разделяемой памяти)
|
referee--8------|-> front_end --9-->shm_man
|
В итоге referee информирует shm_man об отсоединении (8 и 9). В данном случае referee также не ожидает подтверждения о том, что shm_man действительно отсоединился.
Далее показаны остальные действия:
Сеть
(Компьютер-владелец) | (Арбитрирующий компьютер)
|
| |
ядро |<--12--employer | referee
| | | |
| +-11-<front_end<-|-----10-+
Теперь referee сообщает оригинальному employer о том, что тот может продолжать работу (10 и 11); employer далее сообщит ядру о том, что и исходный пользовательский процесс может продолжаться (12).
Не предпринимается особых действий, когда владелец не может быть проинформирован об удалении. В таком случае владелец удалит структуру в то время, как другие машины, имеющие структуры с таким же ключом, не будут об этом ничего "знать".
Обратите внимание и на то, что возможна ситуация, когда ряд компьютеров временно недоступен или они не могут быстро удалять свои структуры. Как уже было сказано, referee не заботится о таких вещах: не предпринимается специальных действий, если он не может подключиться к компьютеру и сообщить ему об удалении. К тому же, он не ждет подтверждения перед тем, как продолжить работу (См. программы в каталоге tools, позволяющие частично решить такие задачи).
После того, как структура удалена, она может быть удалена ``окончательно'' (это осуществляется во всех случаях, когда имеются очереди сообщений и наборы семафоров). Поскольку структура удаляется окончательно, referee информируется об этом, а также referee окончательно удаляет данную машину из своих таблиц - как ``держателя'' данной структуры. Ниже показано, что происходит в этом случае:
Сеть
(Запрашивающий компьютер) | (Арбитрирующий компьютер)
|
|-1->back_end~>-2-+ |
| | |
ядро | employer--3------|-> referee
|
Когда на компьютере окончательно удаляется структура IPC, об этом сообщается back_end (1). Он раздваивает employer (2) и ``приносит'' эти новости referee (3), который окончательно удаляет свои соответствующие элементы, проверяет наличие такой структуры в разделяемой памяти и является ли действующий компьютер единственным, содержащим эту структуру. Он должен быть владельцем. В этом случае referee действует как показано на схеме:
Сеть
(Арбитрирующий компьютер) | (Владелец разделяемой памяти)
|
referee --4------|-> front_end --5-->shm_man
В итоге referee сообщает shm_man об отсоединении (4 и 5). Все похоже на случай с простым удалением из разделяемой памяти структуры IPC.
Далее следует все остальное:
Сеть
(Компьютер-владелец) | (Арбитрирующий~компьютер)
|
| |
ядро |<----8--employer | referee
| | | |
| +-7-< front_end <-|------6-+
Здесь referee информирует employer о том, что все действия сделаны (6 и 7); employer информирует ядро о том, что исходный пользовательский процесс, который вызвал окончательное удаление, может продолжаться.
Никаких специальных действий не предпринимается, когда
referee
не может быть информирован об окончательном удалении: referee
будет считать, что компьютер по-прежнему имеет структуру и давать ошибочные ответы
о данной структуре другим машинам (См. программы в каталоге tools,
позволяющие частично решить такую задачу).
В системах Linux концепция сигналов была расширена. Это вызвано следующими недостатками старого подхода ANSI-C:
int sigemptyset(sigset_t *sig_m);
int sigaddset(sigset_t *sig_m, int signr);
int sigdelset(setsig_t *sig_m, int signr);
int sigismember(sigset_t sig_m,int signr);
Существует функция для сохранения или изменения маски сигналов:
int sigprocmask(int mode, const sigset_t *sig_m,
sigset_t *alt_sig_m);
int sigsuspend(const sigset_t *sig_m);
Linux не разрабатывался как распределенная система. Множество информации, которую Вы найдете в ней, производится независимо любым из компьютеров и она имеет смысл только на машине, которая ее произвела. Это распространяется и на значения времени, идентификаторов пользователей, идентификаторов групп и идентификаторов процессов. Вы не можете сослаться на процессы с помощью их идентификаторов, взятых с некой машины. Процесса с таковым номером на данном компьютере может просто не быть, или, что еще хуже: вы можете найти полностью обособленный процесс.
Некоторые из этих проблем могут быть решены путем использования альтернативных средств идентификации (например, использования логина вместо идентификатора пользователя; см. раздел о безопасности), а другие решения весьма затруднительны в реализации и могут быть вообще неосуществимы без внесения порции модификаций в ядро Linux при его разработке и реализации, а это может привести к потере совместимости. Так, информация о времени и номерах процессов в структурах IPC, например та, которая возвращается системными вызовами xxxctl() вследствие команды IPC_STAT, на прочих машинах не имеет смысла.
Пользовательские идентификаторы пользователей Linux дифференцированы между ними. Реальные пользователи получают права доступа на какие-либо действия на основе сведений о том, кем они являются (владелец в некоторой группе и др.) в отношении объекта доступа. Значения пользовательских идентификаторов назначаются независимо на каждом компьютере, так что двум различным пользователям на разных машинах могут быть назначены одинаковые идентификаторы. Программы, использующие DIPC, нуждаются в исполнении кода на разных компьютерах - по большому счету, для доступа к структурам ядра. Их вызовы должны обеспечивать некоторый уровень безопасности в системе.
Для DIPC установлено, что пользователь, для которого обеспечивается защита исполнения удаленного системного вызова, должен быть известен на соответствующей удаленной машине под тем же логином. Исполнение удаленных вызовов программ DIPC предполагает наличие определенных эффективных пользовательских идентификаторов наряду с именем пользователя. Очевидно, что с целью обеспечения полезности, и даже значимости, это зафиксированное имя должно однозначно идентифицировать соответствующее лицо на двух машинах.
Единственным исключением из приведенного правила является пользователь root, который имеет максимальные полномочия на Linux-компьютере. Выполнение роли root на одной машине не налагает обязательств выполнять роль root на другой машине. По этой причине все пользователи root преобразуются в одного пользователя с именем dipcd. Администраторы могут контролировать этого пользователя путем корректировки его пользовательского и группового идентификаторов в отношении к другим группам. Программисты могут выбирать права доступа для структур IPC, чтобы разрешить или запретить доступ к ним.
Остерегайтесь случайных конфликтов имен в одном кластере, что может дать возможность неавторизированным пользователям влиять на структуры IPC других лиц. Администраторы должны гарантировать уникальность имени для конкретной персоны в пределах кластера.
Другой мерой безопасности, предложенной Майклом Шмицем (Michael Schmitz), является проблема избавления от вторжения злоумышленников в кластер DIPC. В файле /etc/dipc.allow перечисляются адреса компьютеров, которые могут быть частью кластера DIPC, т.е. ``надежных'' машин. Арбитр будет просто отбрасывать запросы от компьютеров, чьи адреса не находятся в данном файле. Опция -s (secure) заставит back_end также не выполнять никаких действий при запросах от ненадежных компьютеров (Обратитесь к файлу dipcd.doc для получения более подробной информации).
``Подделка'' IP-адресов при DIPC ``не пройдет''. Причиной этого является то, что dipcd всегда использует новые TCP-соединения для подтверждения запросов, т.е. дает подтверждение, что информация будет направляться достоверному компьютеру, а не ``самозванцу''.
Выполнение любого из приведенных ниже условий приводит к тому, что системный вызов DIPC выполняется локально - на машине, сделавшей этот вызов:
На следующей схеме показано ``прохождение'' пользовательского системного вызова DIPC (например, msgsnd()), обрабатываемого с помощью RPC.
Сеть
(Вызывающий компьютер) | (Компьютер-владелец)
|
|-1->back_end>--2-+ | |
| | | |
ядро |<----------9--employer --3-------|->front_end--4-->worker -5->| ядро
| | | | | |
+-8-<front_end<-|------------7-----+ +-6----<|
Здесь back_end отыскивает запросы в ядре (1), причем, адрес машины-владельца должен быть однозначно определен на уровне ядра. Затем back_end раздваивает процесс employer для обработки запроса (2); employer подключается к front_end на машине-владельце (3). После чего front_end раздвоит worker (4), который непосредственно исполнит системный вызов (5) и соберет все результаты (6). Результаты посылаются назад front_end на вызывающий компьютер (7), который передает их оригинальному employer (8). Наконец, employer отдаст результаты ядру (9), откуда пользовательский процесс и получит их.
В сети направление посылки пары запросов может отличаться от направления получения их подтверждений. Для обеспечения гарантии того, что ``гибридизации'' не произойдет, операции над структурами IPC упорядочиваются последовательно: пока процесс на удаленной машине что-либо ожидает, другие процессы, "желающие" использовать ту же самую структуру, также приостанавливаются.
Ошибки, обнаруженные при работе back_end и employer, в виде соответствующего результирующего сообщения об ошибке передаются ядру. При других обстоятельствах ошибки игнорируются и только результирующие сообщения об ошибках выводятся процессами dipcd, которые столкнулись с ними. Только после наступления тайм-аута employer проинформирует об этом ядро.
Далее перечислены поддерживаемые системные вызовы:
Выше было показано, что может выполняться достаточно большое число операций копирования между ядром и пользовательским пространством при одном удаленном системном вызове. Это сильно снижает производительность, особенно, когда копируются большие блоки данных. К счастью, большинство системных вызовов IPC System V передают данные только в одном направлении. Например, msgrcv() только принимает данные, поэтому они копируются из оригинальной задачи в ядро с небольшими затратами. Кроме того, многие другие системные вызовы IPC имеют немного байтов данных, являющихся их параметрами. Одним из примеров может быть xxxctl() с флагом IPC_RMID. Издержки копирования необходимых данных и результатов, даже с учетом задействования сети, незначительны.
Результатом системных вызовов xxxctl() вследствие команды IPC_RMID на машине - владельце, в успешном случае, будет взаимодействие с referee.
В качестве примера рассматривается программа вычисления определенного
интеграла по правилу трапеции. Последовательный вариант вычисляет
![]() разделением интервала
разделением интервала
![]() на
на
![]() равных сегментов и суммированием частных оценок интеграла для
каждого сегмента по формуле:
равных сегментов и суммированием частных оценок интеграла для
каждого сегмента по формуле:
Здесь ![]() , и
, и ![]() где i = 0, 1, ..., n. Если поместить
вычисление
где i = 0, 1, ..., n. Если поместить
вычисление ![]() в отдельную функцию, то последовательный вариант
программы выглядит так:
в отдельную функцию, то последовательный вариант
программы выглядит так:
float f(float x) {
float return_val;
/* Вычисляет f(x).
Запоминает результат в return_val. */
. . .
return return_val;
} /* f */
main() {
float integral; /* Результат вычисления */
float a, b; /* Левая и правая границы */
int n; /* Количество интервалов */
float h; /* Ширина интервала */
float x;
int i;
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', &a, &b, &n);
h = (b-a)/n;
integral = (f(a) + f(b))/2.0;
x = a;
for (i = 1; i <= n-1; i++) {
x += h;
integral += f(x);
}
integral *= h;
printf(''C n = %d трапециями, интеграл \n'', n);
printf("от %f до %f = %f`\n'', a, b, integral);
} /* main */
Обычно shm_man размещает запросы о доступе в связанном списке. Планирование реализуется через фиксированные интервалы. Во всех случаях, когда наступает нужный интервал времени, shm_man просматривает, есть ли запросы, связанные с разделяемой памятью, и если есть, то он ведет себя так, как уже описано. Если запросов нет, то ничего не происходит. Данный интервал (shm_hold_time) нужен для предотвращения эффекта пинг-понга, когда плохо написанные программы на разных машинах пытаются переносить данные в разделяемую память без использования синхронизации. В таком случае, при каждой пересылке затрачивается много ресурсов.
Новый читатель страницы или целого сегмента будет установлен, если:
Прокси - это рабочий процесс, который исполняется системным
вызовом semop() с флагом SEM_UNDO. Когда worker
исполняет такую функцию, он не прекращает свого выполнения, а записывает
сетевой адрес и идентификатор процесса удаленного процесса (процесс,
для которого исполняется системный вызов) и продолжает работу. Противоположные
действия могут создать эффекты semop(), которые должны исчезать
при выходе из worker. Теперь worker становится
прокси и устанавливает доменный сокет Linux с именем PROXY_<IP_адрес_удаленного_процесса>_
<идентификатор_удаленного_процесса>, используя приведенную выше
информацию. Примером может быть: PROXY_191.72.2.0_234.
Отныне он будет исполнять все операции semop() по защите
исходного удаленного процесса независимо от того, указали ему флаг
SEM_UNDO или нет.
Процесс front_end будет проверять присутствие подходящего прокси перед тем, как раздваивать процесс worker для обработки функции semop(). Если прокси присутствует, он подключается к нему с помощью доменного сокета Linux и ``инструктирует'' его о выполнении semop().
Прокси может исполнять любую функцию, допустимую для
worker,
но в текущей разработке процесс не сообщает прокси о необходимости
выполнения чего-либо, отличного от semop().
Когда исходный удаленный процесс останавливает исполнение, все его прокси информируются о завершении и ``делаются'' все необходимые ``отмены''.
По умолчанию DIPC использует TCP/IP, но, начиная с версии 1.0, она также работает с сетевым протоколом UDP/IP. В результате использования UDP значительно повышается скорость пересылки данных по сети, в основном за счет отсутствия перегрузок, связанных с ориентированными на соединение протоколами, например, TCP. Все компьютеры в одном кластере должны использовать одинаковые сетевые протоколы.
UDP не является достоверным - имеется в виду, что вследствие перманентных или временных ошибок некоторые данные могут не доставляться по назначению. UDP не может преодолевать ошибки. Также он не осуществляет проверку контрольных сумм, следовательно, возможно искажение данных. Существуют и иные сервисы, доступные для TCP и отсутствующие для UDP.
Следующим важным замечанием является то, что UDP не фрагментирует пакеты данных: они слишком велики для хранения в буферах ядра или для передачи по сети. Текущая реализация DIPC не применяет сквозной контроль и фрагментацию кода DIPC.
Сказанное выше означает, что:
Поскольку UDP не создает соединений, каждый пакет передаваемых данных должен содержать в себе адрес назначения.
Важно и то, что любой процесс использует номера портов, назначаемые системой при применении сокетов. Это значит, что каждый процесс должен предоставлять полные адреса другим процессам, чтобы взаимодействовать с ними.
Подпроцессы, запускающиеся при использовании referee или
front_end хорошо ``знают'' порты. При чтении UDP-сокета
также предоставляется адрес отправителя: после первого контакта
процессы обмениваются несколькими байтами данных, тем самым получая
полные адреса друг друга.
Для написания параллельных программ с использованием DIPC следует разрабатывать свое программное обеспечение путем создания независимых процессов, которые обмениваются данными с применением механизмов IPC System V, а именно: разделяемой памяти, семафоров и сообщений.
Программирование для распределенных систем требует наличия трех возможностей: удаленного выполнения программ, обмена данными, синхронизации.
Параллельная программа состоит из нескольких процессов. Часть из них может выполняться на данной машине и, по крайней мере, один должен выполняться на удаленном компьютере. Один из процессов обычно выделяется как главный. Он инициализирует структуры данных, используемые программой, так что другие процессы в системе с началом своего выполнения могут войти в определенное состояние.
Для того, чтобы IPC имела смысл, должны выполняться более одного процесса, использующего ее механизмы. При обычной IPC, эти процессы могут быть созданы с помощью системного вызова fork(). За ним должен следовать вызов exec(). В рамках DIPC использовать fork() для создания удаленного процесса нельзя, потому что он создает локальный процесс. Можно ``вручную'' запустить процессы удаленно, т.е. после того, как главная программа подготовила механизмы DIPC (разделяемая память, очереди сообщений или наборы семафоров), она ожидает соответствующее состояние, например, семафоров. После этого другой пользователь может запускать программы с консоли удаленной машины. Теперь эти программы должны использовать предварительные договоренности о семафорах, чтобы информировать главный процесс о своей готовности. Далее пользователь должен уделить внимание тому, чтобы не запускать удаленные программы слишком быстро - из-за возможной неготовности разделяемых структур. Программы-примеры из каталога examples/message работают именно в таком стиле.
Можно также использовать программы, подобные rsh для осуществления задействования удаленных программ. В данном случае главный процесс подготавливает все необходимое и затем раздваивает некий вспомогательный процесс для исполнения скрипта на Shell. Скрипт использует команды rsh для удаленного исполнения программ. Программы-примеры реализации данного метода располагаются в каталоге examples/image. Применение rsh для таких целей имеет определенное достоинство: после того, как вы разработали свою программу, можете просто отредактировать упомянутый скрипт - с целью указания в нем изменений, связанных с компьютерами, на которых вы хотели бы запускать свои программы - без необходимости перекомпиляции вашей программы и других действий. Аналогично перечень удаленных машин могут задать пользователи - без необходимости наличия доступа к исходным текстам вашей программы, - что может оказаться важным преимуществом коммерческих программ.
Еще одно замечание по поводу rsh: если он исполняется очень часто, то inetd может ``выключить'' соответствующий сервис. Вы можете прибегать к редактированию файла /etc/inetd.conf для регулирования подобного поведения.
Большинство программ принимают некие данные, обрабатывают их соответствующими способами и выдают результаты. ``Легкость'' обмена данными в распределенных системах очень важна. В рамках DIPC вы можете использовать для этих целей сообщения или сегменты разделяемой памяти. Разделяемая память - это асинхронный механизм. Программа может получить к ней доступ, когда ``пожелает''. При этом может возникнуть длинная задержка между временем предоставления доступа и временем действительного приема данных. Программа ничего этого ``не замечает''. Сообщения являются очень доступным способом передачи данных. Вы можете передать только те данные, которые захотите, и к тому же - только нужному процессу. Такой коммуникационный стиль называется стилем ``один - одному''. Сообщения можно представить как синхронный способ обмена данными. Программа приостанавливается системным вызовом msgrcv() до тех пор, пока другой процесс не прибегнет к вызову msgsnd(). Программист должен сам решать, какой из двух приведенных методов нужно использовать.
Каждая страница разделяемой распределенной памяти может
иметь одновременно
несколько читателей на различных компьютерах, но для нее может быть
только один компьютер с процессом-писателем. Если DIPC сконфигурирована
с поддержкой режима посегментной передачи, то сказанное применимо
для сегмента целиком. Это значит, что читатели могут иметь ``разделяемую''
память (страницы) в своей локальной памяти и, следовательно, свободно
ей пользоваться; но запись в одну из ``копий'' приведет к недостоверности
данных на других машинах. Чтобы можно было продолжить чтение, содержимое
памяти должно быть снова передано другим машинам. Если DIPC сконфигурирована
с поддержкой режима посегментной передачи, то внутренний контекст
разделяемого сегмента данных передается по сети. Если же процессы
пользуются различными частями разделяемой памяти, вы должны установить
постраничный режим передачи для DIPC, - чтобы программы, соответствующие
процессам на различных компьютерах, могли адекватно читать страницы
разделяемой памяти и записывать в них.
Каждый может применять режим постраничной передачи для увеличения эффективности пересылок данных: чтение всей требующейся информации из сегмента разделяемой памяти, выполнение всех необходимых обработок в локальной памяти и, наконец, размещение результатов, возможно, в иной разделяемой памяти. Разделяемая память рассматривается как ``дверь'' к другим машинам. Пока вы не пользуетесь сегментом разделяемой памяти, то не будете использовать и сеть.
Рассмотрим возможный сценарий использования разделяемой памяти при режиме посегментной передачи. Главный процесс запускается и размещает входные данные в разделяемой памяти. Затем запускаются другие удаленные процессы, которые могут читать данный разделяемый сегмент. Может одновременно быть несколько читателей, причем читать они могут также одновременно. Кроме того, поскольку одно содержимое сегмента пересылается каждой машине, то вероятность возникновения перегрузки при передачах будет невелика. (Это имеет смысл, только если удаленные процессы нуждаются во всех данных из разделяемого сегмента памяти). После обработки входных данных удаленные задачи могут вернуть результаты в тот же или другой сегмент разделяемой памяти, но могут использовать и сообщения. Так как писатель для разделяемой памяти может быть только один, то каждой удаленной машине рекомендуется предоставлять персональный сегмент для возвращения результатов. Таким образом можно организовать параллелизм. Следует напомнить, что DIPC можно использовать, и не придерживаясь рассмотренных выше указаний, но производительность может снизиться.
Постраничный режим передачи DIPC можно применять для того, чтобы позволить процессам параллельно читать и записывать различные части одной и той же разделяемой памяти.
В большинстве случаев, распределенной программе не нужно ``знать'', где исполняется процесс, к тому же в DIPC нет способа, которым программист мог бы явно сослаться на специфический компьютер в сети. Это создает условия адресной ``независимости'' программ. Программист может использовать иные средства опознавания различных процессов. Например использовать поле mtype структуры msgbuf для записи идентификатора, представляющего процесс, или разместить подобную информацию в некотором заранее оговоренном месте разделяемой памяти. Это предоставляет программисту возможность применять логическую адресацию.
Рассмотрим программирование в гетерогенной среде, где размещаются машины с различными архитектурами. Каждая из них может иметь свои, особые способы представления данных. Например, способы представления чисел с плавающей запятой или даже целых чисел могут у них не совпадать. Но размер, как сообщения, так и сегмента разделяемой памяти, выражается в байтах и эти размеры для всех машин идентичны.
При использовании DIPC смысловая интерпретация данных и осуществление любого преобразования возлагаются на приложение. Но нужно найти способ точно установить, нужны ли преобразования форматов для различных машин. В случае с сообщениями, программист может использовать, например, первый байт для индикации типа исходной машины. Принимающий процесс может самостоятельно решить вопрос о преобразовании. В случае с разделяемой памятью все не так просто. Во время чтения разделяемой памяти или записи в нее процесс может быть приостановлен, содержимое разделяемой памяти передано некой машине отличного типа, данные подменены сгенерированными данными и позже переданы назад оригинальной машине. Все происходит ``прозрачно'' для программы. Однако нужно избрать способ информировать программу об этих событиях.
Информирование выполяется двумя прерываниями. Одно из них - DIPC_SIG_WRITER, второе - DIPC_SIG_READER. Если DIPC сконфигурирована с поддержкой их передачи, то первое передается, когда процесс еще только становится писателем (ранее он мог быть просто читателем или вообще не иметь связей с сегментом). При посегментном режиме передачи процесс ``знает'', что имеет эксклюзивный контроль над сегментом. Процесс, например, может записать идентификатор текущей архитектуры в первые байты сегмента и поместить произведенные им данные в разделяемую память. Второе прерывание посылается, когда процесс становится читателем сегмента (ранее он не пользовался его содержимым). Процесс, например, может проверить первые байты сегмента для того, чтобы установить, нужно ли делать какие-либо преобразования. Обратите внимание на то, что прерывание DIPC_SIG_READER генерируется, если данная машина предварительно была писателем, а теперь стала читателем, т.е. ее права доступа стали более ограниченными.
Только что описанные действия производить не очень удобно, если применяется режим постраничной передачи, так как нет способа передать сигналом какие-либо ``лишние'' параметры получателю. Следовательно, не представляется возможным сообщить процессу, какую именно страницу в настоящий момент он читает или записывает. Программист может помочь себе в разрешении таких ситуаций путем предназначения четко указанных секций разделяемой памяти для определенных нужд.
В любом случае, даже если программист специально запретил (через SIG_IGN) два упомянутых прерывания или системный администратор сконфигурировал DIPC без поддержки передачи прерываний, связанных с разделяемой памятью, программист должен быть всегда готов к обработке такой ситуации. Имеются в виду проверка значений, возвращаемых системными вызовами, и их перезапуск при необходимости.
Удаленные программы должны точно "знать", когда выполнять действия, вовлекающие другие машины. Например, они должны "знать", когда требующиеся им данные доступны. Настоятельно рекомендуется использовать для этой цели семафоры. Другие способы, такие, как частое тестирование и установка переменной в разделяемой памяти, могут отличаться очень низкой производительностью, так как они требуют частых пересылок по сети целого сегмента разделяемой памяти. Это происходит, когда DIPC сконфигурирована с поддержкой режима посегментной передачи. Даже в режиме постраничной передачи результаты не будут намного лучше.
Известно несколько причин, требующих снизить количество сетевых операций вашего приложения. Одна из них - это, очевидно, производительность, поскольку сетевые операции очень ``дорогостоящие'' в сравнении с локальными. Другая причина связана с некоторыми частными ограничениями кода TCP/IP ядра: за короткое время невозможно сделать слишком много сетевых соединений: через некоторое время ядро выдаст: ``Resource temporarily not available'' и ваше приложение завершится ненормально. Вы столкнетесь с этим, если имеете очень быстрые компьютеры, но не сеть.
Ниже приводятся некоторые рекомендации, которые надо учитывать при программировании DIPC:
fd_set fd;
for(; ; ;)
{
/* сначала проверка семафора, затем приостановка */
check_the_semaphore_and_break_if_needed(...);
/* замечание: Вы должны выполнить инициализацию
внутри цикла */
tv.tv_sec = 0;
/* ожидание в течение 0.5 секунды = 2 семафора
за секунду */
tv.tv_usec = 0.5 * 1000000;
FD_ZERO(&fd);
select(FD_SETSIZE, &fd, NULL, NULL, &tv);
}
К поддерживаемым в DIPC формам системных вызовов IPC относятся:
Если dipcd не выполняется, то все описанные системные вызовы исполняются локально, как если бы они были обычными вызовами IPC. Данные системные вызовы могут возвращать код ошибки not found, как и при IPC. Это может означать, например, что произошел сбой сетевой операции или наступил тайм-аут.
При инсталляции программного обеспечения вы можете пользоваться такими подсистемами, как NFS, чтобы освободить себя от бремени переноса дистрибутива на машины и просто копировать исполняемые файлы. Другой вариант - rdist - кажется, очень хороший кандидат для распространения программ.
Вы можете обратиться к программам-примерам за пояснениями всего рассмотренного выше. Просмотрите и файл Readme из каталога с примерами. Программа в каталоге examples/hello проста для инсталляции и выполнения. Вы можете начать с нее.
Интерфейс передачи сообщений MPI представляет собой библиотеку функций и макроопределений, которые могут использоваться в программах на C, Фортране и C++. MPI предназначен для написания программ, которые используют при работе несколько процессоров с помощью обмена сообщениями. Он является одним из первых стандартов для программирования параллельных процессов и первым, основанным на обмене сообщениями. Информация этого раздела предназначена для использования программистами, которые имеют опыт программирования на C, но мало знакомы с механизмами передачи сообщений.
Первой программой на C, которую пишет большинство начинающих программистов, является программа, выводящая сообщение "Привет, мир!". Она просто печатает сообщение "Привет, мир!"на терминал. Многопроцессорный вариант содержит процессы, каждый из которых посылает приветствие другому.
В MPI процессы, участвующие в выполнении параллельной программы, идентифицируются последовательностью неотрицательных целых чисел. Если в выполнении программы участвуют P процессов, то они будут иметь номера (ранги) 0, 1, ..., P-1. В следующей программе каждый процесс с рангом, не равным 0, посылает сообщение в процесс 0, а процесс 0 выводит все сообщения, которые он получил:
#include ''mpi.h''
main(int argc, char** argv) {
int my_rank; /* Ранг процесса */
int p; /* Количество процессов */
int source; /* Ранг посылающего */
int dest; /* Ранг принимающего */
int tag = 50; /* Тэг сообщений */
char message[100]; /* Память для сообщения */
MPI_Status status; /* Статус возврата */
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &p);
if (my_rank != 0) {
sprintf(message, ''Привет из процесса %d!'', my_rank);
dest = 0;
/* Используется strlen(message)+1
чтобы включить '\0' */
MPI_Send(message, strlen(message)+1,
MPI_CHAR, dest, tag, MPI_COMM_WORLD);
} else { /* my_rank == 0 */
for (source = 1; source < p; source++) {
MPI_Recv(message, 100, MPI_CHAR, source, tag,
MPI_COMM_WORLD, &status);
printf(''%s\n'', message);
}
}
MPI-Finalize();
} /* main */
Если программу откомпилировать и запустить для четырех процессов, она выведет:
Привет из процесса 2!
Привет из процесса 3!
Каждая программа MPI содержит директиву препроцессора:
. . .
main(int argc, char** argv) {
. . .
/* Функции MPI нельзя вызывать до этого момента */
MPI_Init(&argc, &argv);
. . .
MPI_Finalize();
/* Функции MPI нельзя вызывать после этого момента */
. . .
} /* main */
MPI предлагает функцию MPI_Comm_rank(), которая возвращает ранг процесса. Ее синтаксис:
Многие конструкции в программах зависят также от общего числа процессов, выполняющих программу. Поэтому MPI содержит функцию MPI_Comm_size() для того, чтобы определять их количество. Синтаксис функции:
Фактическая передача сообщений в программе выполняется функциями MPI_Send() и MPI_Recv(). Первая функция посылает сообщение определенному процессу. Вторая получает сообщение от некоторого процесса. Эти функции являются самыми основными командами передачи сообщений в MPI. Чтобы сообщение было успешно передано, система должна добавить немного информации к данным, которые "желает" передать прикладная программа. Эта дополнительная информация формирует конверт сообщения. В MPI конверт содержит следующую информацию:
Эти детали могут использоваться приемником, чтобы распознавать поступающие сообщения. Аргумент source применяется, чтобы различать сообщения, полученные от разных процессов. Тэг представляет собой указанное пользователем значение int, которое предназначено, чтобы отличить сообщения, полученные от одного процесса. Пусть процесс А посылает два сообщения процессу B; оба сообщения содержат одно значение типа float. Одно из значений должно использоваться в вычислении, а другое должно быть выведено на экран. Чтобы определить, какое из них первое, А использует различные тэги этих сообщений. Если B употребляет те же самые тэги при приеме, он будет "знать", что с ними делать. MPI предполагает, что в качестве тэгов могут применяться целые числа в диапазоне 0 - 32767. Большинство реализаций позволяет использовать гораздо большие значения.
Как уже было отмечено, коммуникатор - это набор процессов, которые могут посылать друг другу сообщения. Если два процесса поддерживают связь при помощи MPI_Send() и MPI_Recv(), коммуникатор употребляется в случае, когда отдельные модули программы разрабатываются независимо друг от друга. Пусть необходимо решить систему дифференциальных уравнений, при этом в ходе решения системы возникает необходимость решить систему линейных уравнений. Вместо того чтобы разрабатывать решатель линейных систем с нуля, можно использовать библиотеку функций для решения линейных систем. При этом возникает необходимость различать собственные сообщения между процессами и сообщения библиотеки для решения линейных уравнений. Без применения коммуникаторов потребуется выделить из множества тэгов подмножество для эксклюзивного использования функциями библиотеки. Такое решение плохо переносится на другие системы. При применении коммуникаторов можно создать коммуникатор, который может использоваться исключительно линейным решателем, и передавать его как аргумент в вызовах функций решателя.
Синтаксис функций приведен ниже:
int MPI_Send(void* message, int count,
MPI_Datatype datatype, int dest, int tag,
MPI_Comm comm)
int MPI_Recv(void* message, int count,
MPI_Datatype datatype, int source, int tag,
MPI_Comm comm, MPI_Status* status)
Содержимое сообщения хранится в блоке памяти, на который указывает
аргумент message. Следующие два аргумента, count
и
| Тип MPI | Соответствующий тип С |
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | - |
| MPI_PACKED | - |
Последние два типа, MPI_BYTE и MPI_PACKED, не соответствуют стандартным типам C. Тип MPI_BYTE используется, если система не должна выполнять преобразование между различными представлениями данных (например, в гетерогенной сети рабочих станций, применяющих различные представления данных). Особенность типов MPI в том, что они позволяют приложениям на гетерогенных архитектурах взаимодействовать единообразно, выполняя необходимые преобразования типов прозрачно для пользователя.
Следует отметить, что количество памяти, выделенной для буфера получения, может точно не соответствовать размеру получаемого сообщении. Например, при работе программы размер сообщения, посылаемый процессом 1 равен strlen (message +1) = 28 символов, а процесс 0 получает сообщение в буфер, который имеет размер 100 символов. В любом случае процесс-получатель не может знать точного размера посланного сообщения. Поэтому MPI позволяет принимать сообщение, пока есть место в выделенной памяти. Если места недостаточно, возникает ошибка выхода за пределы памяти.
Аргументы dest и source соответствуют рангам процессов приема и посылки. MPI позволяет source принимать значение предопределенной константы MPI_ANY_SOURCE, которое может использоваться, если процесс готов получить сообщение от любого иного процесса. Для dest подобной константы нет.
MPI имеет два механизма, предназначенные для разделения пространств сообщении - тэги и коммуникаторы. Аргументы tag и comm соответственно определяют тэг и коммуникатор. Существует групповой тэг MPI_ANY_TAG, определяющий любой тэг для сообщения.
Последний аргумент MPI_Recv(), status, возвращает информацию, относящуюся к фактически полученным данным. Он ссылается на запись с двумя полями: одно - для источника, другое - для тэга. Например, если в качестве источника был указан MPI_ANY_SOURCE, то status будет содержать ранг процесса, который прислал сообщение.
Для посылки сообщений также можно использовать варианты функций MPI_Send(). Эти варианты определяют различные режимы передачи сообщений (стандартный, синхронный, буферизованный и режим передачи по готовности). Информация о режимах приведена в табл. 9.
| Название режима | Условие завершения | Функция |
| Стандартная передача | Как для синхронной или буферизованной | MPI_SEND |
| Синхронная передача | Завершается, когда завершен прием | MPI_SSEND |
| Буферизованная передача | Всегда завершается | MPI_BSEND |
| Передача по готовности | Всегда завершается | MPI_RSEND |
| Прием | Завершается, когда сообщение принято | MPI_RECV |
Буферизованная передача гарантирует немедленное завершение, поскольку сообщение вначале копируется в системный буфер, а затем доставляется. Недостатком ее является необходимость выделения специальных буферов, потребляющих ресурсы системы.
Передача по готовности предполагает инициирование передачи в момент, когда приемник вызывает соответствующий ей прием. Этот режим гарантирует отсутствие в коммуникационной сети блуждающих сообщений.
Взаимная блокировка процессов может возникнуть из-за блокировки файлов. Пусть, например, процесс 1 пытается установить блокировку в некотором файле dead.txt в позиции 10.
Другой процесс с 2 организует блокировку того же самого файла в позиции 20. До сих пор ситуация еще управляема. Далее, процесс 1 хочет организовать следующую блокировку в позиции 20, где уже стоит блокировка процесса 2. При этом используется команда F_SETLKW. При этом процесс 1 приостанавливается до тех пор, пока процесс 2 снова не освободит со своей стороны блокировку в позиции 20. Теперь процесс 2 пытается организовать в позиции 10, где процесс 1 уже поставил свою блокировку, такую же блокировку командой F_SETLKW, и также приостанавливается и ждет, пока процесс 1 снимет блокировку. Теперь оба процесса, 1 и 2, приостановлены и оба ждут друг друга (F_SETLKW), образуя тупик. Никакой из процессов не может возобновить свое выполнение.
Причины возникновения этой ситуации во многом вызваны неудачным проектированием алгоритмов. В Linux не предусмотрены механизмы определения и предотвращения тупика, поскольку присутствие этих механизмов существенно влияет на производительность системы. Ответственность за предотвращение тупика целиком ложится на программиста.
Пример программы, вызывающей тупик:
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
extern int errno;
void status(struct flock *lock)
{
printf("Status: ");
switch(lock->l_type)
{
case F_UNLCK: printf("F_UNLCK\n"); break;
case F_RDLCK: printf("F_RDLCK (pid: %d)\n",
lock->l_pid); break;
case F_WRLCK: printf("F_WRLCK (pid: %d)\n",
lock->l_pid); break;
default : break;
}
}
void writelock(char *proсess, int fd, off_t from,
off_t to) {
struct flock lock;
lock.l_type = F_WRLCK;
lock.l_start=from;
lock.l_whence = SEEK_SET;
lock.l_len=to;
lock.l_pid = getpid();
if (fcntl(fd, F_SETLKW, &lock) < 0)
{
printf("%s : Ошибка
fcntl(fd, F_SETLKW, F_WRLCK) (%s)\n",
proсess,strerror(errno));
printf("\nВозник DEADLOCK (%s - proсess)!\n\n",
proсess);
exit(0);
}
else
printf("%s : fcntl(fd, F_SETLKW, F_WRLCK)
успешно\n", proсess);
status(&lock);
}
int main()
{
int fd, i;
pid_t pid;
if(( fd=creat("dead.txt", S_IRUSR |
S_IWUSR | S_IRGRP | S_IROTH))<0)
{
fprintf(stderr, "Ошибка при создании......\n");
exit(0);
}
/*Заполняем dead.txt 50 байтами символа X*/
for(i=0; i<50; i++)
write(fd, "X", 1);
if((pid = fork()) < 0)
{
fprintf(stderr, "Ошибка fork()......\n");
exit(0);
}
else if(pid == 0) //Потомок
{
writelock("Потомок", fd, 20, 0);
sleep(3);
writelock("Потомок" , fd, 0, 20);
}
else //Родитель
{
writelock("Родитель", fd, 0, 20);
sleep(1);
writelock ("Родитель", fd, 20, 0);
}
exit(0);
}
Вначале создается файл данных dead.txt, в который записывается 50 символов X. Затем родительский процесс организует блокировку от байта 0 до байта 19, а потомок - блокировку от байта 20 до конца файла (EOF). Потомок "засыпает" на 3 сек., а родитель теперь устанавливает блокировку от байта 20 до байта EOF и приостанавливается, так как байты от 20 до EOF блокированы в данный момент потомком, а родитель использует команду F_SETLKW. Наконец, потомок пытается установить блокировку на запись от байта 0 до байта 19, причем он также приостанавливается, так как в этой области уже установлена блокировка родителя и используется команда F_SETLKW. Здесь возникает тупик, что подтверждается выдачей кода ошибки для errno = EDEADLK (возникновение тупика по ресурсам). Тупик может возникнуть только при использовании команды F_SETLKW. Если применять команду F_SETLK, выдается код ошибки для errno = EAGAIN (ресурс временно недоступен).
Вариант параллелизации этой программы сводится к тому, чтобы
просто разделить интервал
![]() между процессами, чтобы
каждый процесс оценил интеграл
между процессами, чтобы
каждый процесс оценил интеграл ![]() на своем подинтервале. Для
оценки величины полного интеграла локальные значения всех процессов
суммируются.
на своем подинтервале. Для
оценки величины полного интеграла локальные значения всех процессов
суммируются.
Пусть программа содержит ![]() процессов и
процессов и ![]() трапеций, где
трапеций, где ![]() является
кратным
является
кратным ![]() . Тогда первый процесс вычисляет область первых
. Тогда первый процесс вычисляет область первых ![]() трапеций, второй - область следующих
трапеций, второй - область следующих ![]() и т.д. Тогда процесс
и т.д. Тогда процесс ![]() будет оценивать интеграл по интервалу
будет оценивать интеграл по интервалу
Каждый процесс должен обладать следующей информацией:
Подведение итогов индивидуальных вычислений процессов состоит в том, чтобы каждый процесс посылал свое локальное значение в процесс 0, а процесс 0 производил заключительное суммирование. Новый вариант программы:
#include ''mpi.h''
float f(float x) {
float return_val;
/* Вычисляет f(x).
Возвращает результат в return_val. */
. . .
return return_val;
}
float Trap(float local_a, float local_b, int local_n,
float h) {
float integral; /* Результат вычислений */
float x;
int i;
integral = (f(local_a) + f(local_b))/2.0;
x = local_a;
for (i = 1; i <= local-n-1; i++) {
x += h;
integral += f(x);
}
integral *= h;
return integral;
} /* Trap */
main(int argc, char** argv) {
int my_rank; /* Ранг процесса */
int p; /* Количество процессов */
float a = 0.0; /* Левая граница */
float b = 1.0; /* Правая граница */
int n = 1024; /* Количество трапеций */
float h; /* Ширина трапеции */
float local_a; /* Левая граница для процесса */
float local_b; /* Правая граница для процесса */
int local_n; /* Количество вычисляемых трапеций */
float integral; /* Значение интеграла по интервалу */
float total; /* Общий интеграл */
int source; /* Процесс, посылающий интеграл */
int dest = 0; /* Пункт назначения процесс 0 */
int tag = 50;
MPI_Status status;
MPI_Init(&argc, &argv);
/* Определить ранг процесса */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
/* Определить количество процессов */
MPI_Comm_size(MPI_COMM_WORLD, &p);
h = (b-a)/n; /* h одинаково для всех процессов */
local_n = n/p; /* Получить количество трапеций */
/* Вычислить границы интервала и частный интеграл*/
local_a = a + my_rank*local_n*h;
local_b = local_a + local_n*h;
integral = Trap(local_a, local_b, local_n, h);
/* Суммировать все интегралы */
if (my_rank == 0) {
total = integral;
for (source = 1; source < p; source++) {
MPI_Recv(&integral, 1, MPI_FLOAT,
source, tag, MPI_COMM_WORLD, &status);
total += integral;
}
} else {
MPI_Send(&integral, 1, MPI_FLOAT, dest,
tag, MPI_COMM_WORLD);
}
/* Вывод результата */
if (my_rank == 0) {
printf(''C n = %d трапециями, оценка\n'', n);
printf(''интеграла от %f до %f = %f`\n'',
a, b, total);
}
/* Завершить приложение MPI */
MPI_Finalize();
} /* main */
В предыдущем примере некоторые значения были жестко определены в коде программы. Чаще всего для таких случаев возникает дополнительная задача обеспечения ввода требуемых величин со стороны пользователя.
Как правило, при обеспечении работы с терминалом вывод и ввод осуществляется через один процесс. Чаще всего это процесс с номером 0. В общем случае, все процессы могут осуществлять ввод / вывод, однако при одновременном выполнении операторов ввода / вывода могут возникать неожиданные эффекты. Поэтому наилучшим вариантом является обеспечение интерфейса через один процесс.
Пусть для примера обмен осуществляется через процесс 0. Необходимо передать другим процессам значения левой и правой границ интервала и количества трапеций. Для этого может использоваться следующая функция:
float* b_ptr, int* n_ptr)
{
int source = 0; /* Локальные переменные */
int dest; /* используемые MPI_Send и MPI_Recv */
int tag;
MPI_Status status;
if (my_rank == 0) {
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', a_ptr, b_ptr, n_ptr);
for (dest = 1; dest < p; dest++) {
tag = 30;
MPI_Send(a_ptr, 1, MPI_FLOAT, dest, tag,
MPI_COMM_WORLD);
tag = 31;
MPI_Send(b_ptr, 1, MPI_FLOAT, dest, tag,
MPI_COMM_WORLD);
tag = 32;
MPI_Send(n_ptr, 1, MPI_INT, dest, tag,
MPI_COMM_WORLD);
}
} else {
tag = 30;
MPI_Recv(a_ptr, 1, MPI_FLOAT, source, tag,
MPI_COMM_WORLD, &status);
tag = 31;
MPI_Recv(b_ptr, 1, MPI_FLOAT, source, tag,
MPI_COMM_WORLD, &status);
tag = 32;
MPI_Recv(n_ptr, 1, MPI_INT, source, tag,
MPI_COMM_WORLD, &status);
}
}/* Get_data */
Производительность программы вычисления интеграла можно значительно повысить. Например, пусть программа выполняется на восьми процессорах.
Все процессы начинают выполнять программу практически одновременно.
Однако после выполнения основных задач (вызовы
MPI_Init(),
MPI_Comm_size() и MPI_Comm_rank()) процессы
1 - 7 будут простаивать, в то время как процесс 0 будет собирать входные
данные. После того как процесс 0 примет входные данные, процессы
большего ранга должны продолжать ожидать, пока процесс 0 рассылает
входные данные всем процессам. Подобная неэффективность наблюдается
и в конце программы, когда процесс 0 собирает и суммирует значения
локальных интегралов.
Основной задачей организации параллельной обработки является равномерное распределение загрузки по всем процессорам системы. Если, как в приведенном случае, основная нагрузка ложится на один из процессов, то в некоторых случаях будет эффективнее использовать однопроцессорную версию.
Равномерное распределение загрузки по процессорам предполагает определенную организацию передач данных в рамках некоторой структуры. Например, при рассылке входных данных между процессами программы вычисления интеграла хороший результат может дать организация дерева процессов, корнем которого является процесс 0 (рис. 2).
На первой стадии распределения данных процесс 0 посылает данные процессу
4. В течение следующей стадии, процесс 0 посылает данные процессу
2, в то время как процесс 4 посылает те же данные процессу 6. В ходе
последней стадии, процесс 0 посылает данные процессу 1, в то время
как процесс 2 посылает данные процессу 3, процесс 4 посылает данные
процессу 5, и наконец, процесс 6 посылает данные процессу 7. При
этом цикл распределения данных уменьшился с 7 этапов до 3. Если существует
![]() процессов, эта процедура позволяет распределять входные данные
в
процессов, эта процедура позволяет распределять входные данные
в
![]() этапов, вместо
этапов, вместо ![]() этапов,
что при достаточно большом
этапов,
что при достаточно большом ![]() существенно ускоряет процесс.
существенно ускоряет процесс.
![\includegraphics[scale = 0.7]{fig1.eps}](img20.png)
Чтобы модифицировать функцию Get_data() для использования
схемы распределения в виде дерева, необходимо ввести цикл из
![]() итераций. Каждый процесс при этом определяет на каждой стадии:
итераций. Каждый процесс при этом определяет на каждой стадии:
Пример коммуникации, в которой участвуют все процессы в коммуникаторе, называется коллективной. Как следствие коллективная связь обычно предполагает участие более двух процессов. Широковещательное сообщение - коллективная коммуникация, когда отдельный процесс посылает одинаковые данные каждому процессу. В MPI существует функция для широковещательной передачи MPI_Bcast():
MPI_Datatype datatype, int root, MPI_Comm comm);
Функцию получения данных Get_data(), используя MPI_Bcast(), можно переписать следующим образом:
int* n_ptr) {
int root = 0; /* Аргументы MPI_Bcast */
int count = 1;
if (my_rank == 0) {
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', a_ptr, b_ptr, n_ptr);
}
MPI_Bcast(a_ptr, 1, MPI_FLOAT, root, MPI_COMM_WORLD);
MPI_Bcast(b_ptr, 1, MPI_FLOAT, root, MPI_COMM_WORLD);
MPI_Bcast(n_ptr, 1, MPI_INT, root, MPI_COMM_WORLD);
} /* Get-data2 */
В рассматриваемой программе после входной стадии каждый процессор
выполняет по существу те же самые команды до заключительной стадии
суммирования. Поэтому, если функция ![]() дополнительно не усложнена
(т. е. не требует значительной работы для оценки интеграла
по некоторым частям отрезка
дополнительно не усложнена
(т. е. не требует значительной работы для оценки интеграла
по некоторым частям отрезка ![]() ), то эта часть программы распределяет
среди процессоров одинаковую нагрузку. В заключительной стадии суммирования
процесс 0 еще раз получает непропорциональное количество работы.
Здесь также можно распределить работу вычисления суммы среди процессоров
по структуре дерева следующим образом:
), то эта часть программы распределяет
среди процессоров одинаковую нагрузку. В заключительной стадии суммирования
процесс 0 еще раз получает непропорциональное количество работы.
Здесь также можно распределить работу вычисления суммы среди процессоров
по структуре дерева следующим образом:
"Общая сумма", которую нужно вычислить представляет собой пример общего класса коллективных операций коммуникации, называемых операциями редукции. В глобальной операции редукции, все процессы (в коммуникаторе) передают данные, которые объединяются с использованием бинарных операций. Типичные бинарные операции - суммирование, максимум и минимум, логические и т.д. MPI содержит специальную функцию для выполнения операции редукции:
MPI_Datatype datatype, MPI_Op op, int root,
MPI_Comm comm)
Аргумент op может принимать фиксированные значения, указанные в табл. 10:
| Название операции | Смысл |
| MPI_MAX | Максимум |
| MPI_MIN | Минимум |
| MPI_SUM | Сумма |
| MPI_PROD | Произведение |
| MPI_LAND | Логическое И |
| MPI_BAND | Битовое И |
| MPI_LOR | Логическое ИЛИ |
| MPI_BOR | Битовое ИЛИ |
| MPI_LXOR | Логическое исключающее ИЛИ |
| MPI_BXOR | Битовое исключающее ИЛИ |
| MPI_MAXLOC | Максимум и его расположение |
| MPI_MINLOC | Минимум и его расположение |
Существует также возможность определения собственных операций.
Таким образом, завершение программы вычисления интеграла будет следующим:
MPI_Reduce(&integral, &total, 1, MPI_FLOAT,
MPI_SUM, 0, MPI_COMM_WORLD);
/* Вывод результата */
Труба является однонаправленным коммуникационным каналом
между двумя
процессами и может использоваться
для поддержки коммуникаций и контроля информационного потока между двумя процессами.
Труба может принимать только определенный объем данных
(обычно 4 Кб). Если труба заполнена, процесс останавливается до тех
пор, пока хотя бы один байт из этой трубы не будет прочитан и не появится
свободное место, чтобы снова заполнить ее данными. С другой стороны,
если труба пуста, то читающий процесс останавливается до тех пор,
пока пишущий процесс не внесёт данные в эту трубу.
Труба описывается двумя дескрипторами файлов. Первый дескриптор служит для чтения, второй - для записи в трубу:
int pipe(int fd[2]);
Второй процесс для организации обмена можно создать с помощью fork(). При этом процесс-потомок наследует от родителя оба открытых дескриптора файлов. После этого, закрыв ненужные дескрипторы, необходимо указать обоим процессам, кто куда пишет и кто что читает.
В приведенном ниже примере процесс-родитель записывает данные в трубу. В этом случае закрываются дескриптор чтения (fd[0]) родительского процесса и дескриптор записи потомка. Потомок будет только читать данные из трубы:
#include <sys/wait.h>
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#define USAGE printf("usage : %s данные\n",
argv[0]);
#define MAX 4096
int main(int argc, char *argv[]) {
int fd[2], fd1,i, n;
pid_t pid;
char buffer[MAX];
FILE *dataptr;
if(argc !=2)
{ USAGE; exit(0); }
if((fd1=open(argv[1], O_RDONLY)) < 0)
{ perror("open : "); exit(0); }
/*Устанавливаем трубу*/
if(pipe(fd) < 0)
{ perror("pipe : "); exit(0); }
/*Создаем новый процесс*/
if((pid=fork()) < 0)
{ perror("pipe : "); exit(0); }
else if(pid > 0) /*Это родитель*/ {
close(fd[0]); /*Закрываем чтение*/
n=read(fd1, buffer, MAX);
if((write(fd[1], buffer, n)) != n)
{ perror(" write : "); exit(0); }
if((waitpid(pid, NULL, 0)) < 0)
{ perror("waitpid : "); exit(0); }
}
else /*Это потомок*/ {
close(fd[1]); /*Закрываем запись*/
n=read(fd[0], buffer, MAX);
if((write(STDOUT_FILENO, buffer, n)) != n)
{ perror(" write : "); exit(0); }
}
exit(0);
}
MPI поддерживает некоторые другие функции для организации коллективных коммуникаций:
MPI_Datatype send_type, void* recv_buf,
int recv_count, MPI_Datatype recv_type, int root,
MPI_comm comm);
MPI_Datatype send_type, void* recv_buf,
int recv_count, MPI_Datatype recv_type, int root,
MPI_Comm comm);
MPI_Datatype send_type, void* recv_buf,
int recv_count, MPI_Datatype recv_type,
MPI_comm comm);
int count, MPI_Datatype datatype, MPI_Op op,
MPI_Comm comm);
Для современных компьютеров посылка сообщения является дорогостоящей операцией. Поэтому чем меньше сообщений будет послано, тем выше будет производительность программы. В рассматриваемом примере при распределении входных данных приходится посылать a, b, n в отдельных сообщениях, независимо от того, используется ли пара MPI_Send() и MPI_Recv(), или функция MPI_Bcast(). Можно попытаться улучшить производительность программы, посылая три входных значения в единственном сообщении. MPI обеспечивает три механизма для того, чтобы сгруппировать индивидуальные переменные в единое сообщение:
Процедуры MPI_Send(), MPI_Recv(), MPI_Bcast(), и MPI_Reduce() используют аргументы count и datatype. Эти два параметра позволяют пользователю группировать элементы данных, имеющие тот же самый основной тип, в единое сообщение. Чтобы использовать эту возможность, сгруппированные элементы данных должны сохраняться в смежных областях памяти. Поскольку C гарантирует, что элементы массива сохраняются именно таким образом, то посылка элементов массива или подмассива может осуществляться в едином сообщении.
В качестве примера приведем процедуру посылки второй половины вектора, содержащего 100 значений с плавающей точкой от процесса 0 к процессу 1:
int tag, count, dest, source;
MPI_Status status;
int p;
int my_rank;
. . .
if (my_rank == 0) {
/* Инициализация и отсылка вектора */
. . .
tag = 47;
count = 50;
dest = 1;
MPI_Send(vector + 50, count, MPI_FLOAT, dest, tag,
MPI_COMM_WORLD);
} else {
/* my_rank == 1 */
tag = 47;
count = 50;
source = 0;
MPI_Recv(vector+50, count, MPI_FLOAT, source, tag,
MPI_COMM_WORLD,
&status);
}
float b;
int n;
Может показаться, что другим вариантом могло бы стать хранение a, b, n в структуре с тремя членами - два числа с плавающей точкой и целое - и попытка использовать аргумент datatype в функции MPI_Bcast(). Трудность здесь состоит в том, что тип datatype является одним из MPI_Datatype(), которые не являются пользовательскими типами, как структуры в C. Если определить тип:
float a;
float b;
int n;
} INDATA_TYPE
MPI обеспечивает частичное решение этой проблемы, разрешая пользователю во время выполнения создавать собственные типы данных MPI. Чтобы построить тип данных для MPI, необходимо определить расположение данных в типе: тип элементов и их относительные местоположения в памяти. Такой тип называют производным типом данных. Ниже приведена функция, которая будет строить производный тип, соответствующий INDATA_TYPE:
MPI-Datatype* message_type_ptr)
{
int block_lengths[3];
MPI_Aint displacements[3];
MPI_Aint addresses[4];
MPI_Datatype typelist[3];
/* Создает производный тип данных, содержащий
* два элемента float и один int */
/* Сначала нужно определить типы элементов */
typelist[0] = MPI_FLOAT;
typelist[1] = MPI_FLOAT;
typelist[2] = MPI_INT;
/* Определить количество элементов каждого типа */
block_lengths[0] = block_lengths[1] =
block_lengths[2] = 1;
/* Вычислить смещения элементов
* относительно indata */
MPI_Address(indata, &addresses[0]);
MPI_Address(&(indata->a), &addresses[1]);
MPI_Address(&(indata->b), &addresses[2]);
MPI_Address(&(indata->n), &addresses[3]);
displacements[0] = addresses[1] - addresses[0];
displacements[1] = addresses[2] - addresses[0];
displacements[2] = addresses[3] - addresses[0];
/* Создать производный тип */
MPI_Type_struct(3, block_lengths, displacements,
typelist, Message_type_ptr);
/* Зарегистрировать его для использования */
MPI_Type_commit(message_type_ptr);
} /* Build_derived_type */
Новый тип данных MPI можно использовать в любых коммуникационных функциях MPI. Чтобы использовать его, необходимо применять стартовый адрес переменной типа INDATA_TYPE в качестве первого аргумента, а производный тип данных - в качестве аргумента datatype. При этом функция Get_data() в примере принимает вид.
MPI_Datatype message_type; /* Аргументы для */
int root = 0; /* MPI_Bcast */
int count = 1;
if (my_rank == 0) {
printf(''Введите a, b, and n\n'');
scanf(''%f %f %d'', &(indata->a),
&(indata->b), &(indata->n));
}
Build_derived_type(indata, &message_type);
MPI_Bcast(indata, count, message_type, root,
MPI_COMM_WORLD);
} /* Get_data3 */
Производные типы данных строятся с помощью функции
MPI_Type_struct().
Синтаксис этой функции таков:
int* array_of_block_lengths,
MPI_Aint* array_of_displacements,
MPI_Datatype* array_of_types,
MPI_Datatype* newtype)
Следует также отметить, что newtype и элементы массива
array_of_types
все имеют тип MPI_Datatype. Поэтому функцию
MPI_Type_struct()
можно вызывать рекурсивно для построения более сложных производных
типов данных.
MPI_Type_struct() является самым общим конструктором типов
данных в MPI. Поэтому пользователь должен обеспечить полное описание
каждого элемента типа. Если данные, которые будут переданы, состоят
из подмножества элементов массива, возможно не стоит обеспечивать
слишком детальную информацию, так как все элементы имеют тот же самый
основной тип. MPI обеспечивает три производных конструктора данных
для того, чтобы работать в этой ситуации: MPI_Type_Contiguous(),
MPI_Type_vector() и
MPI_Type_indexed(). Первый
конструктор строит производный тип, элементами которого являются смежные
элементы массива. Второй конструктор строит тип, элементами которого
являются равномерно разделенные промежутками элементы массива, а третий
строит тип, элементы которого являются произвольными элементами массива.
Прежде чем любой производный тип может быть использован в коммуникации,
он должен быть объявлен вызовом MPI_Type_commit().
Ниже приведены сведения о синтаксисе дополнительных конструкторов типов MPI:
MPI_Datatype oldtype, MPI_Datatype* newtype);
int stride, MPI_Datatype element_type,
MPI_Datatype* newtype);
![]()
int* array_of_block_lengths,
int* array_of_displacements,
MPI_Datatype element_type,
MPI_Datatype* newtype);
Альтернативный подход к группировке данных реализован функциями MPI_Pack() и MPI_Unpack(). MPI_Pack() позволяет явно хранить данные, состоящие из нескольких несмежных участков, в смежных областях памяти. MPI_Unpack() может использоваться для копирования данных из смежного буфера в области памяти, состоящие из нескольких несмежных участков.
Для иллюстрации этих функций можно привести еще один вариант текста функции Get_data():
int* n_ptr) {
int root = 0; /* Аргумент для MPI_Bcast */
char buffer[100]; /* Аргументы для MPI_Pack/Unpack */
int position; /* и MPI_Bcast*/
if (my_rank == 0) {
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', a_ptr, b_ptr, n_ptr);
/* Упаковка данных в буфер */
position = 0; /* Начать с начала буфера */
MPI_Pack(a_ptr, 1, MPI_FLOAT, buffer, 100,
&position, MPI_COMM_WORLD);
/* Position будет увеличена на */
/* sizeof(float) байт */
MPI_Pack(b_ptr, 1, MPI_FLOAT, buffer, 100,
&position, MPI_COMM_WORLD);
MPI_Pack(n_ptr, 1, MPI_INT, buffer, 100,
&position, MPI_COMM_WORLD);
/* Разослать содержимое буфера */
MPI_Bcast(buffer, 100, MPI_PACKED, root,
MPI_COMM_WORLD);
} else {
MPI_Bcast(buffer, 100, MPI_PACKED, root,
MPI_COMM_WORLD);
/* Распаковать содержимое буфера */
position = 0;
MPI_Unpack(buffer, 100, &position, a_ptr, 1,
MPI_FLOAT, MPI_COMM_WORLD);
/* Позиция снова увеличивается на */
/* sizeof(float) байт */
MPI_Unpack(buffer, 100, &position, b_ptr, 1,
MPI_FLOAT, MPI_COMM_WORLD);
MPI_Unpack(buffer, 100, &position, n_ptr, 1,
MPI_INT, MPI_COMM_WORLD);
}
} /* Get-data4 */
Синтаксис вызова MPI_Pack():
MPI_Datatype datatype, void* buffer, int size,
int* position_ptr, MPI_Comm comm)
Синтаксис MPI_Unpack():
int* position_ptr, void* unpack_data,
int count, MPI_Datatype datatype,
MPI_comm comm);
Если данные, которые будут посланы, хранятся в последовательных элементах массива, то лучше всего использовать аргументы count и datatype коммуникационных функций. Этот подход не включает никаких дополнительных действий, например, вызовов для создания производных типов данных или MPI_Pack/MPI_Unpack.
Если большое количество элементов не находится в смежных ячейках памяти, то построение производного типа данных будет дешевле и производительнее, чем большое количество вызовов MPI_Pack / MPI_Unpack.
Если все данные имеют одинаковый тип и хранятся в памяти равномерно (например, колонки матрицы), то наверняка будет проще и быстрее использовать производный тип данных, чем MPI_Pack / MPI_Unpack. Далее, если все данные имеют одинаковый тип, но хранятся в ячейках памяти, распределенных нерегулярно, то легче и эффективнее создать производный тип, используя MPI_Type_indexed. Наконец, если данные являются гетерогенными и процессы неоднократно посылают тот же самый набор данных (например, номер ряда, номер колонки, элемент матрицы), то лучше использовать производный тип. При этом затраты на создание производного типа возникнут только однажды, в то время как затраты на вызов MPI_Pack / MPI_Unpack будут возникать каждый раз, когда передаются данные.
Однако в некоторых ситуациях использование MPI_Pack /
MPI_Unpack
является предпочтительным. Так, можно избежать коллективного
использования системной буферизации при упаковке, поскольку данные явно
сохраняются в определенном пользователем буфере. Система может использовать
это, отметив, что типом сообщения является MPI_PACKED. Пользователь
также может посылать сообщения "переменной длины",
упаковывая число элементов в начале буфера. Пусть, например, необходимо
посылать строки разреженной матрицы. Если строка хранится в виде пары
массивов, где первый содержит индексы колонок, а второй содержит соответствующие
элементы матрицы, то можно посылать строку от процесса 0 к процессу
1 следующим образом:
int* column_subscripts;
/* количество ненулевых элементов в строке */
int nonzeroes;
int position;
int row_number;
char* buffer[HUGE]; /* HUGE является константой */
MPI_Status status;
. . .
if (my_rank == 0) {
/* Получить количество ненулевых элементов строки. */
/* Выделить память для строки. */
/* Инициализировать массивы элементов и индексов */
. . .
/* Упаковать и послать данные */
position = 0;
MPI_Pack(&nonzeroes, 1, MPI_INT, buffer, HUGE,
&position, MPI_COMM_WORLD);
MPI_Pack(&row_number, 1, MPI_INT, buffer, HUGE,
&position, MPI_COMM_WORLD);
MPI_Pack(entries, nonzeroes, MPI_FLOAT, buffer,
HUGE, &position, MPI_COMM_WORLD);
MPI_Pack(column_subscripts, nonzeroes, MPI_INT,
buffer, HUGE, &position, MPI_COMM_WORLD);
MPI_Send(buffer, position, MPI_PACKED, 1, 193,
MPI_COMM_WORLD);
} else { /* my_rank == 1 */
MPI_Recv(buffer, HUGE, MPI_PACKED, 0, 193,
MPI_COMM_WORLD, &status);
position = 0;
MPI_Unpack(buffer, HUGE, &position, &nonzeroes, 1,
MPI_INT, MPI_COMM_WORLD);
MPI_Unpack(buffer, HUGE, &position, &row_number, 1,
MPI_INT, MPI_COMM_WORLD);
/* Выделить память для массивов */
entries = (float *) malloc(nonzeroes*sizeof(float));
column_subscripts =
(int *) malloc(nonzeroes*sizeof(int));
MPI_Unpack(buffer, HUGE, &position, entries,
nonzeroes, MPI_FLOAT, MPI_COMM_WORLD);
MPI_Unpack(buffer, HUGE, &position,
column_subscripts, nonzeroes, MPI_INT,
MPI_COMM_WORLD);
}
Использование коммуникаторов и топологий отличает MPI от большинства других систем передачи сообщений. Как отмечено ранее, коммуникатор представляет собой набор процессов, которые могут посылать сообщения друг другу. Топология - это структура, наложенная на процессы в коммуникаторе, которая позволяет процессам быть адресованными различными способами. Для иллюстрации методов использования коммуникаторов и топологий приведен код, реализующий алгоритм Фокса для умножения двух квадратных матриц.
Пусть перемножаемые матрицы ![]() и
и ![]() имеют порядок
имеют порядок
![]() . Количество процессов
. Количество процессов ![]() является квадратом, квадратный корень
которого кратен
является квадратом, квадратный корень
которого кратен ![]() . В этом случае
. В этом случае ![]() и
и ![]() . В
алгоритме Фокса матрицы разделяются среди процессов в виде клеток
шахматной доски. При этом процессы рассматриваются как виртуальная
двухмерная
. В
алгоритме Фокса матрицы разделяются среди процессов в виде клеток
шахматной доски. При этом процессы рассматриваются как виртуальная
двухмерная ![]() сетка, и каждому процессу назначена подматрица
сетка, и каждому процессу назначена подматрица
![]() каждого множителя. Реализуется отображение:
каждого множителя. Реализуется отображение:
Оно определяет сетку процессов: процесс ![]() относится к строке и
столбцу, заданному
относится к строке и
столбцу, заданному ![]() . Процесс с рангом
. Процесс с рангом
![]() назначается на подматрицы:
назначается на подматрицы:
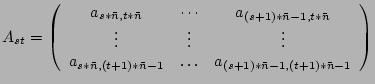
и
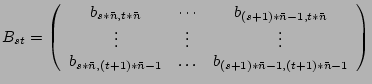
Например, если ![]() ,
,
![]() , и
, и ![]() , то A будет
разделена следующим образом (рис. 4).
, то A будет
разделена следующим образом (рис. 4).
Процесс 0:
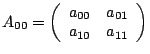 |
Процесс 1:
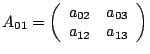 |
Процесс 2:
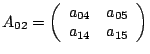 |
Процесс 3:
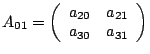 |
Процесс 4:
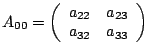 |
Процесс 5:
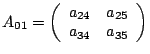 |
Процесс 6:
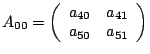 |
Процесс 7:
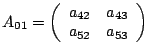 |
Процесс 8:
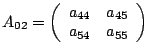 |
В алгоритме Фокса, подматрицы блоков, ![]() и
и ![]() , где
, где
![]() , перемножаются и собираются в процессе
, перемножаются и собираются в процессе
![]() .
Алгоритм состоит в следующем:
.
Алгоритм состоит в следующем:
Выбрать подматрицу A в каждой строке
для всех процессов.
В каждой строке для всех процессов разослать
сетку подматриц, выбранную в этой строке для
других процессов в этой строки.
В каждом процессе, перемножить полученную подматрицу
A на подматрицу B, находящуюся в процессе.
В каждом процессе, отослать подматрицу B процессу,
расположенному выше. (Для процессов первой строки
отослать подматрицу в последнюю строку.)
}
При реализации алгоритма Фокса становится очевидно, что работа будет облегчена, если можно рассматривать некоторые подмножества процессов как коммуникационную область, по крайней мере, временно. Например, в псевдокоде строки 2 полезно рассматривать в виде коммуникационной области каждый ряд процессов, в то время как в строке 4 в виде коммуникационной области нужно рассматривать каждую строку процессов.
Механизмом, который обеспечивает рассмотрение подмножества процессов MPI в виде коммуникационной области, является коммуникатор. В MPI существует два типа коммуникаторов: интракоммуникаторы и интеркоммуникаторы. Интракоммуникаторы представляют собой набор процессов, которые могут посылать сообщения друг другу и участвовать в коллективных взаимодействиях. Например, MPI_COMM_WORLD - это интракоммуникатор. Каждая строка и колонка процессов в алгоритме Фокса должны формировать интракоммуникатор. Интеркоммуникаторы, как подразумевается в их названии, используются для того, чтобы послать сообщения между процессами, принадлежащими непересекающимся интракоммуникаторам. Так, интеркоммуникатор полезно использовать в среде, которая позволяет динамически создавать процессы: только что созданный набор процессов, которые сформировали интракоммуникатор, может быть связан интеркоммуникатором с оригинальным набором процессов (например, MPI_COMM_WORLD) .
Минимальный (интра-)коммуникатор состоит из группы и контекста.
Группа является упорядоченным набором процессов. Если группа состоит
из ![]() процессов, то каждому из них в группе назначен уникальный ранг,
который является неотрицательным целым числом в диапазоне
процессов, то каждому из них в группе назначен уникальный ранг,
который является неотрицательным целым числом в диапазоне ![]() .
Контекст представляет собой определенный системой признак, который
присоединен к группе. Два процесса, которые принадлежат одной
группе и поэтому используют один и тот же контекст, могут связаться
между собой. Соединение группы с контекстом является основной
функцией коммуникатора. С коммуникатором могут быть связаны и другие
данные. В частности, на процессы в коммуникаторе может быть наложена
структура или топология, позволяющая осуществить более естественную схему
адресации.
.
Контекст представляет собой определенный системой признак, который
присоединен к группе. Два процесса, которые принадлежат одной
группе и поэтому используют один и тот же контекст, могут связаться
между собой. Соединение группы с контекстом является основной
функцией коммуникатора. С коммуникатором могут быть связаны и другие
данные. В частности, на процессы в коммуникаторе может быть наложена
структура или топология, позволяющая осуществить более естественную схему
адресации.
Чтобы избавить программиста от лишнего труда, для работы с трубами введена удобная функция popen(). Синтаксис этой функции:
#include <sys/wait.h>
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#define EXIT(s) {fprintf(stderr, "%s",s); exit(0);}
#define USAGE(s) {fprintf(stderr, "%s Данные для
чтения\n",s); exit(0);}
#define MAX 8192
enum {ERROR=-1,SUCCESS};
int main(int argc, char **argv)
{
FILE *pipe_writer, *file;
char buffer[MAX];
if(argc!=2)
USAGE(argv[0]);
if((file=fopen(argv[1], "r")) == NULL)
EXIT("Ошибка открытия файла.........\n");
if(( pipe_writer=popen("./filter" ,"w")) == NULL)
EXIT("Ошибка открытия трубы...........\n");
while(1)
{
if(fgets(buffer, MAX, file) == NULL)
break;
if(fputs(buffer, pipe_writer) == EOF)
EXIT("Ошибка записи........\n");
}
pclose(pipe_writer);
}
Для иллюстрации основ работы с коммуникаторами создается коммуникатор,
основная группа которого состоит из процессов в первой строке виртуальной
сетки. Пусть MPI_COMM_WORLD состоит из ![]() процессов,
где
процессов,
где ![]() . Пусть также
. Пусть также
![]() . При этом первая
строка процессов состоит из процессов с рангами
. При этом первая
строка процессов состоит из процессов с рангами ![]() (Ранги
указаны относительно MPI_COMM_WORLD). Чтобы создать
группу для нового коммуникатора, следует выполнить следующий код:
(Ранги
указаны относительно MPI_COMM_WORLD). Чтобы создать
группу для нового коммуникатора, следует выполнить следующий код:
MPI_Group first_row_group;
MPI_Comm first_row_comm;
int row_size;
int* process_ranks;
/* Создает список процессов нового */
* коммуникатора */
process_ranks = (int*) malloc(q*sizeof(int));
for (proc = 0; proc < q; proc++)
process_ranks[proc] = proc;
/* Получить группу, относящуюся к MPI_COMM_WORLD */
MPI_Comm_group(MPI_COMM_WORLD, &MPI_GROUP_WORLD);
/* Создать новую группу */
MPI_Group_incl(MPI_GROUP_WORLD, q, process_ranks,
&first_row_group);
/* Создать новый коммуникатор */
MPI_Comm_create(MPI_COMM_WORLD, first_row_group,
&first_row_comm);
float* A_00;
/* my_rank определяет ранг процесса в MPI_GROUP_WORLD */
if (my_rank < q) {
MPI_Comm_rank(first_row_comm, &my_rank_in_first_row);
/* Выделить память для A_00, order = n_bar */
A_00 = (float*) malloc (n_bar*n_bar*sizeof(float));
if (my_rank_in_first_row == 0) {
/* Инициализация A_00 */
. . .
}
MPI_Bcast(A_00, n_bar*n_bar, MPI_FLOAT, 0,
first_row_comm);
}
Контексты явно не используются ни в одной из функций MPI. Они неявно связываются с группами при создании коммуникаторов. Операция
int new_group_size, int* ranks_in_old_group,
MPI_Group* new_group)
MPI_Group new_group, MPI_Comm* new_comm)
Существует важное различие между первыми двумя и третьей функциями. Вызовы MPI_Comm_group() и MPI_Group_incl() являются локальными действиями. Это значит, что нет никакого взаимодействия между процессами, участвующими в их выполнении. Операция MPI_Comm_create() - коллективное действие. Процессы в old_comm должны вызывать MPI_Comm_create() с теми же самыми аргументами.
Если создаются несколько коммуникаторов, они должны создаваться в одном и том же порядке во всех процессах.
В программе умножения матриц нужно создать несколько коммуникаторов
- по одному для каждой строки процессов и по одному - для каждой колонки.
Это будет чрезвычайно утомительным процессом, если ![]() достаточно
большое, и каждый коммуникатор создается с использованием трех функции,
обсужденных ранее. Однако MPI содержит функцию MPI_Comm_split(),
которая может создать несколько коммуникаторов одновременно. Для иллюстрации
ее использования создаются коммуникаторы для каждой строки процессов:
достаточно
большое, и каждый коммуникатор создается с использованием трех функции,
обсужденных ранее. Однако MPI содержит функцию MPI_Comm_split(),
которая может создать несколько коммуникаторов одновременно. Для иллюстрации
ее использования создаются коммуникаторы для каждой строки процессов:
int my_row;
/* my_rank это ранг в MPI_COMM_WORLD.
* q*q = p */
my_row = my_rank/q;
MPI_Comm_split(MPI_COMM_WORLD, my_row, my_rank,
&my_row_comm);
Синтаксис вызова MPI_Comm_split():
int rank_key, MPI_Comm* new_comm)
MPI_Comm_split() является коллективной операцией, поэтому ее нужно вызывать всем процессам из old_comm. Функция может использоваться, даже если пользователь не желает назначать каждый процесс на новый коммуникатор. Это можно выполнить, передав предопределенную константу MPI_UNDEFINED в качестве аргумента split_key. Процессы, выполнившие это, получат предопределенное значение MPI_COMM_NULL, возвращенное в new_comm.
Ранее было указано, что существует возможность связать с коммуникатором дополнительную информацию, которая находится вне группы и контекста. Эта дополнительная информация кэширована с коммуникатором, и одной из самых важных ее частей является топология. В MPI топология представляет собой механизм для того, чтобы связать с процессами, принадлежащими группе, различные схемы адресации. Топология MPI - виртуальная, т. е. может не существовать никакого простого отношения между структурой процессов, определенной виртуальной топологией и фактической физической структурой параллельной машины.
Известны два основных типа виртуальной топологии, которая может быть создана MPI, - декартова топология, или топология сетки, и топология графа. Первый тип является подмножеством второго. Однако из-за активного использования сеток в приложениях выделяется отдельное подмножество функций MPI, цель которого - манипуляция виртуальными сетками.
В алгоритме Фокса необходимо идентифицировать процессы
MPI_COMM_WORLD
координатами квадратной сетки, причем каждая строка и колонка
сетки должны формировать свой собственный коммуникатор.
Сначала необходимо связать квадратную структуру сетки с
MPI_COMM_WORLD.
Чтобы сделать это, нужно определить следующую информацию:
int dimensions[2];
int wrap_around[2];
int reorder = 1;
dimensions[0] = dimensions[1] = q;
wrap_around[0] = wrap_around[1] = 1;
MPI_Cart_create(MPI_COMM_WORLD, 2, dimensions,
wrap_around, reorder, &grid_comm);
int my_grid_rank;
MPI_Comm_rank(grid_comm, &my_grid_rank);
MPI_Cart_coords(grid_comm, my_grid_rank, 2,
coordinates);
Обратной функцией к MPI_Cart_coords() является
MPI_Cart_rank():
Синтаксис MPI_Cart_create():
int number_of_dims, int* dim_sizes,
int* periods, int reorder, MPI_Comm* cart_comm)
Процессы в cart_comm ранжируются в порядке строк. При этом
первый ряд состоит из процессов 0, 1,..., dim_sizes[0]-1,
второй ряд - из процессов dim_sizes[0],dim_sizes[0]+1 , ... ,
2*dim_sizes[0]-1
и т.д. Таким образом, иногда выгодно изменить относительное ранжирование
процессов в old_comm. Например, пусть физическая топология
- это сетка 3x3,а процессы (номера) в old_comm назначены
на процессоры (квадраты сетки) следующим образом (рис. 5):
| 3 | 4 | 5 |
| 0 | 1 | 2 |
| 6 | 7 | 8 |
Поскольку MPI_Cart_create() создает новый коммуникатор, она является коллективной операцией.
Синтаксис функций, возвращающих адресную информацию:
int* rank);
int MPI_Cart_coords(MPI_Comm comm, int rank,
int number_of_dims, int* coordinates)
Еще одним способом является деление сетки на участки меньшей размерности. Например, можно создать коммуникатор для каждой строки сетки следующим образом:
MPI_Comm row_comm;
Varying_coords[0] = 0; varying_coords[1] = 1;
MPI_Cart_sub(grid_comm, varying_coords, &);
Varying_coords[0] = 1; varying_coords[1] = 0;
MPI_Cart_sub(grid_comm, varying_coord, col_comm);
Ниже приведена полная программ, реализующая алгоритм Фокса для перемножения матриц. Сначала приведена функция, которая создает различные коммуникаторы и ассоциированную с ними информацию. Так как ее реализация требует большого количества переменных, которые можно использовать в других функциях, их целесообразно поместить в структуру, чтобы облегчить передачу среди различных функций:
int p; /* Общее число процессов */
MPI_Comm comm; /* Коммуникатор для сетки */
MPI_Comm row_comm; /* Коммуникатор строки */
MPI_Comm col_comm; /* Коммуникатор столбца */
int q; /* Порядок сетки */
int my_row; /* Номер строки */
int my_col; /* Номер столбца */
int my_rank; /* Ранг процесса в коммуникаторе сетки */
} GRID-INFO-TYPE;
/* Пространство для сетки выделено
в вызывающей процедуре.*/
void Setup_grid(GRID_INFO_TYPE* grid) {
int old_rank;
int dimensions[2];
int periods[2];
int coordinates[2];
int varying-coords[2];
/* Настройка глобальной информации о сетке */
MPI_Comm_size(MPI_COMM_WORLD, &(grid->p));
MPI_Comm_rank(MPI_COMM_WORLD, &old_rank);
grid->q = (int) sqrt((double) grid->p);
dimensions[0] = dimensions[1] = grid->q;
periods[0] = periods[1] = 1;
MPI_Cart_create(MPI_COMM_WORLD, 2, dimensions,
periods, 1, &(grid->comm));
MPI_Comm_rank(grid->comm, &(grid->my_rank));
MPI_Cart_coords(grid->comm, grid->my_rank, 2,
coordinates);
grid->my_row = coordinates[0];
grid->my_col = coordinates[1];
/* Настройка коммуникаторов для строк и столбцов */
varying_coords[0] = 0; varying_coords[1] = 1;
MPI_Cart_sub(grid->comm, varying_coords,
&(grid->row_comm));
varying_coords[0] = 1; varying_coords[1] = 0;
MPI_Cart_sub(grid->comm, varying_coords,
&(grid->col_comm));
} /* Setup_grid */
Следующая функция выполняет фактическое умножение. Пусть пользователь
сам создает определения типа и функции для локальных матриц. При этом
определение типа находится в
LOCAL_MATRIX_TYPE, а соответствующий
производный тип в
DERIVED_LOCAL_MATRIX. Существуют также
три функции:
Local_matrix_multiply, Local_matrix_allocate,
Set_to_zero.
Можно также предположить, что память для
параметров была выделена в вызывающей функции, и все параметры, кроме
локальной матрицы произведения local_C, уже инициализированы:
LOCAL-MATRIX-TYPE* local-A,
LOCAL_MATRIX_TYPE* local_B,
LOCAL_MATRIX_TYPE* local_C)
{
LOCAL_MATRIX_TYPE* temp_A;
int step;
int bcast_root;
int n_bar; /* порядок подматрицы = n/q */
int source;
int dest;
int tag = 43;
MPI_Status status;
n_bar = n/grid->q;
Set_to_zero(local_C);
/* Вычисление адресов для циклического сдвига B */
source = (grid->my_row + 1) % grid->q;
dest = (grid->my_row + grid->q-1) % grid->q;
/* Выделение памяти для рассылки блоков A */
temp_A = Local_matrix_allocate(n_bar);
for (step = 0; step < grid->q; step++) {
bcast_root = (grid->my_row + step) % grid->q;
if (bcast_root == grid->my_col) {
MPI_Bcast(local_A, 1, DERIVED_LOCAL_MATRIX,
bcast_root, grid->row_comm);
Local_matrix_multiply(local_A, local_B, local_C);
} else {
MPI_Bcast(temp_A, 1, DERIVED_LOCAL_MATRIX,
bcast_root, grid->row_comm);
Local_matrix_multiply(temp_A, local_B, local_C);
}
MPI_Send(local_B, 1, DERIVED_LOCAL_MATRIX, dest, tag,
grid->col_comm);
MPI_Recv(local_B, 1, DERIVED_LOCAL_MATRIX, source,
tag, grid->col_comm, &status);
} /*for*/
}/*Fox*/
Переносимый расширяемый инструментарий для научных вычислений (PETSc) успешно продемонстрировал, что использование современных парадигм программирования может облегчить разработку крупномасштабных научных приложений на языках Фортран, C, и C++. Возникнув несколько лет назад, продукт эволюционировал в мощный набор средств для численного решения дифференциальных уравнений в частных производных и сходных проблем высокопроизводительных вычислений. PETSc состоит из нескольких библиотек (подобных классам C++). Каждая библиотека оперирует определенным семейством объектов (например, векторами) и ее операции применяются к этим объектам. Объекты и операции в PETSc разработаны с учетом опыта разработки научных приложений. Модули PETSc работают с множествами индексов, включая перестановки, для индексации векторов, перенумерации, и т.д.; c векторами; c матрицами (обычно разреженными); c распределенными массивами (используются для параллелизации задач с регулярной сетевой структурой); c методами подпространств Крылова; c предобработчиками, включая мультисеточные и прямые разреженные решатели; c нелинейными решателями; c пошаговыми решателями для дифференциальных уравнений в частных производных во времени.
Каждый модуль содержит абстрактный интерфейс (простой набор последовательностей вызова) и одну или несколько его реализаций, использующих определенные структуры данных. Таким образом, PETSc предлагает прозрачные и эффективные коды для различных фаз решения дифференциальных уравнений в частных производных с единообразным подходом к любому классу проблем. Такое построение гарантирует простое использование и сравнение различных алгоритмов (например, для экспериментов с различными методами подпространств Крылова, предобработчикамии, или сокращенными методами Ньютона). Кроме того, PETSc предоставляет удобную среду для моделирования научных приложений, а также быстрого построения или прототипирования алгоритмов. Библиотеки позволяют провести легкую настройку и расширение как алгоритмов, так и реализации. Этот подход улучшает гибкость систем и позволяет повторное использование кода, а также отделяет собственно параллелизацию от выбора алгоритма. Инфраструктура PETSc создает основу для построения крупномасштабных приложений. Ее полезно проанализировать для определения взаимосвязи между отдельными частями PETSc. Рис. 6 представляет собой диаграмму ее отдельных частей; на рис. 7 некоторые части изображены более детально. Эти рисунки иллюстрируют иерархическую организацию библиотеки, что позволяет пользователям применить уровень абстракции, наиболее подходящий для определенной задачи.
Перед использованием PETSc пользователь должен установить переменную окружения PETSC_DIR, указывающую полный путь к домашнему каталогу PETSc. Например, при работе в UNIX C shell команду вида setenv PETSC_DIR $HOME/petsc нужно поместить в пользовательский файл .cshrc. Дополнительно пользователь должен установить переменную окружения PETSC_ARCH, чтобы указать тип архитектуры (например, rs6000, solaris, IRIX и т.д.), для которой используется PETSc. Для этих целей можно употреблять утилиту ${PETSC_DIR}/bin/petscarch. Например, команда setenv PETSC_ARCH `$PETSC_DIR/bin/petscarch` может быть добавлена в файл .cshrc. Таким образом, даже если несколько машин различных типов разделяют единую файловую систему, при регистрации на любой из них PETSC_ARCH будет устанавливаться корректно .
Все программы PETSc используют стандарт MPI (Message
Passing Interface)
для обмена сообщениями. Поэтому, для выполнения программ PETSc, пользователь
должен быть знаком с процедурой запуска задач MPI на выбранной системе.
Например, при применении MPICH и других реализаций MPI программу,
использующую восемь процессоров, выполняет команда:
petsc_program_name petsc_options
Программы PETSc начинаются с вызова
char *help);,
который инициализирует PETSc и MPI. Аргументы argc и argv являются аргументами командной строки, передаваемыми всем программам C и C++. Аргумент file опционально указывает альтернативное имя файла опций PETSc, .petscrc, который по умолчанию находится в домашнем каталоге пользователя. База опций PETSc используется для настройки программы во время работы. Последний аргумент help является опциональной строкой символов, которая выводится, если программа запущена с опцией -help. В Фортране команда инициализации имеет вид:
PetscInitialize() автоматически вызывает MPI_Init(),
если MPI не был инициализирован ранее. При определенных условиях,
когда MPI нужно инициализировать прямо (или он инициализирован другой
библиотекой), пользователь может вначале вызвать MPI_Init()
(или позволить другой библиотеке это сделать), а затем вызвать PetscInitialize().
По умолчанию PetscInitialize()
устанавливает `общий''
коммуникатор PETSc, определяемый
PETSC_COMM_WORLD на MPI_COMM_WORLD.
Для тех, кто не знаком с MPI, коммуникатор является способом
указания набора процессов, которые совместно участвуют в вычислениях
или коммуникациях. Коммуникаторы являются переменными типа MPI_Comm.
В большинстве случаев пользователи могут пользоваться коммуникатором
PETSC_COMM_WORLD, для указания всех запущенных процессов,
или PETSC_COMM_SELF, для указания одного процесса. MPI предоставляет
процедуры создания новых коммуникаторов, содержащих подмножества процессоров,
хотя пользователи очень редко применяют их. Заметьте, что пользователям
PETSc не нужно программировать основной обмен сообщениями непосредственно
через MPI, но они должны быть знакомы с основными концепциями обмена
сообщениями и вычислений в распределенной памяти. Пользователи, которым
нужно применить процедуры PETSc на некотором множестве процессоров
в большой параллельной задаче, или которые хотят использовать ``главный
'' процесс для управления работой ``подчиненных'' процессов PETSc,
должны указать альтернативный коммуникатор для PETSC_COMM_WORLD,
вызвав
PetscSetCommWorld (MPI Comm comm)
перед вызовом PetscInitialize(), но, конечно, после вызова
MPI_Init().PetscSetCommWorld() может
быть вызван как минимум раз в каждом процессе. Большинству пользователей
может никогда не понадобиться применять функцию PetscSetCommWorld().
Все процедуры PETSc возвращают целое число, указывающее, возникла
ли при вызове ошибка. Код ошибки устанавливается в ненулевое значение,
если ошибка возникла; в противном случае возвращается 0. Для интерфейса
C/C++ код ошибки является возвращаемым значением, в то время как
для версии Фортрана каждая процедура PETSc содержит в качестве последнего
аргумента целочисленную переменную кода ошибки. Все программы PETSc
должны вызывать PetscFinalize() в качестве последнего оператора,
как показано ниже в формате для C/C++ и Фортрана соответственно:
call PetscFinalize (ierr)
Чтобы помочь пользователю начать освоение PETSc немедленно, следует
начать с простого однопроцессорного примера,
который решает одномерную задачу Лапласа с конечными разностями.
Этот последовательный код, который находится в файле
${PETSC_DIR}/src/sles/examples/tutorials/ex1.c,
иллюстрирует решение линейной системы с помощью библиотек SLES, интерфейсов
предобработчиков, методов подпространств Крылова и прямых линейных
решателей PETSc. По мере движения по коду выделяется несколько наиболее
важных частей примера:
/* Program usage: mpirun ex1 [-help] [all PETSc options] */
static char help[] = "Решает тридиагональную линейную систему
через SLES.\n\n";
/*T
Концепция: SLES^решение системы линейных уравнений
Процессоры: 1
T*/
/*
Включаем "petscsles.h" чтобы использовать решатели SLES .
Отметьте, что этот файл автоматически включает:
petsc.h - основные процедуры PETSc petscvec.h - векторы
petscsys.h - системные процедуры petscmat.h - матрицы
petscis.h - индексные множества petscksp.h - методы
подпространств Крылова
petscviewer.h - просмотрщики petscpc.h - предобработчики
Замечание:
Соответствующий параллельный пример находится в файле ex23.c
*/
#include "petscsles.h"
#undef __FUNCT__
#define __FUNCT__ "main"
int main(int argc,char **args)
Vec x, b, u; /* приближенное решение, RHS, точное решение */
Mat A; /* матрица линейной системы */
SLES sles; /* контекст линейного решателя */
PC pc; /* контекст предобработчика */
KSP ksp; /* контекст метода подпространств Крылова */
PetscReal norm; /* допустимая ошибка решения */
int ierr,i,n = 10,col[3],its,size;
PetscScalar neg_one = -1.0,one = 1.0,value[3];
PetscInitialize(&argc,&args,(char *)0,help);
ierr = MPI_Comm_size(PETSC_COMM_WORLD,&size);
CHKERRQ(ierr);
if (size != 1) SETERRQ(1,"Это однопроцессорный пример!");
ierr = PetscOptionsGetInt(PETSC_NULL,"-n",&n,PETSC_NULL);
CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Вычисляет матрицу и правосторонний вектор, который определяет
линейную систему Ax = b.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создает векторы. Заметьте, что первый вектор формируется с нуля,
а затем размножается, если нужно.
*/
ierr = VecCreate(PETSC_COMM_WORLD,&x);CHKERRQ(ierr);
ierr = PetscObjectSetName((PetscObject) x, "Решение");CHKERRQ(ierr);
ierr = VecSetSizes(x,PETSC_DECIDE,n);CHKERRQ(ierr);
ierr = VecSetFromOptions(x);CHKERRQ(ierr);
ierr = VecDuplicate(x,&b);CHKERRQ(ierr);
ierr = VecDuplicate(x,&u);CHKERRQ(ierr);
/*
Создает матрицу. При использовании MatCreate() формат матрицы
можно определять в процессе выполнения.
Замечание по производительности:
Для задач существенного объема предварительное распределение
памяти для матрицы критично для достижения хорошей
производительности. Поскольку предварительное распределение
невозможно средствами общей процедуры создания матрицы MatCreate(),
рекомендуется для конкретных задач использовать
специализированные процедуры, например:
MatCreateSeqAIJ() - последовательная AIJ
(упакованная разреженная строка),
MatCreateSeqBAIJ() - блочная AIJ
См. главу о матрицах руководства пользователя
для более полной информации.
*/
ierr = MatCreate(PETSC_COMM_WORLD,PETSC_DECIDE,PETSC_DECIDE,n,n,&A);
CHKERRQ(ierr);
ierr = MatSetFromOptions(A);CHKERRQ(ierr);
/*
Собирает матрицу
*/
value[0] = -1.0; value[1] = 2.0; value[2] = -1.0;
for (i=1; i<n-1; i++)
col[0] = i-1; col[1] = i; col[2] = i+1;
ierr = MatSetValues(A,1,&i,3,col,value,INSERT_VALUES);
CHKERRQ(ierr);
i = n - 1; col[0] = n - 2; col[1] = n - 1;
ierr = MatSetValues(A,1,&i,2,col,value,INSERT_VALUES);
CHKERRQ(ierr);
i = 0; col[0] = 0; col[1] = 1; value[0] = 2.0; value[1] = -1.0;
ierr = MatSetValues(A,1,&i,2,col,value,INSERT_VALUES);
CHKERRQ(ierr);
ierr = MatAssemblyBegin(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
ierr = MatAssemblyEnd(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
/*
Установим точное решение; затем вычислим правосторонний вектор.
*/
ierr = VecSet(&one,u);CHKERRQ(ierr);
ierr = MatMult(A,u,b);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Создает линейный решатель и устанавливает различные опции
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создает контекст линейного решателя
*/
ierr = SLESCreate(PETSC_COMM_WORLD,&sles);CHKERRQ(ierr);
/*
Устанавливаем операторы. Здесь матрица, которая определяет
линейную систему, служит также в качестве матрицы
предобработчика.
*/
ierr = SLESSetOperators(sles,A,A,DIFFERENT_NONZERO_PATTERN);
CHKERRQ(ierr);
/*
Устанавливаем значения по умолчанию для линейного решателя
(опционально):
- Выделяя контексты KSP и PC из контекста SLES, можно затем
непосредственно вызывать любые процедуры KSP и PC
для установки различных опций.
- Следующие четыре оператора необязательны; все их параметры
можно определить во время выполнения через
SLESSetFromOptions();
*/
ierr = SLESGetKSP(sles,&ksp);CHKERRQ(ierr);
ierr = SLESGetPC(sles,&pc);CHKERRQ(ierr);
ierr = PCSetType(pc,PCJACOBI);CHKERRQ(ierr);
ierr = KSPSetTolerances(ksp,1.e-7,
PETSC_DEFAULT,PETSC_DEFAULT,PETSC_DEFAULT);CHKERRQ(ierr);
/*
Установить опции времени выполнения, например
-ksp_type <type> -pc_type <type> -ksp_monitor -ksp_rtol <rtol>
Эти опции могут переопределить те, которые были указаны выше,
после того, как SLESSetFromOptions() была вызвана после любой
другой процедуры настройки.
*/
ierr = SLESSetFromOptions(sles);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Решаем линейную систему
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
ierr = SLESSolve(sles,b,x,&its);CHKERRQ(ierr);
/*
Смотреть информацию от решателя; вместо этого можно
использовать опцию
-sles_view для вывода этой информации на экран после
завершения SLESSolve().
*/
ierr = SLESView(sles,PETSC_VIEWER_STDOUT_WORLD);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Проверяем решение и очищаем его
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Проверяем ошибки
*/
ierr = VecAXPY(&neg_one,u,x);CHKERRQ(ierr);
ierr = VecNorm(x,NORM_2,&norm);CHKERRQ(ierr);
ierr = PetscPrintf(PETSC_COMM_WORLD,
"Погрешность %A, Итераций %d\n",norm,its); CHKERRQ(ierr);
/*
Освобождаем рабочее пространство. Все объекты PETSc
должны быть уничтожены, как только они станут ненужными.
*/
ierr = VecDestroy(x);CHKERRQ(ierr);
ierr = VecDestroy(u);CHKERRQ(ierr);
ierr = VecDestroy(b);CHKERRQ(ierr);
ierr = MatDestroy(A);CHKERRQ(ierr);
ierr = SLESDestroy(sles);CHKERRQ(ierr);
/* Всегда вызываем PetscFinalize() перед выходом из программы.
Эта процедура
- финализирует библиотеки PETSc и MPI
- предоставляет общую и диагностическую информацию,
если указаны определенные опции времени выполнения
(например, -log_summary).
*/
ierr = PetscFinalize();CHKERRQ(ierr);
return 0;
}
Включаемые файлы C/C++ для PETSc должны использоваться через директивы
#include "petscsles.h",
где petscsles.h - имя включаемого файла библиотеки SLES.
Каждая программа PETSc должна указывать включаемый файл, соответствующий
самому высокому уровню объектов PETSc, используемых в программе; все
требуемые включаемые файлы нижних уровней автоматически вложены в
файлы верхнего уровня. Например, petscsles.h включает petscmat.h
(матрицы), petscvec.h (векторы), и petsc.h (основной
файл PETSc). Включаемые файлы PETSc находятся в каталоге ${PETSC_DIR}/include.
С помощью труб могут общаться только родственные друг другу процессы, полученные с помощью fork(). Именованные каналы FIFO позволяют обмениваться данными с абсолютно ``чужим'' процессом.
С точки зрения ядра ОС FIFO является одним из вариантов реализации трубы. Системный вызов mkfifo() предоставляет процессу именованную трубу в виде объекта файловой системы. Как и для любого другого объекта, необходимо предоставлять процессам права доступа в FIFO, чтобы определить, кто может писать, и кто может читать данные. Несколько процессов могут записывать или читать FIFO одновременно. Режим работы с FIFO - полудуплексный, т.е. процессы могут общаться в одном из направлений. Типичное применение FIFO - разработка приложений ``клиент - сервер''.
Синтаксис функции для создания FIFO следующий:
#include <sys/stat.h>
int mkfifo(const char *fifoname, mode_t mode);
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd_fifo; /*дескриптор FIFO*/
char buffer[]="Текстовая строка для fifo\n";
char buf[100];
/*Если файл с таким именем существует, удалим его*/
unlink("/tmp/fifo0001.1");
/*Создаем FIFO*/
if((mkfifo("/tmp/fifo0001.1", O_RDWR)) == -1)
{
fprintf(stderr, "Невозможно создать fifo\n");
exit(0);
}
/*Открываем fifo для чтения и записи*/
if((fd_fifo=open("/tmp/fifo0001.1", O_RDWR)) == - 1)
{
fprintf(stderr, "Невозможно открыть fifo\n");
exit(0);
}
write(fd_fifo,buffer,strlen(buffer)) ;
if(read(fd_fifo, &buf, sizeof(buf)) == -1)
fprintf(stderr, "Невозможно прочесть из FIFO\n");
else
printf("Прочитано из FIFO : %s\n",buf);
return 0;
}
Если в системе отсутствует функция mkfifo(), можно воспользоваться общей функцией для создания файла:
Здесь pathname указывает обычное имя каталога и имя FIFO. Режим обозначается константой S_IFIFO из заголовочного файла <sys/stat.h>. Здесь же определяются права доступа. Параметр dev не нужен. Пример вызова mknod:
0) == - 1)
{ /*Невозможно создать fifo */
Флаг O_NONBLOCK может использоваться только при доступе для чтения. При попытке открыть FIFO с O_NONBLOCK для записи возникает ошибка открытия. Если FIFO закрыть для записи через close или fclose, это значит, что для чтения в FIFO помещается EOF.
Если несколько процессов пишут в один и тот же FIFO, необходимо обратить внимание на то, чтобы сразу не записывалось больше, чем PIPE_BUF байтов. Это необходимо, чтобы данные не смешивались друг с другом. Установить пределы записи можно следующей программой:
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
unlink("fifo0001");
/*Создаем новый FIFO*/
if((mkfifo("fifo0001", O_RDWR)) == -1)
{
fprintf(stderr, "Невозможно создать FIFO\n");
exit(0);
}
printf("Можно записать в FIFO сразу %ld байтов\n",
pathconf("fifo0001", _PC_PIPE_BUF));
printf("Одновременно можно открыть %ld FIFO \n",
sysconf(_SC_OPEN_MAX));
return 0;
}
При попытке записи в FIFO, который не открыт в данный момент для чтения ни одним процессом, генерируется сигнал SIGPIPE.
В следующем примере организуется обработчик сигнала SIGPIPE, создается FIFO, процесс-потомок записывает данные в этот FIFO, а родитель читает их оттуда. Пример иллюстрирует простое приложение типа ``клиент - сервер'':
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
static volatile sig_atomic_t sflag;
static sigset_t signal_new, signal_old, signal_leer;
static void sigfunc(int sig_nr)
{
fprintf(stderr, "SIGPIPE вызывает завершение
программы\n");
exit(0);
}
void signal_pipe(void)
{
if(signal(SIGPIPE, sigfunc) == SIG_ERR)
{
fprintf(stderr, "Невозможно получить сигнал
SIGPIPE\n");
exit(0);
}
/*Удаляем все сигналы из множества сигналов*/
sigemptyset(&signal_leer);
sigemptyset(&signal_new);
sigaddset(&signal_new, SIGPIPE);
/*Устанавливаем signal_new и сохраняем его*/
/* теперь маской сигналов будет signal_old*/
if(sigprocmask(SIG_UNBLOCK, &signal_new,
&signal_old) < 0)
exit(0);
}
int main()
{
int r_fifo, w_fifo; /*дескрипторы FIFO*/
char buffer[]="Текстовая строка для fifo\n";
char buf[100];
pid_t pid;
signal_pipe();
unlink("/tmp/fifo0001.1");
/*Создаем FIFO*/
if((mkfifo("/tmp/fifo0001.1", O_RDWR)) == -1)
{
fprintf(stderr, "Невозможно создать fifo\n");
exit(0);
}
pid=fork();
if(pid == -1)
{ perror("fork"); exit(0);}
else if(pid > 0) /*Родитель читает из FIFO*/
{
if (( r_fifo=open("/tmp/fifo0001.1", O_RDONLY))<0)
{ perror("r_fifo open"); exit(0); }
/*Ждем окончания потомка*/
while(wait(NULL)!=pid);
/*Читаем из FIFO*/
read(r_fifo, &buf, sizeof(buf));
printf("%s\n",buf);
close(r_fifo);
}
else /*Потомок записывает в FIFO*/
{
if((w_fifo=open("/tmp/fifo0001.1", O_WRONLY))<0)
{ perror("w_fifo open"); exit(0); }
/*Записываем в FIFO*/
write(w_fifo, buffer, strlen(buffer));
close(w_fifo); /*EOF*/
exit(0);
}
return 0;
}
Пользователь может вводить управляющую информацию во время выполнения программы, используя базу опций. В этом примере команда OptionsGetInt(PETSC_NULL,"-n",&n,&flg); проверяет, указал ли пользователь опцию командной строки для установки значения n, т.е. размерности задачи. Если это так, то переменная n устанавливается в нужное значение; в противном случае n остается неизменной.
Можно создать новый параллельный или последовательный вектор x общей размерности M с помощью команд:
VecSetSizes (Vec x, int m, int M);
VecDuplicate(Vec old,Vec *new).
Команды:
VecSetValues (Vec x,int n,int *indices,
PetscScalar *values, INSERT_VALUES);
Использование матриц в PETSc похоже на использование векторов. Пользователь может создать новую параллельную или последовательную матрицу A, у которой M строк и N столбцов, с помощью вызова:
MatCreate (MPI_Comm comm,int m,int n,int M,int N, Mat* A);где формат матрицы может быть определен во время выполнения. Пользователь также может указать каждому процессу локальное число строк и столбцов через параметры m и n. Значения могут быть установлены командой:
PetscScalar *values, INSERT_VALUES);
MatAssemblyEnd (Mat A,MAT_FINAL_ASSEMBLY);
После создания матриц и векторов, определяющих линейную систему Ax = b, пользователь может применить SLES для решения системы следующей последовательностью команд:
SLESSetOperators (SLES sles,Mat A,Mat PrecA,
MatStructure flag);
SLESSetFromOptions (SLES sles);
SLESSolve (SLES sles,Vec b,Vec x,int *its);
SLESDestroy (SLES sles);
Большинство проблем, требующих решения ДУЧП, являются нелинейными. PETSc предлагает интерфейс работы с нелинейными проблемами, называемый SNES. Большинству пользователей PETSc рекомендуется лучше работать непосредственно со SNES, чем использовать PETSc для линейных проблем с нелинейным решателем.
Все процедуры PETSc возвращают целое число, указывающее, возникла
ли ошибка при вызове. Макрос CHKERRQ(ierr) в PETSc проверяет
значение ierr и вызывает обработчик ошибок PETSc, при их обнаружении.
CHKERRQ(ierr) нужно использовать во всех процедурах,
чтобы обеспечить полный контроль ошибок. Ниже приведена трасса,
созданная контролем ошибок в примере программы PETSc. Ошибка возникла
в строке 1673 файла
${PETSC_DIR}/src/mat/impls/aij/seq/aij.c
и была вызвана попыткой распределения памяти для слишком большого
массива. Процедура была вызвана в программе ex3.c, в строке
71.
eagle:mpirun -np 1 ex3 -m 10000
PETSC ERROR: MatCreateSeqAIJ() line 1673
in src/mat/impls/aij/seq/aij.c
PETSC ERROR: Out of memory. This could be due to allocating
PETSC ERROR: too large an object or bleeding by not properly
PETSC ERROR: destroying unneeded objects.
PETSC ERROR: Try running with -trdump for more information.
PETSC ERROR: MatCreate () line 99 in src/mat/utils/gcreate.c
PETSC ERROR: main() line 71
in src/sles/examples/tutorials/ex3.c
MPI Abort by user Aborting program !
Aborting program!
p0 28969: p4 error: : 1
При использовании версий библиотек PETSc для отладки (откомпилированных с опцией BOPT=g) можно также проверять нарушения памяти (запись за границами массива и т.д.). Макрос CHKMEMQ можно вызывать в любом месте кода для проверки текущего состояния памяти и нарушений. Помещая в свой код несколько (или много) таких макросов, вы можете легко отследить, в какой части кода происходит нарушение.
Поскольку PETSc использует модель передачи сообщений для параллельного программирования и пользуется MPI для межпроцессорного взаимодействия, пользователь может свободно употреблять в своем коде процедуры MPI там, где это необходимо. Однако по умолчанию пользователь огражден от многих деталей обмена сообщениями внутри PETSc, поскольку они скрыты в таких параллельных объектах, как векторы, матрицы и решатели. К тому же, PETSc продоставляет такие инструменты, как обобщенную сборку/рассылку векторов и распределенные массивы, чтобы облегчить управление параллельными данными. Помните, что пользователь должен определить коммуникатор перед созданием любого объекта PETSc (такого как вектор, матрица или решатель), чтобы указать процессоры, на которые будет распределен объект. Например, как упоминалось выше, командами для создания матрицы, вектора и линейного решателя являются:
VecCreate (MPI_Comm comm ,Vec *x);
SLESCreate (MPI_Comm comm ,SLES *sles);
/* Запуск программы: mpirun -np <procs> ex2 [-help]
[all PETSc options] */
static char help[] =
"Параллельное решение линейной системы через SLES.\n\
Входные параметры включают:\n\
-random_exact_sol : использовать случайный вектор\
точного решения\n\
-view_exact_sol : вывод вектора точного решения в stdout\n\
-m <mesh_x> : количество узлов сетки по x\n\
-n <mesh_n> : количество узлов сетки по y\n\n";
/*T
Идея: параллельный пример, основанный на SLES;
Идея: SLES^Laplacian, 2d
Идея: Laplacian, 2d
Процессоры: n
T*/
/*
Включаем "petscsles.h", чтобы использовать решатели SLES.
Этот файл автоматически включает:
petsc.h - основные процедуры PETSc petscvec.h - векторы
petscsys.h - системные процедуры petscmat.h - матрицы
petscis.h - индексные множества petscksp.h - методы
подпространств Крылова
petscviewer.h - просмотрщики petscpc.h - предобработчики
*/
#include "petscsles.h"
#undef __FUNCT__
#define __FUNCT__ "main"
int main(int argc,char **args) {
Vec x,b,u; /* приближенное решение, RHS,
точное решение */
Mat A; /* матрица линейной системы */
SLES sles; /* контекст линейного решателя */
PetscRandom rctx; /* контекст генератора случайных чисел */
PetscReal norm; /* погрешность решения */
int i,j,I,J,Istart,Iend,ierr,m = 8,n = 7,its;
PetscTruth flg;
PetscScalar v,one = 1.0,neg_one = -1.0;
KSP ksp;
PetscInitialize(&argc, &args, (char*)0, help);
ierr = PetscOptionsGetInt(PETSC_NULL,"-m",&m,PETSC_NULL);
CHKERRQ(ierr);
ierr = PetscOptionsGetInt(PETSC_NULL,"-n",&n,PETSC_NULL);
CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Вычисляем матрицу и правосторонний вектор, определяющий
линейную систему Ax = b.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создаем параллельную матрицу, определяя только ее общие размеры.
При использовании MatCreate() формат матрицы может быть задан
во время выполнения.
Аналогично параллельное разделение матрицы определяется PETSc
во время выполнения.
Для проблем существенной размерности, предварительное
распределение памяти для матрицы влияет на
производительность.
Поскольку предварительное распределение невозможно при
использовании общей процедуры создания матрицы MatCreate(),
рекомендуется для практических задач вместо этого использовать
процедуры создания матриц специальных форматов, например:
MatCreateMPIAIJ() - параллельная AIJ
(упакованная разреженная строка)
MatCreateMPIBAIJ() - параллельная блочная AIJ
См. главу о матрицах в руководстве пользователя
для детальной информации.
*/
ierr = MatCreate(PETSC_COMM_WORLD,PETSC_DECIDE,PETSC_DECIDE,m*n,
m*n,&A);CHKERRQ(ierr);
ierr = MatSetFromOptions(A);CHKERRQ(ierr);
/*
В настоящее время все параллельные форматы матриц PETSc
разделяются среди процессоров на непрерывные последовательности
строк. Определим, какие строки матрицы получены локально
*/
ierr = MatGetOwnershipRange(A,\&Istart,\&Iend);CHKERRQ(ierr);
/*
Параллельно устанавливаем элементы матрицы для 2-D
пятиточечного шаблона:
- Каждый процессор должен вставить только элементы, которыми
он владеет локально (любые нелокальные элементы будут
пересланы соответствующему процессору во время
сборки матрицы).
- Всегда указывайте глобальные номера строк и столбцов
элементов матрицы.
Здесь используется не совсем стандартная нумерация,
которая перебирает сначала все неизвестные для x = h, затем
для x = 2h и т.д.; поэтому Вы видите J = I +- n вместо
J = I +- m, как Вы ожидали. Более стандартная нумерация сначала
проходит все переменные для y = h, затем y = 2h и т.д.
*/
for (I=Istart; I<Iend; I++) {
v = -1.0; i = I/n; j = I - i*n;
if (i>0) {J = I - n; ierr=MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
if (i<m-1) {J = I+n;ierr=MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
if (j>0) {J = I-1; ierr = MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
if (j<n-1) {J = I+1; ierr=MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
v = 4.0; ierr = MatSetValues(A,1,&I,1,&I,&v,INSERT_VALUES);
CHKERRQ(ierr);
}
/*
Собираем матрицу, используя двухшаговый процесс:
MatAssemblyBegin(), MatAssemblyEnd()}
Можно выполнять вычисления, пока сообщения передаются,
если поместить код между двумя этими операторами.
*/
ierr = MatAssemblyBegin(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
ierr = MatAssemblyEnd(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
/*
Создаем параллельные векторы.
- Первый вектор формируется с нуля, а затем делаются дубликаты,
если нужно.
- При использовании VecCreate(), VecSetSizes и
VecSetFromOptions() в этом примере, определяются только
глобальные размеры вектора; параллельное разделение
определяется во время выполнения.
- При решении линейной системы и векторы, и матрицы должны
соответственно разделяться. PETSc автоматически генерирует
правильно разделенные матрицы и векторы, если процедуры
MatCreate() и VecCreate() используются с одним и тем же
коммуникатором.
- Пользователь может самостоятельно определить локальные
размеры векторов и матриц, если требуется более сложное
разделение (заменив аргумент PETSC_DECIDE в процедуре
VecSetSizes() ниже).
*/
ierr = VecCreate(PETSC_COMM_WORLD,&u);CHKERRQ(ierr);
ierr = VecSetSizes(u,PETSC_DECIDE,m*n);CHKERRQ(ierr);
ierr = VecSetFromOptions(u);CHKERRQ(ierr);
ierr = VecDuplicate(u,&b);CHKERRQ(ierr);
ierr = VecDuplicate(b,&x);CHKERRQ(ierr);
/*
Установим точное решение; затем вычислим правосторонний
вектор. По умолчанию мы используем точное решение вектора
со всеми элементами 1.0; однако использование
опции времени выполнения -random_sol формирует вектор
решения со случайными составляющими.
*/
ierr = PetscOptionsHasName(PETSC_NULL,"-random_exact_sol",&flg);
CHKERRQ(ierr);
if (flg) {
ierr = PetscRandomCreate(PETSC_COMM_WORLD,RANDOM_DEFAULT,&rctx);
CHKERRQ(ierr);}
ierr = VecSetRandom(rctx,u);CHKERRQ(ierr);
ierr = PetscRandomDestroy(rctx);CHKERRQ(ierr);
} else {
ierr = VecSet(&one,u);CHKERRQ(ierr);
}
ierr = MatMult(A,u,b);CHKERRQ(ierr);
/*
Посмотрим вектор точного решения, если хочется
*/
ierr = PetscOptionsHasName(PETSC_NULL,"-view_exact_sol",&flg);
CHKERRQ(ierr);
if (flg) {ierr = VecView(u,PETSC_VIEWER_STDOUT_WORLD);
CHKERRQ(ierr);}
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Создаем линейный решатель и устанавливаем различные опции}
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создаем контекст линейного решателя
*/
ierr = SLESCreate(PETSC_COMM_WORLD,&sles);CHKERRQ(ierr);
/*
Установим операторы. Здесь матрица, определяющая линейную
систему, служит также матрицей предобработчиков.
*/
ierr = SLESSetOperators(sles,A,A,DIFFERENT_NONZERO_PATTERN);
CHKERRQ(ierr);
/*
Установим значения линейного решателя по умолчанию для
этой задачи (необязательно):
- Извлекая контексты KSP и PC из контекста SLES, затем можно
непосредственно вызывать любые процедуры KSP и PC
для установки различных опций.
- Следующие два оператора опциональны; все параметры
могут быть альтернативно заданы во время выполнения
через SLESSetFromOptions().
Все значения по умолчанию можно переопределить
во время выполнения, как показано ниже.
*/
ierr = SLESGetKSP(sles,&ksp);CHKERRQ(ierr);
ierr = KSPSetTolerances(ksp,1.e-2/((m+1)*(n+1)),1.e-50,
PETSC_DEFAULT,PETSC_DEFAULT); CHKERRQ(ierr);
/*
Установим опции времени выполнения, например,
-ksp_type <type> -pc_type <type> -ksp_monitor -ksp_rtol <rtol>
Эти опции могут переопределить значения, указаннаые выше
до тех пор, пока SLESSetFromOptions() будет вызван после любой
процедуры настройки.
*/
ierr = SLESSetFromOptions(sles);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Решаем линейную систему
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
ierr = SLESSolve(sles,b,x,&its);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Проверяем решение и очищаем его
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Проверяем ошибку
*/
ierr = VecAXPY(&neg_one,u,x);CHKERRQ(ierr);
ierr = VecNorm(x,NORM_2,&norm);CHKERRQ(ierr);
/*
Масштабируем ошибку
*/
/* norm *= sqrt(1.0/((m+1)*(n+1))); */
/*
Выводим информацию о сходимости. PetscPrintf() создает единый
оператор вывода из всех процессов, разделяющих коммуникатор.
Альтернативой является PetscFPrintf(), который выводит в файл.
*/
ierr = PetscPrintf(PETSC_COMM_WORLD,"Norm of error %A
iterations %d\n", norm,its); CHKERRQ(ierr);
/*
Освобождаем рабочее пространство. Все объекты PETSc должны быть
удалены, если они больше не нужны.
*/
ierr = SLESDestroy(sles);CHKERRQ(ierr);
ierr = VecDestroy(u);CHKERRQ(ierr);
ierr = VecDestroy(b);CHKERRQ(ierr);
ierr = VecDestroy(x);CHKERRQ(ierr);
ierr = MatDestroy(A);CHKERRQ(ierr);
/*
Всегда вызывайте PetscFinalize() перед выходом из программы.
Эта процедура
- финализирует библиотеки PETSc, а также MPI
- выдает итоговую и диагностическую информацию, если указаны
определенные опции времени выполнения
(например, -log_summary).
*/
ierr = PetscFinalize();CHKERRQ(ierr);
return 0;
}
Ниже приведен пример компиляции и запуска программы PETSc, использующей MPICH:
gcc -pipe -c -I../../../ -I../../..//include
-I/usr/local/mpi/include -I../../..//src -g
-DPETSC_USE_DEBUG -DPETSC_MALLOC -DPETSC_USE_LOG ex1.c
gcc -g -DPETSC_USE_DEBUG -DPETSC_MALLOC -DPETSC_USE_LOG
-o ex1 ex1.o
/home/bsmith/petsc/lib/libg/sun4/libpetscsles.a
-L/home/bsmith/petsc/lib/libg/sun4 -lpetscstencil -lpetscgrid
-lpetscsles -lpetscmat -lpetscvec -lpetscsys -lpetscdraw
/usr/local/lapack/lib/lapack.a /usr/local/lapack/lib/blas.a
/usr/lang/SC1.0.1/libF77.a -lm /usr/lang/SC1.0.1/libm.a -lX11
/usr/local/mpi/lib/sun4/ch p4/libmpi.a
/usr/lib/debug/malloc.o /usr/lib/debug/mallocmap.o
/usr/lang/SC1.0.1/libF77.a -lm /usr/lang/SC1.0.1/libm.a -lm
rm -f ex1.o
eagle: mpirun -np 1 ex2
Norm of error 3.6618e-05 iterations 7
eagle: mpirun -np 2 ex2
Norm of error 5.34462e-05 iterations 9
Отметьте, что различные рабочие места могут иметь различные
библиотеки и имена компиляторов. Пользователи, столкнувшиеся с трудностями
при сборке программ PETSc, могут ознакомиться с руководством по исправлению
ошибок на веб-странице PETSc по адресу http://www.mcs.anl.gov/petsc
или в файле
${PETSC_DIR}/docs/troubleshooting.html.
Опция -log_summary активирует вывод итоговой информации о производительности, включая времена выполнения, скорость операций с плавающей точкой, и активность обмена сообщениями. Следующая глава содержит детальную информацию о профилировании, включая интерпретацию данных. Этот отдельный пример выполняет решение линейной системы на одном процессоре с использованием GMRES и ILU. Малая скорость операций с плавающей точкой в этом примере обусловлена тем, что код решает малую систему. Этот пример предназначен в основном для демонстрации простоты получения информации о производительности:
eagle> mpirun -np 1 ex1 -n 1000 -pc_type ilu -ksp_type gmres
-ksp_rtol 1.e-7 -log_summary
------------------------------- PETSc Performance Summary:---------
ex1 on a sun4 named merlin.mcs.anl.gov with 1 processor,
by curfman Wed Aug 7 17:24:27 1996
Max Min Avg Total
Time (sec): 1.150e-01 1.0 1.150e-01
Objects: 1.900e+01 1.0 1.900e+01
Flops: 3.998e+04 1.0 3.998e+04 3.998e+04
Flops/sec: 3.475e+05 1.0 3.475e+05
MPI Messages: 0.000e+00 0.0 0.000e+00 0.000e+00
MPI Messages: 0.000e+00 0.0 0.000e+00 0.000e+00 (lengths)
MPI Reductions: 0.000e+00 0.0
-------------------------------------------------------------------
Phase Count Time (sec) Flops/sec Global}
Max Ratio Max Ratio Mess Avg len Reduct %T %F %M %L %R
-------------------------------------------------------------------
MatMult 2 2.553e-03 1.0 3.9e+06 1.0 0.0e+00 0.0e+00 0.0e+00 2 25 0 0 0
MatAssemblyBegin 1 2.193e-05 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0
MatAssemblyEnd 1 5.004e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 4 0 0 0 0
MatGetReordering 1 3.004e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 3 0 0 0 0
MatILUFctrSymbol 1 5.719e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 5 0 0 0 0
MatLUFactorNumer 1 1.092e-02 1.0 2.7e+05 1.0 0.0e+00 0.0e+00 0.0e+00 9 7 0 0 0
MatSolve 2 4.193e-03 1.0 2.4e+06 1.0 0.0e+00 0.0e+00 0.0e+00 4 25 0 0 0
MatSetValues 1000 2.461e-02 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 21 0 0 0 0
VecDot 1 60e-04 1.0 9.7e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 5 0 0 0
VecNorm 3 5.870e-04 1.0 1.0e+07 1.0 0.0e+00 0.0e+00 0.0e+00 1 15 0 0 0
VecScale 1 1.640e-04 1.0 6.1e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 3 0 0 0
VecCopy 1 3.101e-04 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0
VecSet 3 5.029e-04 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0
VecAXPY 3 8.690e-04 1.0 6.9e+06 1.0 0.0e+00 0.0e+00 0.0e+00 1 15 0 0 0
VecMAXPY 1 2.550e-04 1.0 7.8e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 5 0 0 0
SLESSolve 1 1.288e-02 1.0 2.2e+06 1.0 0.0e+00 0.0e+00 0.0e+00 11 70 0 0 0
SLESSetUp 1 2.669e-02 1.0 1.1e+05 1.0 0.0e+00 0.0e+00 0.0e+00 23 7 0 0 0
KSPGMRESOrthog 1 1.151e-03 1.0 3.5e+06 1.0 0.0e+00 0.0e+00 0.0e+00 1 10 0 0 0
PCSetUp 1 24e-02 1.0 1.5e+05 1.0 0.0e+00 0.0e+00 0.0e+00 18 7 0 0 0
PCApply 2 4.474e-03 1.0 2.2e+06 1.0 0.0e+00 0.0e+00 0.0e+00 4 25 0 0 0
--------------------------------------------------------------------------------
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants' Mem.
Index set 3 3 12420 0
Vector 8 8 65728 0
Matrix 2 2 184924 4140
Krylov Solver 1 1 16892 41080
Preconditioner 1 1 0 64872
SLES 1 1 0 122844
Примеры в библиотеке демонстрируют использование ПО и могут служить
заготовками для разработки специальных приложений. Новые пользователи
PETSc должны изучить программы в каталогах
$PETSC_DIR/src/<library>/examples/tutorials,
где
<library> обозначает одну из библиотек PETSc, например,
snes или sles. Справочные страницы, расположенные
в каталоге $PETSC DIR/docs/index.html или по адресу http://www.mcs.anl.gov/petsc/ docs/
содержат индексные списки (организованные по названиям функций или
понятиям) к учебным примерам. Чтобы написать новую программу с использоваанием
PETSc, рекомендуется выполнить следующие действия:
Корневой каталог PETSc содержит следующие каталоги:
PETSc включает в себя содержательную и легковесную систему, позволяющую провести профилирование приложений. Процедуры PETSc автоматически фиксируют данные о производительности, если при выполнении указаны определенные опции. Пользователь также может фиксировать информацию о коде приложения для получения полной картины производительности. К тому же, PETSc предоставляет механизм вывода информативных сообщений о ходе вычислений.
Если код приложения и библиотеки PETSc компилировались с флагом
-DPETSC_USE_LOG (установлен по умолчанию для всех версий),
то можно использовать во время выполнения программы различные виды профилирования
кода между вызовами
PetscInitialize() и PetscFinalize().
Отметьте, что флаг
-DPETSC_USE_LOG может быть определен
для инсталляции PETSc в файле ${PETSC_DIR}/bmake/
${PETSC_ARCH}/variables. Опции профилирования включают:
Опция -log_summary после завершения программы выводит
данные профилирования в стандартный вывод.
Данные профилирования могут быть выведены также и в любое время, если
программа вызовет функцию PetscLogPrintSummary(). Данные
о производительности выводятся для каждой процедуры, организованной
в библиотеки PETSc, а затем для всех определенных пользовательских
событий. Для каждой процедуры выводимые данные включают максимальное
время и скорость операций с плавающей точкой (flop) для всех
процессоров. Включается также информация о параллельной производительности.
Для подсчета операций с плавающей точкой в PETSc определяется единица
flop как одна из операций следующего типа: умножение, деление,
сложение или вычитание. Например, одна операция VecAXPY (),
вычисляющая ![]() для векторов длины N, требует
2N flops (состоящих из N сложений и N умножений).
Обратите внимание, что скорость flop представляет только ограниченную
характеристику производительности, поскольку извлечение и запись в
память также влияют на показатели. Для упрощения остальная часть обсуждения
посвящена интерпретации данных профилирвания для библиотеки SLES,
предоставляющей линейные решатели для всего пакета PETSc. Вспомните
иерархическую организацию библиотеки PETSc, показанную на рис. 69.
Каждый решатель SLES состоит из предобработчика PC и части KSP (подпространств
Крылова), котрые в свою очередь используют модули Mat (матрицы) и
Vec (векторы). Поэтому операции в модуле SLES состоят из низкоуровневых
операций нижележащих модулей. Отметьте также факт, что библиотека
нелинейных решателей SNES построена на базе библиотеки SLES, а
библиотека временного интегрирования TS построена на базе SNES .
Линейный решатель SLES
содержит две основных фазы SLESSetUp () и SLESSolve
(), каждая из которых включает множество действий, зависящих от
определенной техники решения. Для использования предобработчика
PCILU и метода подпространств Крылова KSPGMRES последовательность
процедур PETSc приведена ниже. Как указано в иерархии, операции в
SLESSetUp () включают все операции внутри PCSetUp
(), которые в свою очередь включают MatILUFactor () и т.д.:
для векторов длины N, требует
2N flops (состоящих из N сложений и N умножений).
Обратите внимание, что скорость flop представляет только ограниченную
характеристику производительности, поскольку извлечение и запись в
память также влияют на показатели. Для упрощения остальная часть обсуждения
посвящена интерпретации данных профилирвания для библиотеки SLES,
предоставляющей линейные решатели для всего пакета PETSc. Вспомните
иерархическую организацию библиотеки PETSc, показанную на рис. 69.
Каждый решатель SLES состоит из предобработчика PC и части KSP (подпространств
Крылова), котрые в свою очередь используют модули Mat (матрицы) и
Vec (векторы). Поэтому операции в модуле SLES состоят из низкоуровневых
операций нижележащих модулей. Отметьте также факт, что библиотека
нелинейных решателей SNES построена на базе библиотеки SLES, а
библиотека временного интегрирования TS построена на базе SNES .
Линейный решатель SLES
содержит две основных фазы SLESSetUp () и SLESSolve
(), каждая из которых включает множество действий, зависящих от
определенной техники решения. Для использования предобработчика
PCILU и метода подпространств Крылова KSPGMRES последовательность
процедур PETSc приведена ниже. Как указано в иерархии, операции в
SLESSetUp () включают все операции внутри PCSetUp
(), которые в свою очередь включают MatILUFactor () и т.д.:
Итоги, выводимые через -log_summary, отражают эту иерархию процедур. Например, показатели производительности для такой высокоуровневой процедуры, как SLESSolve, включают итоги всех операций, накопленные в низкоуровневых компонентах, составляющих эту процедуру.
Очевидно, что в настоящее время вывод не может быть представлен через -log_summary так, чтобы иерархия процедур PETSc была полностью ясна, в основном потому, что не был определен ясный и единообразный способ сделать это для всей библиотеки. В дальнейшем возможны улучшения. Для определенной задачи пользователь должен иемть представление об основных операциях, требуемых для ее реализации (т.е., какие операции выполняются при использовании GMRES и ILU), чтобы интерпретация данных от -log_summary была относительно прозрачной.
Здесь обсуждается информация о производительности параллельных программ, приведенная в двух примерах ниже, которая представляет собой комбинированный вывод, сгенерированный с помощью опции -log_summary. Программой, которая генерирует эти данные, является ${PETSC_DIR}/src/sles/examples/ex21.c. Данный код загружает матрицу и правосторонний вектор из двоичного файла, а затем решает полученную линейную систему; далее программа повторяет этот процесс для второй линейной системы:
mpirun ex21 -f0 medium -f1 arco6 -ksp_gmres_unmodifiedgramschmidt \
-log_summary -mat_mpibaij -matload_block_size 3 -pc_type \
bjacobi -options_left
Number of iterations = 19
Residual norm = 7.7643e-05
Number of iterations = 55
Residual norm = 6.3633e-01
--------------- Информация о производительности PETSc:-------------
ex21 on a rs6000 named p039 with 4 processors,
by mcinnes Wed Jul 24 16:30:22 1996
Max Min Avg Total
Time (sec): 3.289e+01 1.0 3.288e+01
Objects: 1.130e+02 1.0 1.130e+02
Flops: 2.195e+08 1.0 2.187e+08 8.749e+08
Flops/sec: 6.673e+06 1.0 2.660e+07
MPI Messages: 2.205e+02 1.4 1.928e+02 7.710e+02
MPI Message Lengths: 7.862e+06 2.5 5.098e+06 2.039e+07
MPI Reductions: 1.850e+02 1.0
Summary of Stages:-Time--Flops--Messages--Message-lengths-Reductions
Avg %Total Avg %Total counts %Total avg %Total counts %Total
0: Load System 0: 1.191e+00 3.6% 3.980e+06 0.5% 3.80e+01 4.9%
6.102e+04 0.3% 1.80e+01 9.7%
1: SLESSetup 0: 6.328e-01 2.5% 1.479e+04 0.0% 0.00e+00 0.0%
0.000e+00 0.0% 0.00e+00 0.0%
2: SLESSolve 0: 2.269e-01 0.9% 1.340e+06 0.0% 1.52e+02 19.7%
9.405e+03 0.0% 3.90e+01 21.1%
3: Load System 1: 2.680e+01 107.3% 0.000e+00 0.0% 2.10e+01 2.7%
1.799e+07 88.2% 1.60e+01 8.6%
4: SLESSetup 1: 1.867e-01 0.7% 1.088e+08 2.3% 0.00e+00 0.0%
0.000e+00 0.0% 0.00e+00 0.0%
5: SLESSolve 1: 3.831e+00 15.3% 2.217e+08 97.1% 5.60e+02 72.6%
2.333e+06 11.4% 1.12e+02 60.5%
--------------------------------------------------------------------
.... [Информация различных фаз, см. часть II ниже] ...
--------------------------------------------------------------------
Использование памяти указано в байтах:
Object Type Creations Destructions Memory Descendants' Mem.
Viewer 5 5 0 0
Index set 10 10 127076 0
Vector 76 76 9152040 0
Vector Scatter 2 2 106220 0
Matrix 8 8 9611488 5.59773e+06
Krylov Solver 4 4 33960 7.5966e+06
Preconditioner 4 4 16 9.49114e+06
SLES 4 4 0 1.71217e+07
Этот результат получен на четырехпроцессорном IBM SP с использованием рестартуемого GMRES и блочного предобработчика Якоби, в котором каждый блок решается через ILU. Он представляет общие результаты оценки производительности, включая время, операции с плавающей точкой, скорости вычислений, и активность обмена сообщениями (например, количество и размер посланных сообщений и коллективных операций). Приведены и результаты для различных пользовательских стадий мониторинга. Информация о различных фазах вычислений следует ниже. Наконец, представлена информация об использовании памяти, создании и удалении объектов. Также уделяется внимание итогам различных фаз вычисления, приведенным во втором примере. Итог для каждой фазы представляет максимальное время и скорость операций с плавающей точкой для всех процессоров, а также соотношение максимального и минимального времени и скоростей для всех процессоров. Отношение приближенно равное 1 указывает, что вычисления в данной фазе хорошо сбалансированы между процессорами; если отношение увеличивается, баланс становится хуже. Также для каждой фазы в последней колонке таблицы приведена максимальная скорость вычислений (в единицах MFlops/sec).
Total Mflop/sec = 10
![]() * (сумма flops по всем процессорам) / (максимальное
время для всех процессоров)
* (сумма flops по всем процессорам) / (максимальное
время для всех процессоров)
Общие скорости вычислений < 1 MFlop в данном столбце таблицы результатов показаны как 0. Дополнительная статистика для каждой фазы включает общее количество посланных сообщений, среднюю длину сообщения и количество общих редукций. Итоги по производительности для высокоуровневых процедур PETSc включают статистику для низших уровней, из которых они состоят. Например, коммуникации внутри произведения матрица-вектор MatMult () состоят из операций рассылки вектора, выполняемых процедурами VecScatterBegin () и VecScatterEnd(). Окончательные приведенные данные представляют собой проценты различной статистики (время (%T), flops/sec (%F), сообщения(%M), средняя длина сообщения (%L) и редукции (%R)) для каждого события, относящегося ко всем вычислениям и к любым пользовательским этапам. Эта статистика может оказать помощь в оптимизации производительности, поскольку указывает секции кода, которые могут быть подвержены различным методам настройки. Следующая глава дает советы по достижению хорошей производительности кодов PETSc:
mpirun ex21 -f0 medium -f1 arco6 -ksp_gmres_unmodifiedgramschmidt \
-log_summary -mat_mpibaij -matload_block_size 3 -pc_type \
bjacobi -options_left
-------------Информация о производительности PETSc:--------------
.... [Общие итоги, см. часть I] ...
Информация о фазе:
Count: сколько раз фаза выполнялась
Time and Flops/sec: Max - максимально для всех прцессоров
Ratio - отношение максимума к минимуму для всех процессоров
Mess: количество посланных сообщений
Avg. len: средняя длина сообщения
Reduct: количество глобальных редукций
Global: полное вычисление
Stage: необязательные пользовательские этапы вычислений.
Установите этапы через PLogStagePush() и PLogStagePop().
%T - процент времени в фазе %F - процент операций flops в фазе
%M - процент сообщений в фазе %L - процент длины сообщений в фазе
%R - процент редукций в фазе
Total Mflop/s: 10^6 * (sum of flops over all processors)
/ (max time over all processors)
------------------------------------------------------------------
Phase Count Time (sec) Flops/sec -Global--Stage--Total
Max Ratio Max Ratio Mess Avg len Reduct
%T %F %M %L %R %T %F %M %L %R Mflop/s
------------------------------------------------------------------
...
---Event Stage 4: SLESSetUp 1
MatGetReordering 1 3.491e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 2 0 0 0 0 0
MatILUFctrSymbol 1 6.970e-03 1.2 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 3 0 0 0 0 0
MatLUFactorNumer 1 1.829e-01 1.1 3.2e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 90 99 0 0 0 110
SLESSetUp 2 1.989e-01 1.1 2.9e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 99 99 0 0 0 102
PCSetUp 2 1.952e-01 1.1 2.9e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 97 99 0 0 0 104
PCSetUpOnBlocks 1 1.930e-01 1.1 3.0e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 96 99 0 0 0 105
-----Event Stage 5: SLESSolve 1
MatMult 56 1.199e+00 1.1 5.3e+07 1.0 1.1e+03 4.2e+03
0.0e+00 5 28 99 23 0 30 28 99 99 0 201
MatSolve 57 1.263e+00 1.0 4.7e+07 1.0 0.0e+00 0.0e+00
0.0e+00 5 27 0 0 0 33 28 0 0 0 187
VecNorm 57 1.528e-01 1.3 2.7e+07 1.3 0.0e+00 0.0e+00
2.3e+02 1 1 0 0 31 3 1 0 0 51 81
VecScale 57 3.347e-02 1.0 4.7e+07 1.0 0.0e+00 0.0e+00
0.0e+00 0 1 0 0 0 1 1 0 0 0 184
VecCopy 2 1.703e-03 1.1 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 0
VecSet 3 2.098e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 0
VecAXPY 3 3.247e-03 1.1 5.4e+07 1.1 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 200
VecMDot 55 5.216e-01 1.2 9.8e+07 1.2 0.0e+00 0.0e+00
2.2e+02 2 20 0 0 30 12 20 0 0 49 327
VecMAXPY 57 6.997e-01 1.1 6.9e+07 1.1 0.0e+00 0.0e+00
0.0e+00 3 21 0 0 0 18 21 0 0 0 261
VecScatterBegin 56 4.534e-02 1.8 0.0e+00 0.0 1.1e+03 4.2e+03
0.0e+00 0 0 99 23 0 1 0 99 99 0 0
VecScatterEnd 56 2.095e-01 1.2 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 1 0 0 0 0 5 0 0 0 0 0
SLESSolve 1 3.832e+00 1.0 5.6e+07 1.0 1.1e+03 4.2e+03
4.5e+02 15 97 99 23 61 99 99 99 99 99 222
KSPGMRESOrthog 55 1.177e+00 1.1 7.9e+07 1.1 0.0e+00 0.0e+00
2.2e+02 4 39 0 0 30 29 40 0 0 49 290
PCSetUpOnBlocks 1 1.180e-05 1.1 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 0
PCApply 57 1.267e+00 1.0 4.7e+07 1.0 0.0e+00 0.0e+00
0.0e+00 5 27 0 0 0 33 28 0 0 0 186
-------------------------------------------------------------------
.... [Завершение общих итогов, см. часть I] ...
Для визуализации событий PETSc можно также использовать пакеты Upshot
(или Jumpshot). Эти пакеты поставляются вместе с библиотекой MPE, являющейся
частью MPICH - реализации MPI. Опция -log_mpe [logfile]
создает файл регистрации событий, пригодный для просмотра с помощью
Upshot. Пользователь может применять либо файл регистрации по умолчанию
mpe.log, либо указывать собственное имя файла через параметр
logfile. Для использовыания этой опции регистрации пользователь
может работать с любой реализацией MPI (не обязательно MPICH), но
должен построить и скомпоновать часть MPE из MPICH. Пользователь должен
также откомпилировать библиотеку PETSc с флагом -DPETSC_HAVE_MPE,
не установленным по умолчанию. Включить регистрацию MPE пользователь
может, указав значение
-DPETSC_HAVE_MPE в переменной PCONF
каталога ${PETSC_DIR}/
bmake/${PETSC_ARCH} /packages
и пересобрав все в PETSc. По умолчанию не все события PETSc регистрируются
MPE. Например, поскольку MatSetValues () может вызываться
в программе тысячи раз, по умолчанию ее вызовы не регистрируются MPE.
Для активирования регистрации отдельных событий с помощью MPE, нужно
использовать функцию:
Для отключения регистрации события в MPE, нужно использовать:
Событие может быть либо предопределено в PETSc (как показано в файле ${PETSC_DIR}/include/petsclog.h) или получено через PetscLogEventRegister (). Эти процедуры можно вызывать столько раз, сколько потребуется приложению, так что можно ограничить регистрацию событий с помощью MPE для отдельных сегментов кода. Чтобы увидеть, какие события регистрируются по умолчанию, пользователь может просмотреть исходный код (см. файлы src/plot/src/plogmpe.c и include/petsclog.h). Разрабатываются простая программа и графический интерфейс, позволяющие просмотреть, какие регистрируемые события уже определены, и определить новые. Пользователь также может регистрировать события MPI. Чтобы сделать это, рассматривайте приложение PETSc как приложение MPI и следуйте инструкциям реализации MPI для регистрации вызовов MPI. Например, при использовании MPICH необходимо добавить -llmpi в список библиотек перед -lmpi.
PETSc автоматически регистрирует создание объектов, время, и количество операций с плавающей точкой для библиотечных процедур. Пользователи могут легко использовать эту информацию для мониторинга кодов приложения. Базовые этапы, выполняемые при регистрации пользовательского участка кода, называемого событием, показаны во фрагменте кода ниже:
int USER_EVENT;
PetscLogEventRegister (&USER_EVENT,"User event name",0);
PetscLogEventBegin (USER_EVENT,0,0,0,0);
/* сегмент кода приложения для мониторинга */
/*количество операций flops для этого сегмента кода */
PetscLogFlops();
PetscLogEventEnd (USER_EVENT,0,0,0,0);
PetscObject o2, PetscObject o3,PetscObject o4);
PetscLogEventEnd (int event, PetscObject o1,
PetscObject o2, PetscObject o3,PetscObject o4);
По умолчанию профилирование создает набор статистических данных для всего кода между вызовами процедур PetscInitialize () и PetscFinalize () в программе. Существует возможность создания независимого мониторинга до десяти секций кода, переключение между мониторингом которых производится функциями:
PetscLogStagePop ();
PetscLogStageRegister (int stage,char *name)
позволяет ассоциировать имя с этапом; эти имена выводятся при генерации итогов через -log_summary или PetscLogPrintSummary (). Следующий фрагмент кода использует три этапа профилирования:
/* этап 0 кода здесь */
PetscLogStageRegister (0,"Этап 0 кода");
for (i=0; i<ntimes; i++) {
PetscLogStagePush(1);
PetscLogStageRegister(1,"Этап 1 кода");
/* этап 1 кода здесь */
PetscLogStagePop();
PetscLogStagePush(2);
PetscLogStageRegister(1,"Этап 2 кода");
/* этап 2 кода здесь */
PetscLogStagePop();
}
PetscFinalize ();
Приведенные выше примеры показывают вывод, сгенерированный опцией -log_summary, для программы, использующей несколько этапов профилирования. В частности, эта программа подразделяется на шесть частей: загрузка матрицы и вектора правой стороны из двоичного файла, настройка предобработчика, решение линейной системы; эта последовательность затем повторяется для второй линейной системы. Для простоты во втором примере дан вывод только для этапов 4 и 5 (линейное решение второй системы), которые содержат часть наиболее интересных для нас вычислений с точки зрения мониторинга производительности. Такая организация кода (решение небольшой линейной системы, а затем решение большой) позволяет сгенерировать более точную статистику профилирования для второй системы, избегая часто встречающейся постраничной перегрузки.
