В данной главе дается раз'яснение основных концепций об'единения сетей. Представленная здесь основополагающая информация поможет читателю понять тот технический материал, из которого составлена большая часть данной публикации. В главу включены разделы, касающиеся эталонной модели OSI, важные термины и концепции, а также перечень основных организаций по стандартизации сетей.
Перемещение информации между компьютерами различных схем является чрезвычайно сложной задачей. В начале 1980 гг. Международная Организация по Стандартизации (ISO) признала необходимость в создания модели сети, которая могла бы помочь поставщикам создавать реализации взаимодействующих сетей. Эту потребность удовлетворяет эталонная модель "Взаимодействие Открытых Систем" (OSI), выпущенная в 1984 г.
Эталонная модель OSI быстро стала основной архитектурной моделью для передачи межкомпьютерных сообщений. Несмотря на то, что были разработаны другие архитектурные модели (в основном патентованные), большинство поставщиков сетей, когда им необходимо предоставить обучающую информацию пользователям поставляемых ими изделий, ссылаются на них как на изделия для сети, соответствующей эталонной модели OSI. И действительно, эта модель является самым лучшим средством, имеющемся в распоряжении тех, кто надеется изучить технологию сетей.
Эталонная модель OSI делит проблему перемещения информации между компьютерами через среду сети на семь менее крупных, и следовательно, более легко разрешимых проблем. Каждая из этих семи проблем выбрана потому, что она относительно автономна, и следовательно, ее легче решить без чрезмерной опоры на внешнюю информацию.
Каждая из семи областей проблемы решалась с помощью одного из уровней модели. Большинство устройств сети реализует все семь уровней. Однако в режиме потока информации некоторые реализации сети пропускают один или более уровней. Два самых низших уровня OSI реализуются аппаратным и программным обеспечением; остальные пять высших уровней, как правило, реализуются программным обеспечением.
Справочная модель OSI описывает, каким образом информация проделывает путь через среду сети (например, провода) от одной прикладной программы (например, программы обработки крупноформатных таблиц) до другой прикладной программы, находящейся в другом компьютере. Т.к.информация, которая должна быть отослана, проходит вниз через уровни системы, по мере этого продвижения она становится все меньше похожей на человеческий язык и все больше похожей на ту информацию, которую понимают компьютеры, а именно "единицы" и "нули".
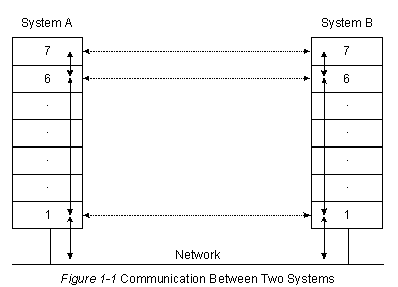
В качесте примера связи типа OSI предположим, что Система А на Рис. 1-1 имеет информацию для отправки в Систему В. Прикладная программа Системы А сообщается с Уровнем 7 Системы А (верхний уровень), который сообщается с Уровнем 6 Системы А, который в свою очередь сообщается с Уровнем 5 Системы А, и т.д. до Уровня 1 Системы А. Задача Уровня 1 - отдавать (а также забирать) информацию в физическую среду сети. После того, как информация проходит через физическую среду сети и поглащается Системой В, она поднимается через слои Системы В в обратном порядке (сначала Уровень 1 , затем Уровень 2 и т.д.), пока она наконец не достигнет прикладную программу Системы В.
Хотя каждый из уровней Системы А может сообщаться со смежными уровнями этой системы, их главной задачей является сообщение с соответствующими уровнями Системы В. Т.е. главной задачей Уровня 1 Системы А является связь с Уровнем 1 Системы В; Уровень 2 Системы А сообщается с Уровнем 2 Системы В и т.д. Это необходимо потому, что каждый уровень Системы имеет свои определенные задачи, которые он должен выполнять. Чтобы выполнить эти задачи, он должен сообщаться с соответствующим уровнем в другой системе.
Уровневая модель OSI исключает прямую связь между соответствующими уровнями других систем. Следовательно, каждый уровень Системы А должен полагаться на услуги, предоставляемые ему смежными уровнями Системы А, чтобы помочь осуществить связь с соответствующим ему уровнем Системы В. Взаимоотношения между смежными уровнями отдельной системы показаны на Рис.1-2.
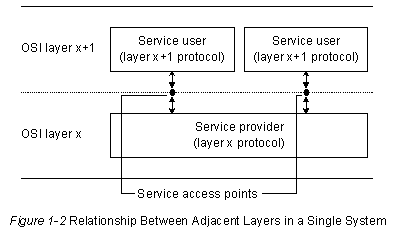
Предположим, что Уровень 4 Системы А должен связаться с Уровнем 4 Системы В. Чтобы выполнить эту задачу, Уровень 4 Системы А должен воспользоваться услугами Уровня 3 Системы А. Уровень 4 называется "пользователем услуг", а Уровень 3 - "источником услуг". Услуги Уровня 3 обеспечиваются Уровню 4 в "точке доступа к услугам" (SAP), которая представляет собой просто местоположение, в котором Уровень 4 может запросить услуги Уровня 3. Как видно из рисунка, Уровень 3 может предоставлять свои услуги множеству об'ектов Уровня 4.
Каким образом Уровень 4 Системы В узнает о том, что необходимо
Уровню 4 Системы А? Специфичные запросы Уровня А запоминаются как
управляющая информация, которая передается между соответствующими
уровнями в блоке, называемом заголовком; заголовок предшествуют
фактической прикладной информации. Например, предположим, что
Система А хочет отправить в Систему В следующий текст (называемый
"данные" или "информация"):
The small grey cat ran up the wall to try to catch
the red bird.
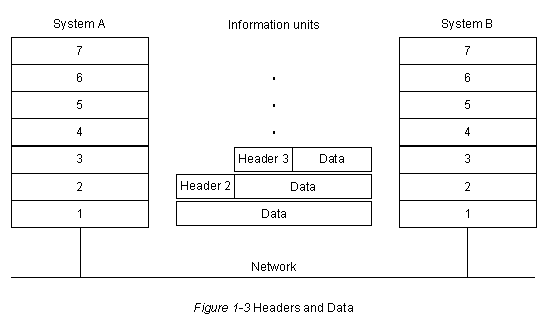
Этот текст передается из прикладной программы Системы А в верхний уровень этой системы. Прикладной уровень Системы А должен передать определенную информацию в прикладной уровень Системы В, поэтому он помещает управляющую информацию (в форме кодированного заголовка) перед фактическим текстом, который должен быть передан. Этот информационный блок передается в Уровень 6 Системы А, который может предварить его своей собственной управляющей информацией. Размеры сообщения увеличиваются по мере того, как оно проходит вниз через уровни до тех пор, пока не достигнет сети, где оригинальный текст и вся связанная с ним управляющая информация перемещаются к Системе В, где они поглащаются Уровнем 1 Системы В. Уровень 1 Системы В отделяет заголовок уровня 1 и прочитывает его, после чего он знает, как обрабатывать данный информационный блок. Слегка уменьшенный в размерах информационный блок передается в Уровень 2, который отделяет заголовок Уровня 2, анализирует его, чтобы узнать о действиях, которые он должен выполнить, и т.д. Когда информационный блок наконец доходит до прикладной программы Системы В, он должен содержать только оригинальный текст.
Концепция заголовка и собственно данных относительна и зависит от перспективы того уровня, который в данный момент анализирует информационный блок. Например, в Уровне 3 информационный блок состоит из заголовка Уровня 3 и следующими за ним данными. Однако данные Уровня 3 могут содержать заголовки Уровней 4, 5, 6 и 7. Кроме того, заголовок Уровня 3 является просто данными для Уровня 2. Эта концепция иллюстрируется на Рис. 1-3. И наконец, не все уровни нуждаются в присоединении заголовков. Некоторые уровни просто выполняют трансформацию фактических данных, которые они получают, чтобы сделать их более или менее читаемыми для смежных с ними уровней.
Эталонная модель OSI не является реализацией сети. Она только определяет функции каждого уровня. В этом отношении она напоминает план для постройки корабля. Точно также, как для выполнения фактической работы по плану могут быть заключены контракты с любым количеством кораблестроительных компаний, любое число поставщиков сети могут построить протокол реализации по спецификации протокола. И если этот план не будет предельно понятным, корабли, построенные различными компаниями, пользующимися одним и тем же планом, пусть незначительно, но будут отличаться друг от друга. Примером самого незначительного отличия могут быть гвозди, забитые в разных местах.
Чем об'ясняется разница в реализациях одного и того же плана корабля (или спецификации протокола)? Частично эта разница вызвана неспособностью любой спецификации учесть все возможные детали реализации. Кроме того, разные люди, реализующие один и тот же проект, всегда интерпретируют его немного по-разному. И наконец, неизбежные ошибки реализации приводят к тому, что изделия разных реализаций отличаются исполнением. Этим об'ясняется то, что реализация протокола Х одной компании не всегда взаимодействует с реализацией этого протокола, осуществленной другой компанией.
После того, как стали понятными основные особенности принципа деления на уровни модели OSI, можно приступить к обсуждению каждого отдельного уровня и его функций. Каждый уровень имеет заранее заданный набор функций, которые он должен выполнить для того, чтобы связь могла состояться.
Прикладной уровень идентифицирует и устанавливает наличие предполагаемых партнеров для связи, синхронизирует совместно работающие прикладные программы, а также устанавливает соглашение по процедурам устранения ошибок и управления целостностью информации. Прикладной уровень также определяет, имеется ли в наличии достаточно ресурсов для предполагаемой связи.
Представительный уровень занят не только форматом и представлением фактических данных пользователя, но также структурами данных, которые используют программы. Поэтому кроме трансформации формата фактических данных (если она необходима), представительный уровень согласует синтаксис передачи данных для прикладного уровня.
Транспортный уровень пытается обеспечить услуги по транспортировке данных, которые избавляют высшие слои от необходимости вникать в ее детали. В частности, заботой транспортного уровня является решение таких вопросов, как выполнение надежной транспортировки данных через об'единенную сеть. Предоставляя надежные услуги, транспортный уровень обеспечивает механизмы для установки, поддержания и упорядоченного завершения действия виртуальных каналов, систем обнаружения и устранения неисправностей транспортировки и управления информационным потоком (с целью предотвращения переполнения системы данными из другой системы).
Т.к. две конечные системы, желающие организовать связь, может разделять значительное географическое расстояние и множество подсетей, сетевой уровень является доменом маршрутизации. Протоколы маршрутизации выбирают оптимальные маршруты через последовательность соединенных между собой подсетей. Традиционные протоколы сетевого уровня передают информацию вдоль этих маршрутов.
Наука об об'единении сетей, как и другие науки, имеет свою собственную терминологию и научную базу. К сожалению, ввиду того, что наука об об'единении сетей очень молода, пока что не достигнуто единое соглашение о значении концепций и терминов об'единенных сетей. По мере дальнейшего совершенствования индустрии об'единенных сетей определение и использование терминов будут более четкими.
Существенным компонентом любой системы сети является оперделение местонахождения компьютерных систем. Существуют различные схемы адресации, используемые для этой цели, которые зависят от используемого семейства протоколов. Другими словами, адресация AppleTalk отличается от адресации TCP/IP, которая в свою очередь отличается от адресации OSI, и т.д.
Двумя важными типами адресов являются адреса канального уровня и адреса сетевого уровня. Адреса канального уровня (называемые также физическими или аппаратными адресами), как правило, уникальны для каждого сетевого соединения. У большинства локальных сетей (LAN) адреса канального уровня размещены в схеме интерфейса; они назначаются той организацией, которая определяет стандарт протокола, представленный этим интерфейсом. Т.к. большинство компьютерных систем имеют одно физическое сетевое соединение, они имеют только один адрес канального уровня. Роутеры и другие системы, соединенные с множеством физических сетей, могут иметь множество адресов канального уровня. В соответствии с названием, адреса канального уровня существуют на Уровне 2 эталонной модели ISO.
Aдреса сетевого уровня (называемые также виртуальными или логическими адресами) существуют на Уровне 3 эталонной модели OSI. В отличие от адресов канального уровня, которые обычно существуют в пределах плоского адресного пространства, адреса сетевого уровня обычно иерархические. Другими словми, они похожи на почтовые адреса, которые описывают местонахождение человека, указывая страну, штат, почтовый индекс, город, улицу, адрес на этой улице и наконец, имя. Хорошим примером одноуровневой адресации является номерная система социальной безопасности США, в соответствии с которой каждый человек имеет один уникальный номер, присвоенный ему службой безопасности.
Иерархические адреса делают сортировку адресов и повторный вызов более легкими путем исключения крупных блоков логически схожих адресов в процессе последовательности операций сравнения. Например, можно исключить все другие страны, если в адресе указана страна "Ирландия". Легкость сортировки и повторного вызова являются причиной того, что роутеры используют адреса сетевого уровня в качестве базиса маршрутизации.
Адреса сетевого уровня различаются в зависимости от используемого семейства протоколов, однако они, как правило, используют соответствующие логические разделы для нахождения компьютерных систем в об'единенной сети. Некоторые из этих логических разделов базируются на физических характеристиках сети (таких, как сегмент сети, в котором находится какая-нибудь система); другие логические разделы базируются на группировках, не имеющих физического базиса (например, "зона" AppleTalk).
Блоки данных, пакеты и сообщения
После того, как по адресам установили местоположение компьютерных систем, может быть произведен обмен информацией между двумя или более системами. В литературе по об'единенным сетям наблюдается непоследовательность в наименовании логически сгруппированных блоков информации, которая перемещается между компьютерными системами. "блок данных", "пакет", "блок данных протокола", "PDU", "сегмент", "сообщение" - используются все эти и другие термины, в зависимости от прихоти тех, кто пишет спецификации протоколов.
В настоящей работе термин "блок данных" (frame) обозначает блок информации, источником и пунктом назначения которого являются об'екты канального уровня. Термин "пакет" (packet) обозначает блок информации, у которого источник и пункт назначения - об'екты сетевого уровня. И наконец, термин "сообщение" (message) oбoзначает информационный блок, у которого об'екты источника и места назначения находятся выше сетевого уровня. Термин "сообщение" используется также для обозначения отдельных информационных блоков низших уровней, которые имеют специальное, хорошо сформулированное назначение.
Без услуг нескольких основных организаций по стандартизации, в области об'единенных сетей было бы значительно больше хаоса, чем его имеется в настоящее время. Организации по стандартизации обеспечивают форум для дискуссий, помогают превратить результаты дискуссий в официальные спецификации, а также распространяют эти спецификации после завершения процесса стандартизации.
Большинство организаций по стандартизации выполняют специфичные
процессы, чтобы превратить идеи в официальные стандарты. И хотя у
различных организаций эти процессы немного отличаются, они схожи в
том, что проходят через несколько раундов организации идей,
обсуждения этих идей, разработки проектов стандартов, голосования
по всем или некоторым аспектам этих стандартов и наконец,
официального выпуска завершенных стандартов.
Наиболее известными организациями по стандартизации являются
следующие огранизации:
В общедоступном значении слова маршрутизация означает передвижение информации от источника к пункту назначения через об'единенную сеть. При этом, как правило, на пути встречается по крайней мере один узел. Маршрутизация часто противопоставляется об'единению сетей с помощью моста, которое, в популярном понимании этого способа, выполняет точно такие же функции. Основное различие между ними заключается в том, что об'единение с помощью моста имеет место на Уровне 2 эталонной модели ISO, в то время как маршрутизация встречается на Уровне 3. Этой разницей об'ясняется то, что маршрутизация и об'единение по мостовой схеме используют различную информацию в процессе ее перемещения от источника к месту назначения. Результатом этого является то, что маршрутизация и об'единение с помощью моста выполняют свои задачи разными способами; фактически, имеется несколько различных видов маршрутизации и об'единения с помощью мостов. Дополнительная информация об об'единении сетей с помощью мостов приведена в Главе 3 "Основы Об'единения сетей с помощью мостов".
Тема маршрутизации освещалась в научной литературе о компьютерах более 2-х десятилетий, однако с коммерческой точки зрения маршрутизация приобрела популярность только в 1970 гг. В течение этого периода сети были довольно простыми, гомогенными окружениями. Крупномасштабное об'единение сетей стало популярно только в последнее время.
Маршрутизация включает в себя два основных компонента: определение оптимальных трактов маршрутизации и транспортировка информационых групп (обычно называемых пакетами) через об'единенную сеть. В настоящей работе последний из этих двух компонентов называется коммутацией. Коммутация относительно проста. С другой стороны, определение маршрута может быть очень сложным процессом.
Определение маршрута может базироваться на различных показателях (величинах, результирующих из алгоритмических вычислений по отдельной переменной - например, длина маршрута) или комбинациях показателей. Программные реализации алгоритмов маршрутизации высчитывают показатели маршрута для определения оптимальных маршрутов к пункту назначения.
Для облегчения процесса определения маршрута, алгоритмы маршрутизации инициализируют и поддерживают таблицы маршрутизации, в которых содержится маршрутная информация. Маршрутная информация изменяется в зависимости от используемого алгоритма маршрутизации.
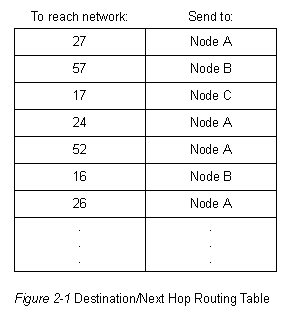
Алгоритмы маршрутизации заполняют маршрутные таблицы неким множеством информации. Ассоциации "Пункт назначения/следующая пересылка" сообщают роутеру, что определенный пункт назначения может быть оптимально достигнут путем отправки пакета в определенный роутер, представляющий "следующую пересылку" на пути к конечному пункту назначения. При приеме поступающего пакета роутер проверяет адрес пункта назначения и пытается ассоциировать этот адрес со следующей пересылкой. На рис. 2-1 приведен пример маршрутной таблицы "место назначения/следующая пересылка".
В маршрутных таблицах может содержаться также и другая информация. "Показатели" обеспечивают информацию о желательности какого-либо канала или тракта. Роутеры сравнивают показатели, чтобы определить оптамальные маршруты. Показатели отличаются друг oт друга в зависимости от использованной схемы алгоритма маршрутизации. Далее в этой главе будет представлен и описан ряд общих показателей.
Роутеры сообщаются друг с другом (и поддерживают свои маршрутные таблицы) путем передачи различных сообщений. Одним из видов таких сообщений является сообщение об "обновлении маршрутизации". Обновления маршрутизации обычно включают всю маршрутную таблицу или ее часть. Анализируя информацию об обновлении маршрутизации, поступающую ото всех роутеров, любой из них может построить детальную картину топологии сети. Другим примером сообщений, которыми обмениваются роутеры, является "об'явление о состоянии канала". Об'явление о состоянии канала информирует другие роутеры о состоянии кааналов отправителя. Канальная информация также может быть использована для построения полной картины топологии сети. После того, как топология сети становится понятной, роутеры могут определить оптимальные маршруты к пунктам назначения.
Алгоритмы коммутации сравнительно просты и в основном одинаковы для большинства протоколов маршрутизации. В большинстве случаев главная вычислительная машина определяет необходимость отправки пакета в другую главную вычислительную машину. Получив определенным способом адрес роутера, главная вычислительная машина-источник отправляет пакет, адресованный специально в физический адрес роутера (уровень МАС), однако с адресом протокола (сетевой уровень) главной вычислительной машины пункта назначения.
После проверки адреса протокола пункта назначения пакета роутер определяет, знает он или нет, как передать этот пакет к следующему роутеру. Во втором случае (когда роутер не знает, как переслать пакет) пакет, как правило, игнорируется. В первом случае роутер отсылает пакет к следующей роутеру путем замены физического адреса пункта назначения на физический адрес следующего роутера и последующей передачи пакета.
Следующая пересылка может быть или не быть главной вычислительной машиной окончательного пункта назначения. Если нет,то следующей пересылкой, как правило, является другой роутер, который выполняет такой же процесс принятия решения о коммутации. По мере того, как пакет продвигается через об'единенную сеть, его физический адрес меняется, однако адрес протокола остается неизменным. Этот процесс иллюстрируется на Рис. 2-2.
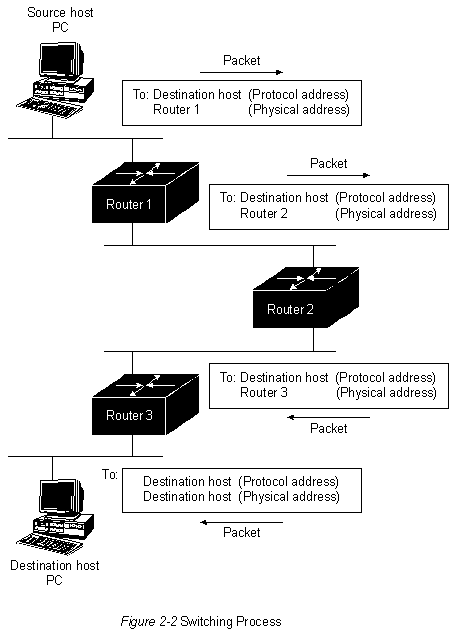
В изложенном выше описании рассмотрена коммутация между источником и системой конечного пункта назначения. Международная Организация по Стандартизации (ISO) разработала иерархическую терминологию, которая может быть полезной при описании этого процесса. Если пользоваться этой терминологией, то устройства сети, не обладающие способностью пересылать пакеты между подсетями, называются конечными системами (ЕS), в то время как устройства сети, имеющие такую способность, называются промежуточными системами (IS). Промежуточные системы далее подразделяются на системы, которые могут сообщаться в пределах "доменов мааршрутизации" ("внутридоменные" IS), и системы, которые могут сообщаться как в пределах домена маршрутизации, так и с другими доменами маршрутизации ("междоменные IS"). Обычно считается, что "домен маршрутизации" - это часть об'единенной сети, находящейся под общим административным управлением и регулируемой пределенным набором административных руководящих принципов. Домены маршрутизации называются также "автономными системами" (AS). Для опрелеленных протоколов домены маршрутизации могут быть дополнительно подразделены на "участки маршрутизации", однако для коммутации как внутри участков, так и между ними также используются внутридоменные протоколы маршрутизации.
Алгоритмы маршрутизации можно дифференцировать, основываясь на нескольких ключевых характеристиках. Во-первых, на работу результирующего протокола маршрутизации влияют конкретные задачи, которые решает разработчик алгоритма. Во-вторых, существуют различные типы алгоритмов маршрутизации, и каждый из них по-разному влияет на сеть и ресурсы маршрутизации. И наконец, алгоритмы маршрутизации используют разнообразные показатели, которые влияют на расчет оптимальных маршрутов. В следующих разделах анализируются эти атрибуты алгоритмов маршрутизации.
Цели разработки алгоритмов маршрутизации
При разработке алгоритмов маршрутизации часто преследуют одну или несколько из перечисленных ниже целей:
Оптимальность, вероятно, является самой общей целью разработки. Она характеризует способность алгоритма маршрутизации выбирать "наилучший" маршрут. Наилучший маршрут зависит от показателей и от "веса" этих показателей, используемых при проведении расчета. Например, алгоритм маршрутизации мог бы использовать несколько пересылок с определенной задержкой, но при расчете "вес" задержки может быть им оценен как очень значительный. Естественно, что протоколы маршрутизации дожны строгo определять свои алгоритмы расчета показателей.
Простота и низкие непроизводительные затраты
Алгоритмы маршрутизации разрабатываются как можно более простыми. Другими словами, алгоритм маршрутизации должен эффективно обеспечивать свои функциональные возможности, с мимимальными затратами программного обеспечения и коэффициентом использования. Особенно важна эффективность в том случае, когда программа, реализующая алгоритм маршрутизации, должна работать в компьютере с ограниченными физическими ресурсами.
Алгоритмы маршрутизации должны обладать живучестью.
Другими словми, они должны четко функционировать в случае
неординарных или непредвиденных обстоятельств, таких как
отказы аппаратуры, условия высокой нагрузки и некорректные
реализации. Т.к. роутеры расположены в узловых точках
сети, их отказ может вызвать значительные проблемы.
Часто наилучшими алгоритмами маршрутизации
оказываются те, которые выдержали испытание временем и
доказали свою надежность в различных условиях работы сети.
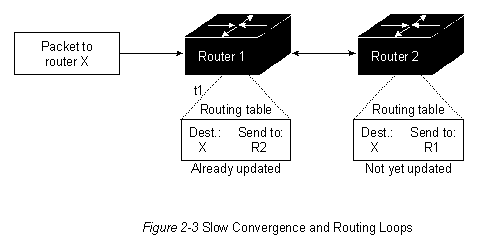
Алгоритмы маршрутизации должны быстро сходиться. Сходимость - это процесс соглашения между всеми роутерами по оптимальным маршрутам. Когда какое-нибудь событие в сети приводит к тому, что маршруты или отвергаются, или ставновятся доступными, роутеры рассылают сообщения об обновлении маршрутизации. Сообщения об обновлении маршрутизации пронизывают сети, стимулируя пересчет оптимальных маршрутов и, в конечном итоге, вынуждая все роутеры придти к соглашению по этим маршрутам. Алгоритмы мааршрутизации, которые сходятся медленно, могут привести к образованию петель маршрутизации или выходам из строя сети.
На Рис. 2-3 изображена петля маршрутизации. В данном
случае, в момент времени t1 к роутеру 1 прибывает
пакет. Роутер 1 уже был обновлен и поэтому он знает,
что оптимальный маршрут к пункту назначения требует, чтобы
следующей остановкой был роутер 2. Поэтому
роутер 1 пересылает пакет в роутер 2. Роутер 2
еще не был обновлен, поэтому он полагает, что следующей
оптимальной пересылкой должен быть роутер 1.
Поэтому роутер 2 пересылает пакет обратно в
роутер 1. Пакет будет продолжать скакать взад и вперед
между двумя роутерами до тех пор, пока роутер 2
не получит корректировку маршрутизации, или пока число
коммутаций данного пакета не превысит допустимого
максимального числа.
Алгоритмы маршрутизации должны быть также гибкими. Другими словами, алгоритмы маршрутизации должны быстро и точно адаптироваться к разнообразным обстоятельствам в сети. Например, предположим, что сегмент сети отвергнут. Многие алгоритмы маршрутизации, после того как они узнают об этой проблеме, быстро выбирают следующий наилучший путь для всех маршрутов, которые обычно используют этот сегмент. Алгоритмы маршрутизации могут быть запрограммированы таким образом, чтобы они могли адаптироваться к изменениям полосы пропускания сети, размеров очереди к роутеру, величины задержки сети и других переменных.
Алгоритмы маршрутизации могут быть классифицированы по типам. Например, алгоритмы могут быть:
Статические или динамические алгоритмы
Статические алгоритмы маршрутизации вообще вряд ли являются алгоритмами. Распределение статических таблиц маршрутизации устанавливется администратором сети до начала маршрутизации. Оно не меняется, если только администратор сети не изменит его. Алгоритмы, использующие статические маршруты, просты для разработки и хорошо работают в окружениях, где трафик сети относительно предсказуем, а схема сети относительно проста.
Т.к. статические системы маршрутизации не могут реагировать на изменения в сети, они, как правило, считаются непригодными для современных крупных, постоянно изменяющихся сетей. Большинство доминирующих алгоритмов маршрутизации 1990гг. - динамические.
Динамические алгоритмы маршрутизации подстраиваются к изменяющимся обстоятельствам сети в масштабе реального времени. Они выполняют это путем анализа поступающих сообщений об обновлении маршрутизации. Если в сообщении указывается, что имело место изменение сети, программы маршрутизации пересчитывают маршруты и рассылают новые сообщения о корректировке маршрутизации. Такие сообщения пронизывают сеть, стимулируя роутеры заново прогонять свои алгоритмы и соответствующим образом изменять таблицы маршрутизации. Динамические алгоритмы маршрутизации могут дополнять статические маршруты там, где это уместно. Например, можно разработать "роутер последнего обращения" (т.е. роутер, в который отсылаются все неотправленные по определенному маршруту пакеты). Такой роутер выполняет роль хранилища неотправленных пакетов, гарантируя, что все сообщения будут хотя бы определенным образом обработаны.
Одномаршрутные или многомаршрутные алгоритмы
Некоторые сложные протоколы маршрутизации обеспечивают множество маршрутов к одному и тому же пункту назначения. Такие многомаршрутные алгоритмы делают возможной мультиплексную передачу трафика по многочисленным линиям; одномаршрутные алгоритмы не могут делать этого. Преимущества многомаршрутных алгоритмов очевидны - они могут обеспечить заначительно большую пропускную способность и надежность.
Одноуровневые или иерархические алгоритмы
Некоторые алгоритмы маршрутизации оперируют в плоском пространстве, в то время как другие используют иерархиии маршрутизации. В одноуровневой системе маршрутизации все роутеры равны по отношению друг к другу. В иерархической системе маршрутизации некоторые роутеры формируют то, что составляет основу (backbone - базу) маршрутизации. Пакеты из небазовых роутеров перемещаются к базовыи роутерам и пропускаются через них до тех пор, пока не достигнут общей области пункта назначения. Начиная с этого момента, они перемещаются от последнего базового роутера через один или несколько небазовых роутеров до конечного пункта назначения.
Системы маршрутизации часто устанавливают логические группы узлов, называемых доменами, или автономными системами (AS), или областями. В иерархических системах одни роутеры какого-либо домена могут сообщаться с роутерами других доменов, в то время как другие роутеры этого домена могут поддерживать связь с роутеры только в пределах своего домена. В очень крупных сетях могут существовать дополнительные иерархические уровни. Роутеры наивысшего иерархического уровня образуют базу маршрутизации.
Основным преимуществом иерархической маршрутизации является то, что она имитирует организацию большинства компаний и следовательно, очень хорошо поддерживает их схемы трафика. Большая часть сетевой связи имеет место в пределах групп небольших компаний (доменов). Внутридоменным роутерам необходимо знать только о других роутерах в пределах своего домена, поэтому их алгоритмы маршрутизации могут быть упрощенными. Соответственно может быть уменьшен и трафик обновления маршрутизации, зависящий от используемого алгоритма маршрутизации.
Алгоритмы с игнтеллектом в главной вычислительной машине или в роутере
Некоторые алгоритмы маршрутизации предполагают, что конечный узел источника определяет весь маршрут. Обычно это называют маршрутизацией от источника. В системах маршрутизации от источника роутеры действуют просто как устойства хранения и пересылки пакета, без всякий раздумий отсылая его к следующей остановке.
Другие алгоритмы предполагают, что главные вычислительные машины ничего не знают о маршрутах. При использовании этих алгоритмов роутеры определяют маршрут через об'единенную сеть, базируясь на своих собственных расчетах. В первой системе, рассмотренной выше, интеллект маршрутизации находится в главной вычислительной машине. В системе, рассмотренной во втором случае, интеллектом маршрутизации наделены роутеры.
Компромисс между маршрутизацией с интеллектом в главной вычислительной машине и маршрутизацией с интеллектом в роутере достигается путем сопоставления оптимальности маршрута с непроизводительными затратами трафика. Системы с интеллектом в главной вычислительной машине чаще выбирают наилучшие маршруты, т.к. они, как правило, находят все возможные маршруты к пункту назначения, прежде чем пакет будет действительно отослан. Затем они выбирают наилучший мааршрут, основываясь на определении оптимальности данной конкретной системы. Однако акт определения всех маршрутов часто требует значительного трафика поиска и большого об'ема времени.
Внутридоменные или междоменные алгоритмы
Некоторые алгоритмы маршрутизации действуют только в пределах доменов; другие - как в пределах доменов, так и между ними. Природа этих двух типов алгоритмов различная. Поэтому понятно, что оптимальный алгоритм внутридоменной маршрутизации не обязательно будет оптимальным алгоритмом междоменной маршрутизации.
Алгоритмы состояния канала или вектора расстояния
Алгоритмы состояния канала (известные также как алгоритмы "первоочередности наикратчайшего маршрута") направляют потоки маршрутной информации во все узлы об'единенной сети. Однако каждый роутер посылает только ту часть маршрутной таблицы, которая описывает состояние его собственных каналов. Алгоритмы вектора расстояния ( известные также как алгоритмы Бэлмана-Форда) требуют от каждогo роутера посылки всей или части своей маршрутной таблицы, но только своим соседям. Алгоритмы состояния каналов фактически направляют небольшие корректировки по всем направлениям, в то время как алгоритмы вектора расстояний отсылают более крупные корректировки только в соседние роутеры.
Отличаясь более быстрой сходимостью, алгоритмы состояния каналов несколько меньше склонны к образованию петель маршрутизации, чем алгоритмы вектора расстояния. С другой стороны, алгоритмы состояния канала характеризуются более сложными расчетами в сравнении с алгоритмами вектора расстояний, требуя большей процессорной мощности и памяти, чем алгоритмы вектора расстояний. Вследствие этого, реализация и поддержка алгоритмов состояния канала может быть более дорогостоящей. Несмотря на их различия, оба типа алгоритмов хорошо функционируют при самых различных обстоятельствах.
Показатели алгоритмов (метрики)
Маршрутные таблицы содержат информацию, которую используют программы коммутации для выбора наилучшего маршрута. Чем характеризуется построение маршрутных таблиц? Какова особенность природы информации, которую они содержат? В данном разделе, посвященном показателям алгоритмов, сделана попытка ответить на вопрос о том, каким образом алгоритм определяет предпочтительность одного маршрута по сравнению с другими.
В алгоритмах маршрутизации используется много различных показателей. Сложные алгоритмы маршрутизации при выборе маршрута могут базироваться на множестве показателей, комбинируя их таким образом, что в результате получается один отдельный (гибридный) показатель. Ниже перечислены показатели, которые используются в алгоритмах маршрутизации:
Длина маршрута является наиболее общим показателем маршрутизации. Некоторые протоколы маршрутизации позволяют администраторам сети назначать произвольные цены на каждый канал сети. В этом случае длиной тракта является сумма расходов, связанных с каждым каналом, который был траверсирован. Другие протоколы маршрутизации определяют "количество пересылок", т.е. показатель, характеризующий число проходов, которые пакет должен совершить на пути от источника до пункта назначения через изделия об'единения сетей (такие как роутеры).
Надежность, в контексте алгоритмов маршрутизации, относится к надежности каждого канала сети (обычно описываемой в терминах соотношения бит/ошибка). Некоторые каналы сети могут отказывать чаще, чем другие. Отказы одних каналов сети могут быть устранены легче или быстрее, чем отказы других каналов. При назначении оценок надежности могут быть приняты в расчет любые факторы надежности. Оценки надежности обычно назначаются каналам сети администраторами сети. Как правило, это произвольные цифровые величины.
Под задержкой маршрутизации обычно понимают отрезок времени, необходимый для передвижения пакета от источника до пункта назначения через об'единенную сеть. Задержка зависит от многих факторов, включая полосу пропускания промежуточных каналов сети, очереди в порт каждого роутера на пути передвижения пакета, перегруженность сети на всех промежуточных каналах сети и физическое расстояние, на которое необходимо переместить пакет. Т.к. здесь имеет место конгломерация нескольких важных переменных, задержка является наиболее общим и полезным показателем.
Полоса пропускания относится к имеющейся мощности трафика какого-либо канала. При прочих равных показателях, канал Ethernet 10 Mbps предпочтителен любой арендованной линии с полосой пропускания 64 Кбайт/сек. Хотя полоса пропускания является оценкой максимально достижимой пропускной способности канала, маршруты, проходящие через каналы с большей полосой пропускания, не обязательно будут лучше маршрутов, проходящих через менее быстродействующие каналы. Например, если более быстродействующий канал почти все время занят, то фактическое время, необходимое для отправки пакета в пункт назначения, для этого быстродействующего канала может оказаться больше.
Нагрузка относится к степени занятости какого-либо источника сети (такого, как роутер). Нагрузка может быть вычислена разнообразными способами, в том числе по коэффициенту использования главного процессора и числу пакетов, обработанных в секунду. Постоянный контроль этих параметров может привести к интенсивному расходованию ресурсов.
Другим важным показателем является стоимость связи. Некоторые компании интересует не столько эффективность, сколько операционные расходы. Даже если задержка в их линии может быть большой, они отправят пакеты через свои собственные линии, а не через линии общего пользования, т.к. им ридется платить за использованное время.
Как правило, термины "routed protocol" и "routing protocol" Постоянно путают. Routed protocol - это протокол, отправленный по определенному маршруту через об'единеннувю сеть. Примерами таких протоколов являются Internet Protocol (IP), DECnet и Apple Talk. "Routing protocol" - это протокол, который реализует алгоритм маршрутизации. Если изложить это просто, они отправляют протоколы по определенному маршруту через об'единенную сеть. Примерами таких протоколов могут быть Interior Gateway Routing Protocol (IGRP), Open Shortest Path First (OSPF), Intermediate System to Intermediate System (IS-IS) и Routing Information Pwrotocol (RIP).
Серийное изготовление мостов началось в начале 1980гг. В то время, когда они появились, мосты о'единяли гомогенные сети, делая возможным прохождение пакетов между ними. В последнее время об'единение различных сетей с помощью мостов также было определено и стандартизировано.
На первый план выдвинулись несколько видов об'единений с помощью мостов. В окружениях Ethernet в основном встречается "transparent bridging" (прозрачное соединение). В окружениях Token Ring в первую очередь используется "Source-route bridging" (соединение маршрут- источник). "Translational bridging" (трансляционное соединение) обеспечивает трансляцию между форматами и принципами передачи различных типов сред (обычно Ethernet и Token Ring). "Source-route transparent bridging" (прозрачное соединение маршрут-источник) об'единяет алгоритмы прозрачного соединения и соединения маршрут- источник, что позволяет передавать сообщения в смешанных окружениях Ethernet/Token Ring.
Уменьшающиеся цены на роутеры и введение во многие из них возможности соединять по мостовой схеме, сделанное в последнее время, значительно сократило долю рынка чистых мостов. Те мосты, которые уцелели, обладают такими характеристиками, как сложные схемы фильтрации, псевдоинтеллектуальный выбор маршрута и высокая производительность. В то время как в конце 1980гг шли бурные дебаты о преимуществах соединения с помощью мостов в сравнении с роутерами, в настоящее время большинство пришло к выводу, что часто оба устройства необходимы в любой полной схеме об'единения сетей.
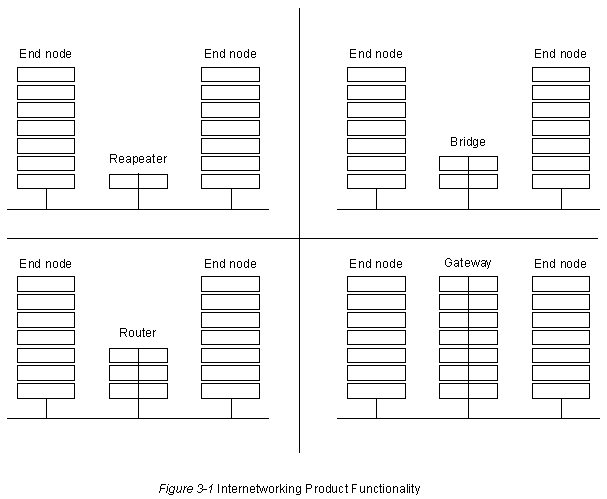
Устройства об'единения сетей обеспечивают связь между сегментами локальных сетей (LAN). Существуют 4 основных типа устройств об'единения сетей: повторители, мосты, роутеры и межсетевые интерфейсы. Эти устройства в самом общем виде могут быть дифференцированы тем уровнем "Межсоединений Открытых Систем" (OSI), на котором они устанавливают соединение между LAN. Повторители соединяют LAN на Уровне 1 OSI; мосты соединяют LAN на Уровне 2; роутеры соединяют LAN на Уровне 3; межсетевые интерфейсы соединяют LAN на Уровнях 4-7. Каждое устройство обеспечивает функциональные возможности, соответствующие своему уровню, а также использует функциональные возможности всех более низких уровней. Эта положение иллюстрируется графически на Рис. 3-1.
Уровень, на котором находит применение об'единение с помощью мостов (называемый канальным уровнем), контролирует поток информации, обрабатывает ошибки передачи, обеспечивает физическую (в отличие от логической) адресацию и управляет доступом к физической среде. Мосты обеспечивают выполнение этих функций путем поддержки различных протоколов канального уровня, которые предписывают определенный поток информации, обработку ошибок, адресацию и алгоритмы доступа к носителю. В качестве примеров популярных протоколов канального уровня можно назвать Ethernet, Token Ring и FDDI.
Мосты - несложные устройства. Они анализируют поступающие фреймы, принимают решение о их продвижении, базируясь на информации, содержащейся в фрейме, и пересылает их к месту назначения. В некоторых случаях (например, при об'единении "источник-маршрут") весь путь к месту назначения содержится в каждом фрейме. В других случаях (например, прозрачное об'единение) фреймы продвигаются к месту назначения отдельными пересылками, по одной за раз. Дополнительная информация по соединению источник-маршрут и прозрачному соединению приведена соответственно в главе 30 "Соединение по мостовой схeмe Источник-Маршрут" и главе 29 "Прозрачное об'единение с помощью мостов".
Основным преимуществом об'единения с помощью мостов является прозрачность протоколов верхних уровней. Т.к. мосты оперируют на канальном уровне, от них не требуется проверки информации высших уровней. Это означает, что они могут быстро продвигать трафик, представляющий любой протокол сетевого уровня. Обычным делом для моста является продвижение Apple Talk, DECnet, TCP/IP, XNS и другого трафика между двумя и более сетями.
Мосты способны фильтровать фреймы, базирующиеся на любых полях Уровня 2. Например, мост можно запрограммировать так, чтобы он отвергал (т.е. не пропускал) все фреймы, посылаемые из определенной сети. Т.к. в информацию канального уровня часто включается ссылка на протокол высшего уровня, мосты обычно фильтруют по этому параметру. Кроме того, мосты могут быть полезны, когда они имеют дело с необязательной информацией пакетов широкой рассылки.
Разделяя крупные сети на автономные блоки, мосты обеспечивают ряд преимуществ. Во-первых, поскольку пересылается лишь некоторый процент трафика, мосты уменьшают трафик, проходящий через устройства всех соединенных сегментов. Во-вторых, мосты действуют как непреодолимая преграда для некоторых потенциально опасных для сети неисправностей. В-третьих, мосты позволяют осуществлять связь между большим числом устройств, чем ее можно было бы обеспечить на любой LAN, подсоединенной к мосту, если бы она была независима. В-четвертых, мосты увеличивают эффективную длину LAN, позволяя подключать еще не подсоединенные отдаленные станции.
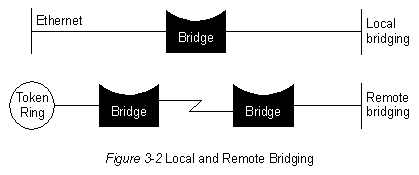
Мосты можно сгруппировать в категории, базирующиеся на различных характеристиках изделий. В соответствии с одной из популярных схем классификации мосты бывают локальные и дистанционные. Локальные мосты обеспечивают прямое соединение множества сегментов LAN, находящихся на одной территории. Дистанционные мосты соединяют множество сегментов LAN на различных территориях, обычно через телекоммуникационные линии. Эти две конфигурации представлены на Рис. 3-2.
Дистанционное мостовое соединение представляет ряд уникальных трудностей об'единения сетей. Одна из них - разница между скоростями LAN и WAN (глобальная сеть). Хотя в последнее время в географически рассредоточенных об'единенных сетях появилось несколько технологий быстродействующих WAN, скорости LAN часто на порядок выше скоростей WAN. Большая разница скоростей LAN и WAN иногда не позволяет пользователям прогoнять через WAN применения LAN, чуствительные к задержкам.
Дистанционные мосты не могут увеличить скорость WAN, однако они могут компенсировать несоответствия в скоростях путем использования достаточных буферных мощностей. Если какое-либо устройство LAN, способной передавать со скоростью 3 Mb/сек, намерено связаться с одним из устройств отдаленной LAN, то локальный мост должен регулировать поток информации, передаваемой со скоростью 3Mb/сек, чтобы не переполнить последовательный канал, который пропускает 64 Kb/сек. Это достигается путем накопления поступающей информации в расположенных на плате буферах и посылки ее через последовательный канал со скоростью, которую он может обеспечить. Это осуществимо только для коротких пакетов информации, которые не переполняют буферные мощности моста.
IEEE (Институт инженеров по электротехнике и радиоэлектронике) поделил канальный уровень OSI на два отдельных подуровня: подуровень MAC (Управление доступом к носителю) и подуровень LLC (Управление логическим каналом). МАС разрешает и оркестрирует доступ к носителю (Например, конфликтные ситуации, эстафетная передача и др.), в то время как подуровень LLC занят кадрированием, управлением потоком информации, управлением неисправностями и адресацией подуровня МАС.
Некоторые мосты являются мостами подуровня МАС. Эти устройства образуют мост между гомогенными сетями (например, IEEE 802.3 и IEEE 802.3). Другие мосты могут осуществлять трансляцию между различными протоколами канального уровня (например, IEEE 802.3 и IEEE 802.5). Базовый механизм такой трансляции показан на Рис. 3-3.

