| Каталог документации / Раздел "Сети, протоколы, сервисы" / Оглавление документа |
| |
Все протоколы обмена маршрутной информацией стека TCP/IP относятся к классу адаптивных протоколов, которые в свою очередь делятся на две группы, каждая из которых связана с одним из следующих типов алгоритмов:
В алгоритмах дистанционно-векторного типа каждый маршрутизатор периодически и широковещательно рассылает по сети вектор расстояний от себя до всех известных ему сетей. Под расстоянием обычно понимается число промежуточных маршрутизаторов через которые пакет должен пройти прежде, чем попадет в соответствующую сеть. Может использоваться и другая метрика, учитывающая не только число перевалочных пунктов, но и время прохождения пакетов по связи между соседними маршрутизаторами. Получив вектор от соседнего маршрутизатора, каждый маршрутизатор добавляет к нему информацию об известных ему других сетях, о которых он узнал непосредственно (если они подключены к его портам) или из аналогичных объявлений других маршрутизаторов, а затем снова рассылает новое значение вектора по сети. В конце-концов, каждый маршрутизатор узнает информацию об имеющихся в интерсети сетях и о расстоянии до них через соседние маршрутизаторы.
Дистанционно-векторные алгоритмы хорошо работают только в небольших сетях. В больших сетях они засоряют линии связи интенсивным широковещательным трафиком, к тому же изменения конфигурации могут отрабатываться по этому алгоритму не всегда корректно, так как маршрутизаторы не имеют точного представления о топологии связей в сети, а располагают только обобщенной информацией - вектором дистанций, к тому же полученной через посредников. Работа маршрутизатора в соответствии с дистанционно-векторным протоколом напоминает работу моста, так как точной топологической картины сети такой маршрутизатор не имеет.
Наиболее распространенным протоколом, основанным на дистанционно-векторном алгоритме, является протокол RIP.
Алгоритмы состояния связей обеспечивают каждый маршрутизатор информацией, достаточной для построения точного графа связей сети. Все маршрутизаторы работают на основании одинаковых графов, что делает процесс маршрутизации более устойчивым к изменениям конфигурации. Широковещательная рассылка используется здесь только при изменениях состояния связей, что происходит в надежных сетях не так часто.
Для того, чтобы понять, в каком состоянии находятся линии связи, подключенные к его портам, маршрутизатор периодически обменивается короткими пакетами со своими ближайшими соседями. Этот трафик также широковещательный, но он циркулирует только между соседями и поэтому не так засоряет сеть.
Протоколом, основанным на алгоритме состояния связей, в стеке TCP/IP является протокол OSPF.
Протокол RIP (Routing Information Protocol) представляет собой один из старейших протоколов обмена маршрутной информацией, однако он до сих пор чрезвычайно распространен в вычислительных сетях. Помимо версии RIP для сетей TCP/IP, существует также версия RIP для сетей IPX/SPX компании Novell.
В этом протоколе все сети имеют номера (способ образования номера зависит от используемого в сети протокола сетевого уровня), а все маршрутизаторы - идентификаторы. Протокол RIP широко использует понятие "вектор расстояний". Вектор расстояний представляет собой набор пар чисел, являющихся номерами сетей и расстояниями до них в хопах.
Вектора расстояний итерационно распространяются маршрутизаторами по сети, и через несколько шагов каждый маршрутизатор имеет данные о достижимых для него сетях и о расстояниях до них. Если связь с какой-либо сетью обрывается, то маршрутизатор отмечает этот факт тем, что присваивает элементу вектора, соответствующему расстоянию до этой сети, максимально возможное значение, которое имеет специальный смысл - "связи нет". Таким значением в протоколе RIP является число 16.
На рисунке 8.1 приведен пример сети, состоящей из шести маршрутизаторов, имеющих идентификаторы от 1 до 6, и из шести сетей от A до F, образованных прямыми связями типа "точка-точка".
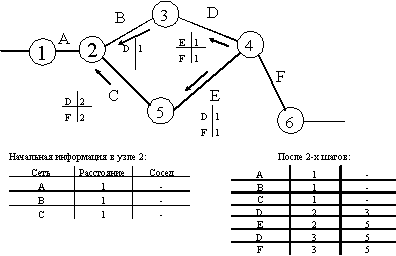
Рис. 8.1. Обмен маршрутной информацией по протоколу RIP
На рисунке приведена начальная информация, содержащаяся в топологической базе маршрутизатора 2, а также информация в этой же базе после двух итераций обмена маршрутными пакетами протокола RIP. После определенного числа итераций маршрутизатор 2 будет знать о расстояниях до всех сетей интерсети, причем у него может быть несколько альтернативных вариантов отправки пакета к сети назначения. Пусть в нашем примере сетью назначения является сеть D.