По умолчанию все операции PETSc регистрируются. Для включения или отключения регистрации индивидуальных событий PETSc используются функции:
PetscLogEventDeactivate (int event);
/* включает PC и KSP */
PetscLogEventDeactivateClass (SLES_COOKIE);
PetscLogEventDeactivateClass (VEC_COOKIE);
PetscLogEventDeactivateClass (SNES_COOKIE);
/* включает PC и KSP */
PetscLogEventActivateClass (SLES_COOKIE);
PetscLogEventActivateClass (VEC_COOKIE);
PetscLogEventActivateClass (SNES_COOKIE);
Пользователи могут активировать вывод на экран дополнительной информации об алгоритмах, структурах данных и т.д., используя опцию -log_info или вызвав PetscLogInfoAllow(PETSC_TRUE). Такая регистрация, характерная для всех библиотек PETSc, может помочь пользователю понять алгоритм и настроить производительность программы. Например, -log_info активирует вывод информации о распределении памяти во время сборки матрицы. Прикладные программисты могут также пользоваться этой возможностью регистрации, используя процедуру:
где obj является объектом PETSc, наиболее тесно ассоциированным с оператором регистрации message. Например, в методах линейного поиска Ньютона, используется оператор:
PetscLogInfo (snes," Кубически определяемый шаг,
lambda %g\n", lambda);
Можно избирательно отключить информативные сообщения о любом из базовых
объектов PETSc (т.е., Mat , SNES ) функцией:
где object_cookie принимает значение MAT_COOKIE, SNES_COOKIE, и т.д. Сообщения могут быть вновь активированы процедурой:
Такая деактивация может пригодиться, когда нужно увидеть информацию о высокоуровневых библиотеках PETSc (например, TS и SNES ) без вывода всех данных нижних уровней (например, Mat). Можно деактивировать события для матриц и линейных решателей во время выполнения программы с помощью опции -log_info [no_mat, no_sles].
Прикладные программисты PETSc могут получить доступ к учету общего времени выполнения с помощью функций:
PetscGetTime (&time);CHKERRQ (ierr);
Весь вывод из программ PETSc (включая информативные сообщения, информацию
профилирования, и даные о сходимости) можно сохранить в файле, используя
опцию командной строки -log_history [filename]. Если
имя файла не указано, вывод сохраняется в файле $HOME/.petschistory.
Отметьте, что эта опция сохраняет только вывод, осуществляемый через
команды PetscPrintf()
и PetscFPrintf(), но не
через стандартные операторы printf() и fprintf().
Одной из проблем при организации параллельного доступа к файлам из нескольких процессов является непредсказуемость порядка доступа. В следующем примере два процесса записывают в файл строку символов по одному символу за операцию:
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
int fd;
int x,y;
pid_t pid;
unlink("/tmp/file"); /*Удаляем предыдущий файл*/
fd=open("/tmp/file", O_WRONLY|O_CREAT, 0777);
if(fd==-1)
{
perror("open : ");
exit(0);
}
if((pid=fork()) == -1)
{
perror("fork :");
exit(0);
}
else if(pid)
{ /*Родительский процесс*/
while(1)
{
for(x=0; x<10; x++){
sleep(1);
write(fd,(char *)"x",1);
}
break;
}
else
{ /*Процесс-потомок*/
while(1)
{
for(y=0; y<10; y++){
sleep(1);
write(fd,(char *)"X",1);
}
break;
}
return 0;
}
После выполнения этой программы содержимое файла
``/tmp/file''
может выглядеть следующим образом:
/*struct flock *flockptr*/);
Одним из факторов, играющим значительную роль в профилировании кода, является страничная поддержка в операционной системе. В общем случае при запуске программы в память загружается только несколько страниц, необходимых для ее старта, но не весь исполняемый файл. Когда выполнение доходит до сегментов кода, не находящихся в памяти, возникает отсутствие страницы, вызывающее запрос на загрузку страниц с диска (очень медленный процесс). Эти действия существенно нарушают результаты профилирования. (Страничный эффект заметен в файлах регистрации, сгенерированных через -log_mpe). Для устранения страничного эффекта при профилировании производительности программ разработана эффективная процедура запуска того же самого кода на маленькой задаче-муляже перед запуском самой задачи. Затем следует убедиться, что весь код, требуемый решателю, загружен в память во время решения малой задачи. Если код работает для действительной задачи и все требуемые страницы уже загружены в основную память, то показатели производительности не пострадают. Когда эта процедура используется в сочетании с пользовательскими этапами профилирования, можно сосредоточиться на самой задаче. Например, эта технология используется в программе, приведенной в ${PETSC_DIR}/src/sles/examples/tutorials/ex10.c для генерации результатов, показанных в примерах этого раздела. В этом случае, профилируемый код (решение линейной системы для большой задачи) появляется в событиях 4 и 5. В частности, макросы:
PreLoadStage (char *stagename),
PreLoadEnd()
Код, откомпилированный с опцией BOPT=O в общем случае работает в два-три раза быстрее, чем код, откомпилированный с BOPT=g, поэтому рекомендуется использовать для оценки производительности одну из оптимизированных версий кода (BOPT = O, BOPT = O_c++, или BOPT = O_complex). Пользователь может указать иные опции компилятора вместо опций по умолчанию, используемых в дистрибутиве PETSc. Можно установить опции компилятора для определенной архитектуры (PETSC_ARCH) и BOPT, отредактировав файл ${PETSC_DIR}/ bmake/${PETSC_ARCH} / variables.
Пользователи не должны тратить время на оптимизацию кода, если не ожидают, что оптимизация сэкономит время решения реальной задачи. Процедуры PETSc автоматически регистрируют данные о производительности, если указаны определенные опции времени выполнения. Например:
Выполнение операций на цепочках данных, а не на одном элементе, в единицу времени может существенно улучшить производительность. Для этого:
Процесс динамического распределения памяти для разреженных
матриц является весьма затратным, поэтому точное предварительное распределение
является критичным для эффективной сборки разреженных матриц. Можно
использовать процедуры создания матриц для определенных структур данных,
например,
MatCreateSeqAIJ() и MatCreateMPIAIJ() -
для упакованных форматов разреженных строк, вместо обычной процедуры
MatCreate(). При решении задач с несколькими степенями свободы для
узла блочные упакованные форматы разреженных строк, созданные с помощью
MatCreateSeqBAIJ() и MatCreateMPIBAIJ(), могут
существенно улучшить производительность.
При символической факторизации матрицы AIJ PETSc должен
вычислить плотность заполнения. Осторожное использование
параметра заполнения в структуре MatILUInfo при вызове
MatLUFactorSymbolic () или MatILUFactorSymbolic ()
может существенно уменьшить количество требуемых операций распределения
и копирования и, таким образом, существенно увеличить производительность
факторизации. Одним из способов определения подходящего значения для
f является запуск программы с опцией -log_info.
Фаза символической факторизации выведет при этом информацию вида
Fill ratio:given 1 needed 2.16423
Пользователи должны употреблять приемлемое количество вызовов PetscMalloc () в своем коде. Сотни и тысячи распределений памяти могут быть допустимы; однако если используются десятки тысяч, то можно порекомендовать уменьшить количество вызовов PetscMalloc (). Например, повторное использование памяти или распределение больших участков и деление их на части может существенно уменьшить нагрузку.
Структуры данных, насколько это возможно, должны использоваться повторно. Например, если код часто создает новые матрицы или векторы, существует и способ повторного использования некоторых из них. Очень существенный выигрыш в производительности можно получить повторным использованием структур данных матриц с одинаковыми ненулевыми шаблонами. Если код создает тысячи объектов матриц или векторов, производительность будет падать. Например, при решении нелинейной задачи или повременном интегрировании повторное использование матриц и их ненулевой структуры для многих этапов может существенно ускорить программу.
Простой техникой для сохранения рабочих векторов, матриц и т.д. является
введение пользовательских контекстов. В языках C и C++ такой контекст
представляет собой структуру, в которой содержатся различные объекты;
в Фортране пользовательский контекст может быть массивом целых чисел,
содержащим параметры и указатели на объекты PETSc
(См. ${PETSC_DIR}/snes/examples/
tutorials/ex5.c и ${PETSC_DIR}/snes/examples/tutorials/ex5f.F
с примерами пользовательских контекстов приложения на языках C и Фортран,
соответственно).
Пользователи PETSc должны выполнять множество тестов. Например, существует большое количество опций для решателей линейных и нелинейных уравнений в PETSc, и различные варианты могут привести к большой разнице в скоростях сходимости и времени выполнения. PETSc использует значения по умолчанию, которые в общем случае подходят для широкого круга задач, но ясно, что эти значения не могут быть наилучшими для всех случаев. Пользователи должны экспериментировать с множеством комбинаций, чтобы определить наилучшую для конкретной задачи и соответствующим образом настроить решатель. Для этого необходимо, в частности:
Общая тенденция развития современных информационных технологий состоит в активном использовании открытых и распределенных систем, а также новых архитектур приложений, таких, как клиент/сервер и параллельные процессы.
Чтобы различные программы могли обмениваться информацией через файлы или общую базу данных, они, как правило, работают через соответствующий программный интерфейс приложения API (Application Programming Interface). Если программы находятся на различных компьютерах, то процесс взаимодействия сопряжен с определенными дополнительными трудностями, например, ограниченной пропускной способностью и сложностью синхронизации. Для организации коммуникации между одновременно работающими процессами применяются средства межпроцессного взаимодействия (Interprocess Communication - IPC).
Выделяются три уровня средств IPC: локальный, удаленный и высокоуровневый.
Средства локального уровня IPC привязаны к процессору и возможны только в пределах компьютера. К этому виду IPC принадлежат практически все механизмы IPC UNIX, а именно, трубы, разделяемая память и очереди сообщений. Коммуникации, или адресное пространство этих IPC, поддерживаются только в пределах компьютерной системы. Из-за этих ограничений для них могут реализовываться более простые и более быстрые интерфейсы.
Удаленные IPC предоставляют механизмы, которые обеспечивают взаимодействие как в пределах одного процессора, так и между программами на различных процессорах, соединенных через сеть. Сюда относятся удаленные вызовы процедур (Remote Procedure Calls - RPC), сокеты Unix, а также TLI (Transport Layer Interface - интерфейс транспортного уровня) фирмы Sun.
Под высокоуровневыми IPC обычно подразумеваются пакеты программного
обеспечения, которые реализуют промежуточный
слой между системной
платформой и приложением. Эти пакеты предназначены для переноса уже
испытанных протоколов коммуникации приложения на более новую архитектуру.
Средства IPC, впервые реализованные в UNIX 4.2BSD, включали в себя многие современные идеи, исходя из требований философии UNIX относительно простоты и краткости.
До введения механизмов межпроцессного взаимодействия UNIX не обладал
удобными возможностями для обеспечения подобных
услуг. Единственным
стандартным механизмом, который позволял двум процессам связываться
между собой, были трубы (pipes). К сожалению, трубы имели очень серьезное
ограничение в том, что два поддерживающих связь процесса были
связаны через общего предка. Кроме того, семантика труб сильно
ограничивает поддержку распределенной вычислительной среды.
Основные проблемы при введении новых средств IPC в состав системы были связаны с тем, что старые средства были привязаны к файловой системе UNIX либо через обозначение, либо через реализацию. Поэтому новые средства IPC были разработаны как полностью независимая подсистема. Вследствие этого, они позволяют процессам взаимодействовать различными способами. Процессы могут теперь взаимодействовать либо через пространство имен, подобное файловой системе UNIX, либо через сетевое пространство имен. В процессе работы новые пространства имен могут быть добавлены с незначительными изменениями, заметными пользователю. Кроме того, средства взаимодействия расширены, чтобы поддерживать другие форматы передачи, а не только простой байтовый поток, обеспечиваемый трубой. Эти расширения вылились в полностью новую часть системы, которая требует детального знакомства.
Простые межпроцессные коммуникации можно организовать с помощью сигналов и труб. Более сложными средствами IPC являются очереди сообщений, семафоры и разделяемые области памяти.
Наряду с обеспечением взаимодействия процессов средства IPC призваны решать проблемы, возникающие при организации параллельных вычислений. Сюда относятся:
Эта структура используется для управления блокировкой и имеет следующее содержание:
short l_type; /*3 режима блокирования
F_RDLCK(Разделение чтения)
F_WRLCK (Разделение записи)
F_UNLCK (Прекратить разделение)*/
off_t l_start; /*относительное смещение в байтах,
зависит от l_whence*/
short l_whence; /*SEEK_SET;SEEK_CUR;SEEK_END*/
off_t l_len; /*длина, 0=разделение до конца файла*/
pid_t l_pid; /*идентификатор, возвращается F_GETLK */
};
flockptr.l_whence=SEEK_SET; /*с начала файла*/
Функции блокирования можно использовать в следующих режимах:
fd=open(data, O_CREAT|O_WRONLY);
fcntl(fd, F_GETLK, &flptr);
if(flptr.l_type==F_UNLCK)
{/*Данные не блокированы*/}
else if(flptr.l_type==F_RDLCK)
{/*Блокировка по чтению*/}
else if(flptr.l_type==F_WRLCK)
{/*Блокировка по записи*/}
flptr.l_whence=SEEK_SET;
flptr.l_len=0;
flptr.l_type=F_RDLCK;
if((fcntl(fd, F_SETLK, &flptr)!=-1)
{/*Установлена блокировка по чтению*/}
flptr.l_start=0;
flptr.l_whence=SEEK_SET;
flptr.l_len=0;
flptr.l_type=F_WRLCK);
if((fcntl(fd, F_SETLK, &sperre)!=-1)
{/*Установлена блокировка по записи*/}
flptr.l_type=F_UNLCK;
if((fcntl(fd, F_SETLK, &flptr)!=-1)
{/*Блокировка снята*/}
Пример, иллюстрирующий режимы блокировки:
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#define FNAME "locki.lck"
void status(struct flock *lock)
{
printf("Status: ");
switch(lock->l_type)
{
case F_UNLCK:
printf("F_UNLCK (Блокировка снята)\n");
break;
case F_RDLCK:
printf("F_RDLCK (pid: %d)
(Блокировка чтения)\n",
lock->l_pid);
break;
case F_WRLCK:
printf("F_WRLCK (pid: %d)
(Блокировка записи)\n",
lock->l_pid);
break;
default : break;
}
}
int main(int argc, char **argv)
{
struct flock lock;
int fd;
char buffer[100];
fd = open(FNAME, O_WRONLY|O_CREAT|O_APPEND,
S_IRWXU);
memset(&lock, 0, sizeof(struct flock));
/*Проверим, установлена ли блокировка*/
fcntl(fd, F_GETLK, &lock);
if(lock.l_type==F_WRLCK || lock.l_type==F_RDLCK)
{
status(&lock);
memset(&lock,0,sizeof(struct flock));
lock.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lock) < 0)
printf("Ошибка при :
fcntl(fd, F_SETLK, F_UNLCK) (%s)\n",
strerror(errno));
else
printf("Успешно снята блокировка:
fcntl(fd, F_SETLK, F_UNLCK)\n");
}
status(&lock);
write(STDOUT_FILENO,"\n Введены данные: ",
sizeof("\n Введены данные: "));
while((read(1,puffer,100))>1)
write(fd,buffer,100);
memset(&lock, 0, sizeof(struct flock));
lock.l_type = F_WRLCK;
lock.l_start=0;
lock.l_whence = SEEK_SET;
lock.l_len=0;
lock.l_pid = getpid();
if (fcntl(fd, F_SETLK, &lock) < 0)
printf("Ошибка при:
fcntl(fd, F_SETLK, F_WRLCK)(%s)\n",
strerror(errno));
else
printf("Успешно: fcntl(fd, F_SETLK, F_WRLCK)\n");
status(&lock);
switch(fork())
{
case -1 : exit(0);
case 0 : if(lock.l_type == F_WRLCK)
{
printf("Потомок:Невозможна запись
в файл (F_WRLCK)\n");
exit(0);
}
else
printf("Потомок готов к записи
в файл\n") ;
exit(0);
default : wait(NULL); break;
}
close(fd);
return 0;
}
Этот пример иллюстрирует возможности сериализации процессов. Тем не менее здесь все равно возможны чтение и запись в процессе-потомке. Такой вариант блокировки называется advisory locking (необязательная блокировка). При его установке не производится никаких дополнительных проверок того, должны ли системные функции open, read и write из-за блокировки запрещаться при вызове. Для advisory locking принимается, что пользователь сам является ответственным за проверку того, существуют ли определенные блокировки или нет. Невозможно запретить всем процессам доступ к файлу. Только процессы, опрашивающие наличие блокировки с помощью fcntl, блокируются при ее наличии (и то не всегда).
Для других случаев имеются так называемые строгие блокировки (mandatory locking). Эти блокировки запрещают процессу получать доступ с помощью функций read или write к данным, которые ранее были блокированы другим процессом через fcntl.
Строгие блокировки можно разрешить, установив бит Set-Group-ID и сняв бит выполнения для группы, например:
{
struct stat statbuffer;
if(fstat(fd, &statbuffer) < 0)
{
fprintf(stderr, "Ошибка при вызове fstat\n");
return 0;
}
if(fchmod(fd (statbuffer.st_mode & ~S_IXGRP) |
S_ISGID) < 0)
{
fprintf(stderr, "Невозможно установить строгую
блокировку...\n");
return 0;
}
return 1;
}
Если с помощью open() открывается файл с флагами O_TRUNC и O_CREAT и для этого файла установлена строгая блокировка, то возвращается ошибка со значением errno=EAGAIN.
Линейные решатели по умолчанию бывают:
PETSc содержит ряд средств, помогающих обнаружить проблемы распределения памяти, включая утечки и неиспользуемое пространство:
Производительность кода определяется различными факторами, включая поведение кэша, наличием других пользователей на машине и т.д. Здесь описаны основные проблемы и способы их устранения:
Чтобы собрать программу с именем ex1, можно использовать команду
Каталог ${PETSC_DIR}/bmake содержит практически все команды
сборочных файлов и настройки для обеспечения переносимости среди различных
архитектур. Большинство команд сборочных файлов для поддержки в системе
PETSc определено в файле
${PETSC_DIR}/bmake/common. Эти
команды, обрабатывающие все соответствующие файлы в каталоге выполнения,
включают:
Каталог ${PETSC_DIR}/bmake имеет подкаталоги для каждой архитектуры, которые содержат информацию, специфичную для архитектуры, обеспечивая переносимость системы сборочных файлов. Например, для компьютеров Sun под управлением OS 5.7, каталог называется solaris. Каждый каталог архитектуры содержит три сборочных файла:
PETSc поддерживает несколько флагов, определяющих способ компиляции
исходного кода. Флаги по умолчанию для определенных версий определяются
переменной PETSCFLAGS базовых файлов
${PETSC_DIR}/bmake/
${PETSC_ARCH}. Флаги включают:
Поддержка переносимых сборочных файлов PETSc очень проста. Далее приведены три примера сборочных файлов. Первый представляет ``минимальный'' сборочный файл для поддержки одной программы, которая использует библиотеки PETSc. Наиболее важной строкой в этом файле является та, которая начинается с include:
CFLAGS =
FFLAGS =
CPPFLAGS =
FPPFLAGS =
include ${PETSC_DIR}/bmake/common/base
ex2: ex2.o chkopts
${CLINKER} -o ex2 ex2.o ${PETSC_LIB}
${RM} ex2.o
Отметьте, что переменная ${PETSC_LIB} (как указано в
строке компоновки в приведенном файле) определяет все различные библиотеки
PETSc в нужном порядке для правильной компоновки. Пользователи, которым
требуются только определенные библиотеки PETSc, могут применять
альтернативные переменные, например ${PETSC_SYS_LIB},
${PETSC_VEC_LIB}, ${PETSC_MAT_LIB},
${PETSC_DM_LIB},
${PETSC_SLES_LIB},${PETSC_SNES_LIB} или
${PETSC_TS_LIB}.
Второй пример сборочного файла управляет созданием нескольких примеров программ:
FFLAGS =
CPPFLAGS =
FPPFLAGS =
include ${PETSC_DIR}/bmake/common/base
ex1: ex1.o
-${CLINKER} -o ex1 ex1.o ${PETSC_LIB}
${RM} ex1.o
ex2: ex2.o
-${CLINKER} -o ex2 ex2.o ${PETSC_LIB}
${RM} ex2.o
ex3: ex3.o
-${FLINKER} -o ex3 ex3.o ${PETSC_FORTRAN_LIB}
${PETSC_LIB}
${RM} ex3.o
ex4: ex4.o
-${CLINKER} -o ex4 ex4.o ${PETSC_LIB}
${RM} ex4.o
runex1: -@${MPIRUN} ex1
runex2:
-@${MPIRUN} -np 2 ex2 -mat_seqdense -options_left
runex3: -@${MPIRUN} ex3 -v -log_summary
runex4: -@${MPIRUN} -np 4 ex4 -trdump
RUNEXAMPLES_1 = runex1 runex2
RUNEXAMPLES_2 = runex4
RUNEXAMPLES_3 = runex3
EXAMPLESC = ex1.c ex2.c ex4.c
EXAMPLESF = ex3.F
EXAMPLES_1 = ex1 ex2
EXAMPLES_2 = ex4
EXAMPLES_3 = ex3
include ${PETSC_DIR}/bmake/common/test
Здесь наиболее важной вновь является строка include, которая включает файлы, определяющие все переменные-макросы. Некоторые дополнительные переменные, которые можно использовать в сборочном файле, определяются следующим образом:
CFLAGS =
SOURCEC = sp1wd.c spinver.c spnd.c spqmd.c sprcm.c
SOURCEF = degree.f fnroot.f genqmd.f qmdqt.f rcm.f
fn1wd.f gen1wd.f genrcm.f qmdrch.f rootls.f fndsep.f
gennd.f qmdmrg.f qmdupd.f
SOURCEH =
OBJSC = sp1wd.o spinver.o spnd.o spqmd.o sprcm.o
OBJSF = degree.o fnroot.o genqmd.o qmdqt.o rcm.o
fn1wd.o gen1wd.o genrcm.o qmdrch.o rootls.o fndsep.o
gennd.o qmdmrg.o qmdupd.o
LIBBASE = libpetscmat
MANSEC = Mat
include ${PETSC_DIR}/bmake/common/base
Библиотека называется libpetscmat.a, а исходные файлы, которые добавляются в нее, указаны переменными SOURCEC (для файлов на C) и SOURCEF (для файлов на Фортране). Отметьте, что переменные OBJSF и OBJSC идентичны SOURCEF и SOURCEC соответственно, за исключением того, что в них использован суффикс .o, а не .c или .f. Переменная MANSEC указывает, что все справочные страницы, сгенерированные из исходных файлов, должны включаться в раздел Mat.
Этот подход к переносимым сборочным файлам имеет некоторые небольшие ограничения, а именно следующие:
Программное обеспечение PVM предоставляет унифицированные
структуры,
с помощью которых параллельные программы могут разрабатываться эффективным
и целенаправленным способом с использованием существующего оборудования.
PVM позволяет группе гетерогенных компьютерных систем восприниматься
как одна параллельная виртуальная машина. PVM прозрачно управляет
обработкой всех сообщений, преобразованием данных и выполнением заданий
в пределах сети, включающей несовместимые компьютерные архитектуры.
Вычислительная модель PVM является простой, весьма обобщенной, поэтому приспосабливается к широкому спектру программных структур приложений. Программный интерфейс преднамеренно сделан ``целевым'', что позволяет доступ к простым программным структурам осуществляеть интуитивным способом. Пользователь пишет свою программу в виде группы взаимосвязанных ``задач''. Задачи получают доступ к ресурсам PVM посредством библиотеки подпрограмм со стандартизированным интерфейсом. Эти подпрограммы позволяют инициировать и завершить задачу в сети, а также обеспечить связь между задачами и их синхронизацию. Примитивы обмена сообщениями PVM ориентированы на гетерогенные операции, включающие строго определенные конструкции для буферизации и пересылки. Коммуникационные конструкции содержат их для передачи и приема структур данных, также, как и высокоуровневые примитивы, такие как широковещательная передача, барьерная синхронизация и глобальное суммирование.
Задачи PVM могут содержать структуры для обеспечения необходимых уровней контроля и зависимости. Другими словами, в любой ``точке'' выполнения взаимосвязанных приложений любая возможная задача может запускать или останавливать другие задачи, добавлять или удалять компьютеры из виртуальной машины. Каждый процесс может взаимодействовать и/или синхронизироваться с любым другим. Каждая специфическая структура для контроля и зависимости может быть реализована в системе PVM адекватным использованием конструкций PVM и управляющих конструкций главного (хост-) языка системы.
Всеобъемлющая природа (специфичная для концепции виртуальной машины), а также ее простой, но функционально полный программный интерфейс, обеспечили системе PVM широкое признание, в том числе и в научном сообществе, связанном с высокоскоростными вычислениями.
PVM (параллельная виртуальная машина) - это побочный продукт продвижения гетерогенных сетевых исследовательских проектов, распространяемый авторами и институтами, в которых они работают. Общими целями этого проекта являются исследование проблематики и разработка решений в области гетерогенных параллельных вычислений. PVM представляет собой набор программных средств и библиотек, которые эмулируют общецелевые, гибкие гетерогенные вычислительные структуры для параллелизма во взаимосвязанных компьютерах с различными архитектурами. Главной же целью системы PVM является обеспечение возможности совместного использования группы компьютеров совместно для взаимосвязанных или параллельных вычислений. Вкратце, основные постулаты, взятые за основу для PVM, следующие:
Вторая часть системы - это библиотека подпрограмм интерфейса PVM. Она содержит функционально полный набор примитивов, которые необходимы для взаимодействия между задачами приложения. Эта библиотека содержит вызываемые пользователем подпрограммы для обмена сообщениями, порождения процессов, координирования задач и модификации виртуальной машины.
Вычислительная модель PVM базируется на предположении, что приложение состоит из нескольких задач. Каждая задача ответственна за часть вычислительной нагрузки приложения. Иногда приложение распараллеливается по функциональному принципу, т. е. каждая задача выполняет свою функцию, например: ввод, порождение, счет, вывод, отображение. Такой процесс часто определяют как функциональный параллелизм. Более часто встречается метод параллелизма приложений, называемый параллелизмом обработки данных. В этом случае все задачи одинаковы, но каждая из них имеет доступ и оперирует только небольшой частью общих данных. Схожая ситуация в вычислительной модели ОКМД (одна команда, множество данных). PVM поддерживает любой из перечисленных методов отдельно или в комплексе. В зависимости от функций задачи могут выполняться параллельно и нуждаться в синхронизации или обмене данными, хотя это происходит не во всех случаях. Диаграмма вычислительной модели PVM показана на рис. 8, а архитектурный вид системы PVM, с выделением гетерогенности вычислительных платформ, поддерживаемых PVM, показан на рис. 9.
В настоящее время PVM поддерживает языки программирования C, C++ и Фортран. Этот набор языковых интерфейсов взят за основу в связи с тем, что преобладающее большинство целевых приложений написаны на C и Фортран, но наблюдается и тенденция экспериментирования с объектно - ориентированными языками и методологиями.
Привязка языков C и C++ к пользовательскому интерфейсу PVM реализована в виде функций, следующих общепринятым подходам, используемым большинством C-систем, включая UNIX - подобные операционные системы. Уточним, что аргументы функции - это комбинация числовых параметров и указателей , а выходные значения отражают результат работы вызова. В дополнение к этому используются макроопределения для системных констант и такие глобальные переменные, как errno и pvm_errno, которые служат для точного определения результата в числе возможных. Прикладные программы, написанные на C и C++, получают доступ к функциям библиотеки PVM путем прилинковки к ним архивной библиотеки (libpvm3.a)как часть стандартного дистрибутива.
Привязка к языку Фортрана реализована скорее в виде подпрограмм, чем в виде функций. Такой подход применен по той причине, что некоторые компиляторы для поддерживаемых архитектур не смогли бы достоверно реализовать интерфейс между C- и Фортран-функциями. Непосредственным следствием из этого является то, что для каждого вызова библиотеки PVM вводится дополнительный аргумент - для возвращения результирующего статуса в вызвавшую его программу. Также унифицированы библиотечные подпрограммы для размещения введенных данных в буферы сообщения и их восстановления, они имеют дополнительный параметр для отображения типа данных. Кроме этих различий (и разницы в стандартных префиксах при именовании: pvm_ - для C и pvmf_ - для Фортран), возможно взаимодействие ``друг с другом'' между двумя языковыми привязками. Интерфейсы PVM на Фортране реализованы в виде библиотечных надстроек, которые в свою очередь, после разбора и/или определения состава аргументов, вызывают нужные C-подпрограммы. Так, Фортран-приложения требуют прилинковки библиотеки-надстройки (libfpvm3.a) в дополнение к C-библиотеке.
![\includegraphics[scale=0.55]{pic21.eps}](img62.png)
Все задачи PVM идентифицируются посредством целочисленного ``идентификатора задачи'' (task identifier - TID). Сообщения передаются и принимаются с помощью идентификаторов задач. Поэтому эти идентификаторы должны быть уникальными в пределах внутренней виртуальной машины, что поддерживается локальным pvmd и поэтому прозрачно для пользователя. Хотя PVM кодирует информацию в каждом TID, пользователь склонен трактовать идентификаторы задач как скрытые целочисленные идентификаторы. PVM содержит несколько подпрограмм, которые возвращают значения в TID, тем самым давая возможность пользовательскому приложению идентифицировать другие задачи в системе.
Существуют приложения, при рассмотрении которых естественно подумать о ``группе задач'', а также случаи, когда пользователю было бы удобно определять свои задачи по номерам: 0 - (p-1), где p - количество задач. PVM поддерживает концепцию именуемых пользователем групп. При этом задача находится в группе и ей присвоен ``случайный'' номер в этой группе. Случайные номера стартуют с 0. В соответствии с философией PVM, групповые функции разрабатываются таким образом, чтобы они были очень обобщенными и понятными для пользователя. Например, любая задача PVM может войти в состав любой группы или покинуть ее в произвольный момент времени, не информируя об этом каждую задачу в данной группе. Кроме того, группы могут перекрываться, а задачи могут рассылать широковещательные сообщения, адресованные тем группам, в которых они не состоят. Для использования любой из групповых функций к программе должна быть прилинкована libgpvm3.a.
Общая парадигма для программирования приложений с помощью PVM описана ниже. Пользователь пишет одну либо несколько последовательных программ на C, C++ или Фортран 77, в которые встроены вызовы библиотеки PVM. Каждая программа порождает задачу, реализующую приложение. Эти программы компилируются по правилам каждой архитектуры в пуле хостов, и в результате получаются объектные файлы, помещаемые по местам, доступным на машинах в пуле хостов. Для выполнения приложения пользователь обычно запускает одну копию задачи (обычно это ``ведущая'' или ``инициирующая'' задача) вручную на машине из пула хостов. Этот процесс последовательно порождает другие задачи PVM; в конечном счете получается группа активных задач, оперирующих локально и обменивающихся сообщениями друг с другом для решения проблемы. Обратите внимание на то, что выше приведен типичный сценарий, но вручную можно запускать столько задач, сколько нужно. Как уже упоминалось, задачи взаимодействуют путем прямого обмена сообщениями с идентификацией определенными системой, скрытыми TID.
![\includegraphics[scale=0.6]{pic22.eps}](img63.png)
Ниже приведена программа PVM hello - простой пример, который иллюстрирует базовую концепцию программирования PVM. Эта программа рассматривается как запускаемая вручную; после вывода на экран своего идентификатора задачи (полученного с помощью pvm_mytid()) она порождает копию другой программы под названием hello_other, используя функцию pvm_spawn(). Успешное порождение заставляет программу выполнить блокирующий прием с помощью pvm_recv(). После приема сообщения программа выводит на экран сообщение, посланное ей абонентом - так же как и свой идентификатор задачи; содержимое буфера извлекается из сообщения применением pvm_upsksrt(). Заключительный вызов pvm_exit ``выводит'' программу из системы PVM:
main()
{
int cc, tid, msgtag;
char buf[100];
printf("Это программа t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "",
1, &tid);
if (cc == 1) {
msgtag = 1;
pvm_recv(tid, msgtag);
pvm_upkstr(buf);
printf("Вывод из t%x: %s\n", tid, buf);
} else
printf("Невозможно запустить hello_other\n");
pvm_exit();
}
main()
{
int ptid, msgtag;
char buf[100];
ptid = pvm_parent();
strcopy(buf, "hello, world from");
msgtag = 1;
gethostname(buf + strlen(buf), 64);
msgtag = 1;
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, msgtag);
pvm_exit();
}
В этом разделе описывается, как установить программный пакет PVM, как сконфигурировать простую виртуальную машину, и как скомпилировать и выполнить программы примеров, поддерживаемые PVM. В первой части раздела описываются использование PVM и наиболее часто встречающиеся ошибки и трудности в процессе установки и эксплуатации. В следующем разделе описываются некоторые расширенные опции, позволяющие читателю настроить среду PVM по своему усмотрению.
Последняя версия исходных текстов PVM и документация всегда доступны посредством netlib. netlib - это сервисная служба по распространению программного обеспечения, установленная в сети Internet, в которой содержится большой набор программного обеспечения компьютеров. Программное обеспечение может быть получено от netlib с помощью ftp, www, xnetlib или e-mail клиентов.
Файлы PVM могут быть загружены из анонимного ftp-сервера по адресу netlib2.cs.utk.edu. Загляните в каталог pvm3. Файл index содержит описание файлов и подкаталогов в этом каталоге.
Используя браузеры, файлы PVM можно забрать по адресу
http://www.netlib.org/pvm3/index_html.
xnetlib - это интерфейс для оболочки X-Window, который позволяет
пользователям просматривать содержимое службы netlib или
искать с ее помощью доступное наработанное программное обеспечение
и автоматически пересылать избранное на пользовательский компьютер.
Для получения xnetlib отправьте электронное письмо
по адресу netlib@ornl.gov с просьбой выслать
xnetlib.shar
с сервера xnetlib или анонимного ftp-сервера
cs.utk.edu/pub/xnetlib.
Запрос на программное обеспечение PVM также можно отправить по электронной почте. Для его получения пошлите электронное письмо по адресу netlib@ornl.gov с сообщением send index from pvm3. Автоматический обработчик почты возвратит список доступных файлов с инструкциями. Преимущество такого способа заключается в простоте получения программного обеспечения каждым желающим, имеющим доступ к электронной почте в сети Internet.
Популярности PVM способствуют простота установки и использования. Для инсталляции PVM не требуется специальных привилегий. Каждый, у кого есть достоверный логин в системе хоста, может это сделать. Кроме того, только одному из лиц в организации требуется проинсталлировать PVM для всеобщего использования в пределах данной организации.
PVM использует две переменных окружения - когда запускается и выполняется. Следовательно, каждый пользователь PVM должен установить эти две переменные для ее использования. Первая переменная - PVM_ROOT - нужна для определения местонахождения инсталлированного каталога pvm3. Вторая переменная - PVM_ARCH - сообщает PVM тип архитектуры данного хоста и, тем самым, что исполняемый код может ``забрать'' из каталога PVM_ROOT.
Наиболее простым способом установки этих двух переменных является
их определение в соответствующем файле .cshrc. Предполагается,
что вы пользуетесь csh. Пример определения PVM_ROOT:
setenv PVM_ROOT $HOME/pvm3
Рекомендуется, чтобы пользователь устанавливал PVM_ARCH, дописывая в файл .cshrc содержимое $PVM_ROOT/lib/cshrc.stub. Для успешного определения PVM_ARCH строка должна помещаться после строки c переменной PATH. Эта строка автоматически задает PVM_ARCH данного хоста и может быть частично использована, когда пользователь разделяет общую файловую систему (например, NFS) в среде с несколькими различными архитектурами.
Исходные тексты PVM для большинства архитектур поставляются совместно с другим содержимым каталогов и файлами сборки. Процесс сборки для каждого из поддерживаемых типов архитектур происходит автоматически - путем логина на хосте, обращения к каталогу PVM_ROOT и ввода make. Файл сборки будет автоматически определять, на какой архитектуре он начал выполняться, создавать соответствующие подкаталоги и ``строить'' pvm, pvmd3, libpvm3, libfpvm3.a, pvmgs, libgpvm3.a. Он поместит все эти файлы в $PVM_ROOT/lib/PVM_ARCH, за исключением pvmgs, который переносится в $PVM_ROOT /bin/PVM_ARCH.
Таким образом, необходимо:
| PVM_ARCH | Тип компьютера | Примечания |
| AFX8 | Alliant FX/8 | |
| ALPHA | DEC Alpha | DEC OSF-1 |
| BAL | Sequent Balance | DYNIX |
| BFLY | BBN Butterfly TC2000 | |
| BSD386 | 80386/486 ПК с системой Unix | BSDI, 386BSD, NetBSD |
| CM2 | Thinking Machines CM2 | наиболее совершенный Sun |
| CM5 | Thinking Machines CM5 | используются оригинальные сообщения |
| CNVX | Convex C-series | IEEE формат п.з. |
| CNVXN | Convex C-series | оригинальная п.з. |
| CRAY | доступны порты C-90 YMP, T3D | UNICOS |
| CRAY2 | Cray2 | |
| CRAYSMP | Cray S-MP | |
| DGAV | Data General Aviion | |
| E88K | Encore 88000 | |
| HP300 | HP-9000 модели 300 | HPUX |
| HPPA | HP-9000 | PA-RISC |
| I860 | Intel iPSC/860 | используются оригинальные сообщения |
| IPSC2 | Intel iPSC/2 386 хост | SysV, используются оригинальные сообщения |
| KSR1 | Kendall Square KSR-1 | OSF-1, используется разделяемая память |
| LINUX | 80386/486 ПК с системой Unix | LINUX |
| MASPAR | Maspar | наиболее совершенный DEC |
| MIPS | MIPS 4680 | |
| NEXT | NeXT | |
| PGON | Intel Paragon | используются оригинальные сообщения |
| PMAX | DECstation 3100, 5100 | Ultrix |
| RS6K | IBM/RS6000 | AIX 3.2 |
| RT | IBM RT | |
| SGI | Silicon Graphics IRIS | IRIX 4.x |
| SGI5 | Silicon Graphics IRIS | IRIX 5.x |
| SGIMP | мультипроцессор SGI | используется разделяемая память |
| SUN3 | Sun 3 | SunOS 4.2 |
| SUN4 | Sun 4, SPARCstation | SunOS 4.2 |
| SUN4SOL2 | Sun 4, SPARCstation | Solaris 2.x |
| SUNMP | мультипроцессор SPARC | Solaris 2.x, используется разделяемая память |
| SYMM | Sequent Symmetry | |
| TITN | Stardent Titan | |
| U370 | IBM 370 | AIX |
| UVAX | DEC MicroVAX |
Прежде чем перейти к компиляции и выполнению параллельных программ,
следует убедиться в том, можно ли запустить PVM и сконфигурировать
виртуальную машину. На любом из хостов, на которых инсталлирована
PVM, вы можете ввести % pvm
После этого должно появиться приглашение консоли PVM, говорящее о
том, что PVM теперь запущена на данном хосте. Можно добавить хосты
в свою виртуальную машину, введя с консоли
pvm> add имя_хоста.
Также можно удалить хосты (исключая тот, за которым вы находитесь)
из своей виртуальной машины, введя
pvm> delete имя_хоста.
Для того, чтобы увидеть, что представляет собой в настоящий момент
виртуальная машина, введите
pvm> conf.
А чтобы увидеть, какие задачи PVM выполняются на виртуальной
машине, введите
pvm> ps -a.
Если ввести quit с консоли, то консоль прекратит свое
существование, но виртуальная машина сохранится, а задачи будут продолжать
выполняться. В случае с любым приглашением Unix на любом хосте из
виртуальной машины можно ввести
% pvm.
и получить сообщение ``pvm already running'' на консоль.
При завершении работы с виртуальной машиной следует ввести
pvm> halt.
Эта команда принудительно завершит работу всех задач PVM, выключит виртуальную машину и произойдет выход из консоли.
Рекомендуемый способ остановки PVM гарантирует нормальное завершение
работы виртуальной машины. Если вы не хотите вводить связку из имен
хостов каждый раз, то воспользуйтесь
опцией hostfile. Вы можете перечислить имена хостов в файле
- по одному в строчке - и затем ввести
pvm> hostfile.
После чего PVM будет сразу добавлять все указанные хосты до появления приглашения консоли. Несколько опций может встречаться в данном файле персонально для каждого из хостов. Описание находится в конце этого раздела - для тех пользователей, которые пожелают подстроить свои виртуальные машины под специфические приложения или среды.
Существуют другие варианты запуска PVM. Функции консоли и монитора
производительности объединены в графическом пользовательском интерфейсе,
названном XPVM, который в нескомпилированном варианте доступен в библиотеке
netlib. Для запуска PVM с графическим интерфейсом X window
введите
% xpvm
При нажатии кнопки под названием hosts ``выпадет'' список
хостов, которые можно добавлять. Если Вы ``кликнете'' имя хоста, то
он будет добавлен, а иконка машины станет анимированной, соответствующей
виртуальной машине. Хост удаляется, если Вы ``кликните'' имя хоста,
который уже был включен в виртуальную машину (см. рис. 10). При запуске
XPVM происходит чтение файла $HOME/.xpvm_hosts, в котором
перечислены хосты для отображения в меню. Все хосты без префикса &
при запуске добавляются сразу.
![\includegraphics[scale=0.6]{pic31.eps}](img64.png)
Назначение кнопок quit и halt аналогично соответствующим командам консоли PVM. Если вы выходите из XPVM и затем перезапускаете его, то XPVM автоматически отображает, что при этом представляет собой виртуальная машина. Попрактикуйтесь в запуске, остановке XPVM и добавлении хостов с его помощью. Возникающие ошибки должны находить отображение в окне, из которого вы запустили XPVM.
Если PVM не может стартовать успешно, она выводит сообщение об ошибке на экран либо в файл протокола /tmp/pvml.<uid>. В этом подразделе описываются наиболее общие трудности, возникающие при запуске и пути их решения.
Если сообщение представляет собой:
[t80040000] Can't start
pvmd,
то прежде всего проверьте соответствующий файл .rhosts на
удаленном хосте - содержится ли в нем имя хоста, на котором
вы запускаете PVM. Внешняя проверка на предмет корректности спецификации
файла .rhosts проводится вводом
% rsh remote_host ls.
Если спецификация файла .rhosts корректна, то вы увидите список своих файлов на удаленном хосте.
Другими причинами ошибок могут оказаться отсутствие
проинсталлированной PVM на удаленном хосте или некорректная спецификация
PVM_ROOT на данном хосте. Проверить это можно вводом
% rsh remote_host $PVM_ROOT/lib/pvmd.
Некоторые оболочки Unix, например ksh, не устанавливают переменные окружения на удаленных хостах при использовании rsh. В PVM версии 3.3 есть два подхода к таким оболочкам. Первый - вы инициализируете переменную окружения PVM_DPATH на ведущем хосте как pvm3/lib/pvmd, тем самым подменяя путь, установленный по умолчанию с помощью dx. Второй подход - нужно явно сообщить PVM, где найти удаленный исполняемый pvmd с помощью опции dx= в файле.
Если работа PVM принудительно завершилась вручную или завершилась ненормально (например, из-за краха системы), то проверьте наличие файла /tmp/pvml.<uid>. Этот файл нужен для аутентификации и должен существовать только в процессе работы PVM. Если этот файл сохранился, он будет препятствовать запуску PVM. Удалите этот файл.
Если сообщение представляет собой
[t80040000] Login incorrect,
это может означать отсутствие аккаунта на удаленной машине с вашим
логином. Если ваш текущий логин отличается от логина на удаленной
машине, то вы должны воспользоваться опцией lo= в файле хоста.
Если вы получили любое другое странное сообщение, проверьте файл .cshrc. Важно, чтобы не было никакого ввода/вывода в файл .cshrc, потому что это повлияет на процесс запуска PVM. Если вы хотите выводить на экран информацию (например, who или uptime) при входе в систему, вы должны обеспечить это с помощью собственного скрипта .login - только не во время выполнения командного скрипта csh.
В этом подразделе вы изучите, как откомпиллировать и выполнить программы PVM. В последующих подразделах излагается, как писать параллельные программы PVM. В этом Вы будете иметь дело с программами-образцами, поддерживаемыми программным обеспечением PVM. Эти образцовые программы создают полезные шаблоны, на основе которых можно создавать собственные PVM программы.
Первым шагом здесь является копирование программы-образца в свою пользовательскую область на диске:
% cd $HOME/pvm3/examples
Программная модель ``ведущий-ведомый'' - наиболее популярная из используемых в распределенных вычислениях. (В области параллельного программирования более популярна модель ОКМД).
Для компиляции примера ``ведущий-ведомый'' на С введите
% aimk master slave.
Если вы предпочитаете работать c Фортраном, откомпилируйте версию на
Фортране
% aimk fmaster fslave.
В зависимости от расположения каталога согласно PVM_ROOT,
выражения INCLUDE в заголовках примеров на Фортране могут
нуждаться в изменениях. Если PVM_ROOT не совпадает с HOME/pvm3,
то замените ее таким образом, чтобы она указывала на $PVM_ROOT
/include/fpvm3.h.
Заметьте, PVM_ROOT для Фортранне ``расширяется'',
поэтому вы должны добавлять определение достоверного пути.
Программа сборки пересылает исполняемые файлы в
$HOME/pvm3/bin/PVM_ARCH,
где PVM по умолчанию будет искать их на всех хостах. Если задействованные
файловые системы на всех хостах PVM не одинаковы, то вам понадобится
дополнительно создавать или копировать (в зависимости от архитектуры)
эти исполняемые файлы на хосты в составе PVM.
Теперь, задействовав одно окно, запустите PVM и сконфигурируйте несколько
хостов. Приводимые примеры разработаны для выполнения на произвольном
числе хостов, начиная с одного. В другом окне смените каталог на HOME/pvm3/bin/PVM_ARCH
и введите % master.
Программа выдаст запрос о количестве задач. В примерах это количество
не обязательно должно совпадать с количеством хостов. Проверьте несколько
комбинаций.
Первый пример иллюстрирует возможность запустить программу PVM из любого терминала Unix на любом хосте виртуальной машины. Этот процесс подобен способу, котором вы запускали бы последовательную программу a.out на рабочей станции. В следующем примере, который также относится к модели ``ведущий-ведомый'', под названием hitc, вы можете увидеть, как порождается работа с консоли PVM, а также из XPVM.
Здесь hitc иллюстрирует балансирование динамической загрузки с
применением парадигмы ``пула задач''. Согласно парадигме пула
задач, ведущая программа управляет большой очередью задач, всегда
посылая ``простаивающим'' ведомым программам больше заданий для
выполнения - до тех пор, пока очередь не опустеет. Такая парадигма
эффективна в ситуациях, когда хосты очень рознятся по вычислительной
мощности, потому что наименее загруженные или более мощные хосты выполняют
больше работы, причем все хосты остаются занятыми до тех пор, пока
задание не будет выполнено. Для компиляции hitc введите
% aimk hitc hitc_slave.
С этого момента hitc не требует никакого пользовательского
ввода, он может быть порожден прямо с консоли PVM. Запустите консоль
PVM и добавьте ограниченное число хостов. В ответ на приглашение консоли
PVM введите pvm> spavn -> hitc.
При порождении, опция -> заставляет все конструкции вывода на экран в hitc и ему подчиненных направлять информацию в видимую область консоли. Эта возможность применима при отладке первых небольших программ PVM. Вы можете поэкспериментировать с этой опцией, помещая конструкции вывода на экран в hitc.f и hitc_slave.f и перекомпилируя их.
Далее, hitc может использоваться для иллюстрирования возможностей анимации в реальном масштабе времени для XPVM. Запустите XPVM и постройте виртуальную машину с четырьмя хостами. ``Кликните'' кнопку tasks и выберите в меню spawn. Введите hitc, когда XPVM запросит команду и ``кликните'' start. Вы увидите подсветку иконок хостов, как только виртуальная машина станет задействованной; увидите порождение задач hitc_slave и все сообщения, которые ``бродят'' между задачами на дисплее Space Time. Можно выбрать несколько других вариантов просмотра с помощью XPVM меню views. Способ task output эквивалентен применению опции -> для консоли PVM. Это заставляет стандартный вывод всех задач принудительно перенаправлять в окно, которое при этом ``всплывает''.
Установлено одно ограничение на программы, которые порождаются из XPVM (и консоли PVM): программы не должны включать никакого интерактивного ввода, например, запроса о числе подчиненных задач для запуска или о том, насколько велика решаемая задача. Этот тип информации может быть считан из файла или помещен в командную строку в качестве аргументов, но при этом никак не возможно осуществить пользовательский ввод с клавиатуры в потенциально удаленную задачу.
Консоль PVM, называемая pvm, - это автономная задача, которая позволяет пользователю запускать, опрашивать и модифицировать виртуальную машину. Консоль может запускаться и останавливаться неограниченное число раз на любом из хостов виртуальной машины без влияния на саму PVM и прочие приложения, которые могут в этот момент выполняться.
Когда запущена pvm, она в свою очередь определяет, работает ли уже PVM; если нет, pvm автоматически запускает pvmd на этом хосте, передавая pvmd опции командной строки и файл с указанием хостов. Таким образом, PVM не обязательно должна работать для того, чтобы можно было запустить консоль:
>pvm.
Консоль может воспринимать команды со стандартного ввода. Возможные команды:
alias h help
alias j jobs
setenv PVM_EXPORT DISPLAY
# print my id
echo new pvm shell
id
Как было установлено ранее, только одному лицу в группе необходимо инсталлировать PVM, но каждый ее пользователь может иметь собственный файл хостов, в котором он описывает свою собственную виртуальную машину.
В ``файле хостов'' определяется начальная их конфигурация, которую PVM объединяет в виртуальную машину. Он также содержит информацию о хостах, которые вы можете добавить в конфигурацию позже.
Файл хостов в его простейшей форме - это просто список имен хостов - по одному в строке. Пустые строки игнорируются, а строки, которые начинаются с # считаются строками комментариев. Такой подход позволяет Вам документировать файл хостов и дополнительно предоставляет ``ручной'' способ модификации начальной конфигурации путем комментирования различных имен хостов. Простейший файл хостов с конфигурацией виртуальной машины приведен ниже:
amox
tf2.evm.bsuir.unibel.by
solaris2
*** Ручной запуск ***
Загрузитесь в "honk" и введите:
pvm3/lib/pvmd -S -d0 -nhonk 1 80a9ca95:0cb6
4096 2 80a95c43:0000
Введите ответ:
Thanks,
после чего оба pvmd должны получить доступ к коммуникации.
Если вы хотите установить любую из приведенных опций как используемую по умолчанию для ряда хостов, то можете поместить нужные опции в одну строку с символом * в поле имени хоста. Эти установки по умолчанию будут иметь эффект для всех подпадающих хостов до тех пор, пока они не будут опровергнуты другой строкой с установками.
Хосты, которые вы не желаете видеть в начальной конфигурации, но хотите добавить позже, могут быть указаны в файле хостов путем внесения в начало соответствующих строк символов &. Пример файла хостов, иллюстрирующего большинство из этих опций, показан ниже:
# (пустые строки игнорируются)
gstws
ipsc dx=/usr/geist/pvm3/lib/I860/pvmd3
ibm1.scri.fsu.edu lo=gst so=pw
# Опции по умолчанию устанавливаются символом *
*ep=$sun/problem1:~/nla/mathlib
amox
#tf1.evm.bsuir.unibel.by
solaris2
# Замена опций по умолчанию новыми значениями
* lo=gageist so=pw ep=problem1
st1.bsu.edu.by
st2.bsu.edu.by
# машины, добавляемые позже, обозначены &
&sun4 ep=problem1
&corsair dx=/usr/local/bin/pvm3
&kill lo=gageist
Разработка приложений для системы PVM - по крайней мере в общем смысле - следует традиционной парадигме программирования микропроцессоров с распределенной памятью, таких как мультипроцессоры семейства Intel nCUBE. Базовые технологии как для логических аспектов программирования, так и для разработки алгоритмов совпадают. Наиболее существенные различия, однако, наблюдаются в следующем:
Параллельные вычисления, используемые в системах, таких как PVM, могут сводиться к вычислениям согласно трем фундаментальным точкам зрения в зависимости от способа организации вычислительных задач. С каждой точки зрения допускаются различные стратегии распределения рабочей нагрузки (они будут рассмотрены позже, в этом разделе). Первая и наиболее общая модель для приложений PVM может быть определена как ``беспорядочные'' вычисления: группа тесно связанных процессов, в типичных случаях реализующих один код и производящих вычисления над различными порциями всех данных, что обычно приводит к периодическим обменам промежуточными результатами. Эта парадигма может, при желании, быть разделена на категории:
Беспорядочные вычисления обычно протекают за три фазы. Первая - это инициализация группы процессов; в случае с ``только станциями'' распространение информации и параметров задания в группе производится соответственно распределению рабочей нагрузки, которое обычно также осуществляется в этой фазе. Вторая фаза - вычисление. Третья фаза - сбор результатов и их вывод в выходной поток; в течение этой фазы, группа процессов расформировывается и завершает свое существование.
Модель ``ведущий-ведомый'' иллюстрируется ниже с использованием хорошо известной последовательности вычислений Манделброта, которая является представительницей класса задач под названием ``смущающий'' параллелизм. Само вычисление сводится к применению рекурсивной функции к группе вершин на некоторой комплексной плоскости до тех пор, пока значения функции не достигнут определенных величин либо начнут отклоняться. В зависимости от этого условия строится графическое представление каждой вершины на плоскости. По существу, так как результат работы функции зависит только от начального значения вершины (и не зависит от других вершин), задача может быть разделена на полностью независимые порции, алгоритм может быть применен к каждой порции, а частичные результаты комбинируются с помощью простых комбинационных схем. Однако эта модель допускает балансировку динамической нагрузки, тем самым позволяя обрабатывающим элементам разделять нагрузку неравномерно. В текущем и последующих примерах в пределах этого раздела показаны только скелеты алгоритмов и, кроме того, допускаются некоторые синтаксические вольности в подпрограммах PVM - в интересах облегчения понимания. Управляющая структура класса приложений ``ведущий-ведомый'' показана на рис 11.
![\includegraphics[scale=0.6]{pic41.eps}](img65.png)
{Начальное размещение}
for i := 0 to NumWorkers - 1
pvm_spawn(<worker name>} {Запуск рабочего i}
pvm_send(<worker tid>,999) {Передача задачи рабочему i}
endfor
{Прием-передача}
while (WorkToDo)
pvm_recv(888) {Прием результата}
pvm_send(<available worker tid>,999)
{Передача следующей задачи доступному рабочему}
display result
endwhile
{Сбор оставшихся результатов}
for i := 0 to NumWorkers - 1
pvm_recv(888) {Прием результата}
pvm_kill(<worker tid i>) {Завершение рабочего i}
display result
endfor
{Алгоритм Манделброта для рабочего}
while (true)
pvm_recv(999) {Прием задачи}
{Вычисление результата}
result := MandelbrotCalculations(task)
{Передача результата ведущему}
pvm_send(<master tid>,888)
endwhile
Пример ``ведущий-ведомый'', описанный выше, не предполагает коммуникаций между ведомыми. Большинство беспорядочных вычислений любой сложности требуют взаимодействия между вычислительными процессами; структура таких приложений проиллюстрирована на примере использования ``только станции'' для матричного умножения по алгоритму Каннона (подробности программирования похожих алгоритмов даются в другом разделе). Пример ``умножения матриц'' графически показан на рис. 12 (локально умножаются подматрицы матриц и используется широковещательная построчная передача строк подматриц A в связке с постолбцовыми сдвигами подматриц матрицы B):
![\includegraphics[scale=0.57]{pic42.eps}](img66.png)
``сдвинуть-умножить-повернуть''}
{Процессор 0 запускает другие процессы}
if (<my processor number>) = 0) then
for i := 1 to MeshDimension*MeshDimension
pvm_spawn(<component name>, ...)
endfor
endif
forall processors Pij, 0 <= i,j < MeshDimension
for k := 0 to MeshDimension-1
{Сдвиг}
if myrow = (mycolumn+k) mod MeshDimension
{Передача A во все Pxy, x = myrow, y <> mycolumn}
pvm_mcast((Pxy, x = myrow, y <> mycolumn,999)
else
pvm_recv(999) {Прием A}
endif
{Умножение. Обработка всего, содержащегося в C}
Multiply(A,B,C)
{Вращение}
{Передача B в Pxy, x = myrow-1, y = mycolumn}
pvm_send((Pxy, x = myrow-1, y = mycolumn),888)
pvm_recv(888) {Прием B}
endfor
endfor
Как уже было упомянуто, древовидная структура вычислений для контроля процессов также во многих случаях соответствует коммуникационным шаблонам. Для иллюстрирования этой модели рассматривается алгоритм параллельной сортировки, который заключается в следующем. Один процесс (вручную запущенный в PVM) обладает (вводит или генерирует) список для сортировки. Он порождает второй процесс и передает ему половину списка. На этом этапе существуют уже два процесса, каждый из которых также порождает свой процесс и передает ему одну половину от уже разделенного списка. Процесс передачи продолжается до тех пор, пока не построено дерево соответствующей разветвленности. При этом каждый процесс независимо сортирует свою порцию списка, а фаза слияния наступает, когда отсортированные подсписки передаются в обратном направлении по ветвям дерева с промежуточными слияниями, делаемыми на каждой из станций. Этот алгоритм является показательным алгоритмом с заранее известной загрузкой; диаграмма с изображением процесса дана на рис. 13; алгоритмическая схема дается ниже.
![\includegraphics[scale=0.54]{pic43.eps}](img67.png)
широковещательной передачи шаблона дерева}
for i := 1 to N, причем 2^N = NumProcs
forall processors P, причем P < 2^i
pvm_spawn(...) {идентификатор процесса P XOR 2^i}
if P < 2^(i-1) then
midpt := PartitionList(list);
{Send list[0..midpt] to P XOR 2^i}
pvm_send((P XOR 2^I,999)
list := list[midpt+1..MAXSIZE]
else
pvm_recv(999) {Прием списка}
endif
endfor
endfor
{Сортировка оставшегося списка}
Quicksort(list[midpt+1..MAXSIZE])
{Сбор/слияние отсортированных подсписков}
for i := N downto 1, причем 2^N = NumProcs
forall processors P, причем P < 2^i
if P >2^(i-1) then
pvm_send((P XOR 2^i),888)
{Send list to P XOR 2^i}
else
pvm_recv(888) {Прием временного списка}
merge templist into list
endif
endfor
endfor
В предыдущем подразделе обсуждалась общая парадигма параллельного программирования с учетом структуры процесса и выделены демонстративные примеры в контексте системы PVM. В этом подразделе рассматривается проблема распределения рабочей нагрузки, следующей за стабилизацией структуры процесса, и описаны несколько обобщенных парадигм, которые используются при параллельных вычислениях в распределенной памяти. Обычно применяются две общих методологии. Первая, называемая ``декомпозицией данных'' или разбиением, исходит из того, что перекрывающиеся задачи приводят к применению вычислительных операций или преобразований над одной или большим числом структур данных, а затем эти данные могут разделяться и обрабатываться. Вторая называется ``функциональная декомпозиция'', что означает - разбиение работы на основе отличий операций и функций. В некотором смысле, вычислительная модель PVM поддерживает оба вида декомпозиции: ``функциональную'' (фундаментально различающиеся задачи выполняют различные операции) и ``данных'' (идентичные задачи оперируют над различными порциями данных).
В качестве простого примера декомпозиции данных рассмотрим сложение
двух векторов ![]() и
и ![]() , в результате чего получится
вектор
, в результате чего получится
вектор ![]() . Если предположить, что над этой задачей работает
. Если предположить, что над этой задачей работает
![]() процессов, разбиение данных приведет к распределению
процессов, разбиение данных приведет к распределению ![]() элементов
каждого вектора для каждого процесса, который вычисляет соответствующие
элементов
каждого вектора для каждого процесса, который вычисляет соответствующие
![]() элементов результирующего вектора. Такое распределение данных может
быть сделано либо ``статически'', когда каждый процесс ``априори''
знает (по крайней мере, в терминах переменных
элементов результирующего вектора. Такое распределение данных может
быть сделано либо ``статически'', когда каждый процесс ``априори''
знает (по крайней мере, в терминах переменных ![]() и
и ![]() ) свою долю рабочей
нагрузки, либо ``динамически'', когда контролирующий процесс (т.е.
ведущий) распределяет подблоки рабочей нагрузки для процессов
- как и когда они освободятся. Принципиальная разница между этими
двумя подходами - это ``диспетчеризация''. При статической диспетчеризации
индивидуальная рабочая нагрузка процесса фиксирована; при динамической,
она варьирует в зависимости от состояния вычислительного
процесса. В большинстве мультипроцессорных сред статическая диспетчеризация
эффективна для таких задач как пример сложения векторов; однако в
обобщенной среде PVM статическая диспетчеризация не очень необходима.
Смысл заключается в том, что среды PVM, базирующиеся на сетевых кластерах,
восприимчивы к внешним воздействиям; поэтому статически диспетчеризированные
задачи с разделенными данными могут конфликтовать с одним или более
процессами, которые реализуют свою порцию рабочей нагрузки намного
быстрее или намного медленнее, чем другие. Эта ситуация может также
возникнуть, когда машины в системе PVM гетерогенны, обладают различными
скоростями ЦПУ, различной памятью и прочими системными атрибутами.
) свою долю рабочей
нагрузки, либо ``динамически'', когда контролирующий процесс (т.е.
ведущий) распределяет подблоки рабочей нагрузки для процессов
- как и когда они освободятся. Принципиальная разница между этими
двумя подходами - это ``диспетчеризация''. При статической диспетчеризации
индивидуальная рабочая нагрузка процесса фиксирована; при динамической,
она варьирует в зависимости от состояния вычислительного
процесса. В большинстве мультипроцессорных сред статическая диспетчеризация
эффективна для таких задач как пример сложения векторов; однако в
обобщенной среде PVM статическая диспетчеризация не очень необходима.
Смысл заключается в том, что среды PVM, базирующиеся на сетевых кластерах,
восприимчивы к внешним воздействиям; поэтому статически диспетчеризированные
задачи с разделенными данными могут конфликтовать с одним или более
процессами, которые реализуют свою порцию рабочей нагрузки намного
быстрее или намного медленнее, чем другие. Эта ситуация может также
возникнуть, когда машины в системе PVM гетерогенны, обладают различными
скоростями ЦПУ, различной памятью и прочими системными атрибутами.
При реальном исполнении даже упомянутой тривиальной задачи сложения векторов выявляется, что ввод и вывод не могут быть проигнорированы. Возникает вопрос: как заставить описанные выше процессы принять свою рабочую нагрузку и что им делать с результирующим вектором? Ответ на этот вопрос зависит от самого приложения и обстоятельств его частичного выполнения, когда:
Параллелизма в среде с распределенной памятью, такой как PVM, можно достичь и разбиением общей рабочей нагрузки по принципу подобия выполняемых операций. Большинство очевидных примеров такой формы декомпозиции связаны с тремя стадиями исполнения типичной программы под названием ``ввод, обработка и вывод результата''. При функциональной декомпозиции такое приложение может состоять из трех отдельных программ, каждая из которых предназначена для реализации одной из трех фаз. Параллелизм достигается параллельным выполнением трех программ и созданием ``конвейера'' (последовательного или дискретного) между ними. Однако обратите внимание на то, что при таком сценарии, параллелизм данных может дополнительно проявляться в каждой фазе. Пример показан на рис. 8 - различные функции реализованы в виде компонентов PVM, - возникает множество ситуаций, когда каждый компонент реализует свою порцию разных алгоритмов с разбитыми данными.
Хотя концепция функциональной декомпозиции и проиллюстрирована выше
тривиальным примером, этот термин, как правило, используется для обозначения
разбиения и распределения рабочей нагрузки функцией within,
относящийся к вычислительной фазе. В типовом случае вычисления приложения
содержат несколько особых подалгоритмов - иногда для одних и тех же
данных (МКОД или сценарий: ``много команд и одни данные''), иногда
в виде конвейеризированной последовательности преобразований, а иногда -
представленных неструктурированными шаблонами обменов. Парадигма обобщенной
функциональной декомпозиции основаывается на гипотетическом
симулировании ``продвижения'' самолета, состоящего из множества
взаимосвязанных и взаимодействующих, функционально декомпозированных
подалгоритмов. Диаграмма,
предоставляющая возможность взглянуть на
такой пример, показана на рис. 14 (кроме того, она будет использоваться
в разделах, где описывается графическое программирование
PVM).
![\includegraphics[scale=0.48]{pic44.eps}](img74.png)
На рисунке каждое состояние, т.е. круг на ``графе'', представляет функционально декомпозированную часть приложения. Функция ввода распределяет частичные параметры задачи на различные функции 2 - 6, после порождения процессов соответствующих подпрограмм, реализующих каждый из подалгоритмов приложения. Некоторые данные могут быть переданы нескольким функциям (как в случае с двумя функциями wing) или данные могут предназначаться только для одной функции. После выполнения некоторого количества вычислений, эти функции доставляют непосредственно конечный результат в функции 7, 8 и 9, которые могут порождаться в начале вычислительного процесса и поэтому быть доступными. Диаграмма отражает первичную концепцию декомпозиции приложений по функциям с тем же успехом, что и отношения зависимости по контролю и данным. Параллелизм достигается благодаря двум причинам: параллельному и независимому исполнению модулей (функциями 2 - 6) плюс одновременному и конвейеризированному исполнению модулей в цепи зависимости (функциями 1, 6, 8 и 9).
Чтобы использовать систему PVM, приложение должно пройти две стадии. Первая заключается в разработке распределенной в памяти параллельной версии алгоритма приложения; эта фаза общая как для системы PVM, так и для других мультипроцессоров с распределенной памятью. Фактические параллельные решения подпадают под две главные категории: одна связана со структурой, другая - с эффективностью. В решениях, связанных со структурой распараллеливаемых приложений, основной упор делается на выбор используемой модели (т.е. беспорядочные вычисления в противовес древовидным вычислениям или функциональной декомпозиции). Решения с упором на эффективность - распараллеливание ведется в среде распределенной памяти - в целом ориентировано на минимизацию частоты и интенсивности коммуникаций. Обычно в отношении последних можно сказать, что процесс распараллеливания различен для PVM и аппаратных мультипроцессоров; для среды PVM, основывающейся на сетях, сильная степень детализации, как правило, повышает производительность. При наличии указанной особенности, процессы распараллеливания для PVM и для других сред с распределенной памятью, включая аппаратные мультипроцессоры, очень похожи.
Распараллеливание приложений можно делать ``интуитивно'', взяв за основу существующие последовательные версии или даже параллельные. В обоих случаях стадии сводятся к выбору подходящего алгоритма для каждой из подзадач приложения - обычно с помощью опубликованных описаний - или изобретению параллельного алгоритма и последующему кодированию этого алгоритма на выбранном языке (C, C++ или Фортран77 - для PVM), а также к реализации интерфейса с другими приложениями, управляющим процессом и прочими конструкциями. При распараллеливании существующих последовательных программ также обычно следуют общим рекомендациям, первичной из которых является ``разрыв петель'': начиная с наиболее удаленных и постепенно продвигаясь вглубь. Основная работа такого процесса заключается в определении зависимостей и разрыве петель таким образом, чтобы зависимости не нарушались при возникновении параллельных выполнений. Процесс такого распараллеливания описан в ряде печатных изданий и учебников по параллельному программированию, хотя в немногих из них обсуждаются практические и специфические аспекты трансформации последовательной программы в параллельную.
Современные параллельные программы могут базироваться либо на парадигме общей памяти, либо на парадигме распределенной памяти. Приспособление написанных программ для общей памяти к PVM похоже на преобразование из последовательного кода, причем версии с общей памятью базируются на векторном или на уровне петель параллелизме. В случае с программами, явно разделяющими память, первичная задача состоит в поиске точек синхронизации и замещении их обменами сообщений. Для преобразования параллельного кода для распределенной памяти в PVM главная задача состоит в преобразовании одного набора параллельных конструкций в другой. Обычно существующие параллельные программы для распределенной памяти написаны либо для аппаратных мультипроцессоров, либо для других сетевых сред, таких как p4 или Express. В обоих случаях, главные изменения требуется провести в отношении подсистемы управлении процессами. В примере с семейством Intel DMMP обычной практикой является запуск процессов с помощью командной строки интерактивных оболочек. Такая парадигма должна замещаться PVM - либо посредством ведущей программы, либо посредством программы для станции, берущей на себя ответственность за порождение процессов. В смысле взаимодействия, при этом, к счастью, много общего между вызовами по обмену сообщениями в различных средах программирования. Основными же различиями PVM и других систем в этом контексте являются:
В этом разделе приведено ознакомительное описание подпрограмм PVM версии 3. Раздел отсортирован по функциям, выполняемым подпрограммами. Например, в подразделе об ``обмене сообщениями'' идет речь о всех подпрограммах передачи и приема данных между двумя задачами PVM и опциях обмена сообщениями PVM.
В PVM версии 3 все задачи идентифицируются с помощью целого числа, предоставляемого pvmd. Далее по тексту такой идентификатор задачи обозначается TID. Это обозначение похоже на обозначение идентификатора процесса (PID), используемое в системе UNIX, предполагающее прозрачность для пользователя; значение TID также не имеет специального значения для пользователя. Фактически, PVM кодирует информацию в TID для своего собственного внутреннего использования.
Все подпрограммы PVM написаны на C. Приложения на C++ могут компоноваться с библиотекой PVM. Приложения на Фортране могут вызывать эти подпрограммы посредством интерфейса Фортран 77, поддерживаемого исходными текстами PVM версии 3. Данный интерфейс переводит аргументы, которые переданы при обращении на Фортранв соответствующие значения - если это нужно - для находящихся в более низком слое C-подпрограмм. Интерфейс также затрагивает формы представлений символьных строк на Фортране и различные соглашения при именовании, которые разные Фортран-компиляторы используют при вызове C-функций.
В коммуникационной модели PVM принято, что любая задача может передавать сообщение всякой задаче PVM и нет никаких ограничений на длину и количество таких сообщений. Поскольку все хосты имеют лимиты физической памяти, которые ограничивают потенциальное буферное пространство, коммуникационная модель не ограничивается этими частичными машинными лимитами, а подразумевает доступность и достаточность памяти. Таким образом, коммуникационная модель PVM предоставляет функции асинхронной блокирующей передачи, асинхронного блокирующего приема и неблокирующего приема. Согласно нашей терминологии блокирующая передача - это задача, которая завершается так быстро, как только буфер передачи освобождается для повторного использования, а асинхронная передача - передача, которая не зависит от состояния приемника, вызвавшего соответствующий прием до того, как передача завершится. В PVM версии 3 есть опции, которые указывают, что данные должны передаваться прямо от задачи к задаче. В этом случае, если сообщение большое, передатчик может блокироваться до тех пор, пока приемник не вызовет соответствующий прием.
Неблокирующий прием непосредственно возвращает либо данные, либо флаг, подтверждающий что данные не прибыли, в то время, как блокирующий прием завершается только после того, как данные появятся в буфере приема. В дополнение к приведенным коммуникационным функциям типа ``точка - точка'', модель поддерживает широковещательную передачу набору задач, в частности определенной пользователем группе задач. Имеются так же функции для нахождения глобального максимума, вычисления глобальной суммы и другие, приеменимые для группы задач. Для указания источника при приеме могут использоваться специальные символы и метки, позволяющие игнорировать контекст полностью или по частям. Подпрограмма может вызываться и с целью получения информации о принятых сообщениях.
Модель PVM гарантирует сохранение порядка сообщений. Если задача 1 посылает сообщение A задаче 2, а затем эта же задача посылает сообщение B той же задаче, то сообщение A поступит задаче 2 раньше, чем сообщение B. Более того, если оба сообщения возникнут до того, как задача 2 выполнит прием, то прием с указанием специальных символов будет всегда возвращать сообщение A.
Буферы сообщений распределяются динамически. Однако максимальная длина сообщения, которое может быть передано или принято, ограничивается объемом доступной памяти на данном хосте. В PVM версии 3.3 встроен только ``ограничительный'' текущий контроль. PVM может выдавать пользователю ошибку ``Can't get memory'' в тех случаях, когда суммарный объем входящих сообщений превышает размер доступной памяти, но при этом PVM не просит другие задачи остановить передачу для данного хоста.
call pvmfmytid (tid)
call pvmfexit(info)
char *where, int ntask, int *tids)
call pvmfspawn (task, argv, flag, where, ntask, tids,
numt)
| Значение | Опция | Cмысл |
| 0 | PvmTaskDefault | Место порождения процессов выбирает сама PVM |
| 1 | PvmTaskHost | аргумент where - определенный хост для порождения |
| 2 | PvmTaskArch | аргумент where - PVM_ARCH для порождения |
| 4 | PvmTaskDebug | запускает задачи под отладчиком |
| 8 | PvmTaskTrace | генерируются трассировочные данные |
| 16 | PvmMppFront | задачи запускаются в среде MPP |
| 32 | PvmHostCompl | where дополняет набор хостов |
Эти имена предопределены в pvm3/include/pvm3.h. На Фортране
все имена предопределяются в параметрических конструкциях, которые
могут быть найдены в разделе include файла
pvm3/include/pvm3.h.
PvmTaskTrace - это новая возможность PVM версии 3.3. Она заставляет порождаемые задачи генерировать трассировочные события. PvmTaskTrace используется XPVM. В ином случае пользователь должен с помощью pvm_setopt() указать, когда генерировать трассировочные события.
При возврате переменной numt присваивается количество успешно порожденных задач или код ошибки, если ни одна из задач не смогла стартовать. Если задачи были запущены, то pwn_spawn вернет вектор, состоящий из идентификаторов порожденных задач; если не смогли стартовать лишь некоторые задачи, соответствующие коды ошибок помещаются в последние ntask - numt позиций вектора.
Вызов pvm_spawn() может также запускать задачи и на мультипроцессорах. В случае с Intel iPSC/860 накладываются следующие ограничения. Каждый порождающий вызов получает подкуб размера ntask и загружает программу task во все соответствующие станции. ОС iPSC/860 имеет распределительное ограничение: 10 подкубов для всех пользователей, так что лучше запустить блок из задач в iPSC/860 одним вызовом, чем несколькими. Два самостоятельных блока задач, порожденные в iPSC/860 раздельно, все равно могут взаимодействовать друг с другом так же, как и с другими задачами PVM, даже с учетом того, что они существуют в разных подкубах. ОС iPSC/860 имеет еще одно ограничение: сообщения, следующие от станций во ``внешний мир'', должны быть меньше 256 КБайтов.
call pvmfkill (tid, info)
call pvmfcatchout (onoff)
Если pvm_exit вызывается предком тогда, когда активирован сбор выходных потоков, он будет блокироваться до тех пор, пока все задачи, выполняющие вывод, не отработают в том порядке, в котором они осуществляли весь свой вывод. Во избежание такой ситуации можно ``выключить сбор выходных потоков'' вызовом pvm_catchout(0) перед тем, как вызвать pvm_exit.
Новые возможности PVM версии 3.3 включают и возможность регистрировать специальные задачи PVM для обработки заданий по включению новых хостов, размещению задач на хостах и запуску новых задач. С этой целью создается интерфейс для ``продвинутых'' пакетных планировщиков (примерами могут быть Condor, DQS и LSF), которые подключаются к PVM и позволяют выполнять задания PVM в пакетном режиме. Такие регистрирующие подпрограммы также создают интерфейс для разработчиков отладчиков - для стимулирования удовлетворительных разработок сложных отладчиков специально для PVM.
Имена таких подпрограмм: pvm_reg_rm(), pvm_reg_hoster()
и
pvm_reg_tasker(). Эти ``продвинутые'' функции не
имеют значения для среднестатистического пользователя PVM и потому
здесь подробно не рассматриваются.
call pvmfparent (tid)
call pvmftidtohost (tid, dtid)
struct pvmhostinfo **hostp)
call pvmfconfig( nhost, narch, dtid, name, arch, speed,
info)
Функции на Фортране возвращают информацию об одном хосте за вызов,
поэтому для ``опроса'' всех хостов нужен цикл. Если
pvmfconfig
вызывается nhost раз, то будет представлена полная внутренняя структура виртуальной
машины. Работа с Фортран-интерфейсом подразумевает
сохранение копии массива hostp и возврат только одного ``вхождения''
за вызов. На всех хостах должны отработать циклы для того, чтобы они
получили обновленный массив hostp. Поэтому, если виртуальная
машина в течение этих вызовов изменяется, то изменение проявится в
параметрах nhost и narch, но не отразится на информации
о хосте. В настоящее время не существует способ ``сбросить'' pvmfconfig()
и заставить его перезапустить цикл в процессе его работы.
struct pvmtaskinfo **taskp)
call pvmftasks ( which, ntask, tid, ptid, dtid, flag,
aout, info)
Количество задач возвращается в ntask. taskp - это указатель на массив структур pvmtaskinfo - массив размера ntask. Каждая структура pvmtaskinfo содержит TID, pvmd TID, TID предка, флаг статуса и имя файла для порождения. (PVM ``не знает'' имя файла вручную запущенной задачи и поэтому ``не заполняет'' это имя.) Функция на Фортране возвращает информацию об одной задаче за вызов, поэтому для ``опроса'' всех задач нужен цикл. Так что, если нужно ``опрашивать'' все задачи и если pvmftasks вызывается ntask раз, то все задачи будут представлены. Фортран-реализации предполагают, что пул задач не подвержен изменениям, пока имеются циклы ``опроса'' задач. Если же пул изменился, эти изменения не проявятся до тех пор, пока не начнется следующий цикл из ntask вызовов.
Примеры использования pvm_config и pvm_tasks можно найти в исходных текстах консоли PVM, которая сама является задачей PVM. Примеры использования Фортран-версий этих подпрограмм можно найти в исходных текстах pvm3/examples/ testall.f.
int *infos)
int info = pvm_delhosts( char **hosts, int nhost,
int *infos)
call pvmfaddhost( hostinfo)
call pvmfdelhost( hostinfo)
Приведенные подпрограммы иногда применяются для установки виртуальной машины, но наиболее часто они используются для повышения гибкости и уровня толерантности к ошибкам больших приложений. Подпрограммы позволяют приложению увеличить в дозволенных пределах вычислительную мощь (добавлением хостов), если устанавливается, что другими способами решение осложняется. Одним из таких примеров может быть программа CAD/CAM, когда в процессе компиляции переопределяется сетка для конечного числа элементов, что сильно усложняет решение. Другим применением может быть повышение уровня толерантности приложения в отношении к ошибкам - можно обнаружить сбой хоста и ввести замену.
call pvmfsendsig( tid, signum, info)
int info = pvm_notify( int what, int msgtag, int cnt,
int tids)
call pvmfnotify( what, msgtag, cnt, tids, info)
Если имеется хост, на котором задача A потерпела неудачу при выполнении, а задача B запросила извещение о выходе из задачи A, то задача B будет извещена даже в том случае, когда выход был вызван косвенно - сбоем на хосте.
int val = pvm_getopt( int what)
call pvmfsetopt( what, val, oldval)
call pvmfgetopt( what, val)
| Опция | Значение | Смысл |
| PvmRoute | 1 | дисциплина маршрутизации |
| PvmDebugMask | 2 | отладочная маска |
| PvmAutoErr | 3 | автоматический рапорт об ошибках |
| PvmOutputTid | 4 | конечная цель stdout потомков |
| PvmOutputCode | 5 | msgtag для выходного потока |
| PvmTraceTid | 6 | конечная цель трассировки потомков |
| PvmTraceCode | 7 | msgtag для трассировки |
| PvmFragSize | 8 | размер фрагментов сообщений |
| PvmResvTids | 9 | разрешение доставки сообщений с зарезервированными тегами для задач с идентификаторами задач |
| PvmSelfOutputTid | 10 | конечная цель собственного stdout |
| PvmSelfOutputCode | 11 | msgtag для собственного выходного потока |
| PvmSelfTraceTid | 12 | конечная цель собственной трассировки |
| PvmSelfTraceCode | msgtag для собственной трассировки |
Наиболее популярное применение pvm_setopt - это ``включение'' прямолинейной маршрутизации между задачами PVM. В соответствии с обобщенными требованиями, пропускная сетевая коммуникационная способность PVM удваивается после вызова:
Посылка сообщения в PVM совершается тремя шагами. Первый: буфер передачи
должен быть инициализирован вызовом
pvm_initsend() или pvm_mkbuf().
Второй: сообщение должно быть ``упаковано'' в этот буфер с помощью
произвольного количества вызовов подпрограмм pvm_pk*()
в любой комбинации. (На Фортране упаковка сообщений делается подпрограммой
pvmfpack().) Третий: подготовленное сообщение посылается
соответствующему процессу вызовом подпрограммы pvm_send()
или широковещательной передачей с помощью подпрограммы pvm_mcast().
Сообщение принимается вызовом подпрограммы либо блокирующего, либо неблокирующего приема, а затем каждый из упакованных фрагментов распаковывается в буфер приема. Подпрограммы приема могут быть настроены на восприятие ``любого'' сообщения, любого сообщения от указанного источника, любого сообщения с указанным тегом, либо только сообщения с данным тегом от данного источника. Существует и ``пробная'' функция, которая проверяет, поступило ли сообщение, но на самом деле не принимает его.
Если требуется, то с помощью PVM версии 3 прием можно обработать в дополнительном контексте. Подпрограмма pvm_recvf() позволяет пользователям определять свои собственные контексты приема, в которых будут работать все последующие подпрограммы приема PVM.
call pvmfinitsend( encodingб bufid)
Опция encoding может иметь следующие значения:
call pvmfmkbuf( encodingб bufid)
call pvmffreebuf(bufidб info)
call pvmfgetsbuf( bufid)
int bufid = pvm_getrbuf( void)
call pvmfgetrbuf( bufid)
Этими подпрограммами буфер с bufid устанавливается как активный буфер передачи (или приема); состояние предыдущего активного буфера сохраняется, а его идентификатор возвращается в oldbuf.
Если при pvm_setsbuf() pvm_setrbuf() bufid установлен в 0, то имеющийся буфер сохраняется, но новый буфер не устанавливается. Такая возможность может быть использована для сохранения текущего состояния сообщений приложения - чтобы математическая библиотека или подсистема графического интерфейса, которые также используют сообщения PVM, не повредили содержимое буферов приложения. После того как прочие подсистемы отработали, буферы сообщения могут быть вновь активированы.
Сообщения можно передать и без упаковки применением подпрограмм, работающих с буферами сообщений. Это иллюстрируется следующим фрагментом:
oldid = pvm_setsbuf (bufid);
info = pvm_send (dst, tag);
info = pvm_freebuf (oldid);
Каждая из следующих подпрограмм C упаковывает массив предоставленных данных определенного типа в активный буфер передачи. Они могут быть вызваны сколько угодно раз для упаковки данных в одно сообщение. Так, сообщение может содержать несколько массивов с данными различных типов. C-структуры в процессе упаковки должны принимать их индивидуальные элементы. На комплексность упаковываемых данных ограничений не накладывается, но приложение должно распаковывать сообщения точно в соответствии с тем, как они были упакованы. Этого требует практика безопасного программирования.
Аргументами для каждой из подпрограмм являются: указатель на первый из элементов для упаковки, nitem - суммарное число элементов для упаковки из данного массива и stride - ``шаг'' для использования во время упаковки. Шаг, равный 1, означает последовательную упаковку вектора, равный 2 - упаковку ``через раз'' и т.д. Исключение составляет подпрограмма pvm_pkstr(), которая завершает упаковку строки символов при появлении NULL и поэтому не требует наличия аргументов nitem и stride.
PVM также поддерживает подпрограммы упаковки с printf - подобными форматами выражений, которые указывают, как и какие данные упаковывать в буфер передачи. Все переменные передаются через адреса - если указаны счетчик и шаг; в противном случае, предполагается, что переменные будут передаваться значениями.
int stride)
int info = pvm_pkcplx( float *xp, int nitem,
int stride)
int info = pvm_pkdcplx( double *zp, int nitem,
int stride)
int info = pvm_pkdouble( double *dp, int nitem,
int stride)
int info = pvm_pkfloat( float *fp, int nitem,
int stride)
int info = pvm_pkint( int *np, int nitem,
int stride)
int info = pvm_pklong( long *np, int nitem,
int stride)
int info = pvm_pkshort( short *np, int nitem,
int stride)
int info = pvm_pkstr( char *cp)
int info = pvm_packfconst( char fmt, ...)
| STRING 0 | REAL4 4 |
| BYTE 1 | COMPLEX8 5 |
| INTEGER2 2 | REAL8 6 |
| INTEGER4 3 | COMPLEX16 7 |
Эти имена уже предопределены в параметрических конструкциях заголовочного файла /pvm3/include/pvm3.h. Ряд производителей может расширять этот список и включать в него поддержку 64-битных архитектур в своей реализации. INTEGER8, REAL16 и др. уже будут добавлены, как только будет реализована XDR-поддержка этих типов данных.
call pvmfsend( tid, msgtag, info)
int info = pvm_mcast( int *tids, int ntask, int msgtag)
call pvmfmcast( ntask, tids, msgtag, info)
Подпрограмма pvm_mcast() помечает сообщение целочисленным идентификатором msgtag и широковещательно передает это сообщение всем задачам, указанным в целочисленном массиве tids (исключая себя). Массив tids имеет длину ntask.
int cnt, int type)
call pvmfpsend( tid, msgtag, xp, cnt, type, info)
| PVM_STR | PVM_FLOAT |
| PVM_BYTE | PVM_CPLX |
| PVM_SHORT | PVM_DOUBLE |
| PVM_INT | PVM_DCPLX |
| PVM_LONG | PVM_UINT |
| PVM_USHORT | PVM_ULONG |
PVM поддерживает несколько методов приема сообщений в задаче. В PVM нет точного соответствия функций, например, применение pvm_send не обязательно требует применения pvm_recv. Каждая из следующих подпрограмм может быть вызвана для любого из поступающих сообщений вне зависимости от того, как оно было передано (или передано широковещательно).
call pvmfrecv( tid, msgtag, bufid)
call pvmfnrecv( tid, msgtag, bufid)
call pvmfprobe( tid, msgtag, bufid)
struct timeval *tmout)
call pvmftrecv( tid, msgtag, sec, usec, bufid)
Подпрограмма pvm_bufinfo() возвращает msgtag, TID источника и длину в байтах сообщения, идентифицированного с помощью bufid. Она может применяться для установления метки и источника сообщений, которые были приняты с использованием специальных символов.
int *msgtag, int *tid)
call pvmfbufinfo( bufid, bytes, msgtag, tid, info)
int cnt, int type, int *rtid, int *rtag,
int *rcnt)
call pvmfprecv( tid, msgtag, xp, cnt, type, rtid, rtag,
rcnt, info)
Следующие подпрограммы на C распаковывают (многократно) данные определенных типов из активного буфера приема. На уровне приложения они должны соответствовать подпрограммам упаковки - по типу, числу элементов и шагу; nitem - число элементов данного типа для распаковки, а stride - шаг.
int stride)
int info = pvm_upkcplx( float *xp, int nitem,
int stride)
int info = pvm_upkdcplx( double *zp, int nitem,
int stride)
int info = pvm_upkdouble( double *dp, int nitem,
int stride)
int info = pvm_upkfloat( float *fp, int nitem,
int stride)
int info = pvm_upkint( int *np, int nitem,
int stride)
int info = pvm_upklong( long *np, int nitem,
int stride)
int info = pvm_upkshort(short *np, int nitem,
int stride)
int info = pvm_upkstr( char *cp)
int info = pvm_unpackf( const char *fmt, ...)
Единственная Фортран-подпрограмма выполняет все перечисленные функции приведенных C-подпрограмм.
Аргумент xp - это массив, куда помещается то, что распаковывается. Целочисленный аргумент what указывает тип данных для распаковки. (Та же опция what, что и для pvmfpack()).
Функции динамической группировки процессов составляют основу ключевых
подпрограмм PVM. Специализированная библиотека
libgpvm3 должна
компоноваться с пользовательскими программами, которые используют
любую групповую функцию; pvmd не реализует групповых функций.
Эта задача обрабатывается групповым сервером, который запускается
автоматически - при первом вызове групповой функции. Здесь приводятся
некоторые сведения о том, как могут обрабатываться группы в среде с
интерфейсом ``обмена сообщениями''. Выводы касаются эффективности
и надежности - в данном случае найден компромисс между статическими
и динамическими группами. Некоторые авторы приводят аргументы в пользу
того, что только задачи из группы могут пользоваться групповыми функциями.
Согласно философии PVM групповые функции разработаны как очень обобщенные и прозрачные для пользователя, что имеет определенную цену с точки зрения эффективности. Каждая задача PVM может присоединиться или покинуть любую группу в любое время - без необходимости информирования все другие задачи затрагиваемой группы. Задачи могут широковещательно передавать сообщения в группы, членами которых они не являются. В целом, любая задача PVM может вызвать любую из следующих функций во всякое время. Исключение составляют pvm_lvgroup(), pvm_barrier() и pvm_reduce(), природа которой требует членства вызывающей задачи в указанной группе.
int info = pvm_lvgroup( char *group)
call pvmfjoingroup( group, inum)
call pvmflvgroup( group, info)
Эти подпрограммы позволяют задаче присоединиться к именованной пользователем
группе и покинуть ее. Первый вызов
pvm_joingroup() создает
группу с именем group и включает в нее вызывающую задачу;
pvm_joingroup возвращает номер экземпляра процесса (inum)
в некоторой группе. Номера экземпляров находятся в диапазоне от нуля
до количества членов в группе - минус один. В PVM версии 3 одна задача
может состоять в нескольких группах.
Если процесс покинул группу и снова пытается присоединиться к ней, то он может получить другой номер экземпляра. Номера экземпляров перераспределяются, поэтому задача, состоящая в группе, будет получать наименьший из доступных номеров экземпляров. Однако если несколько задач состоят в группе, то не гарантируется, что задаче будет ``выдан'' ее предыдущий номер экземпляра.
Чтобы помочь пользователю в управлении последовательностью назначения номеров, независимо от того, происходит присоединение или отсоединение, функция pvm_lvgroup() не завершается до тех пор, пока задача не будет достоверно извещена об этом факте; pvm_joingroup(), вызываемая после этого, назначит вакантный номер экземпляра новой задаче. Ответственность за последовательность назначения номеров экземпляров накладывается на пользователя, если в алгоритме задачи возникает потребность в этом. Если несколько задач покинет группу и в ней не останется членов, то в номерах экземпляров возникнут ``пробелы''.
int inum = pvm_getinst( char *group, int tid)
int size = pvm_gsize( char *group)
call pvmfgettid( group, inum, tid)
call pvmfgetinst( group, tid, inum)
call pvmfgsize( group, size)
call pvmfbarrier( group, count, info)
call pvmfbcast( group, msgtag, info)
int nitem, int datatype, int msgtag, char *group,
int root)
call pvmfreduce( func, data, count, datatype, msgtag,
group, root, info)
PvmMax, PvmMin, PvmSum, PvmProduct
Редуцирующая операция над входными данными выполняется поэлементно. Например, если массив данных состоит из двух чисел с плавающей запятой, а функция - это PvmMax, то результат будет включать два числа: глобальный максимум от всех членов группы - первое - и глобальный максимум ото всех - второе.
В дополнение, пользователи могут определять свои собственные функции для глобальных операций и указывать их в func. Пример дается в исходных текстах PVM. Обратитесь к PVM_ROOT/examples/ gexamples.
Функция pvm_reduce() не блокируется. Если задача вызывает pvm_reduce, а затем покидает группу до того, как результат pvm_reduce появится в root, то может произойти ошибка.
Очереди сообщений как средство межпроцессной связи позволяют процессам взаимодействовать, обмениваясь данными. Данные передаются между процессами дискретными порциями, называемыми сообщениями. Процессы, использующие этот тип межпроцессной связи, могут выполнять две операции: послать или принять сообщение.
Процесс, прежде чем послать или принять какое-либо сообщение, должен запросить систему породить программные механизмы, необходимые для обработки данных операций. Процесс делает это при помощи системного вызова msgget. Обратившись к нему, процесс становится владельцем или создателем некоторого средства обмена сообщениями; кроме того, процесс специфицирует первоначальные права на выполнение операций для всех процессов, включая себя. Впоследствии владелец может уступить право собственности или изменить права на операции при помощи системного вызова msgctl, однако на протяжении всего времени существования определенного средства обмена сообщениями его создатель остается создателем. Другие процессы, обладающие соответствующими правами для выполнения различных управляющих действий, также могут использовать системный вызов msgctl.
Процессы, имеющие права на операции и пытающиеся послать или принять сообщение, могут приостанавливаться, если выполнение операции не было успешным. В частности это означает, что процесс, пытающийся послать сообщение, может ожидать, пока процесс-получатель не будет готов; и наоборот, получатель может ждать отправителя. Если указано, что процесс в таких ситуациях должен приостанавливаться, говорят о выполнении над сообщением ``операции с блокировкой''. Если приостанавливать процесс нельзя, говорят, что над сообщением выполняется ''операция без блокировки''.
Процесс, выполняющий операцию с блокировкой, может быть приостановлен до тех пор, пока не будет удовлетворено одно из условий:
В этом разделе обсуждаются несколько завершенных программ.
Первый пример - forkjoin.c - показывает, как порождать
процессы и синхронизировать их. Второй пример - PSDOT.F -
нужен при обсуждении программы вычисления так называемого точечного произведения
на Фортране. Третьим примером - failure.c - демонстрируется,
как пользователь может применять вызов
pvm_notify() для
создания ``устойчивых'' приложений. Представлен пример матричного
умножения. И наконец, показано, как PVM может быть использована для
вычислений, связанных c высокотемпературной диффузией.
Первым примером демонстрируется, как порождать задачи PVM и синхронизировать их. Программа порождает несколько задач - по умолчанию три. После этого потомок синхронизируется путем передачи сообщения своей задаче-предку. Предок принимает сообщения от каждой порожденной им задачи и выводит на экран информацию, заключенную в этих сообщениях от задач-потомков.
Программа ``раздваивание - присоединение'' (рис. ![]() ) содержит код как задачи-предка,
так и задачи-потомка. Самое
первое действие, которое делает программа - вызов функции pvm_mytid().
Функция должна вызываться для того, чтобы впоследствии можно было
выполнять остальные вызовы PVM. В результате pvm_mytid() всегда
должно возвращаться положительное целое число. Если это не так, то что-то
осуществлено неправильно. В примере ``раздваивание - присоединение''
проверяется значение mytid; если оно отражает ошибку, то
вызывается pvm_perror() и осуществляется выход из программы.
Вызов pvm_perror() выведет на экран сообщение, показывающее,
что при последнем вызове PVM имела место ошибка. В данном случае,
последним вызовом был pvm_mytid(), так что pvm_perror
может вывести на экран сообщение о том, что PVM не смогла запуститься
на текущей машине. Аргумент pvm_perror() - это строка, которой
при выводе на экран непосредственно будет предшествовать само сообщение
об ошибке. В данном случае передается argv[0], который
содержит имя программы в том виде, в котором оно было введено через
командную строку. Функция pvm_perror() вызывается после
функции UNIX perror().
) содержит код как задачи-предка,
так и задачи-потомка. Самое
первое действие, которое делает программа - вызов функции pvm_mytid().
Функция должна вызываться для того, чтобы впоследствии можно было
выполнять остальные вызовы PVM. В результате pvm_mytid() всегда
должно возвращаться положительное целое число. Если это не так, то что-то
осуществлено неправильно. В примере ``раздваивание - присоединение''
проверяется значение mytid; если оно отражает ошибку, то
вызывается pvm_perror() и осуществляется выход из программы.
Вызов pvm_perror() выведет на экран сообщение, показывающее,
что при последнем вызове PVM имела место ошибка. В данном случае,
последним вызовом был pvm_mytid(), так что pvm_perror
может вывести на экран сообщение о том, что PVM не смогла запуститься
на текущей машине. Аргумент pvm_perror() - это строка, которой
при выводе на экран непосредственно будет предшествовать само сообщение
об ошибке. В данном случае передается argv[0], который
содержит имя программы в том виде, в котором оно было введено через
командную строку. Функция pvm_perror() вызывается после
функции UNIX perror().
Допустим, что в результате получается достоверное значение mytid. Теперь вызывается pvm_parent(). Функция pvm_parent() вернет TID задачи, которая породила задачу, сделавшую вызов. Начиная с того момента, как была запущена на выполнение инициирующая программа ``раздваивание-присоединение'' из оболочки UNIX, она не имеет предка; эта инициирующая задача не будет порождаться другими задачами, но может снова запускаться пользователями вручную. Для инициирующей задачи ``раздваивание - присоединение'' результатом pvm_parent будет не определенный идентификатор задачи, а код ошибки PvmNoParent. Таким образом - проверкой эквивалентности результата вызова pvm_parent() значению PvmNoParent - можно отличить задачу-предка ``раздваивание - присоединение'' от потомка. Естественно, если задача является предком, то она должна породить потомка. Если же она предком не является, то должна послать предку сообщение.
Количество задач определяется посредством командной строки - аргументом argv[1]. Если указанное количество задач недопустимо, то программа завершается, вызывая pvm_exit(). Вызов pvm_exit() очень важен, потому что он сообщает PVM, что программа не будет больше пользоваться ее услугами. (В подобном случае, задача выходит из PVM, а PVM сделает вывод о том, что задача ``умерла'' и больше не требует обслуживания. Так или иначе - это правильный стиль ``чистого'' завершения.) Приняв, что количество задач допустимо, после этого программа ``раздваивание - присоединение'' будет пытаться породить потомка.
Вызов pvm_spawn() приказывает PVM запустить ntask
задач с именами argv[0]. Второй параметр - список аргументов
для передачи порождаемым задачам. В данном случае не нужно заботиться
о передаче потомкам частных аргументов через командную строку, поэтому
он равен NULL. Третий параметр при порождении -
PvmTaskDefault
- флаг, приказывающий PVM породить задачи в ``местах'' по умолчанию.
Если бы было необходимо размещение потомков на специфических машинах
или на машинах с особенной архитектурой, то можно было бы воспользоваться
значением флага PvmTaskHost или PvmTaskArch, а четвертым
параметром указать хост или архитектуру. Поскольку не важно, где задачи
будут исполняться, используется значение PvmTaskDefault для
флага и значение NULL для четвертого параметра. Наконец,
через ntask сообщается число задач для запуска; целочисленный
массив для потомков будет содержать идентификаторы задач вновь порожденных
потомков. Возвращаемое pvm_spawn() значение отражает, сколько
задач было порождено успешно. Если info не соответствует
ntask, то в процессе порождения произошел ряд ошибок. В случае
с ошибкой ее код помещается в массив идентификаторов задач вместо
действительного идентификатора задачи соответствующего потомка. В
программе ``раздваивание - присоединение'' этот массив проверяется
с помощью цикла, а идентификаторы задач и возможные коды ошибок выводятся
на экран. Если ни одна задача не порождена успешно, то осуществляется
выход из программы.
От каждой задачи-потомка предок принимает сообщение и выводит его
содержимое на экран. Вызовом pvm_recv() принимается сообщение
(с JOINTAG) от любой задачи. Возвращаемое pvm_recv()
значение - это целое число, определяющее буфер сообщения. Это целое
число может быть использовано как информация для поиска буферов сообщений.
Последующий вызов pvm_bufinfo() определяет
длину, тег и идентификатор задачи передающего процесса для сообщения,
заданного с помощью buf. В программе ``раздваивание-присоединение''
сообщения, посланные потомками, содержат только по одному целочисленному
значению - идентификатору задачи соответствующей задачи-потомка. Вызовом
pvm_upkint() целое число распаковывается из сообщения в
переменную mydata. В программе
``раздваивание - присоединение'' тестируются значения
mydata
и идентификатора задачи, возвращенного pvm_bufinfo(). Если
эти значения различны, то программа содержит ошибку и сообщение об ошибке
выводится на экран. Наконец на экран выводится информация из сообщения,
и на этом работа программы-предка завершается.
Последний сегмент кода программы ``раздваивание - присоединение'' будет исполняться как задача-потомок. Чтобы можно было поместить данные в буфер сообщения, он должен быть инициализирован вызовом pvm_initsend(). Параметр PvmDataDefault говорит о том, что PVM должна преобразовать данные обычным способом, чтобы удостовериться, что они прибыли в формате, корректном для целевого процессора. В некоторых случаях нет необходимости в преобразовании данных. Если пользователь уверен, что целевая машина использует тот же формат данных и, действительно, преобразовывать данные нет нужды, то он может применить PvmDataRaw в качестве параметра pvm_initsend(). Вызов pvm_pkint() размещает единственное целое число - metid - в буфере сообщения. Важно быть уверенными, что соответствующий распаковочный вызов точно соответствует данному упаковочному. Если число упаковывается как целое, а распаковывается как число с плавающей запятой, то такой подход не корректен. Аналогично, если пользователь упаковывает два целых числа одним вызовом, то он не сможет их впоследствии распаковать двойным вызовом pvm_upkint() - по одному вызову на каждое целое число. Таким образом, между упаковочным и распаковочным вызовами должно существовать соответствие ``один к одному''. В завершение сообщение с тегом JOINTAG передается задаче-предку.
Пример "раздваивание - присоединение":
Пример ``раздваивание-присоединение''
Демонстрируется, как порождать процессы и
обмениваться сообщениями
*/
/* определения и прототипы библиотеки PVM */
#include <pvm3.h>
/* максимальное число потомков, которые будут
порождаться этой программой */
#define MAXNCHILD 20
/* тег для использования в сообщениях, связанных
с присоединением */
#define JOINTAG 11
int main(int argc, char* argv[]) {
/* количество задач для порождения, 3 используются
по умолчанию */
int ntask = 3;
/* код возврата для вызовов PVM */
int info;
/* свой идентификатор задачи */
int mytid;
/* свой идентификатор задачи-предка*/
int myparent;
/* массив идентификаторов задач-потомков*/
int child[MAXNCHILD];
int i, mydata, buf, len, tag, tid;
/* поиск своего идентификатора задачи */
mytid = pvm_mytid();
/* проверка на ошибки*/
if (mytid < 0) {
/* вывод на экран сообщения об ошибке*/
pvm_perror(argv[0]);
/* выход из программы */
return -1;
}
/* нахождение числа-идентификатора задачи-предка */
myparent = pvm_parent();
/* выход, если есть ошибки, но не PvmNoParent */
if ((myparent < 0 ) && (myparent != PvmNoParent() {
pvm_perror(argv[0]);
pvm_exit();
return -1;
}
/* если предка не найдено, то это и есть предок */
if (myparent == PvmNoParent) {
/* определение числа задач для порождения */
if (argc == 2) ntask = atoi(argv[1]);
/* удостоверение, что ntask - допустимо */
if ((ntask < 1) || (ntask > MAXNCHILD))
{pvm_exit();
return 0;}
/* порождение задач-потомков*/
info = pvm_spawn(argv[0], (char**)0, PvmTaskDefault,
(char*)0, ntask, child);
/* вывод на экран идентификаторов задач */
for (i = 0; i < ntask; i++)
if (child[i] < 0) /* вывод на экран десятичного
кода ошибки*/
printf(" %d", child[i]);
else /* вывод на экран шестнадцатеричного
идентификатора задачи */
printf("t%x\t", child[i]);
putchar('\n');
/* удостоверение, что порождение произошло успешно */
if (info == 0) {pvm_exit(); return -1;}
/* ожидание ответов только от тех потомков, которые
порождены успешно */
ntask = info;
for (i = 0; i < ntask; i++) {
/* прием сообщения от любого процесса-потомка */
buf = pvm_recv(-1, JOINTAG);
if (buf < 0) pvm_perror("calling recv");
info = pvm_bufinfo(buf, &len, &tag, &tid);
if (info < 0) pvm_perror("calling pvm_bufinfo");
info = pvm_upkint(&mydata, 1, 1);
if (info < 0) pvm_perror("calling pvm_upkint");
if (mydata != tid)
printf("Этого не может быть!\n");
printf("Длина %d, Tag %d, Tid t%x\n",
len, tag, tid);
}
pvm_exit();
return 0;
}
/* это потомок */
info = pvm_initsend(PvmDataDefault);
if (info < 0) {
pvm_perror("calling pvm_initsend"); pvm_exit();
return -1;
}
info = pvm_pkint(&mytid, 1, 1);
if (info < 0) {
pvm_perror("calling pvm_pkint"); pvm_exit();
return -1;
}
info = pvm_send(myparent, JOINTAG);
if (info < 0) {
pvm_perror("calling pvm_initsend"); pvm_exit();
return -1;
}
pvm_exit(); return 0;
}
Ниже показано, что выводит на экран выполняющаяся программа ``раздваивание - присоединание''.
% forkjoin
t10001c t40149 tc0037
Длина 4, Tag 11, Tid t40149
Длина 4, Tag 11, Tid tc0037
Длина 4, Tag 11, Tid t10001c
% forkjoin 4
t10001e t10001d t4014b tc0038
Длина 4, Tag 11, Tid t4014b
Длина 4, Tag 11, Tid tc0038
Длина 4, Tag 11, Tid t10001d
Длина 4, Tag 11, Tid t10001e
Заметьте, что порядок приема сообщений недетерминирован. Поскольку главный цикл предка обрабатывает сообщения по принципу ``первый пришел - первый вышел'', порядок вывода на экран определяется временем, которое сообщения затрачивают на путешествие от задачи-потомка к предку.
В этом разделе приведена простая программа на Фортране - PSDOT - для
вычисления точечного произведения. Программа вычисляет точечное произведение
массивов X и Y. В первую очередь в PSDOT вызываются PVMFMYTID()
и PVMFPARENT(). Вызов PVMFPARENT вернет PVMNOPARENT,
если задача не была ранее порождена другой задачей PVM. Если это случай,
когда PSDOT - ведущая и, следовательно, должна породить отдельные
рабочие копии PSDOT, то у пользователя запрашивается число
рабочих процессов и длина векторов для вычисления. Каждый порождаемый
процесс будет принимать ![]() элементов X и Y, где
элементов X и Y, где ![]() - длина
векторов, а
- длина
векторов, а ![]() - количество процессов, используемых при вычислении.
Если
- количество процессов, используемых при вычислении.
Если ![]() не делится на
не делится на ![]() нацело, то ведущий будет вычислять
точечное произведение ``дополнительных элементов''. Подпрограммой
SGENMAT случайным образом генерируются значения X и Y. После
этого PSDOT порождает
нацело, то ведущий будет вычислять
точечное произведение ``дополнительных элементов''. Подпрограммой
SGENMAT случайным образом генерируются значения X и Y. После
этого PSDOT порождает ![]() своих копий и передает
каждой новой задаче часть массивов X и Y. Каждое сообщение содержит
размеры подмассивов и, собственно, сами подмассивы. После того как
ведущий породил рабочие процессы и передал подвекторы, он вычисляет
точечное произведение своей порции X и Y. Затем ведущий процесс принимает
остальные локальные точечные произведения от рабочих процессов. Обратите
внимание на то, что при вызове PVMFRECV как параметр-идентификатор
задачи используется специальный символ (-1). Это говорит о том, что
сообщение от ``любой'' задачи будет устраивать принимающую сторону.
Применение специального символа таким образом может привести к ``гибридизации''.
Но в данном случае ``гибридизация'' не создаст проблему, поскольку
сложение по природе коммутативно. Другими словами, совершенно
не важно, в каком порядке складываются частичные суммы, полученные
от рабочих. Если кто-то не уверен, что ``гибридизация'' не приведет
к нежелательным программным эффектам, то ему желательно избегать ее
возникновения.
своих копий и передает
каждой новой задаче часть массивов X и Y. Каждое сообщение содержит
размеры подмассивов и, собственно, сами подмассивы. После того как
ведущий породил рабочие процессы и передал подвекторы, он вычисляет
точечное произведение своей порции X и Y. Затем ведущий процесс принимает
остальные локальные точечные произведения от рабочих процессов. Обратите
внимание на то, что при вызове PVMFRECV как параметр-идентификатор
задачи используется специальный символ (-1). Это говорит о том, что
сообщение от ``любой'' задачи будет устраивать принимающую сторону.
Применение специального символа таким образом может привести к ``гибридизации''.
Но в данном случае ``гибридизация'' не создаст проблему, поскольку
сложение по природе коммутативно. Другими словами, совершенно
не важно, в каком порядке складываются частичные суммы, полученные
от рабочих. Если кто-то не уверен, что ``гибридизация'' не приведет
к нежелательным программным эффектам, то ему желательно избегать ее
возникновения.
Как только ведущий принял все локальные точечные произведения и глобально просуммировал их, он вычисляет полное точечное произведение уже локально. Один результат вычитается из второго, а разница между величинами выводится на экран. Несущественная разница вполне ожидаема, ибо существуют погрешности, связанные с округлениями чисел с плавающей точкой.
Если программа PSDOT -это рабочий, то она принимает содержащее подмассивы X и Y сообщение от ведущего процесса. Она вычисляет точечное произведение этих подмассивов и передает результат назад ведущему процессу. В целях краткости сюда не включены подпрограммы SGENMAT и SDOT.
Программа - пример PSDOT.F:
*
* PSDOT параллельно реализует внутреннее (или точечное)
* произведение:
* векторы X и Y сначала находятся на ведущей станции,
* которая затем устанавливает виртуальную машину,
* раздает данные и задания и наконец суммирует
* локальные результаты для получения глобального
* внутреннего произведения.
*
* .. Внешние подпрограммы ..
EXTERNAL PVMFMYTID, PVMFPARENT, PVMFSPAWN, PVMFEXIT
EXTERNAL PVMFINITSEND
EXTERNAL PVMFPACK, PVMFSEND, PVMFRECV, PVMFUNPACK
EXTERNAL SGENMAT
*
* .. Внешние функции ..
INTEGER ISAMAX
REAL SDOT
EXTERNAL ISAMAX, SDOT
*
* .. Внутренние функции ..
INTRINSIC MOD
*
* .. Параметры ..
INTEGER MAXN
PARAMETER ( MAXN = 8000 )
INCLUDE 'fpvm3.h'
*
* .. Скаляры ..
INTEGER N_ LN_ MYTID_ NPROCS_ IBUF_ IERR
INTEGER I, J, K
REAL LDOT, GDOT
*
* .. Массивы ..
INTEGER TIDS(0:63)
REAL X(MAXN), Y(MAXN)
*
* Регистрация в PVM и получение идентификаторов задач
* своего и ведущего процессов.
*
CALL PVMFMYTID( MYTID )
CALL PVMFPARENT( TIDS(0) )
*
* Нужно ли порождать другие процессы
* (Это - ведущий процесс).
*
IF ( TIDS(0) .EQ. PVMNOPARENT ) THEN
*
* Получение исходных данных.
*
WRITE(*.*)
'Сколько процессов нужно создать (1-64)?'
READ(*.*) NPROCS
WRITE(*,2000) MAXN
READ(*.*) N
TIDS(0) = MYTID
IF ( N .GT. MAXN ) THEN
WRITE(*.*) 'N слишком велико.
Увеличьте параметр MAXN'//$ 'для этого случая.'
STOP
END IF
*
* LN - количество элементов точечного произведения
* для локальной обработки. Все имеют одинаковое
* количество, а ``лишние'' элементы достаются ведущему.
* ``Общее'' количество элементов хранится в J.
*
J = N / NPROCS
LN = J + MOD(N, NPROCS)
I = LN + 1
*
* Генерирование случайных X и Y.
*
CALL SGENMAT( N, 1, X, N, MYTID, NPROCS, MAXN, J )
CALL SGENMAT( N, 1, Y, N, I, N, LN, NPROCS )
*
* Обход всех рабочих процессов.
*
DO 10 K = 1, NPROCS-1
*
* Порождение процесса и проверка на ошибки.
*
CALL PVMFSPAWN( 'psdot', 0, 'anywhere', 1, TIDS(K),
IERR )
IF (IERR .NE. 1) THEN
WRITE(*.*) 'ERROR, невозможно создать процесс #',K,
$ '. Dying . . .'
CALL PVMFEXIT( IERR )
STOP
END IF
*
* Рассылка исходных данных.
*
CALL PVMFINITSEND( PVMDEFAULT, IBUF )
CALL PVMFPACK( INTEGER4, J, 1, 1, IERR )
CALL PVMFPACK( REAL4, X(I), J, 1, IERR )
CALL PVMFPACK( REAL4, Y(I), J, 1, IERR )
CALL PVMFSEND( TIDS(K), 0, IERR )
I = I + J
10 CONTINUE
*
* Вычисление ведущим своей части точечного произведения.
*
GDOT = SDOT( LN, X, 1, Y, 1 )
*
* Получение локальных точечных произведений и их
* сложение с целью формирования глобального.
*
DO 20 K = 1, NPROCS-1)
CALL PVMFRECV( -1, 1, IBUF )
CALL PVMFUNPACK( REAL4, LDOT, 1, 1, IERR )
GDOT = GDOT + LDOT
20 CONTINUE
*
* Вывод на экран результатов.
*
WRITE(*,*) ' '
WRITE(*,*) '<x,y> = ',GDOT
*
* ``Последовательное'' вычисление точечного произведения
* и его вычитание из ``распределенного'' точечного
* произведения - с целью проверки
* на допустимость уровня ошибок.
*
LDOT = SDOT( N, X, 1, Y, 1 )
WRITE(*,*) '<x,y> : последовательное произведение.
<x,y>^ : ' $ 'распределенное произведение.'
WRITE(*,*) '| <x,y> - <x,y>^ | = ',ABS(GDOT = LDOT)
WRITE(*,*) 'Завершено.'
*
* Является ли этот процесс рабочим?
*
ELSE
*
* Прием исходных данных.
*
CALL PVMFRECV( TIDS(0), 0, IBUF )
CALL PVMFUNPACK( INTEGER4, LN, 1, 1, IERR )
CALL PVMFUNPACK( REAL, X, LN, 1, IERR )
CALL PVMFUNPACK( REAL, Y, LN, 1, IERR )
*
* Вычисление локального точечного произведения
* и передача его ведущему.
*
LDOT = SDOT( LN, X, 1, Y, 1 )
CALL PVMFINITSEND( PVMDEFAULT, IBUF )
CALL PVMFPACK( REAL4, LDOT, 1, 1, IERR )
CALL PVMFSEND( TIDS(0), 1, IERR )
END IF
*
CALL PVMFEXIT( 0 )
*
1000 FORMAT(I10, 'Успешно порожден процесс #',I2,',
TID =',I10)
2000 FORMAT('Введите длину перемножаемых векторов
(1 -',I7,'):')
STOP
*
* End program PSDOT
*
END
Пример с ошибкой демонстрирует, как кто-либо может принудительно завершать задачи и определять ситуации, когда задачи отрабатывают или завершаются ненормально. В данном примере порождаются несколько задач - так же, как это сделано в предыдущих примерах. Одна из них принудительно завершается предком. Поскольку интерес состоит в нахождении ненормальных завершений задач, после их порождения вызывается pvm_notify(). Вызовом pvm_notify() PVM приказывается передать вызывающей задаче сообщение о завершении работы определенных задач. В данном случае пользователя интересуют все потомки. Заметьте, что задача, вызывающая pvm_notify(), будет получать уведомления о ``прекращении существования'' задач, указанных в массиве их идентификаторов. Нет особого смысла передавать сообщение задаче, которая завершается. Вызов, связанный с извещениями, может также использоваться для информирования задач о том, что новый хост добавлен в виртуальную машину или удален из нее. Это применимо в ситуациях, когда программа стремится динамически адаптироваться к текущему состоянию сети.
После реализации запроса об уведомлениях задача-предок принудительно
завершает работу одного из потомков. Вызовом
pvm_kill()
принудительно завершается работа исключительно той задачи, чей идентификатор
передан как параметр. После завершения одной из порожденных
задач, предок с помощью
pvm_recv(-1, TASKDIED) ожидает сообщения,
уведомляющего о
``смерти'' этой задачи. Идентификатор задачи,
которая завершилась, передается в уведомительном сообщении в виде
одного целого числа. Процесс распаковывает идентификатор ``мертвой''
задачи и выводит его на экран. Хорошим стилем так же считается и вывод
заранее известного идентификатора завершаемой задачи. Эти идентификаторы
должны быть идентичны. Задачи-потомки просто ждут примерно по минуте
и затем спокойно завершаются.
Программа - пример failure.c:
Пример уведомления о сбое
Демонстрируется, как сообщать о фактах завершения задач
*/
/* определения и прототипы библиотеки PVM */
#include <pvm3.h>
/* максимальное число потомков, которые
будут порождаться этой программой */
#define MAXNCHILD 20
/* тег для использования в сообщениях, связанных
с отработкой задач */
#define TASKDIED 11
int
main(int argc, char* argv[])
{
/* количество задач для порождения,
3 используются по умолчанию */
int ntask = 3;
/* код возврата для вызовов PVM */
int info;
/* свой идентификатор задачи */
int mytid;
/* свой идентификатор задачи-предка */
int myparent;
/* массив идентификаторов задач-потомков */
int child[MAXNCHILD];
int i, deadtid;
int tid;
char *argv[5];
/* поиск своего идентификатора задачи */
mytid = pvm_mytid();
/* проверка на ошибки */
if (mytid < 0) {
/* вывод на экран сообщения об ошибке */
pvm_perror(argv[0]);
/* выход из программы */
return -1;
}
/* нахождение числа-идентификатора задачи-предка */
myparent = pvm_parent();
/* выход, если есть ошибки, но не PvmNoParent */
if ((myparent < 0) && (myparent != PvmNoParent)) {
pvm_perror(argv[0]);
pvm_exit();
return -1;
}
/* если предок не найден, то это и есть предок */
if (myparent == PvmNoParent) {
/* определение числа задач для порождения */
if (argc == 2) ntask = atoi(argv[1]);
/* удостоверение, что ntask - допустимо */
if ((ntask < 1) || (ntask > MAXNCHILD)) {pvm_exit();
return 0; }
/* порождение задач-потомков */
info = pvm_spawn(argv[0], (char**), PvmTaskDebug,
(char*)0, ntask, child);
/* удостоверение, что порождение произошло успешно */
if (info != ntask) { pvm_exit(); return -1; }
/* вывод на экран идентификаторов задач */
for (i = 0; i < ntask; i++) printf("t%x\t",child[i]);
putchar('\n');
/* запрос об уведомлении о завершении потомка */
info = pvm_notify(PvmTaskExit, TASKDIED, ntask,
child);
if (info < 0) { pvm_perror("notify"); pvm_exit();
return -1; }
/* уничтожение потомка со ``средним''
идентификатором */
info = pvm_kill(child[ntask/2]);
if (info < 0) { pvm_perror("kill"); pvm_exit();
return -1; }
/* ожидание уведомления */
info = pvm_recv(-1, TASKDIED);
if (info < 0) { pvm_ perror("recv"); pvm_exit();
return -1; }
info = pvm_upkint(&deadtid, 1, 1);
if (info < 0) pvm_perror("calling pvm_upkint");
/* должен быть потомок со ``средним'' номером */
printf("Задача t%x завершилась.\n", deadtid);
printf("Задача t%x является средним потомком.\n",
child[ntask/2]);
pvm_exit();
return 0;
}
/* это потомок */
sleep(63);
pvm_exit();
return 0;
}
В следующем примере программируется алгоритм матричного умножения,
предложенный Фоксом (Fox)[8]. Программа
mmult будет
вычислять ![]() , где
, где ![]() ,
, ![]() и
и ![]() - все квадратные матрицы.
С целью упрощения предполагается, что для вычисления результата будут
использоваться
- все квадратные матрицы.
С целью упрощения предполагается, что для вычисления результата будут
использоваться ![]() задач. Каждая задача будет вычислять подблок
результирующей матрицы
задач. Каждая задача будет вычислять подблок
результирующей матрицы ![]() . Размер блока и значение
. Размер блока и значение ![]() передаются
программе как аргументы командной строки. Матрицы
передаются
программе как аргументы командной строки. Матрицы ![]() и
и ![]() также
устанавливаются в виде блоков, распределенных в среде из
также
устанавливаются в виде блоков, распределенных в среде из ![]() задач.
задач.
Предположим, что существует ``сеть'' из ![]() задач. Каждая
задача (
задач. Каждая
задача (![]() , где
, где ![]() ) первоначально содержит блоки
) первоначально содержит блоки
![]() ,
, ![]() и
и ![]() . Первым шагом алгоритма задачи,
расположенные по диагонали (
. Первым шагом алгоритма задачи,
расположенные по диагонали (![]() , где
, где ![]() ), передают свои
блоки
), передают свои
блоки ![]() всем остальным задачам в строке
всем остальным задачам в строке ![]() . После передачи
. После передачи
![]() каждая задача вычисляет
каждая задача вычисляет
![]() и добавляет
результат к
и добавляет
результат к ![]() . Следующим шагом блоки
. Следующим шагом блоки ![]() поворачиваются
по столбцам. Так, задача
поворачиваются
по столбцам. Так, задача ![]() передает свой блок
передает свой блок ![]() задаче
задаче
![]() (задача
(задача ![]() передает свой блок
передает свой блок ![]() задаче
задаче ![]() ).
Затем задачи возвращаются к первому шагу:
).
Затем задачи возвращаются к первому шагу: ![]() широковещательно
передается всем другим задачам в строке
широковещательно
передается всем другим задачам в строке ![]() - алгоритм продолжается.
После
- алгоритм продолжается.
После ![]() итераций матрица
итераций матрица ![]() будет содержать
будет содержать ![]() , а матрица
, а матрица
![]() вернется к исходному состоянию.
вернется к исходному состоянию.
В PVM не накладывается ограничений на то, как задача может связываться с любой другой задачей. Однако для данной программы хотелось бы представлять задачи в виде двухмерной модели тора. Чтобы учесть задачи, каждая из них включается в группу mmult. Групповые идентификаторы используются для отображения задач на наш тор. При включении в группу первой задачи она получает групповой идентификатор 0. В программе mmult, задача с нулевым групповым идентификатором порождает остальные задачи и передает параметры матричного умножения этим задачам. Такими параметрами являются m и bklsize - квадратный корень числа блоков и соответственно размер блока. После того, как все задачи порождены, а параметры переданы, вызывается pvm_barrier() - чтобы удостовериться, что все задачи присоединились к группе. Если барьер не организован, то последующий вызов pvm_gettid() может завершиться ненормально, так как некая задача к тому моменту может быть еще не в составе группы.
После того как барьер организован, сохраняются идентификаторы задач
из строки myrow в массиве. Это достигается путем
определения групповых идентификаторов всех задач в строке и запрашивания
PVM о соответствующих им идентификаторах задач. Далее, с помощью malloc()
выделяется место для блоков матриц. В действительном программном приложении,
может случиться так, что матрицы уже распределены. Далее программа
определяет строку и столбец блока ![]() , который будет вычисляться.
Это основывается на значениях групповых идентификаторов - в диапазоне
от
, который будет вычисляться.
Это основывается на значениях групповых идентификаторов - в диапазоне
от ![]() до
до ![]() включительно. Так, если допустить построчное отображение
групповых идентификаторов задач, целочисленное деление mygid/m
даст строку задач, а mygid mod m - даст столбец. С использованием
подобного отображения определяется групповой идентификатор задачи,
расположенной в торе ``выше'' или ``ниже'',
и сохраняется соответственно в up и down.
включительно. Так, если допустить построчное отображение
групповых идентификаторов задач, целочисленное деление mygid/m
даст строку задач, а mygid mod m - даст столбец. С использованием
подобного отображения определяется групповой идентификатор задачи,
расположенной в торе ``выше'' или ``ниже'',
и сохраняется соответственно в up и down.
Далее блоки инициализируются вызовом InitBlock(): ![]() - случайными числами,
- случайными числами,
![]() - идентичной матрицей, а
- идентичной матрицей, а ![]() - нулями. Это позволит нам верифицировать вычисление в конце
программы простой проверкой равенства
- нулями. Это позволит нам верифицировать вычисление в конце
программы простой проверкой равенства ![]() .
.
Наконец, выполняется главный вычислительный цикл матричного умножения.
Сначала диагональные задачи широковещательно передают имеющиеся блоки
![]() другим задачам в своих строках. Отметим, что массив myrow
в действительности содержит идентификаторы задач, выполняющих широковещательные
передачи. При повторных вызовах pvm_mcast() сообщения будут
передаваться всем задачам из массива, исключая делающую вызов задачу.
Для задач mmult эта процедура великолепно срабатывает - чтобы
напрасно не обрабатывать ``лишнее'' сообщение, поступающее самой
широковещательно передающей задаче при ``лишнем'' pvm_recv().
Как широковещательно передающая задача, так и задачи, принимающие
блок, вычисляют
другим задачам в своих строках. Отметим, что массив myrow
в действительности содержит идентификаторы задач, выполняющих широковещательные
передачи. При повторных вызовах pvm_mcast() сообщения будут
передаваться всем задачам из массива, исключая делающую вызов задачу.
Для задач mmult эта процедура великолепно срабатывает - чтобы
напрасно не обрабатывать ``лишнее'' сообщение, поступающее самой
широковещательно передающей задаче при ``лишнем'' pvm_recv().
Как широковещательно передающая задача, так и задачи, принимающие
блок, вычисляют ![]() с использованием и диагонального блока
с использованием и диагонального блока
![]() и блоков
и блоков ![]() , принадлежащих задачам.
, принадлежащих задачам.
После того как подблоки умножены и результат добавлен к блоку ![]() ,
вертикально сдвигаются блоки
,
вертикально сдвигаются блоки ![]() . Особенным образом блок
. Особенным образом блок ![]() упаковывается
в сообщение, передается задаче с идентификатором задачи up
и затем принимается новый блок
упаковывается
в сообщение, передается задаче с идентификатором задачи up
и затем принимается новый блок ![]() от задачи с идентификатором
задачи down.
от задачи с идентификатором
задачи down.
Обратите внимание на то, что используются различные теги сообщений
при передачах блоков ![]() и блоков
и блоков ![]() при различных циклических
итерациях. Полностью указываются и идентификаторы задач при выполнении
pvm_recv(). Возникает соблазн применять специальные символы
в полях pvm_recv(), однако, такая практика может быть опасной.
К примеру, если некорректно определить значение для up и
указать специальный символ при pvm_recv() вместо down,
то это может привести к ``неосознанной'' передаче сообщений
не тем задачам. В примере сообщения однозначно направлены, тем самым
уменьшая вероятность возникновения ошибок при приеме сообщений от
не тех задач, т.е. ошибочных фаз алгоритма.
при различных циклических
итерациях. Полностью указываются и идентификаторы задач при выполнении
pvm_recv(). Возникает соблазн применять специальные символы
в полях pvm_recv(), однако, такая практика может быть опасной.
К примеру, если некорректно определить значение для up и
указать специальный символ при pvm_recv() вместо down,
то это может привести к ``неосознанной'' передаче сообщений
не тем задачам. В примере сообщения однозначно направлены, тем самым
уменьшая вероятность возникновения ошибок при приеме сообщений от
не тех задач, т.е. ошибочных фаз алгоритма.
Как только вычисление завершено, проверяется ![]() - только для того,
чтобы убедиться в правильности матричного умножения, т.е. корректности
значений
- только для того,
чтобы убедиться в правильности матричного умножения, т.е. корректности
значений ![]() . Такую проверку не возможно осуществить, например, с помощью
подпрограмм из библиотеки матричного умножения.
. Такую проверку не возможно осуществить, например, с помощью
подпрограмм из библиотеки матричного умножения.
В вызове pvm_lvgroup() нет необходимости, поскольку PVM выгрузит отработавшие задачи и удалит их из группы. Однако хорошим примером является ``явный'' выход из группы перед вызовом pvm_exit(). Команда консоли PVM reset ``сбросит'' все группы PVM. Команда pvm_gstat выведет на экран статус любой из существующих групп.
Матричное умножение
*/
/* определения и прототипы библиотеки PVM */
#include <pvm3.h>
#include <stdio.h>
/* максимальное число потомков, которые
будут порождаться этой программой */
#define MAXNTIDS 100
#define MAXNROW 10
/* теги сообщений */
#define ATAG 2
#define BTAG 3
#define DIMTAG 5
void
InitBlock(float *a, float *b, float *c, int blk,
int row, int col) {
int len, ind;
int i, j;
srand_pvm_mytid__
len = blk*blk;
for (ind = 0; ind < len; ind++)
{ a[ind] = (float)(rand()%1000)/100.0; c[ind] = 0.0; }
for (i = 0; i < blk; i++) {
for (j = 0; i < blk; j++) {
if (row == col)
b[j*blk+i] = (i==j)? 1.0 : 0.0;
else
b[j*blk+i] = 0.0;
}
}
}
void
BlockMult(float* c, float* a, float* b, int blk) {
int i,j,k;
for (i = 0; i < blk; i++)
for (j = 0; i < blk; j++)
for (k = 0; k < blk; k++)
for (j = 0; i < blk; j++)
c[i*blk+j] += (a[i*blk+k] * b[k*blk+j]);
}
int
main(int argc, char* argv[])
{
/* количество задач для порождения, 3 используются
по умолчанию */
int ntask = 2;
/* код возврата для вызовов PVM */
int info;
/* свой идентификатор задачи и групповой
идентификатор */
int mytid, mygid;
/* массив идентификаторов задач-потомков*/
int child[MAXNTIDS-1];
int i, m, blksize;
/* массив идентификаторов задач в своей строке*/
int myrow[MAXROW];
float *a, *b, *c, *atmp;
int row, col, up, down;
/* поиск своего идентификатора задачи */
mytid = pvm_mytid();
pvm_setopt(PvmRoute, PvmRouteDirect);
/* проверка на ошибки*/
if (mytid < 0) {
/* вывод на экран сообщения об ошибке*/
pvm_perror(argv[0]);
/* выход из программы */
return -1;
}
/* присоединение к группе mmult*/
mygid = pvm_joingroup("mmult");
if (mygid < 0) {
pvm_perror(argv[0]); pvm_exit(); return -1;
}
/* если свой групповой идентификатор не равен 0,
то нужно породить другие задачи */
if (mygid == 0) {
/* определение числа задач для порождения */
if (argc == 3) {
m = atoi(argv[1]);
blksize = atoi(argv[2]);
}
if (argc < 3) {
fprintf(stderr, "usage: mmult m blk\n");
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* удостоверение, что ntask - допустимо */
ntask = m*m;
if ((ntask < 1) || (ntask > MAXNTIDS)) {
fprintf(stderr, "ntask = %d not valid.\n",
ntask);
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* порождать не нужно, если имеется
только одна задача */
if (ntask == 1) goto barrier;
/* порождение задач-потомков*/
info = pvm_spawn("mmult", (char**)0,
PvmTaskDefault, (char*)0, ntask-1, child);
/* удостоверение, что порождение
произошло успешно */
if (info != ntask-1) {
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* передача размерности матрицы */
pvm_initsend(PvmDataDefault);
pvm_pkint(&m, 1, 1);
pvm_pkint(&blksize, 1, 1);
pvm_mcast(child, ntask-1, DIMTAG);
}
else {
/* прием размерности матрицы */
pvm_recv(pvm_gettid("mmult", 0), DIMTAG);
pvm_pkint(&m, 1, 1);
pvm_pkint(&blksize, 1, 1);
ntask = m*m;
}
/* удостоверение, что все задачи
присоединились к группе */
barrier:
info = pvm_barrier("mmult",ntask);
if (info < 0) pvm_perror(argv[0]);
/* поиск идентификаторов задач в своей строке */
for (i = 0; i < m; i++)
myrow[i] = pvm_gettid("mmult", (mygid/m)*m + i);
/* распределение памяти для локальных блоков */
a = (float*)malloc(sizeof(float)*blksize+blksize);
b = (float*)malloc(sizeof(float)*blksize+blksize);
c = (float*)malloc(sizeof(float)*blksize+blksize);
atmp = (float*)malloc(sizeof(float)*blksize+blksize);
/* проверка достоверности указателей */
if (!(a && b && c && atmp)) {
fprintf(stderr, "%s: out of memory!\n", argv[0]);
free(a); free(b); free(c); free(atmp);
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* поиск строки и столбца своего блока */
row = mygid/m; col = mygid % m;
/* определение соседей сверху и снизу */
up = pvm_gettid("mmult",
((row)?(row-1):(m-1))*m+col);
down = pvm_gettid("mmult",
((row) == (m-1))?col:(row+1)*m+col));
/* инициализация блоков */
InitBlock(a, b, c, blksize, row, col);
/* выполнение матричного умножения */
for (i = 0; i < m; i++) {
/* широковещательная передача блока матрицы A */
if (col == (row + i)%m) {
pvm_initsend(PvmDataDefault);
pvm_pkfloat(a, blksize*blksize, 1);
pvm_mcast(myrow, m, (i+1)*ATAG);
BlockMult(c,a,b,blksize);
}
else {
pvm_recv(pvm_gettid("mmult", row*m + (row +i)%m),
(i+1)*ATAG);
pvm_upkfloat(atmp, blksize*blksize);
BlockMult(c,atmp,b,blksize);
}
/* поворот столбца B */
pvm_initsend(PvmDataDefault);
pvm_pkfloat(b, blksize*blksize, 1);
pvm_send(up, (i+1)*BTAG);
pvm_recv(down, (i+1)*BTAG);
pvm_upkfloat(b, blksize*blksize, 1);
}
/* проверка */
for (i = 0; i < blksize*blksize; i++)
if (a[i] != c[i])
printf("Error a[%d] (%g) != c[%d] (%g) \n", i,
a[i], i, c[i]);
printf("Done.\n");
free(a); free(b); free(c); free(atmp);
pvm_lvgroup("mmult");
pvm_exit();
return 0;
}
Здесь представлена программа PVM, которая вычисляет температурную диффузию в некой среде - в данном случае это проводник. Уравнение, описывающие одномерную температурную диффузию тонкого проводника:
Дискретизация:
В результате получаем явную формулу:
Начальные и граничные условия:
![]() - для всех
- для всех ![]() ;
;
![]() - для
- для ![]() .
.
Псевдокодом для таких вычислений будет следующий:
t = t+dt;
a(i+1,1)=0;
a(i+1,n+2)=0;
for j = 2:n+1;
a(i+1,j)=a(i,j) + mu*(a(i,j+1)-2*a(i,j)+a(i,j-1));
end;
t;
a(i+1,1:n+2);
plot(a(i,:))
end
В программе heat.c массив solution будет содержать результаты решений уравнения температурной диффузии на каждом шаге. Этот массив - в формате xgraph - будет ``выходным'' при завершении программы (xgraph - программа, предназначенная для вывода данных на графопостроитель). Сначала порождаются задачи heatslv. Далее, подготавливается исходный набор данных. Обратите внимание на то, что для конца проводника значением начальной температуры будет ноль.
Потом, четыре раза исполняется основная часть программы - каждый раз
с новым значением ![]() . Для определения продолжительности времени,
прошедшего от начала вычислений данной фазы, используется таймер.
Начальный набор данных рассылается задачам heatslv. При каждой
посылке совместно с начальным набором данных передаются идентификаторы
задач-соседей слева и справа. Задачи heatslv будут использовать
эту информацию при граничных коммуникациях. (В противном случае нужно
использовать групповые вызовы PVM для отображения задач на сегменты
проводника. При использовании групповых вызовов можно избежать явных
указаний идентификаторов задач ведомых процессов).
. Для определения продолжительности времени,
прошедшего от начала вычислений данной фазы, используется таймер.
Начальный набор данных рассылается задачам heatslv. При каждой
посылке совместно с начальным набором данных передаются идентификаторы
задач-соседей слева и справа. Задачи heatslv будут использовать
эту информацию при граничных коммуникациях. (В противном случае нужно
использовать групповые вызовы PVM для отображения задач на сегменты
проводника. При использовании групповых вызовов можно избежать явных
указаний идентификаторов задач ведомых процессов).
После рассылки исходных данных ведущий процесс ожидает получения результатов. Когда результаты поступают, они интегрируются в результирующую матрицу, вычисляется затраченное время, и решение записывается в xgraph-файл.
Как только все четыре фазы завершены, а результаты сохранены, ведущая программа выводит на экран информацию о временных затратах и принудительно завершает ведомые процессы.
Программа-пример heat.c:
heat.c
Применение PVM для решения дифференциального уравнения,
описывающего простейшую температурную диффузию,
с использованием 1 ведущей программы и 5 ведомых
Ведущая программа формирует данные, посылает их ведомым
и ожидает результаты, возвращаемые ведомыми.
Файлы с полученными результатами
готовы для использования программой xgraph
*/
#include "pvm3.h"
#include <stdio.h>
#include <math.h>
#include <time.h>
#define SLAVENAME "heatslv"
#define NPROC 5
#define TIMESTEP 100
#define PLOTINC 10
#define SIZE 1000
int num_data = SIZE/NPROC;
main()
{
int mytid, task_ids[NPROC], i, j;
int left, right, k, l;
int step = TIMESTEP;
int info;
double init[SIZE], solution[TIMESTEP][SIZE];
double result[TIMESTEP*SIZE/NPROC], deltax2;
FILE *filenum;
char *filename[4][7];
double deltat[4];
time_t t0;
int etime[4];
filename[0][0] = "graph1";
filename[1][0] = "graph2";
filename[2][0] = "graph3";
filename[3][0] = "graph4";
deltat[0] = 5.0e-1;
deltat[1] = 5.0e-3;
deltat[2] = 5.0e-6;
deltat[3] = 5.0e-9;
/* регистрация в PVM */
mytid = pvm_mytid();
/* порождение ведомых задач */
info = pvm_spawn(SLAVENAME,(char **)0,
PvmTaskDefault,"", NPROC,task_ids);
/* создание исходного набора данных */
for (i = 0; i < SIZE; i++)
init[i] = sin(M_PI * ( (double)i /
(double)(SIZE-1) ));
init[0] = 0.0;
init[SIZE-1] = 0.0;
/* четырехразовое выполнение с разными
значениями дельты t */
for (l = 0; l < 4; l++) {
deltax2 = (deltat[l]/pow(1.0/(double)SIZE,2.0));
/*засекаем время*/
time(&t0);
etime[l] = t0;
/* передача исходных данных ведомым */
/* дополнение информацией о соседях -
для реализации возможности
обмена граничными данными */
for (i = 0; i < NPROC; i++) {
pvm_initsend(PvmDataDefault);
left = (i == 0) ? 0 : task_ids[i-1];
pvm_pkint(&left, 1, 1);
right = (i == (NPROC-1)) ? 0 : task_ids[i+1];
pvm_pkint(&right, 1, 1);
pvm_pkint(&step, 1, 1);
pvm_pkdouble(&deltax2, 1, 1)
pvm_pkint(&num_data, 1, 1);
pvm_pkdouble(&init[num_data*i], num_data, 1);
pvm_send(task_ids[i], 4);
}
/* ожидание результатов */
for (i = 0; i < NPROC; i++) {
pvm_recv(task_ids[i], 7);
pvm_upkdouble(&result[0], num_data*TIMESTEP, 1);
/* ``обновление'' решения */
for (j = 0; j < TIMESTEP; j++)
for (k = 0; k < num_data; k++)
solution[j][num_data*i+k] = result[wh(j,k)];
}
/* остановка формирования временных интервалов */
time(&t0);
etime[l] = t0 - etime[l];
/* получение выходных данных */
filenum =(fopen_filename[l][0], "w");
fprintf(filenum,
"TitleText: Wire Heat over Delta Time: %e\n",
deltat[l]);
fprintf(filenum,
"XUnitText: Distance\nYUnitText: Heat\n");
for (i = 0; i < TIMESTEP; i = i + PLOTINC) {
fprintf(filenum,"\"Time index: %d\n",i);
for (j = 0; j < SIZE; j++)
fprintf(filenum,"%d %e\n",j, solution[i][j]);
fprintf(filenum,"\n");
}
fclose (filenum);
}
/* вывод на экран информации о
временных интервалах */
printf("Problem size: %d\n",SIZE);
for (i = 0; i < 4; i++)
printf("Time for run %d: %d sec\n",i,etime[i]);
/* принудительное завершение ведомых процессов */
for (i = 0; i < NPROC; i++) pvm_kill(task_ids[i]);
pvm_exit();
}
int wh(x, y)
int x, y;
{
return(x*num_data+y);
}
Программы heatslv фактически реализуют вычисление температурной диффузии ``на протяжении'' проводника. Ведомая программа состоит из бесконечного цикла: прием исходного набора данных, итеративное вычисление результата на основе этого набора (с обменом граничной информацией с соседями при каждой итерации) и посылка результирующего частичного решения назад, ведущему процессу.
Вместо создания бесконечных циклов в ведомых задачах, можно передавать специальные сообщения с приказами о завершении. Однако во избежание сложностей, связанных с обменом сообщениями, в ведомых задачах используются бесконечные циклы, а завершаются они принудительно из ведущей программы. Третьим вариантом может быть реализация с ведомыми, исполняющимися только один раз и самостоятельно завершающимися после обработки единственных наборов данных, полученных от ведущего. Если бы этот вариант был воплощен, то к полезной нагрузке добавилась бы бесполезная.
В течение каждого шага каждой фазы, происходит обмен граничными значениями температурных матриц. Сначала левосторонние граничные элементы передаются задаче-соседу слева и соответствующие граничные элементы принимаются от задачи-соседа справа. Затем, симметрично, правосторонние граничные элементы передаются правому соседу, а соответствующие - принимаются от левого. Идентификаторы задач-соседей проверяются с целью гарантирования того, что не возникнет попыток передать сообщения несуществующим задачам (или принять их).
Программа-пример heatslv.c:
heatslv.c
Ведомые принимают исходные данные от хоста,
обмениваются граничной информацией с соседями
и вычисляют изменение температуры проводника.