На Рис. 3-3 главная вычислительная машина IEEE 802.3 (Главная вычислительная машина А) формулирует пакет, содержащий прикладную информацию, и герметизирует этот пакет в совместимый с IEEE 802.3 фрейм для передачи через среду IEEE 802.3 в мост. Внутри моста фрейм освобождается от заголовка IEEE 802.3 в подуровне МАС канального уровня и затем передается выше в подуровень LLC для дальнейшей обработки. После обработки пакет снова передается вниз в реализацию IEEE 802.5, которая герметизирует пакет в заголовок IEEE 802.5 для передачи через сеть IEEE 802.5 в главную вычислительную машину IEEE 802.5 (Главная вычислительная машина В).
Трансляция, осуществляемая мостом между различными типами сетей, никогда не бывает безупречной, т.к. всегда имеется вероятность, что одна сеть поддержит определенный фрейм, который не поддерживается другой сетью. Эту ситуацию можно считать примерно аналогичной проблеме, с которой сталкивается эскимос, пытающийся перевести на английский некоторые слова из тех 50 слов, которые обозначают "снег. Более подробно многие из вопросов трансляции через мосты обсуждаются в Главе 31 "Об'единение различных сред с помощью мостов".
Алгоритм Source-Route Bridging (SRB) (об'единение с помощью мостов "источник-маршрут") был разработан IBM и предложен комитету IEEE 802.1 в качестве средства об'единения локальных сетей с помощью мостов. После того, как комитет предпочел другой конкурирующий стандарт (смотри Главу 29 "Прозрачное об'единение с помощью мостов" о стандарте ТВ), сторонники SRB предложили его комитету IEEE 802.5, который впоследствии включил его в спецификацию локальной сети IEEE 802.5/Token Ring.
За первым предложением IBM последовало предложение нового стандарта об'единения с помощью мостов в комитет IEEE 802: Source-Route Transparent (SRT) (Прозрачное об'единение "источник-маршрут") Подробная информация о SRT дается в Главе 31 "Mixed-Media Bridging". SRT полностью устраняет мосты "источник-маршрут" (SRB), предлагая взамен два типа мостов LAN-TB и SRT. Несмотря на то, что SRT получил одобрение, мосты SRB попрежнему широко применяются в сетях.
Свое название мосты SRB получили потому, что они предполагают размещение полного маршрута от источника до пункта назначения во всех межсетевых (LAN) блоках данных, отправляемых источником. SRB хранят и продвигают эти блоки данных в соответствии с указаниями о маршруте, содержащимися в соответствующем поле блока данных. На Рис. 30-1 представлен образец сети SRB.

Предположим, что Хост Х на Рис. 30-1 решила отправить блок данных в Хост Y. Вначале машина Х не знает, где находится машина Y-в той же или в другой LAN. Чтобы определить это, она отправляет тестовый блок данных. Если этот блок данных возвращается к ней без положительного указания о том, что машина Y видела его, то она должна предположить, что машина Y находится в отдаленном сегменте.
Чтобы точно определить местоположение отдаленной машины Y, машина Х отправляет блок данных разведчика (explorer). Каждый мост, получающий этот блок данных (в нашем примере это Мосты 1 и 2), копирует его во все порты отправки сообщений. По мере продвижения блоков данных-разведчиков через об'единенную сеть они дополняются маршрутной информацией. Когда блоки данных-разведчики машины Х доходят до машины Y, то машина Y отвечает каждому отдельно, используя накопленную маршрутную информацию. После получения всех ответных блоков данных машина Х может выбрать маршрут, базирующийся на заранее установленном критерии.
В примере, приведенном на Рис. 30-1, результатом этого процесса будут два маршрута:
После того, как маршрут выбран, он включается в блоки данных, предназначенных для машины Y, в форме поля маршрутной информации (routing information field - RIF). RIF включается только в блоки данных, предназначенных для других LAN. Наличие маршрутной информации в блоке данных указывается путем установки самого значащего бита, называемого битом индикатора маршрутной информации (routing information indicator - RII), в поле адреса источника.
Структура IEEE 802.5 RIF представлена на Рис. 30-2.

Подполе типа (type) в RIF указывает на количество узлов, в которые должен быть отправлен данный блок данных: в один узел, в группу узлов, включающих в себя связующее дерево данной об'единенной сети, или во все узлы. Первый тип называется "специально направленным" (specifically routed) блоком данных, второй тип - "разведчиком связующего дерева" (spanning-tree explorer), а третий тип - "разведчиком всех трактов" (all-paths explorer). Разведчик связующего дерева может быть использован в качестве транзитного механизма для блоков данных с многопунктовой адресацией. Он может быть также использован в качестве замены разведчика всех трактов в запросах об исходящих маршрутах. В этом случае пункт назначения в ответ присылает разведчика всех трактов.
Подполе длины (length) обозначает общую длину RIF в байтах.
Бит D указывает направление движения блока данных (прямое или обратное).
Поле "самый большой" (largest) обозначает самый большой блок данных, который может быть обработан вдоль всего этого маршрута.
Полей описателя маршрута (route descriptor) может быть несколько. Каждое из них содержит пару "номер кольца/номер моста", которая определяет какую-нибудь часть маршрута. Таким образом, маршруты представляют собой просто чередующиеся последовательности номеров LAN и мостов, которые начинаются и заканчиваются номерами LAN.
Прозрачные мосты (transparent bridges - TB) в основном встечаются в сетях Ethernet (смотри Главу 29 "Transparent Bridging"), в то время как мосты SRB встечаются почти исключительно в сетях Token Ring (смотри Главу 30 "Source-Route Bridging"). Оба метода об'единения сетей с помощью мостов (ТВ и SRB) популярны, поэтому естественно возникает вопрос о существовании какого-нибудь метода, который позволил бы об'единить их. Этот основной вопрос иллюстрируется Рис. 31-1 "Об'единение с помощью моста доменов ТВ и SRB".
Трансляционное об'единение с помощью мостов (Translational bridging - TLB) обеспечивает относительно недорогое решение некоторых из многочисленных проблем, связанных с об'единением с помощью моста доменов ТВ и SRB. TLB впервые появился в середине-конце 1980 гг., но ни одна из организаций по стандартам не стала заниматься им. В результате многие аспекты TLB предоставлены для решения тому, кто реализует его.
В 1990 г. IBM устранила некоторые из недостатков TLB путем введения "Прозрачного об'единения с помощью моста "источник-маршрут" (Source-Route Transparent-SRT). SRT может продвигать трафик из конечных узлов сети как с прозрачным об'единением, так и с об'единением "источник-маршрут", и образовывать общее связующее дерево с мостами TB, позволяя тем самым конечным станциям каждого типа сообщаться с конечными станциями такого же типа в сети с произвольной топологией.
В конечном итоге, целью об'единения доменов ТВ и SRB является возможность сообщения между конечными станциями ТВ и SRB. В данной главе описываются технические проблемы, которые должны быть решены алгоритмами, пытающимися сделать это, а также представлены два возможных решения: TLB и SRT.
Трудности трансляции
Существует ряд трудностей, связанных с обеспечением связи между
конечными станциями домена Ethernet/TB и конечными станциями домена
SRB/Token Ring, которые перечислены ниже:
Поскольку порядок связи между двумя типами носителя не был по-настоящему стандартизован, нет ни одной реализации TLB, которую можно назвать точной. Ниже дается описание нескольких популярных методов реализации TLB.
При трансляции между Ethernet и Token Ring протокол TLB переупорядочивает биты адреса источника и пункта назначения. Проблема встроенных адресов МАС может быть решена путем программирования моста таким образом, чтобы он проверял адреса МАС разных типов; однако это техническое решение должно адаптироваться к каждому новому типу встроенных адресов МАС. В некоторых решениях TLB просто проверяются наиболее популярные встроенные адреса МАС. Если программное обеспечение TLB работает в роутере с несколькими протоколами, то этот роутер может успешно назначать тракты для этих протоколов и полностью решить эту проблему.
Поле RIF имеет подполе, которое указывает размер самого большого блока данных, который может быть принят конкретной реализацией SRB. TLB, отправляющие блоки данных из домена ТВ в домен SRB, обычно устанавливают значение поля размера MTU равным 1500 для того, чтобы ограничить размер блоков данных Token Ring, входящих в домен ТВ. Некоторые хосты не могут точно обрабатывать это поле; в этом случае TLB вынуждены просто игнорировать те блоки данных, которые превышают размер MTU Еthernet.
Биты, представляющие функции Token Ring, не имеющие следствия в Ethernet, обычно отбрасываются протоколами TLB. Например, отбрасываются биты приоритета, резервирования и монитора Token Ring. Что касается битов состояния блоков данных Token Ring, то они обрабатываются по-разному в зависимости от изготовителя TLB. Некоторые изготовители TLB просто игнорируют эти биты. Другие обеспечивают установку в мостах бита С, но не обеспечивают бит А. В первом случае узел источника Token Ring не имеет возможности установить, потерян или нет отправленный им блок данных. Сторонники этого метода считают, что механизмы надежности, такие, как отслеживание потерянных блоков данных, лучше реализовать в уровне 4 модели ОSI. Защитники "метода установки бита С" утверждают, что этот бит должен быть задан для отслеживания потерянных блоков данных, но бит А не может быть установлен, т.к. мост не является конечным пунктом назначения.
TLB могут образовывать программный мост между двумя доменами. Для конечных станций SRB мост TLB выглядит как стандартный SRB, т.к. он имеет номер кольца и номер моста, связанного с ним. В этом случае номер кольца фактически отражает весь домен ТВ. Для домена ТВ, TLB является просто еще одним ТВ.
При об'единении с помощью моста доменов SRB и ТВ информация SRB удаляется. RIF обычно сохраняются в кэш для использования последующим возвратным трафиком. При об'единении с помощью моста доменов ТВ и SRB, TLB может проверить блок данных, чтобы узнать, имеет ли он назначение многопунктовой адресации. Если блок данных имеет многопунктовое или широковещательное назначение, он отправляется в домен SRB в качестве разведчика связующего дерева. Если блок данных имеет однопунктовый адрес, то TLB ищет пункт назначения в кэш RIF. Если тракт найден, то он будет использован, а информация RIF включается в блок данных; в противном случае этот блок данных отправляется в качестве разведчика связующего дерева. Т.к. две этих реализации связующего дерева несовместимы, то, как правило, не разрешаются несколько трактов между доменами SRB и ТВ.
SRT комбинируют реализации алгоритмов ТВ и SRB. SRT используют бит индикатора маршрутной информации (routing information indicator - RII), чтобы отличать блоки данных, использующих SRB, от блоков данных, использующих ТВ. Если бит RII равен 1, то RIF присутствует в блоке данных, и данный мост использует алгоритм SRB. Если RII равен 0, то RIF oтсутствует, и данный мост использует ТВ.
Как и мосты TLB, мосты SRT не являются техническим решением, совершенным с точки зрения решения проблем об'единения с помощью мостов смешанных носителей. SRT также должны иметь дело с описанными выше несовместимостями Ethernet/Token Ring. Скорее всего, SRT потребует расширения аппаратных возможностей SRB, чтобы они могли справляться с дополнительной нагрузкой, связанной с анализом каждого пакета. Может потребоваться также программное наращивание SRB. Кроме того, в окружениях смешанных SRT, TB и SRB, выбранные маршруты источника должны пересекать любые доступные SRT и SRB. Результирующие тракты могут быть потенциально значительно хуже маршрутов связующего дерева, образованных мостами ТВ. И наконец, смешанные сети SRB/SRT теряют преимущества SRT, поэтому пользователи поймут, что они вынуждены осуществить полный переход к SRT, требующий значительных расходов. Однако SRT позволяет сосуществование двух несовместимых сред и обеспечивает связь между конечными узлами SRB и ТВ.
Прозрачные мосты (TB) были впервые разработаны Digital Equipment Corporation в начале 1980 гг. Digital представила свою работу в IEEE, который включил ее в стандарт IEEE 802.1. TB очень популярны в сетях Ethernet/IEEE 802.3.
ТВ названы так потому, что их присутствие и работа являются прозрачными для хостов сети. После подачи питания на ТВ, они узнают о топологии сети путем анализа адреса источника блоков данных, приходящих из всех других подключенных сетей. Например, если мост видит, что какой-нибудь блок данных поступил на линию 1 из Хоста А, он делает вывод, что до Хоста А можно добраться через сеть, подключенную к линии 1. С помощью этого процесса ТВ строят таблицу, приведенную на Рис. 29-1.

Мост использует свою таблицу в качестве базиса для продвижения трафика. Когда на один из интерфейсов моста принят блок данных, мост ищет адрес пункта назначения этого блока данных в своей внутренней таблице. Если таблица содержит взаимосвязь между адресом пункта назначения и любым из портов этого моста, за исключением того, в которой был принят этот блок данных, то блок данных продвигается из указанного порта. Если не найдено никакой взаимосвязи, то блок данных отправляется лавинной адресацией во все порты, кроме порта вхождения блока данных. Широковещательные сообщения и сообщения многопунктовой адресации также отправляются лавинной адресацией таким же образом.
ТВ успешно изолирует внутрисегментный трафик, тем самым сокращая трафик, видимый в каждом отдельном сегменте. Это обычно улучшает время реакции сети, видимое пользователю. Степень сокращения трафика и улучшения времени реакции зависят от об'ема межсегментного трафика относительно общего трафика, а также от об'ема широковещательного и многопунктового трафика.
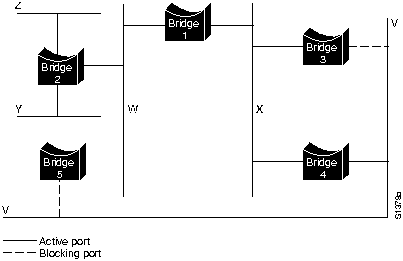
Без протокола взаимодействия между мостами алгоритм ТВ отказывает, когда между двумя любыми LAN об'единенной сети имеется несколько трактов, включающих в себя мосты и локальные сети. Образование петли при об'единении с помощью мостов показано на Рис. 29-2 "Неправильное продвижение пакетов и узнавание информации в средах прозрачного об'единения".

Предположим, что Хост А отправляет блок данных в Хост В. Оба моста принимают этот блок данных и и делают правильный вывод о том, что машина А находится в сети 2. К сожалению, после того, как машина В примет два экземпляра блока данных машины А, оба моста снова получают этот же блок данных на свои интерфейсы с Сетью 1, т.к. все хосты принимают все сообщения широковещательных LAN. В некоторых случаях мосты затем изменяют свои внутренние таблицы, чтобы указать, что машина А находится в Сети 1. В этом случае при ответе машины В на блок данных машины А оба моста примут, а затем проигнорируют эти ответы, т.к. их таблицы укажут, что данный пункт назначения (машина А) находится в том же сегменте сети, что и источник этого блока данных.
Помимо основных проблем связности, подобных описанной выше, потенциально серьезной проблемой является размножение широковещательных сообщений в сетях с петлями. Обратившись снова к Рис. 29-2, предположим, что первоначальный блок данных машины А является широковещательным. Оба моста будут бесконечно продвигать этот блок данных, используя всю доступную ширину полосы сети и блокируя передачу других пакетов в обоих сегментах.
Топология с петлями, подобными изображенной на Рис. 29-2, может быть полезной, но также и потенциально вредной. Петля подразумевает существование нескольких трактов через об'единеннную сеть. В сети с несколькими трактами от источника до пункта назначения общая помехоустойчивость может увеличиться благодаря улучшенной топологической гибкости.
Алгоритм был разработан для того, чтобы сохранить преимущества петель, устранив их проблемы. Первоначально алгоритм был документирован корпорацией Digital - основным поставщиком Ethernet. Новый алгоритм, разработанный Digital, был впоследствии пересмотрен комитетом IEEE 802 и опубликован в спецификации IEE 802. 1d в качестве алгоритма STA.
STA предусматривает свободное от петель подмножество топологии сети путем размещения таких мостов, которые, если они включены, то образуют петли в резервном (блокирующем) состоянии. Порты блокирующего моста могут быть активированы в случае отказа основного канала, обеспечивая новый тракт через об'единенную сеть.
STA пользуются выводом из теории графов в качестве базиса для построения свободного от петель подмножества топологии сети. Теория графов утверждает следующее:

Первым шагом при вычислении связующего дерева является выбор корневого моста (root bridge), который представляет собой мост с наименьшим значением идентификатора моста. На Рис. 29-3 корневым мостом является Мост 1. Далее определяется корневой порт (root port) во всех остальных мостах. Корневой порт моста - это порт, через который можно попасть в корневой мост с наименьшими комбинированными затратами тракта. Эта величина (т.е. наименьшие комбинированные затраты тракта до корневого моста) называется затратами корневого тракта (root path cost).
И наконец, определяются назначенные мосты (designated bridges) и их назначенные порты (designated ports). Назначенный мост - это тот мост каждой локальной сети, который обеспечивает минимальные затраты корневого тракта. Назначенный мост локальной сети является единственным мостом, который позволяет продвигать блоки данных в ту локальную сеть (и из нее), для которой этот мост является назначенным. Назначенный порт локальной сети - это тот порт, который соединяет ее с назначенным мостом.
В некоторых случаях два или более мостов могут иметь одинаковые затраты корневого тракта. Например, на Рис. 29-3 как Мост 4, так и Мост 5 могут достичь Мост 1 (корневой мост) с затратами тракта 10. В этом случае снова используются идентификаторы моста, на этот раз для определения назначеных мостов. При выборе предпочтение отдано порту LAN V Моста 4 перед портом LAN V Моста 5.
При использовании этого процесса устраняются все мосты, непосредственно соединенные с каждой LAN, кроме одного; таким образом, удаляются все петли между двумя LAN. STA также устраняет петли, включающие более двух LAN, в то же время сохраняя связность. На Рис. 29-4 "Сеть ТВ после прогона STA" показаны результаты действия STA в сети, изображенной на Рис. 29-3. На Рис. 29-4 более четко показана топология дерева. Сравнение этого рисунка с рисунком сети до прогона STA показывает, что STA перевел в режим резерва как порты Моста 3 в LAN V, так и порты Moста 5 в LAN V.
Расчет связующего дерева имеет место при подаче питания на мост и во всех случаях обнаружения изменения топологии. Для расчета необходима связь между мостами связующего дерева, которая осуществляется через сообщения конфигурации (иногда называемые протокольными информационными единицами моста - bridge protocol data units, или BPDU). Сообщения конфигурации содержат информацию, идентифицирующую тот мост, который считается корневым (т.е. идентификатор корневого моста), и расстояние от моста-отправителя до корневого моста (затраты корневого тракта). Сообщения конфигурации также содержат идентификаторы моста и порта моста-отправителя, а также возраст информации, содержащейся в сообщении конфигурации.
Мосты обмениваются сообщениями конфигурации через регулярные интервалы времени (обычно 1-4 сек.). Если какой-нибудь мост отказывает (вызывая изменение в топологии), то соседние мосты вскоре обнаруживают отсутствие сообщений конфигурации и инициируют пересчет связующего дерева.
Все решения, связанные с топологией ТВ, принимаются логически. Обмен сообщениями конфигурации производится между соседними мостами. Центральные полномочия или администрация управления сетевой топологией отсутствуют.
Мосты ТВ обмениваются сообщениями конфигурации (configuration messages) и сообщениями об изменении в топологии (topology change). Мосты обмениваются сообщениями конфигурации для установления топологии сети. Сообщения об изменении топологии отправляются после обнаружения какого-нибудь изменения в топологии для указания того, что должен быть произведен повторный прогон STA.
Формат сообщения конфигурации IEEE 802.1d представлен на Рис. 29-5.

Первым полем сообщения конфигурации ТВ является поле идентификатора протокола (protocol identifier), которое содержит нулевое значение.
Вторым полем в сообщении конфигурации ТВ является поле версии (version), которое содержит нулевое значение.
Третьим полем в сообщении ТВ является поле типа сообщения (message type), которое содержит нулевое значение.
Четвертым полем в сообщении конфигурации ТВ является однобайтовое поле флагов (flags). Бит ТС сигнализирует об изменении в топологии. Бит ТСА устанавливается для подтверждения приема сообщения конфигурации с установленным битом ТС. Другие шесть битов этого байта не используются.
Следующим полем в сообщении конфигурации ТВ является поле идентификатора корневого моста (root ID). Это 8-байтовое поле идентифицирует корневой мост путем перечисления его 2-байтового приоритета, за которым следует его 6-байтовый ID.
За полем ID корневого моста идет поле затрат корневого тракта (root path cost), которое содержит затраты тракта от моста, который отправляет конфигурационное сообщение, до корневого моста.
Далее идет поле идентификатора моста (bridge ID), которое идентифицирует приоритет и ID моста, отправляющего сообщение.
Поле идентификатора порта (port ID) идентифицирует порт, из которого отправлено конфигурационное сообщшение. Это поле позволяет обнаруживать и устранять петли, образованные несколькими подключенными мостами.
Поле возраста сообщения (message age) определяет промежуток времени, прошедшего с момента отправки корневым мостом конфигурационного сообщения, на котором базируется текущее конфигурационное сообщение.
Поле максимального возраста (maximum age) указывает, когда текущее конфигурационное сообщение должно быть стерто.
Поле времени приветствия (hello time) обеспечивает период времени между конфигурационными сообщениями корневого моста.
И наконец, поле задержки продвижения (forward delay) обеспечивает промежуток времени, в течение которого мосты должны выжидать, прежде чем перейти в новое состояние после изменения в топологии. Если переходы какого-нибудь моста происходят слишком быстро, то не все каналы сети могут оказаться готовыми для изменения их состояний, в результате чего могут появиться петли.
Сообщения о топологических изменениях состоят всего из 4 байтов. Они включают в себя поле идентификатора протокола (protocol identifier), которое содержит нулевое значение, поле версии (version), которое содержит нулевое значение и поле типа сообщения (message type), которое содержит значение 128.
Начало 1980гг. ознаменовалось резким ростом в области применения сетей. Как только компании поняли, что сетевая технология обеспечивает им сокращение расходов и повышение производительности, они начали устанавливать новые и расширять уже существующие сети почти с такой же скоростью, с какой появлялись новые технологии сетей и изделия для них. К середине 1980гг. стали очевидными проблемы, число которых все более увеличивалось, связанные с этим ростом, особенно у тех компаний, которые применили много разных (и несовместимых) технологий сети.
Основными проблемами, связанными с увеличением сетей, являются каждодневное управление работой сети и стратегическое планирование роста сети. Характерным является то, что каждая новая технология сети требует свою собственную группу экспертов для ее работы и поддержки. В начале 1980гг. стратегическое планирование роста этих сетей превратилось в какой-то кошмар. Одни только требования к числу персонала для управления крупными гетерогенными сетями привели многие организации на грань кризиса. Насущной необходимостью стало автоматизированное управление сетями (включая то, что обычно называется "планированием возможностей сети"), интегрированное по всем различным окружениям.
В настоящей главе описываются технические характеристики, общие для большинства архитектур и протоколов управления сетями. В ней также представлены 5 функциональных областей управления , определенных Международной Оврганизацией по Стандартизации (ISO).
Большинство архитектур управления сети используют одну и ту же базовую структуру и набор взаимоотношений. Конечные станции (managed devices - управляемые устройства), такие как компьютерные системы и другие сетевые устройства, прогoняют программные средства, позволяющие им посылать сигналы тревоги, когда они распознают проблемы. Проблемы распознаются, когда превышен один или более порогов, заданных пользователем. Management entities (управляющие об'екты) запрограммированы таким образом, что после получения этих сигналов тревоги они реагируют выполнением одного, нескольких или группы действий, включающих:
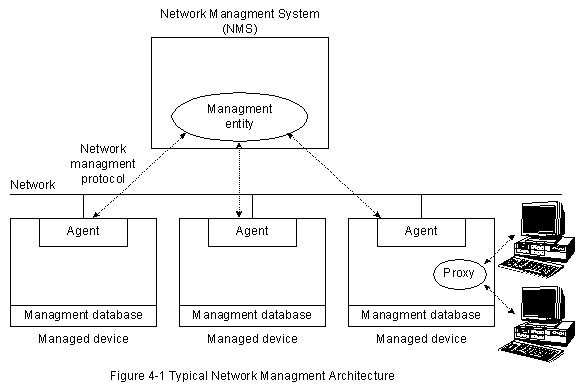
ISO внесла большой вклад в стандартизацию сетей. Модель управления сети этой организации является основным средством для понимания главных функций систем управления сети. Эта модель состоит из 5 концептуальных областей:
Цель управления эффективностью - измерение и обеспечение различных аспектов эффективности сети для того, чтобы межсетевая эффективность могла поддерживаться на приемлемом уровне. Примерами переменных эффективности, которые могли бы быть обеспечены, являются пропускная способность сети, время реакции пользователей и коэффициент использования линии.
Управление эффективностью включает несколько этапов:
Управляемые об'екты постоянно контролируют переменные эффективности. При превышении порога эффективности вырабатывается и посылается в NMS сигнал тревоги.
Каждый из описанных выше этапов является частью процесса установки реактивной системы. Если эффективность становится неприемлемой вследствие превышения установленного пользователем порога, система реагирует посылкой сообщения. Управление эффективностью позволяет также использовать проактивные методы. Например, при проектировании воздействия роста сети на показатели ее эффективности может быть использован имитатор сети. Такие имитаторы могут эффективно предупреждать администраторов о надвигающихся проблемах для того, чтобы можно было принять контрактивные меры.
Цель управления конфигурацией - контролирование информации о сете- вой и системной конфигурации для того, чтобы можно было отслеживать и управлять воздействием на работу сети различных версий аппаратных и программных элементов. Т.к. все аппаратные и программные элементы имеют эксплуатационные отклонения, погрешности, или то и другое вместе, которые могут влиять на работу сети, такая информация важна для поддержания гладкой работы сети.
Каждое устройство сети располагает разнообразной информацией о версиях, ассоциируемых с ним. Например, АРМ проектировщика может иметь следующую конфигурацию:
Управление учетом использования ресурсов
Цель управления учетом использования ресурсов - измерение параметров использования сети, чтобы можно было соответствующим образом регулировать ее использование индивидуальными или групповыми пользователями. Такое регулирование минимизирует число проблем в сети (т.к. ресурсы сети могут быть поделены исходя из возможностей источника) и максимизировать равнодоступность к сети для всех пользователей.
Как и для случая управления эффективностью, первым шагом к соответствующему управлению учетом использования ресурсов является измерение коэффициента использования всех важных сетевых ресурсов. Анализ результатов дает возможность понять текущую картину использования. В этой точке могут быть установлены доли пользования. Для достижения оптимальной практики получения доступа может потребоваться определенная коррекция. Начиная с этого момента, последующие измерения использования ресурсов могут выдавать информацию о выставленных счетах, наряду с информацией, использованной для оценки наличия равнодоступности и оптимального каоэффициента использования источника.
Цель управления неисправностями - выявить, зафиксировать, уведомить пользователей и (в пределах возможного) автоматически устранить проблемы в сети с тем, чтобы эффективно поддерживать работу сети. Т.к. неисправности могут привести к простоям или недопустимой деградации сети, управление несправностями, по всей вероятности, является наиболее широко используемым элементом модели управления сети ISO.
Управление неисправностями включает в себя несколько шагов:
Цель управления защитой данных - контроль доступа к сетевым ресурсам в соответствии с местными руководящими принципами, чтобы сделать невозможными саботаж сети и доступ к чувствительной информации лицам, не имеющим соответствующего разрешения. Например, одна из подсистем управления защитой данных может контролировать регистрацию пользователей ресурса сети, отказывая в доступе тем, кто вводит коды доступа, не соответствующие установленным.
Подсистемы управления защитой данных работают путем разделения источников на санкционированные и несанкционированные области. Для некоторых пользователей доступ к любому источнику сети является несоответствующим. Такими пользователями, как правило, являются не члены компании. Для других пользователей сети (внутренних) несоответствующим является доступ к информации, исходящей из какого- либо отдельного отдела. Например, доступ к файлам о людских ресурсах является несоответствующим для любых пользователей, не принадлежащих к отделу управления людскими ресурсами (исключением может быть администраторский персонал).
Подсистемы управления защитой данных выполняют следующие функции:
![]()
Историческая справка
Сравнение Ethernet и IEEE 802.3
Физическое подключение
Форматы кадра
Ethernet был разработан Исследовательским центром в Пало Альто (PARC) корпорации Xerox в 1970-м году. Ethernet стал основой для спецификации IEEE 802.3, которая появилась 1980-м году. После недолгих споров компании Digital Equipment Corporation, Intel Corporation и Xerox Corporation совместно разработали и приняли спецификацию (Version 2.0), которая была частично совместима с 802.3. На сегодняшний день Ethernet и IEEE 802.3 являются наиболее распространенными протоколами локальных вычислительных сетей (ЛВС). Сегодня термин Ethernet чаще всего используется для описания всех ЛВС работающих по принципу множественный доступ с обнаружением несущей (carrier sense multiple access/collision detection (CSMA/CD)), которые соотвествуют Ethernet, включая IEEE 802.3.
Когда Ethernet был разработан, он должен был заполнить нишу между глобальными сетями, низкоскоростными сетями и специализированными сетями компьтерных центров, которые работали на высокой скрости, но очень органиченном расстоянии. Ethernet хорошо подходит для приложений где локальные коммуникации должны выдерживать высокие нагрузки при высоких скоростях в пиках.
Ethernet и IEEE 802.3 определены как сходные технологии. Оба стандарта используют метод доступа в сети CSMA/CD (carrier-sense multiple access/collision detection) - множественный доступ с обнаружением несущей. Станции, использующие этот метод могут получить доступ к несущей в любое время. Перед тем как послать данные, такая станция "прослушивает" сеть, чтобы удостовериться, что никто больше не использует её. Если среда передачи в данный момент кем-то используется, станция задерживает передачу. Если же -нет, то станция начинает передавать. Коллизия происходит когда две станции, прослушав сетевой трафик и обнаружив "тишину", начинают передачу одновременно. В этом случае обе передачи прерываются, и станции должны повторить передачу спустя некоторое время. Специальный алгоритм "задержки" определяет, когда конфликтующие станции повторят передачу. Станции, использующие метод CSMA/CD могут обнаружить коллизии в сети и, следовательно, они знают, когда надо повторять передачу.
Оба стандарта определяют сети, как сети с широковещательными сообщениями. Другими словами, все станции видят все кадры, не обращая внимания на назначение пакета. Каждая станция должна проверить принятый пакет, чтобы определить является ли она станцией назначения. Если это так, пакет пропускается к протоколу верхнего уровня для соответствующей обработки.
Различия между Ethernet и IEEE 802.3 стандартами очень незначительны. Ethernet обеспечивает сервисы соответствующие 1-му и 2-му уровням рекомендованной модели OSI, в то время как IEEE 802.3 определяет физический уровень (Уровень 1 OSI) и часть канального уровня (Уровень 2 OSI) - протокол доступа к среде, но не определяет протокол управления логической связью. Как Ethernet так и IEEE 802.3 реализованы в аппаратной части оборудования. Обычно физически эти протоколы реализуются, или на интерфейсной плате сетевого устройства, или в схеме главной платы сетевого устройства.
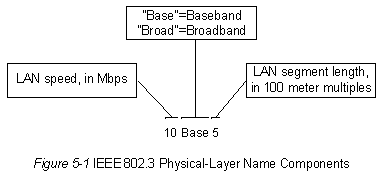
IEEE 802.3 определяет несколько различных стандартов физического уровня, в то время Ethernet определяет только один. Каждый из стандартов протокола физического уровня IEEE 802.3 имеет наименование, в котором отражены его важнейшие характеристики. Пример такого нименования приведен на
Рисунке 5-1.Рисунок 5-1 : Компоненты наименования стандартов физического уровня согласно IEEE 802.3
Краткая справка по физическим характеристикам стандартов Ethernet Версии 2 и IEEE 802.3 представлена в
Таблице 5-1.
Таблица 5-1 : Физические характеристики стандартов Ethernet Версии 2 и IEEE 802.3
|
Характеристики |
Ethernet |
IEEE 802.3 |
||||
|
|
|
10Base5 |
10Base2 |
1Base5 |
10BaseT |
10Broad36 |
|
Скорость, Mbps |
10 |
10 |
10 |
1 |
10 |
10 |
|
Метод передачи |
Baseband |
Baseband |
Baseband |
Baseband |
Baseband |
Broadband |
|
Макс. длина сегмента, м |
500 |
500 |
185 |
250 |
100 |
1800 |
|
Среда передачи |
50-Ом коаксиал (толстый) |
50-Ом коаксиал (толстый) |
50-Ом коаксиал (тонкий) |
неэкр. витая пара |
неэкр. витая пара |
75-ohm coax |
|
Топология |
Шина |
Шина |
Шина |
Звезда |
Звезда |
Шина |
Ethernet соответствует стандарту 10Base5 IEEE 802.3. Оба этих протокола определяют шинную топологию сети с соединительным кабелем между конечной станцией и действующей сетевой средой. В случае Ethernet, этот кабель называется трансиверный кабель. Трансиверный кабель соединяется сприемопередающим устройствоь, подключенным к физической сетевой среде. Конфигурация IEEE 802.3 почти такая же, за исключением того, что соединительный кабель известен как
attachment unit interface (AUI) - интерфейс подключения устройства, и приемопередатчик называется medium attachment unit (MAU) - блок подключения к среде. В обоих случаях соединительный кабель подключается к интерфейсной плате (или схеме) на конечном сетевом устройстве.Формат кадров стандартов Ethernet и IEEE 802.3 показан на
Рисунке 5-2.Рисунок 5-2 : Формат кадров Ethernet и IEEE 802.3
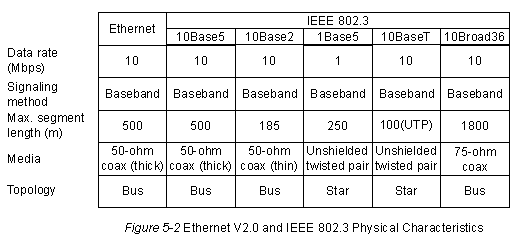
Как кадр Ethernet, так и кадр IEEE 802.3 начинаются с чередующейся последовательности нулей и единиц, называемой преамбулой. Преамбула извещает принимающую станцию о начале кадра.
Байт перед адресом назначения в обоих кадрах является разделителем начала кадра -
start-of-frame (SOF) delimiter.Этот байт заканчивается двумя единицами и служит для синхронизации приема всеми станциями сети.Следующими полями в кадрах Ethernet и IEEE 802.3 являются поля адресов назначения (
destination) и источника ( source), длиной по 6 байтов. Адреса прошиваются в аппаратной части интерфейсных карт. Первые три байта определяют изготовителя интерфейсной карты, в то время как следующие три байта определяются самим изготовителем. Адрес источника всегда является адресом отдельного устройства, а адрес назначения может быть адресом отдельного устройства, групповым адресом, либо широковещательным.В кадре Ethernet 2-байтовое поле, следующее за адресом источника, является полем типа. Это поле определяет протокол верхнего уровня, принимающий данные для последующей обработки, после того как завершится работа Ethernet.
В кадре IEEE 802.3 2-байтовое поле, следующее за адресом источника, является полем длины, показывающее количество байт данных, которые будут следовать за этим полем и предшествовать полю контрольной последовательности - frame check sequence
(FCS).Следующее за полем типа/длины поле содержит данные передаваемые в кадре. После того как процессы физического и канального уровней завершатся, эти данные будут переданы протоколу верхнего уровня. В случае Ethernet протокол верхнего уровня определяется значением поля тип. В случае IEEE 802.3 тип протокола верхнего уровня определяется данными, содержащимися в кадре. Длина поля данных заполняется байтами набивки до минимальной длины кадра - 64 байта.
После поля данных следует 4-байтовое поле проверочной последовательности - FCS, содержащее величину проверки избыточности цикла - cyclic redundancy check (CRC). Эту величина вычисляется устройством-источником, а затем заново высчитывается устройством-приемником для проверки целостности информации.
Сеть Token Ring первоначально была разработана компанией IBM в 1970 гг. Она попрежнему является основной технологией IBM для локальных сетей (LAN) , уступая по популярности среди технологий LAN только Ethernet/IEEE 802.3. Спецификация IEEE 802.5 почти идентична и полностью совместима с сетью Token Ring IBM. Спецификация IEEE 802.5 была фактически создана по образцу Token Ring IBM, и она продолжает отслеживать ее разработку. Термин "Token Ring" oбычно применяется как при ссылке на сеть Token Ring IBM, так и на сеть IEEE 802.5.
Сети Token Ring и IEEE 802.5 в основном почти совместимы, хотя их спецификации имеют относительно небольшие различия. Сеть Token Ring IBM оговаривает звездообразное соединение, причем все конечные устройства подключаются к устройству, называемому "устройством доступа к многостанционной сети" (MSAU), в то время как IEEE 802.5 не оговаривает топологию сети (хотя виртуально все реализации IEEE 802.5 также базируются на звездообразной сети). Имеются и другие отличия, в том числе тип носителя (IEEE 802.5 не оговаривает тип носителя, в то время как сети Toke Ring IBM используют витую пару) и размер поля маршрутной информации (смотри далее в этой главе обсуждение характеристик полей маршрутной информации). На Рис. 6-1 представлены обобщенные характеристики сетей Token Ring и IЕЕЕ 802.5.
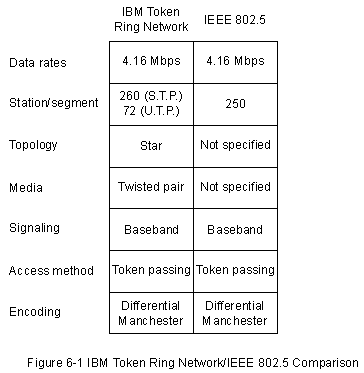
Token Ring и IEEE 802.5 являются главными примерами сетей с передачей маркера. Сети с передачей маркера перемещают вдоль сети небольшой блок данных, называемый маркером. Владение этим маркером гарантирует право передачи. Если узел, принимающий маркер, не имеет информации для отправки, он просто переправляет маркер к следующей конечной станции. Каждая станция может удерживать маркер в течение определенного максимального времени.
Если у станции, владеющей маркером, имеется информации для передачи, она захватывает маркер, изменяет у него один бит (в результате чего маркер превращается в последовательность "начало блока данных"), дополняет информацией, которую он хочет передать и, наконец, отсылает эту информацию к следующей станции кольцевой сети. Когда информационный блок циркулирует по кольцу, маркер в сети отсутствует (если только кольцо не обеспечивает "раннего освобождения маркера" - early token release), поэтому другие станции, желающие передать информацию, вынуждены ожидать. Следовательно, в сетях Token Ring не может быть коллизий. Если обеспечивается раннее высвобождение маркера, то новый маркер может быть выпущен после завершения передачи блока данных.
Информационный блок циркулирует по кольцу, пока не достигнет предполагаемой станции назначения, которая копирует информацию для дальнейшей обработки. Информационный блок продолжает циркулировать по кольцу; он окончательно удаляется после достижения станции, отославшей этот блок. Станция отправки может проверить вернувшийся блок, чтобы убедиться, что он был просмотрен и затем скопирован станцией назначения.
В отличие от сетей CSMA/CD (например, Ethernet) сети с передачей маркера являются детерминистическими сетями. Это означает, что можно вычислить максимальное время, которое пройдет,прежде чем любая конечная станция сможет передавать. Эта характеристика, а также некоторые характеристики надежности, которые будут рассмотрены дальше, делают сеть Token Ring идеальной для применений, где задержка должна быть предсказуема и важна устойчивость функционирования сети. Примерами таких применений является среда автоматизированных станций на заводах.
Станции сети IBM Token Ring напрямую подключаются к MSAU, которые могут быть об'единены с помощью кабелей, образуя одну большую кольцевую сеть (смотри Рис. 6-2). Кабели- перемычки соединяют MSAU со смежными MSAU. Кабели-лепестки подключают MSAU к станциям. В составе МSAU имеются шунтирующие реле для исключения станций из кольца.
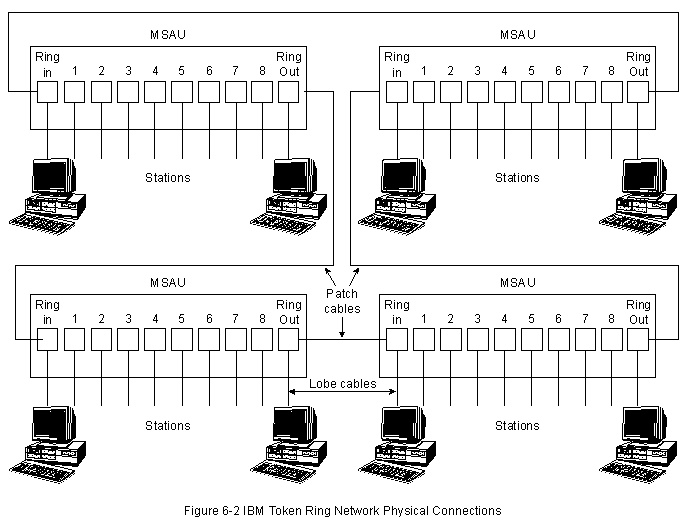
Сети Тоkеn Ring используют сложную систему приоритетов, которая позволяет некоторым станциям с высоким приоритетом, назначенным пользователем, более часто пользоваться сетью. Блоки данных Token Ring содержат два поля, которые управляют приоритетом: поле приоритетов и поле резервирования.
Только станции с приоритетом, который равен или выше величины приоритета, содержащейся в маркере, могут завладеть им. После того, как маркер захвачен и изменен( в результате чего он превратился в информационный блок), только станции, приоритет которых выше приоритета передающей станции, могут зарезервировать маркер для следующего прохода по сети. При генерации следующего маркера в него включается более высокий приоритет данной резервирующей станции. Станции, которые повышают уровень приоритета маркера, должны восстановить предыдущий уровень приоритета после завершения передачи.
Сети Token Ring используют несколько механизмов обнаружения и компенсации неисправностей в сети. Например, одна станция в сети Token Ring выбирается "активным монитором" (active monitor). Эта станция, которой в принципе может быть любая станция сети, действует как централизованный источник синхронизирующей информации для других станций кольца и выполняет разнообразразные функции для поддержания кольца. Одной из таких функций является удаление из кольца постоянно циркулирующих блоков данных. Если устройство, отправившее блок данных, отказало, то этот блок может постоянно циркулировать по кольцу. Это может помешать другим станциям передавать собственные блоки данных и фактически блокирует сеть. Активный монитор может выявлять и удалять такие блоки и генерировать новый маркер.
Звездообразная топология сети IBM Token Ring также способствует повышению общей надежности сети. Т.к. вся информация сети Token Ring просматривется активными MSAU, эти устройства можно запрограммировать так, чтобы они проверяли наличие проблем и при необходимости выборочно удаляли станции из кольца.
Алгоритм Token Ring, называемый "сигнализирующим" (beaconing), выявляет и пытается устранить некоторые неисправности сети. Если какая-нибудь станция обнаружит серьезную проблему в сети (например такую, как обрыв кабеля), она высылает сигнальный блок данных. Сигнальный блок данных указывает домен неисправности, в который входят станция, сообщающая о неисправности, ее ближайший активный сосед, находящийся выше по течению потока информации (NAUN), и все, что находится между ними. Сигнализация инициализирует процесс, называемый "автореконфигурацией" (autoreconfiguration), в ходе которого узлы, расположенные в пределах отказавшего домена, автоматически выполняют диагностику, пытаясь реконфигурировать сеть вокруг отказавшей зоны. В физическом плане MSAU может выполнить это с помощью электрической реконфигурации.
Сети Token Ring определяют два типа блока данных: блоки маркеров и блоки данных/блоки команд. Оба формата представлены на Рис.6-3.
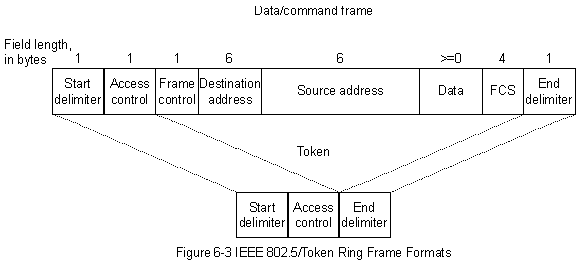
Стандарт на "Волоконно-оптический интерфейс по распределенным данным" (FDDI) был выпущен ANSI X3Т9.5 (комитет по разработке стандартов) в середине 1980 гг. В этот период быстродействующие АРМ проектировщика уже начинали требовать максимального напряжения возможностей существующих локальных сетей (LAN) (в oсновном Ethernet и Token Ring). Возникла необходимость в новой LAN, которая могла бы легко поддерживать эти АРМ и их новые прикладные распределенные системы. Одновременно все большее значение уделяется проблеме надежности сети, т.к. администраторы систем начали переносить критические по назначению прикладные задачи из больших компьютеров в сети. FDDI была создана для того, чтобы удовлетворить эти потребности.
После завершения работы над FDDI, ANSI представила его на рассмотрение в ISO. ISO разработала международный вариант FDDI, который полностью совместим с вариантом стандарта, разработанным ANSI.
Хотя реализации FDDI сегодня не столь распространены, как Ethernet или Token Ring, FDDI приобрела значительное число своих последователей, которое увеличивается по мере уменьшения стоимости интерфейса FDDI. FDDI часто используется как основа технологий, а также как средство для соединения быстродействующих компьютеров, находящихся в локальной области.
Стандарт FDDI определяет 100 Mb/сек. LAN с двойным кольцом и передачей маркера, которая использует в качестве среды передачи волоконно-оптический кабель. Он определяет физический уровень и часть канального уровня, которая отвечает за доступ к носителю; поэтому его взаимоотношения с эталонной моделью OSI примерно аналогичны тем, которые характеризуют IEEE 802.3 и IЕЕЕ 802.5.
Хотя она работает на более высоких скоростях, FDDI во многом похожа на Token Ring. Oбe сети имеют одинаковые характеристики, включая топологию (кольцевая сеть), технику доступа к носителю (передача маркера), характеристики надежности (например, сигнализация-beaconing), и др. За дополнительной информацией по Token Ring и связанными с ней технологиями обращайтесь к Главе 6 "Token Ring/IEEE 802.5".
Одной из наиболее важных характеристик FDDI является то, что она использует световод в качестве передающей среды. Световод обеспечивает ряд преимуществ по сравнению с традиционной медной проводкой, включая защиту данных (оптоволокно не излучает электрические сигналы, которые можно перехватывать), надежность (оптоволокно устойчиво к электрическим помехам) и скорость (потенциальная пропускная способность световода намного выше, чем у медного кабеля).
FDDI устанавливает два типа используемoгo оптического волокна: одномодовое (иногда называемое мономодовым) и многомодовое. Моды можно представить в виде пучков лучей света, входящего в оптическое волокно под определенным углом. Одномодовое волокно позволяет распространяться через оптическое волокно только одному моду света, в то время как многомодовое волокно позволяет распространяться по оптическому волокну множеству мод света. Т.к. множество мод света, распространяющихся по оптическому кабелю, могут проходить различные расстояния (в зависимости от угла входа), и, следовательно, достигать пункт назначения в разное время (явление, называемое модальной дисперсией), одномодовый световод способен обеспечивать большую полосу пропускания и прогoн кабеля на большие расстояния, чем многомодовые световоды. Благодаря этим характеристикам одномодовые световоды часто используются в качестве основы университетских сетей, в то время как многомодовый световод часто используется для соединения рабочих групп. В многомодовом световоде в качестве генераторов света используются диоды, излучающие свет (LED), в то время как в одномодовом световоде обычно применяются лазеры.
FDDI определяется 4-мя независимыми техническими условиями (смотри Рис. 7-1 "Стандарты FDDI"):

FDDI устанавливает применение двойных кольцевых сетей. Трафик по этим кольцам движется в противоположных направлениях. В физическом выражении кольцо состоит из двух или более двухточечных соединений между смежными станциями. Одно из двух колец FDDI называется первичным кольцом, другое-вторичным кольцом. Первичное кольцо используется для передачи данных, в то время как вторичное кольцо обычно является дублирующим.
"Станции Класса В" или "станции, подключаемые к одному кольцу" (SAS) подсоединены к одной кольцевой сети; "станции класса А" или "станции, подключаемые к двум кольцам" (DAS) подсоединены к обеим кольцевым сетям. SAS подключены к первичному кольцу через "концентратор", который обеспечивает связи для множества SAS. Koнцентратор отвечает за то, чтобы отказ или отключение питания в любой из SAS не прерывали кольцо. Это особенно необходимо, когда к кольцу подключен РС или аналогичные устройства, у которых питание часто включается и выключается.
На Рис. 7-2 "Узлы FDDI: DAS, SAS и концентратор" представлена типичная конфигурация FDDI, включающая как DAS, так и SAS.
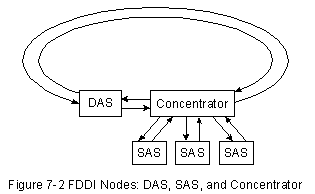
Каждая DAS FDDI имеет два порта, обозначенных А и В. Эти порты подключают станцию к двойному кольцу FDDI. Следовательно, как это показано на Рис. 7-3 "Порты DAS FDDI", каждый порт обеспечивает соединение как с первичным, так и со вторичным кольцом.