При необходимости отправить пакет в сеть D маршрутизатор просматривает свою базу данных маршрутов и выбирает порт, имеющий наименьшее расстояния до сети назначения (в данном случае порт, связывающий его с маршрутизатором 3).
Для адаптации к изменению состояния связей и оборудования с каждой записью таблицы маршрутизации связан таймер. Если за время тайм-аута не придет новое сообщение, подтверждающее этот маршрут, то он удаляется из маршрутной таблицы.
При использовании протокола RIP работает эвристический алгоритм динамического программирования Беллмана-Форда, и решение, найденное с его помощью является не оптимальным, а близким к оптимальному. Преимуществом протокола RIP является его вычислительная простота, а недостатками - увеличение трафика при периодической рассылке широковещательных пакетов и неоптимальность найденного маршрута.
На рисунке 8.2 показан случай неустойчивой работы сети по протоколу RIP при изменении конфигурации - отказе линии связи маршрутизатора M1 с сетью 1. При работоспособном состоянии этой связи в таблице маршрутов каждого маршрутизатора есть запись о сети с номером 1 и соответствующим расстоянием до нее.
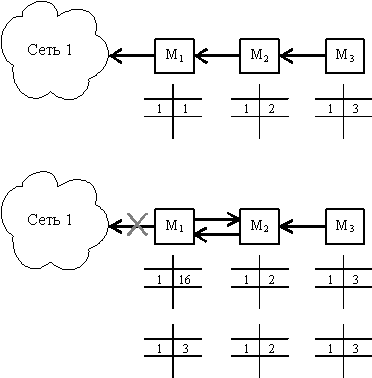
Рис. 8.2. Пример неустойчивой работы сети при использовании протокола RIP
При обрыве связи с сетью 1 маршрутизатор М1 отмечает, что расстояние до этой сети приняло значение 16. Однако получив через некоторое время от маршрутизатора М2 маршрутное сообщение о том, что от него до сети 1 расстояние составляет 2 хопа, маршрутизатор М1 наращивает это расстояние на 1 и отмечает, что сеть 1 достижима через маршрутизатор 2. В результате пакет, предназначенный для сети 1, будет циркулировать между маршрутизаторами М1 и М2 до тех пор, пока не истечет время хранения записи о сети 1 в маршрутизаторе 2, и он не передаст эту информацию маршрутизатору М1.
Для исключения подобных ситуаций маршрутная информация об известной маршрутизатору сети не передается тому маршрутизатору, от которого она пришла.
Существуют и другие, более сложные случаи нестабильного поведения сетей, использующих протокол RIP, при изменениях в состоянии связей или маршрутизаторов сети.
Большинство протоколов маршрутизации, применяемых в современных сетях с коммутацией пакетов, ведут свое происхождение от сети Internet и ее предшественницы - сети ARPANET. Для того, чтобы понять их назначение и особенности, полезно сначала познакомится со структурой сети Internet, которая наложила отпечаток на терминологию и типы протоколов.
Internet изначально строилась как сеть, объединяющая большое количество существующих систем. С самого начала в ее структуре выделяли магистральную сеть (core backbone network), а сети, присоединенные к магистрали, рассматривались как автономные системы (autonomous systems). Магистральная сеть и каждая из автономных систем имели свое собственное административное управление и собственные протоколы маршрутизации. Общая схема архитектуры сети Internet показана на рисунке 8.3. Далее маршрутизаторы будут называться шлюзами для следования традиционной терминологии Internet.
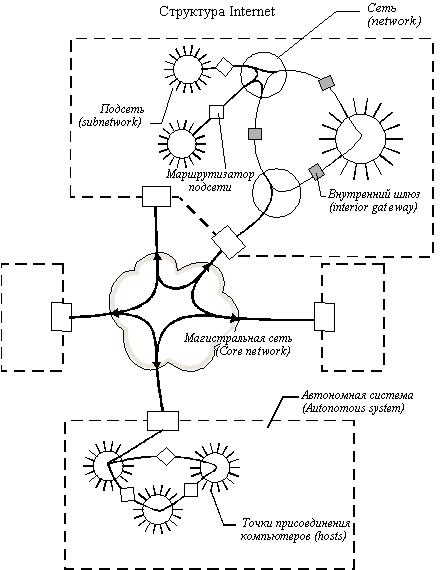
Рис. 8.3. Архитектура сети Internet
Шлюзы, которые используются для образования подсетей внутри автономной системы, называются внутренними шлюзами (interior gateways), а шлюзы, с помощью которых автономные системы присоединяются к магистрали сети, называются внешними шлюзами (exterior gateways). Непосредственно друг с другом автономные системы не соединяются. Соответственно, протоколы маршрутизации, используемые внутри автономных систем, называются протоколами внутренних шлюзов (interior gateway protocol, IGP), а протоколы, определяющие обмен маршрутной информацией между внешними шлюзами и шлюзами магистральной сети - протоколами внешних шлюзов (exterior gateway protocol, EGP). Внутри магистральной сети также может использоваться любой собственный внутренний протокол IGP.