Это делается за несколько итераций -
``под руководством'' ведущего
*/
#include "pvm3.h"
#include <stdio.h>
int num_data;
main()
{
int mytid, left, right, i, j, master;
int timestep;
double *init, *A;
double leftdata, rightdata, delta, leftside,
rightside;
/* регистрация в PVM */
mytid = pvm_mytid();
master = pvm_parent();
/* прием своих данных от ведущей программы */
while(1) {
pvm_recv(master, 4);
pvm_upkint(&lef, 1, 1);
pvm_upkint(&right, 1, 1);
pvm_upkint(×tep, 1, 1);
pvm_upkdouble(&delta, 1, 1);
pvm_upkint(&num_data, 1, 1);
init = (double *) malloc(num_data*sizeof(double));
pvm_upkdouble(init, num_data, 1);
/* копирование исходных данных
в свой рабочий массив */
A = (double *)
malloc(num_data * timestep * sizeof(double));
for (i = 0; i < num_data; i++) A[i] = init[i];
/* реализация вычисления */
for (i = 0; i < timestep-1; i++) {
/* обмен граничной информацией
со своими соседями */
/* передача налево, прием справа */
if (left != 0) {
pvm_initsend(PvmDataDefault);
pvm_pkdouble(&A[wh(i,0)],1,1);
pvm_send(left, 5);
}
if (right != 0) {
pvm_recv(right, 5);
pvm_upkdouble(&rightdata, 1, 1);
/* передача направо, прием слева */
pvm_initsend(PvmDataDefault);
pvm_pkdouble(&A[wh(i,num_data-1)],1,1);
pvm_send(right, 6);
}
if (left != 0) {
pvm_recv(left, 6);
pvm_upkdouble(&leftdata, 1, 1);
}
/* выполнение вычислений данной итерации */
for (j = 0; j < num_data; j++) {
leftside = (j == 0) ? leftdata : A[wh(i,j-1)];
rightside =
(j == (num_data-1)) ? rightdata : A[wh(i,j+1)];
if ((j == 0) && (left == 0))
A[wh(i+1,j)] = 0.0;
else if ((j == (num_data-1)) && (right == 0))
A[wh(i+1,j)] = 0.0;
else
A[wh(i+1,j)] =
A[wh(i,j)]+
delta*(rightside-2*A[wh(i,j)]+leftside);
}
}
/* передача результатов назад ведущей программе */
pvm_initsend(PvmDataDefault);
pvm_pkdouble(&A[0],num_data*timestep,1);
pvm_send(master,7);
}
/* только при удачном исходе */
pvm_exit();
}
int wh(x, y);
int x, y;
{
return(x*num_data+y);
}
GCC - это свободно доступный оптимизирующий компилятор для языков C, C++, Ada 95, а также Objective C. Его версии применяются для различных реализаций Unix (а также VMS, OS/2 и других систем PC), и позволяют генерировать код для множества процессоров.
Вы можете использовать gcc для компиляции программ в объектные модули и для компоновки полученных модулей в единую исполняемую программу. Компилятор способен анализировать имена файлов, передаваемые ему в качестве аргументов, и определять, какие действия необходимо выполнить. Файлы с именами типа name.cc (или name.C) рассматриваются, как файлы на языке C++, а файлы вида name.o считаются объектными (т.е. внутримашинным представлением).
Чтобы откомпилировать исходный код C++, находящийся в файле F.cc, и создать объектный файл F.o, выполните команду:
gcc -c <compile-options> F.cc
Здесь строка compile-options указывает возможные дополнительные опции компиляции.
Чтобы скомпоновать один или несколько объектных файлов, полученных из исходного кода C++ - F1.o, F2.o, ... - в единый исполняемый файл F, используйте команду:
gcc -o F <link-options> F1.o F2.o ... -lg++ \
<other-libraries>
Здесь строка link-options означает возможные дополнительные опции компоновки, а строка other-libraries - подключение при компоновке дополнительных разделяемых библиотек.
Вы можете совместить два этапа обработки - компиляцию и компоновку - в один общий этап с помощью команды:
gcc -o F <compile-and-link-options> F1.cc ... -lg++\
<other-libraries>
После компоновки будет создан исполняемый файл F, который можно запустить с помощью команды:
./F <arguments>,
где строка arguments определяет аргументы командной строки вашей программы.
В процессе компоновки очень часто приходится использовать библиотеки. Библиотекой называют набор объектных файлов, сгруппированных в единый файл и проиндексированных. Когда команда компоновки обнаруживает некоторую библиотеку в списке объектных файлов для компоновки, она проверяет, содержат ли уже скомпонованные объектные файлы вызовы для функций, определенных в одном из файлов библиотек. Если такие функции найдены, соответствующие вызовы связываются с кодом объектного файла из библиотеки.
Библиотеки обычно определяются через аргументы вида
-llibrary-name. В
частности, -lg++ означает библиотеку стандартных функций C++, а -lm
определяет библиотеку различных математических функций (sin, cos, arctan, sqrt,
и т.д.). Библиотеки должны быть перечислены после исходных или объектных
файлов, содержащих вызовы к соответствующим функциям.
Среди множества опций компиляции и компоновки наиболее часто употребляются следующие:
-c
Только компиляция. Из исходных файлов программы создаются объектные файлы в виде name.o. Компоновка не производится.
-Dname=value
Определить имя name в компилируемой программе как значение value. Эффект такой же, как наличие строки
#define name value
в начале программы. Часть
`=value' может быть опущена, в этом случае значение по умолчанию равно 1.
-o file-name
Использовать file-name в качестве имени для создаваемого gcc файла (обычно это исполняемый файл).
-llibrary-name
Использовать при компоновке указанную библиотеку.
-g
Поместить в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки.
-MM
Вывести заголовочные файлы (но не стандартные заголовочные), используемые в каждом исходном файле, в формате, подходящем для утилиты make. Не создавать объектные или исполняемые файлы.
-pg
Поместить в объектный или исполняемый файл инструкции профилирования для
генерации информации, используемой
утилитой gprof. Опция должна быть указана и
для компиляции, и для компоновки. Профилирование - это процесс
измерения продолжительности выполнения отдельных участков вашей
программы. Когда вы указываете -pg, полученная исполняемая программа
при запуске генерирует файл статистики. Программа gprof на основе этого
файла создает расшифровку, указывающую время, затраченное на выполнение
каждой функции.
-Wall
Вывод сообщений о всех предупреждениях или ошибках, возникающих во время трансляции программы.
-O1
Устанавливает оптимизацию уровня 1. Оптимизированная трансляции требует несколько больше времени и несколько больше памяти для больших функций. Без указания опций `-O' цель компилятора состoит в том, чтобы уменьшить стоимость трансляции и выдать ожидаемые результаты при отладке. Операторы независимы: если вы останавливаете программу на контрольной точке между операторами, то можете назначить новое значение любой переменной или поставить счетчик команд на любой другой оператор в функции и получить точно такие результаты, которые вы ожидали от исходного текста. С указанием `-O' компилятор пробует уменьшить размер кода и время исполнения.
-O2
Устанавливает оптимизацию уровня 2. GNU CC выполняет почти все поддерживаемые оптимизации, которые не включают уменьшение времени исполнения за счет увеличения длины кода. Компилятор не выполняет раскрутку циклов или подстановку функций, когда вы указываете `-O2'. По сравнения с `-O' эта опция увеличивает как время компиляции, так и эффективность сгенерированного кода.
-O3
Устанавливает оптимизацию уровня 3. `-O3' включает все оптимизации, определяемые `-O2', а также включает опцию `inline-functions'.
-O0
Без оптимизации. Если вы используете многочисленные `-O' опции с номерами или без номеров уровня, действительной является последняя такая опция.
Библиотека GNU C определяет все библиотечные функции, определенные стандартом ISO C и дополнительные возможности, указанные в стандарте POSIX и иных предписаниях для операционных систем Unix, а также расширения, специфичные для систем GNU. Она является наиболее фундаментальной системной библиотекой и обязательно присутствует в любой системе Linux.
В составе библиотеки можно выделить следующие основные группы функций:
Перед тем как посылать или принимать сообщения, должны быть созданы
очередь сообщений с уникальным идентификатором и ассоциированная с
ней структура данных. Порожденный уникальный идентификатор называется
идентификатором очереди сообщений
(msqid); он используется
для обращений к очереди сообщений и ассоциированной структуре данных.
Говоря об очереди сообщений, следует иметь в виду, что реально в ней хранятся не сами сообщения, а их дескрипторы, имеющие следующую структуру:
/* Указатель на следующее сообщение */
struct msg *msg_next;
long msg_type; /* Тип сообщения */
short msg_ts; /* Размер текста сообщения */
short msg_spot; /* Адрес текста сообщения */
};
С каждым уникальным идентификатором очереди сообщений ассоциирована структура данных, которая содержит следующую информацию:
/*Структура прав на выполнение операций*/
struct ipc_perm msg_perm;
/*Указатель на первое сообщение в очереди*/
struct msg *msg_first;
/*Указатель на последнее сообщение в очереди*/
struct msg *msg_last;
/* Текущее число байт в очереди */
ushort msg_cbytes;
/* Число сообщений в очереди */
ushort msg_qnum;
/* Макс. допустимое число байт в очереди */
ushort msg_qbytes;
/* Ид-р последнего отправителя */
ushort msg_lspid;
/* Ид-р последнего получателя */
ushort msg_lrpid;
/* Время последнего отправления */
time_t msg_stime;
/* Время последнего получения */
time_t msg_rtime;
/* Время последнего изменения */
time_t msg_ctime;
};
ushort uid; /* Идентификатор пользователя */
ushort gid; /* Идентификатор группы */
ushort cuid; /* Идентификатор создателя очереди */
ushort cgid; /* Ид-р группы создателя очереди */
ushort mode; /* Права на чтение/запись */
/* Последовательность номеров используемых слотов */
ushort seq;
key_t key; /* Ключ */
};
Если в аргументе msgflg системного вызова msgget установлен только флаг IPC_CREAT, выполняется одно из двух действий:
Кроме того, можно специфицировать ключ key со значением
IPC_PRIVATE.
Если указан такой ``личный'' ключ, для него обязательно выделяется
новый уникальный идентификатор и создаются ассоциированные с ним очередь
сообщений и структура данных (при условии, что это не приведет к превышению
системного лимита). При выполнении утилиты ipcs поле KEY
для подобного идентификатора msqid из соображений секретности
содержит нули.
Если идентификатор msqid со специфицированным значением ключа
key уже существует, выполняется второе действие, т. е.
возвращается ассоциированный идентификатор. Если необходимо
считать
возвращение существующего идентификатора ошибкой, в передаваемом системному
вызову аргументе msgflg нужно установить флаг IPC_EXCL.
При выполнении первого действия процесс, вызвавший msgget, становится владельцем или создателем очереди сообщений; соответственно этому инициализируется ассоциированная структура данных. Впоследствии владелец очереди может быть изменен, однако процесс-создатель всегда остается создателем. При создании очереди сообщений определяются также начальные права на выполнение операций над ней.
После того как созданы очередь сообщений с уникальным идентификатором и ассоциированная с ней структура данных, можно использовать системные вызовы семейства msgop (операции над очередями сообщений) и msgctl (управление очередями сообщений).
Операции, как упоминалось выше, заключаются в посылке и приеме сообщений. Для каждой из этих операций предусмотрен системный вызов, msgsnd() и msgrcv() соответственно.
Для управления очередями сообщений используется системный вызов msgctl. Он позволяет выполнять следующие управляющие действия:
Основная причина, по которой используется ассемблер в Linux - это написание очень небольших по размеру программ, которые не зависят от системных библиотек. Такие программы особенно нужны для встраиваемых систем, где объемы запоминающих устройств обычно невелики.
GAS - это сокращение от GNU Assembler. Поскольку GAS был разработан для поддержки 32-битных компиляторов Unix, он использует стандартный синтаксис ATT, который несколько отличается от обычного ассемблера DOS. Основные отличия синтаксиса GAS от синтаксиса Intel:
mov eax,edx
(передать содержимое регистра edx в регистр eax) будет выглядеть в GAS как
mov %edx,%eax.
movl %edx,%eax. Однако gas не требует соблюдения строгого синтаксиса
ATT, так что суффикс необязателен, если размер может быть определен для
регистрового операнда, либо по умолчанию принимается 32-bit.
addl $5,%eax\end{verbatim}
(добавить константу 5 к регистру eax).
\item Отсутствие префикса операнда указывает на адрес в памяти; поэтому
\begin{verbatim} movl $foo,%eax\end{verbatim} помещает адрес переменной \verb|foo| в регистр \verb|eax|, а
команда \begin{verbatim} movl foo,%eax\end{verbatim} помещает в \verb|eax| содержимое переменной \verb|foo|.
\end{itemize}
Индексация выполняется с помощью заключения индексного регистра в скобки,
например, \verb|in testb \$0x80,17(%ebp)| (проверить установку старшего бита
в байте по смещению 17 от ячейки, указанной \verb|ebp|).
Замечание: известно несколько программ, которые могут помочь вам преобразовать
исходный код для ассемблеров AT\&T и Intel; некоторые из них способны на
преобразование в двух направлениях.
Ассемблер NASM разрабатывается в рамках проекта The Netwide Assembler, и
представляет собой мощный ассемблер на базе i386, написанный на C, который
построен по модульному принципу и обеспечивает поддержку практически вссех
известных синтаксисов и форматов объектных файлов.
Используется синтаксис Intel. Поддерживается обработка
макроопределений.
Среди поддерживаемых форматов объектных файлов есть bin, aout, coff, elf, as86,
obj (DOS), win32, rdf (собственный формат). Кроме того, NASM поставляется
с дизассемблером NDISASM.
Как и для GAS, для NASM применяется несколько программ преобразования
синтаксиса.
В качестве примера здесь приводятся две программы на ассемблере. Программы
написаны с учетом того, что Linux является 32-битной системой, работает в
защищенном режиме, имеет плоскую модель памяти и использует для исполняемых
файлов формат ELF.
Программа обычно делится на разделы: .text -- для программного кода (только
для чтения), .data -- для записи данных (чтение-запись), .bss --
для неинициализируемых данных (чтение-запись); могут также присутствовать и
другие стандартные разделы, а также разделы, определенные пользователем. В
программе должен быть как минимум раздел .text.
Пример для NASM (\texttt{hello.asm}):
\begin{verbatim}
section .data ; описание раздела
msg db "Hello, world!",0xa ; выводимая строка
len equ $ - msg ; длина строки
section .text ; описание раздела
; нам нужно передать точку входа
; компоновщику или
global _start ; загрузчику ELF. Обычно они
; распознают _start по умолчанию
; Используйте ld -e foo,
; чтобы переопределить ее.
_start:
; записываем строку в стандартный вывод
mov edx,len ; третий аргумент:
; длина строки
mov ecx,msg ; второй аргумент:
; указатель на строку
mov ebx,1 ; первый аргумент:
; дескриптор файла (stdout)
mov eax,4 ; номер системного вызова
; (sys_write)
int 0x80 ; обращение к ядру
; и выходим
mov ebx,0 ; первый аргумент: код возврата
mov eax,1 ; номер системного вызова
; (sys_exit)
int 0x80 ; обращение к ядру
Пример для GAS (hello.S):
.data # описание раздела
msg:
.string "Hello, world!\n" # выводимая строка
len = . - msg # длина строки
.text # описание раздела
# нам нужно передать точку входа
# компоновщику или
global _start # загрузчику ELF. Обычно они распознают
# _start по умолчанию.
# Используйте ld -e foo,
# чтобы переопределить ее.
_start:
# записываем строку в стандартный вывод
movl $len,%edx # третий аргумент:
# длина строки
movl $msg,%ecx # второй аргумент:
# указатель на строку
movl $1,%ebx # первый аргумент:
# дескриптор файла (stdout)
movl $4,%eax # номер системного вызова
# (sys_write)
int $0x80 # обращение к ядру
# и выходим
movl $0,%ebx # первый аргумент:
# код возврата
movl $1,%eax # номер системного вызова
# (sys_exit)
int $0x80 # обращение к ядру
Основные опции ассемблера GAS:
--defsym sym=value
определить символом sym величину value перед разбором входного файла; value должно быть целой константой. Как и в C, префикс 0x определяет шестнадцатеричное число, а префикс 0 - восьмеричное;
--help
вывести список опций командной строки;
-I dir
добавить каталог dir в список поиска для директив `.include';
-o objfile
имя объектного файла для вывода из `as';
-R
распознавать вложенные в код разделы данных;
--no-warn
опускать сообщения о предупреждениях;
--fatal-warnings
рассматривать предупреждения как ошибки.
-h
вывести информацию об опциях и поддерживаемых форматах выходных файлов nasm;
-a
ассемблировать файл без предварительного препроцессинга;
-e
выполнить препроцессинг входного файла и вывести результат в stdout (или указанный файл-приемник), но без ассемблирования;
-M
вывести в stdout зависимости в стиле make-файла;
-E filename
перенаправлять сообщения об ошибках в файл filename. Опция предназначена для операционных систем, в которых stderr нельзя перенаправить;
-f format
определить формат выходного файла. Форматы включают в себя bin - для плоских двоичных файлов, и aout или elf - для создания объектных файлов типа Linux a.out и ELF соответственно;
-o outfile
определить точное имя выходного файла, переопределив имя по умолчанию;
-l listfile
перенаправить листинг ассемблера в указанный файл, в котором с правой стороны будет выведен исходный текст (а также текст включаемых файлов и расширенные макросы), а с левой стороны - сгенерированный код в шестнадцатеричном формате;
-s
выводить сообщения об ошибках в файл стандартного вывода;
-w[+-]foo
подключить (или отключить) некоторые классы предупреждающих сообщений,
например, -w+orphan-labels или
-w-macro-params, чтобы соответственно разрешить
сообщения о метках в пустой строке или отключить сообщения о неверном
количестве параметров в вызовах макросов;
-I directory
добавить каталог в путь поиска включаемых файлов.
Отладчиком называется программа, которая выполняет внутри себя другую программу. Основное назначение отладчика - дать возможность пользователю в определенной степени осуществлять контроль за выполняемой программой, т.е. определять, что происходит в процессе ее выполнения. Наиболее известным отладчиком для Linux является программа GNU GDB, которая содержит множество полезных возможностей, но для простой отладки достаточно использовать лишь некоторые из них.
Когда вы запускаете программу, содержащую ошибки, обнаруживаемые лишь на стадии выполнения, возникают несколько вопросов, на которые вам нужно найти ответ:
Эти действия требуют, чтобы пользователь отладчика был в состоянии:
Программа GDB предоставляет все перечисленные возможности. Она называется отладчиком на уровне исходного текста, создавая иллюзию, что вы выполняете операторы C++ из вашей программы, а не машинный код, в который они действительно транслируются.
Для иллюстрации мы используем систему, которая компилирует программы на C++ в исполняемые файлы, содержащие машинный код. В результате этого процесса информация об оригинальном коде C++ теряется при трансляции. Отдельный оператор C++ обычно преобразуется в несколько машинных команд, а большинство имен локальных переменных просто теряется. Информация о именах переменных и операторах C++ в вашей исходной программе не является необходимой для ее выполнения. Поэтому, для правильной работы отладчика на уровне исходного текста, компилятор должен поместить в программу некоторую дополнительную информацию. Обычно ее добавляют к информации, используемой компоновщиком, в исполняемый файл.
Чтобы указать компилятору (gcc), что вы планируете отлаживать вашу программу, и поэтому нуждаетесь в дополнительной информации, добавьте ключ -g в опции компиляции и компоновки. Например, если ваша программа состоит из двух файлов main.C и utils.C, можете откомпилировать ее командами:
gcc -c -g -Wall main.C gcc -c -g -Wall utils.C gcc -g -o myprog main.ob utils.o
или одной командой:
gcc -g -Wall -o myprog main.o utils.o
Обе последовательности команд приводят к созданию исполняемого файла myprog.
Чтобы выполнить полученную программу под управлением gdb, введите
gdb myprog
вы увидите командное приглашение GDB:
(gdb)
Это очень простой, но эффективный тексовый интерфейс отладчика. Его вполне достаточно, чтобы ознакомиться с основными командами gdb.
Когда GDB запускается, ваша программа в нем еще не выполняется; вы должны сами сообщить GDB, когда ее запустить. Как только программа приостанавливается в процессе выполнения, GDB ищет определенную строку исходной программы с вызовом определенной функции - либо строку в программе, где произошел останов, либо строку, содержащую вызов функции, в которой произошел останов, либо строку с вызовом функции и т.д. Далее используется термин ``текущее окно'', чтобы сослаться на точку останова.
Как только возникает командное приглашение, вы можете использовать следующие команды:
help command
выводит краткое описание команды GDB. Просто help выдает список доступных
разделов справки;
run command-line-arguments
запускает Вашу программу с определенными аргументами командной строки. GDB
запоминает переданные аргументы, и простой перезапуск программы с помощью
run приводит к использованию этих аргументов;
where
создает трассу - цепочку вызовов функций, произошедших до попадания программы в текущее место. Синонимом является команда bt;
up
перемещает текущее окно так, чтобы GDB анализировал место, из которого
произошел вызов данного окна. Очень часто Ваша программа может войти в
библиотечную функцию - такую, для которой не доступен исходный код,
например, в процедуру ввода-вывода. вам может понадобиться несколько команд
up, чтобы перейти в точку программы, которая была выполнена последней;
down
производит эффект, обратный up;
print E
выводит значение E в текущем окне программы, где E является выражением C++ (обычно просто переменной). Каждый раз при использовании этой команды, GDB нумерует ее упоминание для будущих ссылок. Например:
(gdb) print A[i] $2 = -16
(gdb) print $2 + ML $3 = -9
сообщает нам, что величина A[i] в текущем окне равна -16, и что при добавлении этого значения к переменной ML получится -9;
quit
выход из GDB;
Ctrl-c
если программа запущена через оболочку shell, Ctrl-c немедленно прекращает ее выполнение. В GDB программа приостанавливается, пока ее выполнение не возобновится;
break place
установить точку останова; программа приостановится при ее достижении. Простейший способ - установить точку останова после входа в функцию, например:
(gdb) break MungeData Breakpoint 1 at 0x22a4:
file main.C, line 16.
Команда break main остановит выполнение в начале программы.
вы можете установить точки останова на определенную строку исходного кода:
(gdb) break 19 Breakpoint 2 at 0x2290:
file main.C, line 19.
(gdb) break utils.C:55 Breakpoint 3 at 0x3778:
file utils.C, line 55.
Когда вы запустите программу и она достигнет точки останова, то увидите сообщение об этом и приглашение, например:
Breakpoint 1, MungeData (A=0x6110, N=7) at main.c:16
(gdb);
delete N
удаляет точку останова с номером N. Если опустить N, будут удалены все точки останова;
cont или continue
продолжает обычное выполнение программы;
step
выполняет текущую строку программы и останавливается на следующем операторе для выполнения;
next
похожа на step, однако, если текущая строка программы содержит вызов функции (так что step должен будет остановиться в начале функции), не входит в эту функцию, а выполняет ее и переходит на следующий оператор;
finish
выполняет команды next без остановки, пока не достигнет конца текущей функции.
M-x gdb, вы получите новое окно с запущенным gdb, воспринимающее все
сокращенные команды. Emacs также интерпретирует вывод от gdb, чтобы вам было
удобнее. Когда достигается точка останова, Emacs получает от gdb имя файла и
номер строки, чтобы показать содержимое этого файла, с отмеченной точкой
останова или ошибкой. Когда вы отлаживаете программу по шагам, Emacs следует
за вами по файлам исходного кода.
KDbg является графическим интерфейсом к gdb в среде KDE. Это означает, что KDbg сам по себе не является отладчиком. Он общается с gdb, отладчиком, использующим командную строку, посылая ему команды и получая их результат, например, значения переменных. Пункты меню и указания "мышью" преобразуются в последовательность команд gdb, а результат преобразуется к более-менее визуальному представлению, такому как структурное содержимое переменных.
KDbg не может делать больше, чем делает gdb. Например, если имеющаяся у вас версия gdb не поддерживает отладку многопоточных программ, то и KDbg не поможет вам в этом (несмотря на то, что он выводит окно потоков).
Графическим интерфейсом для системы X Window является xxgdb. Интерфейсом для графического представления данных является ddd.
Кроме этого, следует упомянуть отладчик DBX, а среди коммерческих приложений - мощное средство TotalView.
Утилита UNIX make является простым и наиболее общим решением данной проблемы. В качестве ввода она принимает описание взаимных зависимостей над множеством исходных файлов, а также команды, необходимые для их компиляции. Это описание называется make-файлом. Утилита проверяет ``возраст'' соответствующих файлов, и выполняет все необходимые команды в соответствии с описанием. Для большего удобства она поддерживает несколько стандартных действий и зависимостей по умолчанию, чтобы не описывать их лишний раз.
Существует несколько диалектов make, как среди версий UNIX / Linux, так и в других операционных системх для ПК. Далее нами описана версия gmake (GNU make).
Makefile for simple editor
edit : edit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o
gcc -g -o edit edit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o -lg++edit.o : edit.cc defs.h
gcc -g -c -Wall edit.cc
kbd.o : kbd.cc defs.h command.h
gcc -g -c -Wall kbd.cc
commands.o : command.cc defs.h command.h
gcc -g -c -Wall commands.cc
display.o : display.cc defs.h buffer.h
gcc -g -c -Wall display.cc
insert.o : insert.cc defs.h buffer.h
gcc -g -c -Wall insert.cc
search.o : search.cc defs.h buffer.h
gcc -g -c -Wall search.cc
files.o : files.cc defs.h buffer.h command.h
gcc -g -c -Wall files.cc
utils.o : utils.cc defs.h
gcc -g -c -Wall utils.cc
Этот файл содержит последовательность девяти правил. В общем виде каждое правило выглядит так:
<цель_1> <цель_2> ... <цель_n>: <зависимость_1>
<зависимость_2> ... <зависимость_n>
<команда_1>
<команда_2>
...
<команда_n>
Правило состоит из строки, содержащей два списка имен, разделенных двоеточием, за которыми следуют одна или несколько строк, начинающихся с табуляции. Любая строка может быть продолжена, как показано выше, если закончить ее наклонной чертой, которая означает пробел, соединяя строку с последующей. Символ `#' отмечает начало комментария, который продолжается до конца данной строки.
Цель (target) - это некий желаемый результат, способ достижения которого описан в правиле. Цель может представлять собой имя файла. В этом случае правило описывает, каким образом можно получить новую версию этого файла.
Цель также может быть именем некоторого действия. В таком случае правило описывает, каким образом совершается указанное действие. Подобного рода цели называются псевдоцели (pseudo targets) или абстрактные цели (phony targets).
Зависимость (dependency)- это некие "исходные данные", необходимые для достижения указанной в правиле цели. Можно сказать что зависимость - это "предварительное условие" для достижения цели. Зависимость может представлять собой имя файла. Этот файл должен существовать, для того чтобы можно было достичь указанной цели. Зависимость также может быть именем некоторого действия. Это действие должно быть предварительно выполнено перед достижением указанной в правиле цели.
Команды - это действия, которые необходимо выполнить для обновления либо достижения цели. Утилита make отличает строки, содержащие команды, от прочих строк make-файла по наличию символа табуляции (символа с кодом 9) в начале строки. Это команды shell (присутствуют в оболочке Linux), которые выполняются в определенном порядке, чтобы создать или обновить цель правила (обычно говорят обновить - update).
Главная цель может быть прямо указана в командной строке при запуске make. В следующем примере make будет стремиться достичь цели edit (получить новую версию файла edit):
make edit
Если не указывать какой-либо цели в командной строке, то make выбирает в качестве главной первую, встреченную в make-файле цель. Схематично ``верхний уровень'' алгоритма работы make можно представить так:
make()
{
главная_цель = Выбрать_Главную_Цель()
Достичь_Цели( главная_цель )
}
После того как главная цель выбрана, make запускает ``стандартную'' процедуру достижения цели. Сначала в make-файле ищется правило, которое описывает способ достижения этой цели (функция НайтиПравило). Затем, к найденному правилу применяется обычный алгоритм обработки правил (функция ОбработатьПравило):
Достичь_Цели( Цель )
{
правило = Найти_Правило( Цель )
Обработать_Правило( правило )
}
Обработка правила разделяется на два основных этапа. На первом этапе обрабатываются все зависимости, перечисленные в правиле (функция ОбработатьЗависимости). На втором этапе принимается решение - нужно ли выполнять указанные в правиле команды (функция НужноВыполнятьКоманды). При необходимости, перечисленные в правиле команды выполняются (функция ВыполнитьКоманды):
Обработать_Правило( Правило )
{
Обработать_Зависимости( Правило )
если Нужно_Выполнять_Команды( Правило )
{
Выполнить_Команды( Правило )
}
}
Функция ОбработатьЗависимости поочередно проверяет все перечисленные в теле правила зависимости. Некоторые из них могут оказаться целями каких-нибудь правил. Для этих зависимостей выполняется обычная процедура достижения цели (функция ДостичьЦели). Те зависимости, которые не являются целями, считаются именами файлов. Для таких файлов проверяется факт их наличия. При их отсутствии make аварийно завершает работу с сообщением об ошибке:
Обработать_Зависимости( Правило )
{
цикл от i=1 до Правило.число_зависимостей
{
если Есть_Такая_Цель( Правило.зависимость[i])
{
Достичь_Цели( Правило.зависимость[i])
}
иначе
{
Проверить_Наличие_Файла(Правило.зависимость[i])
}
}
}
На стадии обработки команд решается вопрос, нужно ли выполнять описанные в правиле команды или нет. Считается, что нужно выполнять команды если:
Нужно_Выполнять_Команды( Правило )
{
если Правило.Цель.Является_Абстрактной()
return true
// цель является именем файла
если Файл_Не_Существует( Правило.Цель )
return true
цикл от i=1 до Правило.Число_зависимостей
{
если Правило.Зависимость[i].Является_Абстрактной()
return true
иначе
// зависимость является именем файла
{
если Время_Модификации(Правило.Зависимость[i])
> Время_Модификации( Правило.Цель )
return true
}
}
return false
}
В указанном примере целью по умолчанию является edit. Первым шагом по его
обновлению будет обновление всех файлов объектов (.o), перечисленных как
зависимости. Обновление edit.o в свою очередь требует обновления edit.cc и
defs.h. Предполагается, что edit.cc является исходным файлом, из которого
создается edit.o, а defs.h является заголовочным файлом, который включается в
edit.cc. Правил, указывающих на эти файлы, нет; поэтому такие файлы, как минимум
должны просто существовать. Теперь edit.o считается готовым, если он изменен
позже, чем edit.cc или defs.h (если он старше их, это значит, что один из этих
файлов изменился со времени последней компиляции edit.o). Если edit.o старше
своих зависимостей, gmake выполняет действие OP ``gcc -g -c -Wall
edit.cc'',
создавая новый edit.o. Когда edit.o и все другие файлы .o будут обновлены,
они будут собраны вместе действием
``gcc -g -o edit ...'', чтобы создать
программу edit, если либо edit еще не существует, либо любой из файлов .o
новее, чем существующий файл edit.
Чтобы вызвать gmake для этого примера, используйте команду:
gmake -f <makefile-name> <target-names>,
где <target-names> - это имена целей, которые вы хотите обновить, а
<makefile-name>, заданное после ключа -f, является именем make-файла.
По умолчанию целью является первое правило в файле. Вы можете (обычно так и
делают) опустить -f makefile-name, и в этом случае по умолчанию будет выбрано
имя makefile или Makefile, если любой из этих файлов существует.
Обычно каждый каталог содержит исходный код для простой части программы.
Принимая правило, что имя программы соответствует первой цели, и что make-файл
для каталога называется
makefile, вы добьетесь того, что вызов команды gmake
без аргументов в любом каталоге приведет к обновлению части программы в этом
каталоге.
Для одной и той же цели может применяться несколько правил, но не более чем одно правило для цели должно иметь действия. Поэтому, мы может переписать последнюю часть примера следующим образом:
edit.o : edit.cc
gcc -g -c -Wall edit.cc
kbd.o : kbd.cc
gcc -g -c -Wall kbd.cc
commands.o : command.cc
gcc -g -c -Wall commands.cc
display.o : display.cc
gcc -g -c -Wall display.cc
insert.o : insert.cc
gcc -g -c -Wall insert.cc
search.o : search.cc
gcc -g -c -Wall search.cc
files.o : files.cc
gcc -g -c -Wall files.cc
utils.o : utils.cc
gcc -g -c -Wall utils.ccedit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o: defs.h
kbd.o commands.o files.o : command.h
display.o insert.o search.o files.o : buffer.h
Порядок, в котором записаны эти правила, не имеет значения. Скорее, он зависит от вашего вкуса и выбора порядка группировки файлов.
compile_flags = -O3 -funroll-loops
-fomit-frame-pointer|
Такой способ поддерживают все варианты утилиты make. Его можно сравнить, например, с заданием макроса в языке Си:
#define compile_flags "-O3 -funroll-loops
-fomit-frame-pointer"
Значение переменной, заданной с помощью оператора '=', будет вычислено в момент ее использования. Например, при обработке make-файла
var1 = one
var2 = $(var1) two
var1 = three
all:
@echo $(var2)
на экран будет выдана строка ``three two''. Значение переменной var2 будет
вычислено непосредственно в момент выполнения команды echo, и будет представлять
собой текущее значение переменной var1, к которому добавлена строка ``two''. Как
следствие - одна и та же переменная не может одновременно фигурировать в левой и
правой части выражения, так как это может привести к бесконечной рекурсии. GNU
Make распознает подобные ситуации и прерывает обработку make-файла. Следующий
пример вызовет ошибку:
compile_flags = -pipe $(compile_flags)
GNU Make поддерживает также и второй, новый способ задания переменной с помощью оператора ':=':
compile_flags := -O3 -funroll-loops
-fomit-frame-pointer
В этом случае переменная работает подобно ``обычным'' текстовым переменным в каком-либо языке программирования. Вот приблизительный аналог этого выражения на языке C++:
string compile_flags = "-O3 -funroll-loops
-fomit-frame-pointer";
Значение переменной вычисляется в момент обработки оператора присваивания. Если, например, записать
var1 := one
var2 := $(var1) two
var1 := three
all:
@echo $(var2),
то при обработке такого make-файла на экран будет выдана строка ``one two''.
Переменная может ``менять'' свое поведение в зависимости от того, какой из операторов присваивания был применен к ней последним. Одна и та же переменная на протяжении ее жизни может вести себя и как ``макрос'', и как ``текстовая переменная''.
Зависимости цели edit в приведенных выше примерах являлись аргументами для команд
компоновки. Можно избежать их повторения, определив переменную, которая будет
содержать имена всех объектных файлов:
Makefile for simple editorСтрока, начинающаяся сOBJS = edit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o
edit : $(OBJS)
gcc -g -o edit $(OBJS)
``OBJS ='' определяет переменную OBJS, на которую
можно в дальнейшем сослаться через ``$(OBJS)'' или ``OBJS''.
Эти более поздние ссылки приводят к тому, что обозначение OBJ будет дословно
заменяться, прежде чем правило будет обработано. Иногда неудобно, что и gmake
и shell используют `$' как префикс для ссылок на переменные; gmake
определяет `$$', такое же, как `$', позволяя вам передавать `$' в shell,
если это необходимо.
Иногда вам может понадобиться величина в виде обычной переменной,
но с некоторыми уточнениями. Например, задавая переменную со списком имен
всех исходных файлов, вы можете попытаться задать имена всем получающимся
объектным файлам. Можно переопределить OBJS следующим образом:
SRCS = edit.cc kbd.cc commands.cc display.ccСуффикс
insert.cc search.cc files.cc utils.cc
OBJS = $(SRCS:.cc=.o)
`:.cc=.o' определяет необходимые уточнения. Теперь у нас
есть переменные для имен всех исходных и объектных файлов, при этом не пришлось
повторять в определениях множество имен.
Переменные могут упоминаться и в командной строке при вызове gmake. Например, если make-файл содержит
edit.o: edit.ccто команда типа
gcc $(DEBUG) -c -Wall edit.cc ,
gmake DEBUG=-g ... приведет к использованию ключа -g
(добавить символическую информацию отладчика) при компиляции, а отсутствие
DEBUG=-g исключит использование этого ключа. Определения
переменных в командной строке имеют преимущество перед определениями
внутри make-файла, что позволяет задать в make-файле значения по умолчанию.
Переменные, не установленные любым из перечисленных методов, могут быть установлены как переменные среды. Поэтому, последовательность команд
setenv DEBUG -g gmake ...
для последнего примера также приведет к использованию ключа -g во время компиляции.
Традиционные реализации make поддерживают так называемую ``суффиксную'' форму записи шаблонных правил:
.<расширение_файлов_зависимостей>.<расширение_файлов_целей>:
<команда_1>
<команда_2>
...
<команда_n>
Например, следующее правило гласит, что все файлы с расширением "o" зависят от соответствующих файлов с расширением "cpp":
.cpp.o:
gcc -c $^
Обратите внимание на использование автоматической переменной $^ для
передачи компилятору имени файла-зависимости. Поскольку шаблонное правило может
применяться к разным файлам, использование автоматических переменных -
единственный способ узнать, для каких файлов сейчас задействуется правило.
Шаблонные правила позволяют упростить make-файл и сделать его более универсальным.
В самом первом примере все правила компиляции для получения файлов типа .o
имеют одинаковую форму. Очень неудобно повторять их снова и снова; это может
привести к ошибке при написании make-файла. Поэтому gmake можно указать -
для известных стандартных случаев - действия и имена файлов по умолчанию для
создания различных типов файлов. Для наших целей наиболее важным является то,
что gmake известно, как создать файл F.o из исходного файла F.cc.
В данном случае gmake автоматически
использует правило
F.o : F.ccкоторое вызывается, чтобы создать
$(CXX) -c -Wall $(CXXFLAGS) F.cc,
F.o, если существует файл C++ с именем
F.cc, но не определяет точные действия для создания F.o. Использование
префикса ``CXX'' является следствием соглашения об именах для переменных,
связанных с C++. Также создается командаF : F.oчтобы сообщить, как создать исполняемый файл
$(CC) $(LDFLAGS) F.o $(LOADLIBES) -o F,
F из F.o.
В результате предыдущий пример можно переписать следующим образом:
Makefile for simple editorSRCS = edit.cc kbd.cc commands.cc display.cc
insert.cc search.cc files.cc utils.ccOBJS = $(SRCS:.cc=.o)
CC = gcc
CXX = gcc
CXXFLAGS = -g
LOADLIBES = -lg++edit : $(OBJS)
edit.o : defs.h
kbd.o : defs.h command.h
commands.o : defs.h command.h
display.o : defs.h buffer.h
insert.o : defs.h buffer.h
search.o : defs.h buffer.h
files.o : defs.h buffer.h command.h
utils.o : defs.h
gmake действия для цели будут выполняться всякий
раз, когда gmake обратится к ней. Обычно это используют для помещения в
make-файл стандартной операции ``очистки'', определяющей способ
удаления неиспользуемых файлов. Например, вы часто можете встретить в
make-файле такое правило:
clean:
rm -f *.o
Каждый раз, при выполнении команды gmake clean, это действие будет
удалять все файлы .o.
Программа gmake обычно выводит информацию о выполнении каждого действия, но
иногда это не желательно. Поэтому символ `@' в начале действия может запретить
вывод по умолчанию. Вот пример его обычного использования:
edit : $(OBJS)|Результатом этих действий будет то, что в начале компиляции вы увидите строку
@echo Linking edit ...
@gcc -g -o edit $(OBJS)
@echo Done
``Linking edit...'', а в конце компиляции - строку ``Done''.
Когда gmake встречает действие, возвращающее ненулевой код выхода, т.е.,
сообщение об ошибке по соглашениям UNIX, его стандартной реакцией является
прекращение обработки. Коды ошибок от строк действий, начинающихся с символа
`--' (возможно с предшествующим `@') игнорируются. Ключ -k для gmake
приводит в случае ошибки к прекращению обработки только текущего правила (и
всех, зависящих от него целей), позволяя продолжить обработку всех
последующих.
Cинтаксис системного вызова msgget выглядит так:
#include <sys/ipc.h>
#include <sys/msg.h>
int msgget ( key_t key,int msgflg);
Целочисленное значение, возвращаемое в случае успешного завершения системного вызова, есть идентификатор очереди сообщений (msqid). В случае неудачи результат равен -1.
Новый идентификатор msqid, очередь сообщений и ассоциированная с ней структура данных выделяются в каждом из двух случаев:
| Права на операции | Восьмеричное значение |
| Чтение для владельца | 0400 |
| Запись для владельца | 0200 |
| Чтение для группы | 0040 |
| Запись для группы | 0020 |
| Чтение для остальных | 0004 |
| Запись для остальных | 0002 |
В каждом конкретном случае нужная комбинация прав задается как результат операции побитного ИЛИ для значений, соответствующих элементарным правам. Так, например, правам на чтение и запись для владельца и на чтение для членов группы и прочих пользователей соответствует восьмеричное число 0644. Следует отметить полную аналогию с правами доступа к файлам.
Флаги определены во включаемом файле <sys/ipc.h>. В табл. 3 сведены мнемонические имена флагов и соответствующие им восьмеричные значения:
Значение аргумента msgflg в целом является, следовательно, результатом операции побитного ИЛИ (операция | в языке C) для прав на выполнение операций и флагов, например:
msqid = msgget (key, (IPC_CREAT | IPC_EXCL | 0400));
msqid = msgget (IPC_PRIVATE, msgflg);
приведет к попытке выделения нового идентификатора очереди сообщений
и ассоциированной информации, независимо от значения аргумента msgflg.
Попытка может быть неудачной только из-за превышения системного лимита
на общее число очередей сообщений, задаваемого настраиваемым параметром
MSGMNI.
При использовании флага IPC_EXCL в сочетании с IPC_CREAT системный вызов msgget завершается неудачей в том и только в том случае, когда с указанным ключом key уже ассоциирован идентификатор. Флаг IPC_EXCL необходим, чтобы предотвратить ситуацию процесса, когда надежда получить новый (уникальный) идентификатор очереди сообщений не сбывается. Иными словами, когда используются и IPC_CREAT и IPC_EXCL, при успешном завершении системного вызова обязательно возвращается новый идентификатор msqid.
В файле справки по msgget описывается начальное значение ассоциированной структуры данных, формируемое после успешного завершения системного вызова. Там же содержится перечень условий, приводящих к ошибкам, и соответствующих им мнемонических имен для значений переменной errno.
Программа-пример для msgget, приведенная ниже, управляется посредством меню. Она позволяет поупражняться со всевозможными комбинациями системного вызова msgget, проследить, как передаются аргументы и получаются результаты. Имена переменных выбраны максимально близкими к именам, используемым в спецификации синтаксиса системного вызова, что облегчает чтение программы.
Выполнение программы начинается с приглашения ввести шестнадцатеричный ключ key, восьмеричный код прав на операции и, наконец, выбираемую при помощи меню комбинацию флагов. В меню предлагаются все возможные комбинации, даже бессмысленные, что позволяет при желании проследить за реакцией на ошибку. Затем выбранные флаги комбинируются с правами на операции, после чего выполняется системный вызов, результат которого заносится в переменную msqid. Если значение msqid равно -1, выдается сообщение об ошибке и выводится значение внешней переменной errno. Если ошибки не произошло, выводится значение полученного идентификатора очереди сообщений:
возможности системного вызова msgget()
(получение идентификатора очереди сообщений) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <errno.h>
main ()
{
key_t key; /* Тип описан как целое */
int opperm, flags; /* Права на операции и флаги */
int msgflg, msqid;
/* Ввести требуемый ключ */
printf ("\nВведите шестнадцатеричный ключ: ");
scanf ("%x", &key);
/* Ввести права на операции */
printf ("\nВведите права на операции ");
printf ("в восьмеричной записи: ");
scanf ("%o", &opperm);
/* Установить требуемые флаги */
printf ("\nВведите код, соответствущий ");
printf ("нужной комбинации флагов:\n");
printf (" Нет флагов = 0\n");
printf (" IPC_CREAT = 1\n");
printf (" IPC_EXCL = 2\n");
printf (" IPC_CREAT и IPC_EXCL = 3\n");
printf (" Выбор = ");
/* Получить флаги, которые нужно установить */
scanf ("%d", &flags);
/* Проверить значения */
printf ("\nключ = 0x%x, права = 0%o, флаги = %d\n",
key, opperm, flags);
/* Объединить флаги с правами на операции */
switch (flags) {
case 0: /* Флаги не устанавливать */
msgflg = (opperm | 0);
break;
case 1: /* Установить флаг IPC_CREAT */
msgflg = (opperm | IPC_CREAT);
break;
case 2: /* Установить флаг IPC_EXCL */
msgflg = (opperm | IPC_EXCL);
break;
case 3: /* Установить оба флага */
msgflg = (opperm | IPC_CREAT | IPC_EXCL);
}
/* Выполнить системный вызов msgget */
msqid = msgget (key, msgflg);
if (msqid == -1) {
/* Сообщить о неудачном завершении */
printf ("\nmsgget завершился неудачей!\n"
printf ("Код ошибки = %d\n", errno);
}
else
/* При успешном завершении сообщить msqid */
printf ("\nИдентификатор msqid = %d\n", msqid);
exit (0);
}
PROGRAM = <REPLACE WITH PROGRAM NAME>
LOADLIBES = <EXTRA LOAD LIBRARIES> -lg++
CXX.SRCS = <C++ SOURCE FILE NAMES>
CC = gcc
LDFLAGS = -g
CXX = gcc
CXXFLAGS = -g -Wall -fno-builtins
OBJS = $(CXX.SRCS:.cc=.o)
$(PROGRAM) : $(OBJS)
$(CC) $(LDFLAGS) $(OBJS) $(LOADLIBES) -o $(PROGRAM)
clean:
/bin/rm -f *.o $(PROGRAM)*
depend:
$(CXX) -MM $(CXX.SRCS)
<DEPENDENCIES ON .h FILES GO HERE>
Скопировав подобную заготовку и заменив разделы, ограниченные символами <> нужным текстом, Вы получите работающий make-файл:
PROGRAM = edit
LOADLIBES = -lg++
CXX.SRCS = edit.cc kbd.cc commands.cc display.cc
insert.cc search.cc files.cc utils.cc
CC = gcc
LDFLAGS = -g
CXX = gcc
CXXFLAGS = -g -Wall -fno-builtins
OBJS = $(CXX.SRCS:.cc=.o)
$(PROGRAM) : $(OBJS)
$(CC) $(LDFLAGS) $(OBJS) $(LOADLIBES) -o $(PROGRAM)
clean:
/bin/rm -f *.o $(PROGRAM)*
depend:
$(CXX) -MM $(CXX.SRCS)edit.o : defs.h
kbd.o : defs.h command.h
commands.o : defs.h command.h
display.o : defs.h buffer.h
insert.o : defs.h buffer.h
search.o : defs.h buffer.h
files.o : defs.h buffer.h command.h
utils.o : defs.h
Пусть заданы некоторое конечное множество слов (лексем) в некотором
языке и некоторое входное слово. Лексический анализ - это распознавание
лексем в определенном входном потоке. Необходимо установить, какой
элемент множества (если он существует) совпадает с данным входным
словом. Обычно лексический анализ выполняется так называемым лексическим
анализатором (ЛА). ЛА - это программа, LEX - генератор программ лексического
анализа. Лексический анализ применяется во многих случаях, например,
для построения редакторов или в качестве распознавателя директив в
диалоговой программе и т.д. Однако наиболее важное применение ЛА -
использование его в различного рода компиляторах, где он выполняет
функцию программы ввода данных. ЛА выполняет первую стадию компиляции:
читает строки компилируемой программы, выделяет лексемы и передает
их на дальнейшие стадии компиляции (синтаксический анализ и генерацию
кода). ЛА распознает тип каждой лексемы и соответствующим образом
помечает ее. Например, при компиляции программы на языке Си могут
быть выделены следующие типы лексем: число, идентификатор, оператор
и др. Необходимо не только выделить лексему, но и выполнить некоторые
преобразования. Например, если лексема - число, то его необходимо
перевести во внутреннюю (двоичную) форму записи как число с плавающей
или фиксированной точкой. Если лексема - идентификатор, то его необходимо
разместить в таблице для того, чтобы в дальнейшем обращаться к нему
не по имени, а по адресу в таблице. Хотя лексический анализ по
идее достаточно прост, эта фаза работы компилятора часто занимает
больше времени, чем любая другая. Частично это происходит из-за необходимости
просматривать и анализировать исходный текст символ за символом. Происходит
это потому, что часто бывает трудно определить, где проходят границы
лексемы. Пусть имеются две лексемы:make и makefile.
Пусть из входного потока поступает набор литеральных символов:...makefile....
При анализе входного потока может быть выделена лексема make, хотя правильно было бы выделить лексему makefile. Единственный способ преодолеть это затруднение - просмотр полученной цепочки вперед и назад. В примере при выделении лексемы make нужно просмотреть следующий поступающий литерал, и, если он будет символом f, то вполне возможно, что поступает лексема makefile. Процесс просмотра входного потока можно рассматривать как движение рамки влево и вправо над цепочкой символов. При этом анализируется только тот символ, который охвачен рамкой:
...
. .
source make.f.ile file compiler
. .
...
Анализ заключается в определении соответствия рассматриваемой последовательности
некоторому, так называемому регулярному выражению. Например, регулярное
выражение (\+?[0-9])+|(-?[0-9])+
позволяет выделить во входном потоке все лексемы типа целое, перед
которыми либо стоит знак (+ или -), либо не стоит.
В тех случаях, когда выделение лексемы затруднено вследствие того, что одно регулярное выражение не позволяет ее однозначно определить, либо из-за того, что одна лексема является частью другой, приходится прибегать к контекстно-зависимым алгоритмам анализа с использованием левого и правого направлений просмотра входной цепочки.
Для любого компилятора можно выделить три языка:
LEX частично или полностью автоматизирует процесс написания программы лексического анализа. Генерируемые с помощью LEX ЛА описываются на языке LEX. Последовательность использования LEX схематически показана на рис. 15:
![\includegraphics[ scale=0.45]{lex_ris.eps}](img110.png)
Таким образом в этой последовательности можно выделить три этапа:
lex из файла (например, program.lex), описывающего
ЛА некоторого языка и написанного на языке LEX (входной язык для lex),
получается файл (например, lex.yy.c) с текстом ЛА на языке Си (выходной
язык для lex).
cc из файла (lex.yy.c) на языке Си (входной язык
для cc) получается исполняемый файл (например, a.out) с машинными
кодами (выходной язык для cc), непосредственно реализующими ЛА.
a.out) осуществляется интерактивный
лексический анализ вводимого с клавиатуры текста или лексический анализ
файла, написанного на некотором языке (входной язык ЛА), и, возможно,
вывод на экран или в файл информации, связанной с разбором (выходной
язык ЛА). Гибкие возможности системы UNIX по управлению потоками позволяют
использовать входной и выходной файлы и на этом этапе.
lex, в конечном счете генерирующая ЛА, впрочем,
как и сама система UNIX, написаны на Си. Исполняемый файл команды
lex, как и других команд получается при компиляции во время установки
системы с применением все того же компилятора Си, привязанного к определенной
аппаратной платформе. Таким образом, компилятор Си cc (написанный
разработчиком, например, на Си и ассемблере для выбранной платформы
и поставляемый вместе с системой) является базой.
В целом подсистема LEX для систем UNIX включает следующие файлы:
/usr/ccs/bin/lex; lex.yy.c; /usr/ccs/lib/lex/ncform; /usr/lib/libl.a; /usr/lib/libl.so.В каталоге
/usr/ccs/lib/lex имеется файл-заготовка ncform, который
LEX используется для построения ЛА. Этот файл является уже готовой
программой лексического анализа. Но в нем не определены действия,
которые необходимо выполнять при распознавании лексем, отсутствуют
и сами лексемы, не сформированы рабочие массивы и т.д. С помощью команды
lex файл ncform достраивается. В результате мы получаем файл со стандартным
именем lex.yy.c. Если LEX-программа размещена в файле program.l, то
для получения ЛА с именем program необходимо выполнить следующий набор
команд:
lex program.l cc lex.yy.c -ll -o programЕсли имя входного файла для команды
lex не указано, то будет использоваться
файл стандартного ввода. Флаг -ll требуется для подключения
/usr/ccs/lib/libl.a - библиотеки LEX. Если необходимо получить самостоятельную
программу, как в данном случае, подключение библиотеки обязательно,
поскольку из нее подключается главная функция main. В противном
случае, если имеется необходимость включить ЛА в качестве функции
в другую программу (например, в программу синтаксического анализа),
эту библиотеку необходимо вызвать уже при сборке. Тогда, если main
определен в вызывающей ЛА программе, редактор связей не будет подключать
раздел main из библиотеки LEX.
Общий формат вызова команды lex:
lex [-ctvn -V -Q[y|n]] [file]Флаги:
-c - включает фазу генерации Си-файла (устанавливается по умолчанию);
-t - поместить результат в стандартный файл вывода, а не в файл lex.yy.c;
-v - вывести размеры внутренних таблиц;
-n - не выводить размеры таблиц (устанавливается по умолчанию);
-V - вывести информацию о версии LEX в стандартный файл ошибок;
-Q - вывести (Qy) либо не выводить (Qn, устанавливается по умолчанию)
информацию о версии в файл lex.yy.c.
В LEX-программе регулярные выражения используются для определения лексем. (Кроме того, регулярные выражения широко используются при описании синтаксиса команд в разделах помощи UNIX-систем). Ниже приводится полное описание регулярных выражений применительно к LEX.
Регулярное выражение может содержать буквы латинского и русского алфавитов
в верхнем и нижнем регистрах, цифры, знаки препинания и т.д. (литеральные
символы), а также символы-операторы (метасимволы). Кроме того, в регулярных
выражениях можно использовать управляющие символы потока stdout языка
Си, например:
\восьмеричный код - указание символа его восьмеричным
кодом;
\xшестнадцатеричный код - указание символа его шестнадцатеричным
кодом;
\n - символ новой строки;
\t - символ табуляции;
\b - возврат курсора на один шаг назад.
В данном разделе понятие ``символ'' используется в смысле языка программирования Си, т.е. подразумевается прежде всего литеральный символ. Операторы позволяют расширить возможности для описания цепочек символов. Регулярные выражения допускают использование операций конкатенации, т.е., ``стыковки'' друг с другом. Если в выражении используется символ пробела и он не находится внутри квадратных скобок, то его необходимо экранировать по правилам, описанным ниже, так как пробел и табуляция используются в качестве разделителей внутри LEX-программы.
Операторы обозначаются символами-операторами, к которым относятся:
\ "" . [] - * + / | ? $ ^ {} <> ()
Каждый из этих символов или пар скобок в регулярном выражении играет
свою роль:
\ и "" - операторы экранирования.
Используются для отмены специального значения символа, обозначающего
оператор, либо последовательности таких символов.
\c - отменяет специальное значение символа c. В общем
случае c может быть любым символом (в том числе и ),
кроме цифры и скобки (т.е. специальное значение скобок таким способом
отменить нельзя).
"сс" - отменяет специальное значение последовательности
символов c. В общем случае в двойные кавычки можно заключать любую
последовательность символов, но специальное значение
таким способом отменить нельзя.
abc+ ,где + является символом-оператором, а в выражении
abc\+
специальное значение + отменяется.
[] - оператор выделения символа из определенного класса. Используется
для определения вхождения одного любого символа из числа заключенных
в квадратные скобки. Заключение символа в квадратные скобки также
выполняет роль экранирования. Квадратные скобки внутри квадратных
скобок также теряют свой специальный смысл.
[xy] - означает вхождение либо символа x, либо символа y.
[x-z] - означает вхождение любого символа из лексикографически
упорядоченной последовательности от x до z.
[A-z]
[+-0-9]
x* - означает любое (в том числе и нулевое) число вхождений символа
x.
x+ - означает одно и более вхождений символа x.
[A-z]*
[A-ZА-Яa-zа-я0-9]*
[A-z]+
/, |, ?, $, ^ - операторы выбора. Управляют процессом
выбора символов.
x/y - означает, что вхождение x учитывается только тогда, когда за
ним следует y.
x? - означает необязательность вхождения символа x.
x$ - означает учет вхождения символа x, если он является последним
в строке (cтоит перед символом n).
^x - означает учет вхождения символа x, если он является
первым символом строки.
[^x] - означает вхождение любого символа, кроме
x. Внутри квадратных скобок ^ должен обязательно
стоять первым.
_?[A-Za-z]*
-?[0-9]+
^[A-Z]
{} - оператор имеет два различных применения:
x{n,m} - означает от n до m вхождений x (здесь n и m натуральные,
m > n).
{имя} - означает, что вместо имени в данное место выражения будет
подставлено определение имени из области определений LEX-программы.
a{2,7}
<> - оператор используется для учета состояния ЛА при определении
вхождений.
<состояние>x - означает учет вхождения x, если ЛА находится в положении
"состояние".
() - оператор изменения группировки регулярного выражения. Все перечисленные
выше операторы имеют соответствующим образом определенные приоритеты.
Заключение в круглые скобки позволяет необходимым способом изменить
приоритеты для правильного описания входной информации.
+,
/, |, ?, , <> и (), принято называть расширенными регулярными
выражениями.
LEX-программа, написанная на языке LEX, имеет следующий формат:
определения %% правила %% пользовательские_подпрограммыТаким образом, LEX-программа включает секции опредeлений
%%Здесь нет никаких определений и никаких правил. Все строки, в которых занята первая позиция, относятся к LEX-программе. Любая строка, не являющаяся частью правила или действия, которая начинается с пробела или табуляции, копируется в генерируемый файл
lex.yy.c.
Определения, предназначенные для LEX, помещаются перед первым %%.
Любая строка этой секции, не содержащаяся между
%START имя1 имя2 ...Если начальные условия определены, то эта строка должна быть первой в LEX-программе.
Непосредственно определения задаются в форме:
имя трансляцияВ качестве разделителя используется один или более пробелов или табуляций. Имя (name) - это, как обычно, любая последовательность букв и цифр, начинающаяся с буквы. Трансляция (translation) - это регулярное выражение (или его часть), которое будет подставлено всюду, где указано имя. Пример:
БУКВА [A-ZА-Яa-zа-я_]
ЦИФРА [0-9]
ИДЕНТИФИКАТОР {БУКВА}({БУКВА}|{ЦИФРА})*
%%
{ИДЕНТИФИКАТОР} printf("\n%s",yytext);
. . .
LEX построит ЛА, который будет находить и выводить все идентификаторы
Си-программы из входного файла. В этом примере
ИДЕНТИФИКАТОР
заменит БУКВА(БУКВА|ЦИФРА), затем на
A-ZА-Яa-zа-я(A-ZА-Яa-zа-я|0-9).
yytext - это внешний массив символов программы lex.yy.c, которую строит
LEX; yytext формируется в процессе чтения входного файла и содержит
текст, для которого установлено соответствие какому-либо выражению.
Этот массив доступен пользовательским разделам LEX-программы. Функция
printf выводит каждый идентификатор на новой строке.
Фрагменты пользовательских подпрограмм вводятся двумя способами:
отступ фрагмент;или
%{
фрагмент
%}
Включение пользовательского фрагмента необходимо, например, для ввода
макроопределений Си, которые должны начинаться в первой колонке строки.
Все строки фрагмента пользовательской подпрограммы, размещенные в
разделе определений, будут внешними для любой функции lex.yy.c.
Таблица наборов символов задается в виде:
%T целое_число строка_символов . . . целое_число строка_символов %TСгенерированная программа
lex.yy.c осуществляет ввод/вывод символов
посредством библиотечных функций LEX с именами input,
output, unput.
Таким образом, LEX помещает в массив yytext символы в представлении,
используемом в этих библиотечных функциях. Для внутреннего использования
символ представляется целым числом, значение которого образовано набором
битов, представляющих символ в конкретной ЭВМ. Пользователю представляется
возможность менять представление символов (целых констант) с помощью
таблицы наборов символов. Если таблица символов присутствует в разделе
определений, то любой символ, появляющийся либо во входном потоке,
либо в правилах, должен быть определен в таблице символов. Символам
нельзя назначать число 0 и число, большее числа, выделенного для внутреннего
представления символов конкретной ЭВМ. Пример:
%T 1 Aa 2 Bb 3 Cc . . . 26 Zz 27 \n 28 + 29 - 30 0 31 1 . . . 39 9 %TЗдесь символы верхнего и нижнего регистров переводятся в числа 1 - 26, символ новой строки - в число 27, + и - переводятся в числа 28 и 29, а цифры - в числа 30 - 39.
Указатель хост-языка имеет вид:
%Cдля языка Си. Для других языков программирования, например Фортрана, указатель выглядит соответственно. Если указатель хост-языка отсутствует, то по умолчанию принимается Си.
Изменения размеров внутренних массивов задаются в форме:
%x числоЧисло - новый размер массива, x - одна из букв: p - позиции (positions), n - состояния (states), e - узлы дерева разбора (parse tree nodes), a - упакованные переходы (transitions), k - упакованные классы символов (packet character classes), o - массив выходных элементов (output array). LEX имеет внутренние таблицы, размеры которых ограничены. При построении программы лексического анализа может произойти переполнение любой из этих таблиц, о чем LEX сообщит при построении ЛА. Представляется возможность изменить размеры этих таблиц (сокращая размеры одних и увеличивая размеры других) таким образом, чтобы они не переполнялись. Естественно, эти изменения возможны лишь в пределах той памяти, которая выделяется под процесс. Ниже перечислены размеры таблиц, которые устанавливаются по умолчанию: p - 1500 позиций, n - 300 состояний, e - 600 узлов, a - 1500 упакованных переходов, k - 1000 упакованных классов символов, o - 1500 выходных элементов. Для того чтобы определить, каковы размеры таблиц и насколько они заняты, можно использовать флаг
-v при вызове
команды lex. Число перед / показывает сколько элементов массива занято,
а число за / показывает установленный размер массива.
Комментарии в разделе определений задаются в форме хост-языка и должны начинаться не с первой колонки строки.
Все, что находится после первой пары и до конца LEX-программы или до второй пары , если она присутствует, относится к секции правил. Секция правил может содержать правила и также фрагменты пользовательских подпрограмм.
Секция правил может включать список активных и неактивных (помеченных) правил. Активные и неактивные правила могут располагаться в любом порядке. Любое правило должно начинаться с первой позиции строки, пробелы и табуляции недопустимы - они используются как разделители между регулярным выражением и действием в правиле.
Активное правило имеет вид:
регулярное_выражение действиеАктивные правила выполняются всегда. По регулярным выражениям (regular expressions), содержащимся в левой части правил, LEX строит детерминированный конечный автомат. Этот автомат осуществляет интерпретацию, а не компиляцию, и переходит из одного состояния в другое. Количество правил и их сложность не влияют на скорость лексического анализа, если только правила не требуют слишком большого объема повторных просмотров входной последовательности символов. Однако с ростом числа правил и их сложности растет размер конечного автомата, интерпретирующего их, и, следовательно, растет размер Си-программы, реализующей этот конечный автомат.
LEX-программа, приведенная ниже, переводит на русский язык названия месяцев и дней недели.
%%
[jJ][aA][nN][uU][aA][rR][yY] {printf("Январь");}
[fF][eE][bB][rR][uU][aA][rR][yY] {printf("Февраль");}
[mM][aA][rR][cC][hH] {printf("Март");}
[aA][pP][rR][iI][lL] {printf("Апрель");}
[mM][aA][yY] {printf("Май");}
[jJ][uU][nN][eE] {printf("Июнь");}
[jJ][uU][lL][yY] {printf("Июль");}
[aA][uU][gG][uU][sS][tT] {printf("Август");}
[sS][eE][pP][tT][eE][mM][bB][eE][rR] {printf("Сентябрь");}
[oO][cC][tT][oO][bB][eE][rR] {printf("Октябрь");}
[nN][oO][vV][eE][mM][bB][eE][rR] {printf("Ноябрь");}
[dD][eE][cC][eE][mM][bB][eE][rR] {printf("Декабрь");}
[mM][oO][nN][dD][aA][yY] {printf("Понедельник");}
[tT][uU][eE][sS][dD][aA][yY] {printf("Вторник");}
[wW][eE][dD][nN][eE][sS][dD][aA][yY] {printf("Среда");}
[tT][hH][uU][rR][sS][dD][aA][yY] {printf("Четверг");}
[fF][rR][iI][dD][aA][yY] {printf("Пятница");}
[sS][aA][tT][uU][rR][dD][aA][yY] {printf("Суббота");}
[sS][uU][nN][dD][aA][yY] {printf("Воскресенье");}
Каждое правило здесь определяет действие (оно взято в фигурные скобки). Открывающая фигурная скобка стоит в той же строке, что и правило, - это требование LEX. Действие в каждом правиле данной LEX-программы - это вывод русского значения найденного английского слова. В качестве оператора, выполняющего действие, используется библиотечная функция языка Си. Пара фигурных скобок определяет блок (в смысле языка Си), который может содержать любое количество строк. Если действие содержит всего одну строку Си, то можно ее записать без фигурных скобок, как обычно. Единственное условие - она должна начинаться в той же строке, где и регулярное выражение. В программе содержится только раздел правил, их всего 19. Регулярное выражение каждого правила определяет английское слово, написанное строчными или прописными латинскими символами. Например, ``may'' (май) определен как mMaAyY. По этому регулярному выражению будет выделена во входном потоке лексема ``may'', а по действию этого правила будет выведено ``Май''. Наличие строчной и прописной буквы в квадратных скобках обеспечивает распознавание слова ``may'', написанного любым способом. После запуска на выполнение ЛА получим:
May Май MONDAY Понедельник . . . Ctrl-cДействие (action) можно представлять либо как специальное действие LEX, либо как оператор Си. Если имеется необходимость выполнить достаточно большой набор преобразований, то действие
ncform, будет просто копировать входной поток в выходной. Часто бывает
необходимо избавиться от подобного копирования. Для этой цели используется
пустой оператор Си. Например, правило
[ \t\n] ;запрещает вывод пробелов, табуляций и символов ``новая строка''. Запрет выражается в том, что для указанных символов во входном потоке осуществляется действие ; - пустой оператор Си, и эти символы не копируются в выводной поток символов.
Как отмечалось выше, в качестве действий могут выступать специальные действия языка LEX:
BEGIN | ECHO REJECTДля нескольких регулярных выражений можно указывать одно действие. Для этого используется специальное действие |, которое свидетельствует о том, что действие для данного регулярного выражения совпадает с действием для следующего. Например:
" " | \t | \n ;Специальное действие
BEGIN имеет следующий формат:
BEGIN метка;Если LEX-программа содержит активные и неактивные правила, то активные правила работают всегда. Специальное действие BEGIN просто расширяет список активных правил, активизируя помеченные меткой неактивные правила.
BEGIN 0; удаляет из ``списка активных'' все помеченные правила,
которые до этого были активизированы, и тем самым возвращает ЛА в
самое начальное состояние. Кроме того, если из помеченного и активного
в данный момент времени правила осуществляется специальное действие
BEGIN, то из помеченных правил активными останутся либо станут только
те, которые помечены меткой, указанной в этом специальном действии.
Например, в качестве первого правила секции правил может быть:
BEGIN начало;В этом правиле отсутствует регулярное выражение, и первым действием в секции правил будет активизация помеченных меткой начало правил.
Когда необходимо вывести или преобразовать текст, соответствующий
некоторому регулярному выражению, используется внешний массив символов
yytext, который формирует LEX и доступен в действиях правил.
Например, по правилу
[A-Z]+ printf("%s",yytext);
распознается и выводится на экран слово, содержащее прописные латинские
буквы. Операция вывода распознанного выражения используется очень
часто, поэтому имеется сокращенная форма записи этого действия, выражающаяся
специальным действием ECHO:
[A-Z]+ ECHO;Результат действия этого правила аналогичен результату предыдущего примера. В файле
lex.yy.c ECHO определяется как макроподстановка:
#define ECHO fprintf(yyout,"%s",yytext);Когда необходимо знать длину обнаруженной последовательности, используется счетчик найденных символов
yyleng, который также доступен в действиях.
Например, действием
[A-Z]+ printf("%c",yytext[yyleng-1]);
будет выводится последний символ слова, соответствующего регулярному
выражению A-Z+. Еще один пример:
[A-Z]+ {число_слов++; число_букв += yyleng;}
Здесь ведется подсчет числа распознанных слов и количества символов
во всех словах.
Обычно LEX разделяет входной поток, не осуществляя поиска всех возможных соответствий каждому выражению. Это означает, что каждый символ рассматривается один и только один раз. Предположим, что мы хотим подсчитать все вхождения she и he во входном тексте. Для этого мы могли бы записать следующие правила:
she s++; he h++; . | \n ;Поскольку she включает в себя he, ЛА не распознает те вхождения he, которые включены в she, так как прочитав один раз she, эти символы он не вернет во входной поток. Иногда нужно изменить подобную ситуацию. Специальное действие
REJECT означает - ``выбрать следующую альтернативу''.
Это приводит к тому, что, каким бы ни было правило, после него необходимо
выполнить второй выбор. Соответственно изменится и положение указателя
во входном потоке:
she {s++; REJECT;}
he {h++; REJECT;}
. |
\n ;
Здесь после выполнения одного правила символы возвращаются во
входной поток и выполняется другое правило. Слово the содержит как
th, так и he. Если имеется двухмерный массив digram, тогда:
%%
[a-z][a-z] {
digram[yytext[0]][yytext[1]]++;
REJECT;
}
\n ;
Здесь REJECT используется для выделения буквенных пар, начинающихся
на каждой букве, а не на каждой следующей. Как видно, REJECT полезно
применять для определения всех вхождений,
причем вхождения могут перекрываться или включать друг друга.
Неактивное (помеченное) правило имеет вид:
<метка> регулярное_выражение действиеили
<метка1,метка2,...> регулярное_выражение действиеНеактивные правила выполняются только в тех случаях, когда выполняется некоторое начальное условие. Количество помеченных
START вводится список начальных условий как список меток
соответствующих состояний автомата (states). Метка формируется так
же, как и метка в Си. Неактивные правила помечаются начальными условиями,
а специальное действие BEGIN позволяет активизировать правила, помеченные
начальными условиями, т.е. автомат переходит в соответствующее состояние.
Пример:
%Start КОММ
КОММ_НАЧАЛО "/*"
КОММ_КОНЕЦ "*/"
%%
{КОММ_НАЧАЛО} {
ECHO;
BEGIN КОММ;
};
[\t\n]* ;
<КОММ>[\^*]* ECHO;
<КОММ>\*/[^/] ECHO;
<КОММ>{КОММ_КОНЕЦ} {
ECHO;
printf("\n");
BEGIN 0;
};
LEX строит ЛА, который выделяет комментарии в Си-программе и записывает
их в стандартный файл вывода. Программа начинается с ключевого слова
START (можно записывать и как Start), за которым поставлена метка
начального условия КОММ. В данном случае оператор <КОММ>x означает
учет x, если ЛА находится в начальном условии КОММ. Специальное действие
BEGIN КОММ; переводит ЛА в состояние, соответствующее начальному условию
КОММ. После этого ЛА уже находится в новом состоянии КОММ, и теперь
разбор входного потока будет осуществляется и теми правилами, которые
начинаются с <КОММ>. Например, правилом
<КОММ>[\^*]* ECHO;теперь будет записываться в стандартный файл вывода любое число (включая и ноль) символов, отличных от символа *. Оператор
BEGIN
0; переводит ЛА в исходное состояние.
LEX-программа может содержать несколько помеченных начальных условий. Например, если LEX-программа начинается строкой
%Start AA BB CC DD, то это означает, что она управляет четырьмя начальными состояниями ЛА. В каждое из этих начальных состояний ЛА можно перевести, используя
BEGIN. Пример с несколькими начальными условиями:
%START AA BB CC
БУКВА [A-ZА-Яa-zа-я_]
ЦИФРА [0-9]
ИДЕНТИФИКАТОР {БУКВА}({БУКВА}|{ЦИФРА})*
%%
^# BEGIN AA;
^[ \t]*main BEGIN BB;
^[ \t]*{ИДЕНТИФИКАТОР} BEGIN CC;
\t ;
\n BEGIN 0;
<AA>define printf("Определение.\n");
<AA>include printf("Включение.\n");
<AA>ifdef printf("Условная компиляция.\n");
<BB>[^\,]*","[^\,]*")" printf("main с аргументами.\n");
<BB>[^\,]*")" printf("main без аргументов.\n");
<CC>":"/[ \t] printf("Метка.\n");
Программа содержит активные и неактивные правила. Все неактивные правила
помечены. LEX-программа управляет тремя начальными условиями, в соответствии
с которыми активизируются помеченные правила. Здесь представлен ЛА,
который будет распознавать в Си-программе строки макропроцессора Си-компилятора,
выделять функцию main, распознавая с аргументами она или без них,
распознавать метки. ЛА не выводит ничего, кроме сообщений о выделенных
лексемах.
Таким образом, в процессе работы ЛА список активных правил может ``видоизменяться'' за счет действий оператора BEGIN. В процессе распознавания лексем во входном потоке может оказаться так, что одна цепочка символов удовлетворяет нескольким правилам и, следовательно, возникает проблема: действие какого правила должно выполняться? Для разрешения этого противоречия можно использовать ``разбиение'' регулярных выражений этих правил LEX-программы на такие новые регулярные выражения, которые дадут однозначное распознавание лексем. Однако, если это не сделано, LEX использует определенный детерминированный механизм разрешения такого противоречия:
[Мм][Аа][Йй] ECHO; [А-Яа-я]+ ECHO;Слово ``Май'' распознают оба правила, однако выполнится первое из них, так как и первое и второе правила распознали лексему одинакового размера (3 символа). Если во входном потоке будет слово ``майский'', то первые 3 символа удовлетворяют первому правилу, а все 7 символов удовлетворяют второму правилу и, следовательно, выполнится второе правило, так как ему соответствует более длинная последовательность.
Фрагменты пользовательских подпрограмм, содержащиеся в секции правил,
становятся частью функции yylex файла lex.yy.c. Они вводятся следующим
образом:
%{
фрагмент
%}
Пример:
%%
%{
#include file.h
%}
Здесь строка include file.h станет строкой функции yylex.
Все, что размещено за вторым набором, относится к секции пользовательских
подпрограмм. Содержимое этой секции копируется в выходной файл lex.yy.c
без каких-либо изменений. В файле lex.yy.c строки этого раздела рассматриваются
как функции Си. Эти функции могут вызываться в действиях
правил и, как обычно, передавать и возвращать значения аргументов.
Комментарии можно вводить во всех разделах LEX-программы. Формат комментариев должен соответствовать формату комментариев хост-языка, т.е. языка Си. Однако в каждой секции LEX - программы комментарии вводятся по-разному:
%Start КОММ
/*
* Программа записывает в стандартный файл вывода
* комментарии Си-программы. Обратите внимание на то,
* что здесь строки комментариев начинаются не с первой
* позиции строки!
*/
КОММ_НАЧАЛО "/*"
КОММ_КОНЕЦ "*/"
%%
{КОММ_НАЧАЛО} {ECHO;
BEGIN КОММ;}
[\t\n]* ;
<КОММ>[^*]* ECHO;
<КОММ>\*/[^/] ECHO;
<КОММ>{КОММ_КОНЕЦ} {ECHO;
printf("\n");
/*
* Здесь приведен пример использования комментариев в
* разделе правил LEX-программы. Обратите внимание на то,
* что комментарий находится внутри блока, определяющего
* действие правила.
*/
BEGIN 0;}
%%
/*
* Здесь приведен пример комментариев в разделе
* пользовательских подпрограмм.
*/
LEX строит программу ЛА на языке Си, которая размещается в файле со
стандартным именем lex.yy.c. Так как файл lex.yy.c - это Си-программа,
то в него можно внести любые необходимые изменения и добавления. Эта
программа содержит ряд основных и вспомогательных функций:
Синтаксис системного вызова msgctl:
#include <sys/ipc.h>
#include <sys/msg.h>
int msgctl ( int msqid, int cmd,
struct msqid_ds *buf);
В качестве аргумента msqid должен выступать идентификатор очереди сообщений, предварительно полученный системным вызовом msgget.
Управляющее действие определяется значением аргумента cmd. Допустимых значений три:
Программа-пример в этом разделе иллюстрирует управление очередью. В программе использованы следующие переменные:
Если выбрано действие IPC_STAT (код 1), выполняется системный вызов и распечатывается информация о состоянии очереди; в программе распечатываются только те поля структуры, которые могут быть переустановлены. Если системный вызов завершается неудачей, распечатывается информация о состоянии очереди на момент последнего успешного выполнения системного вызова. Кроме того, выводится сообщение об ошибке и распечатывается значение переменной errno. Если системный вызов завершается успешно, выводится сообщение, уведомляющее об этом, и значение использованного идентификатора очереди сообщений.
Если выбрано действие IPC_SET (код 2), программа прежде всего получает информацию о текущем состоянии очереди сообщений с заданным идентификатором. Это необходимо, поскольку в примере обеспечивается изменение только одного поля за один раз, в то время как системный вызов изменяет всю структуру целиком. Кроме того, если в одно из полей структуры, находящейся в области памяти пользователя, будет занесено некорректное значение, это может вызвать неудачи в выполнении управляющих действий, повторяющиеся до тех пор, пока значение поля не будет исправлено. Затем программа предлагает ввести код, соответствующий полю структуры, которое должно быть изменено. Этот код заносится в переменную choice. Далее, в зависимости от указанного поля, программа предлагает ввести то или иное новое значение. Значение заносится в соответствующее поле структуры данных, расположенной в области памяти пользователя, и выполняется системный вызов.
Если выбрано действие IPC_RMID (код 3), выполняется системный вызов, удаляющий из системы идентификатор msqid, очередь сообщений и ассоциированную с ней структуру данных. Отметим, что для выполнения этого управляющего действия аргумент buf не требуется, поэтому его значение может быть заменено нулем (NULL):
возможности системного вызова msgctl()
(управление очередями сообщений) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
main ()
{
extern int errno;
int msqid, command, choice, rtrn;
struct msqid_ds msqid_ds, *buf;
buf = &msqid_ds;
/* Ввести идентификатор и действие */
printf ("Введите идентификатор msqid: ");
scanf ("%d", &msqid);
printf ("Введите номер требуемого действия:\n");
printf (" IPC_STAT = 1\n");
printf (" IPC_SET = 2\n");
printf (" IPC_RMID = 3\n");
printf (" Выбор = ");
scanf ("%d", &command);
/* Проверить значения */
printf ("идентификатор = %d, действие = %d\n",
msqid, command);
switch (command) {
case 1: /* Скопировать информацию
о состоянии очереди сообщений
в пользовательскую структуру
и вывести ее */
rtrn = msgctl (msqid, IPC_STAT, buf);
printf ("\n Идентификатор пользователя =
%d\n",
buf->msg_perm.uid);
printf ("\n Идентификатор группы = %d\n",
buf->msg_perm.gid);
printf ("\n Права на операции = 0%o\n",
buf->msg_perm.mode);
printf ("\n Размер очереди в байтах =
%d\n",
buf->msg_qbytes);
break;
case 2: /* Выбрать и изменить поле (поля)
ассоциированной структуры данных */
/* Сначала получить исходное значение
структуры данных */
rtrn = msgctl (msqid, IPC_STAT, buf);
printf ("\nВведите номер поля, ");
printf ("которое нужно изменить:\n");
printf (" msg_perm.uid = 1\n");
printf (" msg_perm.gid = 2\n");
printf (" msg_perm.mode = 3\n");
printf (" msg_qbytes = 4\n");
printf (" Выбор = ");
scanf ("%d", &choice);
switch (choice) {
case 1:
printf ("\nВведите ид-р
пользователя: ");
scanf ("%d", &buf->msg_perm.uid);
printf ("\nИд-р пользователя =
%d\n",
buf->msg_perm.uid);
break;
case 2:
printf ("\nВведите ид-р
группы: ");
scanf ("%d", &buf->msg_perm.gid);
printf ("\nИд-р группы = %d\n",
buf->msg_perm.uid);
break;
case 3:
printf ("\nВведите восьмеричный
код прав: ");
scanf ("%o", &buf->msg_perm.mode);
printf ("\nПрава на операции =
0%o\n",
buf->msg_perm.mode);
break;
case 4:
printf ("\nВведите размер
очереди = ");
scanf ("%d", &buf->msg_qbytes);
printf ("\nЧисло байт в очереди =
%d\n", buf->msg_qbytes);
break;
}
/* Внести изменения */
rtrn = msgctl (msqid, IPC_SET, buf);
break;
case 3: /* Удалить идентификатор и
ассоциированные с ним очередь
сообщений и структуру данных */
rtrn = msgctl (msqid, IPC_RMID, NULL);
}
if (rtrn == -1) {
/* Сообщить о неудачном завершении */
printf ("\nmsgctl завершился неудачей!\n");
printf ("\nКод ошибки = %d\n", errno);
}
else {
/* При успешном завершении сообщить msqid */
printf ("\nmsgctl завершился успешно,\n");
printf ("идентификатор = %d\n", msqid);
}
exit (0);
}
Функция содержит разделы действий всех правил, которые определены
пользователем. Файл lex.yy.c генерируется из файла - заготовки /usr/lib/lex/ncform,
в котором отсутствует функция yylex(). Эта функция включается в lex.yy.c
в процессе генерации. С полным текстом файла ncform можно ознакомиться
в соответствующем каталоге.
Функция реализует детерминированный конечный автомат, который осуществляет разбор входного потока символов в соответствии с регулярными выражениями правил LEX-программы.
Функция используется для определения конца файла, из которого ЛА читает
поток символов. Если yywrap возвращает 1, ЛА прекращает работу. Однако
иногда появляется необходимость начать ввод данных из другого источника
и продолжить работу. В этом случае нужно написать свою подпрограмму
yywrap, которая организует новый входной поток и возвращает 0, что
служит сигналом к продолжению работы ЛА. По умолчанию yywrap всегда
возвращает 1 при завершении входного потока символов. В LEX-программе
невозможно записать правило, которое будет обнаруживать конец файла.
Единственный способ это сделать - использовать функцию yywrap. Эта
функция также удобна, когда необходимо выполнить какие-либо действия
по завершению входного потока символов. Пример:
%START AA BB CC
/*
* Строится ЛА, который распознает наличие включений
* файлов в Си-программе, условных компиляций,
* макроопределений, меток и головной функции main.
* Анализатор ничего не выводит
* пока осуществляется чтение всего входного потока.
* По завершении выводится статистика.
*/
БУКВА [A-ZА-Яa-zа-я_]
ЦИФРА [0-9]
ИДЕНТИФИКАТОР {БУКВА}({БУКВА}|{ЦИФРА})*
int a1,a2,a3,b1,b2,c;
%%
{a1=a2=a3=b1=b2=c=0;}
^# BEGIN AA;
^[ \t]*main BEGIN BB;
^[ \t]*{ИДЕНТИФИКАТОР} BEGIN CC;
\t ;
\n BEGIN 0;
<AA>define {a1++;}
<AA>include {a2++;}
<AA>ifdef {a3++;}
<BB>[^\,]*","[^\,]*")" {b1++;}
<BB>[^\,]*")" {b2++;}
<CC>":"/[ \t] {c++;}
%%
yywrap()
{
if(b1==0&&b2==0)
printf("В программе отсутствует функция main.\n");
if(b1>=1&&b2>=1)
printf("Многократное определение функции main.\n");
else
{
if(b1==1) printf("Функция main с аргументами.\n");
if(b2==1) printf("Функция main без аргументов.\n");
}
printf("Включений файлов: %d.\n",a2);
printf("Условных компиляций: %d.\n",a3);
printf("Определений: %d.\n",a1);
printf("Меток: %d.\n",c);
return(1);
}
Оператор return(1) в функции yywrap указывает, что ЛА должен завершить
работу. Если необходимо продолжить работу ЛА для чтения данных из
нового файла, нужно ипользовать return(0), предварительно осуществив
операции закрытия и открытия файлов. Однако если yywrap не возвращает
1, то это приводит к бесконечному циклу.
В обычной ситуации содержимое yytext обновляется всякий раз, когда
на входе появляется следующая строка (в yytext всегда находятся символы
распознанной цепочки). Иногда возникает необходимость добавить к текущему
содержимому yytext следующую распознанную цепочку символов. Для этой
цели используется функция yymore. Пример использования функции yymore:
.
.
.
\"[^"]* {
if(yytext[yyleng-1]=='\\') yymore();
else
{/*
* Здесь должна быть часть программы,
* обрабатывающая закрывающую кавычку.
*/}
}
.
.
.
В этом примере распознаются строки симвoлов, взятые в двойные кавычки,
причем символ двойных кавычек внутри этой строки может изображаться
с предшествующей косой чертой. ЛА должен распознавать кавычку, ограничивающую
строку, и кавычку, являющуюся частью строки, когда она изображена
как \". Если на вход поступает строка абв\"где",
то сначала будет распознана цепочка "абв
и так как последним символом в этой цепочке будет символ \,
выполнится вызов yymore. В результате к цепочке "абв\
будет добавлено "где, и в yytext мы получим "абв\"где",
что и требовалось.
В некоторых случаях возникает необходимость использовать не все символы
распознанной цепочки в yytext, а только необходимое число. Для
этой цели используется функция yyless(n), где n указывает, что в данный
момент необходимо только n символов строки из yytext. Остальные найденные
символы будут возвращены во входной поток. Пример использования функции
yyless:
.
.
.
=-[A-ZА-Яa-zа-я] {
printf("Oператор (=-) двусмысленный.\n");
yyless(yyleng-2);
/*
* Здесь необходимо записать действия для
* случая "=-"
*/
}
.
.
.
В этом примере разрешается двусмысленность выражения =- буква в языке
Си. Это выражение можно рассматривать как =- буква или как = -буква.
Предположим, что эту ситуацию нужно рассматривать как = -буква и выводить
предупреждение. В примере правило распознает эту ситуацию, выводит
предупреждение и затем, после вызова yyless(yyleng - 2); два
символа -буква будут возвращены во входной поток, а знак = останется
в yytext для обработки, как и в нормальной ситуации. Таким образом,
при продолжении чтения входного потока уже будет обрабатываться цепочка
-буква, что и требовалось.
Функция читает символ из входного потока символов. Если читается файл и достигнут его конец, то функция возвращает NULL.
Функция возвращает символ обратно во входной поток для повторного
его чтения следующим вызовом input.
Функция выводит в выходной поток символ c.
Последние три функции (6-8), определены как макроподстановки и их можно переопределть в секции подпрограмм пользователя.
При сборке программы лексического анализа редактор связи ld по флагу
-ll подключает головную функцию main, если она не определена. Ниже
приведен полный исходный текст такой библиотеки libl.a:
#include "stdio.h"
main()
{
yylex();
exit(0);
}
Основой входной спецификации является набор грамматических правил. Каждое правило описывает допустимую структуру языка и дает ей имя. Например, правило может быть таким:
date : month_name day ',' year ;Здесь
date, monthname, day, и year представляют собой структуры языка
(нетерминалы) описанные где-то еще, а запятая, заключенная в кавычки
означает, что после нетерминала day ожидается символ ',' как литера.
Двоеточие и точка с запятой являются знаками пунктуации Yacc. Таким
образом, строка January 1, 2000 попадает под вышеприведенное правило.
Yacc на основе входных спецификаций осуществляет синтаксический разбор текста, пользуясь при этом результатами лексического анализа, выполняемого внешней (по отношению к нему) подпрограммой, которая должна читать символы из входного потока, распознавать конструкции низкого уровня (лексемы) и передавать их на вход синтаксического анализатора, создаваемого Yacc. Традиционно конструкции, распознаваемые лексическим анализатором, называют терминальными символами, а распознаваемые синтаксическим - нетерминальными. В дальнейшем, во избежание путаницы, терминальные символы мы будем называть токенами (tokens).
Существует определенная свобода в выборе конструкций, распознаваемых лексическим и синтаксическим анализаторами, например, в предыдущем примере вполне могут быть использованы правила:
month_name : 'J' 'a' 'n' ; month_name : 'F' 'e' 'b' ; . . . month_name : 'D' 'e' 'c' ;В этом случае лексический анализатор должен только распознавать отдельные литеры, а monthname является нетерминальным символом. Но на работу с такими низкоуровневыми правилами тратится много времени и памяти, неимоверно распухают входные спецификации Yacca, поэтому обычно лексический анализатор (как более простой прием) распознает названия месяцев и выдает только признак того, что встретилось такое название. В этом случае
monthname является токеном (терминальным символом). Специальные
символы, такие, как в нашем примере, должны также
распознавальтся лексическим анализатором.
Описание грамматики в виде правил является очень гибким, поэтому очень легко добавить к примеру правило:
date : month '/' day '/' year ;позволяющее вводить
1 / 1 / 2000, как синоним для
January 1, 2000.
В большинстве случаев новое правило может быть введено в работающую
систему легко и с минимальным риском испортить уже работающие правила.
Разбираемый текст может (иногда) не соответствовать спецификациям, что чвляется синонимом синтаксической ошибки. Такие ошибки обнаруживаются настолько быстро, насколько это возможно теоретически при сканировании слева направо. Частью входных спецификаций являются специальные правила обработки ошибок, позволяющие либо исправить неправильные символы, либо продолжить разбор после пропуска неправильных символов.
В некоторых случаях компилятором Yacc не удастся построить анализатор по входным спецификациям, так как либо заданная грамматика не является LALR(1), либо у Yacca не хватает мощности. Обычно эта проблема решается пересмотром системы правил, либо созданием более мощного лексического анализатора. Следует также заметить, что конструкции неподвластные Yacc, часто также непосильны и человеческому разуму...
Синтаксис системных вызовов msgop для операций над очередями выглядит так:
#include <sys/ipc.h>
#include <sys/msg.h>
int msgsnd (int msqid, struct msgbuf * msgp,
int msgsz, int msgflg)
int msgrcv (int msqid, struct msgbuf * msgp,
int msgsz, long msgtyp, int msgflg)
Значение поля msg_qbytes у ассоциированной
структуры данных может быть уменьшено с предполагаемой по умолчанию
величины MSGMNB при помощи управляющего действия IPC_SET
системного вызова msgctl, однако впоследствии увеличить его
может только суперпользователь. Аргумент msgflg позволяет
специфицировать выполнение ``операции с блокировкой'';
для этого флаг IPC_NOWAIT должен быть сброшен (msgflg
&
IPC_NOWAIT = 0). Блокировка имеет место, если либо текущее
число байт в очереди уже равно максимально допустимому значению для
указанной очереди (т. е. значению поля msg_qbytes или
MSGMNB), либо общее число сообщений во всех очередях равно
максимально допустимому системой (системный параметр MSGTQL).
Если в такой ситуации флаг IPC_NOWAIT установлен, то системный
вызов msgsnd() завершается неудачей и возвращает -1.
При успешном завершении системного вызова msgrcv() результат равен числу принятых байт; в случае неудачи возвращается -1. В качестве аргумента msqid должен выступать идентификатор очереди сообщений, предварительно полученный системным вызовом msgget. Аргумент msgp является указателем на структуру в области памяти пользователя, содержащую тип принимаемого сообщения и его текст. Аргумент msgsz специфицирует длину принимаемого сообщения. В случае, если значение данного аргумента меньше, чем длина сообщения в массиве, возникает ошибка (см. описание аргумента msgflg).
Аргумент msgtyp используется для выбора из очереди первого сообщения определенного типа. Если значение аргумента равно нулю, запрашивается первое сообщение в очереди, если больше нуля - первое сообщение типа msgtyp, а если меньше нуля - первое сообщение наименьшего типа, превосходящего абсолютной величины аргумента msgtyp.
Аргумент msgflg позволяет специфицировать выполнение
``операции с блокировкой''; для этого должен быть сброшен
флаг
IPC_NOWAIT (msgflg & IPC_NOWAIT = 0). Блокировка
имеет место, если в очереди нет сообщения с запрашиваемым
типом (msgtyp). Если флаг IPC_NOWAIT установлен
и в очереди нет сообщения требуемого типа, системный вызов немедленно
завершается неудачей. Аргумент msgflg может также указывать,
что системный вызов закончится неудачей, если размер сообщения
в очереди больше значения msgsz; для этого в данном аргументе
должен быть сброшен флаг MSG_NOERROR (msgflg &
MSG_NOERROR = 0). Если флаг MSG_NOERROR установлен, сообщение
обрезается до длины, указанной аргументом msgsz.
В примере этого раздела используются следующие переменные:
Если выбрана операция посылки сообщения, указатель msgp
инициализируется
адресом структуры данных sndbuf. После этого запрашивается
идентификатор очереди сообщений, в которую должно быть послано сообщение;
идентификатор заносится в переменную msqid. Затем должен
быть введен тип сообщения; он заносится в поле mtype структуры
данных, обозначаемой msgp.
После этого программа принимает текст посылаемого сообщения и выполняет цикл, в котором символы читаются и заносятся в массив mtext структуры данных. Ввод продолжается до тех пор, пока не будет обнаружен признак конца файла; для функции getchar() таким признаком является символ CTRL+D, непосредственно следующий за символом возврата каретки. После того как признак конца обнаружен, определяется размер сообщения: он на единицу больше значения счетчика i, поскольку элементы массива, в который заносится сообщение, нумеруются с нуля. Следует помнить, что сообщение будет содержать заключительные символы и, следовательно, будет казаться, что сообщение на три символа короче, чем указывает аргумент msgsz.
Чтобы обеспечить пользователю обратную связь, текст сообщения, содержащийся в массиве mtext структуры sndbuf, немедленно выводится на экран.
Следующее, и последнее, действие заключается в определении, должен ли быть установлен флаг IPC_NOWAIT. Чтобы выяснить это, программа предлагает ввести 1, если флаг нужно установить, или любое другое число, если он не нужен. Введенное значение заносится в переменную flag. Если введена единица, аргумент msgflg полагается равным IPC_NOWAIT, в противном случае msgflg устанавливается равным нулю.
После этого выполняется системный вызов msgsnd(). Если вызов завершается неудачей, выводится сообщение об ошибке, а также ее код. Если вызов завершается успешно, печатается возвращенное им значение, которое должно быть равно нулю.
При каждой успешной отсылке сообщения обновляются три поля ассоциированной структуры данных. Изменения можно описать следующим образом:
Если указано, что требуется принять сообщение, начальное значение указателя msgp устанавливается равным адресу структуры данных rcvbuf. Запрашивается код требуемой комбинации флагов, который заносится в переменную flags. Переменная msgflg устанавливается в сответствии с выбранной комбинацией. В заключение запрашивается, сколько байт нужно принять; указанное значение заносится в переменную msgsz. После этого выполняется системный вызов msgrcv().
Если вызов завершается неудачей, выводится сообщение об ошибке, а также ее код. Если вызов завершается успешно, программа сообщает об этом, а также выводит размер и текст сообщения. При каждом успешном приеме сообщения обновляются три поля ассоциированной структуры данных. Изменения можно описать следующим образом:
msg_qnum - определяет общее число сообщений в очереди; в результате выполнения операции уменьшается на единицу;
msg_lrpid - содержит идентификатор процесса, который последним получил сообщение; полю присваивается соответствующий идентификатор;
msg_rtime - содержит время последнего получения сообщения, время измеряется в секундах, начиная с 00:00:00 1 января 1970 г. (по Гринвичу).
возможности системных вызовов msgsnd() и msgrcv()
(операции над очередями сообщений) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#define MAXTEXTSIZE 8192
struct msgbufl {
long mtype;
char mtext [MAXTEXTSIZE];
} sndbuf, rcvbuf, *msgp;
main () {
extern int errno;
int flag, flags, choice, rtrn, i, c;
int rtrn, msqid, msgsz, msgflg;
long msgtyp;
struct msqid_ds msqid_ds, *buf;
buf = &msqid_ds;
/* Выбрать требуемую операцию */
printf ("\nВведите код, соответствующий ");
printf ("посылке или приему сообщения:\n");
printf (" Послать = 1\n");
printf (" Принять = 2\n");
printf (" Выбор = ");
scanf ("%d", &choice);
if (choice == 1) {
/* Послать сообщение */
msgp = &sndbuf; /* Указатель на структуру */
printf ("\nВведите идентификатор ");
printf ("очереди сообщений,\n");
printf ("в которую посылается сообщение: ");
scanf ("%d", &msqid);
/* Установить тип сообщения */
printf ("\nВведите положительное число - ");
printf ("тип сообщения: ");
scanf ("%d", &msgp->mtype);
/* Ввести посылаемое сообщение */
printf ("\nВведите сообщение: \n");
/* Управляющая последовательность CTRL+D
завершает ввод сообщения */
/* Прочитать символы сообщения
и поместить их в массив mtext */
for (i = 0; ((c = getchar ()) != EOF); i++)
sndbuf.mtext [i] = c;
/* Определить размер сообщения */
msgsz = i + 1;
/* Выдать текст посылаемого сообщения */
for (i = 0; i < msgsz; i++)
putchar (sndbuf.mtext [i]);
/* Установить флаг IPC_NOWAIT, если это нужно */
printf ("\nВведите 1, если хотите установить ");
printf ("флаг IPC_NOWAIT: ");
scanf ("%d", &flag);
if (flag == 1) msgflg = IPC_NOWAIT;
else msgflg = 0;
/* Проверить флаг */
printf ("\nФлаг = 0%o\n", msgflg);
/* Послать сообщение */
rtrn = msgsnd (msqid, msgp, msgsz, msgflg);
if (rtrn == -1) {
printf ("\nmsgsnd завершился неудачей!\n");
printf ("Код ошибки = %d\n", errno); }
else {
/* Вывести результат; при успешном
завершении он должен равняться нулю */
printf ("\nРезультат = %d\n", rtrn);
/* Вывести размер сообщения */
printf ("\nРазмер сообщения = %d\n", msgsz);
/* Опрос измененной структуры данных */
msgctl (msqid, IPC_STAT, buf);
/* Вывести изменившиеся поля */
printf ("Число сообщений в очереди = %d\n",
buf->msg_qnum);
printf ("Ид-р последнего отправителя = %d\n",
buf->msg_lspid);
printf ("Время последнего отправления = %d\n",
buf->msg_stime); }
}
if (choice == 2) {
/* Принять сообщение */
msgp = &rcvbuf;
/* Определить нужную очередь сообщений */
printf ("\nВведите ид-р очереди сообщений: ");
scanf ("%d", &msqid);
/* Определить тип сообщения */
printf ("\nВведите тип сообщения: ");
scanf ("%d", &msgtyp);
/* Сформировать управляющие флаги
для требуемых действий */
printf ("\nВведите код, соответствущий ");
printf ("нужной комбинации флагов:\n");
printf (" Нет флагов = 0\n");
printf (" MSG_NOERROR = 1\n");
printf (" IPC_NOWAIT = 2\n");
printf (" MSG_NOERROR и IPC_NOWAIT = 3\n");
printf (" Выбор = ");
scanf ("%d", &flags);
switch (flags) {
/* Установить msgflg как побитное ИЛИ
соответствующих констант */
case 0: msgflg = 0;
break;
case 1: msgflg = MSG_NOERROR;
break;
case 2: msgflg = IPC_NOWAIT;
break;
case 3:
msgflg = MSG_NOERROR | IPC_NOWAIT;
break;
}
/* Определить, какое число байт принять */
printf ("\nВведите число байт, которое ");
printf ("нужно принять (msgsz): ");
scanf ("%d", &msgsz);
/* Проверить значение аргументов */
printf ("\nИдентификатор msqid = %d\n", msqid);
printf ("Тип сообщения = %d\n", msgtyp);
printf ("Число байт = %d\n", msgsz);
printf ("Флаги = %o\n", msgflg);
/* Вызвать msgrcv для приема сообщения */
rtrn = msgrcv (msqid, msgp, msgsz,
msgtyp, msgflg);
if (rtrn == -1) {
printf ("\nmsgrcv завершился неудачей!\n");
printf ("Код oшибки = %d\n", errno); }
else {
printf ("\nmsgrcv завершился успешно,\n");
printf ("Идентификатор очереди =
%d\n", msqid);
/* Напечатать число принятых байт,
оно равно возвращаемому значению */
printf ("Принято байт: %d\n", rtrn);
/* Распечатать принятое сообщение */
for (i = 0; i < rtrn; i++)
putchar (rcvbuf.mtext [i]);
}
/* Опрос ассоциированной структуры данных */
msgctl (msqid, IPC_STAT, buf);
printf ("\nЧисло сообщений в очереди = %d\n",
buf->msg_qnum);
printf ("Ид-р последнего получателя = %d\n",
buf->msg_lrpid);
printf ("Время последнего получения = %d\n",
buf->msg_rtime); }
exit (0);
}
Имена относятся либо к токенам, либо к нетерминалам. Компилятор Yacc требует, чтобы все токены были специально описаны, часто желательно, чтобы лексический анализатор был включен в файл входных спецификаций. Впрочем и другие подпрограммы туда тоже можно включать. Таким образом, файл входных спецификаций состоит из трех секций: объявлений (declarations); грамматики (правил/rules); программ (подпрограмм).
Секции отделяются друг от друга двойным процентом (%%).
(Процент вообще используется Yaccом как специальный символ). Другими
словами, файл входных спецификаций выглядит так:
declarations (объявления) %% rules (правила) %% programs (программы)Секция объявлений может быть пустой, кроме того, если пуста секция программ, можно опустить и второй разделитель (
%%). Таким образом,
самая короткая спецификация может выглядеть так:
%% rulesПробелы, табуляции и возвраты каретки игнорируются, но не должны появляться в именах и зарезервированых символах. Везде, где может стоять имя, может быть и комментарий (как в Си):
/* . . . */Секция правил состоит из одного или более грамматических правил в форме:
A : BODY ;здесь
A - имя нетерминала, а BODY представляет собой
последовательность из нуля или более имен и литералов. Двоеточие и
точка с запятой - символы пунктуации Yacca. Имена могут быть произвольной
длины и состоять из букв, точек, подчеркиваний и цифр, но не должны
начинаться с цифры. Прописные и строчные буквы различаются. Имена,
использованые в теле правила, могут быть именами токенов или нетерминалов.
Литерал - это символ, заключенный в одиночные кавычки. Как и в Си
бакслэш (\) является спецсимволом,
а все Си-шные спецпоследовательности типа n и t воспринимаются.
По многим причинам технического свойства символ с кодом 0 (NULL) не должен никогда использоваться в правилах.
Если есть несколько правил с одинакой левой частью, можно вместо дублирования левой части использовать символ |. Кроме того точка с запятой может быть поставлена и перед символом |. Таким образом, правила:
A : B C D ; A : E F ; A : G ;могут быть записаны так:
A : B C D | E F | G ;или даже так:
A : B C D ; | E F ; | G ;Не обязательно, чтобы правила с одинаковой левой частью были написаны вместе (или рядом), но такая запись делает их более читаемыми и легкими для изменения. Если нетерминалу соответствует пустая строка, он может быть записан так:
empty : ;Имена токенов должны быть объявлены, что проще всего сделать, написав:
%token name1 name2 . . . в секции объявлений.
Каждое имя, не указанное в секции объявлений, предполагается именем нетерминала. Каждый нетерминал должен появиться в левой части хотя бы одного правила.
Из всех нетерминалов, один, называемый начальным нетерминалом, имеет
особое значение. Анализатор строится, чтобы разобрать начальный нетерминал,
который представляет собой наибольшую и наиобщую конструкцию, описанную
правилами. По умолчанию, начальным считается нетерминал, стоящий в
левой части первого правила, но желательно, чтобы он был объявлен
явно при помощи %start nonterminal в секции объявлений.
Об окончании ввода анализатору говорит специальный токен, называемый концевым маркером. Если концевой маркер приходит после разбора правила, соответствующего начальному нетерминалу, анализатор возвращает управление вызвавшей программе, прочитав его. Если маркер приходит в ином контексте, это считается синтаксической ошибкой. Вернуть концевой маркер в нужный момент - это забота лексического анализатора. Обычно коцевой маркер возвращается по концу записи или файла.
Каждому правилу можно поставить в соответствие некое действие, которое будет выполняться всякий раз, как это правило будет распознано. Действия могут возвращать значения и могут пользоваться значениями, возвращенными предыдущими действиями. Более того, лексический анализатор может возвращать значения для токенов (дополнительно), если хочется. Действие - это обычный оператор языка Си, который может выполнять ввод, вывод, вызывать подпрограммы и изменять глобальные переменные.
Действия, состоящие из нескольких операторов, необходимо заключать в фигурные скобки. Например:
A : '(' B ')'
{ hello( 1, "abc" ); }
и
XXX : YYY ZZZ
{ printf("a message\n"); flag = 25; }
являются грамматическими правилами с действиями.
Чтобы обеспечить связь действий с анализатором, используется спецсимвол
"доллар" ($). Чтобы вернуть значение, действие обычно присваивает его
псевдопеременной $$. Например, действие, которое
не делает ничего, но возвращает единицу:
{ $$ = 1; }
Чтобы получить значения, возвращенные предыдущими действиями и лексическим
анализатором, действие может использовать псевдопеременные $1, $2
и т. д., которые соответствуют значениям, возвращенным компонентами
правой части правила, считая слева направо. Таким образом, если правило
имеет вид:
A : B C D ;то
$2 соответствует значению, возвращенному нетерминалом C, a $3
- нетерминалом D. Более конкретный пример:
expr : '(' expr ')' ;
Значением, возвращаемым этим правилом, обычно является значение выражения
в скобках, что может быть записано так:
expr : '(' expr ')'
{ $$ = $2 ; }
По умолчанию, значением правила считается значение, возвращенное первым
элементом ($1). Таким образом, если правило не имеет действия, Yacc
автоматически добаляет его в виде $$=$1; , благодаря чему
для правила вида
A : B ;обычно не требуется самому писать действие.
В вышеприведенных примерах все действия стояли в конце правил, но иногда желательно выполнить что-либо до того, как правило будет полностью разобрано. Для этого Yacc позволяет записывать действия не только в конце правила, но и в его середине. Значение такого действия доступно действиям, стоящим правее, через обычный механизм:
A : B
{ $$ = 1; }
C
{ x = $2; y = $3; }
;
В результате разбора иксу (x) присвоится значение 1, а игреку (y) - значение, возвращенное
нетерминалом C. Действие, стоящее в середине правила, считается за
его компоненту, поэтому x=$2 присваивает X-у значение, возвращенное
действием $$=1;
Для действий, находящихся в середине правил, Yacc создает новый нетерминал и новое правило с пустой правой частью и действие выполняется после разбора этого нового правила. На самом деле Yacc трактует последний пример как
NEW_ACT : /* empty */ /* НОВОЕ ПРАВИЛО */
{ $$ = 1; }
;
A : B NEW_ACT C
{ x = $2; y = $3; }
;
В большинстве приложений действия не выполняют ввода/вывода, а конструируют
и обрабатывают в памяти структуры данных, например дерево разбора.
Такие действия проще всего выполнять вызывая подпрограммы для создания
и модификации структур данных. Предположим, что существует
функция node, написанная так, что вызов node( L, n1, n2) создает вершину
с меткой L, ветвями n1 и n2 и возвращает индекс свежесозданной вершины.
Тогда дерево разбора может строиться так:
expr : expr '+' expr
{ $$ = node( '+', $1, $3 ); }
Программист может также определить собственные переменные, доступные
действиям. Их объявление и определение может быть сделано в секции
объявлений, заключенное в символы %{ и %}.
Такие объявления имеют глобальную область видимости, благодаря
чему доступны как действиям, так и лексическому анализатору. Например:
%{
int variable = 0;
%}
Такие строчки, помещенные в раздел объявлений, объявляют переменную
variable типа int и делают ее доступной для всех
действий. Все имена внутренних переменных Yacca начинаются c двух
букв y, поэтому не следует давать своим переменным
имена типа yymy.
Программист, использующий Yacc должен написать сам (или создать при
помощи программы типа Lex) внешний лексический анализатор, который
будет читать символы из входного потока (какого - это внутреннее дело
лексического анализатора), обнаруживать терминальные символы (токены)
и передавать их синтаксическому анализатору, построенному Yaccом (возможно
вместе с неким значением) для дальнейшего разбора. Лексический анализатор
должен быть оформлен как функция с именем yylex,
возвращающая значение типа int, которое представляет
собой тип (номер) обнаруженного во входном потоке токена. Если есть
желание вернуть еще некое значение (например номер в группе), оно
может быть присвоено глобальной, внешней (по отношению
к yylex) переменной по имени yylval.
Лексический анализатор и Yacc должны использовать одинаковые номера
токенов, чтобы понимать друг друга. Эти номера обычно выбираются Yaccом,
но могут выбираться и человеком. В любом случае механизм define
языка Си позволяет лексическому анализатору возвращать эти значения
в символическом виде. Предположем, что токен по имени DIGIT
был определен в секции объявлений спецификации Yaccа, тогда соответствующий
текст лексического анализатора может выглядеть так:
yylex()
{
extern int yylval;
int c;
...
c = getchar();
...
switch (c) {
. . .
case '0':
case '1':
...
case '9':
yylval = c - '0';
return DIGIT;
. . .
}
. . .
Вышеприведенный фрагмент возвращает номер токена DIGIT и значение,
равное цифре. Если при этом сам текст лексического анализатора был
помещен в секцию программ спецификации Yacca - есть гарантия, что
идентификатор DIGIT был определен номером токена DIGIT, причем тем
самым, который ожидает Yacc.
Такой механизм позволяет создавать понятные, легкие в модификации
лексические анализаторы. Единственным ограничением является запрет
на использование в качестве имени токена слов, зарезервированых или часто используемых
в языке Си слов. Например, использование в качестве имен токенов таких
слов как if или while, почти
наверняка приведет к возникновению проблем при компиляции лексического
анализатора. Кроме этого, имя error зарезервировано
для токена, служащего делу обработки ошибок, и не должно использоваться.
Как уже было сказано, номера токенов выбираются либо Yaccом,
либо человеком, но чаще Yaccом, при этом для отдельных символов
(например для ( или ;) выбирается
номер, равный ASCII коду этого символа. Для других токенов номера выбираются
начиная с 257.
Для того, чтобы присвоить токену (или даже литере) номер вручную, необходимо в секции объявлений после имени токена добавить положительное целое число, которое и станет номером токена или литеры, при этом необходимо позаботиться об уникальности номеров. Если токену не присвоен номер таким образом, Yacc присваивает ему номер по своему выбору.
По традици, концевой маркер должен иметь номер токена, равный, либо меньший нуля, и лексический анализатор должен возвращать ноль или отрицательное число при достижении конца ввода (или файла).
Очень неплохим средством для создания лексических анализаторов является программа Lex. Лексические анализаторы, построенные с ее помощью прекрасно гармонируют с синтаксическими анализаторами, построенными Yaccом. Lex можно легко использовать для построения полного лексического анализатора из файла спецификаций, основанного на системе регулярных выражений (в отличие от системы грамматических правил для Yacca), но, правда, существуют языки (например Фортран) не попадающие ни под какую теоретическю схему, но для них приходится писать лексический анализатор вручную.
http://www.cvshome.org/docs/manual/index.html
С помощью CVS вы легко можете обратиться к старым версиям, чтобы точно выяснить, что именно привело к ошибке. Разумеется, можно сохранять все версии всех файлов, которые были созданы, но это потребует огромного объема дискового пространства. CVS хранит все версии файла в едином файле так, чтобы сохранять только изменения между версиями.
CVS также можно использовать, если вы работаете над одним проектом
совместно с кем-либо еще. Слишком легко переписать чужие изменения,
если вы не очень аккуратны. Некоторые редакторы, такие как GNU Emacs,
стараются проследить, чтобы один и тот же файл не изменяли
одновременно два человека. К сожалению, если кто-то использует другой редактор,
эта предосторожность не будет работать. CVS решает эту проблему, изолируя
разработчиков друг от друга. Каждый разработчик работает в своем каталоге,
а CVS объединяет полученные результаты.
Хотя структура вашего репозитория и файла модулей будут взаимодействовать с системой сборки (т.е. `Makefile'), они независимы друг от друга.
CVS не указывает, как собирать что-то. Она просто хранит файлы для получения нужной вам структуры дерева.
CVS не указывает, как использовать дисковое пространство в полученных рабочих каталогах. Если вы напишете `Makefile' или скрипты в каждом каталоге так, что они должны знать относительное положение чего-то еще, то, возможно, что придется обновлять весь репозиторий.
Если вы постараетесь задать модульную структуру для проекта и создадите систему сборки, которая будет совместно использовать файлы ( посредством ссылок, монтирования, VPATH в `Makefile' и т. д.), то сможете использовать дисковое пространство, как захотите. Но вам надо помнить, что любая подобная система требует серьезной работы по ее созданию и поддержанию. CVS не предназначена для решения возникающих при этом проблем.
Разумеется, вам нужно поместить в CVS средства, созданные для поддержки подобной системы сборки (скрипты, `Makefile' и т. д.).
Вычисление того, какие файлы нуждаются в перекомпилировании
когда что-то меняется, так же не входит в задачи CVS. Одним из
традиционных подходов является использование make для сборки и
использование каких-либо специальных средств для создания зависимостей,
используемых make.
Ваши руководители и главные разработчики ожидают, что вы будете достаточно часто общаться между собой, чтобы знать о графике работ, точках слияния, именах веток и датах выпуска. Если они этого не делают, то никакая CVS вам не поможет. CVS не заменит общения между разработчиками.
Встретившись с конфликтами в одном файле, большинство разработчиков
решают их без особого труда. Однако более общее определение "конфликта"
включает в себя проблемы, которые слишком трудно решить без
взаимодействия между разработчиками.
CVS не может обнаружить, что синхронные изменения в одном или
нескольких файлах привели к логическому конфликту. Понятие конфликта,
которое использует CVS, строго текстовое, возникающее когда изменения
в основном файле достаточно близки, чтобы
"напугать" программу слияния (то есть diff3).
CVS не поможет для вычисления нетекстовых или распределенных конфликтов в логике программы.
Например, вы изменили аргументы функции X, определенные в файле `A'. В то же самое время кто-то еще редактирует файл `B', добавляя новый вызов функции X, используя старые аргументы. Это уже не в компетенции CVS. Возьмите себе за привычку читать спецификации и беседовать с коллегами.
Под контролем изменений имеется в виду несколько вещей. Прежде всего,
это может означать отслеживание ошибок, т.е. хранение базы данных
обнаруженных ошибок и их статуса (исправлена ли она? в какой версии?
согласился ли обнаруживший ее, что она исправлена?). Для взаимодействии
CVS с внешней системой отслеживания ошибок почитайте, как это делается
в файлах `rcsinfo' и `verifymsg'.
Другим аспектом контроля изменений является отслеживание такого факта, что изменения
в нескольких файлах в действительности являются одним и тем же согласованным
изменением. Если вы меняете несколько файлов одной командой cvs commit,
то CVS забывает, что эти файлы были изменены одновременно, и единственная
возможность, их объединения - это одинаковые журнальные записи. Ведение файла
`ChangeLog' в стиле GNU может решить некоторые проблемы.
Еще одним аспектом контроля изменений в некоторых системах является
возможность отслеживать статус каждого изменения. Некоторые изменения
были написаны разработчиком, другие написаны другим разработчиком,
и т.д. Обычно при работе с CVS в этом случае создается diff-файл
(используя cvs diff или diff), который посылается по электронной почте
кому-нибудь, кто потом применит этот diff-файл, используя программу
patch. Это очень гибкий прием, но зависит от внешних по отношению к CVS механизмов,
чтобы быть уверенным, что ничего не упущено.
Хотя и существует возможность принудительного выполнения серии тестов,
используя файл `commitinfo'.
Некоторые системы обеспечивают способы убедиться, что изменения и
релизы проходят через определенные ступени, с различными подтверждениями
на каждой. Этого можно добиться и с помощью CVS, но потребуется
немного больше работы. В некоторых случаях, вам придется использовать файлы
`commitinfo', `loginfo', `rcsinfo' или `verifymsg', чтобы
убедиться, что предприняты определенные шаги,
прежде чем CVS позволит зафиксировать изменение. Подумайте также,
должны ли использоваться такие возможности, как ветви разработки и
метки, чтобы, скажем, поработать над новой веткой разработки, а затем
объединять определенные изменения со стабильной веткой, когда эти
изменения одобрены.
В качестве введения в систему CVS мы приведем здесь типичную сессию работы с ней. В первую очередь необходимо понять, что CVS хранит все файлы в централизованном репозитории.
Предположим, что вы работаете над простым компилятором и репозиторий уже настроен.
Исходный текст
состоит из нескольких C-файлов и `Makefile'. Компилятор называется
`tc' (Trivial Compiler), а репозиторий настроен так, что имеется
модуль `tc'.
`tc'. Используйте
команду\$ cvs checkout tcпри этом будет создан каталог
`tc', в который будут помещены все файлы
с исходными текстами.\$ cd tc \$ ls CVS Makefile backend.c driver.c frontend.c parser.cКаталог `CVS' используется для внутренних нужд CVS. Обычно вам не следует редактировать или удалять файлы, находящиеся в этом каталоге. Вы запускаете свой любимый редактор, работаете над
`backend.c' и через
пару часов вы добавили фазу оптимизации в компилятор. Замечание для
пользователей RCS и RCCS: не требуется блокировать файлы, которые
вы желаете отредактировать.
\$ cvs commit backend.cCVS запускает редактор, чтобы позволить вам ввести журнальную запись. Вы набираете: "Добавлена фаза оптимизации", сохраняете временный файл и выходите из редактора. Переменная окружения
$CVSEDITOR определяет, какой именно редактор
будет вызван. Если $CVSEDITOR не установлена, то используется $EDITOR,
если она, в свою очередь, установлена. Если обе переменные не установлены,
используется редактор по умолчанию для вашей операционной системы,
например, vi под Linux или notepad для Windows 95/NT.Когда CVS запускает редактор,
в шаблоне для ввода журнальной записи
перечислены измененные файлы. Для клиента CVS этот список создается
путем сравнения времени изменения файла с его временем изменения,
когда он был получен или обновлен. Таким образом, если время изменения
файла изменилось, а его содержимое осталось прежним, он будет считаться
измененным. Проще всего в данном случае не обращать на это внимания
- в процессе фиксирования изменений CVS определит, что содержимое
файла не изменилось и поведет себя должным образом. Следующая команда
- update - сообщит CVS, что файл не был изменен и его время изменения
будет возвращено в прежнее значение, так что этот файл не будет помехой
при дальнейших фиксированиях.Если вы хотите избежать запуска редактора, укажите журнальную запись
в командной строке, используя флаг `-m', например:
$ cvs commit -m "Добавлена фаза оптимизации" backend.c
tc. Конечно же, это можно сделать так:$ cd .. $ rm -r tcно лучшим способом будет использование команды release:
$ cd .. $ cvs release -d tc M driver.c ? tc You have [1] altered files in this repository. Are you sure you want to release (and delete) directory `tc': n ** `release' aborted by user choice.Команда
release проверяет, что все ваши изменения были зафиксированы.
Если включено журналирование истории, то в файле истории появляется
соответствующая пометка. Если вы используете команду release с флагом
`-d', то она удаляет вашу рабочую копию. В вышеприведенном примере команда release
выдала несколько строк
`? tc', означающих, что файл `tc' неизвестен CVS. Беспокоиться не
о чем, `tc' - это исполняемый файл компилятора, и его не следует хранить
в репозитории. `M driver.c' - более серьезное сообщение. Оно означает, что файл
`driver.c' был изменен с момента последнего получения из репозитория.
Команда release всегда сообщает, сколько измененных файлов находится
в вашей рабочей копии исходных кодов, а затем спрашивает подтверждения
перед удалением файлов или внесения пометки в файл истории. Вы решаете
перестраховаться и отвечаете n RET, когда release просит подтверждения.
`driver.c', поэтому хотите посмотреть,
что именно случилось с ним:$ cd tc $ cvs diff driver.cЭта команда сравнивает версию файла
`driver.c', находящейся в репозитории,
с вашей рабочей копией. Когда вы рассматриваете изменения, вы вспоминаете,
что добавили аргумент командной строки, разрешающий фазу оптимизации.
Вы фиксируете это изменение и высвобождаете модуль:$ cvs commit -m "Добавлена фаза оптимизации" driver.c Checking in driver.c; /usr/local/cvsroot/tc/driver.c,v <- driver.c new revision: 1.2; previous revision: 1.1 done $ cd .. $ cvs release -d tc ? tc You have [0] altered files in this repository. Are you sure you want to release (and delete) directory `tc': y.
Autoconf -- это утилита для создания shell-скриптов,
которые автоматически конфигурируют пакеты с исходным кодом для адаптирования
ко многим UNIX-подобным системам. Конфигурационные скрипты созданные Autoconf,
не зависят от него при выполнении, так что пользователям не нужно устанавливать Autoconf у себя в системе.
Конфигурационные скрипты, созданные Autoconf, не требуют вмешательства
пользователя для своей работы; обычно им даже не требуются входные аргументы для указания типа системы. Вместо этого, они поочередно тестируют систему на присутствие необходимых для работы пакета средств. (До каждой проверки скрипт выводит однострочное сообщение, в котором указано, что сейчас будет проверяться, так что вам будет не слишком скучно ожидать окончания работы скрипта.) В результате эти скрипты хорошо справляются с системами, которые являются гибридами или специализированными вариантами большинства видов UNIX. Поэтому не нужно поддерживать файлы, которые содержат список возможностей поддерживаемых разными версиями каждого варианта UNIX.
Для каждого пакета, используемого Autoconf, он создает конфигурационный
скрипт из шаблона, содержащего список системных возможностей,
которые необходимы либо могут использоваться пакетом.
После того как shell-код, распознающий и использующий ту или иную системную
возможность, написан, Autoconf позволяет применять этот код во всех пакетах,
которые имеют эту возможность. Если позже, по каким-либо
причинам понадобится изменить код командного процессора, то изменения
необходимо будет внести только в одно место; все скрипты настройки
можно автоматически создать заново, чтобы отразить изменения
кода.
Для создания скриптов Autoconf требует наличия программы GNU m4. Скрипты
конфигурации, создаваемые Autoconf, по принятым соглашениям, называются
configure.
Для того чтобы с помощью Autoconf создать скрипт configure, вам необходимо
написать входной файл с именем `configure.in' и выполнить команду
autoconf. Если вы напишите собственный код тестирования возможностей
системы в дополнение к поставляемым с Autoconf, то вам придется записать
его в файлы с именами
`aclocal.m4' и `acsite.m4'. Если вы используете
заголовочный файл, который содержит директивы define, то вы
должны создать файл `acconfig.h', также вы сможете распространять
с пакетом файл `config.h.in', созданный с помощью Autoconf файл `config.h.in'.
Семафоры являются одним из классических примитивов синхронизации. Значение семафора - это целое число в диапазоне от 0 до 32767. Поскольку во многих приложениях требуется использование более одного семафора, ОС Linux предоставляет возможность создавать множества семафоров. Их максимальный размер ограничен системным параметром SEMMSL. Множества семафоров создаются при помощи системного вызова semget.
Процесс, выполнивший системный вызов semget, становится владельцем
или создателем множества семафоров. Он определяет,
сколько будет семафоров
в множестве; кроме того, он специфицирует первоначальные права на
выполнение операций над множеством для всех процессов, включая себя.
Впоследствии данный процесс может уступить право собственности или
изменить права на операции при помощи системного вызова semctl, предназначенного
для управления семафорами, однако на протяжении всего времени существования
множества семафоров создатель остается создателем. Другие процессы,
обладающие соответствующими правами, для выполнения прочих управляющих
действий также могут использовать системный вызов semctl.
Над каждым семафором, принадлежащим некоторому множеству, при помощи системного вызова semop можно выполнить любую из трех операций:
Операции могут снабжаться флагами. Флаг SEM_UNDO означает, что операция выполняется в проверочном режиме, т. е. требуется только узнать, можно ли успешно выполнить данную операцию.
При отсутствии флага IPC_NOWAIT системный вызов semop должен быть приостановлен до тех пор, пока значение семафора благодаря действиям другого процесса, не позволит успешно завершить операцию (ликвидация множества семафоров также приведет к завершению системного вызова). Подобные операции называются ''операциями с блокировкой''. С другой стороны, если обработка завершается неудачей и не указано, что выполнение процесса должно быть приостановлено, операция над семафором называется ``операцией без блокировки''.
Системный вызов semop оперирует не с отдельным семафором, а со множеством семафоров, применяя к нему ``массив операций''. Массив содержит информацию о том, с какими семафорами нужно оперировать и каким образом. Выполнение массива операций с точки зрения пользовательского процесса является неделимым действием. Это значит, во-первых, что если операции выполняются, то только все вместе и, во-вторых, что другой процесс не может получить доступа к промежуточному состоянию множества семафоров, когда часть операций из массива уже выполнена, а другая часть еще не начиналась.
Операционная система выполняет операции из массива по очереди, причем порядок не оговаривается. Если очередная операция не может быть выполнена, то эффект предыдущих операций аннулируется. Если таковой оказалась операция с блокировкой, выполнение системного вызова приостанавливается. Если неудачу потерпела операция без блокировки, системный вызов немедленно завершается, возвращая значение -1 как признак ошибки, а внешней переменной errno присваивается код ошибки.
Файл с именем `configure.in' содержит вызовы макросов Autoconf, проверяющие
системные возможности, которые он может использовать. Для многих таких
возможностей макросы Autoconf уже написаны.
Для проверок большинства других возможностей вы можете использовать
шаблонные макросы Autoconf, на базе которых можно создать специальные
проверки. Для специализированных потребностей, в файл `configure.in'
может понадобиться включить специально написанные скрипты командного
процессора.
Каждый файл `configure.in' должен в самом начале содержать вызов макроса
ACINIT, а в самом конце вызов макроса ACOUTPUT. Также некоторые
макросы полагаются на то, что другие макросы были вызваны первыми,
поскольку перед принятием решения, они проверяют уже установленные
значения переменных.
Для того чтобы ваши файлы были последовательны и единообразны,
приведем желательный порядок вызова макросов Autoconf:
ACINIT(file) Проверка программ Проверка библиотек Проверка заголовочных файлов Проверка определений типов Проверка структур Проверка характеристик компилятора Проверка библиотечных функций Проверка системных сервисов ACOUTPUT(file...)
При вызове макросов с аргументами, между открывающей скобкой и названием
макроса не должно быть пробелов. Аргументы могут занимать несколько
строк, если они заключены в кавычки языка m4 -
`[' и `]'. Если аргументом является длинная строка, например
список имен файлов, то можно использовать символ обратного слэша в
конце строки для указания, что список продолжается на следующей строке
(эта возможность реализуется командным процессором, без привлечения
возможностей Autoconf).
Некоторые макросы отрабатывают два случая: когда заданное условие
выполняется и когда это условие не выполняется. В некоторых местах вы
можете захотеть сделать что-либо, если условие выполняется, и ничего
не делать в противном случае, и наоборот. Для того, чтобы пропустить
действие при выполнении условия, передайте пустое значение аргументу
action-if-found данного макроса. Для пропуска действия при невыполнении
условия уберите аргумент action-if-not-found данного макроса, включив
предшествующую ему запятую.
В файл `configure.in' можно включать комментарии, начиная их со встроенного
макроса m4 --dnl, который отбрасывает текст вплоть до начала новой
строки. Эти комментарии не появятся в созданных скриптах configure.
Программа autoscan может помочь вам в создании файла
`configure.in'
для программного пакета. Эта программа выполняет анализ дерева исходных
текстов, корень которого указан в командной строке или совпадает с
текущим каталогом. Программа ищет в исходных текстах следы обычных
проблем с переносимостью и создает файл `configure.scan', который
является заготовкой для `configure.in' данного пакета.
Вы должны сами просмотреть файл `configure.scan' перед тем, как переименовать
его в `configure.in': скорее всего, он будет нуждаться в некоторых
исправлениях. Иногда autoscan выдает макросы в неправильном порядке,
и поэтому Autoconf будет выдавать предупреждения; вам необходимо вручную
передвинуть эти макросы. Если же вы хотите, чтобы пакет использовал
заголовочный файл настроек, то сами добавьте вызов макроса
ACCONFIGHEADER. Вам также необходимо добавить или изменить некоторые
директивы препроцессора if в вашей программе, чтобы заставить
ее работать с Autoconf.
Программа autoscan использует несколько файлов данных, чтобы определить,
какие макросы следует использовать при обнаружении определенных символов
в исходных файлах пакета. Эти файлы данных устанавливаются вместе
с дистрибутивными макрофайлами Autoconf и имеют одинаковый формат.
Каждая строка состоит из символа, пробелов и имени макроса Autoconf,
которое выдается в том случае, если заданный символ имеется в исходных
текстах. Строки, начинающиеся с символа `#' являются комментариями.
Чтобы установить программу autoscan вам необходима
программа Perl. Программа autoscan распознает следующие ключи командной строки:
--help
- выдает список ключей командной строки и прекращает работу;
--macrodir=dir
- заставляет программу искать файлы данных в каталоге dir, а не в каталоге,
куда производилась установка. Вы также можете установить значение
переменной окружения
ACMACRODIR равным пути к этому каталогу; данный
ключ командной строки переопределяет значение переменной окружения;
--verbose
- выдает имена исследуемых файлов и потенциально интересные символы,
обнаруженные в этих файлах. Количество выданной информации может быть
довольно объемной;
--version
- выдает номер версии Autoconf и прекращает работу.
Чтобы создать скрипт configure из файла `configure.in',
просто запустите программу autoconf без аргументов; autoconf обработает
файл `configure.in' с помощью макропроцессора m4, используя макросы
autoconf. Если вы зададите в качестве аргумента имя файла, то вместо
`configure.in' будет использоваться заданный файл, а вывод будет производиться
на стандартный вывод, а не в файл configure.
Если в качестве аргумента Autoconf задать `-', то она будет читать
со стандартного ввода, а не из файла `configure.in', а результаты
будут выдаваться на стандартный вывод.
Макросы Autoconf определены в нескольких файлах. Некоторые из них
распространяются вместе с Autoconf; Autoconf читает их в первую очередь.
Затем ищется необязательный файл `acsite.m4' в каталоге, который содержит
распространяемые с Autoconf файлы макросов, и необязательный файл
`aclocal.m4' в текущем каталоге. Эти файлы могут содержать макросы,
специфические для вашей машины или макросы для конкретных пакетов
программного обеспечения.
Программа autoconf распознает следующие ключи командной строки:
--help, -h
- выдает список ключей командной строки и прекращает работу;
--localdir=dir, -l dir
- ищет файл `aclocal.m4' для данного пакета в каталоге dir, а не в
текущем каталоге;
--macrodir=dir
- заставляет программу искать файлы данных в каталоге dir, а не в каталоге,
куда производилась установка. Вы также можете установить значение
переменной окружения
ACMACRODIR, присвоив ей значение пути к этому
каталогу; ключ командной строки переопределяет значение переменной
окружения;
--version
- выдает номер версии autoconf и прекращает работу.
Скриптам, созданным Autoconf, нужна некоторая инициализационная информация.
Например: где найти исходные тексты пакета; какие выходные файлы
создавать. Далее следует описание инициализации и создания выходных файлов
Каждый скрипт configure должен в первую очередь вызвать макрос ACINIT.
AC_INIT (unique-file-in-source-dir)- обрабатывает аргументы командной строки и ищет каталог с исходными текстами.
unique-file-in-source-dir -- это некоторый файл в каталоге
с исходными текстами пакета, который проверяется на существование,
чтобы убедиться, что это именно тот каталог с исходными текстами,
который нужен. Когда указывается неверный каталог, используйте ключ
командной строки `--srcdir'; эта проверка позволит правильно идентифицировать
каталог с исходными текстами.
Каждый скрипт configure, созданный Autoconf, должен заканчиваться
вызовом макроса ACOUTPUT. Этот макрос создает файлы `Makefile' и
дополнительные файлы, которые являются результатом конфигурации.
AC_OUTPUT ([file... [, extra-cmds [, init-cmds]]])- создает выходные файлы. Этот макрос вызывается один раз в конце файла
`configure.in'. Аргумент file... является списком выходных файлов
через пробел; этот список может быть пустым. Макрос создает каждый
из файлов `file', копируя входной файл (по умолчанию `file.in') и
подставляя туда значения выходных переменных.
Если вызывались макросы ACCONFIGHEADER, ACLINKFILES или
ACCONFIGSUBDIRS,
то этот макрос также создаст файлы, указанные в аргументах этих макросов.
Типичный вызов ACOUTPUT выглядит примерно так:
ACOUTPUT(Makefile src/Makefile man/Makefile X/Imakefile).
В параметре extra-cmds можно указать команды, которые будут вставлены
в файл `config.status' и сработают после того, как было сделано все остальное.
В параметре init-cmds можно указать команды, которые будут вставлены
непосредственно перед extra-cmds, причем configure выполнит в них
подстановку переменных, команд и обратных слэшей. Аргумент init-cmds
можно использовать для передачи переменных из configure в extra-cmds.
Если был вызван макрос
ACOUTPUTCOMMANDS, то команды, переданные
ему в качестве аргумента, выполняются прямо перед командами, переданными
макросу ACOUTPUT.
Количество макросов для настроек и различного типа проверок слишком велико, чтобы приводить их здесь, вместо этого вы можете обратиться к документации, чтобы получить их полный список.
Когда вы пишете тест свойства, который будет применяться более чем в
одном пакете программного обеспечения, то лучше всего оформить его
в виде нового макроса. В этом разделе приводятся некоторые инструкции
и указания по написанию макросов Autoconf.
Макросы Autoconf определяются с помощью макроса ACDEFUN, который
подобен встроенному макросу define программы m4. Кроме определения
макроса, ACDEFUN добавляет к нему некоторый код, который используется
для ограничения порядка вызова макросов.
Определение макроса Autoconf выглядит примерно следующим образом:
ACDEFUN(macro-name, macro-body)
Квадратные скобки не указывают на необязательный параметр: они должны присутствовать в определении макроса для избежания проблем расширения макроса. Вы можете ссылаться на передаваемые макросу параметры с помощью переменных `$1', `$2' и т.д.
Все макросы Autoconf названы именами, состоящими из заглавных букв
и начинающихся с префикса `AC', для того, чтобы избежать конфликтов
с другим текстом. Все переменные командного процессора, которые используются
для внутренних целей в этих макросах, как правило, называются именами
из прописных букв и начинаются с `ac'. Чтобы избежать
конфликтов с вашими макросами, вы должны использовать собственный
префикс для ваших макросов и переменных командного процессора. В качестве
возможных значений вы можете использовать свои инициалы, или сокращенное
название вашей организации или пакета программ.
Большинство имен макросов Autoconf отвечают соглашению о структуре
имени, которое показывает, какой тип свойства проверяемого данным макросом.
Имена макросов состоит из нескольких слов, которые разделены символами
подчеркивания, продвигаясь от общих слов к более спецефическим.
Первое слово имени после префикса `AC' обычно сообщает категорию
тестируемого свойства. Следующие категории используются Autoconf для
специфических макросов, один из типов которых вы ,вероятно, захотите
написать. Используйте перечисленные категории при написании ваших
макросов; если нужной категории нет, то вы можете вводить свои собственные.
C - встроенные возможности языка C.
DECL - объявления переменных C в заголовочных файлах.
FUNC - функции в библиотеках.
GROUP - группа UNIX владеющая файлами.
HEADER - заголовочные файлы.
LIB - библиотеки C.
PATH - полные путевые имена файлов, включая программы.
PROG - базовые имена программ.
STRUCT - определения структур C в заголовочных файлах.
SYS - свойства операционной системы.
TYPE - встроенные или объявленные типы C.
VAR - переменные C в библиотеках.
После категории следует имя тестируемого свойства. Любые дополнительные
слова в имени макроса указывают на специфические аспекты тестируемого
свойства. Например, ACFUNCUTIMENULL проверяет поведение функции
utime при вызове ее с указателем, равным NULL.
Макрос, который является внутренней подпрограммой другого макроса,
должен иметь имя, начинается с его имени, за которым
следует одно или несколько слов, описывающих, что делает этот макрос.
Например, макрос ACPATHX имеет внутренние макросы ACPATHXXMKMF
и ACPATHXDIRECT.
Перед тем как использовать семафоры (выполнять операции или управляющие
действия), нужно создать множество семафоров с уникальным идентификатором
и ассоциированной структурой данных. Уникальный идентификатор называется
идентификатором
множества семафоров (semid); он используется для обращений
к множеству и структуре данных. С точки зрения реализации множество
семафоров представляет собой массив структур. Каждая структура соответствует
семафору и определяется следующим образом:
ushort semval; /* Значение семафора */
/* Идентификатор процесса, выполнявшего
последнюю операцию */
short sempid;
/* Число процессов, ожидающих увеличения
значения семафора */
ushort semncnt;
/* Число процессов, ожидающих обнуления
значения семафора */
ushort semzcnt;
};
С каждым идентификатором множества семафоров ассоциирована структура данных, содержащая следующую информацию:
/*Структура прав на выполнение операций*/
struct ipc_perm sem_perm;
/*Указатель на первый семафор в множестве*/
struct sem *sem_base;
/* Количество семафоров в множестве */
ushort sem_nsems;
/* Время последней операции */
time_t sem_otime;
/* Время последнего изменения */
time_t sem_ctime;
};
Поле sem_perm данной структуры использует в качестве шаблона структуру типа ipc_perm, общую для всех средств межпроцессной связи. Системный вызов semget аналогичен вызову msgget (разумеется, с заменой слов ``очередь сообщений'' на ``множество семафоров''). Он также предназначен для получения нового или опроса существующего идентификатора, а нужное действие определяется значением аргумента key. В подобных ситуациях semget терпит неудачу. Единственное отличие состоит в том, что при создании требуется посредством аргумента nsems указывать число семафоров в множестве.
После того как созданы множество семафоров с уникальным идентификатором и ассоциированная с ним структура данных, можно использовать системные вызовы semop для операций над семафорами и semctl - для выполнения управляющих действий.
Некоторые макросы Autoconf зависят от других макросов, которые должны
быть вызваны первыми, чтобы работа производилась правильно. Autoconf
предоставляет возможность проверки того, что нужные макросы были вызваны,
и способ предоставления пользователю информации о макросах, которые
вызываются в неправильном порядке.
Скрипт configure пытается определить правильные значения для различных,
зависящих от системы переменных, которые используются в процессе установки.
Он использует эти переменные для создания файлов `Makefile' в каждом
из каталогов пакета. Дополнительно он может создавать один или несколько
файлов `.h', содержащих зависящие от системы определения. В заключение,
он создает скрипт командного процессора с именем `config.status',
который вы можете в дальнейшем запускать для воссоздания текущей настройки;
также создаются файл `config.cache', который сохраняет результаты
тестов, для ускорения перенастройки, и файл `config.log', содержащий
вывод компилятора (этот файл полезен для отладки configure).
Файл `configure.in' используется для создания скрипта
`configure'
программой Autoconf. Вам необходимо иметь только `configure.in', если
вы хотите изменить его или заново создать скрипт `configure' с помощью
более новой версии Autoconf.
Наиболее простым способом компиляции данного пакета являются следующие действия:
`./configure' в командной строке, чтобы настроить пакет
для вашей системы. Работа configure
займет некоторое время. Во время выполнения скрипт выдает сообщения
о том, какие свойства он проверяет.
`make' для компиляции пакета.
`make check' для запуска любых собственных тестов,
которые поставляются вместе с пакетом.
`make install' для установки программ и файлов данных
и документации.
`make clean'. Для удаления
файлов, созданных configure, наберите `make distclean'. Имеющаяся
цель `make
maintainer-clean' в основном предназначена для
разработчиков программного обеспечения.
Для создания множества семафоров служит системный вызов semget. Синтаксис данного системного вызова:
#include <sys/ipc.h>
#include <sys/sem.h>
int semget (key_t key, int nsems, int semflg);
Смысл аргументов key и semflg тот же, что и у соответствующих аргументов системного вызова msgget. Аргумент nsems задает число семафоров в множестве. Если запрашивается идентификатор существующего множества, значение nsems не должно превосходить числа семафоров в множестве.
Превышение системных параметров SEMMNI, SEMMNS и SEMMSL при попытке создать новое множество всегда ведет к неудачному завершению. Системный параметр SEMMNI определяет максимально допустимое число уникальных идентификаторов множеств семафоров в системе. Системный параметр SEMMNS определяет максимальное общее число семафоров в системе. Системный параметр SEMMSL определяет максимально допустимое число семафоров в одном множестве.
Automake -- это утилита для автоматического создания файлов
`Makefile.in'
из файлов `Makefile.am'. Каждый файл
`Makefile.am' фактически является
набором макросов для программы make (иногда с несколькими правилами).
Полученные таким образом файлы `Makefile.in' соответствуют стандартам
GNU Makefile.
Стандарт GNU Makefile - это длинный, запутанный документ, и его содержание
может в будущем измениться. Automake разработан для того, чтобы освободить от
бремени сопровождения Makefile человека, ведущего проект GNU.
Типичный входной файл Automake является просто набором макроопределений.
Каждый такой файл обрабатывается, и из него создается файл `Makefile.in'.
В каталоге проекта должен быть только один файл `Makefile.am'. Automake
накладывает на проект некоторые ограничения; например, он предполагает,
что проект использует программу Autoconf, а также налагает некоторые
ограничения на содержимое файла `configure.in'. Automake требует наличия
программы perl для генерации файлов `Makefile.in'. Однако дистрибутив,
созданный Automake, является полностью соответствующим стандартам
GNU и не требует наличия perl для компиляции.