FDDI поддерживает распределение полосы пропускания сети в масштабе реального времени, что является идеальным для ряда различных типов прикладных задач. FDDI обеспечивает эту поддержку путем обозначения двух типов трафика: синхронного и асинхронного. Синхронный трафик может потреблять часть общей полосы пропускания сети FDDI, равную 100 Mb/сек; остальную часть может потреблять асинхронный трафик. Синхронная полоса пропускания выделяется тем станциям, которым необходима постоянная возможность передачи. Например, наличие такой возможности помогает при передаче голоса и видеоинформации. Другие станции используют остальную часть полосы пропускания асинхронно. Спецификация SMT для сети FDDI определяет схему распределенных заявок на выделение полосы пропускания FDDI.
Распределение асинхронной полосы пропускания производится с использованием восьмиуровневой схемы приоритетов. Каждой станции присваивается определенный уровень приоритета пользования асинхронной полосой пропускания. FDDI также разрешает длительные диалоги, когда станции могут временно использовать всю асинхронную полосу пропускания. Механизм приоритетов FDDI может фактически блокировать станции, которые не могут пользоваться синхронной полосой пропускания и имеют слишком низкий приоритет пользования асинхронной полосой пропускания.
FDDI характеризуется рядом особенностей отказоустойчивости. Основной особенностью отказоустойчивости является наличие двойной кольцевой сети. Если какая-нибудь станция, подключенная к двойной кольцевой сети, отказывает, или у нее отключается питание, или если поврежден кабель, то двойная кольцевая сеть автоматически "свертывается" ("подгибается" внутрь) в одно кольцо, как показано на Рис.7-4 "Конфигурация восстановления кольца при отказе станции". При отказе Станции 3, изображенной на рисунке, двойное кольцо автоматически свертывается в Станциях 2 и 4, образуя одинарное кольцо. Хотя Станция 3 больше не подключена к кольцу, сеть продолжает работать для оставшихся станций.

На Рис. 7-5 "Конфигурация восстановления сети при отказе кабеля" показано, как FDDI компенсирует отказ в проводке. Станции 3 и 4 свертывают кольцо внутрь себя при отказе проводки между этими станциями.

По мере увеличения размеров сетей FDDI растет вероятность увеличения числа отказов кольцевой сети. Если имеют место два отказа кольцевой сети, то кольцо будет свернуто в обоих случаях, что приводит к фактическому сегментированию кольца на два отдельных кольца, которые не могут сообщаться друг с другом. Последующие отказы вызовут дополнительную сегментацию кольца.
Для предотвращения сегментации кольца могут быть использованы оптические шунтирующие переключатели, которые исключают отказавшие станции из кольца. На Рис. 7-6 показано "Использование оптического шунтирующего переключателя".
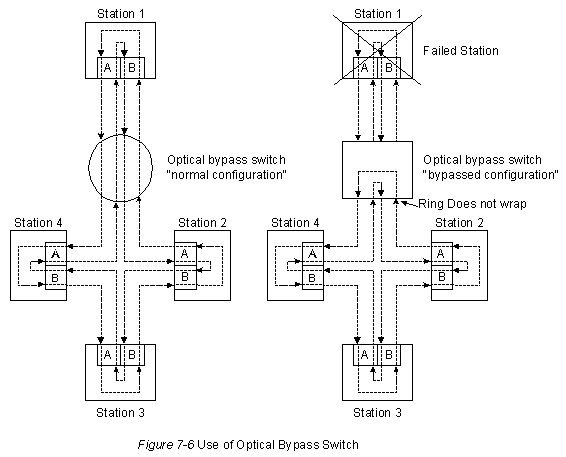
Устройства, критичные к отказам, такие как роутеры или главные универсальные вычислительные машины, могут использовать другую технику повышения отказоустойчивости, называемую "двойным подключением" (dual homing), для того, чтобы обеспечить дополнительную избыточность и повысить гарантию работоспособности. При двойном подключении критичное к отказам устройство подсоединяется к двум концентраторам. Одна пара каналов концентраторов считается активным каналом; другую пару называют пассивным каналом. Пассивный канал находится в режиме поддержки до тех пор, пока не будет установлено, что основной канал (или концентратор, к которому он подключен) отказал. Если это происходит,то пассивный канал автоматически активируется.
Форматы блока данных FDDI (представлены на Рис. 7-7) аналогичны форматам Token Ring.
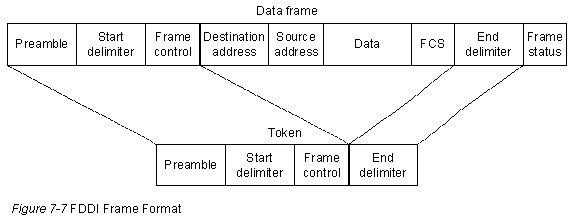
Система сети UltraNet, или просто UltraNet, состоит из семейства высокоскоростных программ для об'единенных сетей и аппаратных изделий, способных обеспечить совокупную пропускную способность в один гигабайт в секунду (Gb/сек). UltraNet производится и реализуется на рынке компанией Ultra Network Technologies. UltraNet oбычно используется для соединения высокоскоростных компьютерных систем, таких как суперкомпьютеры, минисуперкомпьютеры, универсальные вычислительные машины, устройства обслуживания и АРМ. UltraNet может быть сама соединена с другой сетью (например, Ethernet и Token Ring) через роутеры, которые выполняют функции межсетевого интерфейса.
UltraNet обеспечивает услуги, соответствующие четырем низшим уровням эталонной модели OSI. На Рис. 8-1 показаны взаимоотношения между этими уровнями и реализацией UltraNet. В дополнение к перечисленным протоколам UltraNet также обеспечивает Simple Network Management Protocol (SNMP) (Протокол Управления Простой Сетью) и Routing Information Protocol (RIP) (Протокол маршрутной информации). Дополнительная информация по этим протоколам дается соответственно в Главе 23 "RIP" и Главе 32 "SNMP".
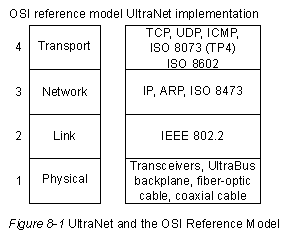
UltraNet использует топологию звездообразной сети с концентратором сети (Hub) в центральной точке звезды. Другими компонентами системы UltraNet являются программное обеспечение для главной вычислительной машины, сетевые процессоры, канальные адаптеры, инструментальные средства управления сети и изделия для об'единения сетей, такие как роутеры и мосты. Сетевые процессоры соединяют главные вычислительные машины с системой UltraNet и обеспечивают виртуальную цепь и услуги дейтаграмм. Главные вычислительные машины, непосредственно подключенные к системе UltraNet, могут быть удалены друг от друга на расстояние до 30 км. Этот предел может быть расширен подключением к глобальной сети (WAN), например, путем использования каналов связи Т3. На Рис. 8-2 приведена схема системы сети UltraNet.