Смысл разделения всей сети Internet на автономные системы в ее многоуровневом представлении, что необходимо для любой крупной системы, способной к расширению в больших масштабах. Внутренние шлюзы могут использовать для внутренней маршрутизации достаточно подробные графы связей между собой, чтобы выбрать наиболее рациональный маршрут. Однако, если информация такой степени детализации будет храниться во всех маршрутизаторах сети, то топологические базы данных так разрастутся, что потребуют наличия памяти гигантских размеров, а время принятия решений о маршрутизации непременно возрастет.
Поэтому детальная топологическая информация остается внутри автономной системы, а автономную систему как единое целое для остальной части Internet представляют внешние шлюзы, которые сообщают о внутреннем составе автономной системы минимально необходимые сведения - количество IP-сетей, их адреса и внутреннее расстояние до этих сетей от данного внешнего шлюза.
При инициализации внешний шлюз узнает уникальный идентификатор обслуживаемой им автономной системы, а также таблицу достижимости (reachability table), которая позволяет ему взаимодействовать с другими внешними шлюзами через магистральную сеть.
Затем внешний шлюз начинает взаимодействовать по протоколу EGP с другими внешними шлюзами и обмениваться с ними маршрутной информацией, состав которой описан выше. В результате, при отправке пакета из одной автономной системы в другую, внешний шлюз данной системы на основании маршрутной информации, полученной от всех внешних шлюзов, с которыми он общается по протоколу EGP, выбирает наиболее подходящий внешний шлюз и отправляет ему пакет.
В протоколе EGP определены три основные функции:
Каждая функция работает на основе обмена сообщениями запрос-ответ.
Так как каждая автономная система работает под контролем своего административного штата, то перед началом обмена маршрутной информацией внешние шлюзы должны согласиться на такой обмен. Сначала один из шлюзов посылает запрос на установление соседских отношений (acquisition request) другому шлюзу. Если тот согласен на это, то он отвечает сообщением подтверждение установления соседских отношений (acquisition confirm), а если нет - то сообщением отказ от установления соседских отношений (acquisition refuse), которое содержит также причину отказа.
После установления соседских отношений шлюзы начинают периодически проверять состояние достижимости друг друга. Это делается либо с помощью специальных сообщений (привет (hello) и Я-услышал-тебя (I-heard-you)), либо встраиванием подтверждающей информации непосредственно в заголовок обычного маршрутного сообщения.
Обмен маршрутной информацией начинается с посылки одним из шлюзов другому сообщения запрос данных (poll request) о номерах сетей, обслуживаемых другим шлюзом и расстояниях до них от него. Ответом на это сообщение служит сообщение обновленная маршрутная информация (routing update). Если же запрос оказался некорректным, то в ответ на него отсылается сообщение об ошибке.
Все сообщения протокола EGP передаются в поле данных IP-пакетов. Сообщения EGP имеют заголовок фиксированного формата (рисунок 8.4).
Поля Тип и Код совместно определяют тип сообщения, а поле Статус - информацию, зависящую от типа сообщения. Поле Номер автономной системы - это номер, назначенный той автономной системе, к которой присоединен данный внешний шлюз. Поле Номер последовательности служит� для синхронизации процесса запросов и ответов.
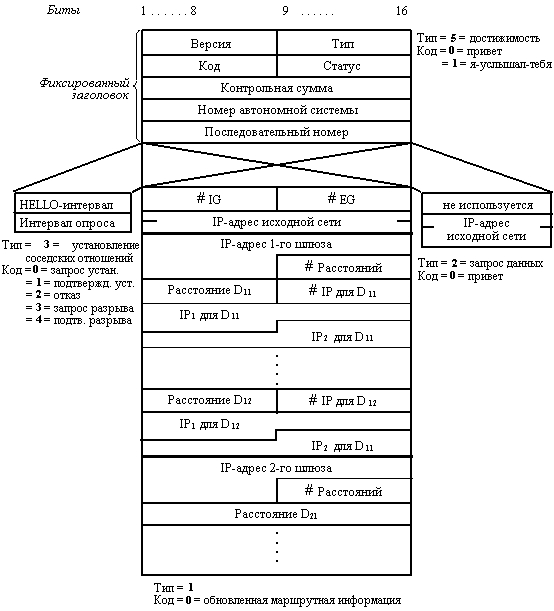
Рис. 8.4. Формат сообщения протокола EGP
Поле IP-адрес исходной сети в сообщениях запроса и обновления маршрутной информации обозначает сеть, соединяющую два внешних шлюза (рисунок 8.5).