Automake читает файл `Makefile.am' и создает на его основе файл `Makefile.in'.
Специальные макросы и цели, определенные в
`Makefile.am', заставляют
Automake генерировать более специализированный код; например, макроопределение
`binPROGRAMS' заставит создать цели для компиляции и компоновки
программ.
Макроопределения и цели из файла `Makefile.am' копируются в файл `Makefile.in'
без изменений. Это позволяет вам добавлять в генерируемый файл `Makefile.in'
произвольный код. Например, дистрибутив Automake включает в себя нестандартную
цель cvs-dist, которую использует человек, сопровождающий Automake,
для создания дистрибутивов из системы контроля исходного кода.
Заметьте, что расширения GNU make не распознаются программой Automake.
Использование таких расширений в файле
`Makefile.am' приведет к ошибкам
или странному поведению программы. Automake пытается сгруппировать комментарии
к расположенным по соседству целям и макроопределениям.
Цель, определенная в `Makefile.am', обычно переопределяет любую цель
с таким же именем, которая была бы автоматически создана Automake.
Хотя этот прием и работает, старайтесь избегать его использования,
поскольку иногда автоматически созданные цели являются очень важными. Аналогичным
образом макрос, определенный в `Makefile.am', будет переопределять
любой макрос, который создает Automake. Это часто более полезно, чем
возможность переопределения цели. Но будьте осторожны, поскольку многие
из макросов, создаваемых программой Automake, считаются макросами
только для внутреннего использования, и их имена могут изменяться
в будущих версиях.
При обработке макроопределения Automake рекурсивно обрабатывает макросы,
на которые есть ссылка в данном макроопределении. Например, если Automake
исследует содержимое fooSOURCES в следующем определении:
xs = a.c b.c foo_SOURCES = c.c $(xs) ,то он будет использовать файлы
`a.c', `b.c' и `c.c' как содержимое
fooSOURCES.
Automake также вводит форму комментария, который не копируется в выходной
файл; все строки, начинающиеся с `', полностью игнорируются Automake.
Очень часто первая строка файла `Makefile.am' выглядит следующим образом:
## Process this file with Automake to produce Makefile.in ## Для получения Makefile.in обработайте этот файл ## программой Automake .
Для полного ознакомления с утилитой Automake рекомендуется прочитать
``Руководство по использованию Automake''.
http://www.gnu.org/software/Automake/manual/Automake|.html)Для подробного описания макросов загляните в справочные страницы
Automake.Здесь же ограничимся подробными примерами, в которых показано, как
использовать Automake для простых целей.
Предположим, что мы только что закончили писать программу zardoz.
Вы использовали Autoconf для обеспечения
переносимости, но ваш файл `Makefile.in' написан бессистемно.
Вы же хотите сделать его "пуленепробиваемым", и поэтому решаете использовать
Automake.
Сначала вам необходимо обновить ваш файл `configure.in', чтобы вставить
в него команды, которые необходимы для работы Automake. Проще всего
для этого добавить строку AM_INIT_Automake сразу после ACINIT:
AM_INIT_Automake(zardoz, 1.0) AM_INIT_Automake ...Поскольку ваша программа не имеет никаких осложняющих факторов (например, она не использует
gettext и не будет создавать разделяемые библиотеки),
то первая стадия на этом и заканчивается. Это легко!
Теперь вы должны заново создать файл `configure'. Но для этого нужно
указать autoconf, где найти новые макросы, которые вы использовали.
Для создания файла `aclocal.m4' удобнее всего будет использовать программу
aclocal. Но будьте осторожны - у вас уже есть `aclocal.m4', поскольку
вы уже написали несколько собственных макросов для вашей программы.
Программа aclocal позволяет вам поместить ваши собственные макросы
в файл `acinclude.m4', так что для сохранения вашей работы просто
переименуйте свой файл с макросами, а уж затем запускайте программу
aclocal:
mv aclocal.m4 acinclude.m4 aclocal autoconfТеперь пришло время написать свой собственный файл
`Makefile.am' для
программы zardoz. Поскольку zardoz является пользовательской программой,
то вам хочется установить ее туда, где располагаются другие пользовательские
программы. К тому же, zardoz содержит в комплекте документацию в формате
Texinfo. Ваш скрипт `configure.in' использует ACREPLACEFUNCS,
поэтому вам необходимо скомпоновать программу с `@LIBOBJS@'. Вот что
вам необходимо написать в `Makefile.am'.
bin_PROGRAMS = zardoz zardoz_SOURCES = main.c head.c float.c vortex9.c gun.c zardoz_LDADD = @LIBOBJS@ info_TEXINFOS = zardoz.texiТеперь можно запустить
Automake --add-missing, чтобы создать файл
`Makefile.in', используя дополнительные файлы.
GNU hello <ftp://ftp.gnu.org/pub/gnu/hello/hello-1.3.tar.gz> известен
своей классической простотой и многогранностью. В этом разделе показывается,
как Automake может быть использован с пакетом GNU Hello. Примеры,
приведенные ниже, взяты из последней бета-версии GNU Hello, но убран
код, предназначенный только для разработчика пакета, а также сообщения
об авторских правах.
Конечно же, GNU Hello использует больше возможностей, чем традиционная
двухстроковая программа: GNU Hello работает с разными языками, выполняет
обработку ключей командной строки, имеет документацию и набор тестов.
Вот файл `configure.in' из пакета GNU Hello:
## Обработайте этот файл autoconf для получения ## скрипта configure. AC_INIT(src/hello.c) AM_INIT_Automake(hello, 1.3.11) AM_CONFIG_HEADER(config.h) ## Установка доступных языков. ALL_LINGUAS="de fr es ko nl no pl pt sl sv" ## Проверка наличия программ. AC_PROG_CC AC_ISC_POSIX ## Проверка библиотек. ## Проверка заголовочных файлов. AC_STDC_HEADERS AC_HAVE_HEADERS(string.h fcntl.h sys/file.h sys/param.h) ## Проверка библиотечных функций. AC_FUNC_ALLOCA ## Проверка st_blksize в структуре stat AC_ST_BLKSIZE ## макрос интернационализации AM_GNU_GETTEXT AC_OUTPUT([Makefile doc/Makefile intl/Makefile po/Makefile.in \ src/Makefile tests/Makefile tests/hello], [chmod +x tests/hello])Макросы
`AM' предоставляются Automake (или библиотекой Gettext);
остальные макросы является макросами Autoconf.
Файл `Makefile.am' в корневом каталоге выглядит следующим образом:
EXTRA_DIST = BUGS ChangeLog.O SUBDIRS = doc intl po src testsКак видите, вся работа выполняется в подкаталогах. Каталоги
`po' и
`intl' автоматически создаются программой gettextize.
В файле `doc/Makefile.am' мы видим строки:
info_TEXINFOS = hello.texi hello_TEXINFOS = gpl.texiЭтого достаточно для сборки, установки и распространения руководства
GNU Hello.
Вот содержимое файла `tests/Makefile.am':
TESTS = hello EXTRA_DIST = hello.in testdataСкрипт
`hello' создается configure, и это единственная возможность для
тестирования. При выполнении make check этот тест будет запущен.
В заключение приведем содержимое `src/Makefile.am', где и выполняется
вся настоящая работа:
bin_PROGRAMS = hello
hello_SOURCES = hello.c version.c getopt.c getopt1.c \
getopt.h system.h
hello_LDADD = @INTLLIBS@ @ALLOCA@
localedir = $(datadir)/locale
INCLUDES = -I../intl -DLOCALEDIR="$(localedir)"
Для создания всех файлов `Makefile.in' пакета запустите программу
Automake в каталоге верхнего уровня без аргументов. Тогда automake автоматически
найдет каждый файл `Makefile.am' и сгенерирует соответствующий файл
`Makefile.in'. Заметьте, что Automake имеет более простое видение
структуры пакета; он предполагает, что пакет имеет только один файл
`configure.in', расположенный в каталоге верхнего уровня. Если в вашем
пакете имеется несколько файлов `configure.in', то вам необходимо
запустить Automake в каждом каталоге, где есть файл `configure.in'.
Вы можете также задать аргумент для Automake: суффикс `.am' добавляется
к аргументу, а результат используется как имя входного файла. В основном
эта возможность применяется для автоматической перегенерации устаревших
файлов `Makefile.in'. Заметьте, что Automake всегда должен запускаться
из каталога верхнего уровня проекта, даже если необходимо перегенерировать
`Makefile.in' в каком-либо подкаталоге. Это необходимо, потому что
Automake должен просканировать файл `configure.in', а также потому,
что Automake в некоторых случаях изменяет свое поведение при обработке
`Makefile.in' в подкаталогах.
Программа Automake принимает следующие ключи командной строки:
`-a',`add-missing'.
В некоторых ситуациях Automake требует наличия некоторых общих файлов;
например, если в `configure.in' выполняется макрос ACCANONICALHOST,
то требуется наличие файла `config.guess'. Automake распространяется
с несколькими такими файлами; этот ключ заставит программу автоматически
добавить к пакету отсутствующие файлы, если это возможно. В общем,
если Automake сообщает вам, что какой-то файл отсутствует, то используйте
этот ключ. По умолчанию Automake пытается создать символьную ссылку
на собственную копию отсутствующего файла; это поведение может быть
изменено с помощью ключа --copy.
`amdir=dir'.
Этот ключ заставляет Automake искать файлы данных в каталоге dir,
а не в каталоге установки; этот ключ обычно используется при отладке
`build-dir=dir'.
Сообщает Automake, где располагается каталог для сборки. Этот ключ
используется при введении зависимостей в файл `Makefile.in',
созданный командой make dist; он не должен использоваться в других
случаях.
`-c',`copy'.
При использовании с ключом --add-missing, заставляет копировать недостающие
файлы. По умолчанию создаются символьные ссылки.
`cygnus'.
Заставляет сгенерированные файлы `Makefile.in' следовать правилам
Cygnus, вместо правил GNU или Gnits.
`foreign'.
Устанавливает глобальную строгость в значение `foreign'.
`gnits'.
Устанавливает глобальную строгость в значение `gnits'.
`gnu'.
Устанавливает глобальную строгость в значение `gnu'. По умолчанию
используется именно такая строгость.
`help'.
Печатает список ключей командной строки и завершается.
`-i','-include-deps'.
Включить всю автоматически генерируемую информацию о зависимостях
в генерируемый файл `Makefile.in'. Это делается в основном при создании
дистрибутива.
`generate-deps'.
Создать файл, объединяющий всю автоматически генерируемую информацию
о зависимостях , этот файл будет называться `.depsegment'. В основном
этот ключ используется при создании дистрибутива; он полезен при сопровождении
`Makefile' или файлов `Makefile' для других платформ (`Makefile.DOS',
и т. п.), а также может использоваться с ключами `--include-deps',
`--srcdir-name' и `--build-dir'. Заметьте, что если задан этот ключ,
то никакой другой обработки не выполняется.
`no-force'.
Обычно Automake создает все файлы `Makefile.in', указанные в `configure.in'.
Этот ключ заставляет обновлять только те файлы `Makefile.in', с учетом зависимостей друг от друга,
которые устарели.
`-odir',`output-dir=dir'.
Поместить сгенерированный файл `Makefile.in' в каталог dir. Обычно
каждый файл `Makefile.in' создается в том же каталоге, что и
соответствующий файл `Makefile.am'. Этот ключ используется при создании
дистрибутивов.
`srcdir-name=dir'.
Сообщает Automake имя каталога с исходными текстами текущего дистрибутива.
Этот ключ используется при включении зависимостей в файл `Makefile.in',
сгенерированный командой make dist; он не должен использоваться в
других случаях.
`-v',`verbose'.
Заставляет Automake выдавать информацию о том, какие файлы читаются
или создаются.
`version'.
Выдает номер версии Automake и завершается.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html mainfile.tex
The translation was initiated by on 2004-06-22
Синтаксис системного вызова semctl:
#include <sys/ipc.h>
#include <sys/sem.h>
int semctl (int semid, int semnum, int cmd, arg);
union semun {
int val;
struct semid_ds *buf;
ushort *array;
} arg;
Аргументы semid и semnum определяют множество или отдельный семафор, над которым выполняется управляющее действие. В качестве аргумента semid должен выступать идентификатор множества семафоров, предварительно полученный при помощи системного вызова semget. Аргумент semnum задает номер семафора во множестве. Семафоры нумеруются с нуля.
Назначение аргумента arg зависит от управляющего действия, которое определяется значением аргумента cmd. Допустимы следующие действия:
Пример работы с семафорами:
возможности системного вызова semctl()
(управление семафорами) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#define MAXSETSIZE 25
main ()
{
extern int errno;
struct semid_ds semid_ds;
int length, rtrn, i, c;
int semid, semnum, cmd, choice;
union semun {
int val;
struct semid_ds *buf;
ushort array [MAXSETSIZE];
} arg;
/* Инициализация указателя на структуру данных */
arg.buf = &semid_ds;
/* Ввести идентификатор множества семафоров */
printf ("Введите ид-р множества семафоров: ");
scanf ("%d", &semid);
/* Выбрать требуемое управляющее действие */
printf ("\nВведите номер требуемого действия:\n");
printf (" GETVAL = 1\n");
printf (" SETVAL = 2\n");
printf (" GETPID = 3\n");
printf (" GETNCNT = 4\n");
printf (" GETZCNT = 5\n");
printf (" GETALL = 6\n");
printf (" SETALL = 7\n");
printf (" IPC_STAT = 8\n");
printf (" IPC_SET = 9\n");
printf (" IPC_RMID = 10\n");
printf (" Выбор = ");
scanf ("%d", &cmd);
/* Проверить значения */
printf ("идентификатор = %d, команда = %d\n",
semid, cmd);
/* Сформировать аргументы и выполнить вызов */
switch (cmd) {
case 1: /* Получить значение */
printf ("\nВведите номер семафора: ");
scanf ("%d", &semnum);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, GETVAL, 0);
printf ("\nЗначение семафора =
%d\n", rtrn);
break;
case 2: /* Установить значение */
printf ("\nВведите номер семафора: ");
scanf ("%d", &semnum);
printf ("\nВведите значение: ");
scanf ("%d", &arg.val);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, SETVAL,
arg.val);
break;
case 3: /* Получить ид-р процесса */
rtrn = semctl (semid, 0, GETPID, 0);
printf ("\Последнюю операцию выполнил:
%d\n",rtrn);
break;
case 4: /* Получить число процессов, ожидающих
увеличения значения семафора */
printf ("\nВведите номер семафора: ");
scanf ("%d", &semnum);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, GETNCNT, 0);
printf ("\nЧисло процессов = %d\n", rtrn);
break;
case 5: /* Получить число процессов, ожидающих
обнуления значения семафора */
printf ("Введите номер семафора: ");
scanf ("%d", &semnum);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, GETZCNT, 0
printf ("\nЧисло процессов = %d\n", rtrn);
break;
case 6: /* Опросить все семафоры */
/* Определить число семафоров в множестве */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
length = arg.buf->sem_nsems;
if (rtrn == -1) goto ERROR;
/* Получить и вывести значения всех
семафоров в указанном множестве */
rtrn = semctl (semid, 0, GETALL, arg.array);
for (i = 0; i < length; i++)
printf (" %d", arg.array [i]);
break;
case 7: /* Установить все семафоры */
/* Определить число семафоров в множестве */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
length = arg.buf->sem_nsems;
if (rtrn == -1) goto ERROR;
printf ("\nЧисло семафоров = %d\n", length);
/* Установить значения семафоров множества */
printf ("\nВведите значения:\n");
for (i = 0; i < length; i++)
scanf ("%d", &arg.array [i]);
/* Выполнить системный вызов */
rtrn = semctl (semid, 0, SETALL, arg.array);
break;
case 8: /* Опросить состояние множества */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
printf ("\nИдентификатор пользователя = %d\n",
arg.buf->sem_perm.uid);
printf ("Идентификатор группы = %d\n",
arg.buf->sem_perm.gid);
printf ("Права на операции = 0%o\n",
arg.buf->sem_perm.mode);
printf ("Число семафоров в множестве = %d\n",
arg.buf->sem_nsems);
printf ("Время последней операции = %d\n",
arg.buf->sem_otime);
printf ("Время последнего изменения = %d\n",
arg.buf->sem_ctime);
break;
case 9: /* Выбрать и изменить поле
ассоциированной структуры данных */
/* Опросить текущее состояние */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
if (rtrn == -1) goto ERROR;
printf ("\nВведите номер поля, ");
printf ("которое нужно изменить: \n");
printf (" sem_perm.uid = 1\n");
printf (" sem_perm.gid = 2\n");
printf (" sem_perm.mode = 3\n");
printf (" Выбор = ");
scanf ("%d", &choice);
switch (choice) {
case 1: /* Изменить ид-р владельца */
printf ("\nВведите ид-р владельца: ");
scanf ("%d", &arg.buf->sem_perm.uid);
printf ("\nИд-р владельца = %d\n",
arg.buf->sem_perm.uid);
break;
case 2: /* Изменить ид-р группы */
printf ("\nВведите ид-р группы = ");
scanf ("%d", &arg.buf->sem_perm.gid);
printf ("\nИд-р группы = %d\n",
arg.buf->sem_perm.uid);
break;
case 3: /* Изменить права на операции */
printf ("\nВведите восьмеричный код
прав доступа: ");
scanf ("%o", &arg.buf->sem_perm.mode);
printf ("\nПрава = 0%o\n",
arg.buf->sem_perm.mode);
break;
}
/* Внести изменения */
rtrn = semctl (semid, 0, IPC_SET, arg.buf);
break;
case 10: /* Удалить ид-р множества семафоров и
ассоциированную структуру данных */
rtrn = semctl (semid, 0, IPC_RMID, 0);
}
if (rtrn == -1) {
/* Сообщить о неудачном завершении */
ERROR:
printf ("\nsemctl завершился неудачей!\n");
printf ("\nКод ошибки = %d\n", errno);
}
else {
printf ("\nmsgctl завершился успешно,\n");
printf ("идентификатор semid = %d\n", semid);
}
exit (0);
}
Cинтаксис системного вызова semop описан так:
#include <sys/ipc.h>
#include <sys/sem.h>
int semop (int semid, struct sembuf *sops,
unsigned int nsops)
В качестве аргумента semid должен выступать идентификатор множества семафоров, предварительно полученный при помощи системного вызова semget.
Аргумент sops (массив структур) определяет, над какими семафорами и какие именно операции будут выполняться. Структура, описывающая операцию над одним семафором, определяется следующим образом:
short sem_num; /* Номер семафора */
short sem_op; /* Операция над семафором */
short sem_flg; /* Флаги операции */
};
Номер семафора задает конкретный семафор в множестве, над которым должна быть выполнена операция.
Выполняемая операция определяется следующим образом:
Пример работы с семафорами приведен ниже:
возможности системного вызова semop()
(операции над множеством семафоров) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#define MAXOPSIZE 10
main ()
{
extern int errno;
struct sembuf sops [MAXOPSIZE];
int semid, flags, i, rtrn;
unsigned nsops;
/* Ввести идентификатор множества семафоров */
printf ("\nВведите идентификатор
множества семафоров,");
printf ("\nнад которым будут
выполняться операции: ");
scanf ("%d", &semid);
printf ("\nИд-р множества семафоров = %d", semid);
/* Ввести число операций */
printf ("\nВведите число операций ");
printf ("над семафорами из этого множества: \n");
scanf ("%d", &nsops);
printf ("\nЧисло операций = %d", nsops);
/* Инициализировать массив операций */
for (i = 0; i < nsops; i++) {
/* Выбрать семафор из множества */
printf ("\nВведите номер семафора: ");
scanf ("%d", &sops [i].sem_num);
printf ("\nНомер = %d", sops [i].sem_num);
/* Ввести число, задающее операцию */
printf ("\nЗадайте операцию над семафором: ");
scanf ("%d", &sops [i].sem_op);
printf ("\nОперация = %d", sops [i].sem_op);
/* Указать требуемые флаги */
printf ("\nВведите код, ");
printf ("соответствующий требуемым флагам:\n");
printf (" Нет флагов = 0\n");
printf (" IPC_NOWAIT = 1\n");
printf (" SEM_UNDO = 2\n");
printf (" IPC_NOWAIT и SEM_UNDO = 3\n");
printf (" Выбор = ");
scanf ("%d", &flags);
switch (flags) {
case 0:
sops [i].sem_flg = 0;
break;
case 1:
sops [i].sem_flg = IPC_NOWAIT;
break;
case 2:
sops [i].sem_flg = SEM_UNDO;
break;
case 3:
sops [i].sem_flg = IPC_NOWAIT | SEM_UNDO;
break;
}
printf ("\nФлаги = 0%o", sops [i].sem_flg);
}
/* Распечатать все структуры массива */
printf ("\nМассив операций:\n");
for (i = 0; i < nsops; i++) {
printf (" Номер семафора = %d\n",
sops [i].sem_num);
printf (" Операция = %d\n", sops [i].sem_op);
printf (" Флаги = 0%o\n", sops [i].sem_flg);
}
/* Выполнить системный вызов */
rtrn = semop (semid, sops, nsops);
if (rtrn == -1) {
printf ("\nsemop завершился неудачей!\n");
printf ("Код ошибки = %d\n", errno);
}
else {
printf ("\nsemop завершился успешно.\n");
printf ("Идентификатор semid = %d\n", semid);
printf ("Возвращенное значение = %d\n", rtrn);
}
exit (0);
}
Разделяемые сегменты памяти как средство межпроцессной связи позволяют процессам иметь общие области виртуальной памяти и, как следствие, разделять содержащуюся в них информацию. Единицей разделяемой памяти являются сегменты, свойства которых зависят от аппаратных особенностей управления памятью.
Разделение памяти обеспечивает наиболее быстрый обмен данными между процессами.
Работа с разделяемой памятью начинается с того, что процесс при помощи системного вызова shmget создает разделяемый сегмент, специфицируя первоначальные права доступа к сегменту (чтение и / или запись) и его размер в байтах. Чтобы затем получить доступ к разделяемому сегменту, его нужно присоединить посредством системного вызова shmat(), который разместит сегмент в виртуальном пространстве процесса. После присоединения в соответствии с правами доступа процессы могут читать данные из сегмента и записывать их (возможно, синхронизируя свои действия с помощью семафоров).
Когда разделяемый сегмент становится ненужным, его следует отсоединить, воспользовавшись системным вызовом shmdt().
Для выполнения управляющих действий над разделяемыми сегментами памяти служит системный вызов shmctl(). В число управляющих действий входит предписание удерживать сегмент в оперативной памяти и обратное предписание о снятии удержания. После того, как последний процесс отсоединил разделяемый сегмент, следует выполнить управляющее действие по удалению сегмента из системы.
Прежде чем воспользоваться разделением памяти, нужно создать разделяемый сегмент с уникальным идентификатором и ассоциированную с ним структуру данных. Уникальный идентификатор называется идентификатором разделяемого сегмента памяти (shmid); он используется для обращений к ассоциированной структуре данных, которая определяется следующим образом:
/*Структура прав на выполнение операций*/
struct ipc_perm shm_perm;
/* Размер сегмента */
int shm_segsz;
/*Указатель на структуру области памяти*/
struct region *shm_reg;
/* Информация для подкачки */
char pad [4];
/* Ид-р процесса, вып. последнюю операцию */
ushort shm_lpid;
/* Ид-р процесса, создавшего сегмент */
ushort shm_cpid;
/* Число присоединивших сегмент */
ushort shm_nattch;
/* Число удерживающих сегмент в памяти */
ushort shm_cnattch;
/* Время последнего присоединения */
time_t shm_atime;
/* Время последнего отсоединения */
time_t shm_dtime;
/* Время последнего изменения */
time_t shm_ctime;
};
Информация о возможных состояниях разделяемых сегментов
памяти содержится в табл. 4:
| Бит удержания | Бит подкачки | Бит размещения | Состояние |
| 0 | 0 | 0 | Неразмещенный сегмент |
| 0 | 0 | 1 | В памяти |
| 0 | 1 | 0 | Не используется |
| 0 | 1 | 1 | На диске |
| 1 | 0 | 0 | Не используется |
| 1 | 0 | 1 | Удержан в памяти |
| 1 | 1 | 0 | Не используется |
| 1 | 1 | 1 | Не используется |
Состояния, упомянутые в таблице, таковы:
После того, как создан уникальный идентификатор разделяемого сегмента памяти и ассоциированная с ним структура данных, можно использовать системные вызовы семейства shmop (операции над разделяемыми сегментами) и shmctl (управление разделяемыми сегментами).
Для создания разделяемого сегмента памяти служит системный вызов shmget. Синтаксис данного системного вызова описан так:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget (key_t key, int size, int shmflg);
Смысл аргументов key и shmflg тот же, что и у соответствующих аргументов системного вызова semget. Аргумент size задает размер разделяемого сегмента в байтах.
Системный параметр SHMMNI определяет максимально допустимое число уникальных идентификаторов разделяемых сегментов памяти (shmid) в системе. Попытка его превышения ведет к неудачному завершению системного вызова.
Системный вызов завершится неудачей и тогда, когда значение аргумента size меньше, чем SHMMIN, либо больше, чем SHMMAX. Данные системные параметры определяют соответственно минимальный и максимальный размеры разделяемого сегмента памяти.
В справочной статье shmctl синтаксис данного системного вызова описан так:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl (int shmid, int cmd, struct shmid_ds *buf);
В качестве аргумента shmid должен выступать идентификатор разделяемого сегмента памяти, предварительно полученный системным вызовом shmget.
Управляющее действие определяется значением аргумента cmd. Допустимы следующие значения:
Управляющие действия SHM_LOCK и SHM_UNLOCK может выполнить только суперпользователь. Для выполнения управляющего действия IPC_STAT процессу требуется право на чтение:
возможности системного вызова shmctl()
(операции управления разделяемыми сегментами) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main ()
{
extern int errno;
int rtrn, shmid, command, choice;
struct shmid_ds shmid_ds, *buf;
buf = &shmid_ds;
/* Ввести идентификатор сегмента и действие */
printf ("Введите идентификатор shmid: ");
scanf ("%d", &shmid);
printf ("Введите номер требуемого действия:\n");
printf (" IPC_STAT = 1\n");
printf (" IPC_SET = 2\n");
printf (" IPC_RMID = 3\n");
printf (" SHM_LOCK = 4\n");
printf (" SHM_UNLOCK = 5\n");
printf (" Выбор = ");
scanf ("%d", &command);
/* Проверить значения */
printf ("\nидентификатор = %d, действие = %d\n",
shmid, command);
switch (command) {
case 1: /* Скопировать информацию
о состоянии разделяемого сегмента
в пользовательскую структуру
и вывести ее */
rtrn = shmctl (shmid, IPC_STAT, buf);
printf ("\nИд-р пользователя = %d\n",
buf->shm_perm.uid);
printf ("Ид-р группы пользователя = %d\n",
buf->shm_perm.gid);
printf ("Ид-р создателя = %d\n",
buf->shm_perm.cuid);
printf ("Ид-р группы создателя = %d\n",
buf->shm_perm.cgid);
printf ("Права на операции = 0%o\n",
buf->shm_perm.mode);
printf ("Последовательность номеров ");
buf->shm_perm.cgid);
printf ("используемых слотов = 0%x\n",
buf->shm_perm.seq);
printf ("Ключ = 0%x\n",
buf->shm_perm.key);
printf ("Размер сегмента = %d\n",
buf->shm_segsz);
printf ("Выполнил последнюю операцию =
%d\n", buf->shm_lpid);
printf ("Создал сегмент = %d\n",
buf->shm_cpid);
printf ("Число присоединивших сегмент =
%d\n", buf->shm_nattch);
printf ("Число удерживаюших в памяти =
%d\n", buf->shm_cnattch);
printf ("Последнее присоединение = %d\n",
buf->shm_atime);
printf ("Последнее отсоединение = %d\n",
buf->shm_dtime);
printf ("Последнее изменение = %d\n",
buf->shm_ctime);
break;
case 2: /* Выбрать и изменить поле (поля)
ассоциированной структуры данных */
/* Получить исходные значения
структуры данных */
rtrn = shmctl (shmid, IPC_STAT, buf);
printf ("Введите номер
изменяемого поля:\n");
printf (" shm_perm.uid = 1\n");
printf (" shm_perm.gid = 2\n");
printf (" shm_perm.mode = 3\n");
printf (" Выбор = ");
scanf ("%d", &choice);
switch (choice) {
case 1:
printf ("\nВведите ид-р
пользователя:"),
scanf ("%d",
&buf->shm_perm.uid);
printf ("\nИд-р пользователя =
%d\n",
buf->shm_perm.uid);
break;
case 2:
printf ("\nВведите ид-р группы: "),
scanf ("%d", &buf->shm_perm.gid);
printf ("\nИд-р группы = %d\n",
buf->shm_perm.uid);
break;
case 3:
printf ("\nВведите восьмеричный
код прав: ");
scanf ("%o", &buf->shm_perm.mode);
printf ("\nПрава на операции
= 0%o\n",
buf->shm_perm.mode);
break;
}
/* Внести изменения */
rtrn = shmctl (shmid, IPC_SET, buf);
break;
case 3: /* Удалить идентификатор и
ассоциированную структуру данных */
rtrn = shmctl (shmid, IPC_RMID, NULL);
break;
case 4: /* Удерживать разделяемый сегмент
в памяти */
rtrn = shmctl (shmid, SHM_LOCK, NULL);
break;
case 5: /* Перестать удерживать сегмент в памяти */
rtrn = shmctl (shmid, SHM_UNLOCK, NULL);
}
if (rtrn == -1) {
/* Сообщить о неудачном завершении */
printf ("\nshmctl завершился неудачей!\n");
printf ("\nКод ошибки = %d\n", errno);
}
else {
/* При успешном завершении сообщить ид-р shmid */
printf ("\nshmctl завершился успешно, ");
printf ("идентификатор shmid = %d\n", shmid);
}
exit (0);
}
Cинтаксис системных вызовов shmat и shmdt описан так:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmat (int shmid, char *shmaddr, int shmflg);
int shmdt (char *shmaddr);
Разумеется, чтобы использовать результат shmat() как указатель, его нужно преобразовать к требуемому типу.
В качестве аргумента shmid должен выступать идентификатор разделяемого сегмента, предварительно полученный системным вызовом shmget. Аргумент shmaddr задает адрес, по которому сегмент должен быть присоединен, т. е. тот адрес в виртуальном пространстве пользователя, который получит начало сегмента. Однако не всякий адрес является приемлемым. Можно порекомендовать адреса вида:
0x80040000
0x80080000
. . .
При успешном завершении системного вызова shmdt() результат равен нулю; в случае неудачи возвращается -1.
Аргумент shmaddr задает начальный адрес отсоединяемого сегмента. После того, как последний процесс отсоединил разделяемый сегмент памяти, этот сегмент вместе с идентификатором и ассоциированной структурой данных следует удалить системным вызовом shmctl.
Пример использования вызовов shmat() и shmdt():
возможности системных вызовов shmat() и shmdt()
(операции над разделяемыми сегментами памяти) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main ()
{
extern int errno;
int shmid, shmaddr, shmflg;
int flags, attach, detach, rtrn, i;
/* Цикл присоединений для данного процесса */
printf ("\nВведите число присоединений ");
printf ("для процесса (1-4): ");
scanf ("%d", &attach);
printf ("\nЧисло присоединений = %d\n", attach);
for (i = 0; i < attach; i++) {
/* Ввести идентификатор разделяемого сегмента */
printf ("\nВведите ид-р разделяемого сегмента,\n");
printf ("над которым нужно выполнить операции: ");
scanf ("%d", &shmid);
printf ("\nИд-р сегмента = %d\n", shmid);
/* Ввести адрес присоединения */
printf ("\nВведите адрес присоединения ");
printf ("в шестнадцатеричной записи: ");
scanf ("%x", &shmaddr);
printf ("\nАдрес присоединения = 0x%x\n", shmaddr);
/* Выбрать требуемые флаги */
printf ("\nВведите номер нужной
комбинации флагов:\n");
printf (" SHM_RND = 1\n");
printf (" SHM_RDONLY = 2\n");
printf (" SHM_RND и SHM_RDONLY = 3\n");
printf (" Выбор = ");
scanf ("%d", &flags);
switch (flags) {
case 1:
shmflg = SHM_RND;
break;
case 2:
shmflg = SHM_RDONLY;
break;
case 3:
shmflg = SHM_RND | SHM_RDONLY;
break;
}
printf ("\nФлаги = 0%o", shmflg);
/* Выполнить системный вызов shmat */
rtrn = shmat (shmid, shmaddr, shmflg);
if (rtrn == -1) {
printf ("\nshmat завершился неудачей!\n");
printf ("\Код ошибки = %d\n", errno);
}
else {
printf ("\nshmat завершился успешно.\n");
printf ("Идентификатор shmid = %d\n", shmid);
printf ("Адрес = 0x%x\n", rtrn);
}
}
/* Цикл отсоединений для данного процесса */
printf ("\nВведите число отсоединений ");
printf ("для процесса (1-4): ");
scanf ("%d", &detach);
printf ("\nЧисло отсоединений = %d\n", detach);
for (i = 0; i < detach; i++) {
/* Ввести адрес отсоединения */
printf ("\nВведите адрес отсоединяемого сегмента ");
printf ("в шестнадцатеричной записи: ");
scanf ("%x", &shmaddr);
printf ("\nАдрес отсоединения = 0x%x\n", shmaddr);
/* Выполнить системный вызов shmdt */
rtrn = shmdt (shmaddr);
if (rtrn == -1) {
printf ("\nshmdt завершился неудачей!\n");
printf ("\Код ошибки = %d\n", errno);
}
else {
printf ("\nshmdt завершился успешно,\n");
printf ("идентификатор shmid = %d\n", shmid);
}
}
exit (0);
}
С помощью процессов можно организовать параллельное выполнение программ. Для этого процессы клонируются вызовами fork() или exec(), а затем между ними организуется взаимодействие средствами IPC. Это довольно дорогостоящий в отношении ресурсов процесс.
С другой стороны, для организации параллельного выполнения и взаимодействия процессов можно использовать механизм многопоточности. Основной единицей здесь является поток.
Поток представляет собой облегченную версию процесса. Чтобы понять, в чем состоит его особенность, необходимо вспомнить основные характеристики процесса.
При корректной реализации потоки имеют определенные преимущества перед процессами. Им требуется:
Если операционная система поддерживает концепции потоков в рамках одного процесса, она называется многопоточной. Многопоточные приложения имеют ряд преимуществ.
Существует две основных категории потоков с точки зрения реализации:
При использовании этого уровня ядро не знает о существовании потоков - все управление потоками реализуется приложением с помощью специальных библиотек. Переключение потоков не требует привилегий режима ядра, а планирование полностью зависит от приложения. При этом ядро управляет деятельностью процесса. Если поток вызывает системную функцию, то будет блокирован весь процесс, но для поточной библиотеки этот поток будет находиться в активном состоянии. Здесь состояние потока не зависит от состояния процесса.
Преимущества пользовательских потоков в следующем:
На этом уровне все управление потоком выполняется ядром. Используется программный интерфейс приложения (системные вызовы) для работы с потоками уровня ядра. Ядро поддерживает информацию о контексте процесса и потоков; переключение потоков требует выполнения дисциплины планирования ядра на уровне этих потоков.
Преимущества потоков уровня ядра:
Функция pthread_create() позволяет добавить новый поток управления к текущему процессу. Прототип функции:
const pthread_attr_t *tattr,
void*(*start_routine)(void *), void *arg);
pthread_attr_t tattr;
pthread_t tid;
extern void *start_routine(void *arg);
void *arg;
int ret;
/* поведение по умолчанию*/
ret = pthread_create(&tid, NULL, start_routine, arg);
/* инициализация с атрибутами по умолчанию */
ret = pthread_attr_init(&tattr);
/* определение поведения по умолчанию*/
ret = pthread_create(&tid, &tattr, start_routine, arg);
Функция pthread_create() вызывается с атрибутом attr,
определяющим необходимое поведение; start_routine - это
функция, с которой новый поток начинает свое выполнение. Когда
start_routine
завершается, поток завершается со статусом выхода, установленным в
значение, возвращенное start_routine.
Если вызов pthread_create() успешно завершен, идентификатор созданного потока сохраняется по адресу tid.
Создание потока с использованием аргумента атрибутов NULL оказывает тот же эффект, что и использование атрибута по умолчанию: оба создают одинаковый поток. При инициализации tattr он обретает поведение по умолчанию; pthread_create() возвращает 0 при успешном завершении. Любое другое значение указывает, что произошла ошибка.
Функция pthread_join() используется для ожидания завершения потока:
pthread_t tid;
int ret;
int status;
/* ожидание завершения потока "tid" со статусом status */
ret = pthread_join(tid, &status);
/* ожидание завершения потока "tid" без статуса */
ret = pthread_join(tid, NULL);
Функция pthread_join() блокирует вызывающий поток, пока указанный поток не завершится. Указанный поток должен принадлежать текущему процессу и не должен быть отделен. Если status не равен NULL, он указывает на переменную, которая принимает значение статуса выхода завершенного потока при успешном завершении pthread_join(). Несколько потоков не могут ждать завершения одного и того же потока. Если они пытаются выполнить это, один поток завершается успешно, а все остальные - с ошибкой ESRCH. После завершения pthread_join(), любое пространство стека, связанное с потоком, может быть использовано приложением.
В следующем примере один поток верхнего уровня вызывает процедуру, которая создает новый вспомогательный поток, выполняющий сложный поиск в базе данных, требующий определенных затрат времени. Главный поток ждет результатов поиска, и в то же время может выполнять другую работу. Он ждет своего помощника с помощью функции pthread_join(). Аргумент pbe является параметром стека для нового потока.
Исходный код для thread.c:
{
struct phonebookentry *pbe;
pthread_attr_t tattr;
pthread_t helper;
int status;
pthread_create(&helper, NULL, fetch, &pbe);
/* выполняет собственную задачу */
pthread_join(helper, &status);
/* теперь можно использовать результат */
}
void fetch(struct phonebookentry *arg)
{
struct phonebookentry *npbe;
/* ищем значение в базе данных */
npbe = search (prog_name)
if (npbe != NULL)
*arg = *npbe;
pthread_exit(0);
}
struct phonebookentry {
char name[64];
char phonenumber[32];
char flags[16];
}
Функция pthread_detach() применяется как альтернатива
pthread_join(),
чтобы утилизировать область памяти для потока, который был создан
с атрибутом detachstate, установленным в значение PTHREAD_CREATE_JOINABLE.
Прототип функции:
pthread_t tid;
int ret;
/* отделить поток tid */
ret = pthread_detach(tid);
В ОС Linux управление процессами является ключевой технологией при разработке многих программ. Процесс - это находящаяся в состоянии выполнения программа вместе со средой ее выполнения.
Так как Linux - это настоящая многозадачная система, в ней одновременно могут выполняться несколько программ (процессов, задач). Термин ``одновременно'' не всегда соответствует действительности. Обычно центральный процессор (ЦП) может работать в данный момент только с одним процессом. Если необходимо выполнить одновременно несколько программ параллельно, нужно использовать либо несколько компьютеров, либо несколько процессоров. Однако для большинства пользователей этот вариант может быть непривлекательным из-за расходов на приобретение дополнительной техники.
Каждый процесс имеет собственное виртуальное адресное пространство. Это необходимо, чтобы гарантировать, что ни один процесс не будет подвержен помехам или влиянию со стороны других.
Отдельные процессы получают доступ к ЦП по очереди. Планировщик процессов решает, как долго и в какой последовательности процессы будут занимать ЦП. При этом создается впечатление, что процессы протекают параллельно.
В Linux реализована вытесняющая многозадачность. Это значит, что система сама решает, как долго конкретный процесс может использовать ЦП, и когда наступит очередь следующего процесса. Если пользователь желает вмешаться в процесс планирования, он может сделать это как root с помощью команды nice.
С помощью команды ps можно узнать, какие процессы выполняются
в настоящий момент: ps -x
При этом выводится список выполняющихся в данный момент процессов. Значение колонок следующее:
PID TTY STAT TIME COMMAND 1234 pts/0 R 0:00 ps -xPID - идентификатор процесса. Каждый процесс получает собственный однозначный идентификатор. Пользуясь этим идентификатором, можно получать доступ к конкретному процессу. Например, можно получить сведения о процессе с ID 1501 с помощью команды:
ps 1501
Если идентификатор процесса не известен, но известна команда, запустившая
этот процесс, то идентификатор можно узнать с помощью команды: pidof /bin/bash
Отметьте, что pidof можно выполнять только как root.
TTY показывает, в каком терминале выполняется процесс. Если в колонке не указано никакого значения, речь идет, как правило, о процессе-демоне.
STAT показывает текущее состояние процесса. В приведенном примере символ R означает выполнение (running). Для процессов применяются следующие обозначения:
TIME указывает время работы процесса.
COMMAND - имя команды, с помощью которой запущен процесс.
В Linux все процессы упорядочены иерархически подобно генеалогическому дереву. Каждый процесс владеет информацией того процесса, от которого он был порожден. То же самое справедливо и для его родительского процесса.
Если нужно узнать, сколько времени ЦП необходимо для каждого процесса, можно использовать команду top. Она показывает в колонке '%CPU', какое время вычислений занимает определенная программа в процессоре.
Однопоточные программы на C содержат два основных класса данных: локальные и глобальные. Для многопоточных программ на C добавляется третий класс: данные потока. Они похожи на глобальные данные, за исключением того, что они являются собственными для потока.
Данные потока являются единственным способом определения и обращения к данным, которые принадлежат отдельному потоку. Каждый элемент данных потока связан с ключом, который является глобальным для всех потоков процесса. Используя ключ, поток может получить доступ к указателю (void *), который поддерживается только для этого потока.
Функция pthread_keycreate() применяется для выделения ключа,
который используется при идентифицикации данных некоторого потока
в составе процесса. Ключ для всех потоков общий, и все потоки вначале
содержат значение ключа NULL. Отдельно для каждого ключа
перед его использованием вызывается
pthread_keycreate().
При этом не происходит никакой синхронизации.
Как только ключ будет создан, каждый поток может связать с ним свое значение.
Значения являются специфичными для потока и поддерживаются
для каждого из них независимо. Связь ключа с потоком удаляется,
когда поток заканчивается, при этом ключ должен быть создан с функцией
деструктора. Прототип функции:
void(*destructor)(void *));
pthread_key_t key;
int ret;
/* создание ключа без деструктора */
ret = pthread_key_create(&key, NULL);
/* создание ключа с деструктором */
ret = pthread_key_create(&key, destructor);
Функция pthread_keydelete() используется, чтобы уничтожить существующий ключ данных для определенного потока. Любая выделенная память, связанная с ключом, может быть освобождена, потому что ключ был удален; попытка ссылки на эту память вызовет ошибку.
Прототип pthread_keydelete():
pthread_key_t key;
int ret;
/* key был создан ранее */
ret = pthread_key_delete(key);
Программист должен сам освобождать любые выделенные потоку ресурсы перед вызовом функции удаления. Эта функция не вызывает деструктора; pthread_keydelete() возвращает 0 - после успешного завершения - или любое другое значение - в случае ошибки.
Функция pthread_setspecific() используется, чтобы установить связку между потоком и указанным ключом данных для потока. Прототип функции:
const void *value);
pthread_key_t key;
void *value;
int ret;
/* key был создан ранее */
ret = pthread_setspecific(key, value);
Чтобы получить привязку ключа для вызывающего потока, используется функция pthread_getspecific(). Полученное значение сохраняется в переменной value. Прототип функции:
pthread_key_t key;
void *value;
/* key был создан ранее */
value = pthread_getspecific(key);
...
while (write(fd, buffer, size) == -1) {
if (errno != EINTR) {
fprintf(mywindow, "%s\n", strerror(errno));
exit(1);
}
}
...
}
Ссылки на errno должны получить код системной ошибки из процедуры, вызванной именно этим конкретным потоком, и никаким другим. Поэтому ссылки на errno в одном потоке относятся к иной области памяти, чем ссылки на errno в других потоках. Переменная mywindow предназначена для обращения к потоку stdio, связанному с окном, которое является частным объектом потока. Так же, как и errno, ссылки на mywindow в одном потоке должны обращаться к отдельной конкретной области памяти (и в конечном счете - к различным окнам). Единственное различие между этими переменными состоит в том, что библиотека потоков реализует раздельный доступ для errno, а программист должен сам реализовать это для mywindow. Следующий пример показывает, как работают ссылки на mywindow. Препроцессор преобразует ссылки на mywindow в вызовы процедур mywindow. Эта процедура в свою очередь вызывает pthread_getspecific(), передавая ему глобальную переменную mywindow_key (это, действительно, глобальная переменная) и выходной параметр win, который принимает идентификатор окна для этого потока.
Следующий фрагмент кода:
FILE *_mywindow(void) {
FILE *win;
pthread_getspecific(mywin_key, &win);
return(win);
}
#define mywindow _mywindow()
void routine_uses_win( FILE *win) {
...
}
void thread_start(...) {
...
make_mywin();
...
routine_uses_win( mywindow )
...
}
Теперь можно устанавливать собственные данные потока:
FILE **win;
static pthread_once_t mykeycreated =
PTHREAD_ONCE_INIT;
pthread_once(&mykeycreated, mykeycreate);
win = malloc(sizeof(*win));
create_window(win, ...);
pthread_setspecific(mywindow_key, win);
}
void mykeycreate(void) {
pthread_keycreate(&mywindow_key, free_key);
}
void free_key(void *win) {
free(win);
}
Следующий шаг состоит в выделении памяти для элемента данных вызывающего
потока. После выделения памяти выполняется вызов процедуры create_window,
устанавливающей окно для потока и выделяющей память для переменной
win, которая ссылается на окно. Наконец выполняется вызов
pthread_setspecific(), который связывает значение win
с ключом. После этого, как только поток вызывает pthread_getspecific(),
передав глобальный ключ, он получает некоторое значение. Это значение
было связано с этим ключом в вызывающем потоке, когда он вызвал функцию
pthread_setspecific().
Когда поток заканчивается, выполняются вызовы функций деструкторов,
которые были настроены при вызове pthread_key_create(). Функция
деструктора вызывается, если завершившийся поток установил значение
для ключа вызовом pthread_setspecific().
Функция pthread_self() вызывается для получения ID вызывающего ее потока:
pthread_t tid;
tid = pthread_self();
pthread_t tid1, tid2;
int ret;
ret = pthread_equal(tid1, tid2);
Функция pthread_once() используется для вызова процедуры инициализации потока только один раз. Последующие вызовы не оказывают никакого эффекта. Пример вызова функции:
void (*init_routine)(void));
int ret;
ret = sched_yield();
Функция pthread_setschedparam() используется, чтобы изменить приоритет существующего потока. Эта функция никоим образом не влияет на дисциплину диспетчеризации:
const struct sched_param *param);
pthread_t tid;
int ret;
struct sched_param param;
int priority;
/* sched_priority указывает приоритет потока */
sched_param.sched_priority = priority;
/* единственный поддерживаемый алгоритм диспетчера*/
policy = SCHED_OTHER;
/* параметры диспетчеризации требуемого потока */
ret = pthread_setschedparam(tid, policy, ¶m);
Функция:
struct schedparam *param)
Пример вызова функции:
pthread_t tid;
sched_param param;
int priority;
int policy;
int ret;
/* параметры диспетчеризации нужного потока */
ret = pthread_getschedparam (tid, &policy, ¶m);
/* sched_priority содержит приоритет потока */
priority = param.sched_priority;
Поток, как и процесс, может принимать различные сигналы:
#include <signal.h>
int sig;
pthread_t tid;
int ret;
ret = pthread_kill(tid, sig);
Если sig имеет значение 0, выполняется проверка ошибок, но сигнал реально не посылается. Таким образом можно проверить правильность tid. Функция возвращает 0 - в случае успешного завершения - или другое значение - в случае ошибки.
Функция pthread_sigmask() может использоваться для изменения или получения маски сигналов вызывающего потока:
sigset_t *old);
#include <signal.h>
int ret;
sigset_t old, new;
/* установка новой маски */
ret = pthread_sigmask(SIG_SETMASK, &new, &old);
/* блокирование маски */
ret = pthread_sigmask(SIG_BLOCK, &new, &old);
/* снятие блокировки */
ret = pthread_sigmask(SIG_UNBLOCK, &new, &old);
Функция pthread_sigmask() возвращает 0 - в случае успешного завершения - или другое значение - в случае ошибки.
Поток может прерваться несколькими способами. Первый способ предполагает возвращение управления из основной процедуры потока start_routine. Второй способ - вызов pthread_exit(), возвращающий статус выхода. Третий способ - прерывание потока с помощью функции pthread_cancel().
Функция void pthread_exit(void *status)
прерывает выполнение потока точно так же, как функция exit()
прерывает процесс:
int status;
/* выход возвращает статус status */
pthread_exit(&status);
Функция pthread_cancel() предназначена для прерывания потока:
pthread_t thread;
int ret;
ret = pthread_cancel(thread);
Для компиляции и сборки многопоточной программы необходимо иметь:
К наиболее частым оплошностям и ошибкам многопоточных программах относятся:
Атрибуты являются способом определить поведение потока, отличное от поведения по умолчанию. При создании потока с помощью pthread_create() или при инициализации переменной синхронизации может быть определен собственный объект атрибутов. Атрибуты определяются только во время создания потока; они не могут быть изменены в процессе использования.
Обычно вызываются три функции:
pthread_attr_t tattr;
pthread_t tid;
void *start_routine;
void arg
int ret;
/* инициализация атрибутами по умолчанию */
ret = pthread_attr_init(&tattr);
/* вызов соответствующих функций для изменения
значений */
ret = pthread_attr_*(&tattr,
SOME_ATRIBUTE_VALUE_PARAMETER);
/* создание потока */
ret = pthread_create(&tid, &tattr, start_routine, arg);
Объект атрибутов является закрытым и не может быть непосредственно изменен операциями присваивания. Существует множество функций, позволяющих инициализировать, конфигурировать и уничтожать любые типы объекта. Как только атрибут инициализируется и конфигурируется, он доступен всему процессу. Поэтому рекомендуется конфигурировать все требуемые спецификации состояния один раз, на ранних стадиях выполнения программы. При этом соответствующий объект атрибутов может использоваться везде, где это нужно. Использование объектов атрибутов имеет два основных преимущества.
Функция pthread_attr_init() используется, чтобы инициализировать объект атрибутов значениями по умолчанию. Память распределяется системой потоков во время выполнения.
Пример вызова функции:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_init(&tattr);
| Атрибут | Значение | Смысл |
| scope | PTHREAD_SCOPE_PROCESS | Новый поток не ограничен - не присоединен ни к одному процессу |
| detachstate | PTHREAD_CREATE_JOINABLE | Статус выхода и поток сохраняются после завершения потока |
| stackaddr | NULL | Новый поток получает адрес стека, выделенного системой |
| stacksize | 1 Мбайт | Новый поток имеет размер стека, определенный системой |
| inheritsched | PTHREAD_INHERIT_SCHED | Поток наследует приоритет диспетчеризации родительского потока |
| schedpolicy | SCHED_OTHER | Новый поток использует диспетчеризацию с фиксированными приоритетами. Поток работает, пока не будет прерван потоком с высшим приоритетом или не приостановится |
Функция возвращает 0 после успешного завершения. Любое другое значение указывает, что произошла ошибка. Код ошибки устанавливается в переменной errno.
Функция pthread_attr_destroy() используется, чтобы удалить память для атрибутов, выделенную во время инициализации. Объект атрибутов становится недействительным.
Пример вызова функции:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_destroy(&tattr);
Если поток создается отделенным (PTHREAD_CREATE_DETACHED), его ID и другие ресурсы могут многократно использоваться, как только он завершится. Если нет необходимости ожидать в вызывающем потоке завершения нового потока, можно вызвать перед его созданием функцию pthread_attr_setdetachstate().
Если поток создается неотделенным (PTHREAD_CREATE_JOINABLE), предполагается, что создающий поток будет ожидать его завершения и выполнять в созданном потоке pthread_join(). Независимо от типа потока процесс не закончится, пока не завершатся все потоки; pthread_attr_setdetachstate() возвращает 0 - после успешного завершения - или любое другое значение - в случае ошибки.
Пример вызова для отсоединения потока:
pthread_attr_t tattr;
int ret;
/* устанавливаем состояние потока */
ret = pthread_attr_setdetachstate(&tattr,
PTHREAD_CREATE_DETACHED);
Функция pthread_attr_getdetachstate() позволяет определить состояние при создании потока, т.е. был ли он отделенным или присоединяемым. Она возвращает 0 - после успешного завершения - или любое другое значение - в случае ошибки. Пример вызова:
pthread_attr_t tattr;
int detachstate;
int ret;
ret = pthread_attr_getdetachstate (&tattr, &detachstate);
Следующий пример иллюстрирует, как можно создать отделенный поток:
pthread_attr_t tattr;
pthread_t tid;
void *start_routine;
void arg
int ret;
ret = pthread_attr_init(&tattr);
ret = pthread_attr_setdetachstate(&tattr,
PTHREAD_CREATE_DETACHED);
ret = pthread_create(&tid, &tattr, start_routine, arg);
Поток может быть ограничен (иметь тип PTHREAD_SCOPE_SYSTEM)
или неограничен (иметь тип PTHREAD_SCOPE_PROCESS). Оба
этих типа доступны только в пределах данного процесса. Функция
pthread_attr_setscope()
позволяет создать потоки указанных типов;
pthread_attr_setscope() возвращает 0 - после успешного завершения -
или любое другое значение - в случае ошибки. Пример вызова функции:
pthread_attr_t attr;
pthread_t tid;
void start_routine;
void arg;
int ret;
/* инициализация атрибутов по умолчанию */
ret = pthread_attr_init (&tattr);
/* ограниченное поведение */
ret = pthread_attr_setscope(&tattr,
PTHREAD_SCOPE_SYSTEM);
ret = pthread_create (&tid, &tattr, start_routine,
arg);
pthread_attr_t tattr;
int scope;
int ret;
ret = pthread_attr_getscope(&tattr, &scope);
Стандарт POSIX определяет несколько значений атрибута планирования: SCHED_FIFO, SCHED_RR (Round Robin) или SCHED_OTHER (метод приложения). Дисциплины SCHED_FIFO и SCHED_RR являются необязательными и поддерживаются только для потоков в режиме реального времени.
Библиотека pthreads поддерживает только значение SCHED_OTHER. Попытка установить другое значение приведет к возникновению ошибки ENOSUP.
Для установки дисциплины диспетчеризации используется следующая функция:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_setschedpolicy(&tattr, SCHED_OTHER);
Функция pthread_attr_setinheritsched() используется для
наследования дисциплины диспетчеризации из родительского потока. Значение
переменной inherit, равное PTHREAD_INHERIT_SCHED
(по умолчанию) проявляется в том, что будет использована дисциплина планирования,
определенная в создающем потоке, а любые атрибуты планирования, определенные
в вызове pthread_create(), будут проигнорированы. Если используется
константа
PTHREAD_EXPLICIT_SCHED, то используются и атрибуты,
переданные в вызове pthread_create().
Функция возвращает 0 - при успешном завершении - и любое другое значение - в случае ошибки. Пример вызова этой функции:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_setinheritsched(&tattr,
PTHREAD_EXPLICIT_SCHED);
Параметры диспетчеризации определены в структуре
sched_param;
в настоящее время поддерживается только приоритет
sched_param.sched_priority.
Этот приоритет задается целым числом, при этом чем выше значение,
тем выше приоритет потока при планировании. Создаваемые потоки получают
этот приоритет.
Функция pthread_attr_setschedparam() используется, чтобы установить значения в этой структуре. При успешном завершении она возвращает 0. Пример использования:
pthread_attr_t tattr;
int newprio;
sched_param param;
/* устанавливает приоритет */
newprio = 30;
param.sched_priority = newprio;
/* устанавливает параметры диспетчеризации */
ret = pthread_attr_setschedparam (&tattr, ¶m);
const struct sched_param *param) используется для получения приоритета текущего потока.
Как правило, стеки потоков начинаются на границах страниц, и любой указанный размер округляется к следующей границе страницы. К вершине стека добавляется страница без разрешения на доступ, чтобы переполнение стека вызвало посылку сигнала SIGSEGV потоку, вызвавшему переполнение.
Если определяется стек, то поток должен создаваться с типом
PTHREAD_CREATE_JOINABLE. Этот стек не может быть освобожден,
пока не произойдет выход из pthread_join() этого потока,
потому что стек потока не может быть освобожден, пока поток не закончится.
Единственный надежный способ закончить такой поток - вызов pthread_join().
В общем случае нет необходимости выделять пространство для стека потоков. Библиотека потоков выделяет один мегабайт виртуальной памяти для стека каждого потока без резервирования пространства выгрузки. (Библиотека использует опцию MAP_NORESERVE для mmap, чтобы выделить память).
Каждый стек потоков, созданный библиотекой потоков, имеет красную зону. Библиотека создает красную зону, добавляя к вершине стека страницу, позволяющую обнаружить переполнение стека. Эта страница не действительна и вызывает ошибку защиты памяти, когда к ней обращаются. Красные зоны добавляются ко всем автоматически распределенным стекам вне зависимости от того, был ли определен размер стека приложением или используется размер по умолчанию.
Обычно создание собственного стека предполагает, что он будет немного отличаться от стека по умолчанию. Как правило, задача состоит в выделении более чем одного мегабайта для стека. Иногда стек по умолчанию, наоборот, является слишком большим. Можно создать тысячи потоков, и тогда виртуальной памяти будет недостаточно, чтобы работать с гигабайтами пространств стека при использовании размера по умолчанию.
Абсолютный минимальный предел размера стека можно определить, вызывая
макрос PTHREAD_STACK_MIN (определенный в
<pthread.h>),
который возвращает количество памяти стека, требуемого для потока,
выполняющего пустую процедуру (NULL). Реальные потоки нуждаются
в большем стеке, поэтому нужно очень осторожно сокращать его размер.
Функция pthread_attr_setstacksize() используется для установки размера стека текущего потока.
Атрибут stacksize определяет размер стека в байтах. Этот стек выделяется системой и его размер не должен быть меньше минимального. При успешном завершении функция возвращает 0. Пример вызова:
pthread_attr_t tattr;
int stacksize;
int ret;
/* установка нового размера */
stacksize = (PTHREAD_STACK_MIN + 0x4000);
ret = pthread_attr_setstacksize(&tattr, stacksize);
Функция pthread_attr_getstacksize(pthread_attr_t *tattr, size_t *size) используется для получения размера стека текущего потока:
pthread_attr_t tattr;
int stacksize;
int ret;
/* получение размера стека */
ret = pthread_attr_getstacksize(&tattr, &stacksize);
Иногда возникает потребность установить базовый адрес стека. Для этого используется функция pthread_attr_setstackaddr():
void *stackaddr);
Следующий пример показывает способ создания потока со стеком определенного размера по указанному адресу:
pthread_attr_t tattr;
pthread_t tid;
int ret;
void *stackbase;
int size = PTHREAD_STACK_MIN + 0x4000;
stackbase = (void *) malloc(size);
/* инициализация значениями по умолчанию */
ret = pthread_attr_init(&tattr);
/* установка размера стека */
ret = pthread_attr_setstacksize(&tattr, size);
/* установка базового адреса стека */
ret = pthread_attr_setstackaddr(&tattr, stackbase);
ret = pthread_create(&tid, &tattr, func, arg);
Системный планировщик использует таблицу процессов, описанную в заголовочном
файле /usr/include/linux/sched.h
Внутри структуры struct task_struct находятся все сведения о состоянии процесса. Они достаточно хорошо прокомментированы. Основными являются следующие сведения:
При выполнении нескольких потоков они будут неизменно взаимодействовать друг с другом, чтобы синхронизироваться. Существует несколько средств синхронизации потоков. Это:
Объекты синхронизации можно разместить в файлах, где они будут находиться независимо от создавшего их процесса.
Основные ситуации, которые требуют использования синхронизации:
Блоки взаимного исключения - общий метод сериализации выполнения потоков. Мьютексы синхронизируют потоки, гарантируя, что только один поток в некоторый момент времени выполняет критическую секцию кода. Мьютексы можно использовать и в однопоточном коде.
Атрибуты мьютекса могут быть связаны с каждым потоком. Чтобы изменить атрибуты мьютекса по умолчанию, можно объявить и инициализировать объект атрибутов мьютекса, а затем изменить определенные значения. Часто атрибуты мьютекса устанавливаются в одном месте, в начале приложения, чтобы можно было быстро найти и изменить их.
После того, как сформированы атрибуты мьютекса, можно непосредственно инициализировать мьютекс. Доступны следующие действия с мьютексом: инициализация, удаление, захват или открытие, попытка захвата.
Функция pthread_mutexattr_init() используется, чтобы инициализировать
атрибуты, связанные с объектом, значениями по умолчанию. Память для
каждого объекта атрибутов выделяется системой поддержки потоков во
время выполнения; mattr - закрытый тип, который содержит системный
объект атрибутов. Возможные значения типа mattr - PTHREAD_PROCESS_PRIVATE
(по умолчанию) и
PTHREAD_PROCESS_SHARED. При вызове этой
функции значение по умолчанию атрибута pshared равно
PTHREAD_PROCESS_PRIVATE, что позволяет использовать инициализированный
мьютекс в пределах процесса.
Прежде, чем повторно инициализировать объект атрибутов мьютекса, его нужно сначала удалить функцией pthread_mutexattr_ destroy(). Вызов функции pthread_mutexattr_init() возвращает указатель на закрытый объект. Если объект не удалить, может произойти утечка памяти; pthread_mutexattr_init() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка.
Пример вызова функции:
pthread_mutexattr_t mattr;
int ret;
/* инициализация атрибутов значениями по умолчанию */
ret = pthread_mutexattr_init(&mattr);
pthread_mutexattr_t mattr;
int ret;
/* удаление атрибутов */
ret = pthread_mutexattr_destroy(&mattr);
Областью видимости мьютекса может быть либо некоторый процесс, либо вся система. Функция pthread_mutexattr_setpshared() используется, чтобы установить область видимости атрибутов мьютекса.
Если мьютекс был создан с атрибутом pshared, установленным
в состояние PTHREAD_PROCESS_SHARED, и он находится
в разделяемой памяти, то он может быть разделен среди потоков нескольких
процессов. Если атрибут pshared у мьютекса установлен в
PTHREAD_PROCESS_PRIVATE,
то оперировать этим мьютексом могут только потоки, созданные тем же
самым процессом. Функция
pthread_mutexattr_setpshared() возвращает 0 - после успешного
завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutexattr_t mattr;
int ret;
ret = pthread_mutexattr_init(&mattr);
/* переустановка на значение по умолчанию: private */
ret = pthread_mutexattr_setpshared(&mattr,
PTHREAD_PROCESS_PRIVATE);
pthread_mutexattr_getpshared(pthread_mutexattr_t *mattr,
int *pshared)
используется для получения области видимости текущего мьютекса потока:
pthread_mutexattr_t mattr;
int pshared, ret;
/* получить атрибут pshared для мьютекса */
ret = pthread_mutexattr_getpshared(&mattr, &pshared);
Функция pthread_mutex_init() предназначена для инициализации мьютекса:
const pthread_mutexattr_t *mattr);
Блокировка через мьютекс не должна повторно инициализироваться или удаляться, пока другие потоки могут его использовать. Если мьютекс инициализируется повторно или удаляется, приложение должно убедиться, что в настоящее время этот мьютекс не используется; pthread_mutex_init() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp = PTHREAD_MUTEX_INITIALIZER;
pthread_mutexattr_t mattr;
int ret;
/* инициализация мьютекса значением по умолчанию */
ret = pthread_mutex_init(&mp, NULL);
ret = pthread_mutexattr_init(&mattr);
/* смена значений mattr с помощью функций */
ret = pthread_mutexattr_*();
/* инициализация мьютекса произвольными значениями */
ret = pthread_mutex_init(&mp, &mattr);
Функция pthread_mute_lock() используется для запирания мьютекса. Если мьютекс уже закрыт, вызывающий поток блокируется и мьютекс ставится в очередь приоритетов. Когда происходит возврат из pthread_mute_lock(), мьютекс запирается, а вызывающий поток становится его владельцем. pthread_mute_lock() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret;
ret = pthread_mutex_lock(&mp);
Мьютекс должен быть закрыт, а вызывающий поток должен быть владельцем, т. е. тем, кто запирал мьютекс. Пока любые другие потоки ждут доступа к мьютексу, поток в начале очереди не блокирован; pthread_mutex_unlock() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret;
ret = pthread_mutex_unlock(&mp);
Функция pthread_mutex_trylock() пытается провести запирание
мьютекса. Она является неблокирующей версией вызова
pthread_mutex_lock().
Если мьютекс уже закрыт, вызов возвращает ошибку. В противном случае,
мьютекс закрывается, а вызывающий процесс становится его владельцем;
pthread_mutex_trylock() возвращает 0 - после успешного завершения -
или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret; ret = pthread_ mutex_trylock(&mp);
Функция pthread_mutex_destroy() используется для удаления мьютекса в любом состоянии. Память для мьютекса не освобождается; pthread_mutex_destroy() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret;
ret = pthread_mutex_destroy(&mp);
Функция increment_count() использует мьютекс, чтобы гарантировать атомарность модификации разделяемой переменной count.
Функция get_count() использует мьютекс, чтобы гарантировать, что переменная count атомарно считывается:
pthread_mutex_t count_mutex;
long long count;
void increment_count() {
pthread_mutex_lock(&count_mutex);
count = count + 1;
pthread_mutex_unlock(&count_mutex);
}
long long get_count() {
long long c;
pthread_mutex_lock(&count_mutex);
c = count;
pthread_mutex_unlock(&count_mutex);
return (c);
}
Иногда может возникнуть необходимость доступа к нескольким ресурсам сразу. При этом возникает затруднение, когда два потока пытаются захватить оба ресурса, но запирают соответствующие мьютексы в различном порядке.
В приведенном ниже примере, два потока запирают мьютексы 1 и 2, и тогда тупик при попытке запереть другой мьютекс:
/* использует ресурс 1 */ | /* использует ресурс 2 */
pthread_mutex_lock(&m1); | pthread_mutex_lock(&m2);
/* теперь захватывает | /* теперь захватывает
ресурсы 2 + 1 */ | ресурсы 1 + 2 */
pthread_mutex_lock(&m2); | pthread_mutex_lock(&m1);
Если блокировка всегда выполняется в указанном порядке, тупик не возникнет. Однако, эта техника может использоваться не всегда. Иногда требуется запирать мьютексы в другом порядке, чем предписанный.
Чтобы предотвратить тупик в этой ситуации, лучше использовать функцию pthread_mutex_trylock(). Один из потоков должен освободить свой мьютекс, если он обнаруживает, что может возникнуть тупик.
Ниже проиллюстрирован подход условной блокировки:
Поток 1:
pthread_mutex_lock(&m2);
/* нет обработки */
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
pthread_mutex_lock(&m2);
if(pthread_mutex_trylock(&m1)==0)
/* захват! */
break;
/* уже заперт */
pthread_mutex_unlock(&m2);
}
/* нет обработки */
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
Для порождения процессов в ОС Linux существует два способа. Один из них позволяет полностью заменить другой процесс, без замены среды выполнения. Другим способом можно создать новый процесс с помощью системного вызова fork(). Синтаксис вызова следующий:
#include <sys/types> #include <unistd.h> pid_t fork(void);pid_t является примитивным типом данных, который определяет идентификатор процесса или группы процессов. При вызове fork() порождается новый процесс (процесс-потомок), который почти идентичен порождающему процессу-родителю. Процесс-потомок наследует следующие признаки родителя:
Процесс-потомок и процесс-родитель получают разные коды возврата после вызова fork(). Процесс-родитель получает идентификатор (PID) потомка. Если это значение будет отрицательным, следовательно при порождении процесса произошла ошибка. Процесс-потомок получает в качестве кода возврата значение 0, если вызов fork() оказался успешным.
Таким образом, можно проверить, был ли создан новый процесс:
switch(ret=fork())
{
case -1: /{*}при вызове fork() возникла ошибка{*}/
case 0 : /{*}это код потомка{*}/
default : /{*}это код родительского процесса{*}/
}
Пример порождения процесса через fork() приведен ниже:
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
main()
{
pid_t pid;
int rv;
switch(pid=fork()) {
case -1:
perror("fork"); /* произошла ошибка */
exit(1); /*выход из родительского процесса*/
case 0:
printf(" CHILD: Это процесс-потомок!\n");
printf(" CHILD: Мой PID -- %d\n", getpid());
printf(" CHILD: PID моего родителя -- %d\n",
getppid());
printf(" CHILD: Введите мой код возврата
(как можно меньше):");
scanf(" %d");
printf(" CHILD: Выход!\n");
exit(rv);
default:
printf("PARENT: Это процесс-родитель!\n");
printf("PARENT: Мой PID -- %d\n", getpid());
printf("PARENT: PID моего потомка %d\n",pid);
printf("PARENT: Я жду, пока потомок
не вызовет exit()...\n");
wait();
printf("PARENT: Код возврата потомка:%d\n",
WEXITSTATUS(rv));
printf("PARENT: Выход!\n");
}
}
Когда потомок вызывает exit(), код возврата передается родителю, который ожидает его, вызывая wait(). WEXITSTATUS() представляет собой макрос, который получает фактический код возврата потомка из вызова wait().
Функция wait() ждет завершения первого из всех возможных потомков родительского процесса. Иногда необходимо точно определить, какой из потомков должен завершиться. Для этого используется вызов waitpid() с соответствующим PID потомка в качестве аргумента. Еще один момент, на который следует обратить внимание при анализе примера, это то, что и родитель, и потомок используют переменную rv. Это не означает, что переменная разделена между процессами. Каждый процесс содержит собственные копии всех переменных.
Рассмотрим следующий пример:
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
char pid{[}255{]};
fork();
fork();
fork();
sprintf(pid, "PID : %d\n",getpid());
write(STDOUT_FILENO, pid, strlen(pid));
exit(0);
}
В этом случае будет создано семь процессов-потомков. Первый вызов fork() создает первого потомка. Как указано выше, процесс наследует положение указателя команд от родительского процесса. Указатель команд содержит адрес следующего оператора программы. Это значит, что после первого вызова fork() указатель команд и родителя, и потомка находится перед вторым вызовом fork().После второго вызова fork() и родитель, и первый потомок производят потомков второго поколения - в результате образуется четыре процесса. После третьего вызова fork() каждый процесс производит своего потомка, увеличивая общее число процессов до восьми.
Так называемые процессы-зомби возникают, если потомок завершился, а родительский процесс не вызвал wait(). Для завершения процессов используют либо оператор возврата, либо вызов функции exit() со значением, которое нужно возвратить операционной системе. Операционная система оставляет процесс зарегистрированным в своей внутренней таблице данных, пока родительский процесс не получит кода возврата потомка, либо не закончится сам. В случае процесса-зомби его код возврата не передается родителю, и запись об этом процессе не удаляется из таблицы процессов операционной системы. При дальнейшей работе и появлении новых зомби таблица процессов может быть заполнена, что приведет к невозможности создания новых процессов.
Вложение элементов запирания мьютекса в связанную структуру данных и простые изменения в коде связного списка позволяют предотвратить тупик, осуществляя блокировку в предписанном порядке.
Структура для блокировки имеет вид:
int value;
struct node1 *link;
pthread_mutex_t lock;
} node1_t;
Чтобы удалить узел из списка, необходимо выполнить следующие действия:
node1_t *prev,
*current; prev = &ListHead;
pthread_mutex_lock(&prev->lock);
while ((current = prev->link) != NULL) {
pthread_mutex_lock(¤t->lock);
if (current->value == value) {
prev->link = current->link;
pthread_mutex_unlock(¤t->lock);
pthread_mutex_unlock(&prev->lock);
current->link = NULL;
return(current);
}
pthread_mutex_unlock(&prev->lock);
prev = current;
}
pthread_mutex_unlock(&prev->lock);
return(NULL);
}
Переменные состояния используются, чтобы атомарно блокировать потоки, пока не наступит специфическое состояние. Переменные состояния всегда используются в сочетании с блокировками мьютексов:
Функция pthread_condattr_init() инициализирует атрибуты,
связанные с объектом значениями по умолчанию. Память для каждого объекта
атрибутов cattr выделяется системой потоков в процессе выполнения;
cattr является закрытым типом данных, который содержит созданный
системой объект атрибутов. Возможные значения признаков видимости
cattr - PTHREAD_PROCESS_PRIVATE и
PTHREAD_PROCESS_SHARED.
Значение по умолчанию атрибута pshared, равное
PTHREAD_PROCESS_PRIVATE, указывает, что инициализированная
переменная состояния может использоваться в пределах процесса.
Прежде чем атрибут переменной состояния сможет использоваться повторно, он должен повторно инициализироваться функцией pthread_condattr_destroy(). Вызов pthread_condattr_init() возвращает указатель на закрытый объект. Если объект не будет удален, возникнет утечка памяти; pthread_condattr_init() возвращает 0 - после успешного завершения. Любое другое значение указывает, что произошла ошибка. Пример вызова функции:
pthread_condattr_t cattr;
int ret;
ret = pthread_condattr_init(&cattr);
Областью видимости переменной состояния может быть либо процесс, либо
вся система, как и для мьютексов. Если переменная состояния создана
с атрибутом pshared, установленным в состояние PTHREAD_PROCESS_SHARED,
и она находится в разделяемой памяти, то эта переменная может разделяться
среди потоков нескольких процессов. Если же атрибут pshared
установлен в значение
PTHREAD_PROCESS_PRIVATE (по умолчанию), то
лишь потоки, созданные тем же самым процессом, могут оперировать этой переменной.
Функция pthread_condattr_setpshared() используется, чтобы
установить область видимости переменной состояния. Она возвращает
0 - после успешного завершения. Любое другое значение указывает, что
произошла ошибка. Пример использования функции:
pthread_condattr_t cattr;
int ret;
/* Область видимости - все процессы */
ret = pthread_condattr_setpshared(&cattr,
PTHREAD_PROCESS_SHARED);
/* Внутренняя переменная для процесса */
ret = pthread_condattr_setpshared(&cattr,
PTHREAD_PROCESS_PRIVATE);
int pthread_condattr_getpshared(
const pthread_condattr_t *cattr, int *pshared)
используется для получения области видимости
переменной состояния.
Функция pthread_cond_init() инициализирует переменную состояния:
const pthread_condattr_t *cattr);
Статические переменные состояния могут инициализироваться непосредственно
значениями по умолчанию с помощью макроса
PTHREAD_COND_INITIALIZER.
Несколько потоков не должны одновременно инициализировать или повторно
инициализировать ту же самую переменную состояния. Если переменная
состояния повторно инициализируется или удаляется, приложение должно
убедиться, что эта переменная состояния больше не используется;
pthread_cond_init() возвращает 0 после успешного завершения.
Любое другое значение указывает, что произошла ошибка. Пример использования
функции:
pthread_cond_t cv;
pthread_condattr_t cattr;
int ret;
/* инициализация значениями по умолчанию */
ret = pthread_cond_init(&cv, NULL);
/* инициализация определенными значениями */
ret = pthread_cond_init(&cv, &cattr);
Функция pthread_cond_wait() используется, чтобы атомарно освободить мьютекс и заставить вызывающий поток блокироваться по переменной состояния. Функция pthread_cond_wait() возвращает 0 - после успешного завершения. Любое другое значение указывает, что произошла ошибка. Пример использования функции:
pthread_cond_t cv;
pthread_mutex_t mutex;
int ret;
ret = pthread_cond_wait(&cv, &mutex);
Проверка состояния обычно проводится в цикле while, который вызывает pthread_cond_wait():
while(condition_is_false)
pthread_cond_wait();
pthread_mutex_unlock();
Следует всегда вызывать pthread_cond_signal() под защитой
мьютекса, используемого с сигнальной переменной состояния. В ином
случае переменная состояния может измениться между тестированием
соответствующего состояния и блокировкой в вызове
pthread_cond_wait(),
что может вызвать бесконечное ожидание. Если никакие потоки не блокированы
по переменной состояния, вызов pthread_cond_signal () не
будет иметь никакого эффекта.
Следующий фрагмент кода иллюстрирует, как избежать бесконечного ожидания, описанного выше:
pthread_cond_t count_nonzero;
unsigned count;
decrement_count() {
pthread_mutex_lock(&count_lock);
while (count == 0)
pthread_cond_wait(&count_nonzero, &count_lock);
count = count - 1;
pthread_mutex_unlock(&count_lock);
}
increment_count() {
pthread_mutex_lock(&count_lock);
if (count == 0)
pthread_cond_signal(&count_nonzero);
count = count + 1;
pthread_mutex_unlock(&count_lock);
}
pthread_mutex_t *mp,
const struct timespec *abstime);
#include <time.h>
pthread_timestruc_t to;
pthread_cond_t cv;
pthread_mutex_t mp;
timestruct_t abstime;
int ret;
/* ожидание переменной состояния */
ret = pthread_cond_timedwait(&cv, &mp, &abstime);
pthread_mutex_lock(&m);
to.tv_sec = time(NULL) + TIMEOUT;
to.tv_nsec = 0;
while (cond == FALSE) {
err = pthread_cond_timedwait(&c, &m, &to);
if (err == ETIMEDOUT) {
/* таймаут */
break;
}
}
pthread_mutex_unlock(&m);
pthread_cond_broadcast() возвращает 0 - после успешного завершения - или любое другое значение в случае ошибки.
Поскольку pthread_cond_broadcast() заставляет все потоки,
блокированные некоторым состоянием, бороться за мьютекс, ее нужно
использовать аккуратно. Например, можно использовать
pthread_cond_broadcast(),
чтобы позволить потокам бороться за изменение количества требуемых
ресурсов, когда ресурсы освобождаются:
pthread_mutex_t rsrc_lock;
pthread_cond_t rsrc_add;
unsigned int resources;
get_resources(int amount) {
pthread_mutex_lock(&rsrc_lock);
while (resources < amount)
pthread_cond_wait(&rsrc_add, &rsrc_lock);
resources -= amount;
pthread_mutex_unlock(&rsrc_lock);
}
add_resources(int amount) {
pthread_mutex_lock(&rsrc_lock);
resources += amount;
pthread_cond_broadcast(&rsrc_add);
pthread_mutex_unlock(&rsrc_lock);
}
pthread_cond_t cv;
int ret;
/* Переменная состояния удалена */
ret = pthread_cond_destroy(&cv);
Сокеты обеспечивают двухстороннюю связь типа ``точка-точка'' между двумя процессами. Они являются основными компонентами межсистемной и межпроцессной связи. Каждый сокет представляет собой конечную точку связи, с которой может быть совмещено некоторое имя. Он имеет определенный тип, и один процесс или несколько, связанных с ним процессов.
Сокеты находятся в областях связи (доменах). Домен сокета - это абстракция, которая определяет структуру адресации и набор протоколов. Сокеты могут соединяться только с сокетами в том же домене. Всего выделено 23 класса сокетов (см. файл <sys/socket.h>), из которых обычно используются только UNIX-сокеты и Интернет-сокеты. Сокеты могут использоваться для установки связи между процессами на отдельной системе подобно другим формам IPC.
Класс сокетов UNIX обеспечивает их адресное пространство для отдельной вычислительной системы. Сокеты области UNIX называются именами файлов UNIX. Сокеты также можно использовать, чтобы организовать связь между процессами на различных системах. Адресное пространство сокетов между связанными системами называют доменом Интернета. Коммуникации домена Интернета используют стек протоколов TCP/IP.
Типы сокетов определяют особенности связи, доступные приложению. Процессы взаимодействуют только через сокеты одного и того же типа. Основные типы сокетов:
| Сервер | Клиент | |
| Установка сокета socket() | Установка сокета socket() | |
| Присвоение имени bind() | ||
| Установка очереди запросов listen() | ||
| Выбор соединения из очереди accept() |
|
Установка соединения connect() |
| read() |
|
write() |
| write() |
|
read() |
Для создания сокета определенного типа в определенном адресном пространстве используется функция socket():
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Удаленный процесс не может идентифицировать определенный сокет, пока ему не будет присвоен адрес. Процессы могут поддерживать связь только через адреса. В пространстве адресов UNIX соединение обычно определяется одним или двумя именами файлов. В пространстве адресов Интернета соединение определяется локальным и удаленным адресами и номерами портов.
Функция bind():
#include <sys/socket.h>
int bind(int s, const struct sockaddr *name,
int namelen);
ushort_t sa_family; /* семейство адресов */
char sa_data[ 14]; /* 14 байт прямого адреса */
};
ushort_t sun_family; /* AF_ UNIX */
char sun_path[ 104]; /* путь к файлу */
};
uchar_t sin_len;
sa_family_t sin_family; /* AF_ INET */
in_port_t sin_port; /* 16-битный порт */
struct in_addr sin_addr; /* Указатель на адрес */
uchar_t sin_zero[ 8]; /* зарезервировано */
};
Соединение сокетов обычно происходит несимметрично. Один из процессов действует как сервер, а другой выполняет роль клиента. Сервер связывает свой сокет с предварительно указанным путем или адресом. После этого для сокетов вида SOCK_STREAM сервер вызывает функцию listen(), которая определяет, сколько запросов на соединение можно поставить в очередь. Клиент запрашивает соединение с сокетом сервера вызовом connect(), а сокет принимает некоторое соединение с помощью функции accept(). Синтаксис вызова listen() следующий:
#include <sys/socket.h>
int listen (int socket, int backlog );
Функция accept() используется сервером для принятия соединения с сокетом. При этом сокет в момент вызова функции должен уже иметь очередь запросов, созданную вызовом listen(). Если сервер устанавливает связь с клиентом, то функция accept() возвращает новый сокет-дескриптор, через который и происходит общение клиента с сервером. Пока устанавливается связь клиента с сервером, функция accept() блокирует другие запросы связи, а после установления связи "прослушивание"запросов возобновляется:
#include <sys/socket.h>
int accept( int socket, struct sockaddr *addr,
int *addrlen );
Функция connect() используется процессом-клиентом для установления связи с сервером:
#include <sys/socket.h>
int connect( int socket, struct sockaddr *name,
int namelength );
Функция exec() (execute) загружает и запускает другую программу. Таким образом, новая программа полностью замещает текущий процесс. Новая программа начинает свое выполнение с функции main. Все файлы вызывающей программы остаются открытыми. Они также являются доступными новой программе. Используется шесть различных вариантов функций exec.
#include <unistd.h>
int execl(char *name, char *arg0, ... /*NULL*/);
int execv(char *name, char *argv[]);
int execle(char *name, char *arg0, ... /*,NULL,
char *envp[]*/);
int execve(char *name, char *arv[], char *envp[]);
int execlp(char *name, char *arg0, ... /*NULL*/);
int execvp(char *name, char *argv[]);
Вызов exec происходит таким образом, что переданная в качестве
аргумента программа загружается в память вместо старой,
которая вызвала exec. Старой программе больше не доступны
сегменты памяти, которые перезаписаны новой программой.
Суффиксы l, v, p, e в именах функций определяют формат и объем аргументов, а также каталоги, в которых нужно искать загружаемую программу:
#include <stdio.h>
int main(int argc, char *argv[])
{
int i=0;
printf("%s\n",argv[0]);
printf("Программа запущена и получила строку : ");
while(argv[++i] != NULL)
printf("%s ",argv[i]);
return 0;
}
Эта программа выводит на экран строку, переданную ей в качестве аргумента.
Пусть она называется hello. Она будет вызвана из другой программы
с помощью функции execl(). Код вызывающей программы приведен ниже
:
#include <stdio.h>
#include <unistd.h>
int main(int argc, int *argv[])
{
printf("Будет выполнена программа %s...\n\n",
argv[0]);
printf("Выполняется %s", argv[0]);
execl("hello"," ","Hello", "World!", NULL);
return 0;
}
В строке execl() аргументы указаны в виде списка. Доступ
к ним также осуществляется последовательно. Если использовать функцию
execv(), то вместо списка будет указан вектор аргументов:
#include <stdio.h>
#include <unistd.h>
int main(int argc, int *argv[])
{
printf("Программа %s будет выполнена...\n\n",
argv[0]);
printf("Выполняется %s", argv[0]);
execv("hello",argv);
return 0;
}
Для обмена данными существуют две группы функций - для записи в сокет и для чтения из него. Функции для записи имеют вид:
#include <sys/socket.h>
#include <sys/uio.h>
int send( int socket, const char *msg, int len,
int flags);
int sendto( int socket, const char *msg, int len,
int flags, const struct sockaddr *to, int tolen );
int sendmsg( int socket, const struct msghdr *msg,
int flags );
Для приема данных процесс-потребитель должен выполнить
функцию приема
или чтения данных из сокета. Варианты функций приема:
#include <sys/socket.h>
#include <sys/uio.h>
int recv( int socket, char *buffer, int len, int
flags);
int recvfrom( int socket, char *buffer, int len,
int flags, const struct sockaddr *from,
int fromlen );
int recvmsg( int socket, const struct msghdr *msg,
int flags );
Функция shutdown() используется для немедленного закрытия всех или некоторых связей для сокета:
#include <sys/uio.h>
int shutdown(int s, int how);
#include <sys/uio.h>
int close (int s);
Пример-оболочка программы "Клиент":
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define ADDRESS "mysocket" /* адрес для связи */
void main () {
char c;
int i, s, len;
FILE *fp;
struct sockaddr_un sa;
/* получаем свой сокет-дескриптор: */
if ((s = socket (AF_UNIX, SOCK_STREAM, 0))<0) {
perror ("client: socket"); exit(1);
}
/* создаем адрес, по которому
будем связываться с сервером: */
sa.sun_family = AF_UNIX;
strcpy (sa.sun_path, ADDRESS);
/* пытаемся связаться с сервером: */
len = sizeof ( sa.sun_family) + strlen ( sa.sun_path);
if ( connect ( s, &sa, len) < 0 ){
perror ("client: connect"); exit (1);
}
/* читаем сообщения сервера */
fp = fdopen (s, "r");
c = fgetc (fp);
/* обрабатываем информацию от сервера
...................................
*/
/* посылаем ответ серверу */
send (s, "client", 7, 0);
/* продолжаем диалог с сервером, пока в этом
есть необходимость.....
*/
/* завершаем сеанс работы */
close (s);
exit (0);
}
Пример-оболочка программы "Сервер":
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define ADDRESS "mysocket" /* адрес для связи */
void main ()
{
char c;
int i, d, d1, len, ca_len;
FILE *fp;
struct sockaddr_un sa, ca;
/* получаем свой сокет-дескриптор: */
if((d = socket (AF_UNIX, SOCK_STREAM, 0)) < 0) {
perror ("client: socket"); exit (1);
}
/* создаем адрес, c которым будут
связываться клиенты */
sa.sun_family = AF_UNIX;
strcpy (sa.sun_path, ADDRESS);
/* связываем адрес с сокетом;
уничтожаем файл с именем ADDRESS,
если он существует, для того, чтобы
вызов bind завершился успешно */
unlink (ADDRESS);
len = sizeof ( sa.sun_family) + strlen (sa.sun_path);
if ( bind ( d, &sa, len) < 0 ) {
perror ("server: bind"); exit (1);
}
/* слушаем запросы на сокет */
if ( listen ( d, 5) < 0 ) {
perror ("server: listen"); exit (1);
}
/* связываемся с клиентом через неименованный сокет
с дескриптором d1:*/
if (( d1 = accept ( d, &ca, &ca_len)) < 0 ) {
perror ("server: accept"); exit (1);
}
/* пишем клиенту: */
send (d1, "server", 7, 0);
/* читаем запрос клиента */
fp = fdopen (d1, "r");
c = fgetc (fp);
/* ................................ */
/* обрабатываем запрос клиента, посылаем ответ и т.д.
........................... */
/* завершаем сеанс работы */
close (d1);
exit (0);
}
Рассмотренные ранее методы синхронизации процессов и коммуникаций предполагали использование одного компьютера. Тем не менее часто приложения должны работать в пределах локальной или распределенной сети. Одним из методов реализации взаимодействия является удаленный вызов процедур (remote procedure calls - RPC). Вызов процедуры представляет собой классическую форму синхронной коммуникации: вызывающий процесс передает управление подпроцессу и ждет возвращения результатов. Используя RPC, программисты распределенных приложений могут не учитывать мелких деталей при обеспечении интерфейса с сетью. Транспортная независимость RPC изолирует приложение от физических и логических элементов механизма коммуникаций данных и позволяет ему использовать разнообразие транспортных протоколов.
RPC делает модель вычислений ``клиент - сервер'' более мощной и более простой для программирования. Использование компиляторов протоколов ONC RPCGEN позволяет клиентам прозрачно осуществлять удаленные вызовы через локальный интерфейс процедур.
Как и при обычном вызове функции, при вызове RPC его аргументы передаются удаленной процедуре, и вызывающий процесс ждет ответа, который будет возвращен из этой удаленной процедуры. Порядок действий следующий.
Клиент осуществляет вызов процедуры, которая посылает запрос серверу и ждет ответа. Поток выполнения блокируется, пока не будет получен ответ или не наступит тайм-аут. Когда приходит запрос, сервер вызывает процедуру диспетчеризации, которая выполняет требуемое действие и посылает ответ клиенту. После того, как вызов RPC закончен, программа клиента продолжает выполнение своих действий.
Удаленная процедура уникально идентифицируется тройкой параметров: номер программы, номер версии, номер процедуры. Номер программы идентифицирует группу соотносящихся удаленных процедур, каждая из которых имеет свой уникальный номер. Программа может состоять из одной или более версий. Каждая версия состоит из множества процедур, которые могут быть вызваны удаленно. Номера версии позволяют использовать одновременно несколько версий. Каждая процедура имеет свой номер.
Для разработки приложения RPC необходимо выполнить следующие шаги:
Самый простой способ определения и реализации протокола состоит в том, чтобы использовать компилятор протоколов rpcgen. Для создания протокола нужно идентифицировать имена сервисных процедур и типы данных для возвращаемых аргументов и параметров. Компилятор протокола считывает определения и автоматически создает коды для сервера и клиента; rpcgen использует собственный язык (язык RPC или RPCL), который очень похож на язык директив препроцессора С; rpcgen реализован в виде автономного компилятора, который работает со специальными файлами, обозначенными расширением .x.
Для обработки файла RPCL необходимо выполнить команду rpcgen~rpcprog.x~
При этом будут созданы четыре файла:
rpcprog_clnt.c - процедуры клиента;
rpcprog_svc.c - процедуры сервера;
rpcprog_xdr.c - фильтры XDR;
rpcprog.h - файл заголовка, необходимый для XDR фильтров.
Внешнее представление данных (XDR - eXternal Data Represen-tation) - это абстракция данных, необходимая для машинно - независимой связи, поскольку клиент и сервер могут работать на компьютерах различных типов и архитектур.
Пусть программа клиента называется rpcprog.c, а программа сервера - rpcsvc.c. Протокол определен в файле rpcprog.x. Этот файл обработан rpcgen, чтобы создать файлы фильтров и процедур: rpcprog_clnt.c, rpcprog_svc.c, rpcprog_xdr.c, rpcprog.h.
Программы клиента и сервера должны включать строку
#include"rpcprog.h"
После этого необходимо:
откомпилировать код клиента:
cc -c rpcprog.c
откомпилировать специальную клиентскую часть:
cc -c rpcprog_clnt.c
откомпилировать фильтр XDR:
cc -c rpcprog_xdr.c
построить выполняемый файл клиента:
cc -o rpcprog rpcprog.o rpcprog_clnt.o rpcprog_xdr.c
откомпилировать серверные процедуры:
cc -c rpcsvc.c
откомпилировать специальную серверную часть:
cc -c rpcprog_svc.c
построить выполняемый файл сервера:
cc -o rpcsvc rpcsvc.o rpcprog_svc.o rpcprog_xdr.c
Теперь можно запустить программы rpcprog и rpcsvc на компьютерах клиента и сервера соответственно. Процедуры сервера должны быть зарегистрированы, прежде чем клиент сможет их вызвать.
Здесь перечислены все процедуры RPC для всех уровней протокола удаленного вызова:
Упрощенный интерфейс - это самый простой уровень использования RPC, потому что он не требует использования других процедур RPC. Он также ограничивает контроль над основными механизмами коммуникации. Разработка программ для этого уровня может осуществляться очень быстро и непосредственно поддерживается компилятором rpcgen. Для большинства приложений достаточно возможностей rpcgen. Некоторые службы RPC не доступны в виде функций C, но они доступны как программы RPC. Процедуры библиотеки упрощенного интерфейса обеспечивают прямой доступ к возможностям RPC для программ, которые не требуют детального управления.
Все процедуры находятся в библиотеке служб RPC librpcsvc.
Пример rusers.c, приведенный ниже, показывает число пользователей на удаленном компьютере. Он вызывает процедуру rusers из библиотеки RPC:
#include <rpcsvc/rusers.h>
#include <stdio.h>
/*
* программа вызывает службу rusers()
*/
main(int argc,char **argv)
{
int num;
if (argc != 2) {
fprintf(stderr, "Использование: %s hostname\n",
argv[0]);
exit(1);
}
if ((num = rnusers(argv[1])) < 0) {
fprintf(stderr, "Ошибка вызова: rusers\n");
exit(1);
}
fprintf(stderr, "%d пользователей на %s\n", num,
argv[1] );
exit(0);
}
Клиентская часть состоит из вызова функции rpc_call():
#include <utmp.h>
#include <rpc/rpc.h>
#include <rpcsvc/rusers.h>
/* программа вызывает удаленную программу RUSERSPROG */
main(int argc, char **argv)
{
unsigned long nusers;
enum clnt_stat cs;
if (argc != 2) {
fprintf(stderr, "Использование: rusers hostname\n");
exit(1);
}
if( cs = rpc_call(argv[1], RUSERSPROG,
RUSERSVERS, RUSERSPROC_NUM, xdr_void,
(char *)0, xdr_u_long, (char *)&nusers,
"visible") != RPC_SUCCESS ) {
clnt_perrno(cs);
exit(1);
}
fprintf(stderr, "%d пользователей на компьютере %s\n",
nusers, argv[1] );
exit(0);
}
Синтаксис функции rpc_call() приведен ниже:
/* Имя сервера */
char *host,
/* Номер программы сервера */
u_long prognum,
/* Номер версии сервера */
u_long versnum,
/* фильтр XDR для кодирования arg */
xdrproc_t inproc,
/* Указатель на аргументы */
char *in,
/* Фильтр декодирования результата */
xdr_proc_t outproc,
/* Адрес сохранения результата */
char *out,
/* Выбор транспортной службы */)
char *nettype
);
Клиент блокируется вызовом rpc_call() до тех пор, пока он не получит ответ от сервера. Если сервер отвечает, то возвращается RPC_SUCCESS со значением 0. Если запрос был неудачен, возвращается значение, отличное от 0. Это значение можно преобразовать к типу clnt_stat - перечислимому типу, определенному в файле RPC (<rpc/rpc.h>) и интерпретируемому функцией clnt_sperrno(). Эта функция возвращает указатель на стандартное сообщение RPC об ошибке, соответствующее коду ошибки. В примере испытываются все "видимые" транспортные службы, внесенные в /etc/netconfig. Настройка количества повторов требует использования более низких уровней библиотеки RPC. Множественные аргументы и результаты обрабатываются с помощью объединения их в структуры.
Поскольку типы данных могут быть представлены на различных машинах различным образом, то для rpc_call() нужно указать и тип аргумента, и указатель на него (аналогично и для результата). Возвращаемое значение для RUSERSPROC_NUM - unsigned long, поэтому первым возвращаемым параметром rpc_call() будет xdr_u_long, а вторым - *nusers. Поскольку RUSERSPROC_NUM не имеет аргументов, функцией шифрования XDR для rpc_call() будет xdr_void(), а ее аргумент имеет значение NULL.
Программа сервера, использующая упрощенный интерфейс, достаточно простая. Она вызывает rpc_reg(), чтобы зарегистрировать процедуру, которая будет вызвана, а затем вызывает svc_run() - диспетчера удаленных процедур библиотеки RPC, который ждет входящих запросов.
Прототип rpc_reg() представлен ниже:
/* Номер программы сервера */
u_long prognum,
/* Номер версии сервера */
u_long versnum,
/* Номер процедуры сервера */
u_long procnum,
/* Имя удаленной функции */
char *procname,
/* Фильтр для кодирования аргумента arg */
xdrproc_t inproc,
/* Фильтр декодирования результата*/
xdrproc_t outproc,
/* Выбор транспортной службы */)
char *nettype;
Функция svc_run() вызывает сервисные процедуры в ответ на вызовы RPC. Диспетчер в rpc_reg() заботится о расшифровывании аргументов удаленных процедур и о зашифровывании результатов, с использованием фильтров XDR, определенных при регистрации удаленной процедуры.
Некоторые замечания относительно программы сервера:
#include <rpc/rpc.h>
#include <rpcsvc/rusers.h>
void *rusers();
main()
{
if(rpc_reg(RUSERSPROG, RUSERSVERS,
RUSERSPROC_NUM, rusers,
xdr_void, xdr_u_long,
"visible") == -1) {
fprintf(stderr, "Невозможно зарегистрировать\n");
exit(1);
}
svc_run(); /* Процедура без возврата */
fprintf(stderr, "Ошибка: Выход из svc_run!\n");
exit(1);
}
rpc_reg() можно вызвать сколько угодно раз, чтобы зарегистрировать все различные программы, версии, и процедуры.
Типы данных, передаваемые и получаемые из удаленных процедур, могут быть любыми из множества предопределенных, либо типом, определенным программистом. RPC работает с произвольными структурами данных, независимо от различий в структуре типов на различных машинах, преобразуя типы к стандартному формату передачи, который называется внешним представлением данных (XDR). Преобразование из машинного представления в XDR называют сериализацией, а обратный процесс - десериализацией. Аргументы транслятора для rpc_call() и rpc_reg() могут определять примитивную процедуру XDR, например xdr_u_long(), или специальную процедуру пользователя, которая обрабатывает полную структуру аргументов. Процедуры обработки аргументов должны принимать только два аргумента: указатель на результат и указатель на обработчик XDR.
Доступны следующие примитивные процедуры XDR для обработки типов данных:
xdr_long() xdr_float() xdr_u_int() xdr_bool()
xdr_short() xdr_double() xdr_u_short() xdr_wrapstring()
xdr_char() xdr_quadruple() xdr_u_char() xdr_void()
В случае собственной процедуры программиста, структура
int a;
short b;
} simple;
#include "simple.h"
bool_t xdr_simple(XDR *xdrsp, struct simple *simplep)
{
if (!xdr_int(xdrsp, &simplep->a))
return (FALSE);
if (!xdr_short(xdrsp, &simplep->b))
return (FALSE);
return (TRUE);
}
Процедура XDR возвращает результат, отличный от нуля, если она завершается успешно, либо 0 - в случае ошибки.
Для более сложных структур данных используют готовые процедуры XDR:
xdr_vector() xdr_union() xdr_pointer()
xdr_string() xdr_opaque()
int *data;
int arrlnth;
} arr;
{
return(xdr_array(xdrsp, (caddr_t)&arrp->data,
(u_int *)&arrp->arrlnth, MAXLEN, sizeof(int),
xdr_int));
}
bool_t xdr_intarr(XDR *xdrsp, int intarr[])
{
return (xdr_vector(xdrsp, intarr, SIZE, sizeof(int),
xdr_int));
}
Строки, законченные пустым указателем, транслируются с помощью функции xdr_string(). Она сходна с xdr_bytes(), но не содержит параметра длины. При сериализации процедура получает длину строки из strlen(), а при десериализации создает строку, заканчивающуюся пустым указателем.
xdr_reference() вызывает встроенные функции xdr_string() и xdr_reference(), которые преобразуют указатели для передачи строки, и struct simple из предыдущего примера. Пример использования xdr_reference():
char *string;
struct simple *simplep;
} finalexample;
bool_t xdr_finalexample(XDR *xdrsp,
struct finalexample *finalp)
{
if (!xdr_string(xdrsp, &finalp->string, MAXSTRLEN))
return (FALSE);
if (!xdr_reference( xdrsp, &finalp->simplep,
sizeof(struct simple), xdr_simple))
return (FALSE);
return (TRUE);
}
Процедура thatxdr_simple() должна вызываться вместо
xdr_reference().
В качестве примера высокоуровневого приложения приведен удаленный аналог команды чтения оглавления каталога.
Вначале рассматривается локальная версия. Программа состоит из двух файлов.
Файл lls.c содержит основную программу, которая вызывает процедуру в локальном модуле read_dir.c:
#include <strings.h>
#include "rls.h"
main (int argc, char **argv)
{
char dir[DIR_SIZE];
/* вызов локальной процедуры */
strcpy(dir, argv[1]);
/* char dir[DIR_SIZE] это имя каталога */
read_dir(dir);
/* вывод результата */
printf("%s\n", dir);
exit(0);
}
аргумент и возвращают один результат. Оба передаются
через указатели. Возвращаемые значения должны
указывать на статические данные. */
#include <stdio.h>
#include <sys/types.h>
#include <sys/dir.h>
#include "rls.h"
read_dir(char *dir) /* char dir[DIR_SIZE] */
{
DIR * dirp;
struct direct *d;
printf("начало");
/* открывает каталог */
dirp = opendir(dir);
if (dirp == NULL)
return(NULL);
/* сохраняет имена файлов в буфер каталога */
dir[0] = NULL;
while (d = readdir(dirp))
sprintf(dir, "%s%s\n", dir, d->d_name);
/* выводит результат */
printf("выход ");
closedir(dirp);
return((int)dir);
}
#define DIR_SIZE 8192.
Понятно, что этот размер должен быть упомянут в обоих файлах. Позже, при разработке RPC-версии, к этому файлу будет добавлена другая информация.
Для того, чтобы модифицировать программу для работы через сеть, выполняются следующие действия:
Для передачи и приема имени каталога и его содержимого можно использовать простые строки, заканчивающиеся пустым указателем. Кроме того, передача этих параметров включена непосредственно в код сервера и клиента.
После этого нужно определить номера программы, процедуры и версии для клиента и сервера. Это можно сделать автоматически, используя rpcgen, или на базе предопределенных макросов упрощенного интерфейса. В примере номера определены вручную.
Сервер и клиент должны заранее согласовать, что они будут использовать логические адреса (физические адреса не имеют значения, поскольку они скрыты от разработчика приложения).
Номера программы определяются стандартным способом:
0x20000000 - 0x3FFFFFFF: Пользовательские
0x40000000 - 0x5FFFFFFF: Переходные
0x60000000 - 0xFFFFFFFF: Резервированные
DIR_SIZE определяет размер буфера для каталога в программах сервера и клиента.
Теперь файл rls.h содержит:
/* номер программы сервера */
#define DIRPROG ((u_long) 0x20000001)
#define DIRVERS ((u_long) 1) /* номер версии */
#define READDIR ((u_long) 1) /* номер процедуры */
Для передачи данных в виде строк нужно определить процедуру XDR - фильтра xdr_dir(), который разделяет данные. При этом можно обрабатывать только один аргумент шифрования и расшифровки. Для этого подходит стандартная процедура xdr_string().
Файл XDR, rls_xrd.c, выглядит так:
#include "rls.h"
bool_t xdr_dir(XDR *xdrs, char *objp)
{ return ( xdr_string(xdrs, &objp, DIR_SIZE) ); }
Для нее можно использовать оригинальный файл read_dir.c. Необходимо лишь зарегистрировать процедуру и запустить сервер.
Процедура регистрируется с помощью функции registerrpc():
u_long prognum /* Номер программы сервера */,
u_long versnum /* Номер версии сервера */,
u_long procnum /* Номер процедуры сервера */,
char *procname /* Имя удаленной функции */,
/* Фильтр для кодирования аргументов */
xdrproc_t inproc,
/* Фильтр декодирования результата */
xdrproc_t outproc);
#include "rls.h"
main()
{
extern bool_t xdr_dir();
extern char * read_dir();
registerrpc(DIRPROG, DIRVERS, READDIR,
read_dir, xdr_dir, xdr_dir);
svc_run();
}
На клиентской стороне просто производится вызов удаленной процедуры. Для этого используется функция callrpc():
u_long prognum /* Номер программы сервера */,
u_long versnum /* Номер версии сервера */,
char *in /* Указатель на аргументы */,
/* Фильтр XDR для кодирования аргумента */
xdrproc_t inproc,
char *out /* Адрес для сохранения результата */,
/* Фильтр декодирования результата */
xdr_proc_t outproc);
Программа rls.c выглядит так:
* rls.c: клиент удаленного чтения каталога
*/
#include <stdio.h>
#include <strings.h>
#include <rpc/rpc.h>
#include "rls.h"
main (argc, argv)
int argc; char *argv[];
{
char dir[DIR_SIZE];
/* вызов удаленной процедуры */
strcpy(dir, argv[2]);
read_dir(argv[1], dir); /* read_dir(host, directory) */
/* вывод результата */
printf("%s\n", dir);
exit(0);
}
read_dir(host, dir)
char *dir, *host;
{
extern bool_t xdr_dir();
enum clnt_stat clnt_stat;
clnt_stat = callrpc ( host, DIRPROG, DIRVERS, READDIR,
xdr_dir, dir, xdr_dir, dir);
if (clnt_stat != 0) clnt_perrno (clnt_stat);
}
Программа rpcgen создает модули интерфейса удаленной программы. Она компилирует исходный код, написанный на языке RPC. Язык RPC подобен по синтаксису и структуре на C; rpcgen создает один или несколько исходных модулей на языке C, которые затем обрабатываются компилятором.
Результатом работы rpcgen являются:
Пусть приложение работает на отдельном компьютере, и его необходимо преобразовать, чтобы использовать в "распределенной" сети. Ниже показано пошаговое преобразование программы, которая выводит сообщения на терминал.
Однопроцессная версия printmesg.c:
#include <stdio.h>
main(int argc, char *argv[])
{
char *message;
if (argc != 2) {
fprintf(stderr, "usage: %s <message>\n",argv[0]);
exit(1);
}
message = argv[1];
if (!printmessage(message)) {
fprintf(stderr,"%s: невозможно вывести сообщение\n",
argv[0]); exit(1);
}
printf("Сообщение выведено!\n");
exit(0);
}
/* Вывод сообщения на терминал.
* Возвращает логическое значение, показывающее
* выведено ли сообщение. */
printmessage(char *msg) {
FILE *f;
f = fopen("/dev/console", "w");
if (f == (FILE *)NULL) return (0);
fprintf(f, "%s\n", msg);
fclose(f);
return(1);
}
Если функцию printmessage() превратить в удаленную процедуру, ее можно вызывать на любой машине сети.
Сначала необходимо определить типы данных всех аргументов вызова процедуры и результата. Аргумент вызова printmessage() представляет собой строку, а результат - целое число. Теперь можно написать спецификацию протокола на языке RPC, который будет описывать удаленную версию printmessage(). Исходный код RPC для данной спецификации:
program MESSAGEPROG {
version PRINTMESSAGEVERS {
int PRINTMESSAGE(string) = 1;
} = 1;
} = 0x20000001;
В этом примере PRINTMESSAGE - это процедура номер 1 в версии 1 удаленной программы MESSAGEPROG с номером программы 0x20000001.
Номера версии увеличиваются, если в удаленной программе изменяются функциональные возможности. При этом могут быть заменены существующие процедуры или добавлены новые. Может быть определена более чем одна версия удаленной программы, а также каждая версия может иметь более одной определенной процедуры.
Необходимо разработать еще две дополнительные программы. Одной из них является сама удаленная процедура. Версия printmsg.c для RPC:
* msg_proc.c: реализация удаленной процедуры
* "printmessage" */
#include <stdio.h>
#include "msg.h" /* msg.h сгенерированный rpcgen */
int * printmessage_1(char **msg, struct svc_req *req) {
static int result; /* должен быть static! */
FILE *f;
f = fopen("/dev/console", "w");
if (f == (FILE *)NULL) {
result = 0;
return (&result);
}
fprintf(f, "%s\n", *msg);
fclose(f);
result = 1;
return (&result);
}
При этом определение удаленной процедуры printmessage_1 отличается от локальной процедуры printmessage в следующих моментах:
* rprintmsg.c: удаленная версия "printmsg.c"
*/
#include <stdio.h>
#include "msg.h" /* msg.h сгенерирован rpcgen */
main(int argc, char **argv)
{
CLIENT *clnt;
int *result;
char *server;
char *message;
if (argc != 3) {
fprintf(stderr, "usage: %s host
message\n", argv[0]);
exit(1);
}
server = argv[1];
message = argv[2];
/*
* Создает клиентский "обрабочик", используемый
* для вызова MESSAGEPROG на сервере
*/
clnt = clnt_create(server, MESSAGEPROG,
PRINTMESSAGEVERS, "visible");
if (clnt == (CLIENT *)NULL) {
/*
* Невозможно установить соединение с сервером.
*/
clnt_pcreateerror(server);
exit(1);
}
/*
* Вызов удаленной процедуры
* "printmessage" на сервере
*/
result = printmessage_1(&message, clnt);
if (result == (int *)NULL) {
/*
* Ошибка при вызове сервера
*/
clnt_perror(clnt, server);
exit(1);
}
/* Успешный вызов удаленной процедуры.
*/
if (*result == 0) {
/*
* Сервер не может вывести сообщение.
*/
fprintf(stderr, "%s: невозможно вывести
сообщение\n", argv[0]);
exit(1);
}
/* Сообщение выведено на терминал сервера
*/
printf("Сообщение доставлено %s\n", server);
clnt_destroy( clnt );
exit(0);
}
Следует отметить следующие особенности клиентской программы вызова printmsg.c:
Для компиляции примера удаленного rprintmsg:
В этом примере не было создано никаких процедур XDR, потому что приложение использует только основные типы, которые включены в libnsl. Теперь нужно рассмотреть, что создано rpcgen на основе входного файла msg.x:
Оригинал: skif.bas-net.by
Садыхов Р.Х., Поденок Л.П., Отвагин А.В., Глецевич И.И., Пынькин Д.А.
Средства параллельного программирования в ОС Linux: Учеб. пособие / Под ред. Р.Х. Садыхова.
- Мн.: ЕГУ, 2004. - 475 с.
ISBN 000-0000-00-0.
Пособие посвящено средствам программирования, позволяющим организовать различные уровни параллельного взаимодействия между процессами в операционной системе Linux. В нем последовательно рассмотрены основные понятия (процессы, потоки, сигналы и т.д.), встроенные средства межпроцессного взаимодействия Linux, высокоуровневые средства построения параллельных приложений, основанные на применении библиотек поддержки параллельных вычислений, таких, как DIPC, MPI, PVM. Отдельный раздел посвящен использованию специализированной библиотеки научных вычислений PETSc на базе MPI.
Пособие предназначено для программистов, желающих освоить принципы и средства разработки параллельных программ в ОС Linux. Оно может также служить начальным руководством для обучения разработке параллельного программного обеспечения, ориентированного на применение в высокопроизводительных кластерах семейства СКИФ.
Садыхов Р.Х., Поденок Л.П., Отвагин А.В., Глецевич И.И., Пынькин Д.А.
Средства параллельного программирования в ОС Linux: Учеб. пособие / Под ред. Р.Х. Садыхова.
- Мн.: ЕГУ, 2004. - 475 с.
ISBN 000-0000-00-0.
Пособие посвящено средствам программирования, позволяющим организовать различные уровни параллельного взаимодействия между процессами в операционной системе Linux. В нем последовательно рассмотрены основные понятия (процессы, потоки, сигналы и т.д.), встроенные средства межпроцессного взаимодействия Linux, высокоуровневые средства построения параллельных приложений, основанные на применении библиотек поддержки параллельных вычислений, таких, как DIPC, MPI, PVM. Отдельный раздел посвящен использованию специализированной библиотеки научных вычислений PETSc на базе MPI.
Пособие предназначено для программистов, желающих освоить принципы и средства разработки параллельных программ в ОС Linux. Оно может также служить начальным руководством для обучения разработке параллельного программного обеспечения, ориентированного на применение в высокопроизводительных кластерах семейства СКИФ.
Сигналы являются программными прерываниями, которые посылаются процессу, когда случается некоторое событие. Сигналы могут возникать синхронно с ошибкой в приложении, например SIGFPE (ошибка вычислений с плавающей запятой) и SIGSEGV (ошибка адресации), но большинство сигналов является асинхронными. Сигналы могут посылаться процессу, если система обнаруживает программное событие, например, когда пользователь дает команду прервать или остановить выполнение, или получен сигнал на завершение от другого процесса. Сигналы могут прийти непосредственно от ядра ОС, когда возникает сбой аппаратных средств ЭВМ. Система определяет набор сигналов, которые могут быть отправлены процессу. В Linux применяется около 30 различных сигналов. При этом каждый сигнал имеет целочисленное значение и приводит к строго определенным действиям.
Механизм передачи сигналов состоит из следующих частей:
Известно три варианта реакции на сигналы:
void(*signal(int signr, void(*sighandler)(int)))(int);
signalfunction *sighandler);
| Номер | Значение | Реакция программы по умолчанию |
| SIGABRT | Ненормальное завершение (abort()) | Завершение |
| SIGALRM | Окончание кванта времени | Завершение |
| SIGBUS | Аппаратная ошибка | Завершение |
| SIGCHLD | Изменение состояния потомка | Игнорирование |
| SIGCONT | Продолжение прерванной программы | Продолжение / игнорирование |
| SIGEMT | Аппаратная ошибка | Завершение |
| SIGFPE | Ошибка вычислений с плавающей запятой | Завершение |
| SIGILL | Неразрешенная аппаратная команда | Завершение |
| SIGINT | Прерывание с терминала | Завершение |
| SIGIO | Асинхронный ввод/вывод | Игнорирование |
| SIGKILL | Завершение программы | Завершение |
| SIGPIPE | Запись в канал без чтения | Завершение |
| SIGPWR | Сбой питания | Игнорирование |
| SIGQUIT | Прерывание с клавиатуры | Завершение |
| SIGSEGV | Ошибка адресации | Завершение |
| SIGSTOP | Остановка процесса | Остановка |
| SIGTTIN | Попытка чтения из фонового процесса | Остановка |
| SIGTTOU | Попытка записи в фоновый процесс | Остановка |
| SIGUSR1 | Пользовательский сигнал | Завершение |
| SIGUSR2 | Пользовательский сигнал | Завершение |
| SIGXCPU | Превышение лимита времени CPU | Завершение |
| SIGXFSZ | Превышение пространства памяти (4GB) | Завершение |
| SIGURG | Срочное событие | Игнорирование |
| SIGWINCH | Изменение размера окна | Игнорирование |
Переменная sighandler определяет функцию обработки сигнала.
В заголовочном файле <signal.h> определены две константы
SIG_DFL и SIG_IGN. SIG_DFL означает
выполнение действий по умолчанию - в большинстве случаев - окончание
процесса. Например, определение signal(SIGINT, SIG_DFL);
приведет к тому, что при нажатии на комбинацию клавиш CTRL+C
во время выполнения сработает реакция по умолчанию на сигнал SIGINT
и программа завершится. С другой стороны, можно определить
signal(SIGINT, SIG_IGN);
Если теперь нажать на комбинацию клавиш CTRL+C, ничего не
произойдет, так как сигнал SIGINT игнорируется. Третьим способом
является перехват сигнала SIGINT и передача управления на
адрес собственной функции, которая должна выполнять действия, если
была нажата комбинация клавиш CTRL+C, например
signal(SIGINT, function);
Пример использования обработчика сигнала приведен ниже:
#include <stdlib.h>
#include <signal.h>
void sigfunc(int sig) {
char c;
if(sig != SIGINT)
return;
else {
printf("\nХотите завершить программу (y/n) : ");
while((c=getchar()) != 'n')
return;
exit (0);
}
}
int main() {
int i;
signal(SIGINT,sigfunc);
while(1)
{
printf(" Вы можете завершить программу с помощью
CTRL+C ");
for(i=0;i<=48;i++)
printf("\b");
}
return 0;
}
rpcgen можно использовать для создания процедур XDR, которые будут преобразовывать локальные структуры данных в формат XDR и наоборот.
Пусть dir.x содержит сервис удаленного чтения каталога, созданный с помощью rpcgen, процедуры сервера и процедуры XDR.
Файл описания протокола RPC dir.x имеет следующий вид:
* dir.x: Протокол вывода удаленного каталога
*/
/*максимальная длина элемента каталога */
const MAXNAMELEN = 255;
/* элемент каталога */
typedef string nametype<MAXNAMELEN>;
/* ссылка в списке */
typedef struct namenode *namelist;
/* Узел в списке каталога */
struct namenode {
nametype name; /* имя элемента каталога */
namelist next; /* следующий элемент */
};
union readdir_res switch (int errno) {
case 0:
namelist list; /* нет ошибок:
возвращает оглавление каталога */
default:
void; /*возникла ошибка: возвращать нечего*/
};
/* Определение программы каталога */
program DIRPROG {
version DIRVERS {
readdir_res
READDIR(nametype) = 1;
} = 1;
} = 0x20000076;
При запуске rpcgen для dir.x создаются четыре файла:
Серверная часть процедуры READDIR, в файле dir_proc.c:
* dir_proc.c: удаленная реализация readdir
*/
#include <dirent.h>
#include "dir.h" /* Создается rpcgen */
extern int errno;
extern char *malloc();
extern char *strdup();
readdir_res *
readdir_1(nametype *dirname, struct svc_req *req)
{
DIR *dirp;
struct dirent *d;
namelist nl;
namelist *nlp;
static readdir_res res; /* должен быть static! */
/* Открыть каталог */
dirp = opendir(*dirname);
if (dirp == (DIR *)NULL) {
res.errno = errno;
return (&res);
}
/* Очистить предыдущий результат */
xdr_free(xdr_readdir_res, &res);
/*
* Собрать элементы каталога.
*/
nlp = &res.readdir_res_u.list;
while (d = readdir(dirp)) {
nl = *nlp = (namenode *)
malloc(sizeof(namenode));
if (nl == (namenode *) NULL) {
res.errno = EAGAIN;
closedir(dirp);
return(&res);
}
nl->name = strdup(d->d_name);
nlp = &nl->next;
}
*nlp = (namelist)NULL;
/* Вывести результат */
res.errno = 0;
closedir(dirp);
return (&res);
}
Клиентская часть процедуры READDIR, файл rls.c:
* rls.c: Клиент для удаленного чтения каталогов
*/
#include <stdio.h>
#include "dir.h" /* создается rpcgen */
extern int errno;
main(int argc, char *argv[])
{
CLIENT *clnt;
char *server;
char *dir;
readdir_res *result;
namelist nl;
if (argc != 3) {
fprintf(stderr, "usage: %s host
directory\n",argv[0]);
exit(1);
}
server = argv[1];
dir = argv[2];
/*
* Создает обработчик клиента,
* вызывающий MESSAGEPROG на сервере
*/
cl = clnt_create(server, DIRPROG, DIRVERS, "tcp");
if (clnt == (CLIENT *)NULL) {
clnt_pcreateerror(server);
exit(1);
}
result = readdir_1(&dir, clnt);
if (result == (readdir_res *)NULL) {
clnt_perror(clnt, server);
exit(1);
}
/* Успешный вызов удаленной процедуры. */
if (result->errno != 0) {
/* Ошибка на удаленной системе.
*/
errno = result->errno;
perror(dir);
exit(1);
}
/* Оглавление каталога получено.
* Вывод на экран.
*/
for (nl = result->readdir_res_u.list;
nl != NULL;
nl = nl->next) {
printf("%s\n", nl->name);
}
xdr_free(xdr_readdir_res, result);
clnt_destroy(cl);
exit(0);
}
Код клиента, создаваемый rpcgen, не освобождает память, выделенную для результатов запроса RPC. Поэтому следует вызывать xdr_free(), чтобы освободить память после завершения работы. Это похоже на вызов free(), за исключением того, что здесь для получения результата передается процедура XDR.
Программа rpcgen поддерживает препроцессор C. При этом препроцессор C применяется ко входным файлам rpcgen перед компиляцией. В исходных файлах .x поддерживаются все стандартные директивы препроцессора C. В зависимости от типа генерируемого выходного файла, пять символов определяются самой rpcgen, обеспечивающей поддержку дополнительных возможностей препроцессинга: любая строка, которая начинается с символа процента (%), передается непосредственно в выходной файл, независимо от содержания.
Чтобы создать файл определенного вида, можно использовать следующие символы:
* time.x: Удаленный протокол времени
*/
program TIMEPROG {
version TIMEVERS {
unsigned int TIMEGET() = 1;
} = 1;
} = 0x20000044;
#ifdef RPC_SVC
%int *
%timeget_1()
%{
% static int thetime;
%
% thetime = time(0);
% return (&thetime);
%}
#endif
DIPC состоит из двух частей: основная часть выполняется в пространстве пользователя как обыкновенный процесс с правами суперпользователя и применяется для управления. Она называется dipcd. Этот демон может привести к снижению производительности, но увеличивает гибкость системы: изменения установок dipcd могут вступить в силу без необходимости замены ядра. Он также упрощает разработку и предохраняет ядро от еще большего усложнения; dipcd создает большое количество дочерних процессов для выполнения различных задач во время своей активности. Другая часть DIPC находится внутри ядра и предоставляет первой части необходимую функциональность и информацию для выполнения ее заданий. Не предоставляется возможным работа dipcd на базе ядра без поддержки DIPC.
Часть DIPC, относящаяся к ядру, ``заглушена'', когда dipcd не выполняется. При отсутствии dipcd, вызовы DIPC в программе должны происходить так же, как если бы они были нормальными вызовами IPC System V. Сам dipcd использует обычные средства для получения доступа к механизмам IPC System V. Эти механизмы изменчивы - так, они предполагают отличие dipcd от других пользовательских процессов. Например, dipcd может получить доступ к сегменту разделяемой памяти с помощью smget(), даже в том случае, если он был удален (shmctl() - вследствие команды IPC_RMID), - но не окончательно из ядра. Все манипуляции dipcd со структурами IPC делаются локально, без проявления вне данной машины. Это противоречит подходам к нормальным пользовательским процессам, когда действия с распределенными структурами IPC могут затронуть другие компьютеры в сети.
DIPC затрагиваются только при передаче данных в распределенной среде. Запуск соответствующих программ на различных компьютерах - это дело пользователя/программиста DIPC. Это значит, что программы для исполнения могут нуждаться в размещении на компьютере, который предназначен для их исполнения. Программы могут быть перенесены на различные компьютеры один раз и использованы множество раз после этого. Это не вызывает перегрузок при передаче кода по сети во всех случаях, когда программа запускается. Считается, что код программы остается без изменений в течение относительно долгого периода, в то время как используемые им данные изменяются часто (может быть, от одного запуска к другому), что в большинстве случаев должно считаться плюсом.
Важно учитывать, что DIPC - это набор механизмов. Речь идет не о выборе стратегии: как распараллеливается программа, где должны запускаться процессы и т.д. - решает пользователь/программист. Известно несколько иных доступных средств для решения данного класса задач, хотя в полной мере удовлетворительного решения пока не известно.
Выделяют два вида активности DIPC:
Система состоит из определенного количества компьютеров, соединенных посредством TCP/IP или UDP/IP сети. Некоторые (или все) машины могут быть в одном ``кластере''. В сети может быть более одного кластера, но каждая машина будет принадлежать только одному из них. Кластеры являются логическими объектами: они могут быть созданы или удалены, членство в них подвергается изменениям без необходимости изменения любого физического свойства сети.
Компьютеры одного кластера могут использовать DIPC для передачи данных и их синхронизации - без вмешательства в работу других кластеров в любом виде, даже в том случае, если они также используют DIPC при выполнении приложений. Другими словами, в течение всего того времени, когда DIPC задействована, компьютеры никогда не взаимодействуют с другими машинами вне пределов своего кластера в любой форме.
Можно осуществить обмен данными между программами, выполняющимися на различных машинах в кластере, который делает DIPC распределенной системой, или выполнять всю гамму процессов разрешающего работу DIPC приложения на единственной машине. Процессы должны вести себя так, будто они используют нормальную IPC System V, поскольку явной ссылки на любой частный компьютер в DIPC нет. Некоторая программа может использовать различные компьютеры в процессе обращения с целью ее успешного завершения, тем самым, освобождая находящуюся в зависимости программу на других машинах с определенными адресами. Отсюда также следует, что программисты могут использовать одиночные машины для разработки своих приложений, а позже выполнять их на многомашинном кластере. Другими словами, пользователь может по своему усмотрению осуществить конечное отображение ресурсов, требующихся программе, на доступных физических ресурсах (cм. в качестве примера программу в каталоге /examples/pi).
В программах, использующих DIPC, могут возникать два вида ошибок:
Процесс попытки вывода системы из ошибочной ситуации (такой, как ошибка сети) сложен, а иногда и невозможен, что добавляет сложности DIPC. Таким образом, когда DIPC обнаруживают ошибку, они не пытаются осуществить повторное выполнение, а делают в точности то, что и IPC: пытаются информировать приложение об ошибке через код возврата, или, в случае, когда процесс пытается получить доступ к разделяемому сегменту памяти через сигнал (SIGSEGV). Остальное возлагается на приложение. Следует помнить, что только ``ответственные'' процессы будут проинформированы об ошибке - для того, чтобы они предприняли что-нибудь, - а не все процессы распределенной программы.
DIPC пытаются что-либо предпринять не более одного раза. Это либо получается, либо не получается, однако повторных попыток не делается (в смысле: ``не более одного раза''). Это означает, что один и тот же запрос не имеет возможности быть обработанным более одного раза.
Следует отметить, что ошибки могут порождаться невнимательным отношением к системе. Например, структура IPC может быть окончательно удалена на одном компьютере, а другие могут не знать об этом. Они могут считать, что структура продолжает существовать - это может вызвать затруднения в дальнейшем (см. программы в каталоге tools, частично разрешающие эту проблематику).
Процессы в кластере могут использовать один и тот же ключ для получения доступа к структуре DIPC. Эта структура должна быть создана первой. Это делается одним из системных вызовов xxxget (shmget(), semget() или msgget()). После создания и инициализации другие процессы, возможно, на других машинах, могут получить доступ к этой структуре. В данном случае ключ имеет одинаковый смысл для всех компьютеров в пределах кластера. Другими словами, компьютеры в кластере имеют общее ключевое пространство DIPC.
Много наработанного программного обеспечения с закрытыми исходными текстами может использовать IPC System V в процессе функционирования, а некоторое - использовать ключи. Поскольку эти программы могут нуждаться в наличии ряда машин в составе кластера, важно обеспечить их работу без конфликтов - с помощью DIPC. Поэтому необходимо ввести в кластер два типа отличающихся друг от друга ключей IPC:
Таким образом, для предоставления возможности запуска старых программ, соответствующие структуры IPC с набором локальных ключей должны находиться в группе компьютеров. И наконец, локальные ключи имеют тип по умолчанию, поэтому создание распределенного ключа требует от программиста явного добавления IPC_DIPC к другим пользовательским флагам в процессе создания структуры IPC или получения доступа к ней с помощью системного вызова xxxget().
Если не обращать внимания на приведенное выше требование, то структура DIPC
может использоваться полностью прозрачно. Даже при написании современных
программ, единственная вещь, которую программист должен сделать -
это указать флаг
DIPC_IPC.
В этом разделе описывается, как используется TCP. Для получения дополнительной информации о UDP, пожалуйста, обратитесь к разделу о UDP/IP.
Обычно пользовательские программы DIPC взаимодействуют только с локальным ядром компьютера, на котором выполняются. Запросы пользовательских программ на действия DIPC, либо синхронного типа - подобно системным вызовам, которые предназначены для удаленного исполнения, - либо асинхронного типа - подобно попыткам чтения разделяемой памяти, чьи страницы не доступны на локальном компьютере, - направляются ядру. Все такие запросы помещаются в один связанный список. Идентификатор процесса запрашивающей пользовательской задачи запоминается и используется для поиска данного начального запроса при возвращении результатов. Этим путем результаты могут быть корректно доставлены в пользовательскую программу.
Ядро в свою очередь будет обращаться к части DIPC, образующей пользовательское пространство (dipcd) для действительной реализации таких запросов. Это значит, что присутствие dipcd не заметно для пользовательской программы и в течение всего периода, когда он затрагивается, ядро обслуживает его запросы.
Часть dipcd внутри ядра находится в постоянном ожидании таких запросов. В момент, когда она отыскивает новый запрос, другие части dipcd активизируются и обрабатывают ситуацию. Эти части получают все необходимые данные (например, параметры системного вызова) для генерации запроса изнутри ядра и возвращении каждого результата в ядро, после чего они будут возвращены исходному пользовательскому процессу.
Именно dipcd реально исполняет удаленные функции, передает любые данные по сети или решает, какой компьютер может читать распределенную разделяемую память или писать в нее. Он также содержит необходимую информацию о структурах IPC в системе и выполняет арбитраж процессов для различных машин, желающих получить доступ к определенным структурам в определенное время.
Необходимо создавать условия, чтобы dipcd смог получить доступ к требующейся информации в структурах ядра. Новый системный вызов, перекликающийся с прочими вызовами IPC System V, добавлен в Linux только с этой целью; dipcd и другие ``инструменты'' DIPC (такие как dipcker) используют его для передачи данных в ядро и из него. Этот новый системный вызов (известный в программах DIPC как dipc()) предназначен для использования dipcd и другими связанными с ним программами. Пользовательские программы непосредственно применять его не должны.
Важно помнить, что системные вызовы IPC, инициированные dipcd, всегда исполняются локальным ядром, даже, когда работа происходит с распределенными структурами IPC. Это подпадает в зону действия ``специального соглашения'' о процессах dipcd в ядре с поддержкой DIPC.
Демон dipcd ``раздваивает'' нужные процессы для выполнения
своей задачи. Вы можете видеть, что все процессы имеют свои собственные
исходные тексты. Ниже приводится список процессов
dipcd
(их осложняют перекрестные ссылки, поэтому для понимания написанного
может понадобится ``многопроходное'' чтение):
Здесь находится функция main() программы dipcd. Только один back_end может присутствовать на каждом компьютере в кластере. back_end и front_end (см. ниже) - это единственные процессы dipcd, которые используют fork() для создания других процессов: back_end запускает систему - он регистрирует себя в ядре, как процесс, ответственный за обработку запросов DIPC, - читает конфигурационный файл, инициализирует переменные и раздваивает задачу front_end. Если машина, на которой он запущен, является арбитражной, то он также раздваивает и арбитражный процесс.
После этого back_end зацикливается на сборе запросов из ядра и связанных с ними данных - в те моменты, когда это возможно. Эти запросы (наряду с другими) могут быть предназначены для чтения распределенной разделяемой памяти и записи в нее, а также могут запрашивать сведения о некоторых структурах IPC. При этом, back_end будет раздваивать процесс employer (см. ниже) для обработки каждого из этих запросов.
Процесс ответственный за обработку входящих запросов и передачу данных для компьютера по сети. На каждой машине в кластере DIPC может быть только один процесс front_end. Его предназначение объясняется тем, что в сетях TCP/IP для подсоединения к компьютеру вам нужно знать не только IP-адрес соответствующей машины, но и номер порта TCP; dipcd при работе создает неизвестное заранее число процессов и многие из них требуют получения информации по сети. Таким образом, для избавления от проблемы, возникающей, когда каждый процесс использует собственный номер порта TCP, было решено обрабатывать все входящие запросы единственной общей задачей. В результате, каждый процесс ``знает'' номер порта TCP, который должен использоваться для подключения к другому компьютеру с поддержкой DIPC.
Каждый процесс для взаимодействия с другими машинами может подключаться прямо к front_end любого компьютера. (Это не приводит к взаимодействию с referee. См. ниже.) Если входящее соединение предназначено для выполнения полезной нагрузки, то front_end раздваивает рабочий процесс для обработки. В противном случае он только переправляет входящие данные процессу, для которого они предназначены и который может быть employer, ожидающим результатов, или менеджером разделяемой памяти (см. shm_man).
Играет важную роль в налаживании порядка в системе. Во всем кластере может быть только один referee, следовательно, он может выполняться только на одном из компьютеров. Для того, чтобы DIPC работала, каждый компьютер должен знать адрес машины, на которой выполняется referee. Подобно случаю с front_end, referee имеет свой собственный номер порта TCP, и прочие процессы могут взаимодействовать непосредственно с ним; referee хранит всю информацию о действующих структурах IPC в нескольких связанных списках (в документации DIPC на них ссылаются, как на арбитражные таблицы). Наличие одних списков связано со структурами IPC, которые уже созданы, а других - со структурами, которые удаленный процесс пытается создать. Такой подход приводит к возложению на referee функции сервера имен DIPC.
В этом случае referee предоставляет механизм ``черного хода'' (используемый в доменных сокетах UNIX), посредством которого процессы могут посылать свои команды и принимать определенную информацию ( См. документацию на программу dipcref (в каталоге tools) для получения дополнительной информации. См. также раздел ``Арбитраж'', находящийся ниже).
Создается на машинах, которые владеют сегментами разделяемой памяти (машины, которые сначала создали соответствующие структуры) как менеджер разделяемой памяти. Имеется по одному процессу shm_man для каждой распределенной разделяемой памяти в системе. Он исполняется задачей employer, которая успешно обработала shmget(); shm_man определяет, кто может читать разделяемую память или записывать в нее и имеет соответствующий счетчик. Он также управляет передачей содержимого разделяемой памяти на нуждающиеся в нем компьютеры. shm_man будет присоединять разделяемую память к себе. Это предохраняет разделяемую память от разрушения, если она удаляется (shmctl() вследствие команды IPC_RMID), а все процессы в машине-создателе отсоединяют ее от себя. Это может привести к осложнениям, если иные процессы на других компьютерах продолжают нуждаться в разделяемой памяти.
Нет необходимости в процессах, раздваиваемых для обработки набора семафоров и очередей сообщений на компьютере, который создал их (т. е. нет sem_man и msg_man). Только в случае с разделяемой памятью вводится управляющий процесс. Это происходит по следующим причинам:
Запускается для обработки при удаленном исполнении системного вызова (такого, как shmctl()) или для обработки других видов запросов (таких, как запросы на чтение/запись разделяемой памяти). Он соединяется с соответствующим компьютером (например, с тем, на котором структура IPC создана первой) и затем перенаправляет необходимые данные ответственному процессу (например, front_end) - с ожиданиями подтверждений. Он использует механизм тайм-аута для обнаружения возможных сетевых или машинных проблем.
Запускается процессом front_end для исполнения запрашиваемых действий. Запросы могут приходить от employer, referee или shm_man и включать исполнение удаленного системного вызова или пересылку содержимого разделяемой памяти из компьютера в компьютер. Для успешного завершения работы worker может подключаться к оригинальной запрашивающей машине и предоставлять соответствующие результаты; worker может обратиться к прокси и оставаться на связи с ним после реализации такого соответствия (См. раздел о прокси для получения более подробной информации).
Функция raise() имеет следующий вид:
int raise(int sig);
int main()
{
int a,b;
printf("Число : ");
scanf("%d",&a);
printf("делится на : ");
scanf("%d",&b);
if(b==0)
raise(SIGFPE);
else
printf("Результат = %d\n",a/b);
return 0;
}
Для передачи сигнала некоторому процессу применяется функция kill(), синтаксис которой приведен ниже.
#include <signal.h>
int kill(pid_t pid, int signalnumber);
Потоки позволяют ``разветвить'' задачи для их параллельного выполнения и предоставить совместный доступ к общему адресному пространству. К сожалению, иногда потоки могут не поддерживаться. Это означает, что если в программе желательно выполнять множество действий в одно и то же время, то в ней нужно использовать системный вызов fork(), предполагая, что общего адресного пространства нет, и заботиться о средствах связи между процессами.
Другим способом разрешения данной проблемы является реализация процессом его предназначения настолько быстро, насколько это возможно - при этом способе процессы отрабатывают один за другим; dipcd использует оба метода: некоторые из процессов раздваиваются, когда ожидается их активность в течение длительного времени (например, referee раздваивается), а некоторые процессы выполняются последовательно, с надеждой, что запросы на обслуживание не будут подавлять их (shm_man работает таким образом).
На рис. 1 показаны взаимоотношения между процессами dipcd и последбвательность их создания.
Различные части dipcd используют структуру, называемую ``сообщением'' (не путайте с сообщениями IPC) для передачи любой информации между собой. В эти сообщения включаются: IP-адреса отправителя и получателя, локальный pid отправителя, функция для реализации, необходимые аргументы и т.д. В некоторых случаях может потребоваться больше данных, чем вмещает структура message - такая информация может ``сопровождать'' сообщение. Содержимое сообщения IPC или структуры msgid_ds, использующееся в msgctl() вследствие команды IPC_SET, - это два примера данных, которые посылаются после сообщения dipcd.
Каждое сообщение имеет поле запроса, которое определяет процесс ``назначения''.
Оно может принимать значения REQ_DOWORK - для рабочих, REQ_SHMMAN
- для менеджера разделяемой памяти и
REQ_REFEREE - для арбитра.
Ответные сообщения содержат в своих полях запроса REQS_DOWORK,
RES_SHMMAN либо RES_REFEREE - в зависимости от того, какой из процессов
отвечает данным сообщением.
TCP/IP или UDP/IP сокеты являются главным средством передачи информации от машины к машине; dipcd должен быть проинформирован о том, какой из этих протоколов в первую очередь использовать с помощью опций командной строки при запуске.
Доменные сокеты UNIX используются для коммуникаций между задачами dipcd, которые всегда выполняются на одном компьютере. Применение сокетов в каждом из случаев унифицирует процесс обмена данными между этими процессами. Сокеты UNIX создаются в домашнем каталоге dipcd.
Процессы, которые устанавливают сокеты TCP/IP - это referee и front_end. Все внутримашинные коммуникации должны вызывать один из них. Процессы, которые устанавливают доменные сокеты UNIX - это employer (для приема каждого результата от front_end на локальной машине), referee (для реализации механизма ``черного хода''), менеджер разделяемой памяти (для приема запросов, связанных с распределенной разделяемой памятью, которой он управляет, а также для реализации механизма ``черного хода'') и worker, когда он переходит к исполнению системного вызова semop(). В случаях с shm_man и employer все данные от других компьютеров первоначально посылаются в TCP/IP сокет front_end, а он копирует их в доменные сокеты UNIX. Доменный сокет UNIX referee доступен локально с помощью средства dipcref. Процесс worker принимает файловый дескриптор, соответствующий межсетевому сокету, когда раздваивается процессом front_end; таким образом, он может непосредственно взаимодействовать с удаленными процессами. Прокси принимают данные от front_end посредством сокетов UNIX.
Имя доменного сокета UNIX для employer назначается примерно так: сначала следует строка DIPC, затем идет тип структуры IPC (SEM - для семафоров, MSG - для очередей сообщений и SHM - для разделяемой памяти) плюс соответствующий структуре IPC ключ и, наконец, идентификатор процесса employer. Это делает имя сокета уникальным, поэтому результаты могут быть отосланы назад ``правильному'' employer. Например, DIPC_SEM.45.89 - дается employer с идентификатором процесса 89, который обрабатывает запрос семафора. Набор семафоров имеет ключевой номер 45. Имя сокета менеджера разделяемой памяти также назначается аналогичным способом, за исключением того, что оно не включает число, соответствующее его идентификатору процесса, так как некоторые процессы могут потребовать связать их без указания таких номеров. Фактически процессы, запрашивающие доступ к разделяемой памяти, не осведомлены о процессе, который управляет этой памятью (См. в разделе о прокси, как эти процессы устанавливают доменные сокеты UNIX).
Некоторые процессы должны использовать сокеты TCP/IP в большинстве случаев информационного обмена (например, между shm_man и front_end, который выполняется на компьютере-читателе разделяемой памяти или писателе), поскольку они обычно находятся на различных компьютерах. Однако бывает, что оба процесса располагаются на одной машине. Для поддержки общих алгоритмов при этом также применяются сокеты TCP/IP, но на сей раз адреса заменяются на так называемые разворачивающие адреса.
Может возникнуть ситуация, когда более одного процесса в кластере стремятся создать структуру IPC с одним и тем же ключом. Эти процессы могут протекать на одной или на нескольких машинах. Поэтому, для предотвращения нежелательных взаимодействий вследствие попыток разных процессов делать одно и то же и предотвращения возможного введения целой системы в противоречивое состояние, создание структуры IPC должно выполняться автоматически: пока один процесс пытается создать структуру IPC, ни один прочий процесс не должен пытаться сделать это с идентичным ключом.
Части ядра, относящиеся к DIPC, препятствуют тому, чтобы более одного процесса на одной машине могли создать структуру IPC в одно и то же время. Они последовательно упорядочиваются внутри ядра. Достижение этого эффекта в пространстве всего кластера возможно введением специального процесса, ответственного за такую работу: он будет играть роль арбитра для запросов от различных машин и регистрировать необходимую информацию о всех структурах IPC в системе. Дополнительно он будет контролировать попытки удалять структуры IPC или, напротив, манипулировать ими. Этот процесс и называется referee.