Сеть UltraNet состоит из различных компонентов, в том числе концентраторов, программного обеспечения для главных вычислительных машин, управляющих сети, сетеых процессоров и канальных адаптеров. Описание этих системных элементов дается в следующих разделах.
Концентратор в UltraNet является центральной точкой связи для главных вычислительных машин сети UltraNet. Он содержит высоко- скоростную внутреннюю параллельную шину (UltraBus), об'единяющую все процессоры в пределах этого концентратора. UltraBus отвечает за коммутируемую информацию в сети UltraNet. Концентраторы UltraNet обеспечивают быстрое согласование, управление перегрузкой каналов связи и прямое подключение каналов.
Программное обеспечение главной вычислительной машины UltraNet состоит из:
Управляющий сети UltraNet обеспечивает инструментальные средства, которые помогают инициализировать и управлять UltraNet. Физическим выражением управляющего является базирующийся на Intel 80386 РС, работающий в операционных системах DOS и Windows, который подключает к концентратору UltraNet через шину управления сети (NMB). NMB представляет собой независимую 1 Mg/сек LAN, базирующуюся на спецификации StarLAN (1Base5). Управляющий UltraNet заменяет информацию управления, пользуясь протоколом SNMP.
Сетеые процессоры UltraNet обеспечивают связи между концентраторами UltraNet и главными вычислительными машинами. Имеются сетевые процессоры, которые поддерживают каналы High-Perfomance Parallel Interface (HIPPI) (Высокопроизводительный параллельный интерфейс), HSX (обеспечивается Cray), ВМС (обеспечивается IBM) и LSC (обеспечивается Cray), а также шины VMEbus, SBus, HP/EISA bus и IBM Micro Channel bus. Сетевые процессоры могут находиться либо в главной вычислительной машине, либо в концентраторе UltraNet.
Сетевой процессор, размещаемый в концентраторе, состоит из платы процессора обработки протоколов, платы персонального модуля и платы пульта ручного управления. Плата процессора обработки протоколов выполняет команды сетевых протоколов; на ней имеются буферы FIFO для выполнения буферизации пакетов и согласования скоростей. Плата персонального модуля управляет обменом информации между процессором обработки протоколов и различными средами сети, каналами главной управляющей машины или специализированной аппаратурой. Плата пульта ручного управления управляет устройством ввода/вывода (I/O) информации между сетевым процессором и главной вычислительной машиной, монитором графического дисплея или другим концентратором.
UltraNet также обеспечивает систему графического изображения с высокой разрешающей способностью, которая принимает информацию в пикселях из главной вычислительной машины UltraNet и отображает ее на мониторе, подключенном к адаптеру. Это устройство называется сетевым процессором кадрового буфера.
Большинство задач обработки сетевых протоколов выполняются сетевыми процессорами UltraNet. Сетевые процессоры могут принимать реализации TCP/IP и связанных с ним протоколов, а также модифицированные пакеты протоколов OSI, чтобы осуществлять связь между главными вычислительными машинами.
Адаптеры каналов связи соединяют и передают информацию между двумя концентраторами UltraNet или между концентратором UltraNet и роутерами Cisco Systems AGS+. Имея в своем составе контроллеры каналов связи, от одного до четырех мультиплексоров каналов связи и одну плату пульта ручного управления для каждого мультиплексора каналов связи, адаптеры каналов связи располагают полностью дублированной частной шиной, мощность полосы пропускания которой равна 1 Гигабит/сек.
На основе регурярно действующего принципа адаптеры каналов связи определяют те адаптеры и концентраторы, к которым они непосредственно подключаются. Адаптеры каналов связи рассылают ту или иную маршрутную информацию в другие адаптеры каналов, чтобы осуществлять динамичное построение и поддержание базы данных маршрутизации, содержащей информацию о наилучшем маршруте до всех главных вычислительных машин в пределах сети.
Протокол Информации Маршрутизации (RIP) является протоколом маршрутизации, который был первоначально разработан для Универсального протокола PARC Xerox (где он назывался GWINFO) и использовался в комплекте протоколов ХNS. RIP начали связывать как с UNIX, так и с TCP/IP в 1982 г., когда версию UNIX, называемую Berkeley Standard Distribution (BSD), начали отгружать с одной из реализацией RIP, крторую называли "трассируемой" (routed) (слово произносится "route dee"). Протокол RIP, который все еще является очень популярным протоколом маршрутизации в сообществе Internet, формально определен в публикации "Протоколы транспортировки Internet" XNS (XNS Internet Transport Protocols) (1981 г.) и в Запросах для комментария (Request for Comments - RFC) 1058 (1988 г.).
RIP был повсеместно принят производителями персональных компьютеров (РС) для использования в их изделиях передачи данных по сети. Например, протокол маршрутизации AppleTalk (Протокол поддержания таблицы маршрутизации - RTMP) является модернизированной версией RIP. RIP также явился базисом для протоколов Novell, 3Com, Ungermann-Bass и Banyan. RIP компаний Novell и 3Com в основном представляет собой стандартный RIP компании Xerox. Ungermann-Bass и Banyan внесли незначительные изменения в RIP для удовлетворения своих нужд.
Каждая запись данных в таблице маршрутизации RIP обеспечивает разнообразную информацию, включая конечный пункт назначения, следующую пересылку на пути к этому пункту назначения и показатель (metric). Показатель обозначает расстояние до пункта назначения, выраженное числом пересылок до него. В таблице маршрутизации может находиться также и другая информация, в том числе различные таймеры, связанные с данным маршрутом. Типичная таблица маршрутизации RIP показана на Рис. 23-1.
RIP поддерживает только самые лучшие маршруты к пункту назначения.
Если новая информация обеспечивает лучший маршрут, то эта информация
заменяет старую маршрутную информацию. Изменения в топологии сети
могут вызывать изменения в маршрутах, приводя к тому, например, что
какой-нибудь новый маршрут становится лучшим маршрутом до конкретного
пункта назначения. Когда имеют место изменения в топологии сети, то
эти изменения отражаются в сообщениях о корректировке маршрутизации.
Например, когда какой-нибудь роутер обнаруживает отказ одного из
каналов или другого роутера, он повторно вычисляет свои маршруты
и отправляет сообщения о корректировке маршрутизации. Каждый
роутер, принимающий сообщение об обновлении маршрутизации,
в котором содержится изменение, корректирует свои таблицы и
распространяет это изменение.
На Рис. 23-2 изображен формат пакета RIP для реализаций IP так, как
он определен в RFC 1058.
Первое поле в пакете RIP-это поле команд (command). Это поле содержит
целое число, обозначающее либо запрос, либо ответ. Команда "запрос"
запрашивает отвечающую систему об отправке всей таблицы маршрутизации
или ее части. Пункты назначения, для которых запрашивается ответ,
перечисляются далее в данном пакете. Ответная команда представляет
собой ответ на запрос или чаще всего какую-нибудь незатребованную
регулярную корректировку маршрутизации. Отвечающая система включает
всю таблицу маршрутизации или ее часть в ответный пакет. Регулярные
сообщения о корректировке маршрутизации включают в себя всю таблицу
мааршрутизации.
Поле версии (version) определяет реализуемую версию RIP. Т.к. в
об'единенной сети возможны многие реализации RIP, это поле может быть
использовано для сигнализирования о различных потенциально
несовместимых реализациях.
За 16-битовым полем, состоящим из одних нулей, идет поле идентификатора
семейства адресов (аddress family identifier). Это поле определяет
конкретное используемое семейство адресов. В сети Internet (крупной
международной сети, об'единяющей научно-исследовательские институты,
правительственные учреждения, университеты и частные предприятия) этим
адресным семейством обычно является IP (значение=2), но могут быть
также представлены другие типы сетей.
Следом за еще одним 16-битовым полем, состоящим из одних нулей, идет
32-битовое поле адреса (address). В реализациях RIP Internet это поле
обычно содержит какой-нибудь адрес IP.
За еще двумя 32-битовыми полями из нулей идет поле показателя RIP
(metric). Этот показатель представляет собой число пересылок (hop
count). Он указывает, сколько должно быть пересечено транзитных
участков (роутеров) об'единенной сети, прежде чем можно добраться
до пункта назначения.
В каждом отдельном пакете RIP IP допускается появление дo 25 вхождений
идентификатора семейства адреса, обеспечиваемых полями показателя.
Другими словами, в каждом отдельном пакете RIP может быть перечислено
до 25 пунктов назначения. Для передачи информации из более крупных
маршрутных таблиц используется множество пакетов RIP.
Как и другие протоколы маршрутизации, RIP использует определенные
таймеры для регулирования своей работы. Таймер корректировки
маршрутизации RIP (routing update timer) обычно устанавливается на
30 сек., что гарантирует отправку каждым роутером полной копии
своей маршрутной таблицы всем своим соседям каждые 30 секунд. Таймер
недействующих маршрутов (route invalid timer) определяет,
сколько должно
пройти времени без получения сообщений о каком-нибудь конкретном
маршруте, прежде чем он будет признан недействительным. Если какой-
нибудь маршрут признан недействительным, то соседи уведомяются об
этом факте. Такое уведомление должно иметь место до истечения времени
таймера отключения маршрута (route flush timer). Когда заданное время
таймера отключения маршрута истекает, этот маршрут удаляется из
таблицы маршрутизации. Типичные исходные значения для этих таймеров-
90 секунд для таймера недействующего маршрута и 270 секунд для таймера
отключения маршрута.
RIP определяет ряд характеристик, предназначенных для более стабильной
работы в условиях быстро изменяющейся топологии сети. В их число входит
ограничение числа пересылок, временные удерживания изменений
(hold-downs),
расщепленные горизонты (split-horizons) и корректировки отмены
(poison reverse updates).
RIP разрешает максимальное число пересылок, равное 15. Любому пункту
назначения, который находится дальше, чем на расстоянии 15 пересылок,
присваивается ярлык "недосягаемого".
Максимальное число пересылок RIP
в значительной мере ограничивает его применение в крупных
об'единенных сетях, однако способствует предотвращению появления
проблемы, называемой счетом до бесконечности (count to infinity),
приводящей к зацикливанию маршрутов в сети. Проблема счета до
бесконечности представлена на Рис. 23-3.
Рассмотрим, что случится, если на Рис. 23-3 канал Роутера 1
(R1) (канал а), связывающий его с сетью А, откажет. R1 проверяет свою
информацию и обнаруживает, что Роутер 2 (R2) связан с сетью А
каналом длиной в одну пересылку. Т.к. R1 знает, что он напрямую соединен
с R2, то он об'являет о маршруте из двух пересылок до сети А и начинает
направлять весь трафик в сеть А через R2. Это приводит к образованию
маршрутной петли. Когда R2 обнаруживает, что R1 может теперь достичь
сеть А за две пересылки, он изменяет запись своих собственных данных в
таблице маршрутизации, чтобы показать, что он имеет тракт длиной в 3
пересылки до сети А. Эта проблема, а также данная маршрутная петля
будут продолжаться бесконечно, или до тех пор, пока не будет навязано
какое-нибудь внешнее граничное условие. Этим граничным условием
является максимальное число пересылок RIP. Когда число пересылок
превысит 15, данный маршрут маркируется как недосягаемый. Через
некоторое время этот маршрут удаляется из таблицы.
Временные удерживания изменений используются для того, чтобы помешать
регулярным сообщениям о корректировке незаконно восстановить в правах
маршрут, который оказался испорченным. Когда какой-нибудь маршрут
отказывает, соседние роутеры обнаруживают это. Затем они
вычисляют новые маршруты и отправляют сообщения об обновлении
маршрутизации, чтобы информировать своих соседей об изменениях в
маршруте. Эта деятельность приводит к появлению целой волны коррекций
маршрутизации, которые фильтруются через сеть.
Приведенные в действие корректировки неодновременно прибывают во все
устройства сети. Поэтому возможно, что какое-нибудь устройство,
которое еще не получило информацию о каком-нибудь отказе в сети, может
отправить регулярное сообщение о корректировке (в котором маршрут,
который только что отказал, все еще числится исправным) в другое
устройство, которое только что получило уведомление об этом отказе в
сети. В этом случае это другое устройство теперь будет иметь (и
возможно, рекламировать) неправильную маршрутную информацию.
Команды о временном удерживании указывают роутерам, чтобы они
на некоторое время придержали любые изменения, которые могут оказать
влияние на только что удаленные маршруты. Этот период удерживания
обычно рассчитывается таким образом, чтобы он был больше периода
времени, необходимого для внесения кокого-либо изменения о
маршрутизации во всю сеть. Удерживание изменений предотвращает
появление проблемы счета до бесконечности.
Расщепленные горизонты используют преимущество того факта, что
никогда не бывает полезным отправлять информацию о каком-нибудь
маршруте обратно в том направлении, из которого пришла эта информация.
Для иллюстрации этого положения рассмотрим Рис. 23-4.
Pоутер 1 (R1) первоначально об'являет, что он располагает каким-
то маршрутом до Сети А. Pоутеру 2 (R2) нет оснований включать
этот маршрут в свою корректировку, отсылаемую обратно роутеру R1,
т.к. R1 ближе к Сети А. Правило расщепленного горизонта гласит, что
R2 должен исключить (попасть на) этот маршрут при любых корректировках, которые
он отправляет в R1.
Правило расщепленного горизонта помогает предотвратить маршрутные петли
между двумя узлами. Например, рассмотрим случай, когда отказывает
интерфейс R1 с Сетью А. При отсутствии расщепленных горизонтов R2
продолжает информировать R1 о том, что он может попасть в Сеть А через
R1. Если R1 не располагает достаточным интеллектом, то он действительно
может выбрать маршрут, предлагаемый R2, в качестве альтернативы для
своей отказавшей прямой связи, что приводит к образованию петли
маршрутизации. И хотя временное удерживание изменений должно
предотвращать это, применение расщепленного горизонта обеспечивает
дополнительную стабильность алгоритма.
В то время как задачей расщепленных горизонтов является предотвращение
образования маршрутных петель между соседними роутерами,
корректировки отмены преданазначены для устранения более крупных
маршрутных петель. В основе их действия лежит положение о том, что
увеличение значения показателей маршрутизации обычно указывает на
наличие маршрутных петель. В этом случае отправляются корректировки
отмены для удаления данного маршрута и помещения его в состояние
временного удерживания.
В создание протокола SNMP внесли свой вклад разработки по трем
направлениям:
Сегодня SNMP является самым популярным протоколом управления различными
коммерческими, университетскими и исследовательскими об'единенными
сетями. Деятельность по стандартизации, связанная с SNMP, продолжается
по мере того, как поставщики разрабатывают и выпускают современные
прикладные программы управления, базирующиеся на SNMP. SNMP
относительно простой протокол, однако набор его характеристик является
достаточно мощным для решения трудных проблем, возникающих при
управлении гетерогенных сетей.
SNMP является протоколом прикладного уровня, предназначенным для
облегчения обмена информацией управления между сетевыми устройствами.
Пользуясь информацией SNMP (такой, как показатель числа пакетов в
секунду и коэффициент сетевых ошибок), сетевые администраторы могут
более просто управлять производительностью сети и обнаруживать и решать
сетевые проблемы.
Управляемое устройство может быть узлом любого типа, находящимся в
какой-нибудь сети: это хосты, служебные
устройства связи, принтеры, роутеры, мосты и концентраторы. Т.к.
некоторые из этих систем могут иметь ограниченные способности
управления программным обеспечением (например, они могут иметь
центральные процессоры с относительно малым быстродействием или
ограниченный об'ем памяти), программное обеспечение управления должно
сделать допущение о наименьшем общем знаменателе. Другими словами,
программы управления должны быть построены таким образом, чтобы
минимизировать воздействие своей производительности на управляемое
устройство.
Т.к. управляемые устройства содержат наименьший общий знаменатель
программного обеспечения управления, тяжесть управления ложится на
NMS. Поэтому NMS обычно являются компьютерами калибра АРМ
проектировщика, которые имеют быстродействующие центральные процессоры,
мегапиксельные цветные устройства отображения, значительный об'ем
памяти и достаточный об'ем диска. В любой управляемой сети может
иметься одна или более NMS. NMS прогоняют прикладные программы
сетевого управления, которые представляют информацию управления
пользователям. Интерфейс пользователя обычно базируется на
стандартизированном графическом интерфейсе пользователя (graphical
user interface - GUI).
Сообщение между управляемыми устройствами и NMS регулируется протоколом
сетевого управления. Стандартный протокол сети Internet, Network
Management Framework, предполагает парадигму дистанционной отладки,
когда управляемые устройства поддерживают значения ряда переменных и
сообщают их по требованию в NMS. Например, управляемое устройство
может отслеживать следующие параметры:
Дерево MIB расширяемо благодаря экспериментальным и частным ветвям.
Например, поставщики могут определять свои собственные ветви для
включения реализаций своих изделий. В настоящее время вся работа по
стандартизации ведется на экспериментальной ветви.
Структуру MIB определяет документ, называемый Структура Информации
Управления (Structure of Management Information - SMI). SMI определяет
следующие типы информации:
Сообщения SNMP состоят из 2 частей: имени сообщества (community name) и
данных (data). Имя сообщества назначает среду доступа для набора NMS,
которые используют это имя. Можно сказать, что NMS, принадлежащие
одному сообществу, находятся под одним и тем же административным
началом. Т.к. устройства, которые не знают правильного имени
сообщества, исключаются из операций SNMP, управляющие сетей также
используют имя сообщества в качестве слабой формы опознавания.
Информационная часть сообщения содержит специфичную операцию SNMP
(get, set, и т.д.) и связанные с ней операнды. Операнды обозначают
реализации об'екта, которые включены в данную транзакцию SNMP.
Сообщения SNMP официально называются протокольными единицами данных
(protocol data units - PDU). На Рис. 32-3 изображен формат пакета SNMP.
PDU операций get и set SNMP состоят из следующих частей:
Бесспорной тенденцией развития сетей является увеличение скорости
связи. В последнее время с появлением интерфейса Fiber Distributed Data
Interface (FDDI) (Волоконно-оптический интерфейс по распределенным
данным) локальные сети переместились в диапазон скоростей до
100 Mb/сек. Прикладные программы для локальных сетей, стимулирующие
это увеличение скоростей, включают передачу изображений, видеосигналов
и современные прикладные задачи передачи распределенной информации
(клиент-устройство обслуживания). Более быстродействующие
компьютерные платформы будут продолжать стимулировать увеличение
скоростей в окружениях локальных сетей по мере того, как они будут
делать возможными новые высокоскоростные прикладные задачи.
Уже разработаны линии глобальных сетей (WAN) с более высокой
пропускной способностью, чтобы соответствовать постоянно
растущим скоростям LAN и сделать возможным увеличение протяженности
канала универсальной вычислительной машины через глобальные сети.
Технологии WAN, такие как Frame Relay (Реле блока данных),
Switched Multimegabit Data Service (SMDS) (Обслуживание
переключаемых мультимегабитовых информационных каналов), Synchronous
Optical Network (Sonet) (Синхронная оптическая сеть) и Broadband
Integrated Services Digital Network (Broadband ISDN, или просто
BISDN) (Широкополосная цифровая сеть с интегрированными услугами),
использовали преимущества новых цифровых и волоконно-оптических
технологий для того, чтобы обеспечить WAN иную роль, чем роль узкого
бутылочного горлышка в сквозной передаче через большие географические
пространства. Дополнительная информация по Frame Relay и SMDS
приведена соответственно в Главе 14
и Главе 15 "SMDS".
С достижением более высоких скоростей в окружениях как локальных,
так и глобальных сетей, насущной необходимостью стал интерфейс
data terminal equipment (DTE)/data circuit-terminating
equipment (DCE) (Интерфейс "терминальное оборудование/оборудование
завершения работы информационной цепи"), который мог бы соединить эти
два различных мира и не стать при этом узким бутылочным
горлышком. Стандарты классических интерфейсов DTE/DCE, таких как
RS-232 и V.35, не способны обеспечить скорости Т3 или аналогичные
им скорости. К концу 1980 гг. стало очевидно, что необходим новый
протокол DTE/DCE.
High-Speed Serial Interface (HSSI) (Высокоскоростной последовательный
интерфейс) является интерфейсом DTE/DCE, разработанным компаниями
Cisco Systems и T3Plus Networking, чтобы удовлетворить перечисленные
выше потребности. Спецификация HSSI доступна для любой организации,
которая хочет реализовать HSSI. Пока что распределено свыше 150 копий
этой спецификации, и десятки компаний либо уже реализовали одно из
технических решений HSSI, либо находятся в стадии реализации. Менее
чем за 3 года HSSI стала настоящим промышленным стандартом.
В настоящее время HSSI находится в стадии процесса официальной
стандартизации в комитете Ассоциации электронной промышленности
(EIA/TIATR30.2) Американскогo национальногo институтa стандартизации
(ANSI). Недавно он был передан в организации "Международный
Консультативный Комитет по Телеграфии и Телефонии" (CCITT) и
"Международная Организация по Стандартизации" (ISO); ожидается,
что он будет стандартизирован обеими организациями.
HSSI определяет как электрический, так и и физический интерфейсы
DTE/DCE. Следовательно, он соответствует физическому уровню
эталонной модели OSI. Технические характеристики HSSI обобщены на
Рис. 9-1.
Максимальная скорость передачи сигнала HSSI равна 52 Mb/сек. На
этой скорости HSSI может оперировать скоростями Т3 (45 Mb/сек)
большинства современных быстродействующих технологий WAN, скоростями
Office Channel (OC)-1 (52 Mb/сек) иерархии синхронной цифровой сети
(SDN), а также может легко обеспечить высокоскоростное соединение
между локальными сетями, такими, как Token Ring и Ethernet.
Применение дифференциальных логических схем с эмиттерным
повторителем (ЕCL) позволяет HSSI добиться высоких скоростей передачи
информации и низких уровней помех. ECL использовалась в интерфейсах
Cray в течение нескольких лет; эта схема определена
стандартом сообщений High-Perfomance Parallel Interface (HIPPI),
разработанным ANSI, для связей LAN с суперкомпьютерами. ECL-это
имеющаяся в готовом виде технология, которая позволяет превосходно
восстанавливать синхронизацию приемника, результатом чего является
достаточный запас надежности по синхронизации.
Гибкость синхронизации и протокола обмена информацией HSSI делает
возможным выделение полосы пропускания пользователю (или поставщику).
DCE управляет синхронизацией путем изменения ее скорости или путем
стирания импульсов синхронизации. Таким образом DCE может распределять
полосу пропускания между прикладными задачами. Например, PВX может
потребовать одну величину полосы пропускания, роутер
другую величину, а расширитель канала-третью. Распределение полосы
пропускания является ключом для того, чтобы сделать Т3 и другие
услуги широкой полосы (broadband) доступными и популярными.
HSSI использует субминиатюрный, одобренный FCC 50-контактный
соединитель, размеры которого меньше, чем у его аналога V.35. Чтобы
уменьшить потребность в адаптерах для соединения двух вилок или двух
розеток, соединители кабеля HSSI определены как вилки. Кабель HSSI
использует такое же число контактов и проводов, как кабель интерфейса
Small Computer Systems Interface 2 (SCSI-2), однако технические
требования HSSI на электрические сигналы более жесткие.
Для любого из высших уровней диагностического ввода, HSSI обеспечивает
четыре проверки петлевого контроля. Эти тесты показаны на Рис. 9-2
"четыре теста петлевого контроля HSSI". Первый тест обеспечивает
контроль кабеля локальной сети, т.к. сигнал закольцовывается, как
только он доходит до порта DTE. Сигнал второго теста доходит до
линейного порта локального DСE. Сигнал трeтьего теста доходит до
линейного порта отдаленной DCE. И наконец, четвертый тест представляет
собой инициируемую DCE проверку устройством DTE порта DCE.
HSSI предполагает, что DCE и DТЕ обладают одинаковым интеллектом.
Протокол управления упрощен, т.к. требуется всего два управляющих
сигнала (DTE available - "DTE доступен" и
DCE available - "DCE доступен").
Оба сигнала должны быть утверждены до того, как информационная цепь
станет действующей. Ожидается, что DTE и DCE будут в состоянии
управлять теми сетями, которые находятся за их интерфейсами.
Уменьшение числа управляющих сигналов улучшает надежность цепи за
счет уменьшения числа цепей, которые могут отказать.
Frame Relay первоначально замышлялся как протокол для использования
в интерфейсах ISDN, и исходные предложения, представленные в CCITT
в 1984 г., преследовали эту цель. Была также предпринята работа над
Frame Relay в аккредитованном ANSI комитете по стандартам T1S1 в США.
Крупное событие в истории Frame Relay произошло в 1990 г., когда
Cisco Systems, StrataCom, Northern Telecom и Digital Equipment
Corporation образовали консорциум, чтобы сосредоточить усилия на
разработке технологии Frame Relay и ускорить появление изделий
Frame Relay, обеспечивающих взаимодействие сетей. Консорциум
разработал спецификацию, отвечающую требованиям базового протокола
Frame Relay, рассмотренного в T1S1 и CCITT; однако он расширил ее,
включив характеристики, обеспечивающие дополнительные возможности
для комплексных окружений межсетевого об'единения. Эти дополнения
к Frame Relay называют обобщенно local management interface (LMI)
(интерфейс управления локальной сетью).
Frame Relay обеспечивает возможность передачи данных с коммутацией
пакетов через интерфейс между устройствами пользователя (например,
маршрутизаторами, мостами, главными вычислительными машинами) и
оборудованием сети (например, переключающими узлами). Устройства
пользователя часто называют терминальным оборудованием (DTE), в то
время как сетевое оборудование, которое обеспечивает согласование
с DTE, часто называют устройством завершения работы информационной
цепи (DCE). Сеть, обеспечивающая интерфейс Frame Relay, может быть
либо общедоступная сеть передачи данных и использованием несущей,
либо сеть с оборудованием, находящимся в частном владении, которая
обслуживает отдельное предприятие.
В роли сетевого интерфейса, Frame Relay является таким же типом
протокола, что и Х.25 (смотри Главу 13 "Х.25").
Однако Frame Relay
значительно отличается от Х.25 по своим функциональным возможностям
и по формату. В частности, Frame Relay является протоколом для линии
с большим потоком информации, обеспечивая более высокую
производительность и эффективность.
В роли интерфейса между оборудованием пользователя и сети, Frame Relay
обеспечивает средства для мультиплексирования большого числа логических
информационных диалогов (называемых виртуальными цепями) через один
физический канал передачи, которое выполняется с помощью статистики.
Это отличает его от систем, использующих только технику временного
мультиплексирования (TDM) для поддержания множества информационных
потоков. Статистическое мультиплексирование Frame Relay обеспечивает
более гибкое и эффективное использование доступной полосы пропускания.
Оно может использоваться без применения техники TDM или как
дополнительное средство для каналов, уже снабженных системами TDM.
Другой важной характеристикой Frame Relay является то, что она
использует новейшие достижения технологии передачи глобальных
сетей. Более ранние протоколы WAN, такие как Х.25, были разработаны
в то время, когда преобладали аналоговые системы передачи данных и
медные носители. Эти каналы передачи данных значительно менее надежны,
чем доступные сегодня каналы с волоконно-оптическим носителем и
цифровой передачей данных. В таких каналах передачи данных
протоколы канального уровня могут предшествовать требующим
значительных временных затрат алгоритмам исправления ошибок, оставляя
это для выполнения на более высоких уровнях протокола. Следовательно,
возможны большие производительность и эффективность без ущерба для
целостности информации. Именно эта цель преследовалась при разработке
Frame Relay. Он включает в себя алгоритм проверки при помощи
циклического избыточного кода (CRC) для обнаружения испорченных битов
(из-за чего данные могут быть отвергнуты), но в нем отсутствуют
какие-либо механизмы для корректирования испорченных данных
средствами протокола (например, путем повторной их передачи на данном
уровне протокола).
Другим различием между Frame Relay и Х.25 является отсутствие явно
выраженного управления потоком для каждой виртуальной цепи. В настоящее
время, когда большинство протоколов высших уровней эффективно выполняют
свои собственные алгоритмы управления потоком, необходимость в этой
функциональной возможности на канальном уровне уменьшилась. Таким
образом, Frame Relay не включает явно выраженных процедур управления
потоком, которые являются избыточными для этих процедур в высших
уровнях. Вместо этого предусмотрены очень простые механизмы
уведомления о перегрузках, позволяющие сети информировать какое-либо
устройство пользователя о том, что ресурсы сети находятся близко к
состоянию перегрузки. Такое уведомление может предупредить протоколы
высших уровней о том, что может понадобиться управление потоком.
Стандарты Current Frame Relay адресованы перманентным виртуальным
цепям (PVC), определение конфигурации которых и управление
осуществляется административным путем в сети Frame Relay. Был также
предложен и другой тип виртуальных цепей - коммутируемые виртуальные
цепи (SVC). Протокол ISDN предложен в качестве средства сообщения
между DTE и DCE для динамичной организации, завершения и управления
цепями SVC. Подробная информацию о ISDN дана в Главе 11
"ISDN".
Как T1S1, так и CCITT ведут работу по включению SVС в стандарты
Frame Relay.
Помимо базовых функций передачи данных протокола Frame Relay,
спецификация консорциума Frame Relay включает дополнения LMI, которые
делают задачу поддержания крупных межсетей более легкой. Некоторые из
дополнений LMI называют "общими"; считается, что они могут быть
реализованы всеми, кто взял на вооружение эту спецификацию. Другие
функции LMI называют "факультативными". Ниже приводится следующая
краткая сводка о дополнениях LMI:
Формат блока данных изображен на Рис. 14-1. Флаги ( flags )
ограничивают начало
и конец блока данных. За открывающими флагами следуют два байта
адресной ( address ) информации. 10 битов из этих двух
байтов составляют
идентификацию (ID) фактической цепи (называемую сокращенно DLCI от
"data link connection identifier").
Центром заголовка Frame Relay является 10-битовое значение DLCI.
Оно идентифицирует ту логическую связь, которая мультиплексируется
в физический канал. В базовом режиме адресации (т.е. не расширенном
дополнениями LMI), DLCI имеет логическое значение; это означает, что
конечные усторойства на двух противоположных концах связи могут
использовать различные DLCI для обращения к одной и той же связи. На
рис. 14-2 представлен пример использования DLCI при адресации в
соответствии с нерасширенным Frame Relay.
Рис. 14-2 предполагает наличие двух цепей PVC: одна между Aтлантой и
Лос-Анджелесом, и вторая между Сан Хосе и Питтсбургом. Лос Анджелес
может обращаться к своей PVC с Атлантой, используя DLCI=12, в то
время как Атланта обращается к этой же самой PVC, используя DLCI=82.
Аналогично, Сан Хосе может обращаться к своей PVC с Питтсбургом,
используя DLCI=62. Сеть использует внутренние патентованные
механизмы поддержания двух логически значимых идентификаторов PVC
различными.
В конце каждого байта DLCI находится бит расширенного адреса (ЕА).
Если этот бит единица, то текущий байт является последним байтом
DLCI. В настоящее время все реализации используют двубайтовый DLCI,
но присутствие битов ЕА означает, что может быть достигнуто соглашение
об использовании в будущем более длинных DLCI.
Бит C/R, следующий за самым значащим байтом DLCI, в настоящее время не
используется.
И наконец, три бита в двубайтовом DLCI являются полями, связанными
с управлением перегрузкой. Бит "Уведомления о явно выраженной
перегрузке в прямом направлении" (FECN) устанавливается сетью Frame
Relay в блоке данных для того, чтобы сообщить DTE, принимающему этот
блок данных, что на тракте от источника до места назначения имела место
перегрузка. Бит "Уведомления о явно выраженной прегрузке в обратном
направлении" (BECN) устанавливается сетью Frame Relay в блоках данных,
перемещающихся в направлении, противоположном тому, в котором
перемещаются блоки данных, встретившие перегруженный тракт. Суть этих
битов заключается в том, что показания FECN или BECN могут быть
продвинуты в какой-нибудь протокол высшего уровня, который может
предпринять соответствующие действия по управлению потоком. (Биты
FECN полезны для протоколов высших уровней, которые используют
управление потоком, контролируемым пользователем, в то время как
биты BECN являются значащими для тех протоколов, которые зависят от
управления потоком, контролируемым источником ("emitter-controlled").
Бит "приемлемости отбрасывания" (DE) устанавливается DTE, чтобы
сообщить сети Frame Relay о том, что какой-нибудь блок данных
имеет более низшее значение, чем другие блоки данных и должен быть
отвергнут раньше других блоков данных в том случае, если сеть начинает
испытывать недостаток в ресурсах. Т.е. он представляет собой очень
простой механизм приоритетов. Этот бит обычно устанавливается только
в том случае, когда сеть перегружена.
В предыдущем разделе описан базовый формат протокола Frame Relay для
переноса блоков данных пользователя. Разработанная консорциумом
спецификация Frame Relay также включает процедуры LMI. Сообщения
LMI отправляются в блоках данных, которые характеризуются DLCI,
специфичным для LMI (определенным в спецификации консорциума как
DLCI=1023). Формат сообщений LMI представлен на Рис. 14-3.
В сообщениях LMI заголовок базового протокола такой же, как в
обычных блоках данных. Фактическое сообщение LMI начинается с четырех
мандатных байтов, за которыми следует переменное число информационных
элементов (IE). Формат и кодирование сообщений LMI базируются на
стандарте ANSI T1S1.
Первый из мандатных байтов (unnumbered information indicator-индикатор
непронумерованной информации) имеет тот же самый формат, что и
индикатор блока непронумерованной информации LAPB (UI) с битом P/F,
установленным на нуль. Подробная информация о LAPB дается в разделе
"Уровень 2" Главы 13 "Х.25".
Следующий байт называют "дискриминатор
протокола" (protocol discriminator); он установлен на величину,
которая
указывает на "LMI". Третий мандатный байт (call reference-ссылка на
обращение) всегда заполнен нулями.
Последний мандатный байт является полем "типа сообщения" (message
type). Определены два типа сообщений. Сообщения "запрос о состоянии"
(status enquiry) позволяют устройствам пользователя делать запросы о
состоянии сети. Сообщения "состояние" (status) являются ответом на
сообщения-запросы о состоянии. Сообщения "продолжайте работать"
(keepalives) (посылаемые через линию связи для подтверждения того, что
обе стороны должны продолжать считать связь действующей) и сообщения
о состоянии PVC являются примерами таких сообщений; это общие свойства
LMI, которые должны быть частью любой реализации, соответствующей
спецификации консорциума.
Сообщения о состоянии и запросы о состоянии совместно обеспечивают
проверку целостности логического и физического каналов. Эта информация
является критичной для окружений маршрутизации, т.к. алгоритмы
маршрутизации принимают решения, которые базируются на целостности
канала.
За полем типа сообщений следуют несколько IЕ. Каждое IЕ состоит из
одно-байтового идентификатора IЕ, поля длины IЕ и одного или более
байтов, содержащих фактическую информацию.
В дополнение к общим характеристикам LMI существуют несколько
факультативных дополнений LMI, которые чрезвычайно полезны в окружении
межсетевого об'единения. Первым важным факультативным дополнением LMI
является глобольная адресация. Как уже отмечалось раньше, базовая
(недополненная) спецификация Frame Relay обеспечивает только
значения поля DLCI, которые идентифицируют цепи PVC с локальным
значением. В этом случае отсутствуют адреса, которые идентифицируют
сетевые интерфейсы или узлы, подсоединенные к этим интерфейсам. Т.к.
эти адреса не существуют, они не могут быть обнаружены с помощью
традиционной техники обнаружения и резолюции адреса. Это означает,
что при нормальной адресации Frame Relay должны быть составлены
статистические карты, чтобы сообщать маршрутизаторам, какие DLCI
использовать для обнаружения отдаленного устройства и связанного с
ним межсетевого адреса.
Дополнение в виде глобальной адресации позволяет использовать
идентификаторы узлов. При использовании этого дополнения значения,
вставленные в поле DLCI блока данных, являются глобально значимыми
адресами индивидуальных устройств конечного пользователя (например,
маршрутизаторов). Реализация данного принципа представлена на Рис.14-4.
Необходимо отметить, что каждый интерфейс, изображенный на Рис.14-4,
имеет свой собственный идентификатор. Предположим, что Питтсбург
должен отправить блок данных в Сан Хосе. Идентификатором Сан Хосе
является число 12, поэтому Питттсбург помещает величину "12" в поле
DLCI и отправляет блок данных в сеть Frame Relay. В точке выхода
из сети содержимое поля DLSI изменяется сетью на 13, чтобы отразить
узел источника блока данных. Т.К. интерфейс каждого маршрутизатора имеет
индивидуальную величину, как у идентификатора его узла, отдельные
устройства могут быть различимы. Это обеспечивает адаптируемую
маршрутизацию в сложных окружениях.
Глобальная адресация обеспечивает значительные преимущества в
крупных комплексных об'единенных сетях, т.к. в этом случае
маршрутизаторы воспринимают сеть Frame Relay на ее периферии как
обычную LAN. Нет никакой необходимости изменять протоколы высших
уровней для того, чтобы использовать все преимущества, обеспечиваемые
их возможностями.
Другой ценной факультативной характеристикой LMI является
многопунктовая адресация. Группы многопунктовой адресации обозначаются
последовательностью из четырех зарезервированных значений DLCI (от
1019 до 1022). Блоки данных, отправляемые каким-либо устройством,
использующим один из этих зарезервированных DLCI, тиражирутся сетью
и отправляются во все выходные точки группы с данным обозначением.
Дополнение о многопунктовой адресации определяет также сообщения LMI,
которые уведомляют устройства пользователя о дополнении, ликвидации
и наличиии групп с многопунктовой адресацией.
В сетях, использующих преимущества динамической маршрутизации,
маршрутная информация должна обмениваться между большим числом
маршрутизаторов. Маршрутные сообщения могут быть эффективно отправлены
путем использования блоков данных с DLCI многопунктовой адресации. Это
обеспечивает отправку сообщений в конкретные группы маршрутизаторов.
Frame Relay может быть использована в качестве интерфейса к услугам
либо общедоступной сети со своей несущей, либо сети с оборудованием,
находящимся в частном владении. Обычным способом реализации частной
сети является дополнение традиционных мультиплексоров Т1 интерфейсами
Frame Relay для информационных устройств, а также интерфейсами (не
являющимися специализированными интерфейсами Frame Relay) для других
прикладных задач, таких как передача голоса и проведение
видео-телеконференций. На Рис. 14-5 "Гибридная сеть Frame Relay"
представлена такая конфигурация сети.
Обслуживание общедоступной сетью Frame Relay разворачивается путем
размещения коммутирующего оборудования Frame Relay в центральных
офисах (CO) телекоммуникационной линии. В этом случае пользователи
могут реализовать экономические выгоды от тарифов начислений за
пользование услугами, чувствительных к трафику, и освобождены от
работы по администрированию, поддержанию и обслуживанию оборудования
сети.
Для любого типа сети линии, подключающие устройства пользователя к
оборудованию сети, могут работать на скорости, выбранной из широкого
диапазона скоростей передачи информации. Типичными являются скорости
в диапазоне от 56 Kb/сек до 2 Mb/сек, хотя технология Frame Relay
может обеспечивать также и более низкие и более высокие скорости.
Ожидается, что в скором времени будут доступны реализации, способные
оперировать каналами связи с пропускной способностью свыше 45 Mb/сек
(DS3).
Как в общедоступной, так и в частной сети факт обеспечения устройств
пользователя интерфейсами Frame Relay не является обязательным
условием того, что между сетевыми устройствами используется протокол
Frame Relay. В настоящее время не существует стандартов на оборудование
межсоединений внутри сети Frame Relay. Таким образом, могут быть
использованы традиционные технологии коммутации цепей, коммутации
пакетов, или гибридные методы, комбинирующие эти технологии.
В середине-конце 1970 гг. потребовался определенный набор протоколов,
чтобы обеспечить пользователям связность глобальной сети с
общедоступными сетями передачи данных (PDN). Сети PDN, такие как
TELENET и TYMNET, добились замечательного успеха, однако было ясно,
что стандартизация протоколов еще больше увеличит число абонентов PDN
за счет возросшей совместимости оборудования и более низких цен.
Результатом последующих усилий по разработке в этом направлении была
группа протоколов, самым популярным из которых является Х.25.
Протокол Х.25 (официально называемый CCITT Recommendation X.25 -
"Рекомендация "Х.25 CCITT) был разработан компаниями общественных
линий связи (в основном телефонными компаниями), а не каким-то
отдельным коммерческим предприятием. Поэтому спецификация разработана
так, чтобы обеспечить хорошую работоспособность независимо от типа
системы пользователя или изготовителя. Пользователи заключают контракты
с общедоступными сетями передачи данных, чтобы пользоваться их
сетями с коммутацией пакетов (PSN), и им пред'является счет в
зависимости от времени пользования PDN. Предлагаемые услуги (и
взимаемая плата) регулируются Федеральной Комиссией по Связи (FCC).
Oдним из уникальных свойств Х.25 является его международный
характер. Х.25 и связанными с ним протоколами управляет
одно из агентств Организации Об'единненых Наций, называемое
"Международный Союз по Телекоммуникациям (ITU). Комитет ITU,
ответственный за передачу голоса и данных, называется Международным
консультативным комитетом по телеграфии и телефонии (CCITT).
Членами CCITT являются FCC, Европейские PTT, общедоступные сети
передачи данных и множество компаний, занимающихся компьютерами и
передачей данных. То, что Х.25 стал стандартом подлинно глобального
значения, является прямым следствием присущих ему свойств.
Х.25 определяет характеристики телефонной сети для передачи данных.
Чтобы начать связь, один компьютер обращается к другому с запросом
о сеансе связи. Вызванный компьютер может принять или отклонить связь.
Если вызов принят, то обе системы могут начать передачу информации с
полным дублированием. Любая сторoнa может в любой момент прекратить
связь.
Спецификация Х.25 определяет двухточечное взаимодействие между
терминальным оборудованием (DTE) и оборудованием завершения действия
информационной цепи (DCE). Устройства DTE (терминалы и главные
вычислительные машины в аппаратуре пользователя) подключаются к
устройствам DCE (модемы, коммутаторы пакетов и другие порты в сеть PDN,
обычно расположенные в аппаратуре этой сети), которые соединяются с
"коммутаторами переключения пакетов" (packet switching exchange)
(PSE или просто switches) и другими DCE внутри PSN и, наконец, к
другому устройству DTE. Взаимоотношения между об'ектами сети Х.25
показаны на Рис. 13-1.
DTE может быть терминалом, который не полностью реализует все
функциональные возможности Х.25. Такие DTE подключаются к DCE через
трансляционное устройство, называемое пакетный ассемблер/дизассемблер
- packet assembler/disassembler -
(РAD). Действие интерфейса терминал/PAD, услуги, предлагаемые
PAD и взаимодействие между PAD и главной вычислительной машиной
определены соответственно CCITT Recommendations X.28, X3 и Х.29.
Спецификация Х.25 составляет схемы Уровней 1-3 эталонной модели OSI.
Уровень 3 Х.25 описывает форматы пакетов и процедуры обмена пакетами
между равноправными об'ектами Уровня 3. Уровень 2 Х.25 реализован
Протоколом Link Access Procedure, Balanced (LAPB). LAPB определяет
кадрирование пакетов для звена DTE/DCE. Уровень 1 Х.25 определяет
электрические и механические процедуры активации и дезактивации
физической среды, соединяющей данные DTE и DCE. Это взаимоотношение
представлено на Рис. 13-2. Необходимо отметить, что на Уровни 2 и 3
также ссылаются как на стандарты ISO - ISO 7776 (LAPB) и ISO 8208
(пакетный уровень Х.25).
Сквозная передача между устройствами DTE выполняется через
двунаправленную связь, называемую виртуальной цепью. Виртуальные цепи
позволяют осуществлять связь между различными элементами сети через
любое число промежуточных узлов без назначения частей физической среды,
что является характерным для физических цепей. Виртуальные цепи могут
быть либо перманентными, либо коммутируемыми (временно). Перманентные
виртуальные цепи обычно называют PVC; переключаемые виртуальные цепи-
SVC. PVC обычно применяются для наиболее часто используемых передач
данных, в то время как SVC применяются для спорадических передач
данных. Уровень 3 Х.25 отвечает за сквозную передачу, включающую как
PVC, так и SVC.
После того, как виртуальная цепь организована, DTE отсылает пакет
на другой конец связи путем отправки его в DCE, используя
соответствующую виртуальную цепь. DCE просматривает номер виртуальной
цепи для определения маршрута этого пакета через сеть Х.25. Протокол
Уровня 3 Х.25 осуществляет мультиплексную передачу между всеми DTE,
которые обслуживает устройство DCE, расположенное в сети со стороны
пункта назначения, в результате чего пакет доставлен к DTE пункта
назначения.
Блок данных Х.25 состоит из последовательности полей, показанной на
Рис. 13-3. Поля Х.25 Уровня 3 образуют пакет Х.25; они состоят из
заголовка и данных пользователя. Поля Х.25 Уровня 2 (LAPB) включают
в себя поле управления уровнем блока данных и поле адресации,
встроенный пакет Уровня 2 и проверочную последовательность блока
данных (FCS).
Заголовок Х.25 Уровня 3 образован из "идентификатора универсального
формата" - general format identifier - (GFI),
"идентификатора логического канала"- logical channel identifier -
(LCI) и
"идентификатора типа пакета"- packet type identifier - (PTI).
GFI представляет собой 4-х битовое
поле, которое указывает на универсальный формат заголовка пакета. LCI
представляет собой 12-битовое поле, которое идентифицирует виртуальную
цепь. Поле LCI является логически значимым в интерфейсе DTE/DCE.
Другими словами, для организации виртуальной цепи PDN соединяет два
логических канала, каждый из которых имеет независимый LCI, двумя
интерфейсами DTE/DCE. Поле PTI идентифицирует один из 17 типов пакетов
Х.25.
Поля адресации в пакетах установления обращения обеспечивают адреса
DTE источника и пункта назначения. Они используются для организации
виртуальных цепей, включающих передачу Х.25. Recommendation Х.121
CCITT определяет форматы адресов источника и пункта назначения.
Адреса Х.121 (называемые также International Data Numbers, или IDN)
имеют разную длину, которая может доходить до 14 десятичных знака.
Четвертый байт в пакете организации обращения определяет длину адресов
DTE источника и назначения. Первые четыре цифры IDN называются "код
идентификации сети" - data network identification code - (DNIC).
DNIC поделен на две части; первая часть
(3 цифры) определяет страну, где находится PSN, вторая часть определяет
саму PSN. Остальные цифры называются "номером национального терминала"
- national terminal number - (NTN);
они используются для идентификации определенного DTE в сети
PSN. Формат адреса Х.121 представлен на Рис. 13-4.
Поля адресации, образующие адрес Х.121, необходимы только при
использовании SVC, да и то только на время установления обращения.
После того, как вызов организован, PSN использует поле LCI заголовка
пакета данных для назначения конкретной виртуальную цепь отдаленному
DTE.
Х.25 Уровня 3 использует три рабочих процедуры организации виртуальной
цепи:
Выполнение этих процедур зависит от использованного типа виртуальной
цепи. Для PVC Уровень 3 Х.25 всегда находится в режиме передачи данных,
т.к. цепь организована перманентно. Если применена SVC, то используются
все три процедуры.
Процедура передачи данных зависит от пакетов DATA. Х.25 Уровня 3
сегментирует и подвегает операции "обратный ассеблер" сообщения
пользователя, если длина их превышает максимальный размер пакета
для данной цепи. Каждому пакету DATA присваивается номер
последовательности, поэтому можнo управлять неисправностями и потоком
информации через интерфейс DTE/DCE.
Уровень 2 реализован протоколом LAPB. LAPB позволяет обеим сторонам
(DTE и DCE) инициировать связь друг с другом. В процессе передачи
информации LAPB контролирует, чтобы блоки данных поступали к
приемному устройству в правильной последовательности и без ошибок.
Также, как и аналогичные протоколы канального уровня, LAPB использует
три типа форматов блоков данных:
Поле flag ограничивает блок данных LAPB.
Чтобы предотвратить появление
структуры флага в пределах внутренней части блока данных, используется
вставка битов.
Поле address указывает, что содержит блок данных-команду или ответный
сигнал.
Поле control обеспечивает дальнейшую квалификацию блоков данных и
блоков команд, а также указывает формат блока данных (U, I или S)),
функции блока данных (например, receiver ready - "получатель готов",
или disconnect - "отключение") и номер последовательности отправки/
приема.
Поле data содержит данные высших уровней. Его размер и формат
меняются в зависимости от типа пакета Уровня 3. Максимальная длина
этого поля устанавливается соглашением между администратором PSN и
абонентом во время оформления абонентства.
Поле FCS обеспечивает целостность передаваемых данных.
Уровень 1 Х.25 использует протокол физического уровня Х.21 bis,
который примерно эквивалентен RS-232-С. Протокол X.21 bis является
производным от CCITT Recommendations V24 и V25, которые соответственно
идентифицируют цепи межобмена и характеристики электрических сигналов
интерфейса DTE/DCE. X.21 bis обеспечивает двухточечные связи, скорости
до 19.2 Кб/сек и синхронную передачу с полным дублированием через
четырех-проводной носитель. Максимальное расстояние между DTE и DCE
-15 метров.
Название сети Integrated Services Digital Network (ISDN) (Цифровая
сеть с интегрированными услугами) относится к набору цифровых услуг,
которые становятся доступными для конечных пользователей. ISDN
предполагает оцифровывание телефонной сети для того, чтобы
голос, информация, текст, графические изображения, музыка,
видеосигналы и другие материальные источники могли быть переданы
коанечныму пользователю по имеющимся телефонным проводам и получены
им из одного терминала конечного пользователя. Сторонники ISDN
рисуют картину сети мирового масштаба, во многом похожую на
сегодняшнюю телефонную сеть, за тем исключеним, что в ней
используется передача цирфрового сигнала и появляются новые
разнообразные услуги.
ISDN является попыткой стандартизировать абонентские услуги,
интерфейсы пользователь/сеть и сетевые и межсетевые возможности.
Стандартизация абонентских услуг является попыткой гарантировать
уровень совместимости в международном масштабе. Стандартизация
интерфейса пользователь/сеть стимулирует разработку и сбыт на рынке
этих интерфейсов изготовителями, являющимися третьей участвующей
стороной. Стандартизация сетевых и межсетевых возможностей
помогает в достижении цели возможного об'единения в мировом
масштабе путем обеспечения легкости связи сетей ISDN друг с
другом.
Применения ISDN включают быстродействующие системы обработки
изображений (такие, как факсимиле Group 1V), дополнительные
телефонные линии в домах для обслуживания индустрии дистанционного
доступа, высокоскоростную передачу файлов и проведение видео
конференций. Передача голоса несомненно станет популярной прикладной
программой для ISDN.
Многие коммерческие сети связи начинают предлагать ISDN по ценам
ниже тарифных. В Северной Америке коммерческие сети связи с
коммутатором локальных сетей (Local-exchange carrier) (LEC)
начинают обеспечивать услуги ISDN в качестве альтернативы
соединениям Т1, которые в настоящее время выполняюут большую
часть услуг "глобальной телефонной службы" (WATS) (wide-area
telephone service).
В число компонентов ISDN входят терминалы, терминальные адаптеры
(ТА), устройства завершения работы сети, оборудование завершения
работы линии и оборудование завершения коммутации. Имеется два
типа терминалов ISDN. Специализированные терминалы ISDN называются
"терминальным оборудованием типа 1" (terminal equipment type 1)
(TE1). Терминалы, разрабатывавшиеся не для ISDN, такие, как
DTE, которые появились раньше стандартов ISDN, называются
"терминальным оборудованием типа 2" (terminal equipment type 2)
(TE2). Терминалы ТЕ1 подключают к сети ISDN через цифровую линию
связи из четырех скрученных пар проводов. Терминалы ТЕ2 подключают к
сети ISDN через терминальный адаптер. Teрминальный адаптер (ТА) ISDN
может быть либо автономным устройством, либо платой внутри ТЕ2.
Если ТЕ2 реализован как автономное устройств, то он подключает к ТА
через стандартный интерфейс физического уровня (например, EIA232,
V.24 или V.35).
Следующей точкой соединения в сети ISDN, расположенной за пределами
устройств ТЕ1 и ТЕ2, является NT1 или NT2. Это устройства
завершения работы сети, которые подключают четырехпроводной
абонентский монтаж к традиционному контуру двухпроводной локальной
сети. В Северной Америке NT1 является устройством "оборудования посылок
заказчика" (customer premises equipment) (CPE). В большинстве других
частей света NT1 является частью сети, обеспечиваемой коммерческими
сетями связи. NT2 является более сложным устройством, которое
обычно применяется в "частных цифровых телефонных станциях с
выходом в общую сеть" (PBX), и выполняет функции протоколов
Уровней 2 и 3 и услуги по концентрации данных. Существует также
устройство NT1/2; это отдельное устройство, которое сочетает
функции NT1 и NT2.
В ISDN задано определенное число контрольных точек. Эти контрольные
точки определяют логические интерфейсы между функциональными
группировками, такими, как ТА и NТ1. Контрольными точками ISDN
являются точки "R" (контрольная точка между неспециализированным
оборудованием ISDN и ТА), "S" (контрольная точка между терминалами
пользователя и NT2), "Т" (контрольная точка между устройствами
NT1 и NT2) и "U" (контрольная точка между устройствами NT1 и
оборудованием завершения работы линии в коммерческих сетях связи).
Контрольная точка "U" имеет отношение только к Северной Америке,
где функция NT1 не обеспечивается коммерческими сетями связи.
На Рис. 11-1 показан "Образец конфигурации ISDN". Нa рисунке
изображены три устройства, подключенные к коммутатору ISDN ,
находящемуся на центральной станции. Два из этих устройства
совместимы с ISDN, поэтому их можно подключить к устройствам NT2
через контрольную точку "S". Третье устройство (стандартный,
не специализированный для ISDN тeлефон) подключается к ТА через
контрольную точку "R". Любое из этих устройств может быть также
подключено к устройству NT1/2, которое заменяет оба устройства-
NТ1 и NT2. Аналогичные станции пользователей (не показанные на
рисунке) подключены к самому правому переключателю ISDN.
Услуги "Интерфейса базовой скорости" (Basic Rate Interface) (BRI),
обеспечиваемые ISDN, предлагают два В-канала и один D-канал (2B+D).
Обслуживание В-каналом BRI осуществляется со скоростью 64 Kb/сек; оно
предназначено для переноса управляющей информации и информации
сигнализации, хотя при определенных обстоятельствах может поддерживать
передачу информации пользователя. Протокол обмена сигналами D-канала
включает Уровни 1-3 эталонной модели OSI. BRI обеспечивает также
управление разметкой и другие непроизводительные операции, при этом
общая скорость передачи битов доходит до 192 Kb/сек. Спецификацией
физического уровня BRI является ССIТТ 1.430.
Услуги "Интерфейса первичной скорости" ISDN (Primary Rate Interface)
(PRI) предлагают 23 В-канала и один D-канал в Северной Америке и
Японии, обеспечивающие общую скорость передачи битов 1.544 Mb/сек
(канал-D PRI работает на скорости 64 Kb/сек). PRI ISDN в Европе,
Австралии и других частях света обеспечивает 30 В-каналов и
один 64 Kb/сек D-канал и общую скорость интерфейса 2.048 Mb/сек.
Спецификацией физического уровня PRI является CCITT 1.431.
Форматы блока данных физическoго уровня (Уровень 1) ISDN различаются
в зависимости от того, является блок данных отправляемым за пределы
терминала (из терминала в сеть) или входящим в пределы терминала
(из сети в терминал). Оба вида блока данных физического уровня
показаны на Рис. 11-2 "Форматы блоков данных физического уровня ISDN".
Длина блоков данных равна 48 битам, из которых 36 бит
представляют информацию. Биты "F" обеспечивают синхронизацию. Биты
"L" регулируют среднее значение бита. Биты "Е" используются для
решения конфликтной ситуации, когда несколько терминалов на какой-
нибудь пассивной шине претендуют на один канал. Бит "А"" активирует
усройства. Биты "S" ещe не получили назначения. Биты "В1", "В2" и
"D" предназначены для данных пользователя.
Физически к одной цепи может быть подключено множество устройств
пользователей ISDN. Для такой конфигурации столкновения могут быть
результатом одновременной передачи двух терминалов. Поэтому ISDN
предусматривает средства для определения конфликтов в канале
связи. При получении устройством NT бита D из ТЕ оно отражает этот
бит эхо-сигналом обратно в соседнюю позицию Е-бита. ТЕ ожидает, что
соседний Е бит должен быть тем же самым, что и бит D, который он
передал в последней передаче.
Терминалы не могут передавать в D-канал до тех пор, пока они не
распознают специфичное число единиц (указывающих на "отсутствие
сигнала"), соответствующее заранее установленному приоритету. Если
устройство ТЕ обнаруживает какой-либо бит в канале с эхо-сигналом
(Е), отличающимся от его битов D, oнo должно немедленно прекратить
передачу. Этот простой прием является гарантией того, что одновременно
только один терминал может передавать свои D-сообщения. После
успешной передачи D-сообщения приоритет этого терминала становится
более низким, что обеспечивается путем пред'явления ему требования
до передачи детектировать большее число последовательных единиц.
Приоретет у терминалов может не повыситься до тех пор, пока все
другие устройства на этой линии не получат возможность отправить
D-сообщение. Телефонные связи имеют более высокий приоритет, чем
все другие службы, а информация обмена сигналами имеет более высокий
приоритет, чем несигнализирующая информация.
Уровнем 2 протокола обмена сигналами ISDN является Link Access
Procedure, D channel (Процедура доступа к каналу связи, D-канал),
известная также как LAРD. LAPD аналогична "Управлению каналом передачи
данных высокого уровня" (HDLC) и "Процедуре доступа к каналу связи,
сбалансированной" (LAPB) (смотри Главу 12
"SDLC и его производные" и
Главу 13 "Х.25",
где дается более подробная информация об этих
протоколах). Как видно из раскрытия его акронима, LAPD используется
в D-канале для того, чтобы обеспечить поток и соответствующий прием
управляющей и сигнализирующей информации. Формат блока
данных LAPD (смотри Рис. 11-3) очень похож на формат HDLC; также,
как НDLC, LAPD использует блок данных супервизора, информационный и
и непронумерованный блоки данных. Протокол LAPD формально определен
в CCITT Q.920 и SSITT Q.921.
Поля "флаг" (flag) и "управление" (control)
LAPD идентичны этим
полям у HDLC. Длина поля "адрес" LAPD может составлять один или
два байта. Если в первом байте задан бит расширенного адреса (ЕА),
то адрес состоит из одного байта; если он не задан, то адрес состоит
из двух байтов. Первый байт адресного поля содержит servise access
point identifier (SAPI) (идентификатор точки доступа к услугам),
который идентифицирует главный вход, в котором услуги LAPD
обеспечиваются Уровню 3. Бит C/R указывает, содержит ли блок
данных команду или ответный сигнал. Поле "идентификатора конечной
точки терминала" (terminal end-point identifier) (TEI)
указывает,
является ли терминал единственным или их много. Этот идентификатор
является единственным из перечисленных выше, который указывает на
широковещание.
Для передачи сигналов ISDN используются две спецификации Уровня 3:
CCITT 1.450 (известная также как CCITT Q.930) и CCITT 1.451
(известная также как SSITT Q.931). Вместе оба этих протокола
обеспечивают соединения пользователь-пользователь, соединения с
коммутацией каналов и с коммутацией пакетов. В них определены
разнообразные сообщения по организации и завершению обращения,
информационные и смешанные сообщения, в том числе SETUP
(УСТАНОВКА), CONNECT (ПОДКЛЮЧАТЬ), RELEASE (ОТКЛЮЧЕНИЕ),
USER INFORMATION (ИНФОРМАЦИЯ ПОЛЬЗОВАТЕЛЯ), CANCEL (ОТМЕНА),
STATUS (СОСТОЯНИЕ) и DISCONNECT (РАЗ'ЕДИНЯТЬ). Эти сообщения
функционально схожи с сообщениями, которые обеспечивает протокол
Х.25 (более подробно смотри в Главе 13 "Х.25").
На рис.11-4, взятом из спецификации CCITT 1.451, показаны типичные стадии
обращения с коммутацией каналов ISDN.
IBM разработала протокол Synchronous Data-Link Control (SDLC)
(Управление синхронным каналом передачи данных) в середине 1970 гг.
для применения в окружениях Systems Network Architecture (SNA)
(Архитектура системных сетей). SDLC был первым из протоколов
канального уровня нового важного направления, базирующегося на
синхронном бит-ориентированном режиме работы. По сравнению с
синхронным, ориентированным по символам (например, Bisynk
фирмы IBM) и синхронным, с организацией счета байтов (например,
Digital Data Communications Message Protocol - Протокол Сообщений
Цифровой Связи) протоколами, бит-ориентированные синхронные протоколы
являются более эффективными и гибкими, и очень часто более
быстродействующими.
После разработки SDLC компания IBM представила его на рассмотрение
в различные комитеты по стандартам. Международная Организация по
Стандартизации (ISO) модифицировала SDLC с целью разработки
протокола HDLC (Управление каналом связи высокого уровня).
Впоследствии Международный консультативный комитет по телеграфии и
телефонии (CCITT) модифицировал HDLC с целью создания "Процедуры
доступа к каналу" (LAP), а затем "Процедуры доступа к каналу,
сбалансированной" (LAPB). Институт инженеров по электротехнике и
радиоэлектронике (IEEE) модифицировал HDLC , чтобы разработать
IEEE 802.2. Kaждый из этих протоколов играет важную роль в своей
области. SDLC остается основным протоколом канального уровня SNA
для каналов глобальных сетей.
SDLC поддерживает разнообразные типы соединений и топологий. Он может
применяться в сетях с двухточечными (непосредственными) и
многоточечными связями, со связанным и несвязанным носителем, с
полностью и наполовину дублированными средствами передачи, с
коммутацией цепей и коммутацией пакетов.
SDLC идентифицирует два типа сетевых узлов:
Первичные и вторичные узды SDLC могут быть соединены в соответствии со
следующими четырьмя основными конфигурациями:
Формат блока данных SDLC представлен на Рис. 12-1.
Как видно из рисунка, блоки данных SDLC ограничены уникальной
структурой "флага" (flag). Поле "адрес" (address)
всегда содержит адрес
вторичного узла, задействованного в текущей связи. Т.к. первичный
узел является либо источником связи, либо пунктом назначения, нет
необходимости включать его адрес - он заранее известен всем
вторичным узлам.
"Управляющее" (control) поле использует три разных формата в
зависимости от использованного типа блока данных SDLC. Описание
трех типов блока данных SDLC дается ниже в следующем перечне:
Последовательность проверки блока данных (frame check sequence)
(FCS) предшествует ограничителю завершающего флага. FCS обычно
является остатком расчета "проверки при помощи циклического
избыточного кода" (cyclic redundency check) (CRC). Расчет CRC
выполняется повторно получателем. Если результат отличается от
значения, содержащегося в блоке данных отправителя, считается,
что имеет место ошибка.
Типичная конфигурация сети, базирующейся на SDLC, представлена на
Рис. 12-2. Как показано на рисунке, контроллер организации связи
IBM (раньше называвшийся групповым контроллером) на отдаленном
пункте подключен к "немым" терминалам и к сети Token Ring. На
местном вычислительном центре главная вычислительная машина IBM
подключена (через оборудование подключения каналов) к фронтальному
процессору (FEP), который может также иметь связи с местными
локальными сетями Token Ring и стержнем SNA. Оба пункта соединены
с помощью арендуемой, базирующейся на SDLC, 56-Kb/сек линии.
Несмотря на то, что в HDLC не вoшли несколько характеристик,
используемых в SDLC, он повсеместно считается некой
суперразновидностью SDLC, совместимой с ним. LAP считается
подразновидностью HDLC. LAPB был разработан, чтобы обеспечить
продолжение совместимости с HDLC, который был изменен в начале 1980 гг.
IEEE 802.2 является модификацией HDLC для окружений LAN.
Формат блока данных HDLC такой же, как у SDLC; поля HDLC обеспечивают
те же функциональные возможности, что и соответствующие поля SDLC.
Кроме того, также, как и SDLC, HDLC обеспечивает синхронный режим
работы с полным дублированием.
HDLC имеет несколько незначительных отличий от SDLC. Во-первых, HDLC
имеет вариант для 32-х битовых контрольных сумм. Во-вторых, в отличие
от SDLC, HDLC не обеспечивает конфигурации "loop" и "hub go-ahead".
Главным различием между HDLC и SDLC является то, что SDLC обеспечивает
только один режим передачи, в то время как HDLC обеспечивает три.
HDLC обеспечивает следующие три режима передачи:
LAPB является наиболее популярным протоколом благодаря тому, что он
входит в комплект протоколов Х.25. Формат и типы блока данных, а
также функции поля у LAPB те же самые, что у SDLC и HDLC. Однако
в отличие от любого из этих двух протоколов, LAPB обеспечивает только
один режим передачи ABM, поэтому он подходит только для
комбинированных станций. Кроме того, цепи LAPB могут быть организованы
либо терминальным оборудованием (DTE), либо оборудованием
завершения действия информационной цепи (DCE). Станция, инициирующая
обращение, определяется как первичная, в то время как реагирующая
станция считается вторичной. И наконец, использование протоколом LAPB
бита P/F несколько отличается от его использования другими
протоколами. Подробности смотри в Главе 13
"Х.25".
IEEE 802.2 часто называют Logical Link Control (LLC) (Управление
логическим каналом связи). Он чрезвычайно популярен в окружениях
LAN, где он взаимодействует с такими протоколами, как IEEE 802.3,
IEEE 802.4 и IEEE 802.5.
IEEE 802.2 предлагает три типа услуг. Тип 1 обеспечивает услуги
без установления соединения и подтверждения о приеме. Тип 2
обеспечивает услуги с установлением соединения. Тип 3 обеспечивает
услуги без установления соединения с подтверждением о приеме.
Являясь обслуживанием без установления соединения и подтверждения о
приеме, Тип 1 LLC не подтверждает передачу данных. Т.к. большое
число протоколов верхнего уровня, таких как Transmissin Control
Protocol/ Internet Protocol (ТCP/IP), обеспечивают надежную
передачу информации, которая может компенсировать недостаточную
надежность протоколов низших уровней, Тип 1 является широко
используемой услугой.
Обслуживание Типа 2 LLC (часто называемое LLC2) организует виртуальные
цепи между отправителем и получателем и, следовательно, является
обслуживанием с установлением соединения. LLC2 подтверждает получение
информации; оно используется в системах связи IBM.
Обеспечивая передачу данных с подтверждением, обслуживание Типа 3 LLC
не организует виртуальных цепей. Являясь компромиссом между двумя
другими услугами LLC, Тип 3 LLC бывает полезным в окружениях фабричных
автоматизированных систем, где обнаружение ошибок очень важно, однако
область памяти контекста (для виртуальных цепей) чрезвычайно ограничена.
Конечные станции могут обеспечить множество типов услуг LLC.
Устройство Класса 1 обеспечивает только услуги Типа 1. Устройство
Класса II обеспечивает как услуги Типа 1, так и услуги Типа 2.
Устройства Класса III обеспечивает услуги Типа 1 и Типа 3, в то
время как устройства Класса IV обеспечивают все три типа услуг.
Процессы высших уровней используют услуги IEEE 802.2 через "точки
доступа к услугам" (SAP). Заголовок IEEE 802.2 начинается с поля
"точки доступа к услугам пункта назначения" (DSAP), которое
идентифицирует принимающий процесс высшего уровня. Другими словами,
после того, как реализация IEEE 802.2 принимающего узла завершит
свою обработку, процесс высшего уровня, идентифицированный в
поле DSAP, принимает оставшиеся данные. За адресом DSAP следует
адрес "точки доступа к услугам источника" (SSAP), который
идентифицирует передающий процесс высшего уровня.
Switched Multimegabit Data Service (SMDS) (Служба коммутации данных
мультимегабитного диапазона) является службой дейтаграмм с коммутацией
пакетов, предназначенной для высокоскоростных информационных сообщений
глобальных сетей. Обеспечивая пропускную способность , которая
первоначально будет находиться в диапазоне от 1 до 34 Mg/сек, SMDS
в настоящее время начинает повсеместно использоваться в общедоступных
сетях передачи данных коммерческими сетями связи в результате реакции
на две тенденции. Первая из них-это пролиферация обработки
распределенных данных и других прикладных задач, для реализации
которых необходимы высокопроизводительные об'единенные сети. Второй
тенденцией является уменьшающаюся стоимость и высокий потенциал полосы
пропускания волоконно-оптического носителя, обеспечивающие
жизнеспосособность таких прикладных задач при их использовании в
глобальных сетях.
SMDS описана в серии спецификаций, выпущенных Bell Communications
Reseach (Bellcore) и принятых поставщиками оборудования для
телекоммуникаций и коммерческими сетями связи. Одна из этих
спецификаций описывает SMDS Interface Protocol (SIP) (Протокол
интерфейса SMDS), который является протоколом согласования между
устройством пользователя (называемым также customer premises equipment
- CPE - оборудованием в помещении заказчика) и оборудованием сети SMDS.
SIP базируется на стандартном протоколе IEEE для сетей крупных
городов (MAN), т.е. на стандарте IEEE 802.6 Distribuited Queue Dual
bus (DQDB) (Дублированная шина очередей к распределенной базе данных).
При применении этого протокола устройства CPE, такие как
роутеры, могут быть подключены к сети SMDS и пользоваться
обслуживанием SMDS для высокоскоростных об'единенных сетей.
На рис.15-1 изображен сценарий межсетевого об'единения с
использованием SMDS. Как показано на рисунке, доступ к SMDS
обеспечивается либо через средства передачи с пропускной способностью
1.544-Mgps (DS-1 или Digital Signal 1), либо через средства передачи
с пропускной способностью 44.736-Mgps (DS-3 или Digital Signal 3).
Несмотря на то, что SMDS обычно описывается как обслуживание,
базирующееся на волоконно-оптических носителях, доступ DS-1 может быть
обеспечен либо через волоконно-оптический, либо через базирующийся на
меди носитель с достаточно хорошими показателями характеристики
погрешностей. Пункт разграничения между сетью SMDS частной компании-
владельца сети связи и оборудованием клиента называется интерфейсом
абонент/сеть (SNI).
Единицы данных SMDS могут содержать в себе до 9,188 восьмибитовых
байтов информации пользователя. Следовательно, SMDS способен
формировать все пакеты данных IEEE 802.3, IEEE 802.4, IEEE 802.5
и FDDI. Большой размер пакета согласуется с задачами высокоскоростного
обслуживания.
Как и у других дейтаграммных протоколов, единицы данных SMDS несут адрес
как источника, так и пункта назначения. Получатель единицы данных
может использовать адрес источника для возврата данных отправителю и
для выполнения таких функций, как разрешение адреса (отыскание
соответствия между адресами высших уровней и адресами SMDS). Адреса
SMDS являются 10-значными адресами, напоминающими обычные телефонные
номера.
Кроме того, SMDS обеспечивает групповые адреса, которые позволяют
отправлять одну информационную единицу, которая затем доставляется
сетью нескольким получателям. Групповая адресация аналогична
многопунктовой адресации в локальных сетях и является ценной
характеристикой для прикладных задач об'единенных сетей, где она широко
используется для маршрутизации, разрешения адреса и динамического
нахождения ресурсов сети (таких, как служебные файловые процессоры).
SMDS обеспечивает несколько других характеристик адресации. Адреса
источников подтверждаются сетью для проверки законности назначения
рассматриваемого адреса тому SNI, который является его источником.
Таким образом пользователи защищаются от обманного присвоения адреса
(address spoofing), когда какой-нибудь отправитель
выдает себя за другого отправителя. Возможна также отбраковка
(экранирование) адресов источника и пункта назначения. Отбраковка
адресов источника производится в тот момент, когда информационнные
единицы уходят из сети, в то время как отбраковка адресов пункта
назначения производится в момент входа информационных единиц в сеть.
Если адреса не являются разрешенными адресами, то доставка
информационной единицы не производится. При наличии адресного
экранирования абонент может организовать собственную виртуальную
цепь, которая исключает ненужный трафик. Это обеспечивает абоненту
экран для защиты исходных данных и способствует повышению
эффективности, т.к. устройствам, подключенным к SMDS, не обязательно
тратить ресурсы на обработку ненужного трафика.
Чтобы приспособиться к широкому диапазону требований трафика и
возможностей оборудования, SMDS обеспечивает ряд классов доступа.
Различные классы доступа определяют различные максимальные
поддерживаемые скорости передачи информации, а также допустимую
степень разбивки при отправке пакетов в сеть SMDS.
В интерфейсах скоростей DS-3 классы доступа реализуются через алгоритмы
управления разрешением на передачу очередного пакета данных. Эти
алгоритмы отслеживают равновесие разрешений на передачу очередного
пакета данных для каждого интерфейса заказчика. Разрешения даются
на основе принципа периодичности, вплоть до определенного максимума.
Затем баланс разрешений декрементируется по мере отсылки пакетов в
сеть.
Работа схемы управления разрешением на передачу очередного пакета
в значительной степени ограничивает работу оборудования заказчика до
некоторой поддерживаемой, или средней скорости передачи информации.
Эта средняя скорость передачи меньше пропускной способности устройства
доступа DS-3 при полной информационной загрузке. Для интерфейса доступа
DS-3 обеспечиваются 5 классов доступа, соответствующих средним
скоростям передачи информации 4, 10, 16, 25 и 34 Mb/сек. Схема
управления разрешением на передачу непригодна для интерфейсов доступа
со скоростями DS-1.
Доступ к сети SMDS осуществляется через SIP. SIP базируется на
протоколе DQDB, определяемом стандартом IEEE 802.6 MAN. Протокол
DQDB определяет схему управления доступом к носителю, которая позволяет
об'единять между собой множество систем через две однонаправленные
логические шины.
В соответствии с IEEE 802.6, стандарт DQDB может быть использован для
построения частных, базирующихся на волоконно-оптических носителях
сетей MAN, поддерживающих различные прикладные задачи, в том числе
передачу данных, голоса и видеосигналов. Этот протокол был выбран в
качестве базиса для SIP по той причине, что это был открытый стандарт,
который мог обеспечить все характеристики обслуживания SMDS и
совместимость со стандартами передачи для коммерческих линий связи,
а также с новыми стандартами для Broadband ISDN (BISDN). По мере
совершенствования и распространения технологии BISDN, коммерческие
линии связи собираются обеспечить не только SMDN, но
также и широкополосное видео и речевое обслуживание.
Для сопряжения с сетями SMDS необходима только часть протокола
IEEE 802.6, касающаяся передачи данных без установления соединения.
Поэтому SIP не определяет поддержку применений, связанных с передачей
голоса или видеосигналов.
Если протокол DQDB используется для получения доступа к сети SMDS,
то результатом его работы является "доступ DQDB" (access DQDB). Термин
"доступ DQDB" отличает работу протокола DQDB в интерфейсе SNI от его
работы в других окружениях (таких, как внутри сети SMDS). Один
переключатель в сети SMDS воздействует на доступ DQDB как одна
станция, в то время как оборудование заказчика воздействует на доступ
DQDB как одна или более станций.
Т.к. протокол DQDB предназначался для поддержки информационных и
неинформационных систем, а также потому, что это протокол управления
коллективным доступом к среде, он является относительно сложным
протоколом. Он состоит из двух частей:
Существуют две возможные конфигурации оборудования СРЕ для получения
доступа DQDB к сети SMDS (смотри рис.15-2). При конфигурации с одним
СРЕ доступ DQDB просто соединяет переключатель в коммерческой сети