Сообщение об обновленной маршрутной информации содержит список адресов сетей, которые достижимы в данной автономной системе. Этот список упорядочен по внутренним шлюзам, которые подключены к исходной сети и через которые достижимы данные сети, а для каждого шлюза он упорядочен по расстоянию до каждой достижимой сети от исходной сети, а не от данного внутреннего шлюза. Для примера, приведенного на рисунке 8.5, внешний шлюз R2 в своем сообщении указывает, что сеть 4 достижима с помощью шлюза R3 и расстояние ее равно 2, а сеть 2 достижима через шлюз R2 и ее расстояние равно 1 (а не 0, как если бы шлюз измерял ее расстояние от себя, как в протоколе RIP).
Протокол EGP имеет достаточно много ограничений, связанных с тем, что он рассматривает магистральную сеть как одну неделимую магистраль.
Развитием протокола EGP является протокол BGP (Border Gateway Protocol), имеющий много общего с EGP и используемый наряду с ним в магистрали сети Internet.
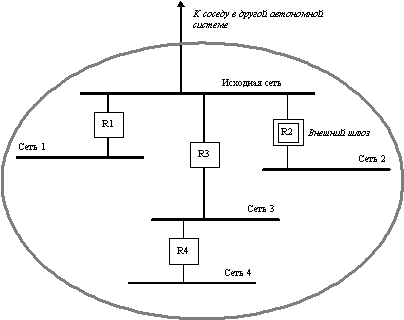
Рис. 8.5. Пример автономной системы
Протокол OSPF (Open Shortest Path Firs) является достаточно современной реализацией алгоритма состояния связей (он принят в 1991 году) и обладает многими особенностями, ориентированными на применение в больших гетерогенных сетях.
Протокол OSPF вычисляет маршруты в IP-сетях, сохраняя при этом другие протоколы обмена маршрутной информацией.
Непосредственно связанные (то есть достижимые без использования промежуточных маршрутизаторов) маршрутизаторы называются "соседями". Каждый маршрутизатор хранит информацию о том, в каком состоянии по его мнению находится сосед. Маршрутизатор полагается на соседние маршрутизаторы и передает им пакеты данных только в том случае, если он уверен, что они полностью работоспособны. Для выяснения состояния связей маршрутизаторы-соседи достаточно часто обмениваются короткими сообщениями HELLO.
Для распространения по сети данных о состоянии связей маршрутизаторы обмениваются сообщениями другого типа. Эти сообщения называются router links advertisement - объявление о связях маршрутизатора (точнее, о состоянии связей). OSPF-маршрутизаторы обмениваются не только своими, но и чужими объявлениями о связях, получая в конце-концов информацию о состоянии всех связей сети. Эта информация и образует граф связей сети, который, естественно, один и тот же для всех маршрутизаторов сети.
Кроме информации о соседях, маршрутизатор в своем объявлении перечисляет IP-подсети, с которыми он связан непосредственно, поэтому после получения информации о графе связей сети, вычисление маршрута до каждой сети производится непосредственно по этому графу по алгоритму Дэйкстры. Более точно, маршрутизатор вычисляет путь не до конкретной сети, а до маршрутизатора, к которому эта сеть подключена. Каждый маршрутизатор имеет уникальный идентификатор, который передается в объявлении о состояниях связей. Такой подход дает возможность не тратить IP-адреса на связи типа "точка-точка" между маршрутизаторами, к которым не подключены рабочие станции.
Маршрутизатор вычисляет оптимальный маршрут до каждой адресуемой сети, но запоминает только первый промежуточный маршрутизатор из каждого маршрута. Таким образом, результатом вычислений оптимальных маршрутов является список строк, в которых указывается номер сети и идентификатор маршрутизатора, которому нужно переслать пакет для этой сети. Указанный список маршрутов и является маршрутной таблицей, но вычислен он на основании полной информации о графе связей сети, а не частичной информации, как в протоколе RIP.
Описанный подход приводит к результату, который не может быть достигнут при использовании протокола RIP или других дистанционно-векторных алгоритмов. RIP предполагает, что все подсети определенной IP-сети имеют один и тот же размер, то есть, что все они могут потенциально иметь одинаковое число IP-узлов, адреса которых не перекрываются. Более того, классическая реализация RIP требует, чтобы выделенные линии "точка-точка" имели IP-адрес, что приводит к дополнительным затратам IP-адресов.
В OSPF такие требования отсутствуют: сети могут иметь различное число хостов и могут перекрываться. Под перекрытием понимается наличие нескольких маршрутов к одной и той же сети. В этом случае адрес сети в пришедшем пакете может совпасть с адресом сети, присвоенным нескольким портам.
Если адрес принадлежит нескольким подсетям в базе данных маршрутов, то продвигающий пакет маршрутизатор использует наиболее специфический маршрут, то есть адрес подсети, имеющей более длинную маску.