Может быть только один арбитр в пределах кластера. Все машины в данном кластере должны знать, на каком из компьютеров в текущий момент выполняется арбитр, и обращаться к нему при необходимости. Фактически единственный арбитр помещает две или более машины в кластер. Другими словами, кластер создается машинами с одним арбитром. Адрес арбитра может быть задан системным администратором с помощью конфигурационного файла dipc.conf. Изменение адреса арбитра на компьютере перемещает этот компьютер в другой кластер. Машина, на которой выполняется процесс арбитра, может работать в кластере, как и всякая другая машина.
При обычной IPC системные вызовы исполняются локально. Данные, предоставленные процессом как параметры системного вызова, копируются в ядро и удерживаются там. Каждый вызов IPC должен возвратить некий результат в адресное пространство вызывающего процесса. Вызывающий процесс не сможет продолжиться до тех пор, пока к нему не вернутся результаты. В течение этого времени он находится в ядре в состоянии ожидания. Период времени между генерацией вызова и получением ответа может сильно варьироваться для различных системных вызовов и зависеть от состояния структуры IPC.
Некоторые
вызовы (например, xxxctl() вследствие команды
IPC_STAT)
отрабатывают быстро, другие (например, вызов semop()) - могут
отнимать очень длительное, если не бесконечное время:
Сначала параметры копируются в ядро (1), а затем возвращаются результаты (2).
Таким образом, системный вызов IPC требует осуществления двух операций копирования между адресными пространствами пользователя и ядра. Обратите внимание на то, что порция копируемых данных (параметры или результаты) может быть очень маленькой (одно целое число, совпадающее с кодом ошибки) или весьма большой (содержимое сообщения IPC).
В дальнейшем помните, что программа dipcd выполняется в пользовательском адресном пространстве и применяет обычные средства взаимодействия с ядром. Не подразумевается также, что пользовательский процесс обязательно выполняется на машине владельца. Под ``данными'' понимаются либо входные параметры, либо результаты.
Удаленный вызов процедур (Remote Procedure Call - RPC) применяется для исполнения системного вызова на удаленном компьютере. Для обеспечения ``прозрачности'' ни один из процессов, использующих DIPC, не должен ``видеть'' какие-либо изменения в сравнении с нормальной (локальной) активностью IPC. К тому же, данные процесса копируются в память ядра. Затем dipcd переносит эти данные в свое адресное пространство и передает их по сети компьютеру, ответственному за обработку запроса. Это должен быть компьютер, на котором структура IPC создана в первую очередь, - в этом случае он называется владельцем данной структуры (см. раздел о владельцах для получения более подробной информации). Удаленный dipcd будет копировать вновь прибывшие данные в пространство ядра машины-владельца. В результате, при такой симуляции системного вызова на целевом компьютере получается три копирования и одно ``задействование'' в сети - для процесса.
После этого системный вызов может исполняться dipcd на удаленном ядре, а результаты будут отсылаться назад тем же самым способом, который описан выше: удаленное ядро будет копировать данные в пользовательское пространство, после чего dipcd сможет передать их по сети; dipcd на стороне оригинального процесса принимает эти данные и передает их своему локальному ядру. Наконец, данные копируются в адресное пространство оригинального процесса:
{Генерация вызова через сеть:
(Запрашивающий компьютер) | (Запрашиваемый компьютер)
процесс-1-> локальное ядро |
| |
+-2-> локальный dipcd --|-3->dipcd владельца-4->удаленное
| ядро
|
Получение результатов: |
локальный~dipcd~<--|-6-dipcd владельца<-5-удаленное
| | ядро
процесс <-8-локальное ядро<-7-+|
Процесс приостанавливается до тех пор, пока результаты не возвратятся.
Как видно, пользовательский процесс взаимодействует лишь с локальным ядром и не отмечает изменений при вызовах подпрограмм IPC System V.
Помните, что передача данных по сети требует дополнительного копирования в ядро и из него. Это происходит вследствие ``дизайна'' сетевой поддержки внутри ядра и поэтому неизбежно.
Следующий алгоритм отображает, как производится решение проблемы удаленного исполнения операций.
ЕСЛИ присутствует dipcd и вызывающий процесс - не dipcd ТО
ЕСЛИ операция поддерживается DIPC ТО
ЕСЛИ операция - в достоверной распределенной структуре и
это - не компьютер владельца ТО исполнить вызов удаленно
КОНЕЦ
Очевидно, что доступ к сети обеспечить весьма непросто. В некоторых операционных системах используется переотображение адресов (с помощью блока управления памятью (Memory Management Unit - MMU) - для предоставления доступа к части памяти процесса другому процессу), следовательно, пересылки данных между адресными пространствами ядра и пользователя должны быть очень ``дешевыми''. К сожалению, Linux не поддерживает этого метода при реализации механизмов IPC System V.
Одним из возможных путей уменьшения числа копирований между адресными пространствами пользователя и ядра является воздержание от копирования данных из адресного пространства процесса в память ядра в тех случаях, когда нужный процесс на вызываемой машине еще не выполняется, а данные снова будут скопированы в адресное пространство dipcd для посылки по сети. Этот подход также помогает избегать копирований данных, поступающих из сети, в ядро, когда известно, что они будут скопированы повторно в адресное пространство пользовательского процесса.
Можно использовать и ``заглушки'' в пользовательском пространстве для перемещения обычного кода IPC System V в ядро. Код "заглушки" должен протестировать данные и цель и решить, нужно ли послать данные по сети, не беспокоясь о локальном ядре. Другой процесс на вызываемой машине должен принять эти данные, выполнить операцию и передать результаты назад, после чего они доставляются оригинальному процессу-заглушке. Для этого необходимо предоставить возможность этому процессу заменить обычные заглушки IPC. Следует также обеспечить наличие объектных файлов, которые должны прикомпоновываться к программе или, что еще лучше, изменить стандартные библиотеки C.
Эти две проблемы можно сформулировать так:
Первая причина состоит в том, что решение рассматриваемых проблем указанными методами в простой и удовлетворительной форме не представляется возможным.
Вторая причина состоит в том, что необходимость прикомпоновки специального объектного файла к программе может столкнуться с помехами и вызвать ошибки. К тому же часто нет доступа к исходным текстам стандартных библиотек C. В любом случае обновление DIPC может потребовать перекомпиляции использующих его программ. Еще одним сдерживающим фактором является то, что более старые программы, которые не скомпонованы с измененными заглушками, не смогут информировать DIPC о своем ``присутствии'' и не будут предоставлять ему необходимую информацию. DIPC должна "знать" обо всех ключах IPC в кластере, даже если они представляют собой обычные структуры IPC. Программы, скомпилированные без новых заглушек, могут привести DIPC к недееспособности.
Необходимо также иметь в виду, что некоторые пользователи могут пожелать использовать DIPC посредством языков, отличных от C, - при этом могут воникнуть неразрешимые проблемы предоставления альтернативных объектных файлов поддержки всех этих языков.
Использование среды ядра для информационной пересылки и приостановления выполнения задачи дает ряд преимуществ:
Нормальное поведение программ, желающих воспользоваться механизмами System V IPC для обмена данными, заключается в следующем. Процесс сначала создает структуру IPC посредством доступного системного вызова xxxget(), используя заранее оговоренный ключ. Другие процессы после этого могут использовать xxxget() для получения доступа к этой же ранее созданной структуре. При ``нормальной'' IPC первый процесс инициирует ``установку'' адекватных структур внутри ядра. При последующих вызовах xxxget() просто возвращается значение числового идентификатора, которое может использоваться для обращения к структуре. Таким образом, все перечисленные процессы будут использовать одну структуру и манипулировать ею.
DIPC пытаются ``скрыть'' эту ситуацию настолько, насколько возможно. Процессам на разных машинах нужно использовать один и тот же ключ, чтобы обращаться к одной структуре IPC. При DIPC, когда процесс желает организовать или получить доступ к структуре IPC с определенным ключом, локальное ядро в первую очередь отслеживает, используется ли уже данный ключ. При ``нормальной'' IPC эти процессы очень похожи. Если структура найдена, запрос обрабатывается локально, без обращения к арбитру. Но если структура IPC с указанным ключом не найдена, то арбитру нужно осуществить поиск и выяснить, используется ли уже такой ключ в кластере. Арбитр ищет ключ в своих таблицах и сообщает запрашивающему процессу, найден ключ или нет и, если найден, является ли он распределенным ключом или нет. Арбитр может ответить незамедлительно, если ключ присутствует или отсутствует, но ни одна из машин не запрашивает его. После посылки информации в запрашивающий компьютер арбитр ожидает подтверждения, создала ли данная машина локально структуру IPC с этим ключом или нет, чтобы при необходимости смочь обновить свою информацию. Но если ключ не найден, а арбитр уже послал соответствующее сообщение машине, то он не отвечает на все последующие запросы такого ключа, пока машина не ответит, создала ли она структуру IPC. Когда информация поступит, арбитр сможет обслужить прочие поступающие запросы.
Такой централизованный (последовательный) алгоритм прост и легок в реализации. Распределенный алгоритм может быть комплексным, требующим большого числа обменов сообщениями. Также считается, что на создание структуры IPC затрачивается относительно малая доля времени, затраченного на выполнение программы.
В двух приведенных ниже таблицах (табл. 6 и 7),
тип_удаленного_ключа
- это тип, зарегистрированный арбитром, и возвращенный запрашивающему
компьютеру.
тип_запрашиваемого_ключа -
желательный для локального запрашивающего компьютера. Во всех
случаях, сам ключ не найден в структурах IPC локального ядра.
В табл. 6 показано, как процесс решает, может ли он при необходимости создать ранее не существовавшую структуру IPC (xxxget() с флагом IPC_CREAT).
| Тип запрашиваемого ключа | Тип удаленного ключа | Действие |
| локальный | не_существующий | создание |
| локальный | локальный | создание |
| локальный | распределенный | ошибка |
| распределенный | не_существующий | создание |
| распределенный | локальный | ошибка |
| распределенный | распределенный | ошибка |
В табл. 7 показано, как процесс решает, может ли он создать
структуру при необходимости получения доступа к предварительно созданной
структуре IPC (xxxget() без флага IPC_CREAT).
| Тип запрашиваемого ключа | Тип удаленного ключа | Действие |
| локальный | не_существующий | ошибка |
| локальный | локальный | ошибка |
| локальный | распределенный | ошибка |
| распределенный | не_существующий | ошибка |
| распределенный | локальный | ошибка |
| распределенный | распределенный | проверка |
Проверка подразумевает выполнение действий с целью получения гарантии того, что указанные флаги для xxxget() и права доступа к распределенной структуре IPC позволяют процессу получить доступ к структуре. В успешном случае, ``действие'' становится ``созданием''.
В данном случае, правила проверки флагов близки к правилам для обычной IPC. Например, указание IPC_EXCL и IPC_DIPC при одном системном вызове приводит к ошибке, если структура IPC с указанным распределенным ключом уже присутствует на другой машине. Метод, применяющийся для проверки прав доступа: имя эффективного пользовательского логина, наряду со всеми параметрами xxxget() передается машине, которая имеет структуру с распределенным ключом. Затем dipcd исполняет системный вызов xxxget() на этом компьютере. Если он завершается успешно, то осуществляется попытка выполнения тех же действий на оригинальной запрашивающей машине. Если любое из приведенных действий завершается ненормально, то и оригинальный xxxget() также потерпит неудачу. Для получения более подробной информации о том, как DIPC обрабатывает имена пользователей, обратитесь к разделу о безопасности.
Если ``действие'' - это ``создание'', локальная структура будет создана даже в том случае, если иная структура с тем же самым ключом присутствует где-либо еще в кластере. Короче говоря, на любой машине, где определенные процессы используют ключ для коммуникаций, есть структура с этим ключом.
Ниже показано, как DIPC обрабатывает запрос о новом создании IPC.
Первая фаза: поиск
Сеть
(Запрашивающий компьютер) | (Арбитрирующий компьютер)
|-1->back_end >-2-+ |
| |
ядро|<--------6--employer --3-------|-> referee
| | |
+-5-< front_end <-|<-----4-+
Предполагается, что структура IPC с указанным ключом на вызывающей машине не заменяется. В этом случае back_end находит запрос о поиске ключа (1) и раздваивает employer для его обработки (2); employer вызывает referee и ``спрашивает'' его (3); referee посылает ответ (нашел или нет ...) процессу front_end запрашивающего компьютера (4) и затем ответ доставляется оригинальному employer (5), который отдает результаты назад в ядро (6). Ядро должно однозначно определить, может быть создана структура IPC или нет. По ходу дела referee запускает таймер - для того, чтобы гарантировать своевременное предоставление информации. После этого может начинаться вторая фаза (непосредственная передача).
Вы можете обратиться к предыдущей схеме для понимания второй фазы.
Во время фазы непосредственной передачи referee информируется
о результате работы системного вызова xxxget(). Все действия
аналогичны действиям во время предыдущей фазы:
back_end
находит сведения о результате работы xxxget() (1) и информирует
referee (2 и 3), но на сей раз целью действий (4), (5) и
(6) является обеспечение гарантии того, что исходный запрашивающий
процесс будет продолжен только после того, как информация referee
будет обновлена.
Рассмотрите следующий алгоритм, показывающий, насколько часть ядра DIPC зависит от того, как создается новая структура или происходит доступ к ней. Символ (*) нужен для индикации возможного привлечения сети.
НАЧАЛО
ЕСЛИ указанный ключ используется в локальной структуре ТО
~КОНЕЦ~алгоритма
ЕСЛИ dipcd присутствует и вызывающий процесс - это не dipcd ТО
искать с помощью referee ключ (*)
ЕСЛИ ключ найден ТО
протестировать совместимость запрашиваемой структуры с
удаленной структурой. В СЛУЧАЕ если обе структуры
являются распределенными
ВЫПОЛНИТЬ проверку прав доступа (*).
ЕСЛИ все условия обеспечены ТО попытаться
создать структуру
информировать referee о результатах (непосредственная передача)(*)
КОНЕЦ
Проблемы с back_end и employer мгновенно передаются
ядру. Прочие ошибки обнаруживаются с помощью механизмов тайм-аута
для employer и referee.
Если в системе отсутствует возможность получения необходимой информации от referee, то принимается, что данный ключ не используется, и она ведет себя так, как будто referee сказал ``да''. Это значит, что система будет проявлять себя ``владельцем'' (см. следующий раздел). Хотя такой подход и заставляет процесс продолжаться, он может создать проблемы тогда, когда структуры IPC с тем же самым ключом будут на других машинах. Аналогичные проблемы могут возникнуть, если во время непосредственного обмена не окажется с referee. В таком случае будет наступать тайм-аут, а referee будет предполагать, что запрашивающий процесс при попытке создания структуры завершился ненормально. Таким образом, referee может владеть ошибочной информацией.
Данная концепция применима только к структурам IPC с распределенными ключами. Когда процесс впервые создает структуру IPC в пределах кластера при помощи xxxget(), компьютер, на котором он выполняется, становится ее ``владельцем''. Все операции манипулирования с данной структурой проводятся на машине-владельце. Фактически это означает, что может существовать только один активный экземпляр структуры IPC. Это свойство сильно влияет на простоту и семантику при обеспечении сохранности DIPC.
При DIPC процесс-производитель и процесс-потребитель данных могут состоять в следующих отношениях:
Все запросы об удалении структуры IPC (xxxctl() вследствие команды IPC_RMID) посылаются машине-владельцу. Если структура действительно удалена, то об этом информируется referee, который, в свою очередь, информирует другие машины со структурами с таким же ключом - с целью удаления и этих структур. Удаление делается при наличии прав суперпользователя.
Схема ниже показывает, как обрабатывается ключевое удаление:
Сеть
(Компьютер-владелец) | (Арбитрирующий компьютер)
|
|-1->back_end >-2-+ |
| | |
ядро | employer-3--|-> referee
| |
Здесь структура IPC удаляется на компьютере-владельце;
back_end
находит запрос об этом (1) и раздваивает employer для его
обработки (2), employer информирует referee об удалении
(3).
На следующей схеме показано, что происходит после того, как referee получает эту информацию:
Сеть
(Арбитрирующий компьютер) | (Компьютер с ключом)
|
| |
referee~--4------|-> front_end -->worker -6->| ядро
| | |
| +-7--<---|
То, что показано выше, происходит на всех компьютерах, которые имеют созданные структуры IPC с данным ключом: referee посылает запрос об удалении ключа front_end (4), который раздваивает worker для реализации xxxctl() и непосредственного удаления с привилегиями суперпользователя; worker получает результаты этого процесса, но referee не беспокоится (не ожидает) об этом.
Дополнительно referee проверяет, находится ли структура IPC в разделяемой памяти и только ли один компьютер имеет такую структуру. Если это так, то посылается запрос менеджеру разделяемой памяти (shm_man) этой машины об отсоединении от разделяемой памяти. Это можно сделать по следующей причине: известно, что нет такого процесса на любом из компьютеров, имеющих разделяемую память, который будет обращаться к ней, так как при изначальном присоединении (предотвращение разрушения разделяемой памяти, когда все процессы на машине-владельце завершились) не ставилась цель захватывать что-либо еще. На следующей схеме показаны соответствующие действия для случая, когда сказанное выше справедливо:
Сеть
(Арбитрирующий компьютер | (Владелец разделяемой памяти)
|
referee--8------|-> front_end --9-->shm_man
|
В итоге referee информирует shm_man об отсоединении (8 и 9). В данном случае referee также не ожидает подтверждения о том, что shm_man действительно отсоединился.
Далее показаны остальные действия:
Сеть
(Компьютер-владелец) | (Арбитрирующий компьютер)
|
| |
ядро |<--12--employer | referee
| | | |
| +-11-<front_end<-|-----10-+
Теперь referee сообщает оригинальному employer о том, что тот может продолжать работу (10 и 11); employer далее сообщит ядру о том, что и исходный пользовательский процесс может продолжаться (12).
Не предпринимается особых действий, когда владелец не может быть проинформирован об удалении. В таком случае владелец удалит структуру в то время, как другие машины, имеющие структуры с таким же ключом, не будут об этом ничего "знать".
Обратите внимание и на то, что возможна ситуация, когда ряд компьютеров временно недоступен или они не могут быстро удалять свои структуры. Как уже было сказано, referee не заботится о таких вещах: не предпринимается специальных действий, если он не может подключиться к компьютеру и сообщить ему об удалении. К тому же, он не ждет подтверждения перед тем, как продолжить работу (См. программы в каталоге tools, позволяющие частично решить такие задачи).
После того, как структура удалена, она может быть удалена ``окончательно'' (это осуществляется во всех случаях, когда имеются очереди сообщений и наборы семафоров). Поскольку структура удаляется окончательно, referee информируется об этом, а также referee окончательно удаляет данную машину из своих таблиц - как ``держателя'' данной структуры. Ниже показано, что происходит в этом случае:
Сеть
(Запрашивающий компьютер) | (Арбитрирующий компьютер)
|
|-1->back_end~>-2-+ |
| | |
ядро | employer--3------|-> referee
|
Когда на компьютере окончательно удаляется структура IPC, об этом сообщается back_end (1). Он раздваивает employer (2) и ``приносит'' эти новости referee (3), который окончательно удаляет свои соответствующие элементы, проверяет наличие такой структуры в разделяемой памяти и является ли действующий компьютер единственным, содержащим эту структуру. Он должен быть владельцем. В этом случае referee действует как показано на схеме:
Сеть
(Арбитрирующий компьютер) | (Владелец разделяемой памяти)
|
referee --4------|-> front_end --5-->shm_man
В итоге referee сообщает shm_man об отсоединении (4 и 5). Все похоже на случай с простым удалением из разделяемой памяти структуры IPC.
Далее следует все остальное:
Сеть
(Компьютер-владелец) | (Арбитрирующий~компьютер)
|
| |
ядро |<----8--employer | referee
| | | |
| +-7-< front_end <-|------6-+
Здесь referee информирует employer о том, что все действия сделаны (6 и 7); employer информирует ядро о том, что исходный пользовательский процесс, который вызвал окончательное удаление, может продолжаться.
Никаких специальных действий не предпринимается, когда
referee
не может быть информирован об окончательном удалении: referee
будет считать, что компьютер по-прежнему имеет структуру и давать ошибочные ответы
о данной структуре другим машинам (См. программы в каталоге tools,
позволяющие частично решить такую задачу).
В системах Linux концепция сигналов была расширена. Это вызвано следующими недостатками старого подхода ANSI-C:
int sigemptyset(sigset_t *sig_m);
int sigaddset(sigset_t *sig_m, int signr);
int sigdelset(setsig_t *sig_m, int signr);
int sigismember(sigset_t sig_m,int signr);
Существует функция для сохранения или изменения маски сигналов:
int sigprocmask(int mode, const sigset_t *sig_m,
sigset_t *alt_sig_m);
int sigsuspend(const sigset_t *sig_m);
Linux не разрабатывался как распределенная система. Множество информации, которую Вы найдете в ней, производится независимо любым из компьютеров и она имеет смысл только на машине, которая ее произвела. Это распространяется и на значения времени, идентификаторов пользователей, идентификаторов групп и идентификаторов процессов. Вы не можете сослаться на процессы с помощью их идентификаторов, взятых с некой машины. Процесса с таковым номером на данном компьютере может просто не быть, или, что еще хуже: вы можете найти полностью обособленный процесс.
Некоторые из этих проблем могут быть решены путем использования альтернативных средств идентификации (например, использования логина вместо идентификатора пользователя; см. раздел о безопасности), а другие решения весьма затруднительны в реализации и могут быть вообще неосуществимы без внесения порции модификаций в ядро Linux при его разработке и реализации, а это может привести к потере совместимости. Так, информация о времени и номерах процессов в структурах IPC, например та, которая возвращается системными вызовами xxxctl() вследствие команды IPC_STAT, на прочих машинах не имеет смысла.
Пользовательские идентификаторы пользователей Linux дифференцированы между ними. Реальные пользователи получают права доступа на какие-либо действия на основе сведений о том, кем они являются (владелец в некоторой группе и др.) в отношении объекта доступа. Значения пользовательских идентификаторов назначаются независимо на каждом компьютере, так что двум различным пользователям на разных машинах могут быть назначены одинаковые идентификаторы. Программы, использующие DIPC, нуждаются в исполнении кода на разных компьютерах - по большому счету, для доступа к структурам ядра. Их вызовы должны обеспечивать некоторый уровень безопасности в системе.
Для DIPC установлено, что пользователь, для которого обеспечивается защита исполнения удаленного системного вызова, должен быть известен на соответствующей удаленной машине под тем же логином. Исполнение удаленных вызовов программ DIPC предполагает наличие определенных эффективных пользовательских идентификаторов наряду с именем пользователя. Очевидно, что с целью обеспечения полезности, и даже значимости, это зафиксированное имя должно однозначно идентифицировать соответствующее лицо на двух машинах.
Единственным исключением из приведенного правила является пользователь root, который имеет максимальные полномочия на Linux-компьютере. Выполнение роли root на одной машине не налагает обязательств выполнять роль root на другой машине. По этой причине все пользователи root преобразуются в одного пользователя с именем dipcd. Администраторы могут контролировать этого пользователя путем корректировки его пользовательского и группового идентификаторов в отношении к другим группам. Программисты могут выбирать права доступа для структур IPC, чтобы разрешить или запретить доступ к ним.
Остерегайтесь случайных конфликтов имен в одном кластере, что может дать возможность неавторизированным пользователям влиять на структуры IPC других лиц. Администраторы должны гарантировать уникальность имени для конкретной персоны в пределах кластера.
Другой мерой безопасности, предложенной Майклом Шмицем (Michael Schmitz), является проблема избавления от вторжения злоумышленников в кластер DIPC. В файле /etc/dipc.allow перечисляются адреса компьютеров, которые могут быть частью кластера DIPC, т.е. ``надежных'' машин. Арбитр будет просто отбрасывать запросы от компьютеров, чьи адреса не находятся в данном файле. Опция -s (secure) заставит back_end также не выполнять никаких действий при запросах от ненадежных компьютеров (Обратитесь к файлу dipcd.doc для получения более подробной информации).
``Подделка'' IP-адресов при DIPC ``не пройдет''. Причиной этого является то, что dipcd всегда использует новые TCP-соединения для подтверждения запросов, т.е. дает подтверждение, что информация будет направляться достоверному компьютеру, а не ``самозванцу''.
Выполнение любого из приведенных ниже условий приводит к тому, что системный вызов DIPC выполняется локально - на машине, сделавшей этот вызов:
На следующей схеме показано ``прохождение'' пользовательского системного вызова DIPC (например, msgsnd()), обрабатываемого с помощью RPC.
Сеть
(Вызывающий компьютер) | (Компьютер-владелец)
|
|-1->back_end>--2-+ | |
| | | |
ядро |<----------9--employer --3-------|->front_end--4-->worker -5->| ядро
| | | | | |
+-8-<front_end<-|------------7-----+ +-6----<|
Здесь back_end отыскивает запросы в ядре (1), причем, адрес машины-владельца должен быть однозначно определен на уровне ядра. Затем back_end раздваивает процесс employer для обработки запроса (2); employer подключается к front_end на машине-владельце (3). После чего front_end раздвоит worker (4), который непосредственно исполнит системный вызов (5) и соберет все результаты (6). Результаты посылаются назад front_end на вызывающий компьютер (7), который передает их оригинальному employer (8). Наконец, employer отдаст результаты ядру (9), откуда пользовательский процесс и получит их.
В сети направление посылки пары запросов может отличаться от направления получения их подтверждений. Для обеспечения гарантии того, что ``гибридизации'' не произойдет, операции над структурами IPC упорядочиваются последовательно: пока процесс на удаленной машине что-либо ожидает, другие процессы, "желающие" использовать ту же самую структуру, также приостанавливаются.
Ошибки, обнаруженные при работе back_end и employer, в виде соответствующего результирующего сообщения об ошибке передаются ядру. При других обстоятельствах ошибки игнорируются и только результирующие сообщения об ошибках выводятся процессами dipcd, которые столкнулись с ними. Только после наступления тайм-аута employer проинформирует об этом ядро.
Далее перечислены поддерживаемые системные вызовы:
Выше было показано, что может выполняться достаточно большое число операций копирования между ядром и пользовательским пространством при одном удаленном системном вызове. Это сильно снижает производительность, особенно, когда копируются большие блоки данных. К счастью, большинство системных вызовов IPC System V передают данные только в одном направлении. Например, msgrcv() только принимает данные, поэтому они копируются из оригинальной задачи в ядро с небольшими затратами. Кроме того, многие другие системные вызовы IPC имеют немного байтов данных, являющихся их параметрами. Одним из примеров может быть xxxctl() с флагом IPC_RMID. Издержки копирования необходимых данных и результатов, даже с учетом задействования сети, незначительны.
Результатом системных вызовов xxxctl() вследствие команды IPC_RMID на машине - владельце, в успешном случае, будет взаимодействие с referee.
DIPC обеспечивает строгую совместимость, т. е. при чтении будет возвращаться последнее записанное значение. Это явление хорошо знакомо программистам. В одно и то же время может быть большое количество читателей разделяемой памяти, но только один писатель. Менеджер разделяемой памяти, выполняющийся на владельце разделяемой памяти, будет получать запросы о чтении или записи целыми сегментами или индивидуальными страницами. Он будет решать, кто получит право на чтение или запись и при необходимости предоставлять запрашивающей машине адекватное содержимое разделяемой памяти.
Поэтому следует всегда помнить, что процессы будут только претендовать на разделяемую память. Они никого не ставят в известность о завершении своего доступа. Значит, нет возможности ожидать завершения использования ими разделяемой памяти для того, чтобы разрешить доступ другим процессам.
Чтобы защитить страницы разделяемой памяти от записи, нужно подвергнуть изменениям таблицы MMU. Аналогично делается и защита страниц от записи (в версиях DIPC до 2.0 желательно подгрузить страницу свопа для того, чтобы защитить ее от записи). Любой процесс, при попытке прочитать или записать защищенные от чтения страницы, столкнется со страничной ошибкой и будет приостановлен ядром. Для того чтобы страницы снова стали доступными для чтения или записи, новое содержимое передается по сети и замещает старое. С этого момента пользовательские процессы могут обращаться к нему.
DIPC может воспринимать в связке множество страниц виртуальной памяти, одновременно управляя ими всеми и передавая требующиеся. Это значит, что для любого целого n >= 1:
n * <размер_страницы_виртуальной_памяти>.
Установка большего размера страницы DIPC будет означать меньшие затраты при пересылках, а также создаст возможность для компьютеров с различными исходными размерами страниц совместно работать, используя DIPC. Значение должно устанавливаться исходя из максимального размера страниц виртуальной памяти компьютеров кластера.
Писатели имеют более высокий приоритет, чем читатели. Ситуация могла бы быть обратной, но философия реализации требует обновления информации писателями в то время, когда ей пользуются только читатели. Так что, писатель будет получать доступ к разделяемой информации даже тогда, когда с ней работают другие, ``желающие быть читателями'', процессы.
Для информирования процессов о том, что они становятся писателями или читателями используются два сигнала - процессы могут выполнять любые необходимые преобразования данных в гетерогенной среде. В настоящее время при записи используется сигнал SIGURG, а при чтении - SIGPWR. В дальнейшем возможны изменения, если этим сигналам будет найдено иное применение. Они приемлемы для программ с именами DIPC_SIG_READER и DIPC_SIG_WRITER.
Все процессы на одной машине имеют одинаковый статус в отношении разделяемой памяти. Либо они все могут читать ее или записывать в нее, либо никто из них не может этого делать. Когда тип доступа машины к разделяемой памяти меняется, это затрагивает все процессы на данной машине.
Система DIPC может быть сконфигурирована для управления разделяемой памятью и ее постраничной передачей. Это так называемый режим страничной передачи. Он позволяет различным компьютерам в кластере одновременно читать или записывать различные страницы разделяемой памяти. DIPC также может воспринимать целый сегмент как неделимый блок. В этом случае можно сказать, что она оперирует в режиме посегментной передачи. Каждый участник кластера DIPC, сконфигурированный для использования собственных режимов передачи, может работать с любым другим, хотя он не всегда может получить то, что просит. Ниже показано, как два компьютера с различными режимами передачи управляют работой друг друга:
Следствия разрешения пересылок целыми сегментами при DIPC:
Компьютер-владелец разделяемой памяти - это ее первостепенный писатель, которого всегда ``окружают'' читатели (если имеется хотя бы один читатель). Последовательность действий компьютера-владельца, всегда присутствующего среди читателей разделяемой памяти, примерно такая. Владелец всегда запускается как писатель, а когда возникает запрос о чтении, он конвертируется в читателя. Если процесс на другом компьютере "желает" записать данные в разделяемую память, то владелец не сможет иметь никаких прав доступа. Как только возникает запрос о чтении, менеджер разделяемой памяти размещает его перед изначальным запросом о чтении - от имени машины-владельца. В этом случае, владелец сначала становится читателем, забирающим содержимое разделяемой памяти от текущего писателя (см. ниже). Затем он предоставляет содержимое изначальному читателю (и, возможно другим ``просителям'').
Описанное поведение упрощает алгоритмы: поскольку всегда известно, как забрать содержимое разделяемой памяти, то выбирают дополнительно к существующим читателям нового. Но если надо использовать одного читателя из группы, то следует обеспечить и способы разрешения сетевых трудностей, чтобы этот пользователь не потерпел неудачи.
Короче говоря, в текущей версии DIPC лишь одна машина всегда ответственна за предоставление другим компьютерам содержимого разделяемой памяти: если это писатели, то и машина является писателем. Если присутствуют один или более читателей, то машина является владельцем. В обоих случаях, если встретилась ошибка, по большому счету ничего нельзя сделать. Если писатель не может передать содержимое, то места с обновленными данными не может быть. И если владелец терпит неудачу при выдаче запрашивающей машине данных - либо из-за ошибок сети, либо ошибок запрашивающей машины - то опять можно сделать очень немного, потому что использование отдельного читателя, возможно, завершится с тем же результатом.
Как при запросе о чтении, так и при запросе о записи, запрашивающий компьютер (если находится на связи) в конечном счете будет искать причину ошибки посредством тайм-аута и передавать SIGSEGV (сбой сегментации) всем процессам, которые имеют распределенную память, присоединенную к их адресному пространству.
Возможны следующие четыре варианта запроса машинами доступа к разделяемой памяти:
На схеме показано, как это происходит:
Сеть
(Запрашивающий компьютер) | (Компьютер-владелец)
|
|-1->back_end >-2-+ | <----------5----+ |
| | | | | |
ядро| employer--3--|->front_end --4-->shm_man |ядро
| | | |
| | +--6-->worker |
Когда процесс "желает" прочесть разделяемую память, уместное содержимое которой отсутствует, возникает исключение, о чем уведомляется часть DIPC в ядре. Внутри ядра подготавливается запрос, который для ``пробуждения'' порождает back_end (1) и раздваивает employer (2); employer подключается к компьютеру-владельцу (3) и доставляет запрос о чтении соответствующего содержимого разделяемой памяти процессу shm_man (4); shm_man посылает сообщение front_end (используя ``разворачивающий'' Internet-сокет) (5); front_end раздваивает worker (6) для действительного выполнения пересылки.
Процесс shm_man никогда не передает данные сам, а использует для этого worker на одной из отдельных машин. Для того, чтобы соблюдать общность, он делает то же самое даже на машине, на которой запущен. Дальнейшая последовательность операций показана на следующей схеме:
Сеть
(Запрашивающий компьютер)|(Компьютер-владелец)
|
| | |
| | |
ядро | +-8-<front_end<---|-------7---worker | ядро
| | | | | |
|<-11-worker<-------------|--10--------+ +-9--<|
Итак, worker на машине-владельце ``отдает'' разделяемую память (с помощью системного вызова shmget()) и подключается к front_end на запрашивающей машине (7), который раздваивает еще один worker (8). Затем worker на машине-владельце читает соответствующее содержимое разделяемой памяти (9) и сразу передает его (без вмешательства front_end) вновь раздвоенному worker (10), который помещает его в разделяемую память запрашивающего компьютера (11). После этого, запрашивающая машина наконец получает информацию, которую хотела.
Ниже представлены оставшиеся действия:
Сеть
(Запрашивающий компьютер) | (Компьютер-владелец)
|
| worker--------12-----|------------->front_end
| | |
| | |
ядро| front_end <----|--14--shm_man <-13-+
| | |
|<-16-employer<-15-+
После того, как worker поместил содержимое в разделяемую память, он посылает подтверждение shm_man (12 и 13). Затем shm_man посылает сигнальное сообщение оригинальному employer, который передает запрос о чтении (14 и 15); employer сообщает ядру об этом (16) и ядро перезапускает процессы, "желающие" читать разделяемую память. На этом вся операция завершается.
Сеть
(Запрашивающий компьютер) | (Компьютер-владелец)
|
|-1->back_end>-2-+ | |
| | | |
ядро| employer--3----|->front_end--4-->shm_man|ядро
| | |
Запрос о записи попадает внутрь ядра, и back_end активируется для его обработки (1). В дальнейшем об этом информируется shm_man на машине-владельце (2, 3 и 4). Заметьте, что все сказанное может происходить на одном компьютере (если владелец хочет записывать в разделяемую память). Иногда все показанные процессы, действительно, выполняются на одной машине:
Сеть
(Компьютер-читатель) | (Компьютер-владелец)
| |
ядро |<-7-worker<-6-front_end<--|------------5-----shm_man
| |
Менеджер разделяемой памяти посылает защищенное от чтения сообщение всем компьютерам-читателям (среди которых может быть и машина-владелец - в этом случае используется разворачивающий адрес) (5); front_end на каждой машине раздваивает worker (6) и запрос исполняется (7). С этого момента все попытки чтения или записи соответствующего содержимого разделяемой памяти любым из этих компьютеров приведут к остановке ответственных процессов. Указанные выше действия повторяются для каждого читателя.
Если компьютер, запрашивающий возможность записи, был одним из читателей, ему содержимое не посылается: владелец ответственен за предоставление новому ``просителю'' содержимого разделяемой памяти.
Далее shm_man ожидает подтверждение, и когда оно прибывает, посылает сигнал employer, который изначально инициировал все процессы.
Если shm_man ``включает'' владельца, как ``желающую читать'' машину, происходит следующее:
Сеть
(Компьютер-писатель) | (Компьютер-владелец)
| |
ядро | worker <-6- front_end <--|------------5-----shm_man
| |
Владелец будет запрашивать у действующего компьютера - писателя о передаче ему соответствующего содержимого разделяемой памяти. Это реализуется посылкой запроса процессу front_end писателя (5), который в свою очередь разветвит worker для выполнения пересылки (6).
Соответствующее содержимое разделяемой памяти передается компьютеру - владельцу (компьютер - владелец заменяется компьютером - писателем, а запрашивающий компьютер - владельцем).
Когда владелец становится читателем разделяемой памяти, он обслуживает оригинальный запрос о чтении. Данная ситуация похожа на ситуацию, описанную в первом пункте.
Сначала shm_man уведомляется о запросе. Затем он пошлет сообщение текущему писателю защитить от записи соответствующие части разделяемой памяти и передаст содержимое новому писателю.
Обычно shm_man размещает запросы о доступе в связанном списке. Планирование реализуется через фиксированные интервалы. Во всех случаях, когда наступает нужный интервал времени, shm_man просматривает, есть ли запросы, связанные с разделяемой памятью, и если есть, то он ведет себя так, как уже описано. Если запросов нет, то ничего не происходит. Данный интервал (shm_hold_time) нужен для предотвращения эффекта пинг-понга, когда плохо написанные программы на разных машинах пытаются переносить данные в разделяемую память без использования синхронизации. В таком случае, при каждой пересылке затрачивается много ресурсов.
Новый читатель страницы или целого сегмента будет установлен, если:
Прокси - это рабочий процесс, который исполняется системным
вызовом semop() с флагом SEM_UNDO. Когда worker
исполняет такую функцию, он не прекращает свого выполнения, а записывает
сетевой адрес и идентификатор процесса удаленного процесса (процесс,
для которого исполняется системный вызов) и продолжает работу. Противоположные
действия могут создать эффекты semop(), которые должны исчезать
при выходе из worker. Теперь worker становится
прокси и устанавливает доменный сокет Linux с именем PROXY_<IP_адрес_удаленного_процесса>_
<идентификатор_удаленного_процесса>, используя приведенную выше
информацию. Примером может быть: PROXY_191.72.2.0_234.
Отныне он будет исполнять все операции semop() по защите
исходного удаленного процесса независимо от того, указали ему флаг
SEM_UNDO или нет.
Процесс front_end будет проверять присутствие подходящего прокси перед тем, как раздваивать процесс worker для обработки функции semop(). Если прокси присутствует, он подключается к нему с помощью доменного сокета Linux и ``инструктирует'' его о выполнении semop().
Прокси может исполнять любую функцию, допустимую для
worker,
но в текущей разработке процесс не сообщает прокси о необходимости
выполнения чего-либо, отличного от semop().
Когда исходный удаленный процесс останавливает исполнение, все его прокси информируются о завершении и ``делаются'' все необходимые ``отмены''.
По умолчанию DIPC использует TCP/IP, но, начиная с версии 1.0, она также работает с сетевым протоколом UDP/IP. В результате использования UDP значительно повышается скорость пересылки данных по сети, в основном за счет отсутствия перегрузок, связанных с ориентированными на соединение протоколами, например, TCP. Все компьютеры в одном кластере должны использовать одинаковые сетевые протоколы.
UDP не является достоверным - имеется в виду, что вследствие перманентных или временных ошибок некоторые данные могут не доставляться по назначению. UDP не может преодолевать ошибки. Также он не осуществляет проверку контрольных сумм, следовательно, возможно искажение данных. Существуют и иные сервисы, доступные для TCP и отсутствующие для UDP.
Следующим важным замечанием является то, что UDP не фрагментирует пакеты данных: они слишком велики для хранения в буферах ядра или для передачи по сети. Текущая реализация DIPC не применяет сквозной контроль и фрагментацию кода DIPC.
Сказанное выше означает, что:
Поскольку UDP не создает соединений, каждый пакет передаваемых данных должен содержать в себе адрес назначения.
Важно и то, что любой процесс использует номера портов, назначаемые системой при применении сокетов. Это значит, что каждый процесс должен предоставлять полные адреса другим процессам, чтобы взаимодействовать с ними.
Подпроцессы, запускающиеся при использовании referee или
front_end хорошо ``знают'' порты. При чтении UDP-сокета
также предоставляется адрес отправителя: после первого контакта
процессы обмениваются несколькими байтами данных, тем самым получая
полные адреса друг друга.
Для написания параллельных программ с использованием DIPC следует разрабатывать свое программное обеспечение путем создания независимых процессов, которые обмениваются данными с применением механизмов IPC System V, а именно: разделяемой памяти, семафоров и сообщений.
Программирование для распределенных систем требует наличия трех возможностей: удаленного выполнения программ, обмена данными, синхронизации.
Сигналы позволяют осуществить самый примитивный способ коммуникации между двумя процессами. С помощью функции kill() процесс может послать сигнал другому процессу, а затем процесс-приемник может реагировать на принятый сигнал. Разумеется, в качестве IPC сигналы используются крайне редко. Для примера приведена программа, которая создает с помощью fork() второй процесс. Затем оба процесса (родитель и потомок) обмениваются данными и выводят сообщения на экран. При этом потомок переводится в состояние ожидания, пока родительский процесс выводит сообщение. Родитель посылает сигнал потомку посредством kill(), а затем сам переводится в состояние ожидания. Потомок выводит сообщение, пробуждает родительский процесс и переводится в состояние ожидания и все повторяется. Программа приведена ниже:
#include <stdio.h>
#include <signal.h>
#include <sys/types.h>
enum { FALSE, TRUE };
sigset_t sig_m1, sig_m2, sig_null;
int signal_flag=FALSE;
void sig_func(int signr) {
start_signalset();
signal_flag = TRUE;
}
void start_signalset() {
if(signal(SIGUSR1, sig_func) == SIG_ERR)
exit(0);
if(signal(SIGUSR2, sig_func) == SIG_ERR)
exit(0);
sigemptyset(&sig_m1);
sigemptyset(&sig_null);
sigaddset(&sig_m1,SIGUSR1);
sigaddset(&sig_m1,SIGUSR2);
if(sigprocmask(SIG_BLOCK, &sig_m1, &sig_m2) < 0)
exit(0);
}
void message_for_parents(pid_t pid) {
kill(pid,SIGUSR2);
}
void wait_for_parents() {
while(signal_flag == FALSE)
sigsuspend(&sig_null);
signal_flag = FALSE;
if(sigprocmask(SIG_SETMASK, &sig_m2, NULL) < 0)
exit(0);
}
void message_for_child(pid_t pid) {
kill(pid, SIGUSR1);
}
void wait_for_child(void) {
while(signal_flag == FALSE)
sigsuspend(&sig_null);
signal_flag = FALSE;
if(sigprocmask(SIG_SETMASK, &sig_m2, NULL) < 0)
exit(0);
}
int main()
{
pid_t pid;
char x,y;
start_signalset();
switch( pid = fork())
{
case -1 : fprintf(stderr, "Ошибка fork()\n");
exit(0);
case 0 : /*...в потомке...*/
for(x=2;x<=10;x+=2) {
wait_for_parents();
write(STDOUT_FILENO, "ping-",
strlen("ping-"));
message_for_parents(getppid());
}
exit(0);
default : /*...в родителе....*/
for(y=1;y<=9;y+=2) {
write(STDOUT_FILENO, "pong-",
strlen("pong-"));
message_for_child(pid);
wait_for_child();
}
}
printf("\n\n");
return 0; }
Параллельная программа состоит из нескольких процессов. Часть из них может выполняться на данной машине и, по крайней мере, один должен выполняться на удаленном компьютере. Один из процессов обычно выделяется как главный. Он инициализирует структуры данных, используемые программой, так что другие процессы в системе с началом своего выполнения могут войти в определенное состояние.
Для того, чтобы IPC имела смысл, должны выполняться более одного процесса, использующего ее механизмы. При обычной IPC, эти процессы могут быть созданы с помощью системного вызова fork(). За ним должен следовать вызов exec(). В рамках DIPC использовать fork() для создания удаленного процесса нельзя, потому что он создает локальный процесс. Можно ``вручную'' запустить процессы удаленно, т.е. после того, как главная программа подготовила механизмы DIPC (разделяемая память, очереди сообщений или наборы семафоров), она ожидает соответствующее состояние, например, семафоров. После этого другой пользователь может запускать программы с консоли удаленной машины. Теперь эти программы должны использовать предварительные договоренности о семафорах, чтобы информировать главный процесс о своей готовности. Далее пользователь должен уделить внимание тому, чтобы не запускать удаленные программы слишком быстро - из-за возможной неготовности разделяемых структур. Программы-примеры из каталога examples/message работают именно в таком стиле.
Можно также использовать программы, подобные rsh для осуществления задействования удаленных программ. В данном случае главный процесс подготавливает все необходимое и затем раздваивает некий вспомогательный процесс для исполнения скрипта на Shell. Скрипт использует команды rsh для удаленного исполнения программ. Программы-примеры реализации данного метода располагаются в каталоге examples/image. Применение rsh для таких целей имеет определенное достоинство: после того, как вы разработали свою программу, можете просто отредактировать упомянутый скрипт - с целью указания в нем изменений, связанных с компьютерами, на которых вы хотели бы запускать свои программы - без необходимости перекомпиляции вашей программы и других действий. Аналогично перечень удаленных машин могут задать пользователи - без необходимости наличия доступа к исходным текстам вашей программы, - что может оказаться важным преимуществом коммерческих программ.
Еще одно замечание по поводу rsh: если он исполняется очень часто, то inetd может ``выключить'' соответствующий сервис. Вы можете прибегать к редактированию файла /etc/inetd.conf для регулирования подобного поведения.
Большинство программ принимают некие данные, обрабатывают их соответствующими способами и выдают результаты. ``Легкость'' обмена данными в распределенных системах очень важна. В рамках DIPC вы можете использовать для этих целей сообщения или сегменты разделяемой памяти. Разделяемая память - это асинхронный механизм. Программа может получить к ней доступ, когда ``пожелает''. При этом может возникнуть длинная задержка между временем предоставления доступа и временем действительного приема данных. Программа ничего этого ``не замечает''. Сообщения являются очень доступным способом передачи данных. Вы можете передать только те данные, которые захотите, и к тому же - только нужному процессу. Такой коммуникационный стиль называется стилем ``один - одному''. Сообщения можно представить как синхронный способ обмена данными. Программа приостанавливается системным вызовом msgrcv() до тех пор, пока другой процесс не прибегнет к вызову msgsnd(). Программист должен сам решать, какой из двух приведенных методов нужно использовать.
Каждая страница разделяемой распределенной памяти может
иметь одновременно
несколько читателей на различных компьютерах, но для нее может быть
только один компьютер с процессом-писателем. Если DIPC сконфигурирована
с поддержкой режима посегментной передачи, то сказанное применимо
для сегмента целиком. Это значит, что читатели могут иметь ``разделяемую''
память (страницы) в своей локальной памяти и, следовательно, свободно
ей пользоваться; но запись в одну из ``копий'' приведет к недостоверности
данных на других машинах. Чтобы можно было продолжить чтение, содержимое
памяти должно быть снова передано другим машинам. Если DIPC сконфигурирована
с поддержкой режима посегментной передачи, то внутренний контекст
разделяемого сегмента данных передается по сети. Если же процессы
пользуются различными частями разделяемой памяти, вы должны установить
постраничный режим передачи для DIPC, - чтобы программы, соответствующие
процессам на различных компьютерах, могли адекватно читать страницы
разделяемой памяти и записывать в них.
Каждый может применять режим постраничной передачи для увеличения эффективности пересылок данных: чтение всей требующейся информации из сегмента разделяемой памяти, выполнение всех необходимых обработок в локальной памяти и, наконец, размещение результатов, возможно, в иной разделяемой памяти. Разделяемая память рассматривается как ``дверь'' к другим машинам. Пока вы не пользуетесь сегментом разделяемой памяти, то не будете использовать и сеть.
Рассмотрим возможный сценарий использования разделяемой памяти при режиме посегментной передачи. Главный процесс запускается и размещает входные данные в разделяемой памяти. Затем запускаются другие удаленные процессы, которые могут читать данный разделяемый сегмент. Может одновременно быть несколько читателей, причем читать они могут также одновременно. Кроме того, поскольку одно содержимое сегмента пересылается каждой машине, то вероятность возникновения перегрузки при передачах будет невелика. (Это имеет смысл, только если удаленные процессы нуждаются во всех данных из разделяемого сегмента памяти). После обработки входных данных удаленные задачи могут вернуть результаты в тот же или другой сегмент разделяемой памяти, но могут использовать и сообщения. Так как писатель для разделяемой памяти может быть только один, то каждой удаленной машине рекомендуется предоставлять персональный сегмент для возвращения результатов. Таким образом можно организовать параллелизм. Следует напомнить, что DIPC можно использовать, и не придерживаясь рассмотренных выше указаний, но производительность может снизиться.
Постраничный режим передачи DIPC можно применять для того, чтобы позволить процессам параллельно читать и записывать различные части одной и той же разделяемой памяти.
В большинстве случаев, распределенной программе не нужно ``знать'', где исполняется процесс, к тому же в DIPC нет способа, которым программист мог бы явно сослаться на специфический компьютер в сети. Это создает условия адресной ``независимости'' программ. Программист может использовать иные средства опознавания различных процессов. Например использовать поле mtype структуры msgbuf для записи идентификатора, представляющего процесс, или разместить подобную информацию в некотором заранее оговоренном месте разделяемой памяти. Это предоставляет программисту возможность применять логическую адресацию.
Рассмотрим программирование в гетерогенной среде, где размещаются машины с различными архитектурами. Каждая из них может иметь свои, особые способы представления данных. Например, способы представления чисел с плавающей запятой или даже целых чисел могут у них не совпадать. Но размер, как сообщения, так и сегмента разделяемой памяти, выражается в байтах и эти размеры для всех машин идентичны.
При использовании DIPC смысловая интерпретация данных и осуществление любого преобразования возлагаются на приложение. Но нужно найти способ точно установить, нужны ли преобразования форматов для различных машин. В случае с сообщениями, программист может использовать, например, первый байт для индикации типа исходной машины. Принимающий процесс может самостоятельно решить вопрос о преобразовании. В случае с разделяемой памятью все не так просто. Во время чтения разделяемой памяти или записи в нее процесс может быть приостановлен, содержимое разделяемой памяти передано некой машине отличного типа, данные подменены сгенерированными данными и позже переданы назад оригинальной машине. Все происходит ``прозрачно'' для программы. Однако нужно избрать способ информировать программу об этих событиях.
Информирование выполяется двумя прерываниями. Одно из них - DIPC_SIG_WRITER, второе - DIPC_SIG_READER. Если DIPC сконфигурирована с поддержкой их передачи, то первое передается, когда процесс еще только становится писателем (ранее он мог быть просто читателем или вообще не иметь связей с сегментом). При посегментном режиме передачи процесс ``знает'', что имеет эксклюзивный контроль над сегментом. Процесс, например, может записать идентификатор текущей архитектуры в первые байты сегмента и поместить произведенные им данные в разделяемую память. Второе прерывание посылается, когда процесс становится читателем сегмента (ранее он не пользовался его содержимым). Процесс, например, может проверить первые байты сегмента для того, чтобы установить, нужно ли делать какие-либо преобразования. Обратите внимание на то, что прерывание DIPC_SIG_READER генерируется, если данная машина предварительно была писателем, а теперь стала читателем, т.е. ее права доступа стали более ограниченными.
Только что описанные действия производить не очень удобно, если применяется режим постраничной передачи, так как нет способа передать сигналом какие-либо ``лишние'' параметры получателю. Следовательно, не представляется возможным сообщить процессу, какую именно страницу в настоящий момент он читает или записывает. Программист может помочь себе в разрешении таких ситуаций путем предназначения четко указанных секций разделяемой памяти для определенных нужд.
В любом случае, даже если программист специально запретил (через SIG_IGN) два упомянутых прерывания или системный администратор сконфигурировал DIPC без поддержки передачи прерываний, связанных с разделяемой памятью, программист должен быть всегда готов к обработке такой ситуации. Имеются в виду проверка значений, возвращаемых системными вызовами, и их перезапуск при необходимости.
Удаленные программы должны точно "знать", когда выполнять действия, вовлекающие другие машины. Например, они должны "знать", когда требующиеся им данные доступны. Настоятельно рекомендуется использовать для этой цели семафоры. Другие способы, такие, как частое тестирование и установка переменной в разделяемой памяти, могут отличаться очень низкой производительностью, так как они требуют частых пересылок по сети целого сегмента разделяемой памяти. Это происходит, когда DIPC сконфигурирована с поддержкой режима посегментной передачи. Даже в режиме постраничной передачи результаты не будут намного лучше.
Известно несколько причин, требующих снизить количество сетевых операций вашего приложения. Одна из них - это, очевидно, производительность, поскольку сетевые операции очень ``дорогостоящие'' в сравнении с локальными. Другая причина связана с некоторыми частными ограничениями кода TCP/IP ядра: за короткое время невозможно сделать слишком много сетевых соединений: через некоторое время ядро выдаст: ``Resource temporarily not available'' и ваше приложение завершится ненормально. Вы столкнетесь с этим, если имеете очень быстрые компьютеры, но не сеть.
Ниже приводятся некоторые рекомендации, которые надо учитывать при программировании DIPC:
fd_set fd;
for(; ; ;)
{
/* сначала проверка семафора, затем приостановка */
check_the_semaphore_and_break_if_needed(...);
/* замечание: Вы должны выполнить инициализацию
внутри цикла */
tv.tv_sec = 0;
/* ожидание в течение 0.5 секунды = 2 семафора
за секунду */
tv.tv_usec = 0.5 * 1000000;
FD_ZERO(&fd);
select(FD_SETSIZE, &fd, NULL, NULL, &tv);
}
К поддерживаемым в DIPC формам системных вызовов IPC относятся:
Если dipcd не выполняется, то все описанные системные вызовы исполняются локально, как если бы они были обычными вызовами IPC. Данные системные вызовы могут возвращать код ошибки not found, как и при IPC. Это может означать, например, что произошел сбой сетевой операции или наступил тайм-аут.
При инсталляции программного обеспечения вы можете пользоваться такими подсистемами, как NFS, чтобы освободить себя от бремени переноса дистрибутива на машины и просто копировать исполняемые файлы. Другой вариант - rdist - кажется, очень хороший кандидат для распространения программ.
Вы можете обратиться к программам-примерам за пояснениями всего рассмотренного выше. Просмотрите и файл Readme из каталога с примерами. Программа в каталоге examples/hello проста для инсталляции и выполнения. Вы можете начать с нее.
Интерфейс передачи сообщений MPI представляет собой библиотеку функций и макроопределений, которые могут использоваться в программах на C, Фортране и C++. MPI предназначен для написания программ, которые используют при работе несколько процессоров с помощью обмена сообщениями. Он является одним из первых стандартов для программирования параллельных процессов и первым, основанным на обмене сообщениями. Информация этого раздела предназначена для использования программистами, которые имеют опыт программирования на C, но мало знакомы с механизмами передачи сообщений.
Первой программой на C, которую пишет большинство начинающих программистов, является программа, выводящая сообщение "Привет, мир!". Она просто печатает сообщение "Привет, мир!"на терминал. Многопроцессорный вариант содержит процессы, каждый из которых посылает приветствие другому.
В MPI процессы, участвующие в выполнении параллельной программы, идентифицируются последовательностью неотрицательных целых чисел. Если в выполнении программы участвуют P процессов, то они будут иметь номера (ранги) 0, 1, ..., P-1. В следующей программе каждый процесс с рангом, не равным 0, посылает сообщение в процесс 0, а процесс 0 выводит все сообщения, которые он получил:
#include ''mpi.h''
main(int argc, char** argv) {
int my_rank; /* Ранг процесса */
int p; /* Количество процессов */
int source; /* Ранг посылающего */
int dest; /* Ранг принимающего */
int tag = 50; /* Тэг сообщений */
char message[100]; /* Память для сообщения */
MPI_Status status; /* Статус возврата */
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &p);
if (my_rank != 0) {
sprintf(message, ''Привет из процесса %d!'', my_rank);
dest = 0;
/* Используется strlen(message)+1
чтобы включить '\0' */
MPI_Send(message, strlen(message)+1,
MPI_CHAR, dest, tag, MPI_COMM_WORLD);
} else { /* my_rank == 0 */
for (source = 1; source < p; source++) {
MPI_Recv(message, 100, MPI_CHAR, source, tag,
MPI_COMM_WORLD, &status);
printf(''%s\n'', message);
}
}
MPI-Finalize();
} /* main */
Если программу откомпилировать и запустить для четырех процессов, она выведет:
Привет из процесса 2!
Привет из процесса 3!
Каждая программа MPI содержит директиву препроцессора:
. . .
main(int argc, char** argv) {
. . .
/* Функции MPI нельзя вызывать до этого момента */
MPI_Init(&argc, &argv);
. . .
MPI_Finalize();
/* Функции MPI нельзя вызывать после этого момента */
. . .
} /* main */
MPI предлагает функцию MPI_Comm_rank(), которая возвращает ранг процесса. Ее синтаксис:
Многие конструкции в программах зависят также от общего числа процессов, выполняющих программу. Поэтому MPI содержит функцию MPI_Comm_size() для того, чтобы определять их количество. Синтаксис функции:
Фактическая передача сообщений в программе выполняется функциями MPI_Send() и MPI_Recv(). Первая функция посылает сообщение определенному процессу. Вторая получает сообщение от некоторого процесса. Эти функции являются самыми основными командами передачи сообщений в MPI. Чтобы сообщение было успешно передано, система должна добавить немного информации к данным, которые "желает" передать прикладная программа. Эта дополнительная информация формирует конверт сообщения. В MPI конверт содержит следующую информацию:
Эти детали могут использоваться приемником, чтобы распознавать поступающие сообщения. Аргумент source применяется, чтобы различать сообщения, полученные от разных процессов. Тэг представляет собой указанное пользователем значение int, которое предназначено, чтобы отличить сообщения, полученные от одного процесса. Пусть процесс А посылает два сообщения процессу B; оба сообщения содержат одно значение типа float. Одно из значений должно использоваться в вычислении, а другое должно быть выведено на экран. Чтобы определить, какое из них первое, А использует различные тэги этих сообщений. Если B употребляет те же самые тэги при приеме, он будет "знать", что с ними делать. MPI предполагает, что в качестве тэгов могут применяться целые числа в диапазоне 0 - 32767. Большинство реализаций позволяет использовать гораздо большие значения.
Как уже было отмечено, коммуникатор - это набор процессов, которые могут посылать друг другу сообщения. Если два процесса поддерживают связь при помощи MPI_Send() и MPI_Recv(), коммуникатор употребляется в случае, когда отдельные модули программы разрабатываются независимо друг от друга. Пусть необходимо решить систему дифференциальных уравнений, при этом в ходе решения системы возникает необходимость решить систему линейных уравнений. Вместо того чтобы разрабатывать решатель линейных систем с нуля, можно использовать библиотеку функций для решения линейных систем. При этом возникает необходимость различать собственные сообщения между процессами и сообщения библиотеки для решения линейных уравнений. Без применения коммуникаторов потребуется выделить из множества тэгов подмножество для эксклюзивного использования функциями библиотеки. Такое решение плохо переносится на другие системы. При применении коммуникаторов можно создать коммуникатор, который может использоваться исключительно линейным решателем, и передавать его как аргумент в вызовах функций решателя.
Синтаксис функций приведен ниже:
int MPI_Send(void* message, int count,
MPI_Datatype datatype, int dest, int tag,
MPI_Comm comm)
int MPI_Recv(void* message, int count,
MPI_Datatype datatype, int source, int tag,
MPI_Comm comm, MPI_Status* status)
Содержимое сообщения хранится в блоке памяти, на который указывает
аргумент message. Следующие два аргумента, count
и
| Тип MPI | Соответствующий тип С |
| MPI_CHAR | signed char |
| MPI_SHORT | signed short int |
| MPI_INT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_UNSIGNED_SHORT | unsigned short int |
| MPI_UNSIGNED | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_BYTE | - |
| MPI_PACKED | - |
Последние два типа, MPI_BYTE и MPI_PACKED, не соответствуют стандартным типам C. Тип MPI_BYTE используется, если система не должна выполнять преобразование между различными представлениями данных (например, в гетерогенной сети рабочих станций, применяющих различные представления данных). Особенность типов MPI в том, что они позволяют приложениям на гетерогенных архитектурах взаимодействовать единообразно, выполняя необходимые преобразования типов прозрачно для пользователя.
Следует отметить, что количество памяти, выделенной для буфера получения, может точно не соответствовать размеру получаемого сообщении. Например, при работе программы размер сообщения, посылаемый процессом 1 равен strlen (message +1) = 28 символов, а процесс 0 получает сообщение в буфер, который имеет размер 100 символов. В любом случае процесс-получатель не может знать точного размера посланного сообщения. Поэтому MPI позволяет принимать сообщение, пока есть место в выделенной памяти. Если места недостаточно, возникает ошибка выхода за пределы памяти.
Аргументы dest и source соответствуют рангам процессов приема и посылки. MPI позволяет source принимать значение предопределенной константы MPI_ANY_SOURCE, которое может использоваться, если процесс готов получить сообщение от любого иного процесса. Для dest подобной константы нет.
MPI имеет два механизма, предназначенные для разделения пространств сообщении - тэги и коммуникаторы. Аргументы tag и comm соответственно определяют тэг и коммуникатор. Существует групповой тэг MPI_ANY_TAG, определяющий любой тэг для сообщения.
Последний аргумент MPI_Recv(), status, возвращает информацию, относящуюся к фактически полученным данным. Он ссылается на запись с двумя полями: одно - для источника, другое - для тэга. Например, если в качестве источника был указан MPI_ANY_SOURCE, то status будет содержать ранг процесса, который прислал сообщение.
Для посылки сообщений также можно использовать варианты функций MPI_Send(). Эти варианты определяют различные режимы передачи сообщений (стандартный, синхронный, буферизованный и режим передачи по готовности). Информация о режимах приведена в табл. 9.
| Название режима | Условие завершения | Функция |
| Стандартная передача | Как для синхронной или буферизованной | MPI_SEND |
| Синхронная передача | Завершается, когда завершен прием | MPI_SSEND |
| Буферизованная передача | Всегда завершается | MPI_BSEND |
| Передача по готовности | Всегда завершается | MPI_RSEND |
| Прием | Завершается, когда сообщение принято | MPI_RECV |
Буферизованная передача гарантирует немедленное завершение, поскольку сообщение вначале копируется в системный буфер, а затем доставляется. Недостатком ее является необходимость выделения специальных буферов, потребляющих ресурсы системы.
Передача по готовности предполагает инициирование передачи в момент, когда приемник вызывает соответствующий ей прием. Этот режим гарантирует отсутствие в коммуникационной сети блуждающих сообщений.
В качестве примера рассматривается программа вычисления определенного
интеграла по правилу трапеции. Последовательный вариант вычисляет
![]() разделением интервала
разделением интервала
![]() на
на
![]() равных сегментов и суммированием частных оценок интеграла для
каждого сегмента по формуле:
равных сегментов и суммированием частных оценок интеграла для
каждого сегмента по формуле:
Здесь ![]() , и
, и ![]() где i = 0, 1, ..., n. Если поместить
вычисление
где i = 0, 1, ..., n. Если поместить
вычисление ![]() в отдельную функцию, то последовательный вариант
программы выглядит так:
в отдельную функцию, то последовательный вариант
программы выглядит так:
float f(float x) {
float return_val;
/* Вычисляет f(x).
Запоминает результат в return_val. */
. . .
return return_val;
} /* f */
main() {
float integral; /* Результат вычисления */
float a, b; /* Левая и правая границы */
int n; /* Количество интервалов */
float h; /* Ширина интервала */
float x;
int i;
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', &a, &b, &n);
h = (b-a)/n;
integral = (f(a) + f(b))/2.0;
x = a;
for (i = 1; i <= n-1; i++) {
x += h;
integral += f(x);
}
integral *= h;
printf(''C n = %d трапециями, интеграл \n'', n);
printf("от %f до %f = %f`\n'', a, b, integral);
} /* main */
Вариант параллелизации этой программы сводится к тому, чтобы
просто разделить интервал
![]() между процессами, чтобы
каждый процесс оценил интеграл
между процессами, чтобы
каждый процесс оценил интеграл ![]() на своем подинтервале. Для
оценки величины полного интеграла локальные значения всех процессов
суммируются.
на своем подинтервале. Для
оценки величины полного интеграла локальные значения всех процессов
суммируются.
Пусть программа содержит ![]() процессов и
процессов и ![]() трапеций, где
трапеций, где ![]() является
кратным
является
кратным ![]() . Тогда первый процесс вычисляет область первых
. Тогда первый процесс вычисляет область первых ![]() трапеций, второй - область следующих
трапеций, второй - область следующих ![]() и т.д. Тогда процесс
и т.д. Тогда процесс ![]() будет оценивать интеграл по интервалу
будет оценивать интеграл по интервалу
Каждый процесс должен обладать следующей информацией:
Подведение итогов индивидуальных вычислений процессов состоит в том, чтобы каждый процесс посылал свое локальное значение в процесс 0, а процесс 0 производил заключительное суммирование. Новый вариант программы:
#include ''mpi.h''
float f(float x) {
float return_val;
/* Вычисляет f(x).
Возвращает результат в return_val. */
. . .
return return_val;
}
float Trap(float local_a, float local_b, int local_n,
float h) {
float integral; /* Результат вычислений */
float x;
int i;
integral = (f(local_a) + f(local_b))/2.0;
x = local_a;
for (i = 1; i <= local-n-1; i++) {
x += h;
integral += f(x);
}
integral *= h;
return integral;
} /* Trap */
main(int argc, char** argv) {
int my_rank; /* Ранг процесса */
int p; /* Количество процессов */
float a = 0.0; /* Левая граница */
float b = 1.0; /* Правая граница */
int n = 1024; /* Количество трапеций */
float h; /* Ширина трапеции */
float local_a; /* Левая граница для процесса */
float local_b; /* Правая граница для процесса */
int local_n; /* Количество вычисляемых трапеций */
float integral; /* Значение интеграла по интервалу */
float total; /* Общий интеграл */
int source; /* Процесс, посылающий интеграл */
int dest = 0; /* Пункт назначения процесс 0 */
int tag = 50;
MPI_Status status;
MPI_Init(&argc, &argv);
/* Определить ранг процесса */
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
/* Определить количество процессов */
MPI_Comm_size(MPI_COMM_WORLD, &p);
h = (b-a)/n; /* h одинаково для всех процессов */
local_n = n/p; /* Получить количество трапеций */
/* Вычислить границы интервала и частный интеграл*/
local_a = a + my_rank*local_n*h;
local_b = local_a + local_n*h;
integral = Trap(local_a, local_b, local_n, h);
/* Суммировать все интегралы */
if (my_rank == 0) {
total = integral;
for (source = 1; source < p; source++) {
MPI_Recv(&integral, 1, MPI_FLOAT,
source, tag, MPI_COMM_WORLD, &status);
total += integral;
}
} else {
MPI_Send(&integral, 1, MPI_FLOAT, dest,
tag, MPI_COMM_WORLD);
}
/* Вывод результата */
if (my_rank == 0) {
printf(''C n = %d трапециями, оценка\n'', n);
printf(''интеграла от %f до %f = %f`\n'',
a, b, total);
}
/* Завершить приложение MPI */
MPI_Finalize();
} /* main */
В предыдущем примере некоторые значения были жестко определены в коде программы. Чаще всего для таких случаев возникает дополнительная задача обеспечения ввода требуемых величин со стороны пользователя.
Как правило, при обеспечении работы с терминалом вывод и ввод осуществляется через один процесс. Чаще всего это процесс с номером 0. В общем случае, все процессы могут осуществлять ввод / вывод, однако при одновременном выполнении операторов ввода / вывода могут возникать неожиданные эффекты. Поэтому наилучшим вариантом является обеспечение интерфейса через один процесс.
Пусть для примера обмен осуществляется через процесс 0. Необходимо передать другим процессам значения левой и правой границ интервала и количества трапеций. Для этого может использоваться следующая функция:
float* b_ptr, int* n_ptr)
{
int source = 0; /* Локальные переменные */
int dest; /* используемые MPI_Send и MPI_Recv */
int tag;
MPI_Status status;
if (my_rank == 0) {
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', a_ptr, b_ptr, n_ptr);
for (dest = 1; dest < p; dest++) {
tag = 30;
MPI_Send(a_ptr, 1, MPI_FLOAT, dest, tag,
MPI_COMM_WORLD);
tag = 31;
MPI_Send(b_ptr, 1, MPI_FLOAT, dest, tag,
MPI_COMM_WORLD);
tag = 32;
MPI_Send(n_ptr, 1, MPI_INT, dest, tag,
MPI_COMM_WORLD);
}
} else {
tag = 30;
MPI_Recv(a_ptr, 1, MPI_FLOAT, source, tag,
MPI_COMM_WORLD, &status);
tag = 31;
MPI_Recv(b_ptr, 1, MPI_FLOAT, source, tag,
MPI_COMM_WORLD, &status);
tag = 32;
MPI_Recv(n_ptr, 1, MPI_INT, source, tag,
MPI_COMM_WORLD, &status);
}
}/* Get_data */
Производительность программы вычисления интеграла можно значительно повысить. Например, пусть программа выполняется на восьми процессорах.
Все процессы начинают выполнять программу практически одновременно.
Однако после выполнения основных задач (вызовы
MPI_Init(),
MPI_Comm_size() и MPI_Comm_rank()) процессы
1 - 7 будут простаивать, в то время как процесс 0 будет собирать входные
данные. После того как процесс 0 примет входные данные, процессы
большего ранга должны продолжать ожидать, пока процесс 0 рассылает
входные данные всем процессам. Подобная неэффективность наблюдается
и в конце программы, когда процесс 0 собирает и суммирует значения
локальных интегралов.
Основной задачей организации параллельной обработки является равномерное распределение загрузки по всем процессорам системы. Если, как в приведенном случае, основная нагрузка ложится на один из процессов, то в некоторых случаях будет эффективнее использовать однопроцессорную версию.
Равномерное распределение загрузки по процессорам предполагает определенную организацию передач данных в рамках некоторой структуры. Например, при рассылке входных данных между процессами программы вычисления интеграла хороший результат может дать организация дерева процессов, корнем которого является процесс 0 (рис. 2).
На первой стадии распределения данных процесс 0 посылает данные процессу
4. В течение следующей стадии, процесс 0 посылает данные процессу
2, в то время как процесс 4 посылает те же данные процессу 6. В ходе
последней стадии, процесс 0 посылает данные процессу 1, в то время
как процесс 2 посылает данные процессу 3, процесс 4 посылает данные
процессу 5, и наконец, процесс 6 посылает данные процессу 7. При
этом цикл распределения данных уменьшился с 7 этапов до 3. Если существует
![]() процессов, эта процедура позволяет распределять входные данные
в
процессов, эта процедура позволяет распределять входные данные
в
![]() этапов, вместо
этапов, вместо ![]() этапов,
что при достаточно большом
этапов,
что при достаточно большом ![]() существенно ускоряет процесс.
существенно ускоряет процесс.
Чтобы модифицировать функцию Get_data() для использования
схемы распределения в виде дерева, необходимо ввести цикл из
![]() итераций. Каждый процесс при этом определяет на каждой стадии:
итераций. Каждый процесс при этом определяет на каждой стадии:
Пример коммуникации, в которой участвуют все процессы в коммуникаторе, называется коллективной. Как следствие коллективная связь обычно предполагает участие более двух процессов. Широковещательное сообщение - коллективная коммуникация, когда отдельный процесс посылает одинаковые данные каждому процессу. В MPI существует функция для широковещательной передачи MPI_Bcast():
MPI_Datatype datatype, int root, MPI_Comm comm);
Функцию получения данных Get_data(), используя MPI_Bcast(), можно переписать следующим образом:
int* n_ptr) {
int root = 0; /* Аргументы MPI_Bcast */
int count = 1;
if (my_rank == 0) {
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', a_ptr, b_ptr, n_ptr);
}
MPI_Bcast(a_ptr, 1, MPI_FLOAT, root, MPI_COMM_WORLD);
MPI_Bcast(b_ptr, 1, MPI_FLOAT, root, MPI_COMM_WORLD);
MPI_Bcast(n_ptr, 1, MPI_INT, root, MPI_COMM_WORLD);
} /* Get-data2 */
В рассматриваемой программе после входной стадии каждый процессор
выполняет по существу те же самые команды до заключительной стадии
суммирования. Поэтому, если функция ![]() дополнительно не усложнена
(т. е. не требует значительной работы для оценки интеграла
по некоторым частям отрезка
дополнительно не усложнена
(т. е. не требует значительной работы для оценки интеграла
по некоторым частям отрезка ![]() ), то эта часть программы распределяет
среди процессоров одинаковую нагрузку. В заключительной стадии суммирования
процесс 0 еще раз получает непропорциональное количество работы.
Здесь также можно распределить работу вычисления суммы среди процессоров
по структуре дерева следующим образом:
), то эта часть программы распределяет
среди процессоров одинаковую нагрузку. В заключительной стадии суммирования
процесс 0 еще раз получает непропорциональное количество работы.
Здесь также можно распределить работу вычисления суммы среди процессоров
по структуре дерева следующим образом:
"Общая сумма", которую нужно вычислить представляет собой пример общего класса коллективных операций коммуникации, называемых операциями редукции. В глобальной операции редукции, все процессы (в коммуникаторе) передают данные, которые объединяются с использованием бинарных операций. Типичные бинарные операции - суммирование, максимум и минимум, логические и т.д. MPI содержит специальную функцию для выполнения операции редукции:
MPI_Datatype datatype, MPI_Op op, int root,
MPI_Comm comm)
Аргумент op может принимать фиксированные значения, указанные в табл. 10:
| Название операции | Смысл |
| MPI_MAX | Максимум |
| MPI_MIN | Минимум |
| MPI_SUM | Сумма |
| MPI_PROD | Произведение |
| MPI_LAND | Логическое И |
| MPI_BAND | Битовое И |
| MPI_LOR | Логическое ИЛИ |
| MPI_BOR | Битовое ИЛИ |
| MPI_LXOR | Логическое исключающее ИЛИ |
| MPI_BXOR | Битовое исключающее ИЛИ |
| MPI_MAXLOC | Максимум и его расположение |
| MPI_MINLOC | Минимум и его расположение |
Существует также возможность определения собственных операций.
Таким образом, завершение программы вычисления интеграла будет следующим:
MPI_Reduce(&integral, &total, 1, MPI_FLOAT,
MPI_SUM, 0, MPI_COMM_WORLD);
/* Вывод результата */
Труба является однонаправленным коммуникационным каналом
между двумя
процессами и может использоваться
для поддержки коммуникаций и контроля информационного потока между двумя процессами.
Труба может принимать только определенный объем данных
(обычно 4 Кб). Если труба заполнена, процесс останавливается до тех
пор, пока хотя бы один байт из этой трубы не будет прочитан и не появится
свободное место, чтобы снова заполнить ее данными. С другой стороны,
если труба пуста, то читающий процесс останавливается до тех пор,
пока пишущий процесс не внесёт данные в эту трубу.
Труба описывается двумя дескрипторами файлов. Первый дескриптор служит для чтения, второй - для записи в трубу:
int pipe(int fd[2]);
Второй процесс для организации обмена можно создать с помощью fork(). При этом процесс-потомок наследует от родителя оба открытых дескриптора файлов. После этого, закрыв ненужные дескрипторы, необходимо указать обоим процессам, кто куда пишет и кто что читает.
В приведенном ниже примере процесс-родитель записывает данные в трубу. В этом случае закрываются дескриптор чтения (fd[0]) родительского процесса и дескриптор записи потомка. Потомок будет только читать данные из трубы:
#include <sys/wait.h>
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#define USAGE printf("usage : %s данные\n",
argv[0]);
#define MAX 4096
int main(int argc, char *argv[]) {
int fd[2], fd1,i, n;
pid_t pid;
char buffer[MAX];
FILE *dataptr;
if(argc !=2)
{ USAGE; exit(0); }
if((fd1=open(argv[1], O_RDONLY)) < 0)
{ perror("open : "); exit(0); }
/*Устанавливаем трубу*/
if(pipe(fd) < 0)
{ perror("pipe : "); exit(0); }
/*Создаем новый процесс*/
if((pid=fork()) < 0)
{ perror("pipe : "); exit(0); }
else if(pid > 0) /*Это родитель*/ {
close(fd[0]); /*Закрываем чтение*/
n=read(fd1, buffer, MAX);
if((write(fd[1], buffer, n)) != n)
{ perror(" write : "); exit(0); }
if((waitpid(pid, NULL, 0)) < 0)
{ perror("waitpid : "); exit(0); }
}
else /*Это потомок*/ {
close(fd[1]); /*Закрываем запись*/
n=read(fd[0], buffer, MAX);
if((write(STDOUT_FILENO, buffer, n)) != n)
{ perror(" write : "); exit(0); }
}
exit(0);
}
MPI поддерживает некоторые другие функции для организации коллективных коммуникаций:
MPI_Datatype send_type, void* recv_buf,
int recv_count, MPI_Datatype recv_type, int root,
MPI_comm comm);
MPI_Datatype send_type, void* recv_buf,
int recv_count, MPI_Datatype recv_type, int root,
MPI_Comm comm);
MPI_Datatype send_type, void* recv_buf,
int recv_count, MPI_Datatype recv_type,
MPI_comm comm);
int count, MPI_Datatype datatype, MPI_Op op,
MPI_Comm comm);
Для современных компьютеров посылка сообщения является дорогостоящей операцией. Поэтому чем меньше сообщений будет послано, тем выше будет производительность программы. В рассматриваемом примере при распределении входных данных приходится посылать a, b, n в отдельных сообщениях, независимо от того, используется ли пара MPI_Send() и MPI_Recv(), или функция MPI_Bcast(). Можно попытаться улучшить производительность программы, посылая три входных значения в единственном сообщении. MPI обеспечивает три механизма для того, чтобы сгруппировать индивидуальные переменные в единое сообщение:
Процедуры MPI_Send(), MPI_Recv(), MPI_Bcast(), и MPI_Reduce() используют аргументы count и datatype. Эти два параметра позволяют пользователю группировать элементы данных, имеющие тот же самый основной тип, в единое сообщение. Чтобы использовать эту возможность, сгруппированные элементы данных должны сохраняться в смежных областях памяти. Поскольку C гарантирует, что элементы массива сохраняются именно таким образом, то посылка элементов массива или подмассива может осуществляться в едином сообщении.
В качестве примера приведем процедуру посылки второй половины вектора, содержащего 100 значений с плавающей точкой от процесса 0 к процессу 1:
int tag, count, dest, source;
MPI_Status status;
int p;
int my_rank;
. . .
if (my_rank == 0) {
/* Инициализация и отсылка вектора */
. . .
tag = 47;
count = 50;
dest = 1;
MPI_Send(vector + 50, count, MPI_FLOAT, dest, tag,
MPI_COMM_WORLD);
} else {
/* my_rank == 1 */
tag = 47;
count = 50;
source = 0;
MPI_Recv(vector+50, count, MPI_FLOAT, source, tag,
MPI_COMM_WORLD,
&status);
}
float b;
int n;
Может показаться, что другим вариантом могло бы стать хранение a, b, n в структуре с тремя членами - два числа с плавающей точкой и целое - и попытка использовать аргумент datatype в функции MPI_Bcast(). Трудность здесь состоит в том, что тип datatype является одним из MPI_Datatype(), которые не являются пользовательскими типами, как структуры в C. Если определить тип:
float a;
float b;
int n;
} INDATA_TYPE
MPI обеспечивает частичное решение этой проблемы, разрешая пользователю во время выполнения создавать собственные типы данных MPI. Чтобы построить тип данных для MPI, необходимо определить расположение данных в типе: тип элементов и их относительные местоположения в памяти. Такой тип называют производным типом данных. Ниже приведена функция, которая будет строить производный тип, соответствующий INDATA_TYPE:
MPI-Datatype* message_type_ptr)
{
int block_lengths[3];
MPI_Aint displacements[3];
MPI_Aint addresses[4];
MPI_Datatype typelist[3];
/* Создает производный тип данных, содержащий
* два элемента float и один int */
/* Сначала нужно определить типы элементов */
typelist[0] = MPI_FLOAT;
typelist[1] = MPI_FLOAT;
typelist[2] = MPI_INT;
/* Определить количество элементов каждого типа */
block_lengths[0] = block_lengths[1] =
block_lengths[2] = 1;
/* Вычислить смещения элементов
* относительно indata */
MPI_Address(indata, &addresses[0]);
MPI_Address(&(indata->a), &addresses[1]);
MPI_Address(&(indata->b), &addresses[2]);
MPI_Address(&(indata->n), &addresses[3]);
displacements[0] = addresses[1] - addresses[0];
displacements[1] = addresses[2] - addresses[0];
displacements[2] = addresses[3] - addresses[0];
/* Создать производный тип */
MPI_Type_struct(3, block_lengths, displacements,
typelist, Message_type_ptr);
/* Зарегистрировать его для использования */
MPI_Type_commit(message_type_ptr);
} /* Build_derived_type */
Новый тип данных MPI можно использовать в любых коммуникационных функциях MPI. Чтобы использовать его, необходимо применять стартовый адрес переменной типа INDATA_TYPE в качестве первого аргумента, а производный тип данных - в качестве аргумента datatype. При этом функция Get_data() в примере принимает вид.
MPI_Datatype message_type; /* Аргументы для */
int root = 0; /* MPI_Bcast */
int count = 1;
if (my_rank == 0) {
printf(''Введите a, b, and n\n'');
scanf(''%f %f %d'', &(indata->a),
&(indata->b), &(indata->n));
}
Build_derived_type(indata, &message_type);
MPI_Bcast(indata, count, message_type, root,
MPI_COMM_WORLD);
} /* Get_data3 */
Производные типы данных строятся с помощью функции
MPI_Type_struct().
Синтаксис этой функции таков:
int* array_of_block_lengths,
MPI_Aint* array_of_displacements,
MPI_Datatype* array_of_types,
MPI_Datatype* newtype)
Следует также отметить, что newtype и элементы массива
array_of_types
все имеют тип MPI_Datatype. Поэтому функцию
MPI_Type_struct()
можно вызывать рекурсивно для построения более сложных производных
типов данных.
MPI_Type_struct() является самым общим конструктором типов
данных в MPI. Поэтому пользователь должен обеспечить полное описание
каждого элемента типа. Если данные, которые будут переданы, состоят
из подмножества элементов массива, возможно не стоит обеспечивать
слишком детальную информацию, так как все элементы имеют тот же самый
основной тип. MPI обеспечивает три производных конструктора данных
для того, чтобы работать в этой ситуации: MPI_Type_Contiguous(),
MPI_Type_vector() и
MPI_Type_indexed(). Первый
конструктор строит производный тип, элементами которого являются смежные
элементы массива. Второй конструктор строит тип, элементами которого
являются равномерно разделенные промежутками элементы массива, а третий
строит тип, элементы которого являются произвольными элементами массива.
Прежде чем любой производный тип может быть использован в коммуникации,
он должен быть объявлен вызовом MPI_Type_commit().
Ниже приведены сведения о синтаксисе дополнительных конструкторов типов MPI:
MPI_Datatype oldtype, MPI_Datatype* newtype);
int stride, MPI_Datatype element_type,
MPI_Datatype* newtype);
![]()
int* array_of_block_lengths,
int* array_of_displacements,
MPI_Datatype element_type,
MPI_Datatype* newtype);
Альтернативный подход к группировке данных реализован функциями MPI_Pack() и MPI_Unpack(). MPI_Pack() позволяет явно хранить данные, состоящие из нескольких несмежных участков, в смежных областях памяти. MPI_Unpack() может использоваться для копирования данных из смежного буфера в области памяти, состоящие из нескольких несмежных участков.
Для иллюстрации этих функций можно привести еще один вариант текста функции Get_data():
int* n_ptr) {
int root = 0; /* Аргумент для MPI_Bcast */
char buffer[100]; /* Аргументы для MPI_Pack/Unpack */
int position; /* и MPI_Bcast*/
if (my_rank == 0) {
printf(''Введите a, b, и n\n'');
scanf(''%f %f %d'', a_ptr, b_ptr, n_ptr);
/* Упаковка данных в буфер */
position = 0; /* Начать с начала буфера */
MPI_Pack(a_ptr, 1, MPI_FLOAT, buffer, 100,
&position, MPI_COMM_WORLD);
/* Position будет увеличена на */
/* sizeof(float) байт */
MPI_Pack(b_ptr, 1, MPI_FLOAT, buffer, 100,
&position, MPI_COMM_WORLD);
MPI_Pack(n_ptr, 1, MPI_INT, buffer, 100,
&position, MPI_COMM_WORLD);
/* Разослать содержимое буфера */
MPI_Bcast(buffer, 100, MPI_PACKED, root,
MPI_COMM_WORLD);
} else {
MPI_Bcast(buffer, 100, MPI_PACKED, root,
MPI_COMM_WORLD);
/* Распаковать содержимое буфера */
position = 0;
MPI_Unpack(buffer, 100, &position, a_ptr, 1,
MPI_FLOAT, MPI_COMM_WORLD);
/* Позиция снова увеличивается на */
/* sizeof(float) байт */
MPI_Unpack(buffer, 100, &position, b_ptr, 1,
MPI_FLOAT, MPI_COMM_WORLD);
MPI_Unpack(buffer, 100, &position, n_ptr, 1,
MPI_INT, MPI_COMM_WORLD);
}
} /* Get-data4 */
Синтаксис вызова MPI_Pack():
MPI_Datatype datatype, void* buffer, int size,
int* position_ptr, MPI_Comm comm)
Синтаксис MPI_Unpack():
int* position_ptr, void* unpack_data,
int count, MPI_Datatype datatype,
MPI_comm comm);
Если данные, которые будут посланы, хранятся в последовательных элементах массива, то лучше всего использовать аргументы count и datatype коммуникационных функций. Этот подход не включает никаких дополнительных действий, например, вызовов для создания производных типов данных или MPI_Pack/MPI_Unpack.
Если большое количество элементов не находится в смежных ячейках памяти, то построение производного типа данных будет дешевле и производительнее, чем большое количество вызовов MPI_Pack / MPI_Unpack.
Если все данные имеют одинаковый тип и хранятся в памяти равномерно (например, колонки матрицы), то наверняка будет проще и быстрее использовать производный тип данных, чем MPI_Pack / MPI_Unpack. Далее, если все данные имеют одинаковый тип, но хранятся в ячейках памяти, распределенных нерегулярно, то легче и эффективнее создать производный тип, используя MPI_Type_indexed. Наконец, если данные являются гетерогенными и процессы неоднократно посылают тот же самый набор данных (например, номер ряда, номер колонки, элемент матрицы), то лучше использовать производный тип. При этом затраты на создание производного типа возникнут только однажды, в то время как затраты на вызов MPI_Pack / MPI_Unpack будут возникать каждый раз, когда передаются данные.
Однако в некоторых ситуациях использование MPI_Pack /
MPI_Unpack
является предпочтительным. Так, можно избежать коллективного
использования системной буферизации при упаковке, поскольку данные явно
сохраняются в определенном пользователем буфере. Система может использовать
это, отметив, что типом сообщения является MPI_PACKED. Пользователь
также может посылать сообщения "переменной длины",
упаковывая число элементов в начале буфера. Пусть, например, необходимо
посылать строки разреженной матрицы. Если строка хранится в виде пары
массивов, где первый содержит индексы колонок, а второй содержит соответствующие
элементы матрицы, то можно посылать строку от процесса 0 к процессу
1 следующим образом:
int* column_subscripts;
/* количество ненулевых элементов в строке */
int nonzeroes;
int position;
int row_number;
char* buffer[HUGE]; /* HUGE является константой */
MPI_Status status;
. . .
if (my_rank == 0) {
/* Получить количество ненулевых элементов строки. */
/* Выделить память для строки. */
/* Инициализировать массивы элементов и индексов */
. . .
/* Упаковать и послать данные */
position = 0;
MPI_Pack(&nonzeroes, 1, MPI_INT, buffer, HUGE,
&position, MPI_COMM_WORLD);
MPI_Pack(&row_number, 1, MPI_INT, buffer, HUGE,
&position, MPI_COMM_WORLD);
MPI_Pack(entries, nonzeroes, MPI_FLOAT, buffer,
HUGE, &position, MPI_COMM_WORLD);
MPI_Pack(column_subscripts, nonzeroes, MPI_INT,
buffer, HUGE, &position, MPI_COMM_WORLD);
MPI_Send(buffer, position, MPI_PACKED, 1, 193,
MPI_COMM_WORLD);
} else { /* my_rank == 1 */
MPI_Recv(buffer, HUGE, MPI_PACKED, 0, 193,
MPI_COMM_WORLD, &status);
position = 0;
MPI_Unpack(buffer, HUGE, &position, &nonzeroes, 1,
MPI_INT, MPI_COMM_WORLD);
MPI_Unpack(buffer, HUGE, &position, &row_number, 1,
MPI_INT, MPI_COMM_WORLD);
/* Выделить память для массивов */
entries = (float *) malloc(nonzeroes*sizeof(float));
column_subscripts =
(int *) malloc(nonzeroes*sizeof(int));
MPI_Unpack(buffer, HUGE, &position, entries,
nonzeroes, MPI_FLOAT, MPI_COMM_WORLD);
MPI_Unpack(buffer, HUGE, &position,
column_subscripts, nonzeroes, MPI_INT,
MPI_COMM_WORLD);
}
Использование коммуникаторов и топологий отличает MPI от большинства других систем передачи сообщений. Как отмечено ранее, коммуникатор представляет собой набор процессов, которые могут посылать сообщения друг другу. Топология - это структура, наложенная на процессы в коммуникаторе, которая позволяет процессам быть адресованными различными способами. Для иллюстрации методов использования коммуникаторов и топологий приведен код, реализующий алгоритм Фокса для умножения двух квадратных матриц.
Пусть перемножаемые матрицы ![]() и
и ![]() имеют порядок
имеют порядок
![]() . Количество процессов
. Количество процессов ![]() является квадратом, квадратный корень
которого кратен
является квадратом, квадратный корень
которого кратен ![]() . В этом случае
. В этом случае ![]() и
и ![]() . В
алгоритме Фокса матрицы разделяются среди процессов в виде клеток
шахматной доски. При этом процессы рассматриваются как виртуальная
двухмерная
. В
алгоритме Фокса матрицы разделяются среди процессов в виде клеток
шахматной доски. При этом процессы рассматриваются как виртуальная
двухмерная ![]() сетка, и каждому процессу назначена подматрица
сетка, и каждому процессу назначена подматрица
![]() каждого множителя. Реализуется отображение:
каждого множителя. Реализуется отображение:
Оно определяет сетку процессов: процесс ![]() относится к строке и
столбцу, заданному
относится к строке и
столбцу, заданному ![]() . Процесс с рангом
. Процесс с рангом
![]() назначается на подматрицы:
назначается на подматрицы:
и
Например, если ![]() ,
,
![]() , и
, и ![]() , то A будет
разделена следующим образом (рис. 4).
, то A будет
разделена следующим образом (рис. 4).
| Процесс 0:
|
Процесс 1:
|
Процесс 2:
|
| Процесс 3:
|
Процесс 4:
|
Процесс 5:
|
| Процесс 6:
|
Процесс 7:
|
Процесс 8:
|
В алгоритме Фокса, подматрицы блоков, ![]() и
и ![]() , где
, где
![]() , перемножаются и собираются в процессе
, перемножаются и собираются в процессе
![]() .
Алгоритм состоит в следующем:
.
Алгоритм состоит в следующем:
Выбрать подматрицу A в каждой строке
для всех процессов.
В каждой строке для всех процессов разослать
сетку подматриц, выбранную в этой строке для
других процессов в этой строки.
В каждом процессе, перемножить полученную подматрицу
A на подматрицу B, находящуюся в процессе.
В каждом процессе, отослать подматрицу B процессу,
расположенному выше. (Для процессов первой строки
отослать подматрицу в последнюю строку.)
}
При реализации алгоритма Фокса становится очевидно, что работа будет облегчена, если можно рассматривать некоторые подмножества процессов как коммуникационную область, по крайней мере, временно. Например, в псевдокоде строки 2 полезно рассматривать в виде коммуникационной области каждый ряд процессов, в то время как в строке 4 в виде коммуникационной области нужно рассматривать каждую строку процессов.
Механизмом, который обеспечивает рассмотрение подмножества процессов MPI в виде коммуникационной области, является коммуникатор. В MPI существует два типа коммуникаторов: интракоммуникаторы и интеркоммуникаторы. Интракоммуникаторы представляют собой набор процессов, которые могут посылать сообщения друг другу и участвовать в коллективных взаимодействиях. Например, MPI_COMM_WORLD - это интракоммуникатор. Каждая строка и колонка процессов в алгоритме Фокса должны формировать интракоммуникатор. Интеркоммуникаторы, как подразумевается в их названии, используются для того, чтобы послать сообщения между процессами, принадлежащими непересекающимся интракоммуникаторам. Так, интеркоммуникатор полезно использовать в среде, которая позволяет динамически создавать процессы: только что созданный набор процессов, которые сформировали интракоммуникатор, может быть связан интеркоммуникатором с оригинальным набором процессов (например, MPI_COMM_WORLD) .
Минимальный (интра-)коммуникатор состоит из группы и контекста.
Группа является упорядоченным набором процессов. Если группа состоит
из ![]() процессов, то каждому из них в группе назначен уникальный ранг,
который является неотрицательным целым числом в диапазоне
процессов, то каждому из них в группе назначен уникальный ранг,
который является неотрицательным целым числом в диапазоне ![]() .
Контекст представляет собой определенный системой признак, который
присоединен к группе. Два процесса, которые принадлежат одной
группе и поэтому используют один и тот же контекст, могут связаться
между собой. Соединение группы с контекстом является основной
функцией коммуникатора. С коммуникатором могут быть связаны и другие
данные. В частности, на процессы в коммуникаторе может быть наложена
структура или топология, позволяющая осуществить более естественную схему
адресации.
.
Контекст представляет собой определенный системой признак, который
присоединен к группе. Два процесса, которые принадлежат одной
группе и поэтому используют один и тот же контекст, могут связаться
между собой. Соединение группы с контекстом является основной
функцией коммуникатора. С коммуникатором могут быть связаны и другие
данные. В частности, на процессы в коммуникаторе может быть наложена
структура или топология, позволяющая осуществить более естественную схему
адресации.
Чтобы избавить программиста от лишнего труда, для работы с трубами введена удобная функция popen(). Синтаксис этой функции:
#include <sys/wait.h>
#include <stdio.h>
#include <sys/types.h>
#include <fcntl.h>
#define EXIT(s) {fprintf(stderr, "%s",s); exit(0);}
#define USAGE(s) {fprintf(stderr, "%s Данные для
чтения\n",s); exit(0);}
#define MAX 8192
enum {ERROR=-1,SUCCESS};
int main(int argc, char **argv)
{
FILE *pipe_writer, *file;
char buffer[MAX];
if(argc!=2)
USAGE(argv[0]);
if((file=fopen(argv[1], "r")) == NULL)
EXIT("Ошибка открытия файла.........\n");
if(( pipe_writer=popen("./filter" ,"w")) == NULL)
EXIT("Ошибка открытия трубы...........\n");
while(1)
{
if(fgets(buffer, MAX, file) == NULL)
break;
if(fputs(buffer, pipe_writer) == EOF)
EXIT("Ошибка записи........\n");
}
pclose(pipe_writer);
}
Для иллюстрации основ работы с коммуникаторами создается коммуникатор,
основная группа которого состоит из процессов в первой строке виртуальной
сетки. Пусть MPI_COMM_WORLD состоит из ![]() процессов,
где
процессов,
где ![]() . Пусть также
. Пусть также
![]() . При этом первая
строка процессов состоит из процессов с рангами
. При этом первая
строка процессов состоит из процессов с рангами ![]() (Ранги
указаны относительно MPI_COMM_WORLD). Чтобы создать
группу для нового коммуникатора, следует выполнить следующий код:
(Ранги
указаны относительно MPI_COMM_WORLD). Чтобы создать
группу для нового коммуникатора, следует выполнить следующий код:
MPI_Group first_row_group;
MPI_Comm first_row_comm;
int row_size;
int* process_ranks;
/* Создает список процессов нового */
* коммуникатора */
process_ranks = (int*) malloc(q*sizeof(int));
for (proc = 0; proc < q; proc++)
process_ranks[proc] = proc;
/* Получить группу, относящуюся к MPI_COMM_WORLD */
MPI_Comm_group(MPI_COMM_WORLD, &MPI_GROUP_WORLD);
/* Создать новую группу */
MPI_Group_incl(MPI_GROUP_WORLD, q, process_ranks,
&first_row_group);
/* Создать новый коммуникатор */
MPI_Comm_create(MPI_COMM_WORLD, first_row_group,
&first_row_comm);
float* A_00;
/* my_rank определяет ранг процесса в MPI_GROUP_WORLD */
if (my_rank < q) {
MPI_Comm_rank(first_row_comm, &my_rank_in_first_row);
/* Выделить память для A_00, order = n_bar */
A_00 = (float*) malloc (n_bar*n_bar*sizeof(float));
if (my_rank_in_first_row == 0) {
/* Инициализация A_00 */
. . .
}
MPI_Bcast(A_00, n_bar*n_bar, MPI_FLOAT, 0,
first_row_comm);
}
Контексты явно не используются ни в одной из функций MPI. Они неявно связываются с группами при создании коммуникаторов. Операция
int new_group_size, int* ranks_in_old_group,
MPI_Group* new_group)
MPI_Group new_group, MPI_Comm* new_comm)
Существует важное различие между первыми двумя и третьей функциями. Вызовы MPI_Comm_group() и MPI_Group_incl() являются локальными действиями. Это значит, что нет никакого взаимодействия между процессами, участвующими в их выполнении. Операция MPI_Comm_create() - коллективное действие. Процессы в old_comm должны вызывать MPI_Comm_create() с теми же самыми аргументами.
Если создаются несколько коммуникаторов, они должны создаваться в одном и том же порядке во всех процессах.
В программе умножения матриц нужно создать несколько коммуникаторов
- по одному для каждой строки процессов и по одному - для каждой колонки.
Это будет чрезвычайно утомительным процессом, если ![]() достаточно
большое, и каждый коммуникатор создается с использованием трех функции,
обсужденных ранее. Однако MPI содержит функцию MPI_Comm_split(),
которая может создать несколько коммуникаторов одновременно. Для иллюстрации
ее использования создаются коммуникаторы для каждой строки процессов:
достаточно
большое, и каждый коммуникатор создается с использованием трех функции,
обсужденных ранее. Однако MPI содержит функцию MPI_Comm_split(),
которая может создать несколько коммуникаторов одновременно. Для иллюстрации
ее использования создаются коммуникаторы для каждой строки процессов:
int my_row;
/* my_rank это ранг в MPI_COMM_WORLD.
* q*q = p */
my_row = my_rank/q;
MPI_Comm_split(MPI_COMM_WORLD, my_row, my_rank,
&my_row_comm);
Синтаксис вызова MPI_Comm_split():
int rank_key, MPI_Comm* new_comm)
MPI_Comm_split() является коллективной операцией, поэтому ее нужно вызывать всем процессам из old_comm. Функция может использоваться, даже если пользователь не желает назначать каждый процесс на новый коммуникатор. Это можно выполнить, передав предопределенную константу MPI_UNDEFINED в качестве аргумента split_key. Процессы, выполнившие это, получат предопределенное значение MPI_COMM_NULL, возвращенное в new_comm.
Ранее было указано, что существует возможность связать с коммуникатором дополнительную информацию, которая находится вне группы и контекста. Эта дополнительная информация кэширована с коммуникатором, и одной из самых важных ее частей является топология. В MPI топология представляет собой механизм для того, чтобы связать с процессами, принадлежащими группе, различные схемы адресации. Топология MPI - виртуальная, т. е. может не существовать никакого простого отношения между структурой процессов, определенной виртуальной топологией и фактической физической структурой параллельной машины.
Известны два основных типа виртуальной топологии, которая может быть создана MPI, - декартова топология, или топология сетки, и топология графа. Первый тип является подмножеством второго. Однако из-за активного использования сеток в приложениях выделяется отдельное подмножество функций MPI, цель которого - манипуляция виртуальными сетками.
В алгоритме Фокса необходимо идентифицировать процессы
MPI_COMM_WORLD
координатами квадратной сетки, причем каждая строка и колонка
сетки должны формировать свой собственный коммуникатор.
Сначала необходимо связать квадратную структуру сетки с
MPI_COMM_WORLD.
Чтобы сделать это, нужно определить следующую информацию:
int dimensions[2];
int wrap_around[2];
int reorder = 1;
dimensions[0] = dimensions[1] = q;
wrap_around[0] = wrap_around[1] = 1;
MPI_Cart_create(MPI_COMM_WORLD, 2, dimensions,
wrap_around, reorder, &grid_comm);
int my_grid_rank;
MPI_Comm_rank(grid_comm, &my_grid_rank);
MPI_Cart_coords(grid_comm, my_grid_rank, 2,
coordinates);
Обратной функцией к MPI_Cart_coords() является
MPI_Cart_rank():
Синтаксис MPI_Cart_create():
int number_of_dims, int* dim_sizes,
int* periods, int reorder, MPI_Comm* cart_comm)
Процессы в cart_comm ранжируются в порядке строк. При этом
первый ряд состоит из процессов 0, 1,..., dim_sizes[0]-1,
второй ряд - из процессов dim_sizes[0],dim_sizes[0]+1 , ... ,
2*dim_sizes[0]-1
и т.д. Таким образом, иногда выгодно изменить относительное ранжирование
процессов в old_comm. Например, пусть физическая топология
- это сетка 3x3,а процессы (номера) в old_comm назначены
на процессоры (квадраты сетки) следующим образом (рис. 5):
| 3 | 4 | 5 |
| 0 | 1 | 2 |
| 6 | 7 | 8 |
Поскольку MPI_Cart_create() создает новый коммуникатор, она является коллективной операцией.
Синтаксис функций, возвращающих адресную информацию:
int* rank);
int MPI_Cart_coords(MPI_Comm comm, int rank,
int number_of_dims, int* coordinates)
Еще одним способом является деление сетки на участки меньшей размерности. Например, можно создать коммуникатор для каждой строки сетки следующим образом:
MPI_Comm row_comm;
Varying_coords[0] = 0; varying_coords[1] = 1;
MPI_Cart_sub(grid_comm, varying_coords, &);
Varying_coords[0] = 1; varying_coords[1] = 0;
MPI_Cart_sub(grid_comm, varying_coord, col_comm);
Ниже приведена полная программ, реализующая алгоритм Фокса для перемножения матриц. Сначала приведена функция, которая создает различные коммуникаторы и ассоциированную с ними информацию. Так как ее реализация требует большого количества переменных, которые можно использовать в других функциях, их целесообразно поместить в структуру, чтобы облегчить передачу среди различных функций:
int p; /* Общее число процессов */
MPI_Comm comm; /* Коммуникатор для сетки */
MPI_Comm row_comm; /* Коммуникатор строки */
MPI_Comm col_comm; /* Коммуникатор столбца */
int q; /* Порядок сетки */
int my_row; /* Номер строки */
int my_col; /* Номер столбца */
int my_rank; /* Ранг процесса в коммуникаторе сетки */
} GRID-INFO-TYPE;
/* Пространство для сетки выделено
в вызывающей процедуре.*/
void Setup_grid(GRID_INFO_TYPE* grid) {
int old_rank;
int dimensions[2];
int periods[2];
int coordinates[2];
int varying-coords[2];
/* Настройка глобальной информации о сетке */
MPI_Comm_size(MPI_COMM_WORLD, &(grid->p));
MPI_Comm_rank(MPI_COMM_WORLD, &old_rank);
grid->q = (int) sqrt((double) grid->p);
dimensions[0] = dimensions[1] = grid->q;
periods[0] = periods[1] = 1;
MPI_Cart_create(MPI_COMM_WORLD, 2, dimensions,
periods, 1, &(grid->comm));
MPI_Comm_rank(grid->comm, &(grid->my_rank));
MPI_Cart_coords(grid->comm, grid->my_rank, 2,
coordinates);
grid->my_row = coordinates[0];
grid->my_col = coordinates[1];
/* Настройка коммуникаторов для строк и столбцов */
varying_coords[0] = 0; varying_coords[1] = 1;
MPI_Cart_sub(grid->comm, varying_coords,
&(grid->row_comm));
varying_coords[0] = 1; varying_coords[1] = 0;
MPI_Cart_sub(grid->comm, varying_coords,
&(grid->col_comm));
} /* Setup_grid */
Следующая функция выполняет фактическое умножение. Пусть пользователь
сам создает определения типа и функции для локальных матриц. При этом
определение типа находится в
LOCAL_MATRIX_TYPE, а соответствующий
производный тип в
DERIVED_LOCAL_MATRIX. Существуют также
три функции:
Local_matrix_multiply, Local_matrix_allocate,
Set_to_zero.
Можно также предположить, что память для
параметров была выделена в вызывающей функции, и все параметры, кроме
локальной матрицы произведения local_C, уже инициализированы:
LOCAL-MATRIX-TYPE* local-A,
LOCAL_MATRIX_TYPE* local_B,
LOCAL_MATRIX_TYPE* local_C)
{
LOCAL_MATRIX_TYPE* temp_A;
int step;
int bcast_root;
int n_bar; /* порядок подматрицы = n/q */
int source;
int dest;
int tag = 43;
MPI_Status status;
n_bar = n/grid->q;
Set_to_zero(local_C);
/* Вычисление адресов для циклического сдвига B */
source = (grid->my_row + 1) % grid->q;
dest = (grid->my_row + grid->q-1) % grid->q;
/* Выделение памяти для рассылки блоков A */
temp_A = Local_matrix_allocate(n_bar);
for (step = 0; step < grid->q; step++) {
bcast_root = (grid->my_row + step) % grid->q;
if (bcast_root == grid->my_col) {
MPI_Bcast(local_A, 1, DERIVED_LOCAL_MATRIX,
bcast_root, grid->row_comm);
Local_matrix_multiply(local_A, local_B, local_C);
} else {
MPI_Bcast(temp_A, 1, DERIVED_LOCAL_MATRIX,
bcast_root, grid->row_comm);
Local_matrix_multiply(temp_A, local_B, local_C);
}
MPI_Send(local_B, 1, DERIVED_LOCAL_MATRIX, dest, tag,
grid->col_comm);
MPI_Recv(local_B, 1, DERIVED_LOCAL_MATRIX, source,
tag, grid->col_comm, &status);
} /*for*/
}/*Fox*/
Переносимый расширяемый инструментарий для научных вычислений (PETSc) успешно продемонстрировал, что использование современных парадигм программирования может облегчить разработку крупномасштабных научных приложений на языках Фортран, C, и C++. Возникнув несколько лет назад, продукт эволюционировал в мощный набор средств для численного решения дифференциальных уравнений в частных производных и сходных проблем высокопроизводительных вычислений. PETSc состоит из нескольких библиотек (подобных классам C++). Каждая библиотека оперирует определенным семейством объектов (например, векторами) и ее операции применяются к этим объектам. Объекты и операции в PETSc разработаны с учетом опыта разработки научных приложений. Модули PETSc работают с множествами индексов, включая перестановки, для индексации векторов, перенумерации, и т.д.; c векторами; c матрицами (обычно разреженными); c распределенными массивами (используются для параллелизации задач с регулярной сетевой структурой); c методами подпространств Крылова; c предобработчиками, включая мультисеточные и прямые разреженные решатели; c нелинейными решателями; c пошаговыми решателями для дифференциальных уравнений в частных производных во времени.
Каждый модуль содержит абстрактный интерфейс (простой набор последовательностей вызова) и одну или несколько его реализаций, использующих определенные структуры данных. Таким образом, PETSc предлагает прозрачные и эффективные коды для различных фаз решения дифференциальных уравнений в частных производных с единообразным подходом к любому классу проблем. Такое построение гарантирует простое использование и сравнение различных алгоритмов (например, для экспериментов с различными методами подпространств Крылова, предобработчикамии, или сокращенными методами Ньютона). Кроме того, PETSc предоставляет удобную среду для моделирования научных приложений, а также быстрого построения или прототипирования алгоритмов. Библиотеки позволяют провести легкую настройку и расширение как алгоритмов, так и реализации. Этот подход улучшает гибкость систем и позволяет повторное использование кода, а также отделяет собственно параллелизацию от выбора алгоритма. Инфраструктура PETSc создает основу для построения крупномасштабных приложений. Ее полезно проанализировать для определения взаимосвязи между отдельными частями PETSc. Рис. 6 представляет собой диаграмму ее отдельных частей; на рис. 7 некоторые части изображены более детально. Эти рисунки иллюстрируют иерархическую организацию библиотеки, что позволяет пользователям применить уровень абстракции, наиболее подходящий для определенной задачи.
Перед использованием PETSc пользователь должен установить переменную окружения PETSC_DIR, указывающую полный путь к домашнему каталогу PETSc. Например, при работе в UNIX C shell команду вида setenv PETSC_DIR $HOME/petsc нужно поместить в пользовательский файл .cshrc. Дополнительно пользователь должен установить переменную окружения PETSC_ARCH, чтобы указать тип архитектуры (например, rs6000, solaris, IRIX и т.д.), для которой используется PETSc. Для этих целей можно употреблять утилиту ${PETSC_DIR}/bin/petscarch. Например, команда setenv PETSC_ARCH `$PETSC_DIR/bin/petscarch` может быть добавлена в файл .cshrc. Таким образом, даже если несколько машин различных типов разделяют единую файловую систему, при регистрации на любой из них PETSC_ARCH будет устанавливаться корректно .
Все программы PETSc используют стандарт MPI (Message
Passing Interface)
для обмена сообщениями. Поэтому, для выполнения программ PETSc, пользователь
должен быть знаком с процедурой запуска задач MPI на выбранной системе.
Например, при применении MPICH и других реализаций MPI программу,
использующую восемь процессоров, выполняет команда:
petsc_program_name petsc_options
Программы PETSc начинаются с вызова
char *help);,
который инициализирует PETSc и MPI. Аргументы argc и argv являются аргументами командной строки, передаваемыми всем программам C и C++. Аргумент file опционально указывает альтернативное имя файла опций PETSc, .petscrc, который по умолчанию находится в домашнем каталоге пользователя. База опций PETSc используется для настройки программы во время работы. Последний аргумент help является опциональной строкой символов, которая выводится, если программа запущена с опцией -help. В Фортране команда инициализации имеет вид:
PetscInitialize() автоматически вызывает MPI_Init(),
если MPI не был инициализирован ранее. При определенных условиях,
когда MPI нужно инициализировать прямо (или он инициализирован другой
библиотекой), пользователь может вначале вызвать MPI_Init()
(или позволить другой библиотеке это сделать), а затем вызвать PetscInitialize().
По умолчанию PetscInitialize()
устанавливает `общий''
коммуникатор PETSc, определяемый
PETSC_COMM_WORLD на MPI_COMM_WORLD.
Для тех, кто не знаком с MPI, коммуникатор является способом
указания набора процессов, которые совместно участвуют в вычислениях
или коммуникациях. Коммуникаторы являются переменными типа MPI_Comm.
В большинстве случаев пользователи могут пользоваться коммуникатором
PETSC_COMM_WORLD, для указания всех запущенных процессов,
или PETSC_COMM_SELF, для указания одного процесса. MPI предоставляет
процедуры создания новых коммуникаторов, содержащих подмножества процессоров,
хотя пользователи очень редко применяют их. Заметьте, что пользователям
PETSc не нужно программировать основной обмен сообщениями непосредственно
через MPI, но они должны быть знакомы с основными концепциями обмена
сообщениями и вычислений в распределенной памяти. Пользователи, которым
нужно применить процедуры PETSc на некотором множестве процессоров
в большой параллельной задаче, или которые хотят использовать ``главный
'' процесс для управления работой ``подчиненных'' процессов PETSc,
должны указать альтернативный коммуникатор для PETSC_COMM_WORLD,
вызвав
PetscSetCommWorld (MPI Comm comm)
перед вызовом PetscInitialize(), но, конечно, после вызова
MPI_Init().PetscSetCommWorld() может
быть вызван как минимум раз в каждом процессе. Большинству пользователей
может никогда не понадобиться применять функцию PetscSetCommWorld().
Все процедуры PETSc возвращают целое число, указывающее, возникла
ли при вызове ошибка. Код ошибки устанавливается в ненулевое значение,
если ошибка возникла; в противном случае возвращается 0. Для интерфейса
C/C++ код ошибки является возвращаемым значением, в то время как
для версии Фортрана каждая процедура PETSc содержит в качестве последнего
аргумента целочисленную переменную кода ошибки. Все программы PETSc
должны вызывать PetscFinalize() в качестве последнего оператора,
как показано ниже в формате для C/C++ и Фортрана соответственно:
call PetscFinalize (ierr)
Чтобы помочь пользователю начать освоение PETSc немедленно, следует
начать с простого однопроцессорного примера,
который решает одномерную задачу Лапласа с конечными разностями.
Этот последовательный код, который находится в файле
${PETSC_DIR}/src/sles/examples/tutorials/ex1.c,
иллюстрирует решение линейной системы с помощью библиотек SLES, интерфейсов
предобработчиков, методов подпространств Крылова и прямых линейных
решателей PETSc. По мере движения по коду выделяется несколько наиболее
важных частей примера:
/* Program usage: mpirun ex1 [-help] [all PETSc options] */
static char help[] = "Решает тридиагональную линейную систему
через SLES.\n\n";
/*T
Концепция: SLES^решение системы линейных уравнений
Процессоры: 1
T*/
/*
Включаем "petscsles.h" чтобы использовать решатели SLES .
Отметьте, что этот файл автоматически включает:
petsc.h - основные процедуры PETSc petscvec.h - векторы
petscsys.h - системные процедуры petscmat.h - матрицы
petscis.h - индексные множества petscksp.h - методы
подпространств Крылова
petscviewer.h - просмотрщики petscpc.h - предобработчики
Замечание:
Соответствующий параллельный пример находится в файле ex23.c
*/
#include "petscsles.h"
#undef __FUNCT__
#define __FUNCT__ "main"
int main(int argc,char **args)
Vec x, b, u; /* приближенное решение, RHS, точное решение */
Mat A; /* матрица линейной системы */
SLES sles; /* контекст линейного решателя */
PC pc; /* контекст предобработчика */
KSP ksp; /* контекст метода подпространств Крылова */
PetscReal norm; /* допустимая ошибка решения */
int ierr,i,n = 10,col[3],its,size;
PetscScalar neg_one = -1.0,one = 1.0,value[3];
PetscInitialize(&argc,&args,(char *)0,help);
ierr = MPI_Comm_size(PETSC_COMM_WORLD,&size);
CHKERRQ(ierr);
if (size != 1) SETERRQ(1,"Это однопроцессорный пример!");
ierr = PetscOptionsGetInt(PETSC_NULL,"-n",&n,PETSC_NULL);
CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Вычисляет матрицу и правосторонний вектор, который определяет
линейную систему Ax = b.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создает векторы. Заметьте, что первый вектор формируется с нуля,
а затем размножается, если нужно.
*/
ierr = VecCreate(PETSC_COMM_WORLD,&x);CHKERRQ(ierr);
ierr = PetscObjectSetName((PetscObject) x, "Решение");CHKERRQ(ierr);
ierr = VecSetSizes(x,PETSC_DECIDE,n);CHKERRQ(ierr);
ierr = VecSetFromOptions(x);CHKERRQ(ierr);
ierr = VecDuplicate(x,&b);CHKERRQ(ierr);
ierr = VecDuplicate(x,&u);CHKERRQ(ierr);
/*
Создает матрицу. При использовании MatCreate() формат матрицы
можно определять в процессе выполнения.
Замечание по производительности:
Для задач существенного объема предварительное распределение
памяти для матрицы критично для достижения хорошей
производительности. Поскольку предварительное распределение
невозможно средствами общей процедуры создания матрицы MatCreate(),
рекомендуется для конкретных задач использовать
специализированные процедуры, например:
MatCreateSeqAIJ() - последовательная AIJ
(упакованная разреженная строка),
MatCreateSeqBAIJ() - блочная AIJ
См. главу о матрицах руководства пользователя
для более полной информации.
*/
ierr = MatCreate(PETSC_COMM_WORLD,PETSC_DECIDE,PETSC_DECIDE,n,n,&A);
CHKERRQ(ierr);
ierr = MatSetFromOptions(A);CHKERRQ(ierr);
/*
Собирает матрицу
*/
value[0] = -1.0; value[1] = 2.0; value[2] = -1.0;
for (i=1; i<n-1; i++)
col[0] = i-1; col[1] = i; col[2] = i+1;
ierr = MatSetValues(A,1,&i,3,col,value,INSERT_VALUES);
CHKERRQ(ierr);
i = n - 1; col[0] = n - 2; col[1] = n - 1;
ierr = MatSetValues(A,1,&i,2,col,value,INSERT_VALUES);
CHKERRQ(ierr);
i = 0; col[0] = 0; col[1] = 1; value[0] = 2.0; value[1] = -1.0;
ierr = MatSetValues(A,1,&i,2,col,value,INSERT_VALUES);
CHKERRQ(ierr);
ierr = MatAssemblyBegin(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
ierr = MatAssemblyEnd(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
/*
Установим точное решение; затем вычислим правосторонний вектор.
*/
ierr = VecSet(&one,u);CHKERRQ(ierr);
ierr = MatMult(A,u,b);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Создает линейный решатель и устанавливает различные опции
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создает контекст линейного решателя
*/
ierr = SLESCreate(PETSC_COMM_WORLD,&sles);CHKERRQ(ierr);
/*
Устанавливаем операторы. Здесь матрица, которая определяет
линейную систему, служит также в качестве матрицы
предобработчика.
*/
ierr = SLESSetOperators(sles,A,A,DIFFERENT_NONZERO_PATTERN);
CHKERRQ(ierr);
/*
Устанавливаем значения по умолчанию для линейного решателя
(опционально):
- Выделяя контексты KSP и PC из контекста SLES, можно затем
непосредственно вызывать любые процедуры KSP и PC
для установки различных опций.
- Следующие четыре оператора необязательны; все их параметры
можно определить во время выполнения через
SLESSetFromOptions();
*/
ierr = SLESGetKSP(sles,&ksp);CHKERRQ(ierr);
ierr = SLESGetPC(sles,&pc);CHKERRQ(ierr);
ierr = PCSetType(pc,PCJACOBI);CHKERRQ(ierr);
ierr = KSPSetTolerances(ksp,1.e-7,
PETSC_DEFAULT,PETSC_DEFAULT,PETSC_DEFAULT);CHKERRQ(ierr);
/*
Установить опции времени выполнения, например
-ksp_type <type> -pc_type <type> -ksp_monitor -ksp_rtol <rtol>
Эти опции могут переопределить те, которые были указаны выше,
после того, как SLESSetFromOptions() была вызвана после любой
другой процедуры настройки.
*/
ierr = SLESSetFromOptions(sles);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Решаем линейную систему
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
ierr = SLESSolve(sles,b,x,&its);CHKERRQ(ierr);
/*
Смотреть информацию от решателя; вместо этого можно
использовать опцию
-sles_view для вывода этой информации на экран после
завершения SLESSolve().
*/
ierr = SLESView(sles,PETSC_VIEWER_STDOUT_WORLD);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Проверяем решение и очищаем его
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Проверяем ошибки
*/
ierr = VecAXPY(&neg_one,u,x);CHKERRQ(ierr);
ierr = VecNorm(x,NORM_2,&norm);CHKERRQ(ierr);
ierr = PetscPrintf(PETSC_COMM_WORLD,
"Погрешность %A, Итераций %d\n",norm,its); CHKERRQ(ierr);
/*
Освобождаем рабочее пространство. Все объекты PETSc
должны быть уничтожены, как только они станут ненужными.
*/
ierr = VecDestroy(x);CHKERRQ(ierr);
ierr = VecDestroy(u);CHKERRQ(ierr);
ierr = VecDestroy(b);CHKERRQ(ierr);
ierr = MatDestroy(A);CHKERRQ(ierr);
ierr = SLESDestroy(sles);CHKERRQ(ierr);
/* Всегда вызываем PetscFinalize() перед выходом из программы.
Эта процедура
- финализирует библиотеки PETSc и MPI
- предоставляет общую и диагностическую информацию,
если указаны определенные опции времени выполнения
(например, -log_summary).
*/
ierr = PetscFinalize();CHKERRQ(ierr);
return 0;
}
Включаемые файлы C/C++ для PETSc должны использоваться через директивы
#include "petscsles.h",
где petscsles.h - имя включаемого файла библиотеки SLES.
Каждая программа PETSc должна указывать включаемый файл, соответствующий
самому высокому уровню объектов PETSc, используемых в программе; все
требуемые включаемые файлы нижних уровней автоматически вложены в
файлы верхнего уровня. Например, petscsles.h включает petscmat.h
(матрицы), petscvec.h (векторы), и petsc.h (основной
файл PETSc). Включаемые файлы PETSc находятся в каталоге ${PETSC_DIR}/include.
С помощью труб могут общаться только родственные друг другу процессы, полученные с помощью fork(). Именованные каналы FIFO позволяют обмениваться данными с абсолютно ``чужим'' процессом.
С точки зрения ядра ОС FIFO является одним из вариантов реализации трубы. Системный вызов mkfifo() предоставляет процессу именованную трубу в виде объекта файловой системы. Как и для любого другого объекта, необходимо предоставлять процессам права доступа в FIFO, чтобы определить, кто может писать, и кто может читать данные. Несколько процессов могут записывать или читать FIFO одновременно. Режим работы с FIFO - полудуплексный, т.е. процессы могут общаться в одном из направлений. Типичное применение FIFO - разработка приложений ``клиент - сервер''.
Синтаксис функции для создания FIFO следующий:
#include <sys/stat.h>
int mkfifo(const char *fifoname, mode_t mode);
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
int fd_fifo; /*дескриптор FIFO*/
char buffer[]="Текстовая строка для fifo\n";
char buf[100];
/*Если файл с таким именем существует, удалим его*/
unlink("/tmp/fifo0001.1");
/*Создаем FIFO*/
if((mkfifo("/tmp/fifo0001.1", O_RDWR)) == -1)
{
fprintf(stderr, "Невозможно создать fifo\n");
exit(0);
}
/*Открываем fifo для чтения и записи*/
if((fd_fifo=open("/tmp/fifo0001.1", O_RDWR)) == - 1)
{
fprintf(stderr, "Невозможно открыть fifo\n");
exit(0);
}
write(fd_fifo,buffer,strlen(buffer)) ;
if(read(fd_fifo, &buf, sizeof(buf)) == -1)
fprintf(stderr, "Невозможно прочесть из FIFO\n");
else
printf("Прочитано из FIFO : %s\n",buf);
return 0;
}
Если в системе отсутствует функция mkfifo(), можно воспользоваться общей функцией для создания файла:
Здесь pathname указывает обычное имя каталога и имя FIFO. Режим обозначается константой S_IFIFO из заголовочного файла <sys/stat.h>. Здесь же определяются права доступа. Параметр dev не нужен. Пример вызова mknod:
0) == - 1)
{ /*Невозможно создать fifo */
Флаг O_NONBLOCK может использоваться только при доступе для чтения. При попытке открыть FIFO с O_NONBLOCK для записи возникает ошибка открытия. Если FIFO закрыть для записи через close или fclose, это значит, что для чтения в FIFO помещается EOF.
Если несколько процессов пишут в один и тот же FIFO, необходимо обратить внимание на то, чтобы сразу не записывалось больше, чем PIPE_BUF байтов. Это необходимо, чтобы данные не смешивались друг с другом. Установить пределы записи можно следующей программой:
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int main()
{
unlink("fifo0001");
/*Создаем новый FIFO*/
if((mkfifo("fifo0001", O_RDWR)) == -1)
{
fprintf(stderr, "Невозможно создать FIFO\n");
exit(0);
}
printf("Можно записать в FIFO сразу %ld байтов\n",
pathconf("fifo0001", _PC_PIPE_BUF));
printf("Одновременно можно открыть %ld FIFO \n",
sysconf(_SC_OPEN_MAX));
return 0;
}
При попытке записи в FIFO, который не открыт в данный момент для чтения ни одним процессом, генерируется сигнал SIGPIPE.
В следующем примере организуется обработчик сигнала SIGPIPE, создается FIFO, процесс-потомок записывает данные в этот FIFO, а родитель читает их оттуда. Пример иллюстрирует простое приложение типа ``клиент - сервер'':
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
static volatile sig_atomic_t sflag;
static sigset_t signal_new, signal_old, signal_leer;
static void sigfunc(int sig_nr)
{
fprintf(stderr, "SIGPIPE вызывает завершение
программы\n");
exit(0);
}
void signal_pipe(void)
{
if(signal(SIGPIPE, sigfunc) == SIG_ERR)
{
fprintf(stderr, "Невозможно получить сигнал
SIGPIPE\n");
exit(0);
}
/*Удаляем все сигналы из множества сигналов*/
sigemptyset(&signal_leer);
sigemptyset(&signal_new);
sigaddset(&signal_new, SIGPIPE);
/*Устанавливаем signal_new и сохраняем его*/
/* теперь маской сигналов будет signal_old*/
if(sigprocmask(SIG_UNBLOCK, &signal_new,
&signal_old) < 0)
exit(0);
}
int main()
{
int r_fifo, w_fifo; /*дескрипторы FIFO*/
char buffer[]="Текстовая строка для fifo\n";
char buf[100];
pid_t pid;
signal_pipe();
unlink("/tmp/fifo0001.1");
/*Создаем FIFO*/
if((mkfifo("/tmp/fifo0001.1", O_RDWR)) == -1)
{
fprintf(stderr, "Невозможно создать fifo\n");
exit(0);
}
pid=fork();
if(pid == -1)
{ perror("fork"); exit(0);}
else if(pid > 0) /*Родитель читает из FIFO*/
{
if (( r_fifo=open("/tmp/fifo0001.1", O_RDONLY))<0)
{ perror("r_fifo open"); exit(0); }
/*Ждем окончания потомка*/
while(wait(NULL)!=pid);
/*Читаем из FIFO*/
read(r_fifo, &buf, sizeof(buf));
printf("%s\n",buf);
close(r_fifo);
}
else /*Потомок записывает в FIFO*/
{
if((w_fifo=open("/tmp/fifo0001.1", O_WRONLY))<0)
{ perror("w_fifo open"); exit(0); }
/*Записываем в FIFO*/
write(w_fifo, buffer, strlen(buffer));
close(w_fifo); /*EOF*/
exit(0);
}
return 0;
}
Пользователь может вводить управляющую информацию во время выполнения программы, используя базу опций. В этом примере команда OptionsGetInt(PETSC_NULL,"-n",&n,&flg); проверяет, указал ли пользователь опцию командной строки для установки значения n, т.е. размерности задачи. Если это так, то переменная n устанавливается в нужное значение; в противном случае n остается неизменной.
Можно создать новый параллельный или последовательный вектор x общей размерности M с помощью команд:
VecSetSizes (Vec x, int m, int M);
VecDuplicate(Vec old,Vec *new).
Команды:
VecSetValues (Vec x,int n,int *indices,
PetscScalar *values, INSERT_VALUES);
Использование матриц в PETSc похоже на использование векторов. Пользователь может создать новую параллельную или последовательную матрицу A, у которой M строк и N столбцов, с помощью вызова:
MatCreate (MPI_Comm comm,int m,int n,int M,int N, Mat* A);где формат матрицы может быть определен во время выполнения. Пользователь также может указать каждому процессу локальное число строк и столбцов через параметры m и n. Значения могут быть установлены командой:
PetscScalar *values, INSERT_VALUES);
MatAssemblyEnd (Mat A,MAT_FINAL_ASSEMBLY);
После создания матриц и векторов, определяющих линейную систему Ax = b, пользователь может применить SLES для решения системы следующей последовательностью команд:
SLESSetOperators (SLES sles,Mat A,Mat PrecA,
MatStructure flag);
SLESSetFromOptions (SLES sles);
SLESSolve (SLES sles,Vec b,Vec x,int *its);
SLESDestroy (SLES sles);
Большинство проблем, требующих решения ДУЧП, являются нелинейными. PETSc предлагает интерфейс работы с нелинейными проблемами, называемый SNES. Большинству пользователей PETSc рекомендуется лучше работать непосредственно со SNES, чем использовать PETSc для линейных проблем с нелинейным решателем.
Все процедуры PETSc возвращают целое число, указывающее, возникла
ли ошибка при вызове. Макрос CHKERRQ(ierr) в PETSc проверяет
значение ierr и вызывает обработчик ошибок PETSc, при их обнаружении.
CHKERRQ(ierr) нужно использовать во всех процедурах,
чтобы обеспечить полный контроль ошибок. Ниже приведена трасса,
созданная контролем ошибок в примере программы PETSc. Ошибка возникла
в строке 1673 файла
${PETSC_DIR}/src/mat/impls/aij/seq/aij.c
и была вызвана попыткой распределения памяти для слишком большого
массива. Процедура была вызвана в программе ex3.c, в строке
71.
eagle:mpirun -np 1 ex3 -m 10000
PETSC ERROR: MatCreateSeqAIJ() line 1673
in src/mat/impls/aij/seq/aij.c
PETSC ERROR: Out of memory. This could be due to allocating
PETSC ERROR: too large an object or bleeding by not properly
PETSC ERROR: destroying unneeded objects.
PETSC ERROR: Try running with -trdump for more information.
PETSC ERROR: MatCreate () line 99 in src/mat/utils/gcreate.c
PETSC ERROR: main() line 71
in src/sles/examples/tutorials/ex3.c
MPI Abort by user Aborting program !
Aborting program!
p0 28969: p4 error: : 1
При использовании версий библиотек PETSc для отладки (откомпилированных с опцией BOPT=g) можно также проверять нарушения памяти (запись за границами массива и т.д.). Макрос CHKMEMQ можно вызывать в любом месте кода для проверки текущего состояния памяти и нарушений. Помещая в свой код несколько (или много) таких макросов, вы можете легко отследить, в какой части кода происходит нарушение.
Поскольку PETSc использует модель передачи сообщений для параллельного программирования и пользуется MPI для межпроцессорного взаимодействия, пользователь может свободно употреблять в своем коде процедуры MPI там, где это необходимо. Однако по умолчанию пользователь огражден от многих деталей обмена сообщениями внутри PETSc, поскольку они скрыты в таких параллельных объектах, как векторы, матрицы и решатели. К тому же, PETSc продоставляет такие инструменты, как обобщенную сборку/рассылку векторов и распределенные массивы, чтобы облегчить управление параллельными данными. Помните, что пользователь должен определить коммуникатор перед созданием любого объекта PETSc (такого как вектор, матрица или решатель), чтобы указать процессоры, на которые будет распределен объект. Например, как упоминалось выше, командами для создания матрицы, вектора и линейного решателя являются:
VecCreate (MPI_Comm comm ,Vec *x);
SLESCreate (MPI_Comm comm ,SLES *sles);
/* Запуск программы: mpirun -np <procs> ex2 [-help]
[all PETSc options] */
static char help[] =
"Параллельное решение линейной системы через SLES.\n\
Входные параметры включают:\n\
-random_exact_sol : использовать случайный вектор\
точного решения\n\
-view_exact_sol : вывод вектора точного решения в stdout\n\
-m <mesh_x> : количество узлов сетки по x\n\
-n <mesh_n> : количество узлов сетки по y\n\n";
/*T
Идея: параллельный пример, основанный на SLES;
Идея: SLES^Laplacian, 2d
Идея: Laplacian, 2d
Процессоры: n
T*/
/*
Включаем "petscsles.h", чтобы использовать решатели SLES.
Этот файл автоматически включает:
petsc.h - основные процедуры PETSc petscvec.h - векторы
petscsys.h - системные процедуры petscmat.h - матрицы
petscis.h - индексные множества petscksp.h - методы
подпространств Крылова
petscviewer.h - просмотрщики petscpc.h - предобработчики
*/
#include "petscsles.h"
#undef __FUNCT__
#define __FUNCT__ "main"
int main(int argc,char **args) {
Vec x,b,u; /* приближенное решение, RHS,
точное решение */
Mat A; /* матрица линейной системы */
SLES sles; /* контекст линейного решателя */
PetscRandom rctx; /* контекст генератора случайных чисел */
PetscReal norm; /* погрешность решения */
int i,j,I,J,Istart,Iend,ierr,m = 8,n = 7,its;
PetscTruth flg;
PetscScalar v,one = 1.0,neg_one = -1.0;
KSP ksp;
PetscInitialize(&argc, &args, (char*)0, help);
ierr = PetscOptionsGetInt(PETSC_NULL,"-m",&m,PETSC_NULL);
CHKERRQ(ierr);
ierr = PetscOptionsGetInt(PETSC_NULL,"-n",&n,PETSC_NULL);
CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Вычисляем матрицу и правосторонний вектор, определяющий
линейную систему Ax = b.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создаем параллельную матрицу, определяя только ее общие размеры.
При использовании MatCreate() формат матрицы может быть задан
во время выполнения.
Аналогично параллельное разделение матрицы определяется PETSc
во время выполнения.
Для проблем существенной размерности, предварительное
распределение памяти для матрицы влияет на
производительность.
Поскольку предварительное распределение невозможно при
использовании общей процедуры создания матрицы MatCreate(),
рекомендуется для практических задач вместо этого использовать
процедуры создания матриц специальных форматов, например:
MatCreateMPIAIJ() - параллельная AIJ
(упакованная разреженная строка)
MatCreateMPIBAIJ() - параллельная блочная AIJ
См. главу о матрицах в руководстве пользователя
для детальной информации.
*/
ierr = MatCreate(PETSC_COMM_WORLD,PETSC_DECIDE,PETSC_DECIDE,m*n,
m*n,&A);CHKERRQ(ierr);
ierr = MatSetFromOptions(A);CHKERRQ(ierr);
/*
В настоящее время все параллельные форматы матриц PETSc
разделяются среди процессоров на непрерывные последовательности
строк. Определим, какие строки матрицы получены локально
*/
ierr = MatGetOwnershipRange(A,\&Istart,\&Iend);CHKERRQ(ierr);
/*
Параллельно устанавливаем элементы матрицы для 2-D
пятиточечного шаблона:
- Каждый процессор должен вставить только элементы, которыми
он владеет локально (любые нелокальные элементы будут
пересланы соответствующему процессору во время
сборки матрицы).
- Всегда указывайте глобальные номера строк и столбцов
элементов матрицы.
Здесь используется не совсем стандартная нумерация,
которая перебирает сначала все неизвестные для x = h, затем
для x = 2h и т.д.; поэтому Вы видите J = I +- n вместо
J = I +- m, как Вы ожидали. Более стандартная нумерация сначала
проходит все переменные для y = h, затем y = 2h и т.д.
*/
for (I=Istart; I<Iend; I++) {
v = -1.0; i = I/n; j = I - i*n;
if (i>0) {J = I - n; ierr=MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
if (i<m-1) {J = I+n;ierr=MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
if (j>0) {J = I-1; ierr = MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
if (j<n-1) {J = I+1; ierr=MatSetValues(A,1,&I,1,&J,&v,
INSERT_VALUES); CHKERRQ(ierr);}
v = 4.0; ierr = MatSetValues(A,1,&I,1,&I,&v,INSERT_VALUES);
CHKERRQ(ierr);
}
/*
Собираем матрицу, используя двухшаговый процесс:
MatAssemblyBegin(), MatAssemblyEnd()}
Можно выполнять вычисления, пока сообщения передаются,
если поместить код между двумя этими операторами.
*/
ierr = MatAssemblyBegin(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
ierr = MatAssemblyEnd(A,MAT_FINAL_ASSEMBLY);CHKERRQ(ierr);
/*
Создаем параллельные векторы.
- Первый вектор формируется с нуля, а затем делаются дубликаты,
если нужно.
- При использовании VecCreate(), VecSetSizes и
VecSetFromOptions() в этом примере, определяются только
глобальные размеры вектора; параллельное разделение
определяется во время выполнения.
- При решении линейной системы и векторы, и матрицы должны
соответственно разделяться. PETSc автоматически генерирует
правильно разделенные матрицы и векторы, если процедуры
MatCreate() и VecCreate() используются с одним и тем же
коммуникатором.
- Пользователь может самостоятельно определить локальные
размеры векторов и матриц, если требуется более сложное
разделение (заменив аргумент PETSC_DECIDE в процедуре
VecSetSizes() ниже).
*/
ierr = VecCreate(PETSC_COMM_WORLD,&u);CHKERRQ(ierr);
ierr = VecSetSizes(u,PETSC_DECIDE,m*n);CHKERRQ(ierr);
ierr = VecSetFromOptions(u);CHKERRQ(ierr);
ierr = VecDuplicate(u,&b);CHKERRQ(ierr);
ierr = VecDuplicate(b,&x);CHKERRQ(ierr);
/*
Установим точное решение; затем вычислим правосторонний
вектор. По умолчанию мы используем точное решение вектора
со всеми элементами 1.0; однако использование
опции времени выполнения -random_sol формирует вектор
решения со случайными составляющими.
*/
ierr = PetscOptionsHasName(PETSC_NULL,"-random_exact_sol",&flg);
CHKERRQ(ierr);
if (flg) {
ierr = PetscRandomCreate(PETSC_COMM_WORLD,RANDOM_DEFAULT,&rctx);
CHKERRQ(ierr);}
ierr = VecSetRandom(rctx,u);CHKERRQ(ierr);
ierr = PetscRandomDestroy(rctx);CHKERRQ(ierr);
} else {
ierr = VecSet(&one,u);CHKERRQ(ierr);
}
ierr = MatMult(A,u,b);CHKERRQ(ierr);
/*
Посмотрим вектор точного решения, если хочется
*/
ierr = PetscOptionsHasName(PETSC_NULL,"-view_exact_sol",&flg);
CHKERRQ(ierr);
if (flg) {ierr = VecView(u,PETSC_VIEWER_STDOUT_WORLD);
CHKERRQ(ierr);}
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Создаем линейный решатель и устанавливаем различные опции}
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Создаем контекст линейного решателя
*/
ierr = SLESCreate(PETSC_COMM_WORLD,&sles);CHKERRQ(ierr);
/*
Установим операторы. Здесь матрица, определяющая линейную
систему, служит также матрицей предобработчиков.
*/
ierr = SLESSetOperators(sles,A,A,DIFFERENT_NONZERO_PATTERN);
CHKERRQ(ierr);
/*
Установим значения линейного решателя по умолчанию для
этой задачи (необязательно):
- Извлекая контексты KSP и PC из контекста SLES, затем можно
непосредственно вызывать любые процедуры KSP и PC
для установки различных опций.
- Следующие два оператора опциональны; все параметры
могут быть альтернативно заданы во время выполнения
через SLESSetFromOptions().
Все значения по умолчанию можно переопределить
во время выполнения, как показано ниже.
*/
ierr = SLESGetKSP(sles,&ksp);CHKERRQ(ierr);
ierr = KSPSetTolerances(ksp,1.e-2/((m+1)*(n+1)),1.e-50,
PETSC_DEFAULT,PETSC_DEFAULT); CHKERRQ(ierr);
/*
Установим опции времени выполнения, например,
-ksp_type <type> -pc_type <type> -ksp_monitor -ksp_rtol <rtol>
Эти опции могут переопределить значения, указаннаые выше
до тех пор, пока SLESSetFromOptions() будет вызван после любой
процедуры настройки.
*/
ierr = SLESSetFromOptions(sles);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Решаем линейную систему
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
ierr = SLESSolve(sles,b,x,&its);CHKERRQ(ierr);
/*
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Проверяем решение и очищаем его
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
*/
/*
Проверяем ошибку
*/
ierr = VecAXPY(&neg_one,u,x);CHKERRQ(ierr);
ierr = VecNorm(x,NORM_2,&norm);CHKERRQ(ierr);
/*
Масштабируем ошибку
*/
/* norm *= sqrt(1.0/((m+1)*(n+1))); */
/*
Выводим информацию о сходимости. PetscPrintf() создает единый
оператор вывода из всех процессов, разделяющих коммуникатор.
Альтернативой является PetscFPrintf(), который выводит в файл.
*/
ierr = PetscPrintf(PETSC_COMM_WORLD,"Norm of error %A
iterations %d\n", norm,its); CHKERRQ(ierr);
/*
Освобождаем рабочее пространство. Все объекты PETSc должны быть
удалены, если они больше не нужны.
*/
ierr = SLESDestroy(sles);CHKERRQ(ierr);
ierr = VecDestroy(u);CHKERRQ(ierr);
ierr = VecDestroy(b);CHKERRQ(ierr);
ierr = VecDestroy(x);CHKERRQ(ierr);
ierr = MatDestroy(A);CHKERRQ(ierr);
/*
Всегда вызывайте PetscFinalize() перед выходом из программы.