и одну станцию, принадлежащую абоненту (СРЕ). Для конфигурации с
большим числом СРЕ, доступ DQDB состоит из переключателя в сети и
множества об'единенных СРЕ в местоположении абонента. Для второй
конфигурации, все СРЕ должны принадлежать одному и тому же абоненту.
Для случая с одним СРЕ, доступ DQDB фактически представляет собой
просто подсеть DQDB из двух узлов. Каждый из этих узлов (переключатель
и СРЕ) передают данные другому через однонаправленную логическую
шину. Конкуренция на получение этой шины отсутствует, т.к. других
станций нет. Поэтому нет необходимости использовать алгоритм
распределенного доступа с организацией очереди. При отсутствии той
сложности, которую создает применение алгоритма распределенного
доступа с организацией очереди, SIP для конфигурации с одним СРЕ
намного проще, чем SIP для конфигурации с большим числом СРЕ.
SIP может быть логически разделен на 3 уровня, как это показано
на Рис. 15-3 "Формирование пакета данных пользователя уровнями SIP".
Уровень 3
Задачи, выполняемые уровнем 3 SIP, включают в себя формирование пакета
"единиц данных обслуживания SMDS" (service data units (SDU)) в
заголовке
и концевике уровня 3. Затем "eдиницы данных протокола" (protocol data
units (PDU)) разбиваются на PDU уровня 2 таким образом, чтобы
соответствовать спецификациям уровня 2.
PDU уровня 3 SIP достаточно сложна. Она изображена на Рис. 15-4.
Поля на рисунке, помеченные знаком Х+, не используются средствами
SMDS; они присутствуют в протоколе для того, чтобы обеспечить
выравнивание формата SIP с форматом протокола DQDB. Значения,
помещенные в этих полях оборудованием CPE, должны быть доставлены
сетью в неизмененном виде.
Два резервных поля (reserved) должны быть заполнены нулями. Два
поля BEtag содержат идентичные значения и используются для
формирования
связи между первым и последним сегментами, или "единицами данных
протокола" (PDU) уровня 2 одной из PDU уровня 3 SIP. Эти поля могут
быть использованы для определения условия, при котором как последний
сегмент одной PDU уровня 3, так и первый сегмент следующей PDU уровня 3
потеряны, что приводит к приему неисправной PDU уровня 3.
Адреса пункта назначения (destination) и источника (source)
состоят
из двух частей: типа адреса (address type) и адреса (address).
Тип адреса для обоих случаев занимает четыре наиболее значимых бита
данного поля. Если адрес является адресом пункта назначения, то тип
адреса может представлять собой либо "1100", либо "1110". Первое
значение обозначает 60-битовый индивидуальный адрес, в то время
как второе значение обозначает 60-битовый групповой адрес. Если адрес
является адресом истрочника, то поле типа адреса может означать
только индивидуальный адрес.
Bellcore Technical Advisories (Техническое Консультативное Заключение
Bellcore) определяет, каким образом у адресов,
формат которых согласуется с North American Numbering Plan (NANP),
должны быть закодированы адресные поля источника и места назначения.
В этом случае четыре наиболее значащих бита каждого из подполей
адреса источника и пункта назначения содержат значение "0001", которое
является международным кодом страны для Северной Америки. Следующие
40 битов содержат значения 10-значных адресов SMDS, закодированных в
двоично-десятичных числах (BCD) и выровненных в соответствии с NANP.
Последние 16 битов (наименее значащих) заполнены незначащей
информацией (единицами).
Поле "идентификатора протокола высшего уровня" (higher-layer protocol
identifier) указывает, какой тип протокола заключен в информационном
поле. Это значение является важным для систем, использующим сеть
SMDS (таких, как роутеры Cisco), но онo не обрабатывается
и не изменяется сетью SMDS.
Поле "длины расширения заголовка" (header extesion length (HEL))
указывает на число 32-битовых слов в поле расширения заголовка.
В настоящее время установлен размер этого поля для SMDS, равный 12
байтам. Следовательно, значение HEL всегда "0011".
Поле расширения заголовка (header extension (HE)) в настоящее время
определяется как имеющее два назначения. Одно из них - содержать номер
версии SMDS, который используется для определения версии протокола.
Второе - сообщать о "значении для выбора несущей" (carrier selection
value), которое обеспечивает возможность выбирать конкретную несущую
межобмена для того, чтобы переносить трафик SMDS из одной локальной
коммерческой сети связи в другую. При необходимости в будущем может
быть определена другая информация, о которой будет сообщаться в
поле расширения заголовка.
Уровень 2
PDU уровня 3 сегментируются на PDU уровня 2 с одинаковым размером
(53-восьмибитовых байта), которые часто называют "слотами" (slots)
или "секциями" (cells). Формат PDU уровня 2 SIP представлен на
Рис. 15-5.
Поле "управления доступом" (access control) PDU уровня 2 SIP содержит
различные значения, зависящие от направления информационного потока.
Если слот отправлен из переключателя в CPE, то важным является только
указание о том, содержит или нет данное PDU информацию. Если слот
отправлен из СРЕ в переключатель, и при этом конфигурация представляет
собой конфигурацию с несколькими СРЕ, то это поле может также
содержать биты запроса, которые обозначают запросы шины для этих
слотов, соединяющей переключатель и СРЕ. Дальнейшие подробности об
использовании этих битов запроса для реализации управления
распределенным доступом к среде с организацией очереди могут быть
получены из стандарта IEEE 802.6.
Поле "информации управления сетью" (network control information)
может
содержать только два возможных значения. Одна из двух конкретных
структур битов включается в том случае, если PDU содержит информацию;
другая используется , когда она отсутствует.
Поле "типа сегмента" (segment type) указывает, является ли данная PDU
уровня 2 начальным, последним или каким-нибудь слотом из середины
PDU уровня 3. Значения типов сегмента представлены на Рис. 15-6.
Поле "идентификатора (ID) сообщения" (message ID) обеспечивает связь
PDU уровня 2 с каким-либо PDU уровня 3. ID сообщения
одинаково для всех сегментов данного PDU уровня 3. Для
доступа DQDB с множеством СРЕ, PDU, выходящие из разных СРЕ, должны
иметь разные ID сообщения. Это позволяет сети SMDS, принимающей
чередующиеся слоты от различных PDU уровня 3, ассоциировать каждый
PDU уровня 2 с соответствующим PDU уровня 3. Следующие друг за
другом PDU уровня 3 из одного и того же СРЕ могут иметь идентичные
ID сообщения. Это не вносит никакой неопределенности, т.к. любой
отдельный СРЕ должен отправить все PDU уровня 2, входящие в какой-
либо PDU уровня 3, прежде чем он приступит к отправке PDU уровня 2,
принадлежащих к другому PDU уровня 3.
Поле "единицы сегментации" (segmentation unit) является информационной
частью PDU. В том случае, когда PDU уровня 2 незаполнена, это поле
заполняется нулями.
Поле "длины полезной нагрузки" (payload length) указывает, какое
число байтов PDU уровня 3 фактически содержится в поле единицы
сегментации. Если данная PDU уровня 2 незаполнена, то это поле также
заполняется нулями.
И наконец, поле "CRC полезной нагрузки" (payload CRC) содержит
10-битовое значение "проверки при помощи циклического избыточного
кода" (cyclic redundancy check (CRC)), используемое для обнаружения
неисправностей в полях типа сегмента, ID сообщений, единицы
сегментации, длины полезной нагрузки и CRC полезной нагрузки. Данная
проверка CRC не охватывает поля информации управления доступом или
управления сетью.
Уровень 1
Уровень 1 SIP обеспечивает протокол физического канала, который
действует при скоростях DS-3 или DS-1 между СРЕ и сетью. Уровень 1
SIP разделен на 2 части: подуровень системы передачи (transmission
system) и Протокол конвергенции физического уровня (Physical
Layer Convergence Protocol (PLCP)). Первая часть определяет
характеристики и метод подключения к каналу передачи, т.е. DS-3 или
DS-1. Вторая часть определяет, каким образом должны быть организованы
PDU уровня 2 или слоты в зависимости от блока данных DS-3 или DS-1,
a также часть информации управления.
Т.к. SIP базируется на IEEE 802.6, у него есть преимущество-
совместимость с будущими интерфейсами BISDN, которые обеспечат
применения, связанные не только с передачей данных, но также и
видеосигналов и голоса. Однако ценой обеспечения этой совместимости
стали некоторые непроизводительные затраты протокола, которые
необходимо учитывать при подсчете общей пропускной способности,
которую можно получить при использовании SIP. Общая полоса пропускания
через доступ DQDB DS-3, доступная для данных пользователя
PDU уровня 3, составляет примерно 34 Mb/сек. Через доступ DS-1 может
быть перенесено примерно 1.2 Mb/сек информации пользователя.
Использование протокола "управления доступом к носителю" (МАС)
IEEE 802.6 МАN в качестве базиса для SMDS SIP означает, что возможна
локальная связь между СРЕ, совместно использующих один и тот же доступ
DQDB. Часть этой локальной связи будет видимой для переключателя,
обслуживающего SNI, а часть нет. Поэтому переключатель должен
использовать адрес пункта назначения единицы данных, чтобы
дифференцировать информационные единицы, предназначенные для передач
SMDS, и информационные единицы, предназначенные для локальной передачи
между несколькими СРЕ, совместно использующими один доступ DQDB.
Внутри коммерческой сети возможность коммутации пакетов на большой
скорости, которая необходима для SMDS, может быть обеспечена
применением нескольких различных технологий. В настоящее время в ряд
сетей вводятся переключатели, базирующиеся на технологии MAN, например,
на стандарте DQDB. Ряд Technical Advisories (Технических
консультативных заключений), выпущенных Bellcore, определяют требования
стандарта на сетевое оборудование для таких функций, как:
Как уже отмечалось, протокол IEEE 802.6 и SIP были специально
разработаны так, чтобы соответствовать основному протоколу BISDN,
называемому "Режим асинхронной передачи" (АТМ). АТМ и IEEE 802.6
принадлежат к классу протоколов, часто называемых протоколами
"быстрой коммутации пакетов" или "реле сегментов" (cell relay).
Эти протоколы организуют информацию в небольшие, с фиксированными
размерами сегменты (в соответствии с терминологией SIP, это PDU
уровня 2). Сегменты с фиксированными размерами могут обрабатываться
и коммутироваться в аппаратуре на очень высоких скоростях. Это
накладывает жесткие ограничения на характеристики задержки, делая
протоколы реле сегментов пригодными для применений, связанных с
голосом и видеосигналами. После того, как станет доступным
коммутирующее оборудование, базирующееся на АТМ, эта технология также
будет внедрена в сети, обеспечивающие SMDS.
В конце 1980 гг. Internet (крупная международная сеть, соединяющая
множество иссследовательских организаций, университетoв и
коммерческих концернов) начала испытывать резкий рост числа главных
вычислительных машин, обеспечивающих TCP/IP. Преобладающая часть
этих главных вычислительных машин была подсоединена к локальным сетям
(LAN) различных типов, причем наиболее популярной была Ethernet.
Большая часть других главных вычислительных машин.соединялись через
глобальные сети (WAN), такие как общедоступные сети передачи данных
(PDN) типа Х.25. Сравнительно небольшое число главных вычислительных
машин были подключены к каналам связи с непосредственным (двухточечным)
соединением (т.е. к последовательным каналами связи). Однако каналы
связи с непосредственным соединением принадлежат к числу старейших
методов передачи информации, и почти каждая главная вычислительная
машина поддерживает непосредственные соединения. Например, асинхронные
интерфейсы RS-232-С встречаются фактически повсюду.
Одной из причин малого числа каналов связи IP с непосредственным
соединением было отсутствие стандартного протокола формирования
пакета данных Internet. Протокол Point-to-Point Protocol (PPP)
(Протокол канала связи с непосредственным соединением) предназначался
для решения этой проблемы. Помимо решения проблемы формирования
стандартных пакетов данных Internet IP в каналах с непосредственным
соединением, РРР также должен был решить другие проблемы, в том числе
присвоение и управление адресами IP, асинхронное (старт/стоп) и
синхронное бит-ориентированное формирование пакета данных,
мультиплексирование протокола сети, конфигурация канала
связи, проверка качества канала связи, обнаружение ошибок и
согласование варианта для таких способностей, как согласование
адреса сетевого уровня и согласование компрессии информации. РРР
решает эти вопросы путем обеспечения расширяемого Протокола
Управления Каналом (Link Control Protocol) (LCP) и семейства
Протоколов Управления Сетью (Network Control Protocols) (NCP),
которые позволяют согласовывать факультативные параметры конфигурации
и различные возможности. Сегодня PPP, помимо IP, обеспечивает также
и другие протоколы, в том числе IPX и DECnet.
РРР обеспечивает метод передачи дейтаграмм через последовательные
каналы связи с непосредственным соединением. Он содержит три
основных компонента:
Для того, чтобы организовать связь через канал связи с непосредственным
соединением, инициирующий РРР сначала отправляет пакеты LCР для выбора
конфигурации и (факультативно) проверки канала передачи данных.
После того, как канал установлен и пакетом LCР проведенo необходимое
согласование факультативных средств, инициирующий РРР отправляет пакеты
NCP, чтобы выбрать и определить конфигурацию одного или более протоколов
сетевого уровня. Как только конфигурация каждого выбранного протокола
оперделена, дейтаграммы из каждого протокола сетевого уровня
могут быть отправлены через данный канал. Канал сохраняет свою
конфигурацию для связи до тех пор, пока явно выраженные пакеты
LCP или NCP не закроют этот канал, или пока не произойдет какое-нибудь
внешнее событие (например, истечет срок бездействия таймера или
вмешается какой-нибудь пользователь).
РРР может работать через любой интерфейс DTE/DCE (например,
EIA RS-232-C, EIA RS-422, EIA RS-423 и CCITT V.35). Единственным
абсолютным требованием, которое пред'являет РРР, является требование
обеспечения дублированных схем (либо специально назначенных, либо
переключаемых), которые могут работать как в синхронном, так и в
асинхронном последовательном по битам режиме, прозрачном для
блоков данных канального уровня РРР. РРР не пред'являет каких-либо
ограничений, касающихся скорости передачи информации, кроме тех,
которые определяются конкретным примененным интерфейсом DTE/DCE.
РРР использует принципы, терминологию и структуру блока данных
процедур HDLC (ISO 3309-1979) Международной Организации по
Стандартизации (ISO), модифицированных стандартом ISO
3309-1984/PDAD1
"Addendum 1:Start/stop Trasmission"
(Приложение 1:
Стартстопная передача"). ISO 3309-1979 определяет структуру блока
данных HLDC для применения в синхронных окружениях.
ISO 3309-1984/PDAD1 определяет предложенные для стандарта
ISO 3309-1979 модификации, которые позволяют его использование в
асинхронных окружениях. Процедуры управления РРР используют дефиниции
и кодирование управляющих полей, стандартизированных ISO 4335-1979 и
ISO 4335-1979/Addendum 1-1979.
Нa Рис. 10-1 приведен формат блока данных РРР.
Link Control Protocol (LCP) может согласовывать модификации
стандартной структуры блока
данных РРР. Однако модифицированные блоки данных всегда будут
четко различимы от стандартных блоков данных.
LCP обеспечивает метод организации, выбора конфигурации, поддержания
и окончания работы канала с непосредственным соединением. Процесс LCD
проходит через 4 четко различаемые фазы:
Существует три класса пакетов LCP:
Эти пакеты используются для достижения работоспособности каждой
из фаз LCP.
В начале 1980 гг. Apple Computer готовилась к выпуску компьютера
Macintosh. Инженеры компании знали, что в скором времени сети станут
насущной необходимостью, а не просто интересной новинкой. Они хотели
также добиться того, чтобы базирующаяся на компьютерах Macintosh
сеть была бесшовным расширением интерфейса пользователя Macintosh,
совершившим подлинную революцию в этой области. Имея в виду эти два
фактора, Apple решила встроить сетевой интерфейс в каждый
Macintosh и интегрировать этот интерфейс в окружение настольной
вычислительной машины. Новая сетевая архитектура Apple получила
название Apple Talk.
Хотя Apple Talk является патентованной сетью, Apple опубликовала
характеристики Apple Talk, пытаясь поощрить разработку при
участии третьей стороны. В настоящее время большое число компаний
успешно сбывают на рынке базирующиеся на Apple Talk изделия; в их
числе Novell, Inc. и Мicrosoft Corparation.
Оригинальную реализацию Apple Talk, разработанную для локальных
рабочих групп, в настоящее время обычно называют Apple Talk Phase I.
Однако после установки свыше 1.5 мил. компьютеров Macintosh в течение
первых пяти лет существования этого изделия, Apple обнаружила, что
некоторые крупные корпорации превышают встроенные возможности Apple
Talk Phase I, поэтому протокол был модернизирован. Расширенные
протоколы стали известнны под названием Apple Talk Phase II. Oни
расширили возможности маршрутизации Apple Talk, обеспечив их успешное
применение в более крупных сетях.
Apple Talk была разработана как система распределенной сети клиент-
сервер. Другими словами, пользователи совместно
пользуются сетевыми ресурсами (такими, как файлы и принтеры).
Компьютеры, обеспечивающие эти ресурсы, называются служебными
устройствами (servers); компьютеры, использующие сетевые ресурсы
служебных устройств, называются клиентами (clients).
Взаимодействие со
служебными устройствами в значительной степени является прозрачным
для пользователя, т.к. сам компьютер определяет местоположение
запрашиваемого материала и обращается к нему без получения
дальнейшей информации от пользователя. В дополнение к простоте
использования, распределенные системы также имеют экономические
преимущества по сравнению с системами, где все равны, т.к.важные
материалы могут быть помещены в нескольких, а не во многих
местоположениях.
Apple Talk относительно хорошо согласуется с эталонной моделью OSI.
На Рис. 16-1 "Apple Talk и эталонная модель OSI" представлены протоколы
Apple Talk, смежные с теми уровнями OSI, с которыми у них установлено
соответствие. Этот рисунок отличается от других изображений связи
пакета протоколов Apple Talk с моделью OSI тем, что на нем NBP, ZIP и
RTMP размещены на Уровне 3, а АЕР-на Уровне 7. По мнению Cisco, NBP,
ZIP и RТМP по своим функциональным возможностям стоят в ряду ближе
к Уровню 3 модели OSI, хотя они и пользуются услугами DDP, другого
протокола Уровня 3. Аналогично, Cisco полагает, что АРЕ следует
включить в перечень протоколов прикладного уровня, т.к. он обычно
используется для обеспечения функциональных возможностей прикладного
уровня. В частности, АЕР помогает определить возможность отдаленных
узлов принимать следующие соединения.
Apple разработала AppleTalk таким образом, чтобы он был независимым
от канального уровня. Другими словами, теоретически он может
работать в дополнение к любой реализации канального уровня. Apple
обеспечивает различные реализации канального уровня, включая
Ethernet, Token Ring, FDDI и LocalTalk. Apple ссылается на AppleTalk,
работающий в Ethernet, как нa EtherTalk,
в Тоkеn Ring-кaк на TokenTalk
и в FDDI-как на FDDITalk. Информация о технических характеристиках
Ethernet, TokenRing и FDDI приведена соответственно в
главе 5 "Ethernet/IEEE 802.3",
главе 6 "Token Ring/IEEE 802.5" и
главе 7 "FDDI".
LocalTalk - это запатентованная компанией Apple система доступа к
носителю. Он базируется на конкуренции на получение доступа,
топологии об'единения с помощью шины и передаче сигналов базовой
полосы (baseband signaling) и работает на носителе, представляющим
собой экранированную витую пару, со скоростью 230.4 Kb/сек.
Физическим интерфейсом является RS-422; это сбалансированный интерфейс
для передачи электрических сигналов, поддерживаемый интерфейсом RS-449.
Сегменты LocalTalk могут переноситься на расстояния до 300 метров и
обеспечивать до 32 узлов.
В данном разделе описываются концепции, принятые для сетевого
уровня AppleTalk, и протоколы для этого уровня. В нем рассматриваются
назначение адреса протокола, сетевые об'екты и протоколы AppleTalk,
которые обеспечивают функциональные возможности Уровня 3 эталонной
модели OSI.
Для обеспечения минимальных затрат, связанных с работой администратора
сети, aдреса узлов AppleTalk назначаются динамично. Когда Macintosh,
прогоняющий AppleTalk, начинает работать, он выбирает какой-нибудь
адрес протокола (сетевого уровня) и проверяет его, чтобы убедиться,
что этот адрес используется в данный момент. Если это не так, то этот
новый узел успешно присваивает себе какой-нибудь адрес. Если этот адрес
используется в данный момент, то узел с конфликтным адресом отправляет
сообщение, указывающее на наличие проблемы, а новый узел выбирает
другой адрес и повторяет этот процесс. На Рис. 16-2 представлен процесс
выбора адреса AppleTalk.
Фактические механизмы выбора адреса AppleTalk зависят от носителя.
Для установления связи адресов AppleTalk с конкретными адресами
носителя используется протокoл разрешения адреса AppleTalk (AARP).
AARP также устанавливает связи между адресами других протоколов и
аппаратными адресами. Если пакет протоколов AppleTalk или любого
другой пакет протоколов должен отправить пакет данных в другой сетевой
узел, то адрес протокола передается в AARP. AARP сначала проверяет
адресный кэш, чтобы определить, является ли уже установленной связь
между адресом этого протокола и аппаратным адресом. Если это так, то
эта связь передается в запрашивающий пакет протоколов. Если это не так,
то AARP инициирует широковещательное или многопунктовое сообщение,
запрашивающее об аппаратном адресе данного протокольного адреса. Если
широковещательное сообщение доходит до узла с этим протокольным
адресом, то этот узел в ответном сообщении указывает свой аппаратный
адрес. Эта информация передается в запрашивающий пакет протоколов,
который использует этот аппаратный адрес для связи с этим узлом.
AppleTalk идентифицирует несколько сетевых об'ектов. Самым простым
является узел (node), который является просто любым устройством,
соединенным с сетью AppleTalk. Наиболее распространенными узлами
являются компьютеры Macintosh и лазерные принтеры, однако многие
другие компьютеры также способны осуществлять связь AppleTalk, в
том числе компьютеры IBM PC, Digital Equipment Corparation VAX и
различные АРМ. Следующим об'ектом, определяемым AppleTalk, является
сеть. Сеть AppleTalk представляет собой просто отдельный логический
кабель. Хотя этот логический кабель часто является отдельным
физическим кабелем, некоторые вычислительные центры используют мосты
для об'единения нескольких физических кабелей. И наконец, зона (zone)
АppleTalk является логической группой из нескольких сетей (возможно
находящихся далеко друг от друга). Об'екты AppleTalk изображены
на Рис. 16-3.
Основным протоколом сетевого уровня AppleTalk является протокол DDP.
DDP обеспечивает обслуживание без установления соединения между
сетевыми гнездами. Гнезда могут назначаться либо статистически, либо
динамически.
Адреса AppleTalk, назначаемые DDP, состоят из 2 компонентов:
16-битового номера сети (network number) и 8-битового номера узла
(node number). Эти два компонента обычно записываются в виде
десятичных номеров, разделенных точкой (например, 10.1 означает
сеть 10, узел 1). Если номер сети и номер узла дополнены
8-битовым гнездом (socket), обозначающим какой-нибудь особый процесс,
то это означает, что в сети задан какой-нибудь уникальный процесс.
AppleTalk Phase II делает различие между нерасширенными (nоnextended)
и расширенными (extended) сетями. В нерасширенных сетях, таких как
LocalTalk, номер каждого узла AppleTalk уникален. Нерасширенные сети
были единственным типом сети, определенным в AppleTalk Phase I. В
расширенных сетях, таких как EtherTalk и TokenTalk, уникальной
является комбинация номер каждой сети/номер узла.
Зоны определяются управляющим сети AppleTalk в процессе конфигурации
роутера. Каждый узел AppleTalk принадлежит к отдельной
конкретной зоне. Расширенные сети могут иметь несколько зон, которые
ассоциируются с ними. Узлы в расширенных сетях могут принадлежать к
любой отдельной зоне, которая ассоциируется с этой расширенной сетью.
Протокол, который организует и поддерживает маршрутные таблицы
AppleTalk, называется Протоколом поддержки маршрутной таблицы (RTMP).
Маршрутные таблицы RTMP содержат данные о каждой сети, до которой
может дойти дейтаграмма. В эти данные входит порт роутера,
который ведет к сети пункта назначения, ID узла следующего
роутера, который принимает данный пакет, расстояние до сети
назначения, выраженное числом пересылок, и текущее состояние этих
данных (хорошее, подозрительное или плохое). Периодический обмен
маршрутными таблицами позволяет роутерам об'единенных сетей
гарантировать обеспечение непротиворечивой текущей информацией.
На Рис. 16-4 представлен образец таблицы RTMP и соответствующая
архитектура сети.
Протокол привязки по именам AppleTalk (Name Binding Protocol - NBP)
устанавливает связь имен AppleTalk (которые выражаются как
об'екты, видимые для сети - network-visible entities, или NVE) с
адресами. NVE является адресуемой сетью AppleTalk услугой, такой как
гнездо. NVE ассоциируются с более, чем одним именем об'ектов и
перечнем атрибутов. Имена об'ектов представляют собой
последовательность символов, например такую: printer@net1,
в то время как перечень атрибутов определяет характеристики NVE.
Связь между NVE с присвоенными именами и сетевыми адресами
устанавливается через процесс привязки имени. Привязка имени может
быть произведена в момент запуска узла или динамично, непосредственно
перед первым использованием. NBP управляет процессом привязки имени,
в который входят регистрация имени, подтверждение имени, стирание
имени и поиск имени.
Зоны позволяют проводить поиск имени в группе логически связанных
узлов. Чтобы произвести поиск имен в пределах какой-нибудь зоны,
отправляется запрос о поиске в местный роутер, который
рассылает широковещательный запрос во все сети, которые имеют узлы,
принадлежащие заданной зоне. Протокол информации зоны (Zone
Information Protocol - ZIP) координирует эти действия.
ZIP поддерживает соответствие номер сети/номер зоны в информационных
таблицах зоны (zone information tables-ZIT). ZIT хранятся в
роутерах, которые являются основными пользователями ZIP, однако
конечные узлы используют ZIP в процессе запуска для выбора своих зон
и получения межсетевой информации о зонах. ZIP использует
маршрутные таблицы RTMP для отслеживания изменений в топологии сети.
Если ZIP находит данные о маршрутной таблице, которох нет в данной
ZIT, она образует запись данных о новой ZIT. На Рис. 16-5 представлен
образец ZIT.
Транспортный уровень AppleTalk реализуется двумя основными протоколами
AppleTalk: AppleTalk Transaction Protocol (ATP) (Протокол транзакций
AppleTalk) и AppleTalk Data Stream Protocol (ADSP) (Протокол потока
данных АppleTalk). АТР является транзакционно-ориентированным, в то
время как ADSP является ориентированным по потоку данных.
ATP является одним из протоколов транспортного уровня Appletalk. АТР
пригоден для применений, базирующихся на транзакциях, которые можно
встретить в банках или магазинах розничной торговли.
В транзакции АТР входят запросы (от клиентов) (requests) и ответы (от
служебных устройств) (replies). Каждая пара запрос/ответ имеет
отдельный ID транзакции. Транзакции имеют место между двумя гнездами
клиентов. АТР использует транзакции "точно-один раз" (exactly once - XO)
и "по крайней мере один раз" (at-least-once - ALO), Транзакции ХО
требуются в тех ситуациях, когда случайное выполнение транзакции
более одного раза неприемлемо. Банковские транзакциии являются
примером таких неидемпотентных (nonidempotent) ситуаций (ситуаций,
когда повторение какой-нибудь транзакции вызывает проблемы, что
достигается тем, что делаются недействительными данные, участвующие
в данной транзакции).
АТР способен выполнять наиболее важные функции транспортного уровня,
в том числе подтверждение о приеме данных и повторную передачу,
установление последовательности пакетов, а также фрагментирование
и повторную сборку. АТР ограничивает сегментирование сообщений до
8 пакетов; пакеты АТР не могут содержать более 578 информационных
байтов.
ADSP является другим важным протоколом транспортного уровня Apple
Talk. Как видно из его названия, ADSP является ориентированным по
потоку данных, а не по транзакциям. Он организует и поддерживает
полностью дублированный поток данных между двумя гнездами в
об'единенной сети AppleTalk.
ADSP является надежным протоколом в том плане, что он гарантирует
доставку байтов в том же порядке, в каком они были отправлены, а
также то, что они не будут дублированы. ADSP нумерует каждый байт,
чтобы отслеживать отдельные элементы потока данных.
ADSP также определяет механизм управления потоком. Пункт назначения
может в значительной степени замедлять передачи источника путем
сокращения размера об'явленного окна на прием.
ADSP также обеспечивает механизм сообщений управления "выхода из
полосы" (out-of-band) между двумя об'ектами AppleTalk. В качестве
средства для перемещения сообщений управления выхода из полосы
между двумя об'ектами AppleTalk используются пакеты "внимания"
(attention packets).Эти пакеты используют отдельный поток номеров
последовательностей, чтобы можно было отличать их от обычных пакетов
данных ADSP.
AppleTalk обеспечивает несколько протоколов высшего уровня. Протокол
сеансов AppleTalk ( AppleTalk Session Protocol - ASP)
организует и поддерживает сеансы (логические
диалоги) между клиентом AppleTalk и служебным устройством. Протокол
доступа к принтеру ( Printer Access Protocol - РАР)
AppleTalk является ориентированным по связи
протоколом, который организует и поддерживает связи между клиентами
и служебными устройствами (использование термина printer в заголовке
этого протокола является просто исторической традицией). Эхо-протокол
AppleTalk (AppleTalk Echo Protocol - AEP) является очень простым
протоколом, генерирующим пакеты, которые могут быть использованы
для проверки способности различных узлов сети создавать повторное эхо.
И наконец, Протокол ведения картотеки AppleTalk (AppleTalk Filing
Protocol - AFP) помогает клиентам коллективно использовать служебные
файлы в сети.
Digital Equipment Corporation (Digital) разработала семейство
протоколов DECnet с целью обеспечения своих компьютеров рациональным
способом сообщения друг с другом. Выпущенная в 1975 г. первая версия
DECnet обеспечивала возможность сообщения двух напрямую подключенных
миникомпьютеров PDP-11. В последние годы Digital включила подддержку
для непатентованных протоколов, однако DECnet попрежнему остается
наиболее важным из сетевых изделий, предлагаемых Digital.
В настоящее время выпущена пятая версия основного изделия DECnet
( которую иногда называют Phase V, a в литературе компании Digital -
DECnet/OSI). DECnet Phase V представляет собой надлежащим образом
расширенный набор комплекта протоколов OSI, поддерживающий все
протоколы OSI, а также несколько других патентованных и стандартных
протоколов, которые поддерживались предыдущими версиями DECnet. Что
касается ранее внесенных изменений в протокол, DECnet Phase V
совместим с предыдущей версией (т.е. Phase IV).
В противоположность бытующему мнению, DECnet вовсе не является
архитектурой сети, а представляет собой ряд изделий, соответсвующих
Архитектуре Цифровой сети ( Digital Network Architecture - DNA)
компании Digital. Как и большинство
других сложных сетевых архитектур, поставляемых крупными поставщиками
систем, DNA поддерживает большой набор как патентованных, так и
стандартных протоколов. Перечень технологий, которые поддерживает DNA,
постоянно растет по мере того, как Digital реализует новые протоколы.
Рис. 17-1 иллюстрирует неполную картину DNA и связь некоторых ее
компонентов с эталонной моделью OSI.
Как видно из Рис. 17-1, DNA поддерживает различные реализации
физического и канального уровней. Среди них такие известные стандарты,
как Ethernet, Token Ring, Fiber Distributed Data Interface (FDDI),
IEEE 802..2 и Х.25. Подробная информация об этих протоколах дается
в Главе 5 "Ethernet/IEEE 802.3",
Главе 6 "Token Ring/IEEE 802.5",
Главе 7 "FDDI",
Главе 12 "SDLC и его производные" и
Главе 13 "X.25".
DNA также предлагает протокол канального уровня для традиционного
двухточечного соединения, который называется Digital Data
Communications Message Protocol (DDCMP) (Протокол сообщений цифровой
связи) и шину с пропускной способностью 70 Mb/sek , используемую для
группы абонентов VAX, которая называется Computer-room Interconnect
bus (CI bus) (шина межсоединений машинного зала).
DECnet поддерживает сетевые уровни как без установления соединения,
так и с установлением соединения. Оба сетевых уровня реализуются
протоколами OSI. Реализации без установления соединения используют
Connectionless Network Protocol (CLNP) (Протокол сети без
установления соединения) и Connectionless Network Service (CLNS)
(Услуги сети без установления соединения). Сетевой уровень с
установлением соединения использует X.25 Packet-Level Protocol (PLP)
(Протокол пакетного уровня), который также известен как X.25 level 3
(Уровень 3 Х.25), и Connection-Mode Network Protocol (CMNP) (Протокол
сети с установлением соединения). Более подробно эти протоколы OSI
описываются в Главе 20 "Протоколы OSI".
Хотя в DECnet Phase V значительная часть DNA была приведена
в соответствие с OSI, уже в DECnet Phase IV маршрутизация была очень
схожа с маршрутизацией OSI. Маршрутизация DNA Phase V включает в
себя маршрутизацию OSI (ES-IS и IS-IS) и постоянную поддержку
протокола маршрутизации DECnet Phase IV. ЕS-IS и IS-IS описаны в
Главе 28 "Маршрутизация OSI".
Протокол маршрутизации DECnet Phase IV имеет несколько отличий от
IS-IS. Одно из них-это разница в заголовках протоколов. Заголовок
слоя маршрутизации DNA Phase IV приведен на Рис. 17-2; форматы
пакетов IS-IS даны в
Главе 28 "Маршрутизация OSI".
Первое поле в заголовке маршрутизации DNA Phase IV-это поле флагов
маршрутизации (routing flags), которое состоит из:
Последнее поле в заголовке маршрутизации DNA Phase IV-поле
траверсированных узлов ( nodes traversed ), которое показывает число
узлов, которые пересек пакет на пути к пункту назначения. Это поле
обеспечивает реализацию подсчета максимального числа пересылок для
того, чтобы можно было удалить из сети вышедшие из употребления пакеты.
DECnet различает два типа узлов: конечные узлы и узлы маршрутизации.
Как конечные узлы, так и узлы маршрутизации могут отправлять и
принимать информацию, но обеспечивать услуги маршрутизации для других
узлов DECnet могут только узлы маршрутизации.
Маршрутные решения DECnet базируются на затратах (cost)-арбитражном
показателе, назначаемом администратором сети для использования при
сравнении различных путей через среду об'единенной сети. Затраты обычно
базируются на числе пересылок, ширине полосы носителя и других
показателях. Чем меньше затраты, тем лучше данный тракт. Если в сети
имеют место неисправности, то протокол маршрутизации DECnet Phase IV
использует значения затрат для повторного вычисления наилучшего
мааршрута к каждому пункту назначения. Рис. 17-3 иллюстрирует расчет
затрат в среде маршрутизации DECnet Phase IV.
Адреса DECnet не связаны с физическими сетями, к которым подключены
узлы. Вместо этого DECnet размещает главные вычислительные машины,
используя пары адресов область/узел (area/node address). В диапазон
значений адресов области входят значения от 1 до 63 (включительно).
Адрес узла может иметь значение от 1 до 1023 (включительно).
Следовательно, каждая область может иметь 1023 узла, а в сети DECnet
адресация может быть произведена примерно к 65,000 узлам. Области
могут перекрывать несколько роутеров, и отдельный кабель может
обеспечивать несколько областей. Следовательно, если какой-нибудь узел
имеет несколько сетевых интерфейсов, то он использует один и тот же
адрес область/узел для каждого интерфейса. На Рис. 17-4 "Адреса DECnet"
изображен пример сети DECnet с несколькими адресуемыми об'ектами.
Главные вычислительные машины DECnet не используют адреса уровня МАС
(Media Access Control - Управлениe доступом к носителю), назначаемые
производителем. Вместо этого адреса сетевого уровня встраиваются в
адреса уровня МАС в соответствии с алгоритмом, который перемножает
номер области на 1024 и прибавляет к результату номер узла.
Результирующий 16-битовый десятичный адрес преобразуется в
шестнадцатеричное число и добавляется к адресу АА00.0400 таким
образом, что байты оказываются переставленными, так что наименее
значимый байт оказывается первым. Например, адрес 12.75 DECnet
становится числом 12363 (основание 10), которое равняется числу
304В (основание 16). После этого адрес с переставленными байтами
добавляется к ставндартному префиксу адреса МАС DECnet; результирующим
адресом является выражение АА00.0400.4В30.
Узлы маршрутизации DECnet называются либо роутерами Уровня 1,
либо роутерами Уровня 2. Роутер Уровня 1 сообщается с
конечными узлами и с другими роутерами Уровня 1 в отдельной
конкретной области. Роутеры Уровня 2 сообщаются с роутерами
Уровня 1 той же самой области и роутерами Уровня 2 других
областей. Таким образом, роутеры Уровня 1 и Уровня 2 вместе
формируют иерархическую схему маршрутизации. Рассмотренные
взаимоотношения иллюстрируются на Рис. 17-5.
Конечные системы отправляют запросы о маршрутах в назначенный
роутер Уровня 1. На роль назначенного роутера выбирается
роутер Уровня 1 с наивысшим приоритетом. Если два роутера
имеют одинаковый приоритет, то назначенным роутером становится
тот, который имеет большее число узлов. Конфигурацию приоритета
любого роутера можно вибирать ручным способом, вынуждая
его на роль назначенного роутера.
Как показано на Рис.17-5, в любой области может быть несколько
роутеров Уровня 2. Если роутеру Уровня 1 необходимо
отправить пакет за пределы своей области, он направляет этот пакет
какому-нибудь роутеру Уровня 2 в этой же области. В некоторых
случаях этот роутер Уровня 2 может не иметь оптимального маршрута
к пункту назначения, однако конфигурация узловой сети обеспечивает
такую степень устойчивости к ошибкам, которая не может быть обеспечена
при назначении только одного роутера Уровня 2 на область.
Транспортный уровень DNA реализуется различными протоколами
транспортного уровня, как патентованными, так и стандартными.
Поддерживаются следующие протоколы транспортного уровня OSI: ТР0,
ТР2 и ТР4. Подробное описание этих протоколов дается в Главе 20
"Протоколы OSI".
Принадлежащий Digital Протокол услуг сети ( Network services
protocol -
NSP) по функциональным возможностям похож на ТР4 тем, что он
обеспечивает ориентированное на соединение, с контролируемым потоком
обслуживание, с фрагментацией и повторной сборкой сообщений .
Обеспечиваются два подканала - один для нормальных данных, второй для
срочных данных и информации управления потоком. Обеспечивается два
типа управления потоком - простой механизм старт/стоп, при котором
получатель сообщает отправителю, когда следует завершать и возобновлять
передачу данных, и более сложная техника управления потоком, при
которой получатель сообщает отправителю, сколько сообщений он может
принять. NSP может также реагировать на уведомления о перегрузке,
поступающие из сетевого уровня, путем уменьшения числа невыполненных
сообщений, которое он может допустить.
Для уровней, лежащих выше транспортного уровня, DECnet обеспечивает
свои собственные патентованные протоколы высших уровней наряду со
стандартными протоколами OSI для высших уровней. Протоколы прикладного
уровня DECnet используют протокол управления сеансами DNA и службу
назначения имен DNA. Протоколы прикладного уровня OSI обеспечиваются
реализациями представительного и сеансового уровней OSI. Подробная
информация по этим протоколам OSI дана в
Главе 20 "Протоколы OSI".
В первые годы появления межкомпьютерной связи программное обеспечение
организации сетей создавалось бессистемно, для каждого отдельного
случая. После того, как сети приобрели достаточную популярность,
некоторые из разработчиков признали необходимость стандартизации
сопутствующих изделий программного обеспечения и разработки аппаратного
обеспечения. Считалось, что стандартизация позволит поставщикам
разработать системы аппаратного и программного обеспечения, которые
смогут сообщаться друг с другом даже в том случае, если в их основе
лежат различные архитектуры. Поставив перед собой эту цель, ISO начала
разработку эталонной модели Open Systems Interconnections (OSI)
(Взаимодействие открытых систем). Эталонная модель OSI была завершена
и выпущена в 1984 г.
В настоящее время эталонная модель OSI (подробно рассмотренная в
Главе 1 "Введение в об'единенные сети" )
является самой
выдающейся в мире моделью архитектуры об'единенных сетей. Она также
является самым популярным средством приобретения знаний о сетях.
С другой стороны, у протоколов OSI был длинный период созревания.
И хотя известно о некоторых реализациях OSI, протоколы OSI все еще
не завоевали той популярности, которой пользуются многие патентованные
протоколы (например, DECnet и АppleTalk) и действующие стандарты
(например, протоколы Internet).
Об'единение сетей OSI использует уникальную терминологию.
Также, как и некоторые другие современные 7-уровневые комплекты
протоколов, комплект OSI включает в себя многие популярные сегодня
протоколы доступа к носителю. Это позволяет другим комплектам
протоколов существовать наряду с OSI в одном и том же носителе. В
OSI входят IEEE 802.2, IEEE 802.3, IEEE 802.5, FDDI, X.21, V.35, X.25
и другие. Большинство из этих протоколов доступа к носителю OSI уже
рассматривались в данной книге.
OSI предлагает услуги сетевого уровня как без установления соединения,
так и ориентированные на установления логического соединения.
Услуги без установления соединения
описаны в ISO 8473 (обычно называемом Connectionless Network
Protocol - CLNP - Протокол сети без установления соединения).
Обслуживание, ориентированное на установление логического соединения
(иногда называемое
Connection-Oriented Network Service - CONS) описывается в ISO 8208
(X.25 Packet-Level Protocol - Протокол пакетного уровня X.25,
иногда называемый Connection-Mode Network Protocol - CMNP)
и ISO 8878 (в котором
описывается, как пользоваться ISO 8208, чтобы обеспечить
ориентированные на установление логического соединения услуги OSI).
Дополнительный документ
ISO 8881 описывает, как обеспечить работу Протокола пакетного уровня
X.25 в локальных сетях IEEE 802. OSI также определяет несколько
протоколов маршрутизации, которые рассмотрены в
Главе 28 "Маршрутизация OSI".
X.25 рассмотрен в Главе 13 "Х.25".
В дополнение к уже упоминавшимся спецификациям протоколов и услуг,
имеются другие документы, связанные с сетевым уровнем OSI, в число
которых входят:
Как видно из названия, CLNP является протоколом дейтаграмм без
установления соединения, который используется для переноса данных
и указателей неисправности. По своим функциональным возможностям он
похож на Internet Protocol (IP), описанный в
Главе 18 "Протоколы Internet".
Он не содержит средств обнаружения ошибок и их коррекции,
полагаясь на способность транспортного уровня обеспечить
соответствующим образом эти услуги. Он содержит только одну фазу,
которая называется "передача информации" (data transfer).
Каждый вызов
какого-либо примитива услуг не зависит от всех других вызовов, для чего
необходимо, чтобы вся адресная информация полностью содержалась в
составе примитива.
В то время как CLNP определяет действующий протокол, выполняющий
типичные функции сетевого уровня, CLNS (Обслуживание сети без
установления соединения) описывает услуги, предоставляемые
транспортному уровню, в котором запрос о передаче информации
реализуется доставкой, выполненной с наименьшими затратами (best
effort). Такая доставка не гарантирует, что данные не будут потеряны,
испорчены, что в них не будет нарушен порядок, или что они не будут
скопированы. Обслуживание без установления соединения предполагает,
что при необходимости все эти проблемы будут устранены в транспортном
уровне. CLNS не обеспечивает никаких видов информации о соединении
или состоянии, и не выполняет настройку соединения. Т.к. CLNS
обеспечивает транспортные уровни интерфейсом услуг, сопрягающим с
CLNP, протоколы CNLS и CLNP часто рассматриваются вместе.
Услуги сети OSI с установлением соединения определяются ISO 8208 и
ISO 8878. OSI использует X.25 Racket-Level Protocol для перемещения
данных и указателей ошибок с установлением соединения. Для об'ектов
транспортного уровня предусмотрено 6 услуг (одна для установления
соединения, другая для раз'единения соединения, и четыре для
передачи данных). Услуги вызываются определенной комбинацией из 4
примитив: запрос (request), указатель (indication),
ответ (response) и подтверждение (confirmation).
Взаимодействие этих четырех
примитив показано на Рис. 20-1.
В момент времени t1 транспортный уровень ES 1 отправляет примитив-
запрос в сетевой уровень ES 1. Этот запрос помещается в подсеть ES 1
протоколами подсети низших уровней и в конечном итоге принимается
ES 2, который отправляет информацию вверх в сетевой уровень. В
мотент времени t2 сетевой уровень ES 2 отправляет примитив-указатель
в свой транспортный уровень. После завершения необходимой обработки
пакета в высших уровнях, ES 2 инициирует ответ в ES 1, используя
примитив-ответ, отправленный из транспортного уровня в сетевой
уровень. Отправленный в момень времени t3 ответ возвращается
в ES 1, который отправляет информацию вверх в сетевой уровень, где
генерируется примитив-подтверждение, отправляемый в
транспортный уровень в момент t3.
Услуги сети OSI предоставляются транспортному уровню через
концептуальную точку на границе сетевого и транспортного уровней,
известную под названием "точки доступа к услугам сети" (network
service access point - NSAP). Для каждого об'екта транспортного
уровня имеется одна NSAP.
Каждая NSAP может быть индивидуально адресована в об'единенной
глобальной сети с помощью адреса NSAP (в обиходе существует неточное
название - просто NSAP). Таким образом, любая конечная система OSI
имеет, как правило, множество адресов NSAP. Эти адреса обычно
отличаются только последним байтом, называемом n-selector.
Возможны случаи, когда полезно адресовать сообщение сетевому уровня
системы в целом, не связывая его с конкретным об'ектом транспортного
уровня, например, когда система участвует в протоколах маршрутизации
или при адресации к какой-нибудь промежуточной системе
(к роутеру). Подобная адресация выполняется через специальный
адрес сети, известный под названием network entity title (NET)
(титул об'екта сети). Структурно NET идентичен адресу NSAP, но он
использует специальное значение n-selector "00". Большинство конечных
и промежуточных систем имеют только один NET, в отличие от
роутеров IP, которые обычно имеют по одному адресу на каждый
интерфейс. Однако промежуточная система, участвующая в нескольких
областях или доменах, имеет право выборa на обладание несколькими
NET.
Адреса NET и NSAP являются иерархическими адресами. Адресация к
иерархическим системам облегчает как управление (путем обеспечения
нескольких уровней управления), так и маршрутизацию (путем кодирования
информации о топологии сети). Адрес NSAP сначала разделяется на две
части: исходная часть домена (initial domain part - IDP) и специфичнaя
часть домена (domain specific part - DSP).
IDP далее делится на идентификатор формата и
полномочий (authority and format identifier - AFI) и идентификатор
исходного домена (initial domain identifier - IDI).
AFI обеспечивает информацию о структуре и содержании полей IDI и DSP,
в том числе информацию о том, является ли IDI идентификатором
переменной длины и использует ли DSP десятичную или двоичную
систему счислений. IDI определяет об'ект, который может назначать
различные значения части DSP адреса.
DSP далее подразделяется полномочным лицом, ответственным за ее
управление. Как правило, далее следует идентификатор другого
управляющего авторитета, чем обеспечивается дальнейшее делегирование
управления адресом в подорганы управления. Далее идет
информация, используемая для маршрутизации, такая, как домены
маршрутизации, область (area) с доменом маршрутизации, идентификатор
(ID) станции в пределах этой области и селектор (selector) в пределах
этой станции. Рис. 20-2 иллюстрирует формат адреса OSI.
Как обычно для сетевого уровня OSI, oбеспечиваются услуги как без
установления соединения, так и с установлением соединения. Фактически
имеется 5 протоколов транспортного уровня OSI с установлением
соединения: ТР0, ТР1, ТР2, ТР3 и ТР4.
Все они, кроме ТР4, работают
только с услугами сети OSI с установлением соединения. ТР4 работает с
услугами сети как с установлением соединения, так и без установления
соединения.
ТР0 является самым простым протоколом транспортного уровня OSI,
ориентированным на установления логического соединения.
Из набора классических функций протокола
транспортного уровня он выполняет только сегментацию и повторную
сборку. Это означает, что ТР0 обратит внимание на протокольную
информационную единицу (protocol data unit - PDU) с самым маленьким
максимальным размером,
который поддерживается лежащими в основе подсетями, и разобьет пакет
транспортного уровня на менее крупные части, которые не будут слишком
велики для передачи по сети.
В дополнение к сегментации и повторной сборке ТР1 обеспечивает
устранение базовых ошибок. Он нумерует все PDU и повторно
отправляет те, которые не были подтверждены. ТР1 может также повторно
инициировать соединение в том случае, если имеет место превышение
допустимого числа неподтвержденных РDU.
ТР2 может мультиплексировать и демультиплексировать потоки данных через
отдельную виртуальную цепь. Эта способность делает ТР2 особенно
полезной в общедоступных информационных сетях (PDN), где каждая
виртуальная цепь подвергается отдельной загрузке. Подобно ТР0
и ТР1, ТР2 также сегментирует и вновь собирает PDU.
ТР3 комбинирует в себе характеристики ТР1 и ТР2.
ТР4 является самым популярным протоколом транспортного уровня OSI.
ТР4 похож на протокол ТСР из комплекта протоколов Internet;
фактически, он базировался на ТСР. В дополнение к характеристикам
ТР3, ТР4 обеспечивает надежные услуги по транспортировке. Его
применение предполагает сеть, в которой проблемы не выявляются.
Основные протоколы высших уровней OSI представлены на Рис. 20-3.
Протоколы сеансового уровня OSI преобразуют в сеансы потоки данных,
поставляемых четырьмя низшими уровнями, путем реализации
различных управляющих механизмов. В число этих механизмов входит
ведение учета, управление диалогом (т.е. определение, кто и когда
может говорить) и согласование параметров сеанса.
Управление диалогом сеанса реализуется путем использования маркера
(token), обладание которым обеспечивает право на связь. Маркер можно
запрашивать, и конечным системам ES могут быть присвоены приоритеты,
обеспечивающие неравноправное пользование маркером.
Представительный уровень OSI, как правило, является просто проходным
протоколом для информации из соседних уровней. Хотя многие считают,
что Abstract Syntax Notation 1 (ASN.1) (Абстрактное представление
синтаксиса) является протоколом представительного уровня OSI, ASN.1
используется для выражения форматов данных в независимом от машины
формате. Это позволяет осуществлять связь между прикладными задачами
различных компьютерных систем способом, прозрачным для этих прикладных
задач.
Прикладной уровень ОSI включает действующие протоколы прикладного
уровня, а также элементы услуг прикладного уровня (application service
elements - ASE). ASE обеспечивают легкую связь протоколов прикладного
уровня с низшими уровнями. Тремя наиболее важными ASE являются Элемент
услуг управления ассоциацией (Association Control Service Element -
ACSE), Элемент услуг получения доступа к операциям отдаленного
устройства (Remote Operations Service Element - ROSE) и Элемент услуг
надежной передачи (Reliable Transfer Service Element - RTSE). При
подготовке к связи между двумя протоколами прикладного уровня
ACSE об'единяет их имена друг с другом. ROSE реализует родовой
(generic) механизм "запрос/ответ", который разрешает доступ к операциям
отдаленного устройства способом, похожим на вызовы процедуры обращений
к отделенной сети (remote procedure calls - RPC). RTSE способствует
надежной доставке, делая конструктивные элементы сеансового уровня
легкими для использования.
Наибольшего внимания заслуживают следующие пять протоколов прикладного
уровня OSI:
При содействии Международной Организации по Стандартизации (ISO) уже
разработаны или разрабатываются в настоящее время несколько протоколов
маршрутизации. ISO ссылается на Протокол Обмена Внутридоменной
Маршрутизации Промежуточных Систем (Intermediate System to Intermediate
System Intra-Domain Routing Exchange Protocol (IS-IS)) как на ISO 10589.
Двигательной силой стандартизации ISO документа IS-IS был комитет
Х.3S3.3 Американского Национального Института Стандартов (ANSI),
занимающийся сетевым и транспортным уровнями. В числе других протоколов
ISO, связанных с маршрутизацией, протоколы ISO 9542 (End System to
Intermediate System, или ES-IS - Конечная система-Промежуточная
Система) и ISO 10747 (IS-IS Inter-Domain Routing Protocol, или IDRP -
Протокол междоменной маршрутизации промежуточных систем). Об этих
протоколах будет вкратце упомянуто в данной главе, однако oсновное
внимание уделено внутридоменной версии IS-IS.
IS-IS базируется на работе, которая была впервые выполнена Digital
Equipment Corporation при разработке Phase V DECnet. Хотя IS-IS
предназначался для маршрутизации в сетях протокола CLNP ISO, со
временем была разработана одна из его версий для поддержки как сетей
CLNP, так и сетей IP. На эту версию IS-IS обычно ссылаются как на
Integrated IS-IS (интегрированный);
ее также называют Dual IS-IS
(двойственный). Integrated IS-IS также рассматривается вкратце.
Об'единенные сети OSI используют уникальную терминологию. Термин
"конечная система" (end system - ES)
относится к любому узлу сети,
который не занимается маршрутизацией; термин "промежуточная система"
(intermediate system-IS) относится к роутеру. На этих терминах
базируются протоколы OSI ES-IS (который позволяет ES и IS находить
друг друга) и IS-IS (который обеспечивает маршрутизацию между IS).
Ниже дается определение некоторых других важных терминов об'единенных
сетей OSI:
На Рис. 28-1 "Иерархия об'единенных сетей OSI" показана взаимосвязь
между этими терминами.
С чисто технологической точки зрения IS-IS почти аналогичен протоколу
маршрутизации OSPF
(смотри Главу 25 "OSPF").
Оба протокола являются
протоколами с указанием состояния канала. Оба они обеспечивают
различные характеристики, которые не обеспечивает RIP, в том числе
иерархии маршрутизации (routing hierachies), дробление путей
(path splitting), обеспечение типа услуги
(type-of-service - TOS),
удостоверение (authentication), поддержка нескольких протоколов сетевого
уровня и поддержка (совместно с протоколом Integrated IS-IS) масок
подсети переменной длины.
ES-IS в большей мере является протоколом обнаружения, чем протоколом
маршрутизации. Через ES-IS системы ES и IS узнают друг о друге. Этот
процесс известен как конфигурация (configuration). Т.к. конфигурация
должна иметь место прежде, чем может начаться маршрутизация между ES,
протокол ES-IS рассматривается в первую очередь.
ES-IS различает три разных типа подсетей:
Информация конфигурации передается через определенные интервалы времени
с помощью сообщений двух типов. Приветственные сообщения ES (Es hello
messages - ESHs) генерируются ES и отправляются в каждую
IS данной подсети.
Приветственные сообщения IS (IS hello messages - ISH)
генерируются IS и
отправляются всем ES данной подсети. Эти приветственные сообщения в
основном предназначены для переноса адресов подсетей и адресов сетевого
уровня тех систем, которые генерируют их.
При возможности ES-IS пытается отправить информацию конфигурации
одновременно в несколько систем. В широковещательных подсетях
приветственные сообщения ES-IS отправляются во все IS с помощью
специальной многопунктовой адресации. IS отправляют приветственные
сообщения по специальному адресу многопунктовой адресации,
определенного для всех конечных систем. При работе в подсети с общей
топологией ES-IS обычно не передает информацию конфигурации из-за
больших затрат на передачи многопунктовой адресации.
ES-IS переносит как адреса сетевого уровня, так и адреса подсетей.
Адреса сетевого уровня OSI идентифицируют либо точку доступа к услугам
сети (NSAP), которая представляет собой интерфейс между Уровнями 3 и 4,
либо титул об'екта сети (NET), который является об'ектом сетевого
уровня в OSI IS. Адреса подсетей OSI (иногда называемые адресами
точки подключения подсети - subnetwork point of attachment - SNPA)
являются точками, в которых ES или IS физически подключена к какой-нибудь
подсети. Адрес SNPA уникальным образом идентифицирует каждую
систему, подключенную к данной подсети. В сети Ethernet, например, SNPA
является 48-битовым адресом управления доступом к носителю (МАС).
Часть информации конфигурации, которую передает ES-IS, представляет
собой отображение соответствия между NSAP и SNPA или между NET и SNPA.
На Рис. 28-2 представлены форматы пакетов ESH и ISH.
IS-IS является протоколом маршрутизации с указанием состояния канала.
В этом роли он передает по сети лавинной адресацией информацию о
состоянии канала для построения полной, последовательной картины
топологии сети.
IS уровня 2 формируют стержень внутридоменной маршрутизации. Другими
словами, IS уровня 2 могут попасть в другие IS уровня 2 путем
пересечения только IS уровня 2. Наличие такого стержня упрощает схему,
т.к. в этом случае IS уровня 1 нужно уметь только попадать в ближайший
IS уровня 2. Протокол стержневой маршрутизации может также вносить
изменения, не оказывая влияния на протокол внутриобластной
маршрутизации.
Каждая IS генерирует корректировку, определяющую ES и IS, с которыми
она соединена, а также связанные с ней показатели. Эта корректировка
отправляется во все соседние IS, которые продвигают ее своим соседям,
и т.д. (лавинная адресация). Номера последовательностей прекращают
лавинную адресацию и отличают старые корректировки от новых. Т.к.
каждая IS получает корректировки о состоянии канала от всех других IS,
то каждая IS может построить полную базу данных всей топологии сети.
При изменении топологии отправляются новые корректировки.
IS-IS также определяет три дополнительных показателя (затраты)
в качестве опций для тех администраторов, которые испытывают в них
необходимость. Затраты задержки (delay) отражают величину задержки в
канале. Затраты на издержки (expense) отражают коммуникационные
затраты, связанные с использованием данного канала. Затраты на ошибки
(error) отражают коэффициент ошибок данного канала.
IS-IS обеспечивает соответствие этих четырех показателей опции качества
обслуживания (quality-of-service - QOS) в заголовке пакета CLNP.
Пользуясь этим соответствием, IS-IS может вычислять маршруты через
об'единенную сеть.
Каждый из этих трех пакетов IS-IS имеет сложный формат с тремя
различными логическими частями. Первой частью является 8-байтовый
фиксированный заголовок, общий для всех трех типов пакетов. Второй
частью является специфичная для данного типа пакета часть с
фиксированным форматом. Третья логическая часть также является
специфичной для типа пакета, но имеет переменную длину. Логический
формат пакетов IS-IS представлен на Рис. 28-3.
Каждый из трех типов пакета имеет общий заголовок, как это показано
на Рис. 28-4.
Первым полем в общем заголовке IS-IS является идентификатор протокола
(protocol identifier), который идентифицирует протокол IS-IS.
Это поле содержит константу (131).
Следующим полем общего заголовка является поле длины заголовка (header
length). Это поле содержит фиксированную длину заголовка. Эта длина
всегда равняется 8 байтам, но она включена таким образом, чтобы пакеты
IS-IS незначительно отличались от пакетов CLNP.
За полем длины следует поле версии (version), которое равняется единице
в текущей спецификации IS-IS.
За полем версии идет поле длины ID, которое определяет размеры части
ID (идентификатора) NSAP, если eго значение лежит в пределах от 1 до
8 (включительно). Если поле содержит нуль, то часть ID равняется 6
байтам. Если поле содержит 255 (одни единицы), то часть ID равна 0
байтов.
Следующим полем является поле типа пакета (packet type), которое
определяет тип пакета IS-IS (hello, LSP или SNP).
За полем типа пакета повторно следует поле версии.
За вторым полем версии идет поле резерва (reserved), которое равно
нулю и которое игнорируется получателем.
Последним полем общего заголовка является поле максимума адресов
области. Это поле определяет число адресов, разрешeнных для этой
области.
За общим заголовком идет дополнительная фиксированная часть, разная
для каждого типа пакета, за которой следует переменная часть.
Интегрированный IS-IS является одной из версий IS-IS, которая
использует один алгоритм маршрутизации для поддержки нескольких
протоколов сетевого уровня, а не только одного протокола CLNP.
Интегрированный IS-IS иногда называют Двойственным IS-IS (Dual IS-IS),
по имени одной из версий, предназначенных для сетей IP и CLNP.
Пакеты IS-IS дополнены несколькими полями, что позволяет IS-IS
поддерживать дополнительные сетевые уровни. Эти поля сообщают
роутерам следующую информацию:
Интегрированный IS-IS представляет один из двух способов поддержки
в роутере нескольких протоколов сетевого уровня; другим способом
является применение метода "корабли ночью" (ships in the night). Этот
метод пропагандирует использование совершенно отдельного и отличного
от других протокола маршрутизации для каждого сетевого протокола сети
так, чтобы несколько протоколов маршрутизации фактически существовали
независимо друг от друга (с разными типами маршрутной информации,
проходящей подобно кораблям ночью). Возможность направлять по
определенным маршрутам несколько протоколов сетевого уровня с помощью
таблиц, рассчитанных одним протоколом маршрутизации, экономит ресурсы
роутеров.
IDRP является протоколом OSI, предназначенным для перемещения
информации между доменами маршрутизации. Он предназначен для бесшовной
работы с CLNP, ES-IS и IS-IS. IDRP базируется на Протоколе граничных
роутеров (BGP), который является протоколом междоменной
маршрутизации, впервые появившемся в сообществе IP
(смотри Главу 27 "BGP").
IDRP вводит несколько новых терминов, в том числе следующие:
Маршрут IDRP представляет собой последовательность RDI. Некоторые из
этих RDI могут быть конфедерациями. При конфигурации каждой BIS она
знает о RD и конфедерациях, к которым она принадлежит, а также узнает
о других BIS, RD и конфедерациях из информации, которой она
обменивается с каждым соседом. Как и для маршрутизации с вектором
расстояния, маршруты в какой-нибудь конкретный пункт назначения
накапливаются вне данного пункта назначения. Только маршруты, которые
удовлетворяют требованиям местной политики какой-нибудь BIS и были
выбраны для использования, будут переданы в другие BIS. Пересчет
маршрутов носит частичный характер и имеет место при наличии одного их
следующих трех событий: получена инкрементная корректировка
маршрутизации с новыми маршрутами, отказывает какая-нибудь соседняя
BIS или появляется новая соседняя BIS.
В число характеристик IDRP входят следующие:
Открытый протокол, базирующийся на алгоритме поиска наикратчайшего
пути (Open Shortest Path Fisrt - OSPF) является протоколом маршрутизации,
разработанным для сетей IP рабочей группой Internet Engineering Task
Force (IETF), занимающейся разработкой протоколов для внутрисистемных
роутеров (interior gateway protocol - IGP). Рабочая группа была
образована в 1988 г. для разработки протокола IGP, базирующегося на
алгоритме "поиска наикратчайшего пути"
(shortest path first - SPF), с
целью его использования в Internet, крупной международной сети,
об'единяющей научно-исследовательские институты, правительственные
учреждения, университеты и частные предприятия. Как и протокол IGRP
(смотри Главу 24 "IGRP"),
OSPF был разработан по той причине, что к
середине 1980 гг. непригодность RIP для обслуживания крупных
гетерогенных об'единенных систем стала все более очевидна
(смотри Главу 23 "RIP").
ОSPF явился результатом научных исследований по нескольким
направлениям, включающим:
(Информация о IS-IS дается в
Главе 28 "Maршрутизация OSI").
Как видно из его названия, OSPF имеет две основных характеристики.
Первая из них-это то, что протокол является открытым, т.е. его
спецификация является общественным достоянием. Спецификация OSPF
опубликована в форме Запроса для Комментария (RFC) 1247. Второй его
главной характеристикой является то, что он базируется на алгоритме
SPF. Алгоритм SPF иногда называют алгоритмом Dijkstra по имени автора,
который его разработал.
OSPF является протоколом маршрутизации с об'явлением состояния о канале
(link-state). Это значит, что он требует отправки об'явлений о
состоянии канала (link-state advertisement - LSA) во все роутеры,
которые находятся в пределах одной и тойже иерархической области. В
oб'явления LSA протокола OSPF включается информация о подключенных
интерфейсах, об использованных показателях и о других переменных. По
мере накопления роутерами OSPF информации о состоянии канала,
они используют алгоритм SPF для расчета наикратчайшего пути к каждому
узлу.
Являясь алгоритмом с об'явлением состояния канала, OSPF отличается от
RIP и IGRP, которые являются протоколами маршрутизации с вектором
расстояния. Роутеры, использующие алгоритм вектора расстояния,
отправляют всю или часть своей таблицы маршрутизации в сообщения о
корректировке маршрутизации, но только своим соседям.
В отличие от RIP, OSPF может работать в пределах некоторой
иерархической системы. Самым крупным об'ектом в этой иерархии является
автономная система (Autonomous System - AS)
AS является набором сетей, которые находятся
под единым управлением и совместно используют общую стратегию
маршрутизации. OSPF является протоколом маршрутизации внутри AS, хотя
он и способен принимать маршруты из других AS и отправлять маршруты в
другие AS.
Любая AS может быть разделена на ряд областей (area).
Область - это группа
смежных сетей и подключенных к ним хостов.
Роутеры, имеющие несколько интерфейсов, могут участвовать в
нескольких областях. Такие роутеры, которые называются
роутерами границы областей (area border routers),
поддерживают отдельные топологические
базы данных для каждой области.
Топологическая база (topological database)
данных фактически представляет собой общую картину
сети по отношению к роутерам. Топологическая база данных содержит
набор LSA, полученных от всех роутеров, находящихся в одной
области. Т.к. роутеры одной области коллективно пользуются одной
и той же информацией, они имеют идентичные топологические базы данных.
Термин "домен" (domain) исользуется для описания части сети,
в которой
все роутери имеют идентичную топологическую базу данных. Термин
"домен" часто используется вместо AS.
Топология области является невидимой для об'ектов, находящихся вне этой
области. Путем хранения топологий областей отдельно, OSPF добивается
меньшего трафика маршрутизации, чем трафик для случая, когда AS не
разделена на области.
Разделение на области приводит к образованию двух различных типов
маршрутизации OSPF, которые зависят от того, находятся ли источник и
пункт назначения в одной и той же или разных областях. Маршрутизация
внутри области имеет место в том случае, когда источник и пункт
назначения находятся в одной области; маршрутизация между областями -
когда они находятся в разных областях.
Стержневая часть OSPF (backbone) отвечает за распределение маршрутной
информации между областями. Она включает в себя все роутеры
границы области, сети, которые не принадлежат полностью како-либо из
областей, и подключенные к ним роутеры. На Рис. 25-1 представлен
пример об'единенной сети с несколькими областями.
На этом рисунке роутеры 4, 5, 6, 10, 11 и 12 образуют стержень.
Если хост Н1 Области 3 захочет отправить
пакет хосту Н2 Области 2, то пакет отправляется
в роутер 13, который продвигает его в роутер 12, который в
свою очередь отправляет его в роутер 11. Роутер 11
продвигает пакет вдоль стержня к роутеру 10 границы области,
который отправляет пакет через два внутренних роутера этой
области (роутеры 9 и 7) до тех пор, пока он не будет продвинут
к хосту Н2.
Сам стержень представляет собой одну из областей OSPF, поэтому все
стержневые роутеры используют те же процедуры и алгоритмы
поддержания маршрутной информации в пределах стержневой области,
которые используются любым другим роутером. Топология стержневой
части невидима для всех внутренних роутеров точно также, как
топологии отдельных областей невидимы для стержневой части.
Область может быть определена таким образом, что стержневая часть не
будет смежной с ней. В этом случае связность стержневой части должна
быть восстановлена через виртуальные соединения. Виртуальные соединения
формируются между любыми роутерами стержневой области, которые
совместно используют какую-либо связь с любой из нестержневых областей;
они функционируют так, как если бы они были непосредственными связями.
Граничные роутеры AS, использующие OSPF, узнают о внешних
роутерах через протоколы внешних роутеров (EGPs), таких, как
Exterior Gateway Protocol (EGP) или
Border Gateway Protocol (BGP),
или через информацию о конфигурации (информация об этих протоколах
дается соответственно в
Главе 26 "EGP" и
Главе 27 "BGP").
Алгоритм маршрутизации SPF является основой для операций OSPF. Когда
на какой-нибудь роутер SPF подается питание, он инициилизирует
свои структуры данных о протоколе маршрутизации, а затем ожидает
индикации от протоколов низшего уровня о том, что его интерфейсфы
работоспособны.
После получения подтверждения о работоспособности своих интерфейсов
роутер использует приветственный протокол (hello protocol) OSPF,
чтобы приобрести соседей (neighbor). Соседи - это роутеры с
интерфейсами с общей сетью. Описываемый роутер отправляет своим
соседям приветственные пакеты и получает от них такие же пакеты.
Помимо оказания помощи в приобретении соседей, приветственные пакеты
также действуют как подтверждение дееспособности, позволяя другим
роутерам узнавать о том, что другие роутери все еще
функционируют.
В сетях с множественным доступом (multi-access networks)
(сетях, поддержиающих более одного роутера),
протокол Hello выбирает назначенный
роутер (designated router) и дублирующий назначенный
роутер. Назначеный роутер, помимо других функций, отвечает
за генерацию LSA для всей сети с множественным доступом. Назначенные
роутеры позволяют уменьшить сетевой трафик и об'ем топологической
базы данных.
Если базы данных о состоянии канала двух роутеров являются
синхронными, то говорят, что эти роутеры смежные (adjacent). В
сетях с множественным доступом назначенные роутеры определяют,
какие роутеры должны стать смежными. Топологические базы данных
синхронизируются между парами смежных роутеров. Смежности
управляют распределением пакетов протокола маршрутизации. Эти пакеты
отправляются и принимаются только на смежности.
Каждый роутер периодическив отправляет какое-нибудь LSA. LSA
также отправляются в том случае, когда изменяется состояние какого-
нибудь роутера. LSA включает в себя информацию о смежностях
роутера. При сравнении установленных смежностей с состоянием
канала быстро обнаруживаются отказавшие роутеры, и топология
сети изменяется сооответствующим образом. Из топологической базы
данных, генерируемых LSA, каждый роутер рассчитывает дерево
наикратчайшего пути, корнем которого является он сам. В свою очередь
дерево наикратчайшего пути выдает маршрутную таблицу.
Все пакеты OSPF начинаются с 24-байтового заголовка, как показано
на Рис. 25-2.
Первое поле в заголовке OSPF - это номер версии OSPF (version number).
Номер версии обозначает конкретную используемую реализацию OSPF.
За номером версии идет поле типа (type). Существует 5 типов пакета
OSPF:
Каждое LSA в пакете корректировки состояния канала содержит тип поля.
Существуют 4 типа LSA:
За полем типа заголовка пакета OSPF идет поле длины пакета (packet
length). Это поле обеспечивает длину пакета вместе с заголовком OSPF
в байтах.
Поле идентификатора роутера (router ID) идентифицирует источник
пакета.
Поле идентификатора области (area ID) идентифицирует область, к которой
принадлежит данный пакет. Все пакеты OSPF связаны с одной отдельной
областью.
Стандартное поле контрольной суммы IP (checksum) проверяет содержимое
всего пакета для выявления потенциальных повреждений, имевших место при
транзите.
За полем контрольной суммы идет поле типа удостоверения (authentication
type). Примером типа удостоверения является "простой пароль".
Все обмены протокола OSPF проводятся с установлением достоверности. Тип
удостоверения устанавливается по принципу "отдельный для каждой
области".
За полем типа удостоверения идет поле удостоверения (authentication).
Это поле длиной 64 бита и содержит информацию удостоверения.
В числе дополнительных характеристик OSRF - равные затраты,
многотрактовая маршрутизация (multipath routing)
и маршрутизация, базирующаяся на запросах
типа услуг высшего уровня (type of service - TOS).
Базирующаяся на TOS
маршрутизация поддерживает те протоколы высшего уровня, которые могут
назначать конкретные типы услуг. Например, какая-нибудь прикладная
программа может включить требование о том, что определенная информация
является срочной. Если OSPF имеет в своем распоряжении каналы с высоким
приоритетом, то они могут быть использованы для транспортировки срочных
дейтаграмм.
OSPF обеспечивает один или более показателей. Если используется только
один показатель, то он считается произвольным, и TOS не обеспечивается.
Если используется более одного показателя, то TOS обеспечивается
факультативно путем использования отдельного показателя (и
следовательно, отдельной маршрутной таблицы) для каждой из 8
комбинаций, образованной тремя битами IP TOS: битом задержки (delay),
производительности (throughput) и надежности (reliability).
Например,
если биты IP TOS задают небольшую задержку, низкую производительность
и высокую надежность, то OSPF вычисляет маршруты во все пункты
назначения, базируясь на этом обозначении TOS.
Маски подсети IP включаются в каждый об'явленный пункт назначения,
что позволяет использовать маски подсети переменной длины
(variable-length subnet masks).
С помощью масок подсети переменной длины сеть IP
может быть разбита на несколько подсетей разной величины. Это
обеспечивает администраторам сетей дополнительную гибкость при выборе
конфигурации сети.
Протокол маршрутизации внутренних роутеров (Interior Gateway
Routing Protokol-IGRP) является протоколом маршрутизации, разработанным
в середине 1980 гг. компанией Cisco Systems, Inc. Главной целью,
которую преследовала Cisco при разработке IGRP, было обеспечение
живучего протокола для маршрутизации в пределах автономной системы
(AS), имеющей произвольно сложную топологию и включающую в себя
носитель с разнообразными характеристиками ширины полосы и задержки.
AS является набором сетей, которые находятся под единым управлением
и совместно используют общую стратегию маршрутизации. Обычно AS
присваивается уникальный 16-битовый номер, который назначается
Центром Сетевой Информации (Network Information Center - NIC) Сети
Министерства Обороны (Defence Data Network - DDN).
В середине 1980 гг. самым популярным протоколом маршрутизации внутри
AS был Протокол Информации Маршрутизации (RIP). Хотя RIP был вполне
пригоден для маршрутизации в пределах относительно однородных
об'единенных сетей небольшого или среднего размера, его ограничения
сдерживали рост сетей. В частности, небольшая допустимая величина числа
пересылок (15) RIP ограничивала размер об'единенной сети, а его
единственный показатель (число пересылок) не обеспечивал достаточную
гибкость в сложных средах
(смотри Главу 23 "RIP"). Популярность
роутеров Cisco и живучесть IGRP побудили многие организации,
которые имели крупные об'единенные сети, заменить RIP на IGRP.
Первоначальная реализация IGRP компании Cisco работала в сетях IP.
Однако IGRP был предназначен для работы в любой сетевой среде, и вскоре
Cisco распространила его для работы в сетях использующих Протокол Сет без
Установления Соединения (Connectionless Network Protocol - CLNP) OSI.
IGRP является протоколом внутренних роутеров (IGP) с вектором
расстояния. Протоколы маршрутизации с вектором расстояния требуют от
каждого роутера отправления через определенные интервалы времени
всем соседним роутерам всей или части своей маршрутной
таблицы в сообщениях о корректировке маршрута. По мере того, как
маршрутная информация распространяется по сети, роутеры могут
вычислять расстояния до всех узлов об'единенной сети.
Протоколы маршрутизации с вектором расстояния часто противопоставляют
протоколам маршрутизации с указанием состояния канала, которые
отправляют информацию о локальном соединении во все узлы об'единенной
сети. Рассмотрение двух популярных протоколов, использующих алгоритм
маршрутизации с указанием состояния канала, "Открытый протокол с
алгоритмом поиска наикратчайшего пути" (Open Shortest Path First) и
"Промежуточная система-Промежуточная система" (Intermediate System to
Intermediate System (IS-IS)), дается соответственно в
Главе 25 "OSPF"
и Главе 28 "Маршрутизация OSI".
IGRP использует комбинацию (вектор) показателей. Задержка об'единенной
сети (internetwork delay), ширина полосы (bandwidth), надежность
(reliability) и нагрузка (load) - все эти показатели
учитываются в виде
коэффициентов при принятии маршрутного решения. Администраторы сети