Например, если рабочая группа ответвляется от главной сети, то она имеет адрес главной сети наряду с более специфическим адресом, определяемым маской подсети. При выборе маршрута к хосту в подсети этой рабочей группы маршрутизатор найдет два пути, один для главной сети и один для рабочей группы. Так как последний более специфичен, то он и будет выбран. Этот механизм является обобщением понятия "маршрут по умолчанию", используемого во многих сетях.
Использование подсетей с различным количеством хостов является вполне естественным. Например, если в здании или кампусе на каждом этаже имеются локальные сети, и на некоторых этажах компьютеров больше, чем на других, то администратор может выбрать размеры подсетей, отражающие ожидаемые требования каждого этажа, а не соответствующие размеру наибольшей подсети.
В протоколе OSPF подсети делятся на три категории:
Транзитная сеть является для протокола OSPF особым случаем. В транзитной сети несколько маршрутизаторов являются взаимно и одновременно достижимыми. В широковещательных локальных сетях, таких как Ethernet или Token Ring, маршрутизатор может послать одно сообщение, которое получат все его соседи. Это уменьшает нагрузку на маршрутизатор, когда он посылает сообщения для определения существования связи или обновленные объявления о соседях. Однако, если каждый маршрутизатор будет перечислять всех своих соседей в своих объявлениях о соседях, то объявления займут много места в памяти маршрутизатора. При определении пути по адресам транзитной подсети может обнаружиться много избыточных маршрутов к различным маршрутизаторам. На вычисление, проверку и отбраковку этих маршрутов уйдет много времени.
Когда маршрутизатор начинает работать в первый раз (то есть инсталлируется), он пытается синхронизировать свою базу данных со всеми маршрутизаторами транзитной локальной сети, которые по определению имеют идентичные базы данных. Для упрощения и оптимизации этого процесса в протоколе OSPF используется понятие "выделенного" маршрутизатора, который выполняет две функции.
Во-первых, выделенный маршрутизатор и его резервный "напарник" являются единственными маршрутизаторами, с которыми новый маршрутизатор будет синхронизировать свою базу. Синхронизировав базу с выделенным маршрутизатором, новый маршрутизатор будет синхронизирован со всеми маршрутизаторами данной локальной сети.
Во-вторых, выделенный маршрутизатор делает объявление о сетевых связях, перечисляя своих соседей по подсети. Другие маршрутизаторы просто объявляют о своей связи с выделенным маршрутизатором. Это делает объявления о связях (которых много) более краткими, размером с объявление о связях отдельной сети.
Для начала работы маршрутизатора OSPF нужен минимум информации - IP-конфигурация (IP-адреса и маски подсетей), некоторая информация по умолчанию (default) и команда на включение. Для многих сетей информация по умолчанию весьма похожа. В то же время протокол OSPF предусматривает высокую степень программируемости.
Интерфейс OSPF (порт маршрутизатора, поддерживающего протокол OSPF) является обобщением подсети IP. Подобно подсети IP, интерфейс OSPF имеет IP-адрес и маску подсети. Если один порт OSPF поддерживает более, чем одну подсеть, протокол OSPF рассматривает эти подсети так, как если бы они были на разных физических интерфейсах, и вычисляет маршруты соответственно.
Интерфейсы, к которым подключены локальные сети, называются широковещательными (broadcast) интерфейсами, так как они могут использовать широковещательные возможности локальных сетей для обмена сигнальной информацией между маршрутизаторами. Интерфейсы, к которым подключены глобальные сети, не поддерживающие широковещание, но обеспечивающие доступ ко многим узлам через одну точку входа, например сети Х.25 или frame relay, называются нешироковещательными интерфейсами с множественным доступом или NBMA (non-broadcast multi-access). Они рассматриваются аналогично широковещательным интерфейсам за исключением того, что широковещательная рассылка эмулируется путем посылки сообщения каждому соседу. Так как обнаружение соседей не является автоматическим, как в широковещательных сетях, NBMA-соседи должны задаваться при конфигурировании вручную. Как на широковещательных, так и на NBMA-интерфейсах могут быть заданы приоритеты маршрутизаторов для того, чтобы они могли выбрать выделенный маршрутизатор.
Интерфейсы "точка-точка", подобные PPP, несколько отличаются от традиционной IP-модели. Хотя они и могут иметь IP-адреса и подмаски, но необходимости в этом нет.
В простых сетях достаточно определить, что пункт назначения достижим и найти маршрут, который будет удовлетворительным. В сложных сетях обычно имеется несколько возможных маршрутов. Иногда хотелось бы иметь возможности по установлению дополнительных критериев для выбора пути: например, наименьшая задержка, максимальная пропускная способность или наименьшая стоимость (в сетях с оплатой за пакет). По этим причинам протокол OSPF позволяет сетевому администратору назначать каждому интерфейсу определенное число, называемое метрикой, чтобы оказать нужное влияние на выбор маршрута.