Эта процедура
- финализирует библиотеки PETSc, а также MPI
- выдает итоговую и диагностическую информацию, если указаны
определенные опции времени выполнения
(например, -log_summary).
*/
ierr = PetscFinalize();CHKERRQ(ierr);
return 0;
}
Ниже приведен пример компиляции и запуска программы PETSc, использующей MPICH:
gcc -pipe -c -I../../../ -I../../..//include
-I/usr/local/mpi/include -I../../..//src -g
-DPETSC_USE_DEBUG -DPETSC_MALLOC -DPETSC_USE_LOG ex1.c
gcc -g -DPETSC_USE_DEBUG -DPETSC_MALLOC -DPETSC_USE_LOG
-o ex1 ex1.o
/home/bsmith/petsc/lib/libg/sun4/libpetscsles.a
-L/home/bsmith/petsc/lib/libg/sun4 -lpetscstencil -lpetscgrid
-lpetscsles -lpetscmat -lpetscvec -lpetscsys -lpetscdraw
/usr/local/lapack/lib/lapack.a /usr/local/lapack/lib/blas.a
/usr/lang/SC1.0.1/libF77.a -lm /usr/lang/SC1.0.1/libm.a -lX11
/usr/local/mpi/lib/sun4/ch p4/libmpi.a
/usr/lib/debug/malloc.o /usr/lib/debug/mallocmap.o
/usr/lang/SC1.0.1/libF77.a -lm /usr/lang/SC1.0.1/libm.a -lm
rm -f ex1.o
eagle: mpirun -np 1 ex2
Norm of error 3.6618e-05 iterations 7
eagle: mpirun -np 2 ex2
Norm of error 5.34462e-05 iterations 9
Отметьте, что различные рабочие места могут иметь различные
библиотеки и имена компиляторов. Пользователи, столкнувшиеся с трудностями
при сборке программ PETSc, могут ознакомиться с руководством по исправлению
ошибок на веб-странице PETSc по адресу http://www.mcs.anl.gov/petsc
или в файле
${PETSC_DIR}/docs/troubleshooting.html.
Опция -log_summary активирует вывод итоговой информации о производительности, включая времена выполнения, скорость операций с плавающей точкой, и активность обмена сообщениями. Следующая глава содержит детальную информацию о профилировании, включая интерпретацию данных. Этот отдельный пример выполняет решение линейной системы на одном процессоре с использованием GMRES и ILU. Малая скорость операций с плавающей точкой в этом примере обусловлена тем, что код решает малую систему. Этот пример предназначен в основном для демонстрации простоты получения информации о производительности:
eagle> mpirun -np 1 ex1 -n 1000 -pc_type ilu -ksp_type gmres
-ksp_rtol 1.e-7 -log_summary
------------------------------- PETSc Performance Summary:---------
ex1 on a sun4 named merlin.mcs.anl.gov with 1 processor,
by curfman Wed Aug 7 17:24:27 1996
Max Min Avg Total
Time (sec): 1.150e-01 1.0 1.150e-01
Objects: 1.900e+01 1.0 1.900e+01
Flops: 3.998e+04 1.0 3.998e+04 3.998e+04
Flops/sec: 3.475e+05 1.0 3.475e+05
MPI Messages: 0.000e+00 0.0 0.000e+00 0.000e+00
MPI Messages: 0.000e+00 0.0 0.000e+00 0.000e+00 (lengths)
MPI Reductions: 0.000e+00 0.0
-------------------------------------------------------------------
Phase Count Time (sec) Flops/sec Global}
Max Ratio Max Ratio Mess Avg len Reduct %T %F %M %L %R
-------------------------------------------------------------------
MatMult 2 2.553e-03 1.0 3.9e+06 1.0 0.0e+00 0.0e+00 0.0e+00 2 25 0 0 0
MatAssemblyBegin 1 2.193e-05 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0
MatAssemblyEnd 1 5.004e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 4 0 0 0 0
MatGetReordering 1 3.004e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 3 0 0 0 0
MatILUFctrSymbol 1 5.719e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 5 0 0 0 0
MatLUFactorNumer 1 1.092e-02 1.0 2.7e+05 1.0 0.0e+00 0.0e+00 0.0e+00 9 7 0 0 0
MatSolve 2 4.193e-03 1.0 2.4e+06 1.0 0.0e+00 0.0e+00 0.0e+00 4 25 0 0 0
MatSetValues 1000 2.461e-02 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 21 0 0 0 0
VecDot 1 60e-04 1.0 9.7e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 5 0 0 0
VecNorm 3 5.870e-04 1.0 1.0e+07 1.0 0.0e+00 0.0e+00 0.0e+00 1 15 0 0 0
VecScale 1 1.640e-04 1.0 6.1e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 3 0 0 0
VecCopy 1 3.101e-04 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0
VecSet 3 5.029e-04 1.0 0.0e+00 0.0 0.0e+00 0.0e+00 0.0e+00 0 0 0 0 0
VecAXPY 3 8.690e-04 1.0 6.9e+06 1.0 0.0e+00 0.0e+00 0.0e+00 1 15 0 0 0
VecMAXPY 1 2.550e-04 1.0 7.8e+06 1.0 0.0e+00 0.0e+00 0.0e+00 0 5 0 0 0
SLESSolve 1 1.288e-02 1.0 2.2e+06 1.0 0.0e+00 0.0e+00 0.0e+00 11 70 0 0 0
SLESSetUp 1 2.669e-02 1.0 1.1e+05 1.0 0.0e+00 0.0e+00 0.0e+00 23 7 0 0 0
KSPGMRESOrthog 1 1.151e-03 1.0 3.5e+06 1.0 0.0e+00 0.0e+00 0.0e+00 1 10 0 0 0
PCSetUp 1 24e-02 1.0 1.5e+05 1.0 0.0e+00 0.0e+00 0.0e+00 18 7 0 0 0
PCApply 2 4.474e-03 1.0 2.2e+06 1.0 0.0e+00 0.0e+00 0.0e+00 4 25 0 0 0
--------------------------------------------------------------------------------
Memory usage is given in bytes:
Object Type Creations Destructions Memory Descendants' Mem.
Index set 3 3 12420 0
Vector 8 8 65728 0
Matrix 2 2 184924 4140
Krylov Solver 1 1 16892 41080
Preconditioner 1 1 0 64872
SLES 1 1 0 122844
Примеры в библиотеке демонстрируют использование ПО и могут служить
заготовками для разработки специальных приложений. Новые пользователи
PETSc должны изучить программы в каталогах
$PETSC_DIR/src/<library>/examples/tutorials,
где
<library> обозначает одну из библиотек PETSc, например,
snes или sles. Справочные страницы, расположенные
в каталоге $PETSC DIR/docs/index.html или по адресу http://www.mcs.anl.gov/petsc/ docs/
содержат индексные списки (организованные по названиям функций или
понятиям) к учебным примерам. Чтобы написать новую программу с использоваанием
PETSc, рекомендуется выполнить следующие действия:
Корневой каталог PETSc содержит следующие каталоги:
PETSc включает в себя содержательную и легковесную систему, позволяющую провести профилирование приложений. Процедуры PETSc автоматически фиксируют данные о производительности, если при выполнении указаны определенные опции. Пользователь также может фиксировать информацию о коде приложения для получения полной картины производительности. К тому же, PETSc предоставляет механизм вывода информативных сообщений о ходе вычислений.
Если код приложения и библиотеки PETSc компилировались с флагом
-DPETSC_USE_LOG (установлен по умолчанию для всех версий),
то можно использовать во время выполнения программы различные виды профилирования
кода между вызовами
PetscInitialize() и PetscFinalize().
Отметьте, что флаг
-DPETSC_USE_LOG может быть определен
для инсталляции PETSc в файле ${PETSC_DIR}/bmake/
${PETSC_ARCH}/variables. Опции профилирования включают:
Опция -log_summary после завершения программы выводит
данные профилирования в стандартный вывод.
Данные профилирования могут быть выведены также и в любое время, если
программа вызовет функцию PetscLogPrintSummary(). Данные
о производительности выводятся для каждой процедуры, организованной
в библиотеки PETSc, а затем для всех определенных пользовательских
событий. Для каждой процедуры выводимые данные включают максимальное
время и скорость операций с плавающей точкой (flop) для всех
процессоров. Включается также информация о параллельной производительности.
Для подсчета операций с плавающей точкой в PETSc определяется единица
flop как одна из операций следующего типа: умножение, деление,
сложение или вычитание. Например, одна операция VecAXPY (),
вычисляющая ![]() для векторов длины N, требует
2N flops (состоящих из N сложений и N умножений).
Обратите внимание, что скорость flop представляет только ограниченную
характеристику производительности, поскольку извлечение и запись в
память также влияют на показатели. Для упрощения остальная часть обсуждения
посвящена интерпретации данных профилирвания для библиотеки SLES,
предоставляющей линейные решатели для всего пакета PETSc. Вспомните
иерархическую организацию библиотеки PETSc, показанную на рис. 69.
Каждый решатель SLES состоит из предобработчика PC и части KSP (подпространств
Крылова), котрые в свою очередь используют модули Mat (матрицы) и
Vec (векторы). Поэтому операции в модуле SLES состоят из низкоуровневых
операций нижележащих модулей. Отметьте также факт, что библиотека
нелинейных решателей SNES построена на базе библиотеки SLES, а
библиотека временного интегрирования TS построена на базе SNES .
Линейный решатель SLES
содержит две основных фазы SLESSetUp () и SLESSolve
(), каждая из которых включает множество действий, зависящих от
определенной техники решения. Для использования предобработчика
PCILU и метода подпространств Крылова KSPGMRES последовательность
процедур PETSc приведена ниже. Как указано в иерархии, операции в
SLESSetUp () включают все операции внутри PCSetUp
(), которые в свою очередь включают MatILUFactor () и т.д.:
для векторов длины N, требует
2N flops (состоящих из N сложений и N умножений).
Обратите внимание, что скорость flop представляет только ограниченную
характеристику производительности, поскольку извлечение и запись в
память также влияют на показатели. Для упрощения остальная часть обсуждения
посвящена интерпретации данных профилирвания для библиотеки SLES,
предоставляющей линейные решатели для всего пакета PETSc. Вспомните
иерархическую организацию библиотеки PETSc, показанную на рис. 69.
Каждый решатель SLES состоит из предобработчика PC и части KSP (подпространств
Крылова), котрые в свою очередь используют модули Mat (матрицы) и
Vec (векторы). Поэтому операции в модуле SLES состоят из низкоуровневых
операций нижележащих модулей. Отметьте также факт, что библиотека
нелинейных решателей SNES построена на базе библиотеки SLES, а
библиотека временного интегрирования TS построена на базе SNES .
Линейный решатель SLES
содержит две основных фазы SLESSetUp () и SLESSolve
(), каждая из которых включает множество действий, зависящих от
определенной техники решения. Для использования предобработчика
PCILU и метода подпространств Крылова KSPGMRES последовательность
процедур PETSc приведена ниже. Как указано в иерархии, операции в
SLESSetUp () включают все операции внутри PCSetUp
(), которые в свою очередь включают MatILUFactor () и т.д.:
Итоги, выводимые через -log_summary, отражают эту иерархию процедур. Например, показатели производительности для такой высокоуровневой процедуры, как SLESSolve, включают итоги всех операций, накопленные в низкоуровневых компонентах, составляющих эту процедуру.
Очевидно, что в настоящее время вывод не может быть представлен через -log_summary так, чтобы иерархия процедур PETSc была полностью ясна, в основном потому, что не был определен ясный и единообразный способ сделать это для всей библиотеки. В дальнейшем возможны улучшения. Для определенной задачи пользователь должен иемть представление об основных операциях, требуемых для ее реализации (т.е., какие операции выполняются при использовании GMRES и ILU), чтобы интерпретация данных от -log_summary была относительно прозрачной.
Здесь обсуждается информация о производительности параллельных программ, приведенная в двух примерах ниже, которая представляет собой комбинированный вывод, сгенерированный с помощью опции -log_summary. Программой, которая генерирует эти данные, является ${PETSC_DIR}/src/sles/examples/ex21.c. Данный код загружает матрицу и правосторонний вектор из двоичного файла, а затем решает полученную линейную систему; далее программа повторяет этот процесс для второй линейной системы:
mpirun ex21 -f0 medium -f1 arco6 -ksp_gmres_unmodifiedgramschmidt \
-log_summary -mat_mpibaij -matload_block_size 3 -pc_type \
bjacobi -options_left
Number of iterations = 19
Residual norm = 7.7643e-05
Number of iterations = 55
Residual norm = 6.3633e-01
--------------- Информация о производительности PETSc:-------------
ex21 on a rs6000 named p039 with 4 processors,
by mcinnes Wed Jul 24 16:30:22 1996
Max Min Avg Total
Time (sec): 3.289e+01 1.0 3.288e+01
Objects: 1.130e+02 1.0 1.130e+02
Flops: 2.195e+08 1.0 2.187e+08 8.749e+08
Flops/sec: 6.673e+06 1.0 2.660e+07
MPI Messages: 2.205e+02 1.4 1.928e+02 7.710e+02
MPI Message Lengths: 7.862e+06 2.5 5.098e+06 2.039e+07
MPI Reductions: 1.850e+02 1.0
Summary of Stages:-Time--Flops--Messages--Message-lengths-Reductions
Avg %Total Avg %Total counts %Total avg %Total counts %Total
0: Load System 0: 1.191e+00 3.6% 3.980e+06 0.5% 3.80e+01 4.9%
6.102e+04 0.3% 1.80e+01 9.7%
1: SLESSetup 0: 6.328e-01 2.5% 1.479e+04 0.0% 0.00e+00 0.0%
0.000e+00 0.0% 0.00e+00 0.0%
2: SLESSolve 0: 2.269e-01 0.9% 1.340e+06 0.0% 1.52e+02 19.7%
9.405e+03 0.0% 3.90e+01 21.1%
3: Load System 1: 2.680e+01 107.3% 0.000e+00 0.0% 2.10e+01 2.7%
1.799e+07 88.2% 1.60e+01 8.6%
4: SLESSetup 1: 1.867e-01 0.7% 1.088e+08 2.3% 0.00e+00 0.0%
0.000e+00 0.0% 0.00e+00 0.0%
5: SLESSolve 1: 3.831e+00 15.3% 2.217e+08 97.1% 5.60e+02 72.6%
2.333e+06 11.4% 1.12e+02 60.5%
--------------------------------------------------------------------
.... [Информация различных фаз, см. часть II ниже] ...
--------------------------------------------------------------------
Использование памяти указано в байтах:
Object Type Creations Destructions Memory Descendants' Mem.
Viewer 5 5 0 0
Index set 10 10 127076 0
Vector 76 76 9152040 0
Vector Scatter 2 2 106220 0
Matrix 8 8 9611488 5.59773e+06
Krylov Solver 4 4 33960 7.5966e+06
Preconditioner 4 4 16 9.49114e+06
SLES 4 4 0 1.71217e+07
Этот результат получен на четырехпроцессорном IBM SP с использованием рестартуемого GMRES и блочного предобработчика Якоби, в котором каждый блок решается через ILU. Он представляет общие результаты оценки производительности, включая время, операции с плавающей точкой, скорости вычислений, и активность обмена сообщениями (например, количество и размер посланных сообщений и коллективных операций). Приведены и результаты для различных пользовательских стадий мониторинга. Информация о различных фазах вычислений следует ниже. Наконец, представлена информация об использовании памяти, создании и удалении объектов. Также уделяется внимание итогам различных фаз вычисления, приведенным во втором примере. Итог для каждой фазы представляет максимальное время и скорость операций с плавающей точкой для всех процессоров, а также соотношение максимального и минимального времени и скоростей для всех процессоров. Отношение приближенно равное 1 указывает, что вычисления в данной фазе хорошо сбалансированы между процессорами; если отношение увеличивается, баланс становится хуже. Также для каждой фазы в последней колонке таблицы приведена максимальная скорость вычислений (в единицах MFlops/sec).
Total Mflop/sec = 10
![]() * (сумма flops по всем процессорам) / (максимальное
время для всех процессоров)
* (сумма flops по всем процессорам) / (максимальное
время для всех процессоров)
Общие скорости вычислений < 1 MFlop в данном столбце таблицы результатов показаны как 0. Дополнительная статистика для каждой фазы включает общее количество посланных сообщений, среднюю длину сообщения и количество общих редукций. Итоги по производительности для высокоуровневых процедур PETSc включают статистику для низших уровней, из которых они состоят. Например, коммуникации внутри произведения матрица-вектор MatMult () состоят из операций рассылки вектора, выполняемых процедурами VecScatterBegin () и VecScatterEnd(). Окончательные приведенные данные представляют собой проценты различной статистики (время (%T), flops/sec (%F), сообщения(%M), средняя длина сообщения (%L) и редукции (%R)) для каждого события, относящегося ко всем вычислениям и к любым пользовательским этапам. Эта статистика может оказать помощь в оптимизации производительности, поскольку указывает секции кода, которые могут быть подвержены различным методам настройки. Следующая глава дает советы по достижению хорошей производительности кодов PETSc:
mpirun ex21 -f0 medium -f1 arco6 -ksp_gmres_unmodifiedgramschmidt \
-log_summary -mat_mpibaij -matload_block_size 3 -pc_type \
bjacobi -options_left
-------------Информация о производительности PETSc:--------------
.... [Общие итоги, см. часть I] ...
Информация о фазе:
Count: сколько раз фаза выполнялась
Time and Flops/sec: Max - максимально для всех прцессоров
Ratio - отношение максимума к минимуму для всех процессоров
Mess: количество посланных сообщений
Avg. len: средняя длина сообщения
Reduct: количество глобальных редукций
Global: полное вычисление
Stage: необязательные пользовательские этапы вычислений.
Установите этапы через PLogStagePush() и PLogStagePop().
%T - процент времени в фазе %F - процент операций flops в фазе
%M - процент сообщений в фазе %L - процент длины сообщений в фазе
%R - процент редукций в фазе
Total Mflop/s: 10^6 * (sum of flops over all processors)
/ (max time over all processors)
------------------------------------------------------------------
Phase Count Time (sec) Flops/sec -Global--Stage--Total
Max Ratio Max Ratio Mess Avg len Reduct
%T %F %M %L %R %T %F %M %L %R Mflop/s
------------------------------------------------------------------
...
---Event Stage 4: SLESSetUp 1
MatGetReordering 1 3.491e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 2 0 0 0 0 0
MatILUFctrSymbol 1 6.970e-03 1.2 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 3 0 0 0 0 0
MatLUFactorNumer 1 1.829e-01 1.1 3.2e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 90 99 0 0 0 110
SLESSetUp 2 1.989e-01 1.1 2.9e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 99 99 0 0 0 102
PCSetUp 2 1.952e-01 1.1 2.9e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 97 99 0 0 0 104
PCSetUpOnBlocks 1 1.930e-01 1.1 3.0e+07 1.1 0.0e+00 0.0e+00
0.0e+00 1 2 0 0 0 96 99 0 0 0 105
-----Event Stage 5: SLESSolve 1
MatMult 56 1.199e+00 1.1 5.3e+07 1.0 1.1e+03 4.2e+03
0.0e+00 5 28 99 23 0 30 28 99 99 0 201
MatSolve 57 1.263e+00 1.0 4.7e+07 1.0 0.0e+00 0.0e+00
0.0e+00 5 27 0 0 0 33 28 0 0 0 187
VecNorm 57 1.528e-01 1.3 2.7e+07 1.3 0.0e+00 0.0e+00
2.3e+02 1 1 0 0 31 3 1 0 0 51 81
VecScale 57 3.347e-02 1.0 4.7e+07 1.0 0.0e+00 0.0e+00
0.0e+00 0 1 0 0 0 1 1 0 0 0 184
VecCopy 2 1.703e-03 1.1 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 0
VecSet 3 2.098e-03 1.0 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 0
VecAXPY 3 3.247e-03 1.1 5.4e+07 1.1 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 200
VecMDot 55 5.216e-01 1.2 9.8e+07 1.2 0.0e+00 0.0e+00
2.2e+02 2 20 0 0 30 12 20 0 0 49 327
VecMAXPY 57 6.997e-01 1.1 6.9e+07 1.1 0.0e+00 0.0e+00
0.0e+00 3 21 0 0 0 18 21 0 0 0 261
VecScatterBegin 56 4.534e-02 1.8 0.0e+00 0.0 1.1e+03 4.2e+03
0.0e+00 0 0 99 23 0 1 0 99 99 0 0
VecScatterEnd 56 2.095e-01 1.2 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 1 0 0 0 0 5 0 0 0 0 0
SLESSolve 1 3.832e+00 1.0 5.6e+07 1.0 1.1e+03 4.2e+03
4.5e+02 15 97 99 23 61 99 99 99 99 99 222
KSPGMRESOrthog 55 1.177e+00 1.1 7.9e+07 1.1 0.0e+00 0.0e+00
2.2e+02 4 39 0 0 30 29 40 0 0 49 290
PCSetUpOnBlocks 1 1.180e-05 1.1 0.0e+00 0.0 0.0e+00 0.0e+00
0.0e+00 0 0 0 0 0 0 0 0 0 0 0
PCApply 57 1.267e+00 1.0 4.7e+07 1.0 0.0e+00 0.0e+00
0.0e+00 5 27 0 0 0 33 28 0 0 0 186
-------------------------------------------------------------------
.... [Завершение общих итогов, см. часть I] ...
Для визуализации событий PETSc можно также использовать пакеты Upshot
(или Jumpshot). Эти пакеты поставляются вместе с библиотекой MPE, являющейся
частью MPICH - реализации MPI. Опция -log_mpe [logfile]
создает файл регистрации событий, пригодный для просмотра с помощью
Upshot. Пользователь может применять либо файл регистрации по умолчанию
mpe.log, либо указывать собственное имя файла через параметр
logfile. Для использовыания этой опции регистрации пользователь
может работать с любой реализацией MPI (не обязательно MPICH), но
должен построить и скомпоновать часть MPE из MPICH. Пользователь должен
также откомпилировать библиотеку PETSc с флагом -DPETSC_HAVE_MPE,
не установленным по умолчанию. Включить регистрацию MPE пользователь
может, указав значение
-DPETSC_HAVE_MPE в переменной PCONF
каталога ${PETSC_DIR}/
bmake/${PETSC_ARCH} /packages
и пересобрав все в PETSc. По умолчанию не все события PETSc регистрируются
MPE. Например, поскольку MatSetValues () может вызываться
в программе тысячи раз, по умолчанию ее вызовы не регистрируются MPE.
Для активирования регистрации отдельных событий с помощью MPE, нужно
использовать функцию:
Для отключения регистрации события в MPE, нужно использовать:
Событие может быть либо предопределено в PETSc (как показано в файле ${PETSC_DIR}/include/petsclog.h) или получено через PetscLogEventRegister (). Эти процедуры можно вызывать столько раз, сколько потребуется приложению, так что можно ограничить регистрацию событий с помощью MPE для отдельных сегментов кода. Чтобы увидеть, какие события регистрируются по умолчанию, пользователь может просмотреть исходный код (см. файлы src/plot/src/plogmpe.c и include/petsclog.h). Разрабатываются простая программа и графический интерфейс, позволяющие просмотреть, какие регистрируемые события уже определены, и определить новые. Пользователь также может регистрировать события MPI. Чтобы сделать это, рассматривайте приложение PETSc как приложение MPI и следуйте инструкциям реализации MPI для регистрации вызовов MPI. Например, при использовании MPICH необходимо добавить -llmpi в список библиотек перед -lmpi.
PETSc автоматически регистрирует создание объектов, время, и количество операций с плавающей точкой для библиотечных процедур. Пользователи могут легко использовать эту информацию для мониторинга кодов приложения. Базовые этапы, выполняемые при регистрации пользовательского участка кода, называемого событием, показаны во фрагменте кода ниже:
int USER_EVENT;
PetscLogEventRegister (&USER_EVENT,"User event name",0);
PetscLogEventBegin (USER_EVENT,0,0,0,0);
/* сегмент кода приложения для мониторинга */
/*количество операций flops для этого сегмента кода */
PetscLogFlops();
PetscLogEventEnd (USER_EVENT,0,0,0,0);
PetscObject o2, PetscObject o3,PetscObject o4);
PetscLogEventEnd (int event, PetscObject o1,
PetscObject o2, PetscObject o3,PetscObject o4);
По умолчанию профилирование создает набор статистических данных для всего кода между вызовами процедур PetscInitialize () и PetscFinalize () в программе. Существует возможность создания независимого мониторинга до десяти секций кода, переключение между мониторингом которых производится функциями:
PetscLogStagePop ();
PetscLogStageRegister (int stage,char *name)
позволяет ассоциировать имя с этапом; эти имена выводятся при генерации итогов через -log_summary или PetscLogPrintSummary (). Следующий фрагмент кода использует три этапа профилирования:
/* этап 0 кода здесь */
PetscLogStageRegister (0,"Этап 0 кода");
for (i=0; i<ntimes; i++) {
PetscLogStagePush(1);
PetscLogStageRegister(1,"Этап 1 кода");
/* этап 1 кода здесь */
PetscLogStagePop();
PetscLogStagePush(2);
PetscLogStageRegister(1,"Этап 2 кода");
/* этап 2 кода здесь */
PetscLogStagePop();
}
PetscFinalize ();
Приведенные выше примеры показывают вывод, сгенерированный опцией -log_summary, для программы, использующей несколько этапов профилирования. В частности, эта программа подразделяется на шесть частей: загрузка матрицы и вектора правой стороны из двоичного файла, настройка предобработчика, решение линейной системы; эта последовательность затем повторяется для второй линейной системы. Для простоты во втором примере дан вывод только для этапов 4 и 5 (линейное решение второй системы), которые содержат часть наиболее интересных для нас вычислений с точки зрения мониторинга производительности. Такая организация кода (решение небольшой линейной системы, а затем решение большой) позволяет сгенерировать более точную статистику профилирования для второй системы, избегая часто встречающейся постраничной перегрузки.
По умолчанию все операции PETSc регистрируются. Для включения или отключения регистрации индивидуальных событий PETSc используются функции:
PetscLogEventDeactivate (int event);
/* включает PC и KSP */
PetscLogEventDeactivateClass (SLES_COOKIE);
PetscLogEventDeactivateClass (VEC_COOKIE);
PetscLogEventDeactivateClass (SNES_COOKIE);
/* включает PC и KSP */
PetscLogEventActivateClass (SLES_COOKIE);
PetscLogEventActivateClass (VEC_COOKIE);
PetscLogEventActivateClass (SNES_COOKIE);
Пользователи могут активировать вывод на экран дополнительной информации об алгоритмах, структурах данных и т.д., используя опцию -log_info или вызвав PetscLogInfoAllow(PETSC_TRUE). Такая регистрация, характерная для всех библиотек PETSc, может помочь пользователю понять алгоритм и настроить производительность программы. Например, -log_info активирует вывод информации о распределении памяти во время сборки матрицы. Прикладные программисты могут также пользоваться этой возможностью регистрации, используя процедуру:
где obj является объектом PETSc, наиболее тесно ассоциированным с оператором регистрации message. Например, в методах линейного поиска Ньютона, используется оператор:
PetscLogInfo (snes," Кубически определяемый шаг,
lambda %g\n", lambda);
Можно избирательно отключить информативные сообщения о любом из базовых
объектов PETSc (т.е., Mat , SNES ) функцией:
где object_cookie принимает значение MAT_COOKIE, SNES_COOKIE, и т.д. Сообщения могут быть вновь активированы процедурой:
Такая деактивация может пригодиться, когда нужно увидеть информацию о высокоуровневых библиотеках PETSc (например, TS и SNES ) без вывода всех данных нижних уровней (например, Mat). Можно деактивировать события для матриц и линейных решателей во время выполнения программы с помощью опции -log_info [no_mat, no_sles].
Прикладные программисты PETSc могут получить доступ к учету общего времени выполнения с помощью функций:
PetscGetTime (&time);CHKERRQ (ierr);
Весь вывод из программ PETSc (включая информативные сообщения, информацию
профилирования, и даные о сходимости) можно сохранить в файле, используя
опцию командной строки -log_history [filename]. Если
имя файла не указано, вывод сохраняется в файле $HOME/.petschistory.
Отметьте, что эта опция сохраняет только вывод, осуществляемый через
команды PetscPrintf()
и PetscFPrintf(), но не
через стандартные операторы printf() и fprintf().
Одной из проблем при организации параллельного доступа к файлам из нескольких процессов является непредсказуемость порядка доступа. В следующем примере два процесса записывают в файл строку символов по одному символу за операцию:
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
int main()
{
int fd;
int x,y;
pid_t pid;
unlink("/tmp/file"); /*Удаляем предыдущий файл*/
fd=open("/tmp/file", O_WRONLY|O_CREAT, 0777);
if(fd==-1)
{
perror("open : ");
exit(0);
}
if((pid=fork()) == -1)
{
perror("fork :");
exit(0);
}
else if(pid)
{ /*Родительский процесс*/
while(1)
{
for(x=0; x<10; x++){
sleep(1);
write(fd,(char *)"x",1);
}
break;
}
else
{ /*Процесс-потомок*/
while(1)
{
for(y=0; y<10; y++){
sleep(1);
write(fd,(char *)"X",1);
}
break;
}
return 0;
}
После выполнения этой программы содержимое файла
``/tmp/file''
может выглядеть следующим образом:
/*struct flock *flockptr*/);
Одним из факторов, играющим значительную роль в профилировании кода, является страничная поддержка в операционной системе. В общем случае при запуске программы в память загружается только несколько страниц, необходимых для ее старта, но не весь исполняемый файл. Когда выполнение доходит до сегментов кода, не находящихся в памяти, возникает отсутствие страницы, вызывающее запрос на загрузку страниц с диска (очень медленный процесс). Эти действия существенно нарушают результаты профилирования. (Страничный эффект заметен в файлах регистрации, сгенерированных через -log_mpe). Для устранения страничного эффекта при профилировании производительности программ разработана эффективная процедура запуска того же самого кода на маленькой задаче-муляже перед запуском самой задачи. Затем следует убедиться, что весь код, требуемый решателю, загружен в память во время решения малой задачи. Если код работает для действительной задачи и все требуемые страницы уже загружены в основную память, то показатели производительности не пострадают. Когда эта процедура используется в сочетании с пользовательскими этапами профилирования, можно сосредоточиться на самой задаче. Например, эта технология используется в программе, приведенной в ${PETSC_DIR}/src/sles/examples/tutorials/ex10.c для генерации результатов, показанных в примерах этого раздела. В этом случае, профилируемый код (решение линейной системы для большой задачи) появляется в событиях 4 и 5. В частности, макросы:
PreLoadStage (char *stagename),
PreLoadEnd()
Код, откомпилированный с опцией BOPT=O в общем случае работает в два-три раза быстрее, чем код, откомпилированный с BOPT=g, поэтому рекомендуется использовать для оценки производительности одну из оптимизированных версий кода (BOPT = O, BOPT = O_c++, или BOPT = O_complex). Пользователь может указать иные опции компилятора вместо опций по умолчанию, используемых в дистрибутиве PETSc. Можно установить опции компилятора для определенной архитектуры (PETSC_ARCH) и BOPT, отредактировав файл ${PETSC_DIR}/ bmake/${PETSC_ARCH} / variables.
Пользователи не должны тратить время на оптимизацию кода, если не ожидают, что оптимизация сэкономит время решения реальной задачи. Процедуры PETSc автоматически регистрируют данные о производительности, если указаны определенные опции времени выполнения. Например:
Выполнение операций на цепочках данных, а не на одном элементе, в единицу времени может существенно улучшить производительность. Для этого:
Процесс динамического распределения памяти для разреженных
матриц является весьма затратным, поэтому точное предварительное распределение
является критичным для эффективной сборки разреженных матриц. Можно
использовать процедуры создания матриц для определенных структур данных,
например,
MatCreateSeqAIJ() и MatCreateMPIAIJ() -
для упакованных форматов разреженных строк, вместо обычной процедуры
MatCreate(). При решении задач с несколькими степенями свободы для
узла блочные упакованные форматы разреженных строк, созданные с помощью
MatCreateSeqBAIJ() и MatCreateMPIBAIJ(), могут
существенно улучшить производительность.
При символической факторизации матрицы AIJ PETSc должен
вычислить плотность заполнения. Осторожное использование
параметра заполнения в структуре MatILUInfo при вызове
MatLUFactorSymbolic () или MatILUFactorSymbolic ()
может существенно уменьшить количество требуемых операций распределения
и копирования и, таким образом, существенно увеличить производительность
факторизации. Одним из способов определения подходящего значения для
f является запуск программы с опцией -log_info.
Фаза символической факторизации выведет при этом информацию вида
Fill ratio:given 1 needed 2.16423
Пользователи должны употреблять приемлемое количество вызовов PetscMalloc () в своем коде. Сотни и тысячи распределений памяти могут быть допустимы; однако если используются десятки тысяч, то можно порекомендовать уменьшить количество вызовов PetscMalloc (). Например, повторное использование памяти или распределение больших участков и деление их на части может существенно уменьшить нагрузку.
Структуры данных, насколько это возможно, должны использоваться повторно. Например, если код часто создает новые матрицы или векторы, существует и способ повторного использования некоторых из них. Очень существенный выигрыш в производительности можно получить повторным использованием структур данных матриц с одинаковыми ненулевыми шаблонами. Если код создает тысячи объектов матриц или векторов, производительность будет падать. Например, при решении нелинейной задачи или повременном интегрировании повторное использование матриц и их ненулевой структуры для многих этапов может существенно ускорить программу.
Простой техникой для сохранения рабочих векторов, матриц и т.д. является
введение пользовательских контекстов. В языках C и C++ такой контекст
представляет собой структуру, в которой содержатся различные объекты;
в Фортране пользовательский контекст может быть массивом целых чисел,
содержащим параметры и указатели на объекты PETSc
(См. ${PETSC_DIR}/snes/examples/
tutorials/ex5.c и ${PETSC_DIR}/snes/examples/tutorials/ex5f.F
с примерами пользовательских контекстов приложения на языках C и Фортран,
соответственно).
Пользователи PETSc должны выполнять множество тестов. Например, существует большое количество опций для решателей линейных и нелинейных уравнений в PETSc, и различные варианты могут привести к большой разнице в скоростях сходимости и времени выполнения. PETSc использует значения по умолчанию, которые в общем случае подходят для широкого круга задач, но ясно, что эти значения не могут быть наилучшими для всех случаев. Пользователи должны экспериментировать с множеством комбинаций, чтобы определить наилучшую для конкретной задачи и соответствующим образом настроить решатель. Для этого необходимо, в частности:
Общая тенденция развития современных информационных технологий состоит в активном использовании открытых и распределенных систем, а также новых архитектур приложений, таких, как клиент/сервер и параллельные процессы.
Чтобы различные программы могли обмениваться информацией через файлы или общую базу данных, они, как правило, работают через соответствующий программный интерфейс приложения API (Application Programming Interface). Если программы находятся на различных компьютерах, то процесс взаимодействия сопряжен с определенными дополнительными трудностями, например, ограниченной пропускной способностью и сложностью синхронизации. Для организации коммуникации между одновременно работающими процессами применяются средства межпроцессного взаимодействия (Interprocess Communication - IPC).
Выделяются три уровня средств IPC: локальный, удаленный и высокоуровневый.
Средства локального уровня IPC привязаны к процессору и возможны только в пределах компьютера. К этому виду IPC принадлежат практически все механизмы IPC UNIX, а именно, трубы, разделяемая память и очереди сообщений. Коммуникации, или адресное пространство этих IPC, поддерживаются только в пределах компьютерной системы. Из-за этих ограничений для них могут реализовываться более простые и более быстрые интерфейсы.
Удаленные IPC предоставляют механизмы, которые обеспечивают взаимодействие как в пределах одного процессора, так и между программами на различных процессорах, соединенных через сеть. Сюда относятся удаленные вызовы процедур (Remote Procedure Calls - RPC), сокеты Unix, а также TLI (Transport Layer Interface - интерфейс транспортного уровня) фирмы Sun.
Под высокоуровневыми IPC обычно подразумеваются пакеты программного
обеспечения, которые реализуют промежуточный
слой между системной
платформой и приложением. Эти пакеты предназначены для переноса уже
испытанных протоколов коммуникации приложения на более новую архитектуру.
Средства IPC, впервые реализованные в UNIX 4.2BSD, включали в себя многие современные идеи, исходя из требований философии UNIX относительно простоты и краткости.
До введения механизмов межпроцессного взаимодействия UNIX не обладал
удобными возможностями для обеспечения подобных
услуг. Единственным
стандартным механизмом, который позволял двум процессам связываться
между собой, были трубы (pipes). К сожалению, трубы имели очень серьезное
ограничение в том, что два поддерживающих связь процесса были
связаны через общего предка. Кроме того, семантика труб сильно
ограничивает поддержку распределенной вычислительной среды.
Основные проблемы при введении новых средств IPC в состав системы были связаны с тем, что старые средства были привязаны к файловой системе UNIX либо через обозначение, либо через реализацию. Поэтому новые средства IPC были разработаны как полностью независимая подсистема. Вследствие этого, они позволяют процессам взаимодействовать различными способами. Процессы могут теперь взаимодействовать либо через пространство имен, подобное файловой системе UNIX, либо через сетевое пространство имен. В процессе работы новые пространства имен могут быть добавлены с незначительными изменениями, заметными пользователю. Кроме того, средства взаимодействия расширены, чтобы поддерживать другие форматы передачи, а не только простой байтовый поток, обеспечиваемый трубой. Эти расширения вылились в полностью новую часть системы, которая требует детального знакомства.
Простые межпроцессные коммуникации можно организовать с помощью сигналов и труб. Более сложными средствами IPC являются очереди сообщений, семафоры и разделяемые области памяти.
Наряду с обеспечением взаимодействия процессов средства IPC призваны решать проблемы, возникающие при организации параллельных вычислений. Сюда относятся:
Эта структура используется для управления блокировкой и имеет следующее содержание:
short l_type; /*3 режима блокирования
F_RDLCK(Разделение чтения)
F_WRLCK (Разделение записи)
F_UNLCK (Прекратить разделение)*/
off_t l_start; /*относительное смещение в байтах,
зависит от l_whence*/
short l_whence; /*SEEK_SET;SEEK_CUR;SEEK_END*/
off_t l_len; /*длина, 0=разделение до конца файла*/
pid_t l_pid; /*идентификатор, возвращается F_GETLK */
};
flockptr.l_whence=SEEK_SET; /*с начала файла*/
Линейные решатели по умолчанию бывают:
PETSc содержит ряд средств, помогающих обнаружить проблемы распределения памяти, включая утечки и неиспользуемое пространство:
Производительность кода определяется различными факторами, включая поведение кэша, наличием других пользователей на машине и т.д. Здесь описаны основные проблемы и способы их устранения:
Чтобы собрать программу с именем ex1, можно использовать команду
Каталог ${PETSC_DIR}/bmake содержит практически все команды
сборочных файлов и настройки для обеспечения переносимости среди различных
архитектур. Большинство команд сборочных файлов для поддержки в системе
PETSc определено в файле
${PETSC_DIR}/bmake/common. Эти
команды, обрабатывающие все соответствующие файлы в каталоге выполнения,
включают:
Каталог ${PETSC_DIR}/bmake имеет подкаталоги для каждой архитектуры, которые содержат информацию, специфичную для архитектуры, обеспечивая переносимость системы сборочных файлов. Например, для компьютеров Sun под управлением OS 5.7, каталог называется solaris. Каждый каталог архитектуры содержит три сборочных файла:
PETSc поддерживает несколько флагов, определяющих способ компиляции
исходного кода. Флаги по умолчанию для определенных версий определяются
переменной PETSCFLAGS базовых файлов
${PETSC_DIR}/bmake/
${PETSC_ARCH}. Флаги включают:
Поддержка переносимых сборочных файлов PETSc очень проста. Далее приведены три примера сборочных файлов. Первый представляет ``минимальный'' сборочный файл для поддержки одной программы, которая использует библиотеки PETSc. Наиболее важной строкой в этом файле является та, которая начинается с include:
CFLAGS =
FFLAGS =
CPPFLAGS =
FPPFLAGS =
include ${PETSC_DIR}/bmake/common/base
ex2: ex2.o chkopts
${CLINKER} -o ex2 ex2.o ${PETSC_LIB}
${RM} ex2.o
Отметьте, что переменная ${PETSC_LIB} (как указано в
строке компоновки в приведенном файле) определяет все различные библиотеки
PETSc в нужном порядке для правильной компоновки. Пользователи, которым
требуются только определенные библиотеки PETSc, могут применять
альтернативные переменные, например ${PETSC_SYS_LIB},
${PETSC_VEC_LIB}, ${PETSC_MAT_LIB},
${PETSC_DM_LIB},
${PETSC_SLES_LIB},${PETSC_SNES_LIB} или
${PETSC_TS_LIB}.
Второй пример сборочного файла управляет созданием нескольких примеров программ:
FFLAGS =
CPPFLAGS =
FPPFLAGS =
include ${PETSC_DIR}/bmake/common/base
ex1: ex1.o
-${CLINKER} -o ex1 ex1.o ${PETSC_LIB}
${RM} ex1.o
ex2: ex2.o
-${CLINKER} -o ex2 ex2.o ${PETSC_LIB}
${RM} ex2.o
ex3: ex3.o
-${FLINKER} -o ex3 ex3.o ${PETSC_FORTRAN_LIB}
${PETSC_LIB}
${RM} ex3.o
ex4: ex4.o
-${CLINKER} -o ex4 ex4.o ${PETSC_LIB}
${RM} ex4.o
runex1: -@${MPIRUN} ex1
runex2:
-@${MPIRUN} -np 2 ex2 -mat_seqdense -options_left
runex3: -@${MPIRUN} ex3 -v -log_summary
runex4: -@${MPIRUN} -np 4 ex4 -trdump
RUNEXAMPLES_1 = runex1 runex2
RUNEXAMPLES_2 = runex4
RUNEXAMPLES_3 = runex3
EXAMPLESC = ex1.c ex2.c ex4.c
EXAMPLESF = ex3.F
EXAMPLES_1 = ex1 ex2
EXAMPLES_2 = ex4
EXAMPLES_3 = ex3
include ${PETSC_DIR}/bmake/common/test
Здесь наиболее важной вновь является строка include, которая включает файлы, определяющие все переменные-макросы. Некоторые дополнительные переменные, которые можно использовать в сборочном файле, определяются следующим образом:
CFLAGS =
SOURCEC = sp1wd.c spinver.c spnd.c spqmd.c sprcm.c
SOURCEF = degree.f fnroot.f genqmd.f qmdqt.f rcm.f
fn1wd.f gen1wd.f genrcm.f qmdrch.f rootls.f fndsep.f
gennd.f qmdmrg.f qmdupd.f
SOURCEH =
OBJSC = sp1wd.o spinver.o spnd.o spqmd.o sprcm.o
OBJSF = degree.o fnroot.o genqmd.o qmdqt.o rcm.o
fn1wd.o gen1wd.o genrcm.o qmdrch.o rootls.o fndsep.o
gennd.o qmdmrg.o qmdupd.o
LIBBASE = libpetscmat
MANSEC = Mat
include ${PETSC_DIR}/bmake/common/base
Библиотека называется libpetscmat.a, а исходные файлы, которые добавляются в нее, указаны переменными SOURCEC (для файлов на C) и SOURCEF (для файлов на Фортране). Отметьте, что переменные OBJSF и OBJSC идентичны SOURCEF и SOURCEC соответственно, за исключением того, что в них использован суффикс .o, а не .c или .f. Переменная MANSEC указывает, что все справочные страницы, сгенерированные из исходных файлов, должны включаться в раздел Mat.
Этот подход к переносимым сборочным файлам имеет некоторые небольшие ограничения, а именно следующие:
Функции блокирования можно использовать в следующих режимах:
fd=open(data, O_CREAT|O_WRONLY);
fcntl(fd, F_GETLK, &flptr);
if(flptr.l_type==F_UNLCK)
{/*Данные не блокированы*/}
else if(flptr.l_type==F_RDLCK)
{/*Блокировка по чтению*/}
else if(flptr.l_type==F_WRLCK)
{/*Блокировка по записи*/}
flptr.l_whence=SEEK_SET;
flptr.l_len=0;
flptr.l_type=F_RDLCK;
if((fcntl(fd, F_SETLK, &flptr)!=-1)
{/*Установлена блокировка по чтению*/}
flptr.l_start=0;
flptr.l_whence=SEEK_SET;
flptr.l_len=0;
flptr.l_type=F_WRLCK);
if((fcntl(fd, F_SETLK, &sperre)!=-1)
{/*Установлена блокировка по записи*/}
flptr.l_type=F_UNLCK;
if((fcntl(fd, F_SETLK, &flptr)!=-1)
{/*Блокировка снята*/}
Пример, иллюстрирующий режимы блокировки:
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/stat.h>
#define FNAME "locki.lck"
void status(struct flock *lock)
{
printf("Status: ");
switch(lock->l_type)
{
case F_UNLCK:
printf("F_UNLCK (Блокировка снята)\n");
break;
case F_RDLCK:
printf("F_RDLCK (pid: %d)
(Блокировка чтения)\n",
lock->l_pid);
break;
case F_WRLCK:
printf("F_WRLCK (pid: %d)
(Блокировка записи)\n",
lock->l_pid);
break;
default : break;
}
}
int main(int argc, char **argv)
{
struct flock lock;
int fd;
char buffer[100];
fd = open(FNAME, O_WRONLY|O_CREAT|O_APPEND,
S_IRWXU);
memset(&lock, 0, sizeof(struct flock));
/*Проверим, установлена ли блокировка*/
fcntl(fd, F_GETLK, &lock);
if(lock.l_type==F_WRLCK || lock.l_type==F_RDLCK)
{
status(&lock);
memset(&lock,0,sizeof(struct flock));
lock.l_type = F_UNLCK;
if (fcntl(fd, F_SETLK, &lock) < 0)
printf("Ошибка при :
fcntl(fd, F_SETLK, F_UNLCK) (%s)\n",
strerror(errno));
else
printf("Успешно снята блокировка:
fcntl(fd, F_SETLK, F_UNLCK)\n");
}
status(&lock);
write(STDOUT_FILENO,"\n Введены данные: ",
sizeof("\n Введены данные: "));
while((read(1,puffer,100))>1)
write(fd,buffer,100);
memset(&lock, 0, sizeof(struct flock));
lock.l_type = F_WRLCK;
lock.l_start=0;
lock.l_whence = SEEK_SET;
lock.l_len=0;
lock.l_pid = getpid();
if (fcntl(fd, F_SETLK, &lock) < 0)
printf("Ошибка при:
fcntl(fd, F_SETLK, F_WRLCK)(%s)\n",
strerror(errno));
else
printf("Успешно: fcntl(fd, F_SETLK, F_WRLCK)\n");
status(&lock);
switch(fork())
{
case -1 : exit(0);
case 0 : if(lock.l_type == F_WRLCK)
{
printf("Потомок:Невозможна запись
в файл (F_WRLCK)\n");
exit(0);
}
else
printf("Потомок готов к записи
в файл\n") ;
exit(0);
default : wait(NULL); break;
}
close(fd);
return 0;
}
Этот пример иллюстрирует возможности сериализации процессов. Тем не менее здесь все равно возможны чтение и запись в процессе-потомке. Такой вариант блокировки называется advisory locking (необязательная блокировка). При его установке не производится никаких дополнительных проверок того, должны ли системные функции open, read и write из-за блокировки запрещаться при вызове. Для advisory locking принимается, что пользователь сам является ответственным за проверку того, существуют ли определенные блокировки или нет. Невозможно запретить всем процессам доступ к файлу. Только процессы, опрашивающие наличие блокировки с помощью fcntl, блокируются при ее наличии (и то не всегда).
Для других случаев имеются так называемые строгие блокировки (mandatory locking). Эти блокировки запрещают процессу получать доступ с помощью функций read или write к данным, которые ранее были блокированы другим процессом через fcntl.
Строгие блокировки можно разрешить, установив бит Set-Group-ID и сняв бит выполнения для группы, например:
{
struct stat statbuffer;
if(fstat(fd, &statbuffer) < 0)
{
fprintf(stderr, "Ошибка при вызове fstat\n");
return 0;
}
if(fchmod(fd (statbuffer.st_mode & ~S_IXGRP) |
S_ISGID) < 0)
{
fprintf(stderr, "Невозможно установить строгую
блокировку...\n");
return 0;
}
return 1;
}
Если с помощью open() открывается файл с флагами O_TRUNC и O_CREAT и для этого файла установлена строгая блокировка, то возвращается ошибка со значением errno=EAGAIN.
Программное обеспечение PVM предоставляет унифицированные
структуры,
с помощью которых параллельные программы могут разрабатываться эффективным
и целенаправленным способом с использованием существующего оборудования.
PVM позволяет группе гетерогенных компьютерных систем восприниматься
как одна параллельная виртуальная машина. PVM прозрачно управляет
обработкой всех сообщений, преобразованием данных и выполнением заданий
в пределах сети, включающей несовместимые компьютерные архитектуры.
Вычислительная модель PVM является простой, весьма обобщенной, поэтому приспосабливается к широкому спектру программных структур приложений. Программный интерфейс преднамеренно сделан ``целевым'', что позволяет доступ к простым программным структурам осуществляеть интуитивным способом. Пользователь пишет свою программу в виде группы взаимосвязанных ``задач''. Задачи получают доступ к ресурсам PVM посредством библиотеки подпрограмм со стандартизированным интерфейсом. Эти подпрограммы позволяют инициировать и завершить задачу в сети, а также обеспечить связь между задачами и их синхронизацию. Примитивы обмена сообщениями PVM ориентированы на гетерогенные операции, включающие строго определенные конструкции для буферизации и пересылки. Коммуникационные конструкции содержат их для передачи и приема структур данных, также, как и высокоуровневые примитивы, такие как широковещательная передача, барьерная синхронизация и глобальное суммирование.
Задачи PVM могут содержать структуры для обеспечения необходимых уровней контроля и зависимости. Другими словами, в любой ``точке'' выполнения взаимосвязанных приложений любая возможная задача может запускать или останавливать другие задачи, добавлять или удалять компьютеры из виртуальной машины. Каждый процесс может взаимодействовать и/или синхронизироваться с любым другим. Каждая специфическая структура для контроля и зависимости может быть реализована в системе PVM адекватным использованием конструкций PVM и управляющих конструкций главного (хост-) языка системы.
Всеобъемлющая природа (специфичная для концепции виртуальной машины), а также ее простой, но функционально полный программный интерфейс, обеспечили системе PVM широкое признание, в том числе и в научном сообществе, связанном с высокоскоростными вычислениями.
PVM (параллельная виртуальная машина) - это побочный продукт продвижения гетерогенных сетевых исследовательских проектов, распространяемый авторами и институтами, в которых они работают. Общими целями этого проекта являются исследование проблематики и разработка решений в области гетерогенных параллельных вычислений. PVM представляет собой набор программных средств и библиотек, которые эмулируют общецелевые, гибкие гетерогенные вычислительные структуры для параллелизма во взаимосвязанных компьютерах с различными архитектурами. Главной же целью системы PVM является обеспечение возможности совместного использования группы компьютеров совместно для взаимосвязанных или параллельных вычислений. Вкратце, основные постулаты, взятые за основу для PVM, следующие:
Вторая часть системы - это библиотека подпрограмм интерфейса PVM. Она содержит функционально полный набор примитивов, которые необходимы для взаимодействия между задачами приложения. Эта библиотека содержит вызываемые пользователем подпрограммы для обмена сообщениями, порождения процессов, координирования задач и модификации виртуальной машины.
Вычислительная модель PVM базируется на предположении, что приложение состоит из нескольких задач. Каждая задача ответственна за часть вычислительной нагрузки приложения. Иногда приложение распараллеливается по функциональному принципу, т. е. каждая задача выполняет свою функцию, например: ввод, порождение, счет, вывод, отображение. Такой процесс часто определяют как функциональный параллелизм. Более часто встречается метод параллелизма приложений, называемый параллелизмом обработки данных. В этом случае все задачи одинаковы, но каждая из них имеет доступ и оперирует только небольшой частью общих данных. Схожая ситуация в вычислительной модели ОКМД (одна команда, множество данных). PVM поддерживает любой из перечисленных методов отдельно или в комплексе. В зависимости от функций задачи могут выполняться параллельно и нуждаться в синхронизации или обмене данными, хотя это происходит не во всех случаях. Диаграмма вычислительной модели PVM показана на рис. 8, а архитектурный вид системы PVM, с выделением гетерогенности вычислительных платформ, поддерживаемых PVM, показан на рис. 9.
В настоящее время PVM поддерживает языки программирования C, C++ и Фортран. Этот набор языковых интерфейсов взят за основу в связи с тем, что преобладающее большинство целевых приложений написаны на C и Фортран, но наблюдается и тенденция экспериментирования с объектно - ориентированными языками и методологиями.
Привязка языков C и C++ к пользовательскому интерфейсу PVM реализована в виде функций, следующих общепринятым подходам, используемым большинством C-систем, включая UNIX - подобные операционные системы. Уточним, что аргументы функции - это комбинация числовых параметров и указателей , а выходные значения отражают результат работы вызова. В дополнение к этому используются макроопределения для системных констант и такие глобальные переменные, как errno и pvm_errno, которые служат для точного определения результата в числе возможных. Прикладные программы, написанные на C и C++, получают доступ к функциям библиотеки PVM путем прилинковки к ним архивной библиотеки (libpvm3.a)как часть стандартного дистрибутива.
Привязка к языку Фортрана реализована скорее в виде подпрограмм, чем в виде функций. Такой подход применен по той причине, что некоторые компиляторы для поддерживаемых архитектур не смогли бы достоверно реализовать интерфейс между C- и Фортран-функциями. Непосредственным следствием из этого является то, что для каждого вызова библиотеки PVM вводится дополнительный аргумент - для возвращения результирующего статуса в вызвавшую его программу. Также унифицированы библиотечные подпрограммы для размещения введенных данных в буферы сообщения и их восстановления, они имеют дополнительный параметр для отображения типа данных. Кроме этих различий (и разницы в стандартных префиксах при именовании: pvm_ - для C и pvmf_ - для Фортран), возможно взаимодействие ``друг с другом'' между двумя языковыми привязками. Интерфейсы PVM на Фортране реализованы в виде библиотечных надстроек, которые в свою очередь, после разбора и/или определения состава аргументов, вызывают нужные C-подпрограммы. Так, Фортран-приложения требуют прилинковки библиотеки-надстройки (libfpvm3.a) в дополнение к C-библиотеке.
Все задачи PVM идентифицируются посредством целочисленного ``идентификатора задачи'' (task identifier - TID). Сообщения передаются и принимаются с помощью идентификаторов задач. Поэтому эти идентификаторы должны быть уникальными в пределах внутренней виртуальной машины, что поддерживается локальным pvmd и поэтому прозрачно для пользователя. Хотя PVM кодирует информацию в каждом TID, пользователь склонен трактовать идентификаторы задач как скрытые целочисленные идентификаторы. PVM содержит несколько подпрограмм, которые возвращают значения в TID, тем самым давая возможность пользовательскому приложению идентифицировать другие задачи в системе.
Существуют приложения, при рассмотрении которых естественно подумать о ``группе задач'', а также случаи, когда пользователю было бы удобно определять свои задачи по номерам: 0 - (p-1), где p - количество задач. PVM поддерживает концепцию именуемых пользователем групп. При этом задача находится в группе и ей присвоен ``случайный'' номер в этой группе. Случайные номера стартуют с 0. В соответствии с философией PVM, групповые функции разрабатываются таким образом, чтобы они были очень обобщенными и понятными для пользователя. Например, любая задача PVM может войти в состав любой группы или покинуть ее в произвольный момент времени, не информируя об этом каждую задачу в данной группе. Кроме того, группы могут перекрываться, а задачи могут рассылать широковещательные сообщения, адресованные тем группам, в которых они не состоят. Для использования любой из групповых функций к программе должна быть прилинкована libgpvm3.a.
Общая парадигма для программирования приложений с помощью PVM описана ниже. Пользователь пишет одну либо несколько последовательных программ на C, C++ или Фортран 77, в которые встроены вызовы библиотеки PVM. Каждая программа порождает задачу, реализующую приложение. Эти программы компилируются по правилам каждой архитектуры в пуле хостов, и в результате получаются объектные файлы, помещаемые по местам, доступным на машинах в пуле хостов. Для выполнения приложения пользователь обычно запускает одну копию задачи (обычно это ``ведущая'' или ``инициирующая'' задача) вручную на машине из пула хостов. Этот процесс последовательно порождает другие задачи PVM; в конечном счете получается группа активных задач, оперирующих локально и обменивающихся сообщениями друг с другом для решения проблемы. Обратите внимание на то, что выше приведен типичный сценарий, но вручную можно запускать столько задач, сколько нужно. Как уже упоминалось, задачи взаимодействуют путем прямого обмена сообщениями с идентификацией определенными системой, скрытыми TID.
Ниже приведена программа PVM hello - простой пример, который иллюстрирует базовую концепцию программирования PVM. Эта программа рассматривается как запускаемая вручную; после вывода на экран своего идентификатора задачи (полученного с помощью pvm_mytid()) она порождает копию другой программы под названием hello_other, используя функцию pvm_spawn(). Успешное порождение заставляет программу выполнить блокирующий прием с помощью pvm_recv(). После приема сообщения программа выводит на экран сообщение, посланное ей абонентом - так же как и свой идентификатор задачи; содержимое буфера извлекается из сообщения применением pvm_upsksrt(). Заключительный вызов pvm_exit ``выводит'' программу из системы PVM:
main()
{
int cc, tid, msgtag;
char buf[100];
printf("Это программа t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "",
1, &tid);
if (cc == 1) {
msgtag = 1;
pvm_recv(tid, msgtag);
pvm_upkstr(buf);
printf("Вывод из t%x: %s\n", tid, buf);
} else
printf("Невозможно запустить hello_other\n");
pvm_exit();
}
main()
{
int ptid, msgtag;
char buf[100];
ptid = pvm_parent();
strcopy(buf, "hello, world from");
msgtag = 1;
gethostname(buf + strlen(buf), 64);
msgtag = 1;
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, msgtag);
pvm_exit();
}
В этом разделе описывается, как установить программный пакет PVM, как сконфигурировать простую виртуальную машину, и как скомпилировать и выполнить программы примеров, поддерживаемые PVM. В первой части раздела описываются использование PVM и наиболее часто встречающиеся ошибки и трудности в процессе установки и эксплуатации. В следующем разделе описываются некоторые расширенные опции, позволяющие читателю настроить среду PVM по своему усмотрению.
Последняя версия исходных текстов PVM и документация всегда доступны посредством netlib. netlib - это сервисная служба по распространению программного обеспечения, установленная в сети Internet, в которой содержится большой набор программного обеспечения компьютеров. Программное обеспечение может быть получено от netlib с помощью ftp, www, xnetlib или e-mail клиентов.
Файлы PVM могут быть загружены из анонимного ftp-сервера по адресу netlib2.cs.utk.edu. Загляните в каталог pvm3. Файл index содержит описание файлов и подкаталогов в этом каталоге.
Используя браузеры, файлы PVM можно забрать по адресу
http://www.netlib.org/pvm3/index_html.
xnetlib - это интерфейс для оболочки X-Window, который позволяет
пользователям просматривать содержимое службы netlib или
искать с ее помощью доступное наработанное программное обеспечение
и автоматически пересылать избранное на пользовательский компьютер.
Для получения xnetlib отправьте электронное письмо
по адресу netlib@ornl.gov с просьбой выслать
xnetlib.shar
с сервера xnetlib или анонимного ftp-сервера
cs.utk.edu/pub/xnetlib.
Запрос на программное обеспечение PVM также можно отправить по электронной почте. Для его получения пошлите электронное письмо по адресу netlib@ornl.gov с сообщением send index from pvm3. Автоматический обработчик почты возвратит список доступных файлов с инструкциями. Преимущество такого способа заключается в простоте получения программного обеспечения каждым желающим, имеющим доступ к электронной почте в сети Internet.
Популярности PVM способствуют простота установки и использования. Для инсталляции PVM не требуется специальных привилегий. Каждый, у кого есть достоверный логин в системе хоста, может это сделать. Кроме того, только одному из лиц в организации требуется проинсталлировать PVM для всеобщего использования в пределах данной организации.
PVM использует две переменных окружения - когда запускается и выполняется. Следовательно, каждый пользователь PVM должен установить эти две переменные для ее использования. Первая переменная - PVM_ROOT - нужна для определения местонахождения инсталлированного каталога pvm3. Вторая переменная - PVM_ARCH - сообщает PVM тип архитектуры данного хоста и, тем самым, что исполняемый код может ``забрать'' из каталога PVM_ROOT.
Наиболее простым способом установки этих двух переменных является
их определение в соответствующем файле .cshrc. Предполагается,
что вы пользуетесь csh. Пример определения PVM_ROOT:
setenv PVM_ROOT $HOME/pvm3
Рекомендуется, чтобы пользователь устанавливал PVM_ARCH, дописывая в файл .cshrc содержимое $PVM_ROOT/lib/cshrc.stub. Для успешного определения PVM_ARCH строка должна помещаться после строки c переменной PATH. Эта строка автоматически задает PVM_ARCH данного хоста и может быть частично использована, когда пользователь разделяет общую файловую систему (например, NFS) в среде с несколькими различными архитектурами.
Исходные тексты PVM для большинства архитектур поставляются совместно с другим содержимым каталогов и файлами сборки. Процесс сборки для каждого из поддерживаемых типов архитектур происходит автоматически - путем логина на хосте, обращения к каталогу PVM_ROOT и ввода make. Файл сборки будет автоматически определять, на какой архитектуре он начал выполняться, создавать соответствующие подкаталоги и ``строить'' pvm, pvmd3, libpvm3, libfpvm3.a, pvmgs, libgpvm3.a. Он поместит все эти файлы в $PVM_ROOT/lib/PVM_ARCH, за исключением pvmgs, который переносится в $PVM_ROOT /bin/PVM_ARCH.
Таким образом, необходимо:
| PVM_ARCH | Тип компьютера | Примечания |
| AFX8 | Alliant FX/8 | |
| ALPHA | DEC Alpha | DEC OSF-1 |
| BAL | Sequent Balance | DYNIX |
| BFLY | BBN Butterfly TC2000 | |
| BSD386 | 80386/486 ПК с системой Unix | BSDI, 386BSD, NetBSD |
| CM2 | Thinking Machines CM2 | наиболее совершенный Sun |
| CM5 | Thinking Machines CM5 | используются оригинальные сообщения |
| CNVX | Convex C-series | IEEE формат п.з. |
| CNVXN | Convex C-series | оригинальная п.з. |
| CRAY | доступны порты C-90 YMP, T3D | UNICOS |
| CRAY2 | Cray2 | |
| CRAYSMP | Cray S-MP | |
| DGAV | Data General Aviion | |
| E88K | Encore 88000 | |
| HP300 | HP-9000 модели 300 | HPUX |
| HPPA | HP-9000 | PA-RISC |
| I860 | Intel iPSC/860 | используются оригинальные сообщения |
| IPSC2 | Intel iPSC/2 386 хост | SysV, используются оригинальные сообщения |
| KSR1 | Kendall Square KSR-1 | OSF-1, используется разделяемая память |
| LINUX | 80386/486 ПК с системой Unix | LINUX |
| MASPAR | Maspar | наиболее совершенный DEC |
| MIPS | MIPS 4680 | |
| NEXT | NeXT | |
| PGON | Intel Paragon | используются оригинальные сообщения |
| PMAX | DECstation 3100, 5100 | Ultrix |
| RS6K | IBM/RS6000 | AIX 3.2 |
| RT | IBM RT | |
| SGI | Silicon Graphics IRIS | IRIX 4.x |
| SGI5 | Silicon Graphics IRIS | IRIX 5.x |
| SGIMP | мультипроцессор SGI | используется разделяемая память |
| SUN3 | Sun 3 | SunOS 4.2 |
| SUN4 | Sun 4, SPARCstation | SunOS 4.2 |
| SUN4SOL2 | Sun 4, SPARCstation | Solaris 2.x |
| SUNMP | мультипроцессор SPARC | Solaris 2.x, используется разделяемая память |
| SYMM | Sequent Symmetry | |
| TITN | Stardent Titan | |
| U370 | IBM 370 | AIX |
| UVAX | DEC MicroVAX |
Прежде чем перейти к компиляции и выполнению параллельных программ,
следует убедиться в том, можно ли запустить PVM и сконфигурировать
виртуальную машину. На любом из хостов, на которых инсталлирована
PVM, вы можете ввести % pvm
После этого должно появиться приглашение консоли PVM, говорящее о
том, что PVM теперь запущена на данном хосте. Можно добавить хосты
в свою виртуальную машину, введя с консоли
pvm> add имя_хоста.
Также можно удалить хосты (исключая тот, за которым вы находитесь)
из своей виртуальной машины, введя
pvm> delete имя_хоста.
Для того, чтобы увидеть, что представляет собой в настоящий момент
виртуальная машина, введите
pvm> conf.
А чтобы увидеть, какие задачи PVM выполняются на виртуальной
машине, введите
pvm> ps -a.
Если ввести quit с консоли, то консоль прекратит свое
существование, но виртуальная машина сохранится, а задачи будут продолжать
выполняться. В случае с любым приглашением Unix на любом хосте из
виртуальной машины можно ввести
% pvm.
и получить сообщение ``pvm already running'' на консоль.
При завершении работы с виртуальной машиной следует ввести
pvm> halt.
Эта команда принудительно завершит работу всех задач PVM, выключит виртуальную машину и произойдет выход из консоли.
Рекомендуемый способ остановки PVM гарантирует нормальное завершение
работы виртуальной машины. Если вы не хотите вводить связку из имен
хостов каждый раз, то воспользуйтесь
опцией hostfile. Вы можете перечислить имена хостов в файле
- по одному в строчке - и затем ввести
pvm> hostfile.
После чего PVM будет сразу добавлять все указанные хосты до появления приглашения консоли. Несколько опций может встречаться в данном файле персонально для каждого из хостов. Описание находится в конце этого раздела - для тех пользователей, которые пожелают подстроить свои виртуальные машины под специфические приложения или среды.
Существуют другие варианты запуска PVM. Функции консоли и монитора
производительности объединены в графическом пользовательском интерфейсе,
названном XPVM, который в нескомпилированном варианте доступен в библиотеке
netlib. Для запуска PVM с графическим интерфейсом X window
введите
% xpvm
При нажатии кнопки под названием hosts ``выпадет'' список
хостов, которые можно добавлять. Если Вы ``кликнете'' имя хоста, то
он будет добавлен, а иконка машины станет анимированной, соответствующей
виртуальной машине. Хост удаляется, если Вы ``кликните'' имя хоста,
который уже был включен в виртуальную машину (см. рис. 10). При запуске
XPVM происходит чтение файла $HOME/.xpvm_hosts, в котором
перечислены хосты для отображения в меню. Все хосты без префикса &
при запуске добавляются сразу.
Назначение кнопок quit и halt аналогично соответствующим командам консоли PVM. Если вы выходите из XPVM и затем перезапускаете его, то XPVM автоматически отображает, что при этом представляет собой виртуальная машина. Попрактикуйтесь в запуске, остановке XPVM и добавлении хостов с его помощью. Возникающие ошибки должны находить отображение в окне, из которого вы запустили XPVM.
Если PVM не может стартовать успешно, она выводит сообщение об ошибке на экран либо в файл протокола /tmp/pvml.<uid>. В этом подразделе описываются наиболее общие трудности, возникающие при запуске и пути их решения.
Если сообщение представляет собой:
[t80040000] Can't start
pvmd,
то прежде всего проверьте соответствующий файл .rhosts на
удаленном хосте - содержится ли в нем имя хоста, на котором
вы запускаете PVM. Внешняя проверка на предмет корректности спецификации
файла .rhosts проводится вводом
% rsh remote_host ls.
Если спецификация файла .rhosts корректна, то вы увидите список своих файлов на удаленном хосте.
Другими причинами ошибок могут оказаться отсутствие
проинсталлированной PVM на удаленном хосте или некорректная спецификация
PVM_ROOT на данном хосте. Проверить это можно вводом
% rsh remote_host $PVM_ROOT/lib/pvmd.
Некоторые оболочки Unix, например ksh, не устанавливают переменные окружения на удаленных хостах при использовании rsh. В PVM версии 3.3 есть два подхода к таким оболочкам. Первый - вы инициализируете переменную окружения PVM_DPATH на ведущем хосте как pvm3/lib/pvmd, тем самым подменяя путь, установленный по умолчанию с помощью dx. Второй подход - нужно явно сообщить PVM, где найти удаленный исполняемый pvmd с помощью опции dx= в файле.
Если работа PVM принудительно завершилась вручную или завершилась ненормально (например, из-за краха системы), то проверьте наличие файла /tmp/pvml.<uid>. Этот файл нужен для аутентификации и должен существовать только в процессе работы PVM. Если этот файл сохранился, он будет препятствовать запуску PVM. Удалите этот файл.
Если сообщение представляет собой
[t80040000] Login incorrect,
это может означать отсутствие аккаунта на удаленной машине с вашим
логином. Если ваш текущий логин отличается от логина на удаленной
машине, то вы должны воспользоваться опцией lo= в файле хоста.
Если вы получили любое другое странное сообщение, проверьте файл .cshrc. Важно, чтобы не было никакого ввода/вывода в файл .cshrc, потому что это повлияет на процесс запуска PVM. Если вы хотите выводить на экран информацию (например, who или uptime) при входе в систему, вы должны обеспечить это с помощью собственного скрипта .login - только не во время выполнения командного скрипта csh.
В этом подразделе вы изучите, как откомпиллировать и выполнить программы PVM. В последующих подразделах излагается, как писать параллельные программы PVM. В этом Вы будете иметь дело с программами-образцами, поддерживаемыми программным обеспечением PVM. Эти образцовые программы создают полезные шаблоны, на основе которых можно создавать собственные PVM программы.
Первым шагом здесь является копирование программы-образца в свою пользовательскую область на диске:
% cd $HOME/pvm3/examples
Программная модель ``ведущий-ведомый'' - наиболее популярная из используемых в распределенных вычислениях. (В области параллельного программирования более популярна модель ОКМД).
Для компиляции примера ``ведущий-ведомый'' на С введите
% aimk master slave.
Если вы предпочитаете работать c Фортраном, откомпилируйте версию на
Фортране
% aimk fmaster fslave.
В зависимости от расположения каталога согласно PVM_ROOT,
выражения INCLUDE в заголовках примеров на Фортране могут
нуждаться в изменениях. Если PVM_ROOT не совпадает с HOME/pvm3,
то замените ее таким образом, чтобы она указывала на $PVM_ROOT
/include/fpvm3.h.
Заметьте, PVM_ROOT для Фортранне ``расширяется'',
поэтому вы должны добавлять определение достоверного пути.
Программа сборки пересылает исполняемые файлы в
$HOME/pvm3/bin/PVM_ARCH,
где PVM по умолчанию будет искать их на всех хостах. Если задействованные
файловые системы на всех хостах PVM не одинаковы, то вам понадобится
дополнительно создавать или копировать (в зависимости от архитектуры)
эти исполняемые файлы на хосты в составе PVM.
Теперь, задействовав одно окно, запустите PVM и сконфигурируйте несколько
хостов. Приводимые примеры разработаны для выполнения на произвольном
числе хостов, начиная с одного. В другом окне смените каталог на HOME/pvm3/bin/PVM_ARCH
и введите % master.
Программа выдаст запрос о количестве задач. В примерах это количество
не обязательно должно совпадать с количеством хостов. Проверьте несколько
комбинаций.
Первый пример иллюстрирует возможность запустить программу PVM из любого терминала Unix на любом хосте виртуальной машины. Этот процесс подобен способу, котором вы запускали бы последовательную программу a.out на рабочей станции. В следующем примере, который также относится к модели ``ведущий-ведомый'', под названием hitc, вы можете увидеть, как порождается работа с консоли PVM, а также из XPVM.
Здесь hitc иллюстрирует балансирование динамической загрузки с
применением парадигмы ``пула задач''. Согласно парадигме пула
задач, ведущая программа управляет большой очередью задач, всегда
посылая ``простаивающим'' ведомым программам больше заданий для
выполнения - до тех пор, пока очередь не опустеет. Такая парадигма
эффективна в ситуациях, когда хосты очень рознятся по вычислительной
мощности, потому что наименее загруженные или более мощные хосты выполняют
больше работы, причем все хосты остаются занятыми до тех пор, пока
задание не будет выполнено. Для компиляции hitc введите
% aimk hitc hitc_slave.
С этого момента hitc не требует никакого пользовательского
ввода, он может быть порожден прямо с консоли PVM. Запустите консоль
PVM и добавьте ограниченное число хостов. В ответ на приглашение консоли
PVM введите pvm> spavn -> hitc.
При порождении, опция -> заставляет все конструкции вывода на экран в hitc и ему подчиненных направлять информацию в видимую область консоли. Эта возможность применима при отладке первых небольших программ PVM. Вы можете поэкспериментировать с этой опцией, помещая конструкции вывода на экран в hitc.f и hitc_slave.f и перекомпилируя их.
Далее, hitc может использоваться для иллюстрирования возможностей анимации в реальном масштабе времени для XPVM. Запустите XPVM и постройте виртуальную машину с четырьмя хостами. ``Кликните'' кнопку tasks и выберите в меню spawn. Введите hitc, когда XPVM запросит команду и ``кликните'' start. Вы увидите подсветку иконок хостов, как только виртуальная машина станет задействованной; увидите порождение задач hitc_slave и все сообщения, которые ``бродят'' между задачами на дисплее Space Time. Можно выбрать несколько других вариантов просмотра с помощью XPVM меню views. Способ task output эквивалентен применению опции -> для консоли PVM. Это заставляет стандартный вывод всех задач принудительно перенаправлять в окно, которое при этом ``всплывает''.
Установлено одно ограничение на программы, которые порождаются из XPVM (и консоли PVM): программы не должны включать никакого интерактивного ввода, например, запроса о числе подчиненных задач для запуска или о том, насколько велика решаемая задача. Этот тип информации может быть считан из файла или помещен в командную строку в качестве аргументов, но при этом никак не возможно осуществить пользовательский ввод с клавиатуры в потенциально удаленную задачу.
Консоль PVM, называемая pvm, - это автономная задача, которая позволяет пользователю запускать, опрашивать и модифицировать виртуальную машину. Консоль может запускаться и останавливаться неограниченное число раз на любом из хостов виртуальной машины без влияния на саму PVM и прочие приложения, которые могут в этот момент выполняться.
Когда запущена pvm, она в свою очередь определяет, работает ли уже PVM; если нет, pvm автоматически запускает pvmd на этом хосте, передавая pvmd опции командной строки и файл с указанием хостов. Таким образом, PVM не обязательно должна работать для того, чтобы можно было запустить консоль:
>pvm.
Консоль может воспринимать команды со стандартного ввода. Возможные команды:
alias h help
alias j jobs
setenv PVM_EXPORT DISPLAY
# print my id
echo new pvm shell
id
Как было установлено ранее, только одному лицу в группе необходимо инсталлировать PVM, но каждый ее пользователь может иметь собственный файл хостов, в котором он описывает свою собственную виртуальную машину.
В ``файле хостов'' определяется начальная их конфигурация, которую PVM объединяет в виртуальную машину. Он также содержит информацию о хостах, которые вы можете добавить в конфигурацию позже.
Файл хостов в его простейшей форме - это просто список имен хостов - по одному в строке. Пустые строки игнорируются, а строки, которые начинаются с # считаются строками комментариев. Такой подход позволяет Вам документировать файл хостов и дополнительно предоставляет ``ручной'' способ модификации начальной конфигурации путем комментирования различных имен хостов. Простейший файл хостов с конфигурацией виртуальной машины приведен ниже:
amox
tf2.evm.bsuir.unibel.by
solaris2
*** Ручной запуск ***
Загрузитесь в "honk" и введите:
pvm3/lib/pvmd -S -d0 -nhonk 1 80a9ca95:0cb6
4096 2 80a95c43:0000
Введите ответ:
Thanks,
после чего оба pvmd должны получить доступ к коммуникации.
Если вы хотите установить любую из приведенных опций как используемую по умолчанию для ряда хостов, то можете поместить нужные опции в одну строку с символом * в поле имени хоста. Эти установки по умолчанию будут иметь эффект для всех подпадающих хостов до тех пор, пока они не будут опровергнуты другой строкой с установками.
Хосты, которые вы не желаете видеть в начальной конфигурации, но хотите добавить позже, могут быть указаны в файле хостов путем внесения в начало соответствующих строк символов &. Пример файла хостов, иллюстрирующего большинство из этих опций, показан ниже:
# (пустые строки игнорируются)
gstws
ipsc dx=/usr/geist/pvm3/lib/I860/pvmd3
ibm1.scri.fsu.edu lo=gst so=pw
# Опции по умолчанию устанавливаются символом *
*ep=$sun/problem1:~/nla/mathlib
amox
#tf1.evm.bsuir.unibel.by
solaris2
# Замена опций по умолчанию новыми значениями
* lo=gageist so=pw ep=problem1
st1.bsu.edu.by
st2.bsu.edu.by
# машины, добавляемые позже, обозначены &
&sun4 ep=problem1
&corsair dx=/usr/local/bin/pvm3
&kill lo=gageist
Взаимная блокировка процессов может возникнуть из-за блокировки файлов. Пусть, например, процесс 1 пытается установить блокировку в некотором файле dead.txt в позиции 10.
Другой процесс с 2 организует блокировку того же самого файла в позиции 20. До сих пор ситуация еще управляема. Далее, процесс 1 хочет организовать следующую блокировку в позиции 20, где уже стоит блокировка процесса 2. При этом используется команда F_SETLKW. При этом процесс 1 приостанавливается до тех пор, пока процесс 2 снова не освободит со своей стороны блокировку в позиции 20. Теперь процесс 2 пытается организовать в позиции 10, где процесс 1 уже поставил свою блокировку, такую же блокировку командой F_SETLKW, и также приостанавливается и ждет, пока процесс 1 снимет блокировку. Теперь оба процесса, 1 и 2, приостановлены и оба ждут друг друга (F_SETLKW), образуя тупик. Никакой из процессов не может возобновить свое выполнение.
Причины возникновения этой ситуации во многом вызваны неудачным проектированием алгоритмов. В Linux не предусмотрены механизмы определения и предотвращения тупика, поскольку присутствие этих механизмов существенно влияет на производительность системы. Ответственность за предотвращение тупика целиком ложится на программиста.
Пример программы, вызывающей тупик:
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
#include <errno.h>
extern int errno;
void status(struct flock *lock)
{
printf("Status: ");
switch(lock->l_type)
{
case F_UNLCK: printf("F_UNLCK\n"); break;
case F_RDLCK: printf("F_RDLCK (pid: %d)\n",
lock->l_pid); break;
case F_WRLCK: printf("F_WRLCK (pid: %d)\n",
lock->l_pid); break;
default : break;
}
}
void writelock(char *proсess, int fd, off_t from,
off_t to) {
struct flock lock;
lock.l_type = F_WRLCK;
lock.l_start=from;
lock.l_whence = SEEK_SET;
lock.l_len=to;
lock.l_pid = getpid();
if (fcntl(fd, F_SETLKW, &lock) < 0)
{
printf("%s : Ошибка
fcntl(fd, F_SETLKW, F_WRLCK) (%s)\n",
proсess,strerror(errno));
printf("\nВозник DEADLOCK (%s - proсess)!\n\n",
proсess);
exit(0);
}
else
printf("%s : fcntl(fd, F_SETLKW, F_WRLCK)
успешно\n", proсess);
status(&lock);
}
int main()
{
int fd, i;
pid_t pid;
if(( fd=creat("dead.txt", S_IRUSR |
S_IWUSR | S_IRGRP | S_IROTH))<0)
{
fprintf(stderr, "Ошибка при создании......\n");
exit(0);
}
/*Заполняем dead.txt 50 байтами символа X*/
for(i=0; i<50; i++)
write(fd, "X", 1);
if((pid = fork()) < 0)
{
fprintf(stderr, "Ошибка fork()......\n");
exit(0);
}
else if(pid == 0) //Потомок
{
writelock("Потомок", fd, 20, 0);
sleep(3);
writelock("Потомок" , fd, 0, 20);
}
else //Родитель
{
writelock("Родитель", fd, 0, 20);
sleep(1);
writelock ("Родитель", fd, 20, 0);
}
exit(0);
}
Вначале создается файл данных dead.txt, в который записывается 50 символов X. Затем родительский процесс организует блокировку от байта 0 до байта 19, а потомок - блокировку от байта 20 до конца файла (EOF). Потомок "засыпает" на 3 сек., а родитель теперь устанавливает блокировку от байта 20 до байта EOF и приостанавливается, так как байты от 20 до EOF блокированы в данный момент потомком, а родитель использует команду F_SETLKW. Наконец, потомок пытается установить блокировку на запись от байта 0 до байта 19, причем он также приостанавливается, так как в этой области уже установлена блокировка родителя и используется команда F_SETLKW. Здесь возникает тупик, что подтверждается выдачей кода ошибки для errno = EDEADLK (возникновение тупика по ресурсам). Тупик может возникнуть только при использовании команды F_SETLKW. Если применять команду F_SETLK, выдается код ошибки для errno = EAGAIN (ресурс временно недоступен).
Разработка приложений для системы PVM - по крайней мере в общем смысле - следует традиционной парадигме программирования микропроцессоров с распределенной памятью, таких как мультипроцессоры семейства Intel nCUBE. Базовые технологии как для логических аспектов программирования, так и для разработки алгоритмов совпадают. Наиболее существенные различия, однако, наблюдаются в следующем:
Параллельные вычисления, используемые в системах, таких как PVM, могут сводиться к вычислениям согласно трем фундаментальным точкам зрения в зависимости от способа организации вычислительных задач. С каждой точки зрения допускаются различные стратегии распределения рабочей нагрузки (они будут рассмотрены позже, в этом разделе). Первая и наиболее общая модель для приложений PVM может быть определена как ``беспорядочные'' вычисления: группа тесно связанных процессов, в типичных случаях реализующих один код и производящих вычисления над различными порциями всех данных, что обычно приводит к периодическим обменам промежуточными результатами. Эта парадигма может, при желании, быть разделена на категории:
Беспорядочные вычисления обычно протекают за три фазы. Первая - это инициализация группы процессов; в случае с ``только станциями'' распространение информации и параметров задания в группе производится соответственно распределению рабочей нагрузки, которое обычно также осуществляется в этой фазе. Вторая фаза - вычисление. Третья фаза - сбор результатов и их вывод в выходной поток; в течение этой фазы, группа процессов расформировывается и завершает свое существование.
Модель ``ведущий-ведомый'' иллюстрируется ниже с использованием хорошо известной последовательности вычислений Манделброта, которая является представительницей класса задач под названием ``смущающий'' параллелизм. Само вычисление сводится к применению рекурсивной функции к группе вершин на некоторой комплексной плоскости до тех пор, пока значения функции не достигнут определенных величин либо начнут отклоняться. В зависимости от этого условия строится графическое представление каждой вершины на плоскости. По существу, так как результат работы функции зависит только от начального значения вершины (и не зависит от других вершин), задача может быть разделена на полностью независимые порции, алгоритм может быть применен к каждой порции, а частичные результаты комбинируются с помощью простых комбинационных схем. Однако эта модель допускает балансировку динамической нагрузки, тем самым позволяя обрабатывающим элементам разделять нагрузку неравномерно. В текущем и последующих примерах в пределах этого раздела показаны только скелеты алгоритмов и, кроме того, допускаются некоторые синтаксические вольности в подпрограммах PVM - в интересах облегчения понимания. Управляющая структура класса приложений ``ведущий-ведомый'' показана на рис 11.
{Начальное размещение}
for i := 0 to NumWorkers - 1
pvm_spawn(<worker name>} {Запуск рабочего i}
pvm_send(<worker tid>,999) {Передача задачи рабочему i}
endfor
{Прием-передача}
while (WorkToDo)
pvm_recv(888) {Прием результата}
pvm_send(<available worker tid>,999)
{Передача следующей задачи доступному рабочему}
display result
endwhile
{Сбор оставшихся результатов}
for i := 0 to NumWorkers - 1
pvm_recv(888) {Прием результата}
pvm_kill(<worker tid i>) {Завершение рабочего i}
display result
endfor
{Алгоритм Манделброта для рабочего}
while (true)
pvm_recv(999) {Прием задачи}
{Вычисление результата}
result := MandelbrotCalculations(task)
{Передача результата ведущему}
pvm_send(<master tid>,888)
endwhile
Пример ``ведущий-ведомый'', описанный выше, не предполагает коммуникаций между ведомыми. Большинство беспорядочных вычислений любой сложности требуют взаимодействия между вычислительными процессами; структура таких приложений проиллюстрирована на примере использования ``только станции'' для матричного умножения по алгоритму Каннона (подробности программирования похожих алгоритмов даются в другом разделе). Пример ``умножения матриц'' графически показан на рис. 12 (локально умножаются подматрицы матриц и используется широковещательная построчная передача строк подматриц A в связке с постолбцовыми сдвигами подматриц матрицы B):
``сдвинуть-умножить-повернуть''}
{Процессор 0 запускает другие процессы}
if (<my processor number>) = 0) then
for i := 1 to MeshDimension*MeshDimension
pvm_spawn(<component name>, ...)
endfor
endif
forall processors Pij, 0 <= i,j < MeshDimension
for k := 0 to MeshDimension-1
{Сдвиг}
if myrow = (mycolumn+k) mod MeshDimension
{Передача A во все Pxy, x = myrow, y <> mycolumn}
pvm_mcast((Pxy, x = myrow, y <> mycolumn,999)
else
pvm_recv(999) {Прием A}
endif
{Умножение. Обработка всего, содержащегося в C}
Multiply(A,B,C)
{Вращение}
{Передача B в Pxy, x = myrow-1, y = mycolumn}
pvm_send((Pxy, x = myrow-1, y = mycolumn),888)
pvm_recv(888) {Прием B}
endfor
endfor
Как уже было упомянуто, древовидная структура вычислений для контроля процессов также во многих случаях соответствует коммуникационным шаблонам. Для иллюстрирования этой модели рассматривается алгоритм параллельной сортировки, который заключается в следующем. Один процесс (вручную запущенный в PVM) обладает (вводит или генерирует) список для сортировки. Он порождает второй процесс и передает ему половину списка. На этом этапе существуют уже два процесса, каждый из которых также порождает свой процесс и передает ему одну половину от уже разделенного списка. Процесс передачи продолжается до тех пор, пока не построено дерево соответствующей разветвленности. При этом каждый процесс независимо сортирует свою порцию списка, а фаза слияния наступает, когда отсортированные подсписки передаются в обратном направлении по ветвям дерева с промежуточными слияниями, делаемыми на каждой из станций. Этот алгоритм является показательным алгоритмом с заранее известной загрузкой; диаграмма с изображением процесса дана на рис. 13; алгоритмическая схема дается ниже.
широковещательной передачи шаблона дерева}
for i := 1 to N, причем 2^N = NumProcs
forall processors P, причем P < 2^i
pvm_spawn(...) {идентификатор процесса P XOR 2^i}
if P < 2^(i-1) then
midpt := PartitionList(list);
{Send list[0..midpt] to P XOR 2^i}
pvm_send((P XOR 2^I,999)
list := list[midpt+1..MAXSIZE]
else
pvm_recv(999) {Прием списка}
endif
endfor
endfor
{Сортировка оставшегося списка}
Quicksort(list[midpt+1..MAXSIZE])
{Сбор/слияние отсортированных подсписков}
for i := N downto 1, причем 2^N = NumProcs
forall processors P, причем P < 2^i
if P >2^(i-1) then
pvm_send((P XOR 2^i),888)
{Send list to P XOR 2^i}
else
pvm_recv(888) {Прием временного списка}
merge templist into list
endif
endfor
endfor
В предыдущем подразделе обсуждалась общая парадигма параллельного программирования с учетом структуры процесса и выделены демонстративные примеры в контексте системы PVM. В этом подразделе рассматривается проблема распределения рабочей нагрузки, следующей за стабилизацией структуры процесса, и описаны несколько обобщенных парадигм, которые используются при параллельных вычислениях в распределенной памяти. Обычно применяются две общих методологии. Первая, называемая ``декомпозицией данных'' или разбиением, исходит из того, что перекрывающиеся задачи приводят к применению вычислительных операций или преобразований над одной или большим числом структур данных, а затем эти данные могут разделяться и обрабатываться. Вторая называется ``функциональная декомпозиция'', что означает - разбиение работы на основе отличий операций и функций. В некотором смысле, вычислительная модель PVM поддерживает оба вида декомпозиции: ``функциональную'' (фундаментально различающиеся задачи выполняют различные операции) и ``данных'' (идентичные задачи оперируют над различными порциями данных).
В качестве простого примера декомпозиции данных рассмотрим сложение
двух векторов ![]() и
и ![]() , в результате чего получится
вектор
, в результате чего получится
вектор ![]() . Если предположить, что над этой задачей работает
. Если предположить, что над этой задачей работает
![]() процессов, разбиение данных приведет к распределению
процессов, разбиение данных приведет к распределению ![]() элементов
каждого вектора для каждого процесса, который вычисляет соответствующие
элементов
каждого вектора для каждого процесса, который вычисляет соответствующие
![]() элементов результирующего вектора. Такое распределение данных может
быть сделано либо ``статически'', когда каждый процесс ``априори''
знает (по крайней мере, в терминах переменных
элементов результирующего вектора. Такое распределение данных может
быть сделано либо ``статически'', когда каждый процесс ``априори''
знает (по крайней мере, в терминах переменных ![]() и
и ![]() ) свою долю рабочей
нагрузки, либо ``динамически'', когда контролирующий процесс (т.е.
ведущий) распределяет подблоки рабочей нагрузки для процессов
- как и когда они освободятся. Принципиальная разница между этими
двумя подходами - это ``диспетчеризация''. При статической диспетчеризации
индивидуальная рабочая нагрузка процесса фиксирована; при динамической,
она варьирует в зависимости от состояния вычислительного
процесса. В большинстве мультипроцессорных сред статическая диспетчеризация
эффективна для таких задач как пример сложения векторов; однако в
обобщенной среде PVM статическая диспетчеризация не очень необходима.
Смысл заключается в том, что среды PVM, базирующиеся на сетевых кластерах,
восприимчивы к внешним воздействиям; поэтому статически диспетчеризированные
задачи с разделенными данными могут конфликтовать с одним или более
процессами, которые реализуют свою порцию рабочей нагрузки намного
быстрее или намного медленнее, чем другие. Эта ситуация может также
возникнуть, когда машины в системе PVM гетерогенны, обладают различными
скоростями ЦПУ, различной памятью и прочими системными атрибутами.
) свою долю рабочей
нагрузки, либо ``динамически'', когда контролирующий процесс (т.е.
ведущий) распределяет подблоки рабочей нагрузки для процессов
- как и когда они освободятся. Принципиальная разница между этими
двумя подходами - это ``диспетчеризация''. При статической диспетчеризации
индивидуальная рабочая нагрузка процесса фиксирована; при динамической,
она варьирует в зависимости от состояния вычислительного
процесса. В большинстве мультипроцессорных сред статическая диспетчеризация
эффективна для таких задач как пример сложения векторов; однако в
обобщенной среде PVM статическая диспетчеризация не очень необходима.
Смысл заключается в том, что среды PVM, базирующиеся на сетевых кластерах,
восприимчивы к внешним воздействиям; поэтому статически диспетчеризированные
задачи с разделенными данными могут конфликтовать с одним или более
процессами, которые реализуют свою порцию рабочей нагрузки намного
быстрее или намного медленнее, чем другие. Эта ситуация может также
возникнуть, когда машины в системе PVM гетерогенны, обладают различными
скоростями ЦПУ, различной памятью и прочими системными атрибутами.
При реальном исполнении даже упомянутой тривиальной задачи сложения векторов выявляется, что ввод и вывод не могут быть проигнорированы. Возникает вопрос: как заставить описанные выше процессы принять свою рабочую нагрузку и что им делать с результирующим вектором? Ответ на этот вопрос зависит от самого приложения и обстоятельств его частичного выполнения, когда:
Параллелизма в среде с распределенной памятью, такой как PVM, можно достичь и разбиением общей рабочей нагрузки по принципу подобия выполняемых операций. Большинство очевидных примеров такой формы декомпозиции связаны с тремя стадиями исполнения типичной программы под названием ``ввод, обработка и вывод результата''. При функциональной декомпозиции такое приложение может состоять из трех отдельных программ, каждая из которых предназначена для реализации одной из трех фаз. Параллелизм достигается параллельным выполнением трех программ и созданием ``конвейера'' (последовательного или дискретного) между ними. Однако обратите внимание на то, что при таком сценарии, параллелизм данных может дополнительно проявляться в каждой фазе. Пример показан на рис. 8 - различные функции реализованы в виде компонентов PVM, - возникает множество ситуаций, когда каждый компонент реализует свою порцию разных алгоритмов с разбитыми данными.
Хотя концепция функциональной декомпозиции и проиллюстрирована выше
тривиальным примером, этот термин, как правило, используется для обозначения
разбиения и распределения рабочей нагрузки функцией within,
относящийся к вычислительной фазе. В типовом случае вычисления приложения
содержат несколько особых подалгоритмов - иногда для одних и тех же
данных (МКОД или сценарий: ``много команд и одни данные''), иногда
в виде конвейеризированной последовательности преобразований, а иногда -
представленных неструктурированными шаблонами обменов. Парадигма обобщенной
функциональной декомпозиции основаывается на гипотетическом
симулировании ``продвижения'' самолета, состоящего из множества
взаимосвязанных и взаимодействующих, функционально декомпозированных
подалгоритмов. Диаграмма,
предоставляющая возможность взглянуть на
такой пример, показана на рис. 14 (кроме того, она будет использоваться
в разделах, где описывается графическое программирование
PVM).
На рисунке каждое состояние, т.е. круг на ``графе'', представляет функционально декомпозированную часть приложения. Функция ввода распределяет частичные параметры задачи на различные функции 2 - 6, после порождения процессов соответствующих подпрограмм, реализующих каждый из подалгоритмов приложения. Некоторые данные могут быть переданы нескольким функциям (как в случае с двумя функциями wing) или данные могут предназначаться только для одной функции. После выполнения некоторого количества вычислений, эти функции доставляют непосредственно конечный результат в функции 7, 8 и 9, которые могут порождаться в начале вычислительного процесса и поэтому быть доступными. Диаграмма отражает первичную концепцию декомпозиции приложений по функциям с тем же успехом, что и отношения зависимости по контролю и данным. Параллелизм достигается благодаря двум причинам: параллельному и независимому исполнению модулей (функциями 2 - 6) плюс одновременному и конвейеризированному исполнению модулей в цепи зависимости (функциями 1, 6, 8 и 9).
Чтобы использовать систему PVM, приложение должно пройти две стадии. Первая заключается в разработке распределенной в памяти параллельной версии алгоритма приложения; эта фаза общая как для системы PVM, так и для других мультипроцессоров с распределенной памятью. Фактические параллельные решения подпадают под две главные категории: одна связана со структурой, другая - с эффективностью. В решениях, связанных со структурой распараллеливаемых приложений, основной упор делается на выбор используемой модели (т.е. беспорядочные вычисления в противовес древовидным вычислениям или функциональной декомпозиции). Решения с упором на эффективность - распараллеливание ведется в среде распределенной памяти - в целом ориентировано на минимизацию частоты и интенсивности коммуникаций. Обычно в отношении последних можно сказать, что процесс распараллеливания различен для PVM и аппаратных мультипроцессоров; для среды PVM, основывающейся на сетях, сильная степень детализации, как правило, повышает производительность. При наличии указанной особенности, процессы распараллеливания для PVM и для других сред с распределенной памятью, включая аппаратные мультипроцессоры, очень похожи.
Распараллеливание приложений можно делать ``интуитивно'', взяв за основу существующие последовательные версии или даже параллельные. В обоих случаях стадии сводятся к выбору подходящего алгоритма для каждой из подзадач приложения - обычно с помощью опубликованных описаний - или изобретению параллельного алгоритма и последующему кодированию этого алгоритма на выбранном языке (C, C++ или Фортран77 - для PVM), а также к реализации интерфейса с другими приложениями, управляющим процессом и прочими конструкциями. При распараллеливании существующих последовательных программ также обычно следуют общим рекомендациям, первичной из которых является ``разрыв петель'': начиная с наиболее удаленных и постепенно продвигаясь вглубь. Основная работа такого процесса заключается в определении зависимостей и разрыве петель таким образом, чтобы зависимости не нарушались при возникновении параллельных выполнений. Процесс такого распараллеливания описан в ряде печатных изданий и учебников по параллельному программированию, хотя в немногих из них обсуждаются практические и специфические аспекты трансформации последовательной программы в параллельную.
Современные параллельные программы могут базироваться либо на парадигме общей памяти, либо на парадигме распределенной памяти. Приспособление написанных программ для общей памяти к PVM похоже на преобразование из последовательного кода, причем версии с общей памятью базируются на векторном или на уровне петель параллелизме. В случае с программами, явно разделяющими память, первичная задача состоит в поиске точек синхронизации и замещении их обменами сообщений. Для преобразования параллельного кода для распределенной памяти в PVM главная задача состоит в преобразовании одного набора параллельных конструкций в другой. Обычно существующие параллельные программы для распределенной памяти написаны либо для аппаратных мультипроцессоров, либо для других сетевых сред, таких как p4 или Express. В обоих случаях, главные изменения требуется провести в отношении подсистемы управлении процессами. В примере с семейством Intel DMMP обычной практикой является запуск процессов с помощью командной строки интерактивных оболочек. Такая парадигма должна замещаться PVM - либо посредством ведущей программы, либо посредством программы для станции, берущей на себя ответственность за порождение процессов. В смысле взаимодействия, при этом, к счастью, много общего между вызовами по обмену сообщениями в различных средах программирования. Основными же различиями PVM и других систем в этом контексте являются:
В этом разделе приведено ознакомительное описание подпрограмм PVM версии 3. Раздел отсортирован по функциям, выполняемым подпрограммами. Например, в подразделе об ``обмене сообщениями'' идет речь о всех подпрограммах передачи и приема данных между двумя задачами PVM и опциях обмена сообщениями PVM.
В PVM версии 3 все задачи идентифицируются с помощью целого числа, предоставляемого pvmd. Далее по тексту такой идентификатор задачи обозначается TID. Это обозначение похоже на обозначение идентификатора процесса (PID), используемое в системе UNIX, предполагающее прозрачность для пользователя; значение TID также не имеет специального значения для пользователя. Фактически, PVM кодирует информацию в TID для своего собственного внутреннего использования.
Все подпрограммы PVM написаны на C. Приложения на C++ могут компоноваться с библиотекой PVM. Приложения на Фортране могут вызывать эти подпрограммы посредством интерфейса Фортран 77, поддерживаемого исходными текстами PVM версии 3. Данный интерфейс переводит аргументы, которые переданы при обращении на Фортранв соответствующие значения - если это нужно - для находящихся в более низком слое C-подпрограмм. Интерфейс также затрагивает формы представлений символьных строк на Фортране и различные соглашения при именовании, которые разные Фортран-компиляторы используют при вызове C-функций.
В коммуникационной модели PVM принято, что любая задача может передавать сообщение всякой задаче PVM и нет никаких ограничений на длину и количество таких сообщений. Поскольку все хосты имеют лимиты физической памяти, которые ограничивают потенциальное буферное пространство, коммуникационная модель не ограничивается этими частичными машинными лимитами, а подразумевает доступность и достаточность памяти. Таким образом, коммуникационная модель PVM предоставляет функции асинхронной блокирующей передачи, асинхронного блокирующего приема и неблокирующего приема. Согласно нашей терминологии блокирующая передача - это задача, которая завершается так быстро, как только буфер передачи освобождается для повторного использования, а асинхронная передача - передача, которая не зависит от состояния приемника, вызвавшего соответствующий прием до того, как передача завершится. В PVM версии 3 есть опции, которые указывают, что данные должны передаваться прямо от задачи к задаче. В этом случае, если сообщение большое, передатчик может блокироваться до тех пор, пока приемник не вызовет соответствующий прием.
Неблокирующий прием непосредственно возвращает либо данные, либо флаг, подтверждающий что данные не прибыли, в то время, как блокирующий прием завершается только после того, как данные появятся в буфере приема. В дополнение к приведенным коммуникационным функциям типа ``точка - точка'', модель поддерживает широковещательную передачу набору задач, в частности определенной пользователем группе задач. Имеются так же функции для нахождения глобального максимума, вычисления глобальной суммы и другие, приеменимые для группы задач. Для указания источника при приеме могут использоваться специальные символы и метки, позволяющие игнорировать контекст полностью или по частям. Подпрограмма может вызываться и с целью получения информации о принятых сообщениях.
Модель PVM гарантирует сохранение порядка сообщений. Если задача 1 посылает сообщение A задаче 2, а затем эта же задача посылает сообщение B той же задаче, то сообщение A поступит задаче 2 раньше, чем сообщение B. Более того, если оба сообщения возникнут до того, как задача 2 выполнит прием, то прием с указанием специальных символов будет всегда возвращать сообщение A.
Буферы сообщений распределяются динамически. Однако максимальная длина сообщения, которое может быть передано или принято, ограничивается объемом доступной памяти на данном хосте. В PVM версии 3.3 встроен только ``ограничительный'' текущий контроль. PVM может выдавать пользователю ошибку ``Can't get memory'' в тех случаях, когда суммарный объем входящих сообщений превышает размер доступной памяти, но при этом PVM не просит другие задачи остановить передачу для данного хоста.
call pvmfmytid (tid)
call pvmfexit(info)
char *where, int ntask, int *tids)
call pvmfspawn (task, argv, flag, where, ntask, tids,
numt)
| Значение | Опция | Cмысл |
| 0 | PvmTaskDefault | Место порождения процессов выбирает сама PVM |
| 1 | PvmTaskHost | аргумент where - определенный хост для порождения |
| 2 | PvmTaskArch | аргумент where - PVM_ARCH для порождения |
| 4 | PvmTaskDebug | запускает задачи под отладчиком |
| 8 | PvmTaskTrace | генерируются трассировочные данные |
| 16 | PvmMppFront | задачи запускаются в среде MPP |
| 32 | PvmHostCompl | where дополняет набор хостов |
Эти имена предопределены в pvm3/include/pvm3.h. На Фортране
все имена предопределяются в параметрических конструкциях, которые
могут быть найдены в разделе include файла
pvm3/include/pvm3.h.
PvmTaskTrace - это новая возможность PVM версии 3.3. Она заставляет порождаемые задачи генерировать трассировочные события. PvmTaskTrace используется XPVM. В ином случае пользователь должен с помощью pvm_setopt() указать, когда генерировать трассировочные события.
При возврате переменной numt присваивается количество успешно порожденных задач или код ошибки, если ни одна из задач не смогла стартовать. Если задачи были запущены, то pwn_spawn вернет вектор, состоящий из идентификаторов порожденных задач; если не смогли стартовать лишь некоторые задачи, соответствующие коды ошибок помещаются в последние ntask - numt позиций вектора.
Вызов pvm_spawn() может также запускать задачи и на мультипроцессорах. В случае с Intel iPSC/860 накладываются следующие ограничения. Каждый порождающий вызов получает подкуб размера ntask и загружает программу task во все соответствующие станции. ОС iPSC/860 имеет распределительное ограничение: 10 подкубов для всех пользователей, так что лучше запустить блок из задач в iPSC/860 одним вызовом, чем несколькими. Два самостоятельных блока задач, порожденные в iPSC/860 раздельно, все равно могут взаимодействовать друг с другом так же, как и с другими задачами PVM, даже с учетом того, что они существуют в разных подкубах. ОС iPSC/860 имеет еще одно ограничение: сообщения, следующие от станций во ``внешний мир'', должны быть меньше 256 КБайтов.
call pvmfkill (tid, info)
call pvmfcatchout (onoff)
Если pvm_exit вызывается предком тогда, когда активирован сбор выходных потоков, он будет блокироваться до тех пор, пока все задачи, выполняющие вывод, не отработают в том порядке, в котором они осуществляли весь свой вывод. Во избежание такой ситуации можно ``выключить сбор выходных потоков'' вызовом pvm_catchout(0) перед тем, как вызвать pvm_exit.
Новые возможности PVM версии 3.3 включают и возможность регистрировать специальные задачи PVM для обработки заданий по включению новых хостов, размещению задач на хостах и запуску новых задач. С этой целью создается интерфейс для ``продвинутых'' пакетных планировщиков (примерами могут быть Condor, DQS и LSF), которые подключаются к PVM и позволяют выполнять задания PVM в пакетном режиме. Такие регистрирующие подпрограммы также создают интерфейс для разработчиков отладчиков - для стимулирования удовлетворительных разработок сложных отладчиков специально для PVM.
Имена таких подпрограмм: pvm_reg_rm(), pvm_reg_hoster()
и
pvm_reg_tasker(). Эти ``продвинутые'' функции не
имеют значения для среднестатистического пользователя PVM и потому
здесь подробно не рассматриваются.
call pvmfparent (tid)
call pvmftidtohost (tid, dtid)
struct pvmhostinfo **hostp)
call pvmfconfig( nhost, narch, dtid, name, arch, speed,
info)
Функции на Фортране возвращают информацию об одном хосте за вызов,
поэтому для ``опроса'' всех хостов нужен цикл. Если
pvmfconfig
вызывается nhost раз, то будет представлена полная внутренняя структура виртуальной
машины. Работа с Фортран-интерфейсом подразумевает
сохранение копии массива hostp и возврат только одного ``вхождения''
за вызов. На всех хостах должны отработать циклы для того, чтобы они
получили обновленный массив hostp. Поэтому, если виртуальная
машина в течение этих вызовов изменяется, то изменение проявится в
параметрах nhost и narch, но не отразится на информации
о хосте. В настоящее время не существует способ ``сбросить'' pvmfconfig()
и заставить его перезапустить цикл в процессе его работы.
struct pvmtaskinfo **taskp)
call pvmftasks ( which, ntask, tid, ptid, dtid, flag,
aout, info)
Количество задач возвращается в ntask. taskp - это указатель на массив структур pvmtaskinfo - массив размера ntask. Каждая структура pvmtaskinfo содержит TID, pvmd TID, TID предка, флаг статуса и имя файла для порождения. (PVM ``не знает'' имя файла вручную запущенной задачи и поэтому ``не заполняет'' это имя.) Функция на Фортране возвращает информацию об одной задаче за вызов, поэтому для ``опроса'' всех задач нужен цикл. Так что, если нужно ``опрашивать'' все задачи и если pvmftasks вызывается ntask раз, то все задачи будут представлены. Фортран-реализации предполагают, что пул задач не подвержен изменениям, пока имеются циклы ``опроса'' задач. Если же пул изменился, эти изменения не проявятся до тех пор, пока не начнется следующий цикл из ntask вызовов.
Примеры использования pvm_config и pvm_tasks можно найти в исходных текстах консоли PVM, которая сама является задачей PVM. Примеры использования Фортран-версий этих подпрограмм можно найти в исходных текстах pvm3/examples/ testall.f.
int *infos)
int info = pvm_delhosts( char **hosts, int nhost,
int *infos)
call pvmfaddhost( hostinfo)
call pvmfdelhost( hostinfo)
Приведенные подпрограммы иногда применяются для установки виртуальной машины, но наиболее часто они используются для повышения гибкости и уровня толерантности к ошибкам больших приложений. Подпрограммы позволяют приложению увеличить в дозволенных пределах вычислительную мощь (добавлением хостов), если устанавливается, что другими способами решение осложняется. Одним из таких примеров может быть программа CAD/CAM, когда в процессе компиляции переопределяется сетка для конечного числа элементов, что сильно усложняет решение. Другим применением может быть повышение уровня толерантности приложения в отношении к ошибкам - можно обнаружить сбой хоста и ввести замену.
call pvmfsendsig( tid, signum, info)
int info = pvm_notify( int what, int msgtag, int cnt,
int tids)
call pvmfnotify( what, msgtag, cnt, tids, info)
Если имеется хост, на котором задача A потерпела неудачу при выполнении, а задача B запросила извещение о выходе из задачи A, то задача B будет извещена даже в том случае, когда выход был вызван косвенно - сбоем на хосте.
int val = pvm_getopt( int what)
call pvmfsetopt( what, val, oldval)
call pvmfgetopt( what, val)
| Опция | Значение | Смысл |
| PvmRoute | 1 | дисциплина маршрутизации |
| PvmDebugMask | 2 | отладочная маска |
| PvmAutoErr | 3 | автоматический рапорт об ошибках |
| PvmOutputTid | 4 | конечная цель stdout потомков |
| PvmOutputCode | 5 | msgtag для выходного потока |
| PvmTraceTid | 6 | конечная цель трассировки потомков |
| PvmTraceCode | 7 | msgtag для трассировки |
| PvmFragSize | 8 | размер фрагментов сообщений |
| PvmResvTids | 9 | разрешение доставки сообщений с зарезервированными тегами для задач с идентификаторами задач |
| PvmSelfOutputTid | 10 | конечная цель собственного stdout |
| PvmSelfOutputCode | 11 | msgtag для собственного выходного потока |
| PvmSelfTraceTid | 12 | конечная цель собственной трассировки |
| PvmSelfTraceCode | msgtag для собственной трассировки |
Наиболее популярное применение pvm_setopt - это ``включение'' прямолинейной маршрутизации между задачами PVM. В соответствии с обобщенными требованиями, пропускная сетевая коммуникационная способность PVM удваивается после вызова:
Посылка сообщения в PVM совершается тремя шагами. Первый: буфер передачи
должен быть инициализирован вызовом
pvm_initsend() или pvm_mkbuf().
Второй: сообщение должно быть ``упаковано'' в этот буфер с помощью
произвольного количества вызовов подпрограмм pvm_pk*()
в любой комбинации. (На Фортране упаковка сообщений делается подпрограммой
pvmfpack().) Третий: подготовленное сообщение посылается
соответствующему процессу вызовом подпрограммы pvm_send()
или широковещательной передачей с помощью подпрограммы pvm_mcast().
Сообщение принимается вызовом подпрограммы либо блокирующего, либо неблокирующего приема, а затем каждый из упакованных фрагментов распаковывается в буфер приема. Подпрограммы приема могут быть настроены на восприятие ``любого'' сообщения, любого сообщения от указанного источника, любого сообщения с указанным тегом, либо только сообщения с данным тегом от данного источника. Существует и ``пробная'' функция, которая проверяет, поступило ли сообщение, но на самом деле не принимает его.
Если требуется, то с помощью PVM версии 3 прием можно обработать в дополнительном контексте. Подпрограмма pvm_recvf() позволяет пользователям определять свои собственные контексты приема, в которых будут работать все последующие подпрограммы приема PVM.
call pvmfinitsend( encodingб bufid)
Опция encoding может иметь следующие значения:
call pvmfmkbuf( encodingб bufid)
call pvmffreebuf(bufidб info)
call pvmfgetsbuf( bufid)
int bufid = pvm_getrbuf( void)
call pvmfgetrbuf( bufid)
Этими подпрограммами буфер с bufid устанавливается как активный буфер передачи (или приема); состояние предыдущего активного буфера сохраняется, а его идентификатор возвращается в oldbuf.
Если при pvm_setsbuf() pvm_setrbuf() bufid установлен в 0, то имеющийся буфер сохраняется, но новый буфер не устанавливается. Такая возможность может быть использована для сохранения текущего состояния сообщений приложения - чтобы математическая библиотека или подсистема графического интерфейса, которые также используют сообщения PVM, не повредили содержимое буферов приложения. После того как прочие подсистемы отработали, буферы сообщения могут быть вновь активированы.
Сообщения можно передать и без упаковки применением подпрограмм, работающих с буферами сообщений. Это иллюстрируется следующим фрагментом:
oldid = pvm_setsbuf (bufid);
info = pvm_send (dst, tag);
info = pvm_freebuf (oldid);
Каждая из следующих подпрограмм C упаковывает массив предоставленных данных определенного типа в активный буфер передачи. Они могут быть вызваны сколько угодно раз для упаковки данных в одно сообщение. Так, сообщение может содержать несколько массивов с данными различных типов. C-структуры в процессе упаковки должны принимать их индивидуальные элементы. На комплексность упаковываемых данных ограничений не накладывается, но приложение должно распаковывать сообщения точно в соответствии с тем, как они были упакованы. Этого требует практика безопасного программирования.
Аргументами для каждой из подпрограмм являются: указатель на первый из элементов для упаковки, nitem - суммарное число элементов для упаковки из данного массива и stride - ``шаг'' для использования во время упаковки. Шаг, равный 1, означает последовательную упаковку вектора, равный 2 - упаковку ``через раз'' и т.д. Исключение составляет подпрограмма pvm_pkstr(), которая завершает упаковку строки символов при появлении NULL и поэтому не требует наличия аргументов nitem и stride.
PVM также поддерживает подпрограммы упаковки с printf - подобными форматами выражений, которые указывают, как и какие данные упаковывать в буфер передачи. Все переменные передаются через адреса - если указаны счетчик и шаг; в противном случае, предполагается, что переменные будут передаваться значениями.
int stride)
int info = pvm_pkcplx( float *xp, int nitem,
int stride)
int info = pvm_pkdcplx( double *zp, int nitem,
int stride)
int info = pvm_pkdouble( double *dp, int nitem,
int stride)
int info = pvm_pkfloat( float *fp, int nitem,
int stride)
int info = pvm_pkint( int *np, int nitem,
int stride)
int info = pvm_pklong( long *np, int nitem,
int stride)
int info = pvm_pkshort( short *np, int nitem,
int stride)
int info = pvm_pkstr( char *cp)
int info = pvm_packfconst( char fmt, ...)
| STRING 0 | REAL4 4 |
| BYTE 1 | COMPLEX8 5 |
| INTEGER2 2 | REAL8 6 |
| INTEGER4 3 | COMPLEX16 7 |
Эти имена уже предопределены в параметрических конструкциях заголовочного файла /pvm3/include/pvm3.h. Ряд производителей может расширять этот список и включать в него поддержку 64-битных архитектур в своей реализации. INTEGER8, REAL16 и др. уже будут добавлены, как только будет реализована XDR-поддержка этих типов данных.
call pvmfsend( tid, msgtag, info)
int info = pvm_mcast( int *tids, int ntask, int msgtag)
call pvmfmcast( ntask, tids, msgtag, info)
Подпрограмма pvm_mcast() помечает сообщение целочисленным идентификатором msgtag и широковещательно передает это сообщение всем задачам, указанным в целочисленном массиве tids (исключая себя). Массив tids имеет длину ntask.
int cnt, int type)
call pvmfpsend( tid, msgtag, xp, cnt, type, info)
| PVM_STR | PVM_FLOAT |
| PVM_BYTE | PVM_CPLX |
| PVM_SHORT | PVM_DOUBLE |
| PVM_INT | PVM_DCPLX |
| PVM_LONG | PVM_UINT |
| PVM_USHORT | PVM_ULONG |
PVM поддерживает несколько методов приема сообщений в задаче. В PVM нет точного соответствия функций, например, применение pvm_send не обязательно требует применения pvm_recv. Каждая из следующих подпрограмм может быть вызвана для любого из поступающих сообщений вне зависимости от того, как оно было передано (или передано широковещательно).
call pvmfrecv( tid, msgtag, bufid)
call pvmfnrecv( tid, msgtag, bufid)
call pvmfprobe( tid, msgtag, bufid)
struct timeval *tmout)
call pvmftrecv( tid, msgtag, sec, usec, bufid)
Подпрограмма pvm_bufinfo() возвращает msgtag, TID источника и длину в байтах сообщения, идентифицированного с помощью bufid. Она может применяться для установления метки и источника сообщений, которые были приняты с использованием специальных символов.
int *msgtag, int *tid)
call pvmfbufinfo( bufid, bytes, msgtag, tid, info)
int cnt, int type, int *rtid, int *rtag,
int *rcnt)
call pvmfprecv( tid, msgtag, xp, cnt, type, rtid, rtag,
rcnt, info)
Следующие подпрограммы на C распаковывают (многократно) данные определенных типов из активного буфера приема. На уровне приложения они должны соответствовать подпрограммам упаковки - по типу, числу элементов и шагу; nitem - число элементов данного типа для распаковки, а stride - шаг.
int stride)
int info = pvm_upkcplx( float *xp, int nitem,
int stride)
int info = pvm_upkdcplx( double *zp, int nitem,
int stride)
int info = pvm_upkdouble( double *dp, int nitem,
int stride)
int info = pvm_upkfloat( float *fp, int nitem,
int stride)
int info = pvm_upkint( int *np, int nitem,
int stride)
int info = pvm_upklong( long *np, int nitem,
int stride)
int info = pvm_upkshort(short *np, int nitem,
int stride)
int info = pvm_upkstr( char *cp)
int info = pvm_unpackf( const char *fmt, ...)
Единственная Фортран-подпрограмма выполняет все перечисленные функции приведенных C-подпрограмм.
Аргумент xp - это массив, куда помещается то, что распаковывается. Целочисленный аргумент what указывает тип данных для распаковки. (Та же опция what, что и для pvmfpack()).
Функции динамической группировки процессов составляют основу ключевых
подпрограмм PVM. Специализированная библиотека
libgpvm3 должна
компоноваться с пользовательскими программами, которые используют
любую групповую функцию; pvmd не реализует групповых функций.
Эта задача обрабатывается групповым сервером, который запускается
автоматически - при первом вызове групповой функции. Здесь приводятся
некоторые сведения о том, как могут обрабатываться группы в среде с
интерфейсом ``обмена сообщениями''. Выводы касаются эффективности
и надежности - в данном случае найден компромисс между статическими
и динамическими группами. Некоторые авторы приводят аргументы в пользу
того, что только задачи из группы могут пользоваться групповыми функциями.
Согласно философии PVM групповые функции разработаны как очень обобщенные и прозрачные для пользователя, что имеет определенную цену с точки зрения эффективности. Каждая задача PVM может присоединиться или покинуть любую группу в любое время - без необходимости информирования все другие задачи затрагиваемой группы. Задачи могут широковещательно передавать сообщения в группы, членами которых они не являются. В целом, любая задача PVM может вызвать любую из следующих функций во всякое время. Исключение составляют pvm_lvgroup(), pvm_barrier() и pvm_reduce(), природа которой требует членства вызывающей задачи в указанной группе.
int info = pvm_lvgroup( char *group)
call pvmfjoingroup( group, inum)
call pvmflvgroup( group, info)
Эти подпрограммы позволяют задаче присоединиться к именованной пользователем
группе и покинуть ее. Первый вызов
pvm_joingroup() создает
группу с именем group и включает в нее вызывающую задачу;
pvm_joingroup возвращает номер экземпляра процесса (inum)
в некоторой группе. Номера экземпляров находятся в диапазоне от нуля
до количества членов в группе - минус один. В PVM версии 3 одна задача
может состоять в нескольких группах.
Если процесс покинул группу и снова пытается присоединиться к ней, то он может получить другой номер экземпляра. Номера экземпляров перераспределяются, поэтому задача, состоящая в группе, будет получать наименьший из доступных номеров экземпляров. Однако если несколько задач состоят в группе, то не гарантируется, что задаче будет ``выдан'' ее предыдущий номер экземпляра.
Чтобы помочь пользователю в управлении последовательностью назначения номеров, независимо от того, происходит присоединение или отсоединение, функция pvm_lvgroup() не завершается до тех пор, пока задача не будет достоверно извещена об этом факте; pvm_joingroup(), вызываемая после этого, назначит вакантный номер экземпляра новой задаче. Ответственность за последовательность назначения номеров экземпляров накладывается на пользователя, если в алгоритме задачи возникает потребность в этом. Если несколько задач покинет группу и в ней не останется членов, то в номерах экземпляров возникнут ``пробелы''.
int inum = pvm_getinst( char *group, int tid)
int size = pvm_gsize( char *group)
call pvmfgettid( group, inum, tid)
call pvmfgetinst( group, tid, inum)
call pvmfgsize( group, size)
call pvmfbarrier( group, count, info)
call pvmfbcast( group, msgtag, info)
int nitem, int datatype, int msgtag, char *group,
int root)
call pvmfreduce( func, data, count, datatype, msgtag,
group, root, info)
PvmMax, PvmMin, PvmSum, PvmProduct
Редуцирующая операция над входными данными выполняется поэлементно. Например, если массив данных состоит из двух чисел с плавающей запятой, а функция - это PvmMax, то результат будет включать два числа: глобальный максимум от всех членов группы - первое - и глобальный максимум ото всех - второе.
В дополнение, пользователи могут определять свои собственные функции для глобальных операций и указывать их в func. Пример дается в исходных текстах PVM. Обратитесь к PVM_ROOT/examples/ gexamples.
Функция pvm_reduce() не блокируется. Если задача вызывает pvm_reduce, а затем покидает группу до того, как результат pvm_reduce появится в root, то может произойти ошибка.
Очереди сообщений как средство межпроцессной связи позволяют процессам взаимодействовать, обмениваясь данными. Данные передаются между процессами дискретными порциями, называемыми сообщениями. Процессы, использующие этот тип межпроцессной связи, могут выполнять две операции: послать или принять сообщение.
Процесс, прежде чем послать или принять какое-либо сообщение, должен запросить систему породить программные механизмы, необходимые для обработки данных операций. Процесс делает это при помощи системного вызова msgget. Обратившись к нему, процесс становится владельцем или создателем некоторого средства обмена сообщениями; кроме того, процесс специфицирует первоначальные права на выполнение операций для всех процессов, включая себя. Впоследствии владелец может уступить право собственности или изменить права на операции при помощи системного вызова msgctl, однако на протяжении всего времени существования определенного средства обмена сообщениями его создатель остается создателем. Другие процессы, обладающие соответствующими правами для выполнения различных управляющих действий, также могут использовать системный вызов msgctl.
Процессы, имеющие права на операции и пытающиеся послать или принять сообщение, могут приостанавливаться, если выполнение операции не было успешным. В частности это означает, что процесс, пытающийся послать сообщение, может ожидать, пока процесс-получатель не будет готов; и наоборот, получатель может ждать отправителя. Если указано, что процесс в таких ситуациях должен приостанавливаться, говорят о выполнении над сообщением ``операции с блокировкой''. Если приостанавливать процесс нельзя, говорят, что над сообщением выполняется ''операция без блокировки''.
Процесс, выполняющий операцию с блокировкой, может быть приостановлен до тех пор, пока не будет удовлетворено одно из условий:
В этом разделе обсуждаются несколько завершенных программ.
Первый пример - forkjoin.c - показывает, как порождать
процессы и синхронизировать их. Второй пример - PSDOT.F -
нужен при обсуждении программы вычисления так называемого точечного произведения
на Фортране. Третьим примером - failure.c - демонстрируется,
как пользователь может применять вызов
pvm_notify() для
создания ``устойчивых'' приложений. Представлен пример матричного
умножения. И наконец, показано, как PVM может быть использована для
вычислений, связанных c высокотемпературной диффузией.
Первым примером демонстрируется, как порождать задачи PVM и синхронизировать их. Программа порождает несколько задач - по умолчанию три. После этого потомок синхронизируется путем передачи сообщения своей задаче-предку. Предок принимает сообщения от каждой порожденной им задачи и выводит на экран информацию, заключенную в этих сообщениях от задач-потомков.
Программа ``раздваивание - присоединение'' (рис. ![]() ) содержит код как задачи-предка,
так и задачи-потомка. Самое
первое действие, которое делает программа - вызов функции pvm_mytid().
Функция должна вызываться для того, чтобы впоследствии можно было
выполнять остальные вызовы PVM. В результате pvm_mytid() всегда
должно возвращаться положительное целое число. Если это не так, то что-то
осуществлено неправильно. В примере ``раздваивание - присоединение''
проверяется значение mytid; если оно отражает ошибку, то
вызывается pvm_perror() и осуществляется выход из программы.
Вызов pvm_perror() выведет на экран сообщение, показывающее,
что при последнем вызове PVM имела место ошибка. В данном случае,
последним вызовом был pvm_mytid(), так что pvm_perror
может вывести на экран сообщение о том, что PVM не смогла запуститься
на текущей машине. Аргумент pvm_perror() - это строка, которой
при выводе на экран непосредственно будет предшествовать само сообщение
об ошибке. В данном случае передается argv[0], который
содержит имя программы в том виде, в котором оно было введено через
командную строку. Функция pvm_perror() вызывается после
функции UNIX perror().
) содержит код как задачи-предка,
так и задачи-потомка. Самое
первое действие, которое делает программа - вызов функции pvm_mytid().
Функция должна вызываться для того, чтобы впоследствии можно было
выполнять остальные вызовы PVM. В результате pvm_mytid() всегда
должно возвращаться положительное целое число. Если это не так, то что-то
осуществлено неправильно. В примере ``раздваивание - присоединение''
проверяется значение mytid; если оно отражает ошибку, то
вызывается pvm_perror() и осуществляется выход из программы.
Вызов pvm_perror() выведет на экран сообщение, показывающее,
что при последнем вызове PVM имела место ошибка. В данном случае,
последним вызовом был pvm_mytid(), так что pvm_perror
может вывести на экран сообщение о том, что PVM не смогла запуститься
на текущей машине. Аргумент pvm_perror() - это строка, которой
при выводе на экран непосредственно будет предшествовать само сообщение
об ошибке. В данном случае передается argv[0], который
содержит имя программы в том виде, в котором оно было введено через
командную строку. Функция pvm_perror() вызывается после
функции UNIX perror().
Допустим, что в результате получается достоверное значение mytid. Теперь вызывается pvm_parent(). Функция pvm_parent() вернет TID задачи, которая породила задачу, сделавшую вызов. Начиная с того момента, как была запущена на выполнение инициирующая программа ``раздваивание-присоединение'' из оболочки UNIX, она не имеет предка; эта инициирующая задача не будет порождаться другими задачами, но может снова запускаться пользователями вручную. Для инициирующей задачи ``раздваивание - присоединение'' результатом pvm_parent будет не определенный идентификатор задачи, а код ошибки PvmNoParent. Таким образом - проверкой эквивалентности результата вызова pvm_parent() значению PvmNoParent - можно отличить задачу-предка ``раздваивание - присоединение'' от потомка. Естественно, если задача является предком, то она должна породить потомка. Если же она предком не является, то должна послать предку сообщение.
Количество задач определяется посредством командной строки - аргументом argv[1]. Если указанное количество задач недопустимо, то программа завершается, вызывая pvm_exit(). Вызов pvm_exit() очень важен, потому что он сообщает PVM, что программа не будет больше пользоваться ее услугами. (В подобном случае, задача выходит из PVM, а PVM сделает вывод о том, что задача ``умерла'' и больше не требует обслуживания. Так или иначе - это правильный стиль ``чистого'' завершения.) Приняв, что количество задач допустимо, после этого программа ``раздваивание - присоединение'' будет пытаться породить потомка.
Вызов pvm_spawn() приказывает PVM запустить ntask
задач с именами argv[0]. Второй параметр - список аргументов
для передачи порождаемым задачам. В данном случае не нужно заботиться
о передаче потомкам частных аргументов через командную строку, поэтому
он равен NULL. Третий параметр при порождении -
PvmTaskDefault
- флаг, приказывающий PVM породить задачи в ``местах'' по умолчанию.
Если бы было необходимо размещение потомков на специфических машинах
или на машинах с особенной архитектурой, то можно было бы воспользоваться
значением флага PvmTaskHost или PvmTaskArch, а четвертым
параметром указать хост или архитектуру. Поскольку не важно, где задачи
будут исполняться, используется значение PvmTaskDefault для
флага и значение NULL для четвертого параметра. Наконец,
через ntask сообщается число задач для запуска; целочисленный
массив для потомков будет содержать идентификаторы задач вновь порожденных
потомков. Возвращаемое pvm_spawn() значение отражает, сколько
задач было порождено успешно. Если info не соответствует
ntask, то в процессе порождения произошел ряд ошибок. В случае
с ошибкой ее код помещается в массив идентификаторов задач вместо
действительного идентификатора задачи соответствующего потомка. В
программе ``раздваивание - присоединение'' этот массив проверяется
с помощью цикла, а идентификаторы задач и возможные коды ошибок выводятся
на экран. Если ни одна задача не порождена успешно, то осуществляется
выход из программы.
От каждой задачи-потомка предок принимает сообщение и выводит его
содержимое на экран. Вызовом pvm_recv() принимается сообщение
(с JOINTAG) от любой задачи. Возвращаемое pvm_recv()
значение - это целое число, определяющее буфер сообщения. Это целое
число может быть использовано как информация для поиска буферов сообщений.
Последующий вызов pvm_bufinfo() определяет
длину, тег и идентификатор задачи передающего процесса для сообщения,
заданного с помощью buf. В программе ``раздваивание-присоединение''
сообщения, посланные потомками, содержат только по одному целочисленному
значению - идентификатору задачи соответствующей задачи-потомка. Вызовом
pvm_upkint() целое число распаковывается из сообщения в
переменную mydata. В программе
``раздваивание - присоединение'' тестируются значения
mydata
и идентификатора задачи, возвращенного pvm_bufinfo(). Если
эти значения различны, то программа содержит ошибку и сообщение об ошибке
выводится на экран. Наконец на экран выводится информация из сообщения,
и на этом работа программы-предка завершается.
Последний сегмент кода программы ``раздваивание - присоединение'' будет исполняться как задача-потомок. Чтобы можно было поместить данные в буфер сообщения, он должен быть инициализирован вызовом pvm_initsend(). Параметр PvmDataDefault говорит о том, что PVM должна преобразовать данные обычным способом, чтобы удостовериться, что они прибыли в формате, корректном для целевого процессора. В некоторых случаях нет необходимости в преобразовании данных. Если пользователь уверен, что целевая машина использует тот же формат данных и, действительно, преобразовывать данные нет нужды, то он может применить PvmDataRaw в качестве параметра pvm_initsend(). Вызов pvm_pkint() размещает единственное целое число - metid - в буфере сообщения. Важно быть уверенными, что соответствующий распаковочный вызов точно соответствует данному упаковочному. Если число упаковывается как целое, а распаковывается как число с плавающей запятой, то такой подход не корректен. Аналогично, если пользователь упаковывает два целых числа одним вызовом, то он не сможет их впоследствии распаковать двойным вызовом pvm_upkint() - по одному вызову на каждое целое число. Таким образом, между упаковочным и распаковочным вызовами должно существовать соответствие ``один к одному''. В завершение сообщение с тегом JOINTAG передается задаче-предку.
Пример "раздваивание - присоединение":
Пример ``раздваивание-присоединение''
Демонстрируется, как порождать процессы и
обмениваться сообщениями
*/
/* определения и прототипы библиотеки PVM */
#include <pvm3.h>
/* максимальное число потомков, которые будут
порождаться этой программой */
#define MAXNCHILD 20
/* тег для использования в сообщениях, связанных
с присоединением */
#define JOINTAG 11
int main(int argc, char* argv[]) {
/* количество задач для порождения, 3 используются
по умолчанию */
int ntask = 3;
/* код возврата для вызовов PVM */
int info;
/* свой идентификатор задачи */
int mytid;
/* свой идентификатор задачи-предка*/
int myparent;
/* массив идентификаторов задач-потомков*/
int child[MAXNCHILD];
int i, mydata, buf, len, tag, tid;
/* поиск своего идентификатора задачи */
mytid = pvm_mytid();
/* проверка на ошибки*/
if (mytid < 0) {
/* вывод на экран сообщения об ошибке*/
pvm_perror(argv[0]);
/* выход из программы */
return -1;
}
/* нахождение числа-идентификатора задачи-предка */
myparent = pvm_parent();
/* выход, если есть ошибки, но не PvmNoParent */
if ((myparent < 0 ) && (myparent != PvmNoParent() {
pvm_perror(argv[0]);
pvm_exit();
return -1;
}
/* если предка не найдено, то это и есть предок */
if (myparent == PvmNoParent) {
/* определение числа задач для порождения */
if (argc == 2) ntask = atoi(argv[1]);
/* удостоверение, что ntask - допустимо */
if ((ntask < 1) || (ntask > MAXNCHILD))
{pvm_exit();
return 0;}
/* порождение задач-потомков*/
info = pvm_spawn(argv[0], (char**)0, PvmTaskDefault,
(char*)0, ntask, child);
/* вывод на экран идентификаторов задач */
for (i = 0; i < ntask; i++)
if (child[i] < 0) /* вывод на экран десятичного
кода ошибки*/
printf(" %d", child[i]);
else /* вывод на экран шестнадцатеричного
идентификатора задачи */
printf("t%x\t", child[i]);
putchar('\n');
/* удостоверение, что порождение произошло успешно */
if (info == 0) {pvm_exit(); return -1;}
/* ожидание ответов только от тех потомков, которые
порождены успешно */
ntask = info;
for (i = 0; i < ntask; i++) {
/* прием сообщения от любого процесса-потомка */
buf = pvm_recv(-1, JOINTAG);
if (buf < 0) pvm_perror("calling recv");
info = pvm_bufinfo(buf, &len, &tag, &tid);
if (info < 0) pvm_perror("calling pvm_bufinfo");
info = pvm_upkint(&mydata, 1, 1);
if (info < 0) pvm_perror("calling pvm_upkint");
if (mydata != tid)
printf("Этого не может быть!\n");
printf("Длина %d, Tag %d, Tid t%x\n",
len, tag, tid);
}
pvm_exit();
return 0;
}
/* это потомок */
info = pvm_initsend(PvmDataDefault);
if (info < 0) {
pvm_perror("calling pvm_initsend"); pvm_exit();
return -1;
}
info = pvm_pkint(&mytid, 1, 1);
if (info < 0) {
pvm_perror("calling pvm_pkint"); pvm_exit();
return -1;
}
info = pvm_send(myparent, JOINTAG);
if (info < 0) {
pvm_perror("calling pvm_initsend"); pvm_exit();
return -1;
}
pvm_exit(); return 0;
}
Ниже показано, что выводит на экран выполняющаяся программа ``раздваивание - присоединание''.
% forkjoin
t10001c t40149 tc0037
Длина 4, Tag 11, Tid t40149
Длина 4, Tag 11, Tid tc0037
Длина 4, Tag 11, Tid t10001c
% forkjoin 4
t10001e t10001d t4014b tc0038
Длина 4, Tag 11, Tid t4014b
Длина 4, Tag 11, Tid tc0038
Длина 4, Tag 11, Tid t10001d
Длина 4, Tag 11, Tid t10001e
Заметьте, что порядок приема сообщений недетерминирован. Поскольку главный цикл предка обрабатывает сообщения по принципу ``первый пришел - первый вышел'', порядок вывода на экран определяется временем, которое сообщения затрачивают на путешествие от задачи-потомка к предку.
В этом разделе приведена простая программа на Фортране - PSDOT - для
вычисления точечного произведения. Программа вычисляет точечное произведение
массивов X и Y. В первую очередь в PSDOT вызываются PVMFMYTID()
и PVMFPARENT(). Вызов PVMFPARENT вернет PVMNOPARENT,
если задача не была ранее порождена другой задачей PVM. Если это случай,
когда PSDOT - ведущая и, следовательно, должна породить отдельные
рабочие копии PSDOT, то у пользователя запрашивается число
рабочих процессов и длина векторов для вычисления. Каждый порождаемый
процесс будет принимать ![]() элементов X и Y, где
элементов X и Y, где ![]() - длина
векторов, а
- длина
векторов, а ![]() - количество процессов, используемых при вычислении.
Если
- количество процессов, используемых при вычислении.
Если ![]() не делится на
не делится на ![]() нацело, то ведущий будет вычислять
точечное произведение ``дополнительных элементов''. Подпрограммой
SGENMAT случайным образом генерируются значения X и Y. После
этого PSDOT порождает
нацело, то ведущий будет вычислять
точечное произведение ``дополнительных элементов''. Подпрограммой
SGENMAT случайным образом генерируются значения X и Y. После
этого PSDOT порождает ![]() своих копий и передает
каждой новой задаче часть массивов X и Y. Каждое сообщение содержит
размеры подмассивов и, собственно, сами подмассивы. После того как
ведущий породил рабочие процессы и передал подвекторы, он вычисляет
точечное произведение своей порции X и Y. Затем ведущий процесс принимает
остальные локальные точечные произведения от рабочих процессов. Обратите
внимание на то, что при вызове PVMFRECV как параметр-идентификатор
задачи используется специальный символ (-1). Это говорит о том, что
сообщение от ``любой'' задачи будет устраивать принимающую сторону.
Применение специального символа таким образом может привести к ``гибридизации''.
Но в данном случае ``гибридизация'' не создаст проблему, поскольку
сложение по природе коммутативно. Другими словами, совершенно
не важно, в каком порядке складываются частичные суммы, полученные
от рабочих. Если кто-то не уверен, что ``гибридизация'' не приведет
к нежелательным программным эффектам, то ему желательно избегать ее
возникновения.
своих копий и передает
каждой новой задаче часть массивов X и Y. Каждое сообщение содержит
размеры подмассивов и, собственно, сами подмассивы. После того как
ведущий породил рабочие процессы и передал подвекторы, он вычисляет
точечное произведение своей порции X и Y. Затем ведущий процесс принимает
остальные локальные точечные произведения от рабочих процессов. Обратите
внимание на то, что при вызове PVMFRECV как параметр-идентификатор
задачи используется специальный символ (-1). Это говорит о том, что
сообщение от ``любой'' задачи будет устраивать принимающую сторону.
Применение специального символа таким образом может привести к ``гибридизации''.
Но в данном случае ``гибридизация'' не создаст проблему, поскольку
сложение по природе коммутативно. Другими словами, совершенно
не важно, в каком порядке складываются частичные суммы, полученные
от рабочих. Если кто-то не уверен, что ``гибридизация'' не приведет
к нежелательным программным эффектам, то ему желательно избегать ее
возникновения.
Как только ведущий принял все локальные точечные произведения и глобально просуммировал их, он вычисляет полное точечное произведение уже локально. Один результат вычитается из второго, а разница между величинами выводится на экран. Несущественная разница вполне ожидаема, ибо существуют погрешности, связанные с округлениями чисел с плавающей точкой.
Если программа PSDOT -это рабочий, то она принимает содержащее подмассивы X и Y сообщение от ведущего процесса. Она вычисляет точечное произведение этих подмассивов и передает результат назад ведущему процессу. В целях краткости сюда не включены подпрограммы SGENMAT и SDOT.
Программа - пример PSDOT.F:
*
* PSDOT параллельно реализует внутреннее (или точечное)
* произведение:
* векторы X и Y сначала находятся на ведущей станции,
* которая затем устанавливает виртуальную машину,
* раздает данные и задания и наконец суммирует
* локальные результаты для получения глобального
* внутреннего произведения.
*
* .. Внешние подпрограммы ..
EXTERNAL PVMFMYTID, PVMFPARENT, PVMFSPAWN, PVMFEXIT
EXTERNAL PVMFINITSEND
EXTERNAL PVMFPACK, PVMFSEND, PVMFRECV, PVMFUNPACK
EXTERNAL SGENMAT
*
* .. Внешние функции ..
INTEGER ISAMAX
REAL SDOT
EXTERNAL ISAMAX, SDOT
*
* .. Внутренние функции ..
INTRINSIC MOD
*
* .. Параметры ..
INTEGER MAXN
PARAMETER ( MAXN = 8000 )
INCLUDE 'fpvm3.h'
*
* .. Скаляры ..
INTEGER N_ LN_ MYTID_ NPROCS_ IBUF_ IERR
INTEGER I, J, K
REAL LDOT, GDOT
*
* .. Массивы ..
INTEGER TIDS(0:63)
REAL X(MAXN), Y(MAXN)
*
* Регистрация в PVM и получение идентификаторов задач
* своего и ведущего процессов.
*
CALL PVMFMYTID( MYTID )
CALL PVMFPARENT( TIDS(0) )
*
* Нужно ли порождать другие процессы
* (Это - ведущий процесс).
*
IF ( TIDS(0) .EQ. PVMNOPARENT ) THEN
*
* Получение исходных данных.
*
WRITE(*.*)
'Сколько процессов нужно создать (1-64)?'
READ(*.*) NPROCS
WRITE(*,2000) MAXN
READ(*.*) N
TIDS(0) = MYTID
IF ( N .GT. MAXN ) THEN
WRITE(*.*) 'N слишком велико.
Увеличьте параметр MAXN'//$ 'для этого случая.'
STOP
END IF
*
* LN - количество элементов точечного произведения
* для локальной обработки. Все имеют одинаковое
* количество, а ``лишние'' элементы достаются ведущему.
* ``Общее'' количество элементов хранится в J.
*
J = N / NPROCS
LN = J + MOD(N, NPROCS)
I = LN + 1
*
* Генерирование случайных X и Y.
*
CALL SGENMAT( N, 1, X, N, MYTID, NPROCS, MAXN, J )
CALL SGENMAT( N, 1, Y, N, I, N, LN, NPROCS )
*
* Обход всех рабочих процессов.
*
DO 10 K = 1, NPROCS-1
*
* Порождение процесса и проверка на ошибки.