могут устанавливать факторы весомости для каждого из этих показателей.
IGRP использует либо установленные администратором, либо
устанавливаемые по умолчанию весомости для автоматического расчета
оптимальных маршрутов.
IGRP предусматривает широкий диапазон значений для своих показателей.
Например, надежность и нагрузка могут принимать любое значение в
интервале от 1 до 255, ширина полосы может принимать значения,
отражающие скорости пропускания от 1200 до 10 гигабит в секунду, в то
время как задержка может принимать любое значение от 1-2 до 24-го
порядка. Широкие диапазоны значений показателей позволяют производить
удовлетворительную регулировку показателя в об'единенной сети с большим
диапазоном изменения характеристик производительности. Самым важным
является то, что компоненты показателей об'единяются по алгоритму,
который определяет пользователь. В результате администраторы сети могут
оказывать влияние на выбор маршрута, полагаясь на свою интуицию.
Для обеспечения дополнительной гибкости IGRP разрешает многотрактовую
маршрутизацию. Дублированные линии с одинаковой шириной полосы могут
пропускать отдельный поток трафика циклическим способом с
автоматическим переключением на вторую линию, если первая линия
выходит из строя. Несколько трактов могут также использоваться даже
в том случае, если показатели этих трактов различны. Например, если
один тракт в три раза лучше другого благодаря тому, что его показатели
в три раза ниже, то лучший тракт будет использоваться в три раза чаще.
Только маршруты с показателями, которые находятся в пределах
определенного диапазона показателей наилучшего маршрута, используются
для многотрактовой маршрутизации.
Формат пакета IGRP представлен на Рис. 24-1.
Первое поле пакета IGRP содержит номер версии (version number). Этот
номер версии указывает на используемую версию IGRP и сигнализирует о
различных, потенциально несовместимых реализациях.
За полем версии идет поле операционного кода (opcode). Это поле
обозначает тип пакета. Операционный код, равный 1, обозначает пакет
корректировки; равный 2-пакет запроса. Пакеты запроса используются
источником для запроса маршрутной таблицы из другого роутера.
Эти пакеты состоят только из заголовка, содержащего версию,
операционный код и поля номера AS. Пакеты корректировки содержат
заголовок, за которым сразу же идут записи данных маршрутной таблицы.
На записи данных маршрутной таблицы не накладывается никаких
ограничений, за исключением того, что пакет не может превышать 1500
байтов, вместе с заголовком IP. Если этого недостаточно для того,
чтобы охватить весь об'ем маршрутной таблицы, то используются несколько
пакетов.
За полем операционного кода идет поле выпуска (edition). Это
поле содержит последовательный номер, который инкрементируется, когда
маршрутная таблица каким-либо образом изменяется. Это значение номера
выпуска используется для того, чтобы позволить роутерам избежать
обработки корректировок, содержащих информацию, которую они уже видели.
За полем выпуска идет поле, содержащее номер AS (AS number). Это
поле необходимо по той причине, что роутеры Cisco могут
перекрывать несколько AS. Несколько AS (или процессов IGRP) в одном
роутере хранят информацию маршрутизации AS отдельно.
Следующие три поля обозначают номер подсетей, номер главных сетей и
номер внешних сетей в пакете корректировки. Эти поля присутствуют
потому, что сообщения корректировки IGRP состоят из трех частей:
внутренней для данной подсети, внутренней для текущей AS и внешней
для текущей AS. Сюда включаются только подсети сети, связанной с тем
адресом, в который отправляется данная корректировка. Главные сети
(т.е. не подсети) помещаются во "внутреннюю для текущей AS" часть
пакета, если только они не помечены четко как внешние. Сети
помечаются как внешние, если информация о них поступает во внешней
части сообщения из другого роутера.
Последним полем в заголовке IGRP является поле контрольной суммы
(checksum). Это поле содержит какую-нибудь контрольную сумму для
заголовка IGRP и любую информацию корректировки, содержащуюся в данном
пакете. Вычисление контрольной суммы позволяет принимающему
роутеру проверять достоверность входящего пакета.
Сообщения о корректировке содержат последовательность из семи полей
данных для каждой записи данных маршрутной таблицы. Первое из этих
полей содержит три значащих байта адреса (address) (в случае
адреса IP). Следующие пять полей содержат значения показателей. Первое
из них обозначает задержку (delay), выраженную в десятках микросекунд.
Диапазон перекрывает значения от 10 мксек. до 167 сек. За полем
задержки следует поле ширины полосы (bandwidth). Ширина полосы
выражена в единицах 1 Кбит/сек и перекрывает диапазон от линии
с шириной полосы 1200 бит/сек до 10 Гбит/сек. Затем идет поле MTU,
которое обеспечивет размер MTU в байтах. За полем MTU идет поле
надежности (reliability), указывающее процент успешно переданных и
принятых пакетов. Далее идет поле нагрузки (load), которое обозначает
занятую часть канала в процентном отношении. Последним полем в каждой
записи данных маршрутизации является поле числа пересылок (hop count).
И хотя использование числа пересылок не явно выражено при определении
показателя, тем не менее это поле содержится в пакете IGRP и
инкрементируется после обработки пакета, обеспечивая использование
подсчета пересылок для предотвращения петель.
IGRP обладает рядом характеристик, предназначенных для повышения
своей стабильности. В их число входят временное удерживание изменений,
расщепленные горизонты и корректировки отмены.
Временное удерживание изменений используется для того, чтобы помешать
регулярным сообщениям о коррректировке незаконно восстановить
в правах маршрут, который возможно был испорчен. Когда какой-нибудь
роутер выходит из строя, соседние роутеры обнаруживают это
через отсутствие регурярного поступления запланированных сообщений.
Далее эти роутеры вычисляют новые маршруты и отправляют сообщения
о корректировке маршрутизации, чтобы информировать своих соседей о
данном изменении маршрута. Результатом этой деятельности является
запуск целой волны корректировок, которые фильтруются через сеть.
Приведенные в действие корректировки поступают в каждое сетевое
устройство не одновременно. Поэтому возможно, что какое-нибудь
устройство, которое еще не было оповещено о неисправности в сети,
может отправить регулярное сообщение о корректировке (указывающее, что
какой-нибудь маршрут, который только что отказал, все еще считается
исправным) в другое устройство, которое только что получило уведомление
о данной неисправности в сети. В этом случае последнее устройство будет
теперь содержать (и возможно, рекламировать) неправильную информацию
о маршрутизации.
Команды о временном удерживании изменений предписывают роутерам
удерживать в течение некоторого периода времени любые изменения,
которые могут повлиять на маршруты. Период удерживания изменений
обычно рассчитывается так, чтобы он был больше периода времени,
необходимого для корректировки всей сети в соответствии с каким-либо
изменением маршрутизации.
Понятие о расщепленных горизонтах проистекает из того факта, что
никогда не бывает полезным отправлять информацию о каком-нибудь
маршруте обратно в том направлении, из которого она пришла. Для
иллюстрации этого положения рассмотрим Рис. 24-2.
Роутер 1 (R1) первоначально об'являет, что у него есть какой-то
маршрут до Сети А. Роутеру 2 (R2) нет оснований включать этот
маршрут в свою корректировку, отправляемую в R1, т.к. R1 ближе к
Сети А. В правиле о расщепленных горизонтах говорится, что R2 должен
исключить этот маршрут независимо от того, какие корректировки он
отправляет в R1.
Правило о расщепленных горизонтах помогает предотвращать
зацикливание маршрутов. Например, рассмотрим случай, когда интерфейс R1
с Сетью А отказывает. Без расщепленных горизонтов R2 продолжал бы
информировать R1, что он может попасть в Сеть А (через R1!). Если R1
не располагает достаточным интеллектом, он действительно может выбрать
маршрут, предлагаемый R2, в качестве альтернативы своему отказавшему
прямому соединению, что приводит к образованию маршрутной петли. И хотя
удерживание изменений должно помешать этому, в IGRP реализованы также
расщепленные горизонты, т.к. они обеспечивают дополнительную
стабильность алгоритма.
В то время как расщепленные горизонты должны препятствовать
зацикливанию маршрутов между соседними роутерами, корректировки
отмены маршрута предназначены для борьбы с более крупными маршрутными
петлями. Увеличение значений показателей маршрутизации обычно указывает
на появление маршрутных петель. В этом случае посылаются корректировки
отмены, чтобы удалить этот маршрут и перевести его в состояние
удерживания. В реализации IGRP компании Cisco корректировки отмены
отправляются в том случае, если показатель маршрута увеличивается на
коэффициент 1.1 или более.
IGRP обеспечивает ряд таймеров и переменных, содержащих временные
интервалы. Сюда входят таймер корректировки, таймер недействующих
маршрутов, период времени удерживания изменений и таймер отключения.
Таймер корректировки определяет, как часто должны отправляться
сообщения о корректировке маршрутов. Для IGRP значение этой
переменной, устанавливаемое по умолчанию, равно 90 сек. Таймер
недействующих маршрутов определяет, сколько времени должен ожидать
роутер при отсутствии сообщений о корректировке какого-нибудь
конкретного маршрута, прежде чем об'явить этот маршрут недействующим.
Время по умолчанию IGRP для этой переменной в три раза превышает период
корректировки. Переменная величина времени удерживания определяет
промежуток времени удерживания. Время по умолчанию IGRP для этой
переменной в три раза больше периода таймера корректировки, плюс
10 сек. И наконец, таймер отключения указывает, сколько времени
должно пройти прежде, чем какой-нибудь роутер должен быть
исключен из маршрутной таблицы. Время по умолчанию IGRP для этой
величины в семь раз превышает период корректировки маршрутизации.
Протокол внешних роутеров (Exterior Gateway Protocol-EGP)
является протоколом междоменной досягаемости, который применяется в
Internet - международной сети, об'единяющей университеты,
правительственные учреждения, научно-исследовательские организации и
частные коммерческие концерны. EGP документально оформлен в Запросах
для Комментария (RFC) 904, опубликованных в апреле 1984 г.
Являясь первым протоколом внешних роутеров, который получил
широкое признание в Internet, EGP сыграл важную роль. К сожалению,
недостатки EGP стали более очевидными после того, как Internet стала
более крупной и совершенной сетью. Из-за этих недостатков EGP в
настоящее время не отвечает всем требованиям Internet и заменяется
другими протоколами внешних роутеров, такими, как Протокол
граничных роутеров (Border Gateway Protocol - BGP) и Протокол
междоменной маршрутизации (Inter-Domain Routing Protocol - IDRP) (смотри
Главу 27 "BGP" и
Главу 28 "Маршрутизация OSI").
EGP первоначально предназначался для передачи информации о досягаемости
в стержневые роутеры ARPANET и получения ее от них. Информация
передавалась из отдельных узлов источника, находящихся в различных
административных доменах, называемых автономными системами (AS), вверх
в стержневые роутеры, которые передавали эту информацию через
стержневую область до тех пор, пока ее можно было передать вниз к сети
пункта назначения, находящейся в пределах другой AS. Эти
взаимоотношения между EGP и другими компонентами ARPANET показаны на
Рис. 26-1.
Несмотря на то, что EGP является динамическим протоколом маршрутизации,
он использует очень простую схему. Он не использует показатели, и
следовательно, не может принимать по настоящему интеллектуальных
решений о маршрутизации. Корректировки маршрутизации EGP содержат
информацию о досягаемости сетей. Другими словами, они указывают,
что в определенные сети попадают через определенные роутеры.
EGP имеет три основных функции. Во-первых, роутеры, работающие с
EGP, организуют для себя определенный набор соседей. Соседи - это просто
другие роутеры, с которыми какой-нибудь роутер хочет
коллективно пользоваться информацией о досягаемости сетей; какие-либо
указания о географическом соседстве не включаются. Во-вторых,
роутеры EGP опрашивают своих соседей для того, чтобы убедиться
в их работоспособности. В-третьих, роутеры EGP oтправляют
сообщения о корректировках, содержащих информацию о досягаемости сетей
в пределах своих AS.
Пакет EGPпредставлен на Рис. 26-2.
Первым полем в заголовке пакета EGP является поле номера версии EGP
(EGP version number).
Это поле обозначает текущую версию EGP и проверяется приемными
устройствами для определения соответствия между номерами версий
отправителя и получателя.
Следующим полем является поле типа (type), которое обозначает тип
сообщения. EGP выделяет 5 отдельных типов сообщения.
Table 26-1 : EGP Message Types
За полем типа следует поле кода (code). Это поле определяет различие
между подтипами сообщений.
Следующее поле - поле состояния (status), которое содержит информацию
о состоянии, зависящую от сообщения. В число кодов состояния входят
коды недостатка ресурсов (insufficient resources), неисправных
параметров (parameter problem), нарушений протокола (protocol
violation), и другие.
За полем состояния идет поле контрольной суммы (checksum). Контрольная
сумма используется для обнаружения возможных проблем, которые могли
появиться в пакете в результате транспортировки.
За полем контрольной суммы идет поле номера автономной системы
(autonomous system number). Оно обозначает AS, к которой принадлежит
роутер-отправитель.
Последним полем заголовка пакета EGP является поле номера
последовательности (sequence number). Это поле позволяет двум
роутерам EGP, которые oбмениваются сообщениями, согласовывать
запросы с ответами. Когда определен какой-нибудь новый сосед, номер
последовательности устанавливается в исходное нулевое значение и
инкрементируется на единицу с каждой новой транзакцией запрос-ответ.
За заголовком EGP идут дополнительные поля. Содержимое этих полей
различается в зависимости от типа сообщения (определяемого полем типа).
За заголовком EGP идут дополнительные поля. Содержимое этих полей
различается в зависимости от типа сообщения (определяемого полем типа).
В пределах одного блока роутера EGP перечисляет сети по
расстояниям. Например, на расстоянии три может быть четыре сети. Эти
сети перечислены по адресам. Следующей группой сетей могут быть сети,
находящиеся на расстоянии 4, и т.д.
ЕGP не расшифровывает показатели расстояния, содержащиеся в сообщениях
о корректировке маршрутов. EGP фактически использует поле расстояния
для указания существования какого-либо маршрута; значение расстояния
может быть использовано только для сравнения трактов, если эти тракты
полностью находятся в пределах одного конкретного AS. По этой причине
EGP является скорее протоколом досягаемости, чем протоколом
маршрутизации. Это ограничение приводит также к ограничениям в
структуре Internet. Характерно, что любая часть EGP сети Internet
должна представлять собой структуру дерева, у которого стержневой
роутер является корнем, и в пределах которого отсутствуют
петли между другими AS. Это ограничение является основным ограничением
EGP; оно стало причиной его постепенного вытеснения другими, более
совершенными протоколами внешних роутеров.
Протоколы внешних роутеров предназначены для маршрутизации
между доменами маршрутизации. В терминологии Internet (международной
сети, об'единяющей университеты, правительственные учреждения,
научно-исследовательские организации и частные коммерческие концерны)
доменом маршрутизации называется автономная система (AS). Первым
протоколом внешних роутеров, получившим широкое признание в
Internet, был протокол EGP
(Смотри Главу 26 "ЕGP").
Хотя технология
EGP пригодна для сетей, он имеет ряд недостатков, в том числе тот факт,
что это скорее протокол досягаемости, а не маршрутизации.
Протокол Граничных роутеров (Border Gateway Protocol - BGP)
является попыткой решить самую серьезную проблему EGP. BGP
является протоколом маршрутизации между AS, созданным для применения
в Internet. В отличие от EGP, BGP предназначен для обнаружения
маршрутных петель. BGP можно назвать следующим поколением EGP. И
действительно, BGP и другие протоколы маршрутизации между AS постепенно
вытесняют EGP из Internet. Версия 3 BGP определена в Запросах для
Комментария (RFC) 1163.
Хотя BGP разработан как протокол маршрутизации между AS, он может
использоваться для маршрутизации как в пределах, так и между AS. Два
соседа BGP, сообщающихся из различных AS, должны находиться в
одной и той же физической сети. Роутеры BGP, находящиеся в
пределах одной и той же AS, сообщаются друг с другом, чтобы обеспечить
согласующееся представление о данной AS и определить, какой из
роутеров BGP данной AS будет служить в качестве точки соединения
при передаче сообщений в определенные внешние AS и при их приеме.
Некоторые AS являются просто каналами для прохождения через них
сетевого трафика. Другими словами, некоторые AS переносят трафик,
источник которого не находится в их пределах и который не предназначен
для них. BGP должен взаимодействовать с любыми протоколами
маршрутизации внутри AS, которые существуют в пределах этих проходных
AS.
Сообщения о корректировках BGP состоят из пар "сетевой номер/тракт AS".
Тракт AS содержит последовательность из AS, через которые может быть
достигнута указанная сеть. Эти сообщения о корректировке отправляются
с помощью механизма транспортировки TCP для обеспечения надежной
доставки.
Обмен исходной информацией между двумя роутерами является
содержанием всей маршрутной таблицы BGP. С изменением маршрутной
таблицы отправляются инкрементные корректировки. В отличие от некоторых
других протоколов маршрутизации BGP не требует периодического
обновления всей маршрутной таблицы. Вместо этого роутеры BGP
хранят новейшую версию маршрутной таблицы каждого равноправного
члена. Хотя BGP поддерживает маршрутную таблицу всех возможных
трактов к какой-нибудь конкретной сети, в своих сообщениях о
корректировке он об'являет только об основных (оптимальных) маршрутах.
Показатель BGP представляет собой произвольное число единиц,
характеризующее степень предпочтения какого-нибудь конкретного
маршрута. Эти показатели обычно устанавливаются администратором сети
с помощью конфигурационных файлов. Степень предпочтения может
базироваться на любом числе критериев, включая число AS (тракты с
меньшим числом AS как правило лучше), тип канала (стабильность,
быстродействие и надежность канала) и другие факторы.
Формат пакета представлен на Рис. 27-1.
Пакеты BGP имеют общий 19-байтовый заголовок, состоящий их трех полей.
Поле маркера (marker) имеет длину 16 байтов и содержит величину,
которую получатель сообщения может предсказывать. Это поле используется
для установки подлинности.
Поле длины (length) содержит полную длину сообщения в байтах.
Поле типа (type) определяет тип сообщения.
RFC 1163 определяет 4 типа сообщений:
После того, как соединение протокола транспортного уровня организовано,
первым сообщением, отправляемым каждой стороной, является открывающее
сообщение. Если открывающее сообщение приемлемо для получателя, то
отправителю отсылается сообщение keepalive, подтверждающее получение
открывающего сообщения. После успешного подтверждения принятия
открывающего сообщения может быть произведен обмен корректировками,
сообщениями keepalive и уведомлениями.
В середине 1970 гг. Агентство по Внедрению Научно-исследовательских
Проектов Передовой технологии при Министерстве обороны (DARPA)
заинтересовалось организацией сети с коммутацией пакетов для
обеспечения связи между научно-исследовательскими институтами в США.
DARPA и другие правительственные организации понимали, какие
потенциальные возможности скрыты в технологии сети с коммутацией
пакетов; они только что начали сталкиваться с проблемой, с которой
сейчас приходится иметь дело практически всем компаниям, а именно с
проблемой связи между различными компьютерными системами.
Поставив задачу добиться связности гетерогенных систем, DARPA
финансировала исследования, проводимые Стэнфордским университетом и
компаниями Bolt, Beranek и Newman (BBN) с целью создания ряда
протоколов связи. Результатом этих работ по разработке, завершенных
в конце 1970 гг., был комплект протоколов Internet, из которых наиболее
известными являются Transmission Control Protocol (TCP) и
Internet Protocol (IP).
Протоколы Internet можно использовать для передачи сообщений через
любой набор об'единенных между собой сетей. Они в равной мере пригодны
для связи как в локальных, так и в глобальных сетях. Комплект
протоколов Internet включает в себя не только спецификации низших
уровней (такие, как ТСР и IP), но также спецификации для таких общих
применений, как почта, эмуляция терминалов и передача файлов. На
Рис. 18-1 представлены некоторые из наиболее важных протоколов
Internet и их связь с эталонной моделью OSI.
Процесс разработки и выдачи документации протоколов Internet скорее
напоминает академический исследовательский проект, чем что-либо другое.
Протоколы определяются в документах, называемых Requests for Comments
(RFC) (Запросы для Комментария). RFC публикуются, а затем рецензируются
и анализируются специалистами по Internet. Уточнения к протоколам
публикуются в новых RFC. Взятые вместе, RFC обеспечивают красочную
историю людей, компаний и направлений, которые формировали разработку
компекта протоколов для открытой системы, который сегодня является
самым популярным в мире.
IP является основным протоколом Уровня 3 в комплекте протоколов
Internet. В дополнение к маршрутизации в об'единенных сетях, IР
обеспечивает фрагментацию и повторную сборку дейтаграмм, а также
сообщения об ощибках. Наряду с ТСР, IP представляет основу комплекта
протоколов Internet. Формат пакета IP представлен на Рис. 18-2.
Заголовок IР начинается с номера версии (version number), который
указывает номер используемой версии IP.
Поле длины заголовка (IHL) обозначает длину заголовка дейтаграммы в
32-битовых словах.
Поле типа услуги (type-of-service) указывает, каким образом должна
быть обработана текущая дейтаграмма в соответствии с указаниями
конкретного протокола высшего уровня. С помощью этого поля
дейтаграммам могут быть назначены различные уровни значимости.
Поле общая длина (total length) определяет длину всего пакета IP
в байтах, включая данные и заголовок.
Поле идентификации (identification) содержит целое число, обозначающее
текущую дейтаграмму. Это поле используется для соединения фрагментов
дейтаграммы.
Поле флагов (flags) (содержащее бит DF, бит MF и сдвиг фрагмента)
определяет, может ли быть фрагментирована данная дейтаграмма и
является ли текущий фрагмент последним.
Поле срок жизни (time-to-live) поддерживает счетчик, значение
которого постепенно уменьшается до нуля; в этот момент дейтаграмма
отвергается. Это препятствует зацикливанию пакетов.
Поле протокола (protocol) указывает, какой протокол высшего уровня
примет входящие пакеты после завершения обработки IP.
Поле контрольной суммы заголовка (header checksum) помогает
обеспечивать целостность заголовка ID.
Поля адресов источника и пункта назначения (source and destination
address) oбoзначают отправляющий и принимающий узлы.
Поле опции (options) позволяет IP обеспечивать факультативные
возможности, такие, как защита данных.
Поле данных (data) содержит информацию высших уровней.
Как и у других протоколов сетевого уровня, схема адресации IP
является интегральной по отношению к процессу маршрутизации
дейтаграмм IP через об'единенную сеть. Длина адреса IP составляет
32 бита, разделенных на две или три части. Первая часть обозначает
адрес сети, вторая (если она имеется) - адрес подсети, и третья - адрес
главной вычислительной машины. Адреса подсети присутствуют только в том
случае, если администратор сети принял решение о разделении сети на
подсети. Длина полей адреса сети, подсети и главной вычислительной
машины являются переменными величинами.
Адресация IP обеспечивает пять различных классов сети. Самые крайние
левые биты обозначают класс сети.
Адреса IP записываются в формате десятичного числа с проставленными
точками, например, 34.0.0.1. На рис. 18-3 представлены форматы
адресов для сетей IP классов А, В и С.
Сети IP могут также быть разделены на более мелкие единицы, называемые
подсетями (subnets). Подсети обеспечивают дополнительную гибкость для
администратора сети. Например, предположим, что какой-то сети назначен
адрес класса В , и что все узлы в сети в данный момент соответствуют
формату адреса класса В. Далее предположим, что представлением адреса
этой сети в виде десятичного числа с точками является 128.10.0.0.
(наличие одних нулей в поле адреса главной вычислительной машины
обозначает всю сеть). Вместо того, чтобы изменять все адреса на
какой-то другой базовый сетевой номер, администратор может подразделить
сеть, воспользовавшись организацией подсетей. Это выполняется путем
заимствования битов из части адреса, принадлежащей главной
вычислительной машине, и их использования в качестве поля адреса
подсети, как показано на Рис. 18-4.
Если администратор сети решил использовать восемь битов для
организации подсети, то третья восьмерка адреса IP класса В
обеспечивает номер этой подсети. В нашем примере адрес 128.10.0.
относится к сети 128.10, подсети 1; адрес 128.10.2.0. относится к
сети 128.10, подсети 2, и т.д.
Число битов, занимаемых для адреса подсети, является переменной
величиной. Для задания числа используемых битов IP обеспечивает маску
подсети. Маски подсети используют тот же формат и технику
представления адреса, что и адреса IP. Маски подсети содержат единицы
во всех битах, кроме тех, которые определяют поле главной
вычислительной машины. Например, маска подсети, которая назначает 8
битов организации подсети для адреса 34.0.0.0. класса А,
представляет собой выражение 255.255.0.0. Маска подсети, которая
определяет 16 битов организации подсети для адреса 34.0.0.0. класса А,
представляется выражением 255.255.255.0. Обе эти маски изображены
на Рис. 18-5.
Для некоторых носителей (таких как локальные сети IEEE 802), адреса
носителя и адреса IP определяются динамически путем использования
двух других составляющих комплекта протоколов Internet: Address
Resolution Protocol (ARP) (Протокол разрешения адреса) и Reverse
Address Resolution Protocol (RARP) (Протокол разрешения обратного
адреса). ARP использует широковещательные сообщения для определения
аппаратного адреса (уровень МАС), соответствующего конкретному
межсетевому адресу. ARP обладает достаточной степенью универсальности,
чтобы позволить использование IP с практически любым типом механизма,
лежащего в основе доступа к носителю. RARP использует
широковещательные сообщения для определения адреса об'единенной сети,
связанного с конкретным аппаратным адресом. RARP особенно важен для
узлов, не имеющих диска, которые могут не знать своего межсетевого
адреса, когда они выполняют начальную загрузку.
Устройства маршрутизации в сети Internet традиционно называются
шлюзами (gateway), что является очень неудачнным
термином, т.к. повсеместно в индустрии сетей этот термин применяют
для обозначения устройства с несколько иными функциональными
возможностями. Шлюзы (которые мы с этого момента
будем называть роутерами) в сети Internet организованы в
соответствии с иерархическим принципом. Некоторые роутеры
исползуются для перемещения информации через одну конкретную группу
сетей, находящихся под одним и тем же административным началом и
управлением (такой об'ект называется автономной системой -
autonomous system).
Роутеры, используемые для обмена информацией в пределах
автономных систем, называются внутренними роутерами (interior
routers); они используют различные протоколы для внутренних
роутеров (interior gateway protocol - IGP) для выполнения этой
задачи. Роутеры, которые перемещают информацию между автономными
системами, называются внешними роутерами (exterior routers);
для этого они
используют протоколы для внешних роутеров. Архитектура Internet
представлена на Рис. 18-6.
Протоколы маршрутизации IP-это динамичные протоколы. При динамичной
маршрутизации (dynamic routing) запросы о маршрутах должны
рассчитываться программным обеспечением устройств маршрутизации через
определенные интервалы времени. Этот процесс противоположен
статической маршрутизации (static routing), при которой маршруты
устанавливаются администратором сети и не меняются до тех пор, пока
администратор сети не поменяет их. Таблица маршрутизации IP состоит
из пар "адрес назначения/следующая пересылка". Образец записи данных,
показанный на Рис. 18-7, интерпретируется как имеющий значение
"добраться до сети 34.1.0.0. (подсеть 1 сети 34), следующей
остановкой является узел с адресом 54.34.23.12."
Маршрутизация IP определяет характер перемещения дейтаграмм IP через
об'единенные сети (по одной пересылке за раз). В начале путешествия
весь маршрут не известен. Вместо этого на каждой остановке
вычисляется следующий пункт назначения путем сопоставления
адреса пункта назначения, содержащегося в дейтаграмме, с записью
данных в маршрутной таблице текущего узла. Участие каждого узла в
процессе маршрутизации состоит только из продвижения пакетов,
базируясь только на внутренней информации, вне зависимости от того,
насколько успешным будет процесс и достигнет или нет пакет конечного
пункта назначения. Другими словами, IP не обеспечивает отправку в
источник сообщений о неисправностях, когда имеют место аномалии
маршрутизации. Выполнение этой задачи предоставлено другому протоколу
Internet, а именно Протоколу управляющих сообщений Internet (Internet
Control Message Protocol - ICMP).
ICMP выполняет ряд задач в пределах об'единенной сети IP. В дополнение
к основной задаче, для выполнения которой он был создан (сообщение
источнику об отказах маршрутизации), ICMP обеспечивает также метод
проверки способности узлов образовывать повторное эхо в об'единенной
сети (сообщения Echo и Reply ICMP), метод стимулирования более
эффективной маршрутизации (сообщение Redirect ICMP -
переадресация ICMP),
метод информирования источника о том, что какая-то дейтаграмма
превысила назначенное ей время существования в пределах данной
об'единенной сети (сообщение Time Exceeded ICMP - "время превыщено") и
другие полезные сообщения. Сделанное недавно дополнение к IСМР
обеспечивает для новых узлов возможность нахождения маски подсети,
используемой в межсети в данный момент. В целом, ICMP является
интегральной частью любых реализаций IP, особенно таких, которые
используются в роутерах.
Конкретные протоколы маршрутизации IP рассматриваются в других главах
данной книги. Например, RIP рассматривается в
Главе 23 "RIP",
IGRP - в Главе 24 "IGRP",
OSPF - в Главе 25 "OSPF",
EGP - в главе 26 "EGP" и
BGP - в Главе 27 "BGP".
IS-IS также является официальным протоколом
маршрутизации IP; он рассматривается в
Главе 28 "OSI Routing".
Транспортный уровень Internet реализуется ТСР и Протоколом Дейтаграмм
Пользователя (User Datagram Protocol - UDP). ТСР обеспечивает
транспортировку данных с установлением соединения, в то время как
UDP работает без установления соединения.
Transmission Control Protocol (TCP) обеспечивает полностью
дублированные, с подтверждением и управлением потоком данных,
услуги для протоколов высших уровней. Он перемещает данные в
непрерывном неструктурированном потоке, в котором байты
идентифицируются по номерам последовательностей. ТСР может также
поддерживать многочисленные одновременные диалоги высших уровней.
Формат пакета ТСР представлен на Рис. 18-8.
Поле "порт источника" (source port) обозначает точку, в которой
конкретный процесс высшего уровня источника принимает услуги ТСР;
поле "порт пункта назначения" (destination port) обозначает порт
процесса высшего уровня пункта назначения для услуг ТСР.
Поле "номер последовательности" (sequence number) обычно обозначает
номер, присвоенный первому байту данных в текущем сообщении. В
некоторых случаях оно может также использоваться для обозначения
номера исходной последовательности, который должен использоваться в
предстоящей передаче.
Поле "номер подтверждения" (acknowledgement number) содержит номер
последовательности следующего байта данных, которую отправитель пакета
ожидает для приема.
Поле "сдвиг данных" (data offset) обозначает число 32-битовых слов
в заголовке ТСР.
Поле "резерв" (reserved) зарезервировано для использования
разработчиками протокола в будущем.
Поле "флаги" (flags) содержит различную управляющую информацию.
Поле "окно" (window) обозначает размер окна приема отправителя
(буферный об'ем, доступный для поступающих данных).
Поле "контрольная сумма" (checksum) указывает, был ли заголовок
поврежден при транзите.
Поле "указатель срочности" (urgent pointer) указывает на первый
байт срочных данных в пакете.
Поле "опции" (options) обозначает различные факультативные возможности
ТСР.
Протокол UDP намного проще, чем ТСР; он полезен в ситуациях, когда
мощные механизмы обеспечения надежности протокола ТСР не обязательны.
Заголовок UDP имеет всего четыре поля: поле порта источника (source
port), поле порта пункта назначения (destination port),
поле длины
(length) и поле контрольной суммы UDP (checksum UDP).
Поля порта
источника и порта назначения выполняют те же функции, что и в заголовке
ТСР. Поле длины обозначает длину заголовка UDP и данных; поле
контрольной суммы обеспечивает проверку целостности пакета.
Контрольная сумма UDP является факультативной возможностью.
Комплект протоколов Internet включает в себя большое число протоколов
высших уровней, представляющих самые разнообразные применения, в
том числе управление сети, передача файлов, распределенные услуги
пользования файлами, эмуляция терминалов и электронная почта. На
Рис. 18-9 показана связь между наиболее известными протоколами
высших уровней Internet и применениями, которые они поддерживают.
Протокол передачи файлов (File Transfer Protocol - FTP) обеспечивает
способ перемещения файлов между компьютерными системами. Telnet
обеспечивает виртуальную терминальную эмуляцию. Протокол управления
простой сетью (Simle network management protocol - SNMP) является
протоколом управления сетью, используемым для сообщения об
аномальных условиях в сети и установления значений допустимых
порогов в сети. X Windows является популярным протоколом, который
позволяет терминалу с интеллектом связываться с отдаленными
компьютерами таким образом, как если бы они были непосредственно
подключенными мониторами. Комбинация протоколов Network File System
(NFS) (Система сетевых файлов), External Data Representation (XDP)
(Представление внешней информации) и Remote Procedure Call (RPC)
(Вызов процедуры обращений к отдаленной сети) обеспечивает прозрачный
доступ к ресурсам отдаленной сети. Простой протокол передачи почты
(Simple Mail Transfer Protocol - SMTP) обеспечивает механизм передачи
электронной почты. Эти и другие применения используют услуги ТСР/IP
и других протоколов Internet низших уровней, чтобы обеспечить
пользователей базовыми сетевыми услугами.
IBM была одной из первых компаний, которые признали важность полной
интегрированной стратегии управления сетями. В 1986 г. IBM предложила
Open Network Management (ONA) (Управление открытыми сетями) -
структуру,
описывающую обобщенную архитектуру управления сетями. NetView, самое
первое изделие сетевого управления для универсальной вычислительной
машины IBM, фактически является компонентом ONA. NetView обеспечивает
связный набор услуг централизованного управления сетями, который дает
возможность пользователям контролировать, управлять и перестраивать
конфигурацию своих сетей SNA (Systems Network Architecture -
Aрхитектура Системной Сети).
За время, прошедшее с момента появления ONA и NetView, IBM постоянно
совершенствовала, расширяла и и вносила другие изменения в
технологическую базу управления сетями. В настоящее время сетевое
управление IBM является всеоб'емлющим и чрезвычайно сложным. В
последующих разделах дается описание наиболее важных основ некоторых
из компонентов сетевого управления IBM.
IBM делит сетевое управление на 5 функций, ориентированных на
пользователя:
Эти функции сетевого управления не совсем точно коррелируются с
функциями, предложенными ISO в модели OSI. Сравнение функций сетевого
управления OSI и IBM приведено на Рис. 33-1.
С помощью средств управления конфигурацией пользователи могут
поддерживать ведомость сетевых ресурсов. Управление конфигурацией
помогает гарантировать быстроту и точность отражения изменений
сетевой конфигурации в базе данных конфигурационного управления.
Информация управления конфигурацией используется системами управления
проблемами для сравнения различий в версиях и для локализации,
идентификации и проверки характеристик сетевых ресурсов. Системы
управления изменениями могут использовать данные управления
конфигурацией для анализа эффекта, произведенного изменениями, и для
составления графика внесения изменений в моменты минимального
сетевого воздействия.
Услуга управления SNA, называемая "идентификация изделия запроса"
(query product identification), извлекает программную и аппаратную
физическую информацию из базы данных управления конфигурацией.
Извлеченная информация иногда называется "данными жизненноважного
изделия" (vital product data).
Управление производительностью и учетом включает в себя учет ресурсов,
контролирование времени реакции, доступности, утилизации и компонентной
задержки, а также регулировку, отслеживание и управление
производительностью. Информация от работы каждой из этих функций может
привести к инициированию процедуры определения проблемы, если уровни
производительности не отвечают требуемым.
Услуги общих операций обеспечивают управление ресурсами, которыми
другие категории SNA занимаются в неявно выраженном виде, путем
обеспечения специализированной связи с этими ресурсами с помощью новых,
более производительных прикладных программ. Двумя очень важными
услугами, которые обеспечивают эту производительность, являются команда
execute (выполняй) и услуга управления ресурсами. Команда execute
обеспечивает стандартизированные средства выполнения какой-нибудь
дистанционной команды. Услуги управления ресурсами обеспечивают
возможность транспортировки информации независимым от контекста
способом.
Услуги управления операциями обеспечивают возможность управления
дистанционными ресурсами путем активации и дезактивации ресурсов,
отмены команды и установки часов сетевых ресурсов. Услуги управления
операциями могут быть инициированы автоматически в результате
продвижения уведомления о системной проблеме, тем самым позволяя
автоматическую обработку дистанционных проблем.
Хотя наличие проблем приводит к изменению, изменение также может
вызвать проблемы. Управление изменением пытается минимизировать
проблемы, вызванные изменением, путем поощрения упорядоченного
изменения и отслеживания изменений.
IBM предлагает несколько архитектур управления и важных платформ
управления.
Фокусы (focal points) обеспечивают поддержку операций централизованного
сетевого управления. Это те об'екты управления, которые уже были
названы ранее в описанной общей модели. Фокусы отвечают на
предупреждения конечных станций, поддерживают базы данных управления и
обеспечивают интерфейс пользователя с оператором управления сети.
Существуют два вида фокусов: первичный (primary) и вторичный
(secondary). Первичные фокусы соответствуют описанным выше. Вторичные
фокусы обеспечивают резерв для первичных фокусов и используются при
отказе первичных фокусов.
Вложенные фокусы (nested focal points) обеспечивают поддержку
распределенного управления для частей крупных сетей. Они продвигают
критичную информацию в другие глобальные фокусы.
Точки сбора (collection points) передают инфрмацию из автономных
подсетей SNA в фокусы. Точки сбора обычно используются для продвижения
данных из сети IBM с равноправными узлами в иерархию ONA.
Точки ввода (entry points) являются устройствами SNA, которые могут
реализовать ONA для себя и для других устройств. Большинство
стандартных устройств SNA могут быть точками ввода.
Точки обслуживания (service points) являются системами, которые
обеспечивают доступ в ONA для устройств, не являющихся устройствами
SNA. Toчки обслуживания способны отправлять в фокусы информацию
сетевого управления о системах, не являющихся системами SNA, а также
принимать команды из фокусов, транслируя их в формат, приемлемый для
устройств, не являющихся устройствами SNA, и продвигать их в эти
устройства для выполнения. Точки обслуживания фактически являются
сетевыми интерфейсами с ONA.
NetWare является операционной системой сети (network operating
system - NOS) и связанной с ней средой обеспечения услуг,
разработанной Novell, Inc. и представленной на рынок в начале 1980 гг.
В то время сети были небольшими и преимущественно гомогенными, связь
рабочих групп с помощью локальных сетей была еще новым явлением, а
идея о персональном компьютере еще только начала завоевывать
популярность.
Большая часть технологии организации сетей NetWare была заимствована
из Xerox Network Systems (XNS) - системы организации сетей,
разработанной Xerox Corporation в конце 1970 гг. Подробная информация
о XNS приведена в
Главе 22 "XNS".
K началу 1990 гг. доля в рынке NOS NetWare возросла до 50-75 %
(данные зависят от исследовательских групп, занимавшихся изучением
рынка). Установив свыше 500,000 сетей NetWare по всему миру
и ускорив продвижение по пути об'единения сетей с другими сетями,
NetWare и подддерживающие ее протоколы часто сосуществуют на одном и
том же физическом канале с многими другими популярными протоколами, в
том числе ТСР/IP, DECnet и AppleTalk.
В качестве среды NOS, NetWare определяет пять высших уровней
эталонной модели OSI. Она обеспечивает совместное пользование файлами
и принтером, поддержку различных прикладных задач, таких как передача
электронной почты и доступ к базе данных, и другие услуги. Также, как и
другие NOS, такие как Network File System (NFS) компании Sun
Microsystems, Inc. и LAN Manager компании Microsoft Corporation,
NetWare базируется на архитектуре клиент-сервер
(slient-server architecture). В таких архитектурах клиенты (иногда
называемые рабочими станциями) запрашивают у серверов
определенные услуги, такие как доступ к файлам и принтеру.
Первоначально клиентами NetWare были небольшие РС, в то время как
серверами были ненамного более мощные РС. После
того, как NetWare стала более популярной, она была перенесена на
другие компьютерные платформы. В настоящее время клиенты и сервера
могут быть представлены практически любым видом
компьютерной системы, от РС до универсальных вычислительных машин.
Основная характеристика системы клиент-сервер
заключается в том, что доступ к отдаленной сети является прозрачным для
пользователя. Это достигается с помощью удаленного вызовова процедур
(remote procedure calls) - такого процесса, когда
программа местного компьютера, работающая на оборудовании клиента,
отправляет вызов в удаленный сервер. Этот сервер
выполняет указанную процедуру и
возвращает запрошенную информацию клиенту местного компьютера.
Рис. 19-1 иллюстрирует в упрощенном виде известные протоколы
NetWare и их связь с эталонной моделью OSI. При наличии соответствующих
драйверов, NetWare может работать с любым протоколом доступа к
носителю. На рисунке перечислены те протоколы доступа к носителю,
которые в настоящее время обеспечиваются драйверами NetWare.
NetWare работает с Ethenet/IEEE 802.3, Token Ring/IEEE 802.5, Fiber
Distributed Data Interface (FDDI) и ARCnet.
Информация о Ethernet/IEEE 802.3 дается в
Главе 5 "Ethernet/IEEE 802.3", о
Token Ring/IEEE 802.5 - в
Главе 6 "Token Ring/IEEE 802.5", o
FDDI - в Главе 7 "FDDI".
NetWare также работает в синхронных каналах глобальных сетей,
использующих Point-to-Point Protocol (PPP) (Протокол непосредственных
соединений). РРР подробно рассматривается в
Главе 10 "РРР".
ARСnet представляет собой систему простой сети, которая поддерживает
все три основных носителя (скрученную пару, коаксиальный кабель и
волоконно-оптический кабель) и две топологии (шина и звезда). Она
была разработана корпорацией Datapoint Corporation и выпущена в 1977.
Хотя ARCnet не приобрела такую популярность, какой пользуются
Ethernet и Token Ring, ее гибкость и низкая стоимость завоевали много
верных сторонников.
Internet Packet Exchange (IPX) является оригинальным протоколом
сетевого
уровня Novell. Если устройство, с которым необходимо установить
связь, находится в другой сети, IPX прокладывает маршрут для
прохождения информации через любые промежуточные сети, которые могут
находиться на пути к пункту назначения. На Рис. 19-2 представлен
формат пакета IPX.
Пакет IPX начинается с 16-битового поля контрольной суммы (checksum),
которое устанавливается на единицы.
16-битовое поле длины (length) определяет длину полной дейтаграммы
IPX в байтах. Пакеты IPX могут быть любой длины, вплоть до размеров
максимальной единицы передачи носителя (MTU). Фрагментация
пакетов не применяется.
За полем длины идет 8-битовое поле управления транспортировкой
(transport control), которое обозначает число роутеров, через
которые прошел пакет. Когда значение этого поля доходит до 15,
пакет отвергается исходя из предположения, что могла иметь место
маршрутная петля.
8-битовое поле типа пакета (packet type) определяет протокол высшего
уровня для приема информации пакета. Двумя общими значениями этого
поля являются 5, которое определяет Sequenced Packet Exchange (SPX)
(Упорядоченный обмен пакетами) и 17, которое определяет NetWare Core
Protocol (NCP) (Основной протокол NetWare).
Информация адреса пункта назначения (destination address) занимает
следующие три поля. Эти поля определяют сеть, главную вычислительную
машину и гнездо (процесс) пункта назначения.
Следом идут три поля адреса источника (source address), определяющих
сеть, главную вычислительную машину и гнездо источника.
За полями пункта назначения и источника следует поле данных (data).
Оно содержит информацию для процессов высших уровней.
Хотя IPX и является производной XNS, он имеет несколько уникальных
характеристик. С точки зрения маршрутизации , наиболее важное
различие заключается в механизмах формирования пакетов данных этих
двух протоколов. Формирование пакета данных - это процесс упаковки
информации протокола высшего уровня и данных в блок данных. Блоки
данных являются логическими группами информации, очень похожими на
слова телефонного разговора. XNS использует стандартное формирование
блока данных Ethernet, в то время как пакеты IPX формируются в блоки
данных Ethernet Version 2.0 или IEEE 802.3 без информации IEEE 802.2,
которая обычно сопровождает эти блоки данных. Рис.19-3 иллюстрирует
формирование пакета данных Ethernet, стандарта IEEE 802.3 и IPX.
Для маршрутизации пакетов в об'единенных сетях IPX использует протокол
динамической маршрутизации, называемый Routing Information Protocol
(RIP) (Протокол маршрутной информации). Также, как и XNS, RIP получен
в результате усилий компании Xerox по разработке семейства протоколов
XNS. В настоящее время RIP является наиболее часто используемым
протоколом для внутренних роутеров (interior gateway protocol-IGP) в
сообществе Internet-среде международной сети, обеспечивающей связность
практически со всеми университетами и исследовательскими институтами
и большим числом коммерческих организаций в США, а также со многими
иностранными организациями. Подробная информация о RIP приведена в
Главе 23 "RIP".
В дополнение к разнице в механизмах формирования пакетов, Novell также
дополнительно включила в свое семейство протоколов IPX протокол,
называемый Service Adverticement Protocol (SAP) (Протокол об'явлений
об услугах). SAP позволяет узлам, обеспечивающим услуги, об'являть
о своих адресах и услугах, которые они обеспечивают.
Novell также поддерживает "Блок адресуемой сети" LU 6.2 компании
IBM (LU 6.2 network addressable unit - NAU). LU 6.2 обеспечивает
связность по принципу равноправных систем через среду сообщений IBM.
Используя возможности LU 6.2, которые имеются у NetWare, узлы
NetWare могут обмениваться информацией через сеть IBM. Пакеты
NetWare формируются в пределах пакетов LU 6.2 для передачи через
сеть IBM.
Sequenced Packet Exchange (SPX) (Упорядоченный обмен пакетами)
является наиболее часто используемым протоколом транспортного
уровня NetWare. Novell получила этот протокол в результате доработки
Sequenced Packet Protocol (SPP) системы XNS. Как и протокол ТСР
(Transmission Control Protocol) и многие другие протоколы
транспортного уровня, SPX является надежным, с установлением
соединения протоколом, который дополняет услуги дейтаграмм,
обеспечиваемые протоколами Уровня 3.
Novell также предлагает поддержку протокола Internet Protocol (IP)
в виде формирования протоколом User Datagram Protocol(UDP)/IP других
пакетов Novell, таких как пакеты SPX/IPX. Для транспортировки
через об'единенные сети, базирующиеся на IP, дейтаграммы IPX
формируются внутри заголовков UDP/IP. Общая информация о протоколах
UPD и Internet дается в
Главе 18 "Протоколы Internet".
NetWare поддерживает большое разнообразие протоколов высших уровней;
некоторые из них несколько более популярны, чем другие. NetWare shell
(командный процессор) работает в оборудовании клиентов (которое часто
называется рабочими станциями среди специалистов по NetWare) и
перехватывает обращения прикладных задач к устройству Ввод/Вывод,
чтобы определить, требуют ли они доступ к сети для удовлетворения
запроса. Если это так, то NetWare shell организует пакеты запросов и
отправляет их в программное обеспечение низшего уровня для обработки и
передачи по сети. Если это не так, то они просто передаются в ресурсы
местного устройства Ввода/Вывода. Прикладные задачи клиента не
осведомлены о каких-либо доступах к сети, необходимых для выполнения
обращений прикладных задач. NetWare Remote Procedure Call (Netware
RPC) (Вызов процедуры обращения к отдаленной сети) является еще
одним более общим механизмом переадресации, поддерживаемым Novell.
Netware Core Protocol (NCP) (Основной протокол NetWare) представляет
собой ряд программ для сервера, предназначенных для
удовлетворения запросов прикладных задач, приходящих, например, из
NetWare shell. Услуги, предоставляемые NCP, включают доступ к файлам,
доступ к принтеру, управление именами, учет использования ресурсов,
защиту данных и синхронизацию файлов.
NetWare также поддерживает спецификацию интерфейса сеансового
уровня Network Basic I/O System (NetBIOS) компаний IBM и Microsoft.
Программа эмуляции NetBIOS, обеспечиваемая NetWare, позволяет
программам, написанным для промышленного стандартного интерфейса
NetBIOS, работать в пределах системы NetWare.
Услуги прикладного уровня NetWare включают
NetWare Message Handling Service (NetWare MHS)
(Услуги по обработке сообщений),
Btrieve,
NetWare Loadable Modules (NLM) (Загружаемые модули NetWare)
и различные
характеристики связности IBM. NetWare MHS является системой доставки
сообщений, которая обеспечивает транспортировку электронной почты.
Btrieve представляет собой реализацию механизма доступа к базе данных
двоичного дерева (btree) Novell. NLM реализуются как дополнительные
модули, которые подключаются к системе NetWare. В настоящее время
компания Novell и третьи участвующие стороны предоставляют NLM
для чередующихся комплектов протоколов (alternate protocol stacks),
услуги связи, услуги доступа
к базе данных и много других услуг.
Протоколы Xerox Network Systems (XNS) разработаны корпорацией
Xerox в конце 1970-начале 1980 гг. Они предназначены для использования
в разнообразных средах передачи, процессорах и прикладных задачах офиса.
Несколько протоколов XNS похожи на Протокол Internet (IP) и Протокол
управления передачей (TCP), разработанных агентством DARPA для
Министерства обороны США (DoD). Информация по этим и связанным с
ними протоколам дается в
Главе 18 "Протоколы Internet".
Все
протоколы XNS соответствуют основным целям проектирования эталонной
модели OSI.
Благодаря своей доступности и раннему появлению на рынке, XNS был
принят большинством компаний, использовавших локальные сети с момента
их появления, в том числе компаниями Novell, Inc., Ungermann-Bass, Inc.
(которая теперь является частью Tandem Computers) и 3Com Corporation.
За время,прошедшее с тех пор, каждая из этих компаний внесла
различные изменения в протоколы XNS. Novell дополнила их
Протоколом доступа к услугам (Service access protocol - SAP), чтобы
обеспечить об'явление о ресурсах, и модифицировала протоколы Уровня 3
OSI (которые Novell переименовала в
Internetwork Packet Exchange - IPX -
Oбмен межсетевыми пакетами) для работы в сетях IEEE 802.3, а не
в сетях Ethernet. Ungermann-Bass модифицировала RIP для поддержания
задержки, а также числа пересылок. Были также внесены другие
незначительные изменения. С течением времени реализации XNS для
об'единенных в сети РС стали более популярными, чем XNS в том виде, в
котором они были первоначально разработаны компанией Xerox.
Несмотря на то, что они имеют общие цели проектирования, концепция XNS
о иерархии протоколов несколько отличается от той концепции, которую
предлагает эталонная модель OSI. На Рис. 22-1 показано приблизительное
сравнение XNS и эталонной модели OSI.
Как видно из Рис. 22-1, Xerox обеспечивает 5-уровневую модель передачи
пакетов. Уровень 0, который отвечает за доступ к каналу и манипуляцию
потока битов, примерно соответствует Уровням 1 и 2 OSI. Уровень 1
примерно соответствует той части Уровня 3 OSI, которая относится к
сетевому трафику. Уровень 2 примерно соответствует части Уровня 3,
которая связана с маршрутизацией в об'единенной сети, и Уровню 4 OSI,
который занимается связью внутри отдельных процессов. Уровни 3 и 4
примерно соответствуют двум верхним уровням модели OSI, которые
заняты структурированием данных, взаимодействием между отдельными
процессами и прикладными задачами. XNS не имеет протокола,
соответствующего Уровню 5 OSI (сеансовый уровень).
Несмотря на то, что в документации XNS упоминаются X.25, Ethernet и
HDLC, XNS не дает четкого определения того, что она называет
протоколом уровня 0. Также, как и многие другие комплекты протоколов,
XNS оставляет вопрос о протоколе доступа к носителю открытым, косвенным
образом позволяя любому такому протоколу выполнять главную роль в
транспортировке пакетов XNS через физический носитель.
Протокол сетевого уровня XNS называется Протоколом дейтаграмм Internet
(Internet Datagram Protocol - IDP).
IDP выполняет стандартные функции Уровня 3, в число которых
входят логическая адресация и сквозная доставка дейтаграмм через
об'единенную сеть. Формат пакета IDP представлен на Рис. 22-2.
Первым полем в пакете IDP является 16-битовое поле контрольной суммы
(checksum), которое помогает проверить целостность пакета после его
прохождения через об'единенную сеть.
За полем контрольной суммы следует 16-битовое поле длины (length),
которое содержит информацию о полной длине (включая контрольную
сумму) текущей дейтаграммы.
За полем длины идет 8-битовое поле управления транспортировкой
(transport control) и 8-битовое поле типа пакета (packet type).
Поле
управления транспортировкой состоит из подполей числа пересылок
(hop count) и максимального времени существования пакета (maximum
packet lifetime - MPL). Значение подполя числа пересылок
устанавливается источником в исходное состояние 0 и инкрементируется на
1 при прохождении данной дейтаграммы через один роутер.
Когда значение поля числа пересылок доходит до 16, дейтаграмма
отвергается на основании допущения, что имеет место петля
маршрутизации. Подполе MPL содержит максимальное время (в секундах),
в течение которого пакет может оставаться в об'единенной сети.
За полем управления транспортировкой следует 8-битовое поле типа
пакета (packet type). Это поле определяет формат поля данных.
Каждый из адресов сети источника и назначения имеют три поля: 32-
битовый номер сети (network number), который уникальным образом
обозначает сеть в об'единенной сети, 48-битовый номер хоста
(host number), который является уникальным для
всех когда-либо выпущенных хостов, и 16-битовый
номер гнезда (socket number), который уникальным образом
идентифицирует гнездо (процесс) в пределах конкретнго хоста.
Адреса IEEE 802 эквивалентны номерам хостов,
поэтому хосты, подключенные более чем к одной
сети IEEE 802, имеют тот же самый адрес в каждом сегменте. Это делает
сетевые номера избыточными, но тем не менее полезными для
маршрутизации. Некоторые номера гнезд являются хорошо известными
(well-known); это означает, что услуга, выполняемая программным
обеспечением с использованием этих номеров гнезд, является статически
определенной. Все другие номера гнезд допускают многократное
использование.
XNS поддерживает пакеты с однопунктовой (из одного пункта в другой
пункт), многопунктовой и широковещательной адресацией. Многопунктовые
и широковещательные адреса далее делятся на 2 типа: прямые (directed)
и глобальные (global). Прямые многопунктовые адреса доставляют пакеты
членам группы многопунктовой адресации данной сети, заданной в адресе
сети назначения с многопунктовой адресацией. Прямые широковещательные
адреса доставляют пакеты всем членам заданной сети. Глобальные
многопунктовые адреса доставляют пакеты всем членам данной группы
в пределах всей об'единенной сети, в то время как глобальные
широковещательные адреса доставляют пакеты во все адреса об'единенной
сети. Один бит в номере хоста обозначает
отдельный адрес в противовес многопунктовому адресу. Все единицы в
поле хоста обозначают широковещательный адрес.
Для маршрутизации пакетов в об'единенной сети XNS использует схему
динамической маршрутизации, называемую Протоколом информации
маршрутизации (RIP). В настоящее время RIP является наиболее широко
используемым Протоколом внутренних роутеров (interior gateway
protocol - IGP) в сообществе Internet-среде международной сети,
обеспечивющей связность практически со всеми университетами и научно-
исследовательскими институтами, а также многими коммерческими
организациями в США. Подробная информация о RIP дается в
Главе 23 "RIP".
Функции транспортного уровня OSI реализуются несколькими протоколами.
Каждый из перечисленных ниже протоколов описан в спецификации ХNS как
протокол уровня два.
Протокол упорядоченной передачи пакетов
(Sequenced Packet Protocol - SPP)
обеспечивает надежную, с установлением соединения и управлением потока,
передачу пакетов от лица процессов клиента. По выполняемым функциям
он похож на протокол TСР
из комплекта протоколов Internet и на
протокол ТР4
из комплекта протоколов OSI (смотри соответственно Главу
18 "Протоколы Internet" и
Главу "Протоколы OSI" 20).
Каждый пакет SPP включает в себя номер последовательности (sequence
number), который используется для упорядочивания пакетов и определения
тех из них, которые были скопированы или потеряны. Пакеты SPP
также содержат два 16-битовых идентификатора соединения (connection
identifier). Каждый конец соединения определяет один идентификатор
соединения. Оба идентификатора соединения вместе уникальным образом
идентифицируют логическое соединение между процессами клиента.
Длина пакетов SPP не может быть больше 576 байтов. Процессы клиента
могут согласовывать использование различных размеров пакетов во время
организации соединения, однако SPP не определяет характер такого
согласования.
Протокол обмена пакетами (Packet Exchange Protocol - PEP)
является протоколом типа запрос-ответ,
предназначенным обеспечивать надежность, которая больше надежности
простых услуг дейтаграмм (например, таких, которые обеспечивает IDP),
но меньше надежности SPP. По своим функциональным возможностям РЕР
аналогичен Протоколу дейтаграмм пользователя
(UDP)
из комплекта
протоколов Internet (смотри
Главу 18 "Протоколы Internet").
PEP
базируется на принципе одного пакета, обеспечивая повторные передачи,
но не обеспечивая выявление дублированных пакетов. Он полезен для
прикладных задач, в которых транзакции запрос-ответ являются
идемпотентными (повторяемыми без повреждения контекста), или в которых
надежная передача выполняется на другом уровне.
Протокол неисправностей (Error Protocol - EP) может быть использован
любым процессом клиента для уведомления другого процесса клиента о
том, что в сети имеет место ошибка. Например, этот протокол
используется в ситуациях, когда какая-нибудь реализация SPP
распознала дублированный пакет.
XNS предлагает несколько протоколов высших уровней. Протокол
"Печатание" (Printing) обеспечивает услуги принтера. Протокол
"Ведение картотеки" (Filing) обеспечивает услуги доступа к файлам.
Протокол "Очистка9 (Сlearinghouse) обеспечивает услуги, связанные с
присвоением имени. Каждый из этих протоколов работает в дополнение
к протоколу "Курьер" (Сourier), который обеспечивает соглашения для
структурирования данных и взаимодействия процессов.
XNS также определяет протоколы уровня четыре. Это протоколы прикладного
уровня, но поскольку они имеют мало общего с фактическими функциями
связи, в спецификации XNS нет каких-либо определений по существу.
И наконец, протокол "Эхо" (Echo Protocol) используется для
тестирования
надежности узлов сети XNS. Он используется для поддержки таких функций,
как функции, обеспечиваемые командой ping, которую можно встретить в
Unix и других средах. Спецификация XNS описывает протокол "Эхо" как
протокол уровня два.
Компания Banyan Virtual Network System (VINES) реализовала систему
распределенной сети, базирующуюся на семействе патентованных
протоколов, разработанных на основе протоколов Xerox Network Systems
(XNS) компании XEROX (смотри
главу 22 "XNS").
Среда распределенной
системы обеспечивает прозрачный для пользователя обмен информации
между клиентами (компьютерами пользователя) и служебными устройствами
(компьютерами специального назначения, которые обеспечивают услуги,
такие, как файловое и принтерное обслуживание). Наряду с NetWare
компании Novell, LAN Server компании IBM и LAN Manager компании
Microsoft, VINES является одной из самых популярных сред распределенной
системы для сетей, базирующихся на микрокомпьютерах.
Комплект протоколов VINES представлен на Рис. 21-1.
Два низших уровня комплекта протоколов VINES реализованы с помощью
различных общеизвестных механизмов доступа к носителю, включая
Управление информационным каналом высшего уровня (HDLC) (смотри Главу
12 "SDLC и его производные"),
Х.25 (смотри Главу 13 "Х.25"),
Ethernet (смотри Главу 5 "Ethernet/IEEE 802.3")
и Тоken Ring (смотри
Главу 6 "Token Ring/IEEE 802.5").
Для выполнения функций Уровня 3 (в том числе маршрутизации в
об'единенной сети) VINES использует Протокол межсетевого обмена VINES
(VINES Internetwork Protocol - VIP).
VINES также обеспечивает собственный
Протокол разрешения адреса (ARP), собственную версию Протокола
информации маршрутизации (Routing Information Protocol - RIP), которая
называется Протоколом корректировки маршрутизации (Routing Update
Protocol - RTP) и Протокол управления Internet (ICP), который
обеспечивает обработку исключительных состояний и специальной
информации о затратах маршрутизации. Пакеты ICP, RTP и ARP формируются
в заголовке VIP.
Адреса сетевого уровня VINES являются 48-битовыми об'ектами,
подразделенными на сетевую (32 бита) и подсетевую (16 битов) части.
Сетевой номер можно описать как номер какого-нибудь служебного
устройства, т.к. он получается непосредственно из ключа (key)
служебного устройства (аппаратного модуля, который обозначает
уникальный номер и программные опции для данного служебного
устройства). Подсетевая часть адреса VINES лучше всего описывается
как номер хоста, т.к. он используется для
обозначения хоста в сетех VINES. Рис. 21-2
иллюстрирует формат адреса VINES.
Сетевой номер обозначает логическую сеть VINES, которая представлена
в виде двухуровневого дерева, корень которого находится в узле
обслуживания (service node). Узлы обслуживания, которыми обычно
являются служебные устройства, обеспечивают услуги резрешения адреса
и услуги
маршрутизации клиентам (client), которые являются листьями этого
дерева. Узел обслуживания назначает адреса VIP клиентам.
Когда какой-нибудь клиент включает питание, он направляет
широковещательный запрос служебным устройствам. Все служебные
устройства, которые получают этот запрос, посылают ответ. Клиент
выбирает первый ответ и запрашивает у данного служебного устройства
адрес подсети (хоста). Служебное устройство
отвечает адресом, состоящим из его собственного сетевого адреса
(полученного из его ключа), об'единенного с адресом подсети (хоста),
который он выбрал сам. Адреса подсети клиента
обычно назначаются последовательно, начиная с 8001H. Адреса подсети
служебного устройства всегда 1. Процесс выбора адреса VINES показан
на Рис. 21-3.
Динамичное назначение адреса не является уникальным явлением в
индустрии сетей (AppleTalk также использует этот процесс); однако
этот процесс определенно не является таким обычным процессом, как
статическое назначение адреса. Т.к. адреса выбираются исключительно
каким-нибудь одним конкретным служебным устройством (чей адрес является
уникальным вследствие уникальности аппаратного ключа), вероятность
дублирования адреса (что является потенциально опасной проблемой для
сети Internet Protocol (IP) и других сетей) очень мала.
В схеме сети VINES все служебные устройства с несколькими интерфейсами
в основном являются роутерами. Клиенты всегда выбирают свое
собственное служебное устройство в качестве роутера для первой
пересылки, даже если другое служебное устройство, подключенное к этому
же кабелю, обеспечивает лучший маршрут к конечному пункту назначения.
Клиенты могут узнать о других роутерах, получая переадресованные
сообщения от своего служебного устройства. Т.К. клиенты полагаются на
свои служебные устройства при первой пересылке маршрутизации,
служебные устройства VINES поддерживают маршрутные таблицы, которые
помогают им находить отдаленные узлы.
Маршрутные таблицы VINES состоят из пар "хост/затраты",
гдe хост соответствует сетевому
узлу, до которого можно дойти, а затраты - временной задержке в
миллисекундах, необходимой для достижения этого узла. RTP помогает
служебным устройствам VINES находить соседних клиентов, служебные
устройства и роутеры.
Все клиенты периодически об'являют как о своих адресах сетевого
уровня, так и о адресах МАС-уровня с помощью пакета, эквивалентого
пакету "hello" (приветственное сообщение).
Пакеты "hello" означают,
что данный клиент все еще работает и сеть готова. Сами служебные
устройства периодически отправляют в другие служебные устройства
маршрутные корректировки. Маршрутные корректировки извещают другие
роутеры об изменениях адресов узлов и топологии сети.
Когда какое-нибудь служебное устройство VINES принимает пакет, оно
проверяет его, чтобы узнать, для чего он предназначается - для другого
служебного устройства или для широкого вещания. Если пунктом назначения
является данное служебное устройство, то это служебное устройство
соответствующим образом обрабатывает этот запрос. Если пунктом
назначения является другое служебное устройство, то данное служебное
устройство либо непосредственно продвигает этот пакет (если это
служебное устройство является его соседом), либо направляет его в
служебное устройство/роутер, которые являются следующими в
очереди. Если данный пакет является широковещательным, то данное
служебное устройство проверяет его, чтобы узнать, пришел ли этот пакет
с маршрута с наименьшими затратами. Если это не так, то пакет
отвергается. Если же это так, то пакет продвигается на всех
интерфейсах, за исключением того, на котором этот пакет был принят.
Такой метод помогает уменьшить число широковещательных возмущений,
которые являются обычной проблемой в других сетевых окружениях.
Aлгоритм маршрутизации VINES представлен на Рис. 21-4.
Формат пакета VIP представлен на Рис. 21-5.
Пакет VIP начинается с поля контрольной суммы (checksum), используемой
для обнаружения искажений в пакете.
За полем контрольной суммы идет поле длины пакета (packet length),
которое обозначает длину всего пакета VIP.
Следующим полем является поле управления транспортировкой (transport
control), которое состоит из нескольких подполей. Если пакет является
широковещательным, то предусматривается два подполя: подполе класса
(class) (с 1 по 3 биты) и подполе числа пересылок (hop-count)
(с 4 по 7 биты). Если пакет не является широковещательным пакетом, то
предусматривается 4 подполя: подполе ошибки (error), подполе
показателя (metric), подполе переадресации (redirect),
и подполе
числа пересылок (hop count). Подполе класса определяет тип узла,
который должен принимать широковещательное сообщение. С этой целью узлы
разделяются на несколько различных категорий, зависящих от типа узла и
типа канала, к которому принадлежит узел. Определяя тип узлов, которые
должны принимать широковещательные сообщения, подполе класса
уменьшает вероятность срывов в работе, вызываемых широковещательными
сообщениями. Подполе числа пересылок представляет собой число пересылок
(число пересеченных роутеров), через которые прошел пакет.
Подполе ошибок определяет, надо ли протоколу ICP отправлять пакет
уведомления об исключительной ситуации в источник пакета, если пакет
окажется немаршрутизируемым. Подполе показателя устанавливается в 1
транспортным об'ектом, когда ему необходимо узнать затраты
маршрутизации при перемещения пакетов между каким-нибудь узлом
обслуживания и одним из соседей. Подполе переадресации определяет,
должен ли роутер генерировать сигнал переадресации (при
соответствующих обстоятельствах).
Далее идет поле типа протокола (protocol type),
указывающее на протокол
сетевого или транспортного уровня, для которого предназначен пакет
показателя или пакет уведомления об исключении.
За полем типа протокола следуют адресные поля VIP. За полями номера
сети назначения (destination network number) и номера подсети
назначения (destination subnetwork number) идут поля номера сети
источника (sourсe network number) и номера подсети источника (source
subnetwork number).
RTR распределяет информацию о топологии сети. Пакеты корректировки
маршрутизации периодически пересылаются широкой рассылкой как клиентом,
так и узлами обслуживания. Эти пакеты информируют соседей о
существовании какого-нибудь узла, а также указывают, является ли этот
узел клиентом или узлом обслуживания. В каждый пакет корректировки
маршрутизации узла обслуживания также включается перечень всех
известных сетей и коэффициенты затрат, связанные с достижением этих
сетей.
Поддерживаются две маршрутные таблицы: таблица всех известных сетей и
таблица соседей. Для узлов обслуживания таблица всех известных сетей
содержит запись данных о каждой известной сети, за исключением
собственной сети узла обслуживания. Каждая запись содержит номер сети,
показатель маршрутизации и указатель на запись данных следующей
пересылки на пути к данной сети в таблице соседей. Таблица соседей
содержит запись данных каждого узла обслуживания соседа и узла клиента.
Записи включают в себя номер сети, номер подсети, протокол доступа к
носителю (например, Ethernent), который использовался для достижения
этого узла, адрес локальной сети (если средой, соединяющей с соседом,
является локальная сеть) и показатель соседа.
RTR определяет 4 типа пакетов:
Пакеты RTR имеют 4-байтовый заголовок, состоящий из однобайтового
поля типа операций (operation type), однобайтового поля типа узла
(node type), однобайтового поля типа контроллера
(controller type)
и однобайтового поля типа машины (machine type). Поле типа операций
указывает на тип пакета. Поле типа узла указывает, пришел пакет
из узла обслуживания или из необслуживающего узла. Поле типа
контроллера указывает, содержит ли контроллер узла, передающего пакет
RTR, многобуферный контроллер. Это поле используется для облегчения
регулирования информационного потока между сетевыми узлами. И наконец,
поле типа машины указывает, является ли процессор отправителя RTR
быстодействующим или нет. Как и поле типа контроллера, поле
типа машины также используется для регулирования скорости передачи.
Об'екты протокола ARP классифицируются либо как клиенты разрешения
адреса (address resolution clients), либо как услуги разрешения адреса
(address resolution services). Клиенты разрешения адреса обычно
реализуются в узлах клиентов, в то время как услуги разрешения адреса
обычно обеспечиваются узлами обслуживания.
Пакеты ARP имеют 8-байтовый заголовок, состоящий из 2-байтового
типа пакета (packet type),
4-байтового номера сети (network number)
и 2-байтового номера подсети (subnet number).
Имеется 4 типа
пакетов: запрос-заявка (query request), который является запросом
какой-либо услуги ARP; ответ об услуге (service response), который
является ответом на запрос-заявку, запрос о присваивании адреса
(assignment request), который отправляется какой-нибудь услуге ARP
для запроса адреса об'единенной сети VINES, и ответ о присваивании
адреса (assignment response), который отправляется данной услугой ARP
в качестве ответа на запрос о присваивании адреса. Поля номера сети и
номера подсети имеют значение только в пакете ответа о присваивании
адреса.
Когда какой-нибудь клиент приступает к работе, клиенты и услуги ARP
реализуют следующий алгоритм. Сначала данный клиент отправляет широкой
рассылкой пакеты запросов-заявок. Затем каждая услуга, которая
является соседом данного клиента, отвечает пакетом ответа об услуге.
Далее данный клиент выдает пакет запроса о присваивании адреса в первую
услугу, которая ответила на его пакет запроса-заявки. Услуга отвечает
пакетом ответа о присваивании адреса, содержащем присвоенный адрес
об'единенной сети.
ICP определяет пакеты уведомления об исключительных ситуациях
(exception notification) и уведомления о показателе (metric
notification). Пакеты уведомления об исключительных ситуациях
обеспечивают информацию об исключительных ситуациях сетевого уровня;
пакеты уведомления о показателе содержат информацию о последней
передаче, которая была использована для достижения узла клиента.
Уведомления об исключительной ситуации отправляются в том случае,
когда какой-нибудь пакет VIP не может быть соответствующим образом
маршрутизирован, и устанавливается подполе ошибки в поле управления
транспортировкой заголовка VIP. Эти пакеты также содержат поле,
идентифицирующее конкретную исключительную ситуацию по коду ошибки,
соответствующему этой ситуации.
Об'екты ICP в узлах обслуживания генерируют сообщения уведомления
о показателе в том случае, когда устанавливается подполе показателя
в поле управления транспортировкой заголовка VIP, и адрес пункта
назначения в пакете узла обслуживания определяет одного из соседей
этого узла обслуживания.
VINES обеспечивает три услуги транспортного уровня:
Являясь распределенной сетью, VINES использует модель вызова
процедуры обращений к отдаленной сети (remote procedure call - RPC)
для связи между клиентами и служебными устройствами. RCP является
основой сред распределенных услуг. Протокол NetRPC (Уровни 5 и 6)
обеспечивает язык программирования высшего уровня, который позволяет
осуществлять доступ к отдаленным услугам способом, прозрачным как для
пользователя, так и для прикладной программы.
На Уровне 7 VINES обеспечивает протоколы файловых услуг и услуг
принтера, а также протокол услуг "StreetTalk name/directory".
StreetTalk,
один из протоколов с торговым знаком компании VINES, обеспечивает
службу постоянных имен в глобальном масштабе для всей об'единенной сети.
VINES также обеспечивает среду разработки интегрированных применений
при наличии нескольких операционных систем, включая DOS и UNIX. Taкая
среда разработки позволяет третьей участвующей стороне осуществлять
разработку как клиентов, так и услуг, действующих в среде VINES.
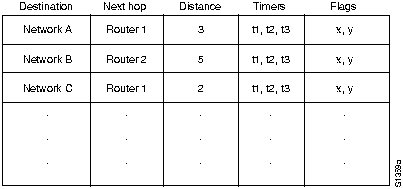
Формат пакета (Реализация IP)
ПРИМЕЧАНИЕ:
На Рис. 23-2 представлен формат RIP, используемый для
сетей IP в Internet. В некоторые другие варианты RIP внесены
незначительные изменения формата и (или) имен файлов, которые
здесь перечислены, но функциональные возможности базового алгоритма
маршрутизации те же самые.
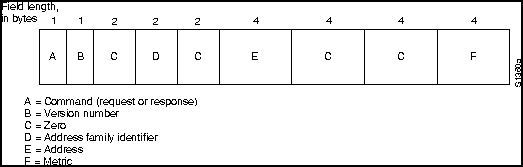
Характеристики стабильности
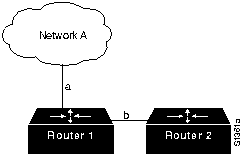
Временные удерживания изменений
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 32. SNMP.
Библиографическая справка
Достоинства и недостатки этих трех методов (HEMS, SGMP и CMOT) часто
и горячо обсуждались в течение второй половины 1987 г. В начале 1988 г.
был образован комитет Internet Activities Board - IAB (IAB - это группа,
ответственная за техническую разработку протоколов Internet) для
разрешения дебатов по поводу протокола сетевого управления. В конечном
итоге комитет IAB пришел к соглашению, что улучшенная версия SGMP,
которая должна была называться SNMP, должна стать временным решением;
для долгосрочного применения должна быть проанализирована одна из
технологий, базирующихся на OSI (либо СМОТ, либо сам СMIP). Для
обеспечения легкого пути наращивания была разработана общая структура
сетевого управления (которая теперь называется стандартной Структурой
Управления Сети - Network Management Framework).
![]() High-level Entity Management System (HEMS)
High-level Entity Management System (HEMS)
![]() Simple Gateway Monitoring Protocol (SGMP)
Simple Gateway Monitoring Protocol (SGMP)
![]() CMIP over TCP (CMOT)
CMIP over TCP (CMOT)
Основы технологии
Модель управления
Агентами в SNMP являются программные модули, которые работают в
управляемых устройствах. Агенты собирают информацию об управляемых
устройствах, в которых они работают, и делают эту информацию доступной
для систем управления сетями (network management systems - NMS) с
помощью протокола SNMP. Эта модель представлена графически на
Рис. 32-1.