Число, используемое в качестве метрики пути, может быть назначено произвольным образом по желанию администратора. Но по умолчанию в качестве метрики используется время передачи бита в 10-ти наносекундных единицах (10 Мб/с Ethernet'у назначается значение 10, а линии 56 Кб/с - число 1785). Вычисляемая протоколом OSPF метрика пути представляет собой сумму метрик всех проходимых в пути связей; это очень грубая оценка задержки пути. Если маршрутизатор обнаруживает более, чем один путь к удаленной подсети, то он использует путь с наименьшей стоимостью пути.
В протоколе OSPF используется несколько временных параметров, и среди них наиболее важными являются интервал сообщения HELLO и интервал отказа маршрутизатора (router dead interval).
HELLO - это сообщение, которым обмениваются соседние, то есть непосредственно связанные маршрутизаторы подсети, с целью установить состояние линии связи и состояние маршрутизатора-соседа. В сообщении HELLO маршрутизатор передает свои рабочие параметры и говорит о том, кого он рассматривает в качестве своих ближайших соседей. Маршрутизаторы с разными рабочими параметрами игнорируют сообщения HELLO друг друга, поэтому неверно сконфигурированные маршрутизаторы не будут влиять на работу сети. Каждый маршрутизатор шлет сообщение HELLO каждому своему соседу по крайней мере один раз на протяжении интервала HELLO. Если интервал отказа маршрутизатора истекает без получения сообщения HELLO от соседа, то считается, что сосед неработоспособен, и распространяется новое объявление о сетевых связях, чтобы в сети произошел пересчет маршрутов.
Пример маршрутизации по алгоритму OSPF
Представим себе один день из жизни транзитной локальной сети. Пусть у нас имеется сеть Ethernet, в которой есть три маршрутизатора - Джон, Фред и Роб (имена членов рабочей группы Internet, разработавшей протокол OSPF). Эти маршрутизаторы связаны с сетями в других городах с помощью выделенных линий.
Пусть произошло восстановление сетевого питания после сбоя. Маршрутизаторы и компьютеры перезагружаются и начинают работать по сети Ethernet. После того, как маршрутизаторы обнаруживают, что порты Ethernet работают нормально, они начинают генерировать сообщения HELLO, которые говорят о их присутствии в сети и их конфигурации. Однако маршрутизация пакетов начинает осуществляться не сразу - сначала маршрутизаторы должны синхронизировать свои маршрутные базы (рисунок 8.6).
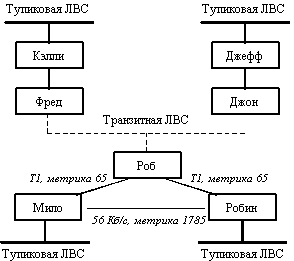
Рис. 8.6. Гипотетическая сеть с OSPF маршрутизаторами
На протяжении интервала отказа маршрутизаторы продолжают посылать сообщения HELLO. Когда какой-либо маршрутизатор посылает такое сообщение, другие его получают и отмечают, что в локальной сети есть другой маршрутизатор. Когда они посылают следующее HELLO, они перечисляют там и своего нового соседа.
Когда период отказа маршрутизатора истекает, то маршрутизатор с наивысшим приоритетом и наибольшим идентификатором объявляет себя выделенным (а следующий за ним по приоритету маршрутизатор объявляет себя резервным выделенным маршрутизатором) и начинает синхронизировать свою базу данных с другими маршрутизаторами.
С этого момента времени база данных маршрутных объявлений каждого маршрутизатора может содержать информацию, полученную от маршрутизаторов других локальных сетей или из выделенных линий. Роб, например, вероятно получил информацию от Мило и Робина об их сетях, и он может передавать туда пакеты данных. Они содержат информацию о собственных связях маршрутизатора и объявления о связях сети.
Базы данных теперь синхронизированы с выделенным маршрутизатором, которым является Джон. Джон суммирует свою базу данных с каждой базой данных своих соседей - базами Фреда, Роба и Джеффа - индивидуально. В каждой синхронизирующейся паре объявления, найденные только в какой-либо одной базе, копируются в другую. Выделенный маршрутизатор, Джон, распространяет новые объявления среди других маршрутизаторов своей локальной сети. Например, объявления Мило и Робина передаются Джону Робом, а Джон в свою очередь передает их Фреду и Джеффри. Обмен информацией между базами продолжается некоторое время, и пока он не завершится, маршрутизаторы не будут считать себя работоспособными. После этого они себя таковыми считают, потому что имеют всю доступную информацию о сети.