*
CALL PVMFSPAWN( 'psdot', 0, 'anywhere', 1, TIDS(K),
IERR )
IF (IERR .NE. 1) THEN
WRITE(*.*) 'ERROR, невозможно создать процесс #',K,
$ '. Dying . . .'
CALL PVMFEXIT( IERR )
STOP
END IF
*
* Рассылка исходных данных.
*
CALL PVMFINITSEND( PVMDEFAULT, IBUF )
CALL PVMFPACK( INTEGER4, J, 1, 1, IERR )
CALL PVMFPACK( REAL4, X(I), J, 1, IERR )
CALL PVMFPACK( REAL4, Y(I), J, 1, IERR )
CALL PVMFSEND( TIDS(K), 0, IERR )
I = I + J
10 CONTINUE
*
* Вычисление ведущим своей части точечного произведения.
*
GDOT = SDOT( LN, X, 1, Y, 1 )
*
* Получение локальных точечных произведений и их
* сложение с целью формирования глобального.
*
DO 20 K = 1, NPROCS-1)
CALL PVMFRECV( -1, 1, IBUF )
CALL PVMFUNPACK( REAL4, LDOT, 1, 1, IERR )
GDOT = GDOT + LDOT
20 CONTINUE
*
* Вывод на экран результатов.
*
WRITE(*,*) ' '
WRITE(*,*) '<x,y> = ',GDOT
*
* ``Последовательное'' вычисление точечного произведения
* и его вычитание из ``распределенного'' точечного
* произведения - с целью проверки
* на допустимость уровня ошибок.
*
LDOT = SDOT( N, X, 1, Y, 1 )
WRITE(*,*) '<x,y> : последовательное произведение.
<x,y>^ : ' $ 'распределенное произведение.'
WRITE(*,*) '| <x,y> - <x,y>^ | = ',ABS(GDOT = LDOT)
WRITE(*,*) 'Завершено.'
*
* Является ли этот процесс рабочим?
*
ELSE
*
* Прием исходных данных.
*
CALL PVMFRECV( TIDS(0), 0, IBUF )
CALL PVMFUNPACK( INTEGER4, LN, 1, 1, IERR )
CALL PVMFUNPACK( REAL, X, LN, 1, IERR )
CALL PVMFUNPACK( REAL, Y, LN, 1, IERR )
*
* Вычисление локального точечного произведения
* и передача его ведущему.
*
LDOT = SDOT( LN, X, 1, Y, 1 )
CALL PVMFINITSEND( PVMDEFAULT, IBUF )
CALL PVMFPACK( REAL4, LDOT, 1, 1, IERR )
CALL PVMFSEND( TIDS(0), 1, IERR )
END IF
*
CALL PVMFEXIT( 0 )
*
1000 FORMAT(I10, 'Успешно порожден процесс #',I2,',
TID =',I10)
2000 FORMAT('Введите длину перемножаемых векторов
(1 -',I7,'):')
STOP
*
* End program PSDOT
*
END
Пример с ошибкой демонстрирует, как кто-либо может принудительно завершать задачи и определять ситуации, когда задачи отрабатывают или завершаются ненормально. В данном примере порождаются несколько задач - так же, как это сделано в предыдущих примерах. Одна из них принудительно завершается предком. Поскольку интерес состоит в нахождении ненормальных завершений задач, после их порождения вызывается pvm_notify(). Вызовом pvm_notify() PVM приказывается передать вызывающей задаче сообщение о завершении работы определенных задач. В данном случае пользователя интересуют все потомки. Заметьте, что задача, вызывающая pvm_notify(), будет получать уведомления о ``прекращении существования'' задач, указанных в массиве их идентификаторов. Нет особого смысла передавать сообщение задаче, которая завершается. Вызов, связанный с извещениями, может также использоваться для информирования задач о том, что новый хост добавлен в виртуальную машину или удален из нее. Это применимо в ситуациях, когда программа стремится динамически адаптироваться к текущему состоянию сети.
После реализации запроса об уведомлениях задача-предок принудительно
завершает работу одного из потомков. Вызовом
pvm_kill()
принудительно завершается работа исключительно той задачи, чей идентификатор
передан как параметр. После завершения одной из порожденных
задач, предок с помощью
pvm_recv(-1, TASKDIED) ожидает сообщения,
уведомляющего о
``смерти'' этой задачи. Идентификатор задачи,
которая завершилась, передается в уведомительном сообщении в виде
одного целого числа. Процесс распаковывает идентификатор ``мертвой''
задачи и выводит его на экран. Хорошим стилем так же считается и вывод
заранее известного идентификатора завершаемой задачи. Эти идентификаторы
должны быть идентичны. Задачи-потомки просто ждут примерно по минуте
и затем спокойно завершаются.
Программа - пример failure.c:
Пример уведомления о сбое
Демонстрируется, как сообщать о фактах завершения задач
*/
/* определения и прототипы библиотеки PVM */
#include <pvm3.h>
/* максимальное число потомков, которые
будут порождаться этой программой */
#define MAXNCHILD 20
/* тег для использования в сообщениях, связанных
с отработкой задач */
#define TASKDIED 11
int
main(int argc, char* argv[])
{
/* количество задач для порождения,
3 используются по умолчанию */
int ntask = 3;
/* код возврата для вызовов PVM */
int info;
/* свой идентификатор задачи */
int mytid;
/* свой идентификатор задачи-предка */
int myparent;
/* массив идентификаторов задач-потомков */
int child[MAXNCHILD];
int i, deadtid;
int tid;
char *argv[5];
/* поиск своего идентификатора задачи */
mytid = pvm_mytid();
/* проверка на ошибки */
if (mytid < 0) {
/* вывод на экран сообщения об ошибке */
pvm_perror(argv[0]);
/* выход из программы */
return -1;
}
/* нахождение числа-идентификатора задачи-предка */
myparent = pvm_parent();
/* выход, если есть ошибки, но не PvmNoParent */
if ((myparent < 0) && (myparent != PvmNoParent)) {
pvm_perror(argv[0]);
pvm_exit();
return -1;
}
/* если предок не найден, то это и есть предок */
if (myparent == PvmNoParent) {
/* определение числа задач для порождения */
if (argc == 2) ntask = atoi(argv[1]);
/* удостоверение, что ntask - допустимо */
if ((ntask < 1) || (ntask > MAXNCHILD)) {pvm_exit();
return 0; }
/* порождение задач-потомков */
info = pvm_spawn(argv[0], (char**), PvmTaskDebug,
(char*)0, ntask, child);
/* удостоверение, что порождение произошло успешно */
if (info != ntask) { pvm_exit(); return -1; }
/* вывод на экран идентификаторов задач */
for (i = 0; i < ntask; i++) printf("t%x\t",child[i]);
putchar('\n');
/* запрос об уведомлении о завершении потомка */
info = pvm_notify(PvmTaskExit, TASKDIED, ntask,
child);
if (info < 0) { pvm_perror("notify"); pvm_exit();
return -1; }
/* уничтожение потомка со ``средним''
идентификатором */
info = pvm_kill(child[ntask/2]);
if (info < 0) { pvm_perror("kill"); pvm_exit();
return -1; }
/* ожидание уведомления */
info = pvm_recv(-1, TASKDIED);
if (info < 0) { pvm_ perror("recv"); pvm_exit();
return -1; }
info = pvm_upkint(&deadtid, 1, 1);
if (info < 0) pvm_perror("calling pvm_upkint");
/* должен быть потомок со ``средним'' номером */
printf("Задача t%x завершилась.\n", deadtid);
printf("Задача t%x является средним потомком.\n",
child[ntask/2]);
pvm_exit();
return 0;
}
/* это потомок */
sleep(63);
pvm_exit();
return 0;
}
В следующем примере программируется алгоритм матричного умножения,
предложенный Фоксом (Fox)[8]. Программа
mmult будет
вычислять ![]() , где
, где ![]() ,
, ![]() и
и ![]() - все квадратные матрицы.
С целью упрощения предполагается, что для вычисления результата будут
использоваться
- все квадратные матрицы.
С целью упрощения предполагается, что для вычисления результата будут
использоваться ![]() задач. Каждая задача будет вычислять подблок
результирующей матрицы
задач. Каждая задача будет вычислять подблок
результирующей матрицы ![]() . Размер блока и значение
. Размер блока и значение ![]() передаются
программе как аргументы командной строки. Матрицы
передаются
программе как аргументы командной строки. Матрицы ![]() и
и ![]() также
устанавливаются в виде блоков, распределенных в среде из
также
устанавливаются в виде блоков, распределенных в среде из ![]() задач.
задач.
Предположим, что существует ``сеть'' из ![]() задач. Каждая
задача (
задач. Каждая
задача (![]() , где
, где ![]() ) первоначально содержит блоки
) первоначально содержит блоки
![]() ,
, ![]() и
и ![]() . Первым шагом алгоритма задачи,
расположенные по диагонали (
. Первым шагом алгоритма задачи,
расположенные по диагонали (![]() , где
, где ![]() ), передают свои
блоки
), передают свои
блоки ![]() всем остальным задачам в строке
всем остальным задачам в строке ![]() . После передачи
. После передачи
![]() каждая задача вычисляет
каждая задача вычисляет
![]() и добавляет
результат к
и добавляет
результат к ![]() . Следующим шагом блоки
. Следующим шагом блоки ![]() поворачиваются
по столбцам. Так, задача
поворачиваются
по столбцам. Так, задача ![]() передает свой блок
передает свой блок ![]() задаче
задаче
![]() (задача
(задача ![]() передает свой блок
передает свой блок ![]() задаче
задаче ![]() ).
Затем задачи возвращаются к первому шагу:
).
Затем задачи возвращаются к первому шагу: ![]() широковещательно
передается всем другим задачам в строке
широковещательно
передается всем другим задачам в строке ![]() - алгоритм продолжается.
После
- алгоритм продолжается.
После ![]() итераций матрица
итераций матрица ![]() будет содержать
будет содержать ![]() , а матрица
, а матрица
![]() вернется к исходному состоянию.
вернется к исходному состоянию.
В PVM не накладывается ограничений на то, как задача может связываться с любой другой задачей. Однако для данной программы хотелось бы представлять задачи в виде двухмерной модели тора. Чтобы учесть задачи, каждая из них включается в группу mmult. Групповые идентификаторы используются для отображения задач на наш тор. При включении в группу первой задачи она получает групповой идентификатор 0. В программе mmult, задача с нулевым групповым идентификатором порождает остальные задачи и передает параметры матричного умножения этим задачам. Такими параметрами являются m и bklsize - квадратный корень числа блоков и соответственно размер блока. После того, как все задачи порождены, а параметры переданы, вызывается pvm_barrier() - чтобы удостовериться, что все задачи присоединились к группе. Если барьер не организован, то последующий вызов pvm_gettid() может завершиться ненормально, так как некая задача к тому моменту может быть еще не в составе группы.
После того как барьер организован, сохраняются идентификаторы задач
из строки myrow в массиве. Это достигается путем
определения групповых идентификаторов всех задач в строке и запрашивания
PVM о соответствующих им идентификаторах задач. Далее, с помощью malloc()
выделяется место для блоков матриц. В действительном программном приложении,
может случиться так, что матрицы уже распределены. Далее программа
определяет строку и столбец блока ![]() , который будет вычисляться.
Это основывается на значениях групповых идентификаторов - в диапазоне
от
, который будет вычисляться.
Это основывается на значениях групповых идентификаторов - в диапазоне
от ![]() до
до ![]() включительно. Так, если допустить построчное отображение
групповых идентификаторов задач, целочисленное деление mygid/m
даст строку задач, а mygid mod m - даст столбец. С использованием
подобного отображения определяется групповой идентификатор задачи,
расположенной в торе ``выше'' или ``ниже'',
и сохраняется соответственно в up и down.
включительно. Так, если допустить построчное отображение
групповых идентификаторов задач, целочисленное деление mygid/m
даст строку задач, а mygid mod m - даст столбец. С использованием
подобного отображения определяется групповой идентификатор задачи,
расположенной в торе ``выше'' или ``ниже'',
и сохраняется соответственно в up и down.
Далее блоки инициализируются вызовом InitBlock(): ![]() - случайными числами,
- случайными числами,
![]() - идентичной матрицей, а
- идентичной матрицей, а ![]() - нулями. Это позволит нам верифицировать вычисление в конце
программы простой проверкой равенства
- нулями. Это позволит нам верифицировать вычисление в конце
программы простой проверкой равенства ![]() .
.
Наконец, выполняется главный вычислительный цикл матричного умножения.
Сначала диагональные задачи широковещательно передают имеющиеся блоки
![]() другим задачам в своих строках. Отметим, что массив myrow
в действительности содержит идентификаторы задач, выполняющих широковещательные
передачи. При повторных вызовах pvm_mcast() сообщения будут
передаваться всем задачам из массива, исключая делающую вызов задачу.
Для задач mmult эта процедура великолепно срабатывает - чтобы
напрасно не обрабатывать ``лишнее'' сообщение, поступающее самой
широковещательно передающей задаче при ``лишнем'' pvm_recv().
Как широковещательно передающая задача, так и задачи, принимающие
блок, вычисляют
другим задачам в своих строках. Отметим, что массив myrow
в действительности содержит идентификаторы задач, выполняющих широковещательные
передачи. При повторных вызовах pvm_mcast() сообщения будут
передаваться всем задачам из массива, исключая делающую вызов задачу.
Для задач mmult эта процедура великолепно срабатывает - чтобы
напрасно не обрабатывать ``лишнее'' сообщение, поступающее самой
широковещательно передающей задаче при ``лишнем'' pvm_recv().
Как широковещательно передающая задача, так и задачи, принимающие
блок, вычисляют ![]() с использованием и диагонального блока
с использованием и диагонального блока
![]() и блоков
и блоков ![]() , принадлежащих задачам.
, принадлежащих задачам.
После того как подблоки умножены и результат добавлен к блоку ![]() ,
вертикально сдвигаются блоки
,
вертикально сдвигаются блоки ![]() . Особенным образом блок
. Особенным образом блок ![]() упаковывается
в сообщение, передается задаче с идентификатором задачи up
и затем принимается новый блок
упаковывается
в сообщение, передается задаче с идентификатором задачи up
и затем принимается новый блок ![]() от задачи с идентификатором
задачи down.
от задачи с идентификатором
задачи down.
Обратите внимание на то, что используются различные теги сообщений
при передачах блоков ![]() и блоков
и блоков ![]() при различных циклических
итерациях. Полностью указываются и идентификаторы задач при выполнении
pvm_recv(). Возникает соблазн применять специальные символы
в полях pvm_recv(), однако, такая практика может быть опасной.
К примеру, если некорректно определить значение для up и
указать специальный символ при pvm_recv() вместо down,
то это может привести к ``неосознанной'' передаче сообщений
не тем задачам. В примере сообщения однозначно направлены, тем самым
уменьшая вероятность возникновения ошибок при приеме сообщений от
не тех задач, т.е. ошибочных фаз алгоритма.
при различных циклических
итерациях. Полностью указываются и идентификаторы задач при выполнении
pvm_recv(). Возникает соблазн применять специальные символы
в полях pvm_recv(), однако, такая практика может быть опасной.
К примеру, если некорректно определить значение для up и
указать специальный символ при pvm_recv() вместо down,
то это может привести к ``неосознанной'' передаче сообщений
не тем задачам. В примере сообщения однозначно направлены, тем самым
уменьшая вероятность возникновения ошибок при приеме сообщений от
не тех задач, т.е. ошибочных фаз алгоритма.
Как только вычисление завершено, проверяется ![]() - только для того,
чтобы убедиться в правильности матричного умножения, т.е. корректности
значений
- только для того,
чтобы убедиться в правильности матричного умножения, т.е. корректности
значений ![]() . Такую проверку не возможно осуществить, например, с помощью
подпрограмм из библиотеки матричного умножения.
. Такую проверку не возможно осуществить, например, с помощью
подпрограмм из библиотеки матричного умножения.
В вызове pvm_lvgroup() нет необходимости, поскольку PVM выгрузит отработавшие задачи и удалит их из группы. Однако хорошим примером является ``явный'' выход из группы перед вызовом pvm_exit(). Команда консоли PVM reset ``сбросит'' все группы PVM. Команда pvm_gstat выведет на экран статус любой из существующих групп.
Матричное умножение
*/
/* определения и прототипы библиотеки PVM */
#include <pvm3.h>
#include <stdio.h>
/* максимальное число потомков, которые
будут порождаться этой программой */
#define MAXNTIDS 100
#define MAXNROW 10
/* теги сообщений */
#define ATAG 2
#define BTAG 3
#define DIMTAG 5
void
InitBlock(float *a, float *b, float *c, int blk,
int row, int col) {
int len, ind;
int i, j;
srand_pvm_mytid__
len = blk*blk;
for (ind = 0; ind < len; ind++)
{ a[ind] = (float)(rand()%1000)/100.0; c[ind] = 0.0; }
for (i = 0; i < blk; i++) {
for (j = 0; i < blk; j++) {
if (row == col)
b[j*blk+i] = (i==j)? 1.0 : 0.0;
else
b[j*blk+i] = 0.0;
}
}
}
void
BlockMult(float* c, float* a, float* b, int blk) {
int i,j,k;
for (i = 0; i < blk; i++)
for (j = 0; i < blk; j++)
for (k = 0; k < blk; k++)
for (j = 0; i < blk; j++)
c[i*blk+j] += (a[i*blk+k] * b[k*blk+j]);
}
int
main(int argc, char* argv[])
{
/* количество задач для порождения, 3 используются
по умолчанию */
int ntask = 2;
/* код возврата для вызовов PVM */
int info;
/* свой идентификатор задачи и групповой
идентификатор */
int mytid, mygid;
/* массив идентификаторов задач-потомков*/
int child[MAXNTIDS-1];
int i, m, blksize;
/* массив идентификаторов задач в своей строке*/
int myrow[MAXROW];
float *a, *b, *c, *atmp;
int row, col, up, down;
/* поиск своего идентификатора задачи */
mytid = pvm_mytid();
pvm_setopt(PvmRoute, PvmRouteDirect);
/* проверка на ошибки*/
if (mytid < 0) {
/* вывод на экран сообщения об ошибке*/
pvm_perror(argv[0]);
/* выход из программы */
return -1;
}
/* присоединение к группе mmult*/
mygid = pvm_joingroup("mmult");
if (mygid < 0) {
pvm_perror(argv[0]); pvm_exit(); return -1;
}
/* если свой групповой идентификатор не равен 0,
то нужно породить другие задачи */
if (mygid == 0) {
/* определение числа задач для порождения */
if (argc == 3) {
m = atoi(argv[1]);
blksize = atoi(argv[2]);
}
if (argc < 3) {
fprintf(stderr, "usage: mmult m blk\n");
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* удостоверение, что ntask - допустимо */
ntask = m*m;
if ((ntask < 1) || (ntask > MAXNTIDS)) {
fprintf(stderr, "ntask = %d not valid.\n",
ntask);
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* порождать не нужно, если имеется
только одна задача */
if (ntask == 1) goto barrier;
/* порождение задач-потомков*/
info = pvm_spawn("mmult", (char**)0,
PvmTaskDefault, (char*)0, ntask-1, child);
/* удостоверение, что порождение
произошло успешно */
if (info != ntask-1) {
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* передача размерности матрицы */
pvm_initsend(PvmDataDefault);
pvm_pkint(&m, 1, 1);
pvm_pkint(&blksize, 1, 1);
pvm_mcast(child, ntask-1, DIMTAG);
}
else {
/* прием размерности матрицы */
pvm_recv(pvm_gettid("mmult", 0), DIMTAG);
pvm_pkint(&m, 1, 1);
pvm_pkint(&blksize, 1, 1);
ntask = m*m;
}
/* удостоверение, что все задачи
присоединились к группе */
barrier:
info = pvm_barrier("mmult",ntask);
if (info < 0) pvm_perror(argv[0]);
/* поиск идентификаторов задач в своей строке */
for (i = 0; i < m; i++)
myrow[i] = pvm_gettid("mmult", (mygid/m)*m + i);
/* распределение памяти для локальных блоков */
a = (float*)malloc(sizeof(float)*blksize+blksize);
b = (float*)malloc(sizeof(float)*blksize+blksize);
c = (float*)malloc(sizeof(float)*blksize+blksize);
atmp = (float*)malloc(sizeof(float)*blksize+blksize);
/* проверка достоверности указателей */
if (!(a && b && c && atmp)) {
fprintf(stderr, "%s: out of memory!\n", argv[0]);
free(a); free(b); free(c); free(atmp);
pvm_lvgroup("mmult"); pvm_exit(); return -1;
}
/* поиск строки и столбца своего блока */
row = mygid/m; col = mygid % m;
/* определение соседей сверху и снизу */
up = pvm_gettid("mmult",
((row)?(row-1):(m-1))*m+col);
down = pvm_gettid("mmult",
((row) == (m-1))?col:(row+1)*m+col));
/* инициализация блоков */
InitBlock(a, b, c, blksize, row, col);
/* выполнение матричного умножения */
for (i = 0; i < m; i++) {
/* широковещательная передача блока матрицы A */
if (col == (row + i)%m) {
pvm_initsend(PvmDataDefault);
pvm_pkfloat(a, blksize*blksize, 1);
pvm_mcast(myrow, m, (i+1)*ATAG);
BlockMult(c,a,b,blksize);
}
else {
pvm_recv(pvm_gettid("mmult", row*m + (row +i)%m),
(i+1)*ATAG);
pvm_upkfloat(atmp, blksize*blksize);
BlockMult(c,atmp,b,blksize);
}
/* поворот столбца B */
pvm_initsend(PvmDataDefault);
pvm_pkfloat(b, blksize*blksize, 1);
pvm_send(up, (i+1)*BTAG);
pvm_recv(down, (i+1)*BTAG);
pvm_upkfloat(b, blksize*blksize, 1);
}
/* проверка */
for (i = 0; i < blksize*blksize; i++)
if (a[i] != c[i])
printf("Error a[%d] (%g) != c[%d] (%g) \n", i,
a[i], i, c[i]);
printf("Done.\n");
free(a); free(b); free(c); free(atmp);
pvm_lvgroup("mmult");
pvm_exit();
return 0;
}
Здесь представлена программа PVM, которая вычисляет температурную диффузию в некой среде - в данном случае это проводник. Уравнение, описывающие одномерную температурную диффузию тонкого проводника:
Дискретизация:
В результате получаем явную формулу:
Начальные и граничные условия:
![]() - для всех
- для всех ![]() ;
;
![]() - для
- для ![]() .
.
Псевдокодом для таких вычислений будет следующий:
t = t+dt;
a(i+1,1)=0;
a(i+1,n+2)=0;
for j = 2:n+1;
a(i+1,j)=a(i,j) + mu*(a(i,j+1)-2*a(i,j)+a(i,j-1));
end;
t;
a(i+1,1:n+2);
plot(a(i,:))
end
В программе heat.c массив solution будет содержать результаты решений уравнения температурной диффузии на каждом шаге. Этот массив - в формате xgraph - будет ``выходным'' при завершении программы (xgraph - программа, предназначенная для вывода данных на графопостроитель). Сначала порождаются задачи heatslv. Далее, подготавливается исходный набор данных. Обратите внимание на то, что для конца проводника значением начальной температуры будет ноль.
Потом, четыре раза исполняется основная часть программы - каждый раз
с новым значением ![]() . Для определения продолжительности времени,
прошедшего от начала вычислений данной фазы, используется таймер.
Начальный набор данных рассылается задачам heatslv. При каждой
посылке совместно с начальным набором данных передаются идентификаторы
задач-соседей слева и справа. Задачи heatslv будут использовать
эту информацию при граничных коммуникациях. (В противном случае нужно
использовать групповые вызовы PVM для отображения задач на сегменты
проводника. При использовании групповых вызовов можно избежать явных
указаний идентификаторов задач ведомых процессов).
. Для определения продолжительности времени,
прошедшего от начала вычислений данной фазы, используется таймер.
Начальный набор данных рассылается задачам heatslv. При каждой
посылке совместно с начальным набором данных передаются идентификаторы
задач-соседей слева и справа. Задачи heatslv будут использовать
эту информацию при граничных коммуникациях. (В противном случае нужно
использовать групповые вызовы PVM для отображения задач на сегменты
проводника. При использовании групповых вызовов можно избежать явных
указаний идентификаторов задач ведомых процессов).
После рассылки исходных данных ведущий процесс ожидает получения результатов. Когда результаты поступают, они интегрируются в результирующую матрицу, вычисляется затраченное время, и решение записывается в xgraph-файл.
Как только все четыре фазы завершены, а результаты сохранены, ведущая программа выводит на экран информацию о временных затратах и принудительно завершает ведомые процессы.
Программа-пример heat.c:
heat.c
Применение PVM для решения дифференциального уравнения,
описывающего простейшую температурную диффузию,
с использованием 1 ведущей программы и 5 ведомых
Ведущая программа формирует данные, посылает их ведомым
и ожидает результаты, возвращаемые ведомыми.
Файлы с полученными результатами
готовы для использования программой xgraph
*/
#include "pvm3.h"
#include <stdio.h>
#include <math.h>
#include <time.h>
#define SLAVENAME "heatslv"
#define NPROC 5
#define TIMESTEP 100
#define PLOTINC 10
#define SIZE 1000
int num_data = SIZE/NPROC;
main()
{
int mytid, task_ids[NPROC], i, j;
int left, right, k, l;
int step = TIMESTEP;
int info;
double init[SIZE], solution[TIMESTEP][SIZE];
double result[TIMESTEP*SIZE/NPROC], deltax2;
FILE *filenum;
char *filename[4][7];
double deltat[4];
time_t t0;
int etime[4];
filename[0][0] = "graph1";
filename[1][0] = "graph2";
filename[2][0] = "graph3";
filename[3][0] = "graph4";
deltat[0] = 5.0e-1;
deltat[1] = 5.0e-3;
deltat[2] = 5.0e-6;
deltat[3] = 5.0e-9;
/* регистрация в PVM */
mytid = pvm_mytid();
/* порождение ведомых задач */
info = pvm_spawn(SLAVENAME,(char **)0,
PvmTaskDefault,"", NPROC,task_ids);
/* создание исходного набора данных */
for (i = 0; i < SIZE; i++)
init[i] = sin(M_PI * ( (double)i /
(double)(SIZE-1) ));
init[0] = 0.0;
init[SIZE-1] = 0.0;
/* четырехразовое выполнение с разными
значениями дельты t */
for (l = 0; l < 4; l++) {
deltax2 = (deltat[l]/pow(1.0/(double)SIZE,2.0));
/*засекаем время*/
time(&t0);
etime[l] = t0;
/* передача исходных данных ведомым */
/* дополнение информацией о соседях -
для реализации возможности
обмена граничными данными */
for (i = 0; i < NPROC; i++) {
pvm_initsend(PvmDataDefault);
left = (i == 0) ? 0 : task_ids[i-1];
pvm_pkint(&left, 1, 1);
right = (i == (NPROC-1)) ? 0 : task_ids[i+1];
pvm_pkint(&right, 1, 1);
pvm_pkint(&step, 1, 1);
pvm_pkdouble(&deltax2, 1, 1)
pvm_pkint(&num_data, 1, 1);
pvm_pkdouble(&init[num_data*i], num_data, 1);
pvm_send(task_ids[i], 4);
}
/* ожидание результатов */
for (i = 0; i < NPROC; i++) {
pvm_recv(task_ids[i], 7);
pvm_upkdouble(&result[0], num_data*TIMESTEP, 1);
/* ``обновление'' решения */
for (j = 0; j < TIMESTEP; j++)
for (k = 0; k < num_data; k++)
solution[j][num_data*i+k] = result[wh(j,k)];
}
/* остановка формирования временных интервалов */
time(&t0);
etime[l] = t0 - etime[l];
/* получение выходных данных */
filenum =(fopen_filename[l][0], "w");
fprintf(filenum,
"TitleText: Wire Heat over Delta Time: %e\n",
deltat[l]);
fprintf(filenum,
"XUnitText: Distance\nYUnitText: Heat\n");
for (i = 0; i < TIMESTEP; i = i + PLOTINC) {
fprintf(filenum,"\"Time index: %d\n",i);
for (j = 0; j < SIZE; j++)
fprintf(filenum,"%d %e\n",j, solution[i][j]);
fprintf(filenum,"\n");
}
fclose (filenum);
}
/* вывод на экран информации о
временных интервалах */
printf("Problem size: %d\n",SIZE);
for (i = 0; i < 4; i++)
printf("Time for run %d: %d sec\n",i,etime[i]);
/* принудительное завершение ведомых процессов */
for (i = 0; i < NPROC; i++) pvm_kill(task_ids[i]);
pvm_exit();
}
int wh(x, y)
int x, y;
{
return(x*num_data+y);
}
Программы heatslv фактически реализуют вычисление температурной диффузии ``на протяжении'' проводника. Ведомая программа состоит из бесконечного цикла: прием исходного набора данных, итеративное вычисление результата на основе этого набора (с обменом граничной информацией с соседями при каждой итерации) и посылка результирующего частичного решения назад, ведущему процессу.
Вместо создания бесконечных циклов в ведомых задачах, можно передавать специальные сообщения с приказами о завершении. Однако во избежание сложностей, связанных с обменом сообщениями, в ведомых задачах используются бесконечные циклы, а завершаются они принудительно из ведущей программы. Третьим вариантом может быть реализация с ведомыми, исполняющимися только один раз и самостоятельно завершающимися после обработки единственных наборов данных, полученных от ведущего. Если бы этот вариант был воплощен, то к полезной нагрузке добавилась бы бесполезная.
В течение каждого шага каждой фазы, происходит обмен граничными значениями температурных матриц. Сначала левосторонние граничные элементы передаются задаче-соседу слева и соответствующие граничные элементы принимаются от задачи-соседа справа. Затем, симметрично, правосторонние граничные элементы передаются правому соседу, а соответствующие - принимаются от левого. Идентификаторы задач-соседей проверяются с целью гарантирования того, что не возникнет попыток передать сообщения несуществующим задачам (или принять их).
Программа-пример heatslv.c:
heatslv.c
Ведомые принимают исходные данные от хоста,
обмениваются граничной информацией с соседями
и вычисляют изменение температуры проводника.
Это делается за несколько итераций -
``под руководством'' ведущего
*/
#include "pvm3.h"
#include <stdio.h>
int num_data;
main()
{
int mytid, left, right, i, j, master;
int timestep;
double *init, *A;
double leftdata, rightdata, delta, leftside,
rightside;
/* регистрация в PVM */
mytid = pvm_mytid();
master = pvm_parent();
/* прием своих данных от ведущей программы */
while(1) {
pvm_recv(master, 4);
pvm_upkint(&lef, 1, 1);
pvm_upkint(&right, 1, 1);
pvm_upkint(×tep, 1, 1);
pvm_upkdouble(&delta, 1, 1);
pvm_upkint(&num_data, 1, 1);
init = (double *) malloc(num_data*sizeof(double));
pvm_upkdouble(init, num_data, 1);
/* копирование исходных данных
в свой рабочий массив */
A = (double *)
malloc(num_data * timestep * sizeof(double));
for (i = 0; i < num_data; i++) A[i] = init[i];
/* реализация вычисления */
for (i = 0; i < timestep-1; i++) {
/* обмен граничной информацией
со своими соседями */
/* передача налево, прием справа */
if (left != 0) {
pvm_initsend(PvmDataDefault);
pvm_pkdouble(&A[wh(i,0)],1,1);
pvm_send(left, 5);
}
if (right != 0) {
pvm_recv(right, 5);
pvm_upkdouble(&rightdata, 1, 1);
/* передача направо, прием слева */
pvm_initsend(PvmDataDefault);
pvm_pkdouble(&A[wh(i,num_data-1)],1,1);
pvm_send(right, 6);
}
if (left != 0) {
pvm_recv(left, 6);
pvm_upkdouble(&leftdata, 1, 1);
}
/* выполнение вычислений данной итерации */
for (j = 0; j < num_data; j++) {
leftside = (j == 0) ? leftdata : A[wh(i,j-1)];
rightside =
(j == (num_data-1)) ? rightdata : A[wh(i,j+1)];
if ((j == 0) && (left == 0))
A[wh(i+1,j)] = 0.0;
else if ((j == (num_data-1)) && (right == 0))
A[wh(i+1,j)] = 0.0;
else
A[wh(i+1,j)] =
A[wh(i,j)]+
delta*(rightside-2*A[wh(i,j)]+leftside);
}
}
/* передача результатов назад ведущей программе */
pvm_initsend(PvmDataDefault);
pvm_pkdouble(&A[0],num_data*timestep,1);
pvm_send(master,7);
}
/* только при удачном исходе */
pvm_exit();
}
int wh(x, y);
int x, y;
{
return(x*num_data+y);
}
GCC - это свободно доступный оптимизирующий компилятор для языков C, C++, Ada 95, а также Objective C. Его версии применяются для различных реализаций Unix (а также VMS, OS/2 и других систем PC), и позволяют генерировать код для множества процессоров.
Вы можете использовать gcc для компиляции программ в объектные модули и для компоновки полученных модулей в единую исполняемую программу. Компилятор способен анализировать имена файлов, передаваемые ему в качестве аргументов, и определять, какие действия необходимо выполнить. Файлы с именами типа name.cc (или name.C) рассматриваются, как файлы на языке C++, а файлы вида name.o считаются объектными (т.е. внутримашинным представлением).
Чтобы откомпилировать исходный код C++, находящийся в файле F.cc, и создать объектный файл F.o, выполните команду:
gcc -c <compile-options> F.cc
Здесь строка compile-options указывает возможные дополнительные опции компиляции.
Чтобы скомпоновать один или несколько объектных файлов, полученных из исходного кода C++ - F1.o, F2.o, ... - в единый исполняемый файл F, используйте команду:
gcc -o F <link-options> F1.o F2.o ... -lg++ \
<other-libraries>
Здесь строка link-options означает возможные дополнительные опции компоновки, а строка other-libraries - подключение при компоновке дополнительных разделяемых библиотек.
Вы можете совместить два этапа обработки - компиляцию и компоновку - в один общий этап с помощью команды:
gcc -o F <compile-and-link-options> F1.cc ... -lg++\
<other-libraries>
После компоновки будет создан исполняемый файл F, который можно запустить с помощью команды:
./F <arguments>,
где строка arguments определяет аргументы командной строки вашей программы.
В процессе компоновки очень часто приходится использовать библиотеки. Библиотекой называют набор объектных файлов, сгруппированных в единый файл и проиндексированных. Когда команда компоновки обнаруживает некоторую библиотеку в списке объектных файлов для компоновки, она проверяет, содержат ли уже скомпонованные объектные файлы вызовы для функций, определенных в одном из файлов библиотек. Если такие функции найдены, соответствующие вызовы связываются с кодом объектного файла из библиотеки.
Библиотеки обычно определяются через аргументы вида
-llibrary-name. В
частности, -lg++ означает библиотеку стандартных функций C++, а -lm
определяет библиотеку различных математических функций (sin, cos, arctan, sqrt,
и т.д.). Библиотеки должны быть перечислены после исходных или объектных
файлов, содержащих вызовы к соответствующим функциям.
Среди множества опций компиляции и компоновки наиболее часто употребляются следующие:
-c
Только компиляция. Из исходных файлов программы создаются объектные файлы в виде name.o. Компоновка не производится.
-Dname=value
Определить имя name в компилируемой программе как значение value. Эффект такой же, как наличие строки
#define name value
в начале программы. Часть
`=value' может быть опущена, в этом случае значение по умолчанию равно 1.
-o file-name
Использовать file-name в качестве имени для создаваемого gcc файла (обычно это исполняемый файл).
-llibrary-name
Использовать при компоновке указанную библиотеку.
-g
Поместить в объектный или исполняемый файл отладочную информацию для отладчика gdb. Опция должна быть указана и для компиляции, и для компоновки.
-MM
Вывести заголовочные файлы (но не стандартные заголовочные), используемые в каждом исходном файле, в формате, подходящем для утилиты make. Не создавать объектные или исполняемые файлы.
-pg
Поместить в объектный или исполняемый файл инструкции профилирования для
генерации информации, используемой
утилитой gprof. Опция должна быть указана и
для компиляции, и для компоновки. Профилирование - это процесс
измерения продолжительности выполнения отдельных участков вашей
программы. Когда вы указываете -pg, полученная исполняемая программа
при запуске генерирует файл статистики. Программа gprof на основе этого
файла создает расшифровку, указывающую время, затраченное на выполнение
каждой функции.
-Wall
Вывод сообщений о всех предупреждениях или ошибках, возникающих во время трансляции программы.
-O1
Устанавливает оптимизацию уровня 1. Оптимизированная трансляции требует несколько больше времени и несколько больше памяти для больших функций. Без указания опций `-O' цель компилятора состoит в том, чтобы уменьшить стоимость трансляции и выдать ожидаемые результаты при отладке. Операторы независимы: если вы останавливаете программу на контрольной точке между операторами, то можете назначить новое значение любой переменной или поставить счетчик команд на любой другой оператор в функции и получить точно такие результаты, которые вы ожидали от исходного текста. С указанием `-O' компилятор пробует уменьшить размер кода и время исполнения.
-O2
Устанавливает оптимизацию уровня 2. GNU CC выполняет почти все поддерживаемые оптимизации, которые не включают уменьшение времени исполнения за счет увеличения длины кода. Компилятор не выполняет раскрутку циклов или подстановку функций, когда вы указываете `-O2'. По сравнения с `-O' эта опция увеличивает как время компиляции, так и эффективность сгенерированного кода.
-O3
Устанавливает оптимизацию уровня 3. `-O3' включает все оптимизации, определяемые `-O2', а также включает опцию `inline-functions'.
-O0
Без оптимизации. Если вы используете многочисленные `-O' опции с номерами или без номеров уровня, действительной является последняя такая опция.
Библиотека GNU C определяет все библиотечные функции, определенные стандартом ISO C и дополнительные возможности, указанные в стандарте POSIX и иных предписаниях для операционных систем Unix, а также расширения, специфичные для систем GNU. Она является наиболее фундаментальной системной библиотекой и обязательно присутствует в любой системе Linux.
В составе библиотеки можно выделить следующие основные группы функций:
Перед тем как посылать или принимать сообщения, должны быть созданы
очередь сообщений с уникальным идентификатором и ассоциированная с
ней структура данных. Порожденный уникальный идентификатор называется
идентификатором очереди сообщений
(msqid); он используется
для обращений к очереди сообщений и ассоциированной структуре данных.
Говоря об очереди сообщений, следует иметь в виду, что реально в ней хранятся не сами сообщения, а их дескрипторы, имеющие следующую структуру:
/* Указатель на следующее сообщение */
struct msg *msg_next;
long msg_type; /* Тип сообщения */
short msg_ts; /* Размер текста сообщения */
short msg_spot; /* Адрес текста сообщения */
};
С каждым уникальным идентификатором очереди сообщений ассоциирована структура данных, которая содержит следующую информацию:
/*Структура прав на выполнение операций*/
struct ipc_perm msg_perm;
/*Указатель на первое сообщение в очереди*/
struct msg *msg_first;
/*Указатель на последнее сообщение в очереди*/
struct msg *msg_last;
/* Текущее число байт в очереди */
ushort msg_cbytes;
/* Число сообщений в очереди */
ushort msg_qnum;
/* Макс. допустимое число байт в очереди */
ushort msg_qbytes;
/* Ид-р последнего отправителя */
ushort msg_lspid;
/* Ид-р последнего получателя */
ushort msg_lrpid;
/* Время последнего отправления */
time_t msg_stime;
/* Время последнего получения */
time_t msg_rtime;
/* Время последнего изменения */
time_t msg_ctime;
};
ushort uid; /* Идентификатор пользователя */
ushort gid; /* Идентификатор группы */
ushort cuid; /* Идентификатор создателя очереди */
ushort cgid; /* Ид-р группы создателя очереди */
ushort mode; /* Права на чтение/запись */
/* Последовательность номеров используемых слотов */
ushort seq;
key_t key; /* Ключ */
};
Если в аргументе msgflg системного вызова msgget установлен только флаг IPC_CREAT, выполняется одно из двух действий:
Кроме того, можно специфицировать ключ key со значением
IPC_PRIVATE.
Если указан такой ``личный'' ключ, для него обязательно выделяется
новый уникальный идентификатор и создаются ассоциированные с ним очередь
сообщений и структура данных (при условии, что это не приведет к превышению
системного лимита). При выполнении утилиты ipcs поле KEY
для подобного идентификатора msqid из соображений секретности
содержит нули.
Если идентификатор msqid со специфицированным значением ключа
key уже существует, выполняется второе действие, т. е.
возвращается ассоциированный идентификатор. Если необходимо
считать
возвращение существующего идентификатора ошибкой, в передаваемом системному
вызову аргументе msgflg нужно установить флаг IPC_EXCL.
При выполнении первого действия процесс, вызвавший msgget, становится владельцем или создателем очереди сообщений; соответственно этому инициализируется ассоциированная структура данных. Впоследствии владелец очереди может быть изменен, однако процесс-создатель всегда остается создателем. При создании очереди сообщений определяются также начальные права на выполнение операций над ней.
После того как созданы очередь сообщений с уникальным идентификатором и ассоциированная с ней структура данных, можно использовать системные вызовы семейства msgop (операции над очередями сообщений) и msgctl (управление очередями сообщений).
Операции, как упоминалось выше, заключаются в посылке и приеме сообщений. Для каждой из этих операций предусмотрен системный вызов, msgsnd() и msgrcv() соответственно.
Для управления очередями сообщений используется системный вызов msgctl. Он позволяет выполнять следующие управляющие действия:
Основная причина, по которой используется ассемблер в Linux - это написание очень небольших по размеру программ, которые не зависят от системных библиотек. Такие программы особенно нужны для встраиваемых систем, где объемы запоминающих устройств обычно невелики.
GAS - это сокращение от GNU Assembler. Поскольку GAS был разработан для поддержки 32-битных компиляторов Unix, он использует стандартный синтаксис ATT, который несколько отличается от обычного ассемблера DOS. Основные отличия синтаксиса GAS от синтаксиса Intel:
mov eax,edx
(передать содержимое регистра edx в регистр eax) будет выглядеть в GAS как
mov %edx,%eax.
movl %edx,%eax. Однако gas не требует соблюдения строгого синтаксиса
ATT, так что суффикс необязателен, если размер может быть определен для
регистрового операнда, либо по умолчанию принимается 32-bit.
addl $5,%eax\end{verbatim}
(добавить константу 5 к регистру eax).
\item Отсутствие префикса операнда указывает на адрес в памяти; поэтому
\begin{verbatim} movl $foo,%eax\end{verbatim} помещает адрес переменной \verb|foo| в регистр \verb|eax|, а
команда \begin{verbatim} movl foo,%eax\end{verbatim} помещает в \verb|eax| содержимое переменной \verb|foo|.
\end{itemize}
Индексация выполняется с помощью заключения индексного регистра в скобки,
например, \verb|in testb \$0x80,17(%ebp)| (проверить установку старшего бита
в байте по смещению 17 от ячейки, указанной \verb|ebp|).
Замечание: известно несколько программ, которые могут помочь вам преобразовать
исходный код для ассемблеров AT\&T и Intel; некоторые из них способны на
преобразование в двух направлениях.
Ассемблер NASM разрабатывается в рамках проекта The Netwide Assembler, и
представляет собой мощный ассемблер на базе i386, написанный на C, который
построен по модульному принципу и обеспечивает поддержку практически вссех
известных синтаксисов и форматов объектных файлов.
Используется синтаксис Intel. Поддерживается обработка
макроопределений.
Среди поддерживаемых форматов объектных файлов есть bin, aout, coff, elf, as86,
obj (DOS), win32, rdf (собственный формат). Кроме того, NASM поставляется
с дизассемблером NDISASM.
Как и для GAS, для NASM применяется несколько программ преобразования
синтаксиса.
В качестве примера здесь приводятся две программы на ассемблере. Программы
написаны с учетом того, что Linux является 32-битной системой, работает в
защищенном режиме, имеет плоскую модель памяти и использует для исполняемых
файлов формат ELF.
Программа обычно делится на разделы: .text -- для программного кода (только
для чтения), .data -- для записи данных (чтение-запись), .bss --
для неинициализируемых данных (чтение-запись); могут также присутствовать и
другие стандартные разделы, а также разделы, определенные пользователем. В
программе должен быть как минимум раздел .text.
Пример для NASM (\texttt{hello.asm}):
\begin{verbatim}
section .data ; описание раздела
msg db "Hello, world!",0xa ; выводимая строка
len equ $ - msg ; длина строки
section .text ; описание раздела
; нам нужно передать точку входа
; компоновщику или
global _start ; загрузчику ELF. Обычно они
; распознают _start по умолчанию
; Используйте ld -e foo,
; чтобы переопределить ее.
_start:
; записываем строку в стандартный вывод
mov edx,len ; третий аргумент:
; длина строки
mov ecx,msg ; второй аргумент:
; указатель на строку
mov ebx,1 ; первый аргумент:
; дескриптор файла (stdout)
mov eax,4 ; номер системного вызова
; (sys_write)
int 0x80 ; обращение к ядру
; и выходим
mov ebx,0 ; первый аргумент: код возврата
mov eax,1 ; номер системного вызова
; (sys_exit)
int 0x80 ; обращение к ядру
Пример для GAS (hello.S):
.data # описание раздела
msg:
.string "Hello, world!\n" # выводимая строка
len = . - msg # длина строки
.text # описание раздела
# нам нужно передать точку входа
# компоновщику или
global _start # загрузчику ELF. Обычно они распознают
# _start по умолчанию.
# Используйте ld -e foo,
# чтобы переопределить ее.
_start:
# записываем строку в стандартный вывод
movl $len,%edx # третий аргумент:
# длина строки
movl $msg,%ecx # второй аргумент:
# указатель на строку
movl $1,%ebx # первый аргумент:
# дескриптор файла (stdout)
movl $4,%eax # номер системного вызова
# (sys_write)
int $0x80 # обращение к ядру
# и выходим
movl $0,%ebx # первый аргумент:
# код возврата
movl $1,%eax # номер системного вызова
# (sys_exit)
int $0x80 # обращение к ядру
Основные опции ассемблера GAS:
--defsym sym=value
определить символом sym величину value перед разбором входного файла; value должно быть целой константой. Как и в C, префикс 0x определяет шестнадцатеричное число, а префикс 0 - восьмеричное;
--help
вывести список опций командной строки;
-I dir
добавить каталог dir в список поиска для директив `.include';
-o objfile
имя объектного файла для вывода из `as';
-R
распознавать вложенные в код разделы данных;
--no-warn
опускать сообщения о предупреждениях;
--fatal-warnings
рассматривать предупреждения как ошибки.
-h
вывести информацию об опциях и поддерживаемых форматах выходных файлов nasm;
-a
ассемблировать файл без предварительного препроцессинга;
-e
выполнить препроцессинг входного файла и вывести результат в stdout (или указанный файл-приемник), но без ассемблирования;
-M
вывести в stdout зависимости в стиле make-файла;
-E filename
перенаправлять сообщения об ошибках в файл filename. Опция предназначена для операционных систем, в которых stderr нельзя перенаправить;
-f format
определить формат выходного файла. Форматы включают в себя bin - для плоских двоичных файлов, и aout или elf - для создания объектных файлов типа Linux a.out и ELF соответственно;
-o outfile
определить точное имя выходного файла, переопределив имя по умолчанию;
-l listfile
перенаправить листинг ассемблера в указанный файл, в котором с правой стороны будет выведен исходный текст (а также текст включаемых файлов и расширенные макросы), а с левой стороны - сгенерированный код в шестнадцатеричном формате;
-s
выводить сообщения об ошибках в файл стандартного вывода;
-w[+-]foo
подключить (или отключить) некоторые классы предупреждающих сообщений,
например, -w+orphan-labels или
-w-macro-params, чтобы соответственно разрешить
сообщения о метках в пустой строке или отключить сообщения о неверном
количестве параметров в вызовах макросов;
-I directory
добавить каталог в путь поиска включаемых файлов.
Отладчиком называется программа, которая выполняет внутри себя другую программу. Основное назначение отладчика - дать возможность пользователю в определенной степени осуществлять контроль за выполняемой программой, т.е. определять, что происходит в процессе ее выполнения. Наиболее известным отладчиком для Linux является программа GNU GDB, которая содержит множество полезных возможностей, но для простой отладки достаточно использовать лишь некоторые из них.
Когда вы запускаете программу, содержащую ошибки, обнаруживаемые лишь на стадии выполнения, возникают несколько вопросов, на которые вам нужно найти ответ:
Эти действия требуют, чтобы пользователь отладчика был в состоянии:
Программа GDB предоставляет все перечисленные возможности. Она называется отладчиком на уровне исходного текста, создавая иллюзию, что вы выполняете операторы C++ из вашей программы, а не машинный код, в который они действительно транслируются.
Для иллюстрации мы используем систему, которая компилирует программы на C++ в исполняемые файлы, содержащие машинный код. В результате этого процесса информация об оригинальном коде C++ теряется при трансляции. Отдельный оператор C++ обычно преобразуется в несколько машинных команд, а большинство имен локальных переменных просто теряется. Информация о именах переменных и операторах C++ в вашей исходной программе не является необходимой для ее выполнения. Поэтому, для правильной работы отладчика на уровне исходного текста, компилятор должен поместить в программу некоторую дополнительную информацию. Обычно ее добавляют к информации, используемой компоновщиком, в исполняемый файл.
Чтобы указать компилятору (gcc), что вы планируете отлаживать вашу программу, и поэтому нуждаетесь в дополнительной информации, добавьте ключ -g в опции компиляции и компоновки. Например, если ваша программа состоит из двух файлов main.C и utils.C, можете откомпилировать ее командами:
gcc -c -g -Wall main.C gcc -c -g -Wall utils.C gcc -g -o myprog main.ob utils.o
или одной командой:
gcc -g -Wall -o myprog main.o utils.o
Обе последовательности команд приводят к созданию исполняемого файла myprog.
Чтобы выполнить полученную программу под управлением gdb, введите
gdb myprog
вы увидите командное приглашение GDB:
(gdb)
Это очень простой, но эффективный тексовый интерфейс отладчика. Его вполне достаточно, чтобы ознакомиться с основными командами gdb.
Когда GDB запускается, ваша программа в нем еще не выполняется; вы должны сами сообщить GDB, когда ее запустить. Как только программа приостанавливается в процессе выполнения, GDB ищет определенную строку исходной программы с вызовом определенной функции - либо строку в программе, где произошел останов, либо строку, содержащую вызов функции, в которой произошел останов, либо строку с вызовом функции и т.д. Далее используется термин ``текущее окно'', чтобы сослаться на точку останова.
Как только возникает командное приглашение, вы можете использовать следующие команды:
help command
выводит краткое описание команды GDB. Просто help выдает список доступных
разделов справки;
run command-line-arguments
запускает Вашу программу с определенными аргументами командной строки. GDB
запоминает переданные аргументы, и простой перезапуск программы с помощью
run приводит к использованию этих аргументов;
where
создает трассу - цепочку вызовов функций, произошедших до попадания программы в текущее место. Синонимом является команда bt;
up
перемещает текущее окно так, чтобы GDB анализировал место, из которого
произошел вызов данного окна. Очень часто Ваша программа может войти в
библиотечную функцию - такую, для которой не доступен исходный код,
например, в процедуру ввода-вывода. вам может понадобиться несколько команд
up, чтобы перейти в точку программы, которая была выполнена последней;
down
производит эффект, обратный up;
print E
выводит значение E в текущем окне программы, где E является выражением C++ (обычно просто переменной). Каждый раз при использовании этой команды, GDB нумерует ее упоминание для будущих ссылок. Например:
(gdb) print A[i] $2 = -16
(gdb) print $2 + ML $3 = -9
сообщает нам, что величина A[i] в текущем окне равна -16, и что при добавлении этого значения к переменной ML получится -9;
quit
выход из GDB;
Ctrl-c
если программа запущена через оболочку shell, Ctrl-c немедленно прекращает ее выполнение. В GDB программа приостанавливается, пока ее выполнение не возобновится;
break place
установить точку останова; программа приостановится при ее достижении. Простейший способ - установить точку останова после входа в функцию, например:
(gdb) break MungeData Breakpoint 1 at 0x22a4:
file main.C, line 16.
Команда break main остановит выполнение в начале программы.
вы можете установить точки останова на определенную строку исходного кода:
(gdb) break 19 Breakpoint 2 at 0x2290:
file main.C, line 19.
(gdb) break utils.C:55 Breakpoint 3 at 0x3778:
file utils.C, line 55.
Когда вы запустите программу и она достигнет точки останова, то увидите сообщение об этом и приглашение, например:
Breakpoint 1, MungeData (A=0x6110, N=7) at main.c:16
(gdb);
delete N
удаляет точку останова с номером N. Если опустить N, будут удалены все точки останова;
cont или continue
продолжает обычное выполнение программы;
step
выполняет текущую строку программы и останавливается на следующем операторе для выполнения;
next
похожа на step, однако, если текущая строка программы содержит вызов функции (так что step должен будет остановиться в начале функции), не входит в эту функцию, а выполняет ее и переходит на следующий оператор;
finish
выполняет команды next без остановки, пока не достигнет конца текущей функции.
M-x gdb, вы получите новое окно с запущенным gdb, воспринимающее все
сокращенные команды. Emacs также интерпретирует вывод от gdb, чтобы вам было
удобнее. Когда достигается точка останова, Emacs получает от gdb имя файла и
номер строки, чтобы показать содержимое этого файла, с отмеченной точкой
останова или ошибкой. Когда вы отлаживаете программу по шагам, Emacs следует
за вами по файлам исходного кода.
KDbg является графическим интерфейсом к gdb в среде KDE. Это означает, что KDbg сам по себе не является отладчиком. Он общается с gdb, отладчиком, использующим командную строку, посылая ему команды и получая их результат, например, значения переменных. Пункты меню и указания "мышью" преобразуются в последовательность команд gdb, а результат преобразуется к более-менее визуальному представлению, такому как структурное содержимое переменных.
KDbg не может делать больше, чем делает gdb. Например, если имеющаяся у вас версия gdb не поддерживает отладку многопоточных программ, то и KDbg не поможет вам в этом (несмотря на то, что он выводит окно потоков).
Графическим интерфейсом для системы X Window является xxgdb. Интерфейсом для графического представления данных является ddd.
Кроме этого, следует упомянуть отладчик DBX, а среди коммерческих приложений - мощное средство TotalView.
Утилита UNIX make является простым и наиболее общим решением данной проблемы. В качестве ввода она принимает описание взаимных зависимостей над множеством исходных файлов, а также команды, необходимые для их компиляции. Это описание называется make-файлом. Утилита проверяет ``возраст'' соответствующих файлов, и выполняет все необходимые команды в соответствии с описанием. Для большего удобства она поддерживает несколько стандартных действий и зависимостей по умолчанию, чтобы не описывать их лишний раз.
Существует несколько диалектов make, как среди версий UNIX / Linux, так и в других операционных системх для ПК. Далее нами описана версия gmake (GNU make).
Makefile for simple editor
edit : edit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o
gcc -g -o edit edit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o -lg++edit.o : edit.cc defs.h
gcc -g -c -Wall edit.cc
kbd.o : kbd.cc defs.h command.h
gcc -g -c -Wall kbd.cc
commands.o : command.cc defs.h command.h
gcc -g -c -Wall commands.cc
display.o : display.cc defs.h buffer.h
gcc -g -c -Wall display.cc
insert.o : insert.cc defs.h buffer.h
gcc -g -c -Wall insert.cc
search.o : search.cc defs.h buffer.h
gcc -g -c -Wall search.cc
files.o : files.cc defs.h buffer.h command.h
gcc -g -c -Wall files.cc
utils.o : utils.cc defs.h
gcc -g -c -Wall utils.cc
Этот файл содержит последовательность девяти правил. В общем виде каждое правило выглядит так:
<цель_1> <цель_2> ... <цель_n>: <зависимость_1>
<зависимость_2> ... <зависимость_n>
<команда_1>
<команда_2>
...
<команда_n>
Правило состоит из строки, содержащей два списка имен, разделенных двоеточием, за которыми следуют одна или несколько строк, начинающихся с табуляции. Любая строка может быть продолжена, как показано выше, если закончить ее наклонной чертой, которая означает пробел, соединяя строку с последующей. Символ `#' отмечает начало комментария, который продолжается до конца данной строки.
Цель (target) - это некий желаемый результат, способ достижения которого описан в правиле. Цель может представлять собой имя файла. В этом случае правило описывает, каким образом можно получить новую версию этого файла.
Цель также может быть именем некоторого действия. В таком случае правило описывает, каким образом совершается указанное действие. Подобного рода цели называются псевдоцели (pseudo targets) или абстрактные цели (phony targets).
Зависимость (dependency)- это некие "исходные данные", необходимые для достижения указанной в правиле цели. Можно сказать что зависимость - это "предварительное условие" для достижения цели. Зависимость может представлять собой имя файла. Этот файл должен существовать, для того чтобы можно было достичь указанной цели. Зависимость также может быть именем некоторого действия. Это действие должно быть предварительно выполнено перед достижением указанной в правиле цели.
Команды - это действия, которые необходимо выполнить для обновления либо достижения цели. Утилита make отличает строки, содержащие команды, от прочих строк make-файла по наличию символа табуляции (символа с кодом 9) в начале строки. Это команды shell (присутствуют в оболочке Linux), которые выполняются в определенном порядке, чтобы создать или обновить цель правила (обычно говорят обновить - update).
Главная цель может быть прямо указана в командной строке при запуске make. В следующем примере make будет стремиться достичь цели edit (получить новую версию файла edit):
make edit
Если не указывать какой-либо цели в командной строке, то make выбирает в качестве главной первую, встреченную в make-файле цель. Схематично ``верхний уровень'' алгоритма работы make можно представить так:
make()
{
главная_цель = Выбрать_Главную_Цель()
Достичь_Цели( главная_цель )
}
После того как главная цель выбрана, make запускает ``стандартную'' процедуру достижения цели. Сначала в make-файле ищется правило, которое описывает способ достижения этой цели (функция НайтиПравило). Затем, к найденному правилу применяется обычный алгоритм обработки правил (функция ОбработатьПравило):
Достичь_Цели( Цель )
{
правило = Найти_Правило( Цель )
Обработать_Правило( правило )
}
Обработка правила разделяется на два основных этапа. На первом этапе обрабатываются все зависимости, перечисленные в правиле (функция ОбработатьЗависимости). На втором этапе принимается решение - нужно ли выполнять указанные в правиле команды (функция НужноВыполнятьКоманды). При необходимости, перечисленные в правиле команды выполняются (функция ВыполнитьКоманды):
Обработать_Правило( Правило )
{
Обработать_Зависимости( Правило )
если Нужно_Выполнять_Команды( Правило )
{
Выполнить_Команды( Правило )
}
}
Функция ОбработатьЗависимости поочередно проверяет все перечисленные в теле правила зависимости. Некоторые из них могут оказаться целями каких-нибудь правил. Для этих зависимостей выполняется обычная процедура достижения цели (функция ДостичьЦели). Те зависимости, которые не являются целями, считаются именами файлов. Для таких файлов проверяется факт их наличия. При их отсутствии make аварийно завершает работу с сообщением об ошибке:
Обработать_Зависимости( Правило )
{
цикл от i=1 до Правило.число_зависимостей
{
если Есть_Такая_Цель( Правило.зависимость[i])
{
Достичь_Цели( Правило.зависимость[i])
}
иначе
{
Проверить_Наличие_Файла(Правило.зависимость[i])
}
}
}
На стадии обработки команд решается вопрос, нужно ли выполнять описанные в правиле команды или нет. Считается, что нужно выполнять команды если:
Нужно_Выполнять_Команды( Правило )
{
если Правило.Цель.Является_Абстрактной()
return true
// цель является именем файла
если Файл_Не_Существует( Правило.Цель )
return true
цикл от i=1 до Правило.Число_зависимостей
{
если Правило.Зависимость[i].Является_Абстрактной()
return true
иначе
// зависимость является именем файла
{
если Время_Модификации(Правило.Зависимость[i])
> Время_Модификации( Правило.Цель )
return true
}
}
return false
}
В указанном примере целью по умолчанию является edit. Первым шагом по его
обновлению будет обновление всех файлов объектов (.o), перечисленных как
зависимости. Обновление edit.o в свою очередь требует обновления edit.cc и
defs.h. Предполагается, что edit.cc является исходным файлом, из которого
создается edit.o, а defs.h является заголовочным файлом, который включается в
edit.cc. Правил, указывающих на эти файлы, нет; поэтому такие файлы, как минимум
должны просто существовать. Теперь edit.o считается готовым, если он изменен
позже, чем edit.cc или defs.h (если он старше их, это значит, что один из этих
файлов изменился со времени последней компиляции edit.o). Если edit.o старше
своих зависимостей, gmake выполняет действие OP ``gcc -g -c -Wall
edit.cc'',
создавая новый edit.o. Когда edit.o и все другие файлы .o будут обновлены,
они будут собраны вместе действием
``gcc -g -o edit ...'', чтобы создать
программу edit, если либо edit еще не существует, либо любой из файлов .o
новее, чем существующий файл edit.
Чтобы вызвать gmake для этого примера, используйте команду:
gmake -f <makefile-name> <target-names>,
где <target-names> - это имена целей, которые вы хотите обновить, а
<makefile-name>, заданное после ключа -f, является именем make-файла.
По умолчанию целью является первое правило в файле. Вы можете (обычно так и
делают) опустить -f makefile-name, и в этом случае по умолчанию будет выбрано
имя makefile или Makefile, если любой из этих файлов существует.
Обычно каждый каталог содержит исходный код для простой части программы.
Принимая правило, что имя программы соответствует первой цели, и что make-файл
для каталога называется
makefile, вы добьетесь того, что вызов команды gmake
без аргументов в любом каталоге приведет к обновлению части программы в этом
каталоге.
Для одной и той же цели может применяться несколько правил, но не более чем одно правило для цели должно иметь действия. Поэтому, мы может переписать последнюю часть примера следующим образом:
edit.o : edit.cc
gcc -g -c -Wall edit.cc
kbd.o : kbd.cc
gcc -g -c -Wall kbd.cc
commands.o : command.cc
gcc -g -c -Wall commands.cc
display.o : display.cc
gcc -g -c -Wall display.cc
insert.o : insert.cc
gcc -g -c -Wall insert.cc
search.o : search.cc
gcc -g -c -Wall search.cc
files.o : files.cc
gcc -g -c -Wall files.cc
utils.o : utils.cc
gcc -g -c -Wall utils.ccedit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o: defs.h
kbd.o commands.o files.o : command.h
display.o insert.o search.o files.o : buffer.h
Порядок, в котором записаны эти правила, не имеет значения. Скорее, он зависит от вашего вкуса и выбора порядка группировки файлов.
compile_flags = -O3 -funroll-loops
-fomit-frame-pointer|
Такой способ поддерживают все варианты утилиты make. Его можно сравнить, например, с заданием макроса в языке Си:
#define compile_flags "-O3 -funroll-loops
-fomit-frame-pointer"
Значение переменной, заданной с помощью оператора '=', будет вычислено в момент ее использования. Например, при обработке make-файла
var1 = one
var2 = $(var1) two
var1 = three
all:
@echo $(var2)
на экран будет выдана строка ``three two''. Значение переменной var2 будет
вычислено непосредственно в момент выполнения команды echo, и будет представлять
собой текущее значение переменной var1, к которому добавлена строка ``two''. Как
следствие - одна и та же переменная не может одновременно фигурировать в левой и
правой части выражения, так как это может привести к бесконечной рекурсии. GNU
Make распознает подобные ситуации и прерывает обработку make-файла. Следующий
пример вызовет ошибку:
compile_flags = -pipe $(compile_flags)
GNU Make поддерживает также и второй, новый способ задания переменной с помощью оператора ':=':
compile_flags := -O3 -funroll-loops
-fomit-frame-pointer
В этом случае переменная работает подобно ``обычным'' текстовым переменным в каком-либо языке программирования. Вот приблизительный аналог этого выражения на языке C++:
string compile_flags = "-O3 -funroll-loops
-fomit-frame-pointer";
Значение переменной вычисляется в момент обработки оператора присваивания. Если, например, записать
var1 := one
var2 := $(var1) two
var1 := three
all:
@echo $(var2),
то при обработке такого make-файла на экран будет выдана строка ``one two''.
Переменная может ``менять'' свое поведение в зависимости от того, какой из операторов присваивания был применен к ней последним. Одна и та же переменная на протяжении ее жизни может вести себя и как ``макрос'', и как ``текстовая переменная''.
Зависимости цели edit в приведенных выше примерах являлись аргументами для команд
компоновки. Можно избежать их повторения, определив переменную, которая будет
содержать имена всех объектных файлов:
Makefile for simple editorСтрока, начинающаяся сOBJS = edit.o kbd.o commands.o display.o
insert.o search.o files.o utils.o
edit : $(OBJS)
gcc -g -o edit $(OBJS)
``OBJS ='' определяет переменную OBJS, на которую
можно в дальнейшем сослаться через ``$(OBJS)'' или ``OBJS''.
Эти более поздние ссылки приводят к тому, что обозначение OBJ будет дословно
заменяться, прежде чем правило будет обработано. Иногда неудобно, что и gmake
и shell используют `$' как префикс для ссылок на переменные; gmake
определяет `$$', такое же, как `$', позволяя вам передавать `$' в shell,
если это необходимо.
Иногда вам может понадобиться величина в виде обычной переменной,
но с некоторыми уточнениями. Например, задавая переменную со списком имен
всех исходных файлов, вы можете попытаться задать имена всем получающимся
объектным файлам. Можно переопределить OBJS следующим образом:
SRCS = edit.cc kbd.cc commands.cc display.ccСуффикс
insert.cc search.cc files.cc utils.cc
OBJS = $(SRCS:.cc=.o)
`:.cc=.o' определяет необходимые уточнения. Теперь у нас
есть переменные для имен всех исходных и объектных файлов, при этом не пришлось
повторять в определениях множество имен.
Переменные могут упоминаться и в командной строке при вызове gmake. Например, если make-файл содержит
edit.o: edit.ccто команда типа
gcc $(DEBUG) -c -Wall edit.cc ,
gmake DEBUG=-g ... приведет к использованию ключа -g
(добавить символическую информацию отладчика) при компиляции, а отсутствие
DEBUG=-g исключит использование этого ключа. Определения
переменных в командной строке имеют преимущество перед определениями
внутри make-файла, что позволяет задать в make-файле значения по умолчанию.
Переменные, не установленные любым из перечисленных методов, могут быть установлены как переменные среды. Поэтому, последовательность команд
setenv DEBUG -g gmake ...
для последнего примера также приведет к использованию ключа -g во время компиляции.
Традиционные реализации make поддерживают так называемую ``суффиксную'' форму записи шаблонных правил:
.<расширение_файлов_зависимостей>.<расширение_файлов_целей>:
<команда_1>
<команда_2>
...
<команда_n>
Например, следующее правило гласит, что все файлы с расширением "o" зависят от соответствующих файлов с расширением "cpp":
.cpp.o:
gcc -c $^
Обратите внимание на использование автоматической переменной $^ для
передачи компилятору имени файла-зависимости. Поскольку шаблонное правило может
применяться к разным файлам, использование автоматических переменных -
единственный способ узнать, для каких файлов сейчас задействуется правило.
Шаблонные правила позволяют упростить make-файл и сделать его более универсальным.
В самом первом примере все правила компиляции для получения файлов типа .o
имеют одинаковую форму. Очень неудобно повторять их снова и снова; это может
привести к ошибке при написании make-файла. Поэтому gmake можно указать -
для известных стандартных случаев - действия и имена файлов по умолчанию для
создания различных типов файлов. Для наших целей наиболее важным является то,
что gmake известно, как создать файл F.o из исходного файла F.cc.
В данном случае gmake автоматически
использует правило
F.o : F.ccкоторое вызывается, чтобы создать
$(CXX) -c -Wall $(CXXFLAGS) F.cc,
F.o, если существует файл C++ с именем
F.cc, но не определяет точные действия для создания F.o. Использование
префикса ``CXX'' является следствием соглашения об именах для переменных,
связанных с C++. Также создается командаF : F.oчтобы сообщить, как создать исполняемый файл
$(CC) $(LDFLAGS) F.o $(LOADLIBES) -o F,
F из F.o.
В результате предыдущий пример можно переписать следующим образом:
Makefile for simple editorSRCS = edit.cc kbd.cc commands.cc display.cc
insert.cc search.cc files.cc utils.ccOBJS = $(SRCS:.cc=.o)
CC = gcc
CXX = gcc
CXXFLAGS = -g
LOADLIBES = -lg++edit : $(OBJS)
edit.o : defs.h
kbd.o : defs.h command.h
commands.o : defs.h command.h
display.o : defs.h buffer.h
insert.o : defs.h buffer.h
search.o : defs.h buffer.h
files.o : defs.h buffer.h command.h
utils.o : defs.h
gmake действия для цели будут выполняться всякий
раз, когда gmake обратится к ней. Обычно это используют для помещения в
make-файл стандартной операции ``очистки'', определяющей способ
удаления неиспользуемых файлов. Например, вы часто можете встретить в
make-файле такое правило:
clean:
rm -f *.o
Каждый раз, при выполнении команды gmake clean, это действие будет
удалять все файлы .o.
Программа gmake обычно выводит информацию о выполнении каждого действия, но
иногда это не желательно. Поэтому символ `@' в начале действия может запретить
вывод по умолчанию. Вот пример его обычного использования:
edit : $(OBJS)|Результатом этих действий будет то, что в начале компиляции вы увидите строку
@echo Linking edit ...
@gcc -g -o edit $(OBJS)
@echo Done
``Linking edit...'', а в конце компиляции - строку ``Done''.
Когда gmake встречает действие, возвращающее ненулевой код выхода, т.е.,
сообщение об ошибке по соглашениям UNIX, его стандартной реакцией является
прекращение обработки. Коды ошибок от строк действий, начинающихся с символа
`--' (возможно с предшествующим `@') игнорируются. Ключ -k для gmake
приводит в случае ошибки к прекращению обработки только текущего правила (и
всех, зависящих от него целей), позволяя продолжить обработку всех
последующих.
Cинтаксис системного вызова msgget выглядит так:
#include <sys/ipc.h>
#include <sys/msg.h>
int msgget ( key_t key,int msgflg);
Целочисленное значение, возвращаемое в случае успешного завершения системного вызова, есть идентификатор очереди сообщений (msqid). В случае неудачи результат равен -1.
Новый идентификатор msqid, очередь сообщений и ассоциированная с ней структура данных выделяются в каждом из двух случаев:
| Права на операции | Восьмеричное значение |
| Чтение для владельца | 0400 |
| Запись для владельца | 0200 |
| Чтение для группы | 0040 |
| Запись для группы | 0020 |
| Чтение для остальных | 0004 |
| Запись для остальных | 0002 |
В каждом конкретном случае нужная комбинация прав задается как результат операции побитного ИЛИ для значений, соответствующих элементарным правам. Так, например, правам на чтение и запись для владельца и на чтение для членов группы и прочих пользователей соответствует восьмеричное число 0644. Следует отметить полную аналогию с правами доступа к файлам.
Флаги определены во включаемом файле <sys/ipc.h>. В табл. 3 сведены мнемонические имена флагов и соответствующие им восьмеричные значения:
Значение аргумента msgflg в целом является, следовательно, результатом операции побитного ИЛИ (операция | в языке C) для прав на выполнение операций и флагов, например:
msqid = msgget (key, (IPC_CREAT | IPC_EXCL | 0400));
msqid = msgget (IPC_PRIVATE, msgflg);
приведет к попытке выделения нового идентификатора очереди сообщений
и ассоциированной информации, независимо от значения аргумента msgflg.
Попытка может быть неудачной только из-за превышения системного лимита
на общее число очередей сообщений, задаваемого настраиваемым параметром
MSGMNI.
При использовании флага IPC_EXCL в сочетании с IPC_CREAT системный вызов msgget завершается неудачей в том и только в том случае, когда с указанным ключом key уже ассоциирован идентификатор. Флаг IPC_EXCL необходим, чтобы предотвратить ситуацию процесса, когда надежда получить новый (уникальный) идентификатор очереди сообщений не сбывается. Иными словами, когда используются и IPC_CREAT и IPC_EXCL, при успешном завершении системного вызова обязательно возвращается новый идентификатор msqid.
В файле справки по msgget описывается начальное значение ассоциированной структуры данных, формируемое после успешного завершения системного вызова. Там же содержится перечень условий, приводящих к ошибкам, и соответствующих им мнемонических имен для значений переменной errno.
Программа-пример для msgget, приведенная ниже, управляется посредством меню. Она позволяет поупражняться со всевозможными комбинациями системного вызова msgget, проследить, как передаются аргументы и получаются результаты. Имена переменных выбраны максимально близкими к именам, используемым в спецификации синтаксиса системного вызова, что облегчает чтение программы.
Выполнение программы начинается с приглашения ввести шестнадцатеричный ключ key, восьмеричный код прав на операции и, наконец, выбираемую при помощи меню комбинацию флагов. В меню предлагаются все возможные комбинации, даже бессмысленные, что позволяет при желании проследить за реакцией на ошибку. Затем выбранные флаги комбинируются с правами на операции, после чего выполняется системный вызов, результат которого заносится в переменную msqid. Если значение msqid равно -1, выдается сообщение об ошибке и выводится значение внешней переменной errno. Если ошибки не произошло, выводится значение полученного идентификатора очереди сообщений:
возможности системного вызова msgget()
(получение идентификатора очереди сообщений) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#include <errno.h>
main ()
{
key_t key; /* Тип описан как целое */
int opperm, flags; /* Права на операции и флаги */
int msgflg, msqid;
/* Ввести требуемый ключ */
printf ("\nВведите шестнадцатеричный ключ: ");
scanf ("%x", &key);
/* Ввести права на операции */
printf ("\nВведите права на операции ");
printf ("в восьмеричной записи: ");
scanf ("%o", &opperm);
/* Установить требуемые флаги */
printf ("\nВведите код, соответствущий ");
printf ("нужной комбинации флагов:\n");
printf (" Нет флагов = 0\n");
printf (" IPC_CREAT = 1\n");
printf (" IPC_EXCL = 2\n");
printf (" IPC_CREAT и IPC_EXCL = 3\n");
printf (" Выбор = ");
/* Получить флаги, которые нужно установить */
scanf ("%d", &flags);
/* Проверить значения */
printf ("\nключ = 0x%x, права = 0%o, флаги = %d\n",
key, opperm, flags);
/* Объединить флаги с правами на операции */
switch (flags) {
case 0: /* Флаги не устанавливать */
msgflg = (opperm | 0);
break;
case 1: /* Установить флаг IPC_CREAT */
msgflg = (opperm | IPC_CREAT);
break;
case 2: /* Установить флаг IPC_EXCL */
msgflg = (opperm | IPC_EXCL);
break;
case 3: /* Установить оба флага */
msgflg = (opperm | IPC_CREAT | IPC_EXCL);
}
/* Выполнить системный вызов msgget */
msqid = msgget (key, msgflg);
if (msqid == -1) {
/* Сообщить о неудачном завершении */
printf ("\nmsgget завершился неудачей!\n"
printf ("Код ошибки = %d\n", errno);
}
else
/* При успешном завершении сообщить msqid */
printf ("\nИдентификатор msqid = %d\n", msqid);
exit (0);
}
PROGRAM = <REPLACE WITH PROGRAM NAME>
LOADLIBES = <EXTRA LOAD LIBRARIES> -lg++
CXX.SRCS = <C++ SOURCE FILE NAMES>
CC = gcc
LDFLAGS = -g
CXX = gcc
CXXFLAGS = -g -Wall -fno-builtins
OBJS = $(CXX.SRCS:.cc=.o)
$(PROGRAM) : $(OBJS)
$(CC) $(LDFLAGS) $(OBJS) $(LOADLIBES) -o $(PROGRAM)
clean:
/bin/rm -f *.o $(PROGRAM)*
depend:
$(CXX) -MM $(CXX.SRCS)
<DEPENDENCIES ON .h FILES GO HERE>
Скопировав подобную заготовку и заменив разделы, ограниченные символами <> нужным текстом, Вы получите работающий make-файл:
PROGRAM = edit
LOADLIBES = -lg++
CXX.SRCS = edit.cc kbd.cc commands.cc display.cc
insert.cc search.cc files.cc utils.cc
CC = gcc
LDFLAGS = -g
CXX = gcc
CXXFLAGS = -g -Wall -fno-builtins
OBJS = $(CXX.SRCS:.cc=.o)
$(PROGRAM) : $(OBJS)
$(CC) $(LDFLAGS) $(OBJS) $(LOADLIBES) -o $(PROGRAM)
clean:
/bin/rm -f *.o $(PROGRAM)*
depend:
$(CXX) -MM $(CXX.SRCS)edit.o : defs.h
kbd.o : defs.h command.h
commands.o : defs.h command.h
display.o : defs.h buffer.h
insert.o : defs.h buffer.h
search.o : defs.h buffer.h
files.o : defs.h buffer.h command.h
utils.o : defs.h
Пусть заданы некоторое конечное множество слов (лексем) в некотором
языке и некоторое входное слово. Лексический анализ - это распознавание
лексем в определенном входном потоке. Необходимо установить, какой
элемент множества (если он существует) совпадает с данным входным
словом. Обычно лексический анализ выполняется так называемым лексическим
анализатором (ЛА). ЛА - это программа, LEX - генератор программ лексического
анализа. Лексический анализ применяется во многих случаях, например,
для построения редакторов или в качестве распознавателя директив в
диалоговой программе и т.д. Однако наиболее важное применение ЛА -
использование его в различного рода компиляторах, где он выполняет
функцию программы ввода данных. ЛА выполняет первую стадию компиляции:
читает строки компилируемой программы, выделяет лексемы и передает
их на дальнейшие стадии компиляции (синтаксический анализ и генерацию
кода). ЛА распознает тип каждой лексемы и соответствующим образом
помечает ее. Например, при компиляции программы на языке Си могут
быть выделены следующие типы лексем: число, идентификатор, оператор
и др. Необходимо не только выделить лексему, но и выполнить некоторые
преобразования. Например, если лексема - число, то его необходимо
перевести во внутреннюю (двоичную) форму записи как число с плавающей
или фиксированной точкой. Если лексема - идентификатор, то его необходимо
разместить в таблице для того, чтобы в дальнейшем обращаться к нему
не по имени, а по адресу в таблице. Хотя лексический анализ по
идее достаточно прост, эта фаза работы компилятора часто занимает
больше времени, чем любая другая. Частично это происходит из-за необходимости
просматривать и анализировать исходный текст символ за символом. Происходит
это потому, что часто бывает трудно определить, где проходят границы
лексемы. Пусть имеются две лексемы:make и makefile.
Пусть из входного потока поступает набор литеральных символов:...makefile....
При анализе входного потока может быть выделена лексема make, хотя правильно было бы выделить лексему makefile. Единственный способ преодолеть это затруднение - просмотр полученной цепочки вперед и назад. В примере при выделении лексемы make нужно просмотреть следующий поступающий литерал, и, если он будет символом f, то вполне возможно, что поступает лексема makefile. Процесс просмотра входного потока можно рассматривать как движение рамки влево и вправо над цепочкой символов. При этом анализируется только тот символ, который охвачен рамкой:
...
. .
source make.f.ile file compiler
. .
...
Анализ заключается в определении соответствия рассматриваемой последовательности
некоторому, так называемому регулярному выражению. Например, регулярное
выражение (\+?[0-9])+|(-?[0-9])+
позволяет выделить во входном потоке все лексемы типа целое, перед
которыми либо стоит знак (+ или -), либо не стоит.
В тех случаях, когда выделение лексемы затруднено вследствие того, что одно регулярное выражение не позволяет ее однозначно определить, либо из-за того, что одна лексема является частью другой, приходится прибегать к контекстно-зависимым алгоритмам анализа с использованием левого и правого направлений просмотра входной цепочки.
Для любого компилятора можно выделить три языка:
LEX частично или полностью автоматизирует процесс написания программы лексического анализа. Генерируемые с помощью LEX ЛА описываются на языке LEX. Последовательность использования LEX схематически показана на рис. 15:
Таким образом в этой последовательности можно выделить три этапа:
lex из файла (например, program.lex), описывающего
ЛА некоторого языка и написанного на языке LEX (входной язык для lex),
получается файл (например, lex.yy.c) с текстом ЛА на языке Си (выходной
язык для lex).
cc из файла (lex.yy.c) на языке Си (входной язык
для cc) получается исполняемый файл (например, a.out) с машинными
кодами (выходной язык для cc), непосредственно реализующими ЛА.
a.out) осуществляется интерактивный
лексический анализ вводимого с клавиатуры текста или лексический анализ
файла, написанного на некотором языке (входной язык ЛА), и, возможно,
вывод на экран или в файл информации, связанной с разбором (выходной
язык ЛА). Гибкие возможности системы UNIX по управлению потоками позволяют
использовать входной и выходной файлы и на этом этапе.
lex, в конечном счете генерирующая ЛА, впрочем,
как и сама система UNIX, написаны на Си. Исполняемый файл команды
lex, как и других команд получается при компиляции во время установки
системы с применением все того же компилятора Си, привязанного к определенной
аппаратной платформе. Таким образом, компилятор Си cc (написанный
разработчиком, например, на Си и ассемблере для выбранной платформы
и поставляемый вместе с системой) является базой.
В целом подсистема LEX для систем UNIX включает следующие файлы:
/usr/ccs/bin/lex; lex.yy.c; /usr/ccs/lib/lex/ncform; /usr/lib/libl.a; /usr/lib/libl.so.В каталоге
/usr/ccs/lib/lex имеется файл-заготовка ncform, который
LEX используется для построения ЛА. Этот файл является уже готовой
программой лексического анализа. Но в нем не определены действия,
которые необходимо выполнять при распознавании лексем, отсутствуют
и сами лексемы, не сформированы рабочие массивы и т.д. С помощью команды
lex файл ncform достраивается. В результате мы получаем файл со стандартным
именем lex.yy.c. Если LEX-программа размещена в файле program.l, то
для получения ЛА с именем program необходимо выполнить следующий набор
команд:
lex program.l cc lex.yy.c -ll -o programЕсли имя входного файла для команды
lex не указано, то будет использоваться
файл стандартного ввода. Флаг -ll требуется для подключения
/usr/ccs/lib/libl.a - библиотеки LEX. Если необходимо получить самостоятельную
программу, как в данном случае, подключение библиотеки обязательно,
поскольку из нее подключается главная функция main. В противном
случае, если имеется необходимость включить ЛА в качестве функции
в другую программу (например, в программу синтаксического анализа),
эту библиотеку необходимо вызвать уже при сборке. Тогда, если main
определен в вызывающей ЛА программе, редактор связей не будет подключать
раздел main из библиотеки LEX.
Общий формат вызова команды lex:
lex [-ctvn -V -Q[y|n]] [file]Флаги:
-c - включает фазу генерации Си-файла (устанавливается по умолчанию);
-t - поместить результат в стандартный файл вывода, а не в файл lex.yy.c;
-v - вывести размеры внутренних таблиц;
-n - не выводить размеры таблиц (устанавливается по умолчанию);
-V - вывести информацию о версии LEX в стандартный файл ошибок;
-Q - вывести (Qy) либо не выводить (Qn, устанавливается по умолчанию)
информацию о версии в файл lex.yy.c.
В LEX-программе регулярные выражения используются для определения лексем. (Кроме того, регулярные выражения широко используются при описании синтаксиса команд в разделах помощи UNIX-систем). Ниже приводится полное описание регулярных выражений применительно к LEX.
Регулярное выражение может содержать буквы латинского и русского алфавитов
в верхнем и нижнем регистрах, цифры, знаки препинания и т.д. (литеральные
символы), а также символы-операторы (метасимволы). Кроме того, в регулярных
выражениях можно использовать управляющие символы потока stdout языка
Си, например:
\восьмеричный код - указание символа его восьмеричным
кодом;
\xшестнадцатеричный код - указание символа его шестнадцатеричным
кодом;
\n - символ новой строки;
\t - символ табуляции;
\b - возврат курсора на один шаг назад.
В данном разделе понятие ``символ'' используется в смысле языка программирования Си, т.е. подразумевается прежде всего литеральный символ. Операторы позволяют расширить возможности для описания цепочек символов. Регулярные выражения допускают использование операций конкатенации, т.е., ``стыковки'' друг с другом. Если в выражении используется символ пробела и он не находится внутри квадратных скобок, то его необходимо экранировать по правилам, описанным ниже, так как пробел и табуляция используются в качестве разделителей внутри LEX-программы.
Операторы обозначаются символами-операторами, к которым относятся:
\ "" . [] - * + / | ? $ ^ {} <> ()
Каждый из этих символов или пар скобок в регулярном выражении играет
свою роль:
\ и "" - операторы экранирования.
Используются для отмены специального значения символа, обозначающего
оператор, либо последовательности таких символов.
\c - отменяет специальное значение символа c. В общем
случае c может быть любым символом (в том числе и ),
кроме цифры и скобки (т.е. специальное значение скобок таким способом
отменить нельзя).
"сс" - отменяет специальное значение последовательности
символов c. В общем случае в двойные кавычки можно заключать любую
последовательность символов, но специальное значение
таким способом отменить нельзя.
abc+ ,где + является символом-оператором, а в выражении
abc\+
специальное значение + отменяется.
[] - оператор выделения символа из определенного класса. Используется
для определения вхождения одного любого символа из числа заключенных
в квадратные скобки. Заключение символа в квадратные скобки также
выполняет роль экранирования. Квадратные скобки внутри квадратных
скобок также теряют свой специальный смысл.
[xy] - означает вхождение либо символа x, либо символа y.
[x-z] - означает вхождение любого символа из лексикографически
упорядоченной последовательности от x до z.
[A-z]
[+-0-9]
x* - означает любое (в том числе и нулевое) число вхождений символа
x.
x+ - означает одно и более вхождений символа x.
[A-z]*
[A-ZА-Яa-zа-я0-9]*
[A-z]+
/, |, ?, $, ^ - операторы выбора. Управляют процессом
выбора символов.
x/y - означает, что вхождение x учитывается только тогда, когда за
ним следует y.
x? - означает необязательность вхождения символа x.
x$ - означает учет вхождения символа x, если он является последним
в строке (cтоит перед символом n).
^x - означает учет вхождения символа x, если он является
первым символом строки.
[^x] - означает вхождение любого символа, кроме
x. Внутри квадратных скобок ^ должен обязательно
стоять первым.
_?[A-Za-z]*
-?[0-9]+
^[A-Z]
{} - оператор имеет два различных применения:
x{n,m} - означает от n до m вхождений x (здесь n и m натуральные,
m > n).
{имя} - означает, что вместо имени в данное место выражения будет
подставлено определение имени из области определений LEX-программы.
a{2,7}
<> - оператор используется для учета состояния ЛА при определении
вхождений.
<состояние>x - означает учет вхождения x, если ЛА находится в положении
"состояние".
() - оператор изменения группировки регулярного выражения. Все перечисленные
выше операторы имеют соответствующим образом определенные приоритеты.
Заключение в круглые скобки позволяет необходимым способом изменить
приоритеты для правильного описания входной информации.
+,
/, |, ?, , <> и (), принято называть расширенными регулярными
выражениями.
LEX-программа, написанная на языке LEX, имеет следующий формат:
определения %% правила %% пользовательские_подпрограммыТаким образом, LEX-программа включает секции опредeлений
%%Здесь нет никаких определений и никаких правил. Все строки, в которых занята первая позиция, относятся к LEX-программе. Любая строка, не являющаяся частью правила или действия, которая начинается с пробела или табуляции, копируется в генерируемый файл
lex.yy.c.
Определения, предназначенные для LEX, помещаются перед первым %%.
Любая строка этой секции, не содержащаяся между
%START имя1 имя2 ...Если начальные условия определены, то эта строка должна быть первой в LEX-программе.
Непосредственно определения задаются в форме:
имя трансляцияВ качестве разделителя используется один или более пробелов или табуляций. Имя (name) - это, как обычно, любая последовательность букв и цифр, начинающаяся с буквы. Трансляция (translation) - это регулярное выражение (или его часть), которое будет подставлено всюду, где указано имя. Пример:
БУКВА [A-ZА-Яa-zа-я_]
ЦИФРА [0-9]
ИДЕНТИФИКАТОР {БУКВА}({БУКВА}|{ЦИФРА})*
%%
{ИДЕНТИФИКАТОР} printf("\n%s",yytext);
. . .
LEX построит ЛА, который будет находить и выводить все идентификаторы
Си-программы из входного файла. В этом примере
ИДЕНТИФИКАТОР
заменит БУКВА(БУКВА|ЦИФРА), затем на
A-ZА-Яa-zа-я(A-ZА-Яa-zа-я|0-9).
yytext - это внешний массив символов программы lex.yy.c, которую строит
LEX; yytext формируется в процессе чтения входного файла и содержит
текст, для которого установлено соответствие какому-либо выражению.
Этот массив доступен пользовательским разделам LEX-программы. Функция
printf выводит каждый идентификатор на новой строке.
Фрагменты пользовательских подпрограмм вводятся двумя способами:
отступ фрагмент;или
%{
фрагмент
%}
Включение пользовательского фрагмента необходимо, например, для ввода
макроопределений Си, которые должны начинаться в первой колонке строки.
Все строки фрагмента пользовательской подпрограммы, размещенные в
разделе определений, будут внешними для любой функции lex.yy.c.
Таблица наборов символов задается в виде:
%T целое_число строка_символов . . . целое_число строка_символов %TСгенерированная программа
lex.yy.c осуществляет ввод/вывод символов
посредством библиотечных функций LEX с именами input,
output, unput.
Таким образом, LEX помещает в массив yytext символы в представлении,
используемом в этих библиотечных функциях. Для внутреннего использования
символ представляется целым числом, значение которого образовано набором
битов, представляющих символ в конкретной ЭВМ. Пользователю представляется
возможность менять представление символов (целых констант) с помощью
таблицы наборов символов. Если таблица символов присутствует в разделе
определений, то любой символ, появляющийся либо во входном потоке,
либо в правилах, должен быть определен в таблице символов. Символам
нельзя назначать число 0 и число, большее числа, выделенного для внутреннего
представления символов конкретной ЭВМ. Пример:
%T 1 Aa 2 Bb 3 Cc . . . 26 Zz 27 \n 28 + 29 - 30 0 31 1 . . . 39 9 %TЗдесь символы верхнего и нижнего регистров переводятся в числа 1 - 26, символ новой строки - в число 27, + и - переводятся в числа 28 и 29, а цифры - в числа 30 - 39.
Указатель хост-языка имеет вид:
%Cдля языка Си. Для других языков программирования, например Фортрана, указатель выглядит соответственно. Если указатель хост-языка отсутствует, то по умолчанию принимается Си.
Изменения размеров внутренних массивов задаются в форме:
%x числоЧисло - новый размер массива, x - одна из букв: p - позиции (positions), n - состояния (states), e - узлы дерева разбора (parse tree nodes), a - упакованные переходы (transitions), k - упакованные классы символов (packet character classes), o - массив выходных элементов (output array). LEX имеет внутренние таблицы, размеры которых ограничены. При построении программы лексического анализа может произойти переполнение любой из этих таблиц, о чем LEX сообщит при построении ЛА. Представляется возможность изменить размеры этих таблиц (сокращая размеры одних и увеличивая размеры других) таким образом, чтобы они не переполнялись. Естественно, эти изменения возможны лишь в пределах той памяти, которая выделяется под процесс. Ниже перечислены размеры таблиц, которые устанавливаются по умолчанию: p - 1500 позиций, n - 300 состояний, e - 600 узлов, a - 1500 упакованных переходов, k - 1000 упакованных классов символов, o - 1500 выходных элементов. Для того чтобы определить, каковы размеры таблиц и насколько они заняты, можно использовать флаг
-v при вызове
команды lex. Число перед / показывает сколько элементов массива занято,
а число за / показывает установленный размер массива.
Комментарии в разделе определений задаются в форме хост-языка и должны начинаться не с первой колонки строки.
Все, что находится после первой пары и до конца LEX-программы или до второй пары , если она присутствует, относится к секции правил. Секция правил может содержать правила и также фрагменты пользовательских подпрограмм.
Секция правил может включать список активных и неактивных (помеченных) правил. Активные и неактивные правила могут располагаться в любом порядке. Любое правило должно начинаться с первой позиции строки, пробелы и табуляции недопустимы - они используются как разделители между регулярным выражением и действием в правиле.
Активное правило имеет вид:
регулярное_выражение действиеАктивные правила выполняются всегда. По регулярным выражениям (regular expressions), содержащимся в левой части правил, LEX строит детерминированный конечный автомат. Этот автомат осуществляет интерпретацию, а не компиляцию, и переходит из одного состояния в другое. Количество правил и их сложность не влияют на скорость лексического анализа, если только правила не требуют слишком большого объема повторных просмотров входной последовательности символов. Однако с ростом числа правил и их сложности растет размер конечного автомата, интерпретирующего их, и, следовательно, растет размер Си-программы, реализующей этот конечный автомат.
LEX-программа, приведенная ниже, переводит на русский язык названия месяцев и дней недели.
%%
[jJ][aA][nN][uU][aA][rR][yY] {printf("Январь");}
[fF][eE][bB][rR][uU][aA][rR][yY] {printf("Февраль");}
[mM][aA][rR][cC][hH] {printf("Март");}
[aA][pP][rR][iI][lL] {printf("Апрель");}
[mM][aA][yY] {printf("Май");}
[jJ][uU][nN][eE] {printf("Июнь");}
[jJ][uU][lL][yY] {printf("Июль");}
[aA][uU][gG][uU][sS][tT] {printf("Август");}
[sS][eE][pP][tT][eE][mM][bB][eE][rR] {printf("Сентябрь");}
[oO][cC][tT][oO][bB][eE][rR] {printf("Октябрь");}
[nN][oO][vV][eE][mM][bB][eE][rR] {printf("Ноябрь");}
[dD][eE][cC][eE][mM][bB][eE][rR] {printf("Декабрь");}
[mM][oO][nN][dD][aA][yY] {printf("Понедельник");}
[tT][uU][eE][sS][dD][aA][yY] {printf("Вторник");}
[wW][eE][dD][nN][eE][sS][dD][aA][yY] {printf("Среда");}
[tT][hH][uU][rR][sS][dD][aA][yY] {printf("Четверг");}
[fF][rR][iI][dD][aA][yY] {printf("Пятница");}
[sS][aA][tT][uU][rR][dD][aA][yY] {printf("Суббота");}
[sS][uU][nN][dD][aA][yY] {printf("Воскресенье");}
Каждое правило здесь определяет действие (оно взято в фигурные скобки). Открывающая фигурная скобка стоит в той же строке, что и правило, - это требование LEX. Действие в каждом правиле данной LEX-программы - это вывод русского значения найденного английского слова. В качестве оператора, выполняющего действие, используется библиотечная функция языка Си. Пара фигурных скобок определяет блок (в смысле языка Си), который может содержать любое количество строк. Если действие содержит всего одну строку Си, то можно ее записать без фигурных скобок, как обычно. Единственное условие - она должна начинаться в той же строке, где и регулярное выражение. В программе содержится только раздел правил, их всего 19. Регулярное выражение каждого правила определяет английское слово, написанное строчными или прописными латинскими символами. Например, ``may'' (май) определен как mMaAyY. По этому регулярному выражению будет выделена во входном потоке лексема ``may'', а по действию этого правила будет выведено ``Май''. Наличие строчной и прописной буквы в квадратных скобках обеспечивает распознавание слова ``may'', написанного любым способом. После запуска на выполнение ЛА получим:
May Май MONDAY Понедельник . . . Ctrl-cДействие (action) можно представлять либо как специальное действие LEX, либо как оператор Си. Если имеется необходимость выполнить достаточно большой набор преобразований, то действие
ncform, будет просто копировать входной поток в выходной. Часто бывает
необходимо избавиться от подобного копирования. Для этой цели используется
пустой оператор Си. Например, правило
[ \t\n] ;запрещает вывод пробелов, табуляций и символов ``новая строка''. Запрет выражается в том, что для указанных символов во входном потоке осуществляется действие ; - пустой оператор Си, и эти символы не копируются в выводной поток символов.
Как отмечалось выше, в качестве действий могут выступать специальные действия языка LEX:
BEGIN | ECHO REJECTДля нескольких регулярных выражений можно указывать одно действие. Для этого используется специальное действие |, которое свидетельствует о том, что действие для данного регулярного выражения совпадает с действием для следующего. Например:
" " | \t | \n ;Специальное действие
BEGIN имеет следующий формат:
BEGIN метка;Если LEX-программа содержит активные и неактивные правила, то активные правила работают всегда. Специальное действие BEGIN просто расширяет список активных правил, активизируя помеченные меткой неактивные правила.
BEGIN 0; удаляет из ``списка активных'' все помеченные правила,
которые до этого были активизированы, и тем самым возвращает ЛА в
самое начальное состояние. Кроме того, если из помеченного и активного
в данный момент времени правила осуществляется специальное действие
BEGIN, то из помеченных правил активными останутся либо станут только
те, которые помечены меткой, указанной в этом специальном действии.
Например, в качестве первого правила секции правил может быть:
BEGIN начало;В этом правиле отсутствует регулярное выражение, и первым действием в секции правил будет активизация помеченных меткой начало правил.
Когда необходимо вывести или преобразовать текст, соответствующий
некоторому регулярному выражению, используется внешний массив символов
yytext, который формирует LEX и доступен в действиях правил.
Например, по правилу
[A-Z]+ printf("%s",yytext);
распознается и выводится на экран слово, содержащее прописные латинские
буквы. Операция вывода распознанного выражения используется очень
часто, поэтому имеется сокращенная форма записи этого действия, выражающаяся
специальным действием ECHO:
[A-Z]+ ECHO;Результат действия этого правила аналогичен результату предыдущего примера. В файле
lex.yy.c ECHO определяется как макроподстановка:
#define ECHO fprintf(yyout,"%s",yytext);Когда необходимо знать длину обнаруженной последовательности, используется счетчик найденных символов
yyleng, который также доступен в действиях.
Например, действием
[A-Z]+ printf("%c",yytext[yyleng-1]);
будет выводится последний символ слова, соответствующего регулярному
выражению A-Z+. Еще один пример:
[A-Z]+ {число_слов++; число_букв += yyleng;}
Здесь ведется подсчет числа распознанных слов и количества символов
во всех словах.
Обычно LEX разделяет входной поток, не осуществляя поиска всех возможных соответствий каждому выражению. Это означает, что каждый символ рассматривается один и только один раз. Предположим, что мы хотим подсчитать все вхождения she и he во входном тексте. Для этого мы могли бы записать следующие правила:
she s++; he h++; . | \n ;Поскольку she включает в себя he, ЛА не распознает те вхождения he, которые включены в she, так как прочитав один раз she, эти символы он не вернет во входной поток. Иногда нужно изменить подобную ситуацию. Специальное действие
REJECT означает - ``выбрать следующую альтернативу''.
Это приводит к тому, что, каким бы ни было правило, после него необходимо
выполнить второй выбор. Соответственно изменится и положение указателя
во входном потоке:
she {s++; REJECT;}
he {h++; REJECT;}
. |
\n ;
Здесь после выполнения одного правила символы возвращаются во
входной поток и выполняется другое правило. Слово the содержит как
th, так и he. Если имеется двухмерный массив digram, тогда:
%%
[a-z][a-z] {
digram[yytext[0]][yytext[1]]++;
REJECT;
}
\n ;
Здесь REJECT используется для выделения буквенных пар, начинающихся
на каждой букве, а не на каждой следующей. Как видно, REJECT полезно
применять для определения всех вхождений,
причем вхождения могут перекрываться или включать друг друга.
Неактивное (помеченное) правило имеет вид:
<метка> регулярное_выражение действиеили
<метка1,метка2,...> регулярное_выражение действиеНеактивные правила выполняются только в тех случаях, когда выполняется некоторое начальное условие. Количество помеченных
START вводится список начальных условий как список меток
соответствующих состояний автомата (states). Метка формируется так
же, как и метка в Си. Неактивные правила помечаются начальными условиями,
а специальное действие BEGIN позволяет активизировать правила, помеченные
начальными условиями, т.е. автомат переходит в соответствующее состояние.
Пример:
%Start КОММ
КОММ_НАЧАЛО "/*"
КОММ_КОНЕЦ "*/"
%%
{КОММ_НАЧАЛО} {
ECHO;
BEGIN КОММ;
};
[\t\n]* ;
<КОММ>[\^*]* ECHO;
<КОММ>\*/[^/] ECHO;
<КОММ>{КОММ_КОНЕЦ} {
ECHO;
printf("\n");
BEGIN 0;
};
LEX строит ЛА, который выделяет комментарии в Си-программе и записывает
их в стандартный файл вывода. Программа начинается с ключевого слова
START (можно записывать и как Start), за которым поставлена метка
начального условия КОММ. В данном случае оператор <КОММ>x означает
учет x, если ЛА находится в начальном условии КОММ. Специальное действие
BEGIN КОММ; переводит ЛА в состояние, соответствующее начальному условию
КОММ. После этого ЛА уже находится в новом состоянии КОММ, и теперь
разбор входного потока будет осуществляется и теми правилами, которые
начинаются с <КОММ>. Например, правилом
<КОММ>[\^*]* ECHO;теперь будет записываться в стандартный файл вывода любое число (включая и ноль) символов, отличных от символа *. Оператор
BEGIN
0; переводит ЛА в исходное состояние.
LEX-программа может содержать несколько помеченных начальных условий. Например, если LEX-программа начинается строкой
%Start AA BB CC DD, то это означает, что она управляет четырьмя начальными состояниями ЛА. В каждое из этих начальных состояний ЛА можно перевести, используя
BEGIN. Пример с несколькими начальными условиями:
%START AA BB CC
БУКВА [A-ZА-Яa-zа-я_]
ЦИФРА [0-9]
ИДЕНТИФИКАТОР {БУКВА}({БУКВА}|{ЦИФРА})*
%%
^# BEGIN AA;
^[ \t]*main BEGIN BB;
^[ \t]*{ИДЕНТИФИКАТОР} BEGIN CC;
\t ;
\n BEGIN 0;
<AA>define printf("Определение.\n");
<AA>include printf("Включение.\n");
<AA>ifdef printf("Условная компиляция.\n");
<BB>[^\,]*","[^\,]*")" printf("main с аргументами.\n");
<BB>[^\,]*")" printf("main без аргументов.\n");
<CC>":"/[ \t] printf("Метка.\n");
Программа содержит активные и неактивные правила. Все неактивные правила
помечены. LEX-программа управляет тремя начальными условиями, в соответствии
с которыми активизируются помеченные правила. Здесь представлен ЛА,
который будет распознавать в Си-программе строки макропроцессора Си-компилятора,
выделять функцию main, распознавая с аргументами она или без них,
распознавать метки. ЛА не выводит ничего, кроме сообщений о выделенных
лексемах.
Таким образом, в процессе работы ЛА список активных правил может ``видоизменяться'' за счет действий оператора BEGIN. В процессе распознавания лексем во входном потоке может оказаться так, что одна цепочка символов удовлетворяет нескольким правилам и, следовательно, возникает проблема: действие какого правила должно выполняться? Для разрешения этого противоречия можно использовать ``разбиение'' регулярных выражений этих правил LEX-программы на такие новые регулярные выражения, которые дадут однозначное распознавание лексем. Однако, если это не сделано, LEX использует определенный детерминированный механизм разрешения такого противоречия:
[Мм][Аа][Йй] ECHO; [А-Яа-я]+ ECHO;Слово ``Май'' распознают оба правила, однако выполнится первое из них, так как и первое и второе правила распознали лексему одинакового размера (3 символа). Если во входном потоке будет слово ``майский'', то первые 3 символа удовлетворяют первому правилу, а все 7 символов удовлетворяют второму правилу и, следовательно, выполнится второе правило, так как ему соответствует более длинная последовательность.
Фрагменты пользовательских подпрограмм, содержащиеся в секции правил,
становятся частью функции yylex файла lex.yy.c. Они вводятся следующим
образом:
%{
фрагмент
%}
Пример:
%%
%{
#include file.h
%}
Здесь строка include file.h станет строкой функции yylex.
Все, что размещено за вторым набором, относится к секции пользовательских
подпрограмм. Содержимое этой секции копируется в выходной файл lex.yy.c
без каких-либо изменений. В файле lex.yy.c строки этого раздела рассматриваются
как функции Си. Эти функции могут вызываться в действиях
правил и, как обычно, передавать и возвращать значения аргументов.
Комментарии можно вводить во всех разделах LEX-программы. Формат комментариев должен соответствовать формату комментариев хост-языка, т.е. языка Си. Однако в каждой секции LEX - программы комментарии вводятся по-разному:
%Start КОММ
/*
* Программа записывает в стандартный файл вывода
* комментарии Си-программы. Обратите внимание на то,
* что здесь строки комментариев начинаются не с первой
* позиции строки!
*/
КОММ_НАЧАЛО "/*"
КОММ_КОНЕЦ "*/"
%%
{КОММ_НАЧАЛО} {ECHO;
BEGIN КОММ;}
[\t\n]* ;
<КОММ>[^*]* ECHO;
<КОММ>\*/[^/] ECHO;
<КОММ>{КОММ_КОНЕЦ} {ECHO;
printf("\n");
/*
* Здесь приведен пример использования комментариев в
* разделе правил LEX-программы. Обратите внимание на то,
* что комментарий находится внутри блока, определяющего
* действие правила.
*/
BEGIN 0;}
%%
/*
* Здесь приведен пример комментариев в разделе
* пользовательских подпрограмм.
*/
LEX строит программу ЛА на языке Си, которая размещается в файле со
стандартным именем lex.yy.c. Так как файл lex.yy.c - это Си-программа,
то в него можно внести любые необходимые изменения и добавления. Эта
программа содержит ряд основных и вспомогательных функций:
Синтаксис системного вызова msgctl:
#include <sys/ipc.h>
#include <sys/msg.h>
int msgctl ( int msqid, int cmd,
struct msqid_ds *buf);
В качестве аргумента msqid должен выступать идентификатор очереди сообщений, предварительно полученный системным вызовом msgget.
Управляющее действие определяется значением аргумента cmd. Допустимых значений три:
Программа-пример в этом разделе иллюстрирует управление очередью. В программе использованы следующие переменные:
Если выбрано действие IPC_STAT (код 1), выполняется системный вызов и распечатывается информация о состоянии очереди; в программе распечатываются только те поля структуры, которые могут быть переустановлены. Если системный вызов завершается неудачей, распечатывается информация о состоянии очереди на момент последнего успешного выполнения системного вызова. Кроме того, выводится сообщение об ошибке и распечатывается значение переменной errno. Если системный вызов завершается успешно, выводится сообщение, уведомляющее об этом, и значение использованного идентификатора очереди сообщений.
Если выбрано действие IPC_SET (код 2), программа прежде всего получает информацию о текущем состоянии очереди сообщений с заданным идентификатором. Это необходимо, поскольку в примере обеспечивается изменение только одного поля за один раз, в то время как системный вызов изменяет всю структуру целиком. Кроме того, если в одно из полей структуры, находящейся в области памяти пользователя, будет занесено некорректное значение, это может вызвать неудачи в выполнении управляющих действий, повторяющиеся до тех пор, пока значение поля не будет исправлено. Затем программа предлагает ввести код, соответствующий полю структуры, которое должно быть изменено. Этот код заносится в переменную choice. Далее, в зависимости от указанного поля, программа предлагает ввести то или иное новое значение. Значение заносится в соответствующее поле структуры данных, расположенной в области памяти пользователя, и выполняется системный вызов.
Если выбрано действие IPC_RMID (код 3), выполняется системный вызов, удаляющий из системы идентификатор msqid, очередь сообщений и ассоциированную с ней структуру данных. Отметим, что для выполнения этого управляющего действия аргумент buf не требуется, поэтому его значение может быть заменено нулем (NULL):
возможности системного вызова msgctl()
(управление очередями сообщений) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
main ()
{
extern int errno;
int msqid, command, choice, rtrn;
struct msqid_ds msqid_ds, *buf;
buf = &msqid_ds;
/* Ввести идентификатор и действие */
printf ("Введите идентификатор msqid: ");
scanf ("%d", &msqid);
printf ("Введите номер требуемого действия:\n");
printf (" IPC_STAT = 1\n");
printf (" IPC_SET = 2\n");
printf (" IPC_RMID = 3\n");
printf (" Выбор = ");
scanf ("%d", &command);
/* Проверить значения */
printf ("идентификатор = %d, действие = %d\n",
msqid, command);
switch (command) {
case 1: /* Скопировать информацию
о состоянии очереди сообщений
в пользовательскую структуру
и вывести ее */
rtrn = msgctl (msqid, IPC_STAT, buf);
printf ("\n Идентификатор пользователя =
%d\n",
buf->msg_perm.uid);
printf ("\n Идентификатор группы = %d\n",
buf->msg_perm.gid);
printf ("\n Права на операции = 0%o\n",
buf->msg_perm.mode);
printf ("\n Размер очереди в байтах =
%d\n",
buf->msg_qbytes);
break;
case 2: /* Выбрать и изменить поле (поля)
ассоциированной структуры данных */
/* Сначала получить исходное значение
структуры данных */
rtrn = msgctl (msqid, IPC_STAT, buf);
printf ("\nВведите номер поля, ");
printf ("которое нужно изменить:\n");
printf (" msg_perm.uid = 1\n");
printf (" msg_perm.gid = 2\n");
printf (" msg_perm.mode = 3\n");
printf (" msg_qbytes = 4\n");
printf (" Выбор = ");
scanf ("%d", &choice);
switch (choice) {
case 1:
printf ("\nВведите ид-р
пользователя: ");
scanf ("%d", &buf->msg_perm.uid);
printf ("\nИд-р пользователя =
%d\n",
buf->msg_perm.uid);
break;
case 2:
printf ("\nВведите ид-р
группы: ");
scanf ("%d", &buf->msg_perm.gid);
printf ("\nИд-р группы = %d\n",
buf->msg_perm.uid);
break;
case 3:
printf ("\nВведите восьмеричный
код прав: ");
scanf ("%o", &buf->msg_perm.mode);
printf ("\nПрава на операции =
0%o\n",
buf->msg_perm.mode);
break;
case 4:
printf ("\nВведите размер
очереди = ");
scanf ("%d", &buf->msg_qbytes);
printf ("\nЧисло байт в очереди =
%d\n", buf->msg_qbytes);
break;
}
/* Внести изменения */
rtrn = msgctl (msqid, IPC_SET, buf);
break;
case 3: /* Удалить идентификатор и
ассоциированные с ним очередь
сообщений и структуру данных */
rtrn = msgctl (msqid, IPC_RMID, NULL);
}
if (rtrn == -1) {
/* Сообщить о неудачном завершении */
printf ("\nmsgctl завершился неудачей!\n");
printf ("\nКод ошибки = %d\n", errno);
}
else {
/* При успешном завершении сообщить msqid */
printf ("\nmsgctl завершился успешно,\n");
printf ("идентификатор = %d\n", msqid);
}
exit (0);
}
Функция содержит разделы действий всех правил, которые определены
пользователем. Файл lex.yy.c генерируется из файла - заготовки /usr/lib/lex/ncform,
в котором отсутствует функция yylex(). Эта функция включается в lex.yy.c
в процессе генерации. С полным текстом файла ncform можно ознакомиться
в соответствующем каталоге.
Функция реализует детерминированный конечный автомат, который осуществляет разбор входного потока символов в соответствии с регулярными выражениями правил LEX-программы.
Функция используется для определения конца файла, из которого ЛА читает
поток символов. Если yywrap возвращает 1, ЛА прекращает работу. Однако
иногда появляется необходимость начать ввод данных из другого источника
и продолжить работу. В этом случае нужно написать свою подпрограмму
yywrap, которая организует новый входной поток и возвращает 0, что
служит сигналом к продолжению работы ЛА. По умолчанию yywrap всегда
возвращает 1 при завершении входного потока символов. В LEX-программе
невозможно записать правило, которое будет обнаруживать конец файла.
Единственный способ это сделать - использовать функцию yywrap. Эта
функция также удобна, когда необходимо выполнить какие-либо действия
по завершению входного потока символов. Пример:
%START AA BB CC
/*
* Строится ЛА, который распознает наличие включений
* файлов в Си-программе, условных компиляций,
* макроопределений, меток и головной функции main.
* Анализатор ничего не выводит
* пока осуществляется чтение всего входного потока.
* По завершении выводится статистика.
*/
БУКВА [A-ZА-Яa-zа-я_]
ЦИФРА [0-9]
ИДЕНТИФИКАТОР {БУКВА}({БУКВА}|{ЦИФРА})*
int a1,a2,a3,b1,b2,c;
%%
{a1=a2=a3=b1=b2=c=0;}
^# BEGIN AA;
^[ \t]*main BEGIN BB;
^[ \t]*{ИДЕНТИФИКАТОР} BEGIN CC;
\t ;
\n BEGIN 0;
<AA>define {a1++;}
<AA>include {a2++;}
<AA>ifdef {a3++;}
<BB>[^\,]*","[^\,]*")" {b1++;}
<BB>[^\,]*")" {b2++;}
<CC>":"/[ \t] {c++;}
%%
yywrap()
{
if(b1==0&&b2==0)
printf("В программе отсутствует функция main.\n");
if(b1>=1&&b2>=1)
printf("Многократное определение функции main.\n");
else
{
if(b1==1) printf("Функция main с аргументами.\n");
if(b2==1) printf("Функция main без аргументов.\n");
}
printf("Включений файлов: %d.\n",a2);
printf("Условных компиляций: %d.\n",a3);
printf("Определений: %d.\n",a1);
printf("Меток: %d.\n",c);
return(1);
}
Оператор return(1) в функции yywrap указывает, что ЛА должен завершить
работу. Если необходимо продолжить работу ЛА для чтения данных из
нового файла, нужно ипользовать return(0), предварительно осуществив
операции закрытия и открытия файлов. Однако если yywrap не возвращает
1, то это приводит к бесконечному циклу.
В обычной ситуации содержимое yytext обновляется всякий раз, когда
на входе появляется следующая строка (в yytext всегда находятся символы
распознанной цепочки). Иногда возникает необходимость добавить к текущему
содержимому yytext следующую распознанную цепочку символов. Для этой
цели используется функция yymore. Пример использования функции yymore:
.
.
.
\"[^"]* {
if(yytext[yyleng-1]=='\\') yymore();
else
{/*
* Здесь должна быть часть программы,
* обрабатывающая закрывающую кавычку.
*/}
}
.
.
.
В этом примере распознаются строки симвoлов, взятые в двойные кавычки,
причем символ двойных кавычек внутри этой строки может изображаться
с предшествующей косой чертой. ЛА должен распознавать кавычку, ограничивающую
строку, и кавычку, являющуюся частью строки, когда она изображена
как \". Если на вход поступает строка абв\"где",
то сначала будет распознана цепочка "абв
и так как последним символом в этой цепочке будет символ \,
выполнится вызов yymore. В результате к цепочке "абв\
будет добавлено "где, и в yytext мы получим "абв\"где",
что и требовалось.
В некоторых случаях возникает необходимость использовать не все символы
распознанной цепочки в yytext, а только необходимое число. Для
этой цели используется функция yyless(n), где n указывает, что в данный
момент необходимо только n символов строки из yytext. Остальные найденные
символы будут возвращены во входной поток. Пример использования функции
yyless:
.
.
.
=-[A-ZА-Яa-zа-я] {
printf("Oператор (=-) двусмысленный.\n");
yyless(yyleng-2);
/*
* Здесь необходимо записать действия для
* случая "=-"
*/
}
.
.
.
В этом примере разрешается двусмысленность выражения =- буква в языке
Си. Это выражение можно рассматривать как =- буква или как = -буква.
Предположим, что эту ситуацию нужно рассматривать как = -буква и выводить
предупреждение. В примере правило распознает эту ситуацию, выводит
предупреждение и затем, после вызова yyless(yyleng - 2); два
символа -буква будут возвращены во входной поток, а знак = останется
в yytext для обработки, как и в нормальной ситуации. Таким образом,
при продолжении чтения входного потока уже будет обрабатываться цепочка
-буква, что и требовалось.
Функция читает символ из входного потока символов. Если читается файл и достигнут его конец, то функция возвращает NULL.
Функция возвращает символ обратно во входной поток для повторного
его чтения следующим вызовом input.
Функция выводит в выходной поток символ c.
Последние три функции (6-8), определены как макроподстановки и их можно переопределть в секции подпрограмм пользователя.
При сборке программы лексического анализа редактор связи ld по флагу
-ll подключает головную функцию main, если она не определена. Ниже
приведен полный исходный текст такой библиотеки libl.a:
#include "stdio.h"
main()
{
yylex();
exit(0);
}
Основой входной спецификации является набор грамматических правил. Каждое правило описывает допустимую структуру языка и дает ей имя. Например, правило может быть таким:
date : month_name day ',' year ;Здесь
date, monthname, day, и year представляют собой структуры языка
(нетерминалы) описанные где-то еще, а запятая, заключенная в кавычки
означает, что после нетерминала day ожидается символ ',' как литера.
Двоеточие и точка с запятой являются знаками пунктуации Yacc. Таким
образом, строка January 1, 2000 попадает под вышеприведенное правило.
Yacc на основе входных спецификаций осуществляет синтаксический разбор текста, пользуясь при этом результатами лексического анализа, выполняемого внешней (по отношению к нему) подпрограммой, которая должна читать символы из входного потока, распознавать конструкции низкого уровня (лексемы) и передавать их на вход синтаксического анализатора, создаваемого Yacc. Традиционно конструкции, распознаваемые лексическим анализатором, называют терминальными символами, а распознаваемые синтаксическим - нетерминальными. В дальнейшем, во избежание путаницы, терминальные символы мы будем называть токенами (tokens).
Существует определенная свобода в выборе конструкций, распознаваемых лексическим и синтаксическим анализаторами, например, в предыдущем примере вполне могут быть использованы правила:
month_name : 'J' 'a' 'n' ; month_name : 'F' 'e' 'b' ; . . . month_name : 'D' 'e' 'c' ;В этом случае лексический анализатор должен только распознавать отдельные литеры, а monthname является нетерминальным символом. Но на работу с такими низкоуровневыми правилами тратится много времени и памяти, неимоверно распухают входные спецификации Yacca, поэтому обычно лексический анализатор (как более простой прием) распознает названия месяцев и выдает только признак того, что встретилось такое название. В этом случае
monthname является токеном (терминальным символом). Специальные
символы, такие, как в нашем примере, должны также
распознавальтся лексическим анализатором.
Описание грамматики в виде правил является очень гибким, поэтому очень легко добавить к примеру правило:
date : month '/' day '/' year ;позволяющее вводить
1 / 1 / 2000, как синоним для
January 1, 2000.
В большинстве случаев новое правило может быть введено в работающую
систему легко и с минимальным риском испортить уже работающие правила.
Разбираемый текст может (иногда) не соответствовать спецификациям, что чвляется синонимом синтаксической ошибки. Такие ошибки обнаруживаются настолько быстро, насколько это возможно теоретически при сканировании слева направо. Частью входных спецификаций являются специальные правила обработки ошибок, позволяющие либо исправить неправильные символы, либо продолжить разбор после пропуска неправильных символов.
В некоторых случаях компилятором Yacc не удастся построить анализатор по входным спецификациям, так как либо заданная грамматика не является LALR(1), либо у Yacca не хватает мощности. Обычно эта проблема решается пересмотром системы правил, либо созданием более мощного лексического анализатора. Следует также заметить, что конструкции неподвластные Yacc, часто также непосильны и человеческому разуму...
Синтаксис системных вызовов msgop для операций над очередями выглядит так:
#include <sys/ipc.h>
#include <sys/msg.h>
int msgsnd (int msqid, struct msgbuf * msgp,
int msgsz, int msgflg)
int msgrcv (int msqid, struct msgbuf * msgp,
int msgsz, long msgtyp, int msgflg)
Значение поля msg_qbytes у ассоциированной
структуры данных может быть уменьшено с предполагаемой по умолчанию
величины MSGMNB при помощи управляющего действия IPC_SET
системного вызова msgctl, однако впоследствии увеличить его
может только суперпользователь. Аргумент msgflg позволяет
специфицировать выполнение ``операции с блокировкой'';
для этого флаг IPC_NOWAIT должен быть сброшен (msgflg
&
IPC_NOWAIT = 0). Блокировка имеет место, если либо текущее
число байт в очереди уже равно максимально допустимому значению для
указанной очереди (т. е. значению поля msg_qbytes или
MSGMNB), либо общее число сообщений во всех очередях равно
максимально допустимому системой (системный параметр MSGTQL).
Если в такой ситуации флаг IPC_NOWAIT установлен, то системный
вызов msgsnd() завершается неудачей и возвращает -1.
При успешном завершении системного вызова msgrcv() результат равен числу принятых байт; в случае неудачи возвращается -1. В качестве аргумента msqid должен выступать идентификатор очереди сообщений, предварительно полученный системным вызовом msgget. Аргумент msgp является указателем на структуру в области памяти пользователя, содержащую тип принимаемого сообщения и его текст. Аргумент msgsz специфицирует длину принимаемого сообщения. В случае, если значение данного аргумента меньше, чем длина сообщения в массиве, возникает ошибка (см. описание аргумента msgflg).
Аргумент msgtyp используется для выбора из очереди первого сообщения определенного типа. Если значение аргумента равно нулю, запрашивается первое сообщение в очереди, если больше нуля - первое сообщение типа msgtyp, а если меньше нуля - первое сообщение наименьшего типа, превосходящего абсолютной величины аргумента msgtyp.
Аргумент msgflg позволяет специфицировать выполнение
``операции с блокировкой''; для этого должен быть сброшен
флаг
IPC_NOWAIT (msgflg & IPC_NOWAIT = 0). Блокировка
имеет место, если в очереди нет сообщения с запрашиваемым
типом (msgtyp). Если флаг IPC_NOWAIT установлен
и в очереди нет сообщения требуемого типа, системный вызов немедленно
завершается неудачей. Аргумент msgflg может также указывать,
что системный вызов закончится неудачей, если размер сообщения
в очереди больше значения msgsz; для этого в данном аргументе
должен быть сброшен флаг MSG_NOERROR (msgflg &
MSG_NOERROR = 0). Если флаг MSG_NOERROR установлен, сообщение
обрезается до длины, указанной аргументом msgsz.
В примере этого раздела используются следующие переменные:
Если выбрана операция посылки сообщения, указатель msgp
инициализируется
адресом структуры данных sndbuf. После этого запрашивается
идентификатор очереди сообщений, в которую должно быть послано сообщение;
идентификатор заносится в переменную msqid. Затем должен
быть введен тип сообщения; он заносится в поле mtype структуры
данных, обозначаемой msgp.
После этого программа принимает текст посылаемого сообщения и выполняет цикл, в котором символы читаются и заносятся в массив mtext структуры данных. Ввод продолжается до тех пор, пока не будет обнаружен признак конца файла; для функции getchar() таким признаком является символ CTRL+D, непосредственно следующий за символом возврата каретки. После того как признак конца обнаружен, определяется размер сообщения: он на единицу больше значения счетчика i, поскольку элементы массива, в который заносится сообщение, нумеруются с нуля. Следует помнить, что сообщение будет содержать заключительные символы и, следовательно, будет казаться, что сообщение на три символа короче, чем указывает аргумент msgsz.
Чтобы обеспечить пользователю обратную связь, текст сообщения, содержащийся в массиве mtext структуры sndbuf, немедленно выводится на экран.
Следующее, и последнее, действие заключается в определении, должен ли быть установлен флаг IPC_NOWAIT. Чтобы выяснить это, программа предлагает ввести 1, если флаг нужно установить, или любое другое число, если он не нужен. Введенное значение заносится в переменную flag. Если введена единица, аргумент msgflg полагается равным IPC_NOWAIT, в противном случае msgflg устанавливается равным нулю.
После этого выполняется системный вызов msgsnd(). Если вызов завершается неудачей, выводится сообщение об ошибке, а также ее код. Если вызов завершается успешно, печатается возвращенное им значение, которое должно быть равно нулю.
При каждой успешной отсылке сообщения обновляются три поля ассоциированной структуры данных. Изменения можно описать следующим образом:
Если указано, что требуется принять сообщение, начальное значение указателя msgp устанавливается равным адресу структуры данных rcvbuf. Запрашивается код требуемой комбинации флагов, который заносится в переменную flags. Переменная msgflg устанавливается в сответствии с выбранной комбинацией. В заключение запрашивается, сколько байт нужно принять; указанное значение заносится в переменную msgsz. После этого выполняется системный вызов msgrcv().
Если вызов завершается неудачей, выводится сообщение об ошибке, а также ее код. Если вызов завершается успешно, программа сообщает об этом, а также выводит размер и текст сообщения. При каждом успешном приеме сообщения обновляются три поля ассоциированной структуры данных. Изменения можно описать следующим образом:
msg_qnum - определяет общее число сообщений в очереди; в результате выполнения операции уменьшается на единицу;
msg_lrpid - содержит идентификатор процесса, который последним получил сообщение; полю присваивается соответствующий идентификатор;
msg_rtime - содержит время последнего получения сообщения, время измеряется в секундах, начиная с 00:00:00 1 января 1970 г. (по Гринвичу).
возможности системных вызовов msgsnd() и msgrcv()
(операции над очередями сообщений) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/msg.h>
#define MAXTEXTSIZE 8192
struct msgbufl {
long mtype;
char mtext [MAXTEXTSIZE];
} sndbuf, rcvbuf, *msgp;
main () {
extern int errno;
int flag, flags, choice, rtrn, i, c;
int rtrn, msqid, msgsz, msgflg;
long msgtyp;
struct msqid_ds msqid_ds, *buf;
buf = &msqid_ds;
/* Выбрать требуемую операцию */
printf ("\nВведите код, соответствующий ");
printf ("посылке или приему сообщения:\n");
printf (" Послать = 1\n");
printf (" Принять = 2\n");
printf (" Выбор = ");
scanf ("%d", &choice);
if (choice == 1) {
/* Послать сообщение */
msgp = &sndbuf; /* Указатель на структуру */
printf ("\nВведите идентификатор ");
printf ("очереди сообщений,\n");
printf ("в которую посылается сообщение: ");
scanf ("%d", &msqid);
/* Установить тип сообщения */
printf ("\nВведите положительное число - ");
printf ("тип сообщения: ");
scanf ("%d", &msgp->mtype);
/* Ввести посылаемое сообщение */
printf ("\nВведите сообщение: \n");
/* Управляющая последовательность CTRL+D
завершает ввод сообщения */
/* Прочитать символы сообщения
и поместить их в массив mtext */
for (i = 0; ((c = getchar ()) != EOF); i++)
sndbuf.mtext [i] = c;
/* Определить размер сообщения */
msgsz = i + 1;
/* Выдать текст посылаемого сообщения */
for (i = 0; i < msgsz; i++)
putchar (sndbuf.mtext [i]);
/* Установить флаг IPC_NOWAIT, если это нужно */
printf ("\nВведите 1, если хотите установить ");
printf ("флаг IPC_NOWAIT: ");
scanf ("%d", &flag);
if (flag == 1) msgflg = IPC_NOWAIT;
else msgflg = 0;
/* Проверить флаг */
printf ("\nФлаг = 0%o\n", msgflg);
/* Послать сообщение */
rtrn = msgsnd (msqid, msgp, msgsz, msgflg);
if (rtrn == -1) {
printf ("\nmsgsnd завершился неудачей!\n");
printf ("Код ошибки = %d\n", errno); }
else {
/* Вывести результат; при успешном
завершении он должен равняться нулю */
printf ("\nРезультат = %d\n", rtrn);
/* Вывести размер сообщения */
printf ("\nРазмер сообщения = %d\n", msgsz);
/* Опрос измененной структуры данных */
msgctl (msqid, IPC_STAT, buf);
/* Вывести изменившиеся поля */
printf ("Число сообщений в очереди = %d\n",
buf->msg_qnum);
printf ("Ид-р последнего отправителя = %d\n",
buf->msg_lspid);
printf ("Время последнего отправления = %d\n",
buf->msg_stime); }
}
if (choice == 2) {
/* Принять сообщение */
msgp = &rcvbuf;
/* Определить нужную очередь сообщений */
printf ("\nВведите ид-р очереди сообщений: ");
scanf ("%d", &msqid);
/* Определить тип сообщения */
printf ("\nВведите тип сообщения: ");
scanf ("%d", &msgtyp);
/* Сформировать управляющие флаги
для требуемых действий */
printf ("\nВведите код, соответствущий ");
printf ("нужной комбинации флагов:\n");
printf (" Нет флагов = 0\n");
printf (" MSG_NOERROR = 1\n");
printf (" IPC_NOWAIT = 2\n");
printf (" MSG_NOERROR и IPC_NOWAIT = 3\n");
printf (" Выбор = ");
scanf ("%d", &flags);
switch (flags) {
/* Установить msgflg как побитное ИЛИ
соответствующих констант */
case 0: msgflg = 0;
break;
case 1: msgflg = MSG_NOERROR;
break;
case 2: msgflg = IPC_NOWAIT;
break;
case 3:
msgflg = MSG_NOERROR | IPC_NOWAIT;
break;
}
/* Определить, какое число байт принять */
printf ("\nВведите число байт, которое ");
printf ("нужно принять (msgsz): ");
scanf ("%d", &msgsz);
/* Проверить значение аргументов */
printf ("\nИдентификатор msqid = %d\n", msqid);
printf ("Тип сообщения = %d\n", msgtyp);
printf ("Число байт = %d\n", msgsz);
printf ("Флаги = %o\n", msgflg);
/* Вызвать msgrcv для приема сообщения */
rtrn = msgrcv (msqid, msgp, msgsz,
msgtyp, msgflg);
if (rtrn == -1) {
printf ("\nmsgrcv завершился неудачей!\n");
printf ("Код oшибки = %d\n", errno); }
else {
printf ("\nmsgrcv завершился успешно,\n");
printf ("Идентификатор очереди =
%d\n", msqid);
/* Напечатать число принятых байт,
оно равно возвращаемому значению */
printf ("Принято байт: %d\n", rtrn);
/* Распечатать принятое сообщение */
for (i = 0; i < rtrn; i++)
putchar (rcvbuf.mtext [i]);
}
/* Опрос ассоциированной структуры данных */
msgctl (msqid, IPC_STAT, buf);
printf ("\nЧисло сообщений в очереди = %d\n",
buf->msg_qnum);
printf ("Ид-р последнего получателя = %d\n",
buf->msg_lrpid);
printf ("Время последнего получения = %d\n",
buf->msg_rtime); }
exit (0);
}
Имена относятся либо к токенам, либо к нетерминалам. Компилятор Yacc требует, чтобы все токены были специально описаны, часто желательно, чтобы лексический анализатор был включен в файл входных спецификаций. Впрочем и другие подпрограммы туда тоже можно включать. Таким образом, файл входных спецификаций состоит из трех секций: объявлений (declarations); грамматики (правил/rules); программ (подпрограмм).
Секции отделяются друг от друга двойным процентом (%%).
(Процент вообще используется Yaccом как специальный символ). Другими
словами, файл входных спецификаций выглядит так:
declarations (объявления) %% rules (правила) %% programs (программы)Секция объявлений может быть пустой, кроме того, если пуста секция программ, можно опустить и второй разделитель (
%%). Таким образом,
самая короткая спецификация может выглядеть так:
%% rulesПробелы, табуляции и возвраты каретки игнорируются, но не должны появляться в именах и зарезервированых символах. Везде, где может стоять имя, может быть и комментарий (как в Си):
/* . . . */Секция правил состоит из одного или более грамматических правил в форме:
A : BODY ;здесь
A - имя нетерминала, а BODY представляет собой
последовательность из нуля или более имен и литералов. Двоеточие и
точка с запятой - символы пунктуации Yacca. Имена могут быть произвольной
длины и состоять из букв, точек, подчеркиваний и цифр, но не должны
начинаться с цифры. Прописные и строчные буквы различаются. Имена,
использованые в теле правила, могут быть именами токенов или нетерминалов.
Литерал - это символ, заключенный в одиночные кавычки. Как и в Си
бакслэш (\) является спецсимволом,
а все Си-шные спецпоследовательности типа n и t воспринимаются.
По многим причинам технического свойства символ с кодом 0 (NULL) не должен никогда использоваться в правилах.
Если есть несколько правил с одинакой левой частью, можно вместо дублирования левой части использовать символ |. Кроме того точка с запятой может быть поставлена и перед символом |. Таким образом, правила:
A : B C D ; A : E F ; A : G ;могут быть записаны так:
A : B C D | E F | G ;или даже так:
A : B C D ; | E F ; | G ;Не обязательно, чтобы правила с одинаковой левой частью были написаны вместе (или рядом), но такая запись делает их более читаемыми и легкими для изменения. Если нетерминалу соответствует пустая строка, он может быть записан так:
empty : ;Имена токенов должны быть объявлены, что проще всего сделать, написав:
%token name1 name2 . . . в секции объявлений.
Каждое имя, не указанное в секции объявлений, предполагается именем нетерминала. Каждый нетерминал должен появиться в левой части хотя бы одного правила.
Из всех нетерминалов, один, называемый начальным нетерминалом, имеет
особое значение. Анализатор строится, чтобы разобрать начальный нетерминал,
который представляет собой наибольшую и наиобщую конструкцию, описанную
правилами. По умолчанию, начальным считается нетерминал, стоящий в
левой части первого правила, но желательно, чтобы он был объявлен
явно при помощи %start nonterminal в секции объявлений.
Об окончании ввода анализатору говорит специальный токен, называемый концевым маркером. Если концевой маркер приходит после разбора правила, соответствующего начальному нетерминалу, анализатор возвращает управление вызвавшей программе, прочитав его. Если маркер приходит в ином контексте, это считается синтаксической ошибкой. Вернуть концевой маркер в нужный момент - это забота лексического анализатора. Обычно коцевой маркер возвращается по концу записи или файла.
Каждому правилу можно поставить в соответствие некое действие, которое будет выполняться всякий раз, как это правило будет распознано. Действия могут возвращать значения и могут пользоваться значениями, возвращенными предыдущими действиями. Более того, лексический анализатор может возвращать значения для токенов (дополнительно), если хочется. Действие - это обычный оператор языка Си, который может выполнять ввод, вывод, вызывать подпрограммы и изменять глобальные переменные.
Действия, состоящие из нескольких операторов, необходимо заключать в фигурные скобки. Например:
A : '(' B ')'
{ hello( 1, "abc" ); }
и
XXX : YYY ZZZ
{ printf("a message\n"); flag = 25; }
являются грамматическими правилами с действиями.
Чтобы обеспечить связь действий с анализатором, используется спецсимвол
"доллар" ($). Чтобы вернуть значение, действие обычно присваивает его
псевдопеременной $$. Например, действие, которое
не делает ничего, но возвращает единицу:
{ $$ = 1; }
Чтобы получить значения, возвращенные предыдущими действиями и лексическим
анализатором, действие может использовать псевдопеременные $1, $2
и т. д., которые соответствуют значениям, возвращенным компонентами
правой части правила, считая слева направо. Таким образом, если правило
имеет вид:
A : B C D ;то
$2 соответствует значению, возвращенному нетерминалом C, a $3
- нетерминалом D. Более конкретный пример:
expr : '(' expr ')' ;
Значением, возвращаемым этим правилом, обычно является значение выражения
в скобках, что может быть записано так:
expr : '(' expr ')'
{ $$ = $2 ; }
По умолчанию, значением правила считается значение, возвращенное первым
элементом ($1). Таким образом, если правило не имеет действия, Yacc
автоматически добаляет его в виде $$=$1; , благодаря чему
для правила вида
A : B ;обычно не требуется самому писать действие.
В вышеприведенных примерах все действия стояли в конце правил, но иногда желательно выполнить что-либо до того, как правило будет полностью разобрано. Для этого Yacc позволяет записывать действия не только в конце правила, но и в его середине. Значение такого действия доступно действиям, стоящим правее, через обычный механизм:
A : B
{ $$ = 1; }
C
{ x = $2; y = $3; }
;
В результате разбора иксу (x) присвоится значение 1, а игреку (y) - значение, возвращенное
нетерминалом C. Действие, стоящее в середине правила, считается за
его компоненту, поэтому x=$2 присваивает X-у значение, возвращенное
действием $$=1;
Для действий, находящихся в середине правил, Yacc создает новый нетерминал и новое правило с пустой правой частью и действие выполняется после разбора этого нового правила. На самом деле Yacc трактует последний пример как
NEW_ACT : /* empty */ /* НОВОЕ ПРАВИЛО */
{ $$ = 1; }
;
A : B NEW_ACT C
{ x = $2; y = $3; }
;
В большинстве приложений действия не выполняют ввода/вывода, а конструируют
и обрабатывают в памяти структуры данных, например дерево разбора.
Такие действия проще всего выполнять вызывая подпрограммы для создания
и модификации структур данных. Предположим, что существует
функция node, написанная так, что вызов node( L, n1, n2) создает вершину
с меткой L, ветвями n1 и n2 и возвращает индекс свежесозданной вершины.
Тогда дерево разбора может строиться так:
expr : expr '+' expr
{ $$ = node( '+', $1, $3 ); }
Программист может также определить собственные переменные, доступные
действиям. Их объявление и определение может быть сделано в секции
объявлений, заключенное в символы %{ и %}.
Такие объявления имеют глобальную область видимости, благодаря
чему доступны как действиям, так и лексическому анализатору. Например:
%{
int variable = 0;
%}
Такие строчки, помещенные в раздел объявлений, объявляют переменную
variable типа int и делают ее доступной для всех
действий. Все имена внутренних переменных Yacca начинаются c двух
букв y, поэтому не следует давать своим переменным
имена типа yymy.
Программист, использующий Yacc должен написать сам (или создать при
помощи программы типа Lex) внешний лексический анализатор, который
будет читать символы из входного потока (какого - это внутреннее дело
лексического анализатора), обнаруживать терминальные символы (токены)
и передавать их синтаксическому анализатору, построенному Yaccом (возможно
вместе с неким значением) для дальнейшего разбора. Лексический анализатор
должен быть оформлен как функция с именем yylex,
возвращающая значение типа int, которое представляет
собой тип (номер) обнаруженного во входном потоке токена. Если есть
желание вернуть еще некое значение (например номер в группе), оно
может быть присвоено глобальной, внешней (по отношению
к yylex) переменной по имени yylval.
Лексический анализатор и Yacc должны использовать одинаковые номера
токенов, чтобы понимать друг друга. Эти номера обычно выбираются Yaccом,
но могут выбираться и человеком. В любом случае механизм define
языка Си позволяет лексическому анализатору возвращать эти значения
в символическом виде. Предположем, что токен по имени DIGIT
был определен в секции объявлений спецификации Yaccа, тогда соответствующий
текст лексического анализатора может выглядеть так:
yylex()
{
extern int yylval;
int c;
...
c = getchar();
...
switch (c) {
. . .
case '0':
case '1':
...
case '9':
yylval = c - '0';
return DIGIT;
. . .
}
. . .
Вышеприведенный фрагмент возвращает номер токена DIGIT и значение,
равное цифре. Если при этом сам текст лексического анализатора был
помещен в секцию программ спецификации Yacca - есть гарантия, что
идентификатор DIGIT был определен номером токена DIGIT, причем тем
самым, который ожидает Yacc.
Такой механизм позволяет создавать понятные, легкие в модификации
лексические анализаторы. Единственным ограничением является запрет
на использование в качестве имени токена слов, зарезервированых или часто используемых
в языке Си слов. Например, использование в качестве имен токенов таких
слов как if или while, почти
наверняка приведет к возникновению проблем при компиляции лексического
анализатора. Кроме этого, имя error зарезервировано
для токена, служащего делу обработки ошибок, и не должно использоваться.
Как уже было сказано, номера токенов выбираются либо Yaccом,
либо человеком, но чаще Yaccом, при этом для отдельных символов
(например для ( или ;) выбирается
номер, равный ASCII коду этого символа. Для других токенов номера выбираются
начиная с 257.
Для того, чтобы присвоить токену (или даже литере) номер вручную, необходимо в секции объявлений после имени токена добавить положительное целое число, которое и станет номером токена или литеры, при этом необходимо позаботиться об уникальности номеров. Если токену не присвоен номер таким образом, Yacc присваивает ему номер по своему выбору.
По традици, концевой маркер должен иметь номер токена, равный, либо меньший нуля, и лексический анализатор должен возвращать ноль или отрицательное число при достижении конца ввода (или файла).
Очень неплохим средством для создания лексических анализаторов является программа Lex. Лексические анализаторы, построенные с ее помощью прекрасно гармонируют с синтаксическими анализаторами, построенными Yaccом. Lex можно легко использовать для построения полного лексического анализатора из файла спецификаций, основанного на системе регулярных выражений (в отличие от системы грамматических правил для Yacca), но, правда, существуют языки (например Фортран) не попадающие ни под какую теоретическю схему, но для них приходится писать лексический анализатор вручную.
http://www.cvshome.org/docs/manual/index.html
С помощью CVS вы легко можете обратиться к старым версиям, чтобы точно выяснить, что именно привело к ошибке. Разумеется, можно сохранять все версии всех файлов, которые были созданы, но это потребует огромного объема дискового пространства. CVS хранит все версии файла в едином файле так, чтобы сохранять только изменения между версиями.