![]() Число и состояние своих виртуальных цепей
Число и состояние своих виртуальных цепей
![]() Число определенных видов полученных сообщений о неисправности
Число определенных видов полученных сообщений о неисправности
![]() Число байтов и пакетов, входящих и исходящих из данного устройства
Число байтов и пакетов, входящих и исходящих из данного устройства
![]() Максимальная длина очереди на выходе (для роутеров и других
устройств об'единения сетей)
Максимальная длина очереди на выходе (для роутеров и других
устройств об'единения сетей)
![]() Отправленные и принятые широковещательные сообщения
Отправленные и принятые широковещательные сообщения
![]() Отказавшие и вновь появившиеся сетевые интерфейсы
Отказавшие и вновь появившиеся сетевые интерфейсы
Типы команд
Если NMS хочет проконтролировать какое-либо из управляемых устройств,
она делает это путем отправки ему сообщения с указанием об изменении
значения одной из его переменных. В целом управляемые устройства
отвечают на четыре типа команд (или инициируют их):
![]() Reads
Reads
![]() Writes
Writes
![]() Traversal operations
Traversal operations
![]() Traps
Traps
Различия в представлениии информации
Обмен информацией в управляемой сети находится потенциально под угрозой
срыва из-за различий в технике представления данных, используемой
управляемыми устройствами. Другими словами, компьютеры представляют
информацию по-разному; эту несовместимость необходимо
рационализировать, чтобы обеспечить сообщение между различными
системами. Эту функцию выполняет абстрактный синтаксис. SNMP использует
для этой цели подмножество абстрактного синтаксиса, созданного для
OSI - Abstract Syntax Notation One (ASN.1) (Система обозначений для
описания абстрактного синтаксиса). ASN.1 определяет как форматы
пакетов, так и управляемые об'екты. Управляемый об'ект-это просто
характеристика чего-либо, которой можно управлять. Управляемый об'ект
отличается от переменной, которая является конкретной реализацией
об'екта. Управляемые об'екты могут быть скалярными (определяя отдельную
реализацию) или табулярными величинами (определяя несколько связанных
друг с другом реализаций).
Базы данных управления
Все управляемые об'екты содержатся в Информационной базе управления
(Management Information Base - MIB),
которая фактически является базой данных об'ектов. Логически
MIB можно изобразить в виде абстрактного дерева, листьями которого
являются отдельные информационные элементы. Идентификаторы об'ектов
уникальным образом идентифицируют об'екты MIB этого дерева.
Идентификаторы об'ектов похожи на телефонные номера тем, что они
организованы иерархически и их отдельные части назначаются различными
организациями. Например, международные телефонные номера состоят из
кода страны (назначаемого международной организацией) и телефонного
номера в том виде, в каком он определен в данной стране. Телефонные
номера в США далее делятся на код области, номер центральной
телефонной станции (СО) и номер станции, связанной с этой СО.
Аналогично, идентификаторы об'ектов высшего уровня MIB назначаются
Международной Электротехнической Комиссией ISO (ISO IEC). ID об'ектов
низшего уровня назначаются относящимися к ним организациями. На
Рис. 32-2 изображены корневая и несколько наиболее крупных ветвей
дерева MIB.
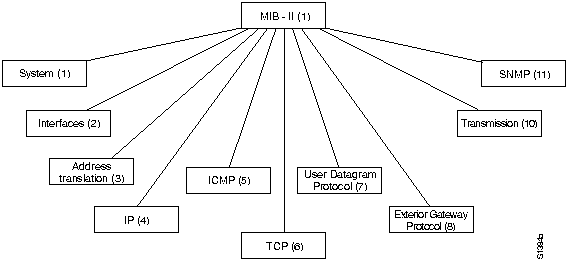
![]() Network addresses (Сетевые адреса)
Network addresses (Сетевые адреса)
![]() Counters (Счетчики)
Counters (Счетчики)
![]() Gauges (Измерительный прибор, мера, размер)
Gauges (Измерительный прибор, мера, размер)
![]() Ticks (Тики)
Ticks (Тики)
![]() Opaque (Мутный)
Opaque (Мутный)
Операции
SNMP является простым протоколом запроса/ответа. Узлы могут отправлять
множество запросов, не получая ответа. Определены следующие 4
операции SNMP:
![]() Get (достань).
Get (достань).
![]() Get-next (достань следующий).
Get-next (достань следующий).
![]() Set (установи).
Set (установи).
![]() Trap (ловушка).
Trap (ловушка).
Формат сообщений
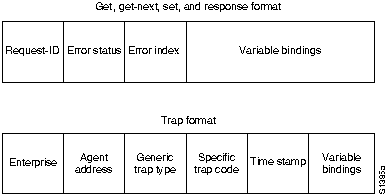
PDU ловушки несколько отличаются от PDU других операций. Они состоят
из следующих частей:
![]() Request-ID (идентификатор запроса).
Request-ID (идентификатор запроса).
![]() Error-status (состояние сбоя).
Error-status (состояние сбоя).
![]() Error-index (индекс ошибки).
Error-index (индекс ошибки).
![]() Variable bindings (переменные привязки).
Variable bindings (переменные привязки).
![]() Enterprise (предметная область).
Enterprise (предметная область).
![]() Agent address (адрес агента).
Agent address (адрес агента).
![]() Generic trap type (групповой тип ловушки).
Generic trap type (групповой тип ловушки).
![]() Specific trap code (специфичный код ловушки).
Specific trap code (специфичный код ловушки).
![]() Time stamp (временной ярлык).
Time stamp (временной ярлык).
![]() Variable bindings (переменные привязки).
Variable bindings (переменные привязки).
Версия: 0.1
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Vladimir Pleshakov , pvv@quorus.ru.
Рисунки Владимир Чепиков.
Vladimir Chepikov , bat@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 9. HSSI.
Библиографическая справка
Основы технологии
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 14. Frame Relay.
Библиографическая справка
Основы технологии
Дополнения LMI
Форматы блока данных