Посмотрим теперь, как Робин вычисляет маршрут через сеть. Две из связей, присоединенных к его портам, представляют линии T-1, а одна - линию 56 Кб/c. Робин сначала обнаруживает двух соседей - Роба с метрикой 65 и Мило с метрикой 1785. Из объявления о связях Роба Робин обнаружил наилучший путь к Мило со стоимостью 130, поэтому он отверг непосредственный путь к Мило, поскольку он связан с большей задержкой, так как проходит через линии с меньшей пропускной способностью. Робин также обнаруживает транзитную локальную сеть с выделенным маршрутизатором Джоном. Из объявлений о связях Джона Робин узнает о пути к Фреду и, наконец, узнает о пути к маршрутизаторам Келли и Джеффу и к их тупиковым сетям.
После того, как маршрутизаторы полностью входят в рабочий режим, интенсивность обмена сообщениями резко падает. Обычно они посылают сообщение HELLO по своим подсетям каждые 10 секунд и делают объявления о состоянии связей каждые 30 минут (если обнаруживаются изменения в состоянии связей, то объявление передается, естественно, немедленно). Обновленные объявления о связях служат гарантией того, что маршрутизатор работает в сети. Старые объявления удаляются из базы через определенное время.
Представим, однако, что какая-либо выделенная линия сети отказала. Присоединенные к ней маршрутизаторы распространяют свои объявления, в которых они уже не упоминают друг друга. Эта информация распространяется по сети, включая маршрутизаторы транзитной локальной сети. Каждый маршрутизатор в сети пересчитывает свои маршруты, находя, может быть, новые пути для восстановления утраченного взаимодействия.
Сравнение протоколов RIP и OSPF по затратам на широковещательный трафик
В сетях, где используется протокол RIP, накладные расходы на обмен маршрутной информацией строго фиксированы. Если в сети имеется определенное число маршрутизаторов, то трафик, создаваемый передаваемой маршрутной информацией, описываются формулой (1):
(1) F = (число объявляемых
маршрутов/25) x 528 (байтов в сообщении)
x
(число копий в единицу времени) x 8
(битов в байте)
В сети с протоколом OSPF загрузка при неизменном состоянии линий связи создается сообщениями HELLO и обновленными объявлениями о состоянии связей, что описывается формулой (2):
(2) F = { [ 20 + 24 + 20 + (4 x число соседей)] x
(число копий HELLO в единицу времени) }x
8 +
[(число объявлений x средний размер
объявления) x
(число копий объявлений в единицу
времени)] x 8,
где 20 - размер заголовка IP-пакета,
24 - заголовок пакета OSPF,
20 - размер заголовка сообщения HELLO,
4 - данные на каждого соседа.
Интенсивность посылки сообщений HELLO - каждые 10 секунд, объявлений о состоянии связей - каждые полчаса. По связям "точка-точка" или по широковещательным локальным сетям в единицу времени посылается только одна копия сообщения, по NBMA сетям типа frame relay каждому соседу посылается своя копия сообщения. В сети frame relay с 10 соседними маршрутизаторами и 100 маршрутами в сети (подразумевается, что каждый маршрут представляет собой отдельное OSPF-обобщение о сетевых связях и что RIP распространяет информацию о всех этих маршрутах) трафик маршрутной информации определяется соотношениями (3) и (4):
(3) RIP: (100 маршрутов / 25 маршрутов в
объявлении) x 528 x
(10 копий / 30 сек) = 5 632 б/с
(4) OSPF: {[20 + 24 + 20 + (4 x 10) x (10 копий / 10
сек)] +
[100 маршрутов x (32 + 24 + 20) + (10 копий / 30 x
60 сек]} x 8 = 1 170 б/с
Как видно из полученных результатов, для нашего гипотетического примера трафик, создаваемый протоколом RIP, почти в пять раз интенсивней трафика, создаваемого протоколом OSPF.
Использование других протоколов маршрутизации
Случай использования в сети только протокола маршрутизации OSPF представляется маловероятным. Если сеть присоединена к Internet'у, то могут использоваться такие протоколы, как EGP (Exterior Gateway protocol), BGP (Border Gateway Protocol, протокол пограничного маршрутизатора), старый протокол маршрутизации RIP или собственные протоколы производителей.
Когда в сети начинает применяться протокол OSPF, то существующие протоколы маршрутизации могут продолжать использоваться до тех пор, пока не будут полностью заменены. В некоторых случаях необходимо будет объявлять о статических маршрутах, сконфигурированных вручную.
В OSPF существует понятие автономных систем маршрутизаторов (autonomous systems), которые представляют собой домены маршрутизации, находящиеся под общим административным управлением и использующие единый протокол маршрутизации. OSPF называет маршрутизатор, который соединяет автономную систему с другой автономной системой, использующей другой протокол маршрутизации, пограничным маршрутизатором автономной системы (autonomous system boundary router, ASBR).