CVS также можно использовать, если вы работаете над одним проектом
совместно с кем-либо еще. Слишком легко переписать чужие изменения,
если вы не очень аккуратны. Некоторые редакторы, такие как GNU Emacs,
стараются проследить, чтобы один и тот же файл не изменяли
одновременно два человека. К сожалению, если кто-то использует другой редактор,
эта предосторожность не будет работать. CVS решает эту проблему, изолируя
разработчиков друг от друга. Каждый разработчик работает в своем каталоге,
а CVS объединяет полученные результаты.
Хотя структура вашего репозитория и файла модулей будут взаимодействовать с системой сборки (т.е. `Makefile'), они независимы друг от друга.
CVS не указывает, как собирать что-то. Она просто хранит файлы для получения нужной вам структуры дерева.
CVS не указывает, как использовать дисковое пространство в полученных рабочих каталогах. Если вы напишете `Makefile' или скрипты в каждом каталоге так, что они должны знать относительное положение чего-то еще, то, возможно, что придется обновлять весь репозиторий.
Если вы постараетесь задать модульную структуру для проекта и создадите систему сборки, которая будет совместно использовать файлы ( посредством ссылок, монтирования, VPATH в `Makefile' и т. д.), то сможете использовать дисковое пространство, как захотите. Но вам надо помнить, что любая подобная система требует серьезной работы по ее созданию и поддержанию. CVS не предназначена для решения возникающих при этом проблем.
Разумеется, вам нужно поместить в CVS средства, созданные для поддержки подобной системы сборки (скрипты, `Makefile' и т. д.).
Вычисление того, какие файлы нуждаются в перекомпилировании
когда что-то меняется, так же не входит в задачи CVS. Одним из
традиционных подходов является использование make для сборки и
использование каких-либо специальных средств для создания зависимостей,
используемых make.
Ваши руководители и главные разработчики ожидают, что вы будете достаточно часто общаться между собой, чтобы знать о графике работ, точках слияния, именах веток и датах выпуска. Если они этого не делают, то никакая CVS вам не поможет. CVS не заменит общения между разработчиками.
Встретившись с конфликтами в одном файле, большинство разработчиков
решают их без особого труда. Однако более общее определение "конфликта"
включает в себя проблемы, которые слишком трудно решить без
взаимодействия между разработчиками.
CVS не может обнаружить, что синхронные изменения в одном или
нескольких файлах привели к логическому конфликту. Понятие конфликта,
которое использует CVS, строго текстовое, возникающее когда изменения
в основном файле достаточно близки, чтобы
"напугать" программу слияния (то есть diff3).
CVS не поможет для вычисления нетекстовых или распределенных конфликтов в логике программы.
Например, вы изменили аргументы функции X, определенные в файле `A'. В то же самое время кто-то еще редактирует файл `B', добавляя новый вызов функции X, используя старые аргументы. Это уже не в компетенции CVS. Возьмите себе за привычку читать спецификации и беседовать с коллегами.
Под контролем изменений имеется в виду несколько вещей. Прежде всего,
это может означать отслеживание ошибок, т.е. хранение базы данных
обнаруженных ошибок и их статуса (исправлена ли она? в какой версии?
согласился ли обнаруживший ее, что она исправлена?). Для взаимодействии
CVS с внешней системой отслеживания ошибок почитайте, как это делается
в файлах `rcsinfo' и `verifymsg'.
Другим аспектом контроля изменений является отслеживание такого факта, что изменения
в нескольких файлах в действительности являются одним и тем же согласованным
изменением. Если вы меняете несколько файлов одной командой cvs commit,
то CVS забывает, что эти файлы были изменены одновременно, и единственная
возможность, их объединения - это одинаковые журнальные записи. Ведение файла
`ChangeLog' в стиле GNU может решить некоторые проблемы.
Еще одним аспектом контроля изменений в некоторых системах является
возможность отслеживать статус каждого изменения. Некоторые изменения
были написаны разработчиком, другие написаны другим разработчиком,
и т.д. Обычно при работе с CVS в этом случае создается diff-файл
(используя cvs diff или diff), который посылается по электронной почте
кому-нибудь, кто потом применит этот diff-файл, используя программу
patch. Это очень гибкий прием, но зависит от внешних по отношению к CVS механизмов,
чтобы быть уверенным, что ничего не упущено.
Хотя и существует возможность принудительного выполнения серии тестов,
используя файл `commitinfo'.
Некоторые системы обеспечивают способы убедиться, что изменения и
релизы проходят через определенные ступени, с различными подтверждениями
на каждой. Этого можно добиться и с помощью CVS, но потребуется
немного больше работы. В некоторых случаях, вам придется использовать файлы
`commitinfo', `loginfo', `rcsinfo' или `verifymsg', чтобы
убедиться, что предприняты определенные шаги,
прежде чем CVS позволит зафиксировать изменение. Подумайте также,
должны ли использоваться такие возможности, как ветви разработки и
метки, чтобы, скажем, поработать над новой веткой разработки, а затем
объединять определенные изменения со стабильной веткой, когда эти
изменения одобрены.
В качестве введения в систему CVS мы приведем здесь типичную сессию работы с ней. В первую очередь необходимо понять, что CVS хранит все файлы в централизованном репозитории.
Предположим, что вы работаете над простым компилятором и репозиторий уже настроен.
Исходный текст
состоит из нескольких C-файлов и `Makefile'. Компилятор называется
`tc' (Trivial Compiler), а репозиторий настроен так, что имеется
модуль `tc'.
`tc'. Используйте
команду\$ cvs checkout tcпри этом будет создан каталог
`tc', в который будут помещены все файлы
с исходными текстами.\$ cd tc \$ ls CVS Makefile backend.c driver.c frontend.c parser.cКаталог `CVS' используется для внутренних нужд CVS. Обычно вам не следует редактировать или удалять файлы, находящиеся в этом каталоге. Вы запускаете свой любимый редактор, работаете над
`backend.c' и через
пару часов вы добавили фазу оптимизации в компилятор. Замечание для
пользователей RCS и RCCS: не требуется блокировать файлы, которые
вы желаете отредактировать.
\$ cvs commit backend.cCVS запускает редактор, чтобы позволить вам ввести журнальную запись. Вы набираете: "Добавлена фаза оптимизации", сохраняете временный файл и выходите из редактора. Переменная окружения
$CVSEDITOR определяет, какой именно редактор
будет вызван. Если $CVSEDITOR не установлена, то используется $EDITOR,
если она, в свою очередь, установлена. Если обе переменные не установлены,
используется редактор по умолчанию для вашей операционной системы,
например, vi под Linux или notepad для Windows 95/NT.Когда CVS запускает редактор,
в шаблоне для ввода журнальной записи
перечислены измененные файлы. Для клиента CVS этот список создается
путем сравнения времени изменения файла с его временем изменения,
когда он был получен или обновлен. Таким образом, если время изменения
файла изменилось, а его содержимое осталось прежним, он будет считаться
измененным. Проще всего в данном случае не обращать на это внимания
- в процессе фиксирования изменений CVS определит, что содержимое
файла не изменилось и поведет себя должным образом. Следующая команда
- update - сообщит CVS, что файл не был изменен и его время изменения
будет возвращено в прежнее значение, так что этот файл не будет помехой
при дальнейших фиксированиях.Если вы хотите избежать запуска редактора, укажите журнальную запись
в командной строке, используя флаг `-m', например:
$ cvs commit -m "Добавлена фаза оптимизации" backend.c
tc. Конечно же, это можно сделать так:$ cd .. $ rm -r tcно лучшим способом будет использование команды release:
$ cd .. $ cvs release -d tc M driver.c ? tc You have [1] altered files in this repository. Are you sure you want to release (and delete) directory `tc': n ** `release' aborted by user choice.Команда
release проверяет, что все ваши изменения были зафиксированы.
Если включено журналирование истории, то в файле истории появляется
соответствующая пометка. Если вы используете команду release с флагом
`-d', то она удаляет вашу рабочую копию. В вышеприведенном примере команда release
выдала несколько строк
`? tc', означающих, что файл `tc' неизвестен CVS. Беспокоиться не
о чем, `tc' - это исполняемый файл компилятора, и его не следует хранить
в репозитории. `M driver.c' - более серьезное сообщение. Оно означает, что файл
`driver.c' был изменен с момента последнего получения из репозитория.
Команда release всегда сообщает, сколько измененных файлов находится
в вашей рабочей копии исходных кодов, а затем спрашивает подтверждения
перед удалением файлов или внесения пометки в файл истории. Вы решаете
перестраховаться и отвечаете n RET, когда release просит подтверждения.
`driver.c', поэтому хотите посмотреть,
что именно случилось с ним:$ cd tc $ cvs diff driver.cЭта команда сравнивает версию файла
`driver.c', находящейся в репозитории,
с вашей рабочей копией. Когда вы рассматриваете изменения, вы вспоминаете,
что добавили аргумент командной строки, разрешающий фазу оптимизации.
Вы фиксируете это изменение и высвобождаете модуль:$ cvs commit -m "Добавлена фаза оптимизации" driver.c Checking in driver.c; /usr/local/cvsroot/tc/driver.c,v <- driver.c new revision: 1.2; previous revision: 1.1 done $ cd .. $ cvs release -d tc ? tc You have [0] altered files in this repository. Are you sure you want to release (and delete) directory `tc': y.
Autoconf -- это утилита для создания shell-скриптов,
которые автоматически конфигурируют пакеты с исходным кодом для адаптирования
ко многим UNIX-подобным системам. Конфигурационные скрипты созданные Autoconf,
не зависят от него при выполнении, так что пользователям не нужно устанавливать Autoconf у себя в системе.
Конфигурационные скрипты, созданные Autoconf, не требуют вмешательства
пользователя для своей работы; обычно им даже не требуются входные аргументы для указания типа системы. Вместо этого, они поочередно тестируют систему на присутствие необходимых для работы пакета средств. (До каждой проверки скрипт выводит однострочное сообщение, в котором указано, что сейчас будет проверяться, так что вам будет не слишком скучно ожидать окончания работы скрипта.) В результате эти скрипты хорошо справляются с системами, которые являются гибридами или специализированными вариантами большинства видов UNIX. Поэтому не нужно поддерживать файлы, которые содержат список возможностей поддерживаемых разными версиями каждого варианта UNIX.
Для каждого пакета, используемого Autoconf, он создает конфигурационный
скрипт из шаблона, содержащего список системных возможностей,
которые необходимы либо могут использоваться пакетом.
После того как shell-код, распознающий и использующий ту или иную системную
возможность, написан, Autoconf позволяет применять этот код во всех пакетах,
которые имеют эту возможность. Если позже, по каким-либо
причинам понадобится изменить код командного процессора, то изменения
необходимо будет внести только в одно место; все скрипты настройки
можно автоматически создать заново, чтобы отразить изменения
кода.
Для создания скриптов Autoconf требует наличия программы GNU m4. Скрипты
конфигурации, создаваемые Autoconf, по принятым соглашениям, называются
configure.
Для того чтобы с помощью Autoconf создать скрипт configure, вам необходимо
написать входной файл с именем `configure.in' и выполнить команду
autoconf. Если вы напишите собственный код тестирования возможностей
системы в дополнение к поставляемым с Autoconf, то вам придется записать
его в файлы с именами
`aclocal.m4' и `acsite.m4'. Если вы используете
заголовочный файл, который содержит директивы define, то вы
должны создать файл `acconfig.h', также вы сможете распространять
с пакетом файл `config.h.in', созданный с помощью Autoconf файл `config.h.in'.
Семафоры являются одним из классических примитивов синхронизации. Значение семафора - это целое число в диапазоне от 0 до 32767. Поскольку во многих приложениях требуется использование более одного семафора, ОС Linux предоставляет возможность создавать множества семафоров. Их максимальный размер ограничен системным параметром SEMMSL. Множества семафоров создаются при помощи системного вызова semget.
Процесс, выполнивший системный вызов semget, становится владельцем
или создателем множества семафоров. Он определяет,
сколько будет семафоров
в множестве; кроме того, он специфицирует первоначальные права на
выполнение операций над множеством для всех процессов, включая себя.
Впоследствии данный процесс может уступить право собственности или
изменить права на операции при помощи системного вызова semctl, предназначенного
для управления семафорами, однако на протяжении всего времени существования
множества семафоров создатель остается создателем. Другие процессы,
обладающие соответствующими правами, для выполнения прочих управляющих
действий также могут использовать системный вызов semctl.
Над каждым семафором, принадлежащим некоторому множеству, при помощи системного вызова semop можно выполнить любую из трех операций:
Операции могут снабжаться флагами. Флаг SEM_UNDO означает, что операция выполняется в проверочном режиме, т. е. требуется только узнать, можно ли успешно выполнить данную операцию.
При отсутствии флага IPC_NOWAIT системный вызов semop должен быть приостановлен до тех пор, пока значение семафора благодаря действиям другого процесса, не позволит успешно завершить операцию (ликвидация множества семафоров также приведет к завершению системного вызова). Подобные операции называются ''операциями с блокировкой''. С другой стороны, если обработка завершается неудачей и не указано, что выполнение процесса должно быть приостановлено, операция над семафором называется ``операцией без блокировки''.
Системный вызов semop оперирует не с отдельным семафором, а со множеством семафоров, применяя к нему ``массив операций''. Массив содержит информацию о том, с какими семафорами нужно оперировать и каким образом. Выполнение массива операций с точки зрения пользовательского процесса является неделимым действием. Это значит, во-первых, что если операции выполняются, то только все вместе и, во-вторых, что другой процесс не может получить доступа к промежуточному состоянию множества семафоров, когда часть операций из массива уже выполнена, а другая часть еще не начиналась.
Операционная система выполняет операции из массива по очереди, причем порядок не оговаривается. Если очередная операция не может быть выполнена, то эффект предыдущих операций аннулируется. Если таковой оказалась операция с блокировкой, выполнение системного вызова приостанавливается. Если неудачу потерпела операция без блокировки, системный вызов немедленно завершается, возвращая значение -1 как признак ошибки, а внешней переменной errno присваивается код ошибки.
Файл с именем `configure.in' содержит вызовы макросов Autoconf, проверяющие
системные возможности, которые он может использовать. Для многих таких
возможностей макросы Autoconf уже написаны.
Для проверок большинства других возможностей вы можете использовать
шаблонные макросы Autoconf, на базе которых можно создать специальные
проверки. Для специализированных потребностей, в файл `configure.in'
может понадобиться включить специально написанные скрипты командного
процессора.
Каждый файл `configure.in' должен в самом начале содержать вызов макроса
ACINIT, а в самом конце вызов макроса ACOUTPUT. Также некоторые
макросы полагаются на то, что другие макросы были вызваны первыми,
поскольку перед принятием решения, они проверяют уже установленные
значения переменных.
Для того чтобы ваши файлы были последовательны и единообразны,
приведем желательный порядок вызова макросов Autoconf:
ACINIT(file) Проверка программ Проверка библиотек Проверка заголовочных файлов Проверка определений типов Проверка структур Проверка характеристик компилятора Проверка библиотечных функций Проверка системных сервисов ACOUTPUT(file...)
При вызове макросов с аргументами, между открывающей скобкой и названием
макроса не должно быть пробелов. Аргументы могут занимать несколько
строк, если они заключены в кавычки языка m4 -
`[' и `]'. Если аргументом является длинная строка, например
список имен файлов, то можно использовать символ обратного слэша в
конце строки для указания, что список продолжается на следующей строке
(эта возможность реализуется командным процессором, без привлечения
возможностей Autoconf).
Некоторые макросы отрабатывают два случая: когда заданное условие
выполняется и когда это условие не выполняется. В некоторых местах вы
можете захотеть сделать что-либо, если условие выполняется, и ничего
не делать в противном случае, и наоборот. Для того, чтобы пропустить
действие при выполнении условия, передайте пустое значение аргументу
action-if-found данного макроса. Для пропуска действия при невыполнении
условия уберите аргумент action-if-not-found данного макроса, включив
предшествующую ему запятую.
В файл `configure.in' можно включать комментарии, начиная их со встроенного
макроса m4 --dnl, который отбрасывает текст вплоть до начала новой
строки. Эти комментарии не появятся в созданных скриптах configure.
Программа autoscan может помочь вам в создании файла
`configure.in'
для программного пакета. Эта программа выполняет анализ дерева исходных
текстов, корень которого указан в командной строке или совпадает с
текущим каталогом. Программа ищет в исходных текстах следы обычных
проблем с переносимостью и создает файл `configure.scan', который
является заготовкой для `configure.in' данного пакета.
Вы должны сами просмотреть файл `configure.scan' перед тем, как переименовать
его в `configure.in': скорее всего, он будет нуждаться в некоторых
исправлениях. Иногда autoscan выдает макросы в неправильном порядке,
и поэтому Autoconf будет выдавать предупреждения; вам необходимо вручную
передвинуть эти макросы. Если же вы хотите, чтобы пакет использовал
заголовочный файл настроек, то сами добавьте вызов макроса
ACCONFIGHEADER. Вам также необходимо добавить или изменить некоторые
директивы препроцессора if в вашей программе, чтобы заставить
ее работать с Autoconf.
Программа autoscan использует несколько файлов данных, чтобы определить,
какие макросы следует использовать при обнаружении определенных символов
в исходных файлах пакета. Эти файлы данных устанавливаются вместе
с дистрибутивными макрофайлами Autoconf и имеют одинаковый формат.
Каждая строка состоит из символа, пробелов и имени макроса Autoconf,
которое выдается в том случае, если заданный символ имеется в исходных
текстах. Строки, начинающиеся с символа `#' являются комментариями.
Чтобы установить программу autoscan вам необходима
программа Perl. Программа autoscan распознает следующие ключи командной строки:
--help
- выдает список ключей командной строки и прекращает работу;
--macrodir=dir
- заставляет программу искать файлы данных в каталоге dir, а не в каталоге,
куда производилась установка. Вы также можете установить значение
переменной окружения
ACMACRODIR равным пути к этому каталогу; данный
ключ командной строки переопределяет значение переменной окружения;
--verbose
- выдает имена исследуемых файлов и потенциально интересные символы,
обнаруженные в этих файлах. Количество выданной информации может быть
довольно объемной;
--version
- выдает номер версии Autoconf и прекращает работу.
Чтобы создать скрипт configure из файла `configure.in',
просто запустите программу autoconf без аргументов; autoconf обработает
файл `configure.in' с помощью макропроцессора m4, используя макросы
autoconf. Если вы зададите в качестве аргумента имя файла, то вместо
`configure.in' будет использоваться заданный файл, а вывод будет производиться
на стандартный вывод, а не в файл configure.
Если в качестве аргумента Autoconf задать `-', то она будет читать
со стандартного ввода, а не из файла `configure.in', а результаты
будут выдаваться на стандартный вывод.
Макросы Autoconf определены в нескольких файлах. Некоторые из них
распространяются вместе с Autoconf; Autoconf читает их в первую очередь.
Затем ищется необязательный файл `acsite.m4' в каталоге, который содержит
распространяемые с Autoconf файлы макросов, и необязательный файл
`aclocal.m4' в текущем каталоге. Эти файлы могут содержать макросы,
специфические для вашей машины или макросы для конкретных пакетов
программного обеспечения.
Программа autoconf распознает следующие ключи командной строки:
--help, -h
- выдает список ключей командной строки и прекращает работу;
--localdir=dir, -l dir
- ищет файл `aclocal.m4' для данного пакета в каталоге dir, а не в
текущем каталоге;
--macrodir=dir
- заставляет программу искать файлы данных в каталоге dir, а не в каталоге,
куда производилась установка. Вы также можете установить значение
переменной окружения
ACMACRODIR, присвоив ей значение пути к этому
каталогу; ключ командной строки переопределяет значение переменной
окружения;
--version
- выдает номер версии autoconf и прекращает работу.
Скриптам, созданным Autoconf, нужна некоторая инициализационная информация.
Например: где найти исходные тексты пакета; какие выходные файлы
создавать. Далее следует описание инициализации и создания выходных файлов
Каждый скрипт configure должен в первую очередь вызвать макрос ACINIT.
AC_INIT (unique-file-in-source-dir)- обрабатывает аргументы командной строки и ищет каталог с исходными текстами.
unique-file-in-source-dir -- это некоторый файл в каталоге
с исходными текстами пакета, который проверяется на существование,
чтобы убедиться, что это именно тот каталог с исходными текстами,
который нужен. Когда указывается неверный каталог, используйте ключ
командной строки `--srcdir'; эта проверка позволит правильно идентифицировать
каталог с исходными текстами.
Каждый скрипт configure, созданный Autoconf, должен заканчиваться
вызовом макроса ACOUTPUT. Этот макрос создает файлы `Makefile' и
дополнительные файлы, которые являются результатом конфигурации.
AC_OUTPUT ([file... [, extra-cmds [, init-cmds]]])- создает выходные файлы. Этот макрос вызывается один раз в конце файла
`configure.in'. Аргумент file... является списком выходных файлов
через пробел; этот список может быть пустым. Макрос создает каждый
из файлов `file', копируя входной файл (по умолчанию `file.in') и
подставляя туда значения выходных переменных.
Если вызывались макросы ACCONFIGHEADER, ACLINKFILES или
ACCONFIGSUBDIRS,
то этот макрос также создаст файлы, указанные в аргументах этих макросов.
Типичный вызов ACOUTPUT выглядит примерно так:
ACOUTPUT(Makefile src/Makefile man/Makefile X/Imakefile).
В параметре extra-cmds можно указать команды, которые будут вставлены
в файл `config.status' и сработают после того, как было сделано все остальное.
В параметре init-cmds можно указать команды, которые будут вставлены
непосредственно перед extra-cmds, причем configure выполнит в них
подстановку переменных, команд и обратных слэшей. Аргумент init-cmds
можно использовать для передачи переменных из configure в extra-cmds.
Если был вызван макрос
ACOUTPUTCOMMANDS, то команды, переданные
ему в качестве аргумента, выполняются прямо перед командами, переданными
макросу ACOUTPUT.
Количество макросов для настроек и различного типа проверок слишком велико, чтобы приводить их здесь, вместо этого вы можете обратиться к документации, чтобы получить их полный список.
Когда вы пишете тест свойства, который будет применяться более чем в
одном пакете программного обеспечения, то лучше всего оформить его
в виде нового макроса. В этом разделе приводятся некоторые инструкции
и указания по написанию макросов Autoconf.
Макросы Autoconf определяются с помощью макроса ACDEFUN, который
подобен встроенному макросу define программы m4. Кроме определения
макроса, ACDEFUN добавляет к нему некоторый код, который используется
для ограничения порядка вызова макросов.
Определение макроса Autoconf выглядит примерно следующим образом:
ACDEFUN(macro-name, macro-body)
Квадратные скобки не указывают на необязательный параметр: они должны присутствовать в определении макроса для избежания проблем расширения макроса. Вы можете ссылаться на передаваемые макросу параметры с помощью переменных `$1', `$2' и т.д.
Все макросы Autoconf названы именами, состоящими из заглавных букв
и начинающихся с префикса `AC', для того, чтобы избежать конфликтов
с другим текстом. Все переменные командного процессора, которые используются
для внутренних целей в этих макросах, как правило, называются именами
из прописных букв и начинаются с `ac'. Чтобы избежать
конфликтов с вашими макросами, вы должны использовать собственный
префикс для ваших макросов и переменных командного процессора. В качестве
возможных значений вы можете использовать свои инициалы, или сокращенное
название вашей организации или пакета программ.
Большинство имен макросов Autoconf отвечают соглашению о структуре
имени, которое показывает, какой тип свойства проверяемого данным макросом.
Имена макросов состоит из нескольких слов, которые разделены символами
подчеркивания, продвигаясь от общих слов к более спецефическим.
Первое слово имени после префикса `AC' обычно сообщает категорию
тестируемого свойства. Следующие категории используются Autoconf для
специфических макросов, один из типов которых вы ,вероятно, захотите
написать. Используйте перечисленные категории при написании ваших
макросов; если нужной категории нет, то вы можете вводить свои собственные.
C - встроенные возможности языка C.
DECL - объявления переменных C в заголовочных файлах.
FUNC - функции в библиотеках.
GROUP - группа UNIX владеющая файлами.
HEADER - заголовочные файлы.
LIB - библиотеки C.
PATH - полные путевые имена файлов, включая программы.
PROG - базовые имена программ.
STRUCT - определения структур C в заголовочных файлах.
SYS - свойства операционной системы.
TYPE - встроенные или объявленные типы C.
VAR - переменные C в библиотеках.
После категории следует имя тестируемого свойства. Любые дополнительные
слова в имени макроса указывают на специфические аспекты тестируемого
свойства. Например, ACFUNCUTIMENULL проверяет поведение функции
utime при вызове ее с указателем, равным NULL.
Макрос, который является внутренней подпрограммой другого макроса,
должен иметь имя, начинается с его имени, за которым
следует одно или несколько слов, описывающих, что делает этот макрос.
Например, макрос ACPATHX имеет внутренние макросы ACPATHXXMKMF
и ACPATHXDIRECT.
Перед тем как использовать семафоры (выполнять операции или управляющие
действия), нужно создать множество семафоров с уникальным идентификатором
и ассоциированной структурой данных. Уникальный идентификатор называется
идентификатором
множества семафоров (semid); он используется для обращений
к множеству и структуре данных. С точки зрения реализации множество
семафоров представляет собой массив структур. Каждая структура соответствует
семафору и определяется следующим образом:
ushort semval; /* Значение семафора */
/* Идентификатор процесса, выполнявшего
последнюю операцию */
short sempid;
/* Число процессов, ожидающих увеличения
значения семафора */
ushort semncnt;
/* Число процессов, ожидающих обнуления
значения семафора */
ushort semzcnt;
};
С каждым идентификатором множества семафоров ассоциирована структура данных, содержащая следующую информацию:
/*Структура прав на выполнение операций*/
struct ipc_perm sem_perm;
/*Указатель на первый семафор в множестве*/
struct sem *sem_base;
/* Количество семафоров в множестве */
ushort sem_nsems;
/* Время последней операции */
time_t sem_otime;
/* Время последнего изменения */
time_t sem_ctime;
};
Поле sem_perm данной структуры использует в качестве шаблона структуру типа ipc_perm, общую для всех средств межпроцессной связи. Системный вызов semget аналогичен вызову msgget (разумеется, с заменой слов ``очередь сообщений'' на ``множество семафоров''). Он также предназначен для получения нового или опроса существующего идентификатора, а нужное действие определяется значением аргумента key. В подобных ситуациях semget терпит неудачу. Единственное отличие состоит в том, что при создании требуется посредством аргумента nsems указывать число семафоров в множестве.
После того как созданы множество семафоров с уникальным идентификатором и ассоциированная с ним структура данных, можно использовать системные вызовы semop для операций над семафорами и semctl - для выполнения управляющих действий.
Некоторые макросы Autoconf зависят от других макросов, которые должны
быть вызваны первыми, чтобы работа производилась правильно. Autoconf
предоставляет возможность проверки того, что нужные макросы были вызваны,
и способ предоставления пользователю информации о макросах, которые
вызываются в неправильном порядке.
Скрипт configure пытается определить правильные значения для различных,
зависящих от системы переменных, которые используются в процессе установки.
Он использует эти переменные для создания файлов `Makefile' в каждом
из каталогов пакета. Дополнительно он может создавать один или несколько
файлов `.h', содержащих зависящие от системы определения. В заключение,
он создает скрипт командного процессора с именем `config.status',
который вы можете в дальнейшем запускать для воссоздания текущей настройки;
также создаются файл `config.cache', который сохраняет результаты
тестов, для ускорения перенастройки, и файл `config.log', содержащий
вывод компилятора (этот файл полезен для отладки configure).
Файл `configure.in' используется для создания скрипта
`configure'
программой Autoconf. Вам необходимо иметь только `configure.in', если
вы хотите изменить его или заново создать скрипт `configure' с помощью
более новой версии Autoconf.
Наиболее простым способом компиляции данного пакета являются следующие действия:
`./configure' в командной строке, чтобы настроить пакет
для вашей системы. Работа configure
займет некоторое время. Во время выполнения скрипт выдает сообщения
о том, какие свойства он проверяет.
`make' для компиляции пакета.
`make check' для запуска любых собственных тестов,
которые поставляются вместе с пакетом.
`make install' для установки программ и файлов данных
и документации.
`make clean'. Для удаления
файлов, созданных configure, наберите `make distclean'. Имеющаяся
цель `make
maintainer-clean' в основном предназначена для
разработчиков программного обеспечения.
Для создания множества семафоров служит системный вызов semget. Синтаксис данного системного вызова:
#include <sys/ipc.h>
#include <sys/sem.h>
int semget (key_t key, int nsems, int semflg);
Смысл аргументов key и semflg тот же, что и у соответствующих аргументов системного вызова msgget. Аргумент nsems задает число семафоров в множестве. Если запрашивается идентификатор существующего множества, значение nsems не должно превосходить числа семафоров в множестве.
Превышение системных параметров SEMMNI, SEMMNS и SEMMSL при попытке создать новое множество всегда ведет к неудачному завершению. Системный параметр SEMMNI определяет максимально допустимое число уникальных идентификаторов множеств семафоров в системе. Системный параметр SEMMNS определяет максимальное общее число семафоров в системе. Системный параметр SEMMSL определяет максимально допустимое число семафоров в одном множестве.
Automake -- это утилита для автоматического создания файлов
`Makefile.in'
из файлов `Makefile.am'. Каждый файл
`Makefile.am' фактически является
набором макросов для программы make (иногда с несколькими правилами).
Полученные таким образом файлы `Makefile.in' соответствуют стандартам
GNU Makefile.
Стандарт GNU Makefile - это длинный, запутанный документ, и его содержание
может в будущем измениться. Automake разработан для того, чтобы освободить от
бремени сопровождения Makefile человека, ведущего проект GNU.
Типичный входной файл Automake является просто набором макроопределений.
Каждый такой файл обрабатывается, и из него создается файл `Makefile.in'.
В каталоге проекта должен быть только один файл `Makefile.am'. Automake
накладывает на проект некоторые ограничения; например, он предполагает,
что проект использует программу Autoconf, а также налагает некоторые
ограничения на содержимое файла `configure.in'. Automake требует наличия
программы perl для генерации файлов `Makefile.in'. Однако дистрибутив,
созданный Automake, является полностью соответствующим стандартам
GNU и не требует наличия perl для компиляции.
Automake читает файл `Makefile.am' и создает на его основе файл `Makefile.in'.
Специальные макросы и цели, определенные в
`Makefile.am', заставляют
Automake генерировать более специализированный код; например, макроопределение
`binPROGRAMS' заставит создать цели для компиляции и компоновки
программ.
Макроопределения и цели из файла `Makefile.am' копируются в файл `Makefile.in'
без изменений. Это позволяет вам добавлять в генерируемый файл `Makefile.in'
произвольный код. Например, дистрибутив Automake включает в себя нестандартную
цель cvs-dist, которую использует человек, сопровождающий Automake,
для создания дистрибутивов из системы контроля исходного кода.
Заметьте, что расширения GNU make не распознаются программой Automake.
Использование таких расширений в файле
`Makefile.am' приведет к ошибкам
или странному поведению программы. Automake пытается сгруппировать комментарии
к расположенным по соседству целям и макроопределениям.
Цель, определенная в `Makefile.am', обычно переопределяет любую цель
с таким же именем, которая была бы автоматически создана Automake.
Хотя этот прием и работает, старайтесь избегать его использования,
поскольку иногда автоматически созданные цели являются очень важными. Аналогичным
образом макрос, определенный в `Makefile.am', будет переопределять
любой макрос, который создает Automake. Это часто более полезно, чем
возможность переопределения цели. Но будьте осторожны, поскольку многие
из макросов, создаваемых программой Automake, считаются макросами
только для внутреннего использования, и их имена могут изменяться
в будущих версиях.
При обработке макроопределения Automake рекурсивно обрабатывает макросы,
на которые есть ссылка в данном макроопределении. Например, если Automake
исследует содержимое fooSOURCES в следующем определении:
xs = a.c b.c foo_SOURCES = c.c $(xs) ,то он будет использовать файлы
`a.c', `b.c' и `c.c' как содержимое
fooSOURCES.
Automake также вводит форму комментария, который не копируется в выходной
файл; все строки, начинающиеся с `', полностью игнорируются Automake.
Очень часто первая строка файла `Makefile.am' выглядит следующим образом:
## Process this file with Automake to produce Makefile.in ## Для получения Makefile.in обработайте этот файл ## программой Automake .
Для полного ознакомления с утилитой Automake рекомендуется прочитать
``Руководство по использованию Automake''.
http://www.gnu.org/software/Automake/manual/Automake|.html)Для подробного описания макросов загляните в справочные страницы
Automake.Здесь же ограничимся подробными примерами, в которых показано, как
использовать Automake для простых целей.
Предположим, что мы только что закончили писать программу zardoz.
Вы использовали Autoconf для обеспечения
переносимости, но ваш файл `Makefile.in' написан бессистемно.
Вы же хотите сделать его "пуленепробиваемым", и поэтому решаете использовать
Automake.
Сначала вам необходимо обновить ваш файл `configure.in', чтобы вставить
в него команды, которые необходимы для работы Automake. Проще всего
для этого добавить строку AM_INIT_Automake сразу после ACINIT:
AM_INIT_Automake(zardoz, 1.0) AM_INIT_Automake ...Поскольку ваша программа не имеет никаких осложняющих факторов (например, она не использует
gettext и не будет создавать разделяемые библиотеки),
то первая стадия на этом и заканчивается. Это легко!
Теперь вы должны заново создать файл `configure'. Но для этого нужно
указать autoconf, где найти новые макросы, которые вы использовали.
Для создания файла `aclocal.m4' удобнее всего будет использовать программу
aclocal. Но будьте осторожны - у вас уже есть `aclocal.m4', поскольку
вы уже написали несколько собственных макросов для вашей программы.
Программа aclocal позволяет вам поместить ваши собственные макросы
в файл `acinclude.m4', так что для сохранения вашей работы просто
переименуйте свой файл с макросами, а уж затем запускайте программу
aclocal:
mv aclocal.m4 acinclude.m4 aclocal autoconfТеперь пришло время написать свой собственный файл
`Makefile.am' для
программы zardoz. Поскольку zardoz является пользовательской программой,
то вам хочется установить ее туда, где располагаются другие пользовательские
программы. К тому же, zardoz содержит в комплекте документацию в формате
Texinfo. Ваш скрипт `configure.in' использует ACREPLACEFUNCS,
поэтому вам необходимо скомпоновать программу с `@LIBOBJS@'. Вот что
вам необходимо написать в `Makefile.am'.
bin_PROGRAMS = zardoz zardoz_SOURCES = main.c head.c float.c vortex9.c gun.c zardoz_LDADD = @LIBOBJS@ info_TEXINFOS = zardoz.texiТеперь можно запустить
Automake --add-missing, чтобы создать файл
`Makefile.in', используя дополнительные файлы.
GNU hello <ftp://ftp.gnu.org/pub/gnu/hello/hello-1.3.tar.gz> известен
своей классической простотой и многогранностью. В этом разделе показывается,
как Automake может быть использован с пакетом GNU Hello. Примеры,
приведенные ниже, взяты из последней бета-версии GNU Hello, но убран
код, предназначенный только для разработчика пакета, а также сообщения
об авторских правах.
Конечно же, GNU Hello использует больше возможностей, чем традиционная
двухстроковая программа: GNU Hello работает с разными языками, выполняет
обработку ключей командной строки, имеет документацию и набор тестов.
Вот файл `configure.in' из пакета GNU Hello:
## Обработайте этот файл autoconf для получения ## скрипта configure. AC_INIT(src/hello.c) AM_INIT_Automake(hello, 1.3.11) AM_CONFIG_HEADER(config.h) ## Установка доступных языков. ALL_LINGUAS="de fr es ko nl no pl pt sl sv" ## Проверка наличия программ. AC_PROG_CC AC_ISC_POSIX ## Проверка библиотек. ## Проверка заголовочных файлов. AC_STDC_HEADERS AC_HAVE_HEADERS(string.h fcntl.h sys/file.h sys/param.h) ## Проверка библиотечных функций. AC_FUNC_ALLOCA ## Проверка st_blksize в структуре stat AC_ST_BLKSIZE ## макрос интернационализации AM_GNU_GETTEXT AC_OUTPUT([Makefile doc/Makefile intl/Makefile po/Makefile.in \ src/Makefile tests/Makefile tests/hello], [chmod +x tests/hello])Макросы
`AM' предоставляются Automake (или библиотекой Gettext);
остальные макросы является макросами Autoconf.
Файл `Makefile.am' в корневом каталоге выглядит следующим образом:
EXTRA_DIST = BUGS ChangeLog.O SUBDIRS = doc intl po src testsКак видите, вся работа выполняется в подкаталогах. Каталоги
`po' и
`intl' автоматически создаются программой gettextize.
В файле `doc/Makefile.am' мы видим строки:
info_TEXINFOS = hello.texi hello_TEXINFOS = gpl.texiЭтого достаточно для сборки, установки и распространения руководства
GNU Hello.
Вот содержимое файла `tests/Makefile.am':
TESTS = hello EXTRA_DIST = hello.in testdataСкрипт
`hello' создается configure, и это единственная возможность для
тестирования. При выполнении make check этот тест будет запущен.
В заключение приведем содержимое `src/Makefile.am', где и выполняется
вся настоящая работа:
bin_PROGRAMS = hello
hello_SOURCES = hello.c version.c getopt.c getopt1.c \
getopt.h system.h
hello_LDADD = @INTLLIBS@ @ALLOCA@
localedir = $(datadir)/locale
INCLUDES = -I../intl -DLOCALEDIR="$(localedir)"
Для создания всех файлов `Makefile.in' пакета запустите программу
Automake в каталоге верхнего уровня без аргументов. Тогда automake автоматически
найдет каждый файл `Makefile.am' и сгенерирует соответствующий файл
`Makefile.in'. Заметьте, что Automake имеет более простое видение
структуры пакета; он предполагает, что пакет имеет только один файл
`configure.in', расположенный в каталоге верхнего уровня. Если в вашем
пакете имеется несколько файлов `configure.in', то вам необходимо
запустить Automake в каждом каталоге, где есть файл `configure.in'.
Вы можете также задать аргумент для Automake: суффикс `.am' добавляется
к аргументу, а результат используется как имя входного файла. В основном
эта возможность применяется для автоматической перегенерации устаревших
файлов `Makefile.in'. Заметьте, что Automake всегда должен запускаться
из каталога верхнего уровня проекта, даже если необходимо перегенерировать
`Makefile.in' в каком-либо подкаталоге. Это необходимо, потому что
Automake должен просканировать файл `configure.in', а также потому,
что Automake в некоторых случаях изменяет свое поведение при обработке
`Makefile.in' в подкаталогах.
Программа Automake принимает следующие ключи командной строки:
`-a',`add-missing'.
В некоторых ситуациях Automake требует наличия некоторых общих файлов;
например, если в `configure.in' выполняется макрос ACCANONICALHOST,
то требуется наличие файла `config.guess'. Automake распространяется
с несколькими такими файлами; этот ключ заставит программу автоматически
добавить к пакету отсутствующие файлы, если это возможно. В общем,
если Automake сообщает вам, что какой-то файл отсутствует, то используйте
этот ключ. По умолчанию Automake пытается создать символьную ссылку
на собственную копию отсутствующего файла; это поведение может быть
изменено с помощью ключа --copy.
`amdir=dir'.
Этот ключ заставляет Automake искать файлы данных в каталоге dir,
а не в каталоге установки; этот ключ обычно используется при отладке
`build-dir=dir'.
Сообщает Automake, где располагается каталог для сборки. Этот ключ
используется при введении зависимостей в файл `Makefile.in',
созданный командой make dist; он не должен использоваться в других
случаях.
`-c',`copy'.
При использовании с ключом --add-missing, заставляет копировать недостающие
файлы. По умолчанию создаются символьные ссылки.
`cygnus'.
Заставляет сгенерированные файлы `Makefile.in' следовать правилам
Cygnus, вместо правил GNU или Gnits.
`foreign'.
Устанавливает глобальную строгость в значение `foreign'.
`gnits'.
Устанавливает глобальную строгость в значение `gnits'.
`gnu'.
Устанавливает глобальную строгость в значение `gnu'. По умолчанию
используется именно такая строгость.
`help'.
Печатает список ключей командной строки и завершается.
`-i','-include-deps'.
Включить всю автоматически генерируемую информацию о зависимостях
в генерируемый файл `Makefile.in'. Это делается в основном при создании
дистрибутива.
`generate-deps'.
Создать файл, объединяющий всю автоматически генерируемую информацию
о зависимостях , этот файл будет называться `.depsegment'. В основном
этот ключ используется при создании дистрибутива; он полезен при сопровождении
`Makefile' или файлов `Makefile' для других платформ (`Makefile.DOS',
и т. п.), а также может использоваться с ключами `--include-deps',
`--srcdir-name' и `--build-dir'. Заметьте, что если задан этот ключ,
то никакой другой обработки не выполняется.
`no-force'.
Обычно Automake создает все файлы `Makefile.in', указанные в `configure.in'.
Этот ключ заставляет обновлять только те файлы `Makefile.in', с учетом зависимостей друг от друга,
которые устарели.
`-odir',`output-dir=dir'.
Поместить сгенерированный файл `Makefile.in' в каталог dir. Обычно
каждый файл `Makefile.in' создается в том же каталоге, что и
соответствующий файл `Makefile.am'. Этот ключ используется при создании
дистрибутивов.
`srcdir-name=dir'.
Сообщает Automake имя каталога с исходными текстами текущего дистрибутива.
Этот ключ используется при включении зависимостей в файл `Makefile.in',
сгенерированный командой make dist; он не должен использоваться в
других случаях.
`-v',`verbose'.
Заставляет Automake выдавать информацию о том, какие файлы читаются
или создаются.
`version'.
Выдает номер версии Automake и завершается.
This document was generated using the LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
The command line arguments were:
latex2html mainfile.tex
The translation was initiated by on 2004-06-22
Синтаксис системного вызова semctl:
#include <sys/ipc.h>
#include <sys/sem.h>
int semctl (int semid, int semnum, int cmd, arg);
union semun {
int val;
struct semid_ds *buf;
ushort *array;
} arg;
Аргументы semid и semnum определяют множество или отдельный семафор, над которым выполняется управляющее действие. В качестве аргумента semid должен выступать идентификатор множества семафоров, предварительно полученный при помощи системного вызова semget. Аргумент semnum задает номер семафора во множестве. Семафоры нумеруются с нуля.
Назначение аргумента arg зависит от управляющего действия, которое определяется значением аргумента cmd. Допустимы следующие действия:
Пример работы с семафорами:
возможности системного вызова semctl()
(управление семафорами) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#define MAXSETSIZE 25
main ()
{
extern int errno;
struct semid_ds semid_ds;
int length, rtrn, i, c;
int semid, semnum, cmd, choice;
union semun {
int val;
struct semid_ds *buf;
ushort array [MAXSETSIZE];
} arg;
/* Инициализация указателя на структуру данных */
arg.buf = &semid_ds;
/* Ввести идентификатор множества семафоров */
printf ("Введите ид-р множества семафоров: ");
scanf ("%d", &semid);
/* Выбрать требуемое управляющее действие */
printf ("\nВведите номер требуемого действия:\n");
printf (" GETVAL = 1\n");
printf (" SETVAL = 2\n");
printf (" GETPID = 3\n");
printf (" GETNCNT = 4\n");
printf (" GETZCNT = 5\n");
printf (" GETALL = 6\n");
printf (" SETALL = 7\n");
printf (" IPC_STAT = 8\n");
printf (" IPC_SET = 9\n");
printf (" IPC_RMID = 10\n");
printf (" Выбор = ");
scanf ("%d", &cmd);
/* Проверить значения */
printf ("идентификатор = %d, команда = %d\n",
semid, cmd);
/* Сформировать аргументы и выполнить вызов */
switch (cmd) {
case 1: /* Получить значение */
printf ("\nВведите номер семафора: ");
scanf ("%d", &semnum);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, GETVAL, 0);
printf ("\nЗначение семафора =
%d\n", rtrn);
break;
case 2: /* Установить значение */
printf ("\nВведите номер семафора: ");
scanf ("%d", &semnum);
printf ("\nВведите значение: ");
scanf ("%d", &arg.val);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, SETVAL,
arg.val);
break;
case 3: /* Получить ид-р процесса */
rtrn = semctl (semid, 0, GETPID, 0);
printf ("\Последнюю операцию выполнил:
%d\n",rtrn);
break;
case 4: /* Получить число процессов, ожидающих
увеличения значения семафора */
printf ("\nВведите номер семафора: ");
scanf ("%d", &semnum);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, GETNCNT, 0);
printf ("\nЧисло процессов = %d\n", rtrn);
break;
case 5: /* Получить число процессов, ожидающих
обнуления значения семафора */
printf ("Введите номер семафора: ");
scanf ("%d", &semnum);
/* Выполнить системный вызов */
rtrn = semctl (semid, semnum, GETZCNT, 0
printf ("\nЧисло процессов = %d\n", rtrn);
break;
case 6: /* Опросить все семафоры */
/* Определить число семафоров в множестве */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
length = arg.buf->sem_nsems;
if (rtrn == -1) goto ERROR;
/* Получить и вывести значения всех
семафоров в указанном множестве */
rtrn = semctl (semid, 0, GETALL, arg.array);
for (i = 0; i < length; i++)
printf (" %d", arg.array [i]);
break;
case 7: /* Установить все семафоры */
/* Определить число семафоров в множестве */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
length = arg.buf->sem_nsems;
if (rtrn == -1) goto ERROR;
printf ("\nЧисло семафоров = %d\n", length);
/* Установить значения семафоров множества */
printf ("\nВведите значения:\n");
for (i = 0; i < length; i++)
scanf ("%d", &arg.array [i]);
/* Выполнить системный вызов */
rtrn = semctl (semid, 0, SETALL, arg.array);
break;
case 8: /* Опросить состояние множества */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
printf ("\nИдентификатор пользователя = %d\n",
arg.buf->sem_perm.uid);
printf ("Идентификатор группы = %d\n",
arg.buf->sem_perm.gid);
printf ("Права на операции = 0%o\n",
arg.buf->sem_perm.mode);
printf ("Число семафоров в множестве = %d\n",
arg.buf->sem_nsems);
printf ("Время последней операции = %d\n",
arg.buf->sem_otime);
printf ("Время последнего изменения = %d\n",
arg.buf->sem_ctime);
break;
case 9: /* Выбрать и изменить поле
ассоциированной структуры данных */
/* Опросить текущее состояние */
rtrn = semctl (semid, 0, IPC_STAT, arg.buf);
if (rtrn == -1) goto ERROR;
printf ("\nВведите номер поля, ");
printf ("которое нужно изменить: \n");
printf (" sem_perm.uid = 1\n");
printf (" sem_perm.gid = 2\n");
printf (" sem_perm.mode = 3\n");
printf (" Выбор = ");
scanf ("%d", &choice);
switch (choice) {
case 1: /* Изменить ид-р владельца */
printf ("\nВведите ид-р владельца: ");
scanf ("%d", &arg.buf->sem_perm.uid);
printf ("\nИд-р владельца = %d\n",
arg.buf->sem_perm.uid);
break;
case 2: /* Изменить ид-р группы */
printf ("\nВведите ид-р группы = ");
scanf ("%d", &arg.buf->sem_perm.gid);
printf ("\nИд-р группы = %d\n",
arg.buf->sem_perm.uid);
break;
case 3: /* Изменить права на операции */
printf ("\nВведите восьмеричный код
прав доступа: ");
scanf ("%o", &arg.buf->sem_perm.mode);
printf ("\nПрава = 0%o\n",
arg.buf->sem_perm.mode);
break;
}
/* Внести изменения */
rtrn = semctl (semid, 0, IPC_SET, arg.buf);
break;
case 10: /* Удалить ид-р множества семафоров и
ассоциированную структуру данных */
rtrn = semctl (semid, 0, IPC_RMID, 0);
}
if (rtrn == -1) {
/* Сообщить о неудачном завершении */
ERROR:
printf ("\nsemctl завершился неудачей!\n");
printf ("\nКод ошибки = %d\n", errno);
}
else {
printf ("\nmsgctl завершился успешно,\n");
printf ("идентификатор semid = %d\n", semid);
}
exit (0);
}
Cинтаксис системного вызова semop описан так:
#include <sys/ipc.h>
#include <sys/sem.h>
int semop (int semid, struct sembuf *sops,
unsigned int nsops)
В качестве аргумента semid должен выступать идентификатор множества семафоров, предварительно полученный при помощи системного вызова semget.
Аргумент sops (массив структур) определяет, над какими семафорами и какие именно операции будут выполняться. Структура, описывающая операцию над одним семафором, определяется следующим образом:
short sem_num; /* Номер семафора */
short sem_op; /* Операция над семафором */
short sem_flg; /* Флаги операции */
};
Номер семафора задает конкретный семафор в множестве, над которым должна быть выполнена операция.
Выполняемая операция определяется следующим образом:
Пример работы с семафорами приведен ниже:
возможности системного вызова semop()
(операции над множеством семафоров) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/sem.h>
#define MAXOPSIZE 10
main ()
{
extern int errno;
struct sembuf sops [MAXOPSIZE];
int semid, flags, i, rtrn;
unsigned nsops;
/* Ввести идентификатор множества семафоров */
printf ("\nВведите идентификатор
множества семафоров,");
printf ("\nнад которым будут
выполняться операции: ");
scanf ("%d", &semid);
printf ("\nИд-р множества семафоров = %d", semid);
/* Ввести число операций */
printf ("\nВведите число операций ");
printf ("над семафорами из этого множества: \n");
scanf ("%d", &nsops);
printf ("\nЧисло операций = %d", nsops);
/* Инициализировать массив операций */
for (i = 0; i < nsops; i++) {
/* Выбрать семафор из множества */
printf ("\nВведите номер семафора: ");
scanf ("%d", &sops [i].sem_num);
printf ("\nНомер = %d", sops [i].sem_num);
/* Ввести число, задающее операцию */
printf ("\nЗадайте операцию над семафором: ");
scanf ("%d", &sops [i].sem_op);
printf ("\nОперация = %d", sops [i].sem_op);
/* Указать требуемые флаги */
printf ("\nВведите код, ");
printf ("соответствующий требуемым флагам:\n");
printf (" Нет флагов = 0\n");
printf (" IPC_NOWAIT = 1\n");
printf (" SEM_UNDO = 2\n");
printf (" IPC_NOWAIT и SEM_UNDO = 3\n");
printf (" Выбор = ");
scanf ("%d", &flags);
switch (flags) {
case 0:
sops [i].sem_flg = 0;
break;
case 1:
sops [i].sem_flg = IPC_NOWAIT;
break;
case 2:
sops [i].sem_flg = SEM_UNDO;
break;
case 3:
sops [i].sem_flg = IPC_NOWAIT | SEM_UNDO;
break;
}
printf ("\nФлаги = 0%o", sops [i].sem_flg);
}
/* Распечатать все структуры массива */
printf ("\nМассив операций:\n");
for (i = 0; i < nsops; i++) {
printf (" Номер семафора = %d\n",
sops [i].sem_num);
printf (" Операция = %d\n", sops [i].sem_op);
printf (" Флаги = 0%o\n", sops [i].sem_flg);
}
/* Выполнить системный вызов */
rtrn = semop (semid, sops, nsops);
if (rtrn == -1) {
printf ("\nsemop завершился неудачей!\n");
printf ("Код ошибки = %d\n", errno);
}
else {
printf ("\nsemop завершился успешно.\n");
printf ("Идентификатор semid = %d\n", semid);
printf ("Возвращенное значение = %d\n", rtrn);
}
exit (0);
}
Разделяемые сегменты памяти как средство межпроцессной связи позволяют процессам иметь общие области виртуальной памяти и, как следствие, разделять содержащуюся в них информацию. Единицей разделяемой памяти являются сегменты, свойства которых зависят от аппаратных особенностей управления памятью.
Разделение памяти обеспечивает наиболее быстрый обмен данными между процессами.
Работа с разделяемой памятью начинается с того, что процесс при помощи системного вызова shmget создает разделяемый сегмент, специфицируя первоначальные права доступа к сегменту (чтение и / или запись) и его размер в байтах. Чтобы затем получить доступ к разделяемому сегменту, его нужно присоединить посредством системного вызова shmat(), который разместит сегмент в виртуальном пространстве процесса. После присоединения в соответствии с правами доступа процессы могут читать данные из сегмента и записывать их (возможно, синхронизируя свои действия с помощью семафоров).
Когда разделяемый сегмент становится ненужным, его следует отсоединить, воспользовавшись системным вызовом shmdt().
Для выполнения управляющих действий над разделяемыми сегментами памяти служит системный вызов shmctl(). В число управляющих действий входит предписание удерживать сегмент в оперативной памяти и обратное предписание о снятии удержания. После того, как последний процесс отсоединил разделяемый сегмент, следует выполнить управляющее действие по удалению сегмента из системы.
Прежде чем воспользоваться разделением памяти, нужно создать разделяемый сегмент с уникальным идентификатором и ассоциированную с ним структуру данных. Уникальный идентификатор называется идентификатором разделяемого сегмента памяти (shmid); он используется для обращений к ассоциированной структуре данных, которая определяется следующим образом:
/*Структура прав на выполнение операций*/
struct ipc_perm shm_perm;
/* Размер сегмента */
int shm_segsz;
/*Указатель на структуру области памяти*/
struct region *shm_reg;
/* Информация для подкачки */
char pad [4];
/* Ид-р процесса, вып. последнюю операцию */
ushort shm_lpid;
/* Ид-р процесса, создавшего сегмент */
ushort shm_cpid;
/* Число присоединивших сегмент */
ushort shm_nattch;
/* Число удерживающих сегмент в памяти */
ushort shm_cnattch;
/* Время последнего присоединения */
time_t shm_atime;
/* Время последнего отсоединения */
time_t shm_dtime;
/* Время последнего изменения */
time_t shm_ctime;
};
Информация о возможных состояниях разделяемых сегментов
памяти содержится в табл. 4:
| Бит удержания | Бит подкачки | Бит размещения | Состояние |
| 0 | 0 | 0 | Неразмещенный сегмент |
| 0 | 0 | 1 | В памяти |
| 0 | 1 | 0 | Не используется |
| 0 | 1 | 1 | На диске |
| 1 | 0 | 0 | Не используется |
| 1 | 0 | 1 | Удержан в памяти |
| 1 | 1 | 0 | Не используется |
| 1 | 1 | 1 | Не используется |
Состояния, упомянутые в таблице, таковы:
После того, как создан уникальный идентификатор разделяемого сегмента памяти и ассоциированная с ним структура данных, можно использовать системные вызовы семейства shmop (операции над разделяемыми сегментами) и shmctl (управление разделяемыми сегментами).
Для создания разделяемого сегмента памяти служит системный вызов shmget. Синтаксис данного системного вызова описан так:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget (key_t key, int size, int shmflg);
Смысл аргументов key и shmflg тот же, что и у соответствующих аргументов системного вызова semget. Аргумент size задает размер разделяемого сегмента в байтах.
Системный параметр SHMMNI определяет максимально допустимое число уникальных идентификаторов разделяемых сегментов памяти (shmid) в системе. Попытка его превышения ведет к неудачному завершению системного вызова.
Системный вызов завершится неудачей и тогда, когда значение аргумента size меньше, чем SHMMIN, либо больше, чем SHMMAX. Данные системные параметры определяют соответственно минимальный и максимальный размеры разделяемого сегмента памяти.
В справочной статье shmctl синтаксис данного системного вызова описан так:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl (int shmid, int cmd, struct shmid_ds *buf);
В качестве аргумента shmid должен выступать идентификатор разделяемого сегмента памяти, предварительно полученный системным вызовом shmget.
Управляющее действие определяется значением аргумента cmd. Допустимы следующие значения:
Управляющие действия SHM_LOCK и SHM_UNLOCK может выполнить только суперпользователь. Для выполнения управляющего действия IPC_STAT процессу требуется право на чтение:
возможности системного вызова shmctl()
(операции управления разделяемыми сегментами) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main ()
{
extern int errno;
int rtrn, shmid, command, choice;
struct shmid_ds shmid_ds, *buf;
buf = &shmid_ds;
/* Ввести идентификатор сегмента и действие */
printf ("Введите идентификатор shmid: ");
scanf ("%d", &shmid);
printf ("Введите номер требуемого действия:\n");
printf (" IPC_STAT = 1\n");
printf (" IPC_SET = 2\n");
printf (" IPC_RMID = 3\n");
printf (" SHM_LOCK = 4\n");
printf (" SHM_UNLOCK = 5\n");
printf (" Выбор = ");
scanf ("%d", &command);
/* Проверить значения */
printf ("\nидентификатор = %d, действие = %d\n",
shmid, command);
switch (command) {
case 1: /* Скопировать информацию
о состоянии разделяемого сегмента
в пользовательскую структуру
и вывести ее */
rtrn = shmctl (shmid, IPC_STAT, buf);
printf ("\nИд-р пользователя = %d\n",
buf->shm_perm.uid);
printf ("Ид-р группы пользователя = %d\n",
buf->shm_perm.gid);
printf ("Ид-р создателя = %d\n",
buf->shm_perm.cuid);
printf ("Ид-р группы создателя = %d\n",
buf->shm_perm.cgid);
printf ("Права на операции = 0%o\n",
buf->shm_perm.mode);
printf ("Последовательность номеров ");
buf->shm_perm.cgid);
printf ("используемых слотов = 0%x\n",
buf->shm_perm.seq);
printf ("Ключ = 0%x\n",
buf->shm_perm.key);
printf ("Размер сегмента = %d\n",
buf->shm_segsz);
printf ("Выполнил последнюю операцию =
%d\n", buf->shm_lpid);
printf ("Создал сегмент = %d\n",
buf->shm_cpid);
printf ("Число присоединивших сегмент =
%d\n", buf->shm_nattch);
printf ("Число удерживаюших в памяти =
%d\n", buf->shm_cnattch);
printf ("Последнее присоединение = %d\n",
buf->shm_atime);
printf ("Последнее отсоединение = %d\n",
buf->shm_dtime);
printf ("Последнее изменение = %d\n",
buf->shm_ctime);
break;
case 2: /* Выбрать и изменить поле (поля)
ассоциированной структуры данных */
/* Получить исходные значения
структуры данных */
rtrn = shmctl (shmid, IPC_STAT, buf);
printf ("Введите номер
изменяемого поля:\n");
printf (" shm_perm.uid = 1\n");
printf (" shm_perm.gid = 2\n");
printf (" shm_perm.mode = 3\n");
printf (" Выбор = ");
scanf ("%d", &choice);
switch (choice) {
case 1:
printf ("\nВведите ид-р
пользователя:"),
scanf ("%d",
&buf->shm_perm.uid);
printf ("\nИд-р пользователя =
%d\n",
buf->shm_perm.uid);
break;
case 2:
printf ("\nВведите ид-р группы: "),
scanf ("%d", &buf->shm_perm.gid);
printf ("\nИд-р группы = %d\n",
buf->shm_perm.uid);
break;
case 3:
printf ("\nВведите восьмеричный
код прав: ");
scanf ("%o", &buf->shm_perm.mode);
printf ("\nПрава на операции
= 0%o\n",
buf->shm_perm.mode);
break;
}
/* Внести изменения */
rtrn = shmctl (shmid, IPC_SET, buf);
break;
case 3: /* Удалить идентификатор и
ассоциированную структуру данных */
rtrn = shmctl (shmid, IPC_RMID, NULL);
break;
case 4: /* Удерживать разделяемый сегмент
в памяти */
rtrn = shmctl (shmid, SHM_LOCK, NULL);
break;
case 5: /* Перестать удерживать сегмент в памяти */
rtrn = shmctl (shmid, SHM_UNLOCK, NULL);
}
if (rtrn == -1) {
/* Сообщить о неудачном завершении */
printf ("\nshmctl завершился неудачей!\n");
printf ("\nКод ошибки = %d\n", errno);
}
else {
/* При успешном завершении сообщить ид-р shmid */
printf ("\nshmctl завершился успешно, ");
printf ("идентификатор shmid = %d\n", shmid);
}
exit (0);
}
Cинтаксис системных вызовов shmat и shmdt описан так:
#include <sys/ipc.h>
#include <sys/shm.h>
int shmat (int shmid, char *shmaddr, int shmflg);
int shmdt (char *shmaddr);
Разумеется, чтобы использовать результат shmat() как указатель, его нужно преобразовать к требуемому типу.
В качестве аргумента shmid должен выступать идентификатор разделяемого сегмента, предварительно полученный системным вызовом shmget. Аргумент shmaddr задает адрес, по которому сегмент должен быть присоединен, т. е. тот адрес в виртуальном пространстве пользователя, который получит начало сегмента. Однако не всякий адрес является приемлемым. Можно порекомендовать адреса вида:
0x80040000
0x80080000
. . .
При успешном завершении системного вызова shmdt() результат равен нулю; в случае неудачи возвращается -1.
Аргумент shmaddr задает начальный адрес отсоединяемого сегмента. После того, как последний процесс отсоединил разделяемый сегмент памяти, этот сегмент вместе с идентификатором и ассоциированной структурой данных следует удалить системным вызовом shmctl.
Пример использования вызовов shmat() и shmdt():
возможности системных вызовов shmat() и shmdt()
(операции над разделяемыми сегментами памяти) */
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
main ()
{
extern int errno;
int shmid, shmaddr, shmflg;
int flags, attach, detach, rtrn, i;
/* Цикл присоединений для данного процесса */
printf ("\nВведите число присоединений ");
printf ("для процесса (1-4): ");
scanf ("%d", &attach);
printf ("\nЧисло присоединений = %d\n", attach);
for (i = 0; i < attach; i++) {
/* Ввести идентификатор разделяемого сегмента */
printf ("\nВведите ид-р разделяемого сегмента,\n");
printf ("над которым нужно выполнить операции: ");
scanf ("%d", &shmid);
printf ("\nИд-р сегмента = %d\n", shmid);
/* Ввести адрес присоединения */
printf ("\nВведите адрес присоединения ");
printf ("в шестнадцатеричной записи: ");
scanf ("%x", &shmaddr);
printf ("\nАдрес присоединения = 0x%x\n", shmaddr);
/* Выбрать требуемые флаги */
printf ("\nВведите номер нужной
комбинации флагов:\n");
printf (" SHM_RND = 1\n");
printf (" SHM_RDONLY = 2\n");
printf (" SHM_RND и SHM_RDONLY = 3\n");
printf (" Выбор = ");
scanf ("%d", &flags);
switch (flags) {
case 1:
shmflg = SHM_RND;
break;
case 2:
shmflg = SHM_RDONLY;
break;
case 3:
shmflg = SHM_RND | SHM_RDONLY;
break;
}
printf ("\nФлаги = 0%o", shmflg);
/* Выполнить системный вызов shmat */
rtrn = shmat (shmid, shmaddr, shmflg);
if (rtrn == -1) {
printf ("\nshmat завершился неудачей!\n");
printf ("\Код ошибки = %d\n", errno);
}
else {
printf ("\nshmat завершился успешно.\n");
printf ("Идентификатор shmid = %d\n", shmid);
printf ("Адрес = 0x%x\n", rtrn);
}
}
/* Цикл отсоединений для данного процесса */
printf ("\nВведите число отсоединений ");
printf ("для процесса (1-4): ");
scanf ("%d", &detach);
printf ("\nЧисло отсоединений = %d\n", detach);
for (i = 0; i < detach; i++) {
/* Ввести адрес отсоединения */
printf ("\nВведите адрес отсоединяемого сегмента ");
printf ("в шестнадцатеричной записи: ");
scanf ("%x", &shmaddr);
printf ("\nАдрес отсоединения = 0x%x\n", shmaddr);
/* Выполнить системный вызов shmdt */
rtrn = shmdt (shmaddr);
if (rtrn == -1) {
printf ("\nshmdt завершился неудачей!\n");
printf ("\Код ошибки = %d\n", errno);
}
else {
printf ("\nshmdt завершился успешно,\n");
printf ("идентификатор shmid = %d\n", shmid);
}
}
exit (0);
}
С помощью процессов можно организовать параллельное выполнение программ. Для этого процессы клонируются вызовами fork() или exec(), а затем между ними организуется взаимодействие средствами IPC. Это довольно дорогостоящий в отношении ресурсов процесс.
С другой стороны, для организации параллельного выполнения и взаимодействия процессов можно использовать механизм многопоточности. Основной единицей здесь является поток.
Поток представляет собой облегченную версию процесса. Чтобы понять, в чем состоит его особенность, необходимо вспомнить основные характеристики процесса.
При корректной реализации потоки имеют определенные преимущества перед процессами. Им требуется:
Если операционная система поддерживает концепции потоков в рамках одного процесса, она называется многопоточной. Многопоточные приложения имеют ряд преимуществ.
Существует две основных категории потоков с точки зрения реализации:
При использовании этого уровня ядро не знает о существовании потоков - все управление потоками реализуется приложением с помощью специальных библиотек. Переключение потоков не требует привилегий режима ядра, а планирование полностью зависит от приложения. При этом ядро управляет деятельностью процесса. Если поток вызывает системную функцию, то будет блокирован весь процесс, но для поточной библиотеки этот поток будет находиться в активном состоянии. Здесь состояние потока не зависит от состояния процесса.
Преимущества пользовательских потоков в следующем:
На этом уровне все управление потоком выполняется ядром. Используется программный интерфейс приложения (системные вызовы) для работы с потоками уровня ядра. Ядро поддерживает информацию о контексте процесса и потоков; переключение потоков требует выполнения дисциплины планирования ядра на уровне этих потоков.
Преимущества потоков уровня ядра:
Функция pthread_create() позволяет добавить новый поток управления к текущему процессу. Прототип функции:
const pthread_attr_t *tattr,
void*(*start_routine)(void *), void *arg);
pthread_attr_t tattr;
pthread_t tid;
extern void *start_routine(void *arg);
void *arg;
int ret;
/* поведение по умолчанию*/
ret = pthread_create(&tid, NULL, start_routine, arg);
/* инициализация с атрибутами по умолчанию */
ret = pthread_attr_init(&tattr);
/* определение поведения по умолчанию*/
ret = pthread_create(&tid, &tattr, start_routine, arg);
Функция pthread_create() вызывается с атрибутом attr,
определяющим необходимое поведение; start_routine - это
функция, с которой новый поток начинает свое выполнение. Когда
start_routine
завершается, поток завершается со статусом выхода, установленным в
значение, возвращенное start_routine.
Если вызов pthread_create() успешно завершен, идентификатор созданного потока сохраняется по адресу tid.
Создание потока с использованием аргумента атрибутов NULL оказывает тот же эффект, что и использование атрибута по умолчанию: оба создают одинаковый поток. При инициализации tattr он обретает поведение по умолчанию; pthread_create() возвращает 0 при успешном завершении. Любое другое значение указывает, что произошла ошибка.
Функция pthread_join() используется для ожидания завершения потока:
pthread_t tid;
int ret;
int status;
/* ожидание завершения потока "tid" со статусом status */
ret = pthread_join(tid, &status);
/* ожидание завершения потока "tid" без статуса */
ret = pthread_join(tid, NULL);
Функция pthread_join() блокирует вызывающий поток, пока указанный поток не завершится. Указанный поток должен принадлежать текущему процессу и не должен быть отделен. Если status не равен NULL, он указывает на переменную, которая принимает значение статуса выхода завершенного потока при успешном завершении pthread_join(). Несколько потоков не могут ждать завершения одного и того же потока. Если они пытаются выполнить это, один поток завершается успешно, а все остальные - с ошибкой ESRCH. После завершения pthread_join(), любое пространство стека, связанное с потоком, может быть использовано приложением.
В следующем примере один поток верхнего уровня вызывает процедуру, которая создает новый вспомогательный поток, выполняющий сложный поиск в базе данных, требующий определенных затрат времени. Главный поток ждет результатов поиска, и в то же время может выполнять другую работу. Он ждет своего помощника с помощью функции pthread_join(). Аргумент pbe является параметром стека для нового потока.
Исходный код для thread.c:
{
struct phonebookentry *pbe;
pthread_attr_t tattr;
pthread_t helper;
int status;
pthread_create(&helper, NULL, fetch, &pbe);
/* выполняет собственную задачу */
pthread_join(helper, &status);
/* теперь можно использовать результат */
}
void fetch(struct phonebookentry *arg)
{
struct phonebookentry *npbe;
/* ищем значение в базе данных */
npbe = search (prog_name)
if (npbe != NULL)
*arg = *npbe;
pthread_exit(0);
}
struct phonebookentry {
char name[64];
char phonenumber[32];
char flags[16];
}
Функция pthread_detach() применяется как альтернатива
pthread_join(),
чтобы утилизировать область памяти для потока, который был создан
с атрибутом detachstate, установленным в значение PTHREAD_CREATE_JOINABLE.
Прототип функции:
pthread_t tid;
int ret;
/* отделить поток tid */
ret = pthread_detach(tid);
В ОС Linux управление процессами является ключевой технологией при разработке многих программ. Процесс - это находящаяся в состоянии выполнения программа вместе со средой ее выполнения.
Так как Linux - это настоящая многозадачная система, в ней одновременно могут выполняться несколько программ (процессов, задач). Термин ``одновременно'' не всегда соответствует действительности. Обычно центральный процессор (ЦП) может работать в данный момент только с одним процессом. Если необходимо выполнить одновременно несколько программ параллельно, нужно использовать либо несколько компьютеров, либо несколько процессоров. Однако для большинства пользователей этот вариант может быть непривлекательным из-за расходов на приобретение дополнительной техники.
Каждый процесс имеет собственное виртуальное адресное пространство. Это необходимо, чтобы гарантировать, что ни один процесс не будет подвержен помехам или влиянию со стороны других.
Отдельные процессы получают доступ к ЦП по очереди. Планировщик процессов решает, как долго и в какой последовательности процессы будут занимать ЦП. При этом создается впечатление, что процессы протекают параллельно.
В Linux реализована вытесняющая многозадачность. Это значит, что система сама решает, как долго конкретный процесс может использовать ЦП, и когда наступит очередь следующего процесса. Если пользователь желает вмешаться в процесс планирования, он может сделать это как root с помощью команды nice.
С помощью команды ps можно узнать, какие процессы выполняются
в настоящий момент: ps -x
При этом выводится список выполняющихся в данный момент процессов. Значение колонок следующее:
PID TTY STAT TIME COMMAND 1234 pts/0 R 0:00 ps -xPID - идентификатор процесса. Каждый процесс получает собственный однозначный идентификатор. Пользуясь этим идентификатором, можно получать доступ к конкретному процессу. Например, можно получить сведения о процессе с ID 1501 с помощью команды:
ps 1501
Если идентификатор процесса не известен, но известна команда, запустившая
этот процесс, то идентификатор можно узнать с помощью команды: pidof /bin/bash
Отметьте, что pidof можно выполнять только как root.
TTY показывает, в каком терминале выполняется процесс. Если в колонке не указано никакого значения, речь идет, как правило, о процессе-демоне.
STAT показывает текущее состояние процесса. В приведенном примере символ R означает выполнение (running). Для процессов применяются следующие обозначения:
TIME указывает время работы процесса.
COMMAND - имя команды, с помощью которой запущен процесс.
В Linux все процессы упорядочены иерархически подобно генеалогическому дереву. Каждый процесс владеет информацией того процесса, от которого он был порожден. То же самое справедливо и для его родительского процесса.
Если нужно узнать, сколько времени ЦП необходимо для каждого процесса, можно использовать команду top. Она показывает в колонке '%CPU', какое время вычислений занимает определенная программа в процессоре.
Однопоточные программы на C содержат два основных класса данных: локальные и глобальные. Для многопоточных программ на C добавляется третий класс: данные потока. Они похожи на глобальные данные, за исключением того, что они являются собственными для потока.
Данные потока являются единственным способом определения и обращения к данным, которые принадлежат отдельному потоку. Каждый элемент данных потока связан с ключом, который является глобальным для всех потоков процесса. Используя ключ, поток может получить доступ к указателю (void *), который поддерживается только для этого потока.
Функция pthread_keycreate() применяется для выделения ключа,
который используется при идентифицикации данных некоторого потока
в составе процесса. Ключ для всех потоков общий, и все потоки вначале
содержат значение ключа NULL. Отдельно для каждого ключа
перед его использованием вызывается
pthread_keycreate().
При этом не происходит никакой синхронизации.
Как только ключ будет создан, каждый поток может связать с ним свое значение.
Значения являются специфичными для потока и поддерживаются
для каждого из них независимо. Связь ключа с потоком удаляется,
когда поток заканчивается, при этом ключ должен быть создан с функцией
деструктора. Прототип функции:
void(*destructor)(void *));
pthread_key_t key;
int ret;
/* создание ключа без деструктора */
ret = pthread_key_create(&key, NULL);
/* создание ключа с деструктором */
ret = pthread_key_create(&key, destructor);
Функция pthread_keydelete() используется, чтобы уничтожить существующий ключ данных для определенного потока. Любая выделенная память, связанная с ключом, может быть освобождена, потому что ключ был удален; попытка ссылки на эту память вызовет ошибку.
Прототип pthread_keydelete():
pthread_key_t key;
int ret;
/* key был создан ранее */
ret = pthread_key_delete(key);
Программист должен сам освобождать любые выделенные потоку ресурсы перед вызовом функции удаления. Эта функция не вызывает деструктора; pthread_keydelete() возвращает 0 - после успешного завершения - или любое другое значение - в случае ошибки.
Функция pthread_setspecific() используется, чтобы установить связку между потоком и указанным ключом данных для потока. Прототип функции:
const void *value);
pthread_key_t key;
void *value;
int ret;
/* key был создан ранее */
ret = pthread_setspecific(key, value);
Чтобы получить привязку ключа для вызывающего потока, используется функция pthread_getspecific(). Полученное значение сохраняется в переменной value. Прототип функции:
pthread_key_t key;
void *value;
/* key был создан ранее */
value = pthread_getspecific(key);
...
while (write(fd, buffer, size) == -1) {
if (errno != EINTR) {
fprintf(mywindow, "%s\n", strerror(errno));
exit(1);
}
}
...
}
Ссылки на errno должны получить код системной ошибки из процедуры, вызванной именно этим конкретным потоком, и никаким другим. Поэтому ссылки на errno в одном потоке относятся к иной области памяти, чем ссылки на errno в других потоках. Переменная mywindow предназначена для обращения к потоку stdio, связанному с окном, которое является частным объектом потока. Так же, как и errno, ссылки на mywindow в одном потоке должны обращаться к отдельной конкретной области памяти (и в конечном счете - к различным окнам). Единственное различие между этими переменными состоит в том, что библиотека потоков реализует раздельный доступ для errno, а программист должен сам реализовать это для mywindow. Следующий пример показывает, как работают ссылки на mywindow. Препроцессор преобразует ссылки на mywindow в вызовы процедур mywindow. Эта процедура в свою очередь вызывает pthread_getspecific(), передавая ему глобальную переменную mywindow_key (это, действительно, глобальная переменная) и выходной параметр win, который принимает идентификатор окна для этого потока.
Следующий фрагмент кода:
FILE *_mywindow(void) {
FILE *win;
pthread_getspecific(mywin_key, &win);
return(win);
}
#define mywindow _mywindow()
void routine_uses_win( FILE *win) {
...
}
void thread_start(...) {
...
make_mywin();
...
routine_uses_win( mywindow )
...
}
Теперь можно устанавливать собственные данные потока:
FILE **win;
static pthread_once_t mykeycreated =
PTHREAD_ONCE_INIT;
pthread_once(&mykeycreated, mykeycreate);
win = malloc(sizeof(*win));
create_window(win, ...);
pthread_setspecific(mywindow_key, win);
}
void mykeycreate(void) {
pthread_keycreate(&mywindow_key, free_key);
}
void free_key(void *win) {
free(win);
}
Следующий шаг состоит в выделении памяти для элемента данных вызывающего
потока. После выделения памяти выполняется вызов процедуры create_window,
устанавливающей окно для потока и выделяющей память для переменной
win, которая ссылается на окно. Наконец выполняется вызов
pthread_setspecific(), который связывает значение win
с ключом. После этого, как только поток вызывает pthread_getspecific(),
передав глобальный ключ, он получает некоторое значение. Это значение
было связано с этим ключом в вызывающем потоке, когда он вызвал функцию
pthread_setspecific().
Когда поток заканчивается, выполняются вызовы функций деструкторов,
которые были настроены при вызове pthread_key_create(). Функция
деструктора вызывается, если завершившийся поток установил значение
для ключа вызовом pthread_setspecific().
Функция pthread_self() вызывается для получения ID вызывающего ее потока:
pthread_t tid;
tid = pthread_self();
pthread_t tid1, tid2;
int ret;
ret = pthread_equal(tid1, tid2);
Функция pthread_once() используется для вызова процедуры инициализации потока только один раз. Последующие вызовы не оказывают никакого эффекта. Пример вызова функции:
void (*init_routine)(void));
int ret;
ret = sched_yield();
Функция pthread_setschedparam() используется, чтобы изменить приоритет существующего потока. Эта функция никоим образом не влияет на дисциплину диспетчеризации:
const struct sched_param *param);
pthread_t tid;
int ret;
struct sched_param param;
int priority;
/* sched_priority указывает приоритет потока */
sched_param.sched_priority = priority;
/* единственный поддерживаемый алгоритм диспетчера*/
policy = SCHED_OTHER;
/* параметры диспетчеризации требуемого потока */
ret = pthread_setschedparam(tid, policy, ¶m);
Функция:
struct schedparam *param)
Пример вызова функции:
pthread_t tid;
sched_param param;
int priority;
int policy;
int ret;
/* параметры диспетчеризации нужного потока */
ret = pthread_getschedparam (tid, &policy, ¶m);
/* sched_priority содержит приоритет потока */
priority = param.sched_priority;
Поток, как и процесс, может принимать различные сигналы:
#include <signal.h>
int sig;
pthread_t tid;
int ret;
ret = pthread_kill(tid, sig);
Если sig имеет значение 0, выполняется проверка ошибок, но сигнал реально не посылается. Таким образом можно проверить правильность tid. Функция возвращает 0 - в случае успешного завершения - или другое значение - в случае ошибки.
Функция pthread_sigmask() может использоваться для изменения или получения маски сигналов вызывающего потока:
sigset_t *old);
#include <signal.h>
int ret;
sigset_t old, new;
/* установка новой маски */
ret = pthread_sigmask(SIG_SETMASK, &new, &old);
/* блокирование маски */
ret = pthread_sigmask(SIG_BLOCK, &new, &old);
/* снятие блокировки */
ret = pthread_sigmask(SIG_UNBLOCK, &new, &old);
Функция pthread_sigmask() возвращает 0 - в случае успешного завершения - или другое значение - в случае ошибки.
Поток может прерваться несколькими способами. Первый способ предполагает возвращение управления из основной процедуры потока start_routine. Второй способ - вызов pthread_exit(), возвращающий статус выхода. Третий способ - прерывание потока с помощью функции pthread_cancel().
Функция void pthread_exit(void *status)
прерывает выполнение потока точно так же, как функция exit()
прерывает процесс:
int status;
/* выход возвращает статус status */
pthread_exit(&status);
Функция pthread_cancel() предназначена для прерывания потока:
pthread_t thread;
int ret;
ret = pthread_cancel(thread);
Для компиляции и сборки многопоточной программы необходимо иметь:
К наиболее частым оплошностям и ошибкам многопоточных программах относятся:
Атрибуты являются способом определить поведение потока, отличное от поведения по умолчанию. При создании потока с помощью pthread_create() или при инициализации переменной синхронизации может быть определен собственный объект атрибутов. Атрибуты определяются только во время создания потока; они не могут быть изменены в процессе использования.
Обычно вызываются три функции:
pthread_attr_t tattr;
pthread_t tid;
void *start_routine;
void arg
int ret;
/* инициализация атрибутами по умолчанию */
ret = pthread_attr_init(&tattr);
/* вызов соответствующих функций для изменения
значений */
ret = pthread_attr_*(&tattr,
SOME_ATRIBUTE_VALUE_PARAMETER);
/* создание потока */
ret = pthread_create(&tid, &tattr, start_routine, arg);
Объект атрибутов является закрытым и не может быть непосредственно изменен операциями присваивания. Существует множество функций, позволяющих инициализировать, конфигурировать и уничтожать любые типы объекта. Как только атрибут инициализируется и конфигурируется, он доступен всему процессу. Поэтому рекомендуется конфигурировать все требуемые спецификации состояния один раз, на ранних стадиях выполнения программы. При этом соответствующий объект атрибутов может использоваться везде, где это нужно. Использование объектов атрибутов имеет два основных преимущества.
Функция pthread_attr_init() используется, чтобы инициализировать объект атрибутов значениями по умолчанию. Память распределяется системой потоков во время выполнения.
Пример вызова функции:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_init(&tattr);
| Атрибут | Значение | Смысл |
| scope | PTHREAD_SCOPE_PROCESS | Новый поток не ограничен - не присоединен ни к одному процессу |
| detachstate | PTHREAD_CREATE_JOINABLE | Статус выхода и поток сохраняются после завершения потока |
| stackaddr | NULL | Новый поток получает адрес стека, выделенного системой |
| stacksize | 1 Мбайт | Новый поток имеет размер стека, определенный системой |
| inheritsched | PTHREAD_INHERIT_SCHED | Поток наследует приоритет диспетчеризации родительского потока |
| schedpolicy | SCHED_OTHER | Новый поток использует диспетчеризацию с фиксированными приоритетами. Поток работает, пока не будет прерван потоком с высшим приоритетом или не приостановится |
Функция возвращает 0 после успешного завершения. Любое другое значение указывает, что произошла ошибка. Код ошибки устанавливается в переменной errno.
Функция pthread_attr_destroy() используется, чтобы удалить память для атрибутов, выделенную во время инициализации. Объект атрибутов становится недействительным.
Пример вызова функции:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_destroy(&tattr);
Если поток создается отделенным (PTHREAD_CREATE_DETACHED), его ID и другие ресурсы могут многократно использоваться, как только он завершится. Если нет необходимости ожидать в вызывающем потоке завершения нового потока, можно вызвать перед его созданием функцию pthread_attr_setdetachstate().
Если поток создается неотделенным (PTHREAD_CREATE_JOINABLE), предполагается, что создающий поток будет ожидать его завершения и выполнять в созданном потоке pthread_join(). Независимо от типа потока процесс не закончится, пока не завершатся все потоки; pthread_attr_setdetachstate() возвращает 0 - после успешного завершения - или любое другое значение - в случае ошибки.
Пример вызова для отсоединения потока:
pthread_attr_t tattr;
int ret;
/* устанавливаем состояние потока */
ret = pthread_attr_setdetachstate(&tattr,
PTHREAD_CREATE_DETACHED);
Функция pthread_attr_getdetachstate() позволяет определить состояние при создании потока, т.е. был ли он отделенным или присоединяемым. Она возвращает 0 - после успешного завершения - или любое другое значение - в случае ошибки. Пример вызова:
pthread_attr_t tattr;
int detachstate;
int ret;
ret = pthread_attr_getdetachstate (&tattr, &detachstate);
Следующий пример иллюстрирует, как можно создать отделенный поток:
pthread_attr_t tattr;
pthread_t tid;
void *start_routine;
void arg
int ret;
ret = pthread_attr_init(&tattr);
ret = pthread_attr_setdetachstate(&tattr,
PTHREAD_CREATE_DETACHED);
ret = pthread_create(&tid, &tattr, start_routine, arg);
Поток может быть ограничен (иметь тип PTHREAD_SCOPE_SYSTEM)
или неограничен (иметь тип PTHREAD_SCOPE_PROCESS). Оба
этих типа доступны только в пределах данного процесса. Функция
pthread_attr_setscope()
позволяет создать потоки указанных типов;
pthread_attr_setscope() возвращает 0 - после успешного завершения -
или любое другое значение - в случае ошибки. Пример вызова функции:
pthread_attr_t attr;
pthread_t tid;
void start_routine;
void arg;
int ret;
/* инициализация атрибутов по умолчанию */
ret = pthread_attr_init (&tattr);
/* ограниченное поведение */
ret = pthread_attr_setscope(&tattr,
PTHREAD_SCOPE_SYSTEM);
ret = pthread_create (&tid, &tattr, start_routine,
arg);
pthread_attr_t tattr;
int scope;
int ret;
ret = pthread_attr_getscope(&tattr, &scope);
Стандарт POSIX определяет несколько значений атрибута планирования: SCHED_FIFO, SCHED_RR (Round Robin) или SCHED_OTHER (метод приложения). Дисциплины SCHED_FIFO и SCHED_RR являются необязательными и поддерживаются только для потоков в режиме реального времени.
Библиотека pthreads поддерживает только значение SCHED_OTHER. Попытка установить другое значение приведет к возникновению ошибки ENOSUP.
Для установки дисциплины диспетчеризации используется следующая функция:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_setschedpolicy(&tattr, SCHED_OTHER);
Функция pthread_attr_setinheritsched() используется для
наследования дисциплины диспетчеризации из родительского потока. Значение
переменной inherit, равное PTHREAD_INHERIT_SCHED
(по умолчанию) проявляется в том, что будет использована дисциплина планирования,
определенная в создающем потоке, а любые атрибуты планирования, определенные
в вызове pthread_create(), будут проигнорированы. Если используется
константа
PTHREAD_EXPLICIT_SCHED, то используются и атрибуты,
переданные в вызове pthread_create().
Функция возвращает 0 - при успешном завершении - и любое другое значение - в случае ошибки. Пример вызова этой функции:
pthread_attr_t tattr;
int ret;
ret = pthread_attr_setinheritsched(&tattr,
PTHREAD_EXPLICIT_SCHED);
Параметры диспетчеризации определены в структуре
sched_param;
в настоящее время поддерживается только приоритет
sched_param.sched_priority.
Этот приоритет задается целым числом, при этом чем выше значение,
тем выше приоритет потока при планировании. Создаваемые потоки получают
этот приоритет.
Функция pthread_attr_setschedparam() используется, чтобы установить значения в этой структуре. При успешном завершении она возвращает 0. Пример использования:
pthread_attr_t tattr;
int newprio;
sched_param param;
/* устанавливает приоритет */
newprio = 30;
param.sched_priority = newprio;
/* устанавливает параметры диспетчеризации */
ret = pthread_attr_setschedparam (&tattr, ¶m);
const struct sched_param *param) используется для получения приоритета текущего потока.
Как правило, стеки потоков начинаются на границах страниц, и любой указанный размер округляется к следующей границе страницы. К вершине стека добавляется страница без разрешения на доступ, чтобы переполнение стека вызвало посылку сигнала SIGSEGV потоку, вызвавшему переполнение.
Если определяется стек, то поток должен создаваться с типом
PTHREAD_CREATE_JOINABLE. Этот стек не может быть освобожден,
пока не произойдет выход из pthread_join() этого потока,
потому что стек потока не может быть освобожден, пока поток не закончится.
Единственный надежный способ закончить такой поток - вызов pthread_join().
В общем случае нет необходимости выделять пространство для стека потоков. Библиотека потоков выделяет один мегабайт виртуальной памяти для стека каждого потока без резервирования пространства выгрузки. (Библиотека использует опцию MAP_NORESERVE для mmap, чтобы выделить память).
Каждый стек потоков, созданный библиотекой потоков, имеет красную зону. Библиотека создает красную зону, добавляя к вершине стека страницу, позволяющую обнаружить переполнение стека. Эта страница не действительна и вызывает ошибку защиты памяти, когда к ней обращаются. Красные зоны добавляются ко всем автоматически распределенным стекам вне зависимости от того, был ли определен размер стека приложением или используется размер по умолчанию.
Обычно создание собственного стека предполагает, что он будет немного отличаться от стека по умолчанию. Как правило, задача состоит в выделении более чем одного мегабайта для стека. Иногда стек по умолчанию, наоборот, является слишком большим. Можно создать тысячи потоков, и тогда виртуальной памяти будет недостаточно, чтобы работать с гигабайтами пространств стека при использовании размера по умолчанию.
Абсолютный минимальный предел размера стека можно определить, вызывая
макрос PTHREAD_STACK_MIN (определенный в
<pthread.h>),
который возвращает количество памяти стека, требуемого для потока,
выполняющего пустую процедуру (NULL). Реальные потоки нуждаются
в большем стеке, поэтому нужно очень осторожно сокращать его размер.
Функция pthread_attr_setstacksize() используется для установки размера стека текущего потока.
Атрибут stacksize определяет размер стека в байтах. Этот стек выделяется системой и его размер не должен быть меньше минимального. При успешном завершении функция возвращает 0. Пример вызова:
pthread_attr_t tattr;
int stacksize;
int ret;
/* установка нового размера */
stacksize = (PTHREAD_STACK_MIN + 0x4000);
ret = pthread_attr_setstacksize(&tattr, stacksize);
Функция pthread_attr_getstacksize(pthread_attr_t *tattr, size_t *size) используется для получения размера стека текущего потока:
pthread_attr_t tattr;
int stacksize;
int ret;
/* получение размера стека */
ret = pthread_attr_getstacksize(&tattr, &stacksize);
Иногда возникает потребность установить базовый адрес стека. Для этого используется функция pthread_attr_setstackaddr():
void *stackaddr);
Следующий пример показывает способ создания потока со стеком определенного размера по указанному адресу:
pthread_attr_t tattr;
pthread_t tid;
int ret;
void *stackbase;
int size = PTHREAD_STACK_MIN + 0x4000;
stackbase = (void *) malloc(size);
/* инициализация значениями по умолчанию */
ret = pthread_attr_init(&tattr);
/* установка размера стека */
ret = pthread_attr_setstacksize(&tattr, size);
/* установка базового адреса стека */
ret = pthread_attr_setstackaddr(&tattr, stackbase);
ret = pthread_create(&tid, &tattr, func, arg);
Системный планировщик использует таблицу процессов, описанную в заголовочном
файле /usr/include/linux/sched.h
Внутри структуры struct task_struct находятся все сведения о состоянии процесса. Они достаточно хорошо прокомментированы. Основными являются следующие сведения:
При выполнении нескольких потоков они будут неизменно взаимодействовать друг с другом, чтобы синхронизироваться. Существует несколько средств синхронизации потоков. Это:
Объекты синхронизации можно разместить в файлах, где они будут находиться независимо от создавшего их процесса.
Основные ситуации, которые требуют использования синхронизации:
Блоки взаимного исключения - общий метод сериализации выполнения потоков. Мьютексы синхронизируют потоки, гарантируя, что только один поток в некоторый момент времени выполняет критическую секцию кода. Мьютексы можно использовать и в однопоточном коде.
Атрибуты мьютекса могут быть связаны с каждым потоком. Чтобы изменить атрибуты мьютекса по умолчанию, можно объявить и инициализировать объект атрибутов мьютекса, а затем изменить определенные значения. Часто атрибуты мьютекса устанавливаются в одном месте, в начале приложения, чтобы можно было быстро найти и изменить их.
После того, как сформированы атрибуты мьютекса, можно непосредственно инициализировать мьютекс. Доступны следующие действия с мьютексом: инициализация, удаление, захват или открытие, попытка захвата.
Функция pthread_mutexattr_init() используется, чтобы инициализировать
атрибуты, связанные с объектом, значениями по умолчанию. Память для
каждого объекта атрибутов выделяется системой поддержки потоков во
время выполнения; mattr - закрытый тип, который содержит системный
объект атрибутов. Возможные значения типа mattr - PTHREAD_PROCESS_PRIVATE
(по умолчанию) и
PTHREAD_PROCESS_SHARED. При вызове этой
функции значение по умолчанию атрибута pshared равно
PTHREAD_PROCESS_PRIVATE, что позволяет использовать инициализированный
мьютекс в пределах процесса.
Прежде, чем повторно инициализировать объект атрибутов мьютекса, его нужно сначала удалить функцией pthread_mutexattr_ destroy(). Вызов функции pthread_mutexattr_init() возвращает указатель на закрытый объект. Если объект не удалить, может произойти утечка памяти; pthread_mutexattr_init() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка.
Пример вызова функции:
pthread_mutexattr_t mattr;
int ret;
/* инициализация атрибутов значениями по умолчанию */
ret = pthread_mutexattr_init(&mattr);
pthread_mutexattr_t mattr;
int ret;
/* удаление атрибутов */
ret = pthread_mutexattr_destroy(&mattr);
Областью видимости мьютекса может быть либо некоторый процесс, либо вся система. Функция pthread_mutexattr_setpshared() используется, чтобы установить область видимости атрибутов мьютекса.
Если мьютекс был создан с атрибутом pshared, установленным
в состояние PTHREAD_PROCESS_SHARED, и он находится
в разделяемой памяти, то он может быть разделен среди потоков нескольких
процессов. Если атрибут pshared у мьютекса установлен в
PTHREAD_PROCESS_PRIVATE,
то оперировать этим мьютексом могут только потоки, созданные тем же
самым процессом. Функция
pthread_mutexattr_setpshared() возвращает 0 - после успешного
завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutexattr_t mattr;
int ret;
ret = pthread_mutexattr_init(&mattr);
/* переустановка на значение по умолчанию: private */
ret = pthread_mutexattr_setpshared(&mattr,
PTHREAD_PROCESS_PRIVATE);
pthread_mutexattr_getpshared(pthread_mutexattr_t *mattr,
int *pshared)
используется для получения области видимости текущего мьютекса потока:
pthread_mutexattr_t mattr;
int pshared, ret;
/* получить атрибут pshared для мьютекса */
ret = pthread_mutexattr_getpshared(&mattr, &pshared);
Функция pthread_mutex_init() предназначена для инициализации мьютекса:
const pthread_mutexattr_t *mattr);
Блокировка через мьютекс не должна повторно инициализироваться или удаляться, пока другие потоки могут его использовать. Если мьютекс инициализируется повторно или удаляется, приложение должно убедиться, что в настоящее время этот мьютекс не используется; pthread_mutex_init() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp = PTHREAD_MUTEX_INITIALIZER;
pthread_mutexattr_t mattr;
int ret;
/* инициализация мьютекса значением по умолчанию */
ret = pthread_mutex_init(&mp, NULL);
ret = pthread_mutexattr_init(&mattr);
/* смена значений mattr с помощью функций */
ret = pthread_mutexattr_*();
/* инициализация мьютекса произвольными значениями */
ret = pthread_mutex_init(&mp, &mattr);
Функция pthread_mute_lock() используется для запирания мьютекса. Если мьютекс уже закрыт, вызывающий поток блокируется и мьютекс ставится в очередь приоритетов. Когда происходит возврат из pthread_mute_lock(), мьютекс запирается, а вызывающий поток становится его владельцем. pthread_mute_lock() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret;
ret = pthread_mutex_lock(&mp);
Мьютекс должен быть закрыт, а вызывающий поток должен быть владельцем, т. е. тем, кто запирал мьютекс. Пока любые другие потоки ждут доступа к мьютексу, поток в начале очереди не блокирован; pthread_mutex_unlock() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret;
ret = pthread_mutex_unlock(&mp);
Функция pthread_mutex_trylock() пытается провести запирание
мьютекса. Она является неблокирующей версией вызова
pthread_mutex_lock().
Если мьютекс уже закрыт, вызов возвращает ошибку. В противном случае,
мьютекс закрывается, а вызывающий процесс становится его владельцем;
pthread_mutex_trylock() возвращает 0 - после успешного завершения -
или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret; ret = pthread_ mutex_trylock(&mp);
Функция pthread_mutex_destroy() используется для удаления мьютекса в любом состоянии. Память для мьютекса не освобождается; pthread_mutex_destroy() возвращает 0 - после успешного завершения - или другое значение, если произошла ошибка. Пример вызова:
pthread_mutex_t mp;
int ret;
ret = pthread_mutex_destroy(&mp);
Функция increment_count() использует мьютекс, чтобы гарантировать атомарность модификации разделяемой переменной count.
Функция get_count() использует мьютекс, чтобы гарантировать, что переменная count атомарно считывается:
pthread_mutex_t count_mutex;
long long count;
void increment_count() {
pthread_mutex_lock(&count_mutex);
count = count + 1;
pthread_mutex_unlock(&count_mutex);
}
long long get_count() {
long long c;
pthread_mutex_lock(&count_mutex);
c = count;
pthread_mutex_unlock(&count_mutex);
return (c);
}
Иногда может возникнуть необходимость доступа к нескольким ресурсам сразу. При этом возникает затруднение, когда два потока пытаются захватить оба ресурса, но запирают соответствующие мьютексы в различном порядке.
В приведенном ниже примере, два потока запирают мьютексы 1 и 2, и тогда тупик при попытке запереть другой мьютекс:
/* использует ресурс 1 */ | /* использует ресурс 2 */
pthread_mutex_lock(&m1); | pthread_mutex_lock(&m2);
/* теперь захватывает | /* теперь захватывает
ресурсы 2 + 1 */ | ресурсы 1 + 2 */
pthread_mutex_lock(&m2); | pthread_mutex_lock(&m1);
Если блокировка всегда выполняется в указанном порядке, тупик не возникнет. Однако, эта техника может использоваться не всегда. Иногда требуется запирать мьютексы в другом порядке, чем предписанный.
Чтобы предотвратить тупик в этой ситуации, лучше использовать функцию pthread_mutex_trylock(). Один из потоков должен освободить свой мьютекс, если он обнаруживает, что может возникнуть тупик.
Ниже проиллюстрирован подход условной блокировки:
Поток 1:
pthread_mutex_lock(&m2);
/* нет обработки */
pthread_mutex_unlock(&m2);
pthread_mutex_unlock(&m1);
pthread_mutex_lock(&m2);
if(pthread_mutex_trylock(&m1)==0)
/* захват! */
break;
/* уже заперт */
pthread_mutex_unlock(&m2);
}
/* нет обработки */
pthread_mutex_unlock(&m1);
pthread_mutex_unlock(&m2);
Для порождения процессов в ОС Linux существует два способа. Один из них позволяет полностью заменить другой процесс, без замены среды выполнения. Другим способом можно создать новый процесс с помощью системного вызова fork(). Синтаксис вызова следующий:
#include <sys/types> #include <unistd.h> pid_t fork(void);pid_t является примитивным типом данных, который определяет идентификатор процесса или группы процессов. При вызове fork() порождается новый процесс (процесс-потомок), который почти идентичен порождающему процессу-родителю. Процесс-потомок наследует следующие признаки родителя:
Процесс-потомок и процесс-родитель получают разные коды возврата после вызова fork(). Процесс-родитель получает идентификатор (PID) потомка. Если это значение будет отрицательным, следовательно при порождении процесса произошла ошибка. Процесс-потомок получает в качестве кода возврата значение 0, если вызов fork() оказался успешным.
Таким образом, можно проверить, был ли создан новый процесс:
switch(ret=fork())
{
case -1: /{*}при вызове fork() возникла ошибка{*}/
case 0 : /{*}это код потомка{*}/
default : /{*}это код родительского процесса{*}/
}
Пример порождения процесса через fork() приведен ниже:
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
main()
{
pid_t pid;
int rv;
switch(pid=fork()) {
case -1:
perror("fork"); /* произошла ошибка */
exit(1); /*выход из родительского процесса*/
case 0:
printf(" CHILD: Это процесс-потомок!\n");
printf(" CHILD: Мой PID -- %d\n", getpid());
printf(" CHILD: PID моего родителя -- %d\n",
getppid());
printf(" CHILD: Введите мой код возврата
(как можно меньше):");
scanf(" %d");
printf(" CHILD: Выход!\n");
exit(rv);
default:
printf("PARENT: Это процесс-родитель!\n");
printf("PARENT: Мой PID -- %d\n", getpid());
printf("PARENT: PID моего потомка %d\n",pid);
printf("PARENT: Я жду, пока потомок
не вызовет exit()...\n");
wait();
printf("PARENT: Код возврата потомка:%d\n",
WEXITSTATUS(rv));
printf("PARENT: Выход!\n");
}
}
Когда потомок вызывает exit(), код возврата передается родителю, который ожидает его, вызывая wait(). WEXITSTATUS() представляет собой макрос, который получает фактический код возврата потомка из вызова wait().
Функция wait() ждет завершения первого из всех возможных потомков родительского процесса. Иногда необходимо точно определить, какой из потомков должен завершиться. Для этого используется вызов waitpid() с соответствующим PID потомка в качестве аргумента. Еще один момент, на который следует обратить внимание при анализе примера, это то, что и родитель, и потомок используют переменную rv. Это не означает, что переменная разделена между процессами. Каждый процесс содержит собственные копии всех переменных.
Рассмотрим следующий пример:
#include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
char pid{[}255{]};
fork();
fork();
fork();
sprintf(pid, "PID : %d\n",getpid());
write(STDOUT_FILENO, pid, strlen(pid));
exit(0);
}
В этом случае будет создано семь процессов-потомков. Первый вызов fork() создает первого потомка. Как указано выше, процесс наследует положение указателя команд от родительского процесса. Указатель команд содержит адрес следующего оператора программы. Это значит, что после первого вызова fork() указатель команд и родителя, и потомка находится перед вторым вызовом fork().После второго вызова fork() и родитель, и первый потомок производят потомков второго поколения - в результате образуется четыре процесса. После третьего вызова fork() каждый процесс производит своего потомка, увеличивая общее число процессов до восьми.
Так называемые процессы-зомби возникают, если потомок завершился, а родительский процесс не вызвал wait(). Для завершения процессов используют либо оператор возврата, либо вызов функции exit() со значением, которое нужно возвратить операционной системе. Операционная система оставляет процесс зарегистрированным в своей внутренней таблице данных, пока родительский процесс не получит кода возврата потомка, либо не закончится сам. В случае процесса-зомби его код возврата не передается родителю, и запись об этом процессе не удаляется из таблицы процессов операционной системы. При дальнейшей работе и появлении новых зомби таблица процессов может быть заполнена, что приведет к невозможности создания новых процессов.
Вложение элементов запирания мьютекса в связанную структуру данных и простые изменения в коде связного списка позволяют предотвратить тупик, осуществляя блокировку в предписанном порядке.
Структура для блокировки имеет вид:
int value;
struct node1 *link;
pthread_mutex_t lock;
} node1_t;
Чтобы удалить узел из списка, необходимо выполнить следующие действия:
node1_t *prev,
*current; prev = &ListHead;
pthread_mutex_lock(&prev->lock);
while ((current = prev->link) != NULL) {
pthread_mutex_lock(¤t->lock);
if (current->value == value) {
prev->link = current->link;
pthread_mutex_unlock(¤t->lock);
pthread_mutex_unlock(&prev->lock);
current->link = NULL;
return(current);
}
pthread_mutex_unlock(&prev->lock);
prev = current;
}
pthread_mutex_unlock(&prev->lock);
return(NULL);
}
Переменные состояния используются, чтобы атомарно блокировать потоки, пока не наступит специфическое состояние. Переменные состояния всегда используются в сочетании с блокировками мьютексов:
Функция pthread_condattr_init() инициализирует атрибуты,
связанные с объектом значениями по умолчанию. Память для каждого объекта
атрибутов cattr выделяется системой потоков в процессе выполнения;
cattr является закрытым типом данных, который содержит созданный
системой объект атрибутов. Возможные значения признаков видимости
cattr - PTHREAD_PROCESS_PRIVATE и
PTHREAD_PROCESS_SHARED.
Значение по умолчанию атрибута pshared, равное
PTHREAD_PROCESS_PRIVATE, указывает, что инициализированная
переменная состояния может использоваться в пределах процесса.
Прежде чем атрибут переменной состояния сможет использоваться повторно, он должен повторно инициализироваться функцией pthread_condattr_destroy(). Вызов pthread_condattr_init() возвращает указатель на закрытый объект. Если объект не будет удален, возникнет утечка памяти; pthread_condattr_init() возвращает 0 - после успешного завершения. Любое другое значение указывает, что произошла ошибка. Пример вызова функции:
pthread_condattr_t cattr;
int ret;
ret = pthread_condattr_init(&cattr);
Областью видимости переменной состояния может быть либо процесс, либо
вся система, как и для мьютексов. Если переменная состояния создана
с атрибутом pshared, установленным в состояние PTHREAD_PROCESS_SHARED,
и она находится в разделяемой памяти, то эта переменная может разделяться
среди потоков нескольких процессов. Если же атрибут pshared
установлен в значение
PTHREAD_PROCESS_PRIVATE (по умолчанию), то
лишь потоки, созданные тем же самым процессом, могут оперировать этой переменной.
Функция pthread_condattr_setpshared() используется, чтобы
установить область видимости переменной состояния. Она возвращает
0 - после успешного завершения. Любое другое значение указывает, что
произошла ошибка. Пример использования функции:
pthread_condattr_t cattr;
int ret;
/* Область видимости - все процессы */
ret = pthread_condattr_setpshared(&cattr,
PTHREAD_PROCESS_SHARED);
/* Внутренняя переменная для процесса */
ret = pthread_condattr_setpshared(&cattr,
PTHREAD_PROCESS_PRIVATE);
int pthread_condattr_getpshared(
const pthread_condattr_t *cattr, int *pshared)
используется для получения области видимости
переменной состояния.
Функция pthread_cond_init() инициализирует переменную состояния:
const pthread_condattr_t *cattr);
Статические переменные состояния могут инициализироваться непосредственно
значениями по умолчанию с помощью макроса
PTHREAD_COND_INITIALIZER.
Несколько потоков не должны одновременно инициализировать или повторно
инициализировать ту же самую переменную состояния. Если переменная
состояния повторно инициализируется или удаляется, приложение должно
убедиться, что эта переменная состояния больше не используется;
pthread_cond_init() возвращает 0 после успешного завершения.
Любое другое значение указывает, что произошла ошибка. Пример использования
функции:
pthread_cond_t cv;
pthread_condattr_t cattr;
int ret;
/* инициализация значениями по умолчанию */
ret = pthread_cond_init(&cv, NULL);
/* инициализация определенными значениями */
ret = pthread_cond_init(&cv, &cattr);
Функция pthread_cond_wait() используется, чтобы атомарно освободить мьютекс и заставить вызывающий поток блокироваться по переменной состояния. Функция pthread_cond_wait() возвращает 0 - после успешного завершения. Любое другое значение указывает, что произошла ошибка. Пример использования функции:
pthread_cond_t cv;
pthread_mutex_t mutex;
int ret;
ret = pthread_cond_wait(&cv, &mutex);
Проверка состояния обычно проводится в цикле while, который вызывает pthread_cond_wait():
while(condition_is_false)
pthread_cond_wait();
pthread_mutex_unlock();
Следует всегда вызывать pthread_cond_signal() под защитой
мьютекса, используемого с сигнальной переменной состояния. В ином
случае переменная состояния может измениться между тестированием
соответствующего состояния и блокировкой в вызове
pthread_cond_wait(),
что может вызвать бесконечное ожидание. Если никакие потоки не блокированы
по переменной состояния, вызов pthread_cond_signal () не
будет иметь никакого эффекта.
Следующий фрагмент кода иллюстрирует, как избежать бесконечного ожидания, описанного выше:
pthread_cond_t count_nonzero;
unsigned count;
decrement_count() {
pthread_mutex_lock(&count_lock);
while (count == 0)
pthread_cond_wait(&count_nonzero, &count_lock);
count = count - 1;
pthread_mutex_unlock(&count_lock);
}
increment_count() {
pthread_mutex_lock(&count_lock);
if (count == 0)
pthread_cond_signal(&count_nonzero);
count = count + 1;
pthread_mutex_unlock(&count_lock);
}
pthread_mutex_t *mp,
const struct timespec *abstime);
#include <time.h>
pthread_timestruc_t to;
pthread_cond_t cv;
pthread_mutex_t mp;
timestruct_t abstime;
int ret;
/* ожидание переменной состояния */
ret = pthread_cond_timedwait(&cv, &mp, &abstime);
pthread_mutex_lock(&m);
to.tv_sec = time(NULL) + TIMEOUT;
to.tv_nsec = 0;
while (cond == FALSE) {
err = pthread_cond_timedwait(&c, &m, &to);
if (err == ETIMEDOUT) {
/* таймаут */
break;
}
}
pthread_mutex_unlock(&m);
pthread_cond_broadcast() возвращает 0 - после успешного завершения - или любое другое значение в случае ошибки.
Поскольку pthread_cond_broadcast() заставляет все потоки,
блокированные некоторым состоянием, бороться за мьютекс, ее нужно
использовать аккуратно. Например, можно использовать
pthread_cond_broadcast(),
чтобы позволить потокам бороться за изменение количества требуемых
ресурсов, когда ресурсы освобождаются:
pthread_mutex_t rsrc_lock;
pthread_cond_t rsrc_add;
unsigned int resources;
get_resources(int amount) {
pthread_mutex_lock(&rsrc_lock);
while (resources < amount)
pthread_cond_wait(&rsrc_add, &rsrc_lock);
resources -= amount;
pthread_mutex_unlock(&rsrc_lock);
}
add_resources(int amount) {
pthread_mutex_lock(&rsrc_lock);
resources += amount;
pthread_cond_broadcast(&rsrc_add);
pthread_mutex_unlock(&rsrc_lock);
}
pthread_cond_t cv;
int ret;
/* Переменная состояния удалена */
ret = pthread_cond_destroy(&cv);
Сокеты обеспечивают двухстороннюю связь типа ``точка-точка'' между двумя процессами. Они являются основными компонентами межсистемной и межпроцессной связи. Каждый сокет представляет собой конечную точку связи, с которой может быть совмещено некоторое имя. Он имеет определенный тип, и один процесс или несколько, связанных с ним процессов.
Сокеты находятся в областях связи (доменах). Домен сокета - это абстракция, которая определяет структуру адресации и набор протоколов. Сокеты могут соединяться только с сокетами в том же домене. Всего выделено 23 класса сокетов (см. файл <sys/socket.h>), из которых обычно используются только UNIX-сокеты и Интернет-сокеты. Сокеты могут использоваться для установки связи между процессами на отдельной системе подобно другим формам IPC.
Класс сокетов UNIX обеспечивает их адресное пространство для отдельной вычислительной системы. Сокеты области UNIX называются именами файлов UNIX. Сокеты также можно использовать, чтобы организовать связь между процессами на различных системах. Адресное пространство сокетов между связанными системами называют доменом Интернета. Коммуникации домена Интернета используют стек протоколов TCP/IP.
Типы сокетов определяют особенности связи, доступные приложению. Процессы взаимодействуют только через сокеты одного и того же типа. Основные типы сокетов:
| Сервер | Клиент | |
| Установка сокета socket() | Установка сокета socket() | |
| Присвоение имени bind() | ||
| Установка очереди запросов listen() | ||
| Выбор соединения из очереди accept() |
|
Установка соединения connect() |
| read() |
|
write() |
| write() |
|
read() |
Для создания сокета определенного типа в определенном адресном пространстве используется функция socket():
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
Удаленный процесс не может идентифицировать определенный сокет, пока ему не будет присвоен адрес. Процессы могут поддерживать связь только через адреса. В пространстве адресов UNIX соединение обычно определяется одним или двумя именами файлов. В пространстве адресов Интернета соединение определяется локальным и удаленным адресами и номерами портов.
Функция bind():
#include <sys/socket.h>
int bind(int s, const struct sockaddr *name,
int namelen);
ushort_t sa_family; /* семейство адресов */
char sa_data[ 14]; /* 14 байт прямого адреса */
};
ushort_t sun_family; /* AF_ UNIX */
char sun_path[ 104]; /* путь к файлу */
};
uchar_t sin_len;
sa_family_t sin_family; /* AF_ INET */
in_port_t sin_port; /* 16-битный порт */
struct in_addr sin_addr; /* Указатель на адрес */
uchar_t sin_zero[ 8]; /* зарезервировано */
};
Соединение сокетов обычно происходит несимметрично. Один из процессов действует как сервер, а другой выполняет роль клиента. Сервер связывает свой сокет с предварительно указанным путем или адресом. После этого для сокетов вида SOCK_STREAM сервер вызывает функцию listen(), которая определяет, сколько запросов на соединение можно поставить в очередь. Клиент запрашивает соединение с сокетом сервера вызовом connect(), а сокет принимает некоторое соединение с помощью функции accept(). Синтаксис вызова listen() следующий:
#include <sys/socket.h>
int listen (int socket, int backlog );
Функция accept() используется сервером для принятия соединения с сокетом. При этом сокет в момент вызова функции должен уже иметь очередь запросов, созданную вызовом listen(). Если сервер устанавливает связь с клиентом, то функция accept() возвращает новый сокет-дескриптор, через который и происходит общение клиента с сервером. Пока устанавливается связь клиента с сервером, функция accept() блокирует другие запросы связи, а после установления связи "прослушивание"запросов возобновляется:
#include <sys/socket.h>
int accept( int socket, struct sockaddr *addr,
int *addrlen );
Функция connect() используется процессом-клиентом для установления связи с сервером:
#include <sys/socket.h>
int connect( int socket, struct sockaddr *name,
int namelength );
Функция exec() (execute) загружает и запускает другую программу. Таким образом, новая программа полностью замещает текущий процесс. Новая программа начинает свое выполнение с функции main. Все файлы вызывающей программы остаются открытыми. Они также являются доступными новой программе. Используется шесть различных вариантов функций exec.
#include <unistd.h>
int execl(char *name, char *arg0, ... /*NULL*/);
int execv(char *name, char *argv[]);
int execle(char *name, char *arg0, ... /*,NULL,
char *envp[]*/);
int execve(char *name, char *arv[], char *envp[]);
int execlp(char *name, char *arg0, ... /*NULL*/);
int execvp(char *name, char *argv[]);
Вызов exec происходит таким образом, что переданная в качестве
аргумента программа загружается в память вместо старой,
которая вызвала exec. Старой программе больше не доступны
сегменты памяти, которые перезаписаны новой программой.
Суффиксы l, v, p, e в именах функций определяют формат и объем аргументов, а также каталоги, в которых нужно искать загружаемую программу:
#include <stdio.h>
int main(int argc, char *argv[])
{
int i=0;
printf("%s\n",argv[0]);
printf("Программа запущена и получила строку : ");
while(argv[++i] != NULL)
printf("%s ",argv[i]);
return 0;
}
Эта программа выводит на экран строку, переданную ей в качестве аргумента.
Пусть она называется hello. Она будет вызвана из другой программы
с помощью функции execl(). Код вызывающей программы приведен ниже
:
#include <stdio.h>
#include <unistd.h>
int main(int argc, int *argv[])
{
printf("Будет выполнена программа %s...\n\n",
argv[0]);
printf("Выполняется %s", argv[0]);
execl("hello"," ","Hello", "World!", NULL);
return 0;
}
В строке execl() аргументы указаны в виде списка. Доступ
к ним также осуществляется последовательно. Если использовать функцию
execv(), то вместо списка будет указан вектор аргументов:
#include <stdio.h>
#include <unistd.h>
int main(int argc, int *argv[])
{
printf("Программа %s будет выполнена...\n\n",
argv[0]);
printf("Выполняется %s", argv[0]);
execv("hello",argv);
return 0;
}
Для обмена данными существуют две группы функций - для записи в сокет и для чтения из него. Функции для записи имеют вид:
#include <sys/socket.h>
#include <sys/uio.h>
int send( int socket, const char *msg, int len,
int flags);
int sendto( int socket, const char *msg, int len,
int flags, const struct sockaddr *to, int tolen );
int sendmsg( int socket, const struct msghdr *msg,
int flags );
Для приема данных процесс-потребитель должен выполнить
функцию приема
или чтения данных из сокета. Варианты функций приема:
#include <sys/socket.h>
#include <sys/uio.h>
int recv( int socket, char *buffer, int len, int
flags);
int recvfrom( int socket, char *buffer, int len,
int flags, const struct sockaddr *from,
int fromlen );
int recvmsg( int socket, const struct msghdr *msg,
int flags );
Функция shutdown() используется для немедленного закрытия всех или некоторых связей для сокета:
#include <sys/uio.h>
int shutdown(int s, int how);
#include <sys/uio.h>
int close (int s);
Пример-оболочка программы "Клиент":
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define ADDRESS "mysocket" /* адрес для связи */
void main () {
char c;
int i, s, len;
FILE *fp;
struct sockaddr_un sa;
/* получаем свой сокет-дескриптор: */
if ((s = socket (AF_UNIX, SOCK_STREAM, 0))<0) {
perror ("client: socket"); exit(1);
}
/* создаем адрес, по которому
будем связываться с сервером: */
sa.sun_family = AF_UNIX;
strcpy (sa.sun_path, ADDRESS);
/* пытаемся связаться с сервером: */
len = sizeof ( sa.sun_family) + strlen ( sa.sun_path);
if ( connect ( s, &sa, len) < 0 ){
perror ("client: connect"); exit (1);
}
/* читаем сообщения сервера */
fp = fdopen (s, "r");
c = fgetc (fp);
/* обрабатываем информацию от сервера
...................................
*/
/* посылаем ответ серверу */
send (s, "client", 7, 0);
/* продолжаем диалог с сервером, пока в этом
есть необходимость.....
*/
/* завершаем сеанс работы */
close (s);
exit (0);
}
Пример-оболочка программы "Сервер":
#include <sys/socket.h>
#include <sys/un.h>
#include <stdio.h>
#define ADDRESS "mysocket" /* адрес для связи */
void main ()
{
char c;
int i, d, d1, len, ca_len;
FILE *fp;
struct sockaddr_un sa, ca;
/* получаем свой сокет-дескриптор: */
if((d = socket (AF_UNIX, SOCK_STREAM, 0)) < 0) {
perror ("client: socket"); exit (1);
}
/* создаем адрес, c которым будут
связываться клиенты */
sa.sun_family = AF_UNIX;
strcpy (sa.sun_path, ADDRESS);
/* связываем адрес с сокетом;
уничтожаем файл с именем ADDRESS,
если он существует, для того, чтобы
вызов bind завершился успешно */
unlink (ADDRESS);
len = sizeof ( sa.sun_family) + strlen (sa.sun_path);
if ( bind ( d, &sa, len) < 0 ) {
perror ("server: bind"); exit (1);
}
/* слушаем запросы на сокет */
if ( listen ( d, 5) < 0 ) {
perror ("server: listen"); exit (1);
}
/* связываемся с клиентом через неименованный сокет
с дескриптором d1:*/
if (( d1 = accept ( d, &ca, &ca_len)) < 0 ) {
perror ("server: accept"); exit (1);
}
/* пишем клиенту: */
send (d1, "server", 7, 0);
/* читаем запрос клиента */
fp = fdopen (d1, "r");
c = fgetc (fp);
/* ................................ */
/* обрабатываем запрос клиента, посылаем ответ и т.д.
........................... */
/* завершаем сеанс работы */
close (d1);
exit (0);
}
Рассмотренные ранее методы синхронизации процессов и коммуникаций предполагали использование одного компьютера. Тем не менее часто приложения должны работать в пределах локальной или распределенной сети. Одним из методов реализации взаимодействия является удаленный вызов процедур (remote procedure calls - RPC). Вызов процедуры представляет собой классическую форму синхронной коммуникации: вызывающий процесс передает управление подпроцессу и ждет возвращения результатов. Используя RPC, программисты распределенных приложений могут не учитывать мелких деталей при обеспечении интерфейса с сетью. Транспортная независимость RPC изолирует приложение от физических и логических элементов механизма коммуникаций данных и позволяет ему использовать разнообразие транспортных протоколов.
RPC делает модель вычислений ``клиент - сервер'' более мощной и более простой для программирования. Использование компиляторов протоколов ONC RPCGEN позволяет клиентам прозрачно осуществлять удаленные вызовы через локальный интерфейс процедур.
Как и при обычном вызове функции, при вызове RPC его аргументы передаются удаленной процедуре, и вызывающий процесс ждет ответа, который будет возвращен из этой удаленной процедуры. Порядок действий следующий.
Клиент осуществляет вызов процедуры, которая посылает запрос серверу и ждет ответа. Поток выполнения блокируется, пока не будет получен ответ или не наступит тайм-аут. Когда приходит запрос, сервер вызывает процедуру диспетчеризации, которая выполняет требуемое действие и посылает ответ клиенту. После того, как вызов RPC закончен, программа клиента продолжает выполнение своих действий.
Удаленная процедура уникально идентифицируется тройкой параметров: номер программы, номер версии, номер процедуры. Номер программы идентифицирует группу соотносящихся удаленных процедур, каждая из которых имеет свой уникальный номер. Программа может состоять из одной или более версий. Каждая версия состоит из множества процедур, которые могут быть вызваны удаленно. Номера версии позволяют использовать одновременно несколько версий. Каждая процедура имеет свой номер.
Для разработки приложения RPC необходимо выполнить следующие шаги:
Самый простой способ определения и реализации протокола состоит в том, чтобы использовать компилятор протоколов rpcgen. Для создания протокола нужно идентифицировать имена сервисных процедур и типы данных для возвращаемых аргументов и параметров. Компилятор протокола считывает определения и автоматически создает коды для сервера и клиента; rpcgen использует собственный язык (язык RPC или RPCL), который очень похож на язык директив препроцессора С; rpcgen реализован в виде автономного компилятора, который работает со специальными файлами, обозначенными расширением .x.
Для обработки файла RPCL необходимо выполнить команду rpcgen~rpcprog.x~
При этом будут созданы четыре файла:
rpcprog_clnt.c - процедуры клиента;
rpcprog_svc.c - процедуры сервера;
rpcprog_xdr.c - фильтры XDR;
rpcprog.h - файл заголовка, необходимый для XDR фильтров.
Внешнее представление данных (XDR - eXternal Data Represen-tation) - это абстракция данных, необходимая для машинно - независимой связи, поскольку клиент и сервер могут работать на компьютерах различных типов и архитектур.
Пусть программа клиента называется rpcprog.c, а программа сервера - rpcsvc.c. Протокол определен в файле rpcprog.x. Этот файл обработан rpcgen, чтобы создать файлы фильтров и процедур: rpcprog_clnt.c, rpcprog_svc.c, rpcprog_xdr.c, rpcprog.h.
Программы клиента и сервера должны включать строку
#include"rpcprog.h"
После этого необходимо:
откомпилировать код клиента:
cc -c rpcprog.c
откомпилировать специальную клиентскую часть:
cc -c rpcprog_clnt.c
откомпилировать фильтр XDR:
cc -c rpcprog_xdr.c
построить выполняемый файл клиента:
cc -o rpcprog rpcprog.o rpcprog_clnt.o rpcprog_xdr.c
откомпилировать серверные процедуры:
cc -c rpcsvc.c
откомпилировать специальную серверную часть:
cc -c rpcprog_svc.c
построить выполняемый файл сервера:
cc -o rpcsvc rpcsvc.o rpcprog_svc.o rpcprog_xdr.c
Теперь можно запустить программы rpcprog и rpcsvc на компьютерах клиента и сервера соответственно. Процедуры сервера должны быть зарегистрированы, прежде чем клиент сможет их вызвать.
Здесь перечислены все процедуры RPC для всех уровней протокола удаленного вызова:
Упрощенный интерфейс - это самый простой уровень использования RPC, потому что он не требует использования других процедур RPC. Он также ограничивает контроль над основными механизмами коммуникации. Разработка программ для этого уровня может осуществляться очень быстро и непосредственно поддерживается компилятором rpcgen. Для большинства приложений достаточно возможностей rpcgen. Некоторые службы RPC не доступны в виде функций C, но они доступны как программы RPC. Процедуры библиотеки упрощенного интерфейса обеспечивают прямой доступ к возможностям RPC для программ, которые не требуют детального управления.
Все процедуры находятся в библиотеке служб RPC librpcsvc.
Пример rusers.c, приведенный ниже, показывает число пользователей на удаленном компьютере. Он вызывает процедуру rusers из библиотеки RPC:
#include <rpcsvc/rusers.h>
#include <stdio.h>
/*
* программа вызывает службу rusers()
*/
main(int argc,char **argv)
{
int num;
if (argc != 2) {
fprintf(stderr, "Использование: %s hostname\n",
argv[0]);
exit(1);
}
if ((num = rnusers(argv[1])) < 0) {
fprintf(stderr, "Ошибка вызова: rusers\n");
exit(1);
}
fprintf(stderr, "%d пользователей на %s\n", num,
argv[1] );
exit(0);
}
Клиентская часть состоит из вызова функции rpc_call():
#include <utmp.h>
#include <rpc/rpc.h>
#include <rpcsvc/rusers.h>
/* программа вызывает удаленную программу RUSERSPROG */
main(int argc, char **argv)
{
unsigned long nusers;
enum clnt_stat cs;
if (argc != 2) {
fprintf(stderr, "Использование: rusers hostname\n");
exit(1);
}
if( cs = rpc_call(argv[1], RUSERSPROG,
RUSERSVERS, RUSERSPROC_NUM, xdr_void,
(char *)0, xdr_u_long, (char *)&nusers,
"visible") != RPC_SUCCESS ) {
clnt_perrno(cs);
exit(1);
}
fprintf(stderr, "%d пользователей на компьютере %s\n",
nusers, argv[1] );
exit(0);
}
Синтаксис функции rpc_call() приведен ниже:
/* Имя сервера */
char *host,
/* Номер программы сервера */
u_long prognum,
/* Номер версии сервера */
u_long versnum,
/* фильтр XDR для кодирования arg */
xdrproc_t inproc,
/* Указатель на аргументы */
char *in,
/* Фильтр декодирования результата */
xdr_proc_t outproc,
/* Адрес сохранения результата */
char *out,
/* Выбор транспортной службы */)
char *nettype
);
Клиент блокируется вызовом rpc_call() до тех пор, пока он не получит ответ от сервера. Если сервер отвечает, то возвращается RPC_SUCCESS со значением 0. Если запрос был неудачен, возвращается значение, отличное от 0. Это значение можно преобразовать к типу clnt_stat - перечислимому типу, определенному в файле RPC (<rpc/rpc.h>) и интерпретируемому функцией clnt_sperrno(). Эта функция возвращает указатель на стандартное сообщение RPC об ошибке, соответствующее коду ошибки. В примере испытываются все "видимые" транспортные службы, внесенные в /etc/netconfig. Настройка количества повторов требует использования более низких уровней библиотеки RPC. Множественные аргументы и результаты обрабатываются с помощью объединения их в структуры.
Поскольку типы данных могут быть представлены на различных машинах различным образом, то для rpc_call() нужно указать и тип аргумента, и указатель на него (аналогично и для результата). Возвращаемое значение для RUSERSPROC_NUM - unsigned long, поэтому первым возвращаемым параметром rpc_call() будет xdr_u_long, а вторым - *nusers. Поскольку RUSERSPROC_NUM не имеет аргументов, функцией шифрования XDR для rpc_call() будет xdr_void(), а ее аргумент имеет значение NULL.
Программа сервера, использующая упрощенный интерфейс, достаточно простая. Она вызывает rpc_reg(), чтобы зарегистрировать процедуру, которая будет вызвана, а затем вызывает svc_run() - диспетчера удаленных процедур библиотеки RPC, который ждет входящих запросов.
Прототип rpc_reg() представлен ниже:
/* Номер программы сервера */
u_long prognum,
/* Номер версии сервера */
u_long versnum,
/* Номер процедуры сервера */
u_long procnum,
/* Имя удаленной функции */
char *procname,
/* Фильтр для кодирования аргумента arg */
xdrproc_t inproc,
/* Фильтр декодирования результата*/
xdrproc_t outproc,
/* Выбор транспортной службы */)
char *nettype;
Функция svc_run() вызывает сервисные процедуры в ответ на вызовы RPC. Диспетчер в rpc_reg() заботится о расшифровывании аргументов удаленных процедур и о зашифровывании результатов, с использованием фильтров XDR, определенных при регистрации удаленной процедуры.
Некоторые замечания относительно программы сервера:
#include <rpc/rpc.h>
#include <rpcsvc/rusers.h>
void *rusers();
main()
{
if(rpc_reg(RUSERSPROG, RUSERSVERS,
RUSERSPROC_NUM, rusers,
xdr_void, xdr_u_long,
"visible") == -1) {
fprintf(stderr, "Невозможно зарегистрировать\n");
exit(1);
}
svc_run(); /* Процедура без возврата */
fprintf(stderr, "Ошибка: Выход из svc_run!\n");
exit(1);
}
rpc_reg() можно вызвать сколько угодно раз, чтобы зарегистрировать все различные программы, версии, и процедуры.
Типы данных, передаваемые и получаемые из удаленных процедур, могут быть любыми из множества предопределенных, либо типом, определенным программистом. RPC работает с произвольными структурами данных, независимо от различий в структуре типов на различных машинах, преобразуя типы к стандартному формату передачи, который называется внешним представлением данных (XDR). Преобразование из машинного представления в XDR называют сериализацией, а обратный процесс - десериализацией. Аргументы транслятора для rpc_call() и rpc_reg() могут определять примитивную процедуру XDR, например xdr_u_long(), или специальную процедуру пользователя, которая обрабатывает полную структуру аргументов. Процедуры обработки аргументов должны принимать только два аргумента: указатель на результат и указатель на обработчик XDR.
Доступны следующие примитивные процедуры XDR для обработки типов данных:
xdr_long() xdr_float() xdr_u_int() xdr_bool()
xdr_short() xdr_double() xdr_u_short() xdr_wrapstring()
xdr_char() xdr_quadruple() xdr_u_char() xdr_void()
В случае собственной процедуры программиста, структура
int a;
short b;
} simple;
#include "simple.h"
bool_t xdr_simple(XDR *xdrsp, struct simple *simplep)
{
if (!xdr_int(xdrsp, &simplep->a))
return (FALSE);
if (!xdr_short(xdrsp, &simplep->b))
return (FALSE);
return (TRUE);
}
Процедура XDR возвращает результат, отличный от нуля, если она завершается успешно, либо 0 - в случае ошибки.
Для более сложных структур данных используют готовые процедуры XDR:
xdr_vector() xdr_union() xdr_pointer()
xdr_string() xdr_opaque()
int *data;
int arrlnth;
} arr;
{
return(xdr_array(xdrsp, (caddr_t)&arrp->data,
(u_int *)&arrp->arrlnth, MAXLEN, sizeof(int),
xdr_int));
}
bool_t xdr_intarr(XDR *xdrsp, int intarr[])
{
return (xdr_vector(xdrsp, intarr, SIZE, sizeof(int),
xdr_int));
}
Строки, законченные пустым указателем, транслируются с помощью функции xdr_string(). Она сходна с xdr_bytes(), но не содержит параметра длины. При сериализации процедура получает длину строки из strlen(), а при десериализации создает строку, заканчивающуюся пустым указателем.
xdr_reference() вызывает встроенные функции xdr_string() и xdr_reference(), которые преобразуют указатели для передачи строки, и struct simple из предыдущего примера. Пример использования xdr_reference():
char *string;
struct simple *simplep;
} finalexample;
bool_t xdr_finalexample(XDR *xdrsp,
struct finalexample *finalp)
{
if (!xdr_string(xdrsp, &finalp->string, MAXSTRLEN))
return (FALSE);
if (!xdr_reference( xdrsp, &finalp->simplep,
sizeof(struct simple), xdr_simple))
return (FALSE);
return (TRUE);
}
Процедура thatxdr_simple() должна вызываться вместо
xdr_reference().
В качестве примера высокоуровневого приложения приведен удаленный аналог команды чтения оглавления каталога.
Вначале рассматривается локальная версия. Программа состоит из двух файлов.
Файл lls.c содержит основную программу, которая вызывает процедуру в локальном модуле read_dir.c:
#include <strings.h>
#include "rls.h"
main (int argc, char **argv)
{
char dir[DIR_SIZE];
/* вызов локальной процедуры */
strcpy(dir, argv[1]);
/* char dir[DIR_SIZE] это имя каталога */
read_dir(dir);
/* вывод результата */
printf("%s\n", dir);
exit(0);
}
аргумент и возвращают один результат. Оба передаются
через указатели. Возвращаемые значения должны
указывать на статические данные. */
#include <stdio.h>
#include <sys/types.h>
#include <sys/dir.h>
#include "rls.h"
read_dir(char *dir) /* char dir[DIR_SIZE] */
{
DIR * dirp;
struct direct *d;
printf("начало");
/* открывает каталог */
dirp = opendir(dir);
if (dirp == NULL)
return(NULL);
/* сохраняет имена файлов в буфер каталога */
dir[0] = NULL;
while (d = readdir(dirp))
sprintf(dir, "%s%s\n", dir, d->d_name);
/* выводит результат */
printf("выход ");
closedir(dirp);
return((int)dir);
}
#define DIR_SIZE 8192.
Понятно, что этот размер должен быть упомянут в обоих файлах. Позже, при разработке RPC-версии, к этому файлу будет добавлена другая информация.
Для того, чтобы модифицировать программу для работы через сеть, выполняются следующие действия:
Для передачи и приема имени каталога и его содержимого можно использовать простые строки, заканчивающиеся пустым указателем. Кроме того, передача этих параметров включена непосредственно в код сервера и клиента.
После этого нужно определить номера программы, процедуры и версии для клиента и сервера. Это можно сделать автоматически, используя rpcgen, или на базе предопределенных макросов упрощенного интерфейса. В примере номера определены вручную.
Сервер и клиент должны заранее согласовать, что они будут использовать логические адреса (физические адреса не имеют значения, поскольку они скрыты от разработчика приложения).
Номера программы определяются стандартным способом:
0x20000000 - 0x3FFFFFFF: Пользовательские
0x40000000 - 0x5FFFFFFF: Переходные
0x60000000 - 0xFFFFFFFF: Резервированные
DIR_SIZE определяет размер буфера для каталога в программах сервера и клиента.
Теперь файл rls.h содержит:
/* номер программы сервера */
#define DIRPROG ((u_long) 0x20000001)
#define DIRVERS ((u_long) 1) /* номер версии */
#define READDIR ((u_long) 1) /* номер процедуры */
Для передачи данных в виде строк нужно определить процедуру XDR - фильтра xdr_dir(), который разделяет данные. При этом можно обрабатывать только один аргумент шифрования и расшифровки. Для этого подходит стандартная процедура xdr_string().
Файл XDR, rls_xrd.c, выглядит так:
#include "rls.h"
bool_t xdr_dir(XDR *xdrs, char *objp)
{ return ( xdr_string(xdrs, &objp, DIR_SIZE) ); }
Для нее можно использовать оригинальный файл read_dir.c. Необходимо лишь зарегистрировать процедуру и запустить сервер.
Процедура регистрируется с помощью функции registerrpc():
u_long prognum /* Номер программы сервера */,
u_long versnum /* Номер версии сервера */,
u_long procnum /* Номер процедуры сервера */,
char *procname /* Имя удаленной функции */,
/* Фильтр для кодирования аргументов */
xdrproc_t inproc,
/* Фильтр декодирования результата */
xdrproc_t outproc);
#include "rls.h"
main()
{
extern bool_t xdr_dir();
extern char * read_dir();
registerrpc(DIRPROG, DIRVERS, READDIR,
read_dir, xdr_dir, xdr_dir);
svc_run();
}
На клиентской стороне просто производится вызов удаленной процедуры. Для этого используется функция callrpc():
u_long prognum /* Номер программы сервера */,
u_long versnum /* Номер версии сервера */,
char *in /* Указатель на аргументы */,
/* Фильтр XDR для кодирования аргумента */
xdrproc_t inproc,
char *out /* Адрес для сохранения результата */,
/* Фильтр декодирования результата */
xdr_proc_t outproc);
Программа rls.c выглядит так:
* rls.c: клиент удаленного чтения каталога
*/
#include <stdio.h>
#include <strings.h>
#include <rpc/rpc.h>
#include "rls.h"
main (argc, argv)
int argc; char *argv[];
{
char dir[DIR_SIZE];
/* вызов удаленной процедуры */
strcpy(dir, argv[2]);
read_dir(argv[1], dir); /* read_dir(host, directory) */
/* вывод результата */
printf("%s\n", dir);
exit(0);
}
read_dir(host, dir)
char *dir, *host;
{
extern bool_t xdr_dir();
enum clnt_stat clnt_stat;
clnt_stat = callrpc ( host, DIRPROG, DIRVERS, READDIR,
xdr_dir, dir, xdr_dir, dir);
if (clnt_stat != 0) clnt_perrno (clnt_stat);
}
Программа rpcgen создает модули интерфейса удаленной программы. Она компилирует исходный код, написанный на языке RPC. Язык RPC подобен по синтаксису и структуре на C; rpcgen создает один или несколько исходных модулей на языке C, которые затем обрабатываются компилятором.
Результатом работы rpcgen являются:
Пусть приложение работает на отдельном компьютере, и его необходимо преобразовать, чтобы использовать в "распределенной" сети. Ниже показано пошаговое преобразование программы, которая выводит сообщения на терминал.
Однопроцессная версия printmesg.c:
#include <stdio.h>
main(int argc, char *argv[])
{
char *message;
if (argc != 2) {
fprintf(stderr, "usage: %s <message>\n",argv[0]);
exit(1);
}
message = argv[1];
if (!printmessage(message)) {
fprintf(stderr,"%s: невозможно вывести сообщение\n",
argv[0]); exit(1);
}
printf("Сообщение выведено!\n");
exit(0);
}
/* Вывод сообщения на терминал.
* Возвращает логическое значение, показывающее
* выведено ли сообщение. */
printmessage(char *msg) {
FILE *f;
f = fopen("/dev/console", "w");
if (f == (FILE *)NULL) return (0);
fprintf(f, "%s\n", msg);
fclose(f);
return(1);
}
Если функцию printmessage() превратить в удаленную процедуру, ее можно вызывать на любой машине сети.
Сначала необходимо определить типы данных всех аргументов вызова процедуры и результата. Аргумент вызова printmessage() представляет собой строку, а результат - целое число. Теперь можно написать спецификацию протокола на языке RPC, который будет описывать удаленную версию printmessage(). Исходный код RPC для данной спецификации:
program MESSAGEPROG {
version PRINTMESSAGEVERS {
int PRINTMESSAGE(string) = 1;
} = 1;
} = 0x20000001;
В этом примере PRINTMESSAGE - это процедура номер 1 в версии 1 удаленной программы MESSAGEPROG с номером программы 0x20000001.
Номера версии увеличиваются, если в удаленной программе изменяются функциональные возможности. При этом могут быть заменены существующие процедуры или добавлены новые. Может быть определена более чем одна версия удаленной программы, а также каждая версия может иметь более одной определенной процедуры.
Необходимо разработать еще две дополнительные программы. Одной из них является сама удаленная процедура. Версия printmsg.c для RPC:
* msg_proc.c: реализация удаленной процедуры
* "printmessage" */
#include <stdio.h>
#include "msg.h" /* msg.h сгенерированный rpcgen */
int * printmessage_1(char **msg, struct svc_req *req) {
static int result; /* должен быть static! */
FILE *f;
f = fopen("/dev/console", "w");
if (f == (FILE *)NULL) {
result = 0;
return (&result);
}
fprintf(f, "%s\n", *msg);
fclose(f);
result = 1;
return (&result);
}
При этом определение удаленной процедуры printmessage_1 отличается от локальной процедуры printmessage в следующих моментах:
* rprintmsg.c: удаленная версия "printmsg.c"
*/
#include <stdio.h>
#include "msg.h" /* msg.h сгенерирован rpcgen */
main(int argc, char **argv)
{
CLIENT *clnt;
int *result;
char *server;
char *message;
if (argc != 3) {
fprintf(stderr, "usage: %s host
message\n", argv[0]);
exit(1);
}
server = argv[1];
message = argv[2];
/*
* Создает клиентский "обрабочик", используемый
* для вызова MESSAGEPROG на сервере
*/
clnt = clnt_create(server, MESSAGEPROG,
PRINTMESSAGEVERS, "visible");
if (clnt == (CLIENT *)NULL) {
/*
* Невозможно установить соединение с сервером.
*/
clnt_pcreateerror(server);
exit(1);
}
/*
* Вызов удаленной процедуры
* "printmessage" на сервере
*/
result = printmessage_1(&message, clnt);
if (result == (int *)NULL) {
/*
* Ошибка при вызове сервера
*/
clnt_perror(clnt, server);
exit(1);
}
/* Успешный вызов удаленной процедуры.
*/
if (*result == 0) {
/*
* Сервер не может вывести сообщение.
*/
fprintf(stderr, "%s: невозможно вывести
сообщение\n", argv[0]);
exit(1);
}
/* Сообщение выведено на терминал сервера
*/
printf("Сообщение доставлено %s\n", server);
clnt_destroy( clnt );
exit(0);
}
Следует отметить следующие особенности клиентской программы вызова printmsg.c:
Для компиляции примера удаленного rprintmsg:
В этом примере не было создано никаких процедур XDR, потому что приложение использует только основные типы, которые включены в libnsl. Теперь нужно рассмотреть, что создано rpcgen на основе входного файла msg.x:
![\includegraphics[scale=0.6]{dipc1}](img5.png)
![\includegraphics[scale=0.6]{figure1.eps}](img58.png)
![\includegraphics[scale=0.5]{figure2.eps}](img59.png)