Формат сообщений LMI
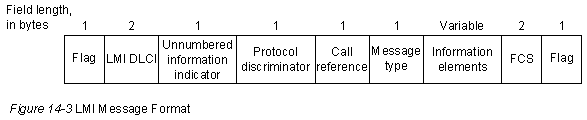
Групповая адресация (multicusting)
Реализация сети

Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 13. X25.
Библиографическая справка
Основы технологии
Формат блока данных
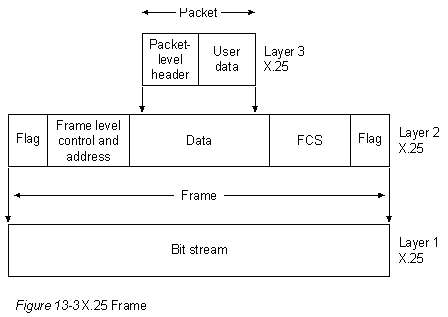
Уровень 3
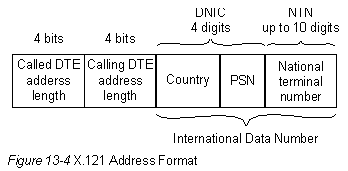
Уровень 2
Блок данных LAPB представлен на Рис. 13-5.

Уровень 1
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 11. ISDN.
Библиографическая справка
Компоненты ISDN
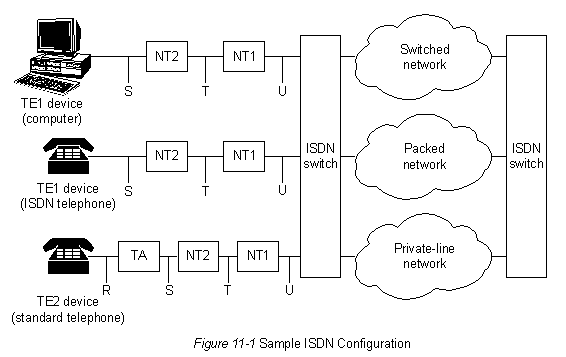
Услуги ISDN
Уровень 1
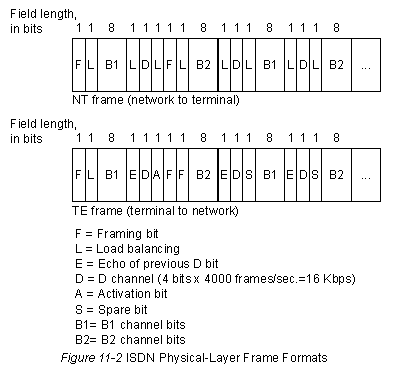
Уровень 2
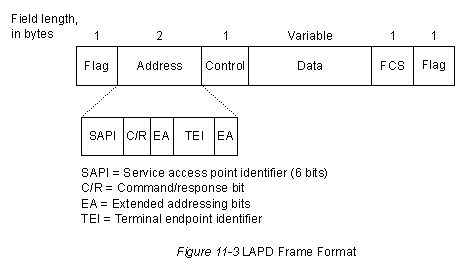
Уровень 3
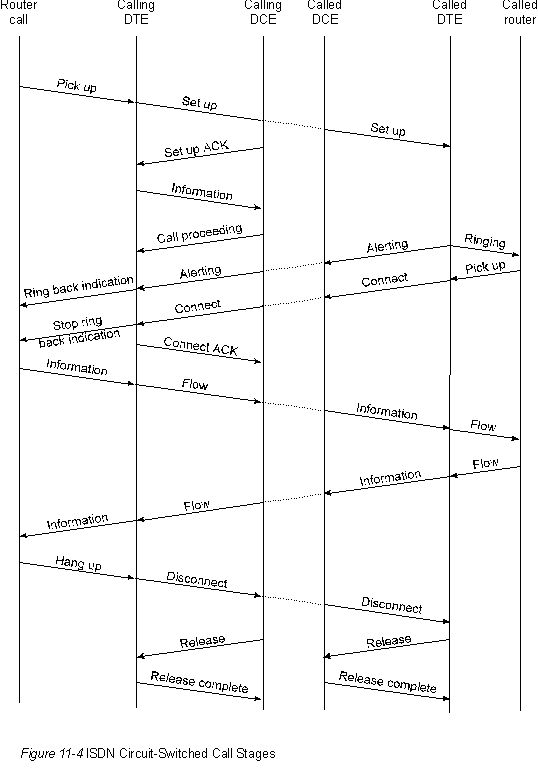
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 12. SDLC и его производные.
Библиографическая справка
Форматы блока данных
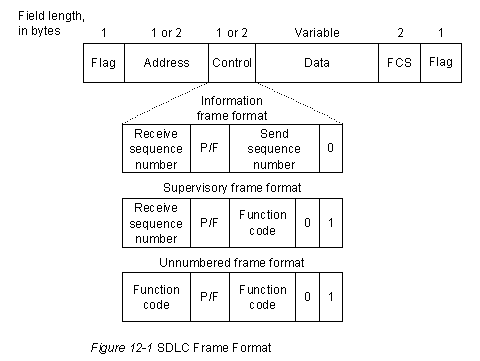
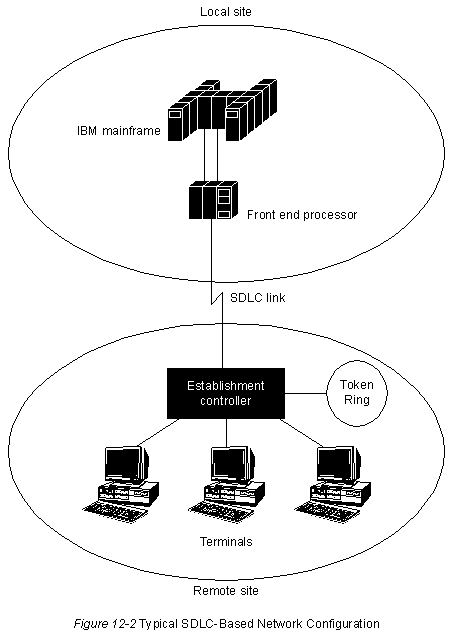
Производные протоколы
HDLC
LAPB
IEEE802.2
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 15. SMDS.
Библиографическая справка
Основы технологии
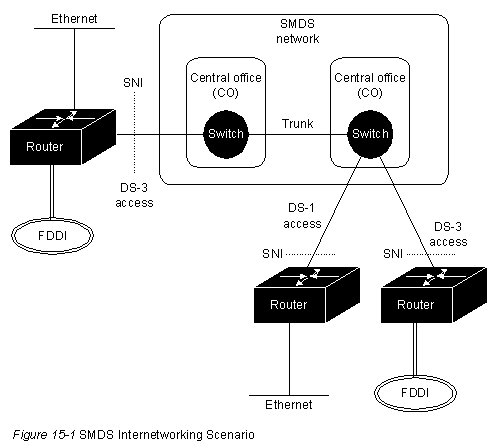
Адресация
Классы доступа
Протокол интерфейса SMDS (SIP)
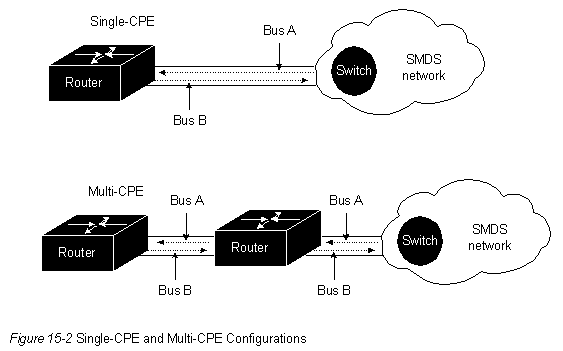

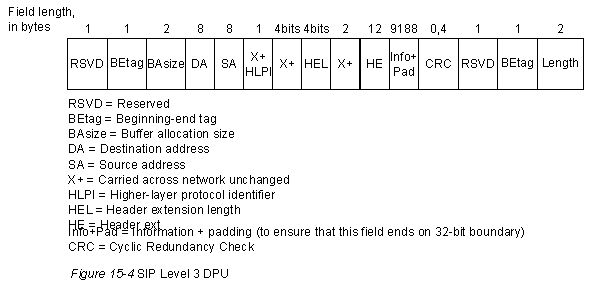
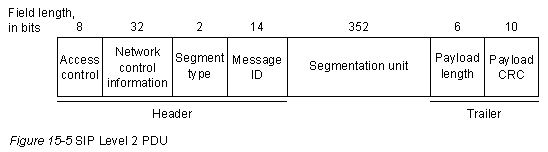

Реализация сети
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 10. PPP.
Библиографическая справка
Компоненты PPP
Основные принципы работы
Требования, определяемые физическим уровнем
Канальный уровень PPP

Протокол управления канала связи PPP (LCP)
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 16. AppleTalk.
Библиографическая справка
Основы технологии
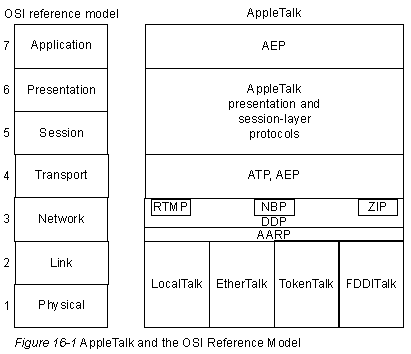
Доступ к среде
Сетевой уровень

Протокол доставки дейтаграмм (DDP)
Протокол поддепжки маршрутной таблицы (RTMP)


Транспортный уровень
Протокол транзакций AppleTalk (ATP)
Протокол потока данных AppleTalk (ADSP)
Протоколы высших уровней
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 17. DECnet.
Библиографическая справка
Архитектура цифровой сети (DNA)
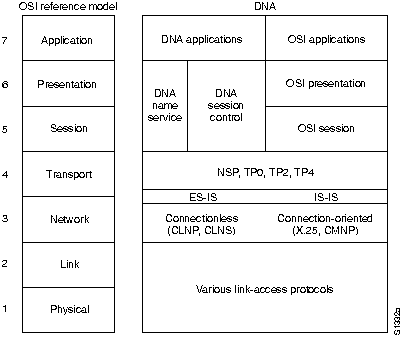
Доступ к среде
Сетевой уровень
Формат длока данных маршрутизации DECnet Phase IV

За полем флагов маршрутизации идут поля узла пункта назначения
(destination node) и узла источника (source node), которые
обозначают сетевые адреса узлов пункта назначения и узла источника.
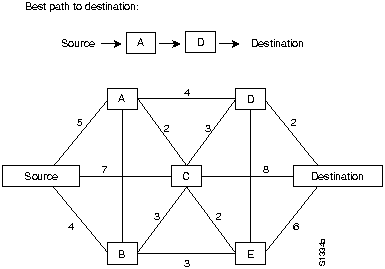

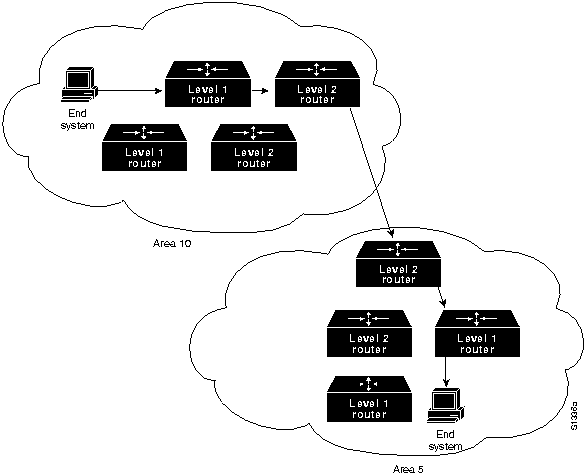
Транспортный уровень
Протоколы высших уровней
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 20. Протоколы OSI.
Библиографическая справка
Основы технологии
![]() End system (ES)
End system (ES)
![]() Intermediate system (IS)
Intermediate system (IS)
![]() Area
Area
![]() Domain
Domain
Доступ к среде
Сетевой уровень
![]() ISO 8648
ISO 8648
![]() ISO 8348
ISO 8348
![]() ISO TR 9575
ISO TR 9575
![]() ISO TR 9577
ISO TR 9577
Услуги без установления соединения
Услуги с установлением соединения
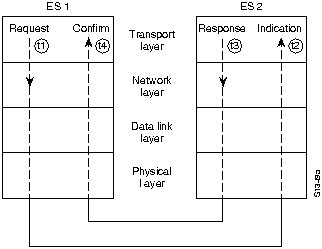
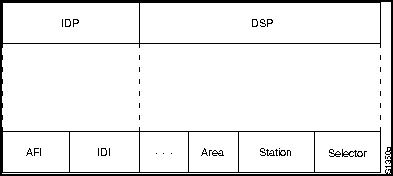
Транспортный уровень
Протоколы высших уровней
![]() Common Management Information Protocol (CMIP)
Common Management Information Protocol (CMIP)
![]() Directory Services (DS)
Directory Services (DS)
![]() File Transfer,Access, and Management (FTAM)
File Transfer,Access, and Management (FTAM)
![]() Massage Handling Systems (MHS)
Massage Handling Systems (MHS)
![]() Virtual Terminal Protocol (VTP)
Virtual Terminal Protocol (VTP)
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 2. Маршрутизация OSI.
Библиографическая справка
Терминология
![]() Area
Area
![]() Domain
Domain
![]() Level 1 routing
Level 1 routing
![]() Level 2 routing
Level 2 routing

ES-IS
![]() Point-to-point subnetworks
Point-to-point subnetworks
![]() Broadcast subnetworks
Broadcast subnetworks
![]() General-topology subnetworks
General-topology subnetworks
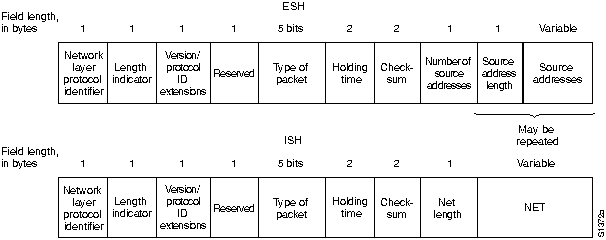
IS-IS
Иерархия маршрутизации
Для упрощения схемы и работы роутера IS-IS различает IS уровней 1
и 2. IS уровня 1 могут сообщаться с другими IS уровня 1, находящимися в
той же области. IS уровня 2 могут сообщаться с IS других областей. Т.е.
IS уровня 1 формируют области уровня 1; IS уровня 2 осуществляют
маршрутизацию между областями уровня 1.
Сообщение между ES
Маршрутизация OSI выполняется следующим образом. Каждая ES принадлежит
конкретной области. ES обнаруживают ближайшую IS путем прослушивания
пакетов ISH. Если какая-нибудь ES захочет отправить пакет в другую ES,
она направляет пакет в одну из IS сети, к которой она непосредственно
подключена. Роутер просматривает адрес пункта назначения и
продвигает пакет по наилучшему маршруту. Если ES пункта назначения
находится в той же подсети, то местная IS узнает об этом в результате
прослушивания ESH и соответствующим образом продвинет пакет. В этом
случае IS может также обеспечить отправку сообщения о переадресации
(redirect - RD) в источник пакета, чтобы сообщить о доступности
более прямого
пути. Если адресом пункта назначения является какая-нибудь ES другой
подсети той же области, то IS узнает о точном маршруте и
соответствующим образом продвинет пакет. Если адресом пункта назначения
является какая-нибудь ES другой области, то IS уровня 1 отправляет этот
пакет в в ближайшую IS уровня 2. Продвижение пакета через IS уровня 2
продолжается до тех пор, пока он не достигнет IS уровня 2 в области
пункта назначения. В пределах области пункта назначения IS продвигают
пакет по наилучшему маршруту, пока не будет достигнутa ES пункта
назначения.
Показатели (метрики)
IS-IS использует один обязательный, устанавливаемый по умолчанию
показатель с максимальным значением пути 1024. Этот показатель
является произвольным и обычно назначается администратором сети. Любой
отдельный канал может иметь максимальное значение 64. Длина путей
вычисляется путем суммирования значений каналов. Максимальные значения
каналов установлены на этих уровнях для обеспечения степени
детализации, чтобы поддерживать различные типы каналов, одновременно
обеспечивая достаточную эффективность алгоритма поиска наикратчайшего
пути, используемого для расчета маршрута.
Формат пакета
IS-IS использует три базовых формата пакета:
![]() IS-IS hello packets - приветственные пакеты IS-IS
IS-IS hello packets - приветственные пакеты IS-IS
![]() Link state packets (LSPs) - пакеты состояния канала
Link state packets (LSPs) - пакеты состояния канала
![]() Sequence numbers packets (SNPs) - пакеты номеров последовательностей
Sequence numbers packets (SNPs) - пакеты номеров последовательностей


Интегрированный IS-IS
![]() Досягаемость сетевых адресов из других комплектов протоколов
Досягаемость сетевых адресов из других комплектов протоколов
![]() Какие протоколы поддерживаются и какими роутерами
Какие протоколы поддерживаются и какими роутерами
![]() Другую информацию, необходимую для какого-нибудь конкретного комплекта протоколов
Другую информацию, необходимую для какого-нибудь конкретного комплекта протоколов
Протокол междоменной маршрутизации (IDRP)
![]() Border intermediate system (BIS)
Border intermediate system (BIS)
![]() Routing domain (RD)
Routing domain (RD)
![]() Routing domain identifier (RDI)
Routing domain identifier (RDI)
![]() Routing information base (RIB)
Routing information base (RIB)
![]() Confederation
Confederation
![]() Поддержка CLNP QOS
Поддержка CLNP QOS
![]() Устранение петель путем ослеживания всех RD, пересекаемых роутером
Устранение петель путем ослеживания всех RD, пересекаемых роутером
![]() Сокращение об'ема маршрутной информации и ее обработки путем
использования конфедераций, компрессии информации путей RD и других
средств
Сокращение об'ема маршрутной информации и ее обработки путем
использования конфедераций, компрессии информации путей RD и других
средств
![]() Обеспечение надежности путем использования встроенных надежных
средств транспортировки
Обеспечение надежности путем использования встроенных надежных
средств транспортировки
![]() Обеспечение защиты данных путем использования криптографической
сигнатуры для каждого пакета
Обеспечение защиты данных путем использования криптографической
сигнатуры для каждого пакета
![]() Наличие узлов обслуживания маршрута
Наличие узлов обслуживания маршрута
![]() Регенерирующие пакеты RIB
Регенерирующие пакеты RIB
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 24. OSPF.
Библиографическая справка
![]() Алгоритм SPF компании Bolt, Beranek и Newman (BBN), разработанный
для Arpanet (программы с коммутацией пакетов, разработанной BBN в
начале 1970 гг., которая явилась поворотным пунктом в истории
разработки сетей) в 1978 г.
Алгоритм SPF компании Bolt, Beranek и Newman (BBN), разработанный
для Arpanet (программы с коммутацией пакетов, разработанной BBN в
начале 1970 гг., которая явилась поворотным пунктом в истории
разработки сетей) в 1978 г.
![]() Исследования Koмпании Radia Perlman по отказоустойчивости широкой
рассылки маршрутной информации (1988).
Исследования Koмпании Radia Perlman по отказоустойчивости широкой
рассылки маршрутной информации (1988).
![]() Исследования BBN по маршрутизации в отдельной области (1986).
Исследования BBN по маршрутизации в отдельной области (1986).
![]() Одна из первых версий протокола маршрутизации IS-IS OSI
Одна из первых версий протокола маршрутизации IS-IS OSI
Основы технологии
Иерархия маршрутизации

Алгоритм SPF
Формат пакета

![]() Hello.
Hello.
![]() Database Description.
Database Description.
![]() Link-State Request
Link-State Request
![]() Link-State Update
Link-State Update
![]() Link-State Acknowledgement
Link-State Acknowledgement
![]() Router links advertisements (RLA)
Router links advertisements (RLA)
![]() Network links advertisements (NLA)
Network links advertisements (NLA)
![]() Summary links advertisements (SLA)
Summary links advertisements (SLA)
![]() AS external links advertisements
AS external links advertisements
Дополнительные характеристики OSPF
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 24. IGRP.
Библиографическая справка
Технология
Формат пакета

Характеристики стабильности
Временные удерживания изменений

Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 26. EGP.
Библиографическая справка
Основы технологии

Формат пакета

Message
Function
Neighbor acquisition
Establishes/de-establishes neighbors
Neighbor reachability
Determines if neighbors are alive
Poll
Determines reachability of a particular network
Routing update
Provides routing updates
Error
Indicates error conditions
Типы сообщений
Приобретение соседа
Сообщение "приобретение соседа" включает в себя интервал
приветствия
(hello interval) и интервал опроса (poll interval).
Поле интервала
приветствия определяет период интервала проверки работоспособности
соседей. Поле интервала опроса определяет частоту корректировки
маршрутизации.
Досягаемость соседа
Сообщения о досягаемости соседа не имеют отдельных полей в числе
полей, идущих за заголовком EGP. Эти сообщения используют поле кода
для указания различия между приветственным сообщением и ответом на
приветственное сообщение. Выделение функции оценки досягаемости из
функции корректировки маршрутизации уменьшает сетевой трафик, т.к.
изменения о досягаемости сетей обычно появляются чаще, чем изменения
параметров маршрутизации. Любой узел EGP заявляет об отказе одного из
своих соседей только после того, как от него не был получен
определенный процент сообщений о досягаемости.
Опрос
Чтобы обеспечить правильную маршрутизацию между AS, ЕGP должен знать
об относительном местоположении отдаленных хостов.
Сообщение опроса позволяет роутерам EGP получать
информацию о досягаемости сетей, в которых находятся эти машины. Такие
сообщения имеют только одно поле помимо обычного заголовка - поле сети
источника IP (source network). Это поле определяет сеть, которая должна
использоваться в качестве контрольной точки для запроса.
Корректиравка маршрутизации
Сообщения о корректировке маршрутизации дают роутерам EGP
возможность указывать местоположение различных сетей в пределах своих
AS. В дополнение к обычному заголовку эти сообщения включают несколько
дополнительных полей. Поле числа внутренних роутеров (number of
interior gateways) указывает на число внутренних роутеров,
появляющихся в сообщении. Поле числа внешних роутеров (number of
exterior gateways) указывает на число внешних роутеров,
появляющихся в сообщении. Поле сети источника IP (IP source network)
обеспечивает адрес IP той сети, от которой измерена досягаемость. За
этим полем идет последовательность блоков роутеров (gateway
blocks). Каждый блок роутеров обеспечивает адрес IP какого-нибудь
роутера и перечень сетей, а также расстояний, связанных с
достижением этих сетей.
Сообщения о неисправностях
Сообщения о неисправностях указывают на различные сбойные ситуации.
В дополнение к общему заголовку EGP сообщения о неисправностях
обеспечивают поле причины (reason), за которым следует заголовок
сообщения о неисправности (message header). В число типичных
неисправностей (причин) EGP входят неисправный формат заголовка EGP
(bad EGP header format), неисправный формат поля данных EGP (bad EGP
data field format), чрезмерная скорость опроса (excessive polling
rate) и невозможность достижения информации (unavailability of
reachability information). Заголовок сообщения о неисправности состоит
из первых трех 32-битовых слов заголовка EGP.
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 27. BGP.
Библиографическая справка
Основы технологии
Формат пакета

Сообщения
![]() Открывающие сообщения
Открывающие сообщения
![]() Сообщения о корректировке
Сообщения о корректировке
![]() Уведомления
Уведомления
![]() Сообщения keepalive (продолжай действовать)
Сообщения keepalive (продолжай действовать)
Открывающие сообщения
В дополнение к обычному заголовку пакета BGP в открывающих сообщениях
выделяют несколько полей. Поле версии (version) обеспечивает номер
версии BGP и дает возможность получателю проверять, совпадает ли его
версия с версией отправителя. Поле автономной системы (autonomous
system) обеспечивает номер AS отправителя. Поле времени удерживания
(hold time) указывает максимальное число секунд, которые могут
пройти без получения какого-либо сообщения от передающего устройства,
прежде чем считать его отказавшим. Поле кода удостоверения
(authentication code) указывает на используемый код удостоверения
(если он имеется). Поле данных удостоверения (autentication data)
содержит фактические данные удостоверения (при их наличии).
Сообщения о корректировке
Сообщения о корректировках BGP обеспечивают корректировки маршрутизации
для других систем BGP. Информация этих сообщений используется для
построения графика, описывающего взаимоотношения между различными AS.
В дополнение к обычному заголовку BGP сообщения о корректировках имеют
несколько дополнительных полей. Эти поля обеспечивают маршрутную
информацию путем перечисления атрибутов трактов, соответствующих
каждой сети.
В настоящее время BGP определяет 5 атрибутов:
![]() Origin
Origin
![]() AS path
AS path
![]() Next hop
Next hop
![]() Unreachable
Unreachable
![]() Inter-AS metric
Inter-AS metric
Сообщения keepalive (продолжай действовать)
Сообщения keepalive не содержат каких-либо дополнительных полей помимо
тех, которые содержатся в заголовке BGP. Эти сообщения отправляются
довольно часто для того, чтобы препятствовать истечению периода времени
удерживания таймера.
Уведомления
Уведомления отправляются в том случае, если была обнаружена сбойная
ситуация, и один роутер хочет сообщить другому, почему он
закрывает соединение между ними. Помимо обычного заголовка BGP
уведомления содержат поле кода ошибки (error code),
поле подкода ошибки
(error subcode) и данные ошибки (error data).
Поле кода ошибки указывает
тип ошибки, который может быть одним из перечисленных ниже:
![]() Message header error
Message header error
![]() Open message error
Open message error
![]() Update message error
Update message error
![]() Hold time expired
Hold time expired
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 18. Протоколы Internet.
Библиографическая справка
Сетевой уровень
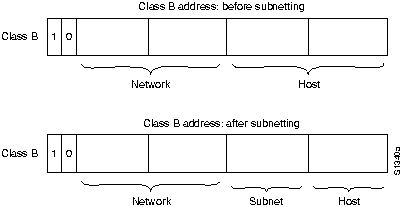

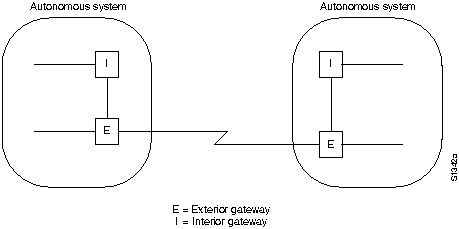

Транспортный уровень
Протокол управления передачей (TCP)
Протокол дейтаграмм пользователя (UDP)
Протоколы высших уровней
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 33. Управление сетями IBM.
Библиографическая справка
Функциональные области управления
![]() Configuration management (управление конфигурацией).
Configuration management (управление конфигурацией).
![]() Perfomance and accounting management (управление производительностью и учетом использования ресурсов).
Perfomance and accounting management (управление производительностью и учетом использования ресурсов).
![]() Problem management (управление проблемами).
Problem management (управление проблемами).
![]() Operations management (Управление операциями).
Operations management (Управление операциями).
![]() Change management (Управление изменениями).
Change management (Управление изменениями).
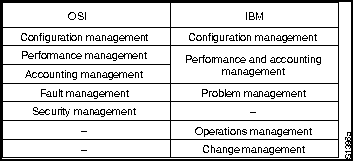
Управление конфигурацией
Конфигурационное управление управляет информацией, описывающей как
физические, так и логические ресурсы информационных систем и их
взаимоотношения друг с другом. Эта информация обычно состоит из
названий ресурсов, адресов, местоположений, контактов и телефонных
номеров. Функция управления конфигурацией IBM очень близко
соответствует концепции OSI об управлении конфигурацией.
Управление производительностью и учетом сетевых ресурсов
Эта функция управления SNA обеспечивает информацию о производительности
сетевых ресурсов. Путем анализа данных управления производительностью и
учетом ресурсов, пользователи могут определять, будут ли удовлетворены
задачи производительности сети.
Управление проблемами
Услуги управления SNA определяют проблему (problem) как сбойную
ситуацию, которая приводит к потере пользователем всех функциональных
свойств ресурсов системы. SNA делит управление проблемами на
несколько областей:
![]() Problem determination (Определение проблемы).
Problem determination (Определение проблемы).
![]() Problem diagnosis (Диагноз проблемы).
Problem diagnosis (Диагноз проблемы).
![]() Problem bypass and recovery (Обход проблемы и восстановление).
Problem bypass and recovery (Обход проблемы и восстановление).
![]() Problem resolution (Решение проблемы).
Problem resolution (Решение проблемы).
![]() Problem tracking and control (Отслеживание и управление проблемой).
Problem tracking and control (Отслеживание и управление проблемой).
Управление операциями
Управление операциями включает в себя управление распределенными
сетевыми ресурсами из центрального пункта. Оно предусматривает два
набора функций: услуги общих операций (common operations service) и
услуги управления операциями (operations management services).
Управление изменениями
Управлениие изменениями помогает пользователям управлять сетевыми или
системными изменениями путем обеспечения отправки, извлечения,
установки и удаления файлов изменений в отдаленных узлах. Кроме того,
управление изменениями обеспечивает активацию узла. Изменения имеют
место либо из-за изменений в требованиях пользователя, либо из-за
необходимости обойти проблему.
Основные архитектуры и платформы управления
Структура управления открытой сети (ONA)
Базовая структура ONA представлена на Рис. 33-2.
System View
IBM об'явила о System View в 1990 г. System View является программой
для разработки прикладных задач управления, способных управлять
информационными системами от нескольких поставщиков. В частности,
System View описывает, как будут выглядеть и работать прикладные
программы, управляющие гетерогенными сетями, а также как они будут
кооперировать с другими системами управления. System View является
официальной стратегией управления системами SAA (Systems Application
Architecture - Архитектура системных прикладных программ).
NetView
NetView является самой всеоб'емлющей платформой управления сети
предметной области. Она содержит следующие основные части:
![]() Command control facility (средства управления командами).
Command control facility (средства управления командами).
![]() Hardware monitor (монитор аппаратного обеспечения).
Hardware monitor (монитор аппаратного обеспечения).
![]() Session monitor (монитор сеанса).
Session monitor (монитор сеанса).
![]() Help function (функция оказания помощи).
Help function (функция оказания помощи).
![]() Status monitor (монитор состояния).
Status monitor (монитор состояния).
![]() Performance monitor (монитор производительности).
Performance monitor (монитор производительности).
![]() Distribution manager (управляющий распределением).
Distribution manager (управляющий распределением).
Управляющий сети LAN
Изделие IBM "Управляющий сети LAN" (LAN Network Manager - LNM)
представляет собой прикладную программу управления сети, базирующуюся
на OS/2 Extended Edition (расширенный вариант), которая позволяет
управлять локальными сетями Token Ring из центрального пункта
поддержки. Для NetView деятельность LNМ может быть видимой (например,
аварийные сигналы). LNM сообщается с программным обеспечением LAN,
называемым LAN Station Manager (LSM) (Управляющий станций LAN),
которое
реализует агентов управления в отдельных конечных станциях LAN.
Сообщение между LNM и LSM осуществляется путем использования Протокола
CMIS/CMIP (OSI Common Management Information Services/Common Management
Information Protocol - Информационные услуги общего управления OSI/
Протокол информации общего управления), который управляет
работой протокола LLC (Logical Link Control - Протокол управления
логическим каналом без установления соединения).
SNMP
IBM недавно включила поддержку протокола SNMP
(смотри Главу 32 "SNMP").
Версия: 0.1
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Vladimir Pleshakov , pvv@quorus.ru.
Рисунки Владимир Чепиков.
Vladimir Chepikov , bat@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 19. Протоколы NetWare.
Библиографическая справка
Основы технологии
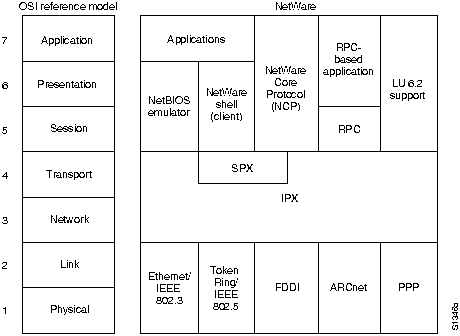
Доступ к среде
Сетевой уровень
Примечание: NetWare 4.0 обеспечивает формирование пакетов IPX
в блоки данных IEEE 802.3.
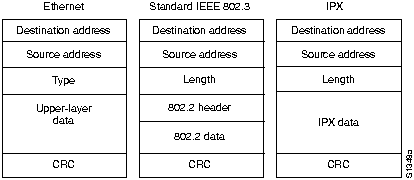
Транспортный уровень
Протоколы высших уровней
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 22. Xerox Network Systems (XNS).
Библиографическая справка
Основы технологии

Доступ к среде
Сетевой уровень

Транспортный уровень
Протоколы высших уровней
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
ГЛАВА 21. Banyan VINES.
Библиографическая справка
Основы технологии
Доступ к среде
Сетевой уровень
Протокол межсетевого обмена VINES (VIP)

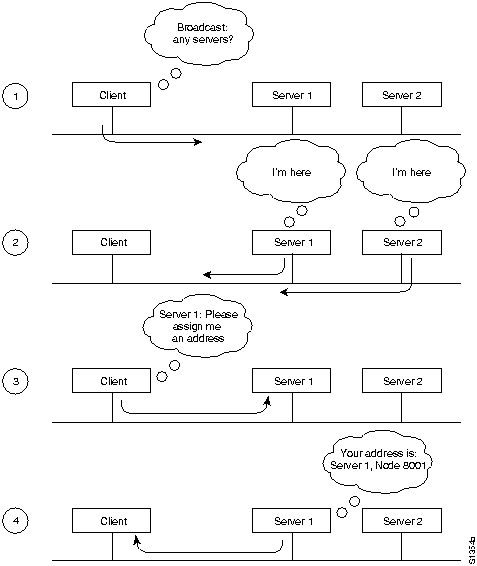

Протокол корректировки маршрутизации (RTR)
Протокол разрешения адреса (ARP)
Протокол управления объединеной сетью (ICP)
Транспортный уровень
Протоколы высших уровней
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
![]()
Internetworking Technology Overview.
List of Figures
Данный документ подготовлен для HTML версии Владимиром Плешаковым.
Версия: 0.1
Vladimir V. Pleshakov , pvv@quorus.ru.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}