В OSPF маршруты (именно маршруты, то есть номера сетей и расстояния до них во внешней метрике, а не топологическая информация) из одной автономной системы импортируются в другую автономную систему и распространяются с использованием специальных внешних объявлений о связях.
Внешние маршруты обрабатываются за два этапа. Маршрутизатор выбирает среди внешних маршрутов маршрут с наименьшей внешней метрикой. Если таковых оказывается больше, чем 2, то выбирается путь с меньшей стоимостью внутреннего пути до ASBR.
Область OSPF - это набор смежных интерфейсов (территориальных линий или каналов локальных сетей). Введение понятия "область" служит двум целям - управлению информацией и определению доменов маршрутизации.
Для понимания принципа управления информацией рассмотрим сеть, имеющую следующую структуру: центральная локальная сеть связана с помощью 50 маршрутизаторов с большим количеством соседей через сети X.25 или frame relay (рисунок 8.7). Эти соседи представляют собой большое количество небольших удаленных подразделений, например, отделов продаж или филиалов банка. Из-за большого размера сети каждый маршрутизатор должен хранить огромное количество маршрутной информации, которая должна передаваться по каждой из линий, и каждое из этих обстоятельств удорожает сеть. Так как топология сети проста, то большая часть этой информации и создаваемого ею трафика не имеют смысла.
Для каждого из удаленных филиалов нет необходимости иметь детальную маршрутную информацию о всех других удаленных офисах, в особенности, если они взаимодействуют в основном с центральными компьютерами, связанными с центральными маршрутизаторами. Аналогично, центральным маршрутизаторам нет необходимости иметь детальную информацию о топологии связей с удаленными офисами, соединенными с другими центральными маршрутизаторами. В то же время центральные маршрутизаторы нуждаются в информации, необходимой для передачи пакетов следующему центральному маршрутизатору. Администратор мог бы без труда разделить эту сеть на более мелкие домены маршрутизации для того, чтобы ограничить объемы хранения и передачи по линиям связи не являющейся необходимой информации. Обобщение маршрутной информации является главной целью введения областей в OSPF.
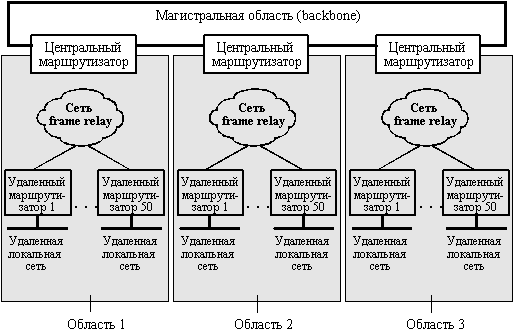
Рис. 8.7. Большая сеть с топологией звезда
В протоколе OSPF определяется также пограничный маршрутизатор области (ABR, area border router). ABR - это маршрутизатор с интерфейсами в двух или более областях, одна из которых является специальной областью, называемой магистральной (backbone area). Каждая область работает с отдельной базой маршрутной информации и независимо вычисляет маршруты по алгоритму OSPF. Пограничные маршрутизаторы передают данные о топологии области в соседние области в обобщенной форме - в виде вычисленных маршрутов с их весами. Поэтому в сети, разбитой на области, уже не действует утверждение о том, что все маршрутизаторы оперируют с идентичными топологическими базами данных.
Маршрутизатор ABR берет информацию о маршрутах OSPF, вычисленную в одной области, и транслирует ее в другую область путем включения этой информации в обобщенное суммарное объявление (summary) для базы данных другой области. Суммарная информация описывает каждую подсеть области и дает для нее метрику. Суммарная информация может быть использована тремя способами: для объявления об отдельном маршруте, для обобщения нескольких маршрутов или же служить маршрутом по умолчанию.
Дальнейшее уменьшение требований к ресурсам маршрутизаторов происходит в том случае, когда область представляет собой тупиковую область (stub area). Этот атрибут администратор сети может применить к любой области, за исключением магистральной. ABR в тупиковой области не распространяет внешние объявления или суммарные объявления из других областей. Вместо этого он делает одно суммарное объявление, которое будет удовлетворять любой IP-адрес, имеющий номер сети, отличный от номеров сетей тупиковой области. Это объявление называется маршрутом по умолчанию. Маршрутизаторы тупиковой области имеют информацию, необходимую только для вычисления маршрутов между собой плюс указания о том, что все остальные маршруты должны проходить через ABR. Такой подход позволяет уменьшить в нашей гипотетической сети количество маршрутной информации в удаленных офисах без уменьшения способности маршрутизаторов корректно передавать пакеты.
Предыдущая глава | Оглавление | Следующая глава



|
Закладки на сайте Проследить за страницей |
Created 1996-2025 by Maxim Chirkov Добавить, Поддержать, Вебмастеру |